data mining association rules and frequent itemsets mining
TRANSCRIPT

Data Mining
Association rules and frequent itemsets mining

Data Mining concepts
• Is the computational process of discovering patterns in very large datasets (rules, correlations, clusters)
• Untrained process: no previous knowledge is provided. Rules are learned from available data
• Will see two methods: rule learning and clustering

3
Association Rule Mining
• Association Rule MiningFinding frequent patterns, associations, correlations, or causal structures among sets of items or objects in transaction databases, relational databases, and other information repositories.
• ApplicationsBasket data analysis, cross-marketing, catalog design, clustering user profiles (e.g. Twitter Friends) , etc.
• Examples– Rule form: “Body Head [support, confidence]”.buys(x, “diapers”) buys(x, “beers”) [0.5%, 60%]follows(x,”KatyPerry”)^follows(x,”LadyGaga”)>follows(x,”BritneySpears”) [0.7%,70%]

4
Overview
• Basic Concepts of Association Rule Mining
• The Apriori Algorithm (Mining single dimensional boolean association rules)
• Methods to Improve Apriori’s Efficiency• Frequent-Pattern Growth (FP-Growth)
Method• From Association Analysis to Correlation
Analysis• Summary

5
Association Model: Problem Statement
• I ={i1, i2, ...., in} a set of items
• J = P(I )= {j1, j2, ...., jN} (powerset) set of all possible subsets of the set of items, N=2n (e.g: jl={ikinim} )
• Elements of J are called itemsets (e.g: jl={ikinim} )
• Transaction T: <tid,j> tid is a transaction identifier, j is an element of P(I)
• Data Base: D = set of transactions
• An association rule is an implication of the form : X-> Y, where X, Y are disjoint subsets of I (elements of J )

6
Transactions ExampleTID Produce
1 MILK, BREAD, EGGS
2 BREAD, SUGAR
3 BREAD, CEREAL
4 MILK, BREAD, SUGAR
5 MILK, CEREAL
6 BREAD, CEREAL
7 MILK, CEREAL
8 MILK, BREAD, CEREAL, EGGS
9 MILK, BREAD, CEREAL
Transaction IDItems
Itemset
7
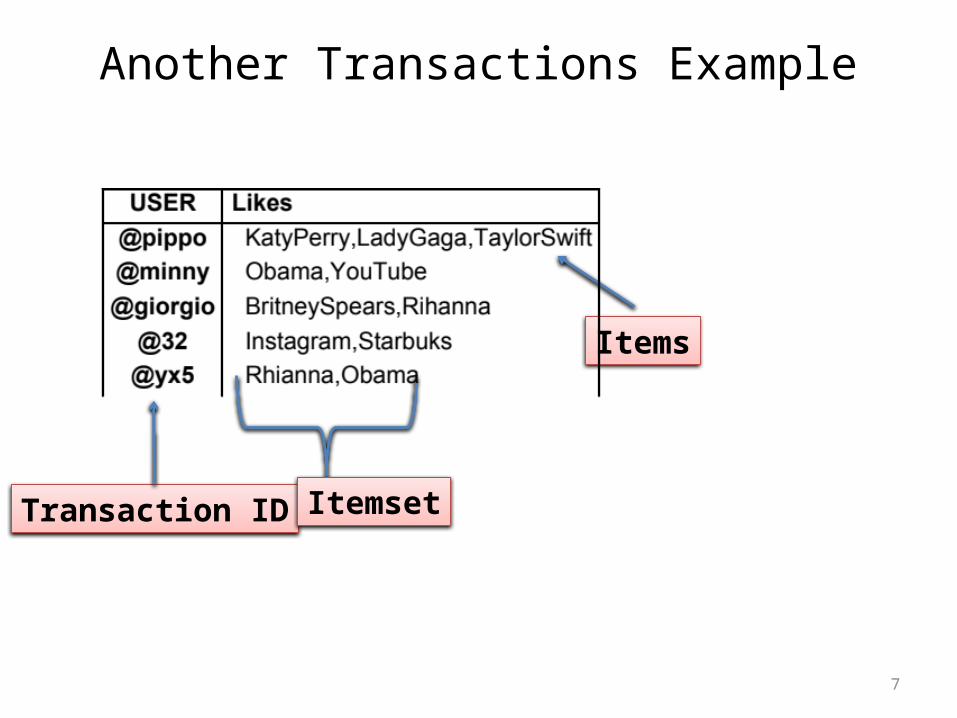
Another Transactions Example
Transaction ID
Items
Itemset

8
Transaction database: Example (neutral)
TID Products
1 A, B, E
2 B, D
3 B, C
4 A, B, D
5 A, C
6 B, C
7 A, C
8 A, B, C, E
9 A, B, C

9
Transaction database: binary representation
TID A B C D E
1 1 1 0 0 1
2 0 1 0 1 0
3 0 1 1 0 0
4 1 1 0 1 0
5 1 0 1 0 0
6 0 1 1 0 0
7 1 0 1 0 0
8 1 1 1 0 1
9 1 1 1 0 0
TID Products
1 A, B, E
2 B, D
3 B, C
4 A, B, D
5 A, C
6 B, C
7 A, C
8 A, B, C, E
9 A, B, C
Attributes converted to binary flags

Simpler ways to express rules
• follows(x,”KatyPerry”)^follows(x,”LadyGaga”)>follows(x,”BritneySpears”)
• KatyPerry,LadyGagaBritneySpears• XY

11
Rule Measures: Support & Confidence
• Simple Formulas:–Confidence (XY) = #tuples
containing both X & Y / #tuples containing X = Pr(Y|X) = Pr(X U Y ) / Pr (X)
– Support (XY) = #tuples containing both X & Y/ total number of tuples = Pr(X U Y)

Support & Confidence
• What do they actually mean ?Find all the rules X Y with confidence and support >= threshold– support, s, probability that a transaction
contains {X, Y}– confidence, c, conditional probability
that a transaction having {X} also contains Z
– Rules with support and confidence over a given threshold are called strong rules

13
Association Rules: finding “strong” rules
• Q: Given a set of transactions, what association rules have min_sup = 2 and min_conf= 50% ?
There are 4 transactions (support) with A and B (1,4,8,9), of which two also include E (1,8)
A, B => E : conf=2/4 = 50%
TID List of items
1 A, B, E
2 B, D
3 B, C
4 A, B, D
5 A, C
6 B, C
7 A, C
8 A, B, C, E
9 A, B, C

14
Association Rules Example, 2• Q: Given items {A,B,E}, what association rules
have minsup = 2 and minconf= 50% ?• There are several rules that can be derived
from {A,B,E}, but only few have the minconf=50%
A, B => E : conf=2/2 = 50% (A,B: 1,4,8,9) A, E => B : conf=2/2 = 100% (A,E:1,8) B, E => A : conf=2/2 = 100% (B,E:1,8) E => A, B : conf=2/2 = 100% (E:1,8)Don’t qualify A =>B, E : conf=2/6 =33%< 50% (A:1,4,5,7,8,9) B => A, E : conf=2/7 = 28% < 50% (B:1,2,3,4,6,8,9)
=> A,B,E : conf: 2/9 = 22% < 50% ({} :1,2,3,4,5,6,7,8,9)
TID List of items
1 A, B, E
2 B, D
3 B, C
4 A, B, D
5 A, C
6 B, C
7 A, C
8 A, B, C, E
9 A, B, C

Generating association rules Usually consists of two subproblems :
1) Finding frequent itemsets whose occurences exceed a predefined minimum support threshold
2) Deriving association rules from those frequent itemsets (with the constrains of minimum confidence threshold)
• These two subproblems are soleved iteratively until new rules no more emerge
• The second subproblem is quite straight- forward and most of the research focus is on the first subproblem

16
Overview
• Basic Concepts of Association Rule Mining• The Apriori Algorithm (Mining single
dimensional boolean association rules)• Methods to Improve Apriori’s Efficiency• Frequent-Pattern Growth (FP-Growth)
Method• From Association Analysis to Correlation
Analysis• Summary

17
The Apriori Algorithm: Basics
The Apriori Algorithm is an influential algorithm for mining frequent itemsets for boolean association rules.
Key Concepts :• Frequent Itemsets: The sets of items which have
minimum support (denoted by Li for itemsets of i elements).
• Apriori Property: Any subset of a frequent itemset must be frequent.
• Join Operation: To find Lk , a set of candidate k-itemsets is generated by joining Lk-1 with itself.

18
The Apriori Algorithm: key ideas
• Find the frequent itemsets: the sets of items that have minimum support
– A subset of a frequent itemset must also be a frequent itemset (Apriori property)
• i.e., if {AB} is a frequent itemset, both {A} and {B} should be a frequent itemset
– Iteratively find frequent itemsets with cardinality from 1 to k (k-itemset)
• Use the frequent itemsets to generate association rules.

Use of Apriori algorithm• Initial information: transactional database D and
user-defined numeric minimun support threshold min_sup
• Algorithm uses knowledge from previous iteration phase to produce frequent itemsets
• This is reflected in the Latin origin of the name that means ”from what comes before”

Creating frequent sets• Let’s define:
Ck as a candidate itemset of size kLk as a frequent itemset of size k
• Main steps of iteration are:1) Find frequent itemset Lk-1 (starting from L1)2) Join step: Ck is generated by joining Lk-1 with itself
(cartesian product Lk-1 x Lk-1)3) Prune step (apriori property): Any (k − 1) size itemset that
is not frequent cannot be a subset of a frequent k size itemset, hence should be removed from Ck
4) Frequent set Lk has been achieved

Creating frequent sets (2)
• Algorithm uses breadth-first search and a hash tree structure to handle candidate itemsets efficiently
• Then frequency for each candidate itemset is counted
• Those candidate itemsets that have frequency higher than minimum support threshold are qualified to be frequent itemsets

Apriori algorithm in pseudocode (2)
Join step and prune step
(Wikipedia)
23
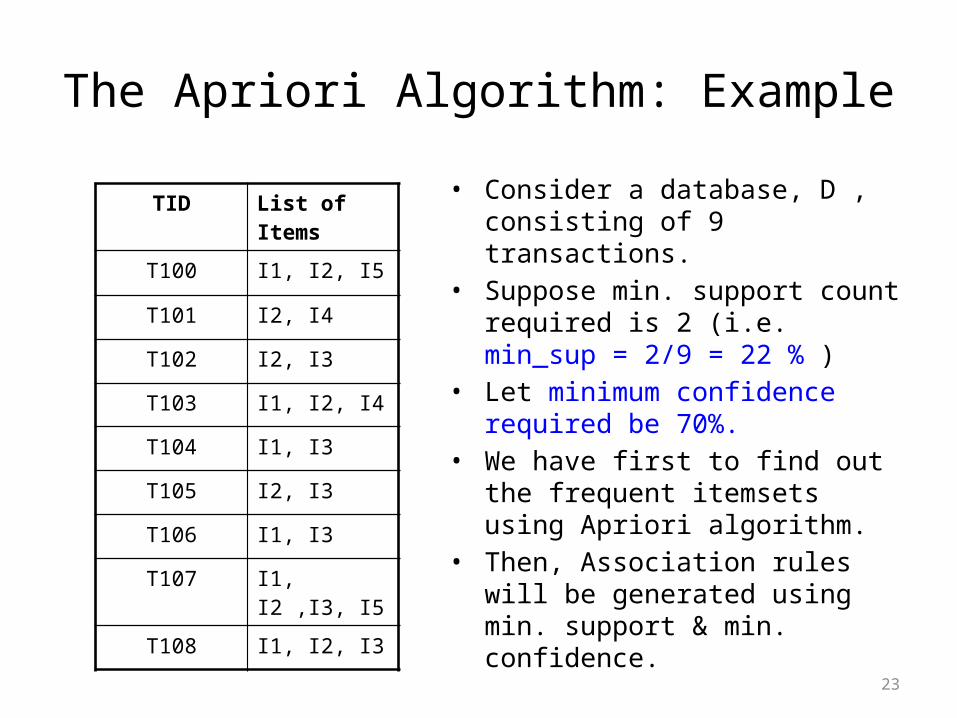
The Apriori Algorithm: Example
• Consider a database, D , consisting of 9 transactions.
• Suppose min. support count required is 2 (i.e. min_sup = 2/9 = 22 % )
• Let minimum confidence required be 70%.
• We have first to find out the frequent itemsets using Apriori algorithm.
• Then, Association rules will be generated using min. support & min. confidence.
TID List of Items
T100 I1, I2, I5
T101 I2, I4
T102 I2, I3
T103 I1, I2, I4
T104 I1, I3
T105 I2, I3
T106 I1, I3
T107 I1, I2 ,I3, I5
T108 I1, I2, I3

24
Step 1: Generating 1-itemset Frequent Pattern
Itemset
Sup.Count
{I1} 6
{I2} 7
{I3} 6
{I4} 2
{I5} 2
Itemset
Sup.Count
{I1} 6
{I2} 7
{I3} 6
{I4} 2
{I5} 2
• In the first iteration of the algorithm, each item is a member of the set of candidate.
• The set of frequent 1-itemsets, L1 , consists of the candidate 1-itemsets satisfying minimum support.
Scan D to count of each candidate
Compare candidate support count with minimum support count
C1 L1
25
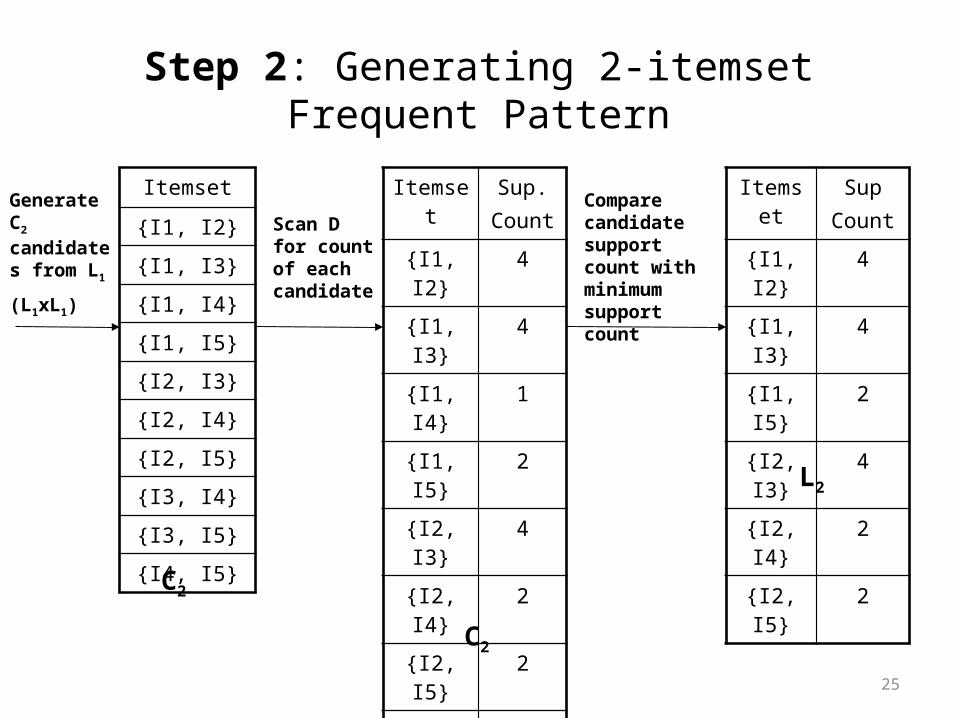
Step 2: Generating 2-itemset Frequent Pattern
Itemset
{I1, I2}
{I1, I3}
{I1, I4}
{I1, I5}
{I2, I3}
{I2, I4}
{I2, I5}
{I3, I4}
{I3, I5}
{I4, I5}
Itemset
Sup.Count
{I1, I2}
4
{I1, I3}
4
{I1, I4}
1
{I1, I5}
2
{I2, I3}
4
{I2, I4}
2
{I2, I5}
2
{I3, I4}
0
{I3, I5}
1
{I4, I5}
0
Itemset
SupCount
{I1, I2}
4
{I1, I3}
4
{I1, I5}
2
{I2, I3}
4
{I2, I4}
2
{I2, I5}
2
Generate C2
candidates from L1
(L1xL1)
C2
C2
L2
Scan D for count of each candidate
Compare candidate support count with minimum support count

26
Step 2: Generating 2-itemset Frequent Pattern [Cont.]
• To discover the set of frequent 2-itemsets, L2 , the algorithm uses L1 Join L1 to generate a candidate set of 2-itemsets, C2.
• Next, the transactions in D are scanned and the support count for each candidate itemset in C2 is accumulated (as shown in the middle table).
• The set of frequent 2-itemsets, L2 , is then determined, consisting of those candidate 2-itemsets in C2 having minimum support.
• Note: We haven’t used Apriori Property yet.

27
Step 3: Generating 3-itemset Frequent Pattern
Itemset
{I1, I2, I3}
{I1, I2, I5}….
Itemset Sup.Count
{I1, I2, I3}
2
{I1, I2, I5}….
2
Itemset SupCoun
t
{I1, I2, I3}
2
{I1, I2, I5}
2C3 C3
L3
Scan D for count of each candidate
Compare candidate support count with min support count
Scan D for count of each candidate
L2xL2
• The generation of the set of candidate 3-itemsets, C3 , involves use of the Apriori Property (see next slide).
• In order to find C3, we compute L2 Join L2.
• C3 = L2 Join L2 = {{I1, I2, I3}, {I1, I2, I5}, {I1, I3, I5}, {I2, I3, I4}, {I2, I3, I5}, {I2, I4, I5}}.
• Now, Join step is complete and Prune step will be used to reduce the size of C3. Prune step helps to avoid heavy computation due to large Ck.

28
Step 3: Generating 3-itemset Frequent Pattern [Cont.]
• Based on the Apriori property that all subsets of a frequent itemset must also be frequent, we can determine that four latter candidates cannot possibly be frequent. How ?
• For example , lets take {I1, I2, I3}. The 2-item subsets of it are {I1, I2}, {I1, I3} & {I2, I3}. Since all 2-item subsets of {I1, I2, I3} are members of L2, we will keep {I1, I2, I3} in C3.
• Lets take another example of {I2, I3, I5} which shows how the pruning is performed. The 2-item subsets are {I2, I3}, {I2, I5} & {I3,I5}.
• BUT, {I3, I5} is not a member of L2 and hence it is not frequent violating Apriori Property. Thus We will have to remove {I2, I3, I5} from C3.
• Therefore, C3 = {{I1, I2, I3}, {I1, I2, I5}} after checking for all members of result of Join operation for Pruning.
• Now, the transactions in D are scanned in order to determine L3, consisting of those candidates 3-itemsets in C3 having minimum support.
{{I1, I2, I3}, {I1, I2, I5}, {I1, I3, I5}, {I2, I3, I4}, {I2, I3, I5}, {I2, I4, I5}}.

29
Step 4: Generating 4-itemset Frequent Pattern
• The algorithm uses L3 Join L3 to generate a candidate set of 4-itemsets, C4. Although the join results in {{I1, I2, I3, I5}}, this itemset is pruned since its subset {{I2, I3, I5}} is not frequent.
• Thus, C4 = φ , and algorithm terminates, having found all of the frequent items. This completes our Apriori Algorithm.
• What’s Next ? These frequent itemsets will be used to generate strong association rules ( where strong association rules satisfy both minimum support & minimum confidence).
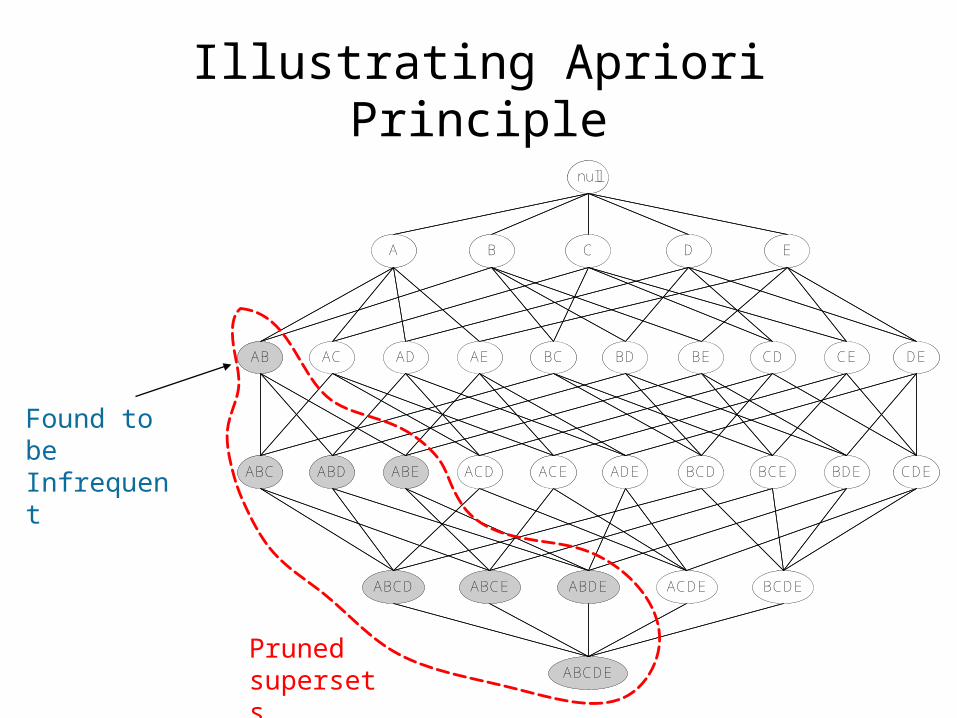
Found to be Infrequent
null
AB AC AD AE BC BD BE CD CE DE
A B C D E
ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE
ABCD ABCE ABDE ACDE BCDE
ABCDE
Illustrating Apriori Principle
null
AB AC AD AE BC BD BE CD CE DE
A B C D E
ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE
ABCD ABCE ABDE ACDE BCDE
ABCDE
Pruned supersets

31
Step 5: Generating Association Rules from Frequent Itemsets
• Procedure:• For each frequent itemset “l”, generate all nonempty
subsets of l.• For every nonempty subset s of l, output the rule “s (l-
s)” if support_count(l) / support_count(s) >= min_conf where min_conf is minimum confidence threshold.
• Back To Example:We had L = {{I1}, {I2}, {I3}, {I4}, {I5}, {I1,I2}, {I1,I3}, {I1,I5}, {I2,I3}, {I2,I4}, {I2,I5}, {I1,I2,I3}, {I1,I2,I5}}.– Lets take l = {I1,I2,I5}. – Its all nonempty subsets are {I1,I2}, {I1,I5}, {I2,I5}, {I1}, {I2},
{I5}.

32
Step 5: Generating Association Rules from Frequent Itemsets [Cont.]
• Let minimum confidence threshold is , say 70%.
• The resulting association rules are shown below, each listed with its confidence.– R1: I1 ^ I2 I5
• Confidence = sc{I1,I2,I5}/sc{I1,I2} = 2/4 = 50%• R1 is Rejected.
– R2: I1 ^ I5 I2 • Confidence = sc{I1,I2,I5}/sc{I1,I5} = 2/2 =
100%• R2 is Selected.
– R3: I2 ^ I5 I1• Confidence = sc{I1,I2,I5}/sc{I2,I5} = 2/2 =
100%• R3 is Selected.
l = {I1,I2,I5}, s: {I1,I2}, {I1,I5}, {I2,I5}, {I1}, {I2}, {I5}

33
Step 5: Generating Association Rules from Frequent Itemsets [Cont.]
– R4: I1 I2 ^ I5• Confidence = sc{I1,I2,I5}/sc{I1} = 2/6 =
33%• R4 is Rejected.
– R5: I2 I1 ^ I5• Confidence = sc{I1,I2,I5}/{I2} = 2/7 = 29%• R5 is Rejected.
– R6: I5 I1 ^ I2• Confidence = sc{I1,I2,I5}/ {I5} = 2/2 =
100%• R6 is Selected. In this way, we have found three strong
association rules.

34
Overview
• Basic Concepts of Association Rule Mining• The Apriori Algorithm (Mining single
dimensional boolean association rules)• Methods to Improve Apriori’s Efficiency• Frequent-Pattern Growth (FP-Growth)
Method• From Association Analysis to Correlation
Analysis• Summary

35
Methods to Improve Apriori’s Efficiency
• Hash-based itemset counting: A k-itemset whose corresponding
hashing bucket count is below the threshold cannot be frequent.
• Transaction reduction: A transaction that does not contain any
frequent k-itemset is useless in subsequent scans.
• Partitioning: Any itemset that is potentially frequent in DB must
be frequent in at least one of the partitions of DB.
• Sampling: mining on a subset of given data, lower support
threshold + a method to determine the completeness.
• Dynamic itemset counting: add new candidate itemsets only
when all of their subsets are estimated to be frequent.

36
Overview
• Basic Concepts of Association Rule Mining• The Apriori Algorithm (Mining single
dimensional boolean association rules)• Methods to Improve Apriori’s Efficiency• Frequent-Pattern Growth (FP-Growth)
Method• From Association Analysis to Correlation
Analysis• Summary

FP-growth: Another Method for Frequent Itemset Generation
• Use a compressed representation of the database using an FP-tree
• Once an FP-tree has been constructed, it uses a recursive divide-and-conquer approach to mine the frequent itemsets

38
Efficiently Mining Frequent Patterns Without Candidate Generation
• Compress a large database into a compact, Frequent-Pattern tree (FP-tree) structure– highly condensed, but complete for frequent pattern
mining– avoid costly database scans
• FP-Growth: allows frequent itemset discovery without candidate itemset generation. Two step approach:– Step 1: Build a compact data structure called the FP-tree
• Built using 2 passes over the data-set.– Step 2: Extracts frequent itemsets directly from the FP-tree

39
FP-Growth Method: Construction of FP-Tree
• First, create the root of the tree, labeled with “null”.• Scan the database D a second time. (First time we scanned
it to create 1-itemset and then L).• The items in each transaction are processed in L order (i.e.
sorted order).• A branch is created for each transaction with items having
their support count separated by colon.• Whenever the same node is encountered in another
transaction, we just increment the support count of the common node or Prefix.
• To facilitate tree traversal, an item header table is built so that each item points to its occurrences in the tree via a chain of node-links.
• Now, The problem of mining frequent patterns in database is transformed to that of mining the FP-Tree.

Example FP-Growth (1)Suppose min-support=3
1. Count item frequency and order items by support
Red numbers are the order of items (by support)

Example (2)
2. Items are ordered in each transaction according to their support

Example (3)
• The root node is null• A branch is created for each
transaction with items having their support count separated by colon.
• We start with T1, every node is an item with its count, in order of support

Example (4)Now consider T2:
First 4 items are in the same order as T1, so we can traverse the branch incrementing counts, and add C at the end
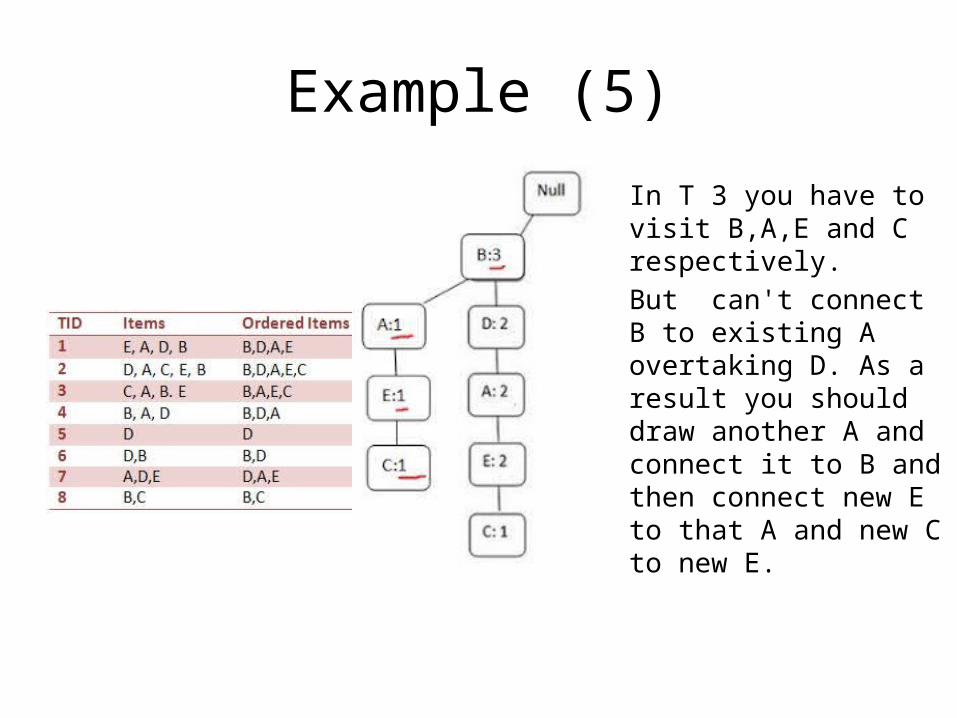
Example (5)
In T 3 you have to visit B,A,E and C respectively. But can't connect B to existing A overtaking D. As a result you should draw another A and connect it to B and then connect new E to that A and new C to new E.

Example (6)
In T 4 we only need to update counts in one of the branches
With T5 we need to add another branch
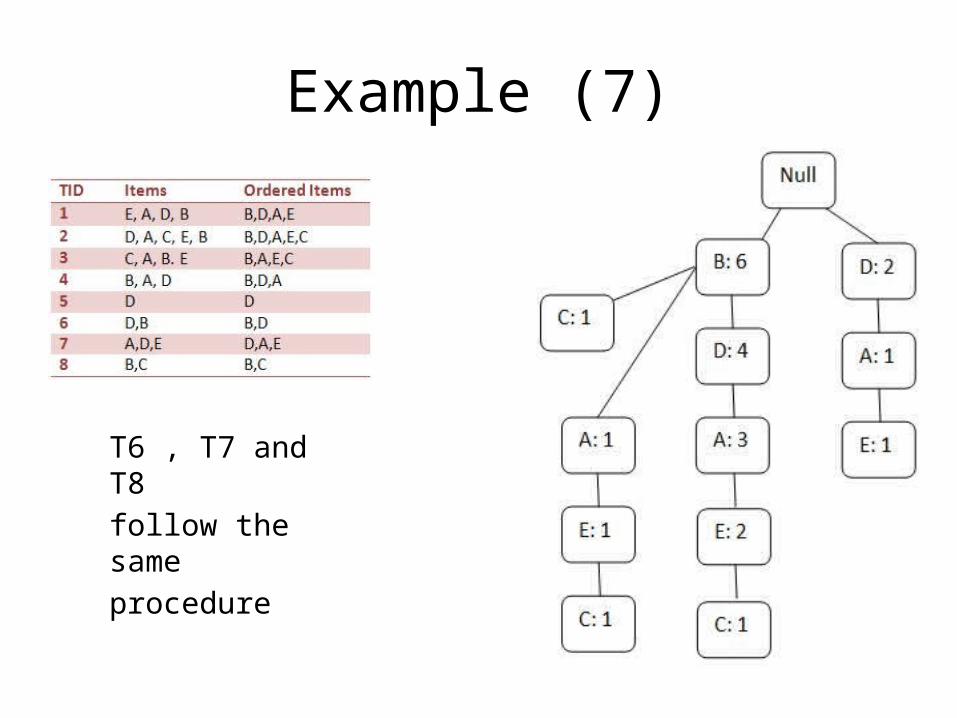
Example (7)
T6 , T7 and T8follow the sameprocedure

47
Phase 2: Mining the FP-Tree by Creating Conditional (sub) pattern bases
Steps:1. Start from each frequent length-1 pattern (as an
initial suffix pattern).2. Construct its conditional pattern base which consists
of the set of prefix paths in the FP-Tree co-occurring with suffix pattern.
3. Then, construct its conditional FP-Tree & perform mining on such a tree.
4. The pattern growth is achieved by concatenation of the suffix pattern with the frequent patterns generated from a conditional FP-Tree.
5. The union of all frequent patterns (generated by step 4) gives the required frequent itemset.

Example : 1. Start from each frequent length-1 pattern (as an initial suffix
pattern).
The Items and their frequency of occurrences can be listed as B:6 D:6 A:5 E:4 C:3
Minimum support count is 3 (as previously stated)
To find frequent itemsets we need to move bottom-up (C)
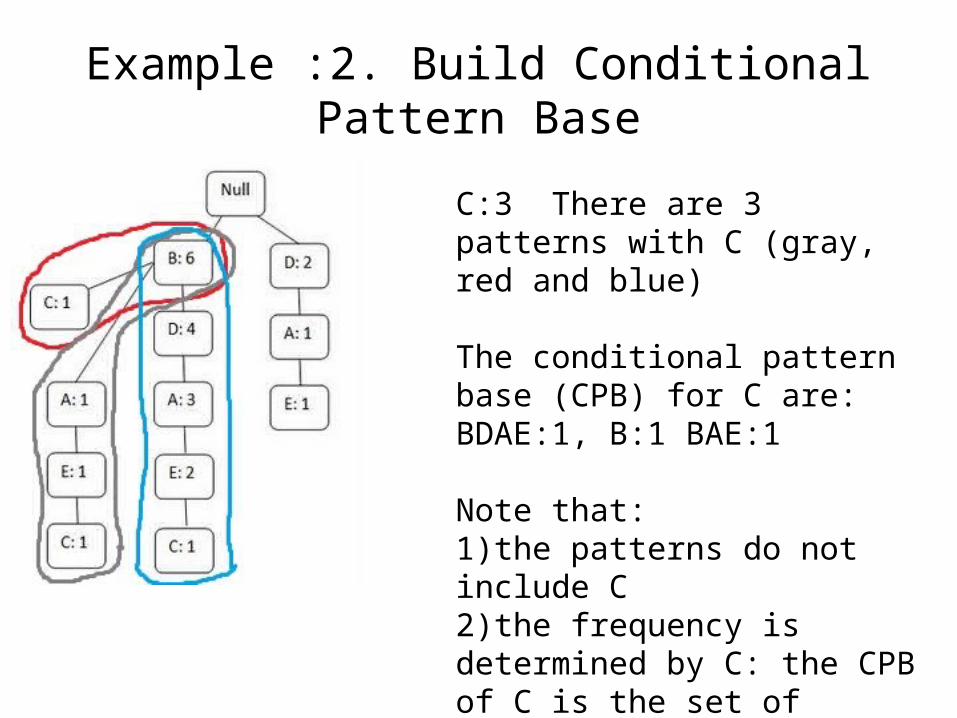
Example :2. Build Conditional Pattern Base
C:3 There are 3 patterns with C (gray, red and blue)
The conditional pattern base (CPB) for C are: BDAE:1, B:1 BAE:1
Note that:1)the patterns do not include C2)the frequency is determined by C: the CPB of C is the set of patterns in which C occurs3)Items in CBP are again in order of relevance
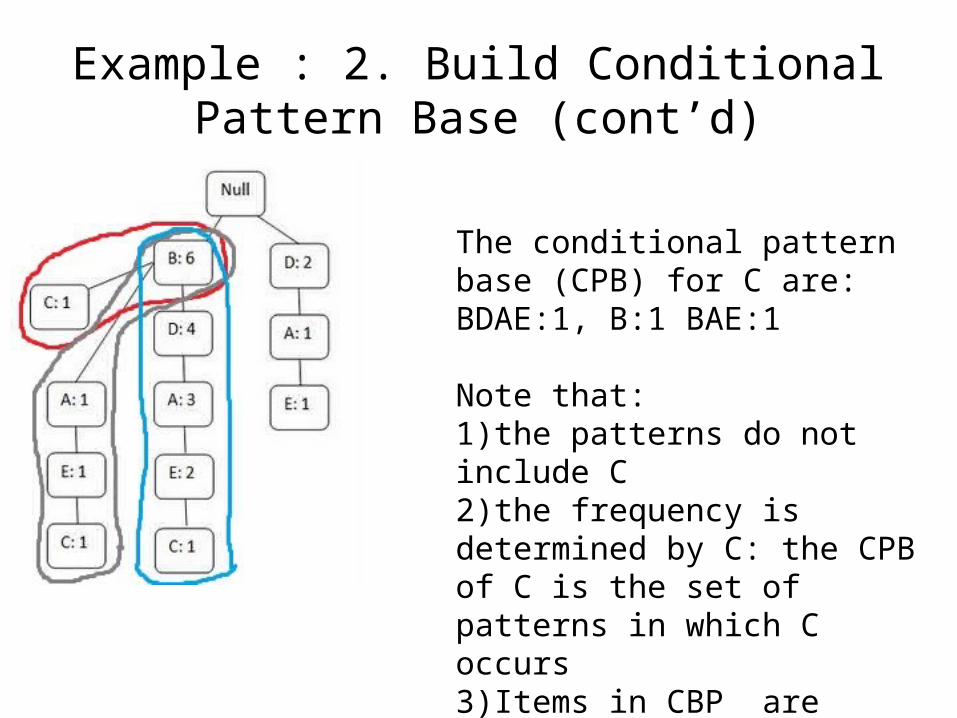
Example : 2. Build Conditional Pattern Base (cont’d)
The conditional pattern base (CPB) for C are: BDAE:1, B:1 BAE:1
Note that:1)the patterns do not include C2)the frequency is determined by C: the CPB of C is the set of patterns in which C occurs3)Items in CBP are again in order of relevance
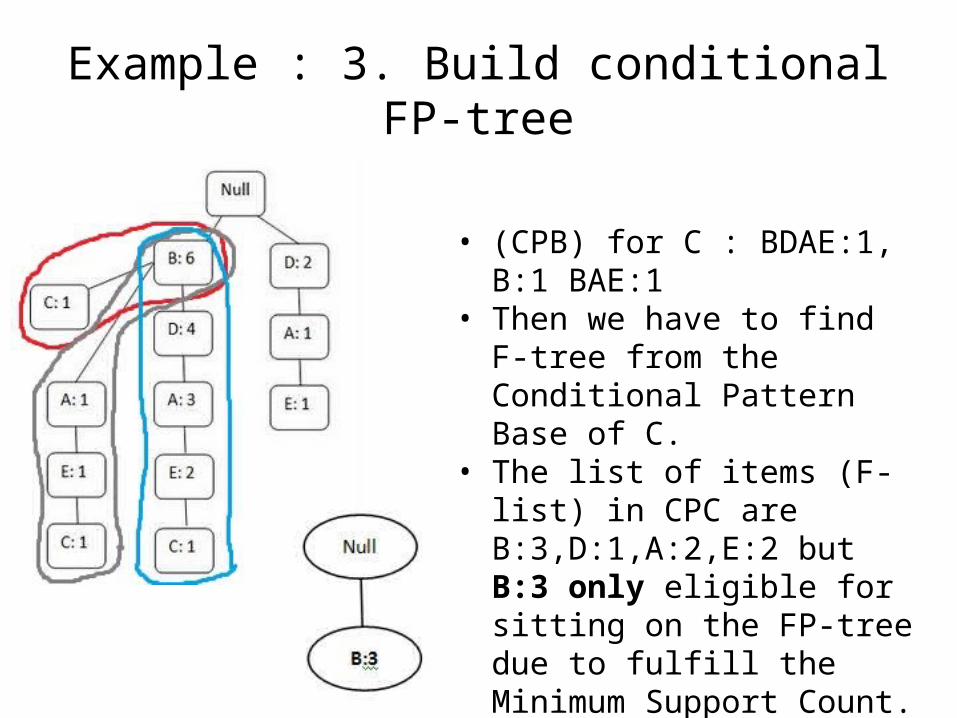
Example : 3. Build conditional FP-tree
• (CPB) for C : BDAE:1, B:1 BAE:1• Then we have to find F-tree
from the Conditional Pattern Base of C.
• The list of items (F-list) in CPC are B:3,D:1,A:2,E:2 but B:3 only eligible for sitting on the FP-tree due to fulfill the Minimum Support Count.
• So the FP-tree is B:3

Example : 4. Extract frequent patterns
All frequent pattern corresponding to suffix C are generated by considering all possible combinations of C and conditional FP-Tree.
Now we can find the FP from the F-tree: C:3, BC:3

Example (cont’d) : Build Conditional Pattern Base for E
Now we consider the item E
The conditional pattern base (CPB) for E are: BDA:2, BA:1 DA:1
And the F-list is:A:4 B:3 D:3

Example : Build F-tree for EF-list is: A:4 B:3 D:3F-tree i build from red and blue patterns (need blue pattern since red has only A:3)
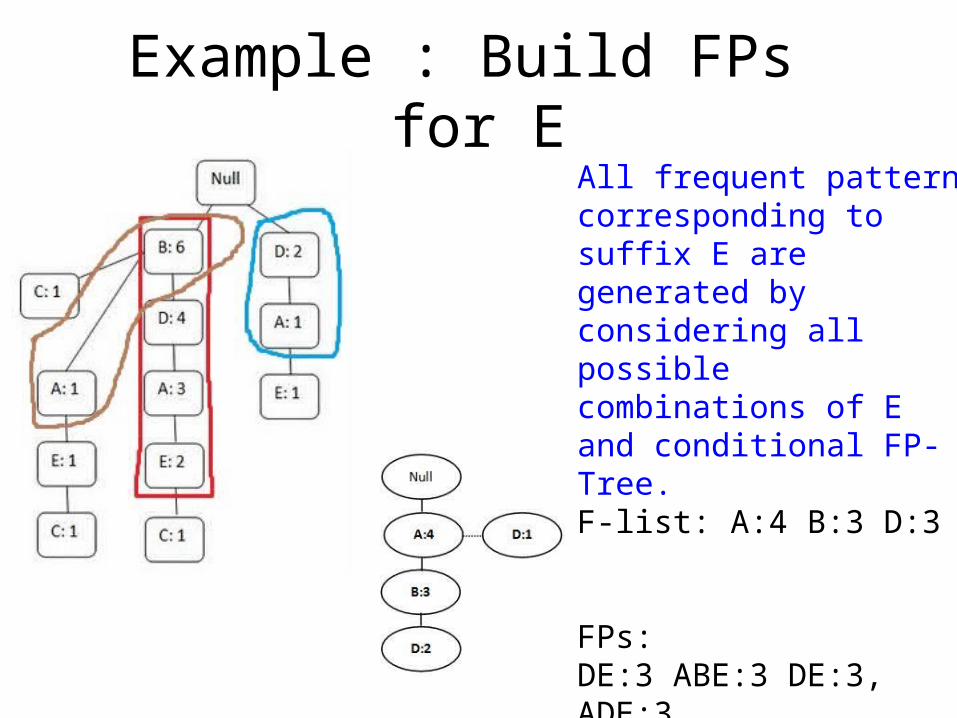
Example : Build FPs for EAll frequent pattern corresponding to suffix E are generated by considering all possible combinations of E and conditional FP-Tree.F-list: A:4 B:3 D:3
FPs:DE:3 ABE:3 DE:3, ADE:3BE:3, ABE:3 AE:4

Benefits of the FP-tree Structure
• Performance study shows– FP-growth is an order of
magnitude faster than Apriori• Reasoning
– No candidate generation, no candidate test
– Use compact data structure– Eliminate repeated database
scan– Basic operation is counting
and FP-tree building0
10
20
30
40
50
60
70
80
90
100
0 0.5 1 1.5 2 2.5 3
Support threshold(%)
Ru
n t
ime(s
ec.)
D1 FP-grow th runtime
D1 Apriori runtime

57
Overview
• Basic Concepts of Association Rule Mining• The Apriori Algorithm (Mining single
dimensional boolean association rules)• Methods to Improve Apriori’s Efficiency• Frequent-Pattern Growth (FP-Growth)
Method• From Association Analysis to Correlation
Analysis• Summary

58
Association & Correlation
• Correlation Analysis provides an alternative framework for finding interesting relationships, or to improve understanding of meaning of some association rules (a lift of an association rule).

59
Correlation Concepts
• Two item sets A and B are independent (the occurrence of A is independent of the occurrence of item set B) iff P(A B) = P(A) P(B)
• Otherwise A and B are dependent and correlated
• The measure of correlation, or correlation between A and B is given by the formula:Corr(A,B)= P(A U B ) / P(A) . P(B)

60
Correlation Concepts [Cont.]
• corr(A,B) >1 means that A and B are positively correlated i.e. the occurrence of one implies the occurrence of the other.
• corr(A,B) < 1 means that the occurrence of A is negatively correlated with ( or discourages) the occurrence of B.
• corr(A,B) =1 means that A and B are independent and there is no correlation between them.

61
Association & Correlation• The correlation formula can be re-written as
– Corr(A,B) = P(B|A) / P(B)
• We already know that– Support(A B)= P(AUB)– Confidence(A B)= P(B|A)– That means that, Confidence(A B)= corr(A,B) P(B)
• So correlation, support and confidence are all different, but the correlation provides an extra information about the association rule (A B).
• We say that the correlation corr(A,B) provides the LIFT of the association rule (A=>B), i.e. A is said to increase (or LIFT) the likelihood of B by the factor of the value returned by the formula for corr(A,B).

62
Summary• Association Rule Mining
– Finding interesting association or correlation relationships.• Association rules are generated from frequent itemsets.• Frequent itemsets are mined using Apriori algorithm or
Frequent-Pattern Growth method.• Apriori property states that all the subsets of frequent
itemsets must also be frequent.• Apriori algorithm uses frequent itemsets, join & prune
methods and Apriori property to derive strong association rules.
• Frequent-Pattern Growth method avoids repeated database scanning of Apriori algorithm.
• FP-Growth method is faster than Apriori algorithm.• Correlation concepts & rules can be used to further support
our derived association rules.