
1
ISAISA(Wrap up)(Wrap up)

2
RISC vs. CISC

3
CISC Evolution
• Storage and Memory
– High cost of memory.
– Need for compact code.
• Support for high-level languages
• Support for new applications (e.g., multimedia)

4
CISC Effects
• Moved complexity from s/w to h/w
• Ease of compiler design (HLLCA)
• Easier to debug
• Lengthened design times
• Increased design errors

5
RISC Evolution
• Increasingly cheap memory
• Improvement in compiler technology
Patterson: “Make the common case fast”

6
RISC Effect
• Move complexity from h/w to s/w
• Provided a single-chip solution
• Better use of chip area
• Better Speed
• Feasibility of pipelining
– Single cycle execution stages
– Uniform Instruction Format

7
Key arguments
• RISC argument – for a given technology, RISC implementation will be faster
– current VLSI technology enables single-chip RISC
– when technology enables single-chip CISC, RISC will be pipelined
– when technology enables pipelined CISC, RISC will have caches
– When CISC have caches, RISC will have multiple cores
• CISC argument – CISC flaws not fundamental (fixed with more transistors)
– Moore’s Law will narrow the RISC/CISC gap (true)
– software costs will dominate (very true)

8
Role of Compiler: RISC vs. CISC
• CISC instruction:
MUL <addr1>, <addr2>• RISC instructions:
LOAD A, <addr1>
LOAD B, <addr2>
MUL A, B
STORE <addr1>• RISC is dependent on optimizing compilers

9
Example CISC ISA: Intel X86Example CISC ISA: Intel X86
12 addressing modes:• Register.• Immediate.• Direct.• Base.• Base + Displacement.• Index + Displacement.• Scaled Index + Displacement.• Based Index.• Based Scaled Index.• Based Index + Displacement.• Based Scaled Index +
Displacement.• Relative.
Operand sizes:• Can be 8, 16, 32, 48, 64, or 80 bits long.
• Also supports string operations.
Instruction Encoding:• The smallest instruction is one byte.
• The longest instruction is 12 bytes long.
• The first bytes generally contain the opcode, mode specifiers, and register fields.
• The remainder bytes are for address displacement and immediate data.

10
Example RISC ISA: PowerPCExample RISC ISA: PowerPC
8 addressing modes:• Register direct.• Immediate.• Register indirect.• Register indirect with immediate index
(loads and stores).• Register indirect with register index
(loads and stores).• Absolute (jumps).• Link register indirect (calls).• Count register indirect (branches).
Operand sizes:• Four operand sizes: 1, 2, 4 or 8 bytes.
Instruction Encoding:• Instruction set has 15 different
formats with many minor variations.•
• All are 32 bits in length.

11
7 addressing modes:• Register• Immediate• Base with displacement• Base with scaled index and
displacement• Predecrement• Postincrement• PC-relative
Operand sizes:• Five operand sizes ranging in powers
of two from 1 to 16 bytes.
Instruction Encoding:• Instruction set has 12 different
formats.•
• All are 32 bits in length.
Example RISC ISA: HP-PAExample RISC ISA: HP-PA

12
Example RISC ISA: SPARCExample RISC ISA: SPARC
Operand sizes:• Four operand sizes: 1, 2, 4 or 8 bytes.
Instruction Encoding:• Instruction set has 3 basic instruction
formats with 3 minor variations.
• All are 32 bits in length.
5 addressing modes:• Register indirect with
immediate displacement.
• Register inderect indexed by another register.
• Register direct.
• Immediate.
• PC relative.

13
CISC vs. RISC Characteristics• RISC vs. CISC controversy is now 20 years old.
• After the initial enthusiasm for RISC machines, there has been a growing realization that – RISC designs may benefit from the inclusion of some CISC features, and
– Vice-versa.
• The result is that more recent RISC design, PowerPC and SPARC, are no longer "pure" RISC and the more recent CISC designs, notably the Pentium, AMD, and Core Duo incorporate core RISC characteristics.
Intel called this hack CRISC. This concept was so moronic that even Intel could not market it!

14
Current Trends
• - x86 instructions decoded into RISC-like instructions (ROps)
Intel called this hack CRISC. This concept was so moronic that even Intel could not market it!
• IA-64 - dependence on compilers for scheduling
• Athlon – both direct execution and micro-programmed instructions

15
Why did Intel (CISC) win?• x86 won because it was the first 16-bit chip.• IBM put it in PCs because there was no competing
choice• Rest is inertia and “financial feedback”
– x86 is most difficult ISA to implement for high performance, but
– Because Intel sells the most processors ...
– It has the most money ...
– Which it uses to hire more and better engineers ...
– Which is uses to maintain competitive performance ...
– And given equal performance, compatibility wins ...
– So Intel sells the most processors.
16
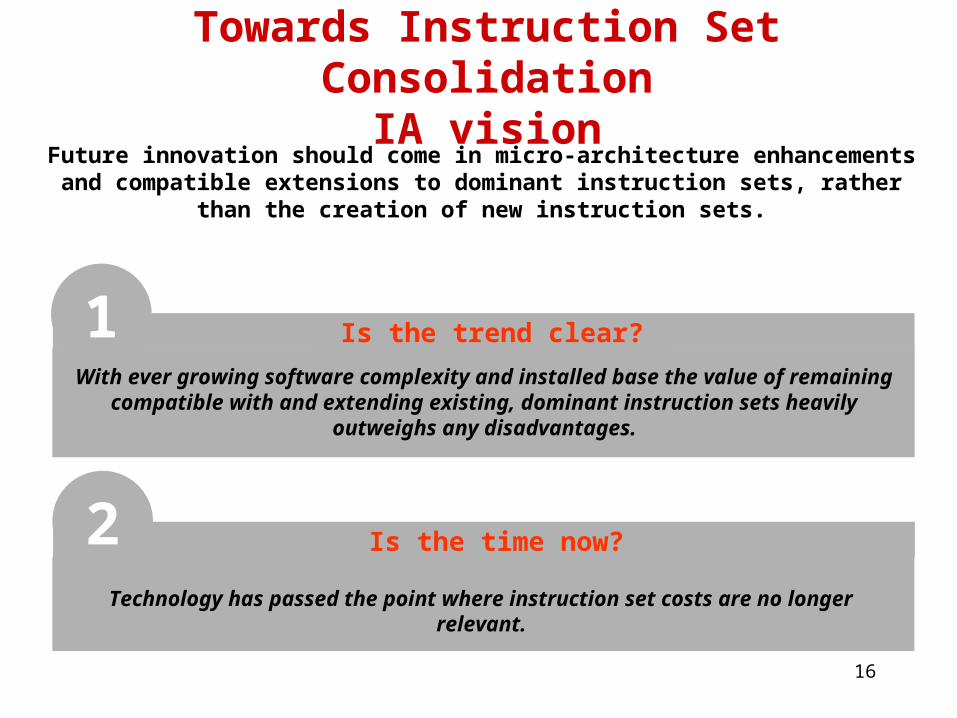
Towards Instruction Set ConsolidationIA vision
Future innovation should come in micro-architecture enhancements and compatible extensions to dominant instruction sets, rather than the
creation of new instruction sets.
With ever growing software complexity and installed base the value of remaining compatible with and extending existing, dominant instruction sets heavily
outweighs any disadvantages.
Is the trend clear?1
Technology has passed the point where instruction set costs are no longer relevant.
Is the time now?2

17
• The economic benefits of moving away from multiple currencies is enormous
What The Euro Can Teach Us

18
Possible SolutionsPort thousands of applications, operating systems, drivers, codecs, tool chains and virtual machines STOP
• Resource intensive
• Slow
• Costly to maintain
x86
ARM
MIPS®
EPIC
PowerPC
SPARC
main() { printf(“Hello World\n”);}
Cell
Other
19
Architectural Evolution Macro-Level
Common Instruction Set
Architecture
No need to port
No need for multiple validations
Built in OS integration
Robust security
Investment protection
DesktopServer
LaptopT
od
ay
Storage
Handheld
Happening
Now
Networking
Ubiquitous
The
Future?
20
Extending x86

21
EPICEPIC(Explicitly Parallel (Explicitly Parallel
Instruction Instruction Computing)Computing)

22
IA- 64: The Itanium Processor
• A radical departure from the traditional paradigms.
• Intel and Hewlett-Packard Co. designed a new architecture, IA-64, that they expected to be much more effective at executing instructions in parallel
• IA-64 is brand new ISA

23
IA - 64
• IA-64 is a 64-bit. In IA-64 designs, instructions are scheduled by the compiler, not by the hardware.
• Much of the logic that groups, schedules, and tracks instructions is not needed thus simplifying the circuitry and promising to improve performance.

24
The EPIC Philosophy
• The acronym EPIC stands for Explicitly Parallel Instruction Computing.
• The entire EPIC design philosophy can be summed up by the following: make use of parallel power whenever and wherever possible; and if it's not possible, make it possible.

25
The EPIC Philosophy

26
Intel IA-64• Massive resources
– 128 GPRs (64-bit, plus poison bit)– 128 FPRs (82-bit)– 64 predicate registers– Also has branch registers for indirect branches
• Contrast to:– RISC: 32 int, 32 FP, handful of control regs– x86: 8 int, 8 fp, handful of control regs
• x86-64 bumps this to 16, SSE adds 8/16 MM regs

27
IA-64 Registers

28
IA-64 Groups
• Compiler assembles groups of instructions
– No register data dependencies between insts in the same group
• Memory deps may exist
– Compiler explicitly inserts “stops” to mark the end of a group
– Group can be arbitrarily long

29
IA-64 Bundles
• Bundle == The “VLIW” Instruction– 5-bit template encoding
• also encodes “stops”
– Three 41-bit instructions
• 128 bits per bundle– average of 5.33 bytes per instruction
• x86 only needs 3 bytes on average
30
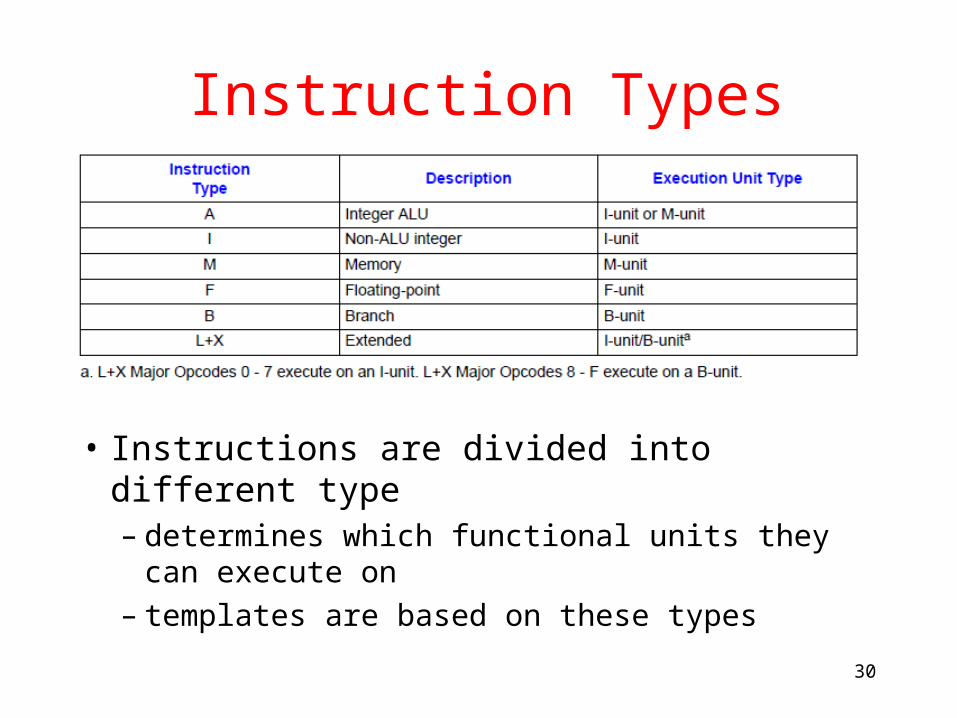
Instruction Types
• Instructions are divided into different type– determines which functional units they can
execute on– templates are based on these types
31
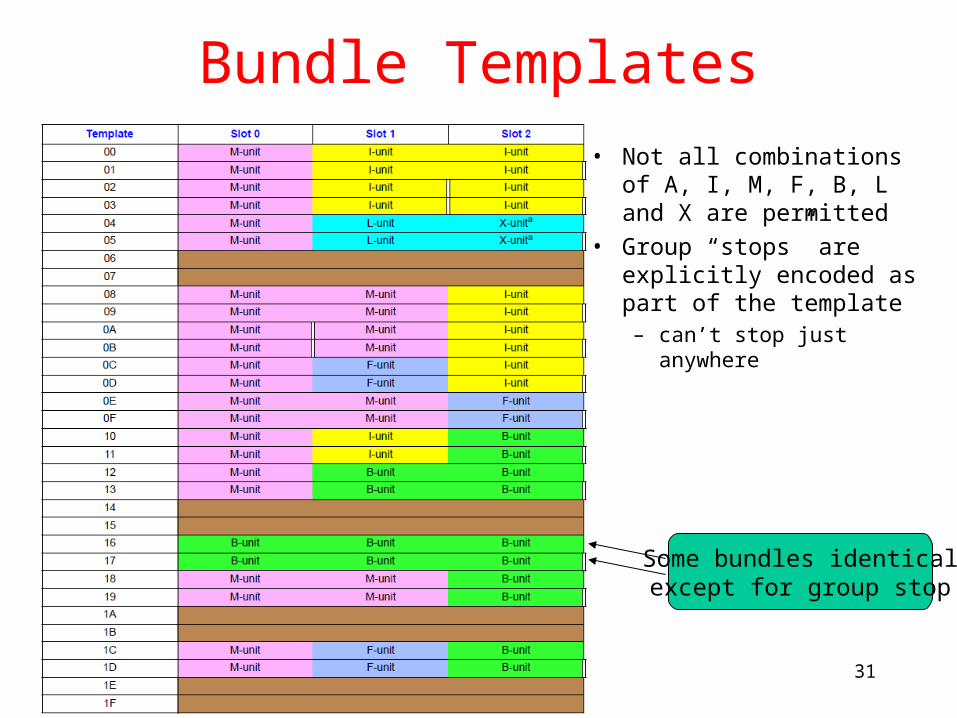
Bundle Templates
• Not all combinations of A, I, M, F, B, L and X are permitted
• Group “stops” are explicitly encoded as part of the template– can’t stop just anywhere
Some bundles identicalexcept for group stop

32
Individual Instruction Formats• Fairly RISC-like like
– easy to decode, fields tend to stay put

33
Instruction Format: Bundles & Templates
•Bundle
•Set of three instructions (41 bits each)
•Template
•Identifies types of instructions in bundle

34
MEM MEM INT INT FP FP B B B
128-bit instruction bundles from I-cacheS2 S1 S0 T
Fetch one or more bundles for execution(Implementation, Itanium® takes two.)
Try to execute all instructions inparallel, depending on available units.
Retired instruction bundles
Processor
Explicitly Parallel Instruction ComputingEPIC
functional units
MEM MEM INT INT FP FP B B B

35
The Role of The Role of CompilersCompilers

36
Compiler and ISA• ISA decisions are no more just for programming assembly
language (AL) easily
• Due to HLL, ISA is a compiler target today
• Performance of a computer will be significantly affected by compiler
• Understanding the compiler technology today is critical to designing and efficiently implementing an instruction set
• Architecture choice affects the code quality and the complexity of building a compiler for it

37
Goal of the Compiler• Primary goal is correctness• Second goal is speed of the object code• Others:
– Speed of the compilation– Ease of providing debug support– Inter-operability among languages– Flexibility of the implementation - languages may
not change much but they do evolve - e. g. Fortran 66 ===> HPF
Make the frequent cases fast and the rare case correct
38
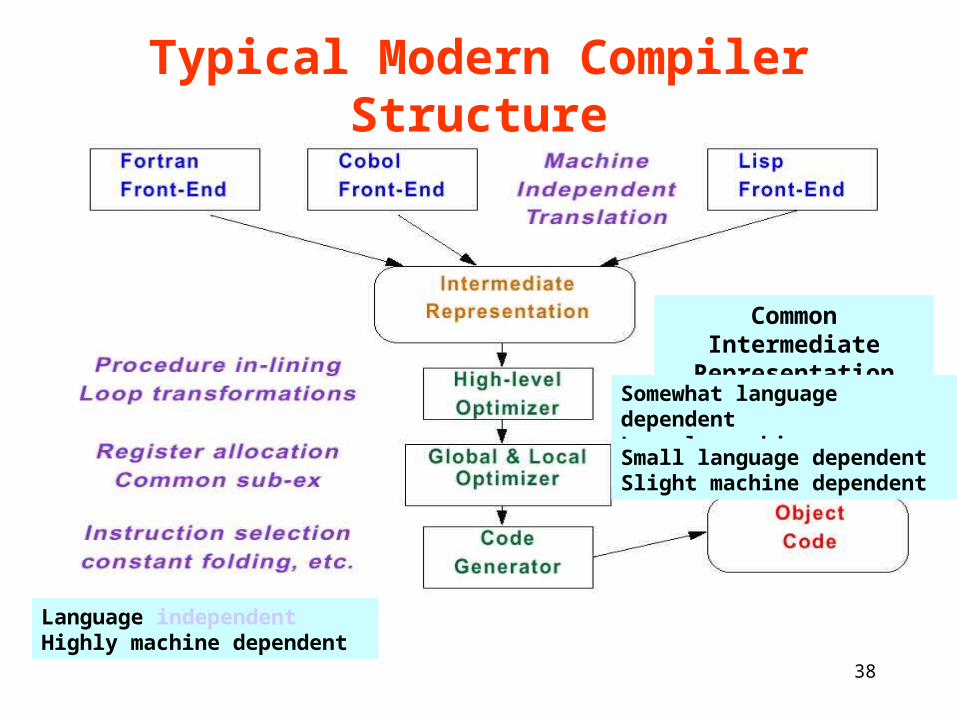
Typical Modern Compiler Structure
Common Intermediate Representation
Somewhat language dependentLargely machine independent
Small language dependentSlight machine dependent
Language independentHighly machine dependent

39
Typical Modern Compiler Structure (Cont.)
• Multi-pass structure easy to write bug-free compilers– Transform HL, more abstract representations, into progressively
low-level representations, eventually reaching the instruction set
• Compilers must make assumptions about the ability of later steps to deal with certain problems– Ex. 1 choose which procedure calls to expand inline before they
know the exact size of the procedure being called
– Ex. 2 Global common sub-expression elimination• Find two instances of an expression that compute the same
value and saves the result of the first one in a temporary– Temporary must be register, not memory (Performance)
– Assume register allocator will allocate temporary into register

40
Optimization Types• High level - done at source code level
– Procedure called only once - so put it in-line and save CALL
• Local - done on basic sequential block (straight-line code)– Common sub-expressions produce same value
– Constant propagation - replace constant valued variable with the constant - saves multiple variable accesses with same value
• Global - same as local but done across branches– Code motion - remove code from loops that compute same value
on each pass and put it before the loop
– Simplify or eliminate array addressing calculations in loop

41
Optimization Types (Cont.)• Register allocation
– Use graph coloring (graph theory) to allocate registers• NP-complete
• Heuristic algorithm works best when there are at least 16 (and preferably more) registers
• Processor-dependent optimization– Strength reduction: replace multiply with shift and add sequence
– Pipeline scheduling: reorder instructions to minimize pipeline stalls
– Branch offset optimization: Reorder code to minimize branch offsets

42
Register Allocation
• One the most important optimizations
• Based on graph coloring techniques– Construct graph of possible allocations to a register
– Use graph to allocate registers efficiently
– Goal is to achieve 100% register allocation for all active variables.
– Graph coloring works best when there are at least 16 general-purpose registers available for integers and more for floating-point variables.

43
Constant propagation
a:= 5; ...// no change to a so far.if (a > b) { . . . }
The statement (a > b) can be replaced by (5 > b). This could free a register when the comparison is executed.
When applied systematically, constant propagation can improve the code significantly.

44
Strength reduction
Example:
for (j = 0; j = n; ++j) A[j] = 2*j;
for (i = 0; 4*i <= n; ++i) A[4*i] = 0;
An optimizing compiler can replace multiplication by 4 by addition by 4.
This is an example of strength reduction.In general, scalar multiplications can be replaced by additions.

45
Major Types of Optimizations and Example in Each Class

46
Change in IC Due to Optimization
Level 1: local optimizations, code scheduling, and local register allocation
Level 2: global optimization, loop transformation (software pipelining), global register allocation
Level 3: + procedure integration

47
How can Architects Help Compiler Writers
• Provide Regularity– Address modes, operations, and data types should be
orthogonal (independent) of each other • Simplify code generation especially multi-pass• Counterexample: restrict what registers can be used for a certain
classes of instructions
• Provide primitives - not solutions– Special features that match a HLL construct are often un-
usable
– What works in one language may be detrimental to others

48
How can Architects Help Compiler Writers (Cont.)
• Simplify trade-offs among alternatives– How to write good code? What is a good code?
• Metric: IC or code size (no longer true) caches and pipeline…
– Anything that makes code sequence performance obvious is a definite win!
• How many times a variable should be referenced before it is cheaper to load it into a register
• Provide instructions that bind the quantities known at compile time as constants– Don’t hide compile time constants
• Instructions which work off of something that the compiler thinks could be a run-time determined value hand-cuffs the optimizer

49
Short Summary -- Compilers• ISA has at least 16 GPR (not counting FP registers) to
simplify allocation of registers using graph coloring
• Orthogonality suggests all supported addressing modes apply to all instructions that transfer data
• Simplicity – understand that less is more in ISA design – Provide primitives instead of solutions
– Simplify trade-offs between alternatives
– Don’t bind constants at runtime
• Counterexample – Lack of compiler support for multimedia instructions

50
MIPS ISAMIPS ISA

51
Growth of Processors
• Language of the Machine• We’ll be working with the
MIPS instruction set architecture– similar to other
architectures developed since the 1980's
– Almost 100 million MIPS processors manufactured in 2002
– used by NEC, Nintendo, Cisco, Silicon Graphics, Sony, …
1400
1300
1200
1100
1000
900
800
700
600
500
400
300
200
100
01998 2000 2001 20021999
Other
SPARC
Hitachi SH
PowerPC
Motorola 68K
MIPS
IA-32
ARM

52
MIPS Instruction Set (RISC)
• Instructions execute simple functions.• Maintain regularity of format – each instruction
is one word, contains opcode and arguments.• Minimize memory accesses – whenever possible
use registers as arguments.• Three types of instructions:
• Register (R)-type – only registers as arguments.• Immediate (I)-type – arguments are registers and numbers
(constants or memory addresses).• Jump (J)-type – argument is an address.

53
MIPS Arithmetic Instructions
• All instructions have 3 operands• Operand order is fixed (destination first)
Example:
C code: a = b + c
MIPS ‘code’: add a, b, c
(we’ll talk about registers in a bit)
“The natural number of operands for an operation like addition is three… requiring every instruction to have exactly three operands conforms to the philosophy of keeping the hardware simple”

54
Arithmetic Instr. (Continued)
• Design Principle: simplicity favors regularity.
• Of course this complicates some things...
C code: a = b + c + d;
MIPS code: add a, b, cadd a, a, d
• Operands must be registers (why?)
• 32 registers provided
• Each register contains 32 bits

55
Registers vs. Memory
Processor I/O
Control
Datapath
Memory
Input
Output
• Arithmetic instructions operands must be registers• 32 registers provided
• Compiler associates variables with registers.• What about programs with lots of variables? Must use memory.

56
Memory Instructions• Load and store instructions• Example:
C code: A[12] = h + A[8];
MIPS code: lw $t0, 32($s3) #addr of A in reg s3add $t0, $s2, $t0 #h in reg s2sw $t0, 48($s3)
• Can refer to registers by name (e.g., $s2, $t2) instead of number• Store word has destination last• Remember arithmetic operands are registers, not memory!
Can’t write: add 48($s3), $s2, 32($s3)

57
• Instructions, like registers and words of data, are also 32 bits long
– Example: add $t1, $s1, $s2– registers have numbers, $t1=8, $s1=17, $s2=18
• Instruction Format:
000000 10001 10010 01000 00000 100000
op rs rt rd shamt funct
Machine Language

58
MIPS64 Instruction FormatMIPS64 Instruction Format166 5 5
ImmediatertrsOpcode
6 5 5 5 5
Opcode rs rt rd func
6 26
Opcode Offset added to PC
J - Type instruction
R - type instruction
Jump and jump and link. Trap and return from exception
Register-register ALU operations: rd rs func rt Function encodes the data path operation: Add, Sub .. Read/write special registers and moves.
Encodes: Loads and stores of bytes, words, half words. All immediates (rd rs op immediate)Conditional branch instructions (rs1 is register, rd unused)Jump register, jump and link register (rd = 0, rs = destination, immediate = 0)
I - type instruction
6
shamt
0 5 6 10 11 15 16 31
0 5 6 10 11 15 16 20 21 25 26 31
0 5 6 31

59
Summary: MIPS Registers and Memory
$s0-$s7, $t0-$t9, $zero, Fast locations for data. In MIPS, data must be in registers to perform
32 registers $a0-$a3, $v0-$v1, $gp, arithmetic. MIPS register $zero always equals 0. Register $at is
$fp, $sp, $ra, $at reserved for the assembler to handle large constants.
Memory[0], Accessed only by data transfer instructions. MIPS uses byte
230 memoryMemory[4], ..., addresses, so sequential words differ by 4. Memory holds data
words Memory[4294967292] structures, such as arrays, and spilled registers, such as those
saved on procedure calls.

60
Summary: MIPS InstructionsMIPS assembly language
Category Instruction Example Meaning Commentsadd add $s1, $s2, $s3 $s1 = $s2 + $s3 Three operands; data in registers
Arithmetic subtract sub $s1, $s2, $s3 $s1 = $s2 - $s3 Three operands; data in registers
add immediate addi $s1, $s2, 100 $s1 = $s2 + 100 Used to add constants
load w ord lw $s1, 100($s2) $s1 = Memory[$s2 + 100]Word from memory to register
store w ord sw $s1, 100($s2) Memory[$s2 + 100] = $s1 Word from register to memory
Data transfer load byte lb $s1, 100($s2) $s1 = Memory[$s2 + 100]Byte from memory to register
store byte sb $s1, 100($s2) Memory[$s2 + 100] = $s1 Byte from register to memoryload upper immediate
lui $s1, 100 $s1 = 100 * 216 Loads constant in upper 16 bits
branch on equal beq $s1, $s2, 25 if ($s1 == $s2) go to PC + 4 + 100
Equal test; PC-relative branch
Conditional
branch on not equal bne $s1, $s2, 25 if ($s1 != $s2) go to PC + 4 + 100
Not equal test; PC-relative
branch set on less than slt $s1, $s2, $s3 if ($s2 < $s3) $s1 = 1; else $s1 = 0
Compare less than; for beq, bne
set less than immediate
slti $s1, $s2, 100 if ($s2 < 100) $s1 = 1; else $s1 = 0
Compare less than constant
jump j 2500 go to 10000 Jump to target address
Uncondi- jump register jr $ra go to $ra For sw itch, procedure return
tional jump jump and link jal 2500 $ra = PC + 4; go to 10000 For procedure call

61
Byte Halfword Word
Registers
Memory
Memory
Word
Memory
Word
Register
Register
1. Immediate addressing
2. Register addressing
3. Base addressing
4. PC-relative addressing
5. Pseudodirect addressing
op rs rt
op rs rt
op rs rt
op
op
rs rt
Address
Address
Address
rd . . . funct
Immediate
PC
PC
+
+
2004 © Morgan Kaufman Publishers
Addressing Modes







