deepgender2: a generative approach toward occlusion and ...xujuefei.com/felix_book17_gender2.pdf ·...
TRANSCRIPT

DeepGender2: A Generative Approach TowardOcclusion and Low Resolution Robust FacialGender Classification via Progressively TrainedAttention Shift Convolutional Neural Networks(PTAS-CNN) and Deep ConvolutionalGenerative Adversarial Networks (DCGAN)
Felix Juefei-Xu, Eshan Verma, and Marios Savvides
Abstract In this work, we have undertaken the task of occlusion and low-resolutionrobust facial gender classification. Inspired by the trainable attention model viadeep architecture, and the fact that the periocular region is proven to be the mostsalient region for gender classification purposes, we are able to design a progres-sive convolutional neural network training paradigm to enforce the attention shiftduring the learning process. The hope is to enable the network to attend to partic-ular high-profile regions (e.g. the periocular region) without the need to change thenetwork architecture itself. The network benefits from this attention shift and be-comes more robust towards occlusions and low-resolution degradations. With theprogressively trained attention shift convolutional neural networks (PTAS-CNN)models, we have achieved better gender classification results on the large-scalePCSO mugshot database with 400K images under occlusion and low-resolution set-tings, compared to the one undergone traditional training. In addition, our progres-sively trained network is sufficiently generalized so that it can be robust to occlu-sions of arbitrary types and at arbitrary locations, as well as low resolution. Oneway to further improve the robustness of the proposed gender classification algo-rithm is to invoke a generative approach for occluded image recovery, such as usingthe deep convolutional generative adversarial networks (DCGAN). The facial occlu-sions degradation studied in this work is a missing data challenge. For the occlusionproblems, the missing data locations are known whether they are randomly scat-tered, or in a contiguous fashion. We have shown, on the PCSO mugshot database,
Felix Juefei-XuCarnegie Mellon University, 5000 Forbes Avenue, Pittsburgh, Pennsylvania 15213, USA, e-mail:[email protected]
Eshan VermaCarnegie Mellon University, 5000 Forbes Avenue, Pittsburgh, Pennsylvania 15213, USA, e-mail:[email protected]
Marios SavvidesCarnegie Mellon University, 5000 Forbes Avenue, Pittsburgh, Pennsylvania 15213, USA, e-mail:[email protected]
1

2 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
that a deep generative model can very effectively recover the aforementioned degra-dation, and the recovered images show significant performance improvement ongender classification tasks.
1 Introduction
Facial gender classification has always been one of the most studied soft-biometrictopics. Over the past decade, gender classification on constrained faces has almostbeen perfected. However, challenges still remain on less constrained faces such asfaces with occlusions, of low resolution, and off-angle poses. Traditional methodssuch as the support vector machines (SVMs) and its kernel extension can workpretty well on this classic two-class problem as listed in Table 8. In this work, weapproach this problem from a very different angle. We are inspired by the boomingdeep convolutional neural network (CNN) and the attention model to achieve occlu-sion and low resolution robust facial gender classification via progressively train-ing the CNN with attention shift. From an orthogonal direction, when images areunder severe degradations such as contiguous occlusions, we utilize a deep genera-tive approach to recover the missing pixels such that the facial gender classificationperformance is further improved on occluded facial images. On one hand, we aimat building a robust gender classifier that is tolerant to image degradations such asocclusions and low resolution, and on the other hand, we aim at mitigating and elim-inating the degradations through a generative approach. Together, we stride towardspushing the boundary of unconstrained facial gender classification.
1.1 Motivation
Xu et al. [70] proposed an attention based model that automatically learns to de-scribe the content of images which has been inspired by recent work in machinetranslation [3] and object detection [2, 57]. In their work, two attention-based imagecaption generators were introduced under a common framework: (1) a ‘soft’ deter-ministic attention mechanism which can be trained by standard back-propagationmethod and (2) a ‘hard’ stochastic attention mechanism which can be trained bymaximizing an approximate variational lower bound. The encoder of the modelsuses a convolutional neural network as a feature extractor, and the decoder is com-prised of a recurrent neural network (RNN) with long short-term memory (LSTM)architecture where the attention mechanism is learned. The authors can then visual-ize that the network can automatically fix its gaze on the salient objects (regions) inthe image while generating the image caption word by word.
For facial gender classification, we know from previous work [16, 56] that theperiocular region provides the most important cues for determining the gender in-formation. The periocular region is also the most salient region on human faces,

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 3
Input Image Image Signature - LAB Image Signature - RGB
Input Image Image Signature - LAB Image Signature - RGB
Fig. 1 (Top) Periocular region on human faces exhibits the highest saliency. (Bottom) Foregroundobject in focus exhibits the highest saliency. Background is blurred with less high-frequency detailspreserved.
such as shown in the top part of Figure 1, using a general purpose saliency detectionalgorithm [14]. Similar results can also be obtained using other saliency detectionalgorithms such as [17] and [15]. We can observe from the saliency heat map thatthe periocular region does fire the most strongly compared to the remainder of theface.
Now we come to think about the following question:
Q: How can we let the CNN shift its attention towards the periocular region,where gender classification has been proven to be the most effective?
The answer comes from our day-to-day experience with photography. If you areusing a DSLR camera with a big aperture lens, and fixing the focal point onto anobject in the foreground, all background beyond the object in focus will becomeout of focus and blurred. This is illustrated in the bottom part of Figure 1 and ascan be seen, the sharp foreground object (cherry blossom in hand) attracts the mostattention in the saliency heat map.

4 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
Thus, we can control the attention region by specifying where the image isblurred or remains sharp. In the context of gender classification, we know that wecan benefit from fixing the attention onto the periocular region. Therefore, we are‘forcing’ what part of the image the network weighs the most, by progressivelytraining the CNN using images with increasing blur levels, zooming into the peri-ocular region, as shown in Table 1. Since we still want to use a full face model, wehope that by employing the mentioned strategy, the learned deep model can be atleast on par with other full face deep models, while harnessing gender cues in theperiocular region.
Q: Why not just use the periocular region crop?
Although experimentally, periocular is the best facial region for gender classifi-cation, we still want to resort to other facial parts (beard/moustache) for providingvaluable gender cues. This is specially true when the periocular region is less ideal.For example, some occlusion like sunglasses could be blocking the eye region, andwe want our network to still be able to generalize well and perform robustly, evenwhen the periocular region is corrupted.
To strike a good balance between full face-only and periocular-only models, wecarry out a progressive training paradigm for CNN that starts with the full face,and progressively zoom into the periocular region by leaving other facial regionsblurred. In addition, we hope that the progressively trained network is sufficientlygeneralized so that it can be robust to occlusions of arbitrary types and at arbitrarylocations.
Q: Why blurring instead of blackening out?
We just want to steer the focus, rather than completely eliminating the back-ground, like the DSLR photo example shown in the bottom part of Figure 1. Black-ening would create abrupt edges that confuse the filters during the training. Whenblurred, low frequency information is still well preserved. One can still recognizethe content of the image, e.g. dog, human face, objects, etc.. from a blurred image.
Blurring outside the periocular region, and leaving the high frequency details atthe periocular region will both help providing global and structural context of theimage, as well as keeping the minute details intact at the region of interest, whichwill help the gender classification, and fine-grained categorization in general.
Q: Why not let CNN directly learn the blurring step?
We know that CNN filters operate on the entire image, and blurring only partof the image is a pixel location dependent operation and thus is difficult to emulatein the CNN framework. Therefore, we carry out the proposed progressive trainingparadigm to enforce where the network attention should be.

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 5
2 Related Work
In this section, we provide relevant background on facial gender classification andattention models.
The periocular region is shown to be the best facial region for recognition pur-poses [44, 25, 28, 38, 27, 35, 32, 28, 62, 26, 31, 24, 23, 33, 59, 43, 42, 63], espe-cially for gender classification tasks [16, 56]. A few recent work also applies CNNfor gender classification [50] and [4]. More related work on gender classification isconsolidated in Table 8.
Attention models such as the one used for image captioning [70] have gainedmuch popularity only very recently. Rather than compressing an entire image into astatic representation, attention allows for salient features to dynamically come to theforefront as needed. This is especially important when there is a lot of clutter in animage. It also helps gaining insight and interpreting the results by visualizing wherethe model attends to for certain tasks. This mechanism can be viewed as a learnablesaliency detector that can be tailored to various tasks, as opposed to the traditionalones such as [14, 17, 15, 8].
It is worth mentioning the key difference between the soft attention and the hardattention. The soft attention is very easy to implement. It produces distribution overinput locations, re-weights features and feeds them as input. It can attend to arbitraryinput locations using spatial transformer networks [19]. On the other hand, the hardattention can only attend to a single input location, and the optimization cannotutilize gradient descent. The common practice is to use reinforcement learning.
Other applications involving attention models may include machine translationwhich applies attention over input [54]; speech recognition which applies attentionover input sounds [6, 9]; video captioning with attention over input frames [72];image, question to answer with attention over image itself [69, 75]; and many more[67, 68].
3 Proposed Method
Our proposed method involves two major components: a progressively trained at-tention shift convolutional neural networks (PTAS-CNN) framework for training theunconstrained gender classifier, as well as a deep convolutional generative adversar-ial networks (DCGAN) for missing pixel recovery on the facial images so that thegender recognition performance can be further improved on images with occlusions.

6 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
3.1 Progressively Trained Attention Shift Convolutional NeuralNetworks (PTAS-CNN)
In this section we detail our proposed method on progressively training the CNNwith attention shift. The entire training procedure involves (k + 1) epoch groupsfrom epoch group 0 to k, where each epoch group corresponds to one particularblur level.
3.1.1 Enforcing Attention in the Training Images
In our experiment, we heuristically choose 7 blur levels, including the one with noblur at all. The example images with increasing blur levels are illustrated in Table 1.We use a Gaussian blur kernel with σ = 7 to blur the corresponding image regions.Doing this is conceptually enforcing the network attention in the training imageswithout the need of changing the network architecture.
Table 1 Blurred images with increasing levels of blur.
13.33% 27.62% 41.90%
56.19% 68.57% 73.33%

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 7
3.1.2 Progressive CNN Training with Attention
We employ the AlexNet [46] architecture for our progressive CNN training. TheAlexNet has 60 million parameters and 650,000 neuron, consisting of 5 convo-lution layers and 3 fully connected layers with a final 1000-way softmax. To re-duce overfitting in the fully-connected layers, AlexNet employs “dropout” and data-augmentation, both of which are preserved in our training. The main difference isthat we only need a 2-way softmax due to the nature of gender classification prob-lems.
As illustrated in Figure 2, the progressive CNN training begins with the firstepoch group (Epoch Group 0, images with no blur), and the first CNN modelM0
is obtained and frozen after convergence. Then, we input the next epoch group fortuning the M0 and in the end produce the second model M1, with attention en-forced through training images. The procedure is carried out sequentially until thefinal modelMk is obtained. EachMj(j = 0, . . . , k) is trained with 1000 epochsand with a batchsize of 128. At the end of the training for step j, the model corre-sponding to best validation accuracy is taken ahead to the next iteration (j + 1).
3.1.3 Implicit Low-Rank Regularization in CNN
Blurring the training images in our paradigm may have more implications. Herewe want to show the similarities between low-pass Fourier analysis and low-rankapproximation in SVD. Through the analysis, we hope to make connections to thelow-rank regularization procedure in the CNN. We have learned from a recent work[65] that enforcing a low-rank regularization and removing the redundancy in theconvolution kernels is important and can help improve both the classification accu-racy and the computation speed. Fourier analysis involves expansion of the originaldata xij (taken from the data matrix X ∈ Rm×n) in an orthogonal basis, which isthe inverse Fourier transform:
xij =1
m
m−1∑k=0
ckei2πjk/m (1)
The connection with SVD can be explicitly illustrated by normalizing the vector{ei2πjk/m} and by naming it v′k:
xij =
m−1∑k=0
bikv′jk =
m−1∑k=0
u′iks′kv′jk (2)
which generates the matrix equation X = U′Σ′V′>. However, unlike the SVD,even though the {v′k} are an orthonormal basis, the {u′k} are not in general orthog-onal. Nevertheless this demonstrates how the SVD is similar to a Fourier transform.Next, we will show that the low-pass filtering in Fourier analysis is closely relatedto the low-rank approximation in SVD.
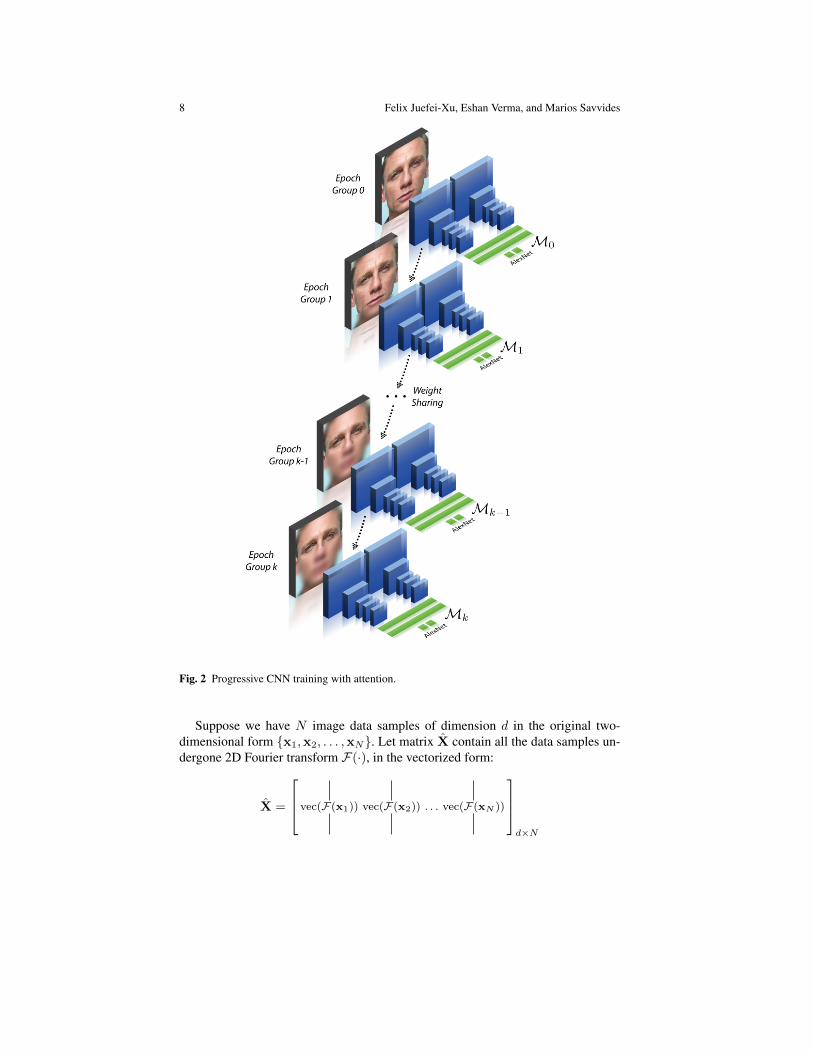
8 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
Fig. 2 Progressive CNN training with attention.
Suppose we have N image data samples of dimension d in the original two-dimensional form {x1,x2, . . . ,xN}. Let matrix X contain all the data samples un-dergone 2D Fourier transform F(·), in the vectorized form:
X =
vec(F(x1)) vec(F(x2)) . . . vec(F(xN ))
d×N

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 9
Matrix X can be decomposed using SVD: X = UΣV>. Without loss of gen-erality, let us assume that N = d for brevity. Let g and g be the Gaussian filter inspatial domain and frequency domain respectively, namely g = F(g). Let G bea diagonal matrix with g on its diagonal. The convolution operation becomes dotproduct in frequency domain, so the blurring operation becomes:
Xblur = G · X = G · UΣV> (3)
where Σ = diag(σ1, σ2, . . . , σd) contains the singular values of Xblur, alreadysorted in descending order: σ1 ≥ σ2 ≥ . . . ≥ σd. Suppose we can find a per-mutation matrix P such that when applied on the diagonal matrix G, the diagonalelements is sorted in descending order according to the magnitude: G′ = PG =diag(g′1, g
′2, . . . , g
′d). Now, let us apply the same permutation operation on Xblur,
we can thus have the following relationship:
P · Xblur = P · G · UΣV> (4)
X′blur = G′ · UΣV> = U · (G′Σ) · V> (5)
= U · diag(g′1σ1, g′2σ2, . . . , g′dσd) · V> (6)
Due to the fact that Gaussian distribution is not a heavy-tailed distribution, thealready smaller singular values will be brought down to 0 by the Gaussian weights.Therefore, Xblur actually becomes low-rank after Gaussian low-pass filtering. Tothis end, we can say that low-pass filtering in Fourier analysis is equivalent to thelow-rank approximation in SVD up to a permutation.
This phenomenon is loosely observed through the visualization of the trainedfilters, as shown in Figure 15, which will be further analyzed and studied in futurework.
3.2 Occlusion Removal via Deep Convolutional GenerativeAdversarial Networks (DCGAN)
In this section, we first review the basics of DCGAN and then show how DCGANcan be utilized for occlusion removal, or missing pixel recovery on face images.
3.2.1 Deep Convolutional Generative Adversarial Networks
The generative adversarial network (GAN) [12] is capable of generating high qualityimages. The framework trains two networks, a generator Gθ(z) : z → x, and adiscriminator Dω(x) : x → [0, 1]. G maps a random vector z, sampled from aprior distribution pz(z), to the image space. D maps an input image to a likelihood.The purpose of G is to generate realistic images, whileD plays an adversarial role to

10 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
discriminate between the image generated from G, and the image sampled from datadistribution pdata. The networks are trained by optimizing the following minimaxloss function:
minG
maxD
V (G,D) = Ex∼pdata(x)
[log(D(x))
]+ Ez∼pz(z)
[log(1−D(G(z))
]where x is the sample from the pdata distribution; z is randomly generated andlies in some latent space. There are many ways to structure G(z). The deep con-volutional generative adversarial network (DCGAN) [60] uses fractionally-stridedconvolutions to upsample images instead of fully-connected neurons as shown inFigure 3.
The generator G is updated to fool the discriminator D into wrongly classifyingthe generated sample, G(z), while the discriminator D tries not to be fooled. In thiswork, both G and D are deep convolutional neural networks and are trained withan alternating gradient descent algorithm. After convergence, D is able to rejectimages that are too fake, and G can produce high quality images faithful to thetraining distribution (true distribution pdata).
Fig. 3 Pipeline of a standard DCGAN with the generator G mapping a random vector z to an imageand the discriminator D mapping the image (from true distribution or generated) to a probabilityvalue.
3.2.2 Occlusion Removal via DCGAN
To take on the missing data challenge, we need to utilize both the G andD networksfrom DCGAN, pre-trained with uncorrupted data. After training, G is able to embedthe images from pdata onto some non-linear manifold of z. An image that is not frompdata (e.g. corrupted face image with missing pixels) should not lie on the learnedmanifold. Therefore, we seek to recover the “closest” image on the manifold to thecorrupted image as the proper reconstruction.

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 11
Let us denote the corrupted image as y. To quantify the “closest” mapping fromy to the reconstruction, we define a function consisting of contextual loss and per-ceptual loss, following the work of Yeh et al. [73].
In order to incorporate the information from the uncorrupted portion of the givenimage, the contextual loss is used to measure the fidelity between the reconstructedimage portion and the uncorrupted image portion, which is defined as:
Lcontextual(z) = ‖M� G(z)−M� y‖1 (7)
where M denotes the binary mask of the uncorrupted region and � denotes theelement-wise Hadamard product operation. The corrupted portion, i.e., (1−M)�yis not used in the loss. The choice of `1-norm is empirical. From the experimentscarried out in [73], images recovered with `1-norm loss tend to be sharper and withhigher quality compared to ones reconstructed with `2-norm.
The perceptual loss encourages the reconstructed image to be similar to thesamples drawn from the training set (true distribution pdata). This is achieved byupdating z to fool D, or equivalently to have a high value of D(G(z)). As a result,D will predict G(z) to be from the data with a high probability. The same loss forfooling D as in DCGAN is used:
Lperceptual(z) = log(1−D(G(z))) (8)
The corrupted image with missing pixels can now be mapped to the closest zin the latent representation space with the defined perceptual and contextual losses.We follow the training procedure in [60] and use Adam [45] for optimization. z isupdated using back-propagation with the total loss:
z = argminz
(Lcontextual(z) + λLperceptual(z)) (9)
where λ is a weighting parameter. After finding the optimal solution z, the halluci-nated full face image can be obtained by:
xhallucinated = M� y + (1−M)� G(z) (10)
Examples of face recovery from contiguous occlusions are shown in Figure 11using DCGAN. Applying this deep generative approach for occluded image recov-ery is expected to improve the performance of unconstrained gender classification.
4 Experiments: Part A
In this section we detail the training and testing protocols employed and various oc-clusions and low resolutions modeled in the testing set. Accompanying figures and
12 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
tables for each sub-section encompass the results and observations and are elabo-rated in each section1.
4.1 Database and Pre-processing
Training set: We source images from 5 different datasets, each containing samplesof both classes. The datasets are J-Mugshot, O-Mugshot, M-Mugshot, P-Mugshotand Pinellas. All the datasets, except Pinellas are evenly separated into males andfemales of different ethnicity. The images are centred. By which, we mean thatwe have landmarked certain points on the face, which are then anchored to fixedpoints in the resulting training image. For example, the eyes are anchored at thesame coordinates in every image. All of our input images have the same dimension168× 210. The details of the training datasets are listed in Table 2. The images arepartitioned into training and validation and the progressive blur is applied to eachimage as explained in the previous section. Hence, for a given model iteration, thetraining set consists of ∼90k images.
Table 2 Datasets used for progressive CNN training.
Database Males Females
J-Mugshot 1900 1371M-Mugshot 1772 805Pinellas Subset 13215 3394P-Mugshot 46346 12402O-Mugshot 4164 3634
67397 21606
Total 89003
Testing set: The testing set was built primarily from the following two datasets:(1) The AR Face database [55] is one of the most widely used face databases withocclusions. It contains 3,288 color images from 135 subjects (76 male subjects + 59female subjects). Typical occlusions include sunglasses and scarves. The databasealso captures expression variations and lighting changes. (2) Pinellas County Sher-rif’s Office (PCSO) mugshot database is a large-scale database of over 1.4 millionimages. We took a subset of around 400K images from this dataset. These imagesare not seen during training.
1 A note on legend: (1) SymbolsM correspond to each model trained, withMF correspondingto the model trained on full face (equivalent to M0), MP to one with just periocular imagesandMk, k ⊆ (1, . . . , 6) to the incremental models trained. (2) The tabular results show modelperformance on the original images in column 1 and corrupted images in other columns.
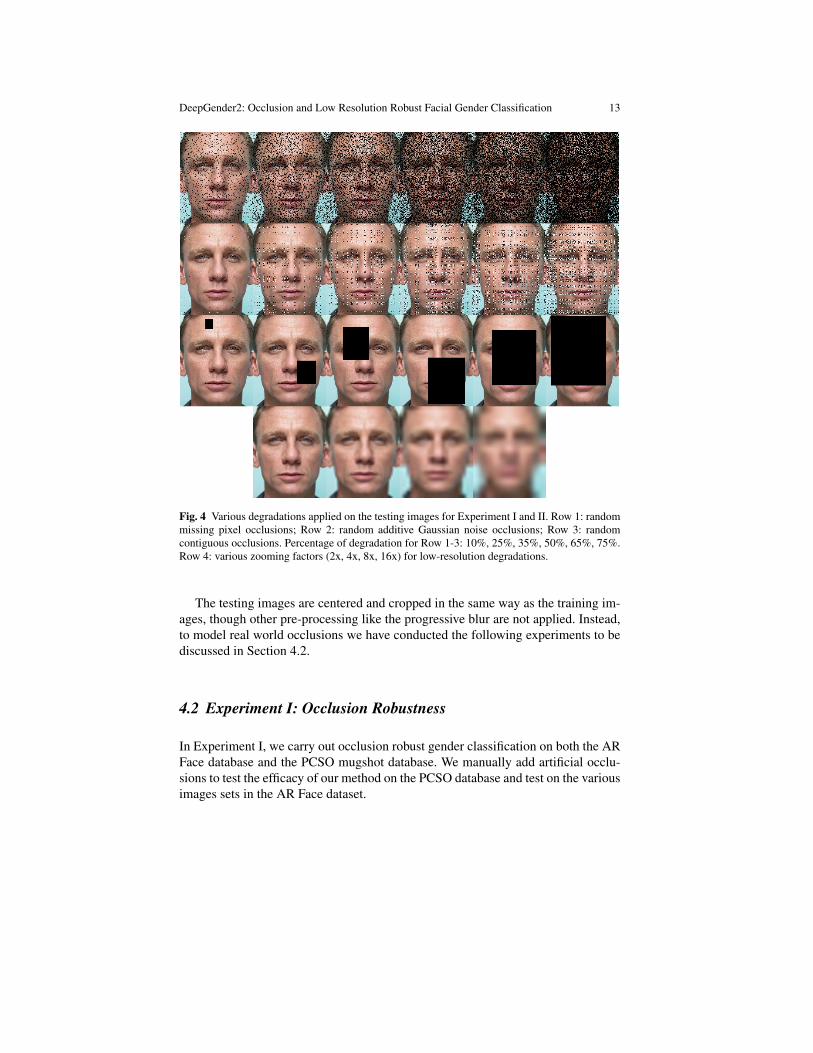
DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 13
Fig. 4 Various degradations applied on the testing images for Experiment I and II. Row 1: randommissing pixel occlusions; Row 2: random additive Gaussian noise occlusions; Row 3: randomcontiguous occlusions. Percentage of degradation for Row 1-3: 10%, 25%, 35%, 50%, 65%, 75%.Row 4: various zooming factors (2x, 4x, 8x, 16x) for low-resolution degradations.
The testing images are centered and cropped in the same way as the training im-ages, though other pre-processing like the progressive blur are not applied. Instead,to model real world occlusions we have conducted the following experiments to bediscussed in Section 4.2.
4.2 Experiment I: Occlusion Robustness
In Experiment I, we carry out occlusion robust gender classification on both the ARFace database and the PCSO mugshot database. We manually add artificial occlu-sions to test the efficacy of our method on the PCSO database and test on the variousimages sets in the AR Face dataset.

14 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
4.2.1 Experiments on the PCSO Mugshot Database
To begin with, the performance of various models on the clean PCSO data is shownin Figure 5. As expected, if the testing images are clean, it should be preferableto use MF , rather than MP . We can see that the progressively trained modelsM1 −M6 are on par withMF .
Fig. 5 Overall classifica-tion accuracy on the PCSO(400K). Images are not cor-rupted.
Model1 2 3 4 5 6
Acc
urac
y
95.5
96
96.5
97
97.5
98Clean Data
Model FModel 1-6Model P
We corrupt the testing images (400K) with three types of facial occlusions. Theseare visualized in Figure 4 with each row corresponding to some modeled occlusions.
(1) Random Missing Pixels Occlusions
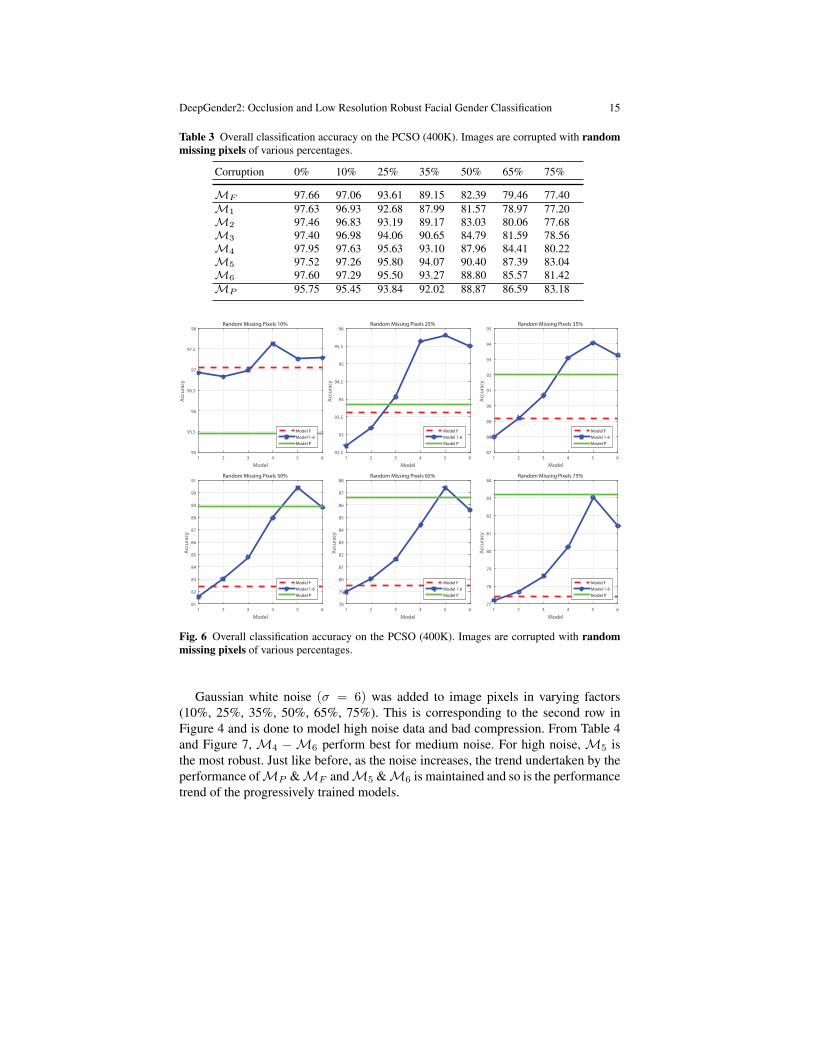
Varying factors of the image pixels (10%, 25%, 35%, 50%, 65%, 75%) weredropped to model lost information and grainy images2. This is corresponding to thefirst row in Figure 4. From Table 3 and Figure 6,M5 performs the best withM6
showing a dip in accuracy suggesting a tighter periocular region is not well suited forsuch applications, i.e., a limit on the periocular region needs to be maintained in theblur-set. There is a flip in performance of the modelsMP andMF going from theoriginal to 25% with the periocular model generalizing better for higher corruptions.As the percentage of missing pixels increases, the performance gap between MP
andMF increases. As hypothesized, the trend of improving performance betweenprogressively trained models is maintained across factors indicating a better learnedmodel towards noise.
(2) Random Additive Gaussian Noise Occlusions
2 This can also model the dead pixel/shot noise of a sensor and these results can be used to accel-erate in-line gender detection by using partially demosaiced images.
DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 15
Table 3 Overall classification accuracy on the PCSO (400K). Images are corrupted with randommissing pixels of various percentages.
Corruption 0% 10% 25% 35% 50% 65% 75%
MF 97.66 97.06 93.61 89.15 82.39 79.46 77.40M1 97.63 96.93 92.68 87.99 81.57 78.97 77.20M2 97.46 96.83 93.19 89.17 83.03 80.06 77.68M3 97.40 96.98 94.06 90.65 84.79 81.59 78.56M4 97.95 97.63 95.63 93.10 87.96 84.41 80.22M5 97.52 97.26 95.80 94.07 90.40 87.39 83.04M6 97.60 97.29 95.50 93.27 88.80 85.57 81.42MP 95.75 95.45 93.84 92.02 88.87 86.59 83.18
Model1 2 3 4 5 6
Acc
urac
y
95
95.5
96
96.5
97
97.5
98Random Missing Pixels 10%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
92.5
93
93.5
94
94.5
95
95.5
96Random Missing Pixels 25%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
87
88
89
90
91
92
93
94
95Random Missing Pixels 35%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
81
82
83
84
85
86
87
88
89
90
91Random Missing Pixels 50%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
78
79
80
81
82
83
84
85
86
87
88Random Missing Pixels 65%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
77
78
79
80
81
82
83
84Random Missing Pixels 75%
Model FModel 1-6Model P
Fig. 6 Overall classification accuracy on the PCSO (400K). Images are corrupted with randommissing pixels of various percentages.
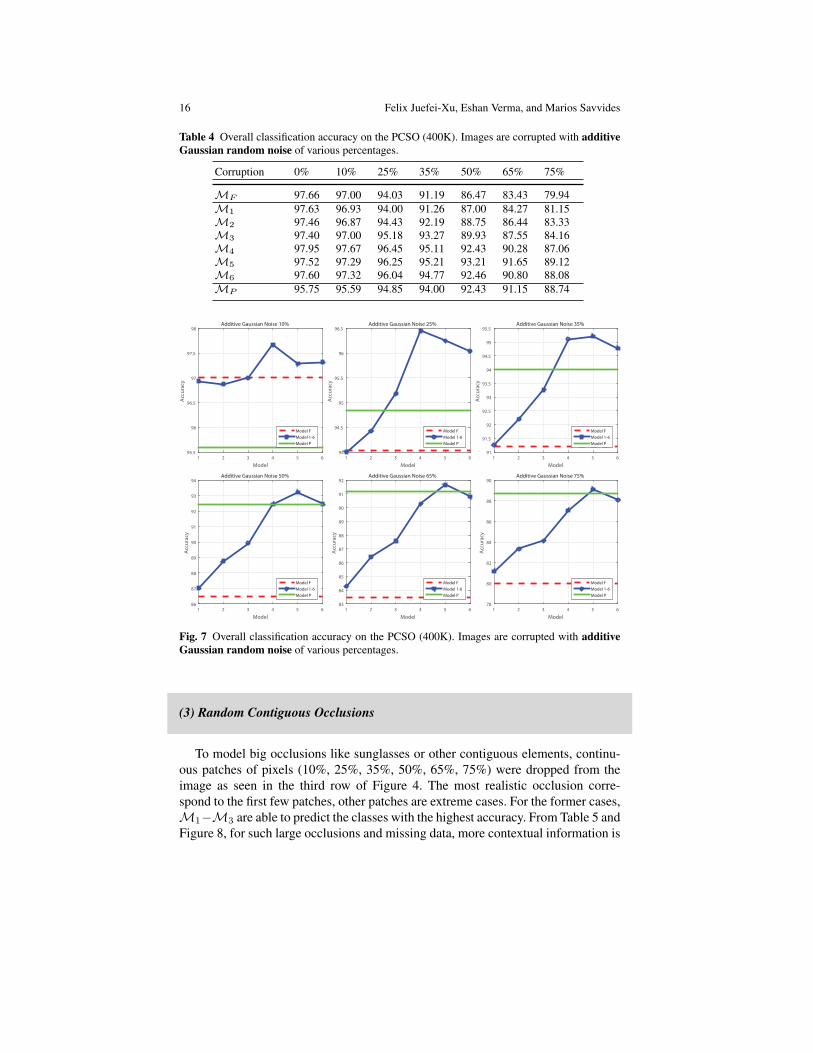
Gaussian white noise (σ = 6) was added to image pixels in varying factors(10%, 25%, 35%, 50%, 65%, 75%). This is corresponding to the second row inFigure 4 and is done to model high noise data and bad compression. From Table 4and Figure 7, M4 −M6 perform best for medium noise. For high noise, M5 isthe most robust. Just like before, as the noise increases, the trend undertaken by theperformance ofMP &MF andM5 &M6 is maintained and so is the performancetrend of the progressively trained models.
16 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
Table 4 Overall classification accuracy on the PCSO (400K). Images are corrupted with additiveGaussian random noise of various percentages.
Corruption 0% 10% 25% 35% 50% 65% 75%
MF 97.66 97.00 94.03 91.19 86.47 83.43 79.94M1 97.63 96.93 94.00 91.26 87.00 84.27 81.15M2 97.46 96.87 94.43 92.19 88.75 86.44 83.33M3 97.40 97.00 95.18 93.27 89.93 87.55 84.16M4 97.95 97.67 96.45 95.11 92.43 90.28 87.06M5 97.52 97.29 96.25 95.21 93.21 91.65 89.12M6 97.60 97.32 96.04 94.77 92.46 90.80 88.08MP 95.75 95.59 94.85 94.00 92.43 91.15 88.74
Model1 2 3 4 5 6
Acc
urac
y
95.5
96
96.5
97
97.5
98Additive Gaussian Noise 10%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
94
94.5
95
95.5
96
96.5Additive Gaussian Noise 25%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
91
91.5
92
92.5
93
93.5
94
94.5
95
95.5Additive Gaussian Noise 35%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
86
87
88
89
90
91
92
93
94Additive Gaussian Noise 50%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
83
84
85
86
87
88
89
90
91
92Additive Gaussian Noise 65%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
78
80
82
84
86
88
90Additive Gaussian Noise 75%
Model FModel 1-6Model P
Fig. 7 Overall classification accuracy on the PCSO (400K). Images are corrupted with additiveGaussian random noise of various percentages.
(3) Random Contiguous Occlusions
To model big occlusions like sunglasses or other contiguous elements, continu-ous patches of pixels (10%, 25%, 35%, 50%, 65%, 75%) were dropped from theimage as seen in the third row of Figure 4. The most realistic occlusion corre-spond to the first few patches, other patches are extreme cases. For the former cases,M1−M3 are able to predict the classes with the highest accuracy. From Table 5 andFigure 8, for such large occlusions and missing data, more contextual information is

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 17
needed for correct classification sinceM1−M3 perform better than other models.However, since they perform better thanMF , our scheme of focused saliency helpsgeneralizing over occlusions.
Table 5 Overall classification accuracy on the PCSO (400K). Images are corrupted with randomcontiguous occlusions of various percentages.
Corruption 0% 10% 25% 35% 50% 65% 75%
MF 97.66 96.69 93.93 88.63 76.54 73.75 64.82M1 97.63 96.95 94.64 90.20 77.47 75.20 53.04M2 97.46 96.76 94.56 90.04 75.99 70.83 56.25M3 97.40 96.63 94.65 90.08 77.13 71.77 68.52M4 97.95 96.82 92.70 86.64 75.25 70.37 61.63M5 97.52 96.56 92.03 83.95 70.36 69.94 66.52M6 97.60 96.61 93.08 86.34 71.91 71.40 69.50MP 95.75 95.00 93.01 88.34 76.82 67.81 49.73
Model1 2 3 4 5 6
Acc
urac
y
95
95.2
95.4
95.6
95.8
96
96.2
96.4
96.6
96.8
97Contiguous Occlusions 10%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
92
92.5
93
93.5
94
94.5
95Contiguous Occlusions 25%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
83
84
85
86
87
88
89
90
91Contiguous Occlusions 35%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
70
71
72
73
74
75
76
77
78Contiguous Occlusions 50%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
67
68
69
70
71
72
73
74
75
76Contiguous Occlusions 65%
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
45
50
55
60
65
70Contiguous Occlusions 75%
Model FModel 1-6Model P
Fig. 8 Overall classification accuracy on the PCSO (400K). Images are corrupted with randomcontiguous occlusions of various percentages.

18 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
4.2.2 Experiments on the AR Face Database
We partitioned the original set to smaller subsets to better understand our methodol-ogy’s performance under different conditions. Set 1 consists of neutral expression,full-face subjects. Set 2 has full-face but varied expressions. Set 3 includes periocu-lar occlusions such as sunglasses and Set 4 includes these and other occlusions likeclothing etc.. Set 5 is the entire dataset including illumination variations.
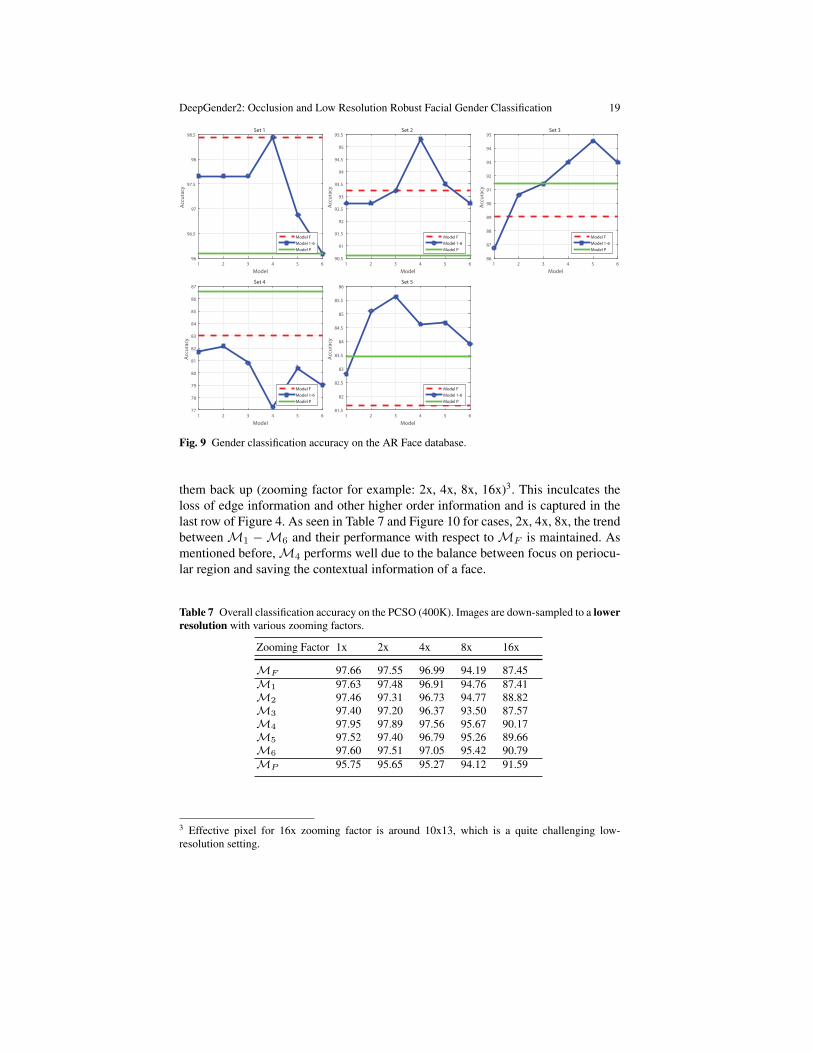
Referring to Table 6 and Figure 9, for Set 1, the full face model performs thebest and this is expected as this model was trained on images very similar to this.Set 2 suggests that the models need more contextual information when expressionsare introduced. Thus,M4 which has focus on periocular but has face informationtoo performs best. For Set 3, we can see two things, one,MP performs better thanMF indicative of its robustness to periocular occlusions. Two, M5 is the best asit combines periocular focus with contextual information gained from incrementaltraining.
Set 4 performance brings out why periocular region is preferred for occludedfaces. We ascertained that some texture and loss of face contour is throwing off themodelsM1 −M6. The performance of the models on Set 5 reiterates previouslystated observations of the combined importance of contextual information aboutface contours and the importance of periocular region. This is the reason for thebest accuracy reported byM3.
Table 6 Gender classification accuracy on the AR Face database.
Sets Set 1 Set 2 Set 3 Set 4 Set 5 (Full Set)
MF 98.44 93.23 89.06 83.04 81.65M1 97.66 92.71 86.72 81.70 82.82M2 97.66 92.71 90.62 82.14 85.10M3 97.66 93.23 91.41 80.80 85.62M4 98.44 95.31 92.97 77.23 84.61M5 96.88 93.49 94.53 80.36 84.67M6 96.09 92.71 92.97 79.02 83.90MP 96.09 90.62 91.41 86.61 83.44
4.3 Experiment II: Low Resolution Robustness
Our scheme of training on Gaussian blurred images should generalize well to lowresolution images. To test this hypothesis, we tested our models on images from thePCSO mugshot dataset by first down-sampling them by a factor and then blowing
DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 19
Model1 2 3 4 5 6
Acc
urac
y
96
96.5
97
97.5
98
98.5Set 1
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
90.5
91
91.5
92
92.5
93
93.5
94
94.5
95
95.5Set 2
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
86
87
88
89
90
91
92
93
94
95Set 3
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
77
78
79
80
81
82
83
84
85
86
87Set 4
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
81.5
82
82.5
83
83.5
84
84.5
85
85.5
86Set 5
Model FModel 1-6Model P
Fig. 9 Gender classification accuracy on the AR Face database.
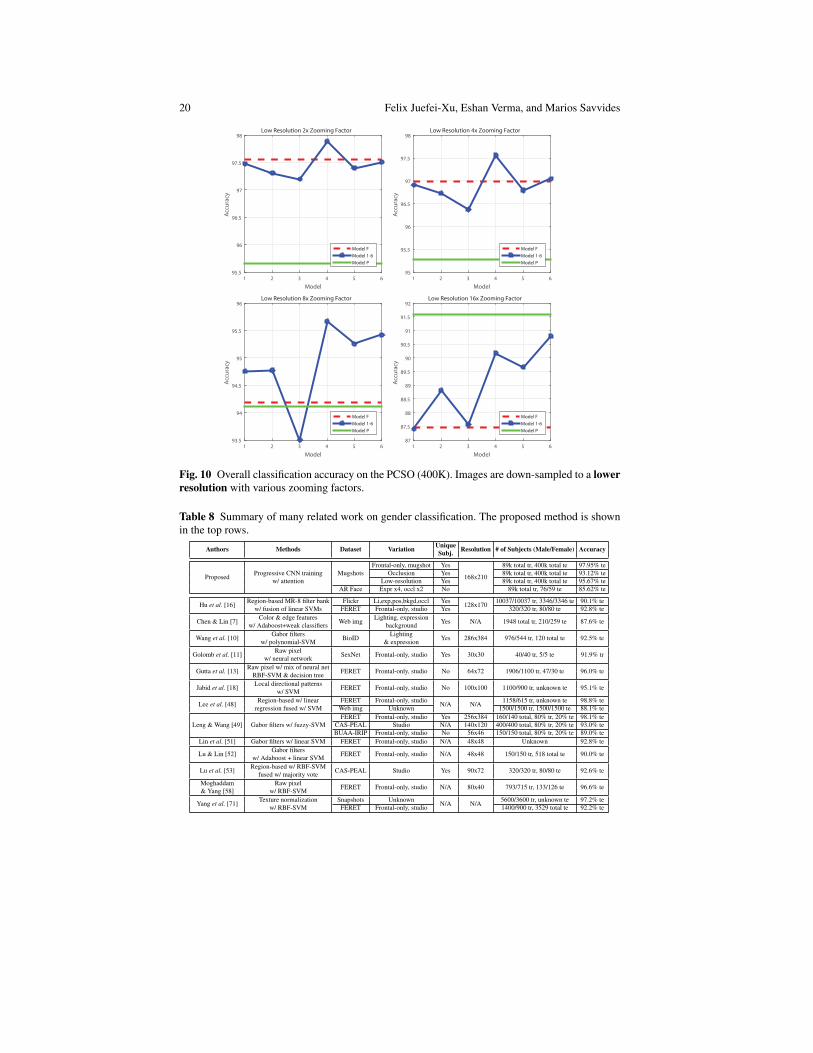
them back up (zooming factor for example: 2x, 4x, 8x, 16x)3. This inculcates theloss of edge information and other higher order information and is captured in thelast row of Figure 4. As seen in Table 7 and Figure 10 for cases, 2x, 4x, 8x, the trendbetweenM1 −M6 and their performance with respect toMF is maintained. Asmentioned before,M4 performs well due to the balance between focus on periocu-lar region and saving the contextual information of a face.
Table 7 Overall classification accuracy on the PCSO (400K). Images are down-sampled to a lowerresolution with various zooming factors.
Zooming Factor 1x 2x 4x 8x 16x
MF 97.66 97.55 96.99 94.19 87.45M1 97.63 97.48 96.91 94.76 87.41M2 97.46 97.31 96.73 94.77 88.82M3 97.40 97.20 96.37 93.50 87.57M4 97.95 97.89 97.56 95.67 90.17M5 97.52 97.40 96.79 95.26 89.66M6 97.60 97.51 97.05 95.42 90.79MP 95.75 95.65 95.27 94.12 91.59
3 Effective pixel for 16x zooming factor is around 10x13, which is a quite challenging low-resolution setting.
20 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
Model1 2 3 4 5 6
Acc
urac
y
95.5
96
96.5
97
97.5
98Low Resolution 2x Zooming Factor
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
95
95.5
96
96.5
97
97.5
98Low Resolution 4x Zooming Factor
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
93.5
94
94.5
95
95.5
96Low Resolution 8x Zooming Factor
Model FModel 1-6Model P
Model1 2 3 4 5 6
Acc
urac
y
87
87.5
88
88.5
89
89.5
90
90.5
91
91.5
92Low Resolution 16x Zooming Factor
Model FModel 1-6Model P
Fig. 10 Overall classification accuracy on the PCSO (400K). Images are down-sampled to a lowerresolution with various zooming factors.
Table 8 Summary of many related work on gender classification. The proposed method is shownin the top rows.
Authors Methods Dataset Variation Unique Resolution # of Subjects (Male/Female) AccuracySubj.
Proposed MugshotsFrontal-only, mugshot Yes
168x210
89k total tr, 400k total te 97.95% teProgressive CNN training Occlusion Yes 89k total tr, 400k total te 93.12% te
w/ attention Low-resolution Yes 89k total tr, 400k total te 95.67% teAR Face Expr x4, occl x2 No 89k total tr, 76/59 te 85.62% te
Hu et al. [16] Region-based MR-8 filter bank Flickr Li,exp,pos,bkgd,occl Yes 128x170 10037/10037 tr, 3346/3346 te 90.1% tew/ fusion of linear SVMs FERET Frontal-only, studio Yes 320/320 tr, 80/80 te 92.8% te
Chen & Lin [7] Color & edge features Web img Lighting, expression Yes N/A 1948 total tr, 210/259 te 87.6% tew/ Adaboost+weak classifiers background
Wang et al. [10] Gabor filters BioID Lighting Yes 286x384 976/544 tr, 120 total te 92.5% tew/ polynomial-SVM & expression
Golomb et al. [11] Raw pixel SexNet Frontal-only, studio Yes 30x30 40/40 tr, 5/5 te 91.9% trw/ neural network
Gutta et al. [13] Raw pixel w/ mix of neural net FERET Frontal-only, studio No 64x72 1906/1100 tr, 47/30 te 96.0% teRBF-SVM & decision tree
Jabid et al. [18] Local directional patterns FERET Frontal-only, studio No 100x100 1100/900 tr, unknown te 95.1% tew/ SVM
Lee et al. [48] Region-based w/ linear FERET Frontal-only, studio N/A N/A 1158/615 tr, unknown te 98.8% teregression fused w/ SVM Web img Unknown 1500/1500 tr, 1500/1500 te 88.1% te
Leng & Wang [49] Gabor filters w/ fuzzy-SVMFERET Frontal-only, studio Yes 256x384 160/140 total, 80% tr, 20% te 98.1% te
CAS-PEAL Studio N/A 140x120 400/400 total, 80% tr, 20% te 93.0% teBUAA-IRIP Frontal-only, studio No 56x46 150/150 total, 80% tr, 20% te 89.0% te
Lin et al. [51] Gabor filters w/ linear SVM FERET Frontal-only, studio N/A 48x48 Unknown 92.8% te
Lu & Lin [52] Gabor filters FERET Frontal-only, studio N/A 48x48 150/150 tr, 518 total te 90.0% tew/ Adaboost + linear SVM
Lu et al. [53] Region-based w/ RBF-SVM CAS-PEAL Studio Yes 90x72 320/320 tr, 80/80 te 92.6% tefused w/ majority voteMoghaddam Raw pixel FERET Frontal-only, studio N/A 80x40 793/715 tr, 133/126 te 96.6% te& Yang [58] w/ RBF-SVM
Yang et al. [71] Texture normalization Snapshots Unknown N/A N/A 5600/3600 tr, unknown te 97.2% tew/ RBF-SVM FERET Frontal-only, studio 1400/900 tr, 3529 total te 92.2% te

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 21
4.4 Discussion
We have proposed a methodology for building a gender recognition system whichis robust to occlusions. It involves training a deep model incrementally over severalbatches of input data pre-processed with progressive blur. The intuition and intentis two-fold, one to have the network focus on periocular regions of the face forgender recognition. And two, to preserve contextual information of facial contoursto generalize better over occlusions.
Through various experiments we have observed that our hypothesis is indeed trueand that for a given occlusion set, it is possible to have high accuracy from a modelthat encompasses both of above stated properties. Irrespective of the fact that wedid not train on any occluded data, or optimize for a particular set of occlusions, ourmodels are able to generalize well over synthetic data and real life facial occlusionimages.
We have summarized the overall experiments and consolidated the results in Ta-ble 8. For PCSO large-scale experiments, we believe that 35% occlusion is the rightamount of degradations, on which accuracies should be reported. Therefore we av-erage the accuracy from our best model on three types of occlusions (missing pixel,additive Gaussian noise, and contiguous occlusions) which gives 93.12% in Table 8.For low-resolution experiments, we believe 8x zooming factor is the right amountof degradations, so we report the accuracy 95.67% in Table 8. Many other relatedwork on gender classification are also listed for a quick comparison. This table isbased on [16].
5 Experiments: Part B
In order to boost the classification accuracy and support the models trained in theprevious section, we trained a GAN to hallucinate occlusions and missing informa-tion in the input image. The next two sections detail our curation of the input dataand the selection of the testing sets for our evaluation. The gender model (Mk) def-initions remain the same as in the previous section. And we use Gz andDx to denotethe Generator and Discriminator models from GAN.
5.1 Network Architecture
The network architectures and approach that we use are similar to the work of [60].The input size of the image is 64×64. While training we used Adam [45] optimiza-tion method because it does not require hand-tuning of the learning rate, momentum,and other hyper-parameters.
For learning z we use the same hyper-parameters as learned in the previousmodel. In our experiments, running 2000 epochs helped converge to a low loss.

22 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
5.2 Database and Pre-processing
In order to train Gz and Dx our approach initially was to use the same input imagesas used to trainMk. However this resulted in the network not converging to a lowloss. In other words, we were not able to learn a generative distribution that thegenerator could sample from. Our analysis and intuition suggested that in order forthe adversarial loss to work, the task had to be a challenge for both Gz and Dx. Ourfully frontal pose images were ill-posed for this model.
Hence to train the GAN, we used the Labeled Faces in the Wild (LFW) database[47] and aligned the faces using dLib as provided by the OpenFace [1]. We trainedon the entire dataset comprising of around 13,000 images with 128 images held outfor the purpose of qualitatively showing the image recovery results as in Figure 11.In this case, by visual analysis as well by analytical analysis the Gz was better ableto learn a distribution of z , pg , that was a strong representation of the data, pdata.That is symbolically, pg = pdata. The results and detailed evaluation of the model isdone later in Section 5.3. In this part of the experiment, we use a subset of the PCSOdatabase containing 10,000 images (5,000 male and 5,000 female) for testing thegender classification accuracy. The reason we did not test on the entire 400K PCSOis simply because the occlusion removal step involves an iterative solver which istime consuming.
5.3 Experiment III: Further Occlusion Robustness via DeepGenerative Approach
As shown in Figure 11, we chose to model occlusions based on percentage of pixelsmissing from the center of the image. The shown images are from the held-outportion of the LFW dataset. We show recovered images in Figure 11 as a visualconfirmation that the DCGAN is able to recover unseen images with high fidelity,even under pretty heavy occlusions as much as 75% in the face center. The recoveryresults on the PCSO datasets to be tested for gender classification is comparable tothat of the LFW, but we are not allowed to display mugshot images in any publishedwork.
For training the Gz and Dx, we used the LFW data that captures a high varianceof poses, illumination and faces. We found this was critical in helping especially theGz converge to a stable weights. The model was able to generalize well to variousfaces and poses. As can be seen in Figure 11, the model is able to generate missinginformation effectively.
Not relying on visual inspection, we plotted the PSNR and SNR of the recovered(occlusion removed) faces from the 10K PCSO subset in Figure 14. This is ourquality measure of occlusion removal using GAN. As can be seen in Table 10, thePSNR/SNR is better for completed images and as expected is higher for images withlesser occlusions.

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 23
10% Masked
Original
75% Masked
65% Masked
50% Masked
35% Masked
25% Masked
Fig. 11 Qualitative results of occlusion removal using DCGAN on images from LFW dataset.
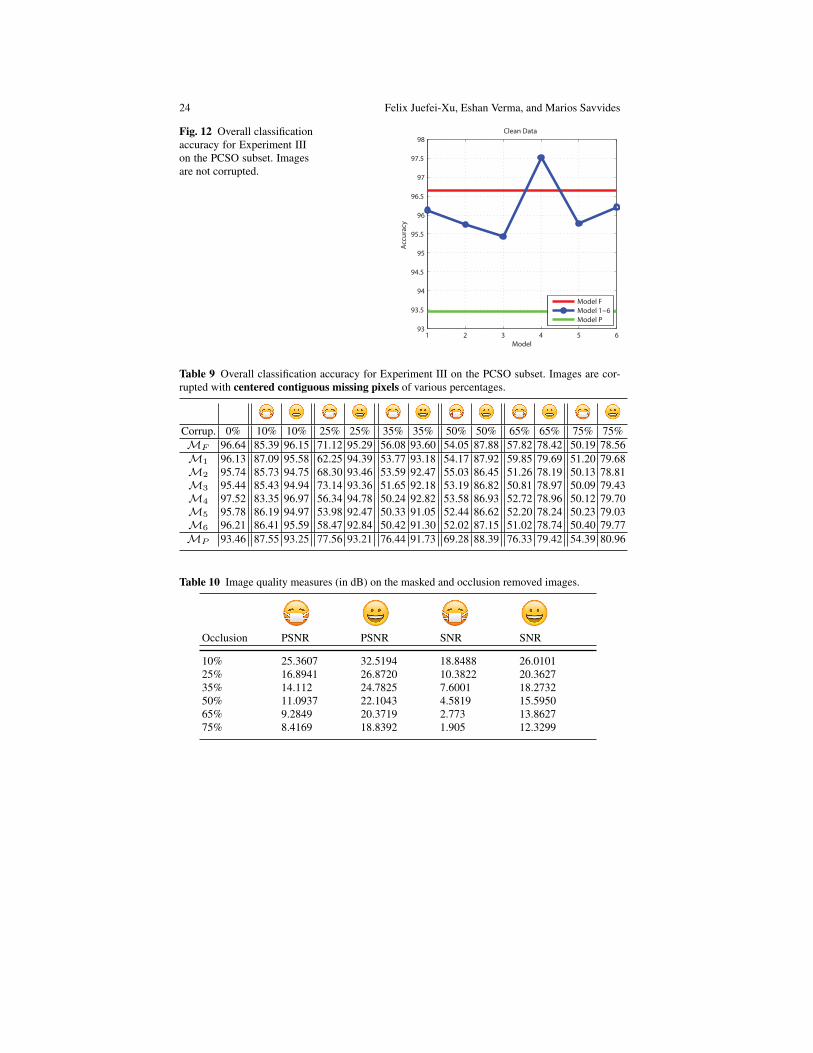
The primary motivation behind training a GAN was to improve the classificationof Mk models. This is covered in Table 9. The first column of the table is ourbaseline case. This was constructed using upsampled images from the resolution asneeded by Gz andDx to the resolution expected byMk. All other accuracies shouldbe evaluated with respect to this case. (Figure 12)
Figure 13 corresponds to the other columns of Table 9. The accuracies on com-pleted images using Gz are significantly better than the accuracies on masked im-
24 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
Fig. 12 Overall classificationaccuracy for Experiment IIIon the PCSO subset. Imagesare not corrupted.
1 2 3 4 5 693
93.5
94
94.5
95
95.5
96
96.5
97
97.5
98
Model
Acc
urac
y
Clean Data
Model FModel 1−6Model P
Table 9 Overall classification accuracy for Experiment III on the PCSO subset. Images are cor-rupted with centered contiguous missing pixels of various percentages.
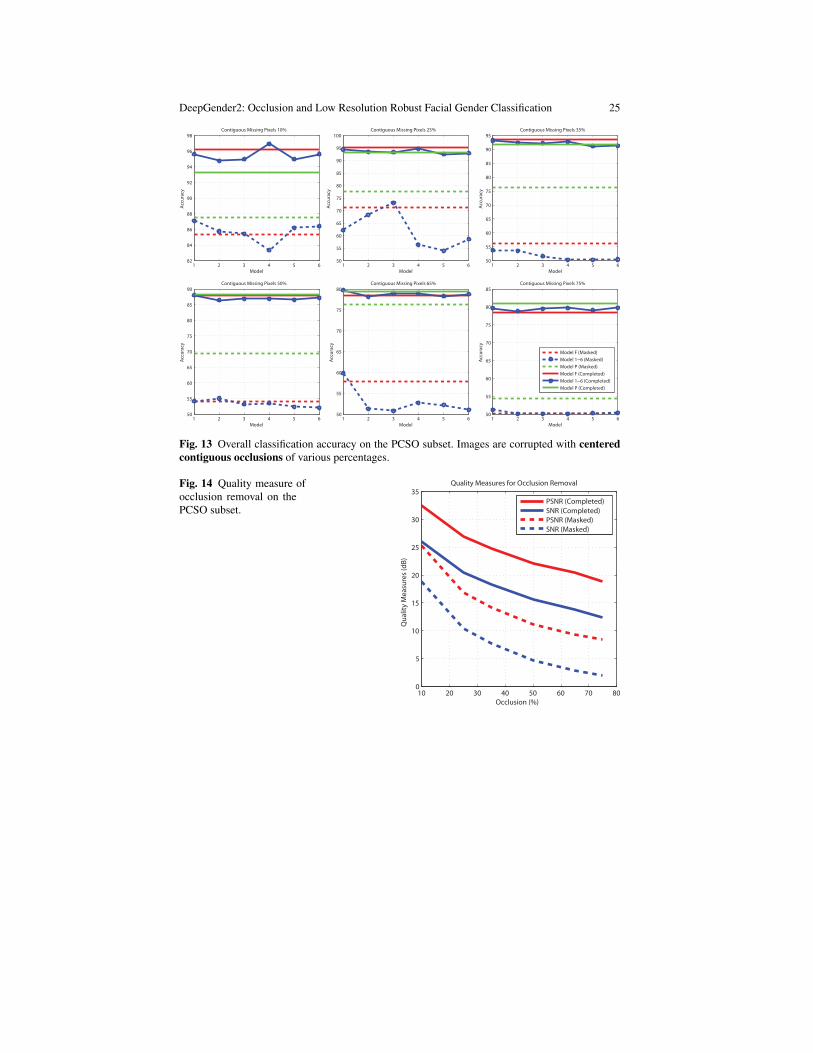
Corrup. 0% 10% 10% 25% 25% 35% 35% 50% 50% 65% 65% 75% 75%MF 96.64 85.39 96.15 71.12 95.29 56.08 93.60 54.05 87.88 57.82 78.42 50.19 78.56M1 96.13 87.09 95.58 62.25 94.39 53.77 93.18 54.17 87.92 59.85 79.69 51.20 79.68M2 95.74 85.73 94.75 68.30 93.46 53.59 92.47 55.03 86.45 51.26 78.19 50.13 78.81M3 95.44 85.43 94.94 73.14 93.36 51.65 92.18 53.19 86.82 50.81 78.97 50.09 79.43M4 97.52 83.35 96.97 56.34 94.78 50.24 92.82 53.58 86.93 52.72 78.96 50.12 79.70M5 95.78 86.19 94.97 53.98 92.47 50.33 91.05 52.44 86.62 52.20 78.24 50.23 79.03M6 96.21 86.41 95.59 58.47 92.84 50.42 91.30 52.02 87.15 51.02 78.74 50.40 79.77MP 93.46 87.55 93.25 77.56 93.21 76.44 91.73 69.28 88.39 76.33 79.42 54.39 80.96
Table 10 Image quality measures (in dB) on the masked and occlusion removed images.
Occlusion PSNR PSNR SNR SNR
10% 25.3607 32.5194 18.8488 26.010125% 16.8941 26.8720 10.3822 20.362735% 14.112 24.7825 7.6001 18.273250% 11.0937 22.1043 4.5819 15.595065% 9.2849 20.3719 2.773 13.862775% 8.4169 18.8392 1.905 12.3299
DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 25
1 2 3 4 5 682
84
86
88
90
92
94
96
98
Model
Acc
urac
y
Contiguous Missing Pixels 10%
1 2 3 4 5 650
55
60
65
70
75
80
85
90
95
100
Model
Acc
urac
y
Contiguous Missing Pixels 25%
1 2 3 4 5 650
55
60
65
70
75
80
85
90
95
Model
Acc
urac
y
Contiguous Missing Pixels 35%
1 2 3 4 5 650
55
60
65
70
75
80
85
90
Model
Acc
urac
y
Contiguous Missing Pixels 50%
1 2 3 4 5 650
55
60
65
70
75
80
Model
Acc
urac
y
Contiguous Missing Pixels 65%
1 2 3 4 5 650
55
60
65
70
75
80
85
Model
Acc
urac
y
Contiguous Missing Pixels 75%
Model F (Masked)Model 1−6 (Masked)Model P (Masked)Model F (Completed)Model 1−6 (Completed)Model P (Completed)
Fig. 13 Overall classification accuracy on the PCSO subset. Images are corrupted with centeredcontiguous occlusions of various percentages.
Fig. 14 Quality measure ofocclusion removal on thePCSO subset.
10 20 30 40 50 60 70 800
5
10
15
20
25
30
35
Occlusion (%)
Qua
lity
Mea
sure
s (d
B)
Quality Measures for Occlusion Removal
PSNR (Completed)SNR (Completed)PSNR (Masked)SNR (Masked)

26 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
ages. This suggests that the hallucinations are able to preserve the gender sensitivityof the original images.
The above statement can also be verified through visual inspection of Figure 11.Even for high percentage occlusions, 50 − 75% the contours and features of theoriginal face are pretty accurately reproduced by Gz .
5.4 Discussion
In the current generative model for image occlusion removal, we assume that the oc-clusion mask is known to the algorithm, which is the M in Equation 7. Although itis beyond the scope of this work to study how an algorithm can automatically deter-mine the occlusion region, it will be an interesting research direction. For example,[61] is able to automatically tell which part is the face or the non-face region.
One big advantage of the DCGAN or GAN in general, is that it is entirely un-supervised. The loss function is based off essentially measuring the similarity oftwo distributions (the true image distribution and the generated image distribution),rather than image-wise comparisons, which may require labeled ground-truth im-ages be provided. The unsupervised nature of the GAN has made the training pro-cess much easier by not needing careful curating of the labeled data.
The effectiveness of the DCGAN is also salient. It not only can recover the high-percentage missing data with high fidelity, which translates to significant improve-ment on the gender classification tasks, but also can be used for future data aug-mentation in a total unsupervised manner. We can essentially generate as muchgender-specific data as needed, which will be an asset for training an even largermodel.
During our experimentation, we find that training the DCGAN using more con-strained faces (less pose variations, less lighting variations, less expression varia-tions, etc.) such as the PCSO mugshot images actually degrades the recovery per-formance. The reason could be as follows. When the training data is less diversified,let us use one extreme case, which is a training dataset comprises thousands ofimages from only one subject. In this case, the ‘true distribution’ becomes a verydensely clustered mass, which means whatever images the generator G tries to comeup with, the discriminatorD will (almost) always say that the generated ones are notfrom the true distribution, because the generated image distribution can hardly hitthat densely clustered mass. This way, we are essentially giving a too easy task forthe discriminator to solve, which prevents the discriminator to become a strong one,which leads to poorly-performing generator as well in this adversarial setting. Ina nutshell, during the DCGAN training, we definitely need more variations in thetraining corpus.

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 27
6 Conclusions and Future Work
In this work, we have undertaken the task of occlusion and low-resolution robustfacial gender classification. Inspired by the trainable attention model via deep ar-chitecture, and the fact that the periocular region is proven to be the most salientregion for gender classification purposes, we are able to design a progressive con-volutional neural network training paradigm to enforce the attention shift during thelearning process. The hope is to enable the network to attend to particular high-profile regions (e.g. the periocular region) without the need to change the networkarchitecture itself. The network benefits from this attention shift and becomes morerobust towards occlusions and low-resolution degradations. With the progressivelytrained CNN models, we have achieved better gender classification results on thelarge-scale PCSO mugshot database with 400K images under occlusion and low-resolution settings, compared to the one undergone traditional training. In addition,our progressively trained network is sufficiently generalized so that it can be robustto occlusions of arbitrary types and at arbitrary locations, as well as low resolution.
To further improve the gender classification performance on occluded facial im-ages, we invoke a deep generative approach via deep convolutional generative ad-versarial networks (DCGAN) to fill in the missing pixels for the occluded facialregions. The recovered images not only show high fidelity as compared to the orig-inal un-occluded images, but also significantly improve the gender classificationperformance.
In summary, on one hand, we aim at building a robust gender classifier that istolerant to image degradations such as occlusions and low resolution, and on theother hand, we aim at mitigating and eliminating the degradations through a gener-ative approach. Together, we are able to push the boundary of unconstrained facialgender classification.
Future work: We have carried out a set of large-scale testing experiments on thePCSO mugshot database with 400K images, shown in the experimental section. Wehave noticed that, under the same testing environment, the amount of time it takesto test on the entire 400K images various dramatically for different progressivelytrained models (M0 − M6). As shown in Figure 15, we can observe a trend oftesting time decrease when testing usingM0 all the way toM6, where the curvescorrespond to the additive Gaussian noise occlusion robust experiments. This sametrend is observed across the board for all the large-scale experiments on PCSO. Thetime difference is stunning. For example, if we look at the green curve,M0 takesover 5000 seconds while M6 only around 500. One of the future directions is tostudy the cause of this phenomenon. One possible direction is to study the sparsityor the smoothness of the learned filters.
Shown in our visualization (Figure 15) of the 64 first-layer filters in AlexNetfor modelsM0,M3, andM6, respectively, we can observe that the progressivelytrained filters seems to be smoother and this may be due to the implicit low-rank reg-ularization phenomenon discussed in Section 3.1.3. Other future work may includestudying how the ensemble of models [22, 21] can further improve the performanceand how various multi-modal soft-biometrics traits [74, 37, 20, 66, 64, 29, 30, 41,

28 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
Model0 1 2 3 4 5 6
Test
ing
Tim
e on
PC
SO (4
00K)
(sec
)
0
1000
2000
3000
4000
5000
6000
Gaussian Noise 10%Gaussian Noise 25%Gaussian Noise 35%Gaussian Noise 50%Gaussian Noise 65%Gaussian Noise 75%
M0 M3 M6
Fig. 15 (Top) Testing time for the additive Gaussian noise occlusion experiments on various mod-els. (Bottom) Visualization of the 64 first-layer filters for modelsM0,M3, andM6, respectively.
34, 39, 36, 5, 40] can be fused for improved gender classification, especially undermore unconstrained scenarios.
References
1. Amos, B., Ludwiczuk, B., Satyanarayanan, M.: Openface: A general-purpose face recognitionlibrary with mobile applications. Tech. rep., CMU-CS-16-118, CMU School of ComputerScience (2016)
2. Ba, J., Mnih, V., Kavukcuoglu, K.: Multiple object recognition with visual attention. arXivpreprint arXiv:1412.7755 (2014)
3. Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align andtranslate. arXiv preprint arXiv:1409.0473 (2014)
4. Bartle, A., Zheng, J.: Gender classification with deep learning. Stanford cs224d Course ProjectReport (2015)
5. Buchana, P., Cazan, I., Diaz-Granados, M., Juefei-Xu, F., M.Savvides: Simultaneous ForgeryIdentification and Localization in Paintings Using Advanced Correlation Filters. In: IEEE

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 29
International Conference on Image Processing (ICIP), pp. 1–5 (2016)6. Chan, W., Jaitly, N., Le, Q.V., Vinyals, O.: Listen, attend and spell. arXiv preprint
arXiv:1508.01211 (2015)7. Chen, D.Y., Lin, K.Y.: Robust gender recognition for uncontrolled environment of real-life
images. Consumer Electronics, IEEE Transactions on 56(3), 1586–1592 (2010)8. Cheng, M.M., Zhang, Z., Lin, W.Y., Torr, P.: Bing: Binarized normed gradients for objectness
estimation at 300fps. In: IEEE CVPR, pp. 3286–3293 (2014)9. Chorowski, J.K., Bahdanau, D., Serdyuk, D., Cho, K., Bengio, Y.: Attention-based models for
speech recognition. In: Advances in Neural Information Processing Systems, pp. 577–585(2015)
10. Chuan-xu, W., Yun, L., Zuo-yong, L.: Algorithm research of face image gender classifica-tion based on 2-d gabor wavelet transform and svm. In: Computer Science and Computa-tional Technology, 2008. ISCSCT’08. International Symposium on, vol. 1, pp. 312–315. IEEE(2008)
11. Golomb, B.A., Lawrence, D.T., Sejnowski, T.J.: Sexnet: A neural network identifies sex fromhuman faces. In: NIPS, vol. 1, p. 2 (1990)
12. Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville,A., Bengio, Y.: Generative adversarial nets. In: Advances in Neural Information ProcessingSystems, pp. 2672–2680 (2014)
13. Gutta, S., Huang, J.R., Jonathon, P., Wechsler, H.: Mixture of experts for classification ofgender, ethnic origin, and pose of human faces. Neural Networks, IEEE Transactions on11(4), 948–960 (2000)
14. Harel, J., Koch, C., Perona, P.: Graph-based visual saliency. In: NIPS, pp. 545–552 (2006)15. Hou, X., Harel, J., Koch, C.: Image signature: Highlighting sparse salient regions. IEEE
TPAMI 34(1), 194–201 (2012)16. Hu, S.Y.D., Jou, B., Jaech, A., Savvides, M.: Fusion of region-based representations for gender
identification. In: IEEE/IAPR IJCB, pp. 1–7 (2011)17. Itti, L., Koch, C., Niebur, E., et al.: A model of saliency-based visual attention for rapid scene
analysis. IEEE Transactions on pattern analysis and machine intelligence 20(11), 1254–1259(1998)
18. Jabid, T., Kabir, M.H., Chae, O.: Gender classification using local directional pattern (ldp). In:IEEE ICPR, pp. 2162–2165. IEEE (2010)
19. Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: NIPS,pp. 2008–2016 (2015)
20. Juefei-Xu, F., Bhagavatula, C., Jaech, A., Prasad, U., Savvides, M.: Gait-ID on the Move: PaceIndependent Human Identification Using Cell Phone Accelerometer Dynamics. In: Biomet-rics: Theory, Applications and Systems (BTAS), 2012 IEEE Fifth International Conferenceon, pp. 8–15 (2012)
21. Juefei-Xu, F., Boddeti, V.N., Savvides, M.: Local binary convolutional neural networks. arXivpreprint arXiv:1608.06049 (2016)
22. Juefei-Xu, F., Boddeti, V.N., Savvides, M.: Local Binary Convolutional Neural Networks. In:Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on (2017)
23. Juefei-Xu, F., Cha, M., Heyman, J.L., Venugopalan, S., Abiantun, R., Savvides, M.: RobustLocal Binary Pattern Feature Sets for Periocular Biometric Identification. In: Biometrics:Theory Applications and Systems (BTAS), 4th IEEE Int’l Conf. on, pp. 1–8 (2010)
24. Juefei-Xu, F., Cha, M., Savvides, M., Bedros, S., Trojanova, J.: Robust Periocular BiometricRecognition Using Multi-level Fusion of Various Local Feature Extraction Techniques. In:IEEE 17th International Conference on Digital Signal Processing (DSP), pp. 1–7 (2011)
25. Juefei-Xu, F., Luu, K., Savvides, M.: Spartans: Single-sample Periocular-based Alignment-robust Recognition Technique Applied to Non-frontal Scenarios. IEEE Trans. on Image Pro-cessing 24(12), 4780–4795 (2015)
26. Juefei-Xu, F., Luu, K., Savvides, M., Bui, T., Suen, C.: Investigating Age Invariant FaceRecognition Based on Periocular Biometrics. In: Biometrics (IJCB), 2011 International JointConference on, pp. 1–7 (2011)

30 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
27. Juefei-Xu, F., Pal, D.K., Savvides, M.: Hallucinating the Full Face from the Periocular Regionvia Dimensionally Weighted K-SVD. In: Computer Vision and Pattern Recognition (CVPR)Workshops, 2014 IEEE Conference on, pp. 1–8 (2014)
28. Juefei-Xu, F., Pal, D.K., Savvides, M.: Methods and Software for Hallucinating Facial Fea-tures by Prioritizing Reconstruction Errors (2014). U.S. Provisional Patent Application SerialNo. 61/998,043, June 17, 2014.
29. Juefei-Xu, F., Pal, D.K., Savvides, M.: NIR-VIS Heterogeneous Face Recognition via Cross-Spectral Joint Dictionary Learning and Reconstruction. In: Computer Vision and PatternRecognition (CVPR) Workshops, 2015 IEEE Conference on, pp. 141–150 (2015)
30. Juefei-Xu, F., Pal, D.K., Singh, K., Savvides, M.: A Preliminary Investigation on the Sen-sitivity of COTS Face Recognition Systems to Forensic Analyst-style Face Processing forOcclusions. In: Computer Vision and Pattern Recognition (CVPR) Workshops, 2015 IEEEConference on, pp. 25–33 (2015)
31. Juefei-Xu, F., Savvides, M.: Can Your Eyebrows Tell Me Who You Are? In: Signal Processingand Communication Systems (ICSPCS), 2011 5th International Conference on, pp. 1–8 (2011)
32. Juefei-Xu, F., Savvides, M.: Unconstrained Periocular Biometric Acquisition and RecognitionUsing COTS PTZ Camera for Uncooperative and Non-cooperative Subjects. In: Applicationsof Computer Vision (WACV), 2012 IEEE Workshop on, pp. 201–208 (2012)
33. Juefei-Xu, F., Savvides, M.: An Augmented Linear Discriminant Analysis Approach for Iden-tifying Identical Twins with the Aid of Facial Asymmetry Features. In: Computer Vision andPattern Recognition (CVPR) Workshops, 2013 IEEE Conference on, pp. 56–63 (2013)
34. Juefei-Xu, F., Savvides, M.: An Image Statistics Approach towards Efficient and Robust Re-finement for Landmarks on Facial Boundary. In: Biometrics: Theory, Applications and Sys-tems (BTAS), 2013 IEEE Sixth International Conference on, pp. 1–8 (2013)
35. Juefei-Xu, F., Savvides, M.: Subspace Based Discrete Transform Encoded Local Binary Pat-terns Representations for Robust Periocular Matching on NIST’s Face Recognition GrandChallenge. IEEE Trans. on Image Processing 23(8), 3490–3505 (2014)
36. Juefei-Xu, F., Savvides, M.: Encoding and Decoding Local Binary Patterns for Harsh FaceIllumination Normalization. In: IEEE International Conference on Image Processing (ICIP),pp. 3220–3224 (2015)
37. Juefei-Xu, F., Savvides, M.: Facial Ethnic Appearance Synthesis. In: Computer Vision -ECCV 2014 Workshops, Lecture Notes in Computer Science, vol. 8926, pp. 825–840. SpringerInternational Publishing (2015)
38. Juefei-Xu, F., Savvides, M.: Pareto-optimal Discriminant Analysis. In: IEEE InternationalConference on Image Processing (ICIP), pp. 611–615 (2015)
39. Juefei-Xu, F., Savvides, M.: Pokerface: Partial Order Keeping and Energy Repressing Methodfor Extreme Face Illumination Normalization. In: Biometrics: Theory, Applications and Sys-tems (BTAS), 2015 IEEE Seventh International Conference on, pp. 1–8 (2015)
40. Juefei-Xu, F., Savvides, M.: Single Face Image Super-Resolution via Solo Dictionary Learn-ing. In: IEEE International Conference on Image Processing (ICIP), pp. 2239–2243 (2015)
41. Juefei-Xu, F., Savvides, M.: Weight-Optimal Local Binary Patterns. In: Computer Vision -ECCV 2014 Workshops, Lecture Notes in Computer Science, vol. 8926, pp. 148–159. SpringerInternational Publishing (2015)
42. Juefei-Xu, F., Savvides, M.: Fastfood Dictionary Learning for Periocular-Based Full Face Hal-lucination. In: Biometrics: Theory, Applications and Systems (BTAS), 2016 IEEE SeventhInternational Conference on, pp. 1–8 (2016)
43. Juefei-Xu, F., Savvides, M.: Learning to Invert Local Binary Patterns. In: 27th British MachineVision Conference (BMVC) (2016)
44. Juefei-Xu, F., Savvides, M.: Multi-class Fukunaga Koontz Discriminant Analysis for En-hanced Face Recognition. Pattern Recognition 52, 186–205 (2016)
45. Kingma, D., Ba, J.: Adam: A method for stochastic optimization. arXiv preprintarXiv:1412.6980 (2014)
46. Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutionalneural networks. In: NIPS, pp. 1097–1105 (2012)

DeepGender2: Occlusion and Low Resolution Robust Facial Gender Classification 31
47. Learned-Miller, G.B.H.E.: Labeled faces in the wild: Updates and new reporting procedures.Tech. Rep. UM-CS-2014-003, University of Massachusetts, Amherst (2014)
48. Lee, P.H., Hung, J.Y., Hung, Y.P.: Automatic gender recognition using fusion of facial strips.In: IEEE ICPR, pp. 1140–1143. IEEE (2010)
49. Leng, X., Wang, Y.: Improving generalization for gender classification. In: IEEE ICIP, pp.1656–1659. IEEE (2008)
50. Levi, G., Hassner, T.: Age and gender classification using convolutional neural networks. In:IEEE CVPRW (2015)
51. Lin, H., Lu, H., Zhang, L.: A new automatic recognition system of gender, age and ethnicity.In: Intelligent Control and Automation, 2006. WCICA 2006. The Sixth World Congress on,vol. 2, pp. 9988–9991. IEEE (2006)
52. Lu, H., Lin, H.: Gender recognition using adaboosted feature. In: Natural Computation, 2007.ICNC 2007. Third International Conference on, vol. 2, pp. 646–650. IEEE (2007)
53. Lu, L., Xu, Z., Shi, P.: Gender classification of facial images based on multiple facial regions.In: Computer Science and Information Engineering, 2009 WRI World Congress on, vol. 6, pp.48–52. IEEE (2009)
54. Luong, M.T., Pham, H., Manning, C.D.: Effective approaches to attention-based neural ma-chine translation. In: Conference on Empirical Methods in Natural Language Processing(EMNLP) (2015)
55. Martinez, A., Benavente, R.: The AR Face Database. CVC Technical Report No.24 (1998)56. Merkow, J., Jou, B., Savvides, M.: An exploration of gender identification using only the
periocular region. In: IEEE BTAS, pp. 1–5 (2010)57. Mnih, V., Heess, N., Graves, A., et al.: Recurrent models of visual attention. In: NIPS, pp.
2204–2212 (2014)58. Moghaddam, B., Yang, M.H.: Gender classification with support vector machines. In: IEEE
FG, pp. 306–311. IEEE (2000)59. Pal, D.K., Juefei-Xu, F., Savvides, M.: Discriminative Invariant Kernel Features: A Bells-
and-Whistles-Free Approach to Unsupervised Face Recognition and Pose Estimation. In:Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on (2016)
60. Radford, A., Metz, L., Chintala, S.: Unsupervised representation learning with deep convolu-tional generative adversarial networks. arXiv preprint arXiv:1511.06434 (2015)
61. Saito, S., Li, T., Li, H.: Real-time facial segmentation and performance capture from rgb input.arXiv preprint arXiv:1604.02647 (2016)
62. Savvides, M., Juefei-Xu, F.: Image Matching Using Subspace-Based Discrete Transform En-coded Local Binary Patterns (2013). US Patent US 2014/0212044 A1
63. Savvides, M., Juefei-Xu, F., Prabhu, U., Bhagavatula, C.: Unconstrained Biometric Identifica-tion in Real World Environments. In: Advances in Human Factors and System Interactions,Vol. 497 of the series Advances in Intelligent Systems and Computing, pp. 231–244 (2016)
64. Seshadri, K., Juefei-Xu, F., Pal, D.K., Savvides, M.: Driver Cell Phone Usage Detection onStrategic Highway Research Program (SHRP2) Face View Videos. In: Computer Vision andPattern Recognition (CVPR) Workshops, 2015 IEEE Conference on, pp. 35–43 (2015)
65. Tai, C., Xiao, T., Wang, X., E, W.: Convolutional neural networks with low-rank regulariza-tion. ICLR abs/1511.06067 (2016). URL http://arxiv.org/abs/1511.06067
66. Venugopalan, S., Juefei-Xu, F., Cowley, B., Savvides, M.: Electromyograph and KeystrokeDynamics for Spoof-Resistant Biometric Authentication. In: Computer Vision and PatternRecognition (CVPR) Workshops, 2015 IEEE Conference on, pp. 109–118 (2015)
67. Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: A neural image caption genera-tor. In: IEEE CVPR, pp. 3156–3164 (2015)
68. Xiao, T., Xu, Y., Yang, K., Zhang, J., Peng, Y., Zhang, Z.: The application of two-level atten-tion models in deep convolutional neural network for fine-grained image classification. In:IEEE CVPR, pp. 842–850 (2015)
69. Xu, H., Saenko, K.: Ask, attend and answer: Exploring question-guided spatial attention forvisual question answering. arXiv preprint arXiv:1511.05234 (2015)

32 Felix Juefei-Xu, Eshan Verma, and Marios Savvides
70. Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., Bengio, Y.:Show, attend and tell - neural image caption generation with visual attention. In: ICML, pp.2048–2057 (2015)
71. Yang, Z., Li, M., Ai, H.: An experimental study on automatic face gender classification. In:IEEE ICPR, vol. 3, pp. 1099–1102. IEEE (2006)
72. Yao, L., Torabi, A., Cho, K., Ballas, N., Pal, C., Larochelle, H., Courville, A.: Describingvideos by exploiting temporal structure. In: IEEE ICCV, pp. 4507–4515 (2015)
73. Yeh, R., Chen, C., Lim, T.Y., Hasegawa-Johnson, M., Do, M.N.: Semantic image inpaintingwith perceptual and contextual losses. arXiv preprint arXiv:1607.07539 (2016)
74. Zehngut, N., Juefei-Xu, F., Bardia, R., Pal, D.K., Bhagavatula, C., Savvides, M.: Investigatingthe Feasibility of Image-Based Nose Biometrics. In: IEEE International Conference on ImageProcessing (ICIP), pp. 522–526 (2015)
75. Zhu, Y., Groth, O., Bernstein, M., Fei-Fei, L.: Visual7w: Grounded question answering inimages. arXiv preprint arXiv:1511.03416 (2015)