distributed systems - brown university
TRANSCRIPT

DistributedSystemsDay17:Distributed FileSystems+IndustryApplications

Life….InMeetingsandSeminars

IndustryStorageSystems
GFS[2003]
Dynamo[2007]
BigTable[2008]
Cassandra[2008]
MegaStore[2011]
NoSQLDBFastDistributedTransactions
NoSQL+RDBMS
Spanner[2012]
Orleans[2013]

GFS:GoogleSearch:IndexBuilding
• GFS:• Downloadallwebsitesà Append-onlywrites+verylargefiles
• Youdon’tgobackandalterdownloaded pages• Build Index:Scanfilestobuild indexà sequential reads
https://www.google.com/search/howsearchworks/crawling-indexing/
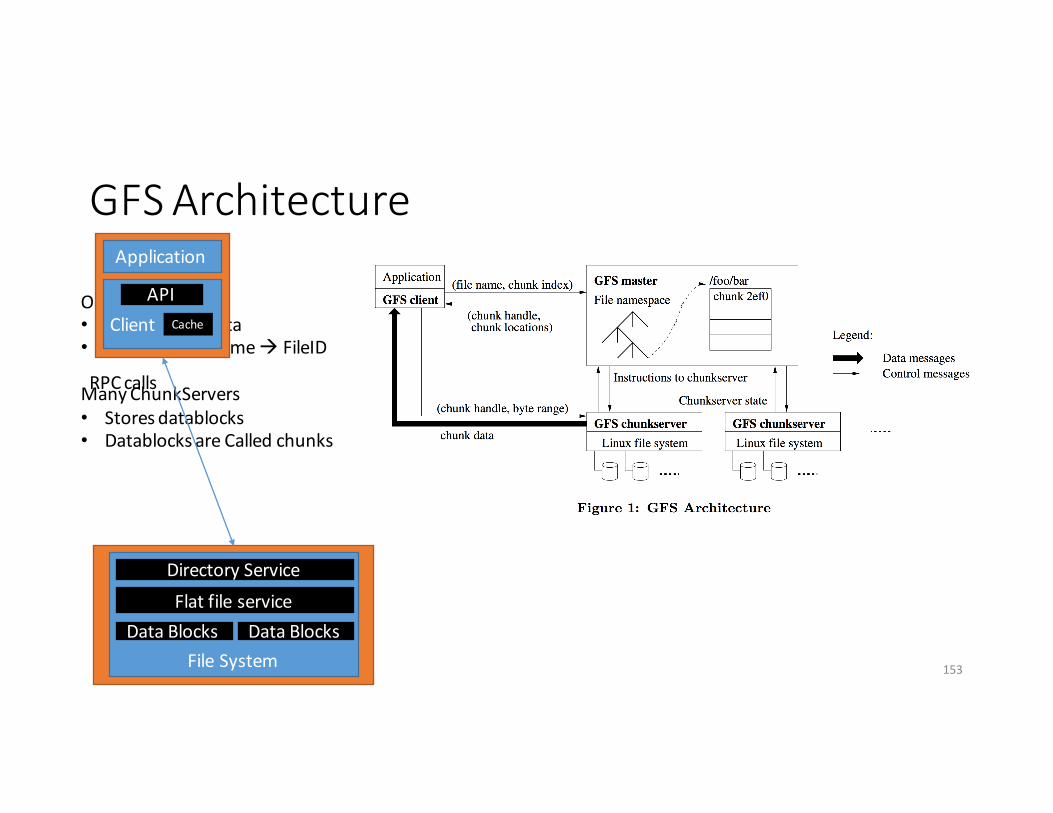
GFSArchitecture
153
OneMaster!!!!• StoresMetaData• Storemapofnameà FileID
ManyChunkServers• Storesdatablocks• Datablocks areCalledchunks
FileSystem
DirectoryServiceFlatfileservice
DataBlocks DataBlocks
RPCcalls
Application
ClientAPI
Cache

GFSArchitecture:MasterScaling+FaultTolerance• SingleMasterà singlepointoffailure
• Limitclient interactions withmaster• Mastermaintains logofmetadataoperations
• Logallowsforrecovery• Multiple ShadowMasters-->thinkfollowerslike raft
• Clientinteractwithmasterformetadata• Filecreate/delete• Andmodificationsà client getsalease tomodifydata• ChunksizesareLARGE sometadataoperationsareinfrequent
• ClientinteractwithChunkserver directlyfor• Dataread/writes• Note:dataread/writes arehugeoperations

GFSArchitecture:MasterScaling+FaultTolerance• SingleMasterà singlepointoffailure
• Limitclient interactions withmaster• Mastermaintains logofmetadataoperations
• Logallowsforrecovery• Multiple ShadowMasters-->thinkfollowerslike raft
• Clientinteractwithmasterformetadata• Filecreate/delete• Andmodificationsà client getsalease tomodifydata• ChunksizesareLARGE sometadataoperationsareinfrequent
• ClientinteractwithChunkserver directlyfor• Dataread/writes• Note:dataread/writes arehugeoperations
• Metadataisstoredonmaster• Fileandchunknamespaces• Mappingfromfilestochunks• Locationsofeachchunk’sreplicas
• Allinmemory(64bytesperchunk)• Fast• Easilyaccessible
• MasterrebuildsMappingofChunktoChunkServers onheartBeat

Master’sResponsiblities
• ChunkServer faulttolerance• Chunksareavailable
• Dataperformanceà fastreads• Nosingle ChunkServer isthebottleneck
• Maintainmetadataconsistency
• Coordinateconsistentwrites

ChunkServerFaultTolerance
• Masterusesheartbeatstotrackchunkservers
• Eachheartbeatcontainslistofchunks@Chunkserver• MasterbuildsmapofchunktoChunkservers usingheartbeats
• Onserverfailure,Mastercanre-replication,rebalancingChunk• Balance spaceutilization andaccessspeed• Re-replicate dataifredundancy islowerthanthreshold• Rebalance datatosmoothoutstorageandrequest load

GFSArchitecture:DataPerformanceandAvailability• Mastercanre-replication,rebalanceChunks
• Balance spaceutilization andaccessspeed
• Re-replicate dataifredundancy islowerthanthreshold
• Rebalance datatosmoothoutstorageandrequest load

Metadata
• Masterhasanoperationlogforpersistentloggingofcriticalmetadataupdates• Persistent onlocaldisk• Replicated• Checkpoints forfasterrecovery
161

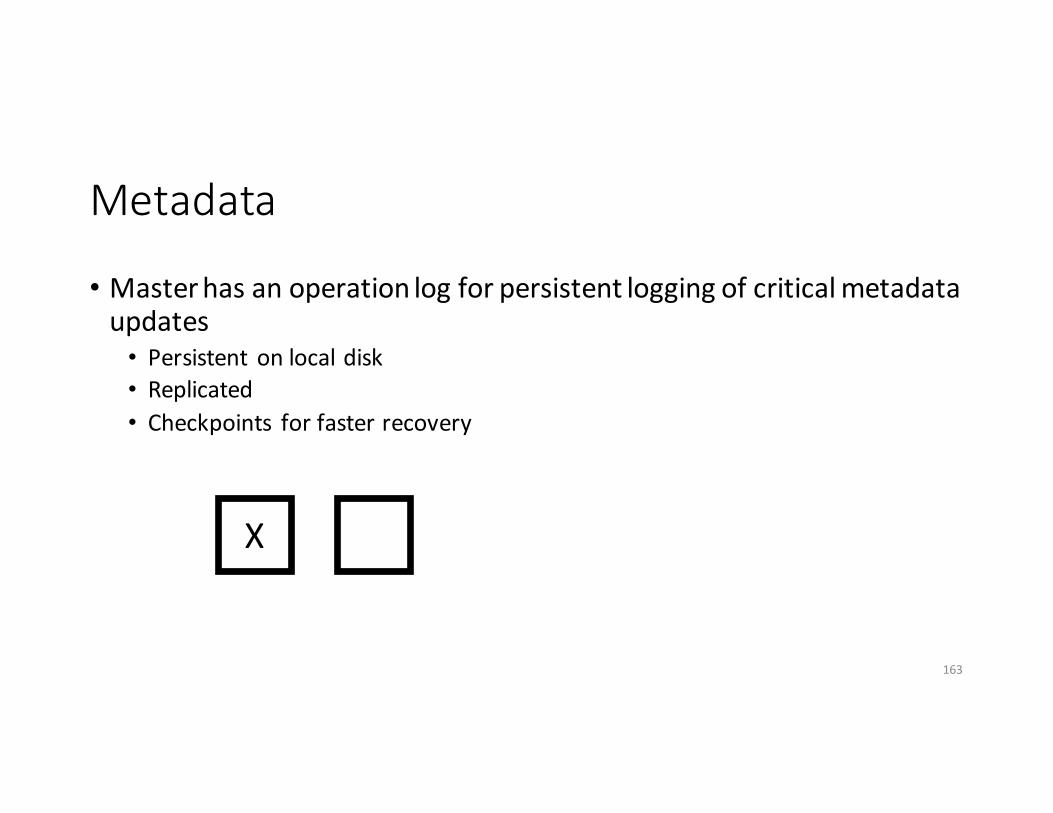
Metadata
• Masterhasanoperationlogforpersistentloggingofcriticalmetadataupdates• Persistent onlocaldisk• Replicated• Checkpoints forfasterrecovery
162
X Y
Metadata
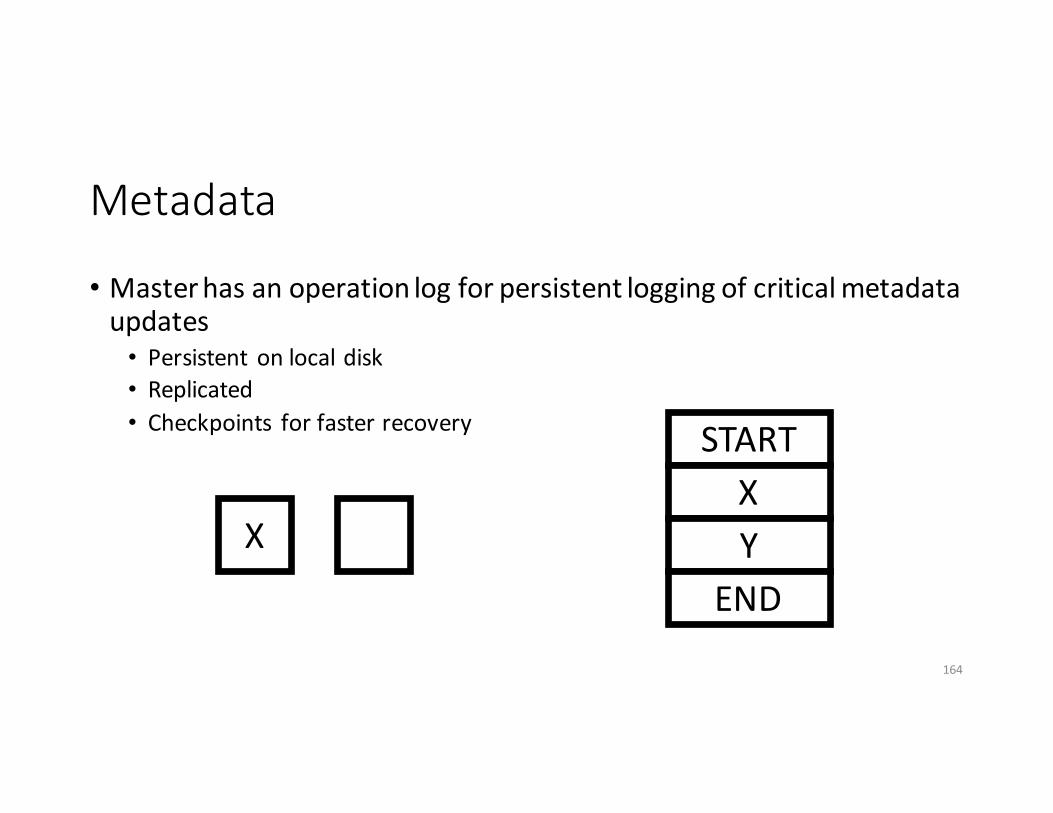
• Masterhasanoperationlogforpersistentloggingofcriticalmetadataupdates• Persistent onlocaldisk• Replicated• Checkpoints forfasterrecovery
163
X
Metadata
• Masterhasanoperationlogforpersistentloggingofcriticalmetadataupdates• Persistent onlocaldisk• Replicated• Checkpoints forfasterrecovery
164
X
STARTXY
END

FileWrites(Mutations)
• Mutation =writeor‘’recordappend’’• Mustbedoneforallreplicas
• Goal:minimizemaster involvement
• Leasemechanism• Masterpicksonreplicaasprimaryandgivesita“lease”formutations• Primarydefinesaserialorderofmutations• Allreplicasfollowsthisorder
• Dataflowdecoupled fromMetaData (control)flow
168

CommonUsagePattern:AtomicRecordAppend• GFSappendsittothefileatomicallyatleastonce
• GFSpickstheoffset• Worksforconcurrentwriters
• Problemswith”atleastonce”• Ifaconcurrentwritefails• SomeReplicawillhavethedataotherswillnot!• Client-librarymustretry:somereplicawillhavetwocopies
• UsedheavilybyGoogleapplications• ApplicationscansuppressduplicatesusingRecordIDs
• Duplicates havesame IDs• Application mustbeable tohandleduplices
169

CommonUsagePattern:AtomicRecordAppend
170
Client
ReplicaA
ReplicaB
ReplicaC
1 2 3
1 2 3
1 2 3
4 4
4
4
AppendID=4RetryAppendID=4

CommonUsagePattern:AtomicRecordAppend• GFSappendsittothefileatomicallyatleastonce
• GFSpickstheoffset• Worksforconcurrentwriters
• Problemswith”atleastonce”• Ifaconcurrentwritefails• SomeReplicawillhavethedataotherswillnot!• Client-librarymustretry:somereplicawillhavetwocopies
• UsedheavilybyGoogleapplications• ApplicationscansuppressduplicatesusingRecordIDs
• Duplicates havesame IDs• Application mustbeable tohandleduplices
171

GFSRecap
• Filesystemoptimizedforindexing• Optimizedforappendsandsequentialreads• Optimizedforlargefiles
• SingleMasterandMultipleChunkServers• Masterstoresmeta-data:onlyinvolvedinmetadatalookupandlocking
• Singlemasterà log+Shadowreplica forperformance/reliability• ChuckServer:storesdataandinvolvedinread/write
• Eachpiece ofdataisstoredonmultiple ChunkServers• #ofreplicas isafunctionofdatapopularity
• AtomicRecordAppend:atleastoncesemantics• DatamaybedifferentatdifferentChunkServers becauseofatleastoncesemantics
172

AllGFSFaultTolerancePrinciples
• Highavailability• Fastrecovery
• Masterandchunksservercanrestartinafewseconds• Chunkreplication
• Defaultisthreereplicas• Mastermaintains logs
• Shadowmasters
• Dataintegrity• Checksumevery64KBblockineachchunk
173
http://googleappengine.blogspot.com/2010/06/datastore-performance-growing-pains.htmlhttp://googleappengine.blogspot.com/2009/09/migration-to-better-datastore.html
MotivationtoMoveBeyondGFS/NoSQL-DB
• Explosioninonlineservices• Moredata,moreusers• Largegeographicfootprint
• Fastapplicationdevelopmentcycles• ACID[Linearizable] iseasytoprogram• NoSQL-DB[eventualconsistency] isnot
• ACID-basedDB(e.g.,RDBMS)areslow• Donotscale!!
https://www.getfilec loud.com/blog/2 014 /08 /lea ding-nosql- database s-to-cons id er/#.XKyW1ZNK jwchttp://sahrzad.net/b log /p rob lem s-wit h-goog le- serv ices/https://www.cbron lin e.com/what- is/what- is- rdbms-49 4541 8/

NoSQL vs.RDBMS
• NoSQL (Bigtable,HBase,Cassandra)• Merits:
+Highlyscalable
• Limitations:-Lessfeaturestobuildapplications
(transaction atthegranularityofsingle key,poorschemasupportandquerycapability,limited API(put/get))
-Looseconsistencymodelswithasynchronousreplication(eventualconsistency)
• RDBMS(mysql)• Merits:
+Mature,richdatamanagementfeatures,easytobuildapplications
+Synchronousreplicationcomeswithstrongtransactionalsemantics
• Limitations:-Hardtoscale-Synchronous replicationmayhave
performanceandscalabilityissues- maynothavefault-tolerant
replicationmechanisms

ConsistencySpectrum• Linearizable:totalorder+realtime(forindividualoperations)• Eventual:eventuallyeveryoneagrees
StrictSerializability
Linearizable
Sequential
Causal+
Eventual
WEAKCONSISTENCY
STRONGCONSISTENCY
SLOWER
BUTEASYTOPROGRAM
FASTandParallel
BUTHARDERTOPROGRAM:needconflictresolution

GFSVersusMegaStore
• GFS:• Downloadallwebsitesà Append-onlywrites+verylargefiles
• Youdon’tgobackandalterdownloaded pages• Build Index:Scanfilestobuild indexà sequential reads
• MegaStore:interactiveservices• Datafordifferentgroupsofusersà abletopartitiondata
• UserAdoesnotdirectlymodifydatafromUserB,e.g.,email• Mosttimes usersarereadingthedataà optimizeforread(writecanbeexpensive)
• Datacanbemovedclosertousersà application controloverplacement

MegaStore:GMail,GMaps…
• GMail:• Eachuserhasmailboxofmessages• UserAdoesnotmodifyUserB’smailbox
• UserAcansendemailtoUserBandthismailgoesoverthe internet
• Gmaps:• WorldMap isreallyupdated• MostoftenlotsofreadsfromMaps• Worldcanbepartitioned into“tiles”˜
• Withfewchangesacrosssquares
https://news.softpedia.com/news/how-to-enable-and-disable-the-new-gmail-interface-520870.shtml#sgal_0https://developers.google.com/maps/documentation/javascript/coordinates
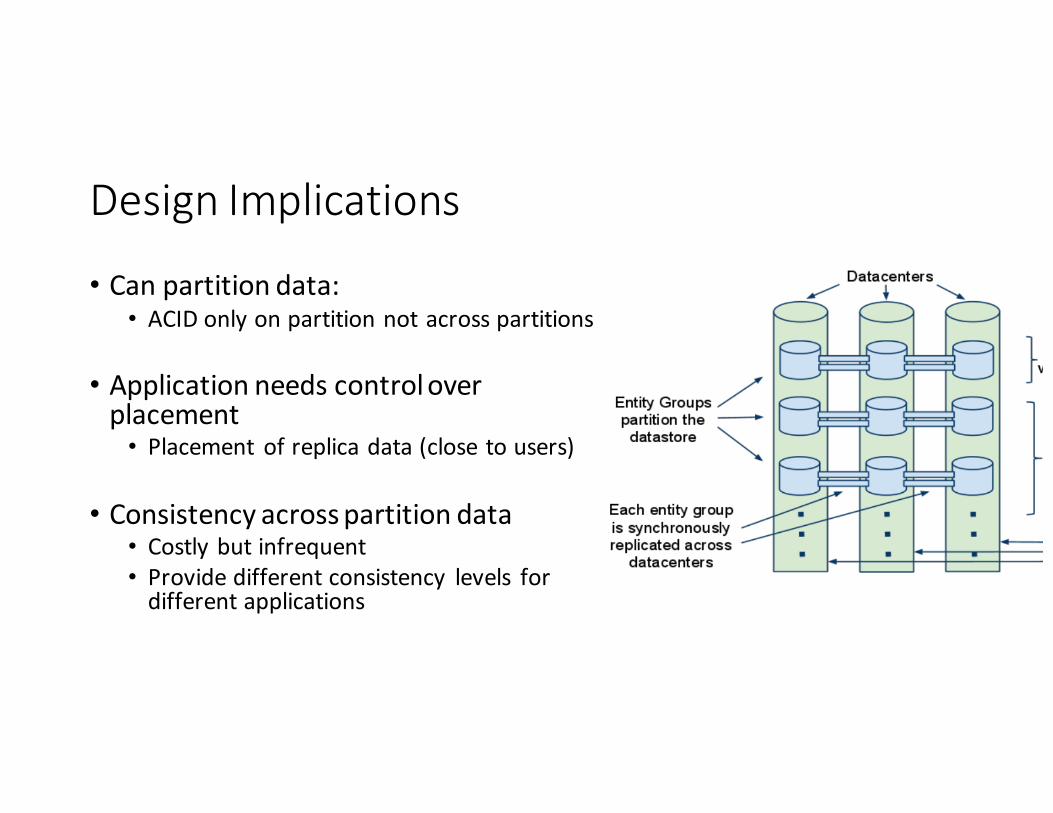
DesignImplications
• Canpartitiondata:• ACIDonlyonpartitionnotacrosspartitions
• Applicationneedscontroloverplacement• Placement ofreplicadata(closetousers)
• Consistencyacrosspartitiondata• Costlybutinfrequent• Providedifferentconsistency levels fordifferentapplications

MegaStoreContributions
• OvercomelimitationsbyCombiningNoSQLw/RDBMS
• Scale• Partitionspace intoanumberofdistinct DBs• EachDBhasACIDtransactions
• FaultTolerance• EachDB,applies areplication scheme (activereplication)• Optimizeforlonglinks

AllFacebookData
NodeA
NodeB
NodeC
Shard1
Shard1
Shard1
NodeD
NodeE
NodeF
Shard2
Shard2
Shard2
Partitiondataintoshards,mapsshardstoserverwithconsistenthashing
k1 v1
k2 v2
k3 v3
k4 v4
k5 v5
k0 v0
Hash table
k4 v4
k5 v5
k4 v4
k5 v5
k4 v4
k5 v5
Maintainm
ultiplecopiesForfaulttoleranceandtoreducelatency
ClientssendrequestsToallreplicas
• Replication• Lazy,Passive,Active• Consistencyforasingleshard
• DistributedTransaction• Consistent/Atomicchangetodatain
multipleshards• Multipleshardsè Canusetraditional
replicationtechniques FE
FE
k2 v2
k3 v3
k2 v2
k3 v3
k2 v2
k3 v3
Replicationscheme
TransactionacrossReplicas

AllFacebookData
NodeA
NodeB
NodeC
Shard1
Shard1
Shard1
NodeD
NodeE
NodeF
Shard2
Shard2
Shard2
Partitiondataintoshards,mapsshardstoserverwithconsistenthashing
k1 v1
k2 v2
k3 v3
k4 v4
k5 v5
k0 v0
Hash table
k4 v4
k5 v5
k4 v4
k5 v5
k4 v4
k5 v5
k2 v2
k3 v3
k2 v2
k3 v3
k2 v2
k3 v3
PartitionandapplyReplicationscheme
TransactionacrossReplicas
NodeA NodeB NodeC
entity Entity EntityEntityGroup
NodeD NodeE NodeF
Entity Entity EntityEntityGroup
TransactionacrossEntityGroups
MegaStoreReplication+Transactions
PartitionandapplyReplicationschem
e
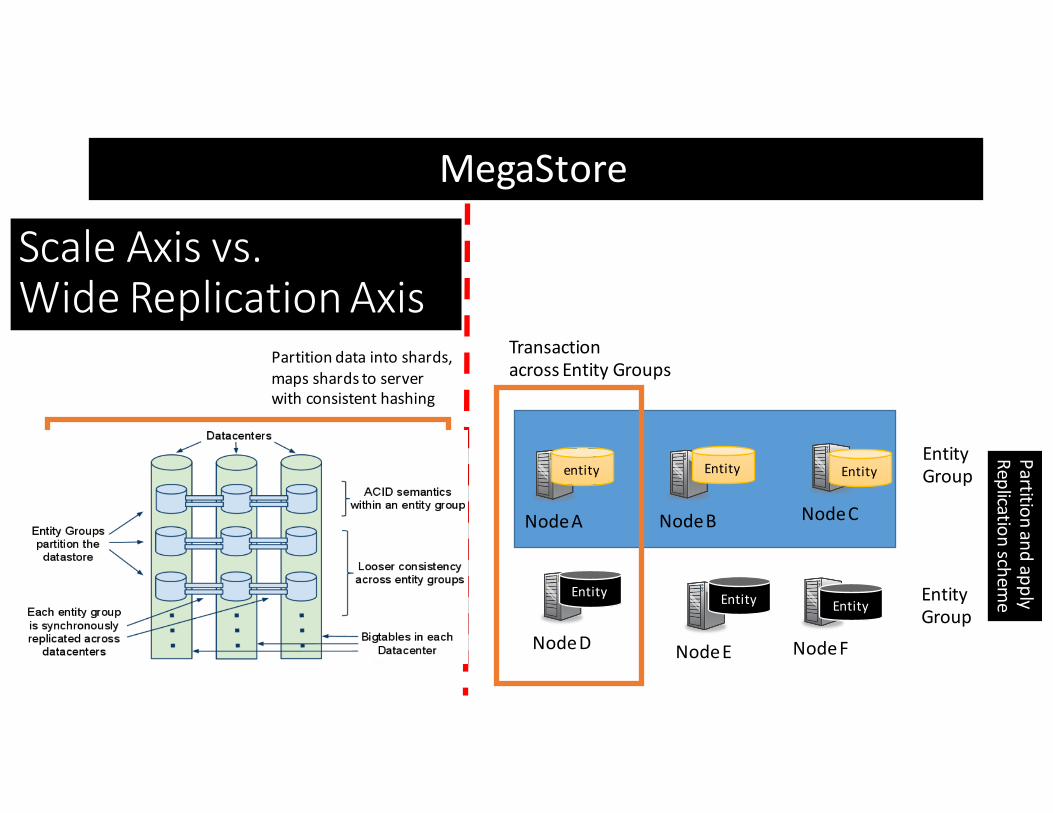
Partitiondataintoshards,mapsshardstoserverwithconsistenthashing
NodeA NodeB NodeC
entity Entity EntityEntityGroup
NodeD NodeE NodeF
Entity Entity EntityEntityGroup
TransactionacrossEntityGroups
PartitionandapplyReplicationschem
e
MegaStore
ScaleAxisvs.WideReplicationAxis
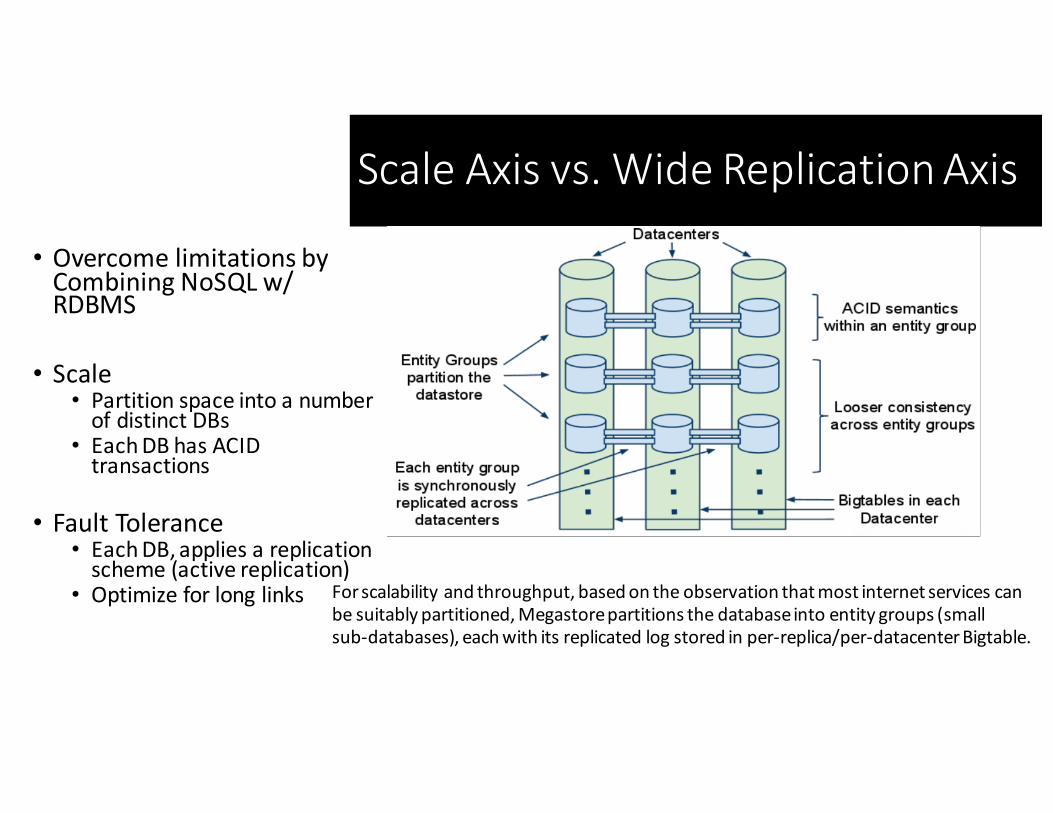
ScaleAxisvs.WideReplicationAxis
Forscalabilityandthroughput,basedontheobservationthatmostinternetservicescanbesuitablypartitioned,Megastorepartitionsthedatabaseintoentitygroups(smallsub-databases),eachwithitsreplicatedlogstoredinper-replica/per-datacenterBigtable.
• OvercomelimitationsbyCombiningNoSQL w/RDBMS
• Scale• PartitionspaceintoanumberofdistinctDBs
• EachDBhasACIDtransactions
• FaultTolerance• EachDB,appliesareplicationscheme(activereplication)
• Optimizeforlonglinks