cs224d deep nlp lecture 4: word window …cs224d.stanford.edu/lectures/cs224d-lecture4.pdfupdating...
TRANSCRIPT

CS224dDeepNLP
Lecture4:WordWindowClassification
andNeuralNetworks
RichardSocher

OverviewToday:
• Generalclassificationbackground
• Updatingwordvectorsforclassification
• Windowclassification&crossentropyerrorderivationtips
• Asinglelayerneuralnetwork!
• (Max-Marginlossandbackprop)
4/7/16RichardSocherLecture1,Slide 2

Classificationsetupandnotation
• Generallywehaveatrainingdatasetconsistingofsamples
{xi,yi}Ni=1
• xi - inputs,e.g.words(indicesorvectors!),contextwindows,sentences,documents,etc.
• yi - labelswetrytopredict,• e.g.otherwords• class:sentiment,namedentities,buy/selldecision,• later:multi-wordsequences
4/7/16RichardSocherLecture1,Slide 3

Classificationintuition
• Trainingdata:{xi,yi}Ni=1
• Simpleillustrationcase:• Fixed2dwordvectorstoclassify• Usinglogisticregression• à lineardecisionboundaryà
• GeneralML:assumexisfixedandonlytrainlogisticregressionweightsWandonlymodifythedecisionboundary
4/7/16RichardSocherLecture1,Slide 4
VisualizationswithConvNetJS byKarpathy!http://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html

Classificationnotation
• Crossentropylossfunctionoverdataset{xi,yi}Ni=1
• Whereforeachdatapair(xi,yi):
• Wecanwritef inmatrixnotation andindexelementsofitbasedonclass:
4/7/16RichardSocherLecture1,Slide 5

Classification:Regularization!
• Reallyfulllossfunctionoveranydatasetincludesregularizationoverallparametersµ:
• Regularizationwillpreventoverfittingwhenwehavealotoffeatures(orlateraverypowerful/deepmodel)• x-axis:morepowerfulmodelormoretrainingiterations
• Blue:trainingerror,red:testerror
4/7/16RichardSocherLecture1,Slide 6

Details:GeneralMLoptimization
• Forgeneralmachinelearningµ usuallyonlyconsistsofcolumnsofW:
• Soweonlyupdatethedecisionboundary
4/7/16RichardSocherLecture1,Slide 7
VisualizationswithConvNetJS byKarpathy
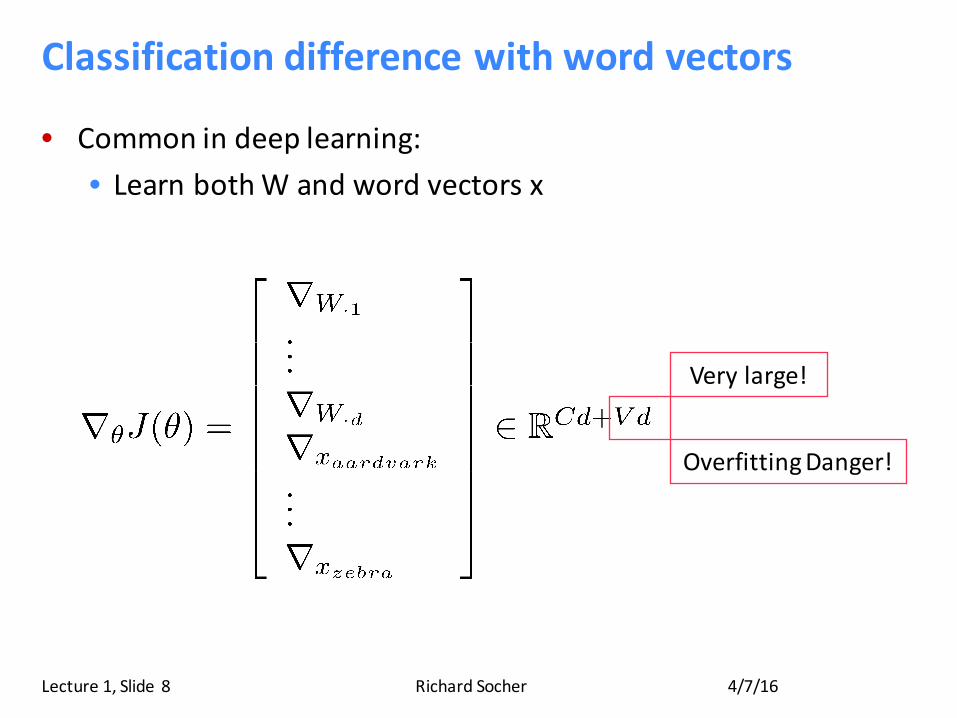
Classificationdifferencewithwordvectors
• Commonindeeplearning:• LearnbothWandwordvectorsx
4/7/16RichardSocherLecture1,Slide 8
Verylarge!
OverfittingDanger!

Losinggeneralizationbyre-trainingwordvectors
• Setting:Traininglogisticregressionformoviereviewsentimentandinthetrainingdatawehavethewords• “TV”and“telly”
• Inthetestingdatawehave• “television”
• Originallytheywereallsimilar(frompre-trainingwordvectors)
• Whathappenswhenwetrainthewordvectors?
4/7/16RichardSocherLecture1,Slide 9
TVtelly
television

Losinggeneralizationbyre-trainingwordvectors
• Whathappenswhenwetrainthewordvectors?• Thosethatareinthetrainingdatamovearound• Wordsfrompre-trainingthatdoNOTappearintrainingstay
• Example:• Intrainingdata:“TV”and“telly”• Intestingdataonly:“television”
4/7/16RichardSocherLecture1,Slide 10
TVtelly
television:(

Losinggeneralizationbyre-trainingwordvectors
• Takehomemessage:
Ifyouonlyhaveasmalltrainingdataset,don’ttrainthewordvectors.
Ifyouhavehaveaverylargedataset,itmayworkbettertotrainwordvectorstothetask.
4/7/16RichardSocherLecture1,Slide 11
TVtelly
television

Sidenoteonwordvectorsnotation
• ThewordvectormatrixLisalsocalledlookuptable• Wordvectors=wordembeddings =wordrepresentations(mostly)• Mostlyfrommethodslikeword2vecorGlove
|V|
L =d ……
aardvarka…meta…zebra• Thesearethewordfeaturesxword fromnowon
• Conceptuallyyougetaword’svectorbyleftmultiplyingaone-hotvectore byL:x =Le2 d£ V¢ V£ 1
[]
12

Windowclassification
• Classifyingsinglewordsisrarelydone.
• Interestingproblemslikeambiguityariseincontext!
• Example:auto-antonyms:• "Tosanction"canmean"topermit"or"topunish.”• "Toseed"canmean"toplaceseeds"or"toremoveseeds."
• Example:ambiguousnamedentities:• Parisà Paris,Francevs ParisHilton• Hathawayà BerkshireHathawayvs AnneHathaway
4/7/16RichardSocherLecture1,Slide 13

Windowclassification
• Idea:classifyawordinitscontextwindowofneighboringwords.
• Forexamplenamedentityrecognitioninto4classes:• Person,location,organization,none
• Manypossibilitiesexistforclassifyingonewordincontext,e.g.averagingallthewordsinawindowbutthatloosespositioninformation
4/7/16RichardSocherLecture1,Slide 14
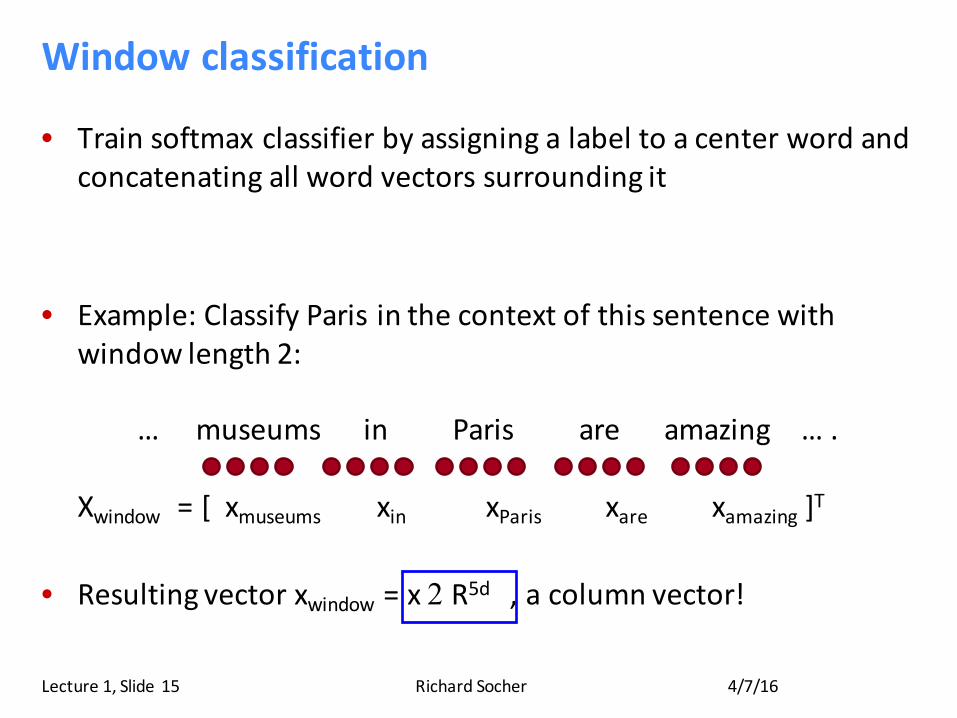
Windowclassification
• Trainsoftmax classifierbyassigningalabeltoacenterwordandconcatenatingallwordvectorssurroundingit
• Example:ClassifyParisinthecontextofthissentencewithwindowlength2:
…museumsinParisareamazing….
Xwindow =[xmuseums xin xParis xare xamazing ]T
• Resultingvectorxwindow =x2 R5d,acolumnvector!
4/7/16RichardSocherLecture1,Slide 15

Simplestwindowclassifier:Softmax
• Withx=xwindow wecanusethesamesoftmax classifierasbefore
• Withcrossentropyerrorasbefore:
• Buthowdoyouupdatethewordvectors?
4/7/16RichardSocherLecture1,Slide 16
same
predictedmodeloutputprobability

Updatingconcatenatedwordvectors
• Shortanswer:Justtakederivativesasbefore
• Longanswer:Let’sgooverthestepstogether(you’llhavetofillinthedetailsinPSet 1!)
• Define:• :softmax probabilityoutputvector(seepreviousslide)• :targetprobabilitydistribution(all0’sexceptatgroundtruthindexofclassy,whereit’s1)
• andfc =c’th elementofthefvector
• Hard,thefirsttime,hencesometipsnow:)
4/7/16RichardSocherLecture1,Slide 17

• Tip1:Carefullydefineyourvariablesandkeeptrackoftheirdimensionality!
• Tip2:Knowthychainruleanddon’tforgetwhichvariablesdependonwhat:
• Tip3:Forthesoftmax partofthederivative:Firsttakethederivativewrt fc whenc=y(thecorrectclass),thentakederivativewrt fc whenc≠ y(alltheincorrectclasses)
Updatingconcatenatedwordvectors
4/7/16RichardSocherLecture1,Slide 18

• Tip4:Whenyoutakederivativewrtoneelementoff,trytoseeifyoucancreateagradientintheendthatincludesallpartialderivatives:
• Tip5:Tolaternotgoinsane&implementation!à resultsintermsofvectoroperationsanddefinesingleindex-ablevectors:
Updatingconcatenatedwordvectors
4/7/16RichardSocherLecture1,Slide 19

• Tip6:Whenyoustartwiththechainrule,firstuseexplicitsumsandlookatpartialderivativesofe.g.xi orWij
• Tip7:Tocleanitupforevenmorecomplexfunctionslater:Knowdimensionalityofvariables&simplifyintomatrixnotation
• Tip8:Writethisoutinfullsumsifit’snotclear!
Updatingconcatenatedwordvectors
4/7/16RichardSocherLecture1,Slide 20

• Whatisthedimensionalityofthewindowvectorgradient?
• x istheentirewindow,5d-dimensionalwordvectors,sothederivativewrt toxhastohavethesamedimensionality:
Updatingconcatenatedwordvectors
4/7/16RichardSocherLecture1,Slide 21

• Thegradientthatarrivesatandupdatesthewordvectorscansimplybesplitupforeachwordvector:
• Let• Withxwindow =[xmuseums xin xParis xare xamazing ]
• Wehave
Updatingconcatenatedwordvectors
4/7/16RichardSocherLecture1,Slide 22

• Thiswillpushwordvectorsintoareassuchtheywillbehelpfulindeterminingnamedentities.
• Forexample,themodelcanlearnthatseeingxin asthewordjustbeforethecenterwordisindicativeforthecenterwordtobealocation
Updatingconcatenatedwordvectors
4/7/16RichardSocherLecture1,Slide 23

• ThegradientofJwrt thesoftmax weightsW!
• Similarsteps,writedownpartialwrt Wij first!• Thenwehavefull
What’smissingfortrainingthewindowmodel?
4/7/16RichardSocherLecture1,Slide 24

Anoteonmatriximplementations
4/7/16RichardSocher25
• Therearetwoexpensiveoperationsinthesoftmax:
• Thematrixmultiplication andtheexp
• Aforloopisneverasefficientwhenyouimplementitcomparedvs whenyouusealargermatrixmultiplication!
• Examplecodeà

Anoteonmatriximplementations
4/7/16RichardSocher26
• Loopingoverwordvectorsinsteadofconcatenatingthemallintoonelargematrixandthenmultiplyingthesoftmax weightswiththatmatrix
• 1000loops,bestof3:639µsperloop10000loops,bestof3:53.8µsperloop

Anoteonmatriximplementations
4/7/16RichardSocher27
• ResultoffastermethodisaCxNmatrix:
• Eachcolumnisanf(x)inournotation(unnormalized classscores)
• Matricesareawesome!
• Youshouldspeedtestyourcodealottoo

Softmax (=logisticregression)isnotverypowerful
4/7/16RichardSocher28
• Softmax onlygiveslineardecisionboundariesintheoriginalspace.
• Withlittledatathatcanbeagoodregularizer
• Withmoredataitisverylimiting!

Softmax (=logisticregression)isnotverypowerful
4/7/16RichardSocher29
• Softmax onlylineardecisionboundaries
• à Lamewhenproblemiscomplex
• Wouldn’titbecooltogetthesecorrect?

NeuralNetsfortheWin!
4/7/16RichardSocher30
• Neuralnetworkscanlearnmuchmorecomplexfunctionsandnonlineardecisionboundaries!

Fromlogisticregressiontoneuralnets
31
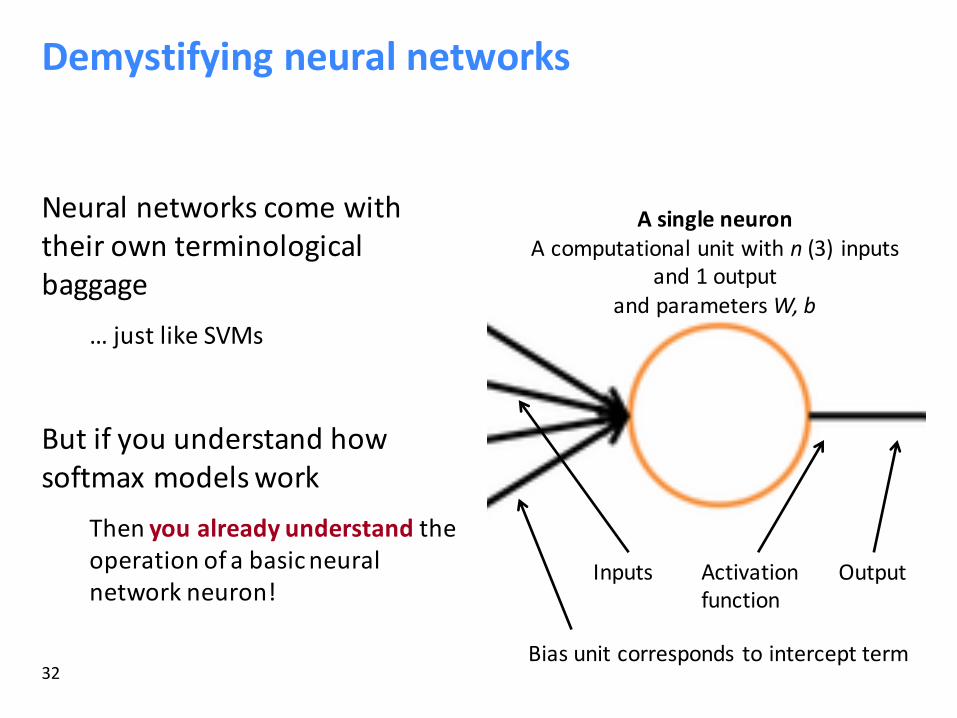
Demystifyingneuralnetworks
Neuralnetworkscomewiththeirownterminologicalbaggage
…justlikeSVMs
Butifyouunderstandhowsoftmax modelswork
Thenyoualreadyunderstand theoperationofabasicneuralnetworkneuron!
AsingleneuronAcomputationalunitwithn(3) inputs
and1outputandparametersW,b
Activationfunction
Inputs
Biasunitcorresponds tointerceptterm
Output
32

Aneuronisessentiallyabinarylogisticregressionunit
hw,b(x) = f (wTx + b)
f (z) = 11+ e−z
w,b aretheparametersofthisneuroni.e.,thislogisticregressionmodel
33
b:Wecanhavean“alwayson”feature,whichgivesaclassprior,orseparateitout,asabiasterm

Aneuralnetwork=runningseverallogisticregressionsatthesametimeIfwefeedavectorofinputsthroughabunchoflogisticregressionfunctions,thenwegetavectorofoutputs…
Butwedon’thavetodecideaheadoftimewhatvariablestheselogisticregressionsaretryingtopredict!
34
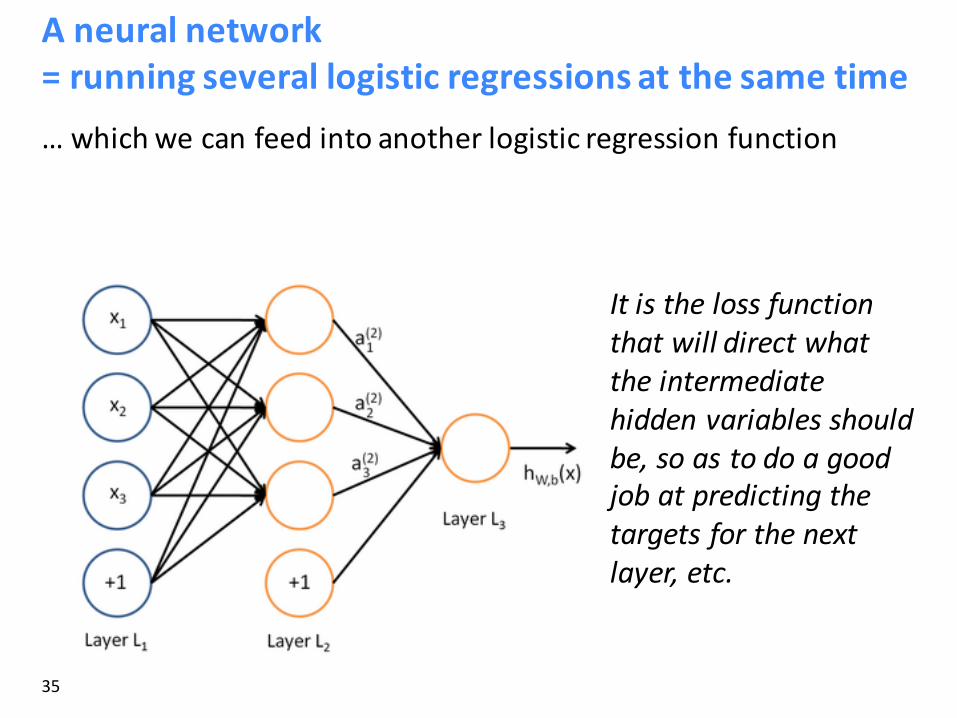
Aneuralnetwork=runningseverallogisticregressionsatthesametime…whichwecanfeedintoanotherlogisticregressionfunction
Itisthelossfunctionthatwilldirectwhattheintermediatehiddenvariablesshouldbe,soastodoagoodjobatpredictingthetargetsforthenextlayer,etc.
35

Aneuralnetwork=runningseverallogisticregressionsatthesametime
Beforeweknowit,wehaveamultilayerneuralnetwork….
36

Matrixnotationforalayer
Wehave
Inmatrixnotation
wheref isappliedelement-wise:
a1
a2
a3
a1 = f (W11x1 +W12x2 +W13x3 + b1)a2 = f (W21x1 +W22x2 +W23x3 + b2 )etc.
z =Wx + ba = f (z)
f ([z1, z2, z3]) = [ f (z1), f (z2 ), f (z3)]37
W12
b3

Non-linearities (f):Whythey’reneeded
• Example:functionapproximation,e.g.,regressionorclassification• Withoutnon-linearities,deepneuralnetworkscan’tdoanythingmorethanalineartransform
• Extralayerscouldjustbecompileddownintoasinglelineartransform:W1W2x =Wx
• Withmorelayers,theycanapproximatemorecomplexfunctions!
38

Amorepowerfulwindowclassifier
• Revisiting
• Xwindow =[xmuseums xin xParis xare xamazing ]
4/7/16RichardSocherLecture1,Slide 39

ASingleLayerNeuralNetwork
• Asinglelayerisacombinationofalinearlayerandanonlinearity:
• Theneuralactivationsacanthenbeusedtocomputesomefunction
• Forinstance,asoftmax probabilityoranunnormalized score:
40

Summary:Feed-forwardComputation
41
Computingawindow’sscorewitha3-layerneuralnet:s=score(museumsinParisareamazing)
Xwindow =[xmuseums xin xParis xare xamazing ]

Nextlecture:
4/7/16RichardSocher42
Trainingawindow-basedneuralnetwork.
Takingmoredeeperderivativesà Backprop
Thenwehaveallthebasictoolsinplacetolearnaboutmorecomplexmodels:)

Probablyfornextlecture…
4/7/16RichardSocher43
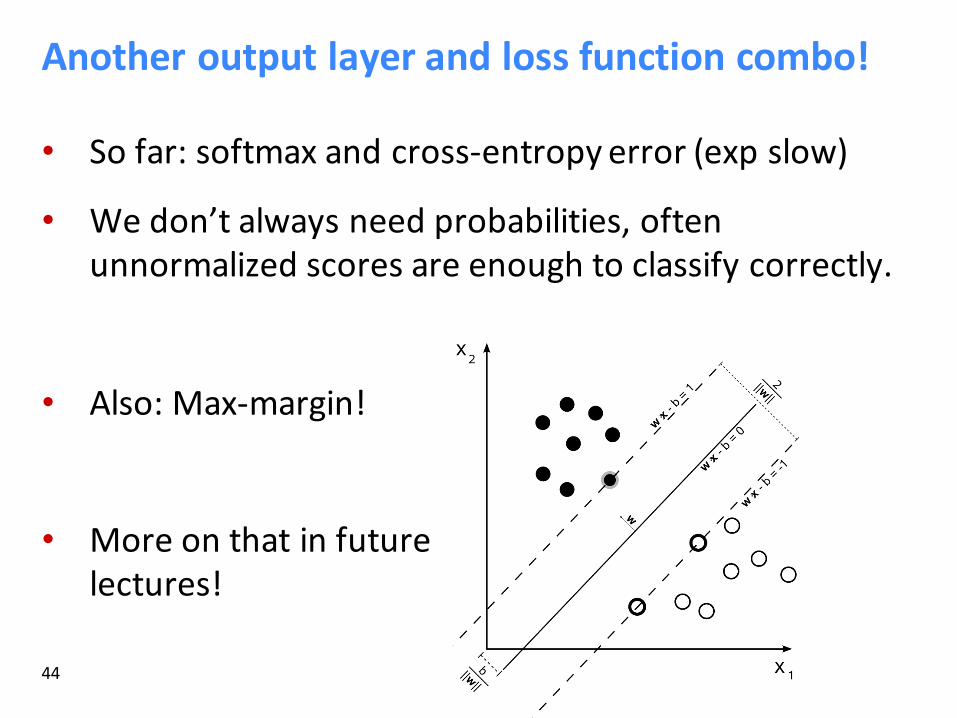
Anotheroutputlayerandlossfunctioncombo!
44
• Sofar:softmax andcross-entropyerror(exp slow)
• Wedon’talwaysneedprobabilities,oftenunnormalized scoresareenoughtoclassifycorrectly.
• Also:Max-margin!
• Moreonthatinfuturelectures!

NeuralNetmodeltoclassifygrammaticalphrases
4/7/16RichardSocher45
• Idea:Trainaneuralnetworktoproducehighscoresforgrammatical phrasesofspecificlengthandlowscoresforungrammaticalphrases
• s =score(catchillsonamat)
• sc =score(catchillsMenloamat)

Anotheroutputlayerandlossfunctioncombo!
• Ideafortrainingobjective• Makescoreoftruewindowlargerandcorruptwindow’sscorelower(untilthey’regoodenough):minimize
• Thisiscontinuous,canperformSGD46

TrainingwithBackpropagation
AssumingcostJis>0,itissimpletoseethatwecancomputethederivativesofs andsc wrt alltheinvolvedvariables:U,W,b,x
47

TrainingwithBackpropagation
• Let’sconsiderthederivativeofasingleweightWij
• Thisonlyappearsinsideai
• Forexample:W23 isonlyusedtocomputea2
x1 x2x3 +1
a1 a2
s U2
W23
48

TrainingwithBackpropagation
DerivativeofweightWij:
49
x1 x2x3 +1
a1 a2
s U2
W23

whereforlogisticf
TrainingwithBackpropagation
DerivativeofsingleweightWij :
Localerrorsignal
Localinputsignal
50
x1 x2x3 +1
a1 a2
s U2
W23

• Wewantallcombinationsofi =1,2 and j=1,2,3
• Solution:Outerproduct:whereisthe“responsibility”comingfromeachactivationa
TrainingwithBackpropagation
• FromsingleweightWij tofullW:
51
x1 x2x3 +1
a1 a2
s U2
W23

TrainingwithBackpropagation
• Forbiasesb,weget:
52
x1 x2x3 +1
a1 a2
s U2
W23

TrainingwithBackpropagation
53
That’salmostbackpropagationIt’ssimplytakingderivativesandusingthechainrule!
Remainingtrick:wecanre-usederivativescomputedforhigherlayersincomputingderivativesforlowerlayers
Example:lastderivativesofmodel,thewordvectorsinx

TrainingwithBackpropagation
• Takederivativeofscorewithrespecttosinglewordvector(forsimplicitya1dvector,butsameifitwaslonger)
• Now,wecannotjusttakeintoconsiderationoneaibecauseeachxj isconnectedtoalltheneuronsaboveandhencexj influencestheoverallscorethroughallofthese,hence:
Re-usedpartofpreviousderivative54

Summary
4/7/16RichardSocher55