cs246 query translation. mind your vocabulary q: what is the problem? a: how to integrate...
Post on 21-Dec-2015
217 views
TRANSCRIPT

CS246
Query Translation

Mind Your Vocabulary
Q: What is the problem? A: How to integrate heterogeneous sources
when their schema & capability are different

Bestbookbuys.com
How to integrate?
Amazon.com bn.com
Mediator
[au = “Clancy, Tom”][fn = “Tom”][ln = “Clancy”]
?[au = “Tom, Clancy”]
[fn = “Tom”][ln = “Clancy”]

Framework
User expresses a query using a mediator schema
Mediator translates the query to source-supported queries
Mediator collects and postprocess results from the sources
Amazon.com bn.com
Mediator
[fn = “Tom”][ln = “Clancy”]
[fn = “Tom”][ln = “Clancy”]
[au = “Clancy, Tom”]

Difference From Previous Studies?
Heterogeneous attributes Different “vocabularies”
Semantic translation necessary Previous studies assumed homogeneous
attributes for all sources Complex Boolean queries
Not just conjunctive queries

Main Challenge
How best to translate a query when the mediator and the source use different model/schema? Author lastname, firstname Western calendar Chinese lunar calendar

Query Translation Example
Q: For the above schema, best translation for [last = “Clancy” & year = “1998” & month = “Jan”]?
A: [author = “Clancy” & date = “winter, 1998”]?
publisher = “publisher”title = “title”author = “last, first?”date = “spring, 2002”
Amazon.com
publisher = “publisher”title = “title”last = “lastname”first = “firstname”year = “2002”month = “may”
Mediator

More Translation Examples
More translations for the same schemas: [publisher = “p” & last = “l” & first = “f”]
[publisher = “p” & author = “l, f”] [title = “t” & last = “l” & first = “f”]
[title = “t” & author = “l, f”] Do we have to translate every possible query
manually? Is it necessary to have separate rules for the above translations? Can the system automatically translate queries?
Any idea?

Observations
The system cannot figure out [last = “l” & first = “f”] [author = “l, f”] No semantic knowledge User needs to provide these types of mappings There seem to exist “basic” mappings
However, system may compose “correct” translation using “basic” translations
[last = “l” & first = “f”] [author = “l, f”] [year = “yy” & month = “Jan”] [date = “spring, yy”]

Framework
Human expert provides a set of “basic” rules [last = “l” & first = “f”] [author = “l, f”] [year = “yy” & month = “Jan”] [date = “spring, yy”]
MediatorContext
SourceContext
Basic rules

Framework
Given a query, the system automatically translates the query using the basic rules
Basic rules
Traslation Algorithm
Qm:First = “Tom”Last = “Clancy”
Qs:Author = “Clancy, Tom”

Advantage of the Proposed Framework
Minimizes manual intervention Human input only for the initial rule writing
Can translate any queries Not just “template” queries

Questions
How do we know whether a translation is “good” or “correct”?
What basic rules are necessary? Do we need a rule for [last = ‘l’ | first = ‘f’]?
How do we translate? Algorithm for “good” translation?

Good Translation?
Q: Why do we think these are good translations? [last = “Clancy” & first = “Tom”]
[author = “Clancy, Tom”] [year = “2002” & month = “Jan”]
[date = “winter, 2002”] A: Results for the translated queries are
“close” to the original queries

Minimum Superset Translation
Definition of “closeness” in the paper Q: original query S(Q): translated query
We also use Q and S(Q) to represent results S(Q): minimal superset of Q expressed in the
source terms
Q S1(Q) S2(Q)
Minimum superset translation

Minimum Superset Translation
Find the minimum superset translation from the original query
“Filter out” false positives by applying filtering condition at the mediator

Any Alternative for “Closeness”?
What about maximum subset translation? Definition of previous studies Maybe a good definition when result is large or
filtering is impossible…
QS1(Q)S2(Q)
Maximum SubsetTranslation

Any Alternative for “Closeness”?
Consider both false positives and false negatives
Maximize |S(Q)Q| / |S(Q)Q|
Other definitions possible depending on scenario
QS(Q)
False positive False negative

Questions
How do we know whether a translation is “good” or “correct”? Minimal subsuming translation
What basic rules are necessary? Do we need a rule for [last = ‘l’ | first = ‘f’]?
How do we translate? Algorithm for “good” translation?

Three Main Concepts
Query Separability Query Safety Cross matching

Query Separability
Q = [ln = “Clancy”] & [fn = “Tom”] & [p = “Wiley”] We still get minimum superset translation if we
separately translate [ln = “Clancy”] & [fn = “Tom”] and
[p = “Wiley”]
Q = C1 C2 C3 ( : & or | ) is separable if S(Q) = S(C1) S(C2) S(C3)

Disjunction Separability Theorem [CGM96]
Disjunctions are always separable Q = C1 | C2 | C3 S(Q) = S(C1) | S(C2) | S(C3)
for any C1, C2 and C3 Assuming minimum superset translation semantics
Implication Basic rules are necessary only for conjunctions
e.g., [c1 & c2], but not [c1 | c2] Why?
Any complex queries can be transformed to DNF Significant simplification for a rule writer

Basic Rules
Only conjunction of constraints Separability of conjunctions is determined by
a human expert [ln & fn] but not [ln & publisher]
User-provided basic rules should be sound and complete Soundness: All mappings are correct (minimal
subsuming translation) Completeness: Contains all inseparable simple
conjunctions

Questions
How do we know whether a translation is “good” or “correct”?
What basic rules are necessary? Do we need a rule for [last = ‘l’ | first = ‘f’]?
How do we translate? Algorithm for “good” translation?

Translation Algorithm
Simple conjunction query
Step 1: Find all matching rules
ln = “l” au = “l”ln = “l” & fn = “f” au = “l, f”p = “p” p = “p”
Q: Rules
ln = “l” fn = “f” p = “p”
&
au = “l” au = “l, f” p = “p”

Translation Algorithm
Simple conjunction query
Step 2: Remove subset matching Superset matching is more “precise”
ln = “l” au = “l”ln = “l” & fn = “f” au = “l, f”p = “p” p = “p”
Q: Rules
ln = “l” fn = “f” p = “p”
&
au = “l” au = “l, f” p = “p”

Translation Algorithm
Simple conjunction query
Step 3: Generate translated query
ln = “l” au = “l”ln = “l” & fn = “f” au = “l, f”p = “p” p = “p”
Q: Rules
ln = “l” fn = “f” p = “p”
&
au = “l, f” p = “p”
&

Translation Algorithm Complex Boolean query?
ln = “l” p = “p”
fn = “f1” fn = “f2”
|
&Q
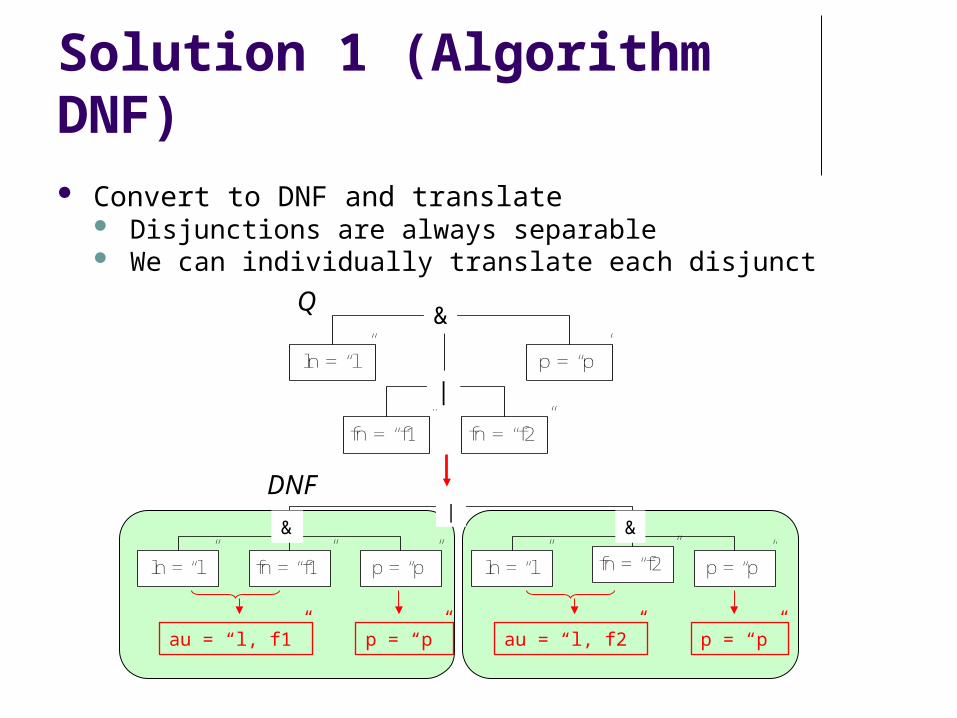
Solution 1 (Algorithm DNF) Convert to DNF and translate
Disjunctions are always separable We can individually translate each disjunct
ln = “l” p = “p”
fn = “f1” fn = “f2”
|
&
au = “l, f1” p = “p” au = “l, f2” p = “p”
Q
ln = “l” fn = “f1” p = “p” ln = “l” fn = “f2” p = “p”
|& &
DNF

What’s Wrong with DNF?
DNF conversion is exponential DNF parse tree is not compactGlobal conversion often not necessary
Translation of C3 is independent of others
x: [fn …] y: [fn …]
z: [ln ...]
[p ...]independent
C1 C2 C3

Partition conjuncts into independent groups
Translate each group separately By rewriting local groups Top level “AND” of C3 is preserved.
Group 1: G1 = {C1,C2} Group 2: G2 = {C3}
Conjunction Partitioning
x: [fn …] y: [fn …]
z: [ln ...]
[p ...] independent
C1 C2 C3

Independent Groups?
Q: How do we know G1 and G2 are “independent”?
A: Q = G1 & G2 is separable Q: How do we know Q = G1 & G2 is
separable?

Safety Condition
Query seperability is difficult to check directly
Safety condition: A practical way to check query separability
Sufficient condition for query separability But not a necessary condition

Safety Condition for Simple Conjunction
M(Q): Matching rules for Q Q = G1 & G2
G1 and G2 are simple conjunction G1 = [C1 & C2], G2 = [C3 & C4]
Q is safe iff M(Q) = M(G1) M(G2) That is, Q is safe if there is no “cross matching” among G1
and G2 Cross matching: a rule that matches some constraints in
G1 and some constraints in G2 Example
G1: [fn=“f1” & fn = “f2”], G2: [ln = “ln”] Q = G1 & G2 unsafe: cross matching of “fn & ln au”

Safety Condition for Complex Disjunction
M(Q): Matching rules for Q Q = G1 & G2 G1 and G2 are complex disjunction
G1 = [C1 | C2], G2 = [C3 | C4]
1. Disjuntivize Q: Q = [C1 & C3] | [C1 & C4] | [C2 & C3] | [C2 & C4]
2. Q is safe iff every disjunct is safe i.e., if all [C1 & C3], [C1 & C4], [C2 & C3], and [C2 & C4] are safe

Important Theorem
A query is separable if it is safe (i.e., query separability safety)
A query is safe if there is no cross matching(i.e., safety no cross matching)
If there is a cross-matching between conjuncts, we cannot separately translate them Put them into the same group

Algorithm TDQM
Recursively traverse the query tree in the top-down order At a disjunction node:
Separately translate its children At a conjunction node:
Put the children with cross matching into the same group and rewrite the query locally in each group

At a disjunction node Separately apply TDQM each child Disjunction separability theorem
Algorithm TDQM
x:[fn…] y:[fn…]
z:[ln ...]
v:[p ...]
w:[y ...]
Recursively traverse the tree top-down

G1 G2
C1 C2 C3
At a conjunction node Group children by identifying “cross-matchings” No cross-matching between groups (safety condition)
Algorithm TDQM
x:[fn…] y:[fn…]
z:[ln ...]
v:[p ...]
w:[y ...]
{x,z} {y,z}cross-matchings:

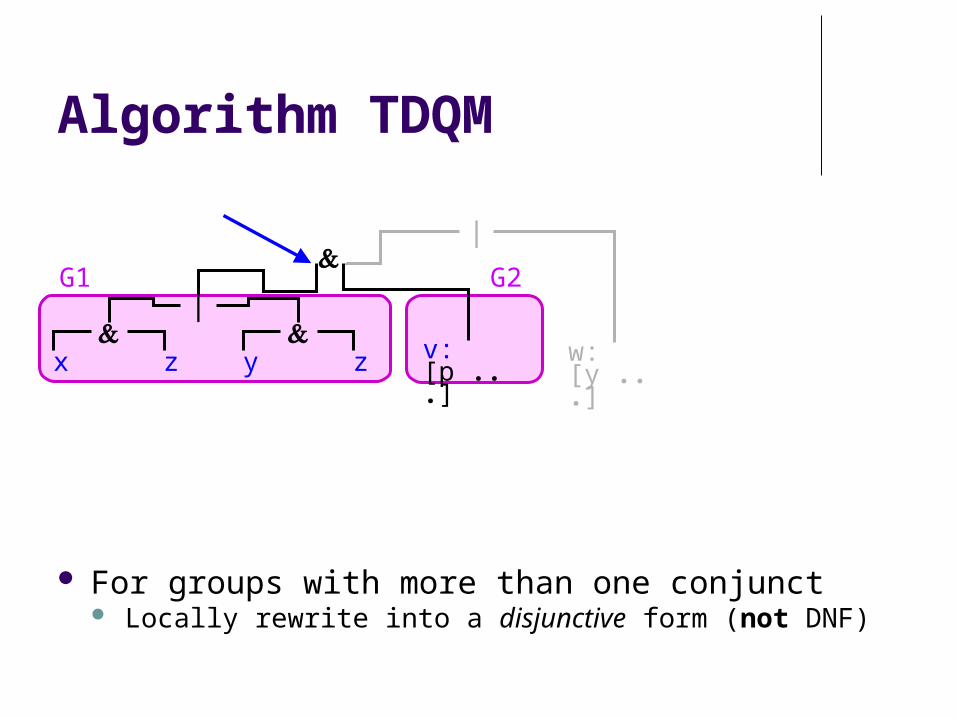
For groups with more than one conjunct Locally rewrite into a disjunctive form (not DNF)
Algorithm TDQM
G1 G2
C1 C2 C3x:[fn…] y:[fn…]
z:[ln ...]
v:[p ...]
w:[y ...]
x
z y z
G2
C3v:[p ...]
G1
For groups with more than one conjunct Locally rewrite into a disjunctive form (not DNF)
Algorithm TDQM
w:[y ...]
x
z y z
G2
v:[p ...]
G1

Continue tree traversal until we reach simple conjunction and apply basic mappings
Algorithm TDQM
w:[y ...]
x
z y z v:[p ...]

Algorithm TDQM
Generates minimum superset translation Resulting translation is “compact”
Assuming the original query is “compact” Convert the tree only when it is necessary

TDQM Summary
Key conceptsSeperability Safety cross matching
Local rewriting for compact translation

A Few Remarks
Final algorithm is straightforward Simply put, separately translate each term if there
is no “cross-matching” Many people can come up with the algorithm But the author developed an amazing theory by
carefully studying basic questions Initial problem looks rather “trivial”
But a mine-field of interesting research topics…

Questions?