databases 2012 file structures - computer science...
TRANSCRIPT

Christian S. Jensen
Computer Science, Aarhus University
Databases 2012
File Structures

2 File Structures
File Structures
Data structure for data stored on disk
Implementation of queries requires
• File structures
• Algorithms for operators
• Sorting, selection (), projection (), join (⋈), Duplicate removal
• Query optimization and execution
We consider typical database file structures

3 File Structures
Data Storage
Relations are stored as bits.
Functionality requirements
• Sequentially process tuples
• Search for tuples that meet some condition
• Insert and delete tuples
Performance objectives
• Achieve a high packing density (little wasted space)
• Achieve fast response time

4 File Structures
File Organization Overview
File
• A database is stored as a collection of files.
• Storage (usually a disk)
• Random access (requires disk arm move)
• Non-volatile
Records
• A file is a set of records, generally of the same type.
• A record is a sequence of fields.
• Record size
• Fixed - same number of fields of same size
• Variable - may have a different number of fields or a field may
vary in size

5 File Structures
Disk Concepts – Files
File systems
• Blocks not necessarily contiguous
• Allocated in blocks
Contiguous block I/O faster (avoids disk seek)
• 8 msec to seek, read
• .4 msec for contiguous block read
Can reorganize to make block chains contiguous
report.doc
block 1 unused
book.htm
block 1
report.doc
block 2
report.doc
block 3
blocks on disk

6 File Structures
Disk Concepts - Blocks
Input/Output entire blocks
Block size is O/S dependent (e.g., 8KB)
Block size is usually much bigger than record size
• Many records in each block
• Exception: spanning – each record bigger than a block
• Fill percentage – percentage of filled space per block
• Supported by some DBMSs (e.g., Oracle)
50% filled
room to grow
100% filled
compact

7 File Structures
Storing a Table
A table is typically stored on disk
Several rows fit into one disk block
Disks are slow
• Accessing a random block is 8ms
• Accessing the next consecutive block is 0.4ms
• RAM access time 8-10 ns (L1+L2 cache even faster)
• One disk access = 1,000,000 RAM accesses!
• Justifies ”count only I/Os” model of complexity
Part of the table may be in RAM (buffer pool)
The table can be stored in sorted order

8 File Structures
Heap File
Assume n records pr table and R records pr block
• Search for 1 record: n/2R accesses O(n) - slow
• Insertion: 2 O(1) - fast
• Deletion (k records): n/R O(n) - slow
• Modification (k records): n/R O(n) - slow
Leonardo
Racquel
Amanda Arnold
Mufasa
Tom
Omar Jamie
Records are stored in blocks, no particular order
Example: Assume records are names
blocks Gerard

9 File Structures
Sequential File
Suitable for applications that need sequential
access.
The records in the file are ordered by a search-
key.
Example: Each record is a name.
Leonardo
Racquel Amanda
Arnold
Mufasa
Tom
Omar
Jamie
blocks
Gerard

10 File Structures
Sequential File
Search for key value, O(log2(n)) cost
Deletion: 1 disk I/O (after search)
Insertion: locate where record is to be inserted
• If there is free space, insert
• If no free space, insert the record in an overflow block
or shift records to previous or next block
Reorganize
• Restore block contiguity, fill percentage
• Remove empty blocks
• O(n) cost

11 File Structures
Sorting a Table
In RAM, many sorting algorithms are available
• Typical time complexity is O(n log2(n))
Those can also be performed on disk
• But they often perform poorly
• Only I/O accesses need to be counted
Specialized versions of algorithms are needed

12 File Structures
An Example Scenario
A 1 GB table with
• 10,000,000 rows
• Each row is 100 bytes
A disk with 4K sized blocks
• Each block holds 40 rows
• 250,000 blocks for the entire table
50MB RAM
• 1/20 of the table

13 File Structures
Recursive Merge Sort
The merge sort algorithm
• Split the list into two sublists
• Recursively sort the sublists
• Merge the sorted sublists to get the sorted list
• The time complexity is O(n log2(n))
Each row is read and written log2(107) = 23 times
Time consumed
• 23 2 10,000,000 8ms = 43 days

14 File Structures
Two-Phase Multiway Merge Sort
Load RAM with 12,500 blocks = 500,000 rows
• Sort those (for ”free”) using any RAM sorting algorithm
Do this 20 times to obtain 20 sorted sublists
• Store the 20 sorted sublists on 20 disks
Merge the sublists using a RAM buffer for each
• Only consecutive reads of blocks
• Only consecutive writes of blocks
Each row is read and written 2 times
Time consumed
• 2 2 20 12,500 0.4ms = 6.7 minutes

15 File Structures
Lessons Learned
Naive algorithms fall short
The reality of storage must be considered
• Use entire block contents
• Read blocks consecutively
• Buffer information in RAM
Two groups at CS address this
• The database/data-intensive systems group (systems)
• The Madalgo group (theory)

16 File Structures
Selection
SELECT *
FROM R
WHERE condition;
Full table scan
• Read all rows in the table
• Report those that satisfy the condition
Fine if many rows will actually be selected
• Rule of thumb is 5-10%

17 File Structures
Point Query
SELECT *
FROM People
WHERE userid = ’amoeller’;
We know that userid is a key
Optimization if People is sorted on userid
• Full table scan can stop sooner
Binary search not necessarily better
• Random disk access vs. sequential access
So, what can help us?

18 File Structures
Indexes
A table can be equipped with an index
• A data structure that helps find rows quickly
• Rows are identified by a subset of the attributes
A table may have several indexes
• In contrast, it can only be sorted on one criterion
Pros and cons of indexes
• Make (some) queries faster
• Make modifications slower

19 File Structures
Indexes in SQL
CREATE INDEX DateIndex
ON Meetings(date);
CREATE INDEX ExamIndex
ON Exams(vip,date,time);
An index on several attributes also gives an index
for any prefix of those attributes
Think of this as a virtual sorting of the table
Each primary key has by default an index

20 File Structures
Using Indexes
CREATE INDEX Idx ON R(a1,a2,...,an);
Some queries are now ”easy”
• A range query or point query on a1
• A point query on a1 combined with a range query on a2
• A range query on a1, a2, and a3
Others are not really easier
• A range query on a17
In case of large modifications of the table
• DROP INDEX Idx;
• Rebuild the index afterwards

21 File Structures
Indexed File
Suitable for applications that require random
access
Usually combined with sequential file
A single-level index is an auxiliary file of entries
<search-key, pointer to record>
ordered on the search-key.
Index is separate from data file
• Usually smaller
10-20% rule of thumb, take with a grain of salt!
• Can have multiple indexes on same relation

22 File Structures
Types of Single-Level Indexes
Primary Index
• Defined on a data file ordered on the primary key
Clustering Index
• Defined on a data file ordered on a non-key field
• One index entry for each distinct value of the field
• Points to first data block of records for search key
Secondary Index
• Defined on a data file not ordered on the index’s search
key
Sparse vs. Dense Index
• A dense index has one entry for each search key value
• Sparse - fewer index entries than search key values

23 File Structures
Example: Primary (Sparse) Index
123456 Melanie 701 Broad Tucson AZ
246800 Eric 701 Broad Tucson AZ
336699 Merrie 123 Speed Tucson AZ
456789 Tom 197 Cardiff Houston TX
555555 Lee 221 Post Houston TX
678900 Jane 197 Cardiff Houston TX
890890 Linda 234 Oak Houston TX
993889 Jeff 564 Alberca Tucson AZ
...
CustomerID Name Street City State
123456 336699 555555
890890
Index
Data File

24 File Structures
Example: Clustering (Dense) Index
456789 Tom 197 Cardiff Houston TX
678900 Jane 197 Cardiff Houston TX
890890 Linda 234 Oak Houston TX
112200 Ken 73 Elm Houston TX
246800 Eric 701 Broad Tucson AZ
123456 Melanie 701 Broad Tucson AZ
147906 Cheryl 89 Pine Wichita KS
034321 Karsten 15 Main Wichita KS
...
CustomerID Name Street City State
Houston Tucson
Wichita
Index
Data File
555555 Lee 221 Post Houston TX

25 File Structures
Example: Secondary (Dense) Index
123456 Melanie 701 Broad Tucson AZ
246800 Eric 701 Broad Tucson AZ
336699 Merrie 123 Speed Tucson AZ
456789 Tom 97 Cardiff Houston TX
555555 Lee 221 Post Houston TX
678900 Jane 97 Cardiff Houston TX
890890 Linda 234 Oak Houston TX
993889 David 64 Alberca Tucson AZ
...
CustomerID Name Street City State
David Eric Jane
Linda
Index
Data File
Lee
Melanie Merrie Tom

26 File Structures
Searching a Single-Level Index
Sequential search
• Faster than linear search of main file.
• Index is smaller than the main file
• Worst-case search cost is still O(n).
Binary search
• Key space:
• Search cost is O(log2(n)) time (n = size of the index).

27 File Structures
Multi-Level Indexes
Observation: A single-level index is an ordered file
• Can create a primary index on another index!
• Original is called the second-level index
• The index to the index is called the top-level index
Multi-level index: repeat the process, until all entries
of the top level index fit in one disk block
• Pin top-level index in main memory (RAM)
• Every level of the index is an ordered file

28 File Structures
Multi-level Index Example
123456 Melanie 701 Broad Tucson AZ
246800 Eric 701 Broad Tucson AZ
336699 Merrie 123 Speed Tucson AZ
456789 Tom 197 Cardiff Houston TX
555555 Lee 221 Post Houston TX
678900 Jane 197 Cardiff Houston TX
890890 Linda 234 Oak Houston TX
993889 Jeff 564 Alberca Tucson AZ
... CustomerID Name Street City State
Second-level
index
Data file
123456
336699
123456
555555
555555
890890
Top-level
index

29 File Structures
B-Trees
A data structure for indexes on tables
• A variation of search trees
• Trades some extra space to gain better performance
Supports the necessary operations
• Insert a new row
• Delete an exisiting row
• Search for a row given the index attribute(s)
”Perfect” for disk storage
• High fanout
• Very robust to data changes, data volumes, etc.
• Used by ALL RDBMSes

30 File Structures
Each node is stored in one disk block
Each row is pointed to by a leaf node
B-Tree Example
12
0
15
0
18
0
30
3
5
11
10
0
10
1
11
0
12
0
13
0
15
0
15
6
17
9
18
0
20
0
30
35
10
0

31 File Structures
B-Tree Internal Node
57
81
95
to keys
< 57
to keys
57 k< 81
to keys
81 k< 95
to keys
95

32 File Structures
B-Tree Leaf Node
57
81
95
to record
with key 57
to record
with key 81
to record
with key 95
to next
leaf node

33 File Structures
B-Tree Invariants
Assume each node (block) holds at most k keys
• Typically k is several hundreds
Each node must hold at least (k+1)/2 pointers
• Except for the root: may have down to 2 pointers
All leaves must be at the same level
This ensures that the tree remains balanced:
• Its height with n rows is at most 1+logk/2(n)
• In practice, the height is 3 or 4 (1-2 top levels in RAM)

34 File Structures
Search path for key 101
Time proportional to the height of the tree
B-Tree Point Query
12
0
15
0
18
0
30
3
5
11
10
0
10
1
11
0
12
0
13
0
15
0
15
6
17
9
18
0
20
0
30
35
10
0

35 File Structures
Subtree for keys between 101 and 166
Time proportional to height + size of range
B-Tree Range Query
12
0
15
0
18
0
30
3
5
11
10
0
10
1
11
0
12
0
13
0
15
0
15
6
17
9
18
0
20
0
30
35
10
0
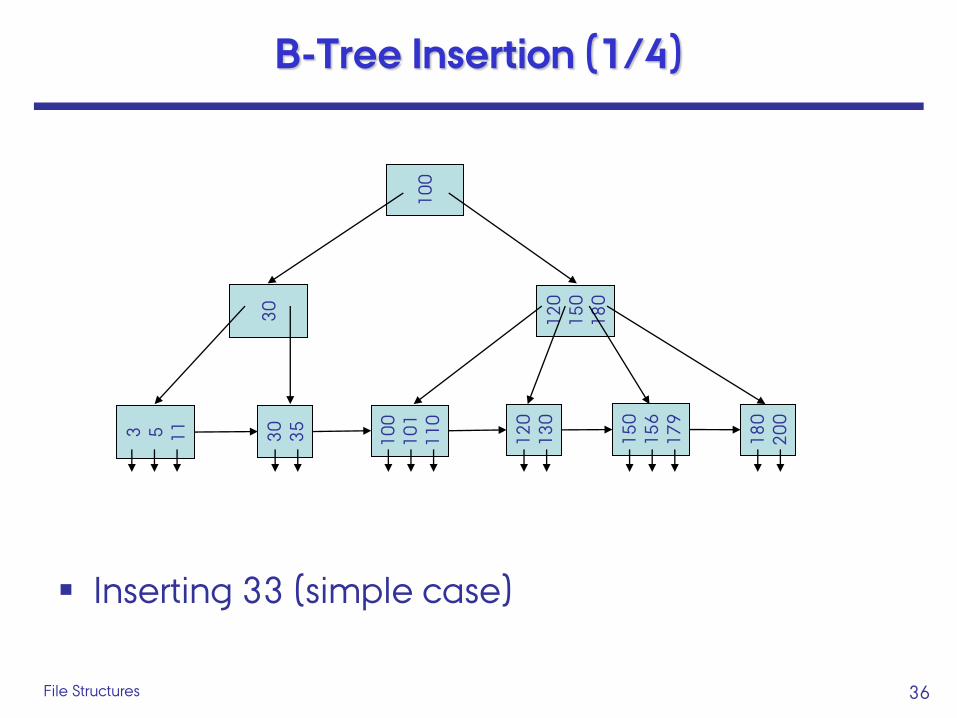
36 File Structures
B-Tree Insertion (1/4)
Inserting 33 (simple case)
12
0
15
0
18
0
30
3
5
11
10
0
10
1
11
0
12
0
13
0
15
0
15
6
17
9
18
0
20
0
30
35
10
0

37 File Structures
B-Tree Insertion (1/4)
Inserting 33 (simple case)
12
0
15
0
18
0
30
3
5
11
10
0
10
1
11
0
12
0
13
0
15
0
15
6
17
9
18
0
20
0
30
33
35
10
0
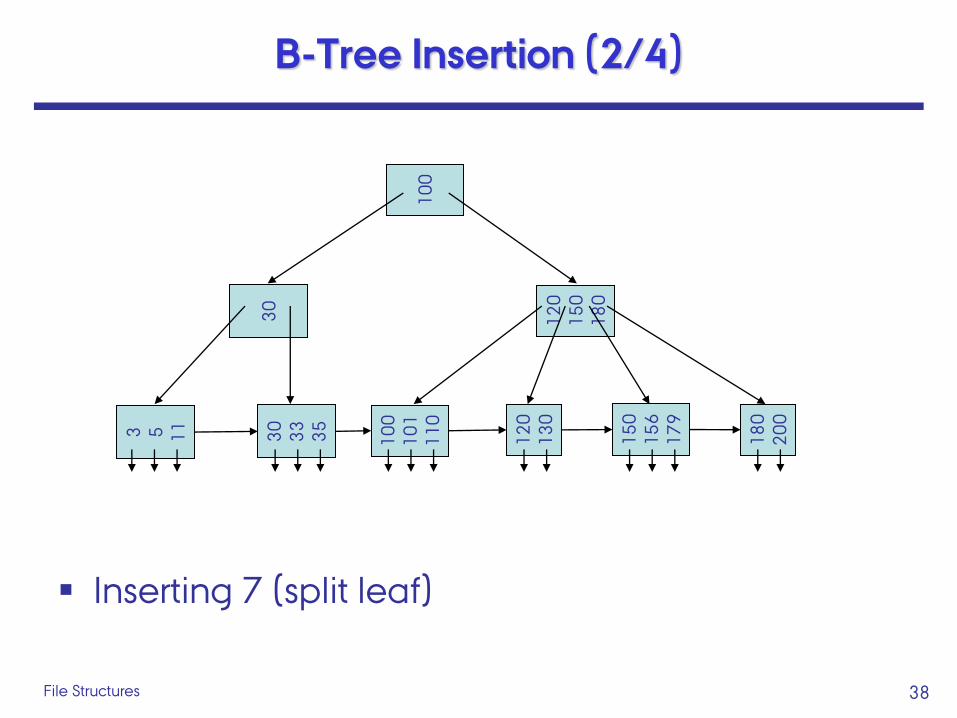
38 File Structures
B-Tree Insertion (2/4)
Inserting 7 (split leaf)
12
0
15
0
18
0
30
3
5
11
10
0
10
1
11
0
12
0
13
0
15
0
15
6
17
9
18
0
20
0
30
33
35
10
0

39 File Structures
B-Tree Insertion (2/4)
Inserting 7 (split leaf)
12
0
15
0
18
0
7
30
7
11
10
0
10
1
11
0
12
0
13
0
15
0
15
6
17
9
18
0
20
0
30
33
35
10
0
3
5

40 File Structures
B-Tree Insertion (3/4)
Inserting 160 (split internal node)
12
0
15
0
18
0
7
30
7
11
10
0
10
1
11
0
12
0
13
0
15
0
15
6
17
9
18
0
20
0
30
33
35
10
0
3
5

41 File Structures
B-Tree Insertion (3/4)
Inserting 160 (split internal node)
12
0
15
0
7
30
7
11
10
0
10
1
11
0
12
0
13
0
15
0
15
6
18
0
20
0
30
33
35
3
5
16
0
17
9
18
0
10
0
16
0
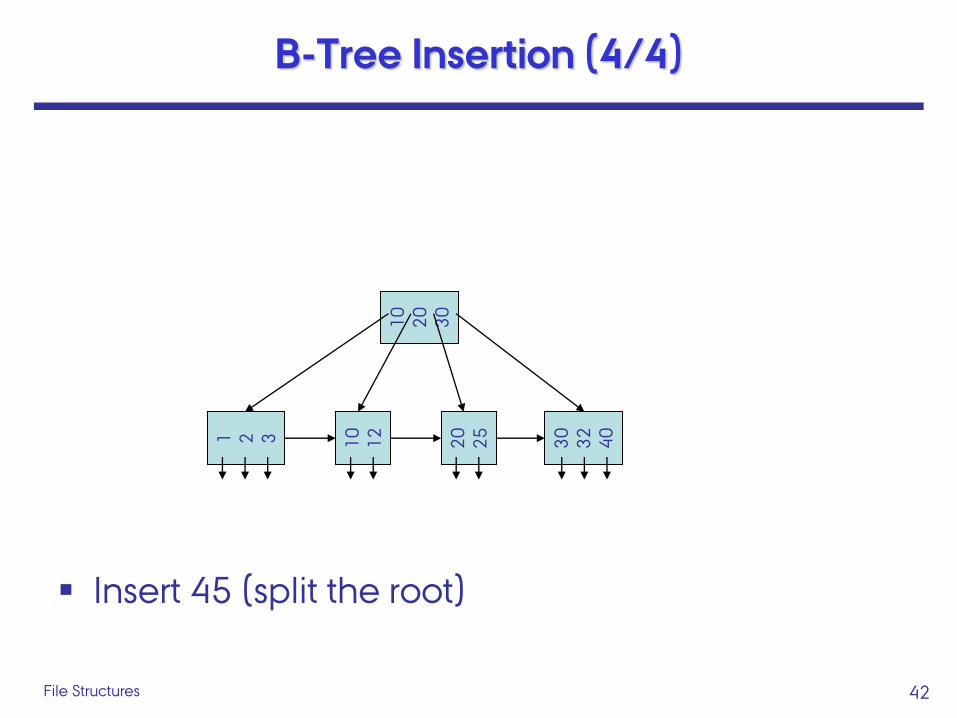
42 File Structures
B-Tree Insertion (4/4)
Insert 45 (split the root)
1
2
3
10
12
10
20
30
2
0
25
30
32
40

43 File Structures
B-Tree Insertion (4/4)
Insert 45 (split the root)
The height increases
1
2
3
10
12
20
25
30
32
40
45
40
30
10
20

44 File Structures
B-Tree Deletion
Balanced deletion is also possible
• There are similar case-based algorithms
Generally, deleted rows are left as tombstones
• The overhead of deletion is too large
Most tables tend to grow with time
• The tombstones quickly get reused
Otherwise, periodically rebuild the index
• Or perform online reorg of the index

45 File Structures
Clustering Index
Generally, indexed rows are scattered in the table
A clustering index has consecutive rows
Equivalent to sorting the table

46 File Structures
Clustering Index
At most one index can be the clustering index
• But other indexes may happen to be clustered too
• Attributes may be correlated
CREATE INDEX ExamIndex
ON Exams
CLUSTER(vip,date,time);
A cluster index on a primary key is a bad idea
• Range queries are not often meaningful
• Keys should not not carry information themselves

47 File Structures
Index Queries
If the query uses only indexed attributes
• ”Virtually constant” time evaluation
SELECT date
FROM Exams
WHERE vip = ’amoeller’;
SELECT vip, COUNT(date) AS Dates
FROM Exams
GROUP BY vip;

48 File Structures
Boolean Index Selection
SELECT *
FROM R
WHERE x=42 AND y>87;
We have one index for x and another for y
• Use index scan to find row pointers for x=42
• Use index scan to find row pointers for y>87
• Compute the intersection of the two pointer set
Similarly, OR corresponds to disjunction