disp gis informatica
DESCRIPTION
ÂTRANSCRIPT

Elementi di Analisi dell’Informazione Geografica
Metodologie di analisi di dati geografici in ambiente GIS
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Filippo Catani Dipartimento di Scienze della Terra – Via La Pira, 4 50121 Firenze Tel. 055 2756223 – Fax. 055 2756296 email: [email protected]

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Analisi dell’Informazione Geografica (Geographic Information Analysis – G.I.A.) Definizione operativa: disciplina che studia gli effetti e le cause dei processi che avvengono nello spazio geografico La GIA utilizza dati che posseggono direttamente o indirettamente una localizzazione geografica. La cartografia tematica è una delle forme in cui i dati possono essere inseriti o estratti prima e dopo operazioni di GIA. Il supporto normalmente utilizzato per la GIA è un sistema GIS, anche se alcune delle operazioni più complesse di analisi geografica non sono normalmente presenti all’interno dei prodotti GIS commerciali. La GIA è un sottoinsieme della più generale Analisi Spaziale dei Dati (Spatial Data Analysis - SDA)

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Analisi Spaziale dei Dati (Spatial Data Analysis – SDA) Il termine è molto vasto ed è inteso generalmente nelle seguenti accezioni, non mutuamente esclusive: • Spatial Data Manipulation – Gestione dei dati spaziali, dall’inserimento alla modifica fino alla restituzione in forma di report. Comprende tutti le principali funzioni comprese nei GIS commerciali. • Spatial Data Analysis – E’ sia descrittiva che esplorativa e comprende le statistiche di base che possono essere applicate generalmente ai dati geografici anche quando essi sono estremamente numerosi. • Spatial Statistical Analysis – Impiega metolodogie statistiche per comprendere se i dati sono concordi o discordi rispetto a distribuzioni statistiche note. • Spatial Modeling – Costruzione di modelli di previsione geografica, sia spaziale che temporale. Un esempio è un modello per la previsione del rischio di frana, basato su parametri ricavati con le tipologie di analisi precedenti. Questo tipo di strumenti è generalmente assente dai pacchetti GIS commerciali.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Modelli dei dati I dati geografici in GIA possono essere rappresentati in vari modi. Tradizionalmente si distinguono i due modelli vettoriale e raster. Il primo si basa sulla rappresentazione delle entità o oggetti geografici tramite vettori definiti da modulo, direzione e verso. Il secondo invece rappresenta lo spazio come una matrice di pixel o celle aventi valori diversi dell’attributo da rappresentare. Questa suddivisione non è in realtà molto utile per la scelta del migliore modello di rappresentazione…
Vettoriale
Raster

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Modello Vettoriale – Primitive di rappresentazione
Poligoni (es. formazioni geologiche)
Archi (es. fiumi, faglie)
Punti (es. pozzi, campioni)
TOPOLOGIA Relazioni geometriche tra gli oggetti nello spazio geografico
(es. contenimento, adiacenza, connessione, sovrapposizione etc.)

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Modello Raster – Metodo di rappresentazione a celle rettangolari
Conversione Vettoriale -> Raster
Un raster a celle rettangolari, comunemente chiamato anche grid, è contraddistinto dalla seguenti proprietà fondamentali: • Dimensione della cella (o risoluzione) • Coordinate x,y di uno dei vertici del raster • Numero di colonne • Numero di righe • Tipologia dei valori associati ad ogni cella • Valore corrispondente a no-data (mancanza di informazione)
CELLE PIÙ PICCOLE -> MAGGIORE RISOLUZIONE -> MAGGIORE OCCUPAZIONE DI
MEMORIA

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Modello Object-Field (Oggetto-Campo) Il modello vettoriale-raster, utile a livello pratico, rende confusa una più importante distinzione, quella tra le concezioni ad oggetti e a campo. Visione ad oggetti In questo modello il mondo è visto come un insieme di entità localizzate nello spazio. Queste entità possono essere rappresentate in vari modi, sia vettoriali che discreti. Le varie entità sono identificate da attributi. Modello più adatto: vettoriale. Visione a campo Il mondo è visto come costituito da proprietà che variano in modo continuo nello spazio, senza interruzioni. Si ha quindi autodefinizione e non c’è bisogno di attributi connessi ad ogni cella. Modello più adatto: raster.
Modello a Campo
Modello ad Oggetti

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Attributi e Misure (di entità e campi) Si dice attributo di una entità qualsiasi caratteristica che sia utilizzata per la rappresentazione, ricerca o trattazione della stessa. ü Normalmente gli attributi dipendono dal livello di misura utilizzato per determinarli. ü La misura è il processo di assegnare una classe o un valore ad un determinato fenomeno sulla base di regole predeterminate ü Le misure debbono essere fatte utilizzando processi definiti, aventi risultati riproducibili e validi. F Processo definito = chi effettua la misura sa quello che sta misurando e può definire e compiere le operazioni necessarie
F Riproducibilità = ripetizioni del procedimento di misura sulla stessa entità o processo danno risultati uguali
F Validità = la misura può essere considerata vera ed accurata

Livelli di misura Sulla base di quanto detto Stevens (1946) definì 4 livelli di misurazione, legati alla concettualizzazione delle entità o alla caratteristica degli strumenti di misura disponibili. 1. Misure Nominali
Sono al più basso livello di conoscenza. Per esse il valore della misura è soltanto una categoria, senza nè unità di misura nè rango nei valori delle categorie. Es. tipi di uso del suolo (bosco, prato, etc.). Le possibili operazioni statistiche che si possono compiere su tali dati sono distribuzioni di frequenza o analisi basate sulla semplice posizione x,y,z degli oggetti.
2. Misure Ordinali Come le precedenti sono rappresentate da classi e non da singoli valori numerici. In più le ordinali hanno però la possibilità di poter essere disposte in un ordine basato su un criterio ben definibile. Es. classi di propensione al terremoto (si sa che la classe 1 ha propensione minore della 2 e la 2 minore della 3 ma la differenza tra le classi 1 e 2 può essere molto diversa della differenza tra le classi 2 e 3). Le statistiche applicabili sono limitate.
3. Misure a Intervalli A differenza delle ordinali le misure ad intervallo assumono una distanza ben definibile tra classe e classe, con una unità di misura fissata. Queste misure mancano però di uno zero di scala inerente. Un esempio sono le scale di temperatura (0° non vuol dire mancanza di temperatura) eccetto la scala Kelvin. Sono numeriche.
4. Misure Cardinali Hanno sia unità di misura fissa numerica che zero inerente. Esempio classico le distanze in metri. Le misure cardinali sono contraddistinte dalla conservazione dei rapporti tra misure al variare dell’unità di misura. Es.: se tra il punto A ed il punto B ci sono 10 km di distanza e tra B e C 20 km il rapporto AB/BC sarà sempre 0.5, in qualsiasi unità di misura (miglia, chilometri, leghe, etc.). Invece se in un’area la temperatura annuale media è 10°C (cioè 50°F) e in un’altra 20°C (68°F), i rapporti tra le temperature delle due aree saranno diversi a seconda dell’unità di misura scelta (20/10=2 se si usano i °C e 68/50=1.36 se si usano i °F). Sia le cardinali che le misure ad intervalli possono essere trattate statisticamente in modo completo.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Caratteristiche e concetti principali nei dati spaziali 1. Autocorrelazione Spaziale 2. Problema della Unità di Area Variabile 3. Sofisma Ecologico 4. Effetto scala 5. Non uniformità ed effetti al contorno 6. Distanza 7. Adiacenza 8. Interazione 9. Prossimità ed aree di influenza

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Autocorrelazione Spaziale Punti vicini geograficamente hanno maggior probabilità di avere caratteristiche simili rispetto a punti posti lontani uno dall’altro. Questa proprietà vìola uno dei requisiti fondamentali per l’applicazione della statistica convenzionale e cioè che i campioni siano casuali e le misurazioni indipendenti. Inoltre, a seconda della particolare struttura di autocorrelazione dei dati, l’informazione aggiunta con nuove misure è diversa da quella ricollegabile alla variazione numerica del campione ad n+1. Misure per la diagnosi delle caratteristiche di autocorrelazione di un insieme di dati geografici sono ad esempio: Ø Joint count statistics Ø Indice I di Moran Ø Indice C di Geary

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Problema dell’Unità di Area Variabile (Modifiable Areal Unit Problem – MAUP) Il livello di aggregazione dell’informazione geografica influenza la distribuzione statistica risultante Molto spesso i dati geografici sono analizzati previa aggregazione sulla base di aree che divengono l’unità di base (es.: dati di popolazione aggregati per comune o provincia) Esempio: generalmente la correlazione tra dati espressa tramite tecniche di regressione aumenta al crescere del grado di aggregazione.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Il Sofisma Ecologico
E’ un problema connesso il MAUP e può manifestarsi quando una relazione statistica verificata ad un certo livello di aggregazione viene ritenuta valida in generale. Ad es.: una forte correlazione a livello provinciale tra reddito medio e danni provocati dai terremoti non vuol dire che, singolarmente, persone con maggiore reddito sono maggiormente soggette ad essere vittime dei terremoti stessi! La spiegazione di una tale relazione statistica alla scala della provincia potrebbe essere invece semplicemente legata al fatto che aree con reddito medio più alto hanno maggiore valore degli elementi a rischio. Si tratta di un problema molto comune e ricorrente nella vita comune, nella politica ma anche nelle scienze e connesso con una ricerca di soluzioni semplici a tutti i costi.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Effetto Scala La scala a cui si rappresenta o si osserva e descrive un fenomeno influenza l’analisi dello stesso. Ad esempio una città può essere rappresentata in vari modi al variare della scala di lavoro:
Scala Oggetto “città”
Continentale – Nazionale Punto o simbolo puntuale
Regionale – Provinciale Poligono
Locale (> 1:25000) Insieme complesso di archi, punti, poligoni etc.
Questo ci dice che la scelta, a volte obbligata, della scala di lavoro influenza fortemente il modo di rappresentazione degli oggetti presenti nello spazio geografico, influenzando così allo stesso modo la statistica applicabile agli stessi ed i risultati delle analisi. E’ spesso impossibile poter dire a priori qual’è la scala più adatta o corretta per lo svolgimento di uno studio di analisi geografica. Questo è uno dei problemi che vanno risolti ed affrontati per primi nella stesura di un progetto GIA-GIS.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Non-uniformità ed Effetti al Bordo La distribuzione statistica di un attributo può dipendere dalla distribuzione non uniforme delle entità cui l’attributo si riferisce. Ad esempio la stessa natura dei dati o il metodo di campionamento scelto possono essere affetti da non omogeneità naturale o artificiale. Ad esempio la distribuzione degli abitanti di una provincia sarà un dato molto disomogeneo, con grandi concentrazioni di dati nelle città e vuoti nelle aree non abitate. Questo tipo di non uniformità è insito nella natura del dato stesso. Se invece queste concentrazioni o vuoti sono generati dal metodo di campionamento, essi rappresentano un tipo di non uniformità generata e non tipica dei dati. Ad esempio se un censimento delle frane in un’area molto grande viene effettuato unendo i censimenti dei singoli comuni che la compongono può generarsi non uniformità dovuta alle diverse modalità o accuratezze con cui gli enti hanno svolto le indagini. Ci potrebbero essere addirittura comuni senza neppure un dato rilevato ma non per questo esenti dal rischio di frana! Anche quando bordi o confini artificiali sono imposti all’area di indagine, che d’altra parte non può essere illimitata, la statistica può risentire delle disomogeneità di distribuzione che ne deriva. Al centro dell’area di indagine un punto avrà altri punti intorno in ogni direzione, mentre uno posto vicino al bordo non avrà punti vicini oltre il bordo stesso.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Concetto e misura di Distanza In aree di piccole dimensioni come nel campo geodetico (circa 60 km di raggio) o ancora meglio nel campo topografico (10-15 km di raggio) le distanze tradizionalmente intese possono essere considerate di tipo Euclideo. In questo caso la distanza tra punti può essere calcolata semplicemente tramite applicazioni del teorema di Pitagora (se si conoscono le coordinate dei punti stessi) o con varie combinazioni di calcoli trigonometrici (nel caso sia nota una posizione e angoli tra lati). Esistono però molte altre definizioni utili di distanza, dipendenti dalla natura del processo fisico o degli oggetti da rappresentare. Ad esempio: Ø distanze di percorso misurate su strade o altre tipologie di grafi e non su linea retta Ø distanze temporali (percorrenza prevista, ottimale, massima etc.) Ø distanze di costo (dove più breve è il percorso che costa meno) Ø distanze pesate su altri parametri (ad es.: numero di città attraversate, percentuale di percorso entro la foresta, percentuale del percorso in area a rischio etc.) Ø altre distanze, quali ad esempio la distanza o il tempo di percorrenza percepiti
22 )()( jijiij yyxxd −+−=

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Concetto di Adiacenza Può essere definito come il corrispondente binario della distanza. Due entità sono adiacenti (1) o non lo sono (0) in base a regole di adiacenza fissate, che possono essere più o meno complesse. E’ da notare che due entità possono essere adiacenti ma non vicine o meno vicine di altre due non adiacenti. Ad esempio, se i nostri oggetti sono le città e le regole di adiacenza sono le rotte aree esistenti tra di esse, Londra e Dublino possono essere definite adiacenti mentre Dublino e Belfast, che sono molto più vicine da un punto di vista euclideo ma anche da quello delle distanze terrestri, sono invece non adiacenti, dal momento che non esistono connessioni aeree dirette tra le due città.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Concetto di Interazione Il concetto di interazione si basa sulla prima legge della geografia (Tobler, 1970) che dice che nello spazio geografico oggetti vicini sono più correlati di oggetti lontani. Il grado di interazione tra due entità può essere espresso da un numero reale compreso tra 0 (nessuna interazione) e 1 (massima interazione). Un modo semplice di rappresentare l’interazione tra due oggetti i e j è supporre che essa sia inversamente proporzionale alla distanza d tra di essi:
wij ∝ 1/dk
dove k è un esponente di distanza che controlla il decadere della interazione con la distanza. Un tipo di interazione più complesso può essere ottenuto calcolando il peso di interazione in funzione della distanza e del valore di un particolare attributo p nei due punti:
wij ∝ pipj/dk Esistono poi interazioni non convenzionali, basate su concetti diversi dalla semplice distanza o di natura maggiormente concettuale. Ad es.: il grado di interazione tra due diversi paesi può essere misurato tramite l’entità degli scambi commerciali reciproci.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Concetto di Prossimità e Intorno In generale, per ogni punto, l’intorno è la regione di spazio associata al punto stesso per quanto riguarda l’attributo/processo di interesse ed in base alle regole di associazione scelte. Tra entità areali a copertura continua la definizione potrebbe essere invece del tipo: tutti i poligoni adiacenti a quello dato. Nei raster a celle rettangolari invece: l’insieme di tutte le celle adiacenti a quella data (oppure a distanza < d da quella data, etc.) La definizione più completa è: regione con caratteristiche interne simili che per questo si distinguono da altre regioni con caratteristiche interne di tipo diverso. Anche questo concetto è strettamente legato alla entità/attributo/processo di riferimento e le regole più opportune di determinazione delle aree di prossimità devono essere stabilite caso per caso.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Matrici di Relazione I Matrici di Distanza Le relazioni di distanza tra insiemi di oggetti possono venir descritte e quindi anche analizzate tramite matrici di distanza. I valori della diagonale sono ovviamente zero, la matrice è simmetrica ed ogni operazione sulle distanze può essere condotta utilizzando la matrice. Nella matrice dji è la distanza tra il punto j ed il punto i . Generalmente la distanza non dipende dal verso di percorrenza e la matrice è simmetrica con dij=dji
mnm
jij
ni
dd
dd
ddd
D
1
1
1111
!…
!………
=

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Matrici di Relazione II Matrici di Adiacenza Sono matrici binarie (0/1), a meno che non si voglia descrivere un grado di adiacenza. Necessitano di una definizione operativa ed esatta delle regole di adiacenza scelte. Tra poligoni le relazioni di adiacenza sono spesso ovvie mentre tra punti si debbono stabilire limiti o soglie, come ad esempio distanze massime oltre le quali i punti non possono più essere ritenuti adiacenti. Possono essere simmetriche o meno, in base alle regole di adiacenza scelte. Se si sceglie che un punto può essere adiacente a sè stesso la diagonale assume valori 1.
mnm
jij
ni
xd
aa
aa
aaa
A
1
1
1111
)(
!…
!………
=≤

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Matrici di Relazione III Matrici di Interazione Anche qui sono necessarie regole di interazione per definire i valori. Ad es. nella matrice a fianco il grado di interazione dipende dall’inverso della distanza tra i punti. Altre volte i valori possono venire normalizzati in modo che la somma di ogni riga sia pari a 1. Si ottiene così che la somma sulla colonne esprima l’interazione relativa di un’entità rispetto alle altre, con:
111
111
11
11
111
−−
−−
−−−
=
mnm
jij
ni
dd
dd
ddd
W!…
!………
11
1 =∑=
−m
jijd
1*1
1
*
1*1
1
*
1
1
*1
1
*1
11
*
*
−−
−−
−−−
=
mnm
jij
ni
dd
dd
ddd
W
!…
!………

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Poligoni di Prossimità Dato un insieme S di punti, si dice poligono di prossimità di un punto dato p∈S il luogo geometrico dei punti del piano per i quali il punto dell’insieme S più vicino è p stesso. Sono di solito rappresentati dai poligoni di Thiessen (o di Voronoi) o da loro equivalenti. Sono facili da costruire per punti. Esistono anche poligoni di prossimità generalizzati (vedi Okabe et al., 2000) che considerano distanze non euclidee, ostacoli, etc. Il duale della triangolazione di Voronoi sono i triangoli di Delaunay, ottenuti congiungendo i centri di poligoni di Voronoi adiacenti. Questi tipi di rappresentazione superano almeno in parte il problema della non uniformità dei dati spaziali. Essi possono inoltre risultare validi supporti per il calcolo e l’analisi (vedi ad esempio i triangoli di Delaunay che stanno alla base dei modelli TIN Triangulated Irregular Networks) Triangoli di Delaunay
Poligoni di Thiessen

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Variogrammi e Geostatistica I variogrammi illustrano le relazioni di continuità ed autocorrelazione tra punti come relazioni tra le reciproche distanze e differenze nei valori di uno o più attributi. Un variogramma assume per la variabile Z nella direzione x la forma (detta semivariogramma):
( )( )
( ) ( )[ ]( ) 2
121∑=
+−=hN
iii hxZxZ
hNhγ
dove h è il vettore di separazione tra il punto xi ed il successivo punto di indagine ed N è il numero dei punti di cui si vuol definire le proprietà. In un semivariogramma allontanandosi dal punto centrale (h crescente) la varianza aumenta fino ad un punto a distanza h detta range nel quale si stabilizza su un valore costante, detto sill. Se i variogrammi sono direzionali, cioè limitati solo ai punti compresi entro un range di direzioni date, dalla loro analisi si possono scoprire anisotropie nei dati.
SILL
RANGE
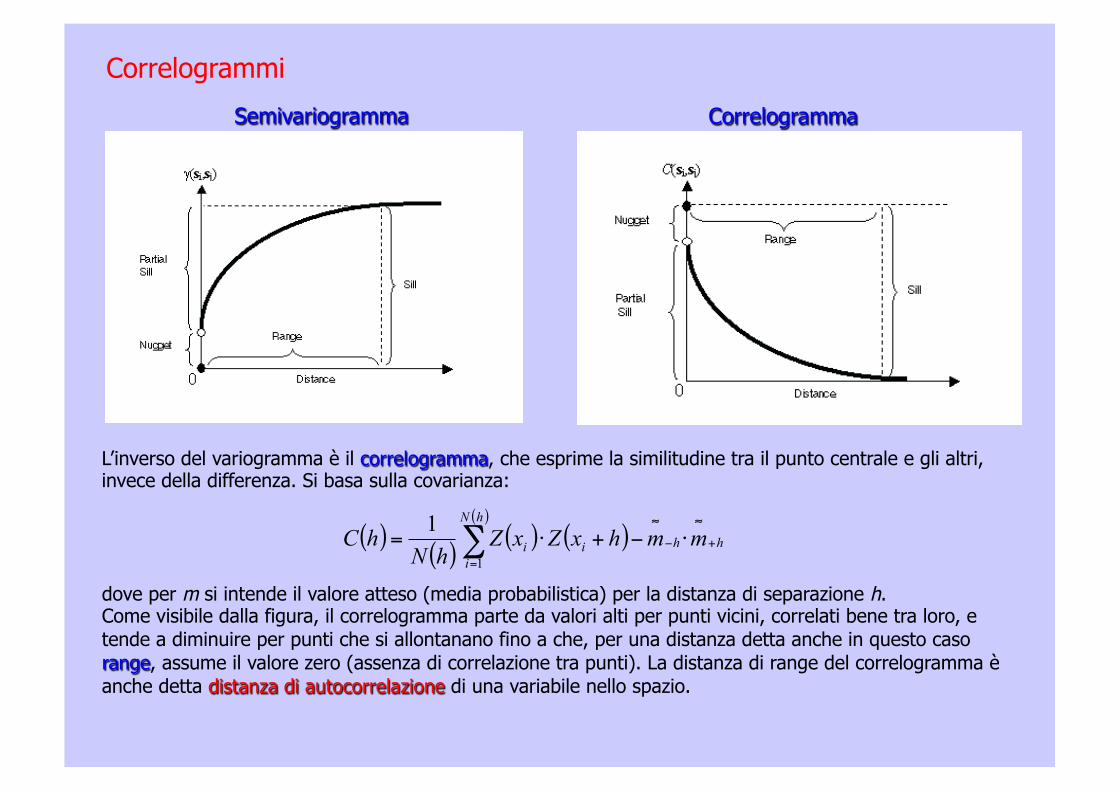
Semivariogramma Correlogramma
L’inverso del variogramma è il correlogramma, che esprime la similitudine tra il punto centrale e gli altri, invece della differenza. Si basa sulla covarianza:
dove per m si intende il valore atteso (media probabilistica) per la distanza di separazione h. Come visibile dalla figura, il correlogramma parte da valori alti per punti vicini, correlati bene tra loro, e tende a diminuire per punti che si allontanano fino a che, per una distanza detta anche in questo caso range, assume il valore zero (assenza di correlazione tra punti). La distanza di range del correlogramma è anche detta distanza di autocorrelazione di una variabile nello spazio.
Correlogrammi
( )( )
( ) ( )( )
∑=
+
≈
−
≈
⋅−+⋅=hN
ihhii mmhxZxZ
hNhC
1
1

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
ANALISI DI INSIEMI DI ENTITÀ PUNTUALI Analizzare distribuzioni di dati puntuali nello spazio per capirne il senso e la struttura, ed eventualmente per dedurne il modello di comportamento di una variabile ambientale, è piuttosto complesso. Esistono due possibili approcci al problema, reciprocamente interconnessi: 1. DENSITÀ DEI PUNTI, che indaga principalmente gli effetti del 1° ordine 2. SEPARAZIONE DEI PUNTI, che è invece più sensibile a quelli di 2° ordine
Effetti del 1° ordine: quello che conta è la tendenza generale di una variabile, quindi la posizione assoluta dei punti Effetti del 2° ordine: sono effetti locali, quindi è importante la posizione relativa dei punti. Aggiungono rumore alla tendenza del 1° ordine, rendendo difficile riconoscere modelli regolari nelle distribuzioni dei punti. E’ difficile distinguere il contributo degli effetti del 1° e del 2° ordine.
Effetto del 1° ordine
Combinazione di effetti di 1°
e 2° ordine
Effetto del 2° ordine

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
DESCRIZIONE GLOBALE DEI PATTERN DI PUNTI Il metodo più semplice di descrivere la tendenza generale di un insieme di punti è adottare la versione spaziale delle misure statistiche di base:
( )⎟⎟
⎠
⎞
⎜⎜
⎝
⎛==
∑∑ ==
ny
nx
sn
i in
i iyx
11 ,,µµ
( ) ( )n
yxd yi
n
i xi2
12 µµ −+−
=∑ =
Centro Medio
Distanza Standard
I due valori s e d per un insieme di punti sono il centro ed il raggio del cerchio standard (standard circle). Se d è calcolato separatamente per x e y si ottiene una ellisse. Questa tecnica fornisce indicazioni generali sulla distribuzione dei punti ma non dice molto sulle caratteristiche interne dato che fornisce un solo valore medio per ogni insieme di punti indagato.
d
(µx,µy)

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
MISURE DI DENSITÀ DI INSIEMI DI PUNTI - I Densità semplice La densità semplice, o intensità totale (overall intensity) di un insieme di punti è:
( )aASn
an ∈==λ
E’ il rapporto tra il numero di punti dell’insieme S che appartengono all’area di studio A e l’area a della regione stessa. E’ però una misura troppo sensibile al diametro di A.
Quadrat Count
Si contano quante celle di una divisione regolare sono occupate da n = {0, 1, …., N} punti dell’insieme S e successivamente si analizza la frequenza degli n trovati.
Il risultato è sensibile alla dimensione della cella usata: celle troppo grandi portano a descrizioni molto mediate mentre celle troppo piccole non riescono a descrivere la distribuzione.
La distribuzione di frequenza che si ottiene può poi essere paragonata a distribuzioni previste in base a modelli ipotizzati.

MISURE DI DENSITÀ DI INSIEMI DI PUNTI - II Kernel Density (KDE) La distribuzione è pensata come avente un valore di densità in ogni punto del piano (o dello spazio) e non solo in corrispondenza dei punti di misura dell’insieme S. Si contano gli eventi che cadono in una regione centrata sul punto di interesse. Per un generico punto p ∈ S su una regione circolare di raggio r:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( )[ ]2
^ ,.r
rpCSnop
πλ
∈=
Dove C(p,r) è la regione circolare centrata su p con raggio r. La kernel density è molto utile per rivelare la presenza di effetti del primo ordine. Anche qui, per r grandi la definizione delle variazioni di densità peggiora finchè, per 2r=larghezza dell’area, si ha un unico valore di densità pari a quello medio dell’insieme S. Quando r è piccolo la distribuzione di densità stimata è troppo focalizzata sui singoli oggetti puntuali. Normalmente si usano distanze di indagine r ragionevoli e che siano significative per il problema trattato. Ad esempio, esaminando una distribuzione di punti frana il raggio r potrebbe essere impostato uguale alla dimensione media dei versanti della zona indagata, oppure di quella dei bacini idrografici di un certo ordine. Esistono anche KDE calcolate con pesi diversi alle varie distanze tra punti trovati.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Esempio di Kernel Density Estimation (KDE) per poligoni di frana

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
MISURE DI DISTANZA DI INSIEMI DI PUNTI Dato che queste tecniche prendono in considerazione le distanze tra coppie di punti dell’insieme S, esse risultano utili principalmente per lo studio degli effetti del 2° ordine. Distanza del punto più vicino (Nearest-Neighbor Distance) E’ l’analisi basata sulla distanza di ogni punto dal punto a lui più vicino, dmin(si). Se si calcolano tutte le distanze dmin(si) nell’insieme dato e se ne fa la media si ottiene la distanza media del punto più vicino:
( )n
sdd
n
i i∑ == 1 minmin
Questa misura ha il difetto di dare un’unica misura per tutto l’insieme S, eliminando così troppa informazione sulle variazioni locali della distanza tra punti.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Funzioni di distanza G, F e K Funzione G E’ la distribuzione di frequenza cumulativa delle distanze minime dmin(Si) tra coppie di punti che sono minori di una distanza data d, in funzione della distanza stessa.
( ) ( )[ ]n
dSdnodG i <= min.
Se gli eventi sono raggruppati G incrementa in modo rapido per piccole distanze d. Se gli eventi sono separati in modo regolare G incrementa in modo lento per piccoli valori di d mentre aumenta in modo più rapido successivamente.
Funzione F E’ la distribuzione di frequenza cumulativa delle distanze dmin(Si) da un insieme di punti casuali P = {p1,...,pi,...,pn} che sono minori di una distanza data d, in funzione della distanza stessa.
( ) ( )[ ]n
dSPpdnodF i <∈=
,. min
Se gli eventi sono raggruppati F cresce in modo costante e poi più lentamente Se gli eventi sono separati in modo regolare F incrementa molto rapidamente già per piccoli valori di distanza d.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Confronto tra G ed F
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
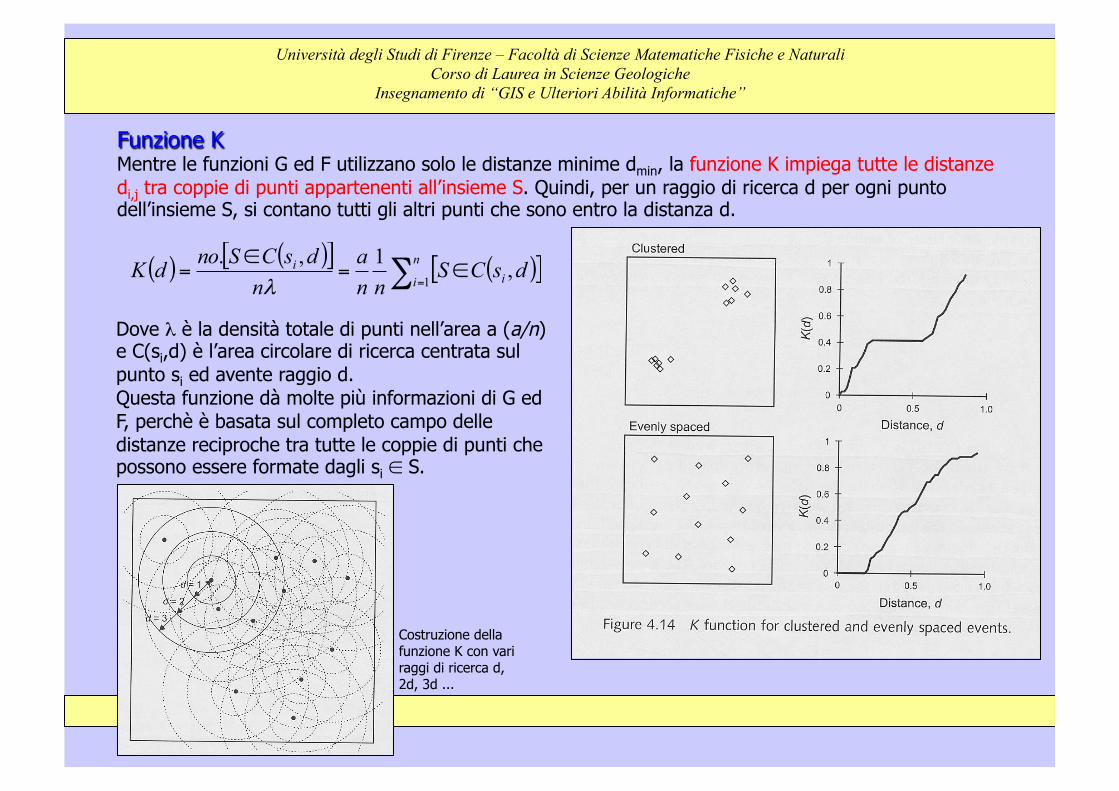
Funzione K Mentre le funzioni G ed F utilizzano solo le distanze minime dmin, la funzione K impiega tutte le distanze di,j tra coppie di punti appartenenti all’insieme S. Quindi, per un raggio di ricerca d per ogni punto dell’insieme S, si contano tutti gli altri punti che sono entro la distanza d.
( ) ( )[ ] ( )[ ]∑ =∈=
∈=
n
i ii dsCS
nna
ndsCSnodK
1,1,.
λ
Dove λ è la densità totale di punti nell’area a (a/n) e C(si,d) è l’area circolare di ricerca centrata sul punto si ed avente raggio d. Questa funzione dà molte più informazioni di G ed F, perchè è basata sul completo campo delle distanze reciproche tra tutte le coppie di punti che possono essere formate dagli si ∈ S.
Costruzione della funzione K con vari raggi di ricerca d, 2d, 3d ...

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
VALUTAZIONE STATISTICA DELLE DISTRIBUZIONI DI PUNTI I metodi di caratterizzazione visti finora sono buoni descrittori, anche quantitativi, della distribuzione spaziale dei punti ma non chiariscono in che modo oppure quanto gli stessi punti siano equispaziati o raggruppati. Questo è invece proprio quel che dobbiamo fare quando analizziamo dei processi naturali e cerchiamo di prevederli. In questo caso quello che ci interessa è quanto la distribuzione dei dati misurati in natura sia aderente (oppure si discosti) da un modello che noi ipotizziamo. Da un qualsiasi modello matematico è possibile solitamente produrre dei valori attesi e/o delle distribuzioni statistiche delle variabili che ci interessano. I sistemi visti finora non consentono di confrontare con test statistici o altro le misure di distribuzione con quelle previste. Ad esempio, per verificare se una distribuzione di punti sul piano è completamente casuale si deve confrontarla con una o più distribuzioni che sappiamo per certo esserlo, per esempio perchè generate con un processo noto (tramite un calcolatore o a mano). Per far questo si devono avere misure statistiche diverse dalle semplici KDE, G, F o K. Ci si deve chiedere: la distribuzione che osservo in natura è un probabile frutto del processo di cui ho ipotizzato l’esistenza e che ritengo responsabile della distribuzione stessa?

Distribuzioni casuali IRP/CSR
Per utilizzare i metodi di test e le possibili distribuzioni di probabilità che vedremo dobbiamo innanzi tutto introdurre una distribuzione di punti sicuramente casuale. La più semplice di queste, priva di qualsiasi vincolo spaziale, è detta processo casuale indipendente (Independent Random Process, IRP) o completa casualità spaziale (Complete Spatial Randomness, CSR).
Si basa su due princìpi:
1. Condizione di Equiprobabilità – ogni punto ha uguale probabilità di ricadere in una qualsiasi posizione del piano rispetto ad un altra
2. Condizione di Indipendenza – il posizionamento di un punto è completamente indipendente dal posizionamento degli altri
Un esempio di processo molto semplice per generare una distribuzione di punti IRP/CSR è quello di generare due serie di numeri casuali {x1,...,xi,...,xn} e {y1,...,yi,...,yn} e poi di impiegare le coppie ordinate (xi, yi) come coordinate cartesiane per generare i punti dell’insieme S da creare.
E’ abbastanza semplice calcolare la distribuzione di probabilità attesa per questo tipo di processi, visto che sono completamente casuali.
E’ importante notare che qui con casuale si intende il processo o il metodo usato per generare la distribuzione dei punti e non la distribuzione stessa! Da un processo generatore casuale potrebbe derivare ad esempio una distribuzione completamente ordinata (anche se le probabilità di questo sono molto basse...).
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Quadrat Count
La distribuzione probabilistica attesa da una operazione di quadrat count su un insieme di punti casuali è una distribuzione binomiale, o meglio la sua approssimazione pratica più nota, la distribuzione di Poisson. In essa, posta λ uguale alla densità media dell’insieme S e k pari al numero di eventi in una cella quadrata, abbiamo:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( )!kekPk λλ −
=
Quindi, per verificare col metodo quadrat count se una distribuzione spaziale di punti non è casuale dovremo confrontarla con la distribuzione di Poisson. Per farlo si sfrutta il fatto che quest’ultima ha media e varianza uguali, cioè rapporto varianza/media uguale a 1 (Variance Mean Ratio, VMR).
Altro sistema è quello di utilizzare il chi-quadro adattato alla distribuzione in oggetto:
( )[ ]µ
µχ ∑ −
=2
2 kxk
dove k è il numero di eventi riscontrati in una cella del quadrat count, µ è la media generale della distribuzione (pari al rapporto tra n° di eventi e n° di celle) e xk è il n° di celle con k eventi.
Se il valore di chi-quadro è maggiore di quello teorico per il livello di confidenza scelto, allora, per quel livello di certezza l’ipotesi è respinta e la distribuzione dei nostri dati NON è casuale.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Quadrat Count - Esempio
Varianza = 85.775/40 = 2.1444 Media semplice = 47/40 = 1.175 ⇒ VMR = 1.825
( )[ ]0.73
175.1775.852
2 ==−
=∑µ
µχ
kxk
Questo valore è superiore a quello per un sistema con 39 gradi di libertà (40 celle meno una) al livello di confidenza del 5% (χ2= 54.57), dell’1% (χ2=62.43 ) ed anche dello 0.1% (χ2= 72.05). Ciò è una indicazione molto netta del fatto che la distribuzione dei punti non è casuale.

Distanza minima o prossima
Qui, per verificare la vicinanza (o il discostarsi) di una distribuzione reale di punti ad una teorica casuale del tipo IRP/CSR, possiamo utilizzare il test R di Clark ed Evans (1954). Il valore atteso per la distanza minima media è:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( )λ21
=dE
Il rapporto R tra la distanza minima media osservata dmin e E(d) può essere usato come test di confronto con una distribuzione generata da un IRP/CSR.
minminmin 221)(
dddE
dR ⋅=== λλ
Per R > 1 ⇒ tendenza al raggruppamento (distanze minime osservate più corte di quelle attese)
Per R < 1 ⇒ tendenza alla distribuzione equispaziata dei punti

Funzioni F e G
Le funzioni F e G hanno lo stesso tipo di valore atteso in caso di processo generatore casuale IRP/CSR. Questo è facilmente comprensibile perchè per una distribuzione totalmente casuale di punti non esiste differenza tra calcolare le distanze minime reciproche tra i vari si∈S (come si fa per la funzione G) o tra questi ed un insieme di punti anch’essi casuali come si fa nel calcolo della funzione F.
Per questo motivo i valori attesi sono uguali:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( )[ ] ( )[ ] 2
1 dedFEdGE λπ−−==
Il grafico dei valori attesi può essere poi plottato assieme a quello dei valori osservati di G ed F così da poter confrontare le due diverse distribuzioni.

Funzione K
Il valore atteso di K per un processo generatore di tipo IRP/CSR è facile da determinare perchè K(d) descrive il numero medio di punti che contiamo in una regione circolare C(si,d). L’area di questo cerchio di ricerca è πd2 e λ è la densità media di eventi per unità di area. Il valore atteso di K(d) è perciò:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( )[ ] 22
dddKE πλ
λπ==
Il confronto si fa però con funzioni di appoggio tali che f(K)→0 se i dati osservati coincidono con quelli attesi per un IRP/CSR. Ad esempio è possibile usare la funzione L:
( ) ( ) ddKdL −=π
che deve essere vicina a zero per verificare l’ipotesi IRP/CSR. Se L(d) > 0 ⇒ ci sono più punti del previsto entro quella distanza Se L(d) < 0 ⇒ ci sono meno punti del previsto entro quella distanza Questi metodi di confronto soffrono però molto di problemi al contorno e di quelli dovuti alla area unitaria variabile.

Simulazioni Numeriche
Spesso le distribuzioni di frequenza attese sono teoriche e difficili da confrontare con quelle reali per effetti bordo, MAUP, etc. Altre volte espressioni analitiche sono difficili da ricavare. Si ricorre allora a simulazioni numeriche al calcolatore.
Con queste si fanno generare n realizzazioni di un processo di tipo scelto (e non solo semplicemente IRP/CSR) e se ne analizza il risultato come distribuzione di frequenza empirica che per un numero n di simulazioni sufficientemente alto approssima la reale distribuzione di probabilità teorica per quel processo generatore.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Questa simulazione ha il vantaggio di essere sempre ricavabile e di essere direttamente confrontabile con la distribuzione reale: essa può infatti essere applicata nello stesso contesto spaziale (stessa area, stesse condizioni al contorno, etc.) rendendo superflue correzioni molto complesse necessarie per tener conto di tutti questi effetti.
Le simulazioni numeriche hanno in definitiva il vantaggio che sono spesso l’unico modo di confrontare dati osservati con dati attesi in base a modelli più complessi dei semplici IRP/CSR, per i quali non sono disponibili forme analitiche per i valori attesi.

Confronto tra insiemi di punti
Spesso, invece di analizzare semplicemente una distribuzione di punti, dobbiamo confrontarne alcune tra di loro. La domanda che ci poniamo è allora: i due insiemi differiscono in modo significativo? Una distribuzione influenza l’altra? Esistono vari metodi per verificarlo.
Tabelle di contingenza
Si crea un insieme di celle contigue ed uguali che copre l’area e si classificano le celle stesse nelle quattro diverse situazioni riportate in tabella:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Eventi Tipo 2
Eventi Tipo 1 Assenti Presenti
Assenti n11 n12
Presenti n21 n22
Usando come ipotesi zero che non c’è legame tra i due insiemi è possibile impiegare il test chi-quadro per effettuare la relativa verifica.

Funzioni di incrocio o confronto (Cross Functions)
Sono versioni adattate delle funzioni G e K nelle quali si confrontano le distanze tra punti di un insieme e punti dell’altro (indicate come G1,2 e K1,2).
Questo, per la funzione G1,2, assomiglia un po’ ad usare una funzione F sull’insieme S1 che ha come insieme di confronto l’insieme S2 invece di uno scelto a caso.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( ) ( )[ ]n
dSSdnodG ii <= 21min
2,1. !
( ) ( )[ ]∑ =∈= 2
1 2121
2,1 ,.n
i i dsCSnonnadK
Per K1,2(d) si calcolano tutte le distanze tra ogni punto dell’insieme S1 e tutti i punti dell’insieme S2.
La K2,1(d) risulta uguale in valore alla K1,2(d), visto che esse confrontano le stesse coppie di punti.
Le due distribuzioni sono indipendenti se K1,2(d) è casuale. Questo test può essere compiuto con l’aiuto di funzioni L di appoggio o con simulazioni tipo Monte Carlo.
In alcuni casi, ad esempio se l’insieme S1 è quello di eventi franosi attivi e l’S2 quello di tutti gli eventi franosi (attivi, inattivi, quiescenti, etc.), il confronto può essere fatto sottraendo le funzioni K(d) semplici dei due insiemi, che in caso di indipendenza degli stessi (cioè assenza di raggruppamento negli eventi attivi) dovrebbero essere uguali.
( ) ( ) ( )dKdKdD 2,21,1 −=

Esercitazione su distribuzione di punti – Dati pluviometrici I La pioggia viene misurata normalmente da stazioni pluviometriche mappate sul territorio come entità puntuali.
Dato un numero n di stazioni la pioggia nelle altre aree può essere valutata con opportune tecniche di interpolazione che possono essere essenzialmente di 2 tipi:
• Deterministiche (basate su una legge fisica empirica che ricava la piovosità P di un punto in base al valore di una variabile ovunque nota)
• Probabilistiche (basate essenzialmente sulla interpolazione geostatistica del valore di P nei punti in base alla loro posizione reciproca)
Nella esercitazione, a partire da una serie di stazioni pluviometriche dell’area del Mugello, per le quali si hanno pioggia media annuale e quota s.l.m., cercheremo di:
1. Interpolare la pioggia per tutta l’area con un operatore geostatistico (kriging)
2. Ricavare una legge empirica che lega pioggia e quota delle stazioni
3. Usare la legge trovata per interpolare i valori di pioggia per tutta l’area
4. Confrontare i risultati ottenuti nei punti 1 e 3
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Esercitazione su distribuzione di punti – Dati pluviometrici II Il metodo deterministico che useremo si basa su una correlazione lineare tra piogge ed altitudine: maggiore è quest’ultima e maggiori saranno le piogge. Questa legge è generalmente valida in vaste aree della Terra, ma non è molto utilizzabile nel nostro paese, se non per stime molto grossolane. Il modello avrà la forma:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
baqP +=
Mettendo in relazione P e q il risultato sarà un grafico la cui retta di correlazione ci darà i valori cercati per i coefficienti a e b.
Nell’esempio a fianco ricaviamo che a=1.1071 mentre b=0.4286
La relazione trovata ci permetterà di calcolare P per qualsiasi punto di cui abbiamo la quota (per esempio da un DTM).
y = 1,1071x + 0,4286R2 = 0,8895
0
2
4
6
8
10
12
14
0 2 4 6 8 10 12
dove P è la pioggia, q è la quota sul livello del mare ed a e b sono costanti empirice da determinare da dati sperimentali. I nostri dati sperimentali sono le stazioni pluviometriche per le quali il dato P è noto.

Esercitazione su distribuzione di punti – Dati pluviometrici III Il metodo geostatistico che useremo si basa invece sull’interpolazione dei valori di pioggia in base ad una serie di funzioni che esprimono, in varie zone dell’area considerata, la migliore approssimazione della correlazione spaziale dei dati in quell’intorno.
Come già indicato in precedenza si utilizzano funzioni che approssimano la variazione di correlazione con la distanza, dette correlogrammi o variogrammi.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
In particolare, il sistema utilizzato si chiama kriging, ed è basato su un utilizzo esteso di queste funzioni per ottenere da una serie di punti un campo di variazione continua. Nel nostro caso, senza entrare nei particolari della metodologia che è molto complessa, impiegheremo un comando apposito del software ArcMap con parametri standard. Confronteremo poi le due distribuzioni ottenute.

RAPPRESENTAZIONE E ANALISI DI INSIEMI DI LINEE In aggiunta a quanto visto per i punti le linee necessitano di altri quattro concetti: lunghezza, direzione, verso e connessione. Naturalmente l’analisi di insiemi di linee riguarda quegli oggetti che sono fisicamente rappresentabili come tali e non rappresentazioni lineari di entità areali, quali ad esempio le curve di livello. La reppresentazione invece è normalmente uguale per tutti e due i casi.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Normalmente i GIS rappresentano le linee come sequenze di punti (x,y oppure x,y,z) detti vertici, connessi da segmenti di retta. Questo tipo di linee spezzate viene chiamato, a seconda dei sistemi, polilinea, arco o in altri modi.
La rappresentazione a spezzata determina ovviamente una approssimazione nella riproduzione dell’oggetto reale.
Nella figura si notano ad esempio la distribuzione non omogenea dei vertici determinata da digitalizzazione manuale e l’effetto della riduzione di scala sull’aspetto di una curva.

Rappresentazione e codifica Un altro sistema di rappresentazione di linee, maggiormente accurato in alcuni casi e anche più efficace dal punto di vista della occupazione della memoria, è il sistema delle splines.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
punti digitalizzati
punti di controllo generati dal metodo
Le splines sono funzioni matematiche che possono essere utilizzate per disegnare curve regolari passanti per punti dati. Invece di memorizzare le informazioni (x,y) di tutti i vertici si possono utilizzare sistemi basati sulle coordinate del primo punto della serie e su regole che derivano la posizione degli altri in relazione ad esso. Uno di questi sistemi, detto Freeman Chain Coding, è basato sul memorizzare dopo il primo punto la sola direzione dei segmenti successivi, tutti di lunghezza uguale.
Si assegna un codice da 0 a 7 per ognuna delle 8 direzioni cardinali predefinite come in figura. E’ così sufficiente un insieme di 3 bit (23=8) per rappresentare ogni vertice.

Dimensione delle linee – Curve frattali La lunghezza più ovvia di una curva, quando sia rappresentata col metodo della spezzata, è ovviamente la somma delle lunghezze dei segmenti di retta che la compongono. Per ognuno di essi avremo naturalmente che la distanza tra gli estremi S1 e S2 sarà:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( ) ( )2122
121212 yyxxd −+−=−= ss
In caso di rappresentazione tipo Freeman Chain Coding il calcolo sarà ancora più semplice perchè basterà contare il numero di segmenti unitari e moltiplicarlo per la lunghezza costante. Ma la lunghezza di una curva reale esistente in natura nasconde un significato molto più complesso, dipendente dalla scala di misurazione e di osservazione. Questo problema ben noto da più di un secolo costituisce la fondazione della teoria dei frattali. L’esempio più ricorrente di curva frattale è quello di una linea di costa frastagliata: la lunghezza della linea suddetta dipenderà dalla precisione con cui la misuriamo. Nella figura, al diminuire del misuratore (10, 5 infine 2.5 km), aumenta la lunghezza misurata della costa.
coeff. ang. retta = log N/log L = D

Dimensionalità Il concetto di frattale ha a che fare col fatto che una curva come quella vista ha una dimensione intermedia tra quella della retta (D=1) e quella del piano (D=2).
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
La dimensionalità di un oggetto è legata al concetto di quante volte la sua dimensione totale aumenta all’aumentare della sua dimensione lineare. Nell’esempio in figura una linea divisa in 3 diviene 3 linee lunghe 1/3, un quadrato col lato diviso in 3 diviene 9=32 quadrati di area 1/9, un cubo col lo spigolo diviso in 3 diviene 27=33 cubi con volume 1/27. Da questo si deduce che c’è una relazione la lunghezza L del misuratore (1, 1/3 nell’esempio), il numero N di oggetti che si ottengono (3, 9, 27) e la dimensione D dell’oggetto stesso:
( )( )21
21
2
112 log
logLLNND
LLNN
D
−=⇒⎟⎟⎠
⎞⎜⎜⎝
⎛=
Nell’esempio dei cubi, se L1=3, L2=1 si ottiene N1=1 e N2=27 così che si ricava D=log27/log3=3. Nel caso di una linea di costa si ottiene invece un valore 1 < D < 2, come coefficiente angolare della retta nel grafico bilogaritmico nella figura precedente.

Considerazioni sulle caratteristiche frattali delle curve naturali - I In natura la dimensione intermedia (o fratta) di una curva non è mai misurabile con precisione assoluta. Ancor meglio: essa non è neppure costante. Ci sono limiti fisici alla misurazione che si può effettuare nella realtà (ad esempio il misuratore usato non può essere ridotto all’infinito nella misura di una costa per ovvie ragioni pratiche).
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
I diagrammi bilogaritmici che confrontano la dimensione del misuratore con il numero di oggetti sono un sistema che riesce a definire il valore di D, nell’intorno in cui la relazione logN/logL è lineare, con una precisione accettabile. Per una singola curva il criterio migliore per misurare D è quello già visto del misuratore (o “righello”). Per un insieme di curve (quali ad esempio le linee di costa di un arcipelago o un reticolo fluviale) si devono utilizzare ovviamente metodi diversi. Il più comune è quello detto box-counting, che consiste nel sovrapporre agli oggetti da misurare un reticolo regolare di rattangoli contando quanti di questi ultimi vengono intersecati dagli oggetti stessi. Si utilizza poi la solita relazione basata sul rapporto tra il logaritmo della misura del lato L della cella usata e quello del numero N di celle che toccano gli oggetti.
METODO BOX_COUNTING

Considerazioni sulle caratteristiche frattali delle curve naturali - II Conseguenza principale della natura frattale di molte curve naturali è che:
Curve con proprietà frattali godono di invarianza scalare, appaiono cioè statisticamente simili se viste a scale di osservazione diversa.Sono quindi oggetti la cui forma non dipende dalla scala, entro i suddetti limiti fisici.
Per contro, oggetti lineari con proprietà frattali non ben definite (grafico bilogaritmico logN/logL non lineare), hanno caratteristiche geometriche, anche statistiche, dipendenti dalla scala.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Ad esempio, non è possibile stabilire a priori se la figura a fianco, sulla quale si prendono le misure con righelli A=2B=2C sia una costa di centinaia di chilometri oppure una serie di insenature di un campione di minerale osservato al microscopio. Per la rappresentazione in un GIS questo implica questioni del tipo: 1. Qual è la vera lunghezza di una curva? 2. E’ possibile paragonare curve misurate con metodi diversi? 3. Che livello di approssimazione esiste quando si rappresenta una curva frattale in un GIS? Una retta è sempre tale, a qualsiasi scala la si osservi. E una curva?

Altre misure su insiemi di linee A parte i concetti complessi della geometria frattale, altre misure più tradizionali possono essere adottate per caratterizzare un insieme di linee o curve.
Ad esempio, se queste rappresentano percorsi, una misura ovvia è la media (e la deviazione standard) delle lunghezze. Un altro concetto utile è la densità dei percorsi:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
ad
Dperc∑=
dove a è l’area della zona considerata. Nel caso che le curve siano il reticolo idrografico questa densità assume il noto nome di densità di drenaggio ed esprime la quantità lineare di fiumi per area unitaria. Il reciproco di Dperc, è chiamata costante di mantenimento del percorso Cperc.
Una alternativa alla densità è la frequenza dei percorsi Fperc che misura semplicemente il numero di oggetti lineari (ad es. fiumi) per unità di superficie. Questa frequenza può essere combinata con la densità Dperc per ottenere il rapporto Υ, che descrive come una serie di percorsi copre un’area per una determinata frequenza degli stessi:
∑=
daCperc
perc
perc
DF2=Υ

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Misure di direzione su insiemi di linee Problema completamente a parte rappresentano le misure di direzione di insiemi di linee. Un esempio molto noto sono le direzioni di vergenza o di immersione. Le direzioni sono espresse normalmente con angoli e questi sono misure di tipo intervallo, nel senso che la loro origine è arbitraria (es: la direzione 0° a nord).
La media di misure di direzione non può pertanto essere una media aritmetica delle misure degli angoli!
Il problema deve essere invece risolto considerando le due componenti x e y di ogni vettore di direzione e mediandole separatamente per poi risommarle in un vettore risultante R.
Si avrà quindi che le direzioni medie risultanti saranno, per n vettori:
∑∑
=
=
=
=n
i iR
n
i iR
senY
X
1
1cos
θ
θE la direzione media finale sarà perciò:
( )⎟⎟
⎠
⎞
⎜⎜
⎝
⎛==
∑∑
=
=−−n
i i
n
i iRR
senXY
1
111
costantan
θ
θθ

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Misure di connessione di insiemi di linee Il concetto di misure di connessione per insiemi di linee è strettamente legato a quello di grafo in geometria. Esistono grafi con o senza circuiti chiusi ma dal momento che i primi possono sempre essere ricondotti ai secondi ci occuperemo qui dei grafi senza circuiti chiusi (o closed loops).
L’esempio naturale più importante di questo tipo di grafo è un reticolo idrografico e molti sono i problemi legati all’ordinamento di uno di tali sistemi, o alla sua gerarchizzazione in ordini.
Lo schema classico di ordinamento per i fiumi è quello suggerito da Horton (1945) e poi modificato da Strahler(1952), illustrato in figura. Partendo dai crinali si inizia con ordine 1 e si aggiunge un ordine ogni volta che due fiumi di pari ordine confluiscono. Un altro schema di ordinamento, dovuto a Shreve (1966), aumenta di un ordine ad ogni intersezione, indipendentemente dall’ordine. Nell’accezione di Strahler e Horton le frequenza dei tratti di ordine n è legata a quella dei tratti di orine n+1 da una legge del tipo:
tNN
n
n cos1
=+

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Reti e grafi - I Un grafo generalizzato, cioè che può includere anche circuiti chiusi, è quello più utilizzato per descrivere reti connesse di qualsiasi tipo. Esempi possono essere reti stradali, acquedotti, oleodotti etc.
Nella teoria dei grafi i punti di giunzione o nodi sono detti vertici mentre i segmenti che li collegano sono detti bordi. Un grafo si occupa di rappresentare la topologia della rete, quindi la sua connettività e adiacenza, senza occuparsi delle distanze tra vertici. Il sistema più compatto di rappresentazione delle relazioni di connessione di un grafo è la forma di matrice, come già detto nella parte introduttiva. Nell’esempio in figura lo stesso grafo può essere rappresentato sia come disegno, nei 2 modi equivalenti riportati, oppure in forma di matrice A.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Reti e grafi - II Matrici di adiacenza e connettività possono essere prodotte per qualsiasi tipo di oggetto, e non solo per reti. Ad esempio si possono costruire matrici di adiacenza tra poligoni o di prossimità fra punti.
Una proprietà molto interessante delle matrici di connettività è che le loro potenze An forniscono le matrici di connettività del grafo in n passaggi. Ad esempio il prodotto A2=AxA dà una matrice che memorizza, per i vertici corrispondenti, il numero di percorsi che li collegano in 2 passaggi, A3 in 3 passaggi e così via.
2111131011211011
0110101111000100
0110101111000100
2 =×=×= ΑΑΑ
I valori sulla diagonale della A2 meritano particolare attenzione: essi rappresentano il numero di percorsi che in 2 passaggi conducono da un vertice ad un altro e poi di nuovo al vertice stesso. E’ ovvio che questo corrisponde, essendo i passaggi da fare solo 2, al numero di vertici direttamente connessi a quello dato. Ad esempio nella figura il vertice c (che ha valore 3 all’incrocio c-c nella matrice A2) è direttamente connesso a tre altri vertici (a, b, d).
Se una coppia di vertici ha un valore 0 sulla matrice di connettività An ciò vuol dire che i vertici in questione non sono connessi da un numero di passaggi ≤ n. Questo implica che, memorizzando per ogni vertice il valore di n a cui il corrispondente valore della An diviene > 0 si ottiene una matrice di distanza che rappresenta i percorsi topologicamente più brevi tra tutte le coppie di vertici.

RAPPRESENTAZIONE E ANALISI DI INSIEMI DI POLIGONI Le caratteristiche che differenziano gli oggetti areali dai precedenti sono principalmente l’area e la forma. Un’importante suddivisione concettuale degli oggetti bidimensionali è quella che distingue aree con confini naturali (uso del suolo, geologia, abitazioni, etc.) da aree con confini determinati da criteri astratti imposti dall’uomo (aree parco, divisioni amministrative, confini di stato, etc.). I poligoni di tipo “naturale” hanno confini definiti in base alla precisione del rilevamento e della successiva informatizzazione del rilevamento stesso. Altre volte questi confini sono solo rappresentazioni ideali o approssimate di confini naturali che in realtà non sono netti ma sfumati o complessi. Ad esempio i poligoni di una carta geologica hanno almeno due tipi di approssimazione: 1. Approssimazione nella precisione del rilevamento dei limiti tra formazioni o unità, dovuta alla scala di rilevamento e a oggettivi problemi di intepretazione, specie in aree coperte (non affiorante) 2. Approssimazione dovuta al fatto che molto spesso il passaggio da una formazione all’altra non è netto ma graduale e discontinuo.
I poligoni con confini imposti dall’uomo hanno di solito precisione dettata solamente dalla scala di interesse alla quale sono determinati ed utilizzati. Talvolta però servono cautele particolari per non commettere errori grossolani. Ad esempio, se i poligoni di cui si parla sono quelli che delimitano le proprietà terriere è molto importante che la precisione di definizione degli stessi sia alta, necessaria a permettere equi calcoli delle imposte o a consentire una risoluzione soddisfacente delle contese o dispute tra proprietari.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Tipologie di insiemi poligonali La divisione operativamente più importante tra insiemi di poligoni è quella che distingue: 1. Coperture complete del territorio in esame, prive di discontinuità (es.: carte geologiche, dell’uso del suolo, catastali, etc.) 2. Coperture discontinue, determinate dalla presenza di poligoni solo dove quella particolare proprietà del territorio risulta presente o definibile (es.: poligoni degli edifici, dei boschi, delle aree incendiate etc.)
Altra importante distinzione è tra insiemi di poligoni che possono sovrapporsi e insiemi nei quali ogni punto del piano può appartenere ad un solo poligono (vedi figura 7.1a e 7.1b). Anche se la rappresentazione e soprattutto la modalità di disegno più usuale per i poligoni è quella vettoriale, tutto quanto detto può anche essere rappresentato in formato raster (fig. 7.1d).
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Strutture dati poligonali nei GIS Esistono due modalità concettuali di memorizzare una serie di poligoni: 1. Codifica esplicita nella quale ogni poligono viene memorizzato nella sua interezza 2. Codifica implicita o destrutturata, nella quale vengono memorizzate esplicitamente (come serie di vertici x,y,z) soltanto le singole le linee che li compongono Nel primo caso abbiamo, a fronte di una certa semplicità intuitiva, grandi problemi di spreco di memoria ed accresciuta possibilità di errore. Questo perchè tutte le volte che due o più poligoni condividono uno più lati i vertici degli stessi vengono memorizzati due volte. Nel secondo caso invece ogni linea viene memorizzata solo una volta ed il suo codice identificativo utilizzato per costruire i poligoni cui appartiene. I metodi logici con cui questo viene realizzato all’interno del sistema possono essere diversi e normalmente dipendono dal GIS utilizzato. La figura a lato mostra un esempio dei due tipi di memorizzazione, confrontandone la struttura dati.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
ID v1 v2 v3
10 (x,y)a (x,y)b (x,y)c
11 (x,y)b (x,y)c ...
13 (x,y)a (x,y)b ...
ID L1 L2 ...
10 A B ...
11 B ... ...
13 A ... ...
ID v1 v2
A (x,y)a (x,y)b
B (x,y)b (x,y)c
... ... ...
A’
A’’ B’
B’’
B B
A
A
13
13
a a
b b c c
a a
b b c c
Codifica esplicita
Codifica implicita
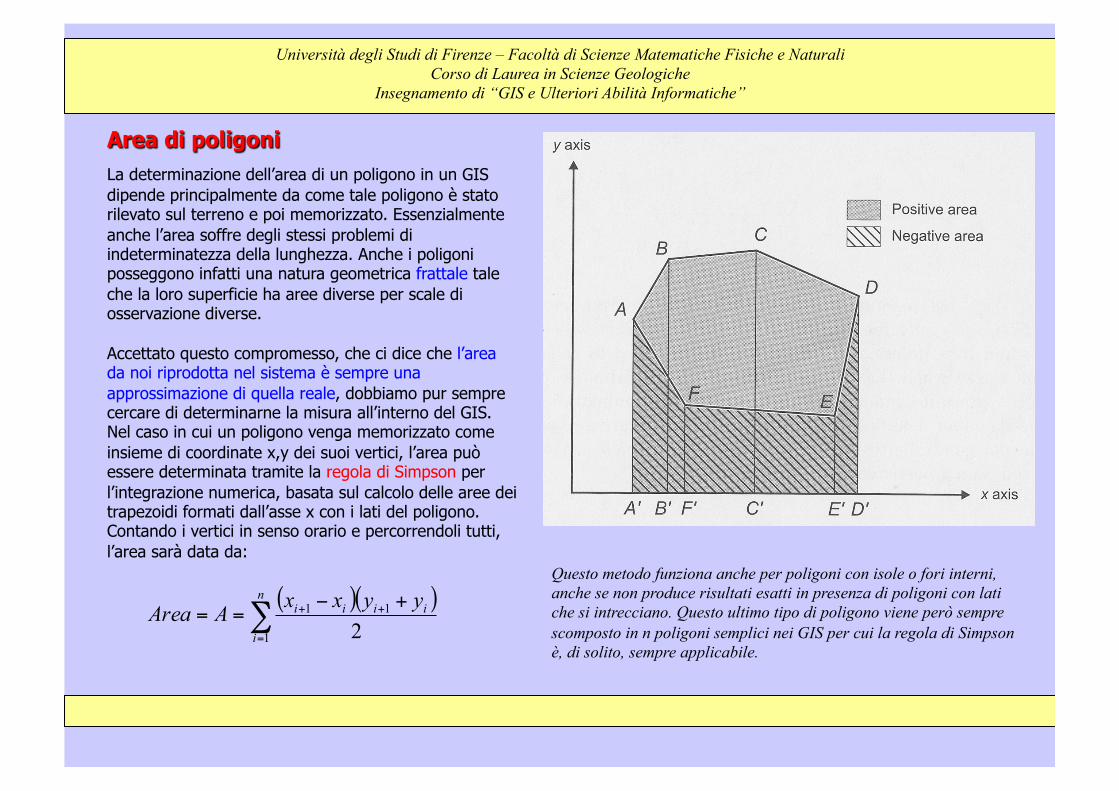
Area di poligoni La determinazione dell’area di un poligono in un GIS dipende principalmente da come tale poligono è stato rilevato sul terreno e poi memorizzato. Essenzialmente anche l’area soffre degli stessi problemi di indeterminatezza della lunghezza. Anche i poligoni posseggono infatti una natura geometrica frattale tale che la loro superficie ha aree diverse per scale di osservazione diverse. Accettato questo compromesso, che ci dice che l’area da noi riprodotta nel sistema è sempre una approssimazione di quella reale, dobbiamo pur sempre cercare di determinarne la misura all’interno del GIS. Nel caso in cui un poligono venga memorizzato come insieme di coordinate x,y dei suoi vertici, l’area può essere determinata tramite la regola di Simpson per l’integrazione numerica, basata sul calcolo delle aree dei trapezoidi formati dall’asse x con i lati del poligono. Contando i vertici in senso orario e percorrendoli tutti, l’area sarà data da:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( )( )∑=
++ +−==
n
i
iiii yyxxAArea1
11
2
Questo metodo funziona anche per poligoni con isole o fori interni, anche se non produce risultati esatti in presenza di poligoni con lati che si intrecciano. Questo ultimo tipo di poligono viene però sempre scomposto in n poligoni semplici nei GIS per cui la regola di Simpson è, di solito, sempre applicabile.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Centro o punto di baricentro dei poligoni Molto spesso è utile poter determinare qual è il centro di un poligono o il punto che lo approssima nel modo migliore. Tale posizione ha importanza per vari motivi, tra i quali: • Posizionamento di etichette (label) • Riduzioni di scala e passaggio dei poligoni a punti • Applicazione di analisi di prossimità o relazione
Alcune tecniche utilizzate: 1. Centro medio del poligono (somma delle distanze dai vertici minimizzata). Ha il problema che a volte il punto trovato cade esternamente al poligono stesso.
2. Centro dello scheletro del poligono, dove col termine scheletro si intende la costruzione geometrica ottenuta con i luoghi geometrici del punti equidistanti dai due lati più vicini (vedi figura). Si costruiscono le bisettrici agli angoli interni e si portano le parallele ai lati originali che divengono via via più corte finchè non si riducono ad uno (o più) possibili punti centrali.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Forma dei poligoni Uno dei concetti geometrici più sfuggenti e difficili da definire in termini univoci e analitici è la forma di un poligono. Può essere definita come l’insieme delle relazioni di posizione reciproca di un insieme di punti sul perimetro del poligono stesso, invarianti al variare della scala. Il miglior modo di definire quantitativamente la forma di un oggetto è costruire un indice che ne esprime la deviazione da una forma regolare di riferimento (molto spesso il cerchio). La figura a fianco mostra alcuni misuramenti possibili che possono essere combinati per costruire indici. Un buon indice è il rapporto di compattezza:
Cr = a/a2-1/2
dove a è l’area del poligono e a2 l’area del cerchio che ha lo stesso perimetro del poligono. Se Cr è 1 il poligono è un cerchio. Altri utili indici di forma sono il rapporto di elongazione L1/L2 e il rapporto di forma a/L1
2.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Esercitazione - Area di poligoni e effetto scala
Come già detto la misura dell’area di un poligono si avvicina a quella “reale” ipotetica all’aumentare della scala e della precisione del rilevamento. Ma la forma e l’area di un oggetto costituito da una spezzata chiusa dipendono strettamente dal numero di vertici che si sono memorizzati. Verifichiamo come il numero di vertici digitalizzati faccia variare l’area di un poligono reale, anche se dotato di confini imposti definiti su base amministrativa. Proviamo a digitalizzare la regione Toscana con un numero crescente di punti, o in altre parole, con segmenti di spezzata via via più corti.
A C B
Nome Area (km2)
A 23322.89
B 22637.03
C 22680.96

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Analisi di insiemi di poligoni – Operazioni tra poligoni Mentre per punti e linee ci siamo limitati alla descrizione delle principali metodologie di analisi e rappresentazione, per i poligoni introdurremo brevemente anche alcune delle operazioni di base da applicare sull’insieme degli oggetti o tra due insiemi di oggetti. Infatti le operazioni tra poligoni possono coinvolgere: 1. Poligoni di uno stesso livello informativo (o tematismo) 2. Poligoni di due o più livelli informativi
Nel primo caso le operazioni sono generalmente di modifica o trasformazione dei singoli oggetti e non comportano (a parte alcune eccezioni) la generazione di dati di nuovo tipo. Nel secondo invece si tratta di unire in qualche modo geometria e dati di insiemi diversi per ottenere un livello informativo nuovo per estensione spaziale o significato.
Entro un tematismo: Unione di poligoni Separazione di poligoni Cancellazione di poligoni Modifica di poligoni Creazione di poligoni Modifica dell’intero insieme . . .
Tra 2 o più tematismi: Unione di tematismi Sottrazione di tematismi Intersezione di tematismi Fusione di aree adiacenti Taglio di un tematismo con un altro Correlazione . . .

Geoprocessing in ArcMap
Le operazioni semplici sui poligoni vengono condotte nel GIS ArcMap (sia versione ArcView che ArcInfo) tramite specifici comandi di editing. Le operazioni più complesse sono invece presenti all’interno di un apposito procedimento semiautomatico detto GeoProcessing wizard. Le funzioni a disposizione sono le 5 in figura.
GIS differenti da quello da noi utilizzato hanno comandi ed accesso alle funzioni di tipo diverso ma posseggono nella maggior parte dei casi lo stesso tipo di funzionalità per il trattamento di insiemi di poligoni.

Dissolve di un tematismo

Taglio tra due tematismi

Intersezione tra due tematismi

Unione tra due tematismi

RAPPRESENTAZIONE E ANALISI DI CAMPI CONTINUI
Abbiamo già spiegato che alcune variabili territoriali possono essere meglio rappresentate se ci immaginiamo la loro distribuzione come un campo di variazione continua dei valori all’interno dell’area considerata. I campi possono essere scalari o vettoriali. Nei primi il valore della variabile rappresentata consiste nel solo modulo. Nel secondo caso invece hanno importanza anche direzione e verso. Nella figura a fianco sono illustrati alcuni metodi di memorizzazione di campi in un GIS.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
La rappresentazione GIS di un campo reale è di solito suddivisa in due operazioni distinte:
1. Campionamento della superficie reale con misure dirette o indirette, che di solito sono puntuali
2. Interpolazione dei valori della variabile di interesse su tutta la superficie considerata, a partire dai dati campionati nella fase precedente.
Un esempio, già visto in una delle esercitazioni precedenti, è l’interpolazione di un campo di pioggia a partire dai dati delle stazioni pluviometriche.

CAMPIONAMENTO DELLA SUPERFICIE REALE Normalmente il campionamento della superficie è effettuato con misure dirette della variabile di interesse (ad esempio la pioggia viene misurata puntualmente con pluviometri, le quote del terreno con misure topografiche, la concentrazione di un inquinante in un punto tramite prelievo ed analisi e così via...) Esistono tuttavia anche metodi di misurazione indiretta delle proprietà come la definizione delle tipologie di uso del suolo dalla risposta radiometrica del terreno rilevabile da immagini da satellite. Molto spesso i dati di campionamento che riguardano la morfologia del terreno derivano da restituzione da coppie stereoscopiche (aeree o terrestri) attraverso i principi della fotogrammetria Deve essere comunque sempre considerato che: 1. I dati che otteniamo sono solamente un campione della popolazione che vogliamo rappresentare. La rappresentatività di questo campione deve essere verificata prima di poter procedere con analisi o interpolazioni basate sulla distribuzione statistica dei valori. 2. Molti campi o comunque livelli informativi continui nello spazio sono variabili nel tempo. Quello che noi misuriamo è solo un campione istantaneo della situazione oppure una media di un qualche tipo dei valori che la variabile ha assunto durante un certo intervallo di tempo (si pensi ancora all’esempio dei dati di pioggia: che significato ha costruire un campo basato sulla pioggia di un singolo evento? e di un interno mese di eventi?). 3. Molto spesso non si ha la possibilità di decidere dove e quanto campionare, per motivi di accessibilità dei dati, di tempi o di costi.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Descrizione delle superfici continue Come già visto in precedenza ci sono vari modi di rappresentare una superficie continua, anche se molto spesso nei GIS questo tipo di dato è normalmente associato a dati di tipo raster o grid. Il metodo di memorizzazione del campo è fondamentale perchè influenza sia i metodi di interpolazione del campo stesso che il tipo di analisi che su di esso è possibile compiere.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
A) ISOLINEE (curve di livello – contour lines)
Si tracciano le curve luogo geometrico dei punti con egual valore della variabile, per valori interi ad intervalli dati (ad esempio: curve di livello che rappresentano la quota sul livello del mare equidistanziate di 50 metri in elevazione).
E’ facile realizzarle, anche con procedure manuali. Sono inoltre molto diffuse e facili da inserire all’interno di un computer tramite digitalizzazione.
Hanno però le seguenti principali limitazioni:
1. Non c’è nessuna informazione tra curva e curva 2. Si ha sovracampionamento lungo le singole curve, con molti vertici aventi la stessa quota molto
vicini tra loro 3. Si ha sovracampionamento nelle aree ad elevato gradiente (curve di livello vicine tra di loro) e
sottocampionamento nelle aree a basso gradiente (curve di livello distanti tra loro) 4. E’ molto complesso condurre analisi numeriche su informazioni di questo tipo, sia per la loro
discontinuità che per la natura vettoriale.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
B) FUNZIONI MATEMATICHE
A partire dai punti di campionamento la superficie viene descritta da una equazione matematica che coinvolge le coordinate o altri attributi della superficie stessa (che può onorare o non onorare i dati campionati).
Ad esempio la quota potrebbe essere espressa da una funzione come quella in figura, che ci dice che la superficie è un piano inclinato.
I vantaggi di questa rappresentazione sono indubbi:
1. Compattezza ed eleganza di rappresentazione
2. Possibilità di calcolare il valore della variabile per qualsiasi punto della superficie utilizzando l’equazione stessa
3. E’ semplice calcolare i dati derivati, derivando l’equazione stessa nel punto di interesse
Tuttavia esistono molti problemi nell’utilizzo di questo metodo, principalmente legati al fatto che è molto raro trovare campi che possano essere descritti in modo soddisfacente da equazioni analitiche semplici. Molto spesso si deve invece ricorrere a superfici analitiche localmente valide, che si adattano in ogni luogo alla superficie da descrivere. Questa soluzione offre tuttavia svantaggi, sia nella fase di interpolazione dei valori che in quella di calcolo e analisi delle quantità derivate.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
C) SISTEMI A PUNTI
Un metodo che non implica già una intepretazione dei dati campionati è quello basato sulla memorizzazione dei soli punti di campionamento. Le differenze tra le varie versioni di questo metodo di rappresentazione sono legate alla maniera in cui i punti sono campionati:
1. Campionamento casuale: punti collocati senza tener conto della superficie da campionare 2. Campionamento mirato alla superficie: punti di campionamento che sono scelti in modo da descrivere bene zone importanti della superficie. Ad esempio la superficie topografica può essere efficientemente campionata con serie di punti che descrivono gli assi delle valli, i crinali, le cime, le depressioni e le altre forme principali del rilievo. 3. Campionamento a griglia regolare: è quello che genera direttamente una matrice regolare (o grid) alla risoluzione di campionamento, senza l’utilizzo di interopolazione se ci si può permettere una vicinanza opportuna dei punti misurati. Ha il vantaggio di avere spaziatura regolare dei punti fin dalle operazioni di campionamento, non richiede inoltre memorizzazione esplicita delle coordinate x,y e consente di eseguire facilmente calcoli sulla superficie. Problemi: che distanza ottimale? spreco di memoria o scarsa risoluzione

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
D) MAGLIE DI TRIANGOLI (TIN – Triangulated Irregular Networks)
In essi i punti di campionamento sono uniti a formare una rete continua di triangoli adiacenti non intrecciati e quanto più possibile equilateri (Triangolazione di Delaunay).
Nelle aree interne ai triangoli la superficie è rappresentata dalla superficie del triangolo stesso. Su questi modelli è immediato calcolare attributi secondari come pendenza, esposizione, direzioni principali di immersione e così via. Si tratta di una rappresentazione molto compatta e flessibile, visto che i punti sono scelti in modo opportuno rendendoli più fitti in aree a rilievo complesso e meno frequenti in aree a bassa energia del rilievo. Si prestano molto bene anche a rappresentazioni tridimensionali ed alla costruzione di scenari simulati, per la loro natura vettoriale che ne facilita il rendering fotorealistico.
Problemi: non si prestano a certi tipi di analisi, specie quelle di sovrapposizione cartografica, perchè i triangoli hanno normalmente aree diverse e disomogeneamente distribuite.

Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

INTERPOLAZIONE SPAZIALE DI SUPERFICI CONTINUE Consiste nel prevedere i valori della variabile di interesse in ogni punto dell’area in esame a partire da una serie di punti noti, nei quali la variabile è stata misurata direttamente. Il risultato di una procedura di interpolazione sarà uno dei tipi di superficie già esaminati in precedenza (TIN, insiemi di punti casuali, specifici, a griglia regolare, funzioni matematiche e curve di livello) Nella interpolazione (o approssimazione) dei valori di un campo è molto importante conoscerne le proprietà di autocorrelazione spaziale. Ricordiamo ancora una volta che la Prima Legge della Geografia (Tobler, 1970) ci dice che in geografia ogni cosa è correlata a tutte le altre ma cose vicine sono più correlate di cose lontane. Questo è molto importante per poter scegliere il metodo di interpolazione. Se non c’è autocorrelazione spaziale allora la misura più probabile per il campo sarà il valore atteso dell’intero campione, cioè la semplice media dei suoi valori. In questo caso la superficie si riduce ad un semplice piano parallelo al piano di riferimento. Ciò è ovviamente insoddisfacente per la gran parte dei campi che rappresentano variabili misurabili in natura. La autocorrelazione spaziale è invece sempre presente nei campi di variabili geografiche per cui per l’interpolazione servono sistemi che tengano conto della POSIZIONE RELATIVA degli oggetti utilizzati per i calcoli. I metodi di interpolazione si distinguono in generali in globali e locali.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Interpolatori globali di classificazione Nel caso in cui le variazioni della proprietà da mappare siano concentrate in zone di transizione lungo i bordi di poligoni si può ricorrere a modelli classificativi basati sulla analisi della varianza (ANOVA). E’ questo il caso in molte interpolazioni che riguardano la litologia, i suoli, le unità di paesaggio, i versanti e così via. Il più semplice modello ANOVA è del tipo: dove z è il valore dell’attributo nel punto x0, µ è la media generale di z nel dominio di interesse, αk è la deviazione tra µ e la media locale del poligono k, ed ε è l’errore residuo o rumore. Per comprendere questo basta pensare che nell’assunzione fatta di poligoni (e classi) quasi-omogenei le variazioni dell’attributo all’interno dei singoli poligoni (o classi) sono molto minori delle variazioni tra poligoni diversi. Ad esempio le variazioni del contenuto in CaCO3 nella formazione del Macigno saranno sicuramente minori delle variazioni di CaCO3 tra Macigno e Marnosa Arenacea. Per l’applicazione di questo modello è necessario che la distribuzione dei valori all’interno di ogni poligono o classe k sia normale. A volte sono necessarie trasformazioni per far diventare la distribuzione dei dati normale. La varianza interna di ogni classe è inoltre ipotizzata uguale ad ε per tutte le classi. La bontà di una stima di questo tipo può essere testata con classici test F.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( ) εαµ ++= kxz 0

Interpolatori globali a superfici di tendenza (Trend Surfaces) Se le variazioni non sono discontinue come nel caso di poligoni a valori quasi-costanti, è possibile tentare l’interpolazione usando una superficie matematica. Il metodo più utilizzato consiste nel trovare la superficie polinomiale che approssima meglio i dati. La bontà dell’approssimazione viene valutata col metodo dei minimi quadrati. Si cerca cioè la superficie che minimizza la somma dei quadrati delle differenze tra punti del campionamento e punti della superficie. In x e y le superfici polinomiali hanno la forma generale del tipo:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
254
23210
210
0
ybxybxbybxbbybxbb
b
+++++
++
In cui p è l’ordine del polinomio. Ci sono P=(p+1)(p+2)/2 coefficienti che sono normalmente scelti per minimizzare la quantità:
( ) ( ){ }∑=
−n
iii fz
0
2xx
Esempi di superfici di tendenza di vario ordine sono:
Sup. piatta
Sup. lineare
Sup. quadratica
( ){ } ( )∑≤+
⋅⋅=psr
srrs yxbyxf ,
minimi quadrati

Interpolatori globali multiregressivi In alcuni casi le variazioni spaziali della quantità che dobbiamo interpolare sono legate ad altre variabili molto più facili da misurare. In questo caso si possono costruire modelli mono o multivariati che legano i valori della variabile dipendente ad una combinazione delle variabili indipendenti scelte. Ad esempio, nel caso univariato, le piogge possono esser ritenute legate alla altitudine e determinate a partire da essa usando la legge che fornisce la migliore regressione. Nel caso invece che le variabili indipendenti siano più di una la regressione diviene multipla e la variabile dipendente in ogni punto verrà alla fine determinata da una funzione del tipo:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
ε+++++= nnii xcxcxccy ……110
dove ci sono i coefficienti da determinare e xi le variabili dipendenti. Prima di decidere quali variabili dipendenti considerare nella regressione si dovranno ovviamente analizzare le correlazioni univariate tra tutte le quantità in gioco.

Interpolatori locali a Poligoni di Prossimità Abbiamo già visto come i poligoni di Thiessen possano essere utilizzati per la rappresentazione di un campo continuo nello spazio bidimensionale cartografico. Lo stesso sistema può essere utilizzato per interpolare i dati assegnando semplicemente ad ogni punto p della superficie il valore della variabile misurato nel punto di campionamento che gli è più vicino. E’ un metodo molto semplice che produce risultati piuttosto scarsi se quello che si vuole ottenere è una superficie continua e regolare. Nel caso in cui invece i dati da interpolare debbano poi essere riclassificati in poche classi e quindi aggregati, oppure nel caso in cui essi siano di natura nominale, i poligoni di prossimità possono dare buoni risultati. Problema principale con dati continui cardinali: al passaggio tra poligono e poligono ci sono cambi improvvisi di valore, che nella maggior parte dei casi sono solo un artefatto del metodo.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Interpolatori locali lineari basati sull’Inverso della Distanza (IDW) Un metodo che è intermedio tra quello dei poligoni (locale) e quello delle superfici di tendenza (globale) è quello basato sull’inverso della distanza. In pratica si stima il valore della variabile incognita in un punto sulla base dei valori degli n punti di campionamento che gli sono più vicini, pesando questi ultimi in maniera inversamente proporzionale alla distanza (visto che due punti più sono distanti e meno si influenzano). La forma generale è del tipo:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( ) ( )
1
ˆ
1
10
=
⋅=
∑
∑
=
=
n
ii
n
iii zz
λ
λ xx dove i pesi λi sono dati da una apposita funzione di peso Φ(d(x,xi)). E’ necessario che Φ(d) tenda al valore misurato al tendere della distanza d a zero.
La forma più comune di Φ(d) è quella nella quale i pesi sono appunto in base all’inverso della distanza, secondo un esponente r:
( ) ( ) ∑∑=
−−
=
⋅=n
i
rij
rij
n
ii ddzz
110ˆ xx
in essa xj sono i punti della superficie da interpolare mentre gli xi sono i punti di campionamento dove il valore di z è noto perché misurato. I risultati che si ottengono dipendono in modo molto marcato dal valore dell’esponente r scelto.

Interpolatori ad Inverso della Distanza in ArcMap - IDW
variabile da interpolare
esponente r della distanza
numero di punti di campionamento da usare
risoluzione del grid di output

Interpolatori locali lineari basati su Splines cubiche
Il metodo delle splines (che per gli inglesi erano in origine righelli flessibili utilizzati dai disegnatori) si basa su equazioni matematiche che definiscono curve che rispettano i punti localmente assicurando allo stesso tempo che le connessioni tra curva e curva siano continue. Si tratta di solito di polinomiali cubiche. Nel caso delle superfici invece delle splines cubiche si usa il loro equivalente bicubico. A volte l’interpolazione delle splines conduce ad artefatti non accettabili ai bordi o in particolari zone dell’area calcolata. In questo caso un sistema che corregge parzialmente gli errori è quello delle thin plate splines, che sostituiscono localmente alle splines esatte delle versioni approssimate in modo da mediare nel miglior modo possibile le irregolarità.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Interpolatori Splines in ArcMap - Spline
variabile da interpolare
metodo da utilizzare per calcolare le splines
peso (dipende dal metodo)
numero di punti vicini da usare
risoluzione del grid di output
Interpolatori geostatistici – Kriging I Il tipo forse più utilizzato di interpolatore per superfici è quello geostatistico, nel quale la funzione di interpolazione viene scelta localmente a seconda di come approssima i dati nell’intorno del punto da determinare. Abbiamo già visto le caratteristiche delle proprietà di autocorrelazione spaziale, nella forma di variogrammi o correlogrammi. Le variazioni con la distanza possono essere isotropiche ma in natura sono quasi sempre anisotropiche. Il variogramma che approssima meglio i dati in una certa area può essere utilizzato per determinare i pesi λi da dare ai valori delle variabili dipendenti misurati nei punti più vicini al punto da interpolare. E’ questo il principio di base del kriging. In particolare si scelgono i pesi in modo da rendere la stima obiettiva e da minimizzare la varianza della stima stessa. Questa varianza minima è data da:
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
( )∑=
+=n
iiie
10
2 ,ˆ φγλσ xx
Ottenuta quando: ( ) ( )01
,, xxxx j
n
ijii γφγλ =+∑
=
per tutti i j
La quantità γ(xi,xj) è la semivarianza della variabile dipendente z tra i punti di campionamento xi e xj. Invece la γ(xi,x0) è la semivarianza tra il punto di campionamento xi ed il punto non noto x0 da interpolare.

Interpolatori geostatistici – Kriging II
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Interpolatori geostatistici in ArcMap - Kriging
variabile da interpolare metodo
semivariogramma
numero di punti vicini da usare
risoluzione del grid di output

Confronto tra metodi di interpolazione Sottrazione delle superfici interpolate da superficie DTM originale generata precedentemente e dalla quale sono stati ricavati i dati del campione per l’interpolazione. Rosso indica sottostima dei dati originari, giallo sovrastima.
IDW Spline Kriging
Max errore positivo = 66.71 m Max errore negativo = -62.35 m Errore medio = -0.69 m Dev. Std. errore = 9.49 m
Max errore positivo = 38.57 m Max errore negativo = -78.98 m Errore medio = 0.26 m Dev. Std. errore = 4.75 m
Max errore positivo = 50.11 m Max errore negativo = -58.09 m Errore medio = 0.23 m Dev. Std. errore = 5.95 m

ANALISI DI DATI RASTER I metodi visti fino a questo momento servono a rappresentare o a ricavare dati continui a partire da dati di altro tipo. Come già visto, il modello logico più utilizzato per le superfici continue è quello raster (o grid), nel quale i dati vengono rappresentati come matrici di pixel aventi un valore unico (grid-code o value nei GIS). L’utilità di questo tipo di struttura dati è la semplicità di elaborazione nel caso in cui si debbano applicare calcoli di tipo distribuito o analisi di sovrapposizione.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
ArcMap utilizza per i grid una struttura detta tile-block nella quale ogni grid è diviso in tile a loro volta divisi in blocks. Un block è poi suddiviso in celle quadrate dette pixel ed organizzate in righe e colonne. La struttura tile-block serve a GIS per poter creare un indice spaziale con il quale ricercare i dati più velocemente. Grid composti da 106 di celle possono essere strutturati in 104 blocchi a loro volta riuniti in 102 tile, un numero quindi molto minore da gestire nelle ricerche spaziali.

Analisi Multirisoluzione La struttura dei grid permette inoltre di operare con analisi anche utilizzando grid a diversa risoluzione. Se due o più grid a diversa risoluzione sono utilizzati in una espressione che li combina in qualche modo, il software li ricampiona automaticamente (cioè ne cambia la risoluzione) tramite una operazione di ricampionamento per prossimità. Questa operazione conduce di solito alla risoluzione minore tra quelle dei grid utilizzati (vedi figura). In altri casi, invece, se non si vuole perdere la precisione di un dato a grande risoluzione, si sceglie invece di operare mantenendo la risoluzione più alta ed interpolando i dati dei grid più grossolani. La valutazione di questo deve essere però fatta con criterio.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Attributi dei GRID Ogni grid possiede un attributo principale che ne determina la natura. Esso viene normalmente indicato con i termini GRID-CODE o VALUE. Nel caso in cui i valori del grid siano in numero finito (cioè nel caso in cui siano dati nominali o classificativi), ad ogni valore del grid può essere associato un record in una tabella, detta, nella struttura ArcMap/ArcInfo tabella VAT (value attribute table). In questa tabella (vedi figura) ad ogni valore (VALUE) possono essere associati altri attributi o possono essere relazionate altre tabelle. Qualsiasi grid anche in virgola mobile (cioè con dati continui) può essere convertito in un grid con tabella semplicemente applicando un operatore che trasforma i valori in NUMERI INTERI (funzione int(grid)).
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Operazioni su GRID Le operazioni possibili su dati grid sono moltissime e dipendono dal software GIS utilizzato. Il sistema ArcMap/ArcInfo comprende funzioni dei tipi seguenti: 1. Aritmetiche (somma, sottrazione, moltiplicazione, divisione, etc.) 2. Booleane (and, or, xor, not etc.) che restituiscono un valore VERO o FALSO, zero o 1. 3. Relazionali (maggiore di, minore di, uguale a, etc.) 4. Operazioni su BIT (shift di bit a destra o sinistra, complemento a due, otto, etc.) 5. Combinatorie (sovrapposizione di grid con riporto degli attirbuti in vario modo) 6. Logiche (contenimento in un insieme etc.) 7. Accumulative (somma, divisione, moltiplicazione, etc. dell’intero grid) 8. Di assegnazione o classificazione (sostituzione dei valori etc.)
Le funzioni su grid possono essere: LOCALI, ZONALI, FOCALI o GLOBALI.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Forma generale di applicazione di operatori o funzioni su grid. Nell’esempio i due grid di input INGRID1 e
INGRID2 vengono sommati con una espressione del tipo OUTGRID=INGRID1+INGRID2.
Il grid di uscita, OUTGRID, avrà in ogni pixel un valore pari alla somma dei valori dei due grid di ingresso.

Operazioni LOCALI Le operazioni LOCALI sono quelle nelle quali il risultato dell’operazione per ogni cella dipende dai valori di input della cella stessa e solo di quella.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Il valore della cella e non la sua posizione determinano il risultato di una funzione locale. Esempi di funzioni locali sono quelle trigonometriche (sin(x), cos(x) etc.), le esponenziali (exp(x,n), sqrt(x)), le logaritmiche (log(x), ln(x), etc.), le funzioni di riclassificazione (es: cambia tutti i valori “4” in “1” oppure tutti i “bosco” in “bosco d’alto fusto”), le funzioni di selezione (es: seleziona tutte le celle con valore > 3), quelle aritimetiche tra grid (somma, sottrazione etc.)

Operazioni LOCALI in ArcMap - Riclassificazione Si accede alle funzioni locali di riclassificazione tramite l’estensione Spatial Analyst, comando “RECLASSIFY…”. Si assegna ad ogni valore (o gruppo di valori) un nuovo valore, anche di tipo diverso).
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Grid da riclassificare
Metodi di riclassificazione
Classi (old values) e valori da assegnare (new values)
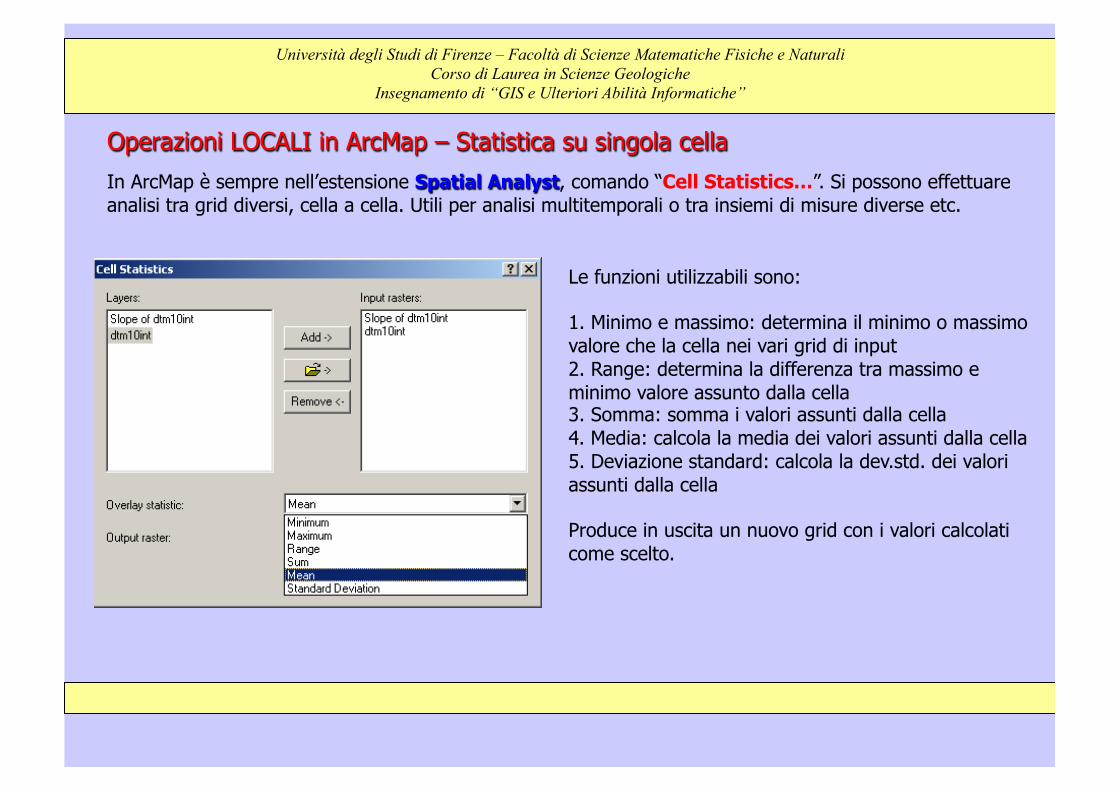
Operazioni LOCALI in ArcMap – Statistica su singola cella In ArcMap è sempre nell’estensione Spatial Analyst, comando “Cell Statistics…”. Si possono effettuare analisi tra grid diversi, cella a cella. Utili per analisi multitemporali o tra insiemi di misure diverse etc.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Le funzioni utilizzabili sono: 1. Minimo e massimo: determina il minimo o massimo valore che la cella nei vari grid di input 2. Range: determina la differenza tra massimo e minimo valore assunto dalla cella 3. Somma: somma i valori assunti dalla cella 4. Media: calcola la media dei valori assunti dalla cella 5. Deviazione standard: calcola la dev.std. dei valori assunti dalla cella
Produce in uscita un nuovo grid con i valori calcolati come scelto.
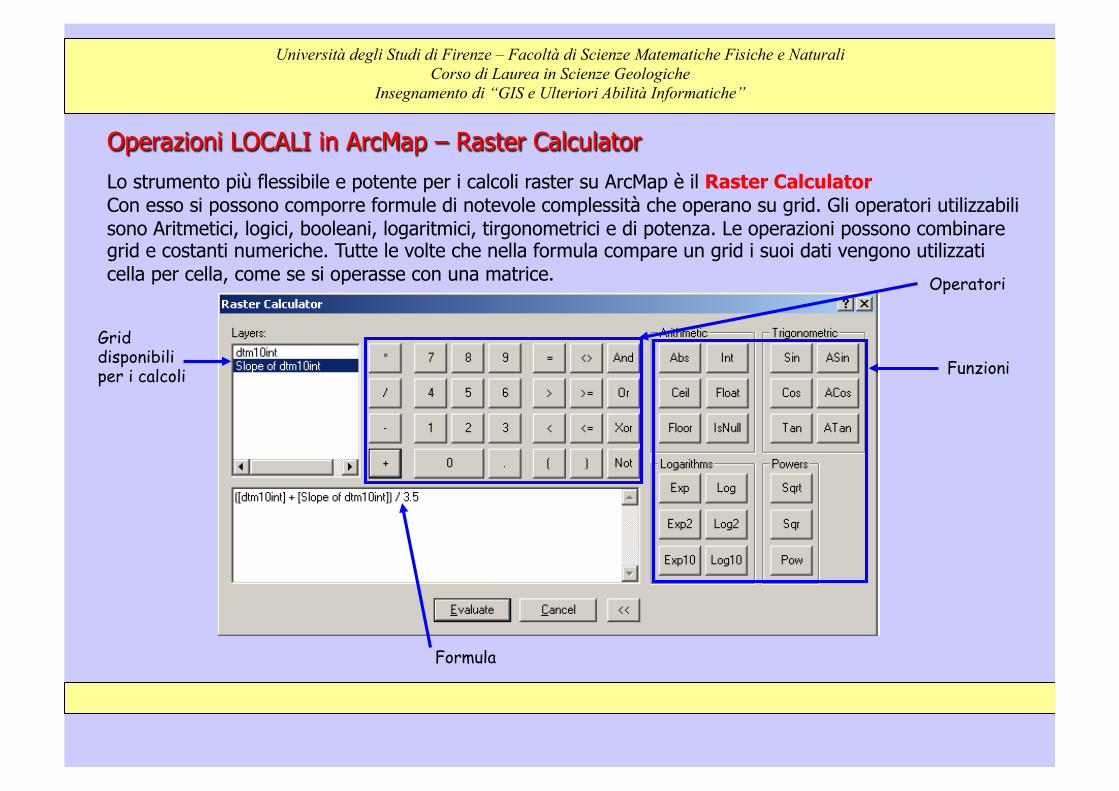
Operazioni LOCALI in ArcMap – Raster Calculator Lo strumento più flessibile e potente per i calcoli raster su ArcMap è il Raster Calculator Con esso si possono comporre formule di notevole complessità che operano su grid. Gli operatori utilizzabili sono Aritmetici, logici, booleani, logaritmici, tirgonometrici e di potenza. Le operazioni possono combinare grid e costanti numeriche. Tutte le volte che nella formula compare un grid i suoi dati vengono utilizzati cella per cella, come se si operasse con una matrice.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Formula
Operatori
Funzioni
Grid disponibili per i calcoli

Operazioni FOCALI Le operazioni FOCALI sono quelle che agiscono su un intorno della cella data e ne calcolano il valore finale sulla base dei valori dell’intorno stesso.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
L’intorno può essere un semplice quadrato di 3x3 celle, un insieme più esteso (4x4, … nxn), un intorno circolare, un anello, un settore di cerchio. Le operazioni che si possono effettuare sono di calcolo di media, mediana, deviazione standard, massimo, minimo, varietà, moda, somma etc. nell’intorno scelto. Il valore ricavato viene poi assegnato al pixel come valore di uscita.
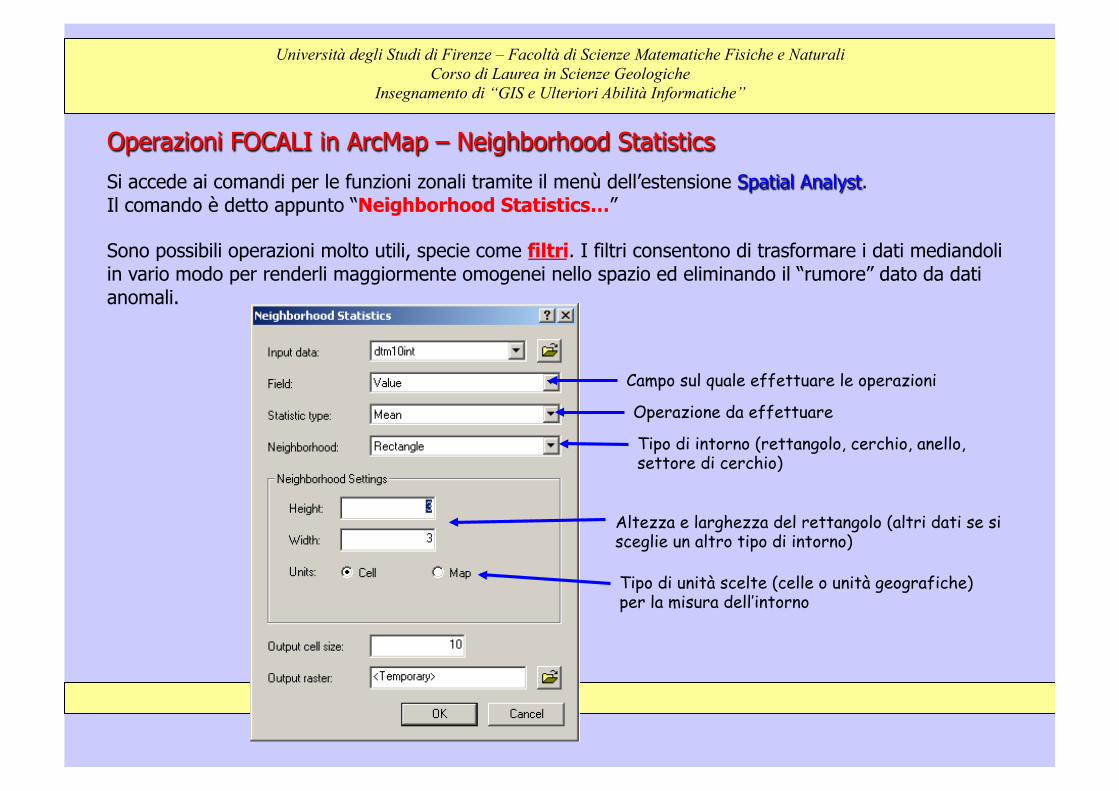
Operazioni FOCALI in ArcMap – Neighborhood Statistics Si accede ai comandi per le funzioni zonali tramite il menù dell’estensione Spatial Analyst. Il comando è detto appunto “Neighborhood Statistics…” Sono possibili operazioni molto utili, specie come filtri. I filtri consentono di trasformare i dati mediandoli in vario modo per renderli maggiormente omogenei nello spazio ed eliminando il “rumore” dato da dati anomali.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Campo sul quale effettuare le operazioni
Operazione da effettuare
Tipo di intorno (rettangolo, cerchio, anello, settore di cerchio)
Altezza e larghezza del rettangolo (altri dati se si sceglie un altro tipo di intorno)
Tipo di unità scelte (celle o unità geografiche) per la misura dell’intorno
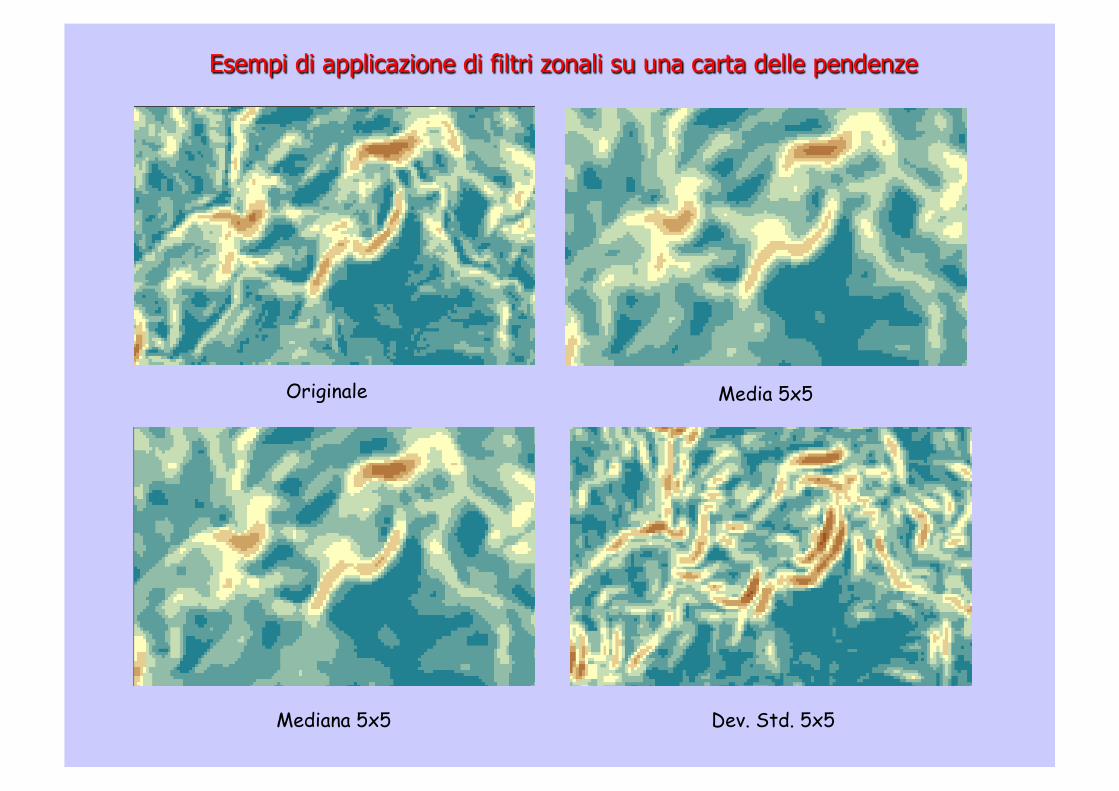
Media 5x5
Mediana 5x5
Originale
Dev. Std. 5x5
Esempi di applicazione di filtri zonali su una carta delle pendenze

Operazioni ZONALI Le operazioni ZONALI calcolano il valore della cella di output operando solo sulle celle che appartengono ad una ZONA definita da un grid opportuno.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
In figura, la somma zonale dà come valore per ogni pixel la somma del valore di tutti i pixel di VALGID1 che hanno lo stesso valore in ZGRID. Ad es.: i pixel nell’angolo in basso a destra assumono valore 13, che è la somma di 5+5+3 dei pixel che hanno valore uguale a 2 nel grid delle zone ZGRID. Le operazioni possibili sono somma, media, minimo, massimo, range, varietà, mediana, etc.

Operazioni GLOBALI Le operazioni GLOBALI calcolano il valore della cella sulla base della totalità delle celle di input, secondo delle regole funzionali.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
Esistono 7 criteri di funzione globale in ArcMap/Arcinfo: 1. Distanza Euclidea 2. Distanza pesata 3. Di superficie 4. Idrologici 5. Delle acque sotterranee 6. Multivariati
Quello a distanza euclidea assegna ad ogni cella un valore pari alla distanza euclidea tra la cella stessa e la più vicina cella origine (source). Quello a distanza pesata e gli altri operano in modo simile ma con regole che pesano i percorsi a seconda della difficoltà di attraversamento, la direzione di flusso possibile etc.

Operazioni su DTM Una classe di operazioni su raster che è di particolare interesse per le scienze della Terra ed in generale per chi opera sul territorio, è quella delle operazioni di calcolo sulla superficie topografica, rappresentabile come un grid nella forma comunemente chiamata DTM o Digital Terrain Model. I DTM, come già visto, si ricavano normalmente per INTERPOLAZIONE da dati di partenza di tipo topografico che possono essere curve di livello, punti quotati, determinazioni dirette con stereorestituzione analogica o digitale, misure di campagna GPS o tradizionali, e così via. Alcune delle tecniche di calcolo che riguardano i DTM sono generiche e possono essere applicate anche ad altre superfici continue (come ad esempio la superficie di falda, lo spessore del suolo etc.). Altre invece sono specifiche e riguardano solo la variabile altitudine e le sue derivazioni. L’importanza dei DTM è notevole perché le elaborazioni su di essi possono essere utili per almeno i seguenti campi: 1. Geomorfologia – per lo studio delle forme e la loro interrelazione con i processi di superficie 2. Geomorfologia e Geologia Applicata – per lo studio dei processi di dissesto del territorio che dipendono dalla topografia, quali l’erosione del suolo e le frane 3. Geologia – per lo studio delle connessioni tra forme di superficie e processi profondi 4. Idrologia – per la comprensione e la modellistica dei processi idrologici di superficie e di innesco delle alluvioni
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Situazione complessiva dell’idrologia di superficie (Selby, 1993)
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
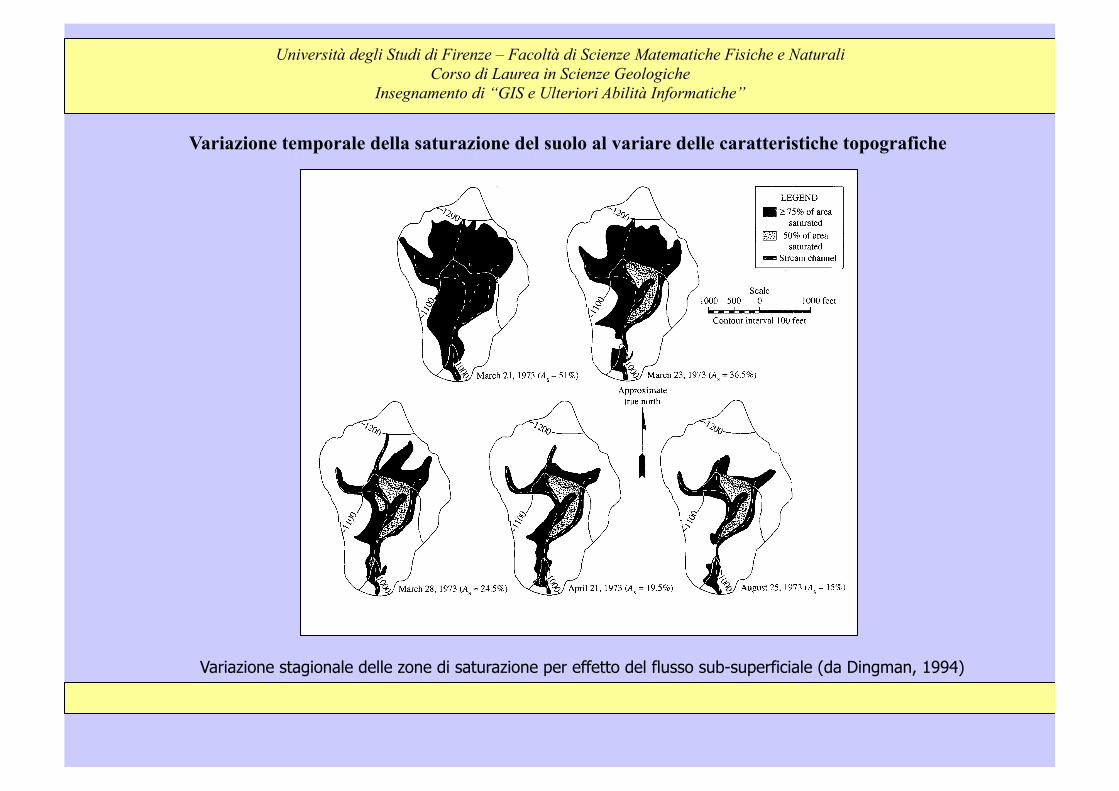
Variazione temporale della saturazione del suolo al variare delle caratteristiche topografiche
Variazione stagionale delle zone di saturazione per effetto del flusso sub-superficiale (da Dingman, 1994)
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Saturazione del suolo: localizzazione di S.O.F. e Return Flow
Ward (1984) ha verificato che saturation overland flow e return flow si verificano, oltre che lungo i corsi d'acqua anche in: • (a) concavità (hollows), dove la convergenza delle linee di flusso dovuta alla concavità della superficie topografica aumenta l'intensità dell'afflusso che supera la conducibilità idraulica del suolo; • (b) rotture di pendio in corrispondenza di concavità, per differenze nel gradiente idraulico • (c) zone di riduzione dello spessore del suolo entro cui scorre il flusso sub-superficiale • (d) porzioni di pendio dove la presenza di un substrato impermeabile a scarsa profondità favorisce il verificarsi del processo sloping slab L’individuazione di porzioni di versanti con queste caratteristiche permette di definire rapidamente siti di probabile instabilità. Si nota già da questa immagine l’importanza dei FATTORI TOPOGRAFICI e LITOLOGICI, quali pendenza, curvatura, spessori e discontinuità.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Modelli digitali del terreno (DTM): tipi di rappresentazione
Modello a maglie quadrate regolari (GRID)
zi
Modello a triangoli (TIN)
zi
Risoluzione dei DTM
Tipici dati di origine dei DTM
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Modelli digitali del terreno (DTM): tipi di rappresentazione II
DTM in formato GRID (Vista Piana)
DTM in formato GRID (Vista Prospettica – Nord verso il basso)
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

• Pendenza (slope): variazione di quota nello spazio. Si esprime come il gradiente di z sulla superficie topografica:
• Esposizione (aspect): orientazione della porzione di versante considerata rispetto al nord
• Curvatura (curvature): variazione di pendenza nello spazio. Si esprime come gradiente di s, cioè:
Modelli digitali del terreno (DTM): parametri morfometrici principali
zs ∇=
zc 2∇=• Curvatura planare: derivata seconda della curva generata dall’intersezione della superficie topografica con un piano verticale tangente alle curve di livello
• Curvatura di profilo: derivata seconda della curva generata dall’intersezione della superficie topografica con un piano verticale perpendicolare alle curve di livello
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Curvatura di profilo: si nota allontanamento tra curve di livello procedendo verso valle nelle aree azzurre (concavità) e avvicinamento in quelle rosse (convessità). Influenza la velocità e l’accelerazione del flusso.
Curvatura planare: si nota bombatura verso valle nelle aree rosse (convesse) e verso monte in quelle azzurre (concave). Importante per determinare la divergenza o la convergenza del flusso.
Convergenza del flusso Divergenza del flusso Profilo convesso Profilo concavo
Vettore velocità del flusso
ν
ν
ν
ν
ν
Curvatura del versante

1. Determinazione delle direzioni di flusso tramite algoritmi con o senza distribuzione di flusso
2. Individuazione delle depressioni chiuse (sink o pit) non reali e loro eliminazione iterativa
3. Delimitazione degli spartiacque geografici per tutti i bacini e sottobacini
4. Determinazione dei poligoni dei bacini 5. Calcolo dell’area drenata per ogni cella del grid tramite conteggio
dell’accumulazione di flusso 6. Estrazione della rete idrografica a partire dai valori dell’area drenata 7. Valutaz ione morfometr ica de l la rete idrograf ica con
gerarchizzazione dei carsi d’acqua
Calcolo dei Parametri Idrologici da DTM - Procedure
Dem
Direzioni di
deflusso
SinksCorrezione
BacinoSpartiacque Accumulo deflussi
Reticolo teorico
Ovviamente questa procedura ed i passaggi sequenziali che essa comporta costituiscono solo uno dei modi possibili per la determinazione degli indici idrologici di base in un bacino idrografico. Per maggiori informazioni si vedano ad esempio Moore et al. (1992, 1993), Burrough & McDonnell (1998), Wilson & Gallant (2000), Tarboton (2001).
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Direzione di flusso
E’ la direzione del flusso lungo la porzione di pendio rappresentata da un pixel (*). Flusso superficiale (overland flow) e sub-superficiale (sub-surface flow) sono considerati entrambi paralleli al versante. Il valore di direzione può essere calcolato in vari modi più o meno sofisticati anche se quelli più adatti al calcolo automatico sono i due illustrati in figura. In zone a concavità planare (valli e impluvi) il flusso tende a concentrarsi e si usa il criterio della unica direzione di flusso (a).
In zone a convessità planare (crinali e creste anche poco accentuate) il flusso tende a suddividersi e si utilizza il criterio della distribuzione su più pixel (b). I GIS normalmente memorizzano le direzioni di flusso con codici numerici interi. ArcInfo e ArcView (© ESRI) utilizzano potenze del 2 a partire da est in senso orario (20=1 est; 21=2 sud-est; 22=4 sud e così via).
(a) (b)
(*)
(*)
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Individuazione e rimozione delle depressioni chiuse
Il calcolo delle direzioni di flusso determina in molti casi la formazione di cicli chiusi, che indicano la presenza di depressioni (sink o pit) come quella indicata nella figura a lato (a). In questi casi non è più possibile determinare la direzione del flusso lungo il versante e l’acqua tende ad accumularsi in modo indefinito. L’algoritmo di rimozione delle depressioni (algoritmo di FILL) usa semplicemente un criterio di riempimento delle stesse e conservando la direzione prevalente dell’intorno (b).
Rete di drenaggio prima della rimozione dei pits. Nei punti indicati si notano interruzioni nella continuità dei canali, dovute alla presenza di aree depresse nelle quali non esiste nessuna direzione di flusso uscente.
Rete di drenaggio dopo la rimozione dei pits. Adesso le aree di incertezza nella definizione delle dierzioni di drenaggio sono state eliminate e il GIS è in grado di determinare l’andamento connesso del reticolo idrografico.
(a)
(b)
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”
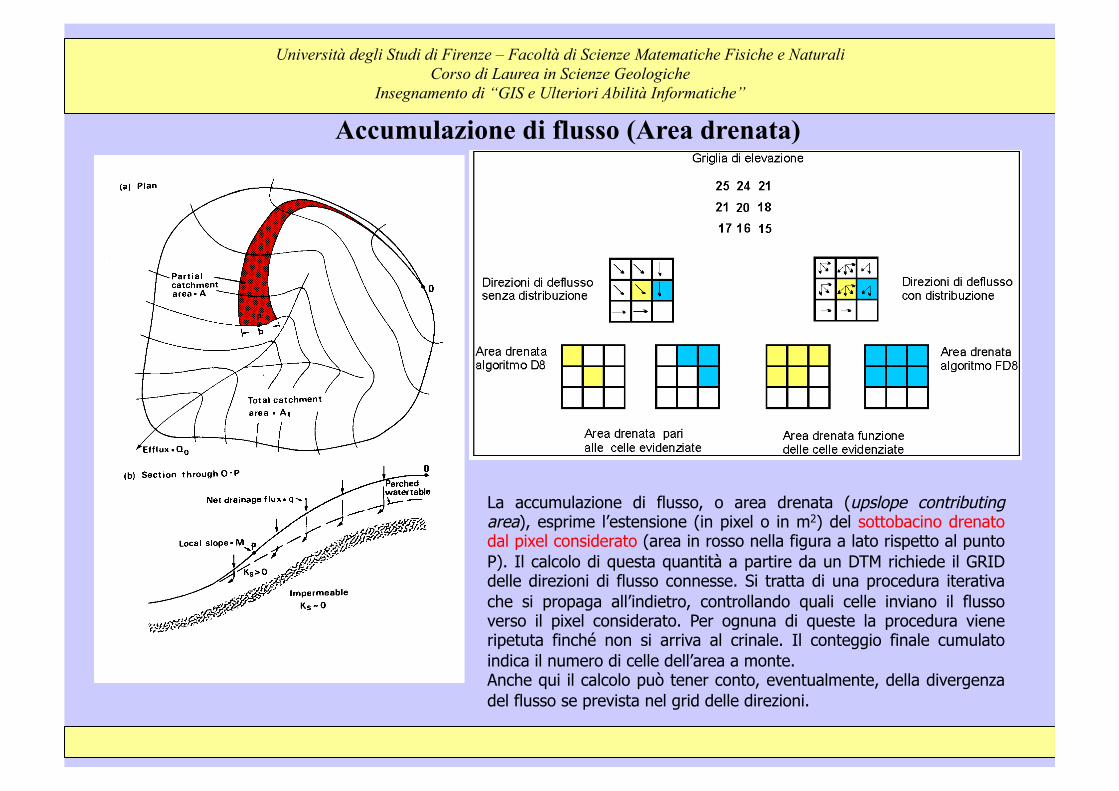
Accumulazione di flusso (Area drenata)
La accumulazione di flusso, o area drenata (upslope contributing area), esprime l’estensione (in pixel o in m2) del sottobacino drenato dal pixel considerato (area in rosso nella figura a lato rispetto al punto P). Il calcolo di questa quantità a partire da un DTM richiede il GRID delle direzioni di flusso connesse. Si tratta di una procedura iterativa che si propaga all’indietro, controllando quali celle inviano il flusso verso il pixel considerato. Per ognuna di queste la procedura viene ripetuta finché non si arriva al crinale. Il conteggio finale cumulato indica il numero di celle dell’area a monte. Anche qui il calcolo può tener conto, eventualmente, della divergenza del flusso se prevista nel grid delle direzioni.
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”

Esempio di Confronto tra D8 e FD8 D8
FD8

Altri indici derivati
Wetness Index (Beven & Kirkby, 1979) Indica approssimativamente l’andamento del contenuto di umidità dei suoli. As è l’area drenata unitaria (m2/m), S è la pendenza del versante espressa come rapporto (m/m). I fondovalle hanno ovviamente i valori maggiori di W. Importante per il riconoscimento di aree asciutte o umide e quindi per l’individuazione di possibili aree di origine di return flow o S.O.F.
SAW Sln=
Stream Power Index (Moore et al., 1992) Indica la possibilità di erosione per flusso incanalato o concentrato. I simboli sono gli stessi che nel caso precedente. Combinata con fattori quali uso del suolo e pedologia costituisce un buon indicatore del probabilità di distacco del suolo. In forma modificata può servire anche per la previsione dell’inizio di erosione per fossi (gully erosion)
SAS ⋅=Ω
Sediment Transport Index (Moore et al., 1992) E’ funzione dell’area drenata e della pendenza locale. Nella formula β indica l’angolo del pendio in radianti. As è l’area drenata unitaria (m2/m).
3.16.0
0896.0sin
13.22 ⎥⎦
⎤⎢⎣
⎡⋅⎥⎦
⎤⎢⎣
⎡=β
τ SA
Università degli Studi di Firenze – Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Scienze Geologiche
Insegnamento di “GIS e Ulteriori Abilità Informatiche”