data structures & algorithms binary search trees
TRANSCRIPT

Data Structures & Algorithms
Binary Search Trees

Long studied problemIntrinsic problem in much of CSBusiness applicationsInformation retrievalCachingMatching problems
SearchSearch

Goal: given a key, find an item(s) that is associated with that key
If search is successful, called a hit.If not, called a miss.
May also extend to approximate search, range queries, etc.
SearchSearch

Defn. 12.1: A symbol table is a data structure of items with keys that supports two basic operations:
• insert an new item, and • return an item with a given key.
Symbol table is otherwise known as:• Dictionary• Associative memory (contrast with
retrieving the item stored at a particular address)
SearchSearch

Examples of symbol tables:• Telephone book• Encyclopedia• Index (vs. table of contents)• Compiler tables of identifiers
Huge advantage of computer-based symbol tables:
• Easy to be dynamic
SearchSearch
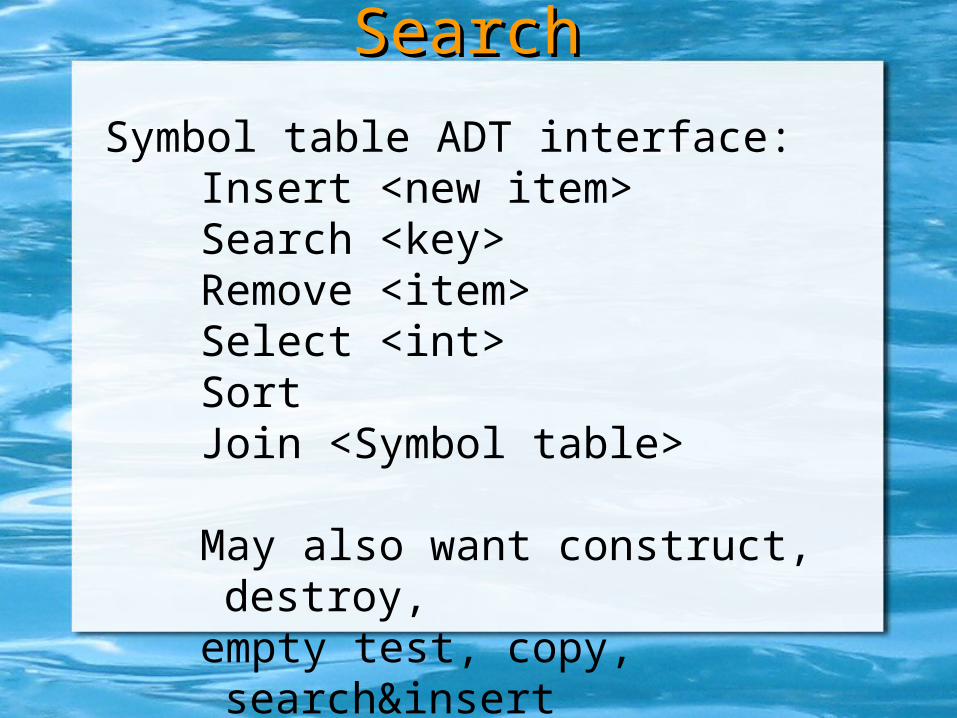
Symbol table ADT interface: Insert <new item>Search <key>Remove <item>Select <int>SortJoin <Symbol table>
May also want construct, destroy,empty test, copy, search&insert
SearchSearch
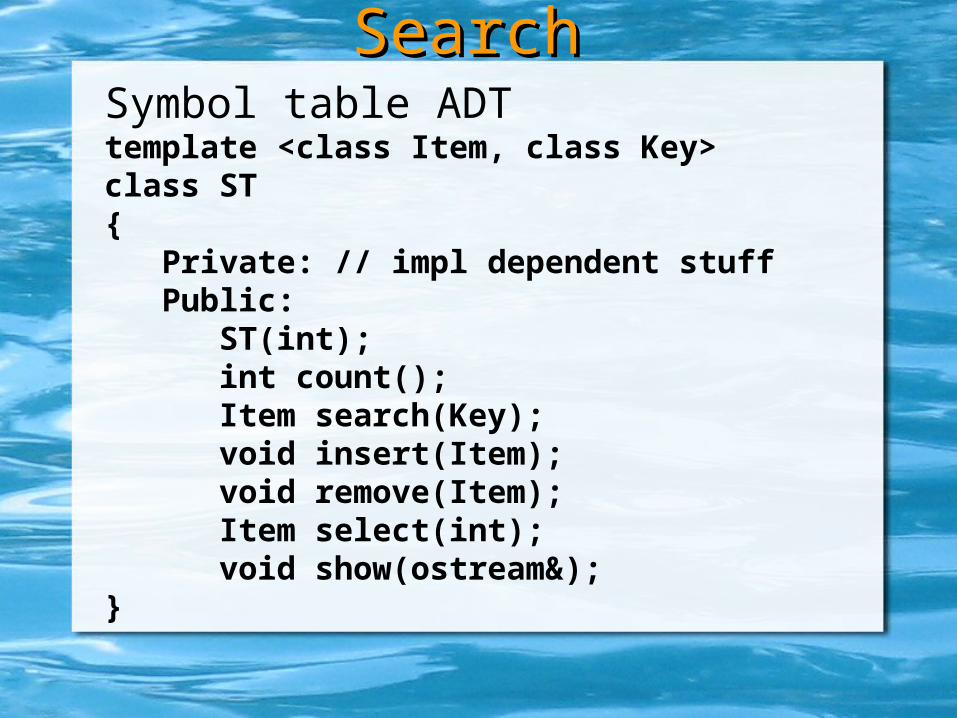
Symbol table ADTtemplate <class Item, class Key>class ST { Private: // impl dependent stuff Public: ST(int); int count(); Item search(Key); void insert(Item); void remove(Item); Item select(int); void show(ostream&);}
SearchSearch
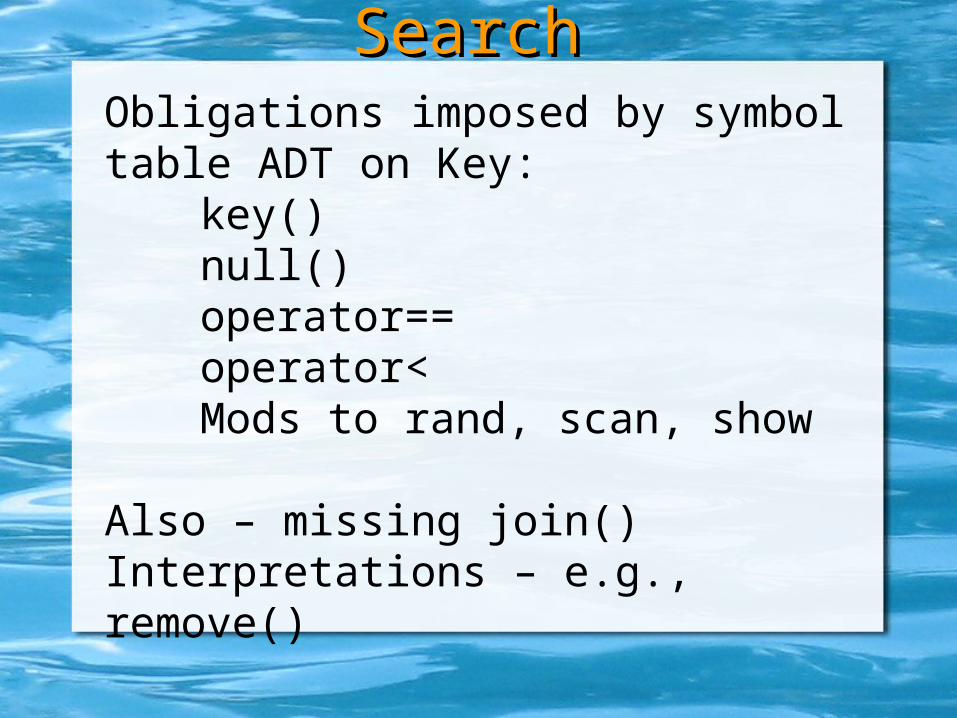
Obligations imposed by symbol table ADT on Key:
key()null()operator==operator<Mods to rand, scan, show
Also – missing join()Interpretations – e.g., remove()
SearchSearch
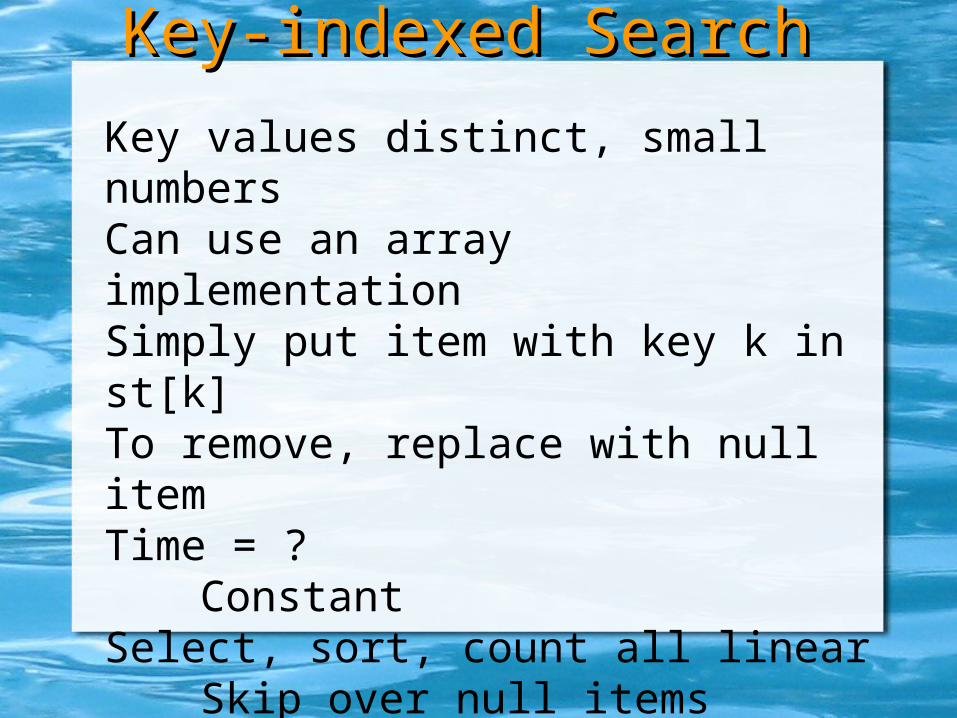
Key values distinct, small numbersCan use an array implementationSimply put item with key k in st[k]To remove, replace with null itemTime = ?
ConstantSelect, sort, count all linear
Skip over null itemsClient has to deal with duplicate keys
Key-indexed SearchKey-indexed Search

If there are no items, just keysUse table of bits
Existence tableBit map
Applications:Allocation tables for memoryBlum filters
Key-indexed SearchKey-indexed Search

Prop 12.1: If key values are positive integers less than M and items have distinct keys, then the symbol-table data type can be implemented with key-indexed arrays of items such that insert, search, and remove require constant time, and initialize, select, and sort require time proportional to M, whenever any of the operations are performed on an N-item table.
Key-indexed SearchKey-indexed Search

If keys are over too large a range to used key-indexed approach, can still use a simple approach:Store contiguously in an array, either
• In order• Unordered
Trade-offs?• Insertion time• Search time• Removal time• Sort time
Sequential SearchSequential Search
If keys are over too large a range to used key-indexed approach, can still use a simple approach:Could also store in linked list, either
In orderUnordered
Trade-offs?Aside from those depending on
ordering, those from arrays vs. linked lists: insert/remove/join times vs. size
Sequential SearchSequential Search

Prop 12.2: Sequential search in a symbol table with N items uses about N/2 comparisons for search hits (on average).
True for any of the four forms (array or linked list, ordered or unordered).
Sequential SearchSequential Search

Prop 12.2: Sequential search in a symbol table with N unordered items uses a constant number of steps for inserts and N comparisons for search misses (always).
True for array or linked list.
Sequential SearchSequential Search

Prop 12.3: Sequential search in a symbol table with N ordered items uses about N/2 comparisons for insertions, search hits, and search misses (on average).
True for array or linked list.
Sequential SearchSequential Search
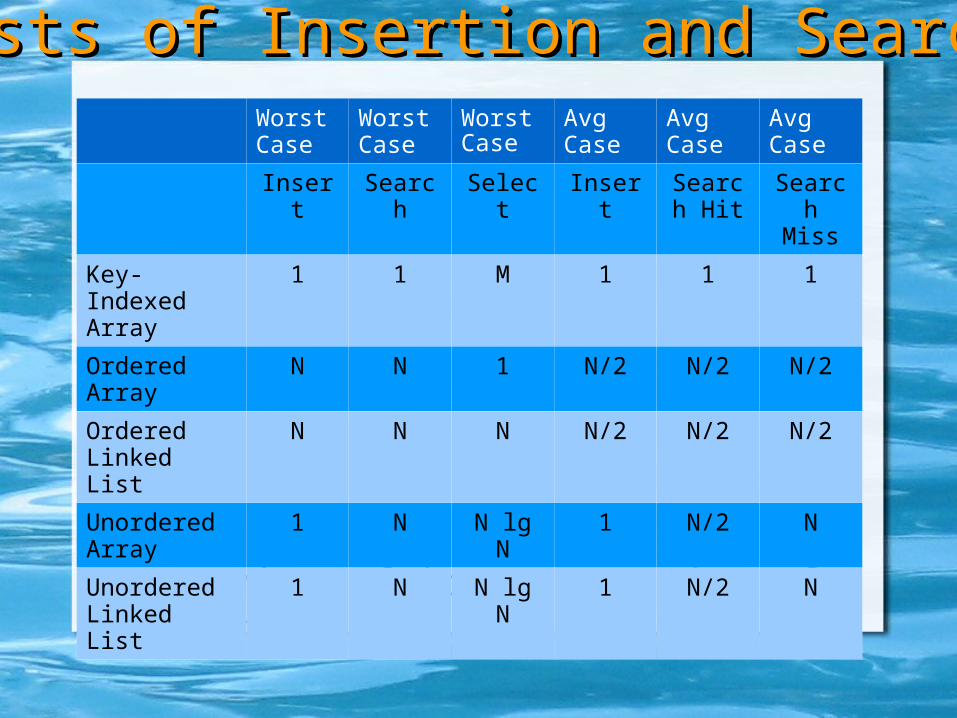
N = number of items, M = size of container
Costs of Insertion and SearchCosts of Insertion and SearchWorst Case
Worst Case
Worst Case
Avg Case
Avg Case
Avg Case
Insert Search Select Insert Search Hit
Search Miss
Key-Indexed Array
1 1 M 1 1 1
Ordered Array
N N 1 N/2 N/2 N/2
Ordered Linked List
N N N N/2 N/2 N/2
Unordered Array
1 N N lg N 1 N/2 N
Unordered Linked List
1 N N lg N 1 N/2 N

N = number of items, M = size of container
Costs of Insertion and SearchCosts of Insertion and SearchWorst Case
Worst Case
Worst Case
Avg Case
Avg Case
Avg Case
Insert Search Select Insert Search Hit
Search Miss
Binary Search N lg N 1 N/2 lg N lg N
Binary Search Tree
N N N lg N lg N lg N
Red-Black Tree
lg N lg N lg N lg N lg N lg N
Randomized Tree
N* N* N* lg N lg N lg N
Hashing 1 N* N lg N 1 1 1

Binary search – compare to middle item in sorted search table, then search appropriate half.
Binary SearchBinary Search
a c f j k m n p q r s t v x y
a c f j k m n p q r s t v x y
a c f j k m n p q r s t v x y
a c f j k m n p q r s t v x y
a c f j k m n p q r s t v x y
k?
hit

Prop 12.4: Binary search in a symbol table with N ordered items never uses more than [lg N] + 1 comparisons for a search (hit or miss).
Note that this is the same as the number of bits in the representation of N.Why?
Binary SearchBinary Search

Keeping table sorted•Expensive using insertion sort•May not matter if table is mostly static, •or if the number of searches is huge (relative to insertions).Improvements:•Interpolation search (try to guess where key will fall in ST)•assumes key values are evenly distributed
Binary SearchBinary Search

Use an explicit tree structure
Defn 12.2: A binary search tree (BST) is a binary tree that has a key associated with each internal node, and the key in a node is >= the keys in its left subtree and <= the keys in its right subtree
Binary Search TreesBinary Search Trees

Defn 12.2: A binary search tree (BST) is a binary tree that has a key associated with each internal node, and the key in a node is >= the keys in its left subtree and <= the keys in its right subtree
Binary Search TreesBinary Search Trees
k
<=k >=k

BST search algorithm sketch
To search a BST T with root h for key k:If h is null (T is empty) – return miss If h.key == k – return hitIf k < h.key search left subtree h.leftelse search right subtree h.right
Binary Search TreesBinary Search Trees

BST insert algorithm
To insert a new item X into a BST:Essentially search, then attach new node (and just as efficient as search): If tree empty set X as root and returnIf X.key < root.key insert X into left subtreeElse insert X into right subtree
Binary Search TreesBinary Search Trees

BST sort algorithm
To sort a BST (i.e., output items stored in BST in order of keys):Inorder traversal of BST
If tree empty returnShow left subtreeShow rootShow right subtree
Binary Search TreesBinary Search Trees

Prop. 12.6: Search hits require about 2 ln N ≈ 1.39 lg N comparisons on average, in a BST built from random keys. (Treating successive < and = operations as one comparison)
Prf: Search hit follows a path from root to the node with the key; average is internal path length over all nodes, + 1.
Binary Search TreesBinary Search Trees

Prop. 12.7: Insertions and search misses require about 2 ln N ≈ 1.39 lg N comparisons on average, in a BST built from random keys. (Treating successive < and = operations as one comparison)
Prf: Search hit follows a path from root to an external node; average is external path length over all nodes.
Binary Search TreesBinary Search Trees

Prop. 12.8: In the worst case, a search in a BST with N keys can take N comparisons.
Prf: The tree may only have one non-empty subtree per internal node.
Binary Search TreesBinary Search Trees

May not want to move actual items around, and may want flexibility in item contents.Here, may use items stored in an array (or parallel arrays), with key extraction, then use parallel arrays for link (i.e., have left[i] and right[i] give indexes for left and right child, resp.)Appl: large or overlapping items (e.g., text strings in corpus)
Index ImplementationsIndex Implementations

Usually, insertion into BST at bottomReplace external node
What if need to insert at root, so new nodes are near the top?
Examine this now, as it will come in handy soon…..
BST InsertionBST Insertion

Wlog, assume new item has a key larger than that of the current root.
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
M
J
I K
N
O
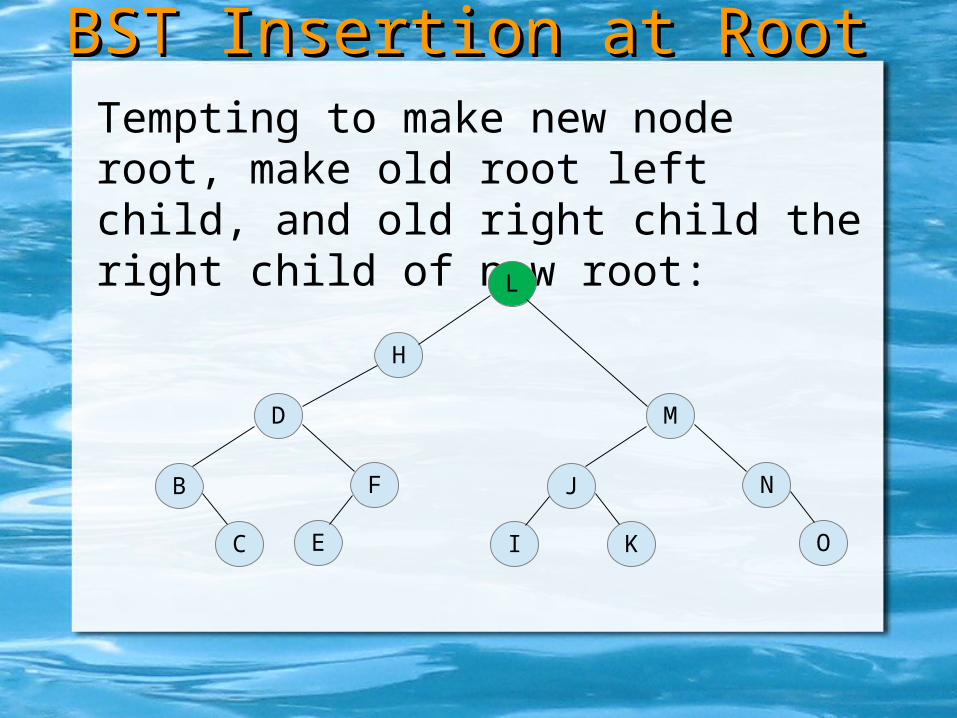
Tempting to make new node root, make old root left child, and old right child the right child of new root:
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
M
J
I K
N
O
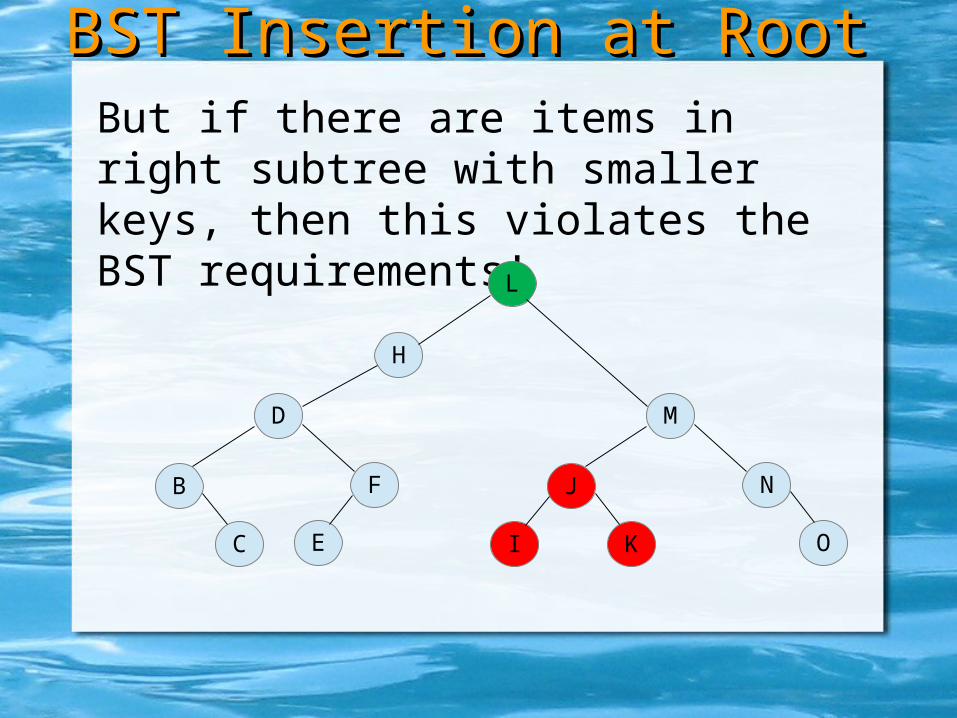
But if there are items in right subtree with smaller keys, then this violates the BST requirements!
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
M
J
I K
N
O
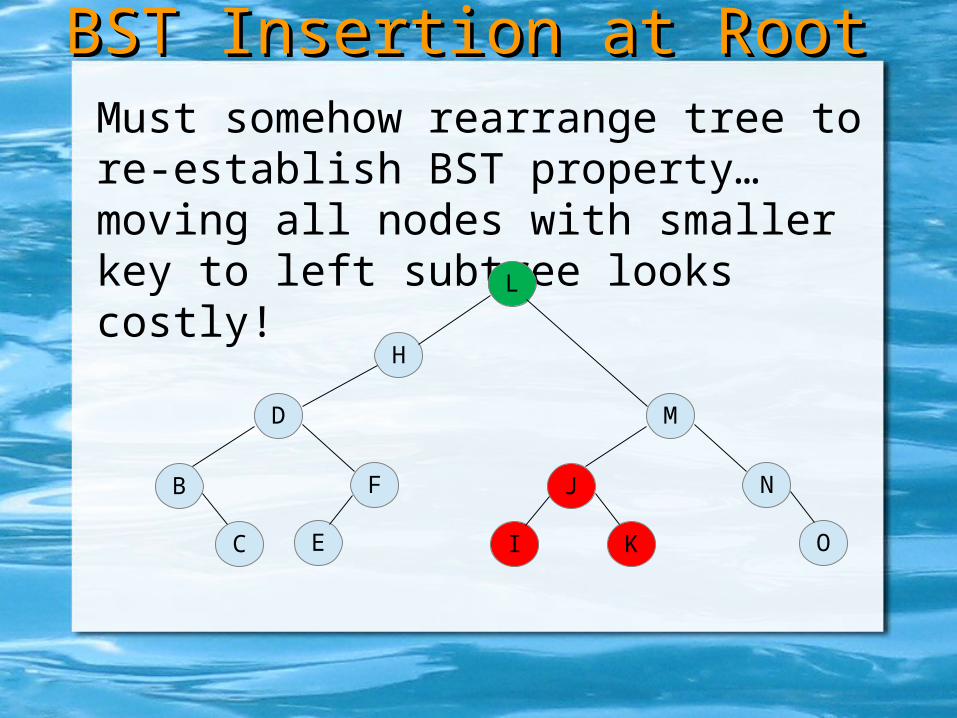
Must somehow rearrange tree to re-establish BST property… moving all nodes with smaller key to left subtree looks costly!
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
M
J
I K
N
O
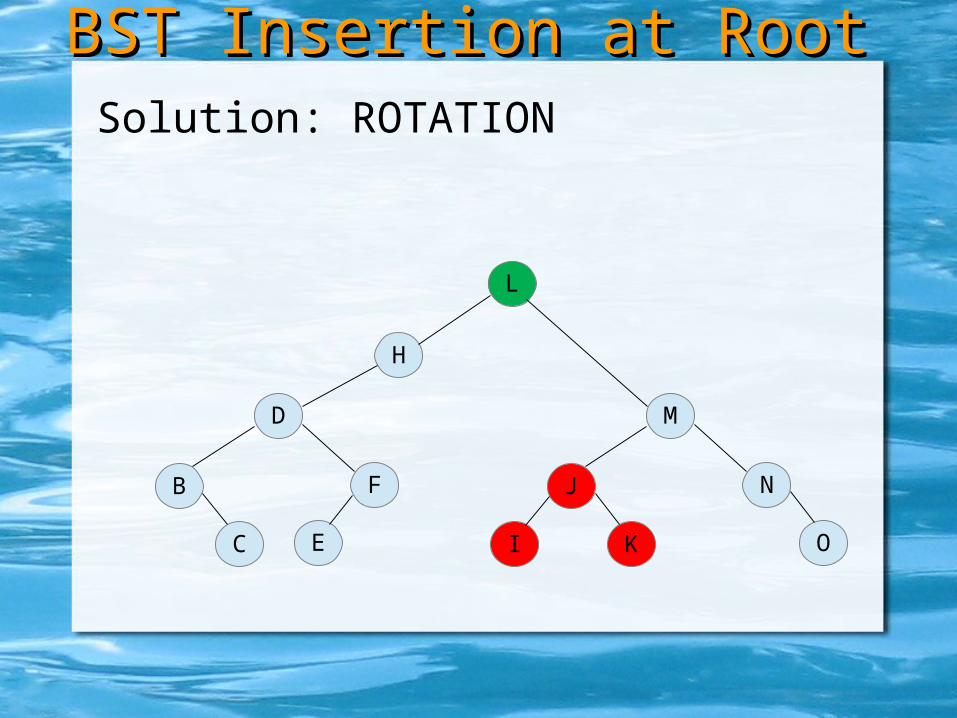
Solution: ROTATION
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
M
J
I K
N
O

>=N
Solution: ROTATION (here in BST)
BST Insertion at RootBST Insertion at Root
L
N
R
A
<=L >=L &<=N
K M

>=N
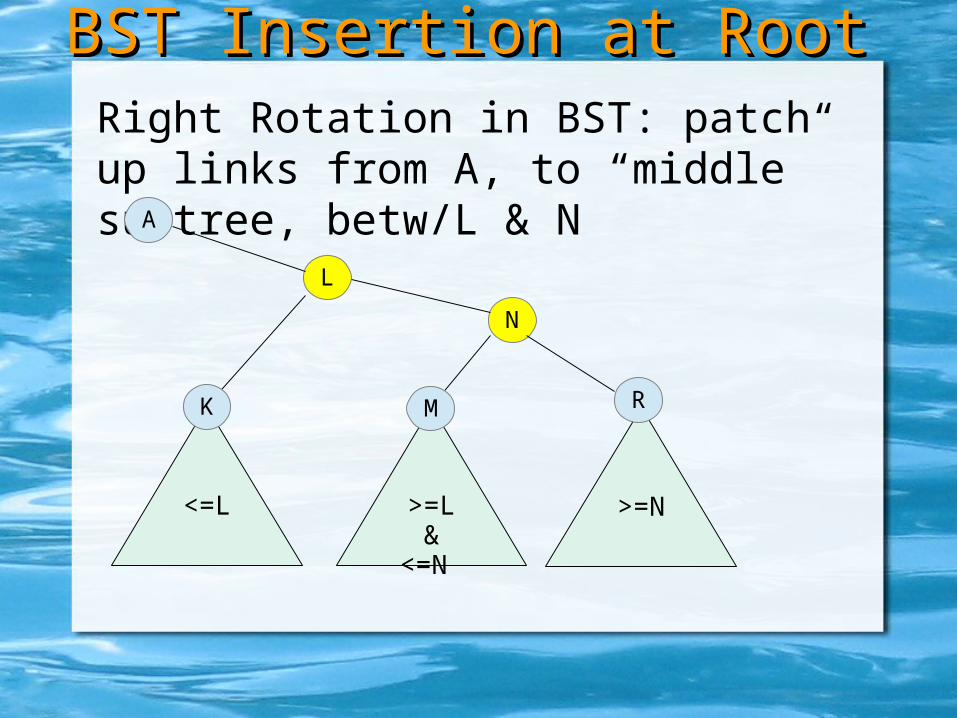
Right Rotation in BST: make left child new root, make old root right child
BST Insertion at RootBST Insertion at Root
L
N
R
A
<=L >=L &<=N
K M
>=N
Right Rotation in BST: patch up links from A, to “middle” subtree, betw/L & N
BST Insertion at RootBST Insertion at Root
L
N
R
A
<=L >=L &<=N
K M

>=N
Result is still BST, and requires a constant number of local changes.
BST Insertion at RootBST Insertion at Root
L
N
R
A
<=L >=L &<=N
K M
>=N
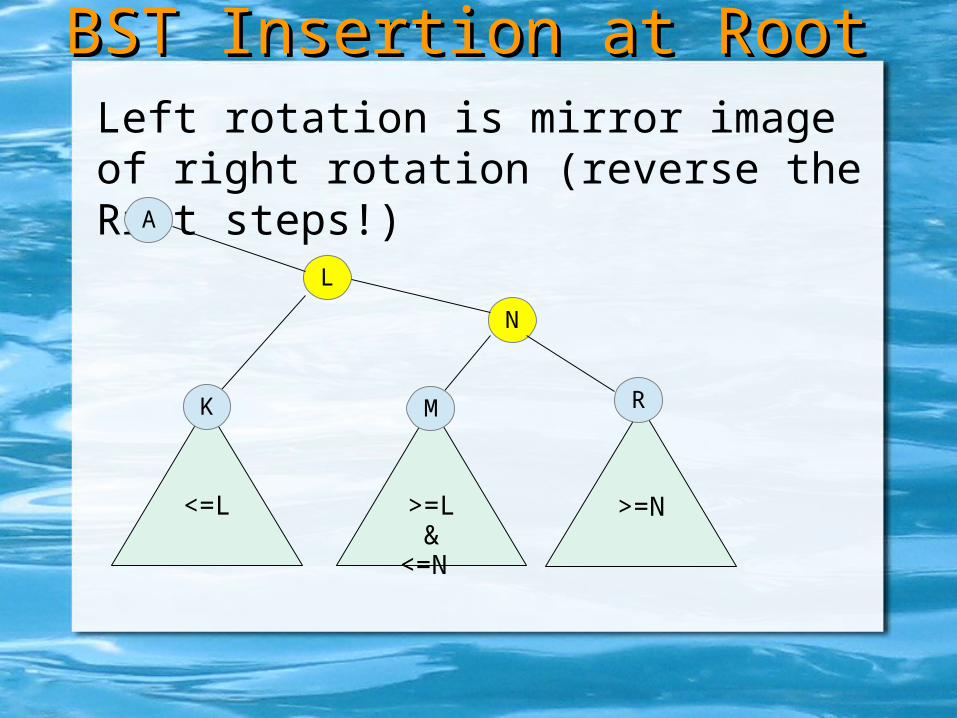
Left rotation is mirror image of right rotation (reverse the Rrot steps!)
BST Insertion at RootBST Insertion at Root
L
N
R
A
<=L >=L &<=N
K M
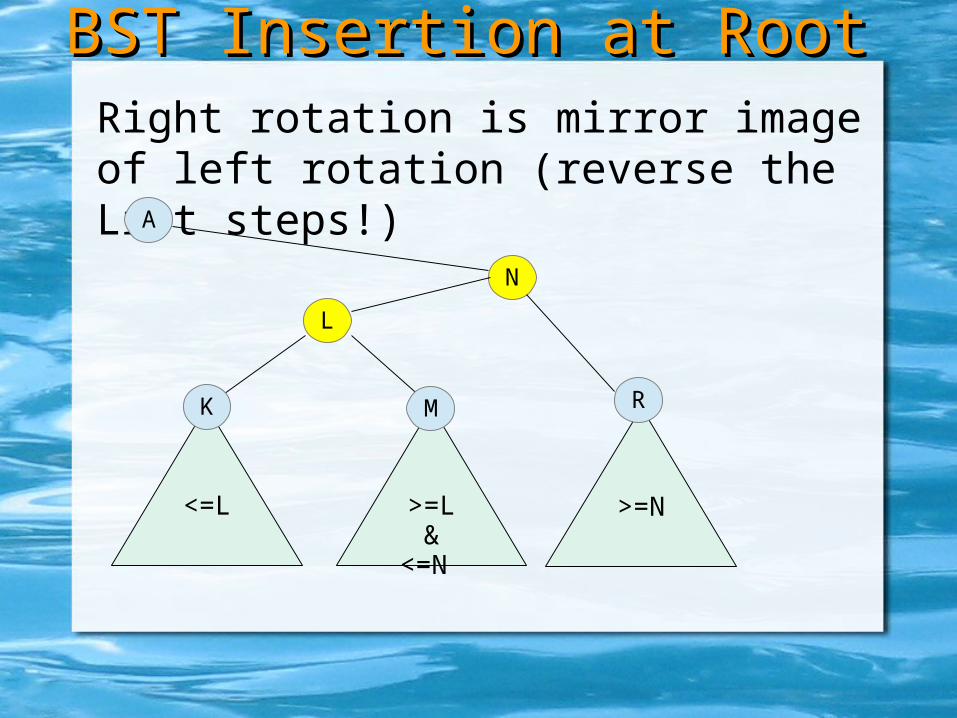
>=N
Right rotation is mirror image of left rotation (reverse the Lrot steps!)
BST Insertion at RootBST Insertion at Root
L
N
R
A
<=L >=L &<=N
K M

Now we can insert at root by inserting at leaf, …
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
M
J
I K
N
O
L
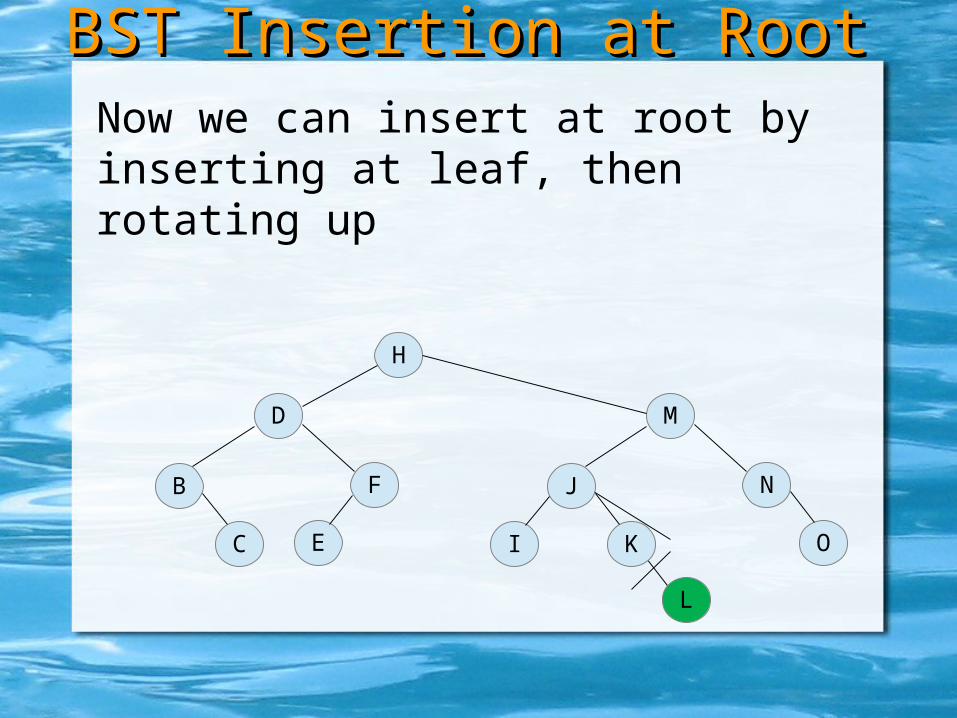
Now we can insert at root by inserting at leaf, then rotating up
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
M
J
I K
N
O
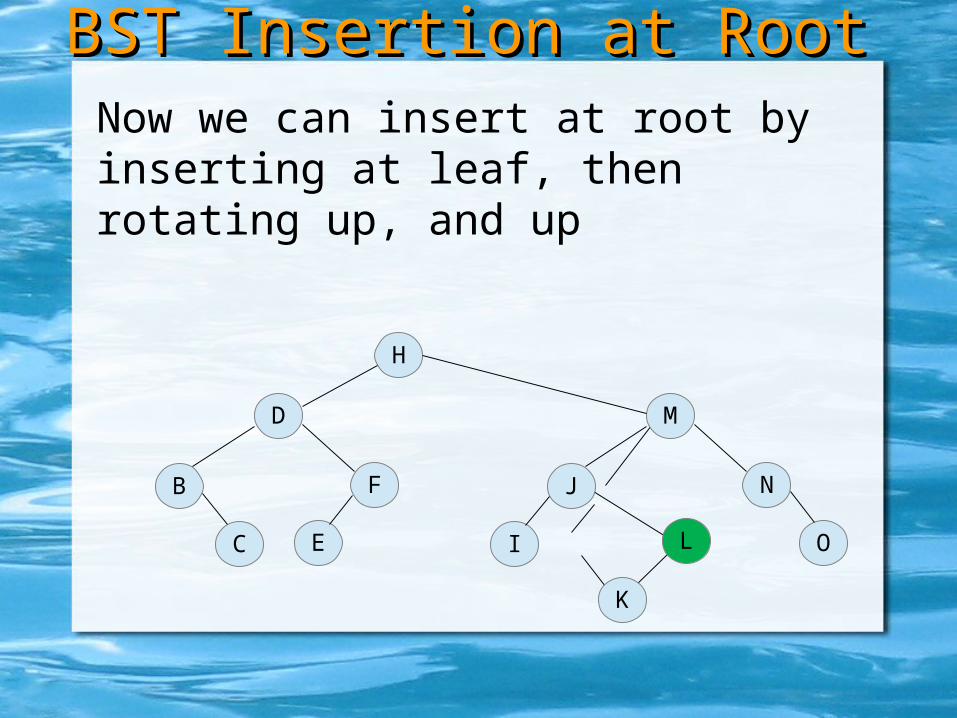
Now we can insert at root by inserting at leaf, then rotating up, and up
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E L
M
J
I
K
N
O

Now we can insert at root by inserting at leaf, then rotating up, and up, and up
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
M
J
I K
N
O
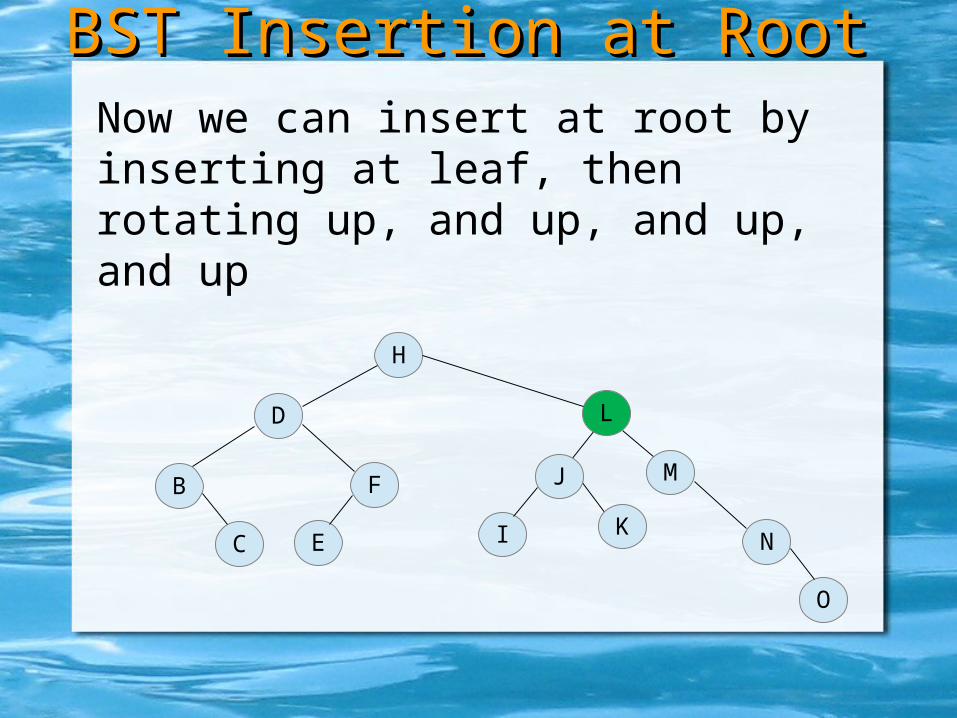
Now we can insert at root by inserting at leaf, then rotating up, and up, and up, and up
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
MJ
I KN
O

Q: How much does it cost?A: path lengthQ: Why do it?
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
M
J
I KN
O

Q: Why do it?A: Often do searches for more recent items – faster if near the root!
BST Insertion at RootBST Insertion at Root
H
D
B
C
F
E
L
M
J
I KN
O

Select k – like quickSort version: Keep count field with size of subtreeRecursively select in subtrees, adjusting k if right subtree
Other BST FunctionsOther BST Functions
H9
D5
B2
C1
F2
E1
L13
M3
J3
I1
K1
N2
O1

Partition: put kth smallest node at rootSelect, then rotate up
Remove: delete node and patch up treeSearch (which subtree?)Replace subtree with one minus nodeIf root of subtree, delete root and
combine the two subsubtreesJoin: many possible ways, none all that attractive in general
Other BST FunctionsOther BST Functions

Remove: a lot of work, disrupts structureNo longer random, even if data wereHeight tends to sqrt(N) instead of lg N
May just mark deleted nodesSkip them on searchUse space to insert new itemsPeriodically remove/restructure to avoid
using up too much space/timeThis lazy approch applies to any structure, not just BSTs or symbol tables!
Other BST FunctionsOther BST Functions

Balanced trees perform welllg N timeNear-balanced is good enough
How to provide performance guarantees?RandomizeAmortizeOptimize
Balancing BSTsBalancing BSTs

RandomizeIntroduce random decision makingReduces chance of worst-case … a lot!
ExamplesQuickSort – random pivotRandomized BSTsSkip Lists
PerformancePerformance

AmortizeDo extra (expensive) work from time to timeTo avoid much more work laterWith “cost” spread over all operationsA particular operation may take more timeBut time for op sequence is always good
ExamplesArray resizingSplay BSTs
PerformancePerformance

OptimizeDo work every timeTo guarantee performance every timeUsually cumbersome to implement
ExamplesAVL treesTop-down 2-3-4 treesRed-Black Trees
PerformancePerformance

Recall analysis of average case for BSTsAssumed items inserted in random orderThus each node equally likely to be rootBut Hey!!Don’t have to rely on random insertions!Can get this by randomly choosing to make new node the root with prob 1/(N+1)
Randomized BSTsRandomized BSTs

Prop 13.1: Building a randomized BST is equivalent to building a standard BST from a random initial permutation of the keys. We use about 2 N ln N comparisons to construct a rBST with N items, and about 2 ln N comparisons for search.
Note distinction in average-case performance in rBSTs and BSTs
Randomized BSTsRandomized BSTs

Note distinction in average-case performance in rBSTs and BSTs
Average case is about same (constant is a little higher in rBSTs)
But assumption in BSTs that items are inserted in random order
Which is often NOT the caseWith rBSTs, this does not matter!
Randomized BSTsRandomized BSTs