dhb: a multiscale framework for analyzing activity dynamicshci.ucsd.edu/hollan/nsf-hsd.pdf · ·...
TRANSCRIPT

DHB: A Multiscale Framework for Analyzing Activity Dynamics
James Hollan, Edwin Hutchins, and Javier Movellan
University of California, San Diego
What conditions can facilitate rapid advances andbreakthroughs in behavioral science to rival thoseseen in the biological and physical sciences in thepast century? The emergence of cognitive scienceand the converging view across multiple disciplinesthat human behavior is a complex dynamic interac-tion among biological, cognitive, linguistic, social andcultural processes are important first steps. Whileempirical and theoretical work is rapidly advancingat the biological end of this continuum, understand-ing such a complex system also necessitates data thatcapture the richness of real-world human activity andanalytic frameworks that can exploit that richness.
In the history of science, changes in technologiesfor capturing data, as well as those for creating andmanipulating representations, have often led to sig-nificant advances. The human genome project, forexample, would have been impossibly complex with-out automatic DNA sequencing [31, 43]. Recent ad-vances in digital technology present unprecedentedopportunities for the capture, storage, analysis, andsharing of human activity data.
Researchers from many disciplines are taking ad-vantage of increasingly inexpensive digital video andstorage facilities to assemble extensive data collec-tions of human activity captured in real-world set-tings. The ability to record and share such data hascreated a critical moment in the practice and scopeof behavioral research. The main obstacles to fullycapitalizing on this opportunity are the huge timeinvestment required for analysis using current meth-ods and understanding how to coordinate analysesfocused at different scales so as to profit fully fromthe theoretical perspectives of multiple disciplines.
We propose to integrate video and multiscale visu-alization facilities with computer vision techniques tocreate a flexible open framework to radically advanceanalysis of time-based records of human activity. Wewill combine automatic annotation with multiscalevisual representations to allow events from multipledata streams to be juxtaposed on the same timelineso that co-occurrence, precedence, and other previ-ously invisible patterns can be observed as analystsexplore data relationships at multiple temporal andspatial scales. Dynamic lenses and annotation toolswill provide interactive visualizations and flexible or-ganizations of data.
Our goals are to (1) accelerate analysis by employ-ing vision-based pattern recognition capabilities topre-segment and tag data records, (2) increase anal-ysis power by visualizing multimodal activity and
macro-micro relationships, and coordinating analysisand annotation across multiple scales, and (3) facil-itate shared use of our developing framework withcollaborators, the wider NSF SIDGrid community,and internationally via our participation in the Rufaeaugmented environments network.
The work we propose builds on our long term com-mitment to understanding cognition “in the wild”[30], developing multiscale visualizations [5], and re-cent experience automatically annotating video offreeway driving. We propose to extend the theoryand methods developed in our earlier work and in-tegrate them with new web-based analysis tools toenable more effective analysis of human activity. Asinitial test domains we will focus on understandingactivity in high-fidelity flight simulators and the ac-tivity histories of workstation usage and the processof writing. We will also evaluate a novel technique toassist in reinstating the context of earlier activities.
Our long range objective is to better understandthe dynamics of human activity as a scientific founda-tion for design. The multidisciplinary research teamwe have assembled, spanning cognitive and computerscience and involving existing research collaborationswith investigators in learning sciences and engineer-ing, is uniquely well qualified to conduct the proposedwork, and has carefully defined a staged research ap-proach and milestone-based management plan.
The intellectual merit of our project will derivefrom developing a multiscale analysis framework forrepresenting and analyzing the dynamics of humanbehavior, integrating it with existing software toolsfor data collection, visualization, and analysis, andevaluating the augmented framework in selected real-world domains.
The broader impact of the proposed activity is toprovide critical analytic capabilities to support re-search networks in areas beyond our topical researchareas. In general, any research using video or othertime-based records in order to document or betterunderstand human activity is a potential beneficiaryof the proposed work.
Our work will be disseminated through publi-cations and a community-oriented website in ac-cordance with University policy. Regular video-conferencing interactions will serve to communicatewith current collaborators, extend interactions to awider community, and encourage continued growthof a research community with shared interests in un-derstanding the dynamics of human activity.
1

A.1 IntroductionWhat conditions can facilitate rapid advancesand breakthroughs in behavioral science to rivalthose seen in the biological and physical sciencesin the past century? The emergence of cognitivescience and the converging view across multipledisciplines that human behavior is best seen asa complex dynamic interaction among biologi-cal, computational, cognitive, linguistic, socialand cultural processes are important first steps.While empirical and theoretical work is rapidlyadvancing at the biological end of this contin-uum, understanding such a complex system alsonecessitates data that capture the richness of realworld activity.
A new generation of inexpensive digitalrecording devices and storage facilities is revo-lutionizing data collection in behavioral science,extending it into situations that have not typi-cally been accessible and enabling examinationof the fine detail of action captured in meaning-ful settings. This is important because to un-derstand the dynamics of human and social ac-tivity, we must first understand the full contextof those activities and this can only be accom-plished by recording and analyzing data of real-world behavior. While such data are certainlyneeded, more data cannot be the whole answer,since many researchers already feel that they aredrowning in data. Data without appropriate the-oretical and analytical frameworks do not lead toscientific advances.
Fortunately the revolution in digital technol-ogy can be coupled with exciting recent devel-opments in cognitive theory. While these de-velopments also heighten the importance of un-derstanding the nature of real-world activities,they are in addition beginning to provide ananalytic framework for understanding how cog-nition is embedded in concrete contexts of hu-man activity. Cognition is increasingly viewedas a process that extends beyond the skin andskull of the individual [16],[17],[31], [28],[45],[47],[49],[51]. This shift in framing the unit of anal-ysis for cognition introduces a host of previ-ously overlooked cognitive phenomena to be doc-umented, studied and understood.
Rich new digital data sources coupled with
this shift in theory promise to advance under-standing the links between what is in the mind,and what the mind is in. For example, justas widespread availability of audio tape record-ing supported the development of conversationalanalysis [22, 29, 50] and the ethnography ofspeaking [3, 24], the advent of inexpensive digi-tal video is starting to have a fundamental im-pact on cognitive science. The ability to record,view, and re-view the fine detail of action inmeaningful settings has made it possible to ex-amine the phenomena at the core of embodied[9, 14, 34, 53, 54], situated [10, 12, 13, 35, 52]and distributed cognition [31, 15]. The rise ofgesture studies in the past decade was made pos-sible by these technological changes and it is nowtransforming fields such as linguistics [43] andeducation [20].
New computational algorithms promise to fur-ther extend this transformation by enabling au-tomatic recognition, tracking, and summariza-tion of meaningful components of audio-videodata [56, 33, 40]. Thus, changes in theory giveus new phenomena to see and provide new rel-evance to things already seen. Developmentsin digital technology create potential for newtools with which to see those things [11]. Thesechanges and developments are central to HSDgoals to understand: human action and devel-opment and organizational, cultural, and soci-etal adaptation; how to anticipate complex con-sequences of change; the dynamics of human andsocial behavior at all levels, including that of thehuman mind; and the cognitive and social struc-tures that create and define change.
This proposal takes advantage of these recentdevelopments in digital technologies and theirimplications for theory in the behavioral sci-ences. We propose to develop a flexible exten-sible framework for multiscale analysis of high-density data recordings of complex human activ-ity and evaluate its effectiveness in two criticaldomains: airline flight instruction, and worksta-tion activity. We will leverage our current col-laborations with other laboratories in the areasof digital video (Stanford Diver group), com-puter vision (UCSD Computer Vision Lab andUCSD Computer Vision and Robotics Lab), and
1

augmented environments (Rufae Research Net-work).
The primary motivation for the current pro-posal derives from our belief that we are at a crit-ical moment in the practice and scope of behav-ioral research. We argue that the main obstaclesto fully capitalizing on this opportunity are thehuge time investment required for analysis usingcurrent methods and understanding how to co-ordinate analyses focused on different levels so asto fully profit from the theoretical perspectivesof multiple disciplines. The research we proposehere is part of an explicit long-term strategy toreduce the cost of performing in-depth analysis,to increase the power of analyses, and to facili-tate the sharing of analyses.
A.1.1 Reducing the Cost of Analysis
Today the high labor cost of analyzing rich ac-tivity data leads to haphazard and incompleteanalyses or, all too commonly, to no analysis atall of much of the data. Even dataset naviga-tion is cumbersome. Data records are chosen foranalysis because of recording quality, interestingphenomena, and interaction density—producinga haphazard sampling of the recorded set. Goodresearchers have a nose for good data, but alsohave a tendency to focus on small segments ofthe record that contain “interesting” behavior,analyze them intensively, and then move on tothe next project.
When analysis is so costly, few analyses can bedone—so datasets are severely underutilized—and researchers come to have a large investmentin the chosen data segments. Since each analysismay appear as an isolated case study, it can bedifficult to know how common the observed phe-nomena may be. Larger patterns and contradic-tory cases can easily go unnoticed. Well-knownhuman confirmation biases can affect the qual-ity of the science when each analysis requires somuch effort. Thus, one focus of our proposed re-search will be on the developing and assemblingtools and practices to speed and improve analy-sis. We will extend our use of computer visiontechniques to automatically annotate video datafrom our focal domains and add facilities to helpmanage and coordinate both data collection and
analysis. The goal is to facilitate the creation,maintenance and manipulation of temporal andsequential relations within and between analyses.
A.1.2 Increasing the Power of Analysis
A significant scientific challenge for all disciplinesis how to represent data so as to make importantpatterns visible. In the behavioral sciences, re-searchers transcribe and code data in a wide va-riety of ways, creating new re-representations ofthe original events [31]. Currently the coordina-tion of multiple re-representations with the orig-inal data is typically done by hand, or not at all.Since this re-representation process—includingall sorts of transcription, coding system develop-ment and implementation, and re-description—is what allows us to do science [21], even smallimprovements in automating coding, transcrip-tion, or coordination of representations can becrucially important. Recent developments in be-havioral science theory create special challengesin this regard.
Increasingly theories are concerned with pat-terns that can emerge from the interactions ofmany dynamically linked elements. Such inter-active patterns may be invisible to approachesthat decompose behavior into the more or less in-dependent components created by historical dis-tinctions among behavioral science disciplines.This is why multidisciplinary behavioral scienceis necessary. But tools that match this multidis-ciplinary vision are also needed.
Visualizing Multimodal ActivityThe richly multimodal nature of real-world hu-
man activity makes analysis difficult. A commonstrategy has been to focus on a single aspect ofbehavior or a single modality of behavior, andto look for patterns there. However, the causalfactors that explain the patterns seen in any onemodality may lie in the patterns of other modal-ities. In fact, recent work suggests that activityunfolds in a complex system of mutual causality.Analysis may still be based on decomposition ofthe activity, as long as there is a way to put thepieces back together again. That is, as long asthere is a way to visualize the relations amongthe many components of multimodal activity.
2

Visualizing Macro-Micro Relations andCoordinating Multiple Scales
The structure of the existing academic disci-plines attests to the fact that human behaviorcan be productively described at many levels ofintegration. Neuroscientists describe regularitiesat a finer scale than psychologists, who describephenomena at a finer scale than linguists, whoin turn tend to describe behavior at a finer scalethan anthropologists. A deep understanding ofthe nature of human behavior demands not onlydescription on multiple levels, but integrationamong the descriptions.
As behavior unfolds in time, describable pat-terns that take place on the scale of millisecondsare located in the context of other describablepatterns that display regularities on the scale ofseconds. Those patterns in turn are typically em-bedded in culturally meaningful activities whosestructure is described on the scale of minutes orhours. Patterns at larger time scales are cre-ated by and form the context for patterns atshorter time scales. Visualizing and reasoningabout such nested temporal relations will requirerepresentations that allow coordination of anal-yses across multiple scales.
A.1.3 Facilitating Sharing of Analyses
The high cost of performing analyses on datathat represent real-world activity means not onlythat too few analyses are conducted, but thatanalyses tend not to be shared. Most often whenresults of a video analysis are published, neitherthe activity of doing the analysis, nor the pro-cedure that was used are shared. This createsa situation in which most analyses are idiosyn-cratic and possibly non-replicable.
The multiscale timeline representation dis-cussed below promise to provide a natural foun-dation for collaborative analysis. Specialists maydo analyses in parallel and then tie them to ashared timeline backbone. Support for the co-ordination and comparison of multiple analysesmay add to the power of the analysis, while si-multaneously providing a medium for assessinginter-rater reliability. It will also make the analy-sis process itself more transparent. Making more
of the analysis process visible to a critical audi-ence of peer researchers makes science stronger.Making it more visible to students learning thetechniques improves training.
We also expect that facilitating the sharing ofanalyses will feed back to reducing the cost andincreasing the power of analyses as new tech-niques and analytic practices are discovered andshared.
A.1.4 Research Questions
The following are the motivating research ques-tions we will address:
• Can multiscale representations facilitateidentification of relationships among pat-terns in human behavior described at dif-ferent levels of integration?
• Can multiscale visualization techniques andlens-based information filtering and man-agement facilities be extended to providemore effective analysis of multimodal data?
• Is it possible using a multiscale timeline tokeep the macro context in view while ex-amining a micro analysis? And can suchtimelines help us address the long-standingproblem of visualizing and managing the re-lationships between analyses performed ondiffering timescales?
• Can existing computer vision algorithms beused effectively to automatically annotatevideo data to assist analysis?
Before detailing how we will approach theseand related questions, we give a brief exampleof a timeline-based visualization and then sketchtwo scenarios to better convey the character offacilities and analyses we are proposing.
In our work on driving, alluded to earlier,we have found timeline-based representations tobe invaluable for analyzing activity data (in-strument recordings and results of computer vi-sion annotations of video) recorded in an instru-mented car. As a simple example, Figure 1 de-picts graphs of selected car parameters coordi-nated by time and linked to GPS-derived freewaylocations.
3
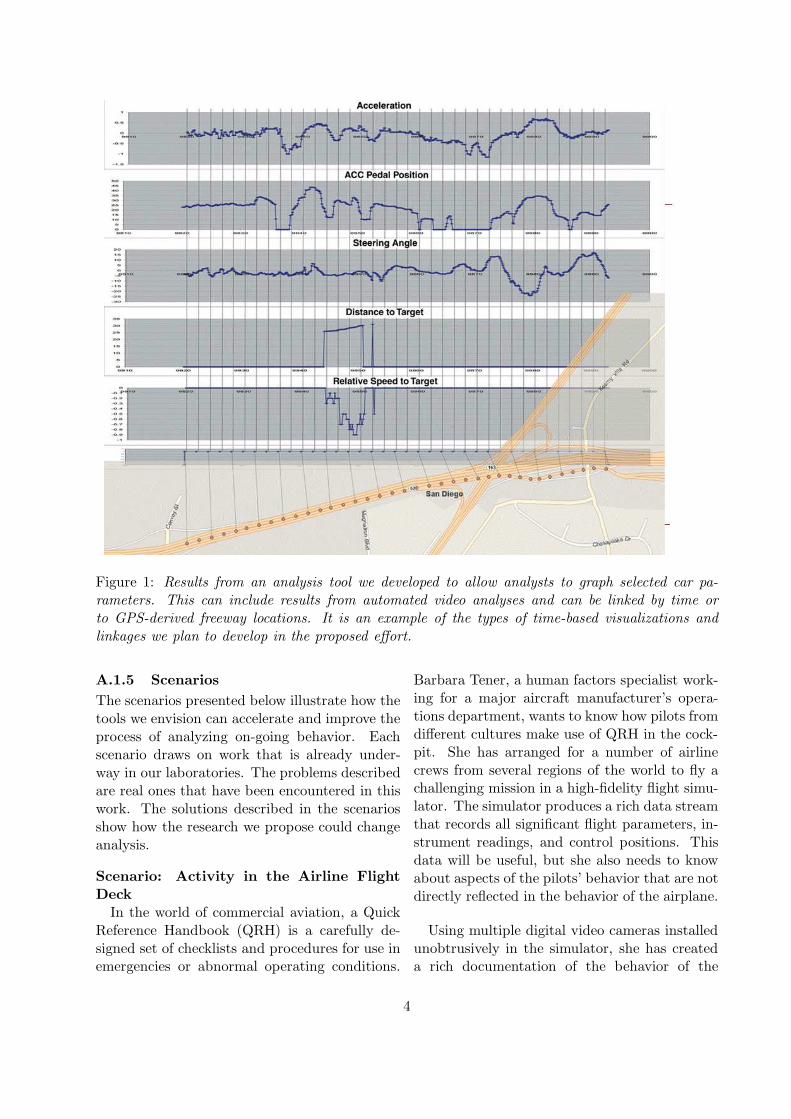
Figure 1: Results from an analysis tool we developed to allow analysts to graph selected car pa-rameters. This can include results from automated video analyses and can be linked by time orto GPS-derived freeway locations. It is an example of the types of time-based visualizations andlinkages we plan to develop in the proposed effort.
A.1.5 Scenarios
The scenarios presented below illustrate how thetools we envision can accelerate and improve theprocess of analyzing on-going behavior. Eachscenario draws on work that is already under-way in our laboratories. The problems describedare real ones that have been encountered in thiswork. The solutions described in the scenariosshow how the research we propose could changeanalysis.
Scenario: Activity in the Airline FlightDeck
In the world of commercial aviation, a QuickReference Handbook (QRH) is a carefully de-signed set of checklists and procedures for use inemergencies or abnormal operating conditions.
Barbara Tener, a human factors specialist work-ing for a major aircraft manufacturer’s opera-tions department, wants to know how pilots fromdifferent cultures make use of QRH in the cock-pit. She has arranged for a number of airlinecrews from several regions of the world to fly achallenging mission in a high-fidelity flight simu-lator. The simulator produces a rich data streamthat records all significant flight parameters, in-strument readings, and control positions. Thisdata will be useful, but she also needs to knowabout aspects of the pilots’ behavior that are notdirectly reflected in the behavior of the airplane.
Using multiple digital video cameras installedunobtrusively in the simulator, she has createda rich documentation of the behavior of the
4

flight crews. In addition to a wide-angle cam-era recording the entire cockpit, there are specialcameras aimed at the pilots and at the slots un-der the cockpit side windows in which the Cap-tain’s and First Officer’s QRHs are stowed. Var-ious audio tracks capture the pilots’ voices, radiotransmissions, and ambient noise.
Barbara would like first to document the vari-ability in the use of the QRH. The behavioraldata from each simulated flight were linked dur-ing data collection. She synchronizes the datastream from the simulator to the behavioralrecords. Then, running the analysis off-line,overnight, she creates timelines for each of thesimulator sessions using automated object recog-nition algorithms to code crew retrievals of theQRH from its storage bin. She also instructsthe analysis program to mark the onset times foreach abnormal condition as recorded in the syn-chronized simulator data stream. These timesare used by the analysis program to re-enterthe video and audio data and collect a set ofsummary videos, each one capturing events fromjust before the abnormal condition arose to theend of the crews’ first action in response to thecondition. When she returns to work in themorning, each simulator session run has been re-represented as two timelines (one for abnormalconditions, and one for QRH retrievals) and acollection of summary videos (each one capturinga proposed abnormal condition, QRH retrievalpair).
Because things can get chaotic in the cock-pit when emergencies occur, Barbara wants toreview the set of videoss collected by the pro-gram, making sure that each observed use ofthe QRH is matched to the correct triggeringcondition. That is an expert judgment, so Bar-bara asks Chuck, one of the company engineer-ing test pilots to join her. Together, Barbara andChuck review the videos detecting and repairinga few mistaken classifications. With the condi-tion/QRH retrieval pairs coded, they create acomposite timeline showing the linked pairs ofevents.
The composite timeline is a powerful repre-sentation. Because temporal relations are repre-
sented as spatial relations in the timeline, Bar-bara and Chuck can do conceptual work usingperceptual processes. They can get a feel for theorganization of the data, for example inferringthat crews respond more quickly as the exper-iment goes on, by visual inspection. The com-posite timeline also contains a measure of the la-tency between the first indication of the failureand the crew retrieving the QRH. The latencymeasure can be exported from the timeline toan off-the-shelf spreadsheet. Chuck is surprisedto see such long latencies in some cases, and goesback to the video data one more time to see whatis accounting for this. He decides he is simplyseeing the difference between test pilots and air-line pilots.
A number of tests are now possible with re-spect to QRH mobilization latency. If thewithin-flight variability is greater than thebetween-flight variability, it suggests that theproperties of the setting are the controlling vari-ables. Inspection of the timelines permits Chuckand Barbara to return to the video data witha new set of questions about the design of thecockpit, the QRH, and the airplane procedures.Using the multiscale interface to manage theinventory of data records Barbara collects therecords by culture. Is the within-group variabil-ity greater than between-group variability? Ifso, that suggests that individual differences mayswamp the effects of culture.
Documenting the variability in QRH usage asdescribed above would be prohibitively expen-sive using the tools and methods available today.And that is just the first step in a much deeperstudy of the dynamics of human behavior in thisimportant work setting. These quantitative re-sults allow researchers to make principled deci-sions about which specific instances merit closerscrutiny. Researchers can return to the videodata knowing whether the events chosen for qual-itative analysis are typical or rare.
This scenario illustrates how analysis can bejump-started by the automatic creation of time-lines. It also illustrates how these representa-tions can facilitate collaborative work, the check-ing of automated codings, noticing and testing
5

quantitative relationships, the flexible manage-ment of multiple data records, and improvedinformation about the nature of the sample ofevents chosen for analysis.
We already have in place an agreement witha major airframe manufacturer that will give usaccess to data of the sort described here. Co-PI Hutchins has eighteen years of experiencestudying the cognitive consequences of cockpitautomation. The role of culture in cockpit op-erations has recently become a critical issue inthe commercial aviation industry, but empiricalstudies based on careful analysis of flight crewbehavior are just beginning [30, 46]. This will beone important focus of our proposed research. Adescription is provided below.
Scenario: Adaptive Response of a Ship’sNavigation Team
Three researchers are working together to con-struct a detailed analysis of video recordingsof the activities of the navigation crew on thebridge of a ship. They have created a macro-leveltimeline of the changing configurations of theteam’s activity before, during, and after the fail-ure of an important piece of navigational equip-ment. This timeline documents the adaptive re-sponse of a social group to a perturbation in theirworking environment. Descriptions at this levelof analysis clearly show the dynamic response:the quality of the output of the navigation teamdeclines sharply when the equipment fails, butthen recovers in fits and starts over a period ofabout 40 minutes. Changes happen in the divi-sion of labor among the members of the team,in the way tools are used, in the way languageis used, and in the organization of the compu-tation the team is performing. Thus, at a rela-tively macro level, it is possible to describe so-cial change as interlocking dynamic reconfigura-tions of several aspects of the activity in multiplemodalities.
But what lower-level mechanisms make thisadaptive response possible? What role do themoment-to-moment dynamics of social interac-tion play in the reconfiguration of the divisionof labor among the members of the navigationteam? The researchers can show that the intro-
duction of a new tool changes the relations of thenavigators to each other and to the activity, andthat seems to facilitate explicit reflection on theorganization of the computation they are per-forming. But how do the changes in the differ-ent sub-systems interact to produce the observedoutcomes? Stated in this way, this is a classicexample of the problem of finding the relationsamong descriptions rendered at different levels ofintegration of events. The long-standing issue ofthe relationship of macro to micro descriptionsand processes is an instance of this problem.
One of the timeline representations encodesthe quality of the series of navigation fixes per-formed by the team (bottom panel in Figure2). This is one of many representations of themacro-level processes. Using representations atthis level, the researchers have identified whatthey consider to be a set of inflection points inthe adaptation of the team to the equipment fail-ure. These are points where the working config-uration of the team seems to undergo dramaticchange.
Moira uses the macro timeline to enter theoriginal video data stream at the first identifiedinflection point. Her work here consists of takingan inventory of sources of information that enterinto the computation performed by the naviga-tion team. She documents when bits of informa-tion become available in the environment andhow they are incorporated into the computationprocess. She does this by creating a new timelineon which she locates the first appearance of eachelement that is subsequently incorporated in thecomputation.
Ted examines the original timeline. It indi-cates the time at which each computational stepwas performed. By juxtaposing Moira’s newtimeline with the original timeline, he can see(as a visual pattern) that early in the adap-tive response the order in which the navigationteam incorporated new elements in their compu-tation was almost entirely driven by the order inwhich the terms appeared in their working envi-ronment. This means that the sequential orga-nization of the navigation team’s behavior wasprobably driven by aspects of the working envi-
6

Figure 2: Analysis timeline linked with ship position.
ronment rather than by an internal plan.
Ted and Alice then examine the original videoat the inflection points looking to see how thenavigator’s body and the tools interact. Movingthe digital video one frame at a time, they no-tice that at a key inflection point the navigationplotter moves his plotting tool on the chart in away that would (if it could be justified) improvethe quality of the position fixes. Using his bodyand his tools in coordination with the chart, theplotter seems to imagine a hypothetical world inwhich the position fixes are improved. A mo-ment later the plotter declares, “I know whatit’s doing!” He then follows through by intro-ducing a new term to the computational proce-dure that does in fact improve the quality of thefixes. Ted and Alice use the multiscale tools tocreate a single representation in which the move-ment of the plotting tool (millisecond timescale)is embedded in the creation and examination ofan hypothetical fix triangle (seconds timescale),which is embedded in the discovery of the newterm (minutes timescale), which is located at a
particular point in the adaptation event.
This scenario illustrates how the proposedwork might enable flexible coordination of macroand micro level representations of the activitiesof a multiperson team jointly engaged in a com-plex task. We hope it helps make the potentialanalytic value of the facilities clear. The time-line representations described in the scenariowould make possible powerful new kinds of anal-ysis. However, at present the construction andcoordination of timeline representations is pro-hibitively expensive. The coordinated timelinesshown in Figure 2, for example, required sev-eral person-months of effort to construct. Mem-bers of our laboratory are collecting digital videoof multiperson activity in a number of domains(e.g., dental hygienist training, everyday activ-ity in Japanese homes, first-responders to emer-gency situations, scientists working in their labo-ratories) and in all of them there are exciting op-portunities to employ the proposed facilitates tobetter understand activity dynamics across timescales.
7

A.2 Proposed Research
In the long term we envision a widely shared re-search infrastructure to advance understandingsof the dynamics of human activity by supportingthe types of analyses characterized in the sce-narios above. The goal of the work we proposehere is to iteratively develop an initial analysisframework and evaluate it in a set of projectscarefully chosen to demonstrate the potential ofautomatic annotation and multiscale visualiza-tion. To move towards this goal we will:
• develop a multiscale timeline for annotating,visualizing, and navigating video and otherrich time-based data
• identify existing computer vision techniquesthat promise to provide effective generalsupport for automatic annotation of videorecords and explore how to make them avail-able to analysts while requiring minimalcomputer vision expertise on their part
• evaluate the developing framework to (1) as-sist analysis of pilots’ behavior in flight sim-ulators, (2) study and characterize worksta-tion activity, and (3) represent the temporalstructure of the writing process
• make the framework available to membersof our laboratory and collaborators1 (UCSDcolleagues Morana Alac, Mike Cole, ChrisHalter, and Randy Souviney, Louis and KimGomez at Northwestern and UIC, ChuckGoodwin at UCLA, and Roy Pea at Stan-ford) in order to provide us with the feed-back necessary for iterative development
• compare automatic and manual video sum-marization as a basis for helping people toreturn to previous work contexts
Our primary concern is to better understandand support the practices and workflow involvedin analyzing actual instances of human activity
1The support letters from Cole and Souviney are rep-resentative of the excitement our colleagues have for theproposed work and of their willingness to collaborate.
(generally in naturally occurring cultural con-texts) and in interpreting, within the wider con-texts in which they are situated, the cognitiveand social import of the fine-scale details of theactivity. For the work we propose this has both amethodological and an meta-methodological as-pect.
All methods for analyzing activity involve cre-ating a cascade of representations down streamfrom the original data records. In the case ofvideo this means multiple transcriptions (e.g.,of verbal behavior, bodily behavior, and inter-actions with material and social resources), fol-lowed by the application of coding schemes, andthe production of graphical representations of re-lations among the entities identified in transcrip-tion and coding. One of our goals in this work isto automate the creation of some of the first rep-resentations in this cascade. By inserting auto-matically generated timelines that are populatedby events and objects identified by computer vi-sion techniques, we hope to increase the volume,quality, and ease navigating and analyzing thecascade of representations that follows.
The meta-methodological aspect derives fromthe fact that we are always examining our ownpractices and attempting to find more powerfultools or more appropriate techniques for doingour work. We are as interested in the so-calledsoft technologies of research practices as we arein the hard technologies of digital media andcomputation.
A.2.1 Research Foundations
Because the proposed research has grown out ofour recent work and collaborations we first dis-cuss these efforts. We end each section with ahighlighted description of how the effort has in-fluenced our plan for the proposed work.
DynapadDynapad2 is a multiscale interface and infor-
mation visualization environment developed atUCSD [1, 2, 25]. It is the third generation in thePad++ lineage of zoomable multiscale systems[5, 4]. The goal of the effort is to understand
2The development of Dynapad was supported by anNSF grant (ITR-001389).
8

Figure 3: Sample PDF portraits of a paper de-scribing and its references.
the cognitive strategies people use in managinginformation collections in visual workspaces andhow to design multiscale representations and aversatile infrastructure of tools to support thosestrategies. Dynapad currently supports multi-scale organization and management of collec-tions of digital photos and iconic representationsof journal articles.
Figure 3 depicts a collection of iconic represen-tations of PDF files. This collection includes arecent paper about Dynapad in the center. Theicons surrounding it are representations of thepapers it references. We find these automati-cally constructed image-based iconizations (thefirst page of a paper with a montage of imagesfrom the paper arrayed on it) to be effective re-minders of a paper’s content. Clicking on an iconloads the PDF in a viewer for reading. We havealso explored the usefulness of informal piles tosupport sense making and structuring of collec-tions of journal articles and of images from digi-tal cameras[1, 2].
Figure 4 depicts a portion of a Dynapadworkspace showing informally structured piles ofpapers. A timeline lens is positioned over pilesof documents to temporarily array them alonga time continuum. In this case the dates storedinside the PDF files at the time of their creationare used to layout the members of the pile. Thelens can also exploit the file date to array thesame set of papers in terms of when they enteredthe file system. The former might be useful forjudging the lineage of the papers while the latterallows easy access to a particular paper based on
when one remembers obtaining it. We expect in-formal spatial structurings and the dynamic lensarchitecture we have developed for Dynapad tobe particularly useful for supporting multiscaletimelines and management of multiscale analysesof time-based activity data.
In the proposed effort we will develop Dynapadlenses for examining video data, provide flexi-ble pile-based facilities for structuring time-baseddata, and examine multiscale representations ofvideo and other time-based data. Our plan is toexplore techniques similar to those we developedfor multiscale piles. For example, as one zoomsout of the piles the more representative imagesbecome larger. We expect that similar approacheswill be effective with video. We will also draw onthe growing video summarization literation. See[36] for a review.
Simile TimelineThe Simile (Semantic Interoperability of
Metadata and Information in unLike Environ-ments) project (http://simile.mit.edu) atMIT recently made available a very interestingopen-source timeline facility. Simile Timelineis a DHTML-based widget for visualizing time-based events in web browsers. It is similar toGoogle Maps in that it can be used without aneed for software installation and a timeline canbe populated via an XML data file.
A Simile Timeline contains one or more bandsthat can be panned by mouse dragging. A bandcan be configured to synchronize with anotherband such that panning one band also pans theother in appropriate ways, even when the twobands represent different time scales. This isa mechanism that can provide a limited formof multiscale access since each band can con-trol the mapping between pixel coordinates anddates/times.
We will integrate Dynapad with Simile Time-lines to support multiscale analysis and naviga-tion of time-based data. There are numeroustradeoffs between web-based interfaces and locallyrunning applications, especially for large videodata corpora. We will explore this tradeoff spaceso as to be able to provide analysts with an effec-tive environment that we expect will incorporate
9

Figure 4: A timeline lens is positioned over document piles in a Dynapad workspace. The lensprovides a temporary chronological ordering (by either PDF-creation date or date of entry into thefile system) of the documents. Year and month are indicated along the bottom of the lens.
both.
The Simile project has also recently added alightweight structured data publishing framework(Exhibit) that doesn’t require a database but pro-vides database-like facilities (e.g., sorting and fil-tering) within a web page. As with the integra-tion of Dynapad and Simile Timelines we willexamine how to best use a combination of web-based and local facilities to support analysis andcollaboration.
DIVERDiver (for ‘Digital Interactive Video Explo-
ration and Reflection’) [48] is an application de-veloped at Stanford for repurposing and com-menting upon audio-video source material. Wehave recently initiated a collaboration with RoyPea and other designers of Diver. Access toDiver software and support from the Diver teamwill be extremely useful for the work we proposehere.
The Stanford project and our colleagues in theTeacher Education Program here at UCSD arefocusing on use of Diver to record activities inclassroom settings using digital video cameras.The current Diver user interface is shown in Fig-ure 5. Users can zoom, pan, and tilt a virtualcamera (indicated by the yellow rectangle in Fig-ure 5) in the source video window to dynami-cally record a video segment. A Dive involves
creating a collection of clips arrayed in panelsthat show thumbnails and allow textual anno-tations. The clips are independently playable.A web-based version of Diver, WebDiver, is alsoavailable. WebDiver can be used to upload theresulting clips to the web to allow shared accessand enable collaborative commentary.
For our purposes, Diver provides an ideal toolfor extracting videos clips in the service of analy-sis, reflection, and annotation. Being able to eas-ily and precisely refer to video source segmentsand annotate them, previously available onlythrough general-purpose video editing software,makes video potentially as plastic and portableas text. To be able, while the video is running,to move the virtual camera around and changeits size and thus the portion of the video framerecorded (e.g., the hand gestures or facial expres-sions of one the participants) provides a simplenatural way to focus analysis.
We will integrate Diver and WebDiver intoour multiscale analysis framework to support ex-traction of video clips, their annotation, and theability to link them to multiscale timeline rep-resentations. We will also support linking be-tween Diver clips, timeline representations, andspreadsheets. We have found that spreadsheetsare commonly used to code and annotate videodata and we want to understand, exploit, and
10

Figure 5: DIVER (Digital Interactive Video Exploration and Reflection). The yellow rectangle onthe left allows positioning of the virtual camera with the mouse to frame sections of interest. Whilethe video is running the virtual camera can be positioned and zoomed to focus on areas of interest.The mark button allows specific positions in the video to be marked for return or replay. Pressingthe record button begins recording of a clip. During recording the virtual camera can be pannedand zoomed. Annotated clips are shown on the right. These and associated videos can be publisheddirectly to the web. See http://diver.stanford.edu for more information.
support that practice.
To effectively link video clips into our timeline-based analysis framework will necessitate ab-stracted graphical representations of the clips.There are numerous approaches for abstractingand summarizing videos. These range from sim-ple sampling-based keyframe extraction to moresophisticated techniques that attempt to analyzethe semantic content of videos. See [36] for anoverview and review. While we will draw on thisliterature and additional computer-vision tech-niques discussed below, our focus will be on de-veloping simple and general representation and
annotation facilities. We expect keyframing andmultiscale timelines to be extremely useful. Wewill support links between video and analysisbands so as to be able to flexibly move betweenthem. We will also explore overlays on the videoitself to represent how segments of video datahave been coded drawing on modern compositingtechniques [8]. In addition, analysts will be ableto easily zoom out and see all the frames of avideo segment with overlayed codes. We expectthese and related views to serve as natural in-dexing mechanisms for navigation of data andanalyses.
11

SIDGrid: The Social Informatics Data(SID) Grid
SIDGrid is an NSF-supported computing in-frastructure being designed to provide integratedcomputational resources for researchers collect-ing real-time multimodal data at multiple timescales. Data is stored in a distributed data ware-house that employs Web and Grid services tosupport storage and access.
The main tool in the existing SIDGrid infras-tructure is Elan. ELAN (EUDICO LinguisticAnnotator) is an open-source annotation toolthat allows one to create, edit, visualize andsearch annotations for video and audio data. Itwas developed at the Max Planck Institute forPsycholinguistics, with the aim to provide sup-port for annotation of multi-media recordings.ELAN is specifically designed for the analysis oflanguage, sign language, and gesture. Figure 6shows the main Elan screen. Members of ourlaboratory have experience with Elan.
We will explore use of ELAN as a componentof our analysis framework and compare and con-trast it with Diver. More importantly we willensure that our overall effort can be integratedwithin SIDGrid and connected to the associatedweb and grid services. One of us (PI Hollan)presented at the December 2006 SIDGrid meetingin Chicago and it is clear that we be welcomed asmembers of this new community. In addition weshould mention that SIDGrid is part of the Tera-Grid open scientific infrastructure and UCSD isone of the nine partner sites on the TeraGrid.
Computer VisionComputer vision techniques have advanced in
capabilities and reliability to the point that theypromise to be highly useful tools for aiding anal-ysis of video data. To characterize this poten-tial we first describe our recent experience [7]developing techniques to automatically annotatevideo of driving activities to assist a researchteam in understanding the cognitive ecology ofdriving and in designing instrumentation andcontrols to improve driver safety. In order toground design in real driving behavior we instru-mented an automobile to record multiple videostreams and time-stamped readings of instru-
Figure 6: The main Elan screen has a videoviewer, annotation density viewer, waveformviewer, timeline viewer, and media player con-trols.
Figure 7: Top: Head-Band “3rd Eye” Camera(left and middle) and view from it (right). Bot-tom: Example views from cameras. (Compositeon left, Omniview in center, and Rear view onleft)
ments and controls. This included video from ahead-band 3rd-Eye camera we developed (Figure7) and from an array of ten cameras positionedto capture views from within and around the car,as well as of the driver’s face and feet.
We are extremely encouraged by our successin automatically annotating video to assist anal-ysis. For example, we developed simple mat-lab code to compute the lateral angular veloc-ity of the head from the 3rd Eye camera video.This allowed identification of even small headposition adjustments as well as glances to therear view mirror, glances to the left or right sidemirror, and large over-the-shoulder head move-ments. We also thresholded the amplitude of
12

Figure 8: SIFT object recognition system[39]. From two training images (left), invariant features areautomatically extracted. When presented with a new, cluttered image that has extensive occlusion(center), the system uses the previously extracted features to recognize the objects (right). A boxis drawn around each recognized object. Smaller squares indicate the locations of the features thatwere used for recognition. Figure from [39].
recorded audio to index times when someonewas speaking in the car. Foot motion and lat-eral foot position were extracted from a “Foot-Cam” video using a simple detection algorithm.In combination with recordings of brake pedalpressure this enabled easily determining, for ex-ample, when drivers move their foot to the brakepedal in preparation for braking. We also devel-oped code to determine where the hands werepositioned on the steering wheel and to auto-matically compute lateral position of the car as abasis for detecting lane changes. Our experienceapplying these techniques to video data [42] willbe invaluable for the research we propose here.
While we do not have space to review all thevision-based techniques we see as applicable andpromising for automatic annotation, we brieflymention three examples: object recognition, faceand emotion detection, and pose estimation. Itis important to again note that our focus is noton developing algorithms but evaluating existingalgorithms for use in our analysis framework. Inaddition, unlike most work in computer vision,we do not typically require real-time processing.For our purposes offline processing is usually suf-ficient.
Object Recognition It would be a boon todigital video analysis if the computer could au-tomatically label all (or even most) frames or
segments of video in which a particular objectis present. For example, if analysts are inter-ested in activities involving interaction with spe-cific objects, they might want to view only thosesegments of video that involve those objects. Toevaluate this capability, we will explore a num-ber of recognition methods. One very promis-ing candidate uses distinctive invariant featuresextracted from training images as a basis formatching between different images of an object.An important aspect of the SIFT (Scale Invari-ant Feature Transform) technique [39] is that itgenerates large numbers of features that denselycover the image over the full range of scales andlocations. The features are invariant to imagescale and rotation, and provide robust matchingacross a substantial range of affine distortion, ad-dition of noise, change in viewpoint, and changein illumination. For example, objects, such asthe toy frog and train depicted in Figure 8, canbe found in complex scenes with extensive occlu-sions.
Since this algorithm is probabilistic, we canallow the user to modify the algorithm’s thresh-old depending upon the task. For example, thethreshold for object detection could be set at alow value in which virtually every frame thatcontains the object is detected, with the priceof having some false alarms (flagged frames in
13

Figure 9: Left: The 3D tracking algorithm GFlow at work in outdoor conditions. The points onthe face are not physical, but are rendered by the computer to demonstrate that it has tracked thedesired facial features. The algorithm simultaneously estimates the pose of the head (3 dimensionalreference axis in bottom left corner) and face deformations. Once the head pose is known, multiplecamera angles (Center) can be synthetically rotated and merged to render the face from any desiredviewpoint (Right).
which the object is not actually present). In thiscase, a small amount of user intervention wouldbe required in order to cull the false alarms fromthe true detections. On the other hand, the ob-ject detection threshold could be set at a highvalue in which there would be virtually no falsealarms (every flagged frame is a true detection),with the price that in some frames the objectwould be present but not detected. Dependingupon the analysis task (finding every instance vs.finding a collection of representative instances),one or the other threshold (or somewhere in be-tween) might be appropriate.
Face and Emotion Detection There aremyriad ways in which computerized face detec-tion and face tracking could enable new typesof analyses with huge potential gain and mini-mal time commitment on the part of the analyst.Current face detection algorithms [55] could beemployed to annotate the video so that appropri-ate video segments could be located quickly andaccurately. One example of the state of the artin current research is work by one of our recentPh.D. students3 [41] to automatically annotate
3The graduate experience of Tim Marks exemplifiesthe type of cross laboratory training we expect to pro-vide for graduate students associated with the proposedproject. While PI Hollan was the chair of his commit-tee, Marks worked both in the Distributed Cognition andHCI Lab in Cognitive Science and the Machine Percep-tion Laboratory in the Institute for Neural Computation,
a video with the subjects’ emotions, as deter-mined by their facial expressions. Computerizedfacial expression analysis can be done with exist-ing technology on frontal views of faces [38]. Toanalyze facial expressions from non-frontal viewsof a person’s face, sophisticated 3D tracking al-gorithms such as G-flow [41] can be used to findthe 3D pose of the face and the 3D locations ofkey points on the face from 2D video of the sub-ject. By fitting the 3D locations of these keypoints to a database of laser scans of humanheads [6], we can synthetically rotate the facefrom any viewpoint to a frontal view (see Fig-ure 9), from which the emotion of the subjectcan be determined using the aforementioned fa-cial expression analysis system.
Head Pose Estimation Erik Murphy-Chutorian just defended his dissertationproposal (PI Hollan is a member of his commit-tee). Erik plans to investigate pose-invarianthead and hand detection, head pose estimation(see Figure 10), tracking of heads and handsacross multiple views, head and hand gestureextraction, and spatio-temporal analysis ofhuman activities.
We will select computer-vision techniques thatare promising for use in the types of automatic
where he was supervised by PI Movellan. Currently Timis a postdoc in the Department of Computer Science andEngineering.
14

Figure 10: Example pose estimates smoothed over time. SIFT-prototype detectors were appliedto every frame and the pose track was smoothed using a Kalman filter. Pose is indicated by thedirection of the blue circle overlay.
annotation we described above. They will rangefrom techniques for simple recognition of objectsto facial, emotion, and pose orientation detec-tion.
In addition, we will explore interfaces to allowanalysts to parameterize these facilities and con-nect them together using a visual interface muchlike the recent Yahoo Pipes interface (http:// pipes.yahoo. com ). For our work the feedswill be video streams (rather than RSS feeds)with connections to recognition and visualizationfacilities. Our goal is to ease connecting andparameterizing annotation functions in order tomake them more accessible to analysts.
While we expect that our students and collab-orators will explore use of our developing analy-sis framework in a wide range of areas, we pro-pose to focus our efforts on three areas: under-standing how airline pilots learn in flight simula-tors, normal workstation activity, and the writ-ing process. The first area is chosen becausethe activity is dynamic and richly multimodaland the outcomes have social significance. Inaddition, the fixed nature of the simulator en-vironment will allow us to exploit that struc-ture to simplify vision-based annotation in wayssimilar to recording in automobiles. The sec-ond area was selected because of the increasingimportance of workstation activity in almost ev-ery aspect of professional and personal life. Hereagain we expect vision-based annotation to ben-efit from the known structure of the display and
interface components as well as methods of in-teraction. In addition, as in our work studyingdriver activity in which we had access to all in-strumentation, with the workstation we have de-tailed access to the process and applications thatare running and in some cases even to video ofworkstation users. Finally, because of develop-ments in another research project we have easyaccess to capture and record the content andtemporal structure of paper-based writing activi-ties. We will capitalize on our recent experienceswith digital pen software to provide us with adifferent form of time-based data, the analysis ofwhich should help us to ensure a greater gener-ality of our framework.
In the next sections we discuss these threedomains and a novel application of repurposedvideo from workstation recording to help peopleto reestablish the context of earlier activity.
A.2.2 Flight Simulator Activity
Under a multi-year agreement with the BoeingCommercial Airplane Group, co-PI Hutchins hasnegotiated access to training activities at a num-ber of airlines outside the US. (Security provi-sions enacted in the wake of the 9/11 terroristattacks have made work with US airlines impos-sible.) Boeing’s interests lie in specific applica-tions and interventions concerning training, op-erating procedures, and flight deck design in thenext generation of airline flight decks. Boeing’sgoals are not the focus of the work we describein this proposal.
15

However, the video data generated by the Boe-ing project are available to us for other sorts ofanalysis. In addition, we already have a HumanResearch Protections Program protocol in placefor collecting and analyzing this data. (UCSDHRPP Project No. 050582, “Flight Deck Cul-ture for the Boeing 787”)
Hutchins has already collected video data inJapan and New Zealand, and expects to acquireadditional data from Australia and Mexico in2007. In addition to collecting data in simula-tors located at the training centers of non-USairlines, the project also collects data in simula-tors located at the Alteon/Boeing training centerin Seattle.
These data provide an absolutely unique lookat complex, highly structured, expert activity ina setting that is spatially, temporally and insti-tutionally constrained. These properties makethis data ideal for the purposes of the currentproposal. The activities that we record in high-fidelity flight simulators are complex. They in-volve the production of multimodal acts of mean-ing making that are embedded in social and ma-terial context. The script-like structure of phasesof flight and of flight deck procedures provides acommon framework with respect to which theactivities of different pilots and even differentpopulations of pilots can be compared. This at-tribute of the activity also makes it a good earlychoice for exploration with time line representa-tions because there are recognizable shifts in ac-tivity structure in successive phases of flight. Bythe time they are in training for commercial airoperations, pilots have high levels of expertise.Studying expert real-world skills is important,but difficult to do because analysts must haveconsiderable expertise themselves in order to in-terpret the significance of the presence (or ab-sence) of particular behaviors. Fortunately, co-PI Hutchins’ years of experince as a jet-rated pi-lot and as an aviation researcher provide the nec-essary analytic expertise. The spatial and tem-poral constraints on activity in the flight deckmake data collection tractible in the sense thatrecording equipment can be installed in fixed lo-cations, or attached to the clothing of the partic-ipants, and the activities to be recorded are sure
to take place in an anticipated amount of time(usually about two hours). The institutionalconstraints guarantee that the data recordingswill be rich in observable activity (little downtime) because of the high cost of operating thesimulator. Finally, it is sometimes possible toacquire a rich digital data stream from the sim-ulator itself (this depends on the practices of thetraining department involved). Time synchingsimulator data to the observational data providesa documentary richness that is simply not pos-sible in most activities. It is, however, an ex-act mirror image of the data collection strategiesto be pursued in our proposed investigation ofworkstation activity described in the next sec-tion.
Our observations in Japan have already re-vealed that language practices in the Japaneseairline flight deck can be seen as adaptations toa complex mix of exogenous constraints. Insti-tutions, such as regulatory agencies, adapt tothe constraints of global operations when settingthe rules that govern airline operations; the deci-sion that air traffic control communications shallbe conducted in English, for example. Airlinesadapt to the regulatory environment, the mar-ketplace, the characteristics of their workforceand the nature of the technology when settingtraining and operational policies. Pilots adaptto the residues of the adaptive behaviors of in-stitutions in constructing meaningful courses ofaction in flight [30].
Commercial aviation is a complex socio-technical system, that has developed mostrapidly in North American and Europe. Becausewe are working with non-US airlines, we are alsoable to examine how other cultures integrate thepractices of commercial aviation into their par-ticular cultural and cognitive ecology [46]. Thisis a unique perspective on the globalization ofone of the most complex socio-technical systemsin today’s world. Dramatic changes in the demo-graphics of the global population of commercialairline pilots are currently underway. For exam-ple, the mean age of pilots worldwide is rapidlydecreasing as aviation expands in Asia and LatinAmerica.
16

The data collected in the Alteon/Boeing train-ing center is expecially interesting from a HSDpoint of view because it involves American flightinstructors working with pilots from other na-tions. These data permit us to examine the dy-namics of a special case of intercultural learning.Airline pilots everywhere share certain elementsof professional culture, but in intercultural train-ing, professional culture becomes a resource forovercoming the boundaries of national culture.They permit us to see the contextual groundingof intercultural communication and learning [30].
Pilot and instructor behavior in flight simula-tor sessions is a class of dymanic human activitythat is both theoretically interesting and method-ologically tractible. The intercultural aspects ofthe globalization of commercial aviation add tothe societal significance of this work. Our at-tempts to analyse this class of activity also pro-vide an excellent testbed for the development oftools that can enhance our understanding of thedynamics of human activity.
A.2.3 Workstation Activity
There is a long history and a recent resur-gence of interest in recording personal activ-ity. Personal storage of all one’s media through-out a lifetime has been desired and discussedsince at least 1945, when Vannevar Bush pub-lished As We May Think, positing the Memex,a device in which an individual stores all theirbooks, records, and communications, and whichis mechanized so that it may be consultedwith exceeding speed and flexibility. His visionwas astonishingly broad for the time, includingfull-text search, annotations, hyperlinks, virtu-ally unlimited storage and even stereo camerasmounted on eyeglasses.
Today, storage, sensor, and computing tech-nology have progressed to the point of makinga Memex-like device feasible and even afford-able. Indeed, we can now look beyond Memexat new possibilities. In particular, while mediacapture has typically been sparse throughout alifetime, we can now consider continuous archivaland retrieval of all media relating to personalexperiences. For example, the MyLifeBits [19]project at Microsoft Research is recording a life-
Figure 11: Examples of attributed-mapped scrollbars from our early work on ReadWear and Ed-itWear. One the left is a normal scroll bar andon the right are examples of visualizing the his-tory of editing activity. We were able to showdata such as who edited and the time taken inediting.
time store of information about the life of Gor-don Bell. This includes not only video but thecapture of a lifetime’s worth of articles, letters,photos, and presentations as well as phone calls,emails, and other activities. This and relatedprojects are documented in the recent series ofACM CARPE workshops on capture, archiving,and retrieval of personal experiences.
Although what we propose is related to andencouraged by this general zeitgeist, our pro-posed effort is primarily complementary to otherwork in this area. Instead of focusing on thetechnology to collect, store, and access rich videoand other records of activity, we will focus ontimeline-based multiscale visualization and anal-
17

ysis of workstation and writing activity.
History-Enriched Digital ObjectsWe have long been interested in visualizing ac-
tivity histories. In our early work on ReadWearand EditWear [26] we modified an editor to col-lect detailed histories of people editing text orcode and made those histories available in thescrollbar of the editor (see Figure 11) in ways toinform subsequent activity.
Over the last few years we have conduced aseries of pilot projects in which we collectedworkstation activity of users. While there arecommercial software products 4 to record suchactivity, none of these products can be modi-fied in ways needed to be integrated into ex-perimental analysis frameworks or linked withour multiscale visualization facilities. Like otherresearchers we have been tempted to build ourown software to perform such recording func-tions. For example, in one of our efforts webuilt facilities to record low-level operating sys-tem call activity on a workstation and then ex-plored parsing that low-level activity record intohigher level activity descriptions. The motiva-tion was to have recording facilities that did notrequire modification to any applications our par-ticipants used in their normal workstation activ-ity.
We are now convinced that unless recordingand analysis software is openly available and in-tegrated within a shared infrastructure it is un-likely to be useful for the growing research com-munity interested in understanding the dynam-ics of human activity. In our proposed work wewill make use of the recently available Glassboxsoftware.
Glass BoxGlass Box is a system being developed by the
government to provide an instrumented infras-tructure for research activity in the intelligencecommunity. The focus is on understanding work-station activity of an intelligence analyst and the
4For example, TechSmith’s Morae product(www.techsmith.com/morae) records screen videowith a list of synchronized system events and Et-nio (www.ethnio.com) designed by one of our formerstudents supports remote recording of workstationactivity.
Figure 12: Glass Box Analysis and Research En-vironments.
general analytic processes that happen online.Glass Box is a component in a larger effort of theAdvanced Research and Development Activity(ARDA) to “create a new generation of analytictools to support human interaction with infor-mation.” [18] The software provides automateddata capture of time-stamped activities such asbrowser activity, active applications, file activ-ity, text that is copied/pasted, keyboard/mouseactivity, and screen captures that provide “over-the-shoulder” video of activity. Also providedare review tools for researchers to view and fil-ter data as well as an API to enable access toa central data repository as well as integrationof experimental components. It is starting to beused by a number of research efforts (e.g., a Parceffort employs it to study web browsing activity).We have recently downloaded the software andare in the process of installing it in our lab.
We will integrate Glass Box software into ourdeveloping visualization and analysis frameworkand explore use of the TeraGrid as a storage in-frastructure to facilitate access by the SIDGridcommunity. We will record workstation activ-ity while participants are conducting their nor-mal activities and evaluate automatic annotationof the resulting video data. One of our students,Gaston Cangiano, is collecting workstation ac-tivity in a legal office with the goal of automat-ically identifying meaningful events in partici-pants workstation activity. We will focus first onthis data. In addition, we will also collect activ-ity data while participants are engaged in othertasks (e.g., work on editing a paper, analyzingdata, or creating a graph or figure for including
18

in a publication) that arise as part of their nor-mal work activities.
Our main focus will be on segmenting videodata (captured from workstation framebuffers)into meaningful units, multiscale visualization ofthose components on timelines, and identifica-tion of landmarks in the activity structure. Wewill use both video annotations and access to ap-plication activity provided by Glass Box faciltiesas a basis for segmentation and landmark iden-tification. Our plan is to compare participants’segmentation and landmarks with both analysts’and those we create automatically.
A.2.4 Writing ActivityOpportunistic use of software from anotherproject [37] will enable us to collect time-basedrecords of the writing process. Francois Guim-bretiere of the University of Maryland, PI Hol-lan, and their collaborators have developed Pa-pierCraft [37], a gesture-based command systemto support interactive paper. It is based onGuimbretiere’s earlier Paper Augmented DigitalDocuments (PADD) work [23]. The motivationof both systems is to explore putting the digitaland paper worlds on equal footing, one in whichpaper and computers are simply different waysto interact with documents during their lifecycle.When paper affordances are needed, a documentis retrieved from a database and printed. Theprinter acts as a normal printer but adds a pen-readable pattern to each document. Using a dig-ital pen, the document can then be marked likea normal paper document. The strokes collectedby the pen are combined with the digital versionof the document. The resulting augmented doc-ument can be edited, shared, archived, or par-ticipate in further cycles between the paper anddigital worlds.
Digital pens provides access to time-stampedrecords of every pen stroke. This time informa-tion is used in our PapierCraft project to helpdisambiguate gestures but for the current work itcan provide histories of the writing process. Thevisualization of such histories will force our de-veloping analysis framework to confront a differ-ent form of time-based data.
While it is beyond the scope of the work we
propose here, we envision a variety of future ap-plications based on access to and analysis of en-capsulations of the history of the writing process.This may open up exciting research and applica-tion possibilities.
A.2.5 Reestablishing Context of ActivityIn recent work we asked participants from ourdriving experiments to return to the lab to viewfirst-person video records of portions of theirdriving activity as part of extended interviews.We were struck by the vividness of participants’recall while viewing video of their own activity.Saadi Lahlou, one of our collaborators5 has re-ported similar findings. He mentions that one ofthe most remarkable properties of viewing sub-cam video is “an exceptional capacity of recollec-tion. Even weeks or months after the recordedepisode, subjects are able to remember emotionsand intentions.”
We were similarly struck by a recent reportfrom the first in-depth study[27] of the Sense-Cam, a novel sensor-augmented wearable stillcamera. Investigators here too found startlingimprovements in recall with first-person video.In this case it was part of a 12-month clinicaltrial with a patient suffering from memory prob-lems originating from brain injury. Not only didreview of images show decided advantage overreview of a detailed diary but memory actuallyimproved during periodic reviews and was main-tained for months afterward. Memory was lostin days with no aid or even with review of a de-tailed diary.
While, as mentioned earlier, there is muchwork on video summarization, to our knowledgenone of this is based on first-person video suchas that we are examining. As part of a specu-lative addition to our main research we will ex-plore how reviewing segments of video from ear-lier workstation and writing activity might helpreestablish the context of those activities. We willcompare conditions in which no aid is presented
5Saadi Lahlou directs the Laboratory of Design forCognition at EDF in Paris and is the originator of theSubcam, a personal video recorder, that we have used inour driver studies. The subcam is a small video cameramounted to glasses and connected to a mini-dv portablebattery operated video recorder.
19

with those in which short video clips are viewed.The video clips will either be created by an ex-perienced videographer (Adriene Jenink, VisualArts professor at UCSD, has agreed to collab-orate with us and also assist in recruiting othervideographers) using advanced video editing facil-ities, by our research team using Diver to createclips, and by a variety of automatic techniqueswe will be exploring as a basis for automatedtimeline annotation of the video data.
A.2.6 Management PlanOur project management plan has two dimen-sions: four activity domains (flight simulator,workstation, writing, and reestablishing context)by three tool building components. We will fo-cus on flight simulator and workstation activ-ity in year one, adding writing and reestablshingcontext in the out years. Each of the three com-ponents to tool building will be led by one ofthe PIs: (1) Exploration of the application ofcomputer-vision techniques, (Movellan) (2) De-velopment of multiscale visualizations (Hollan)and, (3) Coordinating analysis across multiplelevels (Hutchins). Hollan will be in charge ofoverall management of the project. Because thePIs are located on the same campus, it is easy toarrange frequent meetings with students (grad-uate and undergraduates) and other local par-ticipants. In the first two months of the projectwe will have a series of planning meetings andretreats in which we will match the needs of theproject components with the abilities and inter-ests of participants. Since the world of softwareis changing so rapidly, we will also use thesemeetings to adapt our plans to take best advan-tage of the available technologies.
Through our experience in a fundamentallyinterdisciplinary department and laboratory wehave learned how to establish and maintain a re-search culture in which our students appreciatedifferent academic cultures (e.g., engineering andanthropology) and work together in an atmo-sphere of mutual respect. In the planning meet-ings we will also set milestones for each projectcomponent, and for the integration of the com-ponents. The overall milestone structure will in-clude publication each year of at least one paperfor each tool building component.
Once work is underway, we forsee periodicmeetings at three levels of integration. Withineach project component, PIs and students willmeet very frequently to do the work. Meetingsof the assembled project teams will take place atleast monthly. Meetings with our user commu-nities (local in person and extended via telecon-ference) will take place quarterly, at first to up-date users on development progress and to iden-tify requirements, later as part of the on-goingevaluation of their use of newly created analysisfacilities.
Project management will also benefit fromoutside advice. We are well connected to aninternational network of behavioral scientistswho are exploring the organization of real-worldhuman activity (Stanford:Pea, UCLA:Goodwin,Nijmegen:Levinson, Paris:Lahlou). By keepingthe community abreast of our efforts, we ex-pect the community to be able to learn fromour successes as well as our failures. By shar-ing tools and ideas with this community, we ex-pect to be able to better understand the natureof the stumbling blocks that impede progress inbehavioral sciences as well as to better under-stand the role that our evolving multiscale anal-ysis framework can play in removing these stum-bling blocks. We are also fortunate to be ableto seek advice from RUFAE (Research on UserFriendly Augmented Environments), a newlyformed international network of research insti-tutions (see http://www.rufae.net involved indesigning and studying interactive spaces. Wewill draw on the expertise of this group as asounding board for advice about privacy, eval-uation, and other issues that arise. We expectSaadi Lahlou to be an especially valuable re-search contact. He directs one of the largestlabs in Europe devoted to video-based analysisof group interaction. Also Lahlou and NorbertStreitz, another Rufae member, lead a groupmaking recommendations on privacy to the Eu-ropean research community. Privacy policies andissues are central to our proposed research andwe expect them to be an important managementissue as well. One of the expected outcomes ofour project will be documentation of best prac-tices in using digital video in research.
20

B References
[1] Dan Bauer, Pierre Fastrez, and Jim Hol-lan. Compuationally-enriched piles for man-aging digital photo collections. In Pro-ceedings of the IEEE Symposium on VisualLanguages and Human-Centric Computing,2004.
[2] Dan Bauer, Pierre Fastrez, and Jim Hol-lan. Spatial tools for managing personalinformation collections. In Proceedings ofthe 38th Hawaii International Conferenceon System Sciences, 2005.
[3] R. Bauman and J. Sherzer. Explorationsin the Ethnography of Speaking. CambridgeUnivesity Press, 1989.
[4] Ben B. Bederson, James. D. Hollan, KenPerlin, Jon Meyer, David Bacon, andGeorge Furnas. Pad++: A zoomable graph-ical sketchpad for exploring alternate inter-face physics. Journal of Visual Languagesand Computing, 7:3–31, 1996.
[5] Benjamin B. Bederson and James D. Hol-lan. Pad++: A zooming graphical interfacefor exploring alternate interface physics.In Proceedings of the ACM Symposium onUser Interface Software and Technology,pages 17–26, 1994.
[6] Volker Blanz and Thomas Vetter. A mor-phable model for the synthesis of 3D faces.In SIGGRAPH’99 conference proceedings,pages 187–194. ACM, 1999.
[7] E. Boer, D. Forster, C. Joyce, P. Fas-trez, J.B. Haue, M. Chokshi, E. Garvey,T. Mogilner, and J. Hollan. Bridgingethnography and engineering through thegraphical language of petri nets. In Proceed-ings of the 5th International Conference onMethods and Techniques in Behavioral Re-search, 2005.
[8] Ron Brinkmann. The Art and Science ofDigital Compositing. Morgan Kaufmann,San Francisco, 1999.
[9] Rodney Brooks. Intelligence without rep-resentation. Artificial Intelligence, 47:139–159, 1991.
[10] John S. Brown, Allan Collins, and PaulDuguid. Situated cognition and the cul-ture of learning. Educational Researcher,18(1):32–41, 1989.
[11] S. Card, J. D. MacKinlay, and B. Shnei-derman, editors. Readings in InformationVisualization. Morgan Kaufmann, 1999.
[12] S. Chaiklin and J. Lave. UnderstandingPractice. Cambridge University Press, NewYork, 1996.
[13] William Clancey. Situated Cognition: OnHuman Knowledge and Computer Repre-sentations. Cambridge University Press,1997.
[14] Andy Clark. Being There: Putting Brain,Body and World Together Again. MITPress, 1997.
[15] Andy Clark. Mindware. Oxford UniversityPress, 2001.
[16] Andy Clark. Natural-Born Cyborgs: Minds,Technologies and the Future of Human In-telligence. Oxford University Press, 2003.
[17] Michael Cole. Cultural Psychology: A Onceand Future Discipline. Belknap Press, 1996.
[18] Paula Crowley, Lucy Nowell, and JeanScholtz. Glass box: An instrumented in-frastructure for supporting human interac-tion with information. In Proceedings of theHawaii International Conference on SystemSciences, 2005.
[19] Jim Gemmell, Gordon Bell, Roger Lueder,Steven Drucker, and Curtis Wong.Mylifebits: fulfilling the memex vision.In MULTIMEDIA ’02: Proceedings of thetenth ACM international conference onMultimedia, pages 235–238, New York, NY,USA, 2002. ACM Press.
21

[20] Susan Goldin-Meadow. Hearing Gesture:How our hands help us think. Belknap: Har-vard University Press, 2003.
[21] Charles Goodwin. Professional vision.American Anthropologist, 32:1489–1522,2000.
[22] Charles Goodwin and J. Heritage. Conver-sation analysis. Annual Review of Anthro-pology, 96:283–307, 1990.
[23] Francois Guimbretiere. Paper augmenteddigital documents. In Proceedings of theACM Symposium on Suer Interface Soft-ware Technology, pages 51–60, 2003.
[24] J. J. Gumperz and D. Hymes. Directions inSociolinguistics. Blackwell, Oxford, 1986.
[25] Jon Helfman and James Hollan. Imagerepresentations for accessing and organizingweb information. In Proceedings of the SPIEInternational Society for Optical Engineer-ing Internet Imaging II Conference, pages91–101, 2001.
[26] William C. Hill, James D. Hollan, DaveWroblewski, and Tim McCandless. Editwear and read wear. In Proceedings of ACMCHI’92 Conference on Human Factors inComputing Systems, Text and Hypertext,pages 3–9, 1992.
[27] Steve Hodges, Lyndsay Williams, EmmaBerry, Shahram Izadi, James Srinivasan,Alex Butler, Gavin Smyth, Narinder Kapur,and Ken Wood. Sensecam: A retrosepc-tive memory aid. In Proceedings of Ubicomp2006, pages 177–193, 2006.
[28] J. Hollan, E. Hutchins, and D. Kirsh. Dis-tributed cognition: Toward a new theo-retical foundation for human-computer in-teraction research. ACM Transactions onHuman-Computer Interaction, pages 174–196, 2000.
[29] I. Hutchby and R. Wooffitt. ConversationAnalysis. Polity Press, 1998.
[30] E. Hutchins, S. Nomura, and B Holder. Theecology of language practices in worldwideairline flight deck operations. In Proceedingsof the 28th Annual Conference of the Cogni-tive Science Society. Cognitive Science So-ciety, July 2006.
[31] Edwin Hutchins. Cognition in the Wild.MIT Press, Cambridge, 1995.
[32] T. Ideker, T. Galitski, and L. Hood. A newapproach to decoding life: Systems biology.Annual Review Genomics – Human Genet-ics, 2:343–372, 2001.
[33] V. Jones and M. Jones. Robust real-timeface detection. International Journal ofComputer Vision, 57(2):137–154, 2004.
[34] George Lakoff and Mark Johnson. Philoso-phy In the Flesh: The Embodied Mind AndIts Challenge To Western Thought. BasicBooks, 1999.
[35] J. Lave. Cognition in Practice: Mind, Math-ematics and Culture in Everyday life. Cam-bridge University Press, 1988.
[36] Ying Li, Tong Zhang, and Daniel Tret-ter. An overview of video abstraction tech-niques. Technical report, HP LaboratoriesPalo Alto, 2001.
[37] C. Liao, F. Guimbretiere, K. Hinckley,and J. Hollan. Papiercraft: A gesture-based command system for interactive pa-per. ACM Transactions on Computer-Human Interaction, page in press, 2007.
[38] Gwen Littlewort, Marian Stewart Bartlett,Ian Fasel, Joel Chenu, Takayuki Kanda,Hiroshi Ishiguro, and Javier R. Movellan.Towards social robots: Automatic evalu-ation of human-robot interaction by facedetection and expression classification. InAdvances in Neural Information Process-ing Systems. MIT Press, Cambridge, Mas-sachusetts, in press.
[39] David G. Lowe. Distinctive image featuresfrom scale-invariant keypoints. Interna-tional Journal of Computer Vision, in press.
22

[40] T. K. Marks, J. Hershey, J. C. Roddy, andJ. R. Movellan. 3D tracking of morphableobjects using conditionally gaussian nonlin-ear filters. Submitted.
[41] Tim K. Marks, John Hershey, J. CooperRoddey, and Javier R. Movellan. 3d track-ing of morphable objects using conditionallygaussian nonlinear filters. Computer Visionand Image Understanding, Submitted.
[42] J. McCall, A. Achler, M. Trivedi, J. Haue,P. Fastrez, J. Forster, and J. Hollan. Acollaborative approach for human-centereddriver assistance systems. In Proceedings ofIEEE Conference on Intelligent Transporta-tion Systems, 2004.
[43] David McNeil. Gesture and Thought.Chicago University Press, 2005.
[44] A. W. Murray. Whither genomics? GenomeBiology, 1(1):31–36, 2000.
[45] Bonnie Nardi. Context and Consciousness:Activity Theory and Human-Computer In-teraction. MIT Press, 1996.
[46] S. Nomura, E. Hutchins, and B. Holder. Theuses of paper in commercial airline flightoperations. In Proceedings of the 20th An-nual Computer Supported Cooperative WorkConference. ACM SIGCHI, November 2006.
[47] Donald A. Norman. Things that Make UsSmart. Addison-Wesley, 1993.
[48] Roy Pea, Michael Mills, Joseph Rosen, KenDauber, Wolfgang Effeslberg, and Eric Hof-fert. The diver
TM
project: Interactive dig-tial video repurposing. IEEE Multimedia,11(1):54–61, 2004.
[49] Roy D. Pea. Practices of distributed intelli-gence and designs for education. In G. Sa-lomon, editor, Distributed Cognitions, pages47–87. Cambridge University Press, 1993.
[50] C. L. Prvigano and P. J. Thibault. Dis-cussing Coversation Analysis: The Workof Emanuel A. Schegloff. John BengaminsPublishing, 2003.
[51] B. Rogoff. The Cultural Nature of HumanDevelopment. Oxford University Press, NewYork, 2003.
[52] Lucy Suchman. Plans and Situated Actions.Cambridge University Pres, 1987.
[53] E. Thelen and L. Smith. A Dynamic Sys-tems Approach to the Development of Cog-nition and Action. MIT Press, Cambridge,1994.
[54] F. Varela, E. Thompson, and E. Rosch. TheEmbodied Mind. MIT Press, Cambridge,1991.
[55] Paul Viola and Michael Jones. Robust real-time object detection. International Journalof Computer Vision, 2002.
[56] W. Zhao, R. Chellappa, P. J. Phillips, andA. Rosenfeld. Face recognition: A liter-ature survey. ACM Computing Surveys,35(4):399–458, 2003.
23