docker datascience pipeline · save docker image(s) to docker registry move serialized model to...
TRANSCRIPT

Docker Datascience Pipeline
Running datascience models on Docker at ING BIG DATA Conference Vilnius 2018

• Lennard Cornelis
• Big Data Engineer at ING
• DB2, Oracle, AIX, Linux, Hadoop, Hive, Sqoop, Ansible
• Let it all work on the Exploration Environment
• @chiefware
Lets introduce myself
2

Asking yourself how to get to production
Depending on different tools
Why I think you are here
3
You are running Datascience models
Interested in Docker
Asking yourself how to get to production

What is Docker
4
Docker is a tool designed to make it easier to create, deploy, and run applications by using containers. Containers allow a developer to package up an application with all of the parts it needs, such as libraries and other dependencies, and ship it all out as one package. By doing so, thanks to the container, the developer can rest assured that the application will run on any other Linux machine regardless of any customized settings that machine might have that could differ from the machine used for writing and testing the code

Agile way of working in Squads,Chapters and Tribes
5

big data prototype environment
6
Gitlab runner
Citrix Server
Dev node
Hadoop
Artifactory
Gitlab
Automation Server
Access to cluster rdp, browser, putty
Node for datascientists with tools and xrdp
Datanode cluster
Datanode cluster
Pip repo
Datasciences projects
Details about processServer

Pipeline
7
PrototypingDevelopment
TestAcceptance Production
wa
it t
ime
wa
it t
ime
wa
it t
ime
failu
re
failu
re
failu
re

Docker on big data prototype environment
8
Gitlab runner
Citrix Server
Dev node
Hadoop
Openshift
POD/JOB
Artifactory
Gitlab
Automation Server
Access to cluster rdp, browser, putty
Node for datascientists with tools and xrdp
Datanode cluster
Orchestration Containers
docker containers
Docker base Images
Docker files and Datasciences projects

Netezza
Hive
Rapid experimentation
Live modelDeploymen
t
Code versioning
Build Docker image(s) through Gitlab CI/Jenkins
Put serialized model in shared
directory
Save Docker image(s) to
Docker Registry
Move serialized model to HDFS
Data versioning
On each commit
Train and validate model
Setup environment
Docker Registry
Tivoli scheduler
triggers
Monithor
HDFS
Add link to file to Monithor
Add model metrics to Monithor
Git repository with Hive queries
Feature engineering
Data exploration
Cookiecutter
Workspace management
Data service
Retraining
Revalidation
Monitoring
FallbackDS code library
Structured way of
keeping track of dev
models
Continuous Integration
(testing)
Early CD facilitation
Construct pipeline
(Pachyderm or APApeline)
Create virtual environment per project
Checkpointing
Development Continuous Deployement Live
9
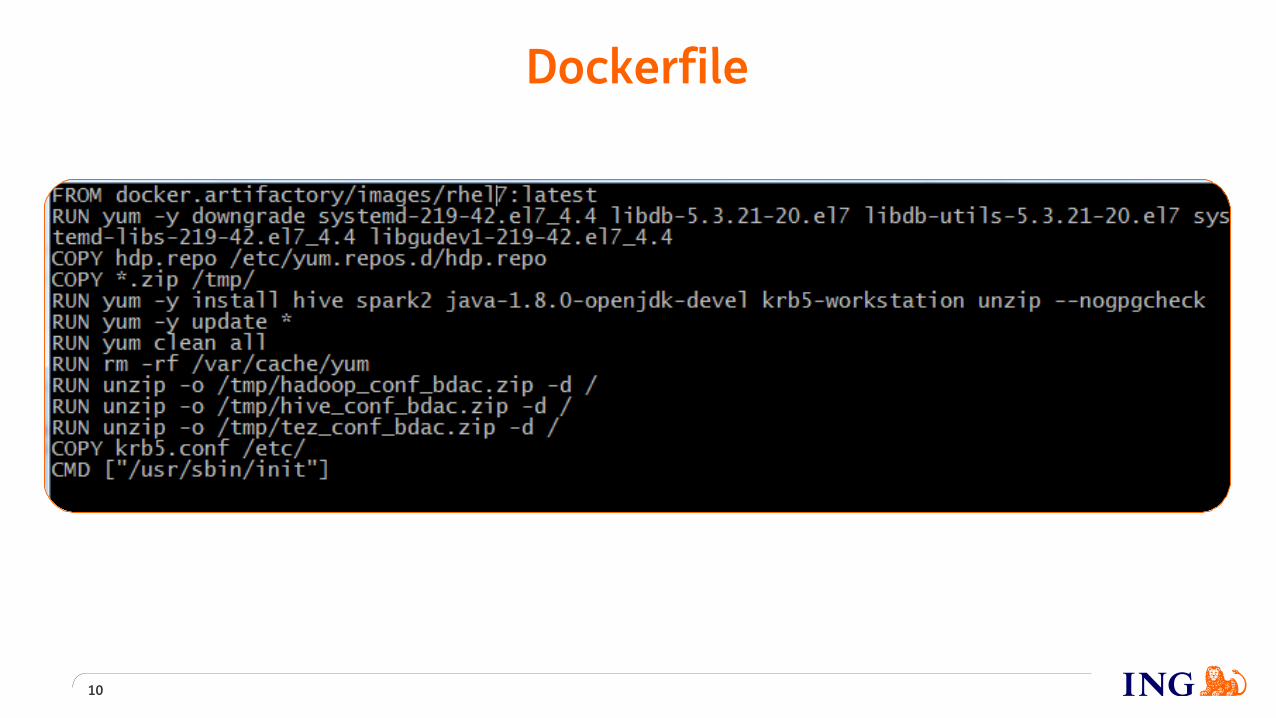
Dockerfile
10

Gitlab runner
11
To register run:gitlab-runner registergitlab-runner list

Gitlab runner
12
.gitlab-ci.yml

Spark
13
• Only submit and forget works in Docker
• spark-submit deploy-mode cluster master yarn
• kinit your keytab file for Kerberos
• create virtual env with conda and zip

Openshift
14
PODS and JOBS

Demo Time
15

considerations
16
Jenkins instead of gitlab-runner
Add gpu nodes to openshift
How to use scheduler tool
How to handle Kerberos files

17
Questions?