desenvolvimento de um sistema de recuperação de informação ... · doutorado do orientador,...
TRANSCRIPT

UN I V E R S I D A D E FE D E R A L D E PE R N A M B U C O DE PA RTA M E N TO D E C I Ê N C I A D A IN FOR M A Ç Ã O
Desenvolvimento de um Sistema de Recuperação de Informação baseado em Mapas de Documentos para a BDTD-UFPE
RELATÓRIO FINAL DE ATIVIDADES DO BOLSISTA DO PIBIC/CNPq – FACEPE
Refere-se às atividades realizadas no período de agosto 2009 a julho de 2010.
Processo número: BIC-1634-1.03/09
RECIFE, AGOSTO DE 2010

2
IDENTIFICAÇÃO Intituição: Universidade Federal de Pernambuco - Departamento de
Ciência da Informação Título do Projeto: Desenvolvimento de um Sistema de Recuperação de
Informação baseado em Mapas de Documentos para a BDTD-UFPE
Número do Processo: BIC-1634-1.03/09 Local da atividade: Departamento de Ciência da Informação Período de realização: 01/08/2009 a 31/07/2010 Nome do Aluno: Bruno Florencio Pinheiro Curso do Aluno: Ciência da Computação Nome do Orientador: Renato Fernandes Corrêa Período de vigência da bolsa:
01/08/2009 a 31/07/2010

3
RESUMO
O seguinte documento tem por objetivo relatar o desenvolvimento de um Sistema de Recuperação de Informação baseado em mapa de documentos para Bibliotecas Digitais, mais especificamente para a Biblioteca Digital de Teses e Dissertações da UFPE (BDTD-UFPE), denominado Mapeador de Teses e Dissertações da UFPE (MTD-UFPE). Para tal, será necessário um estudo sobre o protocolo OAI-PMH, o qual provê a obtenção dos metadados de documentos contidos na BDTD-UFPE. Além disso, serão descritos o uso de bibliotecas em Java para efetuar o pré-processamento dos textos, a criação de índices invertidos, bem como a realização de consultas pelo usuário. Será discutida também a construção do mapa de documentos e interface do sistema.

4
Índice 1. INTRODUÇÃO ...........................................................................................................................5
2. OBJETIVOS ................................................................................................................................5
3. MATERIAL E MÉTODOS .........................................................................................................6
4. RESULTADOS E DISCUSSÃO.................................................................................................7
4.1. BDTD ....................................................................................................................................7
4.2. Aquisição Automática de Metadados de uma BDTD via OAI-PMH ...................................7
4.3. JColtrane................................................................................................................................9
4.4. Lucene ...................................................................................................................................9
4.5. Estrutura do Sistema............................................................................................................10
4.5.1. Aquisição dos documentos...........................................................................................11
4.5.2. Indexação / Preparação dos documentos .....................................................................11
4.5.3. Representação do documento.......................................................................................12
4.6. O Portal MTD-UFPE...........................................................................................................15
4.6.1. Funcionalidades ...........................................................................................................15
4.6.2. Instruções de uso..........................................................................................................15
5. CONCLUSÕES .........................................................................................................................18
6. DIFICULDADES ENCONTRADAS........................................................................................18
7. TRABALHOS FUTUROS ........................................................................................................18
8. ATIVIDADES PARALELAS DESENVOLVIDAS PELO BOLSISTA..................................18
9. REFERÊNCIAS BIBLIOGRÁFICAS.......................................................................................19

5
1. INTRODUÇÃO
Com o constante aumento do número de documentos digitalizados e a necessidade de obter-se informação o mais rápido possível, é imprescindível a utilização do computador para nos auxiliar nesta tarefa de recuperação de documentos. O desenvolvimento de sistemas de recuperação de informação (SRI) requer conhecimento especializado de diversos assuntos e ferramentas que serão apresentadas neste documento.
Para estudar-se a construção do SRI é necessário, basicamente, conhecermos um pouco da área de Ciência da Informação, a qual, juntamente com Biblioteconomia, tem como principais atividades o tratamento e recuperação de documentos e suas particularidades.
Para implementar o SRI baseado em mapa de documentos e torná-lo automatizado, é necessário ter noções de programação e conhecimento sobre redes neurais artificiais. É nesse ponto que entram os cientistas da computação. Esse conhecimento computacional também será necessário ao manipular o protocolo OAI-PMH, JColtrane e o Lucene, ferramentas descritas nesse documento. A construção da interface de navegação e pesquisa do SRI também requer conhecimentos específicos da ciência da computação, e será discutida neste relatório. 2. OBJETIVOS
O objetivo geral deste projeto é selecionar e adaptar métodos e técnicas necessárias para conclusão das etapas de aquisição automática de metadados, preprocessamento dos documentos, criação de índice invertidos, construção do mapa de documentos, e construção da interface, etapas necessárias para construção do Sistema de Recuperação da Informação para a BDTD-UFPE baseado em mapa de documentos.
Como objetivos específicos, este projeto visa contribuir para o estado da arte de construção de SRIs baseados em mapas de documentos, com métodos e técnicas que permitam a construção de um mapa de documentos de melhor qualidade e implementação de um SRI para a BDTD-UFPE muito mais robusto e eficaz.

6
3. MATERIAL E MÉTODOS Os dois primeiros meses do projeto foram dedicados a revisão de literatura sobre
recuperação da informação, sistemas de recuperação da informação e técnicas de harvesting através do protocolo OAI-PMH. Neste período, foram sendo coletadas, lidas e selecionadas as literaturas que interessavam ao projeto como livros, artigos de periódicos científicos, além de teses e dissertações encontradas em bibliotecas ou disponíveis na internet, sempre tendo a preocupação de recorrer a fontes que ofereçam credibilidade nas áreas de ciência da informação e ciência da computação. Essa etapa foi essencial no projeto, pois, forneceu ao bolsista conhecimento básico e inicial para o desenvolvimento das atividades futuras. Tal conhecimento já foi utilizado, nessa mesma etapa, para construir o módulo de coleta dos metadados através do protocolo OAI-PMH.
Os três meses seguintes foram ocupados pela implementação dos módulos de processamento de documentos e construção do índice invertido do SRI. Para essa atividade utilizou-se conhecimentos de HTML, XML e o JColtrane, biblioteca auxiliar em Java. A qual demandou um pequeno tempo para ser estudada e compreendida. Após essa atividade, fez-se necessário pesquisar e estudar ferramentas para o auxilio na preparação e indexação dos documentos. Como resultado, escolheu-se a biblioteca Lucene por ser completa e eficiente.
Passada a construção do índice invertido do SRI, as atenções foram voltadas para a criação do mapa de documentos, que são redes neurais do tipo mapa auto-organizável treinadas com vetores de documentos. Inicialmente foi feita uma revisão de literatura sobre redes neurais do tipo mapa auto-organizáveis e sobre o processo de construção de mapas de documentos. Devido à complexidade de implementação de uma rede neural, treinamento da mesma e o curto intervalo de tempo, decidiu-se, em comum acordo com o orientador, o uso de rotinas implementadas durante o doutorado do orientador, (CORREA, 2008). Para tal, construiu-se um modulo para extrair do índice os vetores que representam documentos no formato de matriz esparsa de documentos por palavras e os armazenam em arquivos textos a serem utilizados como entradas para o módulo da rede neural. Como resultado do treinamento da rede, foram obtidos três arquivos texto. Os quais serão lidos e utilizados na montagem do mapa.
A partir de então, iniciou-se a revisão de literatura e estudos visando o processo de visualização de mapas de documentos e a sua comunicação com a parte lógica do sistema. Para a comunicação interface-servidor, a qual foi responsável pelas consultas e por toda a navegação sobre o mapa, utilizou-se o framework Java Server Faces (JSF). Tal ferramenta foi escolhida por ser a mais completa e eficiente no mercado para a tecnologia Java na WEB. Nessa etapa, para execução e testes do sistema, foi necessário migrar o projeto para um servidor local Tomcat.
Para o módulo visual, conhecimentos de HTML, Javascript e CSS foram necessário para desenhar a interface de maneira limpa e intuitiva para os usuários. Alguns testes de combinação de cores e tonalidades foram realizados para tornar seu uso mais agradável.

7
4. RESULTADOS E DISCUSSÃO
4.1. BDTD A Biblioteca de Teses e Dissertações (BDTD) é um projeto coordenado pelo Instituto
Brasileiro de Informação em Ciência e Tecnologia (IBICT) com apoio da Financiadora de Estudos e Pesquisas (Finep), CNPq, MEC e de três universidades que participam do grupo de trabalho e do plano-piloto (USP, Puc-Rio e UFSC) (IBICT, 2009).
Essas instituições formam o comitê técnico-consultivo (CTC). Criado em abril de 2002, esse colegiado tem como função referendar o desenvolvimento da BDTD, bem como especificar padrões a serem adotados no âmbito do sistema da BDTD. Seu principal fruto foi a aprovação do padrão brasileiro de metadados para teses e dissertações (MTD-BR).
Em geral, o projeto da BDTD objetiva integrar os sistemas de informação de teses e dissertações existentes nas instituições de ensino e pesquisa brasileiras, estimular o registro e a publicação de teses e dissertações em meio eletrônico. Além de prover uma maior visibilidade da produção científica nacional através da publicação das teses e dissertações.
Tal visibilidade é engrandecida pelo uso das tecnologias do Open Archives Initiative (OAI) e a adoção do modelo baseado em padrões de interoperabilidade. O que possibilita o convênio entre a BDTD e a Networked Digital Library of Theses and Dissertation (NDLTD), projeto de diversas universidades norte-americanas para conceber uma biblioteca digital mundial1.
4.2. Aquisição Automática de Metadados de uma BDTD via OAI-PMH Em certos casos, os metadados são utilizados como parâmetro para indexação dos
documentos, evitando-se que o texto todo seja indexado. Para obtenção dos mesmos de forma automática é necessário uma comunicação com o repositório dos documentos. Tal comunicação é feita através de um protocolo que será explicitado em seguida.
Lançado em Janeiro de 2001, o OAI-PMH (Open Archives Initiative - Protocol for
Metadata Harvesting) vem sendo considerado como a alternativa mais prática para a interoperabilidade entre Bibliotecas Digitais (CARDOSO, 2007). Tal interoperabilidade decorre da obrigatoriedade embutida no protocolo para implementação do padrão Dublin Core2 além das respostas em formato XML, interpretáveis por qualquer linguagem computacional.
Através do protocolo é possível executar o harvesting, que é um processo unilateral, onde, os provedores de serviços, a partir da lista de repositórios (provedores de dados) registrados na OAI, realizam periodicamente uma busca a estes provedores de dados, "colhendo" os metadados para exibição sob a forma de consultas efetuadas pelos usuários (GARCIA, 2003).
Para realização da colheita, o protocolo nos oferece uma lista de verbos. Os quais, através de requisições HTTP nos fornecem os metadados desejados. Agregados a esses verbos podemos informar alguns argumentos para refinamento da consulta. Sendo eles de caráter cronológico ou por assunto. No quadro 1, obtido em (CARDOSO, 2007), são descriminados os verbos e seus atributos.
1 http://www.ndltd.org
2 http://clube-oai.incubadora.fapesp.br/portal

8
Quadro 1 - Verbos e argumentos do OAI-PMH Verbo Descrição Argumentos
GetRecord
Recupera os metadados de um item individual de um repositório.
identifier: Obrigatório. Com ele especificamos o identificador único do item de um repositório. metadataPrefix: Obrigatório. Especifica o padrão de metadados adotado que deve estar especificado no Provedor de Dados.
Identify
É usado para coletar informações sobre um repositório
Não há argumentos.
ListRecords
Este verbo recupera os metadados de um repositório.
from: Opcional. Os dados coletados devem ser criados ou alterados a partir da data especificada por este argumento. until: Opcional. Os dados coletados devem ser criados ou alterados até a data especificada pelo argumento. metadataPrefix: Já explicado anteriormente. set: Opcional. Especifica um conjunto, para o havester poder refinar sua coleta. resumptionToken: Exclusivo. Argumento necessário quando os provedores utilizam o controle de fluxo na coleta de metadados.
ListIdentifiers
É uma abreviação do ListRecords, que retorna apenas o header
de um repositório.
from. until. metadataPrefix. set. resumptionToken.
ListMetadataFormats
Retorna os padrões de metadados utilizados em um repositório.
identifier. Opcional (apenas neste verbo). Retorna o padrão de metadados utilizado em um item específico.
ListSets
É utilizado para retornar a estrutura de um repositório, listando todos os conjuntos que compõe os metadados.
resumptionToken.

9
4.3. JColtrane Jcoltrane é um framework para leitura de documentos XML na linguagem Java. O que
significa que ele recebe arquivos no formato XML e extrai dados, de acordo com parametros passados pelo programador, passando-os para objetos em Java.
Esse framework foi resultado do trabalho de graduação do aluno de Engenharia da Computação do Instituto Tecnologico da Aeronáutica(ITA), Renzo dos Santos Nuccitelli. E, em outubro de 2008 foi vencedor do prêmio “XML Programming Context”, categoria do concurso Search for a XML Superstars, realizado pela IBM3.
Seu funcionamento é baseado em Java Annotations e é executado sobre o SAX, framework com o mesmo propósito. Porém, as deficiencias do SAX, como necessidade de implementação de novos métodos, grandes blocos condicionais, estouros de memória, entre outros, foram eliminados e otimizados.
Para um bom uso dessa ferramenta é necessário conhecimento de Java Annotations, XML e Java. No entanto, nenhum conhecimento sobre SAX é requisitado.
4.4. Lucene
Lucene, ou Apache Lucene, é uma biblioteca completa e de alta performance para auxiliar Sistemas de Recuperação da Informação (SRI), escrita na linguagem Java por Doug Cutting e, mais tarde, corrigida e incrementada por outros.
A biblioteca é gerenciada pela Apache Software Foundation e está sob a licença Apache Software License e é uma ferramenta com código aberto. O que possibilita o uso gratuito de todas as suas funcionalidades por qualquer pessoa.
Inicialmente utilizada só na linguagem Java, após algumas adaptações ela já é compatível com diversas outras linguagens. Entre elas, Delphi, Perl, C#, C++, Python, Ruby e PHP.
Lucene provê aos programadores a capacidade de aplicar em seus sistemas funcionalidades como indexação e busca de textos, principais processos de um SRI. Outra tarefa menos evidente, mas muito importante para esses sistemas é a preparação do documento e essa também é suportada pelo Lucene.Tudo isso de uma maneira simples e eficiente.
Tão simples que até os iniciantes nessa nova tecnologia são capazes de utilizar a ferramenta e executar essas duas tarefas. Sendo esse o principal motivo de sua popularidade e sucesso. Por um bom tempo, Lucene vem sendo a biblioteca mais popular em Java para Recuperação da Informação (GOSPODNETIC; HATCHER, 2005).
Tal popularidade é confirmada quando acessamos a lista, disponível na enciclopédia digital do Lucene4, com todas as aplicações que utilizam essa API e vemos empresas como AOL, IBM e Apple, redes sociais como o LinkedIn e o Hi5, e a enciclopédia livre Wikipedia, figurando como a aplicação mais forte dessa lista.
Outro grande fator para essa disseminação do Lucene é o fato de ela ser capaz de indexar qualquer tipo de arquivo desde que seja possível convertê-lo em texto.
Na Figura 1, traduzida de (GOSPODNETIC; HATCHER, 2005), podemos ver uma arquitetura simples de um sistema com Lucene.
3 http://www.ita.br/online/2009/noticias09/concursoibm.htm
4 http://wiki.apache.org/jakarta-lucene/
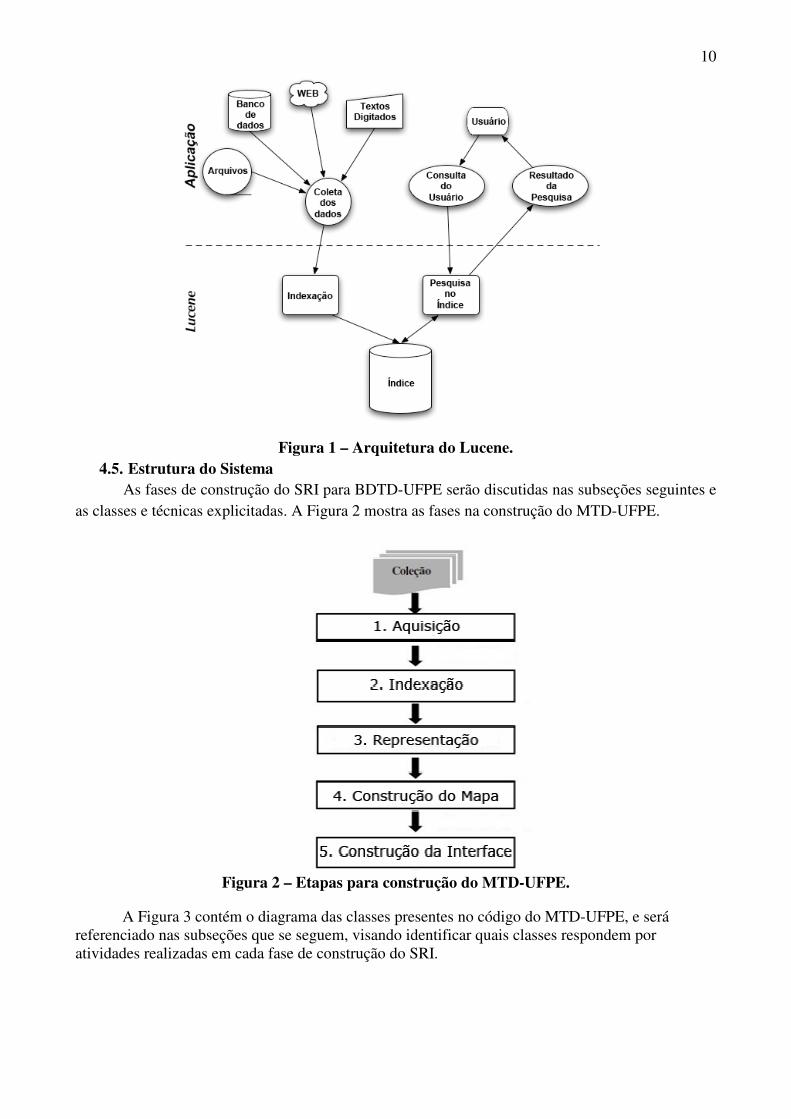
10
Figura 1 – Arquitetura do Lucene.
4.5. Estrutura do Sistema As fases de construção do SRI para BDTD-UFPE serão discutidas nas subseções seguintes e
as classes e técnicas explicitadas. A Figura 2 mostra as fases na construção do MTD-UFPE.
Figura 2 – Etapas para construção do MTD-UFPE.
A Figura 3 contém o diagrama das classes presentes no código do MTD-UFPE, e será referenciado nas subseções que se seguem, visando identificar quais classes respondem por atividades realizadas em cada fase de construção do SRI.

11
Figura 3 - Diagrama de Classes do MTD-UFPE
4.5.1. Aquisição dos documentos
A aquisição dos documentos é feita através do protocolo OAI-PMH citado na subseção 4.2 desse artigo. Sendo a BDTD utilizada para esse projeto a biblioteca digital da UFPE5.
Devido ao sistema TEDE da BDTD-UFPE somente dar suporte ao argumento resumptionToken apenas na requisição do verbo ListIdentifiers, foi preciso, primeiro, obter todos os identificadores dos documentos contidos na base. Em seguida, através dos identificadores armazenados, utilizou-se o verbo GetRecord passando no argumento identifier cada um desses identificadores.
A colheita dos XMLs contendo os metadados de todos os documentos, é possível com o uso das classes mtd.main.coleta.HTTPContentHandler e mtd.main.coleta.DataProvider. E, para a extração dos identificadores e dos resumptionToken obtidos nos arquivos XML, foi implementada a classe mtd.main.coleta.Leitor.
4.5.2. Indexação / Preparação dos documentos
Esta etapa pode ser subdividida nas etapas de preparação de documentos, indexação e armazenamento.
Na área de recuperação da informação, a preparação dos documentos consiste em realizarmos operações sobre o texto. As quais são realizadas com o intuito de criar uma visão lógica do documento.
Podemos ter operações de: Análise léxica, na qual eliminamos pontuações e dígitos; Eliminação de palavras irrelevantes, como artigos e preposições, conhecidas como stopwords;
5 http://www.bdtd.ufpe.br

12
Operações de Stemming, onde reduzimos as palavras ao seu radical; e, identificação de grupos nominais.
Para o idioma português, as duas primeiras etapas são suportadas pelo Lucene, para o inglês o suporte é ampliado com a adição da eliminação de sufixos (stemming). A ultima operação pode ser implementada pelo programador utilizando uma extensão da classe Analyzer. No MTD-UFPE, a classe mtd.main.extracaoXML.TextAnalyzer foi a responsável por toda a análise do documento.
Porém, tendo em vista que o resultado da fase anterior são documentos em XML, para o projeto em questão foi necessário um tratamento do documento antes de passarmos para o Lucene.
Tal tratamento foi realizado com JColtrane, biblioteca em Java utilizada para extrair dados de XML. Essa extração funcionou como um tradutor de XML para Java. Pois, só assim poderíamos aplicar o Lucene.
Devido à grande quantidade de informação contida no XML, o tratamento também funcionou como filtro. Selecionando apenas os campos desejados para indexação. Foram eles: Título, Resumo e palavras-chave.
Para configurar tal tratamento, foi implementada a classe mtd.main.extracaoXML.LeitorDocumentos.
Na fase de indexação, o programador só necessita instanciar a classe IndexWriter, a qual será responsável pela indexação, e adicionar os documentos, que já foram coletados e processados previamente. Cabe ao Lucene realizar automaticamente todo o processo necessário para a construção do índice invertido.
Com o uso do Lucene, a etapa de armazenamento ocorre em conjunto com a indexação. Pois, ao instanciar o IndexWriter, deve-se passar a classe Directory como atributo. A qual é responsável pelo armazenamento do índice invertido.
A biblioteca possibilita duas formas de armazenamento: na memória RAM ou em disco. A diferença entre ambas é que a RAM é mais veloz que o disco, enquanto o disco possui maior capacidade de armazenamento que a RAM. Para testes de unidade utiliza-se a implementação com a memória RAM. Porém, para sistemas de RI em uso é recomendado o uso do disco, pois, a diferença de performance entre um e outro é quase imperceptível (GOSPODNETIC; HATCHER, 2005).
Toda a comunicação entre o MTD-UFPE e o Lucene é realizado pela classe mtd.main.Fachada.
4.5.3. Representação do documento A partir dessa etapa, todos os esforços são voltados para a construção do mapa de
documentos. Em seguida à etapa de indexação, é preciso que todos os documentos estejam representados
na forma de vetores. Pois, só assim a rede neural poderá ser treinada com os mesmos. Essa representação deve seguir o padrão de entrada da rede neural. Na rede utilizada no
projeto, exige-se três arquivos de texto, formatados como matrizes esparsas, para efetuar-se o treinamento. São eles: docTable, que representa o documento e possui como colunas o id do documento na BDTD, o seu assunto na tabela CNPQ e o programa de pós-graduação; wordTable, representando as palavras com os atributos id e palavra; e por fim, o wordDocTable, o qual faz a relação entre documentos, palavras e sua freqüência, através dos atributos idPalavra, idDocumento e freqüência.
Para criar esses três arquivos de textos a partir do índice gerado, também utiliza-se o Lucene. Nesse momento, as classes IndexReader, TermDocs e TermEnum serão necessárias. O primeiro passo é informar à IndexReader onde se encontra o índice e a partir dela obter os

13
documentos, os termos e o relacionamento entre Documentos e Termos. Então, com os documentos e os termos criam-se os arquivos docTable e wordTable, respectivamente. E, por fim, através da classe TermEnum é possível obter a freqüência de um termo em determinado documento, tornando possível a criação do arquivo wordDocTable. A dinâmica de uso destas classes do Lucene foi a seguinte: a partir da classe IndexReader foi possível navegar sobre os documentos seqüencialmente e extrair seus termos; os termos foram associados à classe TermEnum para permitir um melhor controle sobre os termos, instancias da classe Term; para o cálculo da freqüência do termo no documento, utilizou-se a classe TermDocs. Todas essas classes foram instanciadas e utilizadas pela classe mtd.main.Principal.
Esses vetores poderão passar pelas seguintes fases de pré-processamento: redução de dimensionalidade e redução de volume.
A redução de dimensionalidade é importante para coleções com grande número de documentos, podendo ser realizada através do uso de métodos de seleção ou extração de características. No primeiro, as características selecionadas são um subconjunto das características originais. Normalmente escolhe-se as melhores de acordo com o critério pré-determinado. Já o segundo método tem como objetivo principal a criação de características artificiais que não sofram dos problemas de polissemia e sinonímia (CORREA, 2008). Essas características são obtidas através da combinação ou transformação das originais. Existem quatro maneiras de se reduzir a dimensionalidade do vetor: seleção de características; Latent Semantic Indexing; Agrupar termos em categorias semânticas e trabalhar com histograma de categorias; projeção aleatória (Random Mapping). Neste projeto, será utilizada seleção de características com base na freqüência das palavras, por ser um método simples e eficaz. Também será utilizada a eliminação de stopwords na preparação dos documentos, esta operação é considerada por alguns pesquisadores como uma redução de dimensionalidade.
Quanto à redução de volume, consiste de um procedimento de quantização vetorial, onde um conjunto de padrões de treinamento é representado por um conjunto menor de vetores chamados protótipos (CORREA, 2008). Para esse trabalho não será realizada a redução de volume de fato, pois, o volume da BDTD em questão é aceitável, correspondendo a cerca de 7000 documentos. E, ao utilizar este método, geraríamos mais ruído na representação dos documentos, levando a mapas de documentos de qualidade inferior.
4.5.4. Construção do mapa
Após a preparação dos vetores, a rede de mapa auto-organizável será treinada com os mesmos. Para tal, é preciso configurar certos parâmetros como: dimensão do mapa, número de épocas de treinamento, taxa de aprendizado, entre outros. Os valores destes parâmetros serão escolhidos através de experimentos.
O treinamento mais utilizado e tradicional é o de um estágio. Onde, a partir de um mapa aleatório, treina-se até chegar a um estado estacionário, passando-se apenas uma vez pelas fases de ordenação e convergência.
Porém, também existe o treinamento de múltiplos estágios. Nele, treina-se um mapa pequeno em um estágio e em seguida cria-se vários estágios de estimação e refinamento de um mapa maior baseado no estado estacionário de um menor.
O treinamento das redes SOM, sigla em inglês para mapas auto-organizáveis, é competitivo e não supervisionado. Na Figura 4, obtida de (FAUSETT, 1994), descreve-se os passos do seu algoritmo de treinamento.

14
No projeto em questão, todas essas rotinas foram realizadas em MATLAB. Para o treinamento do mapa foi necessário fornecer três arquivos ao MATLAB. O primeiro docTable.txt, contendo tuplas representando id, título e as duas palavras chaves mais significativas do documento. Já as duplas do wordTable.txt, contém o id da palavra e a palavra. Por fim, o wordDocTable.txt faz um relacionamento entre os dois arquivos anteriores, contendo tuplas representando o id da palavra, o id do documento e a freqüência daquela palavra neste documento.
Figura 4 – Algoritmo de treinamento para redes SOM. Fonte: FAUSETT, 1994
4.5.5. Construção da Interface
Analisando trabalhos que construiram SRIs baseados em mapa de documentos é possível perceber um certo padrão na visualização do mapa de documentos. Grande parte dos mapas são desenhados como uma malha bidimensional de neurônios, algumas vezes separados em regiões, por onde o usuário a medida que seleciona um neurônio, sua consulta é especificada e o campo de visão alterado mostrando com mais detalhes a região ou os documentos de um nodo específico. Os neurônios são rotulados com as palavras-chaves que represente melhor o documento ou conjunto de documentos daquela região, isto é feito atribuindo a cada nodo as palavras que possuem maior peso no vetor protótipo do nodo. Esta forma de visualização também foi implementada no MTD-UFPE.
Por se tratar de um sistema web implementado em Java6, foi utilizado o framework JSF (JavaServer Faces)7 em conjunto com as tecnologias HTML, JavaScript e CSS, todas regulamentadas pela w3schools8, para seu desenvolvimento.
6 http://www.sun.com/java/
7 http://www.oracle.com/technetwork/java/javaee/javaserverfaces-139869.html
8 http://www.w3schools.com

15
Para construção da visualização do mapa de documentos, foi necessário, através da classe mtd.util.ArquivosUtil, obter três arquivos da rede neural treinada. Os quais representavam dados de maneira diferente: docfnodedoc.cvs contém tuplas representando o id do nodo e o id do documento; fword.cvs contém tuplas representando o id da palavra e a palavra; docfcodebook.cvs contém triplas representando o id do nodo, id da palavra e o peso da palavra naquele nodo. A partir destes arquivos, foi feito um processamento e obtido o relacionamento dos nodos com os documentos e as palavras mais relevantes de cada nodo. Com esses dados, montou-se uma tabela 10x12 representando o mapa, na qual cada célula representa um nodo com suas três palavras mais relevantes. E, ao clicar em algum dos nodos, o usuário é encaminhado para uma nova página listando os documentos referentes àquele nodo.
Com o objetivo de facilitar a visualização por parte do usuário, os nodos foram divididos em três grandes áreas e coloridos de acordo com as mesmas. Sendo o vermelho para representar as áreas de Ciências da Saúde e Biológicas; Azul para Ciências Exatas e da Natureza; e, verde para Ciências Humanas.
Quanto à consulta por texto, objetivo principal de um SRI, a busca. O Lucene nos auxiliará, mais uma vez, oferecendo diversos tipos de consultas.
São elas: Consultas por termos, método convencional para realizar buscas; Consultas por limites, mais utilizada para datas; Consulta com ausência de caracteres ou parciais; Consultas por proximidade das palavras e similaridade (Fuzzy). Além de ser possível fazer uma combinação de todos esses tipos de buscas através de operações booleanas.
Ao programador resta instanciar a classe IndexSearcher, fornecendo como atributo o índice gerado na indexação, utilizar seu método “search” para passar a consulta do usuário e controlar os resultados. Os quais são ordenados através do método vetorial pelo Lucene.
No projeto em questão, a classe mtd.handler.ConsultaHandler se encarrega de receber a consulta digitada pelo usuário, passá-la a mtd.main.Fachada - a qual realiza a consulta no Lucene - e disponibilizar o resultado para visualização.
4.6. O Portal MTD-UFPE
O sistema, resultado desse trabalho, será hospedado no servidor do laboratório LIBER da UFPE e poderá ser acessado tão logo a implementação do MTD-UFPE seja finalizada.
4.6.1. Funcionalidades A principal funcionalidade do sistema é fornecer ao usuário a capacidade de realizar
consultas sobre os documentos da BDTD-UFPE através de consultas convencionais por palavras-chaves ou pela navegação no mapa, seu maior diferencial.
4.6.2. Instruções de uso O sistema foi pensado para disponibilizar ao usuário uma interface simples de ser usada.
Para tal, logo na página inicial o usuário terá acesso às duas funcionalidades do sistema. A mais convencional encontra-se no topo direito da página, como mostrado na Figura 5.
Para utilizá-la, o usuário deve escrever no campo a sua consulta e clicar no botão “Pesquisar”, destacado na Figura 6. O sistema efetuará a consulta e disponibilizará em uma lista abaixo do mapa, Figura 7. Tal lista possui um sistema de navegação por páginas, onde o usuário poderá procurar o documento desejado. Ao reconhecer o documento através dos campos demonstrados na tabela, deve-se clicar no link da coluna “URL” para acessar o documento.
A segunda maneira de consultar os documentos é através do mapa. Nele, o usuário escolhe a grande área e em seguida clica no quadro que contiver as palavras mais relacionadas à sua necessidade de informação. Feito isto, abrir-se-á uma nova janela com uma lista como da Figura 8,

16
contendo resultados referentes àquela consulta. A configuração dessa lista é semelhante à da lista demonstrada na Figura 7. No entanto, ela possui algumas particularidades como a adição de um campo de busca, destacado na Figura 9, onde à medida que o usuário digita o resultado é refinado; o fato de poder ordenar a lista de documentos pelos valores das colunas; o campo opções de busca, o qual permite selecionar se a busca será feita sobre os resumos dos documentos; e a não paginação da lista de documentos no nodo.
Figura 5 - Página inicial do sistema mostrando o mapa.
Figura 6 - Pesquisa por texto
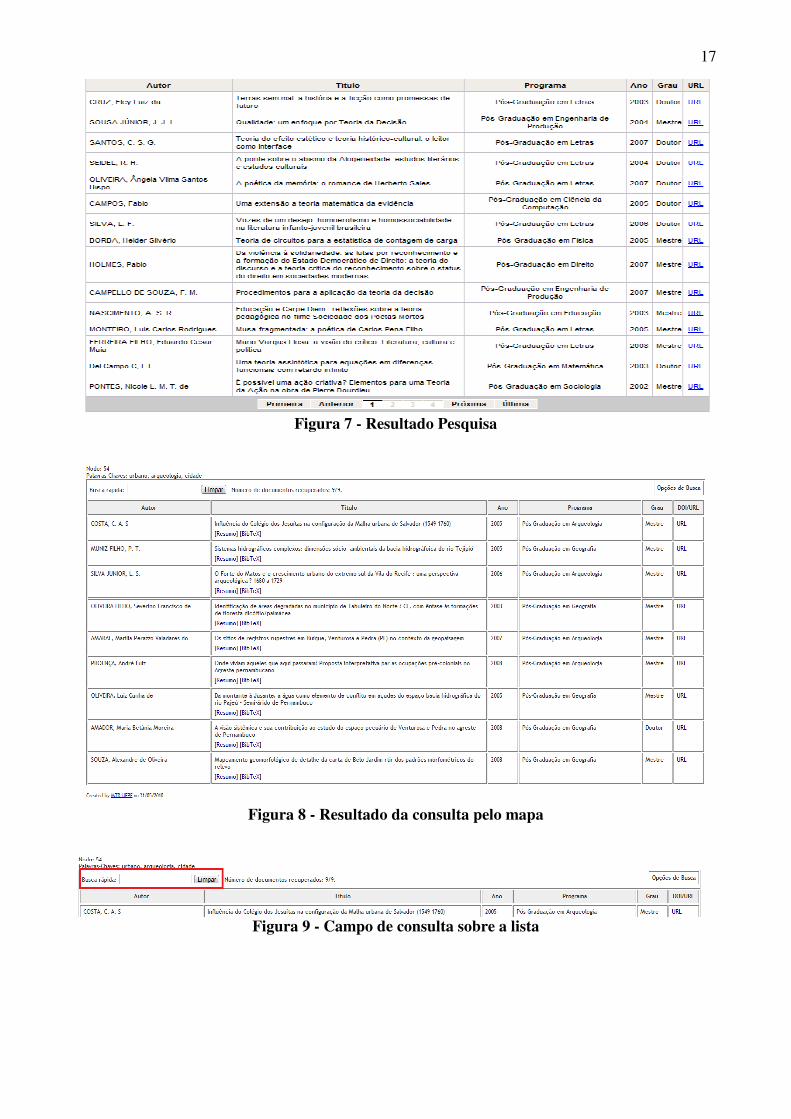
17
Figura 7 - Resultado Pesquisa
Figura 8 - Resultado da consulta pelo mapa
Figura 9 - Campo de consulta sobre a lista

18
5. CONCLUSÕES
Este relatório apresentou as etapas necessárias para o desenvolvimento de um Sistema de Recuperação de Informação para a Biblioteca Digital de Teses e Dissertações da UFPE (BDTD-UFPE), incluindo as ferramentas utilizadas em todas essas etapas.
Mostrou-se o protocolo OAI-PMH, responsável pela colheita de dados em repositórios digitais, seus verbos e suas funcionalidades. As bibliotecas JColtrane, como parser XML, e a Lucene, como ferramenta para indexação e recuperação dos documento. Apresentando-se a aplicação de cada uma dessas ferramentas nas devidas etapas de construção do SRI.
Por fim, foi descrita a estrutura do sistema e a demonstração do funcionamento do mesmo. 6. DIFICULDADES ENCONTRADAS Por o bolsista não ter conhecimento prévio sobre a área de recuperação da informação, a dificuldade inicialmente encontrada foi referente às técnicas utilizadas para preparação e recuperação de documentos. Fez-se necessário um estudo aprofundado para obter-se o entendimento de todo o processo. Outra dificuldade, encontrada já no término do projeto, foi quanto à geração da interface e sua alteração dinamicamente. Por falta de recursos na tecnologia escolhida, o sistema ficou limitado a mostrar o mapa com sua configuração inicial estática. Tal fato, não permitiu que o portal MTD-UFPE marcasse os nodos que possuíssem documentos relevantes à consulta do usuário. Também foram encontradas dificuldades na hospedagem do portal no servidor do LIBER. 7. TRABALHOS FUTUROS
Como trabalho futuro, pretende-se aplicar ao sistema modelos variantes do SOM. Analisando e comparando-os ao modelo utilizado atualmente com objetivo de melhorar a eficiência do sistema. Além de buscar alternativas que permitam a marcação dos nodos de acordo com a consulta realizada pelo usuário. 8. ATIVIDADES PARALELAS DESENVOLVIDAS PELO BOLSISTA Como auxílio ao estudo das técnicas necessárias a um Sistema de Recuperação da Informação, o bolsista cursou a disciplina Tópicos Especiais em Tecnologia da Informação 1, ministrada pelo seu orientador no departamento de Ciência da Informação. Tal disciplina aborda todas as etapas de um SRI, demonstrando como ocorre cada passo. Também foi elaborado o artigo científico a ser apresentado no Simpósio Brasileiro de Redes Neurais(SBRN) 2010 (CORRÊA e PINHEIRO, 2010) em outubro de 2010.

19
9. REFERÊNCIAS BIBLIOGRÁFICAS BDTD-UFPE. Biblioteca Digital de Teses e Dissertações da UFPE. Disponível em: <http://www.bdtd.ufpe.br>. Acesso em: 24 ago. 2009. CARDOSO JUNIOR, M. J. M. Clio-i: Interoperabilidade entre repositórios digitais utilizando o protocolo OAI-PMH. 2007. Dissertação (Mestrado em Ciência da Computação) - Universidade Federal de Pernambuco, Recife. CLUBE OAI BRASIL. Fórum mantido pela Comunidade clube oai brasil. Disponível em: <http://clube-oai.incubadora.fapesp.br/portal>. Acesso em: 23 ago. 2009. CORRÊA, R. F. ; PINHEIRO, B. F. . Self-organizing maps applied to information retrieval of dissertations and theses from BDTD-UFPE. In: 2010 BRAZILIAN SYMPOSIUM ON NEURAL NETWORKS (SBRN 2010), 2010, Ribeirão Preto-SP. PROC. OF THE 2010 BRAZILIAN SYMPOSIUM ON NEURAL NETWORKS (SBRN 2010). Los Alamitos : IEEE Computer Society, 2010. CORRÊA, R. F. Sistemas Baseados em Mapas Auto-organizáveis para Organização Automática de Documentos Texto. Tese de Doutorado. Centro de Informática da UFPE, Recife, 2008. FAUSETT, Laurene V. Fundamentals of neural networks: architectures, algorithms, and applications. Prentice-Hall. 1994. GARCIA, Patricia de Andrade Bueno ; SUNYE, Marcos Sfair . O protocolo OAI-PMH para interoperabilidade em bibliotecas digitais. In: I CONGRESSO DE TECNOLOGIAS PARA GESTÃO DE DADOS E METADADOS DO CONE SUL, 2003, Ponta Grossa. ANAIS DO I CONGRESSO DE TECNOLOGIAS PARA GESTÃO DE DADOS E METADADOS DO CONE SUL - CONGED, 2003. v. 1. GOSPODNETIC, Otis, HATCHER, Erik. Lucene in action: a guide to the Java search engine. Greenwich,USA. Manning, 2005. IBICT. BDTD - Biblioteca Digital de Teses e Dissertações. Disponível em: <http://bdtd2.ibict.br/index.php>. Acesso em: 20 nov. 2009. ITA NOTÍCIAS. Porta de notícias do Instituto Tecnológico de Aeronáutica. Disponível em: <http://www.ita.br/online/2009/noticias09/concursoibm.htm>. Acesso em: 22 jan. 2010. JCOLTRANE. Portal de informações e tutoriais da ferramenta JColtrane. Disponível em: <http://jcoltrane.sourceforge.net/>. Acesso em: 08 set. 2009. NDLTD. Apresenta informações sobre a Networked Digital Library of Theses and Dissertations. Disponível em: <http://www.ndltd.org>. Acesso em: 21 nov.2009.

20
WIKI LUCENE. Enciclopédia digital da ferramenta Lucene. Disponível em: <http://wiki.apache.org/jakarta-lucene/>. Acesso em: 19 nov. 2009.