distributed aggregation for data-parallel computing - sigops
TRANSCRIPT

Distributed Aggregation for Data-Parallel Computing:Interfaces and Implementations
Yuan YuMicrosoft Research
1065 La Avenida Ave.Mountain View, CA [email protected]
Pradeep Kumar GundaMicrosoft Research
1065 La Avenida Ave.Mountain View, CA [email protected]
Michael IsardMicrosoft Research
1065 La Avenida Ave.Mountain View, CA 94043
ABSTRACTData-intensive applications are increasingly designed toexecute on large computing clusters. Grouped aggrega-tion is a core primitive of many distributed programmingmodels, and it is often the most efficient available mecha-nism for computations such as matrix multiplication andgraph traversal. Such algorithms typically require non-standard aggregations that are more sophisticated thantraditional built-in database functions such as Sum andMax. As a result, the ease of programming user-definedaggregations, and the efficiency of their implementation,is of great current interest.
This paper evaluates the interfaces and implementa-tions for user-defined aggregation in several state of theart distributed computing systems: Hadoop, databasessuch as Oracle Parallel Server, and DryadLINQ. We showthat: the degree of language integration between user-defined functions and the high-level query language hasan impact on code legibility and simplicity; the choiceof programming interface has a material effect on theperformance of computations; some execution plans per-form better than others on average; and that in order toget good performance on a variety of workloads a systemmust be able to select between execution plans depend-ing on the computation. The interface and execution plandescribed in the MapReduce paper, and implemented byHadoop, are found to be among the worst-performingchoices.
Categories and Subject DescriptorsD.1.3 [Programming Techniques]: Concurrent Pro-gramming—Distributed programming
General TermsDesign, Languages, Performance
KeywordsDistributed programming, cloud computing, concur-rency
1. INTRODUCTIONMany data-mining computations have as a fun-
damental subroutine a “GroupBy-Aggregate” oper-ation. This takes a dataset, partitions its recordsinto groups according to some key, then performsan aggregation over each resulting group. GroupBy-Aggregate is useful for summarization, e.g. findingaverage household income by zip code from a censusdataset, but it is also at the heart of the distributedimplementation of algorithms such as matrix multi-plication [22, 27]. The ability to perform GroupBy-Aggregate at scale is therefore increasingly impor-tant, both for traditional data-mining tasks and alsofor emerging applications such as web-scale machinelearning and graph analysis.
This paper analyzes the programming models thatare supplied for user-defined aggregation by severalstate of the art distributed systems, evaluates a va-riety of optimizations that are suitable for aggrega-tions with differing properties, and investigates theinteraction between the two. In particular, we showthat the choice of programming interface not only af-fects the ease of programming complex user-definedaggregations, but can also make a material differenceto the performance of some optimizations.
GroupBy-Aggregate has emerged as a canonicalexecution model in the general-purpose distributedcomputing literature. Systems like MapReduce [9]and Hadoop [3] allow programmers to decomposean arbitrary computation into a sequence of mapsand reductions, which are written in a full-fledgedhigh level programming language (C++ and Java,respectively) using arbitrary complex types. The re-sulting systems can perform quite general tasks atscale, but offer a low-level programming interface:even common operations such as database Join re-quire a sophisticated understanding of manual op-timizations on the part of the programmer. Conse-quently, layers such as Pig Latin [19] and HIVE [1]have been developed on top of Hadoop, offering a
1

SQL-like programming interface that simplifies com-mon data-processing tasks. Unfortunately the un-derlying execution plan must still be converted intoa sequence of maps and reductions for Hadoop to ex-ecute, precluding many standard parallel databaseoptimizations.
Parallel databases [15] have for some time per-mitted user-defined selection and aggregation oper-ations that have the same computational expressive-ness as MapReduce, although with a slightly dif-ferent interface. For simple computations the user-defined functions are written using built-in languagesthat integrate tightly with SQL but have restrictedtype systems and limited ability to interact withlegacy code or libraries. Functions of even moderatecomplexity, however, must be written using externalcalls to languages such as C and C++ whose integra-tion with the database type system can be difficultto manage [24].
Dryad [16] and DryadLINQ [26] were designed toaddress some of the limitations of databases andMapReduce. Dryad is a distributed execution en-gine that lies between databases and MapReduce:it abandons much of the traditional functionalityof a database (transactions, in-place updates, etc.)while providing fault-tolerant execution of complexquery plans on large-scale clusters. DryadLINQ isa language layer built on top of Dryad that tightlyintegrates distributed queries into high level .NETprogramming languages. It provides a unified datamodel and programming language that support re-lational queries with user-defined functions. Dryadand DryadLINQ are an attractive research platformbecause Dryad supports execution plans that aremore complex than those provided by a system suchas Hadoop, while the DryadLINQ source is avail-able for modification, unlike that of most paralleldatabases. This paper explains in detail how dis-tributed aggregation can be treated efficiently bythe DryadLINQ optimization phase, and extends theDryadLINQ programming interface as well as the setof optimizations the system may apply.
The contributions of this paper are as follows:
• We compare the programming models for user-defined aggregation in Hadoop, DryadLINQ,and parallel databases, and show the impactof interface-design choices on optimizations.
• We describe and implement a general, rigoroustreatment of distributed grouping and aggrega-tion in the DryadLINQ system.
• We use DryadLINQ to evaluate several opti-mization techniques for distributed aggregation
in real applications running on a medium-sizedcluster of several hundred computers.
The structure of this paper is as follows. Sec-tion 2 explains user-defined aggregation and givesan overview of how a GroupBy-Aggregate compu-tation can be distributed. Section 3 describes theprogramming interfaces for user-defined aggregationoffered by the three systems we consider, and Sec-tion 4 outlines the programs we use for our eval-uation. Section 5 presents several implementationstrategies which are then evaluated in Section 6 us-ing a variety of workloads. Section 7 surveys relatedwork, and Section 8 contains a discussion and con-clusions.
2. DISTRIBUTED AGGREGATIONThis section discusses the functions that must be
supplied in order to perform general-purpose user-defined aggregations. Our example execution planshows a map followed by an aggregation, however ingeneral an aggregation might, for example, consumethe output of more complex processing such as aJoin or a previous aggregation. We explain the con-cepts using the iterator-based programming modeladopted by MapReduce [9] and Hadoop [19], anddiscuss alternatives used by parallel databases andDryadLINQ below in Section 3. We use an integer-average computation as a running example. It ismuch simpler than most interesting user-defined ag-gregations, and is included as a primitive in manysystems, however its implementation has the samestructure as that of many much more complex func-tions.
2.1 User-defined aggregationThe MapReduce programming model [9] supports
grouped aggregation using a user-supplied functionalprogramming primitive called Reduce:
• Reduce: 〈K, Sequence of R〉 → Sequence of Stakes a sequence of records of type R, all withthe same key of type K, and outputs zero ormore records of type S.
Here is the pseudocode for a Reduce function to com-pute integer average:
double Reduce(Key k, Sequence<int> recordSequence){// key is ignoredint count = 0, sum = 0;foreach (r in recordSequence) {sum += r; ++count;
}return (double)sum / (double)count;
}
2

M
D
MG
G
R
X
M
D
MG
G
R
X
M
D
Map
Distribute
Merge
GroupBy
Reduce
Consumer
map
redu
ce
Figure 1: Distributed execution plan for MapReducewhen reduce cannot be decomposed to perform partialaggregation.
With this user-defined function, and merge andgrouping operators provided by the system, it is pos-sible to execute a simple distributed computation asshown in Figure 1. The computation has exactlytwo phases: the first phase executes a Map functionon the inputs to extract keys and records, then per-forms a partitioning of these outputs based on thekeys of the records. The second phase collects andmerges all the records with the same key, and passesthem to the Reduce function. (This second phase isequivalent to GroupBy followed by Aggregate in thedatabase literature.)
As we shall see in the following sections, many op-timizations for distributed aggregation rely on com-puting and combining “partial aggregations.” Sup-pose that aggregating the sequence Rk of all therecords with a particular key k results in output Sk.A partial aggregation computed from a subsequencer of Rk is an intermediate result with the propertythat partial aggregations of all the subsequences ofRk can be combined to generate Sk. Partial aggrega-tions may exist, for example, when the aggregationfunction is commutative and associative, and Sec-tion 2.2 below formalizes the notion of decompos-able functions which generalize this case. For ourrunning example of integer average, a partial aggre-gate contains a partial sum and a partial count:
struct Partial {int partialSum;int partialCount;
}
Often the partial aggregation of a subsequence ris much smaller than r itself: in the case of aver-age for example the partial sum is just two values,
M
G1
D
M
G1
D
M
G1
D
MG
G2
C
MG
G2
C
GroupBy
InitialReduce
Merge
GroupBy
Combine
Merge
GroupBy
FinalReduce
Consumer
map
aggr
egat
ion
tree
redu
ce
IR IRIR
MG
G2
F
X
MG
G2
F
X
Map
Distribute
Figure 2: Distributed execution plan for MapReducewhen reduce supports partial aggregation. The imple-mentation of GroupBy in the first stage may be different tothat in the later stages, as discussed in Section 5.
regardless of the number of integers that have beenprocessed. When there is such substantial data re-duction, partial aggregation can be introduced bothas part of the initial Map phase and in an aggre-gation tree, as shown in Figure 2, to greatly reducenetwork traffic. In order to decompose a user-definedaggregation using partial aggregation it is necessaryto introduce auxiliary functions, called “Combiners”in [9], that synthesize the intermediate results intothe final output. The MapReduce system describedin [9] can perform partial aggregation on each localcomputer before transmitting data across the net-work, but does not use an aggregation tree.
In order to enable partial aggregation a user ofMapReduce must supply three functions:
1. InitialReduce: 〈K, Sequence of R〉 → 〈K, X〉which takes a sequence of records of type R, allwith the same key of type K, and outputs apartial aggregation encoded as the key of typeK and an intermediate type X.
2. Combine: 〈K, Sequence of X〉 → 〈K, X〉 whichtakes a sequence of partial aggregations of type
3

X, all with the same key of type K, and out-puts a new, combined, partial aggregation onceagain encoded as an object of type X with theshared key of type K.
3. FinalReduce: 〈K, Sequence of X〉 → Sequenceof S which takes a sequence of partial aggrega-tions of type X, all with the same key of typeK, and outputs zero or more records of type S.
In simple cases such as Sum or Min the types R, Xand S are all the same, and InitialReduce, Com-bine and FinalReduce can all be computed usingthe same function. Three separate functions areneeded even for straightforward computations suchas integer average:
Partial InitialReduce(Key k,Sequence<int> recordSequence) {
Partial p = { 0, 0 };foreach (r in recordSequence) {p.partialSum += r;++p.partialCount;
}return <k, p>;
}
Partial Combine(Key k,Sequence<Partial> partialSequence) {
Partial p = { 0, 0 };foreach (r in partialSequence) {p.partialSum += r.partialSum;p.partialCount += r.partialCount;
}return <k, p>;
}
double FinalReduce(Key k,Sequence<Partial> partialSequence)
{ // key is ignoredPartial p = Combine(k, partialSequence);return (double)p.partialSum /
(double)p.partialCount;}
2.2 Decomposable functionsWe can formalize the above discussion by intro-
ducing the notion of decomposable functions.
Definition 1. We use x to denote a sequence ofdata items, and use x1 ⊕ x2 to denote the concate-nation of x1 and x2. A function H is decomposableif there exist two functions I and C satisfying thefollowing conditions:1) H is the composition of I and C: ∀x1, x2 :H(x1 ⊕ x2) = C(I(x1 ⊕ x2)) = C(I(x1)⊕ I(x2))
2) I is commutative: ∀x1, x2 : I(x1⊕x2) = I(x2⊕x1)
3) C is commutative: ∀x1, x2 : C(x1⊕x2) = C(x2⊕x1)
Definition 2. A function H is associative-decom-posable if there exist two functions I and C satisfyingconditions 1–3 above, and in addition C is associa-tive: ∀x1, x2, x3 : C(C(x1 ⊕ x2) ⊕ x3) = C(x1 ⊕C(x2 ⊕ x3))
If an aggregation computation can be representedas a set of associative-decomposable functions fol-lowed by some final processing, then it can be splitup in such a way that the query plan in Figure 2can be applied. If the computation is instead formedfrom decomposable functions followed by final pro-cessing then the plan from Figure 2 can be applied,but without any intermediate aggregation stages. Ifthe computation is not decomposable then the planfrom Figure 1 is required.
Intuitively speaking, I and C correspond to theInitialReduce and Combine functions for MapRe-duce that were described in the preceding section.However, there is a small but important difference.Decomposable functions define a class of functionswith certain algebraic properties without referring tothe aggregation-specific key. This separation of thekey type from the aggregation logic makes it possiblefor the system to automatically optimize the execu-tion of complex reducers that are built up from acombination of decomposable functions, as we showbelow in Section 3.4.
3. PROGRAMMING MODELSThis section compares the programming models
for user-defined aggregation provided by the Hadoopsystem, a distributed SQL database, and Dryad-LINQ. We briefly note differences in the way thatuser-defined aggregation is integrated into the querylanguage in each model, but mostly concentrate onhow the user specifies the decomposition of the ag-gregation computation so that distributed optimiza-tions like those in Figure 2 can be employed. Sec-tion 5 discusses how the decomposed aggregation isimplemented in a distributed execution.
The systems we consider adopt two different stylesof interface for user-defined aggregation. The firstis iterator-based, as in the examples in Section 2—the user-defined aggregation function is called onceand supplied with an iterator that can be used toaccess all the records in the sequence. The sec-ond is accumulator-based. In this style, which iscovered in more detail below in Section 3.2, eachpartial aggregation is performed by an object thatis initialized before first use then repeatedly calledwith either a singleton record to be accumulated, oranother partial-aggregation object to be combined.The iterator-based and accumulator-based interfaceshave the same computational expressiveness, how-
4

ever as we shall see in Section 5 the choice has amaterial effect on the efficiency of different imple-mentations of GroupBy. While there is an automaticand efficient translation from the accumulator inter-face to the iterator interface, the other direction ingeneral appears to be much more difficult.
3.1 User-defined aggregation in HadoopThe precise function signatures used for combin-
ers are not stated in the MapReduce paper [9] how-ever they appear to be similar to those provided bythe Pig Latin layer of the Hadoop system [19]. TheHadoop implementations of InitialReduce, Com-bine and FinalReduce for integer averaging are pro-vided in Figure 3. The functions are supplied asoverrides of a base class that deals with system-defined“container”objects DataAtom, correspondingto an arbitrary record, and Tuple, corresponding toa sequence of records. The user is responsible forunderstanding these types, using casts and accessorfunctions to fill in the required fields, and manu-ally checking that the casts are valid. This circum-vents to some degree the strong static typing of Javaand adds substantial apparent complexity to a triv-ial computation like that in Figure 3, but of coursefor more interesting aggregation functions the over-head of casting between system types will be lessnoticeable, and the benefits of having access to afull-featured high-level language, in this case Java,will be more apparent.
3.2 User-defined aggregation in a databaseMapReduce can be expressed in a database system
that supports user-defined functions and aggregatesas follows:SELECT Reduce()FROM (SELECT Map() FROM T) RGROUPBY R.key
where Map is a user-defined function outputting to atemporary table R whose rows contain a key R.key,and Reduce is a user-defined aggregator. (The state-ment above restricts Map and Reduce to each pro-duce a single output per input row, however manydatabases support “table functions” [2, 12] which re-lax this constraint.) Such user-defined aggregatorswere introduced in Postgres [23] and are supportedin commercial parallel database systems includingOracle and Teradata. Database interfaces for user-defined aggregation are typically object-oriented andaccumulator-based, in contrast to the iterator-basedHadoop approach above. For example, in Oracle theuser must supply four methods:
1. Initialize: This is called once before anydata is supplied with a given key, to initialize
// InitialReduce: input is a sequence of raw data tuples;// produces a single intermediate result as outputstatic public class Initial extends EvalFunc<Tuple> {@Override public void exec(Tuple input, Tuple output)
throws IOException {try {output.appendField(new DataAtom(sum(input)));output.appendField(new DataAtom(count(input)));
} catch(RuntimeException t) {throw new RuntimeException([...]);
}}
}
// Combiner: input is a sequence of intermediate results;// produces a single (coalesced) intermediate resultstatic public class Intermed extends EvalFunc<Tuple> {@Override public void exec(Tuple input, Tuple output)
throws IOException {combine(input.getBagField(0), output);
}}
// FinalReduce: input is one or more intermediate results;// produces final output of aggregation functionstatic public class Final extends EvalFunc<DataAtom> {@Override public void exec(Tuple input, DataAtom output)
throws IOException {Tuple combined = new Tuple();if(input.getField(0) instanceof DataBag) {combine(input.getBagField(0), combined);
} else {throw new RuntimeException([...]);
}double sum = combined.getAtomField(0).numval();double count = combined.getAtomField(1).numval();double avg = 0;if (count > 0) {avg = sum / count;
}output.setValue(avg);
}}
static protected void combine(DataBag values, Tuple output)throws IOException {
double sum = 0;double count = 0;for (Iterator it = values.iterator(); it.hasNext();) {Tuple t = (Tuple) it.next();sum += t.getAtomField(0).numval();count += t.getAtomField(1).numval();
}output.appendField(new DataAtom(sum));output.appendField(new DataAtom(count));
}
static protected long count(Tuple input)throws IOException {
DataBag values = input.getBagField(0);return values.size();
}
static protected double sum(Tuple input)throws IOException {
DataBag values = input.getBagField(0);double sum = 0;for (Iterator it = values.iterator(); it.hasNext();) {Tuple t = (Tuple) it.next();sum += t.getAtomField(0).numval();
}return sum;
}
Figure 3: A user-defined aggregator to implementinteger averaging in Hadoop. The supplied functionsare conceptually simple, but the user is responsible for mar-shalling between the underlying data and system types suchas DataAtom and Tuple for which we do not include full defi-nitions here.
5

STATIC FUNCTION ODCIAggregateInitialize( actx IN OUT AvgInterval) RETURN NUMBER ISBEGINIF actx IS NULL THENactx := AvgInterval (INTERVAL ’0 0:0:0.0’ DAY TO
SECOND, 0);ELSEactx.runningSum := INTERVAL ’0 0:0:0.0’ DAY TO SECOND;actx.runningCount := 0;
END IF;RETURN ODCIConst.Success;
END;
MEMBER FUNCTION ODCIAggregateIterate( self IN OUT AvgInterval,val IN DSINTERVAL_UNCONSTRAINED
) RETURN NUMBER ISBEGINself.runningSum := self.runningSum + val;self.runningCount := self.runningCount + 1;RETURN ODCIConst.Success;
END;
MEMBER FUNCTION ODCIAggregateMerge(self IN OUT AvgInterval,ctx2 IN AvgInterval) RETURN NUMBER ISBEGINself.runningSum := self.runningSum + ctx2.runningSum;self.runningCount := self.runningCount +
ctx2.runningCount;RETURN ODCIConst.Success;
END;
MEMBER FUNCTION ODCIAggregateTerminate( self IN AvgInterval,ReturnValue OUT DSINTERVAL_UNCONSTRAINED,flags IN NUMBER
) RETURN NUMBER ISBEGINIF self.runningCount <> 0 THENreturnValue := self.runningSum / self.runningCount;
ELSEreturnValue := self.runningSum;
END IF;RETURN ODCIConst.Success;
END;
Figure 4: A user-defined combiner in the Oracledatabase system that implements integer averag-ing. This example is taken from http://www.oracle.com/technology/oramag/oracle/06-jul/o46sql.html.
the state of the aggregation object.
2. Iterate: This may be called multiple times,each time with a single record with the match-ing key. It causes that record to be accumu-lated by the aggregation object.
3. Merge: This may be called multiple times, eachtime with another aggregation object with thematching key. It combines the two partial ag-gregations.
4. Final: This is called once to output the finalrecord that is the result of the aggregation.
Figure 4 shows an implementation of integer aver-age as an Oracle user-defined aggregator. For func-tions like average, whose types map well to SQL
base types and which can be written entirely us-ing Oracle’s built-in extension language, the type-integration is better than that of Hadoop. Howeverif the user-defined functions and types are more com-plex and must be implemented in a full-fledged lan-guage such as C/C++, the database implementationbecomes substantially more difficult to understandand manage [24].
3.3 User-defined aggregation in the Dryad-LINQ system
DryadLINQ integrates relational operators withuser code by embedding the operators in an existinglanguage, rather than calling into user-defined func-tions from within a query language like Pig Latin orSQL. A distributed grouping and aggregation can beexpressed in DryadLINQ as follows:
var groups = source.GroupBy(KeySelect);var reduced = groups.SelectMany(Reduce);
In this fragment, source is a DryadLINQ collec-tion (which is analagous to a SQL table) of .NETobjects of type R. KeySelect is an expression thatcomputes a key of type K from an object of type R,and groups is a collection in which each element isa “group” (an object of type IGrouping<K,R>) con-sisting of a key of type K and a collection of objectsof type R. Finally, Reduce is an expression thattransforms an element of groups into a sequence ofzero or more objects of type S, and reduced is a col-lection of objects of type S. DryadLINQ programsare statically strongly typed, so the Reduce expres-sion could for example be any function that takesan object of type IGrouping<K,R> and returns acollection of objects of type S, and no type-castingis necessary. Aggregation without grouping is ex-pressed in DryadLINQ using the Aggregate opera-tor. We added a new overloaded Aggregate operatorto DryadLINQ to mirror the use of Select since thestandard LINQ Aggregate operator uses a slightlydifferent interface.
We have implememented both accumulator- anditerator-based interfaces for user-defined aggregationin DryadLINQ. We first describe the iterator-basedinterface in some detail, then briefly outline the ac-cumulator based style.
Iterator-based aggregation. We hard-coded intoDryadLINQ the fact that standard functions such asMax and Sum are associative-decomposable and weadded the following annotation syntax
[AssociativeDecomposable("I", "C")]public static X H(IEnumerable<R> g) {[ ... ]
}
6

public static IntPair InitialReduce(IEnumerable<int> g) {return new IntPair(g.Sum(), g.Count());
}
public static IntPair Combine(IEnumerable<IntPair> g) {return new IntPair(g.Select(x => x.first).Sum(),
g.Select(x => x.second).Sum());}
[AssociativeDecomposable("InitialReduce", "Combine")]public static IntPair PartialSum(IEnumerable<int> g) {return InitialReduce(g);
}
public static double Average(IEnumerable<int> g) {IntPair final = g.Aggregate(x => PartialSum(x));if (final.second == 0) return 0.0;return (double)final.first / (double)final.second;
}
Figure 5: An iterator-based implementation ofAverage in DryadLINQ that uses an associative-decomposable subroutine PartialSum. The annotationon PartialSum indicates that the system may split the com-putation into calls to the two functions InitialReduce andCombine when executing a distributed expression plan.
which a programmer can use to indicate that a func-tion H is associative-decomposable with respect toiterator-based functions I and C, along with a simi-lar annotation to indicate a Decomposable function.The DryadLINQ implementation of iterator-basedinteger averaging is shown in Figure 5. The im-plementations match the Hadoop versions in Fig-ure 3 quite closely, but DryadLINQ’s tighter lan-guage integration means that no marshaling is nec-essary. Note also the LINQ idiom in InitialReduceand Combine of using subqueries instead of loops tocompute sums and counts.
Accumulator-based aggregation. We also im-plemented support for an accumulator interface forpartial aggregation. The user must define three staticfunctions:
public X Initialize();public X Iterate(X partialObject, R record);public X Merge(X partialObject, X objectToMerge);
where X is the type of the object that is used to accu-mulate the partial aggregation, and supply them us-ing a three-argument variant of the AssociativeDe-composable annotation. Figure 6 shows integer av-eraging using DryadLINQ’s accumulator-based in-terface.
3.4 Aggregating multiple functionsWe implemented support within DryadLINQ to
automatically generate the equivalent of combinerfunctions in some cases. We define a reducer inDryadLINQ to be an expression that maps an IEnu-merable or IGrouping object to a sequence of ob-jects of some other type.
public static IntPair Initialize() {return new IntPair(0, 0);
}
public static IntPair Iterate(IntPair x, int r) {x.first += r;x.second += 1;return x;
}
public static IntPair Merge(IntPair x, IntPair o) {x.first += o.first;x.second += o.second;return x;
}
[AssociativeDecomposable("Initialize", "Iterate", "Merge")]public static IntPair PartialSum(IEnumerable<int> g) {return new IntPair(g.Sum(), g.Count());
}
public static double Average(IEnumerable<int> g) {IntPair final = g.Aggregate(x => PartialSum(x));if (final.second == 0) return 0.0;else return (double)final.first / (double)final.second;
}
Figure 6: An accumulator-based implementationof Average in DryadLINQ that uses an associative-decomposable subroutine PartialSum. The annotationon PartialSum indicates that the system may split the com-putation into calls to the three functions Initialize, Iterateand Merge when executing a distributed expression plan.
Definition 3. Let g be the formal argument of areducer. A reducer is decomposable if every termi-nal node of its expression tree satisfies one of thefollowing conditions:1) It is a constant or, if g is an IGrouping, of theform g.Key, where Key is the property of the IGrouping
interface that returns the group’s key.2) It is of the form H(g) for a decomposable functionH.3) It is a constructor or method call whose argu-ments each recursively satisfies one of these condi-tions.
Similarly a reducer is associative-decomposable if itcan be broken into associative-decomposable func-tions.
It is a common LINQ idiom to write a statementsuch asvar reduced = groups.Select(x => new T(x.Key, x.Sum(), x.Count()));
The expression inside the Select statement in thisexample is associative-decomposable since Sum andCount are system-defined associative-decomposablefunctions. When DryadLINQ encounters a state-ment like this we use reflection to discover all thedecomposable function calls in the reducer’s expres-sion tree and their decompositions. In this examplethe decomposable functions are Sum with decompo-sition I=Sum, C=Sum and Count with decompositionI=Count, C=Sum.
7

Our system will automatically generate Initial-Reduce, Combine and FinalReduce functions fromthese decompositions, along with a tuple type tostore the partial aggregation. For example, the Ini-tialReduce function in this example would computeboth the Sum and the Count of its input records andoutput a pair of integers encoding this partial sumand partial count. The ability to do this automaticinference on function compositions is very useful,since it allows programmers to reason about and an-notate their library functions using Definition 1 in-dependent of their usage in distributed aggregation.Any reducer expression that is composed of built-inand user-annotated decomposable functions will en-able the optimization of partial aggregation. A sim-ilar automatic combination of multiple aggregationscould be implemented by the Pig Latin compiler ora database query planner.
Thus the integer average computation could sim-ply be written
public static double Average(IEnumerable<int> g){IntPair final = g.Aggregate(x =>
new IntPair(x.Sum(), x.Count()));if (final.second == 0) return 0.0;else return (double)final.first /
(double)final.second);}
and the system would automatically synthesize es-sentially the same code as is written in Figure 5 orFigure 6 depending on whether the optimizer choosesthe iterator-based or accumulator-based implemen-tation.
As a more interesting example, the following codecomputes the standard deviation of a sequence ofintegers.
g.Aggregate(s => Sqrt(s.Sum(x => x*x) -s.Sum()*s.Sum()))
Because Sum is an associative-decomposable func-tion, the system automatically determines that theexpression passed to Aggregate is also associative-decomposable. DryadLINQ therefore chooses theexecution plan shown in Figure 2, making use of par-tial aggregation for efficiency.
4. EXAMPLE APPLICATIONSThis section lists the three DryadLINQ example
programs that we will evaluate in Section 6. Eachexample contains at least one distributed aggrega-tion step, and though the programs are quite simplethey further illustrate the use of the user-defined ag-gregation primitives we introduced in Section 3.3.For conciseness, the examples use LINQ’s SQL-stylesyntax instead of the object-oriented syntax adopted
in Section 3.1. All of these programs could be imple-mented in Pig Latin, native Hadoop or SQL, thoughperhaps less elegantly in some cases.
4.1 Word StatisticsThe first program computes statistics about word
occurrences in a corpus of documents.
var wordStats =from doc in docsfrom wc in from word in doc.words
group word by word into gselect new WordCount(g.Key, g.Count()))
group wc.count by wc.word into gselect ComputeStats(g.Key, g.Count(),
g.Max(), g.Sum());
The nested query “from wc ...” iterates overeach document doc in the corpus and assembles adocument-specific collection of records wc, one foreach unique word in doc, specifying the word andthe number of times it appears in doc.
The outer query “group wc.count...” combinesthe per-document collections and computes, for eachunique word in the corpus, a group containing allof its per-document counts. So for example if theword “confabulate” appears in three documents inthe corpus, once in one document and twice in eachof the other two documents, then the outer querywould include a group with key “confabulate” andcounts {1, 2, 2}.
The output of the full query is a collection ofrecords, one for each unique word in the collection,where each record is generated by calling the user-defined function ComputeStats. In the case above,for example, one record will be the result of calling
ComputeStats("confabulate", 3, 2, 5).
DryadLINQ will use the execution plan given inFigure 2, since Count, Max and Sum are all associative-decomposable functions. The Map phase computesthe inner query for each document, and the Ini-tialReduce, Combine and FinalReduce stages to-gether aggregate the triple (g.Count(), g.Max(),g.Sum()) using automatically generated functionsas described in Section 3.4.
4.2 Word Top DocumentsThe second example computes, for each unique
word in a corpus, the three documents that have thehighest number of occurences of that word.
[AssociativeDecomposable("ITop3", "CTop3")]public static WInfo[] Top3(IEnumerable<WInfo> g){return g.OrderBy(x => x.count).Take(3).ToArray();
}
public static WInfo[] ITop3(IEnumerable<WInfo> g){
8

return g.OrderBy(x => x.count).Take(3).ToArray();}
public static WInfo[] CTop3(IEnumerable<WInfo[]> g){return g.SelectMany(x => x).OrderBy(x => x.count).
Take(3).ToArray();}
var tops =from doc in docsfrom wc in from word in doc.words
group word by word into gselect new WInfo(g.Key, g.URL, g.Count())
group wc by wc.word into gselect new WordTopDocs(g.Key, Top3(g))
The program first computes the per-document countof occurrences of each word using a nested query asin the previous example, though this time we alsorecord the URL of the document associated witheach count. Once again the outer query regroups thecomputed totals according to unique words acrossthe corpus, but now for each unique word w we usethe function Top3 to compute the three documentsin which w occurs most frequently. While Top3 isassociative-decomposable, our implementation can-not infer its decomposition because we do not knowsimple rules to infer that operator compositions suchas OrderBy.Take are associative-decomposable. Wetherefore use an annotation to inform the systemthat Top3 is associative-decomposable with respectto ITop3 and CTop3. With this annotation, Dryad-LINQ can determine that the expression
new WordTopDocs(g.Key, Top3(g))
is associative-decomposable, so once again the sys-tem adopts the execution plan given in Figure 2.While we only show the iterator-based decomposi-tion of Top3 here, we have also implemented theaccumulator-based form and we compare the two inour evaluation in Section 6.
4.3 PageRankThe final example performs an iterative PageRank
computation on a web graph. For clarity we presenta simplified implementation of PageRank but inter-ested readers can find more highly optimized imple-mentations in [26] and [27].
var ranks = pages.Select(p => new Rank(p.name, 1.0));for (int i = 0; i < interations; i++){
// join pages with ranks, and disperse updatesvar updates =
from p in pagesjoin rank in ranks on p.name equals rank.nameselect p.Distribute(rank);
// re-accumulate.ranks = from list in updates
from rank in list
pages ranks
Iteration 1
Iteration 2
Iteration 3
Figure 7: Distributed execution plan for a multi-iteration PageRank computation. Iterations arepipelined together with the final aggregation at the end ofone iteration residing in the same process as the Join, rank-distribution, and initial aggregation at the start of the nextiteration. The system automatically maintains the partition-ing of the rank-estimate dataset and schedules processes torun close to their input data, so the page dataset is nevertransferred across the network.
group rank.rank by rank.name into gselect new Rank(g.Key, g.Sum());
}
Each element p of the collection pages contains aunique identifier p.name and a list of identifiers spec-ifying all the pages in the graph that p links to. Ele-ments of ranks are pairs specifying the identifier of apage and its current estimated rank. The first state-ment initializes ranks with a default rank for everypage in pages. Each iteration then calls a methodon the page object p to distribute p’s current rankevenly along its outgoing edges: Distribute returnsa list of destination page identifiers each with theirshare of p’s rank. Finally the iteration collects thesedistributed ranks, accumulates the incoming totalfor each page, and generates a new estimated rankvalue for that page. One iteration is analogous toa step of MapReduce in which the “Map” is actu-ally a Join pipelined with the distribution of scores,and the “Reduce” is used to re-aggregate the scores.The final select is associative-decomposable so oncemore DryadLINQ uses the optimized execution planin Figure 2.
The collection pages has been pre-partitioned ac-cording to a hash of p.name, and the initialization ofranks causes that collection to inherit the same par-titioning. Figure 7 shows the execution plan for mul-tiple iterations of PageRank. Each iteration com-putes a new value for ranks. Because DryadLINQknows that ranks and pages have the same parti-tioning, the Join in the next iteration can be com-
9

puted on the partitions of pages and ranks pairwisewithout any data re-partitioning. A well-designedparallel database would also be able to automaticallyselect a plan that avoids re-partitioning the datasetsacross iterations. However, because MapReduce doesnot natively support multi-input operators such asJoin, it is unable to perform a pipelined iterativecomputation such as PageRank that preserves datalocality, leading to much larger data transfer vol-umes for this type of computation when executedon a system such as Hadoop.
5. SYSTEM IMPLEMENTATIONWe now turn our attention to the implementations
of distributed reduction for the class of combiner-enabled computations. This section describes theexecution plan and six different reduction strategieswe have implemented using the DryadLINQ system.Section 6 evaluates these implementations on the ap-plications presented in Section 4.
All our example programs use the execution planin Figure 2 for their distributed GroupBy-Aggregatecomputations. This plan contains two aggregationsteps: G1+IR and G2+C. Their implementation hasa direct impact on the amount of data reduction atthe first stage and also on the degree of pipeliningwith the preceding and following computations. Ourgoal of course is to optimize the entire computation,not a single aggregation in isolation. In this section,we examine the implementation choices and theirtradeoffs.
We consider the following six implementations ofthe two aggregation steps, listing them according tothe implementation of the first GroupBy (G1). Allthe implementations are multi-threaded to take ad-vantage of our multi-core cluster computers.
FullSort This implementation uses the iterator in-terface that is described in Section 2.1. Thefirst GroupBy (G1) accumulates all the objectsin memory and performs a parallel sort on themaccording to the grouping key. The system thenstreams over the sorted objects calling Ini-tialReduce once for each unique key. The out-put of the InitialReduce stage remains sortedby the grouping key so we use a parallel mergesort for the Merge operations (MG) in the sub-sequent stages and thus the later GroupBys(G2) are simple streaming operations since therecords arrive sorted into groups and ready topass to the Combiners. Since the first stagereads all of the input records before doing anyaggregation it attains an optimal data reduc-tion for each partition. However the fact thatit accumulates every record in memory before
sorting completes makes the strategy unsuit-able if the output of the upstream computationis large. Since G2 is stateless it can be pipelinedwith a downstream computation as long as Fi-nalReduce does not use a large amount of mem-ory. Either the accumulator- or iterator-basedinterface can be used with this strategy, andwe use the iterator-based interface in our ex-periments. FullSort is the strategy adopted byMapReduce [9] and Hadoop [3].
PartialSort We again use the iterator interface forPartialSort. This scheme reads a bounded num-ber of chunks of input records into memory,with each chunk occupying bounded storage.Each chunk is processed independently in par-allel: the chunk is sorted; its sorted groupsare passed to InitialReduce; the output isemitted; and the next chunk is read in. Sincethe output of the first stage is not sorted weuse non-deterministic merge for MG, and we useFullSort for G2 since we must aggregate all therecords for a particular key before calling Fi-nalReduce. PartialSort uses bounded storagein the first stage so it can be pipelined withupstream computations. G2 can consume un-bounded storage, but we expect a large degreeof data reduction from pre-aggregation most ofthe time. We therefore enable the pipeliningof downstream computations by default whenusing PartialSort (and all the following strate-gies), and allow the user to manually disableit. Since InitialReduce is applied indepen-dently to each chunk, PartialSort does not ingeneral achieve as much data reduction at thefirst stage as FullSort. The aggregation treestage in Figure 2 may therefore be a useful op-timization to perform additional data reductioninside a rack before the data are sent over thecluster’s core switch.
Accumulator-FullHash This implementation usesthe accumulator interface that is described inSection 3.2. It builds a parallel hash table con-taining one accumulator object for each uniquekey in the input dataset. When a new uniquekey is encountered a new accumulator objectis created by calling Initialize, and placedin the hash table. As each record is read fromthe input it is passed to the Iterate method ofits corresponding accumulator object and thendiscarded. This method makes use of a non-deterministic merge for MG and Accumulator-FullHash for G2. Storage is proportional to thenumber of unique keys rather than the num-
10

ber of records, so this scheme is suitable forsome problems for which FullSort would ex-haust memory. It is also more general than ei-ther sorting method since it only requires equal-ity comparison for keys (as well as the abilityto compute an efficient hash of each key). LikeFullSort, this scheme achieves optimal data re-duction after the first stage of computation.While the iterator-based interface could in prin-ciple be used with this strategy it would fre-quently be inefficient since it necessitates con-structing a singleton iterator to “wrap” each in-put record, creating a new partial aggregate ob-ject for that record, then merging it with thepartial aggregate object stored in the hash ta-ble. We therefore use the accumulator interfacein our experiments. Accumulator-FullHash islisted as a GroupBy implementation by the doc-umentation of commercial databases such asIBM DB2 and recent versions of Oracle.
Accumulator-PartialHash This is a similar im-plementation to Accumulator-FullHash exceptthat it evicts the accumulator object from thehash table and emits its partial aggregationwhenever there is a hash collision. Storage us-age is therefore bounded by the size of the hashtable, however data reduction at the first stagecould be very poor for adversarial inputs. Weuse Accumulator-FullHash for G2 since we mustaggregate all the records for a particular keybefore calling FinalReduce.
Iterator-FullHash This implementation is similarto FullSort in that it accumulates all the recordsin memory before performing any aggregation,but instead of accumulating the records into anarray and then sorting them, Iterator-FullHashaccumulates the records into a hash table ac-cording to their GroupBy keys. Once all therecords have been assembled, each group in thehash table in turn is aggregated and emitted us-ing a single call to InitialReduce. G1 has sim-ilar memory characteristics to FullSort, how-ever G2 must also use Iterator-FullHash becausethe outputs are not partially sorted. Iterator-FullHash, like Accumulator-FullHash, requiresonly equality comparison for the GroupBy key.
Iterator-PartialHash This implementation is sim-ilar to Iterator-FullHash but, like Accumulator-PartialHash, it emits the group accumulated inthe hash table whenever there is a hash colli-sion. It uses bounded storage in the first stagebut falls back to Iterator-FullHash for G2. LikeAccumulator-PartialHash, Iterator-FullHash
may result in poor data reduction in its firststage.
In all the implementations, the aggregation treeallows data aggregation according to data localityat multiple levels (computer, rack, and cluster) inthe cluster network. Since the aggregation tree ishighly dependent on the dynamic scheduling deci-sions of the vertex processes, it is automatically in-serted into the execution graph at run time. This isimplemented using the Dryad callback mechanismthat allows higher level layers such as DryadLINQto implement runtime optimization policies by dy-namically mutating the execution graph. For theaggregation tree, DryadLINQ supplies the aggrega-tion vertex and policies, and Dryad automaticallyintroduces an aggregation tree based on run timeinformation. Aggregation trees can be particularlyuseful for PartialSort and PartialHash when the datareduction in the first stage is poor. They are alsovery beneficial if the input dataset is composed of alot of small partitions.
Note that while the use of merge sort for MG allowsFullSort to perform a stateless GroupBy at G2, it hasa subtle drawback compared to a non-deterministicmerge. Merge sort must open all of its inputs atonce and interleave reads from them, while non-deterministic merge can read sequentially from oneinput at a time. This can have a noticeable impacton disk IO performance when there is a large numberof inputs.
Although FullSort is the strategy used by MapRe-duce and Hadoop, the comparison is a little mislead-ing. The Map stage in these systems always oper-ates on one single small input partition at a time,read directly from a distributed file system. It isnever pipelined with an upstream computation suchas a Join with a large data magnification, or run ona large data partition like the ones in our experi-ments in the following section. In some ways there-fore, MapReduce’s FullSort is more like our Partial-Sort with only computer-level aggregation since itarranges to only read its input in fixed-size chunks.In the evaluation section, we simulated MapReducein DryadLINQ and compared its performance withour implementations.
As far as we know, neither Iterator-PartialHashnor Accumulator-PartialHash has previously beenreported in the literature. However, it should be ap-parent that there are many more variants on theseimplementations that could be explored. We haveselected this set to represent both established meth-ods and those methods which we have found to per-form well in our experiments.
11

6. EXPERIMENTAL EVALUATIONThis section evaluates our implementations of dis-
tributed aggregation, focusing on the effectiveness ofthe various optimization strategies. As explained inSection 4 all of our example programs can be ex-ecuted using the plan shown in Figure 2. In thisplan the stage marked “aggregation tree” is optionaland we run experiments with and without this stageenabled. When the aggregation tree is enabled thesystem performs a partial aggregation within eachrack. For larger clusters this single level of aggre-gation might be replaced by a tree. As noted be-low, our network is quite well provisioned and so wedo not see much benefit from the aggregation tree.In fact it can harm performance, despite the addi-tional data reduction, due to the overhead of startingextra processes and performing additional disk IO.However we also have experience running similar ap-plications on large production clusters with smallercross-cluster bandwidth, and we have found that insome cases aggregation trees can be essential to getgood performance.
We report data reduction numbers for our experi-ments. In each case a value is reported for each stageof the computation and it is computed as the ratiobetween the uncompressed size of the total data in-put to the stage and the uncompressed size of itstotal output. We report these values to show howmuch opportunity for early aggregation is missed byour bounded-size strategies compared to the optimalFullSort and FullHash techniques. Our implemen-tation in fact compresses intermediate data, so thedata transferred between stages is approximately afactor of three smaller than is suggested by thesenumbers, which further reduces the benefit of usingan aggregation tree.
6.1 Dryad and DryadLINQDryadLINQ [26] translates LINQ programs writ-
ten using .NET languages into distributed computa-tions that can be run on the Dryad cluster-computingsystem [16]. A Dryad job is a directed acyclic graphwhere each vertex is a program and edges representdata channels. At run time, vertices are processescommunicating with each other through the chan-nels, and each channel is used to transport a finitesequence of data records. Dryad’s main job is toefficiently schedule vertex processes on cluster com-puters and to provide fault-tolerance by re-executingfailed or slow processes. The vertex programs, datamodel, and channel data serialization code are allsupplied by higher-level software layers, in this caseDryadLINQ. In all our examples vertex processeswrite their output channel data to local disk storage,
and read input channel data from the files writtenby upstream vertices.
At the heart of the DryadLINQ system is the par-allel compiler that generates the distributed execu-tion plan for Dryad to run. DryadLINQ first turnsa raw LINQ expression into an execution plan graph(EPG), and goes through several phases of semantics-preserving graph rewriting to optimize the executionplan. The EPG is a“skeleton”of the Dryad data-flowgraph that will be executed, and each EPG node isexpanded at run time into a set of Dryad verticesrunning the same computation on different parti-tions of a dataset. The optimizer uses many tradi-tional database optimization techniques, both staticand dynamic. More details of Dryad and Dryad-LINQ can be found in [16, 17, 26].
6.2 Hardware ConfigurationThe experiments described in this paper were run
on a cluster of 236 computers. Each of these com-puters was running the Windows Server 2003 64-bitoperating system. The computers’ principal compo-nents were two dual-core AMD Opteron 2218 HECPUs with a clock speed of 2.6 GHz, 16 GBytes ofDDR2 RAM, and four 750 GByte SATA hard drives.The computers had two partitions on each disk. Thefirst, small, partition was occupied by the operat-ing system on one disk and left empty on the re-maining disks. The remaining partitions on eachdrive were striped together to form a large data vol-ume spanning all four disks. The computers wereeach connected to a Linksys SRW2048 48-port full-crossbar GBit Ethernet local switch via GBit Eth-ernet. There were between 29 and 31 computersconnected to each local switch. Each local switchwas in turn connected to a central Linksys SRW2048switch, via 6 ports aggregated using 802.3ad link ag-gregation. This gave each local switch up to 6 GBitsper second of full duplex connectivity. Our researchcluster has fairly high cross-cluster bandwidth, how-ever hierarchical networks of this type do not scaleeasily since the central switch rapidly becomes a bot-tleneck. Many clusters are therefore less well provi-sioned than ours for communication between com-puters in different racks.
6.3 Word StatisticsIn this experiment we evaluate the word statistics
application described in Section 4.1 using a collec-tion of 140 million web documents with a total sizeof 1 TB. The dataset was randomly partitioned into236 partitions each around 4.2 GB in size, and eachcluster computer stored one partition. Each par-tition contains around 500 million words of which
12

0
100
200
300
400
500
600
FullSort PartialSort Accumulator FullHash
Accumulator PartialHash
Iterator FullHash
Iterator PartialHash
Tota
l ela
psed
tim
e in
sec
onds
No Aggregation TreeAggregation Tree
Figure 8: Time in seconds to compute word statisticswith different optimization strategies.
Reduction strategy No Aggregation AggregationFullSort [11.7, 4.5] [11.7, 2.5, 1.8]
PartialSort [3.7, 13.7] [3.7, 7.3, 1.8]Acc-FullHash [11.7, 4.5] [11.7, 2.5, 1.8]
Acc-PartialHash [4.6, 11.4] [4.6, 6.15, 1.85]Iter-FullHash [11.7, 4.5] [11.7, 2.5, 1.8]
Iter-PartialHash [4.1, 12.8] [4.1, 6.6, 1.9]
Table 1: Data reduction ratios for the word statisticsapplication under different optimization strategies.
about 9 million are distinct. We ran this applica-tion using the six optimization strategies describedin Section 5.
Figure 8 shows the elapsed times in seconds of thesix different optimization strategies with and with-out the aggregation tree. On repeated runs the timeswere consistent to within 2% of their averages. Forall the runs, the majority (around 80%) of the to-tal execution time is spent in the map stage of thecomputation. The hash-based implementations sig-nificantly outperform the others, and the partial re-duction implementations are somewhat better thantheir full reduction counterparts.
Table 1 shows the amount of data reduction ateach stage of the six strategies. The first columnshows the experimental results when the aggrega-tion tree is turned off. The two numbers in eachentry represent the data reductions of the map andreduce stages. The second column shows the resultsobtained using an aggregation tree. The three num-bers in each entry represent the data reductions ofthe map, aggregation tree, and reduce stages. Thetotal data reduction for a computation is the prod-uct of the numbers in its entry. As expected, us-ing PartialHash or PartialSort for the map stage al-ways results in less data reduction for that stage thanis attained by their FullHash and FullSort variants.However, their reduced memory footprint (especially
for the hash-based approaches whose storage is pro-portional to the number of records rather than thenumber of groups) leads to faster processing timeand compensates for the inferior data reduction sinceour network is fast.
We compared the performance for this applicationwith a baseline experiment that uses the executionplan in Figure 1, i.e. with no partial aggregation.We compare against FullSort, so we use FullSort asthe GroupBy implementation in the reduce stage.We used the same 236 partition dataset for this ex-periment, but there is a data magnification in theoutput of the map stage so we used 472 reducers toprevent FullSort from running out of memory. Themap stage applies the map function and performs ahash partition. The reduce stage sorts the data andperforms the Groupby-Aggregate computation. Thetotal elapsed execution time is 15 minutes. This isa 346 second (60%) increase in execution time com-pared to FullSort, which can be explained by theoverhead of additional disk and network IO, validat-ing our premise that performing local aggregationcan significantly improve the performance of large-scale distributed aggregation. We performed a simi-lar experiment using the plan in Figure 1 with Full-Hash in the reduce stage, and obtained a similar per-formance degradation compared to using FullHashwith partial aggregation.
6.4 Word PopularityIn this experiment we evaluate the word popu-
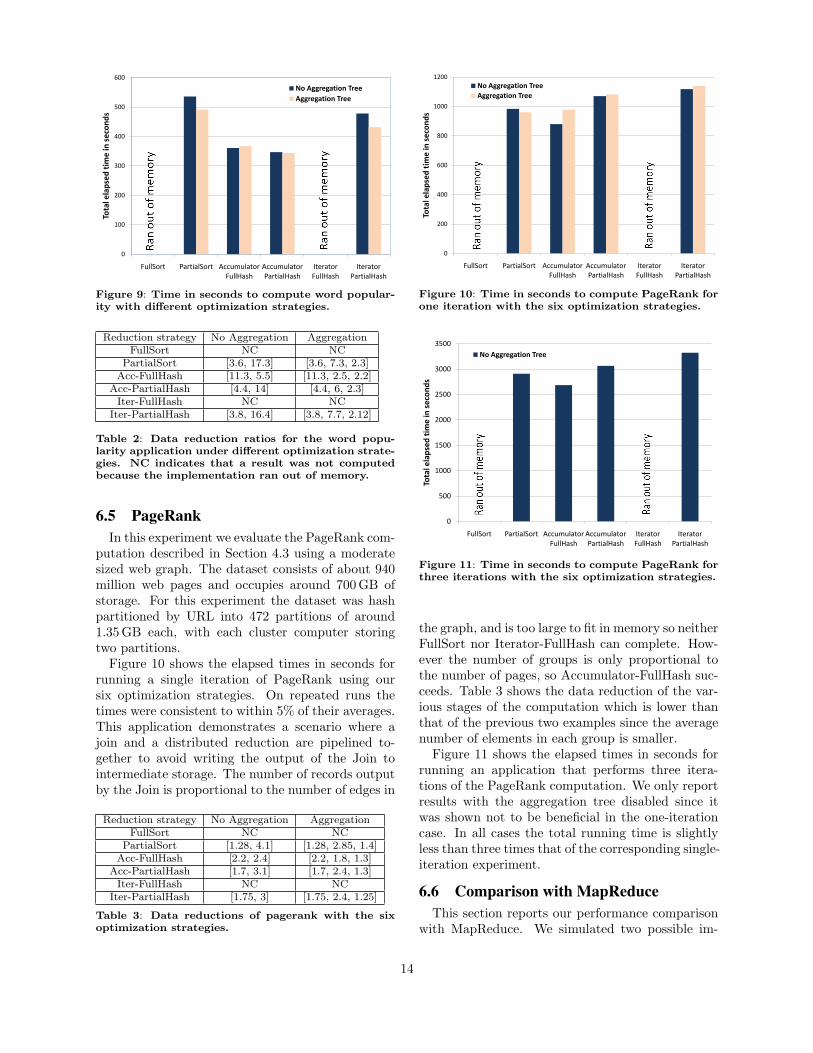
larity application described in Section 4.2 using thesame 1 TB dataset of web documents as in the pre-vious experiment. We again compared six optimiza-tion strategies, with and without the aggregationtree.
Figure 9 and Table 2 show the total elapsed timesand data reductions for each strategy. FullSort andIterator-FullHash could not complete because theyran out of memory. While the input corpus was thesame as for the experiment in Section 6.3, this ap-plication retains the URL of each document alongwith its count and this substantially increases therequired storage. Accumulator-FullHash was ableto complete because it only stores the partially ag-gregated values of the groups, not the groups them-selves. Once again, the aggregation tree achieveda considerable reduction in the data that had to betransmitted between racks to execute the final stage,but gained little in terms of overall performance.The accumulator-based interfaces performed betterthan the iterator-based interfaces, and Accumulator-PartialHash ran a little faster than Accumulator-FullHash.
13
0
100
200
300
400
500
600
FullSort PartialSort Accumulator FullHash
Accumulator PartialHash
Iterator FullHash
Iterator PartialHash
Tota
l ela
psed
tim
e in
sec
onds
No Aggregation TreeAggregation Tree
Figure 9: Time in seconds to compute word popular-ity with different optimization strategies.
Reduction strategy No Aggregation AggregationFullSort NC NC
PartialSort [3.6, 17.3] [3.6, 7.3, 2.3]Acc-FullHash [11.3, 5.5] [11.3, 2.5, 2.2]
Acc-PartialHash [4.4, 14] [4.4, 6, 2.3]Iter-FullHash NC NC
Iter-PartialHash [3.8, 16.4] [3.8, 7.7, 2.12]
Table 2: Data reduction ratios for the word popu-larity application under different optimization strate-gies. NC indicates that a result was not computedbecause the implementation ran out of memory.
6.5 PageRankIn this experiment we evaluate the PageRank com-
putation described in Section 4.3 using a moderatesized web graph. The dataset consists of about 940million web pages and occupies around 700 GB ofstorage. For this experiment the dataset was hashpartitioned by URL into 472 partitions of around1.35 GB each, with each cluster computer storingtwo partitions.
Figure 10 shows the elapsed times in seconds forrunning a single iteration of PageRank using oursix optimization strategies. On repeated runs thetimes were consistent to within 5% of their averages.This application demonstrates a scenario where ajoin and a distributed reduction are pipelined to-gether to avoid writing the output of the Join tointermediate storage. The number of records outputby the Join is proportional to the number of edges in
Reduction strategy No Aggregation AggregationFullSort NC NC
PartialSort [1.28, 4.1] [1.28, 2.85, 1.4]Acc-FullHash [2.2, 2.4] [2.2, 1.8, 1.3]
Acc-PartialHash [1.7, 3.1] [1.7, 2.4, 1.3]Iter-FullHash NC NC
Iter-PartialHash [1.75, 3] [1.75, 2.4, 1.25]
Table 3: Data reductions of pagerank with the sixoptimization strategies.
0
200
400
600
800
1000
1200
FullSort PartialSort Accumulator FullHash
Accumulator PartialHash
Iterator FullHash
Iterator PartialHash
Tota
l ela
psed
tim
e in
sec
onds
No Aggregation TreeAggregation Tree
Figure 10: Time in seconds to compute PageRank forone iteration with the six optimization strategies.
0
500
1000
1500
2000
2500
3000
3500
FullSort PartialSort Accumulator FullHash
Accumulator PartialHash
Iterator FullHash
Iterator PartialHash
Tota
l ela
psed
tim
e in
sec
onds
No Aggregation Tree
Figure 11: Time in seconds to compute PageRank forthree iterations with the six optimization strategies.
the graph, and is too large to fit in memory so neitherFullSort nor Iterator-FullHash can complete. How-ever the number of groups is only proportional tothe number of pages, so Accumulator-FullHash suc-ceeds. Table 3 shows the data reduction of the var-ious stages of the computation which is lower thanthat of the previous two examples since the averagenumber of elements in each group is smaller.
Figure 11 shows the elapsed times in seconds forrunning an application that performs three itera-tions of the PageRank computation. We only reportresults with the aggregation tree disabled since itwas shown not to be beneficial in the one-iterationcase. In all cases the total running time is slightlyless than three times that of the corresponding single-iteration experiment.
6.6 Comparison with MapReduceThis section reports our performance comparison
with MapReduce. We simulated two possible im-
14

plementations of MapReduce (denoted MapReduce-I and MapReduce-II) in DryadLINQ. The implemen-tations differ only in their map phase. MapReduce-Iapplies the Map function, sorts the resulting records,and writes them to local disk, while MapReduce-IIperforms partial aggregation on the sorted recordsbefore outputting them. Both implementations per-form computer-level aggregation after the map stage,and the reduce stage simply performs a merge sortand applies the reduce function. We evaluated thetwo implementations on the word statistics applica-tion from Section 6.3, where the input dataset wasrandomly partitioned into 16000 partitions each ap-proximately 64 MB in size. Each implementationexecuted 16000 mapper processes and 236 reducerprocesses.
The two MapReduce implementations have almostidentical performance on our example, each takingjust over 700 seconds. Comparing to Figure 8, it isclear that they were outperformed by all six imple-mentations described in Section 5. The MapReduceimplementations took about three times longer thanthe best strategy (Accumulator-PartialHash), andtwice as long as PartialSort which is the most similarto MapReduce as noted in Section 5. The bulk ofthe performance difference is due to the overhead ofrunning tens of thousands of short-lived processes.
6.7 AnalysisIn all experiments the accumulator-based inter-
faces perform best, which may explain why this styleof interface was chosen by the database community.The implementations that use bounded memory atthe first stage, but achieve lower data reduction,complete faster in our experiments than those whichuse more memory, but output less data, in the firststage. As discussed above, this and the fact that theaggregation tree is not generally effective may bea consequence of our well-provisioned network, andfor some clusters performing aggressive early aggre-gation might be more effective.
Based on these experiments, if we had to choose asingle implementation strategy it would be Accum-ulator-FullHash, since it is faster than the alterna-tives for PageRank, competitive for the other ex-periments, and achieves a better early data reduc-tion than Accumulator-PartialHash. However sinceit does not use bounded storage there are workloads(and computer configurations) for which it cannot beused, so a robust system must include other strate-gies to fall back on.
The MapReduce strategy of using a very largenumber of small input partitions performs substan-tially worse than the other implementations we tried
due to the overhead of starting a short-lived processfor each of the partitions.
7. RELATED WORKThere is a large body of work studying aggrega-
tion in the parallel and distributed computing litera-ture. Our work builds on data reduction techniquesemployed in parallel databases, cluster data-parallelcomputing, and functional and declarative program-ming. To our knowledge, this paper represents thefirst systematic evaluation of the programming inter-faces and implementations of large scale distributedaggregation.
7.1 Parallel and Distributed DatabasesAggregation is an important aspect of database
query optimization [6, 14]. Parallel databases [11]such as DB2 [4], Gamma [10], Volcano [13], and Or-acle [8] all support pre-aggregation techniques forSQL base types and built-in aggregators. Some sys-tems such as Oracle also support pre-aggregation foruser-defined functions. However, when the aggre-gation involves more complex user-defined functionsand data types, the database programming interfacecan become substantially more difficult to use thanDryadLINQ. Databases generally adopt accumulator-based interfaces. As shown in our evaluation, theseconsistently outperform the iterator interfaces usedby systems like MapReduce.
7.2 Cluster Data-Parallel ComputingInfrastructures for large scale distributed data pro-
cessing have proliferated recently with the introduc-tion of systems such as MapReduce [9], Dryad [16]and Hadoop [3]. All of these systems implementuser-defined distributed aggregation, however theirinterfaces for implementing pre-aggregation are ei-ther less flexible or more low-level than that providedby DryadLINQ. No previously published work hasoffered a detailed description and evaluation of theirinterfaces and implementations for this importantoptimization. The work reported in [18] formalizesMapReduce in the context of the Haskell functionalprogramming language.
7.3 Functional and Declarative Languagesfor Parallel Programming
Our work is also closely related to data aggrega-tion techniques used in functional and declarativeparallel programming languages [7, 21, 25]. The for-malism of algorithmic skeletons underpins our treat-ment of decomposable functions in Sections 2 and 3.
The growing importance of data-intensive compu-tation at scale has seen the introduction of a number
15

of distributed and declarative scripting languages,such as Sawzall [20], SCOPE [5], Pig Latin [19] andHIVE [1]. Sawzall supports user-defined aggregationusing MapReduce’s combiner optimization. SCOPEsupports pre-aggregation for a number of built-in ag-gregators. Pig Latin supports partial aggregationfor algebraic functions, however as explained in Sec-tion 3, we believe that the programming interfaceoffered by DryadLINQ is cleaner and easier to usethan Pig Latin.
8. DISCUSSION AND CONCLUSIONSThe programming models for MapReduce and par-
allel databases have roughly equivalent expressive-ness for a single MapReduce step. When a user-defined function is easily expressed using a built-in database language the SQL interface is slightlysimpler, however more complex user-defined func-tions are easier to implement using MapReduce orHadoop. When sophisticated relational queries arerequired native MapReduce becomes difficult to pro-gram. The Pig Latin language simplifies the pro-gramming model for complex queries, but the under-lying Hadoop platform cannot always execute thosequeries efficiently. In some ways, DryadLINQ seemsto offer the best of the two alternative approaches:a wide range of optimizations; simplicity for commondata-processing operations; and generality when com-putations do not fit into simple types or processingpatterns.
Our formulation of partial aggregation in termsof decomposable functions enables us to study com-plex reducers that are expressed as a combination ofsimpler functions. However, as noted in Section 4.2,the current DryadLINQ system is not sophisticatedenough even to reason about simple operator com-positions such as OrderBy.Take. We plan to addan analysis engine to the system that will be ableto infer the algebraic properties of common opera-tor compositions. This automatic inference shouldfurther improve the usability of partial aggregation.
We show that an accumulator-based interface foruser-defined aggregation can perform substantiallybetter than an iterator-based alternative. Some pro-grammers may, however, consider the iterator inter-face to be more elegant or simpler, so may prefer iteven though it makes their jobs run slower. Many.NET library functions are also defined in the it-erator style. Now that we have implemented bothwithin DryadLINQ we are curious to discover whichwill be more popular among users of the system.
Another clear finding is that systems should se-lect between a variety of optimization schemes whenpicking the execution plan for a particular compu-
tation, since different schemes are suited to differ-ent applications and cluster configurations. Of thethree systems we consider, currently only paralleldatabases are able to do this. Pig Latin and Dryad-LINQ could both be extended to collect statisticsabout previous runs of a job, or even to monitor thejob as it executes. These statistics could be used asprofile-guided costs that would allow the systems’expression optimizers to select between aggregationimplementations, and our experiments suggest thiswould bring substantial benefits for some workloads.
Finally, we conclude that it is not sufficient toconsider the programming model or the executionengine of a distributed platform in isolation: it isthe system that combines the two that determineshow well ease of use can be traded off against per-formance.
9. ACKNOWLEDGMENTSWe would like to thank the member of the Dryad-
LINQ project for their contributions. We would alsolike to thank Frank McSherry and Dennis Fetterlyfor sharing and explaining their implementations ofPageRank, and Martın Abadi and Doug Terry formany helpful comments. Thanks also to the SOSPreview committee and our shepherd Jon Crowcroftfor their very useful feedback.
10. REFERENCES[1] The HIVE project.
http://hadoop.apache.org/hive/.[2] Database Languages—SQL, ISO/IEC
9075-*:2003, 2003.[3] Hadoop wiki. http://wiki.apache.org/hadoop/,
April 2008.[4] C. Baru and G. Fecteau. An overview of DB2
parallel edition. In International Conferenceon Management of Data (SIGMOD), pages460–462, New York, NY, USA, 1995. ACMPress.
[5] R. Chaiken, B. Jenkins, P.-A. Larson,B. Ramsey, D. Shakib, S. Weaver, andJ. Zhou. SCOPE: Easy and efficient parallelprocessing of massive data sets. InInternational Conference of Very Large DataBases (VLDB), August 2008.
[6] S. Chaudhuri. An overview of queryoptimization in relational systems. In PODS’98: Proceedings of the seventeenth ACMSIGACT-SIGMOD-SIGART symposium onPrinciples of database systems, pages 34–43,1998.
[7] M. Cole. Algorithmic skeletons: structuredmanagement of parallel computation. MIT
16

Press, Cambridge, MA, USA, 1991.[8] T. Cruanes, B. Dageville, and B. Ghosh.
Parallel SQL execution in Oracle 10g. In ACMSIGMOD, pages 850–854, Paris, France, 2004.ACM.
[9] J. Dean and S. Ghemawat. MapReduce:Simplified data processing on large clusters. InProceedings of the 6th Symposium onOperating Systems Design and Implementation(OSDI), pages 137–150, Dec. 2004.
[10] D. DeWitt, S. Ghandeharizadeh, D. Schneider,H. Hsiao, A. Bricker, and R. Rasmussen. TheGamma database machine project. IEEETransactions on Knowledge and DataEngineering, 2(1), 1990.
[11] D. DeWitt and J. Gray. Parallel databasesystems: The future of high performancedatabase processing. Communications of theACM, 36(6), 1992.
[12] A. Eisenberg, J. Melton, K. Kulkarni, J.-E.Michels, and F. Zemke. Sql:2003 has beenpublished. SIGMOD Rec., 33(1):119–126, 2004.
[13] G. Graefe. Encapsulation of parallelism in theVolcano query processing system. In SIGMODInternational Conference on Management ofdata, pages 102–111, New York, NY, USA,1990. ACM Press.
[14] G. Graefe. Query evaluation techniques forlarge databases. ACM Computing Surveys,25(2):73–169, 1993.
[15] J. Gray, S. Chaudhuri, A. Bosworth,A. Layman, D. Reichart, M. Venkatrao,F. Pellow, and H. Pirahesh. Data cube: Arelational aggregation operator generalizinggroup-by, cross-tab, and sub-totals. DataMining and Knowledge Discovery, 1(1), 1997.
[16] M. Isard, M. Budiu, Y. Yu, A. Birrell, andD. Fetterly. Dryad: Distributed data-parallelprograms from sequential building blocks. InProceedings of European Conference onComputer Systems (EuroSys), pages 59–72,March 2007.
[17] M. Isard and Y. Yu. Distributed data-parallelcomputing using a high-level programminglanguage. In International Conference onManagement of Data (SIGMOD), June29-July 2 2009.
[18] R. Lammel. Google’s mapreduce programmingmodel – revisited. Science of ComputerProgramming, 70(1):1–30, 2008.
[19] C. Olston, B. Reed, U. Srivastava, R. Kumar,and A. Tomkins. Pig Latin: A not-so-foreignlanguage for data processing. In InternationalConference on Management of Data(Industrial Track) (SIGMOD), Vancouver,Canada, June 2008.
[20] R. Pike, S. Dorward, R. Griesemer, andS. Quinlan. Interpreting the data: Parallelanalysis with Sawzall. Scientific Programming,13(4):277–298, 2005.
[21] F. Rabhi and S. Gorlatch. Patterns andSkeletons for Parallel and DistributedComputing. Springer, 2003.
[22] C. Ranger, R. Raghuraman, A. Penmetsa,G. Bradski, and C. Kozyrakis. Evaluatingmapreduce for multi-core and multiprocessorsystems. In HPCA ’07: Proceedings of the2007 IEEE 13th International Symposium onHigh Performance Computer Architecture,pages 13–24, 2007.
[23] L. A. Rowe and M. R. Stonebraker. Thepostgres data model. In InternationalConference of Very Large Data Bases(VLDB), pages 83–96. Society Press, 1987.
[24] J. Russell. Oracle9i Application Developer’sGuide—Fundamentals. Oracle Corporation,2002.
[25] P. Trinder, H.-W. Loidl, and R. Pointon.Parallel and distributed Haskells. Journal ofFunctional Programming, 12((4&5)):469–510,2002.
[26] Y. Yu, M. Isard, D. Fetterly, M. Budiu,U. Erlingsson, P. K. Gunda, and J. Currey.DryadLINQ: A system for general-purposedistributed data-parallel computing using ahigh-level language. In Proceedings of the 8thSymposium on Operating Systems Design andImplementation (OSDI), December 8-10 2008.
[27] Y. Yu, M. Isard, D. Fetterly, M. Budiu,U. Erlingsson, P. K. Gunda, J. Currey,F. McSherry, and K. Achan. Some sampleprograms written in DryadLINQ. TechnicalReport MSR-TR-2008-74, Microsoft Research,May 2008.
17