
1
Introduction to Supercomputing at ARSC
Kate Hedstrom, Arctic Region Supercomputing Center
(ARSC)[email protected]
Jan, 2004

2
Topics• Introduction to Supercomputers at ARSC
– Computers• Accounts
– Getting an account– Kerberos– Getting help
• Architectures of parallel computers– Programming models
• Running Jobs – Compilers– Storage– Interactive and batch

3
Introduction to ARSC Supercomputers
• They’re all Parallel Computers• Three Classes:
– Shared Memory – Distributed Memory– Distributed & Shared Memory

4
Cray X1: klondike
• 128 MSPs• 4 MSP/node• 4 Vector CPU/MSP, 800 MHz• 512 GB Total• 21 TB Disk• 1600 GFLOPS peak
•NAC required

5
Cray SX-6: rime• 8 500MHz NEC
Vector CPUs• 64 GB of shared
memory• 1 TB RAID-5 Disk• 64 GFLOPS peak• Only one in the USA• On loan from Cray• Non-NAC

6
Cray SV1ex: chilkoot
• 32 Vector CPUs, 500 MHz
• 32 GB Shared memory
• 2 TB Disk• 64 GFLOPS peak• NAC required

7
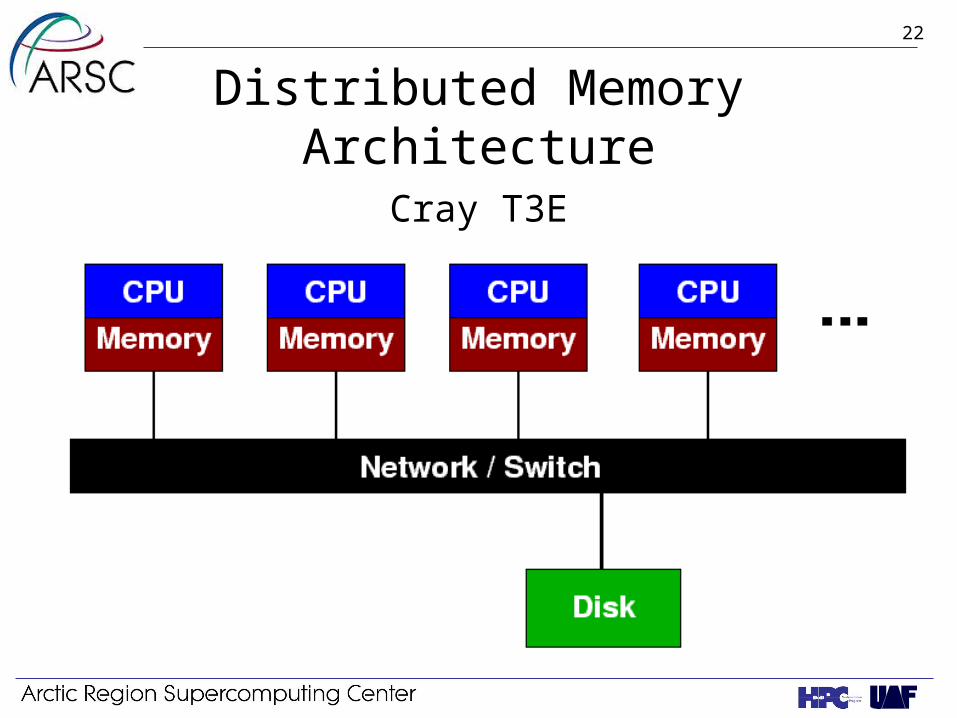
Cray T3E: yukon
• 272 CPUs, 450 MHz
• 256 MB per processor
• 69.6 GB total distributed memory
• 230 GFLOPS peak
• NAC required

8
IBM Power4: iceberg• 2 nodes of 32 p690+s, 1.7 GHz (2 cabinets)
256 GB each• 92 nodes of 8 p655+s, 1.5 GHz (6 cabinets)• 6 nodes of 8 p655s
1.1 GHz (1 cabinet)• 16 GB Mem/Node• 22 TB Disk• 5000 GFLOPS• NAC required

9
IBM Regatta: iceflyer• 8-way, 16GB front end
coming soon• 32 1.7 GHz Power4
CPUs in – 24-way SMP node– 7-way interactive node – 1 test node– 32-way SMP node soon
• 256 GB Memory• 217 GFLOPS• Non-NAC

10
IBM SP Power3: icehawk• 50 4-Way SMP Nodes
=> 200 CPUs, 375 MHz
• 2 GB Memory/Node• 36 GB Disk/Node • 264 GFLOPS peak for
176 CPUs (max per job)
• Leaving soon• NAC required

11
Storing Files• Robotic
tape silos• Two Sun
storage servers
• Nanook – Non-NAC
systems
• Seawolf– NAC
systems

12
Accounts, Logging In
• Getting an Account/Project• Doing a NAC• Logging in with Kerberos

13
Getting an Account/Project
• Academic Applicant for resources is a PI:– Full time faculty or staff research person
– Non-commercial work, must reside in USA
– PI may add users to their project– http://www.arsc.edu/support/accounts/acquire.html
• DoD Applicant– http://www.hpcmo.hpc.mil/Htdocs/SAAA
• Commercial, Federal, State– Contact User Services Director
– Barbara Horner-Miller, [email protected]
– Academic guidelines apply

14
Doing a National Agency Check (NAC)
• Required for HPCMO Resources only– Not required for workstations, Cray SX-6, or IBM Regatta
• Not a security clearance– But there are detailed questions covering last 5-7 years
• Electronic Personnel Security Questionnaire (EPSQ)– Windows only software
• Fill out EPSQ cover sheet– http://www.arsc.edu/support/policy/pdf/OPM_Cover.pdf
• Fingerprinting, Proof of Citizenship (passport, visa, etc.)– See http://www.arsc.edu/support/policy/accesspolicy.html

15
Logging in with Kerberos
• On non-ARSC systems, download kerberos5 client– http://www.arsc.edu/support/howtos/krbclients.html
• Used with SecureID– Uses a pin to generate a key at login time
• Login requires user name, pass phrase, & key– Don’t share your pin or SecureID with anyone
• Foreign Nationals or others with problems– Contact ARSC to use ssh to connect to ARSC gateway– Still need Kerberos & SecureID after connecting

16
SecureID

17
From ARSC System
• Enter username• Enter <return> for principle• Enter pass phrase• Enter SecureID passcode• From that system:
ssh iceflyer• ssh handles X11 handshaking
From ARSC System

18
From Your System
• Get Kerberos clients installed• Get ticket
kinit [email protected]• See tickets
klist• Login into arsc system
krlogin -l username iceflyerssh -l username iceflyerktelnet -l username iceflyer

19
Rime and Rimegate
• Log into rimegate as usual, with your rimegate username (arscxxx)ssh -l arscksh rimegate
• Compile on rimegate (sxf90, sxc++)• Log into rime from rimegate
ssh rime
• Rimegate $HOME is /rimegate/users/username on rime

20
Supercomputer Architectures
• They’re all Parallel Computers• Three Classes:
– Shared Memory – Distributed Memory– Distributed & Shared Memory

21
Shared Memory ArchitectureCray SV1, SX-6, IBM Regatta
22
Distributed Memory Architecture Cray T3E

23
Cluster ArchitectureIBM iceberg, icehawk, Cray X1
• Scalable, distributed, shared-memory parallel processor

24
Programming Models
• Vector Processing– compiler detection or manual directives
• Threaded Processing (SMP)– OpenMP, Pthreads, java threads– shared memory only
• Distributed Processing (MPP)– message passing with MPI– shared or distributed memory

25
Vector Programming
• Vector CPUs are specialized for array/matrix operations– 64-element (SV1, X1), 256-element (SX-6) Vector Registers
– Operations proceed assembly-line fashion
– High memory-to-CPU bandwidth
• Less CPU time wasted waiting for data from memory
– Once loaded, produces one result per clock cycle
• Compiler does a lot of the work

26
Vector Programming
• Codes will run without modification.• Cray compilers automatically detect loops
which are safe to vectorize.• Request listing file to find out what vectorized.• Programmer can assist the compiler:
– Directives and pragmas can force vectorization– Eliminate conditions which inhibit vectorization (e.g.,
subroutine calls and data dependencies in loops)

27
Threaded Programming on Shared-Memory Systems
• OpenMP – Directives/pragmas added to serial programs
– A portable standard implemented on Cray (one node), SGI, IBM (one node), etc...
• Other Threaded Paradigms– Java Threads
– Pthreads

28
OpenMP Fortran Example!$omp parallel do do n = 1,10000 A(n) = x * B(n) + c end do___________________________________________________
On 2 CPUS, this pragma divides work as follows:On 2 CPUS, this pragma divides work as follows:CPU 1:CPU 1:
do n = 1,5000 A(n) = x * B(n) + c end do
CPU 2:
do n = 5001,10000 A(n) = x * B(n) + c end do

29
OpenMP C Example
#pragma omp parallel forfor (n = 0; n < 10000; n++) A[n] = x * B[n] + c;___________________________________________________
On 2 CPUS, this pragma divides work as follows:On 2 CPUS, this pragma divides work as follows:CPU 1:CPU 1:
for (n = 0; n < 5000; n++) A[n] = x * B[n] + c;CPU 2:
for (n = 5000; n < 10000; n++) A[n] = x * B[n] + c;

30
Threads Dynamically Appear and DisappearNumber set by Environment

31
Distributed ProcessingConcept:1) Divide the problem
explicitly2) CPUs Perform
tasks concurrently3) Recombine results4) All processors may
or may not be doing the same thing
Branimir Gjetvaj

32
Distributed Processing
• Data needed by a given CPU must be stored in the memory associated with that CPU
• Performed on distributed or shared memory computer
• Multiple copies of code are running• Messages/data are passed between CPUs• Multi-level: can be combined with vector
and/or OpenMP

33
• Initialization
• Simple send/receive
! Processor 0 sends individual messages to others if (my_rank == 0) then do dest = 1, npes-1 call mpi_send(x, max_size, MPI_FLOAT, dest, 0, comm, ierr); end do else call mpi_recv(x, max_size, MPI_FLOAT, 0, 0, comm, status, ierr); end if
call mpi_init(ierror) call mpi_comm_size (MPI_COMM_WORLD, npes, ierror); call mpi_comm_rank (MPI_COMM_WORLD, my_rank, ierror);
Distributed Processing using MPI (Fortran)

34
• Initialization
• Simple send/receive
/* Processor 0 sends individual messages to others */ if (my_rank == 0) { for (dest = 1; dest < npes; dest++) { MPI_Send(x, max_size, MPI_FLOAT, dest, 0, comm); } } else { MPI_Recv(x, max_size, MPI_FLOAT, 0, 0, comm, &status); }
MPI_Init(&argc, &argv); MPI_Comm_size (MPI_COMM_WORLD, &npes); MPI_Comm_rank (MPI_COMM_WORLD, &my_rank);
Distributed Processing using MPI (C)
35
Number of Processes ConstantNumber set by Environment

36
Message Passing Activity Example

37
Cluster Programming
• Shared-memory between processors on one node:– OpenMP, threads, or MPI
• Distributed-memory methods between processors on multiple nodes – MPI
• Mixed mode– MPI distributes to nodes, OpenMP within node

38
Programming Environments
• Compilers• File Systems• Running jobs
– Interactive
– Batch
• See individual machine documentation– http://www.arsc.edu/support/resources/hardware.html

39
Cray Compilers• SV1, T3E
– f90, cc, CC
• X1– ftn, cc, CC
• SX-6 front end (rimegate)– sxf90, sxc++
• SX-6 (rime)– f90, cc, c++
• No extra flags for MPI, OpenMP

40
IBM Compilers• Serial
– xlf, xlf90, xlf95, xlc, xlC
• OpenMP– Add -qsmp=omp, _r extension for thread-
safe libraries, e.g. xlf_r
• MPI– mpxlf, mpxlf90, mpxlf95, mpcc, mpCC
• Might be best to always use _r extension (mpxlf90_r)

41
File Systems• Local storage
– $HOME– /tmp or /wrktmp or /wrkdir -> $WRKDIR– /scratch -> $SCRATCH
• Permanent storage– $ARCHIVE
• Quotas– quota -v on Cray– qcheck on IBM

42
Running a job
• Get files from $ARCHIVE to system’s disk• Keep source in $HOME, but run in $WRKDIR• Use $SCRATCH for local-to-node temporary
files, clean up before job ends• Put results out to $ARCHIVE• $WRKDIR is purged

43
Iceflyer Filesystems
• Smallish $HOME• Larger /wrkdir/username• $ARCHIVE for longterm storage,
especially larger files• qcheck to check quotas

44
SX6 Filesystems
• Separate from the rest of ARSC systems
• Rimegate has /home, /scratch• Rime mounts them as
/rimegate/home, /rimegate/scratch• Rime has own home, /tmp, /atmp,
etc.

45
Interactive
• Works on the command line• Limits exist on resources
(time, # cpus, memory)• Good for debugging• Larger jobs must be submitted to the
batch system

46
Batch Schedulers
• Cray: NQS– Commands:
• qsub, qstat, qdel
• IBM: LoadLeveler– Commands:
• llclass, llq, llsubmit, llcancel, llmap, xloadl

47
NQS Script (rime)
#@$-q batch # job queue class#@$-s /bin/ksh # which shell#@$-eo # stdout and stderr together#@$-lM 100 MW #@$-lT 30:00 # time requested h:m:s#@$-c 8 # 8 cpus#@$ # required last command
# beginning of shell script
cd $QSUB_WORKDIR # cd to submission directory
export F_PROGINF=DETAILexport OMP_NUM_THREADS=8
./my_job

48
NQS Commands
• qstat to find out job status, list of queues
• qsub to submit job• qdel to delete job from queue

49
LoadLeveler Script (iceflyer)
#!/bin/ksh#@ total_tasks = 4#@ node_usage = shared#@ wall_clock_limit = 1:00:00#@ job_type = parallel#@ output = out.$(jobid)#@ error = err.$(jobid)#@ class = large#@ notification = error#@ queue
poe ./my_job

50
Loadleveler Commands
• llclass to find list of classes• llq to see list of jobs in queue• llsubmit to submit job• llcancel to delete job from queue• llmap is local program to see load on
machine• xloadl X11 interface to loadleveler

51
Getting Help
• Consultants and Specialists are here to serve YOU– [email protected]
– 907-474-5102
• http://www.arsc.edu/support/support.html

52
Homework
• Make sure you can log into– iceflyer– rimegate– rime
• Ask consultants for help if necessary







