(dat309) scaling massive content stores with amazon aurora
TRANSCRIPT

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
John Newton, Founder & CTO Alfresco
@johnnewton
October 2015
DAT309
Scaling Massive Content
Stores with Amazon AuroraAlfresco on AWS

What to expect from the session
• Challenges of scaling to billions of documents
• Architectural approaches of managing data, search, and storage
with Amazon Aurora, Solr, Amazon EBS, and Amazon S3
• The breadth of use cases of content at scale
• How to support user applications that require sub-second response
times
• Moving from large data centers to cost-effective management with
AWS and Amazon Aurora


Alfresco in action
Government
Finance
Manufacturing
Transportation & Utilities
Healthcare Other
Content in dynamic
context
Consumerized search &
discovery
Secure & mobile
collaboration
Invisible Information
Governance
SIMPLE
SMART
Powerful metadata,
rules & relationships
Easy process
creation & analysis
CONTENT PROCESS
Modern & agile
architectureOPEN
Cloud integration,
sync & scale
Open source, open
APIs
Difference
@johnnewton alfresco.com/awsreinvent

Somewhere deep in the Nevada Desert

in a secret underground location

someone is trying to store…
One Billion
Documents!!!
http://www.warnerbros.com/austin-powers-international-man-mystery

Some have tried before … and failed!
We’ll
configure
1 Million
SharePoint
Servers!!!

Digital transformation is driving huge flows of content
Gartner Nexus
PWC 6th Annual Digital IQ Survey, 2014
Digital
Business
Cloud Social
Big DataMobile
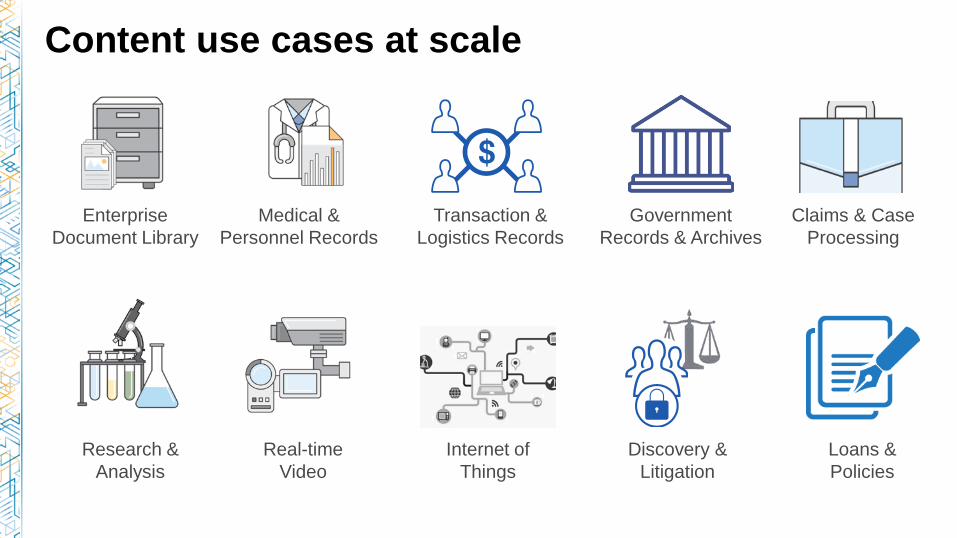
Content use cases at scale
Enterprise
Document Library
Loans &
Policies
Claims & Case
Processing
Transaction &
Logistics Records
Research &
Analysis
Real-time
Video
Internet of
Things
Medical &
Personnel Records
Government
Records & Archives
Discovery &
Litigation

Content management applications
Document
Library
Image
Management
File Sync &
Share
Search &
Retrieval
Business
Process
Management
Records
Management
Case
Management
Media
Management
Information
Archiving

What is this
“Content”?!!!

Content vs. data vs. files vs. EFSS
Data Files EFSS Content and ECM
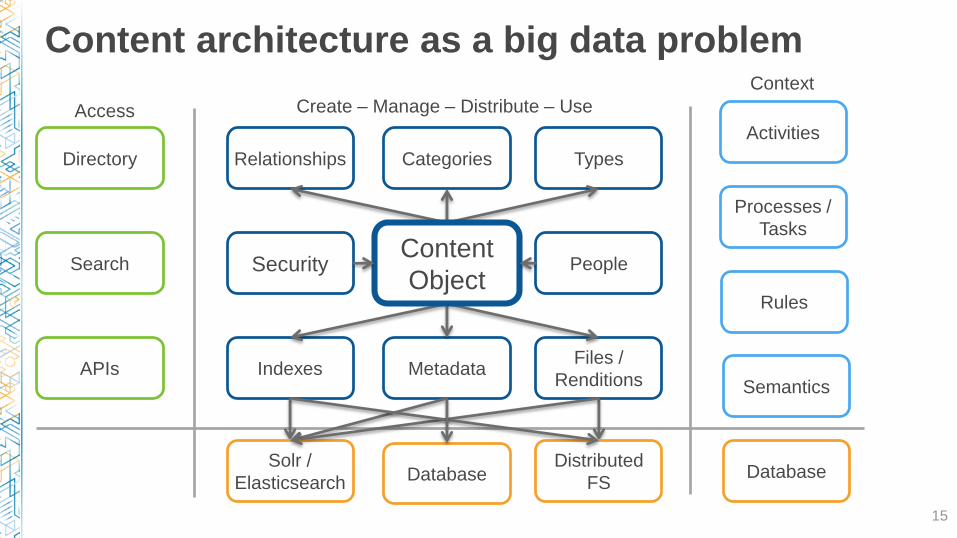
Content architecture as a big data problem
15
Files /
RenditionsMetadata
Directory CategoriesRelationships
Indexes
Search
Activities
Security People
APIs
Processes /
Tasks
Rules
Semantics
Types
Content
Object
Access Create – Manage – Distribute – Use
Context
DatabaseDistributed
FSDatabaseSolr /
Elasticsearch

Content at scale in the enterprise
Users at Scale
Concurrency Content Count
Read/Write
Throughput
Geographic
Distribution
Volume Size
The problem with traditional approaches
Provisioning and
Administration
Geographic Distribution Lack of Agility
Lack of Redundancy Lack of Elasticity

It’s enough to get one “fired”

Unique challenges of very large repositories
19
Scaling Up
• Clustered Servers
• Clustered Database
• Clustered Indexes
• Read Replicas
Scaling Out
• Sharding
• Federation
• Replication
• Shared Nothing
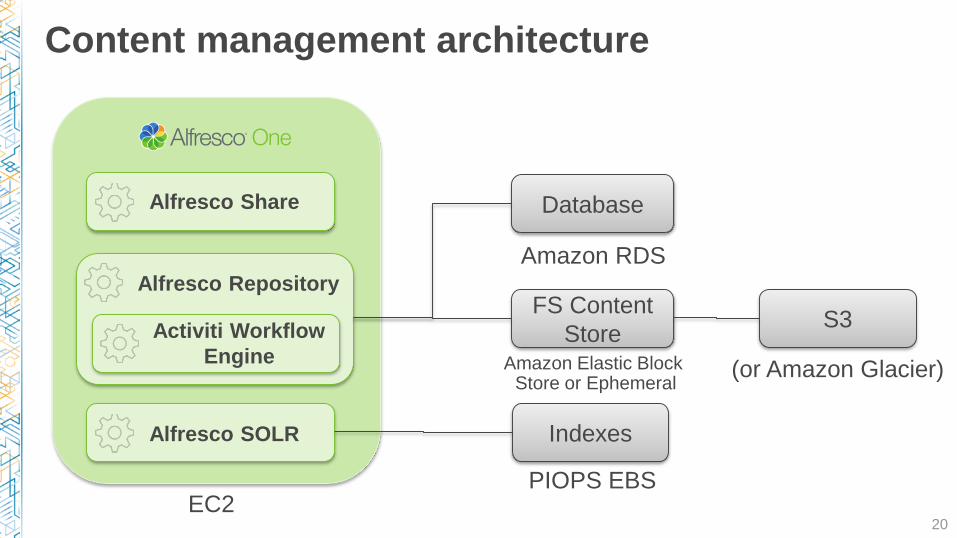
Content management architecture
20
Alfresco Share
Alfresco Repository
Alfresco SOLR
Activiti Workflow
Engine
Database
FS Content
Store
Indexes
S3
Amazon RDS
Amazon Elastic Block Store or Ephemeral
PIOPS EBS
(or Amazon Glacier)
EC2

Content management architecture
21
Alfresco Share
Alfresco
Repository
Alfresco SOLR
Activiti
Workflow
Protocols
APIs (CMIS)
Media
Mgmt
Desktop and
Mail ClientMobile App Cloud Sync
Database
FS Content
Store
Indexes
Records
Management
Reports &
Analytics
Reports and
Analytics Server
Media Transform
Services
Transforms
Authentication
Auditing
Rules/Policies
Web Scripts
Scheduled Jobs

Process management architecture
Database ElasticsearchFiles
Amazon EBS
Process
Mining
Activiti EngineTomcat / Jetty
Process
Virtual
Machine
Tasks Processes Jobs
Activiti REST App REST Admin RESTMS Office
Protocol
Activiti
AnalysisAngularJS
Activiti
AppAngularJS
Activiti
AdminAngularJS
MS
Office
Activiti
MobileiOS / Android
Activiti
DesignerEclipse
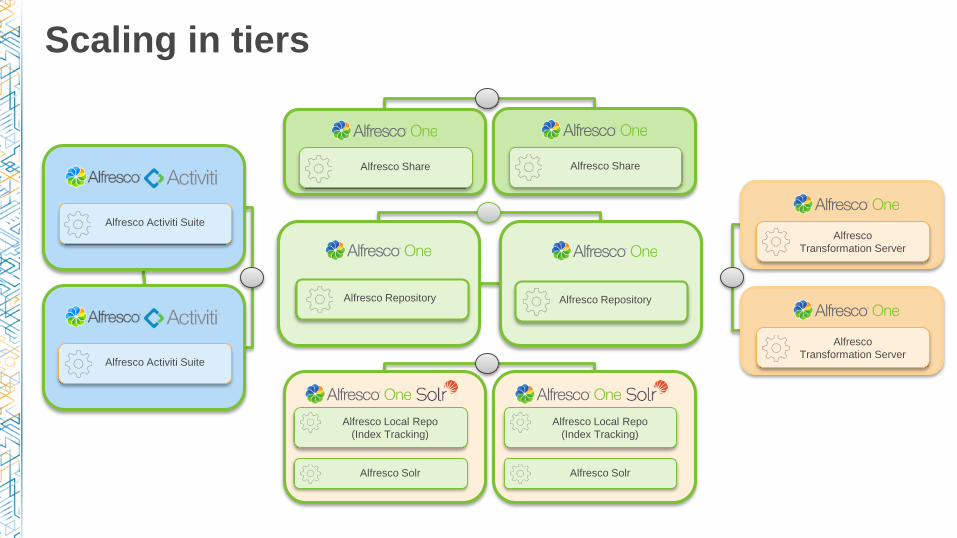
Scaling in tiers
Alfresco
Transformation Server
Alfresco
Transformation Server
Alfresco Solr
Alfresco Local Repo
(Index Tracking)
Alfresco Solr
Alfresco Local Repo
(Index Tracking)
Alfresco Repository Alfresco Repository
Alfresco Share Alfresco Share
Alfresco Activiti Suite
Alfresco Activiti Suite

Multi-tenant Cloud Service on AWS
RDS
Activities
Route53 (DNS)
S3
ELB
Layer7
solr trans
/share
/alfresco
haproxy
haproxy
varnish
/share
/alfresco
haproxy
/share
/alfresco
haproxy
haproxy
varnish
haproxy
varnish
web nodes
alfresco nodes
solr
solr trans
trans

You can scale
my server any
day, Baby!!!

Data meta-model
A
B
C
D
Folder
Folder
Doc
Docrendition
Class
Type Aspect
Property
Association
Constraint
Child
Association
Folder
Document
contains
name
name
content
Auditable who by
when
rendition
Type
Child Association
Type
Association
Property
Property
Property
Aspect
Model Metadata Organization
1 Billion 15 Billion

Database schema
• Tables
• Indexes
• Concurrency
• Throughput Techniques
• Striping
• Parallelism
• Sharding
Table Size (GB)
alf_child_assoc 448
alf_content_data 149
alf_content_url 202
alf_node 711
alf_node_aspects 217
alf_node_properties 1,524

Amazon Aurora difference
AZ 1 AZ 2
EBSmirror
EBSmirror
Amazon S3
EBS
Standby
InstancePrimary
Instance
AZ 1 AZ 3
Amazon S3
Primary
Instance
AZ 2
Replica
Instance
• Highly available — synchronous vs. asynchronous replication
• Significantly more efficient use of network I/O
• Self-healing, fault-tolerant, instant crash recovery
MySQL with standby Amazon Aurora
async
4/6 quorum
PiTR
Sequential
write
Sequential
writeDistributed
writes
Amazon Elastic
Block Store (EBS)

Modifications required for Aurora

Index and search architecture
Full-Text Query
Metadata Query
Facets & Buckets
Security Filters
Results Processing
Credit: Ryan Tobora
ThinkBig, Teradata
http://thinkbig.teradata.com/solrcl
oud-terminology/
Text Extraction
Metadata Injection
& Path Processing
Shingles
ACL Processing
Results ProcessTerm-hit Highlighting
x 20 instances

Storage Layer
File storage architecture
In Place: AWS Import/Export Snowball
Direct
Streaming
Aurora EBS
Metadata Content
Metadata
Content
Archive Layer
S3 Amazon Glacier
Metadata Content
File
System
Protocols
APIs
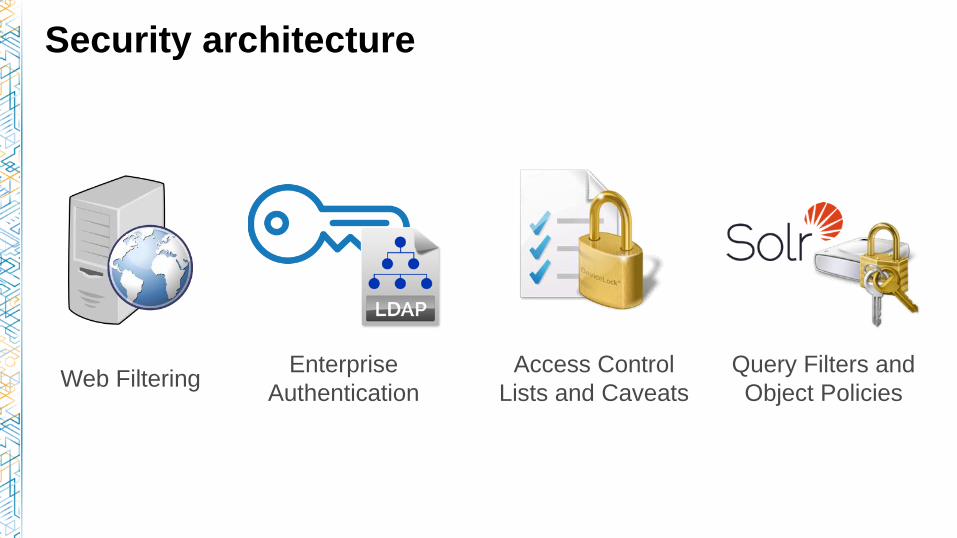
Security architecture
Web FilteringEnterprise
Authentication
Access Control
Lists and Caveats
Query Filters and
Object Policies

Do you suppose we
can put it together
with some string and
Scotch Tape?!!
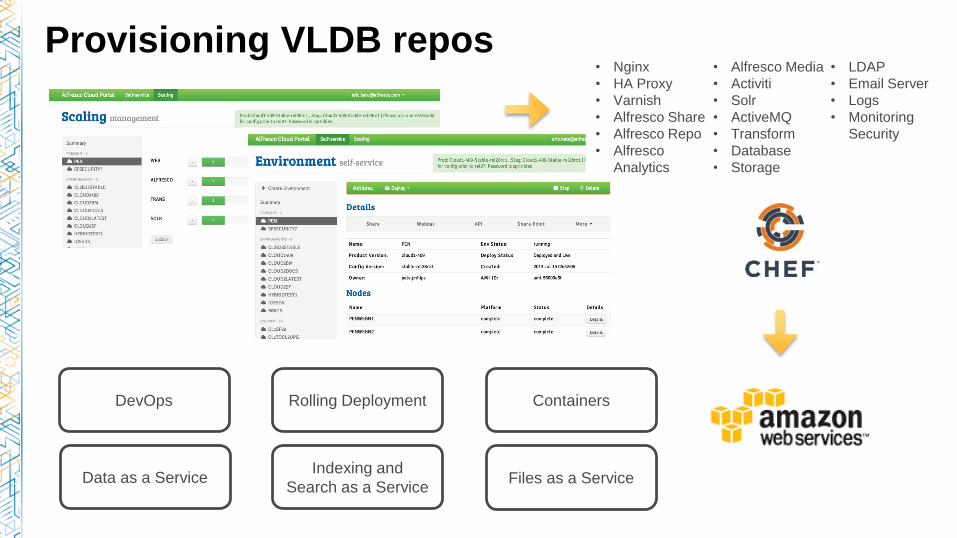
Provisioning VLDB repos
10
Cost Benefit
The following are the benefits of moving from the current environment to the proposed
environment:
Performance Moving to a HA (High Availability) environment where there are 2 or more Alfresco servers and
separation of indexes, not only allows for additional processor for each, but also allows for
benefits such as load balancing and failover. As new projects are brought on-board to the
Alfresco solution, a clustered environment ensures that end users will not be effected by any
additional activity in the product, by distributing load appropriately through each node/instance in
the cluster
Scalability By having a HA (High Availability) environment where there are 2 or more Alfresco servers and
separation of indexes, the environment can be scaled appropriately based on demand. This
new architecture allows room to scale the environment to support 2013 and 2014 roadmap
plans while still supporting an environment that will be reliable and robust.
Additionally, this environment support disaster recovery capabilities as well, guaranteeing that in
case of a severe outage, that backups are stored and quick turn around can occur to restore the
environment.
Below is a screenshot of the Customer Deployment Portal in which Stanford will be able to scale
the Alfresco environment seamlessly within a web based UI.
Flexibility This new architecture will also utilize new Cloud Ops tools that will allow increased flexibility in
the administration of the Alfresco environment. This gives Stanford the flexibility to grow or
shrink the different environments based on demand, pricing, or performance. While the need for
flexibility of the environment might be minimal in production, this will be especially advantageous
as Stanford develops on the Alfresco service, and needs to rapidly spin up and down
test/development environments.
11
Self-Service The Customer Deployment Portal will be one of the benefits of moving to the proposed
environment. The Customer Deployment Portal is a web based administration tool that allows
Stanford to self-service their environment. Stanford will be able to setup, deploy, change, and
monitor the different AWS environments through a user friendly and intuitive web interface.
This includes control over the number of virtual machines, size of the virtual machines, load
balancers, databases, storage sizes and types, and more.
ContainersDevOps
Data as a ServiceIndexing and
Search as a ServiceFiles as a Service
Rolling Deployment
• Nginx
• HA Proxy
• Varnish
• Alfresco Share
• Alfresco Repo
• Alfresco
Analytics
• Alfresco Media
• Activiti
• Solr
• ActiveMQ
• Transform
• Database
• Storage
• LDAP
• Email Server
• Logs
• Monitoring
Security

Large-scale benchmarking
BM01 User scenarios
BM02 User concurrency on single
node
BM03 Solr Performance
BM04 Concurrent Load and Access
– multi-user
BM05 User Invite and Tenant
Provisioning
BM06 Workflow service
performance
BM07 Workflow API performance
BM08 High concurrency in Multi-
Tenancy
https://wiki.alfresco.com/wiki/Benchmark_Testing_with_Alfresco
https://github.com/AlfrescoBenchmark/alfresco-benchmark
Benchmark Server
Tomcat 7
Rest API
MongoDB
Config Data
Services
MongoDB
Test Data
UI
Benchmark Driver (xN)Benchmark Driver (xN)Benchmark Driver
Tomcat 7 Extras
(Selenium)
Servers / APIs Servers / APIs
Load Balancer
Servers / APIs
Test
Services
Rest API
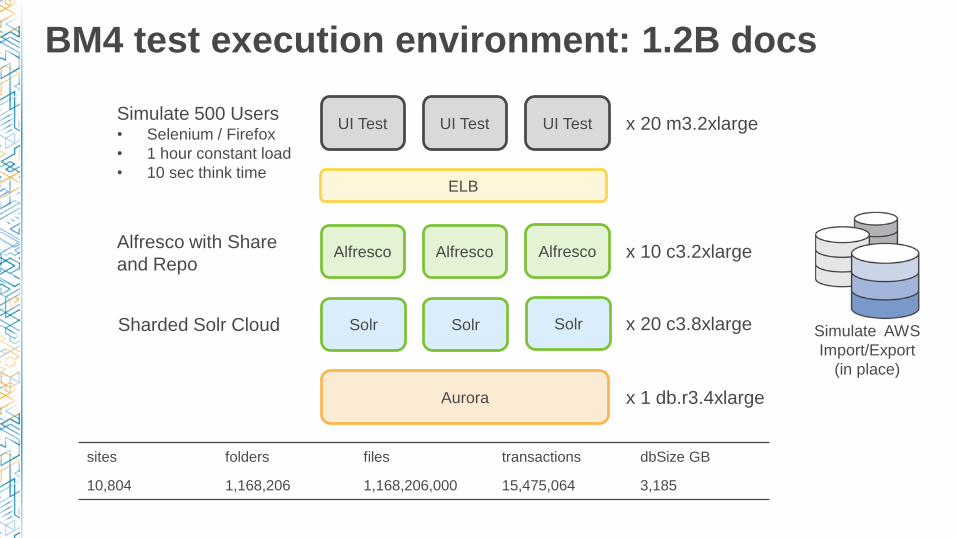
BM4 test execution environment: 1.2B docs
UI Test x 20 m3.2xlarge Simulate 500 Users• Selenium / Firefox
• 1 hour constant load
• 10 sec think time
UI Test UI Test
Alfresco Alfresco Alfresco x 10 c3.2xlarge Alfresco with Share
and Repo
Solr x 20 c3.8xlarge Solr Solr
Aurora x 1 db.r3.4xlarge
ELB
Sharded Solr Cloud
sites folders files transactions dbSize GB
10,804 1,168,206 1,168,206,000 15,475,064 3,185
Simulate AWS
Import/Export
(in place)

Benchmark results
• Document load rate 1200 per sec
• 4.3 Million per Hour on 10 nodes!
• Load rate consistent beyond 1B
• CPU loads:
• Database: 70-80% in Bulk Load
• Alfresco: ~50%
• Solr: <60%
• CMIS API Calls (OASIS Standard)
• Aurora indexes efficient at 3.2TB
• NAME (=, LIKE) ~ 20ms
• IN_FOLDER (sorted, limited) ~ 160ms
• Sub-second login times and good,
linear responses for other actions
• Open Library: ~3s
• Page Results: <1s
• Navigate to Site: ~1s
• Individual search ~1s
• 500 concurrent search: ~3s response
• CPU loads:
• Database: <10%
• Alfresco: 25-30%
• Solr: 25-30%
No size-related bottlenecks with 1.2 billion documents
Bulk Operations User Operations

AWS
What a difference
3-6 Months
Questionable Scale
Little Redundancy
Lots of $$$
< 30 mins
10x Faster
Elastic, Fault-Tolerant
Open, Cost Effective
ECM ECM ECM
Search Search Search
FS FS FS
Hardware Hardware Hardware
Load Balancer
DR Plan
HSM HSM HSM
ECM ECM ECM
ELB
Alfresco Alfresco Alfresco
Solr Solr Solr
S3
EC2 EC2 EC2
AZ1 AZ2 AZ3
Aurora
EBS

What a difference
3-6 Months
Questionable Scale
Little Redundancy
Lots of $$$
< 30 mins
10x Faster
Elastic, Fault-Tolerant
Open, Cost Effective

Well, what am I
supposed to do
with all this
frickin’
hardware?!!

Future: globally distributed environment
41
Distributed FS Distributed FS
Sharding Sharding

Thank you!Vegas, Baby!
Thank you!

What the world
needs now,
is evaluation sheets!
No, not just for some,
But for @johnnewton!
alfresco.com/awsreinvent