design of health technologies lecture 19 john canny 11/14/05
Post on 20-Dec-2015
213 views
TRANSCRIPT

Design of Health TechnologiesDesign of Health Technologieslecture 19lecture 19
John CannyJohn Canny11/14/0511/14/05

Medical Decision-MakingMedical Decision-Making
The perils of probability:
HIV test is positive 98% of the time on individuals carrying the HIV virus.
The same test is negative 99% of the time on individuals without the virus.
Q: In a population where 1 out of every 1000 people have the virus, what is the probability that a person who tests positive actually has the virus?
A: Only 10%!

Bayes ruleBayes rule
V = individual has the virus, NV = doesntP = individual tests positive, NP = doesn’t
Pr(P | V) = 0.98Pr(NP | NV) = 0.99
What is Pr(V | P) ?
Use Bayes rule: Pr(A | B) = Pr(A and B) / Pr(B)

Bayes ruleBayes rule
Bayes rule: Pr(A | B) = Pr(A and B) / Pr(B)
So Pr(V | P) = Pr(V and P) / Pr(P)
Use Bayes again Pr(V and P) = Pr(P | V)Pr(V):
Pr(V | P) = Pr(P | V) Pr(V) / Pr(P)
We know Pr(P | V) = 0.98, Pr(V) = 0.001, need to find Pr(P)…

Bayes ruleBayes rule
Pr(P) = Pr(P and V) + Pr(P and NV)
Pr(P) = Pr(P | V) Pr(V) + Pr(P | NV) Pr(NV)
= 0.98 * 0.001 + 0.01 * 0.999
0.011
Substitute back to Pr(V | P) = Pr(P | V) Pr(V) / Pr(P)
= 0.98 * 0.001 / 0.011 0.09

Human uses of probabilityHuman uses of probability
Terms used by doctors and range of probabilities encoded:

Human probability heuristicsHuman probability heuristics
Representativeness: How similar is user A to users with condition B?
Availability: How available is the physician’s memory of cause B for symptoms A?
Anchoring and Adjustment: Physician makes an initial estimate of probability based on coarse information, and then refines it based on further facts.

Objective EstimatesObjective Estimates
Prevalence: is the probability of occurrence of a condition in the general population.
Prevalence can be estimate from reported rates of the disease, but that may underestimate because of undiagnosed cases.
A random sample of all users can be used in conjunction with a diagnostic test to estimate prevalence.

Objective EstimatesObjective Estimates
Clinical Subgroup: is a group of users with certain attributes who prevalence is known. E.g. users who have been referred to a urologist for possible prostate problems may have the problem at 50% rate.
Referral Bias: disease prevalence is usually much higher in a group of referred patients such as the above, e.g. 50% vs. 5-14%.

TestingTesting
Many diagnostic tests produce continuous values. Thresholds must be set to declare positive/negative results.

TestingTesting
Sensitivity: Likelihood that a diseased patient tests positive. i.e. Pr(P | V) in our example.
Specificity: Likelihood that a non-diseased patient tests negative. i.e. Pr(NP | NV) in our example.
Note: Sensitivity corresponds to recall in information retrieval.
IR precision is Pr(V | P), so it does relate directly to specificity.

Expected ValuesExpected Values
The expected value of a variable is:
E[X] = vi Pr(X = vi)
i.e. it weights the value of events by their likelihood.
It makes a lot of sense over populations of people. Maximizing the expected value of a person’s survival also maximizes the number of people who would survive this procedure in a large population.
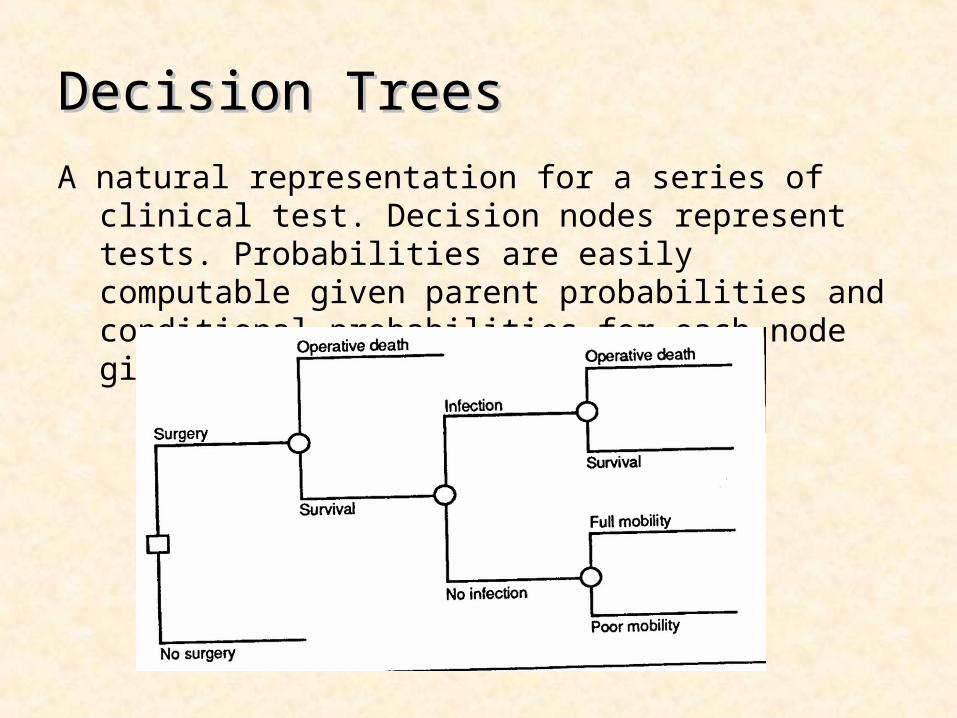
Decision TreesDecision Trees
A natural representation for a series of clinical test. Decision nodes represent tests. Probabilities are easily computable given parent probabilities and conditional probabilities for each node given its ancestors.

QALYsQALYs
A QALY is a Quality-Adjusted Life Year. It’s a way to weigh a patient’s preference for life quality over duration.
e.g. you can ask the patient “how many years of normal mobility would be equivalent to 10 years in a wheelchair?”
This quality adjustment allows you to compare the trade-offs among therapies with various outcomes.

QALY-adjusted decision treeQALY-adjusted decision tree

Time DependenceTime Dependence
Many disease processes have a relatively fixed probability of occurring in a given amount of time. Markov models model such processes very well.
A Markov model has a fixed timestep, and can transition fromone state to another in one time step. The probabilitiesof transition are fixed.
Annual probabilities are shown at right.
0.9
0.06 0.040.4 1.0
0.6

Influence diagramsInfluence diagrams
Represent actual observable data, and latent (unobservable) events. By adding these latent data, more accurate inference can often be made.

Latent Variable ModelsLatent Variable Models
Represent actual observable data, and latent (unobservable) events. By adding these latent data, more accurate inference can often be made.
Applies either to influence diagrams (Bayes nets) or Markov models (DBNs or Dynamic Bayes Nets).

Discussion QuestionsDiscussion Questions With the growth of home monitoring etc. there
are new possibilities for medical and health data-gathering. But there are also new types of biases that can occur. Discuss these new possibilities, the types of bias that might occur, and how to guard against them.
Discuss some weaknesses of the QALY model: e.g. how well do you think users address the tradeoffs? Would their attitudes change over time? What could you do about this in terms of decision-making?