dictionaries and hash tables1 hash tables 0 1 2 3 4 451-229-0004 981-101-0002 025-612-0001
TRANSCRIPT

Dictionaries and Hash Tables 1
Hash Tables
01234 451-229-0004
981-101-0002
025-612-0001

2
HashtablesWhich is better, an array or a linked list?Well, an array is better if we know how many objects will be stored because we can access each element of an array in O(1) time!!!But, a linked list is better if we have to change the number of objects stored dynamically and the changes are significant, or if there are complex relationships between objects that indicate “neighbors”.

3
Implementation of Hashtables
Which is better, an array or a linked list?Well, an array is better if we know how many objects will be stored because we can access each element of an array in O(1) time!!!But, a linked list is better if we have to change the number of objects stored dynamically and the changes are significant, or if there are complex relationships between objects that indicate “neighbors”.
What to do?

4
Which is better, an array or a linked list?Well, an array is better if we know how many objects will be stored because we can access each element of an array in O(1) time!!!But, a linked list is better if we have to change the number of objects stored dynamically and the changes are significant, or if there are complex relationships between objects that indicate “neighbors”.
What to do?
I know! Combine the advantages of both!!!
Implementation of Hashtables

5
Which is better, an array or a linked list?Well, an array is better if we know how many objects will be stored because we can access each element of an array in O(1) time!!!But, a linked list is better if we have to change the number of objects stored dynamically and the changes are significant, or if there are complex relationships between objects that indicate “neighbors”.
What to do?Combine the advantages of both!!!
WELCOME HASHTABLES
Implementation of Hashtables

6
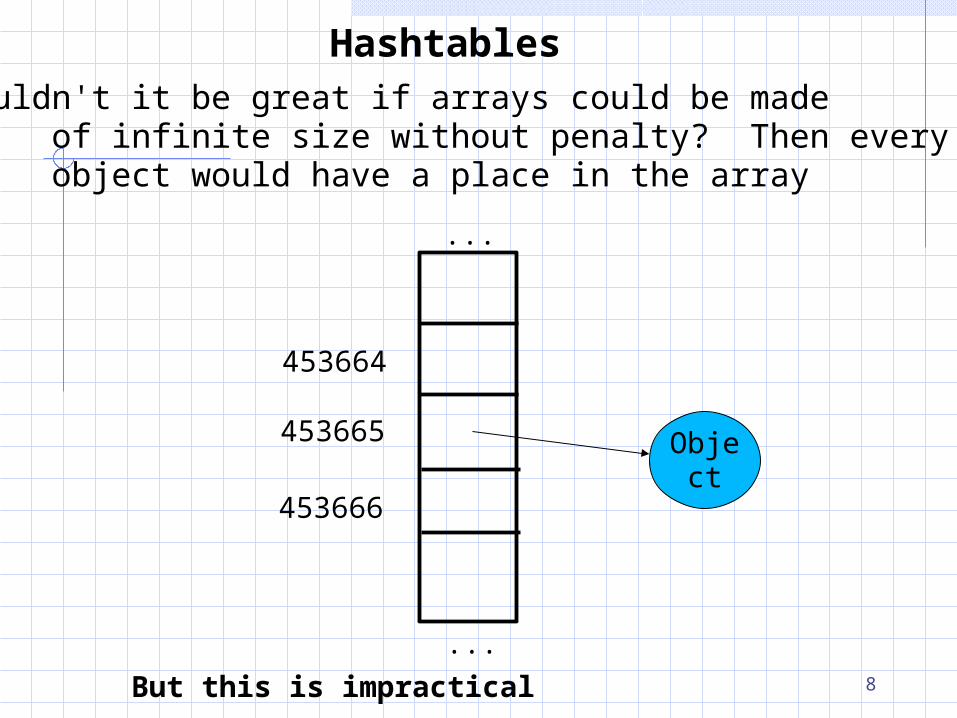
HashtablesWouldn't it be great if arrays could be made of infinite size without penalty? Then every object would have a place in the array

7
HashtablesWouldn't it be great if arrays could be made of infinite size without penalty? Then every object would have a place in the array
...
...
453664
453665
453666
Object
8
HashtablesWouldn't it be great if arrays could be made of infinite size without penalty? Then every object would have a place in the array
...
...
453664
453665
453666
Object
But this is impractical
9
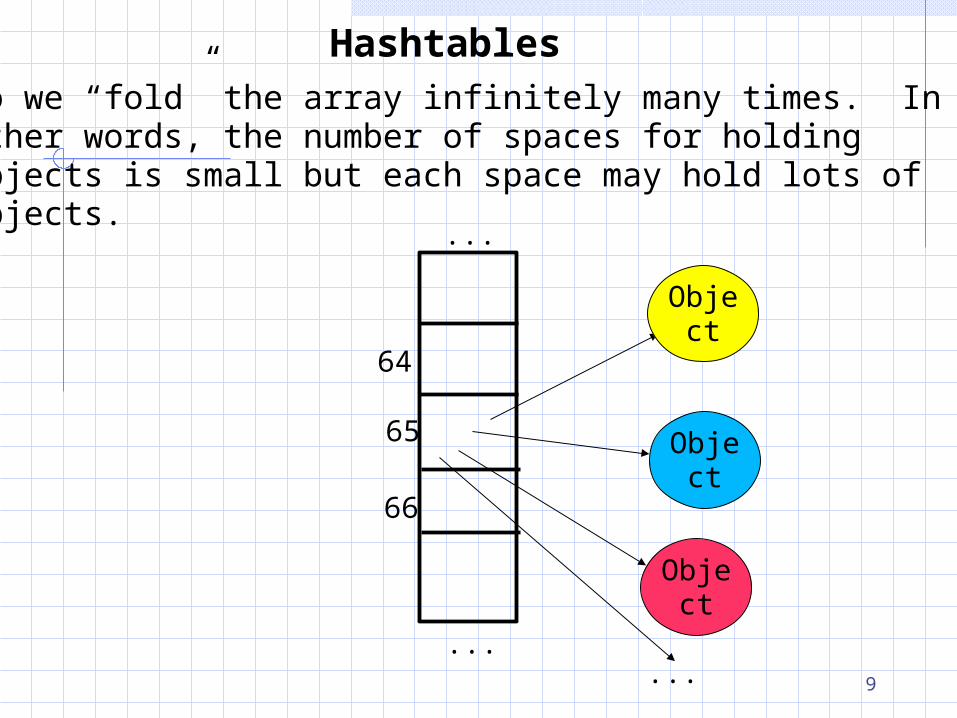
HashtablesSo we “fold” the array infinitely many times. In other words, the number of spaces for holding objects is small but each space may hold lots of objects.
...
...
64
65
66
Object
Object
Object
...
10
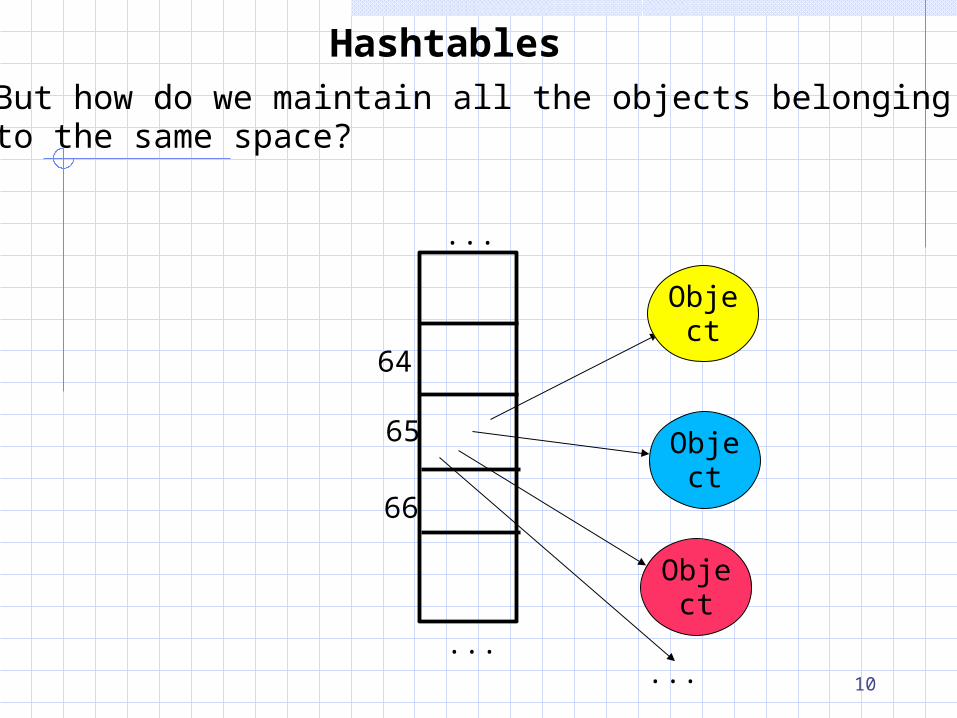
HashtablesBut how do we maintain all the objects belongingto the same space?
...
...
64
65
66
Object
Object
Object
...

11
HashtablesBut how do we maintain all the objects belongingto the same space? Answer: linked list
...
...
64
65
66
Object
Object
Object...
12
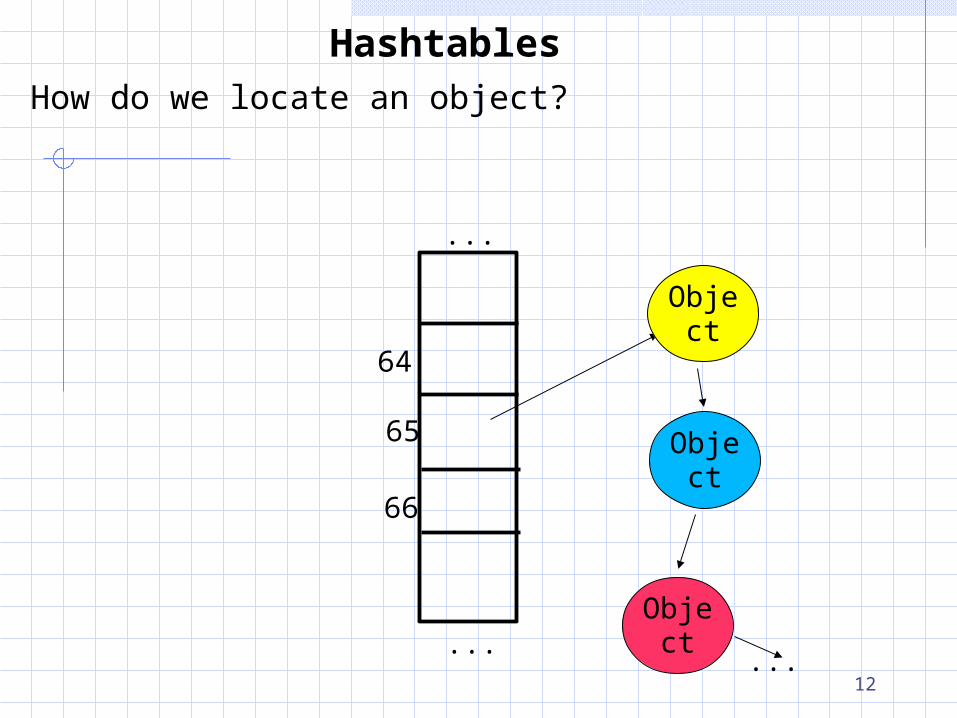
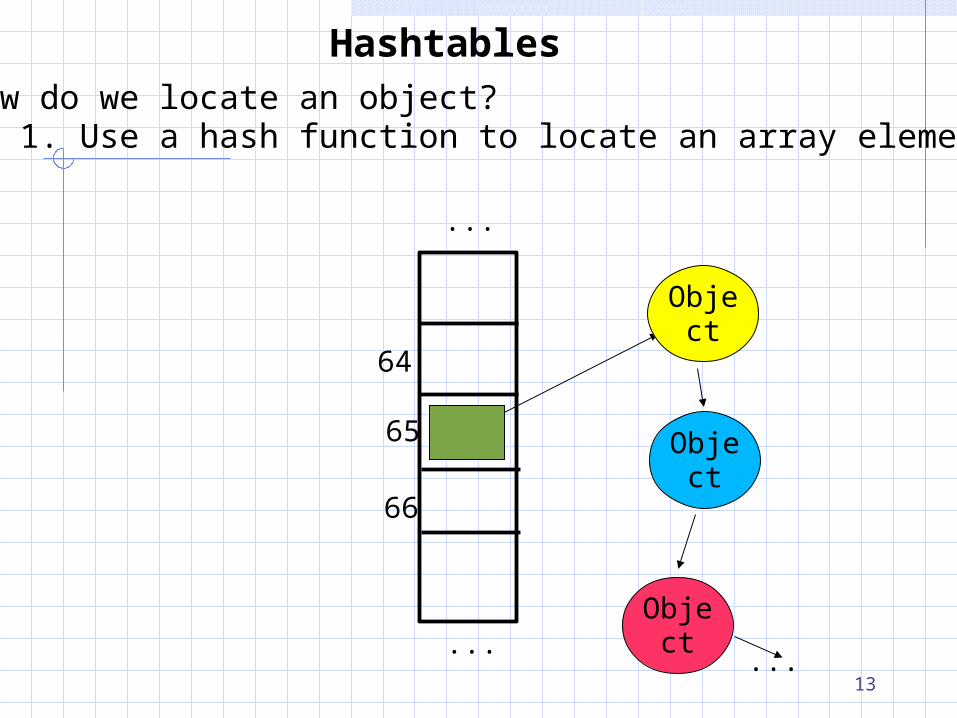
HashtablesHow do we locate an object?
...
...
64
65
66
Object
Object
Object...
13
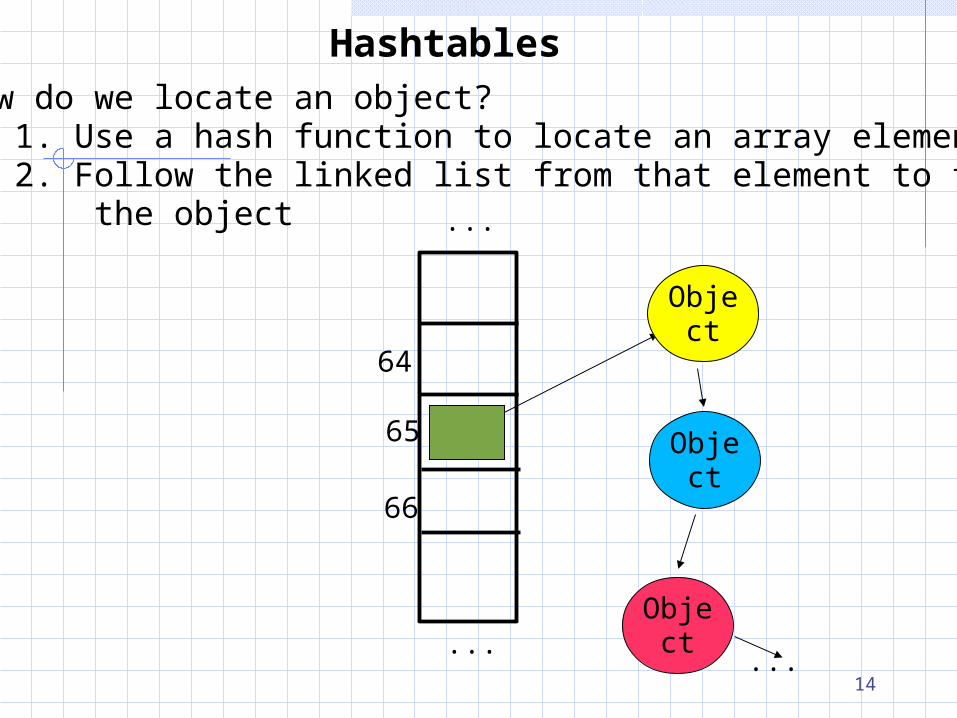
HashtablesHow do we locate an object? 1. Use a hash function to locate an array element
...
...
64
65
66
Object
Object
Object...
14
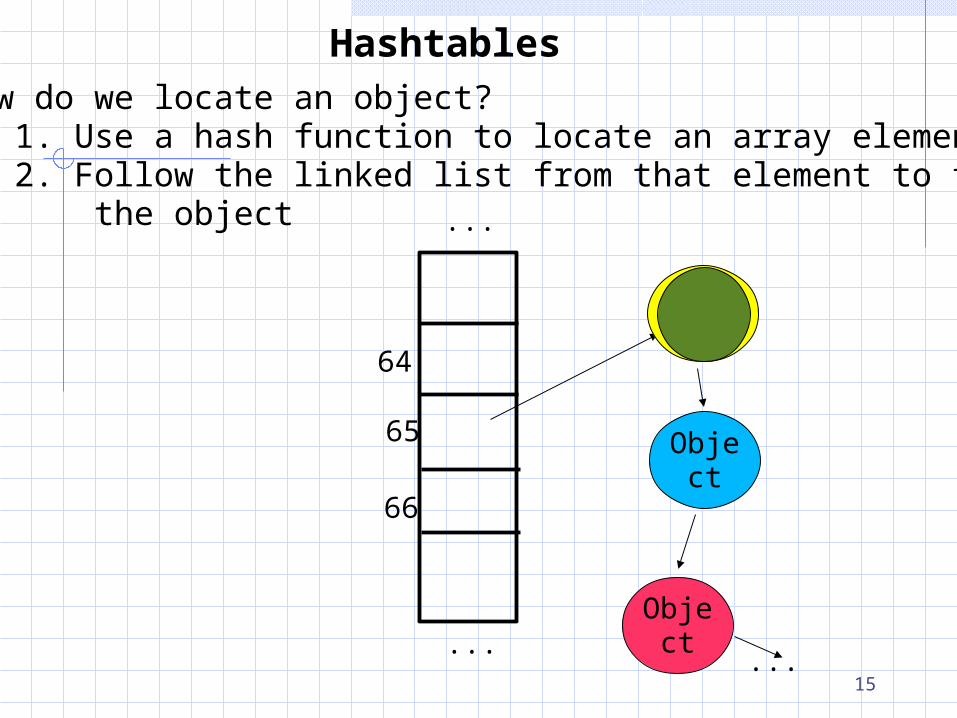
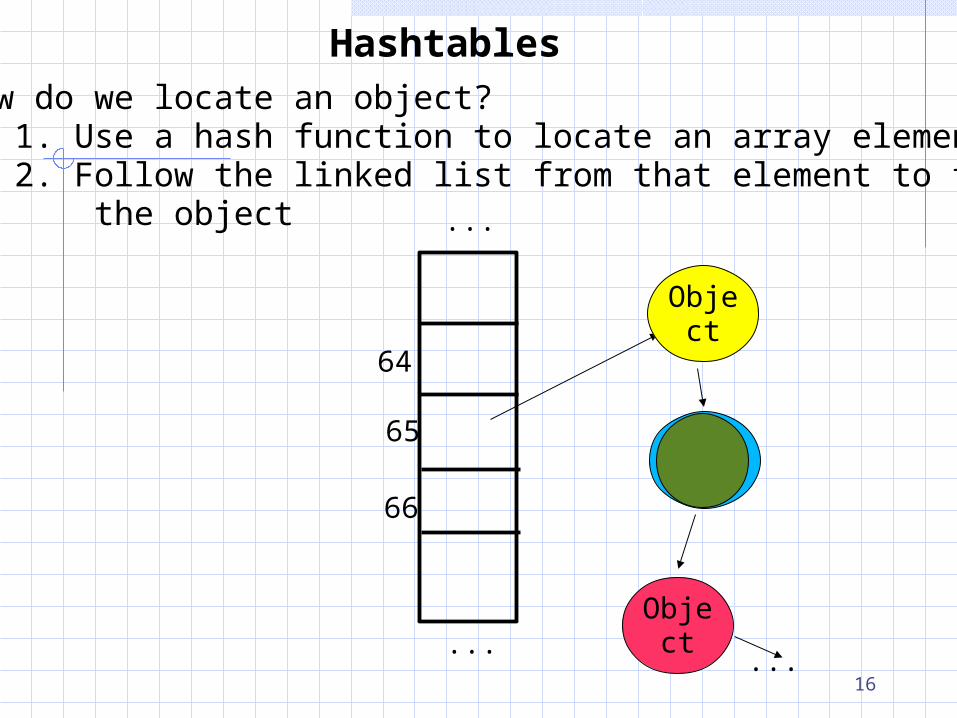
HashtablesHow do we locate an object? 1. Use a hash function to locate an array element 2. Follow the linked list from that element to find the object
...
...
64
65
66
Object
Object
Object...
15
HashtablesHow do we locate an object? 1. Use a hash function to locate an array element 2. Follow the linked list from that element to find the object
...
...
64
65
66
Object
Object
Object...
16
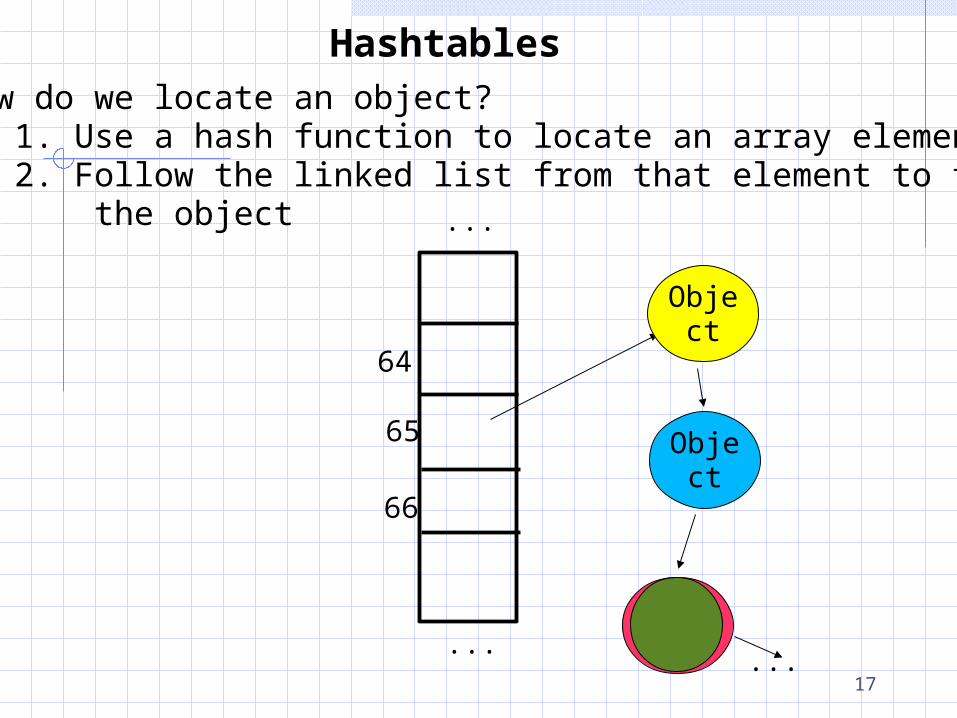
HashtablesHow do we locate an object? 1. Use a hash function to locate an array element 2. Follow the linked list from that element to find the object
...
...
64
65
66
Object
Object
Object...
17
HashtablesHow do we locate an object? 1. Use a hash function to locate an array element 2. Follow the linked list from that element to find the object
...
...
64
65
66
Object
Object
Object...

18
HashtablesNow the problem is how to construct the hashfunction and the hash table size!!!

19
HashtablesNow the problem is how to construct the hashfunction and the hash table size!!!
Let's do the hash function first. The idea is totake some object identity and convert it to somerandom number.

20
Hashtables
Now the problem is how to construct the hashfunction and the hash table size!!!
Let's do the hash function first. The idea is totake some object identity and convert it to somerandom number. Consider...
long hashvalue (void *object) { long n = (long)valfun->value(object); return (long)(n*357 % size);}

21
Table Size?
What about the table size??? If the table size isN and the number of objects stored is M thenthe average length of a linked list is M/N so ifM is about 2N the average length is 2 meaning thatto locate an object takes O(1) time!!!! Just like for arrays!!!

22
Hash ADTThe hash ADT models a searchable collection of key-element itemsThe main operations of a hash system (e.g., dictionary) are searching, inserting, and deleting itemsMultiple items with the same key are allowedApplications:
address book credit card authorization mapping host names (e.g.,
www.me.com) to internet addresses (e.g., 128.148.34.101)
Hash (dictionary) ADT operations:
find(k): if the dictionary has an item with key k, returns the position of this element, else, returns a null position.
insertItem(k, o): inserts item (k, o) into the dictionary
removeElement(k): if the dictionary has an item with key k, removes it from the dictionary and returns its element. An error occurs if there is no such element.
size(), isEmpty() keys(), Elements()

23
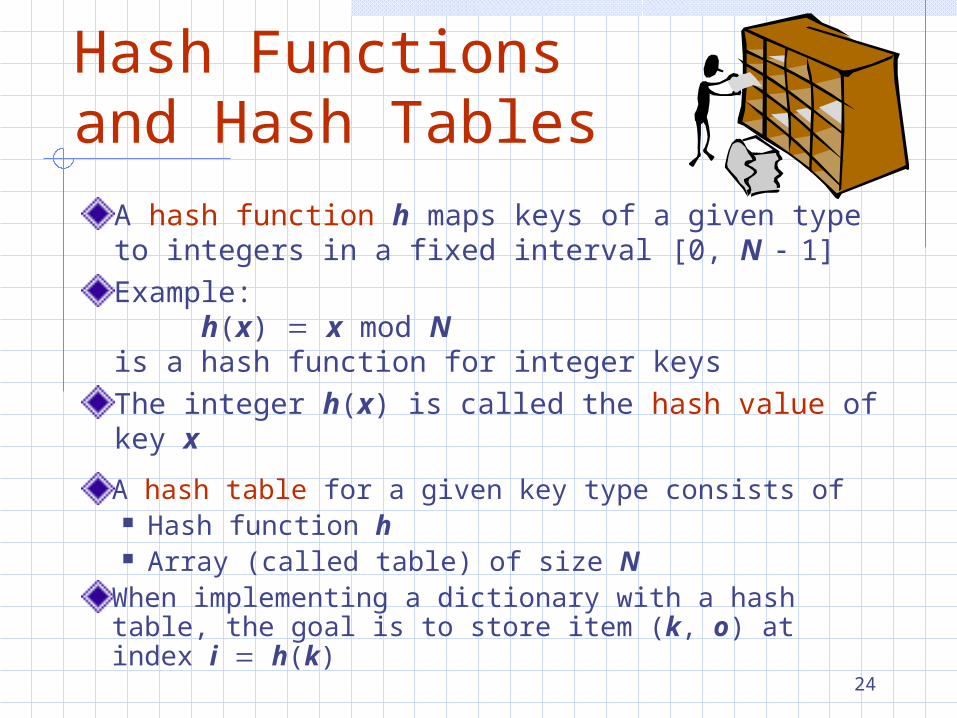
Efficiency of Hash Tables
A dictionary is a hash table implemented by means of an unsorted sequence
We store the items of the dictionary in a sequence (based on a doubly-linked lists or a circular array), in arbitrary order
Performance: insertItem takes O(1) time since we can insert the
new item at the beginning or at the end of the sequence
find and removeElement take O(n) time since in the worst case (the item is not found) we traverse the entire sequence to look for an item with the given key
24
Hash Functions and Hash Tables
A hash function h maps keys of a given type to integers in a fixed interval [0, N1]
Example:h(x) x mod N
is a hash function for integer keysThe integer h(x) is called the hash value of key x
A hash table for a given key type consists of Hash function h Array (called table) of size N
When implementing a dictionary with a hash table, the goal is to store item (k, o) at index i h(k)

25
Example
We design a hash table for a dictionary storing items (TC-no, Name), where TC-no (social security number) is a nine-digit positive integerOur hash table uses an array of size N10,000 and the hash functionh(x)last four digits of x
01234
999799989999
…4512290004
9811010002
2007519998
0256120001

26
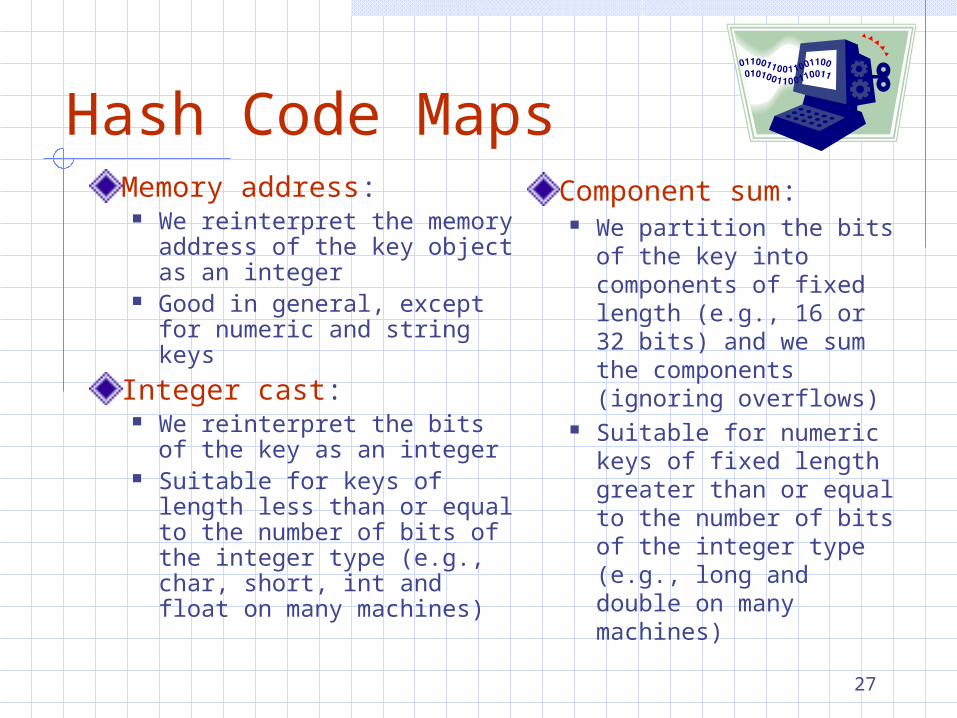
Hash Functions
A hash function is usually specified as the composition of two functions:Hash code map: h1: keys integers
Compression map: h2: integers [0, N1]
The hash code map is applied first, and the compression map is applied next on the result, i.e.,
h(x) = h2(h1(x))
The goal of the hash function is to “disperse” the keys in an apparently random way
27
Hash Code MapsMemory address:
We reinterpret the memory address of the key object as an integer
Good in general, except for numeric and string keys
Integer cast: We reinterpret the bits of
the key as an integer Suitable for keys of length
less than or equal to the number of bits of the integer type (e.g., char, short, int and float on many machines)
Component sum: We partition the bits of
the key into components of fixed length (e.g., 16 or 32 bits) and we sum the components (ignoring overflows)
Suitable for numeric keys of fixed length greater than or equal to the number of bits of the integer type (e.g., long and double on many machines)

28
Hash Code Maps (cont.)Polynomial accumulation:
We partition the bits of the key into a sequence of components of fixed length (e.g., 8, 16 or 32 bits) a0 a1 … an1
We evaluate the polynomialp(z) a0 a1 z a2 z2 …
… an1zn1
at a fixed value z, ignoring overflows
Especially suitable for strings (e.g., the choice z 33 gives at most 6 collisions on a set of 50,000 English words)
Polynomial p(z) can be evaluated in O(n) time using Horner’s rule:
The following polynomials are successively computed, each from the previous one in O(1) time
p0(z) an1
pi (z) ani1 zpi1(z) (i 1, 2, …, n 1)
We have p(z) pn1(z)

2929
Hash Functions Using Horner’s Rule
compute this by Horner’s Rule
1
0
37*]1[keySize
i
iikeySizekey
Izmir University of Economics

30
Horner’s Method: Compute a hash value
A3X3+A2X2+A1X1+A0X0
Can be evaluated as
(((A3)X+A2)X+A1 ) X+A0
Compute the has value of string junk
‘j’ ‘u’ ‘n’ ‘k’
Apply mod (%) after each multiplication!
X = 128

31
Compression Maps
Division: h2 (y) y mod N The size N of the
hash table is usually chosen to be a prime
The reason has to do with number theory and is beyond the scope of this course
Multiply, Add and Divide (MAD): h2 (y) (ay b) mod N a and b are
nonnegative integers such that
a mod N 0 Otherwise, every
integer would map to the same value b

32
Collision Handling
Collisions occur when different elements are mapped to the same cellChaining: let each cell in the table point to a linked list of elements that map there
Chaining is simple, but requires additional memory outside the table
01234 4512290004 9811010004
0256120001

3333
Handling Collisions
Separate ChainingOpen Addressing Linear Probing Quadratic Probing Double Hashing
Izmir University of Economics
3434
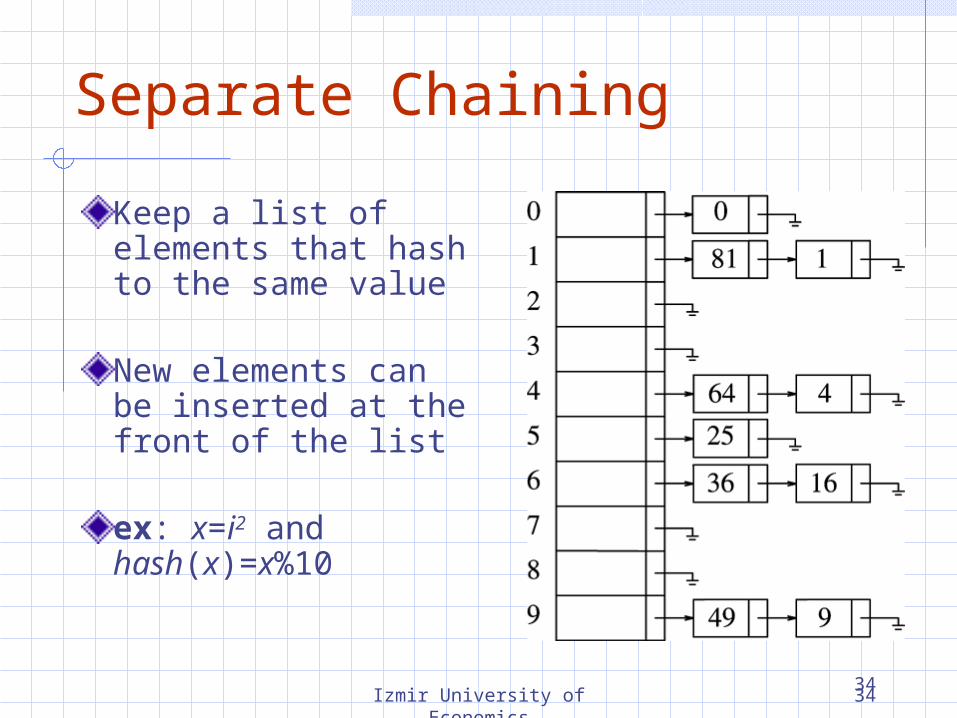
Separate Chaining
Keep a list of elements that hash to the same value
New elements can be inserted at the front of the list
ex: x=i2 and hash(x)=x%10
Izmir University of Economics

3535
Performance of Separate ChainingLoad factor of a hash table, λλ = N/M (# of elements in the table/TableSize)
So the average length of list is λSearch Time = Time to evaluate hash function + the time to traverse the listUnsuccessful search= λ nodes are examinedSuccessful search=1 + ½* (N-1)/M (the node searched + half the expected # of other nodes) =1+1/2 *λObservation: Table size is not important but load factor is.
For separate chaining make λ 1
Izmir University of Economics

3636
Separate Chaining: DisadvantagesParts of the array might never be used.As chains get longer, search time increases to O(N) in the worst case.Constructing new chain nodes is relatively expensive (still constant time, but the constant is high).Is there a way to use the “unused” space in the array instead of using chains to make more space?
Izmir University of Economics
37
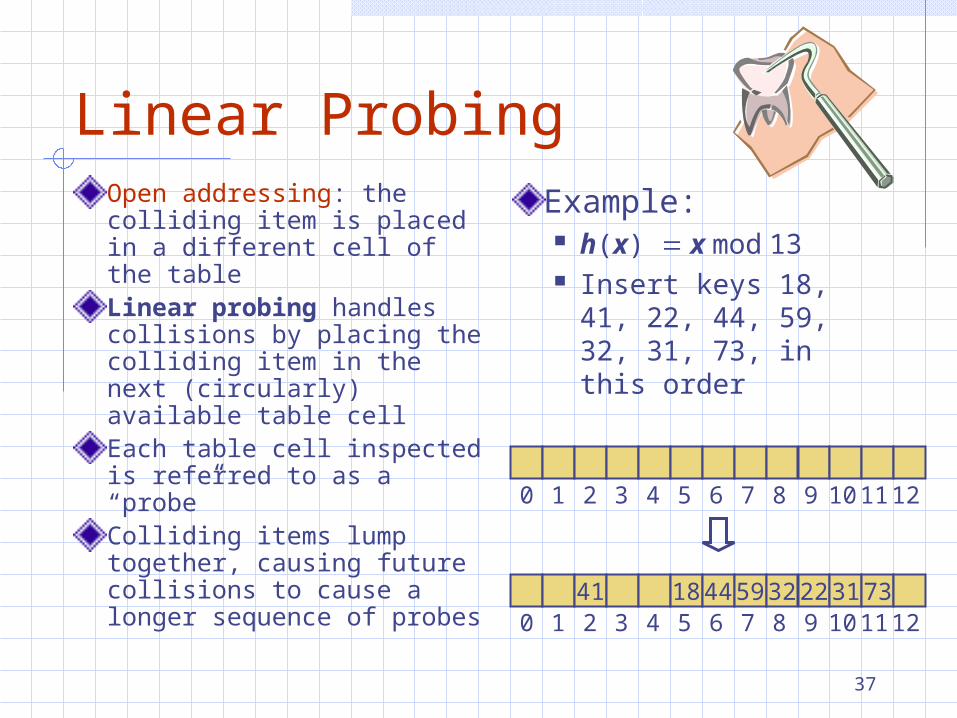
Linear ProbingOpen addressing: the colliding item is placed in a different cell of the tableLinear probing handles collisions by placing the colliding item in the next (circularly) available table cellEach table cell inspected is referred to as a “probe”Colliding items lump together, causing future collisions to cause a longer sequence of probes
Example: h(x) x mod 13 Insert keys 18, 41,
22, 44, 59, 32, 31, 73, in this order
0 1 2 3 4 5 6 7 8 9 10 11 12
41 18445932223173 0 1 2 3 4 5 6 7 8 9 10 11 12

38
Linear Probing: i = h(x) = key % tableSize
89
0
1
2
3
6
7
8
9
5
4
1889
1889
4958
1889
49 Hash(89,10) = 9
Hash(18,10) = 8
Hash(49,10) = 9
Hash(58,10) = 8
Hash(9,10) = 9
After insert 89 After insert 18 After insert 49After insert 58
589
1889
49
After insert 9
Strategy: A[(i+1) %N], A[(i+2) %N], A[(i+3) %N],...
Employing wrap around
i A A A A A

39
Quadratic Probing: i = h(x) = key % tableSize
89
0
1
2
3
6
7
8
9
5
4
1889
1889
49
58
1889
49 Hash(89,10) = 9
Hash(18,10) = 8
Hash(49,10) = 9
Hash(58,10) = 8
Hash(9,10) = 9
After insert 89 After insert 18 After insert 49After insert 58
589
1889
49
After insert 9
Strategy: A[(i+12) %N], A[(i+2 2) %N], A[(i+3 2) %N], ..., Employing wrap around
i A A A A A

40
Search with Linear ProbingConsider a hash table A that uses linear probingfind(k)
We start at cell h(k) We probe consecutive
locations until one of the following occurs
An item with key k is found, or
An empty cell is found, or
N cells have been unsuccessfully probed
Algorithm find(k)i h(k)p 0repeat
c A[i]if c
return Position(null) else if c.key () k
return Position(c) else
i (i 1) mod Np p 1
until p Nreturn Position(null)

41
Updates with Linear Probing
To handle insertions and deletions, we introduce a special object, called AVAILABLE, which replaces deleted elementsremoveElement(k)
We search for an item with key k
If such an item (k, o) is found, we replace it with the special item AVAILABLE and we return the position of this item
Else, we return a null position
insertItem(k, o) We throw an exception
if the table is full We start at cell h(k) We probe consecutive
cells until one of the following occurs
A cell i is found that is either empty or stores AVAILABLE, or
N cells have been unsuccessfully probed
We store item (k, o) in cell i

42
Exercise: A hash function
#include<string.h>
unsigned int hash(const string &key, int tableSize){
unsigned int hashVal = 0;
for (int i= 0;i <key.length(); i++)
hashVal = (hashVal * 128 + key[i]) % tableSize;
return hashVal;
}

43
Exercise: Another hash function// A hash routine for string objects
// key is the string to hash.
// tableSize is the size of the hash table.
#include<string.h>
unsigned int hash(const string &key, int tableSize){
unsigned int hashVal = 0;
for (int i= 0;i <key.length(); i++)
hashVal = (hashVal * 37 + key[i]);
return hashVal % tableSize;
}

44
Performance of Hashing
In the worst case, searches, insertions and removals on a hash table take O(n) timeThe worst case occurs when all the keys inserted into the dictionary collideThe load factor nN affects the performance of a hash tableAssuming that the hash values are like random numbers, it can be shown that the expected number of probes for an insertion with open addressing is
1 (1 )
The expected running time of all the dictionary ADT operations in a hash table is O(1) In practice, hashing is very fast provided the load factor is not close to 100%Applications of hash tables:
small databases compilers browser caches

45
Quadratic Probing With Prime Table Size
Theorem:Theorem: If a Quadratic probing is used and the table size is prime, then A new element can always be inserted if
the table is at least half empty. During the insertion, no cell is probed
twice

46
Exp: Find a prime >= n
#include<string.h>
// prime number must be at least as large as n
int nextPrime(int n)
{
if (n % 2 == ) n++;
for ( ; !isPrime(n); n +=2)
; // NOP
return n;
}

47
Universal Hashing
A family of hash functions is universal if, for any 0<i,j<M-1, Pr(h(j)=h(k)) < 1/N.Choose p as a prime between M and 2M.Randomly select 0<a<p and 0<b<p, and define h(k)=(ak+b mod p) mod N
Theorem: The set of all functions, h, as defined here, is universal.

48
Proof of Universality (Part 1)
Let f(k) = ak+b mod pLet g(k) = k mod NSo h(k) = g(f(k)).f causes no collisions: Let f(k) = f(j). Suppose k<j. Then
pp
bakbakp
p
bajbaj
pp
bak
p
bajkja
)(
So a(j-k) is a multiple of pBut both are less than pSo a(j-k) = 0. I.e., j=k. (contradiction)Thus, f causes no collisions.

49
Proof of Universality (Part 2)If f causes no collisions, only g can make h cause collisions. Fix a number x. Of the p integers y=f(k), different from x, the number such that g(y)=g(x) is at most Since there are p choices for x, the number of h’s that will cause a collision between j and k is at most
There are p(p-1) functions h. So probability of collision is at most
Therefore, the set of possible h functions is universal.
1/ Np
N
ppNpp
)1(1/
Npp
Npp 1
)1(
/)1(