disaster tolerant openvms clusters · wednesday, 25 august 2004 designing solutions for disaster...
TRANSCRIPT

© 2004 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice
Disaster Tolerant OpenVMS Clusters
Laurence FosseyKeith Parris

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 2
Who are we?• Laurence Fossey
• Keith Parris

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 3
Agenda• Introduction and background
• Foundation topics
• Management, monitoring & control, DTCS
• Quorum
• Storage and Volume Shadowing
• Long Distance Issues
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 4
page title / customer:
3:42 PM18 May, 2004
date revised:
Payned
author:
page: 1 of 1
Disaster TolerantComputer Services
i n v e n t
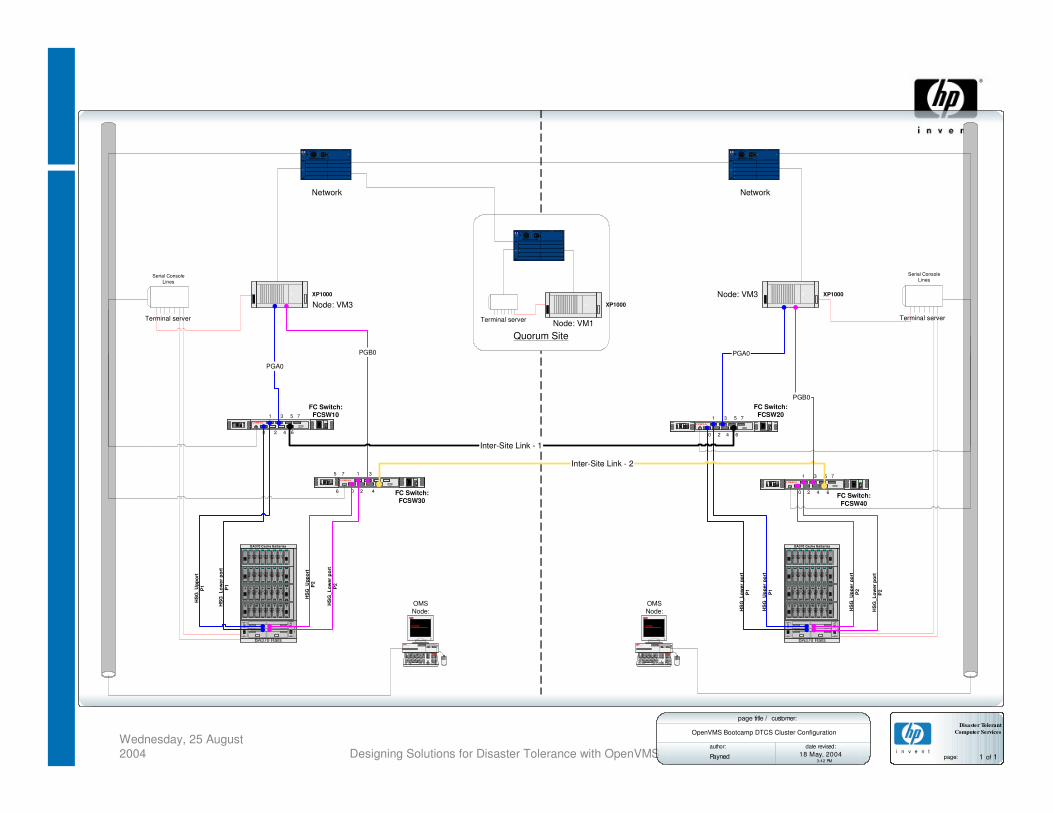
OpenVMS Bootcamp DTCS Cluster Configuration
BA370 Rails
BA370 Cache Batteries
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
BA370 Rails
BA370 Cache Batteries
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
OP
EN
C O M P A Q
0
1 3
2 4
C O MP A Q
1
2
3
4
5
0
7
6
S D
Catalyst8500
Pow er Supply 0CISCO YSTEMSS Power Supply 1
Swit chPr oce sso r
SERIE S
SD
Catalyst8500
Power Supply 0CISCO YSTEMSS Power Supply 1
Swi tchPr oce sso r
S ERIE S
HS
G_U
ppor
tP
1
HS
G_U
ppor
tP
2
HS
G_L
ower
por
tP
1
HS
G_L
ower
por
tP
2
HS
G_L
ower
por
tP
1
HS
G_L
ower
por
tP
2
HS
G_U
pper
por
tP
1
HS
G_U
pper
por
tP
2
FC Switch:FCSW10
FC Switch:FCSW30
FC Switch:FCSW20
5
6
7
Network Network
SD
PROFESSIONAL W ORKSTATIO N
Ω
PROFESSIONAL WORKSTATION
V70
SD
SD
PROFESSIONAL W ORKSTATION
Ω
PROFESSIONAL WORKSTATION
V70
SD
Terminal server Terminal server
Serial ConsoleLines
Serial ConsoleLines
OMSNode:
OMSNode:
XP1000 XP1000
XP1000
S D
Catalyst8500
Power Supply 0CISCO YSTEMSS Power Supply 1
Swi tchProcessor
SERIE S
PGA0
Quorum Site
PGB0
C O MP A Q
31
0 2 4
5 7
6
Inter-Site Link - 1
C OM PA Q
60
1
2
3 7
4
5
FC Switch:FCSW40
Inter-Site Link - 2
PGB0
PGA0
Terminal server
Node: VM3Node: VM3
Node: VM1

Introduction
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 6
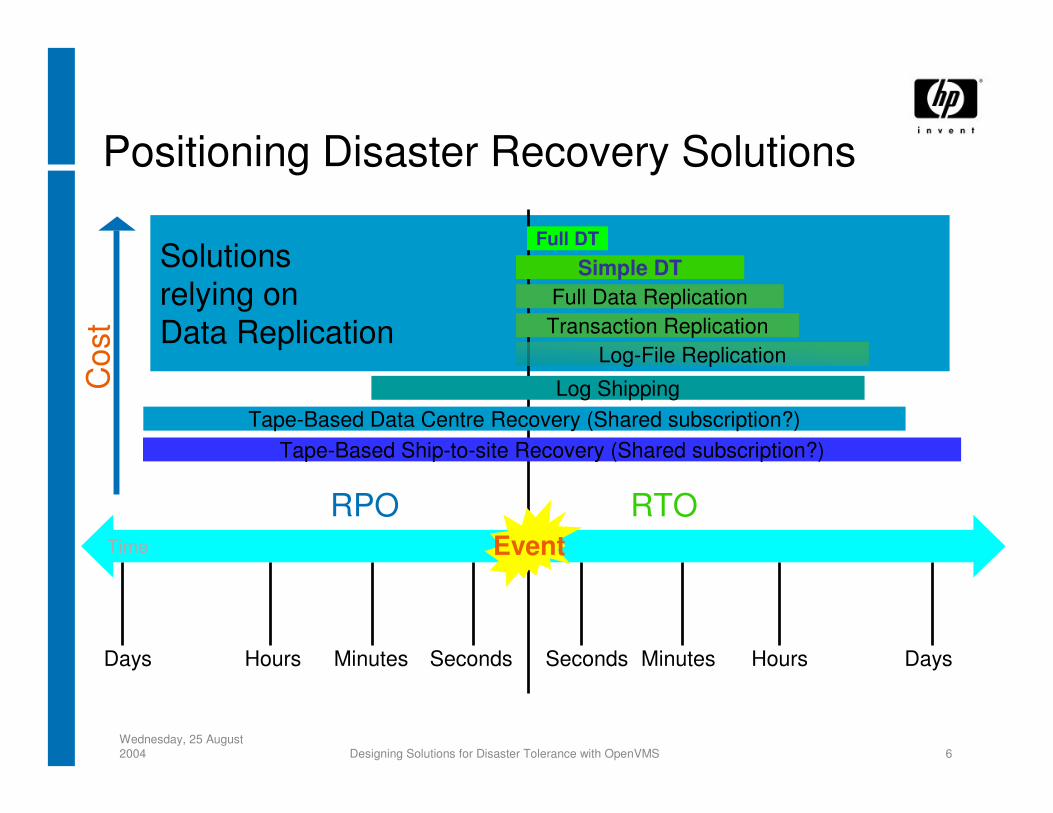
Solutionsrelying onData Replication
Time
Positioning Disaster Recovery Solutions
Event
SecondsMinutesHoursDays Seconds Minutes Hours Days
Tape-Based Ship-to-site Recovery (Shared subscription?)Tape-Based Data Centre Recovery (Shared subscription?)
Log Shipping
Full Data ReplicationSimple DT
Full DT
RPO RTO
Cos
t
Log-File ReplicationTransaction Replication
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 7
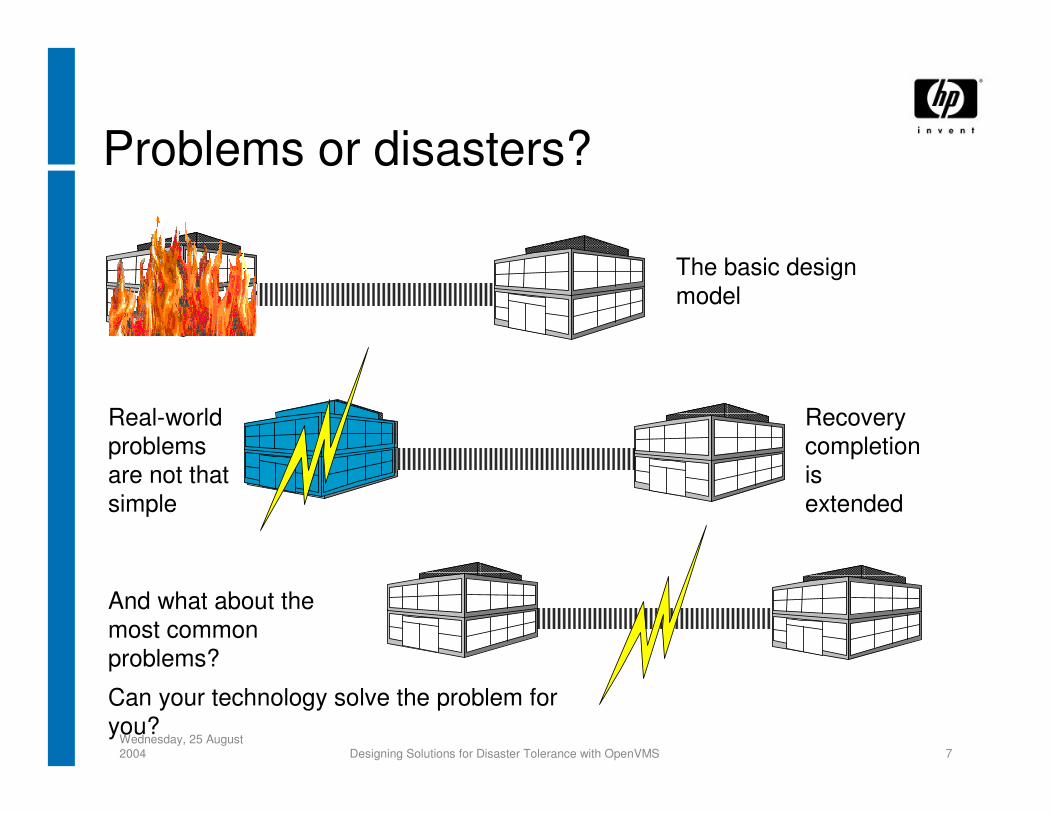
Problems or disasters?
The basic design model
Real-world problems are not that simple
And what about the most common problems?
Recovery completion is extended
Can your technology solve the problem for you?

Foundation for OpenVMS Disaster-Tolerant Clusters

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 13
Disaster-Tolerant Clusters:Foundation• Two or more datacenters a “safe” distance apart
• OpenVMS Cluster Software for coordination
• Inter-site link for cluster interconnect
• Data replication, to provide 2 or more identical copies of data at different sites− e.g. Host-Based Volume Shadowing
• Management and monitoring tools− Remote system console access or KVM system− Failure detection and alerting− Quorum recovery tool (especially for 2-site clusters)

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 14
Disaster-Tolerant Clusters:Foundation• Configuration planning and implementation
assistance, and staff training− HP recommends Disaster Tolerant Cluster
Services (DTCS) package

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 15
Disaster-Tolerant Clusters:Foundation• Carefully-planned procedures for:
− Normal operations− Scheduled downtime and outages− Detailed diagnostic and recovery action plans for
various failure scenarios

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 16
Planning for Disaster Tolerance• Remembering that the goal is to continue
operating despite loss of an entire datacenter− All the pieces must be in place to allow that:
• User access to both sites• Network connections to both sites• Operations staff at both sites
− Business can’t depend on anything that is only at either site

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 17
Multi-Site Clusters• Consist of multiple sites in different locations, with
one or more OpenVMS systems at each site
• Systems at each site are all part of the same OpenVMS cluster, and share resources
• Sites must connected by bridges (or bridge-routers); pure routers don’t pass the SCS protocol used within OpenVMS Clusters

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 18
Bandwidth of Inter-Site Link(s)
Multiples of ATM, GbE, FC, etc.[D]WDM
100 MBMemory Channel
1 or 2 mbFibre Channel
Regular: 10 mb
Fast: 100 mb
Gigabit: 1 gb
Ethernet
155 mb (OC-3) or
622 mb (OC-12)ATM
45 mbDS-3 (a.k.a. T3)
BandwidthLink Type

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 19
System Management Issues• System disks
• System parameters
• Cluster-common disk
• Shadowed data disks

Management, Monitoring, Control and DTCS
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 21
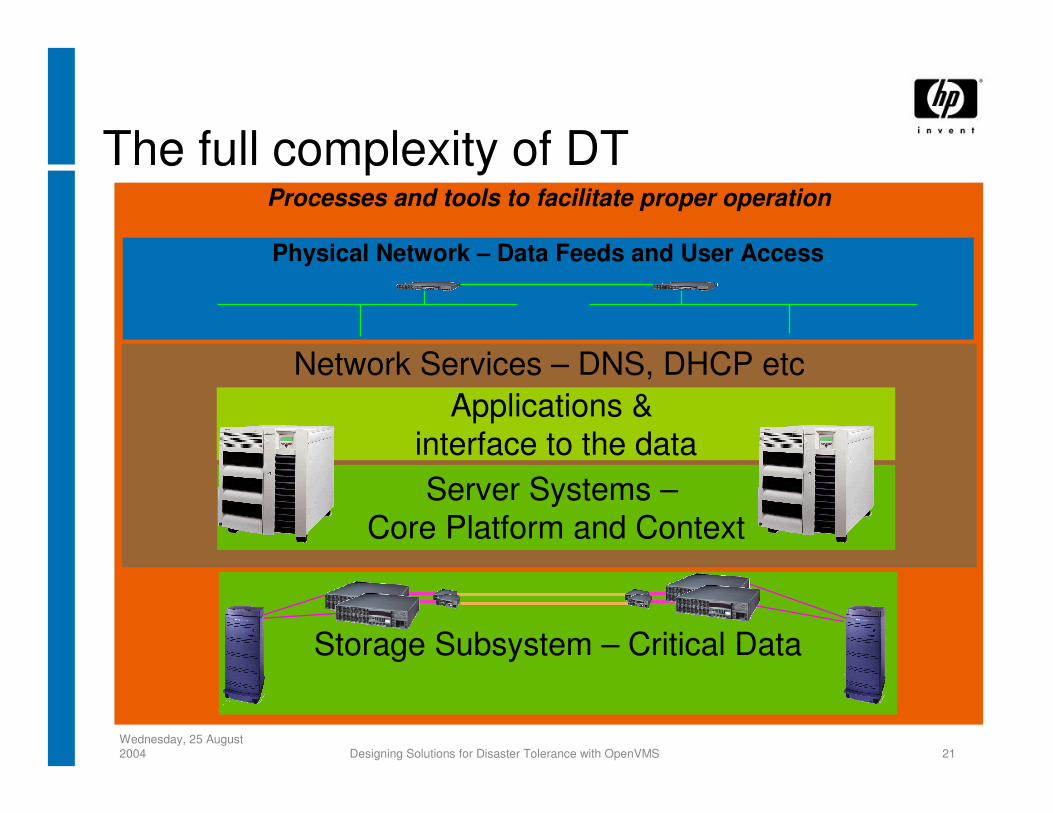
Processes and tools to facilitate proper operation
Network Services – DNS, DHCP etc
The full complexity of DT
Applications & interface to the data
Storage Subsystem – Critical Data
Server Systems –Core Platform and Context
Physical Network – Data Feeds and User Access
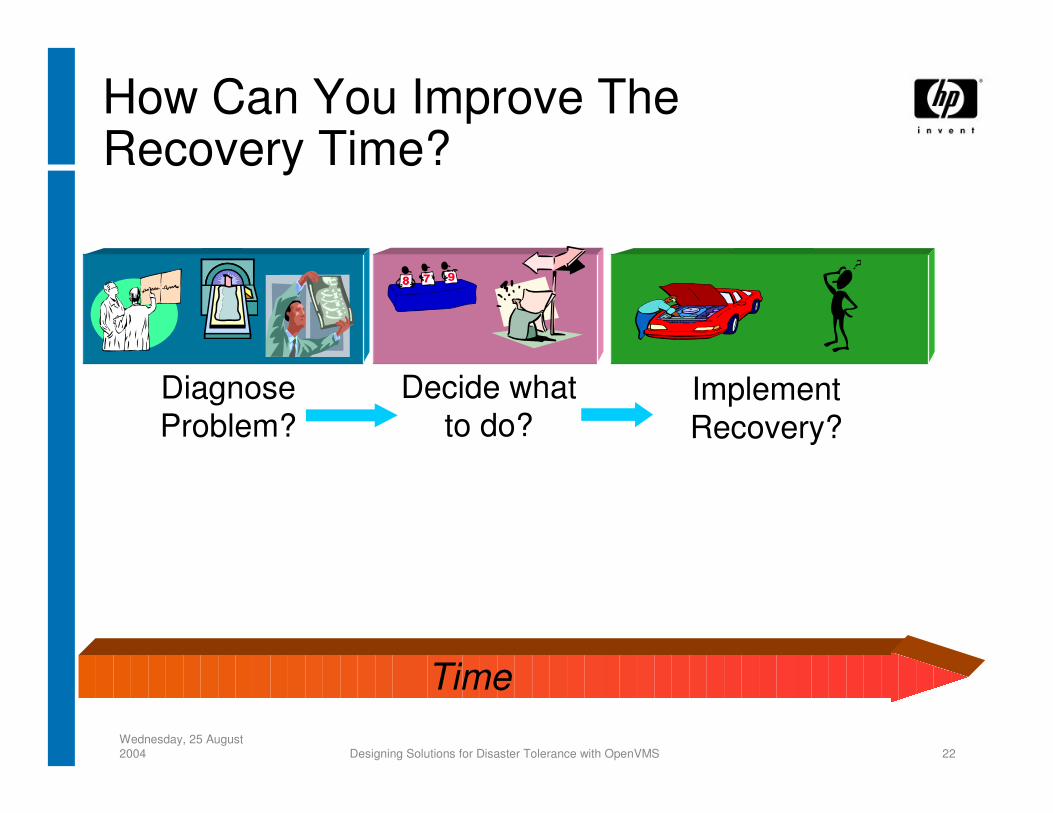
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 22
Time
How Can You Improve The Recovery Time?
Implement Recovery?
DiagnoseProblem?
Decide whatto do?
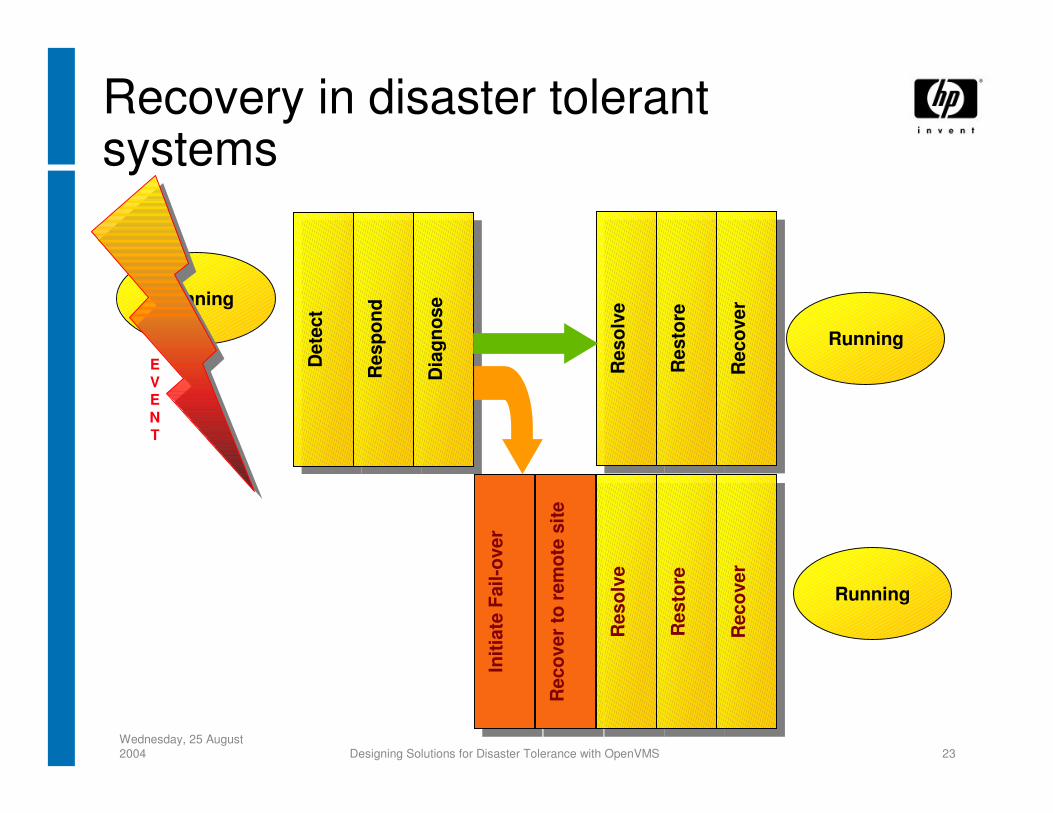
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 23
Recovery in disaster tolerant systems
Running
EVENT
Det
ect
Det
ect
Res
pond
Res
pond
Dia
gnos
eD
iagn
ose
Degraded Running
Running
Running
Initi
ate
Fail-
over
Initi
ate
Fail-
over
Rec
over
to r
emot
e si
teR
ecov
er to
rem
ote
site
Res
olve
Res
olve
Res
tore
Res
tore
Rec
over
Rec
over
Res
olve
Res
olve
Res
tore
Res
tore
Rec
over
Rec
over
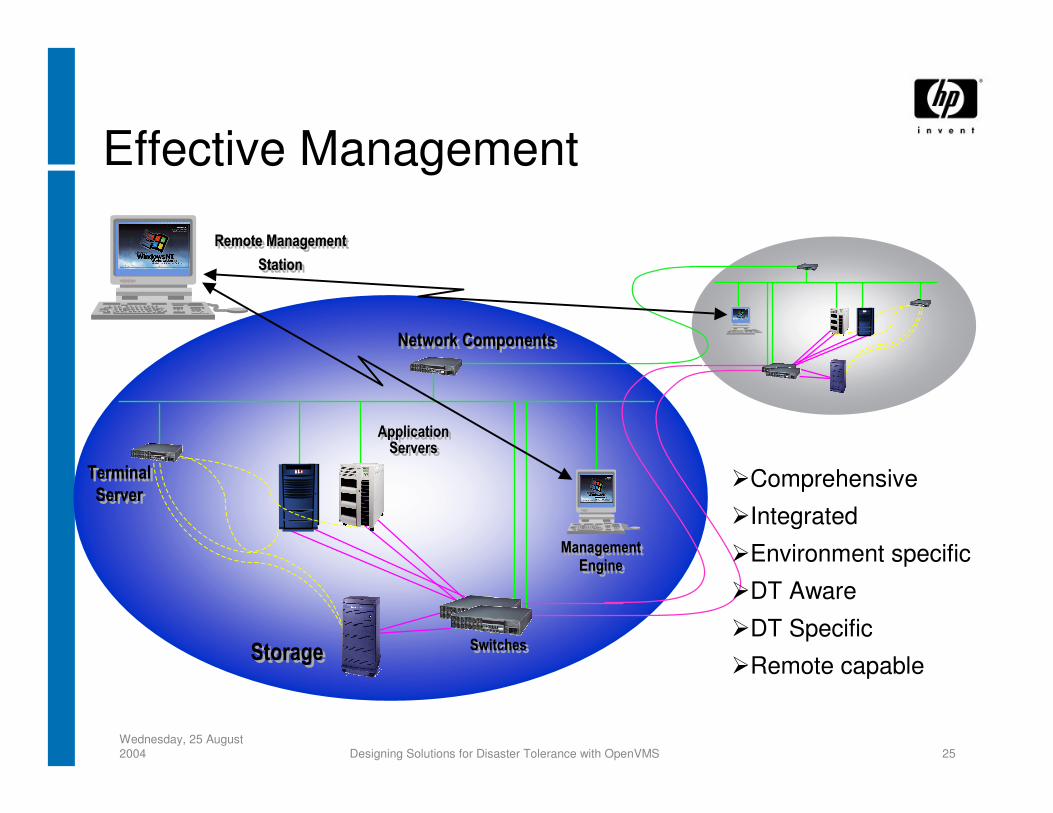
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 25
Effective Management
Comprehensive
Integrated
Environment specific
DT Aware
DT Specific
Remote capable
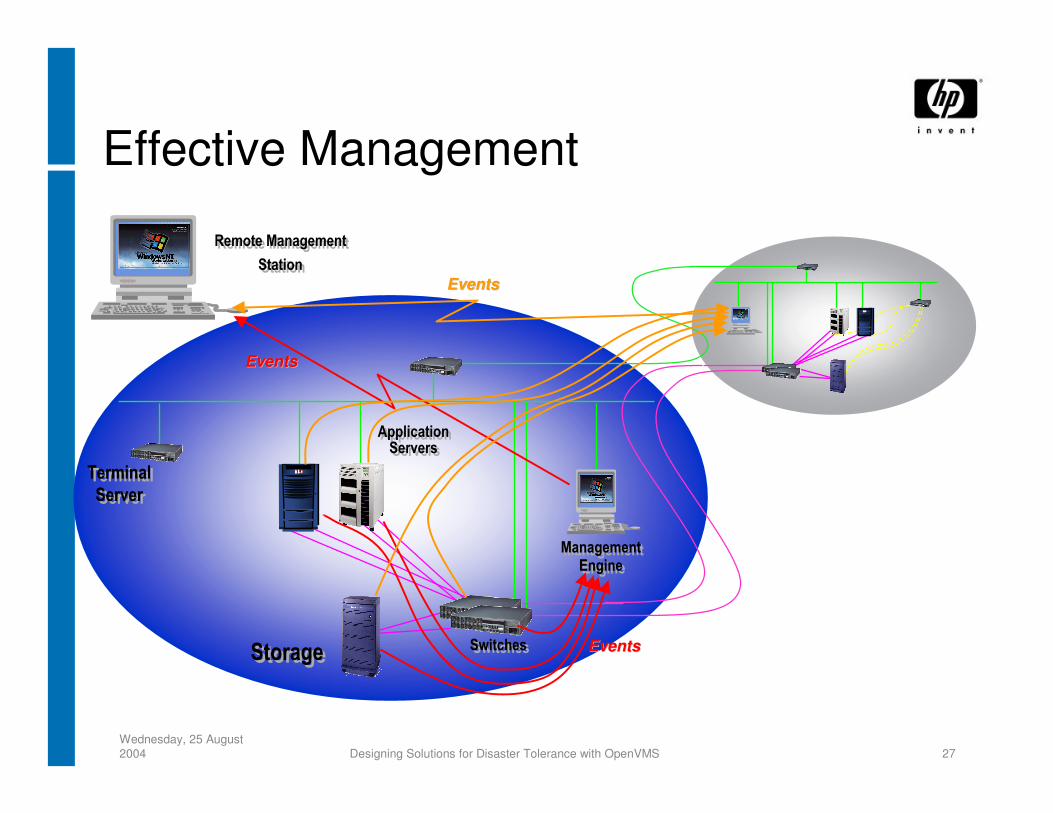
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 27
Effective Management
EventsEvents
EventsEvents
EventsEvents
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 28
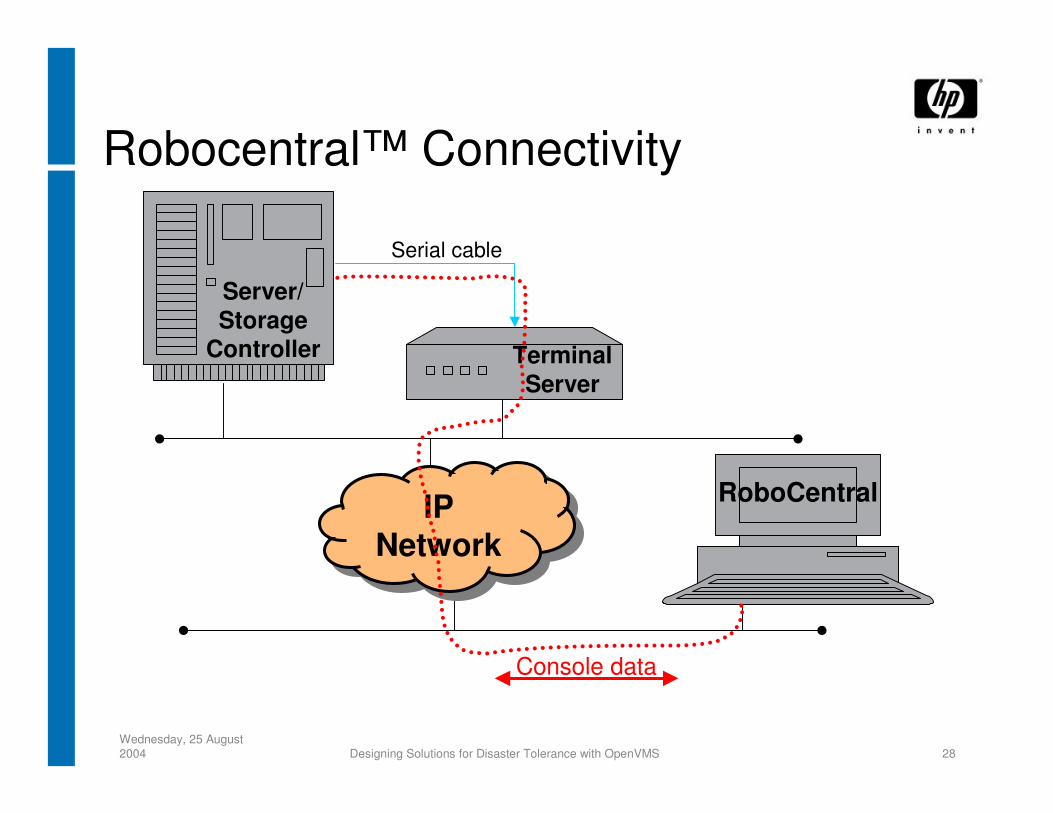
Robocentral™ Connectivity
IP Network
IP Network
Server/ Storage
Controller Terminal Server
Serial cable
RoboCentral
Console data

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 29
OMS Optional Software Components• OpenVMS cluster quorum adjustment tool
− DTCS tool allowing operator to recover an OpenVMS cluster once it has lost Quorum
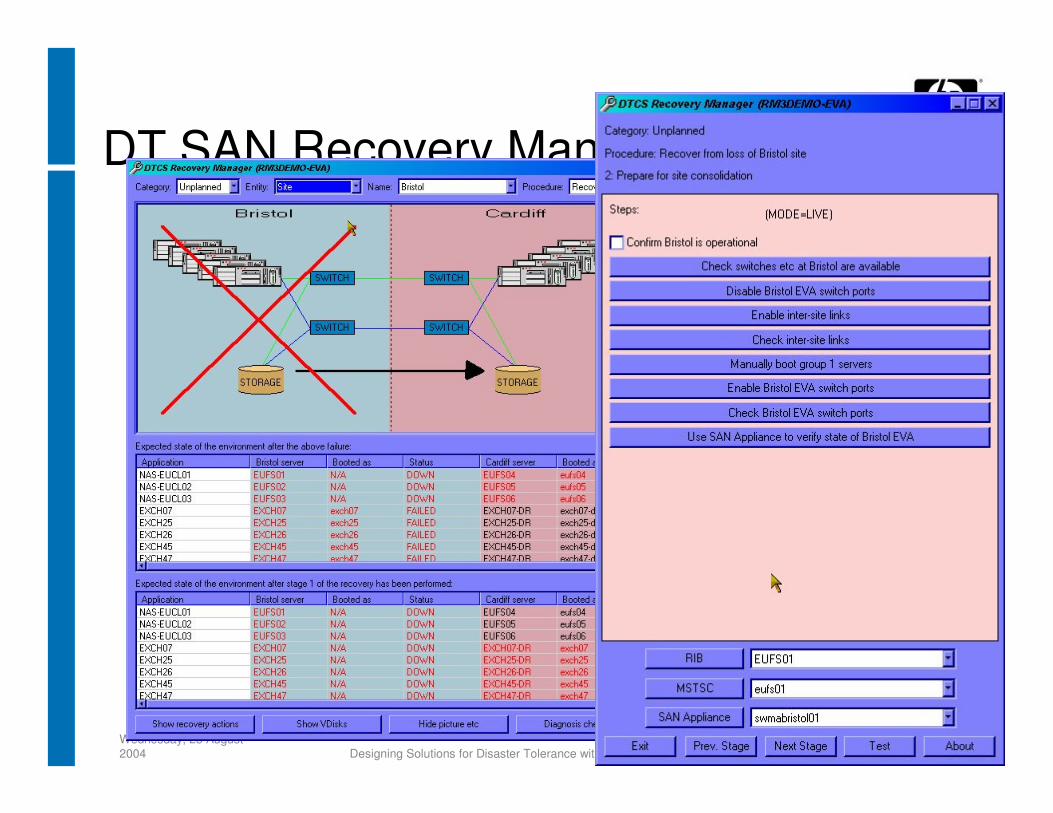
• DTCS recovery manager− DTCS specific GUI allowing management of various
types of dual site storage failures which can occur in a Storage Area Network (SAN) environment when running DRM• Can also be used to good effect in non-Windows environments
such as OpenVMS to support “site swapping”
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 30
DT SAN Recovery Manager for EVA

Quorum Schemes
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 37
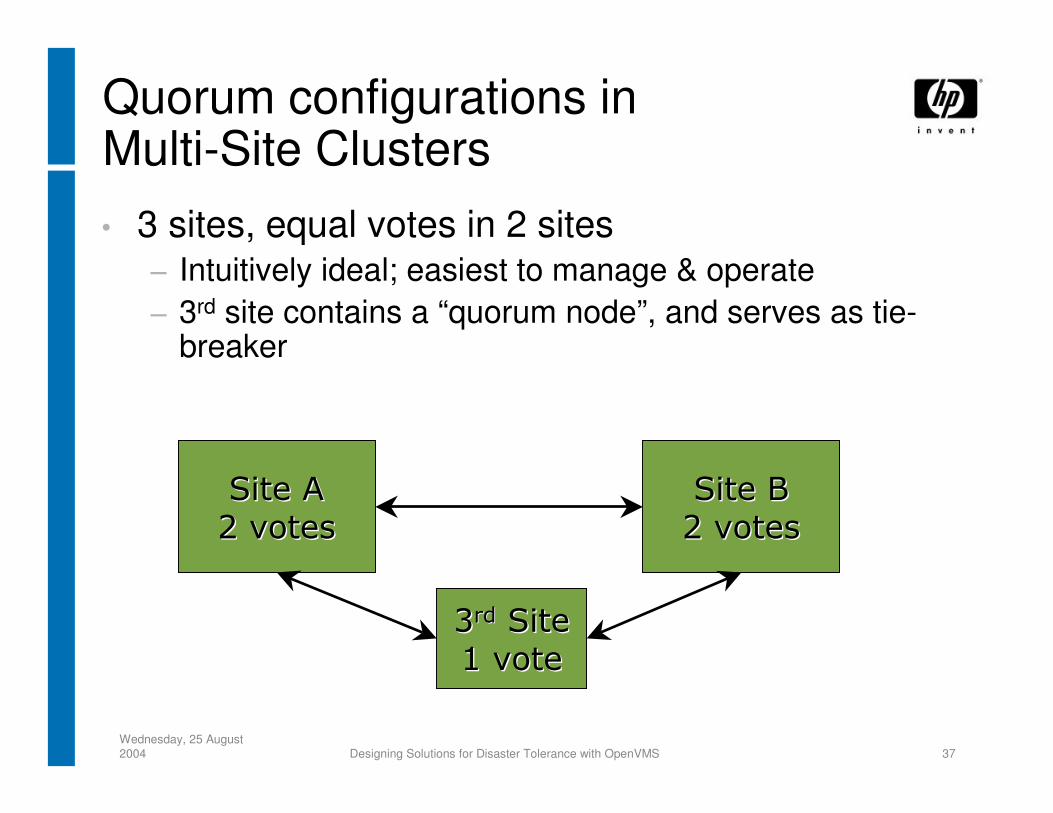
Quorum configurations inMulti-Site Clusters• 3 sites, equal votes in 2 sites
− Intuitively ideal; easiest to manage & operate− 3rd site contains a “quorum node”, and serves as tie-
breaker

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 38
Quorum configurations inMulti-Site Clusters• 2 sites:
− Most common & most problematic:• How do you arrange votes? Balanced? Unbalanced?• If votes are balanced, how do you recover from loss of quorum
which will result when either site or the inter-site link fails?
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 39
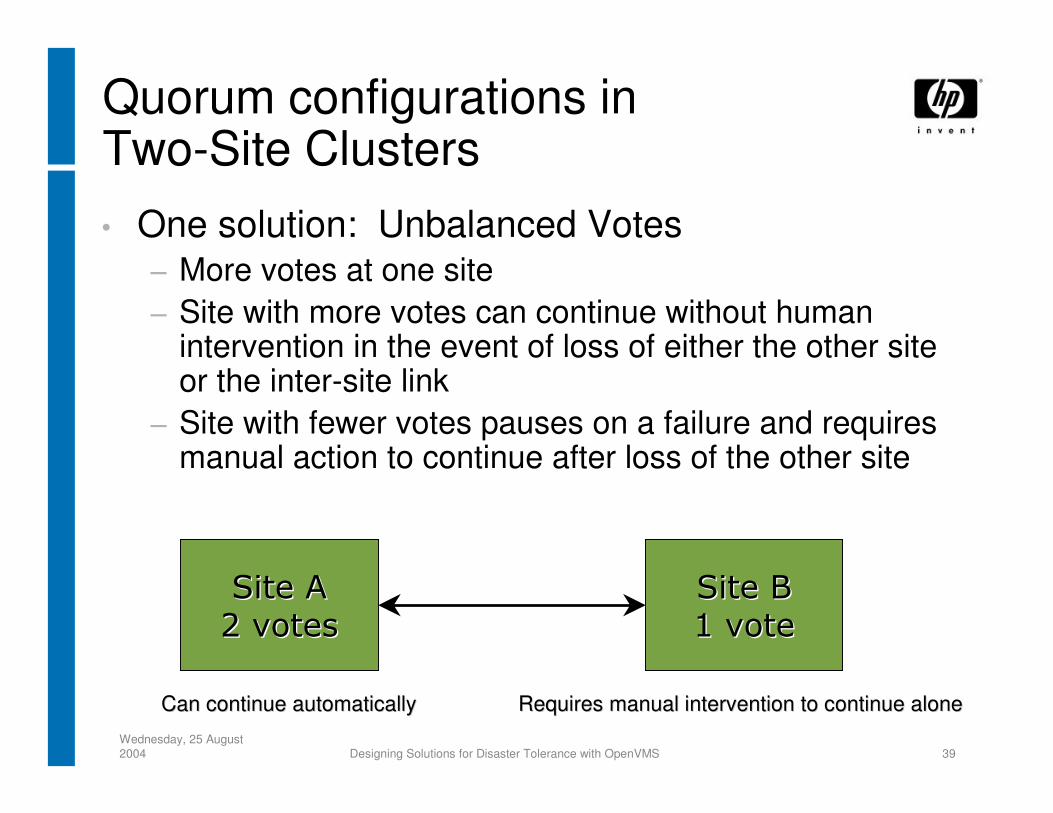
Quorum configurations inTwo-Site Clusters• One solution: Unbalanced Votes
− More votes at one site− Site with more votes can continue without human
intervention in the event of loss of either the other site or the inter-site link
− Site with fewer votes pauses on a failure and requires manual action to continue after loss of the other site
Can continue automaticallyCan continue automatically Requires manual intervention to continue aloneRequires manual intervention to continue alone
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 40
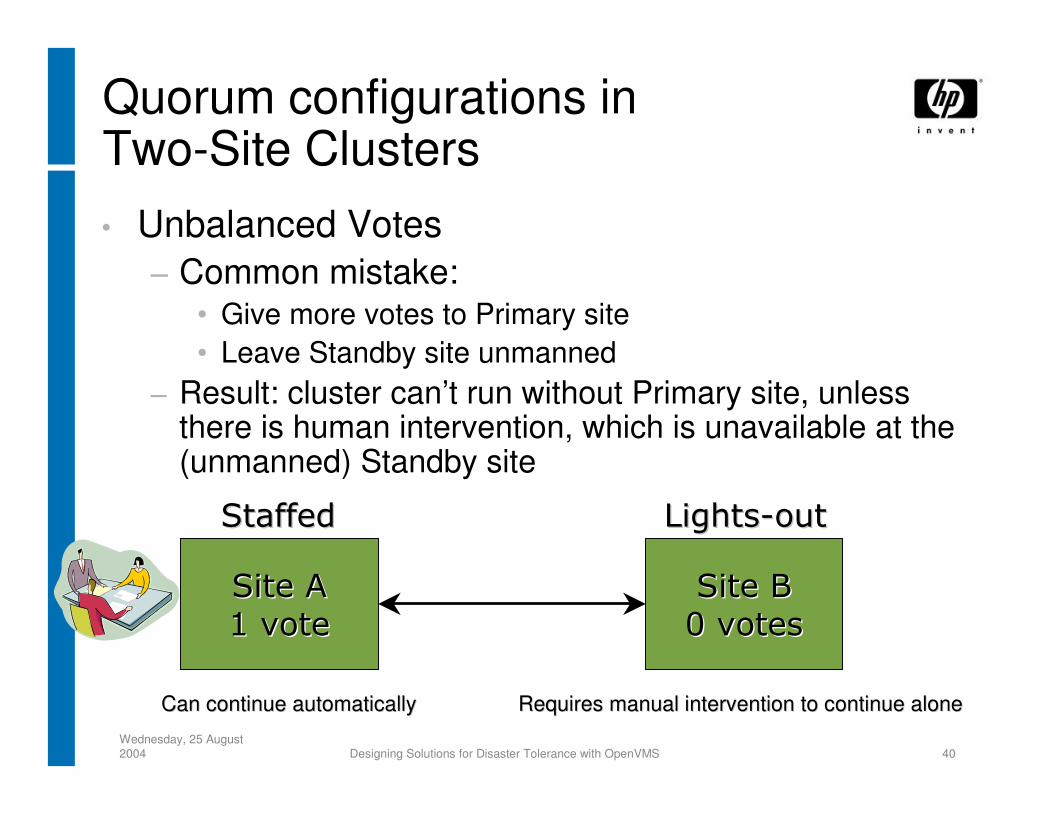
Quorum configurations inTwo-Site Clusters• Unbalanced Votes
− Common mistake:• Give more votes to Primary site• Leave Standby site unmanned
− Result: cluster can’t run without Primary site, unless there is human intervention, which is unavailable at the (unmanned) Standby site
Can continue automaticallyCan continue automatically Requires manual intervention to continue aloneRequires manual intervention to continue alone

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 41
Quorum configurations inTwo-Site Clusters• Unbalanced Votes
− Also very common in remote-shadowing-only clusters (for data vaulting -- not full disaster-tolerant clusters)
• 0 votes is a common choice for the remote site in this case
−But that has its dangers
Can continue automaticallyCan continue automatically Requires manual intervention to continue aloneRequires manual intervention to continue alone

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 42
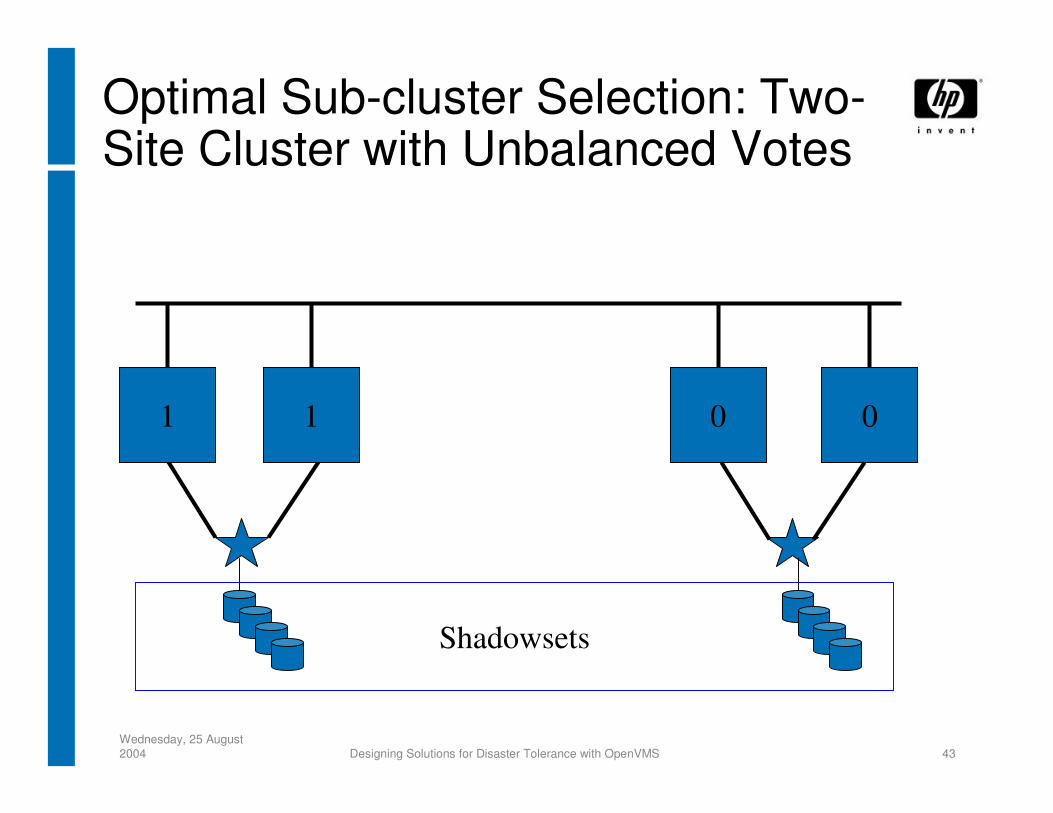
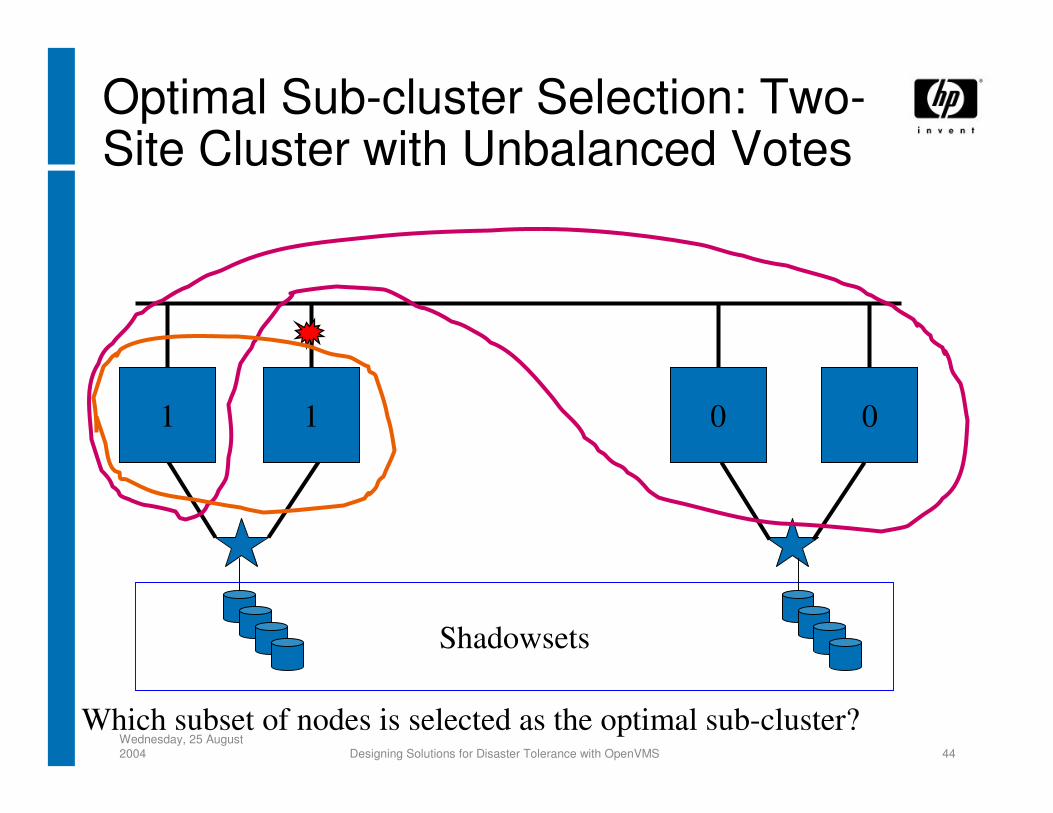
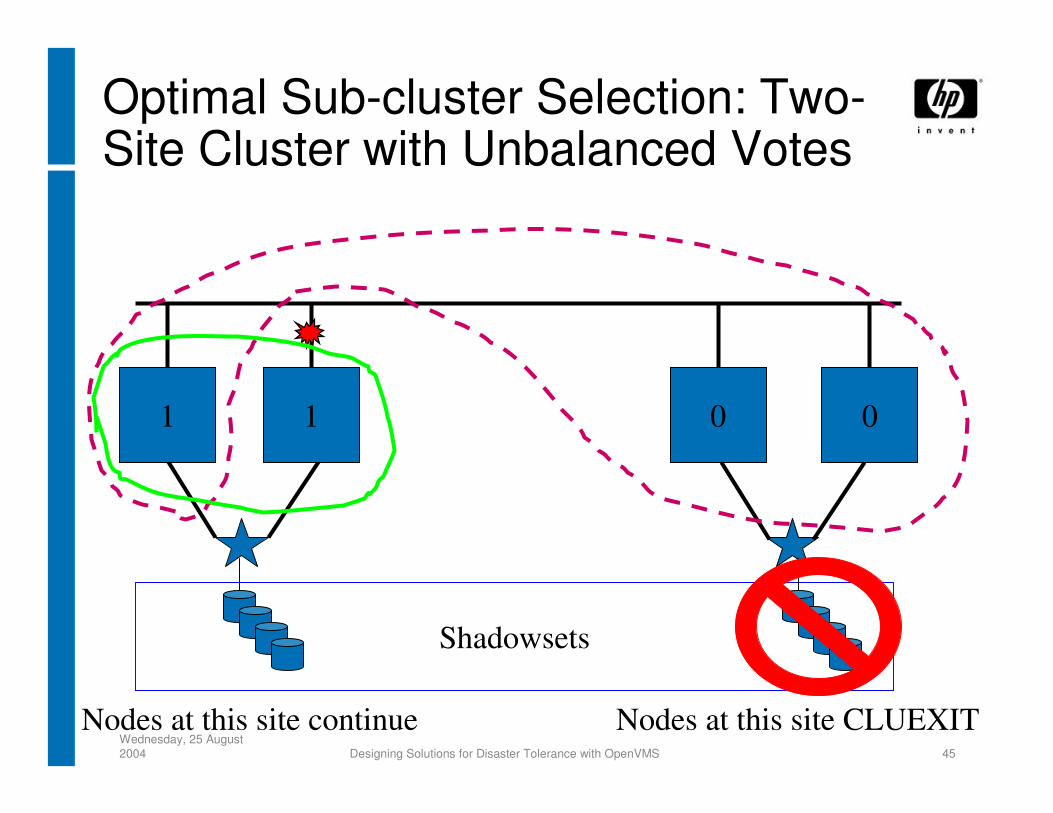
Optimal Sub-cluster SelectionConnection manager compares potential node
subsets that could make up surviving portion of the cluster
1) Pick sub-cluster with the most votes2) If votes are tied, pick sub-cluster with the most nodes3) If nodes are tied, arbitrarily pick a winner
• based on comparing SCSSYSTEMID values of set of nodes with most-recent cluster software revision
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 43
Shadowsets
Optimal Sub-cluster Selection: Two-Site Cluster with Unbalanced Votes
1 01 0
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 44
Shadowsets
Optimal Sub-cluster Selection: Two-Site Cluster with Unbalanced Votes
1 01 0
Which subset of nodes is selected as the optimal sub-cluster?
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 45
Shadowsets
Optimal Sub-cluster Selection: Two-Site Cluster with Unbalanced Votes
1 01 0
Nodes at this site CLUEXITNodes at this site continue
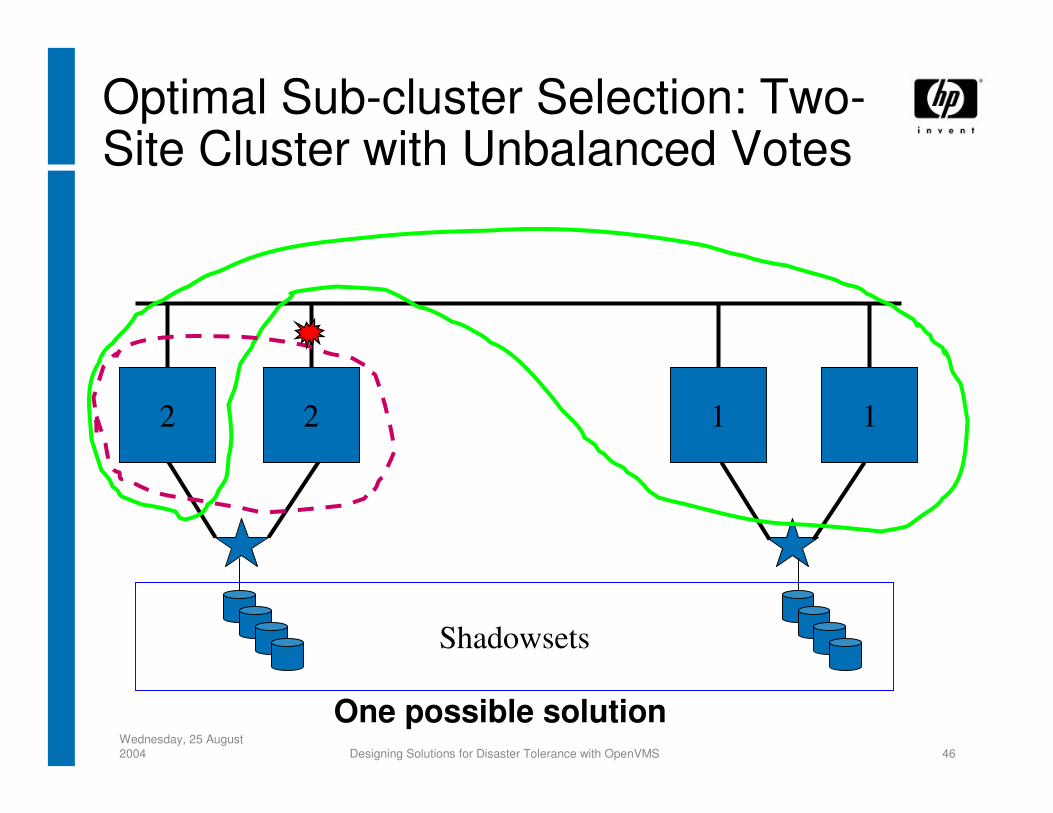
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 46
Shadowsets
Optimal Sub-cluster Selection: Two-Site Cluster with Unbalanced Votes
2 12 1
One possible solution
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 47
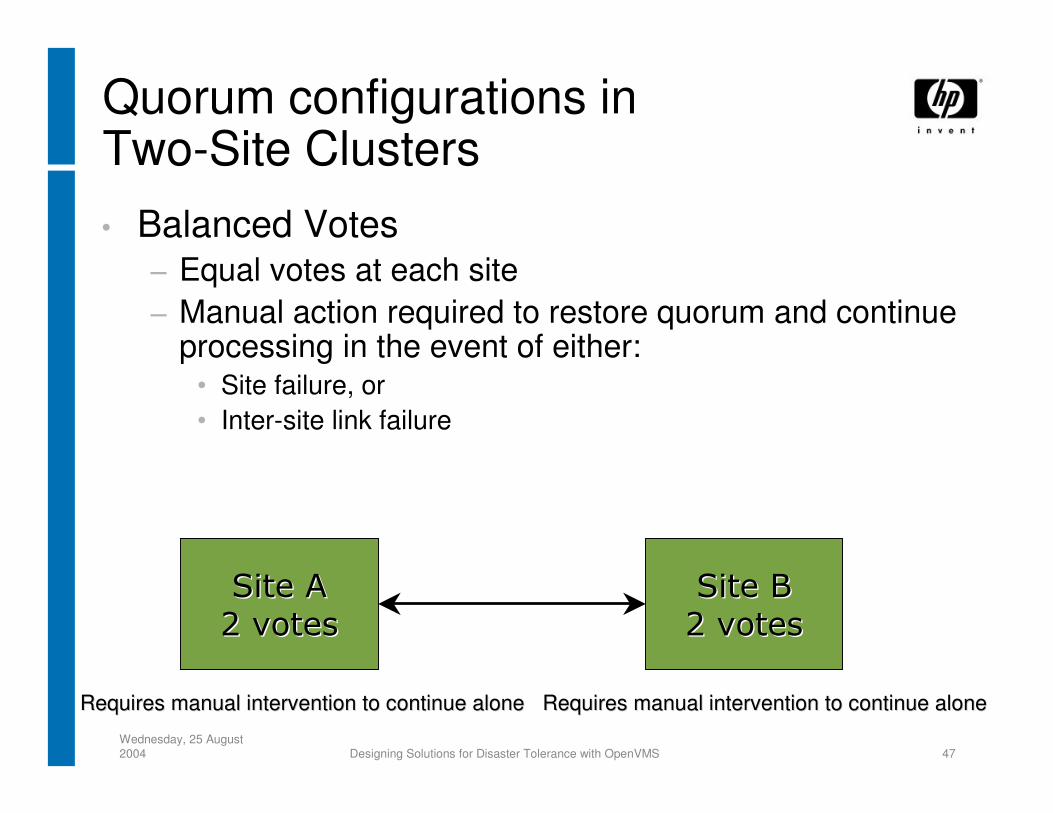
Quorum configurations inTwo-Site Clusters• Balanced Votes
− Equal votes at each site− Manual action required to restore quorum and continue
processing in the event of either:• Site failure, or• Inter-site link failure
Requires manual intervention to continue aloneRequires manual intervention to continue aloneRequires manual intervention to continue aloneRequires manual intervention to continue alone

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 48
Quorum Recovery Methods• Software interrupt at IPL 12 from console
o IPC> Q
• Availability Manager (or DECamds): o System Fix; Adjust Quorum
• DTCS (or BRS) integrated tool, using same RMDRIVER interface as AM / DECamds
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 49
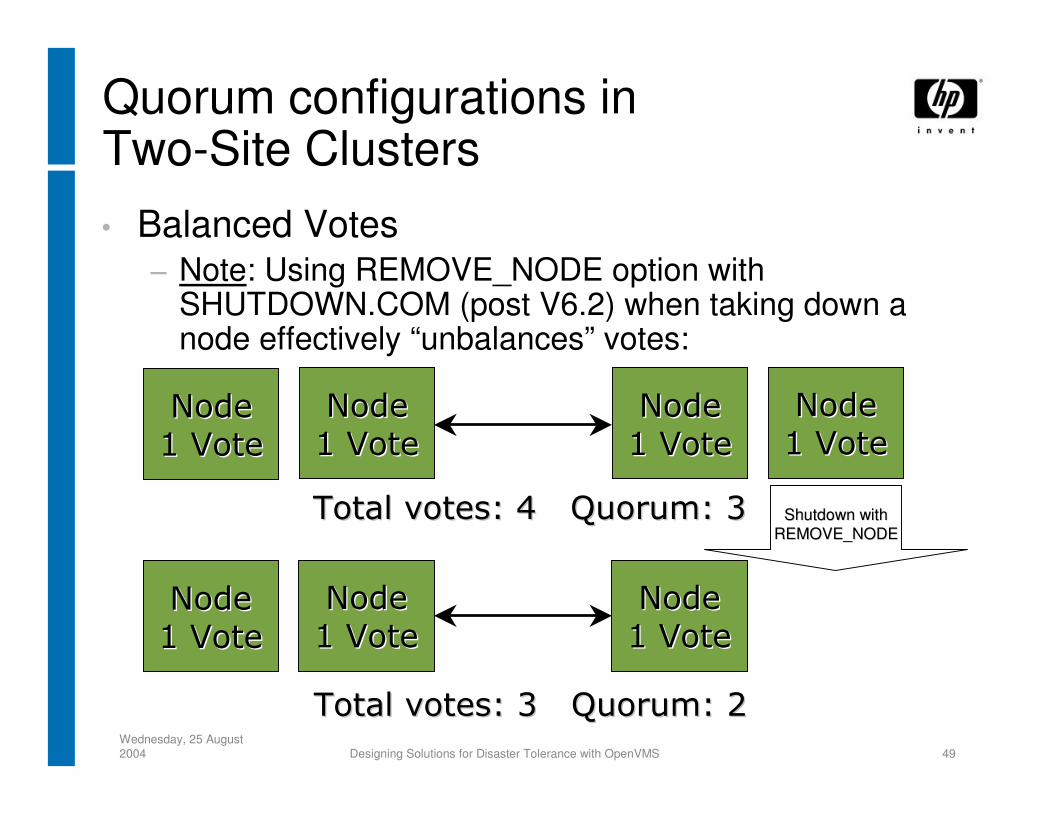
Quorum configurations inTwo-Site Clusters• Balanced Votes
− Note: Using REMOVE_NODE option with SHUTDOWN.COM (post V6.2) when taking down a node effectively “unbalances” votes:
Shutdown withShutdown withREMOVE_NODEREMOVE_NODE

Storage and Volume Shadowing
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 51
Host Based Volume ShadowingData Shadowing
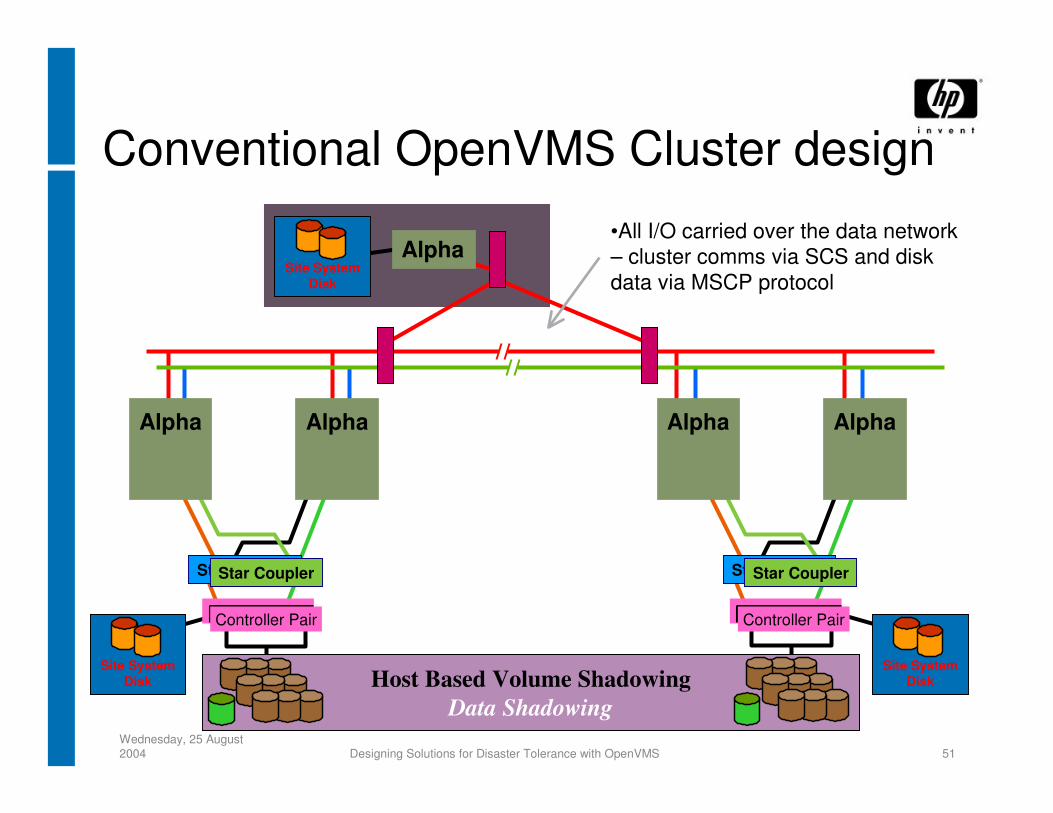
Conventional OpenVMS Cluster design
Controller Pair
AlphaAlpha
Controller Pair
AlphaAlpha
Alpha
Site System Disk
Site System Disk
Site System Disk
Star CouplerStar Coupler Star CouplerStar Coupler
•All I/O carried over the data network – cluster comms via SCS and disk data via MSCP protocol
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 52
Host Based Volume ShadowingData Shadowing
Switch Switch
Fiber
FDDIT3
ATM
Controller Pair
Alpha
Switch Switch
Controller Pair
AlphaAlpha
Alpha
Site System Disk
Site System Disk
Site System Disk
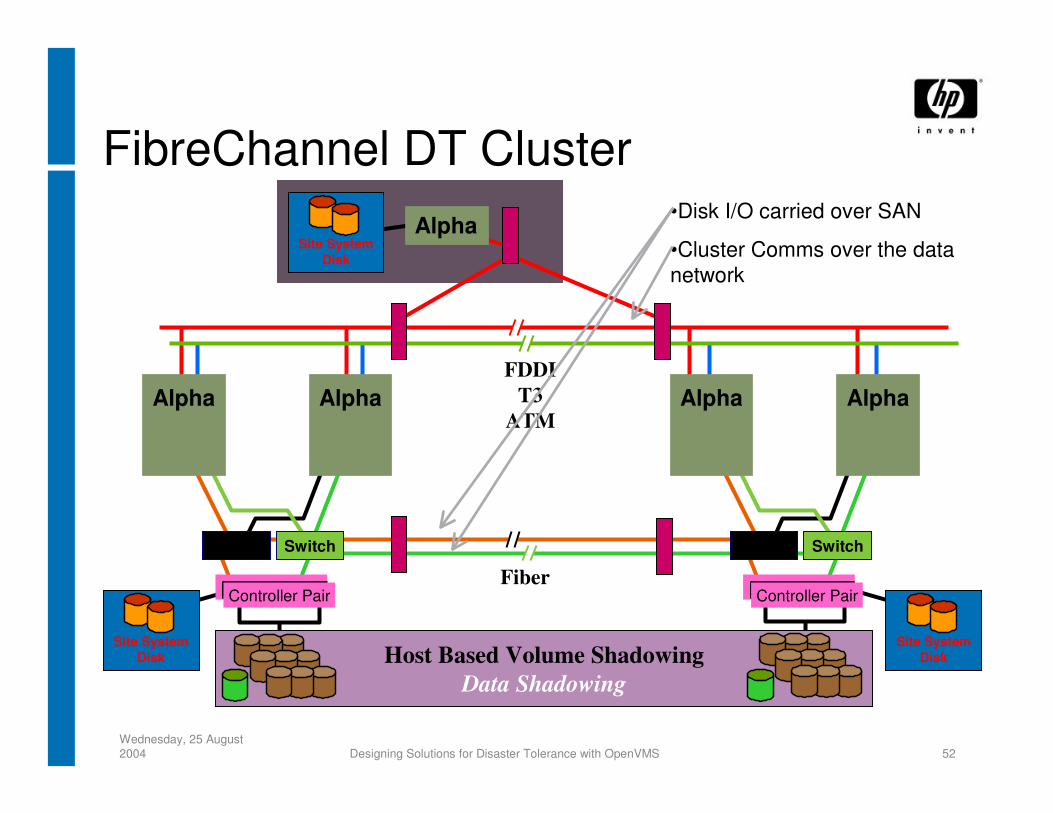
FibreChannel DT Cluster•Disk I/O carried over SAN
•Cluster Comms over the data network
Alpha

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 53
Split-Site OpenVMS with FibreChannel
• Advantages over conventional cluster (MSCP)− Much better performance
• No MSCP server overhead / latency• Not limited by network protocol performance• 100 Mbyte/Second bandwidth throughout (200 Mbyte with 2 Gbit FC)
− “Direct” paths to remote storage• Easier to maintain sites (all nodes in a site can go down without
removing access to storage)
• Disadvantages− Issues with failure modes− Configuration must be handled carefully− Difficult to distinguish between local and remote disks
• Option of using DRM for data replication
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 54
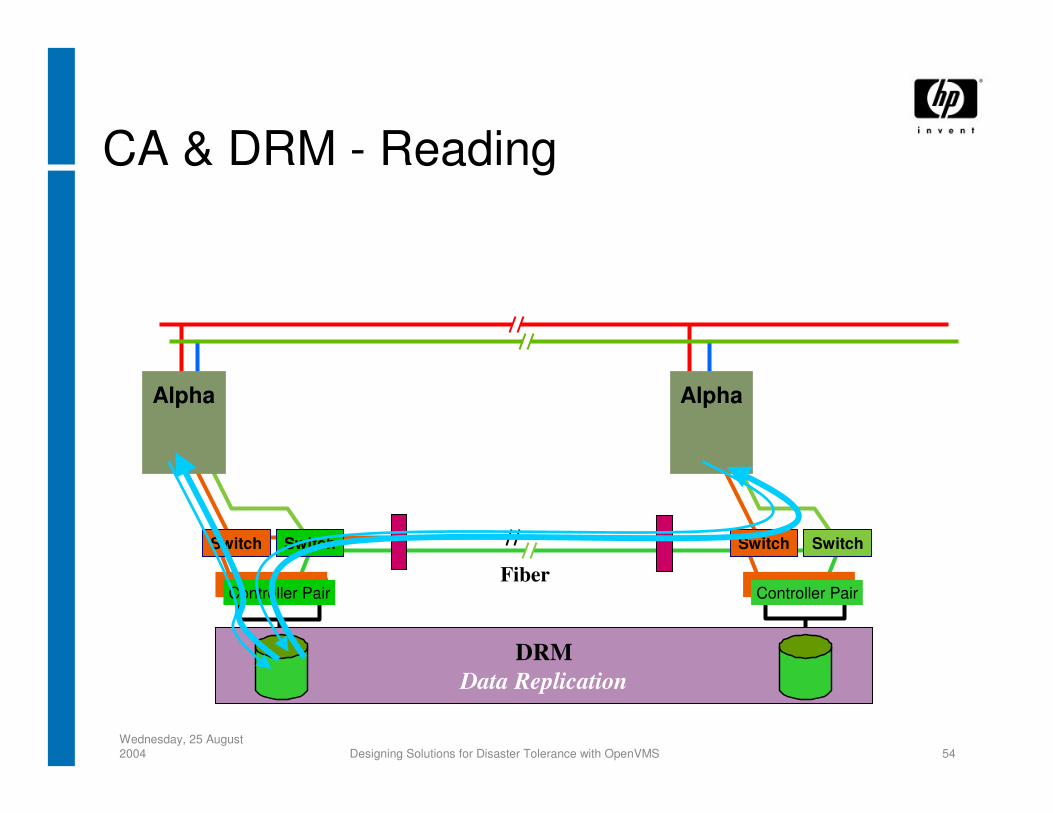
CA & DRM - Reading
DRMData Replication
Switch
Fiber
Alpha
SwitchSwitch
Controller Pair
Switch
Controller Pair
Alpha
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 55
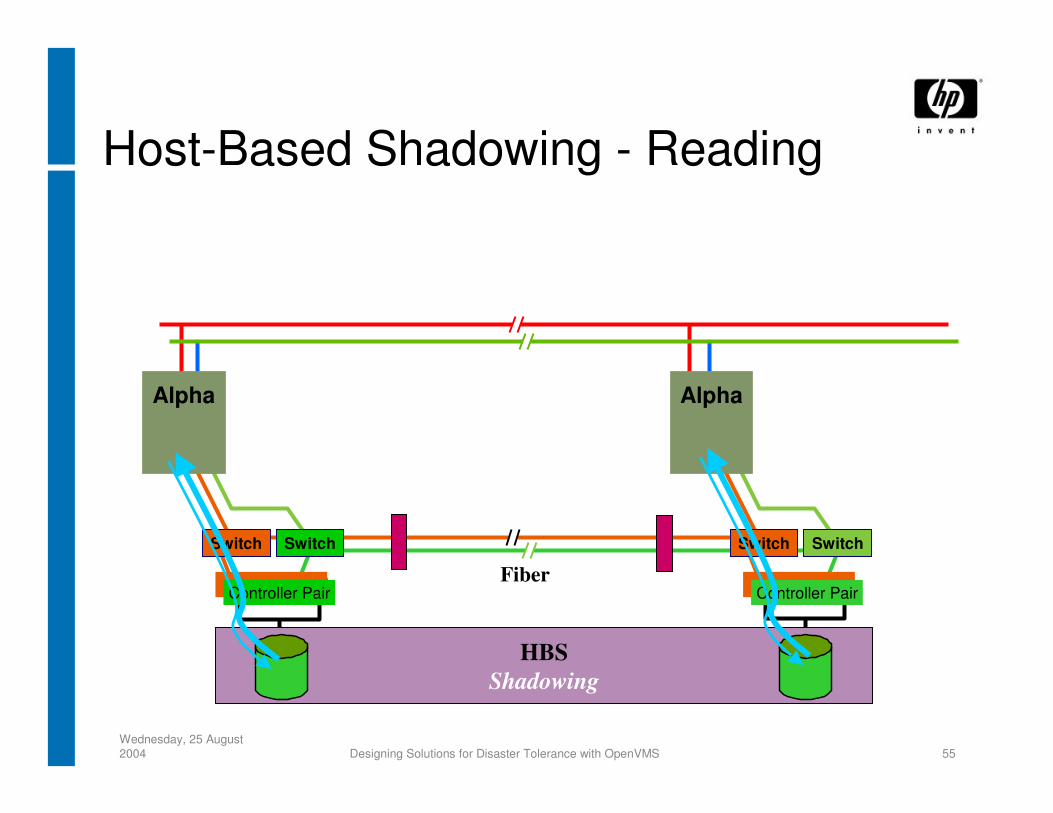
Host-Based Shadowing - Reading
HBSShadowing
Switch
Fiber
Alpha
SwitchSwitch
Controller Pair
Switch
Controller Pair
Alpha
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 56
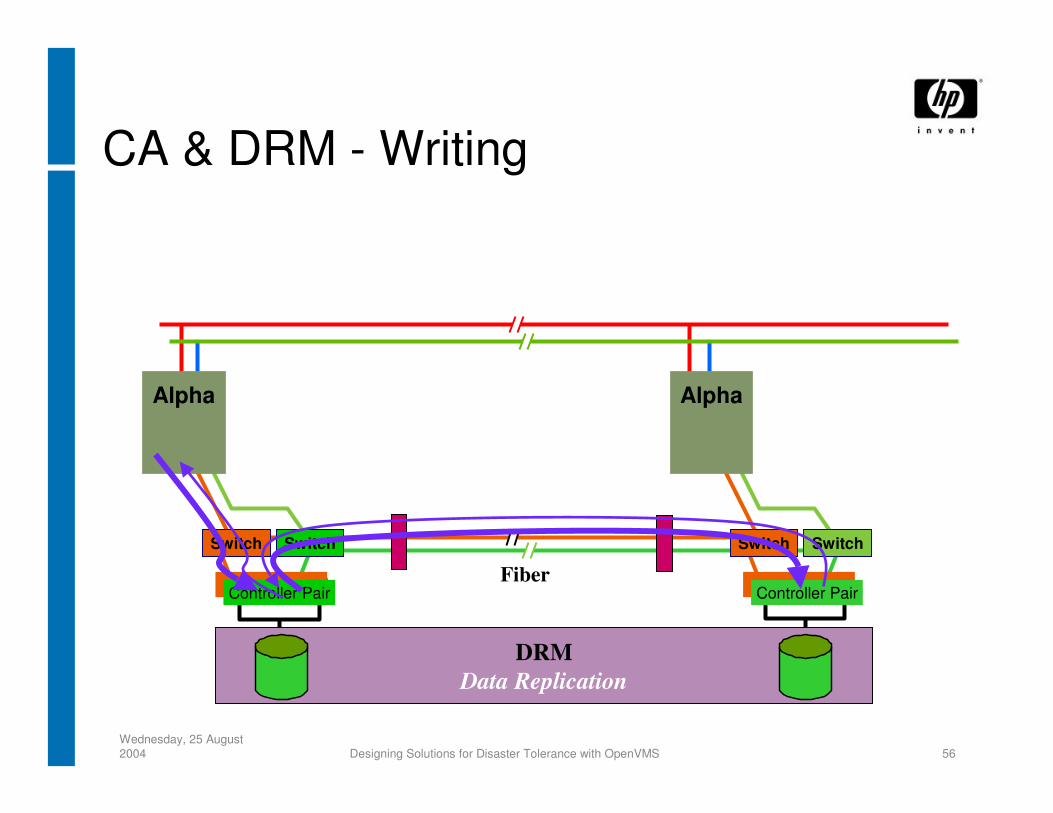
CA & DRM - Writing
DRMData Replication
Switch
Fiber
Alpha
SwitchSwitch
Controller Pair
Switch
Controller Pair
Alpha
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 57
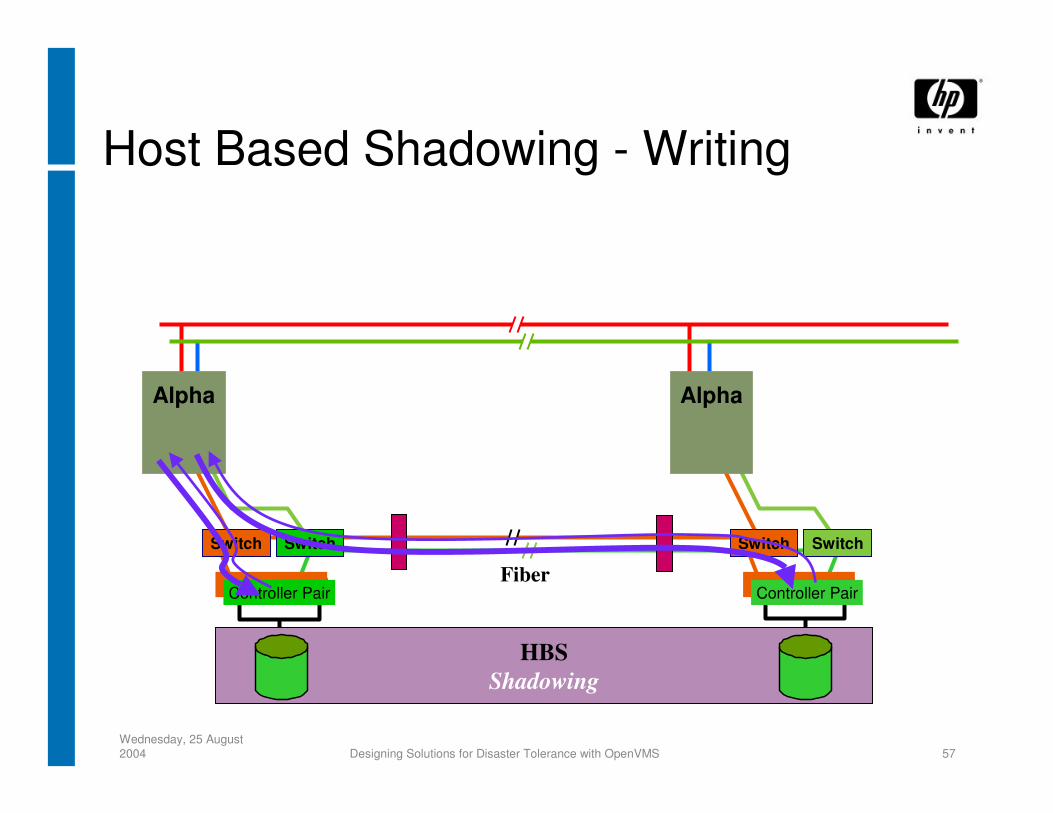
Host Based Shadowing - Writing
HBSShadowing
Switch
Fiber
Alpha
SwitchSwitch
Controller Pair
Switch
Controller Pair
Alpha
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 58
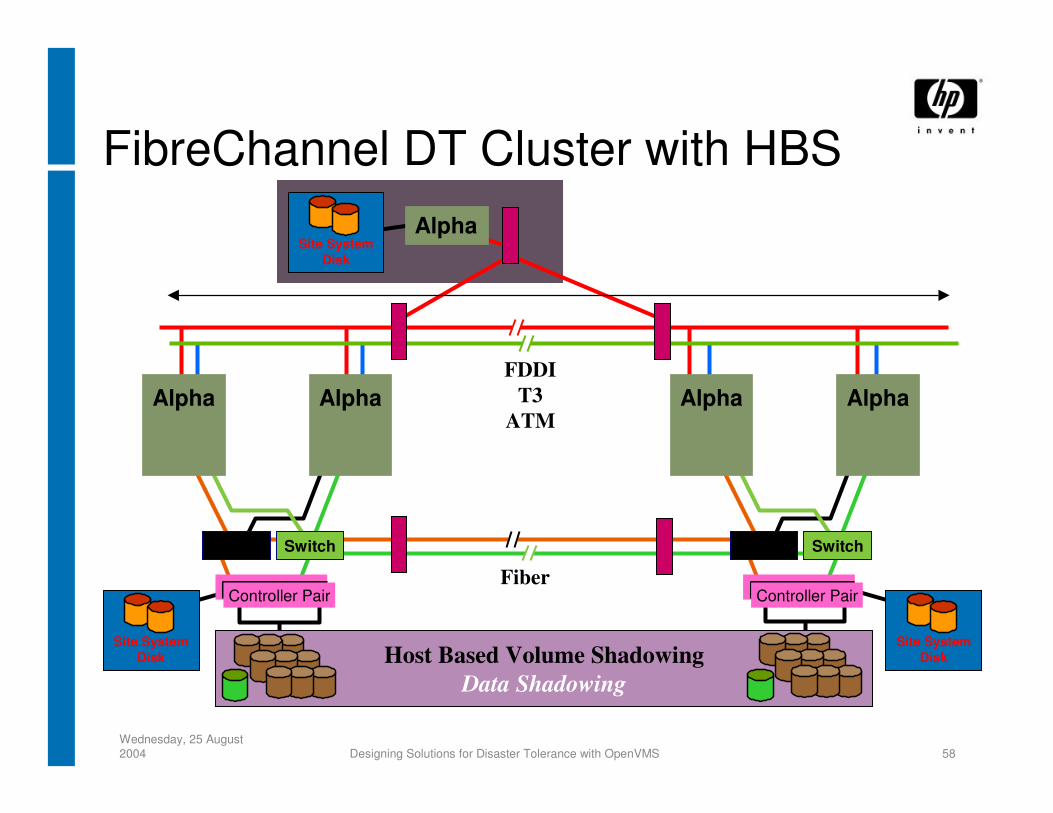
Host Based Volume ShadowingData Shadowing
Switch Switch
Fiber
FDDIT3
ATM
Controller Pair
AlphaAlpha
Switch Switch
Controller Pair
AlphaAlpha
Alpha
Site System Disk
Site System Disk
Site System Disk
FibreChannel DT Cluster with HBS
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 59
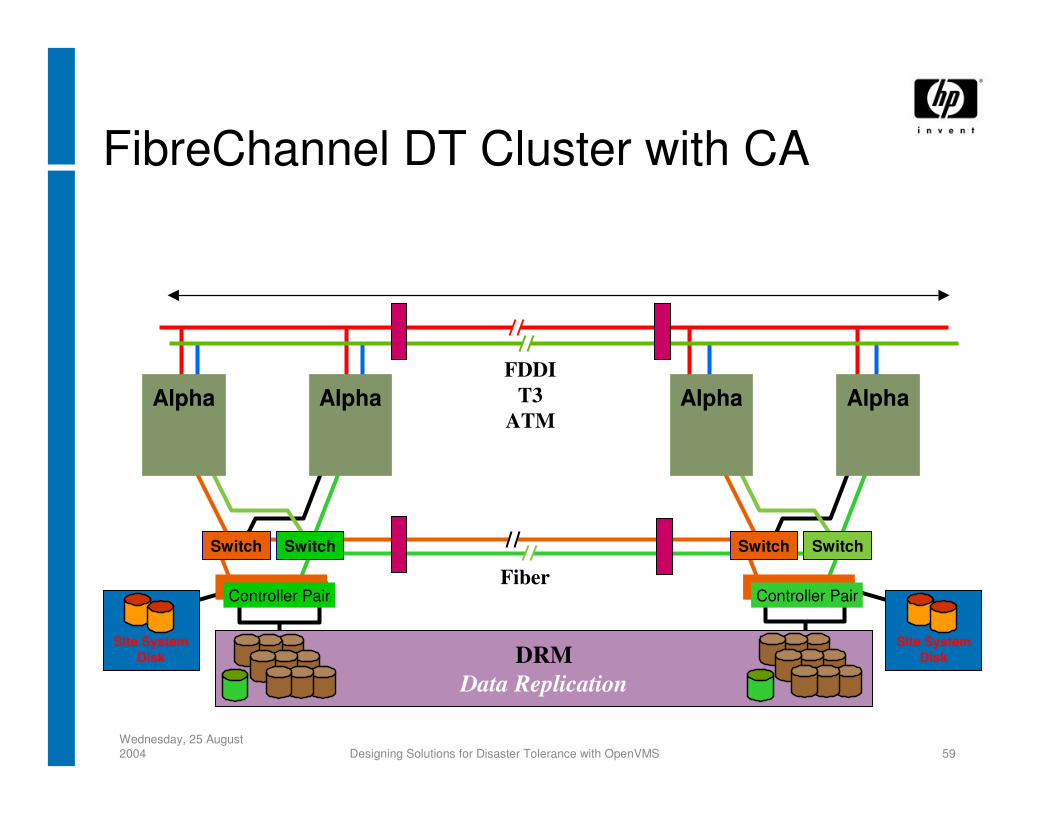
DRMData Replication
Switch
Fiber
FDDIT3
ATMAlphaAlpha
SwitchSwitch
Controller Pair
Switch
Controller Pair
AlphaAlpha
Site System Disk
Site System Disk
FibreChannel DT Cluster with CA
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 60
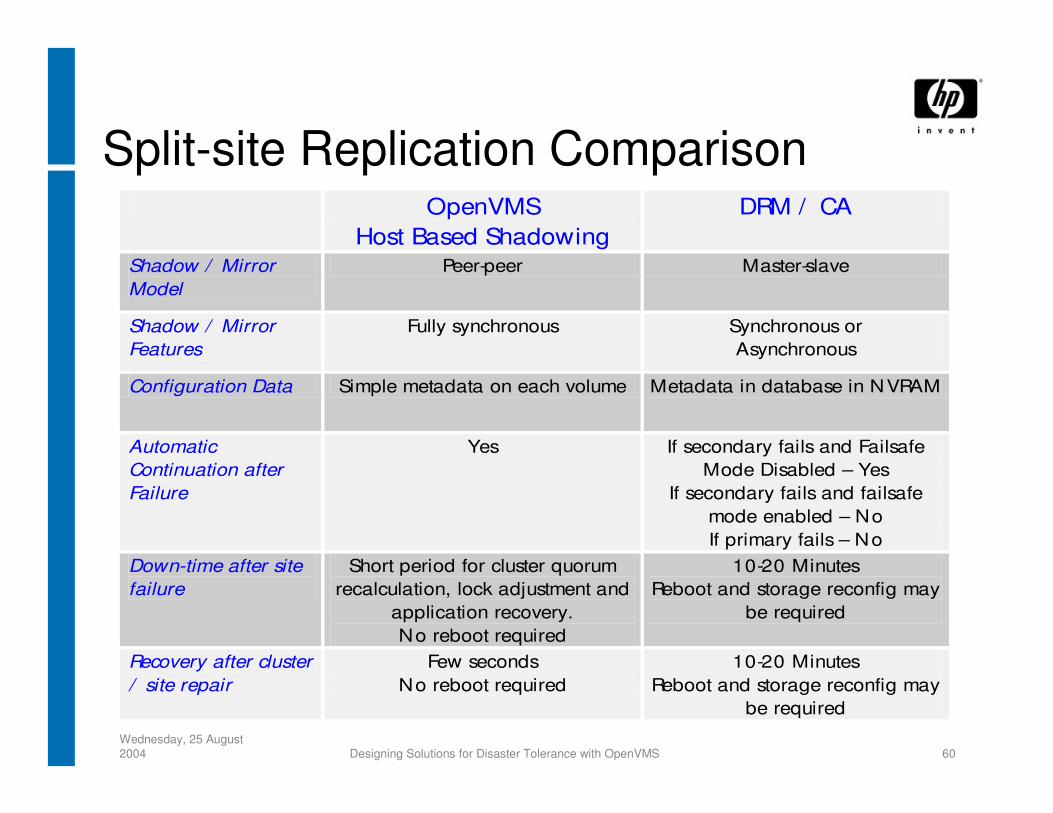
Split-site Replication Comparison OpenVMS
Host Based Shadowing DRM / CA
Shadow / Mirror Model
Peer-peer Master-slave
Shadow / Mirror Features
Fully synchronous Synchronous or Asynchronous
Configuration Data Simple metadata on each volume Metadata in database in NVRAM
Automatic Continuation after Failure
Yes If secondary fails and Failsafe Mode Disabled – Yes
If secondary fails and failsafe mode enabled – No If primary fails – No
Down-time after site failure
Short period for cluster quorum recalculation, lock adjustment and
application recovery. No reboot required
10-20 Minutes Reboot and storage reconfig may
be required
Recovery after cluster / site repair
Few seconds No reboot required
10-20 Minutes Reboot and storage reconfig may
be required

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 61
Split-site Replication Comparison (cont) OpenVMS
Host Based Shadowing DRM / CA
Shadow catchup performance
Host systems provide processing power for shadow copies – overall
performance will reduce as applications will have reduced available CPU power
and I/ O bandwidth
Storage controllers provide processing power for copies – additional load on inter-site link but
otherwise no additional overhead
Merge copies As shadow-catchup but more processing required
(Mini-merge will improve this)
As shadow catchup. Logging also available to improve re-synch
times. Steady-state read performance
OpenVMS can read from either volume – read throughput doubles
OpenVMS only sees a single volume – no performance change
Steady-state write performance
OpenVMS must write to both volumes – write throughput halves
OpenVMS only sees a single volume – no performance impact
Monitoring Fully integrated into OpenVMS – full alert / problem reporting through normal OpenVMS mechanisms
Operators must actively check subsystem for many error conditions
Normal reporting difficult Manageability Fully integrated into OpenVMS – simple
commands to reconfigure / recover Mixed environment.
SAN Appliance for set-up and performance management
DTCS GUI or menus for recovery

Storage and Volume Shadowing

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 63
Host-Based Volume Shadowing• Host software keeps multiple disks identical
• All writes go to all shadowset members
• Reads can be directed to any one member− Different read operations can go to different members at
once, helping throughput
• Synchronization (or Re-synchronization after a failure) is done with a Copy operation
• Re-synchronization after a node failure is done with a Merge operation

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 64
Shadowing Full-Copy Algorithm• Host-Based Volume Shadowing full-copy
algorithm is non-intuitive. 1. Read from source disk2. Do Compare operation with target disk3. If data is identical, we’re done with this segment. If
data is different, write source data to target disk, then go back to Step 1.
• Shadow_Server process does copy I/Os− Does one 127-block segment at a time, from the
beginning of the disk to the end, with no double-buffering or other speed-up tricks

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 65
Speeding Shadow Copies• Implications:
− Shadow copy completes fastest if data is identical beforehand
• Fortunately, this is the most-common case – re-adding a shadow member into shadowset again after it was a member before
• If you know that a member will be removed and later re-added, the Mini-Copy capability can be a great time-saver.

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 66
Data Protection Mechanisms and Scenarios• Protection of the data is obviously extremely
important in a disaster-tolerant cluster
• We’ll examine the mechanisms the Volume Shadowing design uses to protect the data
• We’ll look at one scenario that has happened in real life and resulted in data loss:− “Wrong-way shadow copy”

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 67
Protecting Shadowed Data• Shadowing keeps a “Generation Number” in the
SCB on shadow member disks
• Shadowing “Bumps” the Generation number at the time of various shadowset events, such as mounting, or membership changes

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 68
Protecting Shadowed Data• Generation number is designed to monotonically
increase over time, never decrease
• Implementation is based on OpenVMS timestamp value− During a “Bump” operation it is increased
• to the current time value, or
− if the generation number already represents a time in the future for some reason (such as time skew among cluster member clocks), then it is simply incremented
− The new value is stored on all shadowset members at the time of the Bump operation

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 69
Protecting Shadowed Data• Generation number in SCB on removed members
will thus gradually fall farther and farther behind that of current members
• In comparing two disks, a later generation number should always be on the more up-to-date member, under normal circumstances

System Management

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 71
Documentation• Comprehensive and accurate documentation
essential for FAST recovery.
• DTCS is a business solution, TIME IS MONEY…..
• Many approaches which should include:-− Site Documentation
• include Network and Cluster− Disaster Recovery Plan, components critical to running
of the applications on the DTC

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 72
Topics for Site Documentation -Cluster/Network/SAN
• Cluster Configuration− Disk Controller configuration− Fibre Channel Switches− Node Configurations− System disks− Application disks− SYSGEN parameters− Logical names− Start-up files - map− Page/Swap Files Configuration− License management
information
• Network Configuration− Network device configuration
details (priorities, filters etc..)− Port Usage details− FDDI ring map− Software/firmware rev levels− Changing management & port
modules.− Console port connections
• SAN Configuration− Switch configuration details
(address, ports, ISL etc…)− Switch Zoning
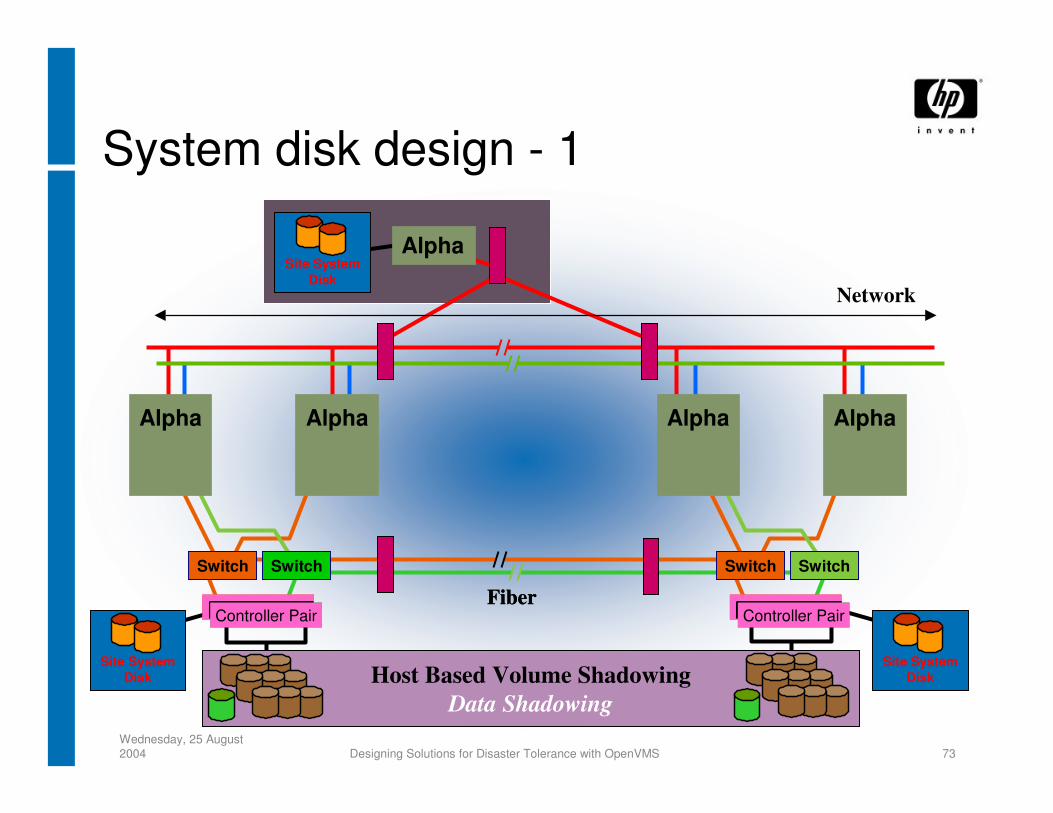
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 73
Switch
FiberSwitchSwitch
Controller Pair
Switch
Controller Pair
Host Based Volume ShadowingData Shadowing
Fiber
Network
Controller Pair
AlphaAlpha
Controller Pair
AlphaAlpha
Alpha
Site System Disk
Site System Disk
Site System Disk
System disk design - 1
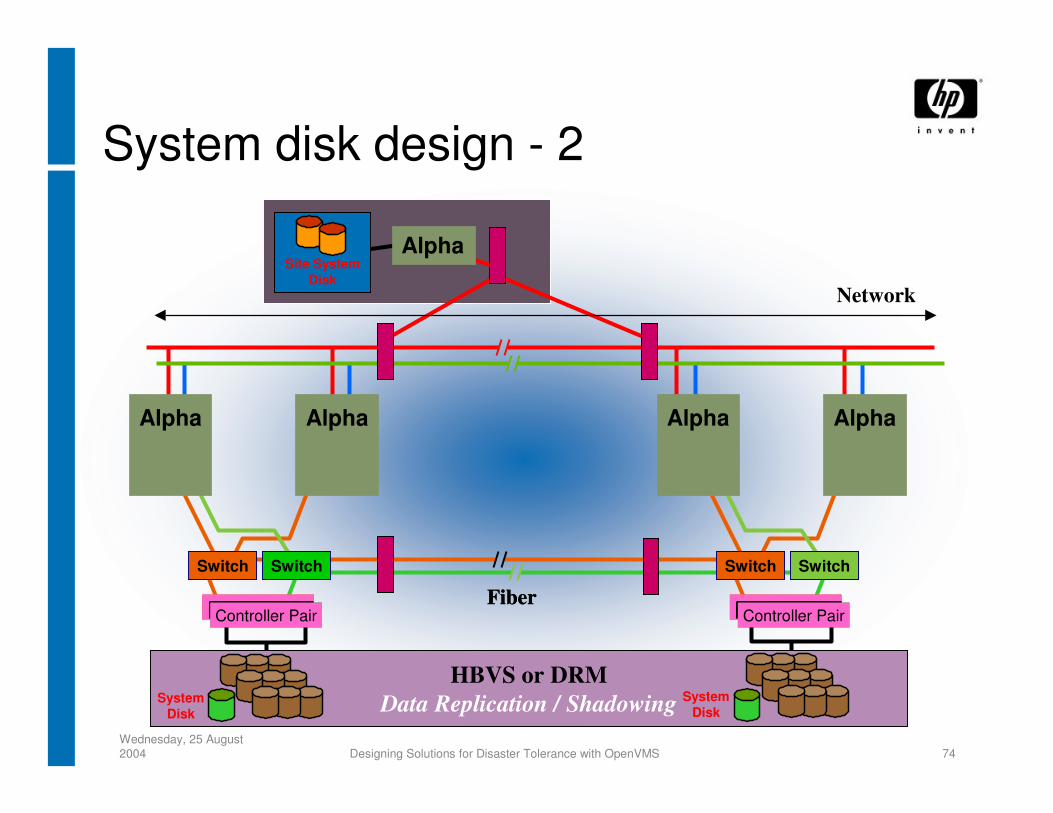
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 74
Switch
FiberSwitchSwitch
Controller Pair
Switch
Controller PairFiber
Controller Pair
AlphaAlpha
Controller Pair
AlphaAlpha
AlphaSite System
Disk
HBVS or DRMData Replication / Shadowing System
DiskSystem
Disk
System disk design - 2
Network
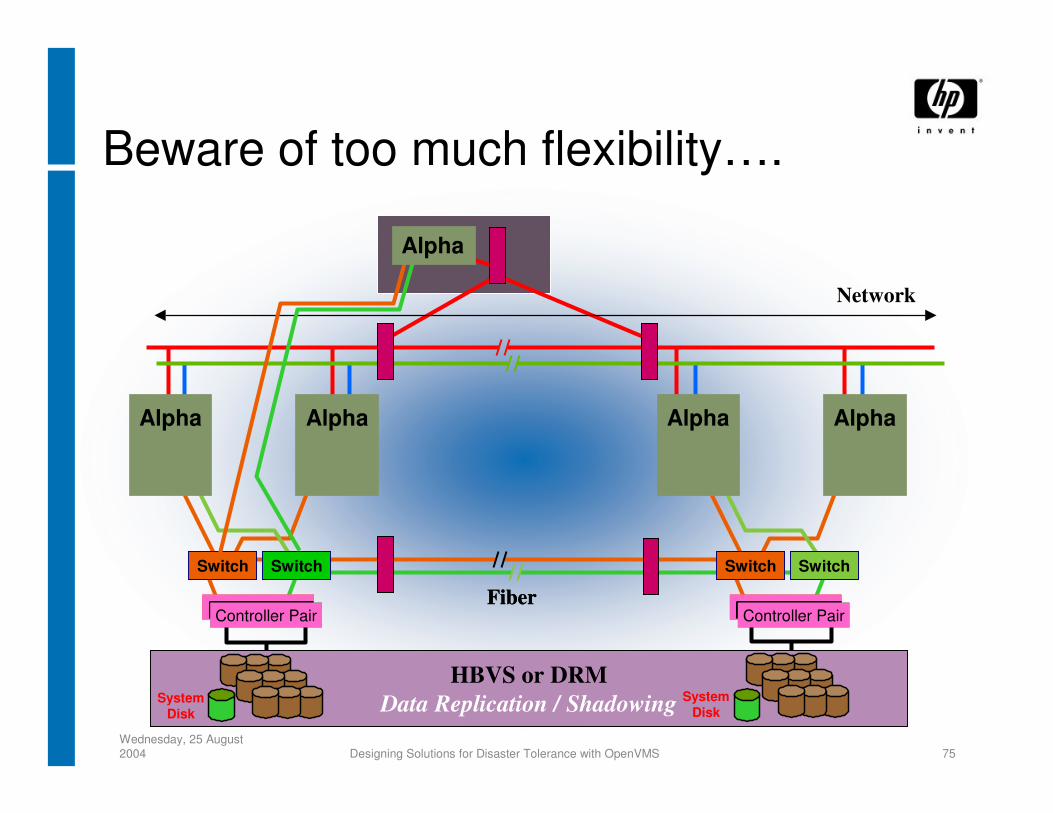
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 75
Switch
FiberSwitchSwitch
Controller Pair
Switch
Controller PairFiber
Controller Pair
AlphaAlpha
Controller Pair
AlphaAlpha
Alpha
Beware of too much flexibility….
HBVS or DRMData Replication / Shadowing System
DiskSystem
Disk
Network

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 76
System disk issues for DT
• separate system disk• upgrade-ability• must have ability to boot from the same physical member• some “insurance” in having 2 system disks• paging?• performance (inter-switch link) esp. latency• must maintain all copies of OpenVMS properly
• single system disk• one copy of VMS to maintain• Cluster will hang
− if inter-site link breaks− If there is a “locking” problem on the disk
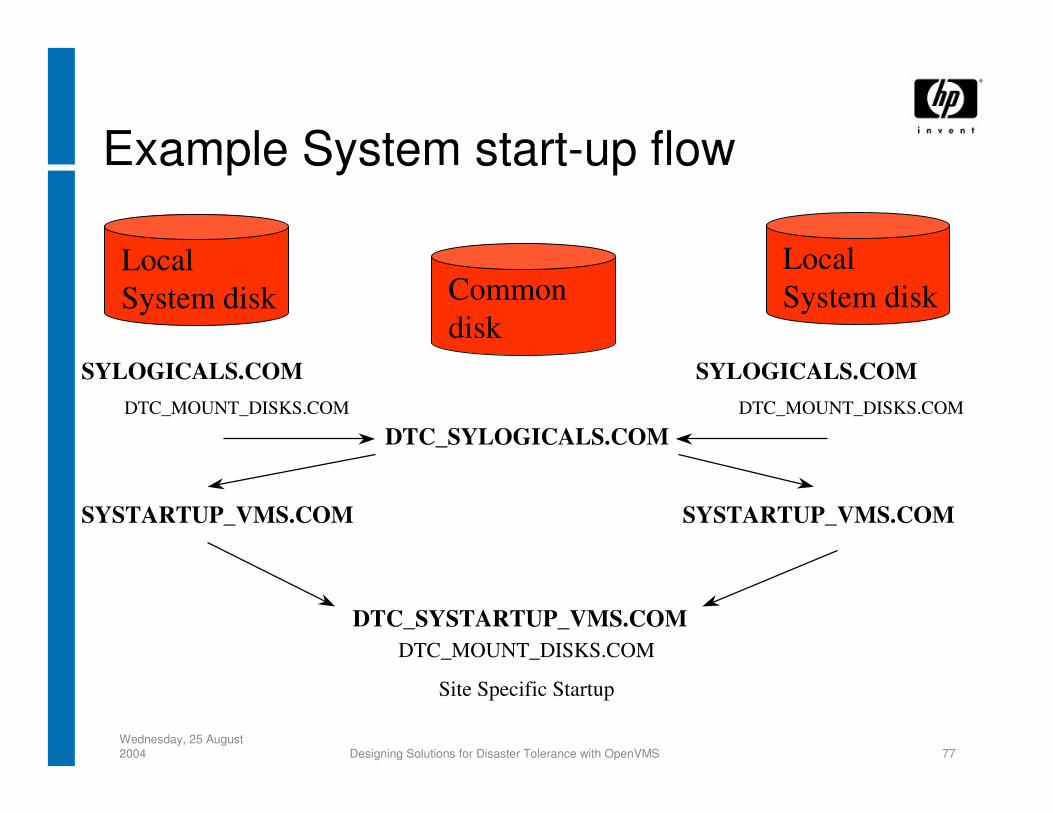
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 77
Example System start-up flow
Local System disk
SYLOGICALS.COMDTC_MOUNT_DISKS.COM
DTC_SYLOGICALS.COM
SYSTARTUP_VMS.COM
DTC_SYSTARTUP_VMS.COMDTC_MOUNT_DISKS.COM
Site Specific Startup
Local System diskCommon
diskSYLOGICALS.COM
DTC_MOUNT_DISKS.COM
SYSTARTUP_VMS.COM
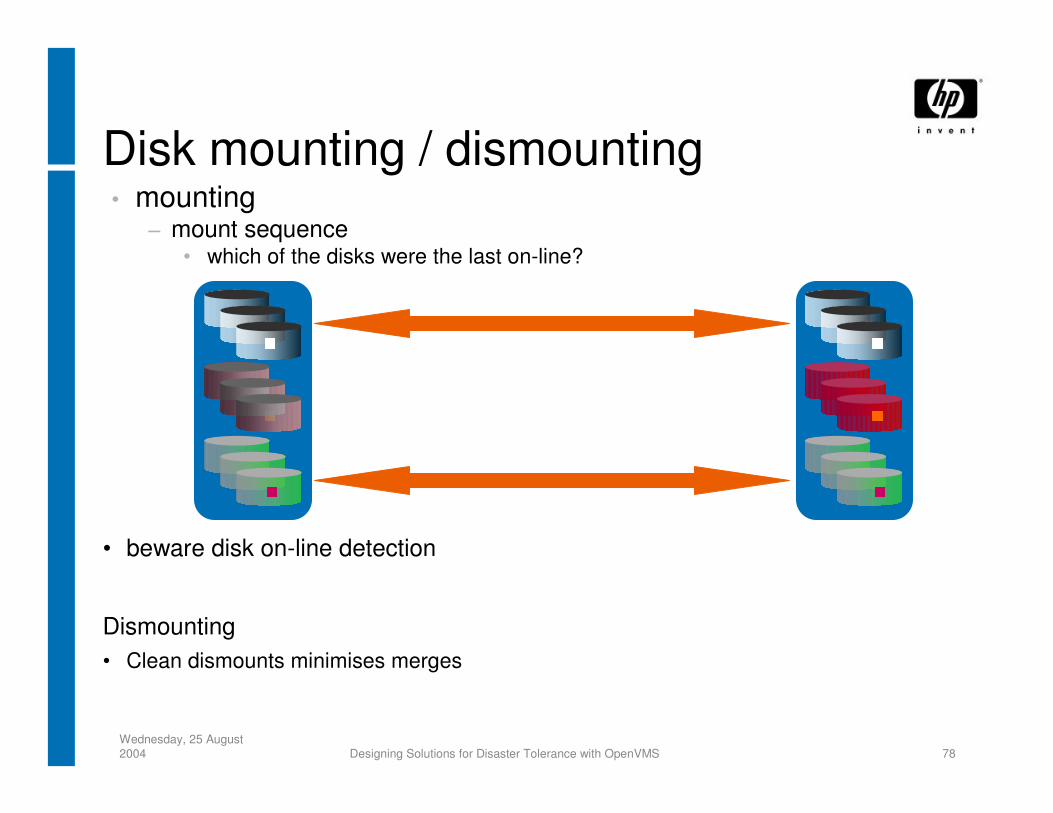
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 78
Disk mounting / dismounting• mounting
− mount sequence• which of the disks were the last on-line?
• beware disk on-line detection
Dismounting• Clean dismounts minimises merges
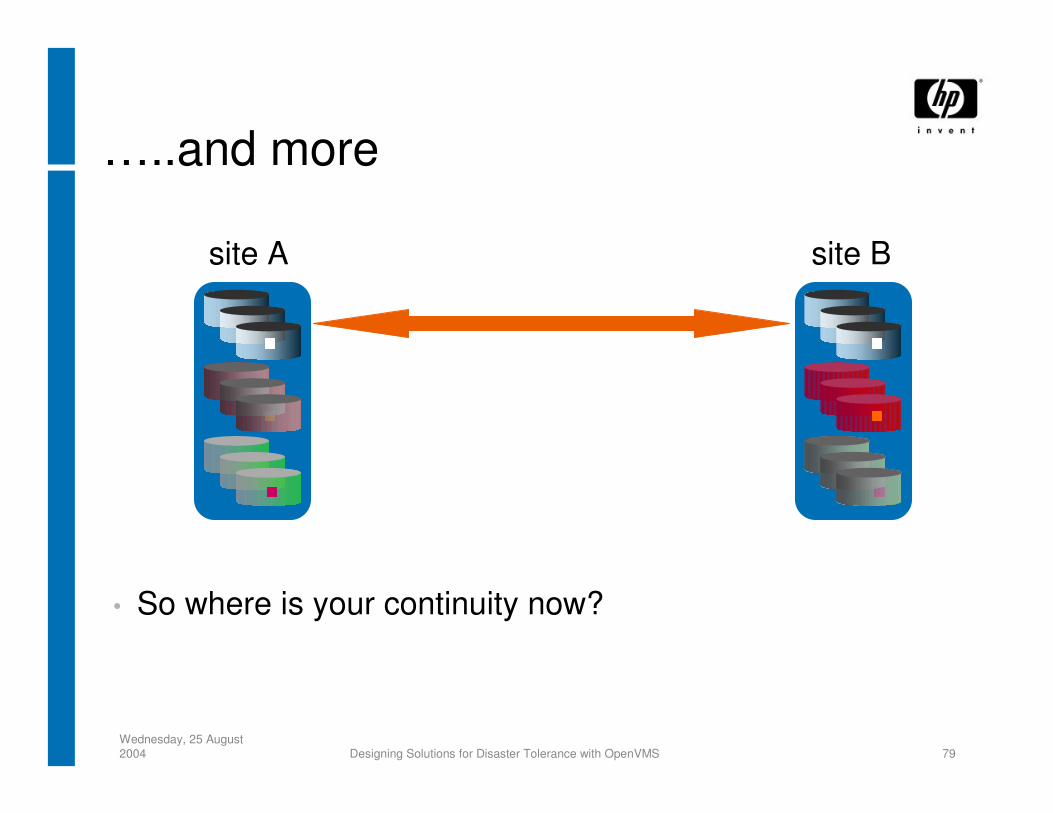
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 79
…..and more
site A site B
• So where is your continuity now?
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 80
Understanding what is critical
site A site B

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 81
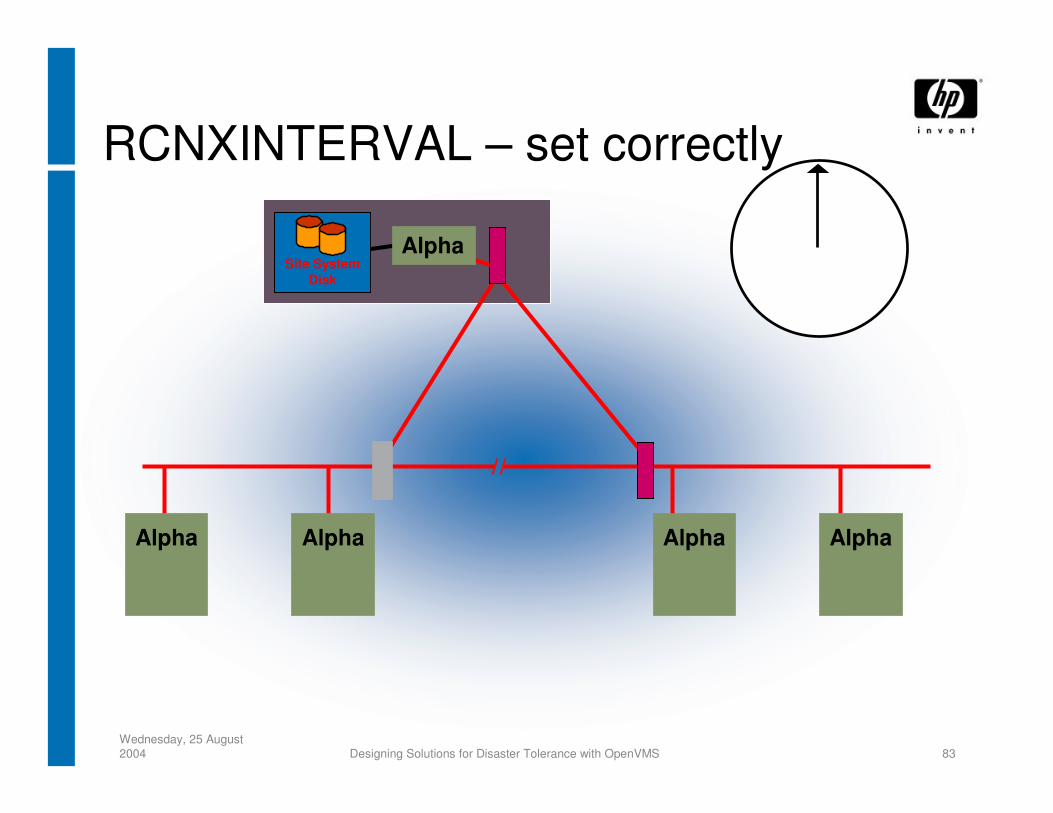
SYSGEN Parameter Tuning for DTCS - 1− RECNXINTERVAL = Big Enough
− SHADOW_MBR_TMO = Bigger than RECNXINTERVAL
− SHADOW_MAX_COPY = ?• Dynamic parameter• Setting is configuration dependent, 4 is the default value
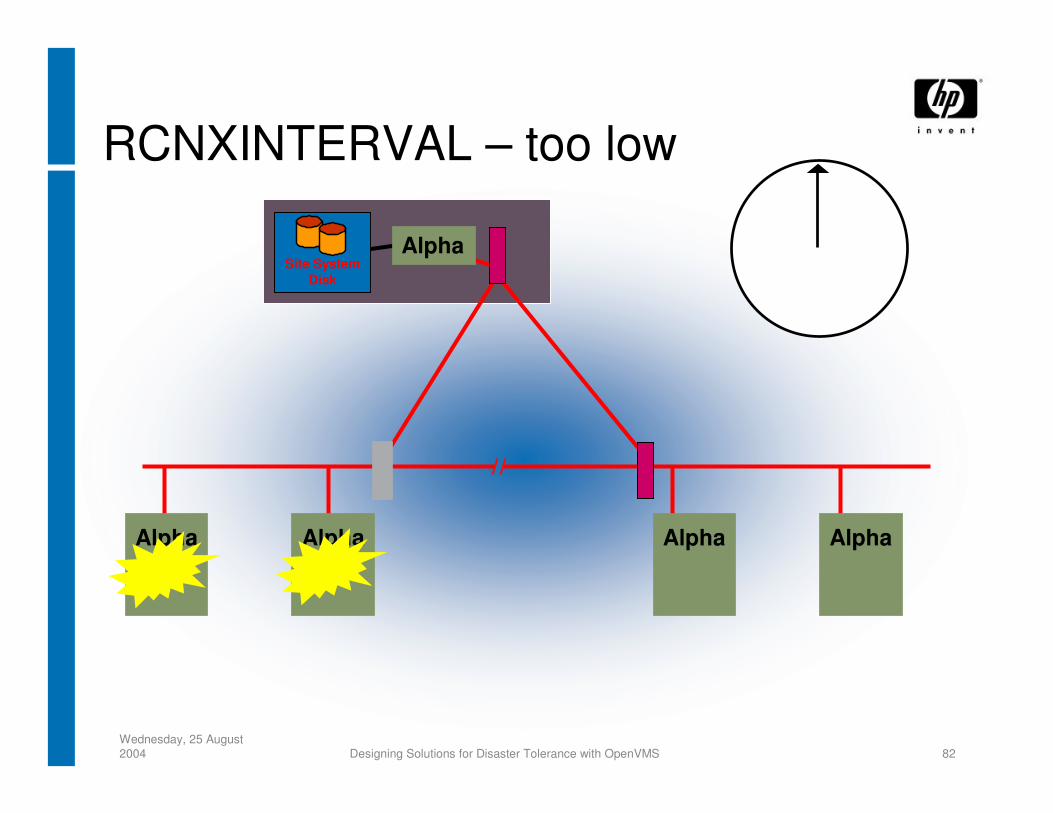
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 82
AlphaAlpha AlphaAlpha
AlphaSite System
Disk
RCNXINTERVAL – too low
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 83
AlphaAlpha AlphaAlpha
AlphaSite System
Disk
RCNXINTERVAL – set correctly

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 84
SYSGEN Parameter Tuning for DTCS - 2− MSCP parameters
• MSCP_CREDITS=128• MSCP_BUFFERS=2048 or larger

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 85
SYSGEN Parameter Tuning for DTCS - 3
• PEDRIVER parameters− NISCS_LOAD_PEA0 =1
• Enables SCS on all LAN adapters− NISCS_PORT_SERVE = 3
• Enables CRC checking on SCS packets− NISCS_MAX_PKTSZ=4468
• (OpenVMS 6.1 & above for FDDI. Not required in OpenVMS V7.3 or above)
− LAN_FLAGS = %x40 (Bit 6) • (OpenVMS V7.3 ATM Jumbo Packet Support)

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 86
SYSGEN Parameter Tuning for DTCS –4
− Parameters/Systems tuned to cope with additional load after data centre failure
• Consider:• GBLPAGES• GBLSECTIONS• MAXPROCESSCNT• NPAGEDYN• Page and Swapfiles
• AUTOGEN does not always do a good job in the split-site cluster case.

Long-Distance Cluster Issues

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 88
Long-Distance Clusters• OpenVMS officially supports distance of up to 500
miles (833 km) between nodes
• Why the limit?− Inter-site latency

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 89
Long-distance Cluster Issues• Latency due to speed of light becomes significant
at higher distances. Rules of thumb:− About 1 ms per 100 miles, one-way or− About 1 ms per 50 miles, round-trip latency
• Actual circuit path length can be longer than highway mileage between sites
• Latency primarily affects performance of:1.Remote lock operations2.Remote I/Os

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 90
3 80 120200270285333440500
4400
0500
100015002000250030003500400045005000
Latency (micro-seconds)
Local nodeGalaxy SMCIMemory ChannelGigabit EthernetFDDI, GigaswitchFDDI, GS via ATMDSSICIATM 15 milesDS-3 250 miles
Lock Request Latencies

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 91
• Can’t get around the speed of light and its latency effects over long distances− Higher-bandwidth link doesn’t mean lower
latency
Differentiate between Latency and Bandwidth

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 92
Latency of Inter-Site Link•Latency affects performance of:− Lock operations that cross the inter-site link
• Lock requests• Directory lookups, deadlock searches
− Write I/Os to remote shadowset members, either:• Over SCS link through the OpenVMS MSCP Server on a node at the
opposite site, or• Direct via Fibre Channel (with an inter-site FC link)Both MSCP and the SCSI-3 protocol used over FC take a minimum of
two round trips for writes

Long Distance Issues
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 96
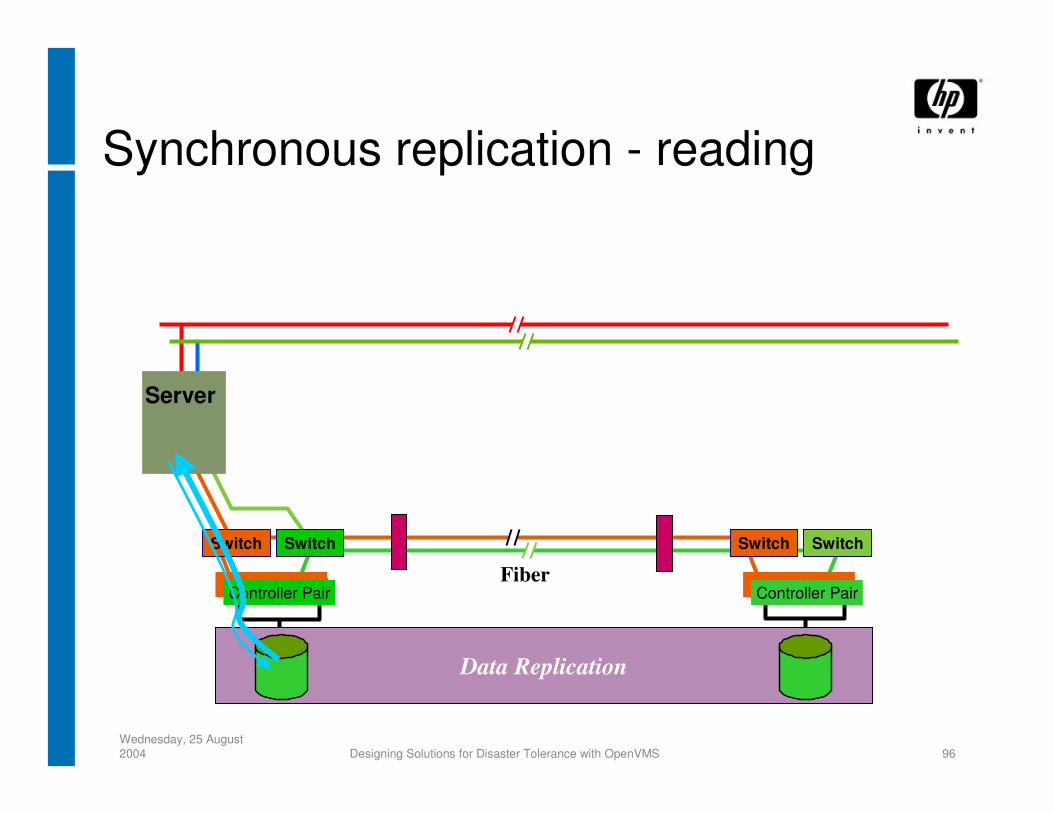
Synchronous replication - reading
Data Replication
Switch
Fiber
Server
SwitchSwitch
Controller Pair
Switch
Controller Pair
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 97
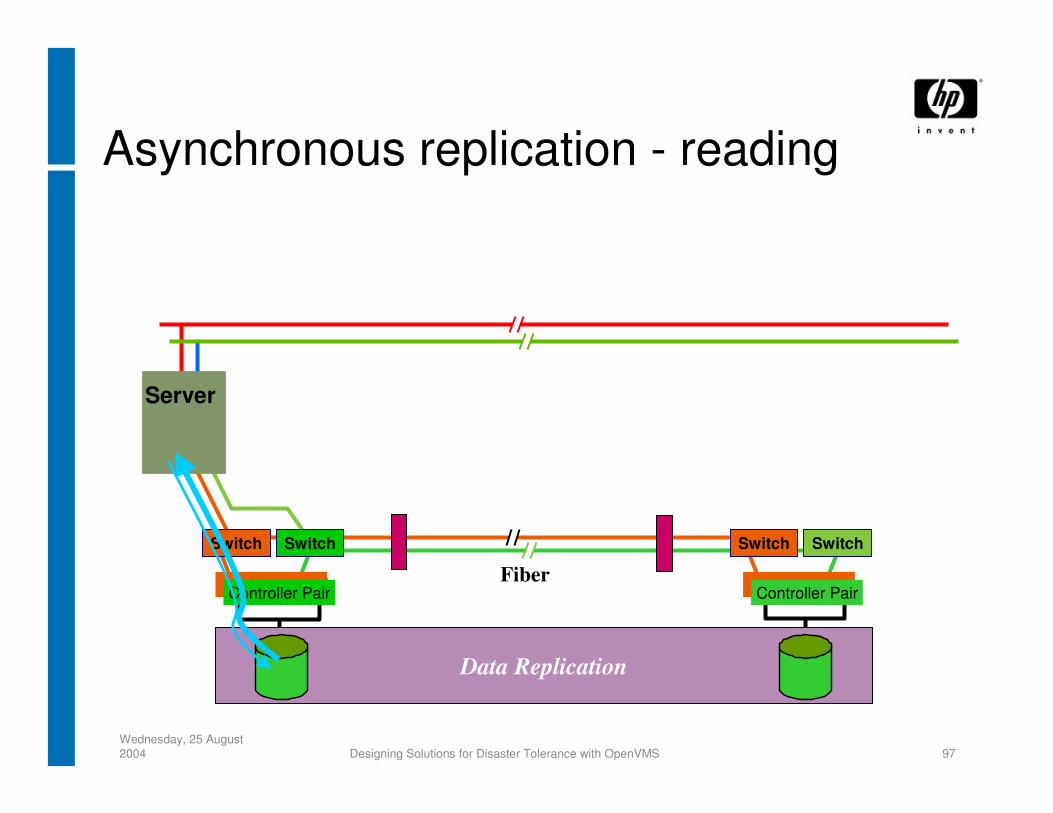
Asynchronous replication - reading
Data Replication
Switch
Fiber
Server
SwitchSwitch
Controller Pair
Switch
Controller Pair
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 98
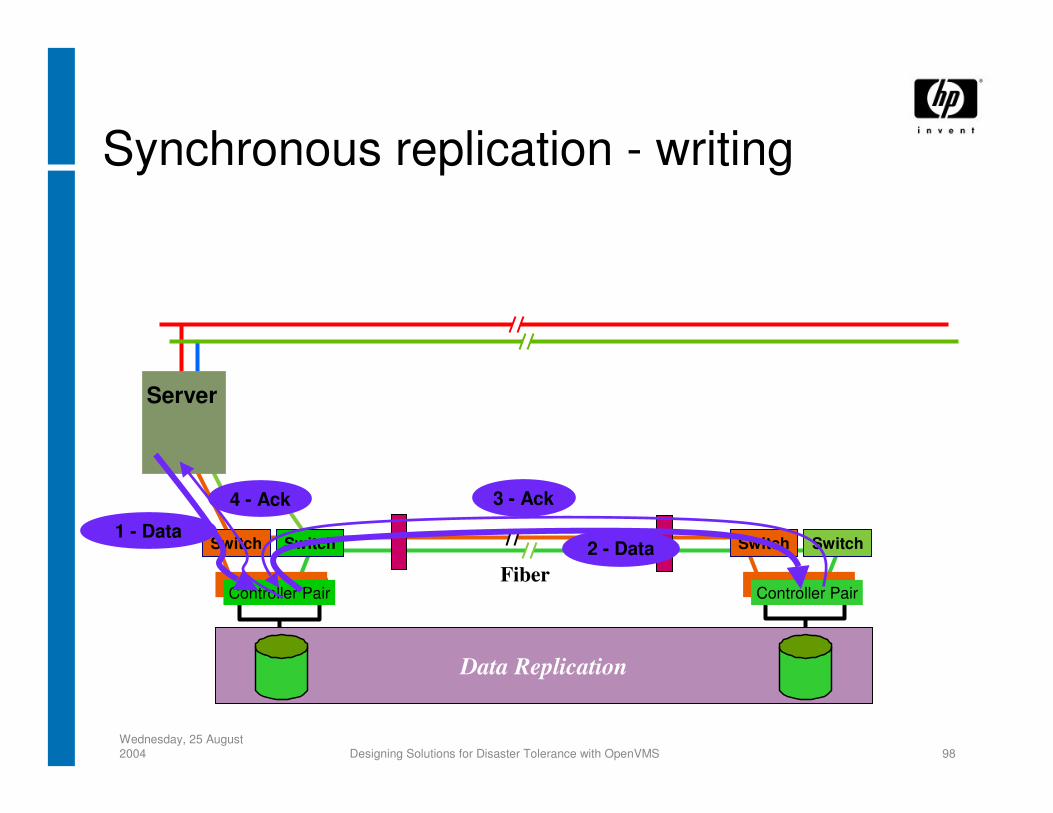
Synchronous replication - writing
Data Replication
Switch
Fiber
Server
SwitchSwitch
Controller Pair
Switch
Controller Pair
1 - Data2 - Data
3 - Ack4 - Ack
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 99
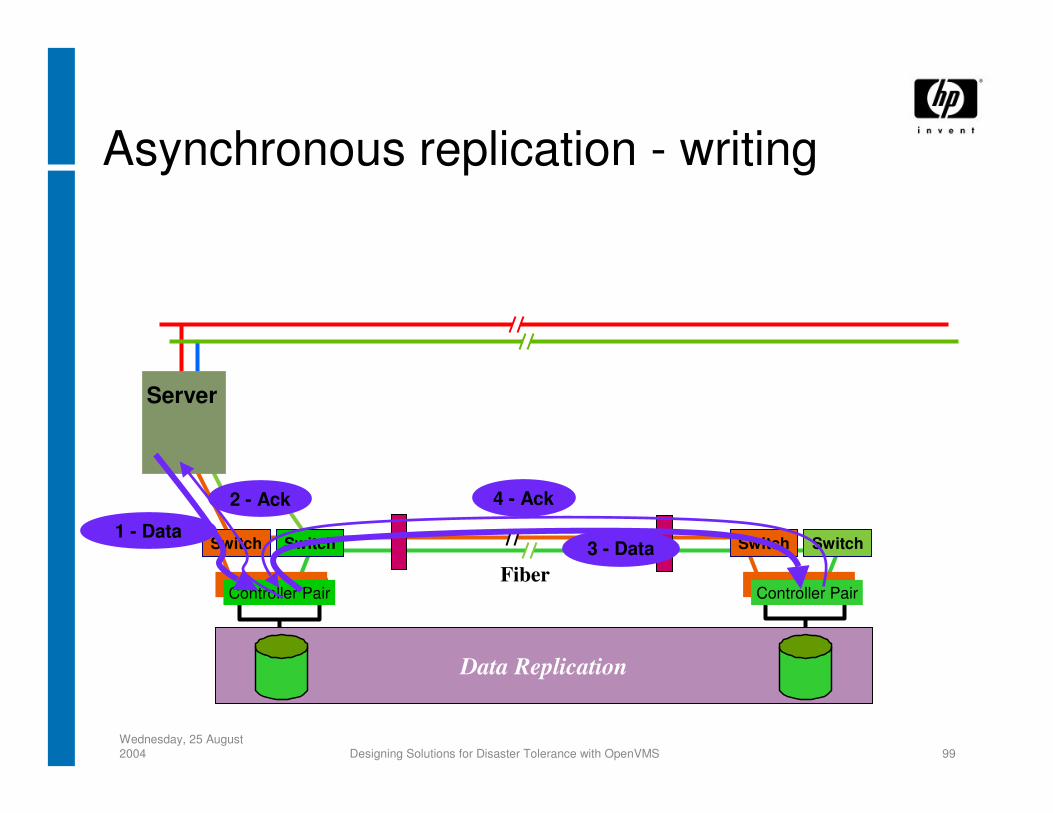
Asynchronous replication - writing
Data Replication
Switch
Fiber
Server
SwitchSwitch
Controller Pair
Switch
Controller Pair
1 - Data3 - Data
4 - Ack2 - Ack

Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 100
Synchronous vs Asynchronous -Perceptions
• Synchronous Will guarantee no loss of data More expensive to implement than asynchronous Needs high bandwidth Doesn’t work over distance
• Asynchronous Will only lose minimal amount of data Cheaper than synchronous Needs lower bandwidth Allows unlimited distance
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 101
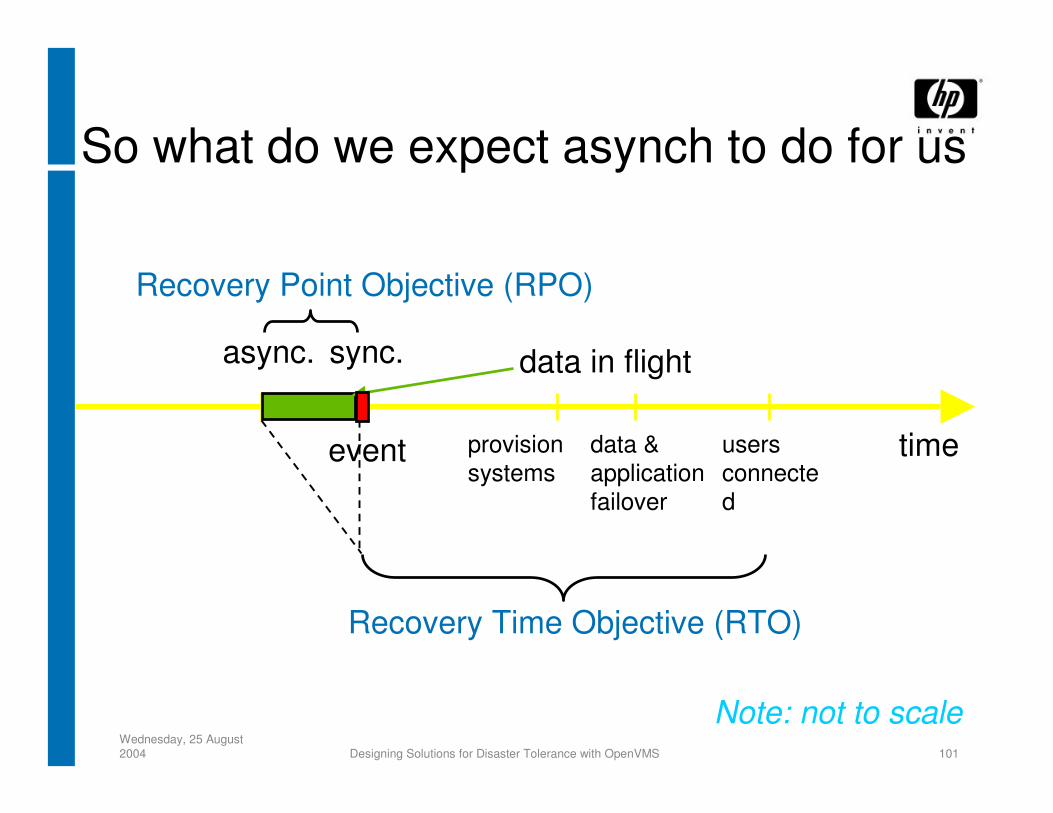
So what do we expect asynch to do for us
timedata & application failover
users connected
Recovery Time Objective (RTO)
sync.async.
Recovery Point Objective (RPO)
data in flight
provision systems
event
Note: not to scale
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 102
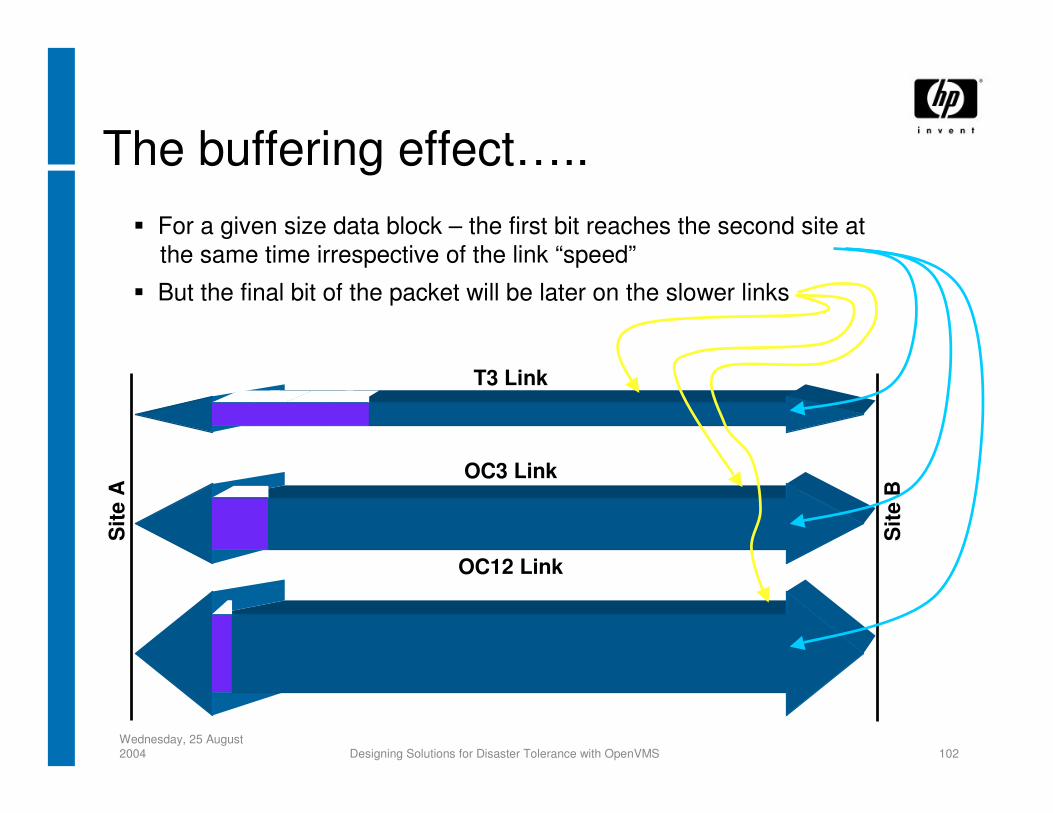
The buffering effect…..S
ite A
Site
B
T3 Link
OC3 Link
OC12 Link
For a given size data block – the first bit reaches the second site atthe same time irrespective of the link “speed”
But the final bit of the packet will be later on the slower links
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 103
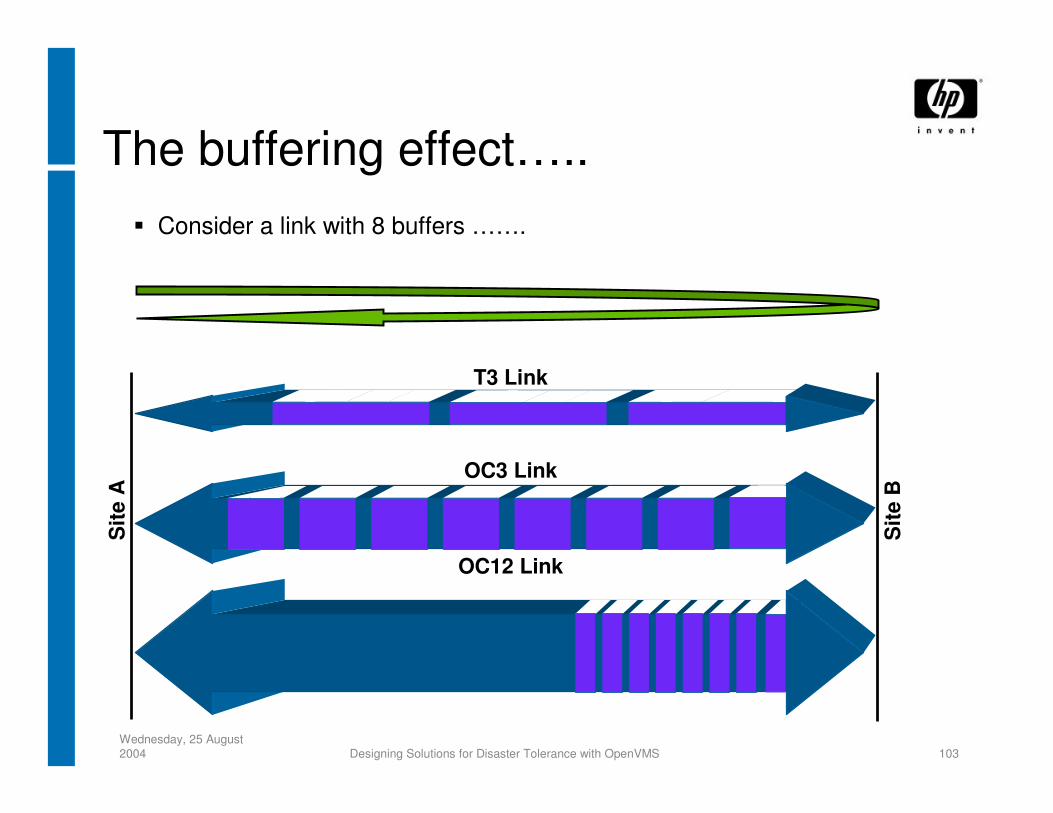
The buffering effect…..S
ite A
Site
B
T3 Link
OC3 Link
OC12 Link
Consider a link with 8 buffers …….
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 104
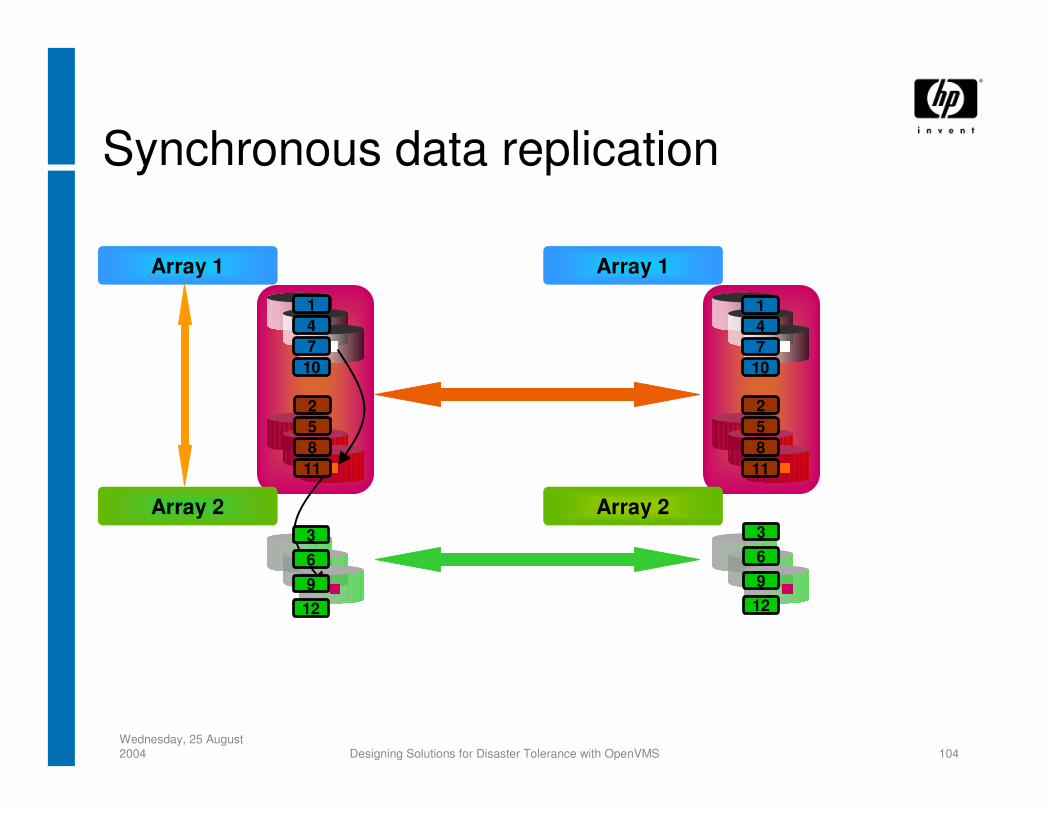
Synchronous data replication
Array 1
Array 2
Array 1
Array 2
1
2
3
4
5
6
7
8
9
10
11
12
1
2
3
4
5
69
12
7
8
10
11
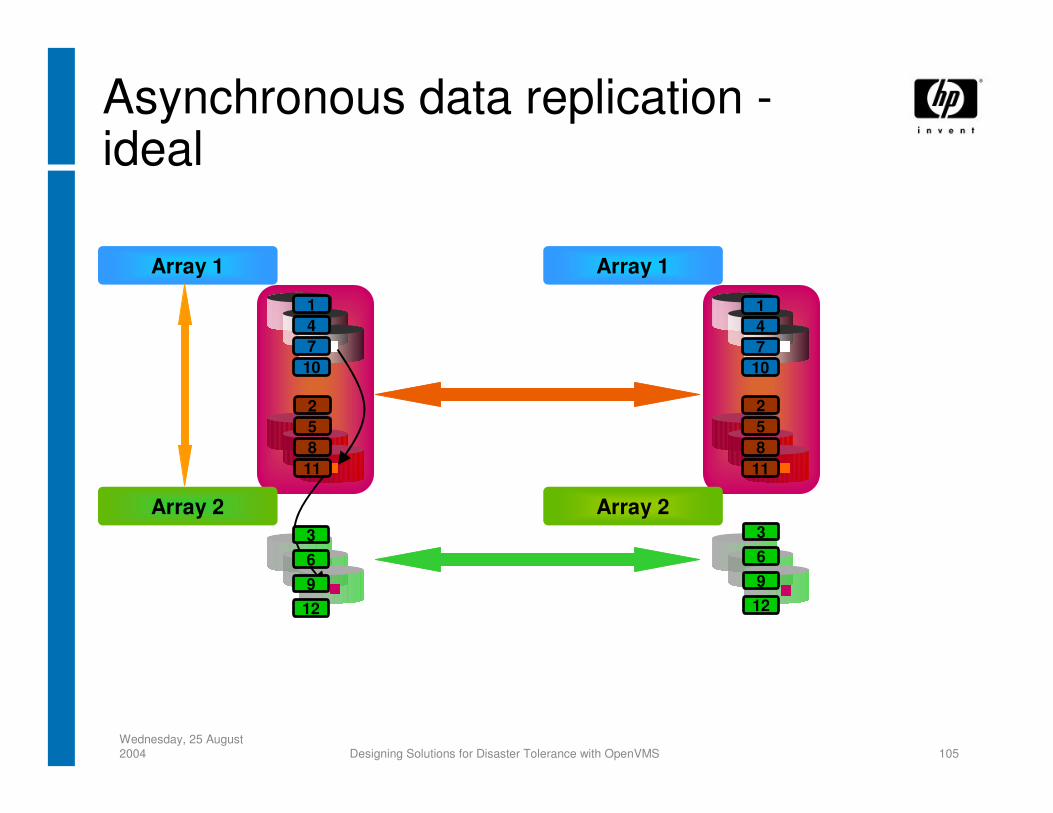
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 105
Array 1
Array 2
Array 1
Array 2
Asynchronous data replication -ideal
1
2
3
4
5
6
7
8
9
10
11
12
1
2
3
4
5
69
12
7
8
10
11
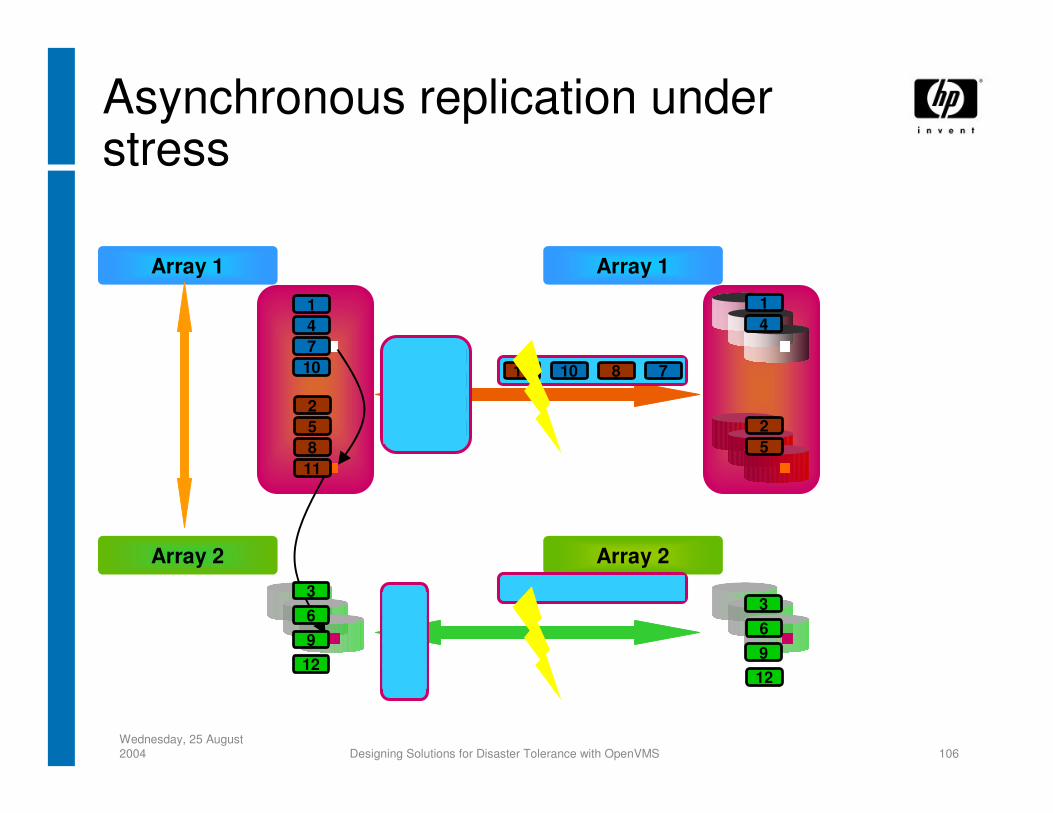
Wednesday, 25 August 2004 Designing Solutions for Disaster Tolerance with OpenVMS 106
Array 1
Array 2
Array 1
Array 2
Asynchronous replication under stress
12
3
45
6
78
9
1011
12
1245
36912
12963
5
4
2
1
781011
1
2
3
4
5
6
7
8
9
10
11
12