Download - 第13回数学カフェ「素数!!」二次会 LT資料「乱数!!」

第353回 確率統計カフェ 「乱数!!」
2016/5/7 Ken’ichi Matsui (@kenmatsu4)




https://twitter.com/_inundata/status/616658949761302528

https://twitter.com/_inundata/status/616658949761302528

x1, x2, · · · , xn xn+1




M
xj+1 := axj + c mod M
a = 1103515245, c = 12345,M = 231
231

xj+1 := axj + c mod M
231
Ma = 1103515245, c = 12345,M = 231

219937 � 1
xk+n := xk+m � (xku | xk+1
l)A k = 0, 1, . . .
219937 � 1

xk+n := xk+m � (xku | xk+1
l)A k = 0, 1, . . .
A =
✓0 Iw�1
aw�1 (aw�2, . . . , a0)
◆
w
=
0
BBBBBBBBB@
0 1 · · · 0...
0...
. . ....
...0 0 · · · 1
aw�1 aw�2 · · · a0
1
CCCCCCCCCA
1 m < n
0 r w � 1
xA =
(shiftright(x)
shiftright(x) + a
xi = (xi(w�1), xi(w�2), · · · , xi(0)) xi(j) 2 {0, 1}

y := x� ((x >> u)&d)
y := y � ((y << s)&b)
y := y � ((y << t)&c)
z := y � (y >> l)
x

y := x� ((x >> u)&d)
y := y � ((y << s)&b)
y := y � ((y << t)&c)
z := y � (y >> l)
(w, n,m, r) = (32, 624, 397, 31)
a = 9908B0DF16
(u, d) = (11,FFFFFFFF16)
(s, b) = (7, 9D2C568016)
(t, c) = (15,EFC6000016)
l = 18
xk+n := xk+m � (xku | xk+1
l)A k = 0, 1, . . .
A =
✓0 Iw�1
aw�1 (aw�2, . . . , a0)
◆
w = 32, n = 624,m = 397, r = 31
nw � r = 19937
2nw�r � 1
219937 � 1
w = 32, n = 624,m = 397, r = 31

y := x� ((x >> u)&d)
y := y � ((y << s)&b)
y := y � ((y << t)&c)
z := y � (y >> l)
(w, n,m, r) = (32, 624, 397, 31)
a = 9908B0DF16
(u, d) = (11,FFFFFFFF16)
(s, b) = (7, 9D2C568016)
(t, c) = (15,EFC6000016)
l = 18
xk+n := xk+m � (xku | xk+1
l)A k = 0, 1, . . .
A =
✓0 Iw�1
aw�1 (aw�2, . . . , a0)
◆
w = 32, n = 624,m = 397, r = 31
nw � r = 19937
2nw�r � 1
219937 � 1
w = 32, n = 624,m = 397, r = 31




x = 1 x = 0
f(x; p) =
8<
:p if x = 1,
1� p if x = 0.
f(x; p) = p
x(1� p)1�x
, x = {0, 1}
x
p
p
1� p




http://www.math.wm.edu/~leemis/2008amstat.pdf
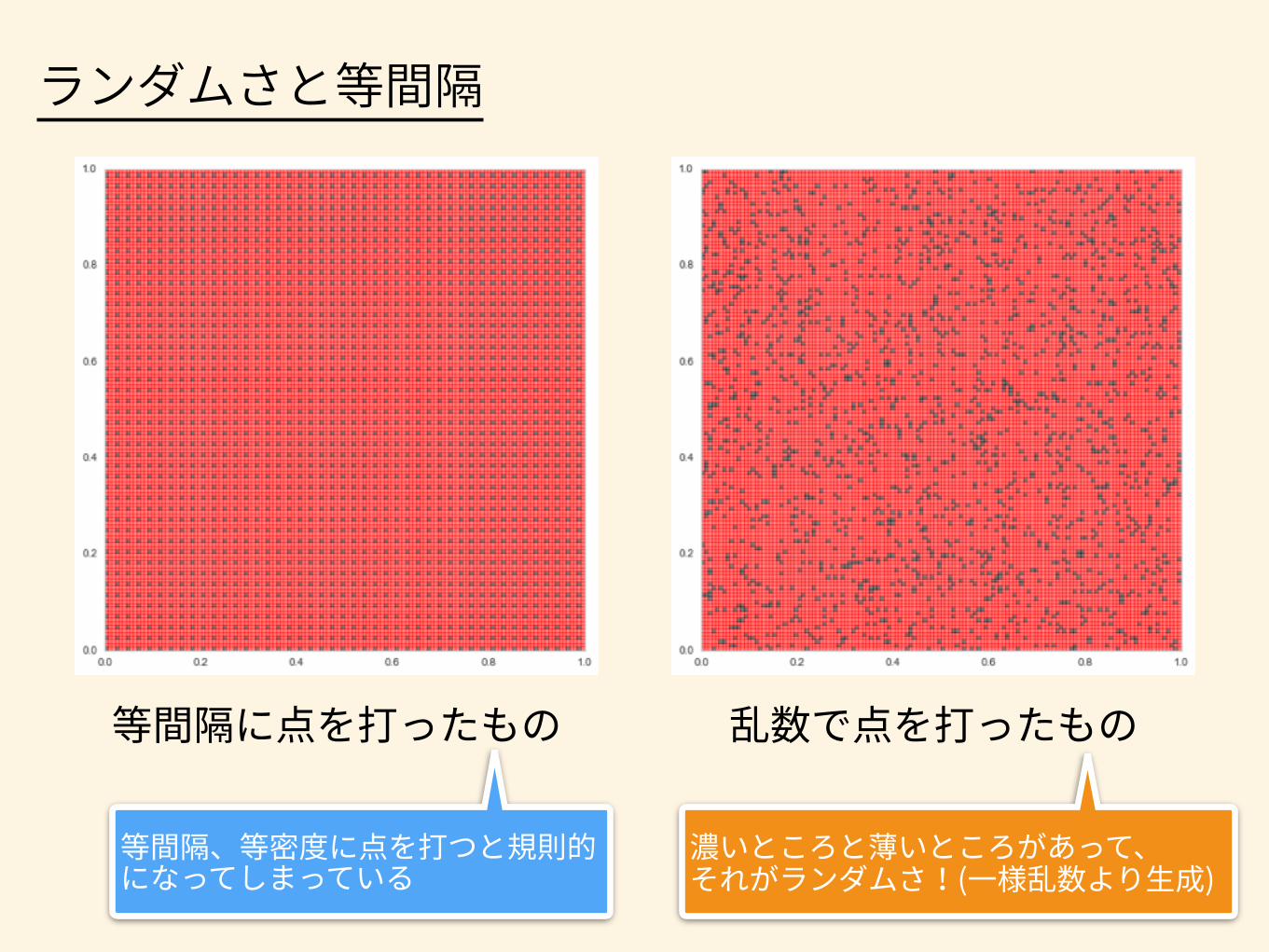
確率分布 曼荼羅
76個 有り〼



P (X = x) = p
x(1� p)1�x
(x = 0, 1)


p = 0.7 trial_size = 10000 set.seed(71)
data <-‐ rbern(trial_size, p)
dens <-‐ data.frame(y=c((1-‐p),p)*trial_size, x=c(0, 1))
ggplot() + layer(data=data.frame(x=data), mapping=aes(x=x), geom="bar", stat="bin", bandwidth=0.1 ) + layer(data=dens, mapping=aes(x=x, y=y), geom="bar", stat="identity", width=0.05, fill="#777799", alpha=0.7)


P (X = x) =n
C
r
p
x(1� p)n�x
(x = 1, 2, · · · , n)


p = 0.7 trial_size = 10000 sample_size = 30 set.seed(71)
gen_binom_var <-‐ function() { return(sum(rbern(sample_size, p))) } result <-‐ rdply(trial_size, gen_binom_var())
dens <-‐ data.frame(y=dbinom(seq(sample_size), sample_size, 0.7))*trial_size
ggplot() + layer(data=resuylt, mapping=aes(x=V1), geom="bar", stat = "bin", binwidth=1, fill="#6666ee", color="gray" ) + layer(data=dens, mapping=aes(x=seq(sample_size)+.5, y=y), geom="line", stat="identity", position="identity",colour="red" ) + ggtitle("Bernoulli to Binomial.")


f(x) =
⇢1 (0 x 1)
0 (otherwise)

Z = x1(1/2)1 + x2(1/2)
2 + · · ·+ xq(1/2)q

width <-‐ 0.02 p <-‐ 0.5; sample_size <-‐ 1000 trial_size <-‐ 100000
gen_unif_rand <-‐ function() {
return (sum(rbern(sample_size, p) * (rep(1/2, sample_size) ** seq(sample_size)))) }
gen_rand <-‐ function(){ return( rdply(trial_size, gen_unif_rand()) ) } system.time(res <-‐ gen_rand())
ggplot() + layer(data=res, mapping=aes(x=V1), geom="bar", stat = "bin", binwidth=width, fill="#6666ee", color="gray" ) + ggtitle("Bernoulli to Standard Uniform")


(0 < x < 1)
Xi ⇠ U(0, 1)iid (i = 1, 2, · · · ,↵+ � � 1)
f(x,↵,�) =1
B(↵,�)x
↵�1(1� x)��1


width <-‐ 0.03; p <-‐ 0.5 digits_length <-‐ 30; set_size <-‐ 3 trial_size <-‐ 30000 gen_unif_rand <-‐ function() {
return (sum(rbern(digits_length, p) * (rep(1/2, digits_length) ** seq(digits_length)))) } gen_rand <-‐ function(){ return( rdply(set_size, gen_unif_rand())$V1 ) }
unif_dataset <-‐ rlply(trial_size, gen_rand, .progress='text') p <-‐ ceiling(set_size * 0.5); q <-‐ set_size -‐ p + 1 get_nth_data <-‐ function(a){ return(a[order(a)][p]) } disp_data <-‐ data.frame(lapply(unif_dataset, get_nth_data)) names(disp_data) <-‐ seq(length(disp_data)); disp_data <-‐ data.frame(t(disp_data)) names(disp_data) <-‐ "V1" x_range <-‐ seq(0, 1, 0.001)
dens <-‐ data.frame(y=dbeta(x_range, p, q)*trial_size*width) ggplot() + layer(data=disp_data, mapping=aes(x=V1), geom="bar", stat = "bin", binwidth=width, fill="#6666ee", color="gray" ) + layer(data=dens, mapping=aes(x=x_range, y=y), geom="line", stat="identity", position="identity", colour="red" ) + ggtitle("Bernoulli to Beta")


P (X = x) = p
x(1� p)1�x
p, 1� p
p ⇠ Beta(↵,�)
p, 1� pp, 1� p

P
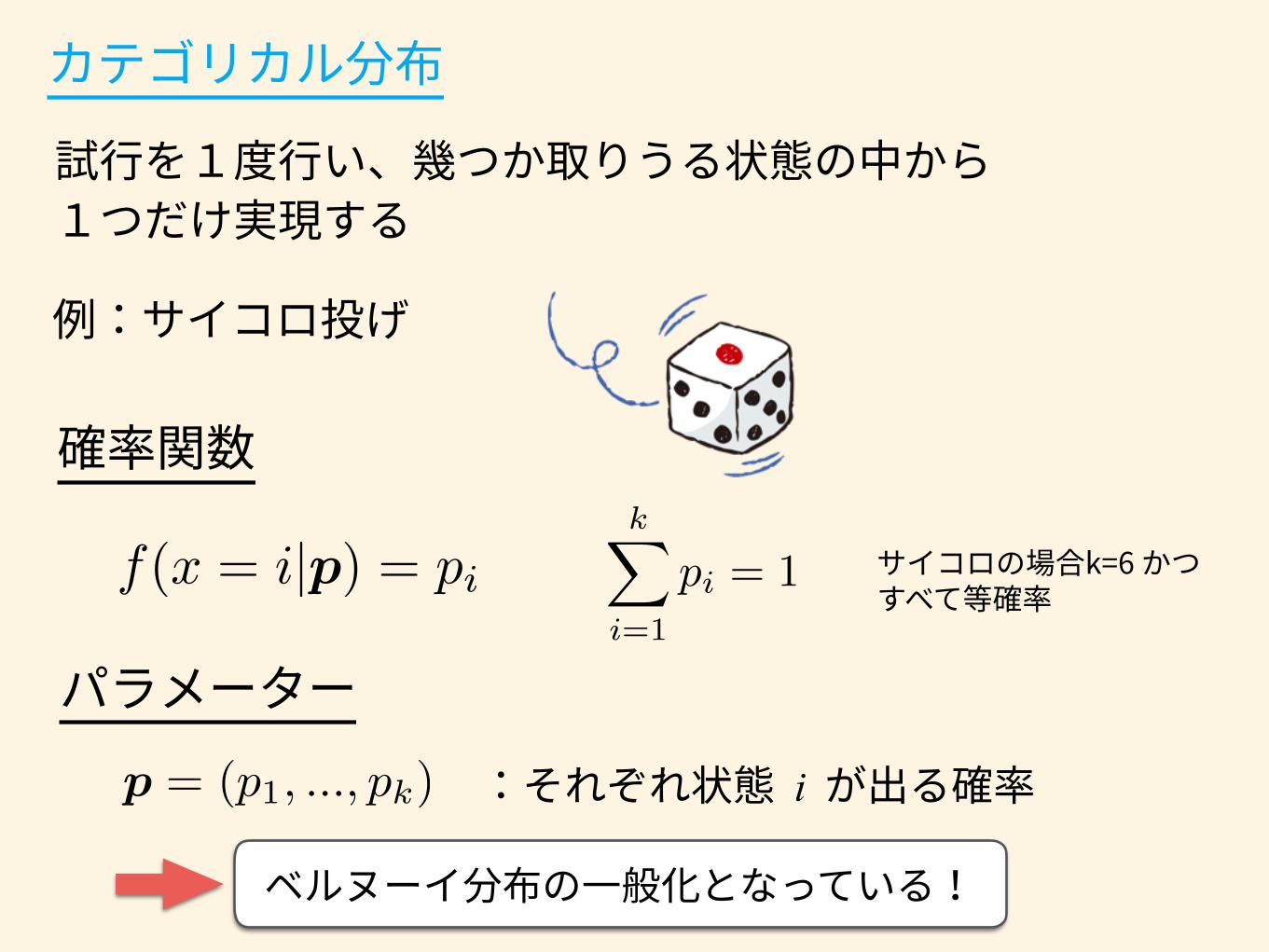
i
f(x = i|p) = pi
p = (p1, ..., pk)
kX
i=1
pi = 1
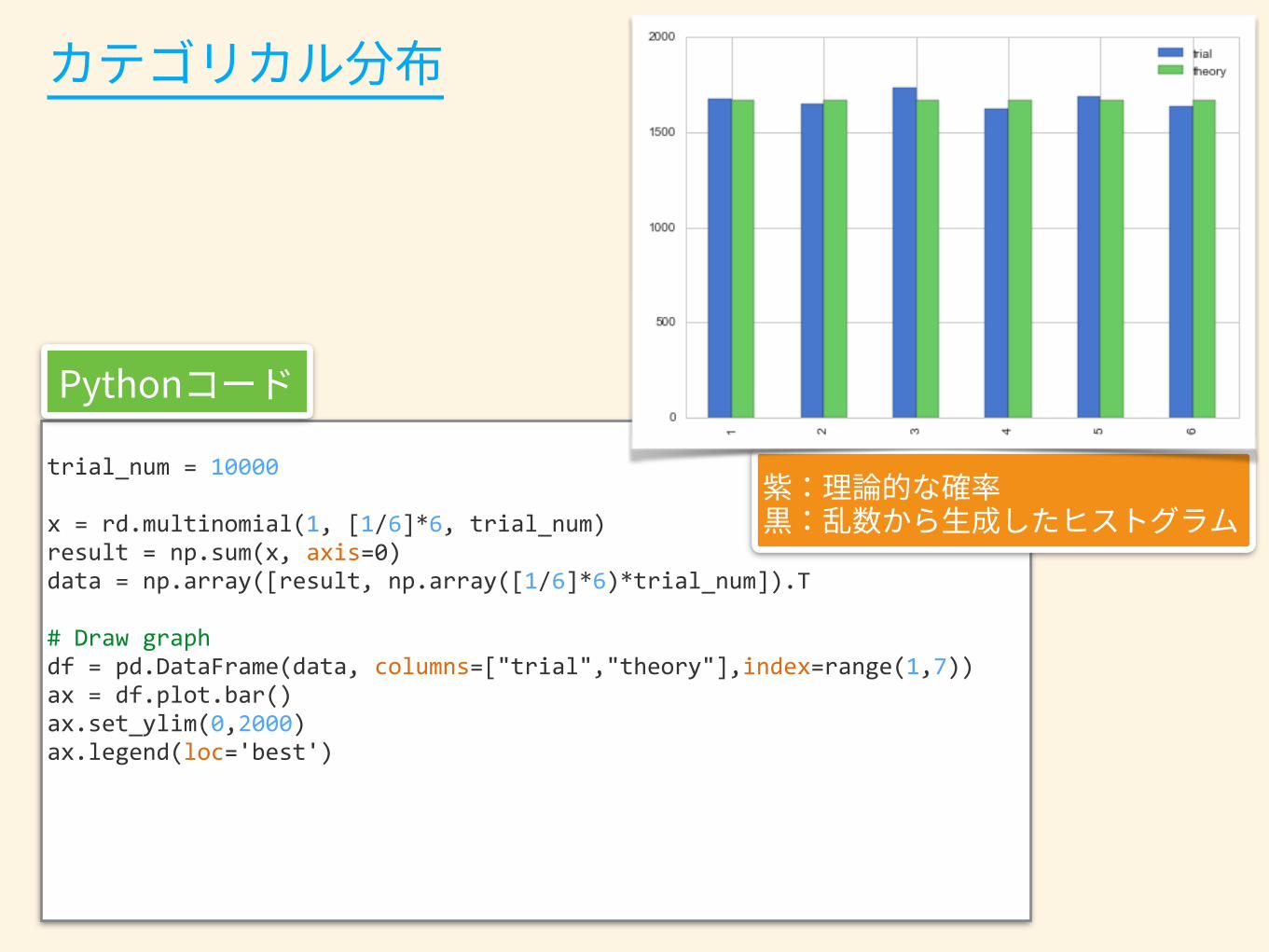
trial_num = 10000
x = rd.multinomial(1, [1/6]*6, trial_num) result = np.sum(x, axis=0) data = np.array([result, np.array([1/6]*6)*trial_num]).T
# Draw graph df = pd.DataFrame(data, columns=["trial","theory"],index=range(1,7)) ax = df.plot.bar() ax.set_ylim(0,2000) ax.legend(loc='best')

P
P

ip = (p1, ..., pk)n
結果の例([[4, 1, 1, 5, 5, 2], [3, 3, 2, 4, 3, 3], [1, 4, 3, 4, 3, 3],
..., [3, 3, 4, 2, 3, 3], [3, 3, 2, 3, 4, 3],
[1, 3, 4, 3, 4, 3]])f(x;p) =
(n!
x1!···xk!p
x11 · · · pxk
k
when
Pk
i=1 xi
= n
0 otherwise.

P
P

↵ = (↵1,↵2, · · · ,↵K)
f(p;↵) =1
B(↵)
KY
i=1
p↵i�1i
pi � 0,X
pi = 1


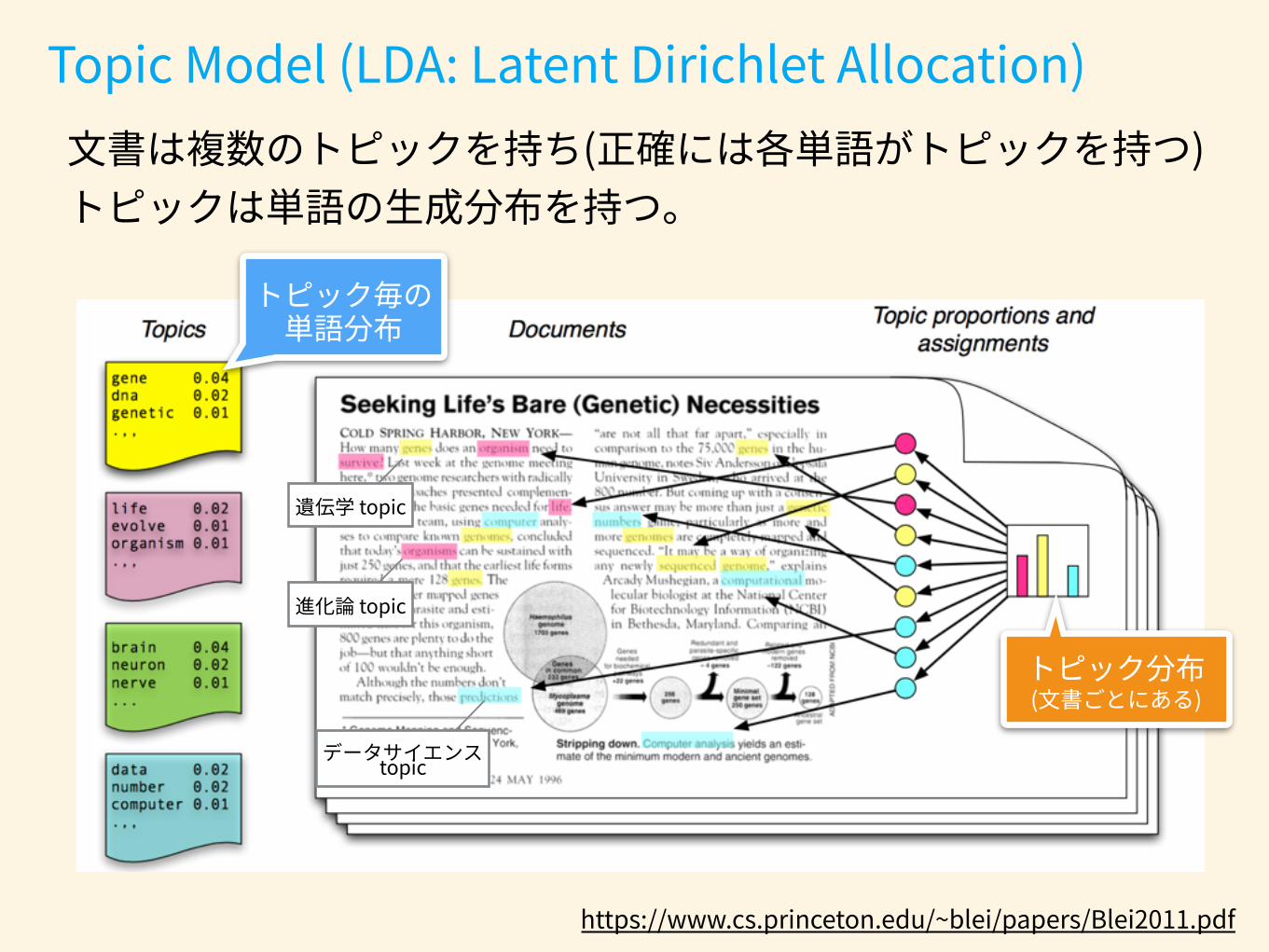

z� w�θ�α�
β� φ�
N� D�:"Observed"variables�
:"Unknown"parameters�
:"Hyper"parameters�
word�topic�topic"generate distribu;on�
word"generate distribu;on�

doc word freq0 128 20 129 20 130 20 131 10 5 10 134 20 7 20 137 10 139 10 140 10 141 10 14 10 16 20 18 20 19 30 20 10 23 10 26 60 28 30 31 20 32 70 36 10 37 10 38 10 42 50 44 10 45 40 46 20 47 30 49 10 52 50 53 10 9 10 57 10 6 10 59 20 60 10 61 10 66 30 67 10 68 10 69 10 70 60 72 20 75 10 76 10 78 10 79 50 81 20 82 10 83 20 84 20 85 20 55 10 89 20 90 10 91 10 92 10 93 10 94 40 95 20 96 30 98 140 99 10 100 20 101 50 103 70 104 40 105 30 106 10 107 1
doc word freq98 142 199 129 199 131 499 5 299 134 399 1 299 136 199 137 199 10 199 139 199 13 199 16 199 3 199 20 199 22 199 25 199 27 199 28 299 29 199 30 299 133 199 36 399 37 199 42 399 45 699 46 199 47 299 8 199 115 299 52 199 53 199 138 199 55 499 57 299 61 199 63 199 67 199 69 199 70 199 72 299 73 199 74 299 75 399 76 499 77 199 79 399 84 399 85 199 89 199 91 399 94 599 144 199 98 299 99 399 101 199 102 299 103 499 105 199 107 199 108 299 109 199 111 199 114 299 19 299 116 299 118 399 119 199 121 199 9 199 123 199 127 1

data { int<lower=2> K; # num topics int<lower=2> V; # num words int<lower=1> M; # num docs int<lower=1> N; # total word instances int<lower=1,upper=V> W[N]; # word n int<lower=1> Freq[N]; # frequency of word n int<lower=1,upper=N> Offset[M,2]; # range of word index per doc vector<lower=0>[K] Alpha; # topic prior vector<lower=0>[V] Beta; # word prior } parameters { simplex[K] theta[M]; # topic dist for doc m simplex[V] phi[K]; # word dist for topic k } model { # prior for (m in 1:M) theta[m] ~ dirichlet(Alpha); for (k in 1:K) phi[k] ~ dirichlet(Beta);
# likelihood for (m in 1:M) { for (n in Offset[m,1]:Offset[m,2]) { real gamma[K]; for (k in 1:K) gamma[k] <-‐ log(theta[m,k]) + log(phi[k,W[n]]); increment_log_prob(Freq[n] * log_sum_exp(gamma)); } } }





✓ �

✓

�











