cs 5614: (big) data management...
TRANSCRIPT

CS5614:(Big)DataManagementSystems
B.AdityaPrakashLecture#19:MachineLearning2

SupervisedLearning§ Example:Spamfiltering
§ Instancespacex∈X(|X|=ndatapoints)– Binaryorreal-valuedfeaturevectorxofwordoccurrences
– dfeatures(words+otherthings,d~100,000)§ Classy∈Y
– y:Spam(+1),Ham(-1)
§ Goal:EsJmateafuncEonf(x)sothaty=f(x)VTCS5614 2Prakash2017

Moregenerally:SupervisedLearning
§ WouldliketodopredicJon:esJmateafuncEonf(x)sothaty=f(x)
§ Whereycanbe:– Realnumber:Regression– Categorical:ClassificaJon– Complexobject:
• Rankingofitems,Parsetree,etc.
§ Dataislabeled:– Havemanypairs{(x,y)}
• x…vectorofbinary,categorical,realvaluedfeatures• y…class({+1,-1},orarealnumber)
VTCS5614 3Prakash2017

SupervisedLearning§ Task:Givendata(X,Y)buildamodelf()topredictY’
basedonX’§ Strategy:EsJmate
on.Hopethatthesamealsoworkstopredictunknown– The“hope”iscalledgeneralizaJon
• Overfi\ng:Iff(x)predictswellYbutisunabletopredictY’– Wewanttobuildamodelthatgeneralizeswelltounseendata
• Buthowcanwewellondatawehaveneverseenbefore?!?
Prakash2017 VTCS5614 4
X Y
X’ Y’Test data
Training data

SupervisedLearning§ Idea:Pretendwedonotknowthedata/labelsweactuallydoknow– Buildthemodelf(x)onthetrainingdataSeehowwellf(x)doesonthetestdata
• Ifitdoeswell,thenapplyitalsotoX’
§ Refinement:CrossvalidaJon– Spli^ngintotraining/validaEonsetisbrutal– Let’ssplitourdata(X,Y)into10-folds(buckets)– Takeout1-foldforvalidaEon,trainonremaining9– Repeatthis10Emes,reportaverageperformance
VTCS5614 5
X Y
X’
Validation set
Training set
Test set
Prakash2017

LinearmodelsforclassificaJon§ BinaryclassificaJon:
§ Input:Vectorsx(j)andlabelsy(j)– Vectorsx(j)arerealvaluedwhere
§ Goal:Findvectorw = (w1, w2 ,... , wd ) – Eachwiisarealnumber
VTCS5614 6
f (x) = +1 if w1 x1 + w2 x2 +. . . wd xd ≥ θ -1 otherwise {
w ⋅ x = 0 - --- ---- -
- -
- --
-
θ−⇔
∀⇔
,
1,
ww
xxxNote:
Decisionboundaryislinear
w
Prakash2017
||x||2 = 1

Perceptron[Rosenbla`‘58]
§ (very)LoosemoJvaJon:Neuron§ Inputsarefeaturevalues§ Eachfeaturehasaweightwi
§ AcJvaJonisthesum:– f(x) = Σi wi xi = w⋅ x
§ Ifthef(x)is:– PosiJve:Predict+1– NegaJve:Predict-1
VTCS5614 7
∑
x1x2x3x4
≥0?
w1w2w3w4
viagranigeria
Spam=1
Ham=-1 w
x(1)x(2)
w⋅x=0
Prakash2017

Perceptron:EsJmaJngw§ Perceptron:y’=sign(w⋅x)§ Howtofindparametersw?
– Startwithw0=0– Picktrainingexamplesx(t)onebyone(fromdisk)– Predictclassofx(t)usingcurrentweights
• y’=sign(w(t)⋅x(t))
– Ify’iscorrect(i.e.,yt=y’)• Nochange:w(t+1)=w(t)
– Ify’iswrong:adjustw(t)w(t+1)=w(t)+η⋅y(t)⋅x(t)
– ηisthelearningrateparameter– x(t)isthet-thtrainingexample– y(t)istruet-thclasslabel({+1,-1})
VTCS5614 8
w(t)
η⋅y(t)⋅x(t)
x(t), y(t)=1
w(t+1)
Note that the Perceptron is a conservative algorithm: it ignores samples that it classifies correctly.
Prakash2017

Perceptron:TheGoodandtheBad
§ Good:Perceptronconvergencetheorem:– Ifthereexistasetofweightsthatareconsistent(i.e.,thedataislinearlyseparable)thePerceptronlearningalgorithmwillconverge
§ Bad:Neverconverges:Ifthedataisnotseparableweightsdancearoundindefinitely
§ Bad:MediocregeneralizaJon:– Findsa“barely”separaEngsoluEon
VTCS5614 9Prakash2017

UpdaJngtheLearningRate§ Perceptronwilloscillateandwon’tconverge§ So,whentostoplearning?§ (1)Slowlydecreasethelearningrateη
– Aclassicwayisto:η=c1/(t+c2)• But,wealsoneedtodetermineconstantsc1andc2
§ (2)Stopwhenthetrainingerrorstopschanging§ (3)Haveasmalltestdatasetandstopwhenthetestseterrorstopsdecreasing
§ (4)Stopwhenwereachedsomemaximumnumberofpassesoverthedata
VTCS5614 10Prakash2017

SUPPORTVECTORMACHINES
Prakash2017 VTCS5614 11

SupportVectorMachines
§ Wanttoseparate“+”from“-”usingaline
VTCS5614 12
Data:§ Trainingexamples:
– (x1,y1)…(xn,yn)§ Eachexamplei:
– xi=(xi(1),…,xi(d))• xi(j)isrealvalued
– yi∈{-1,+1}§ Innerproduct:
++
+
+
+ + --
-
---
-
Whichisbestlinearseparator(definedbyw)?Prakash2017
w · x =Pd
j=1 w(j) · x(j)

+ +
++
+
+
+
+
+
-
--
--
-
-
-
-
A
B
C
LargestMargin§ DistancefromtheseparaJnghyperplanecorrespondstothe“confidence”ofpredicJon
§ Example:– WearemoresureabouttheclassofAandBthanofC
VTCS5614 13Prakash2017

LargestMargin§ Margin:Distanceofclosestexamplefromthedecisionline/hyperplane
VTCS5614 14The reason we define margin this way is due to theoretical convenience and existence of
generalization error bounds that depend on the value of margin. Prakash2017

Whymaximizing𝜸agoodidea?
§ Remember:Dotproduct𝑨⋅𝑩=‖𝑨‖⋅‖𝑩‖⋅ 𝐜𝐨𝐬𝜽
VTCS5614 15
‖𝑨‖𝒄𝒐𝒔𝜽
Prakash2017
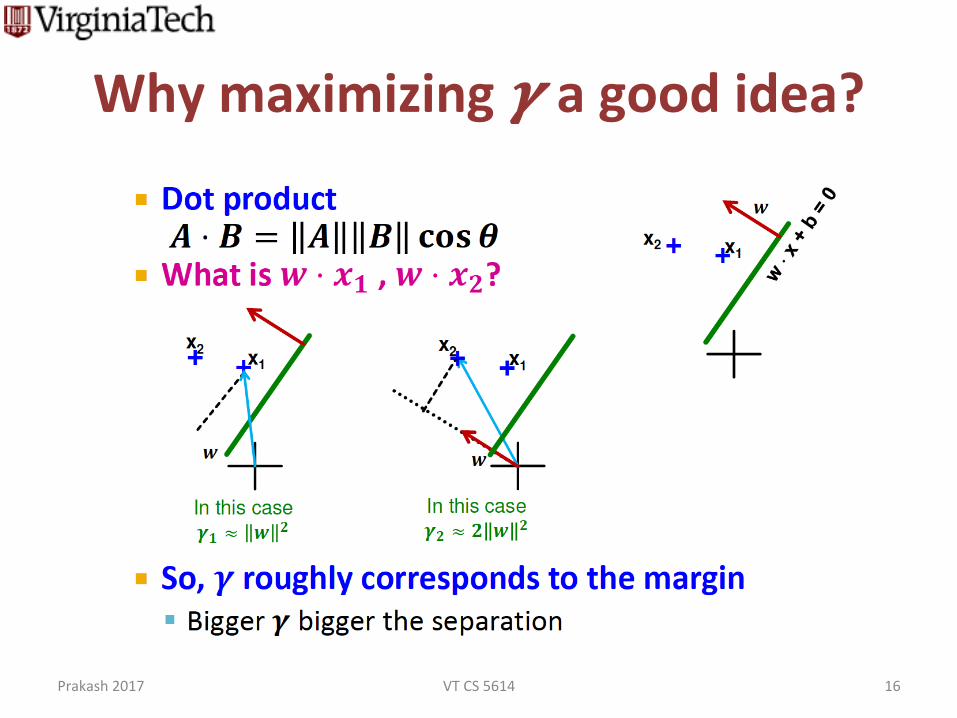
Whymaximizing𝜸agoodidea?
Prakash2017 VTCS5614 16

A(xA(1),xA(2))
M(x1,x2)
H
d(A, L) = |AH| = |(A-M) · w| = |(xA
(1) – xM(1)) w(1) + (xA
(2) – xM(2)) w(2)|
= xA(1) w(1) + xA
(2) w(2) + b = w · A + b
Remember xM(1)w(1) + xM
(2)w(2) = - b since M belongs to line L
wL
+
Whatisthemargin?§ Let:
– LineL:w·x+b=w(1)x(1)+w(2)x(2)+b=0
– w=(w(1),w(2))– PointA=(xA(1),xA(2))– PointMonaline=(xM(1),xM(2))
(0,0)
VTCS5614 17Prakash2017

LargestMargin
Prakash2017 VTCS5614 18

SupportVectorMachine§ Maximizethemargin:
– GoodaccordingtointuiJon,theory(VCdimension)&pracJce
– 𝜸ismargin…distancefromismargin…distancefromtheseparaJnghyperplane
VTCS5614 19
++ +
++
+
+
+-
- ----
-
w⋅x+b=0
γγ
Maximizingthemargin
γγ
γγ
≥+⋅∀ )(,..
max,
bxwyits ii
w
Prakash2017

SUPPORTVECTORMACHINES:DERIVINGTHEMARGIN
Prakash2017 VTCS5614 20
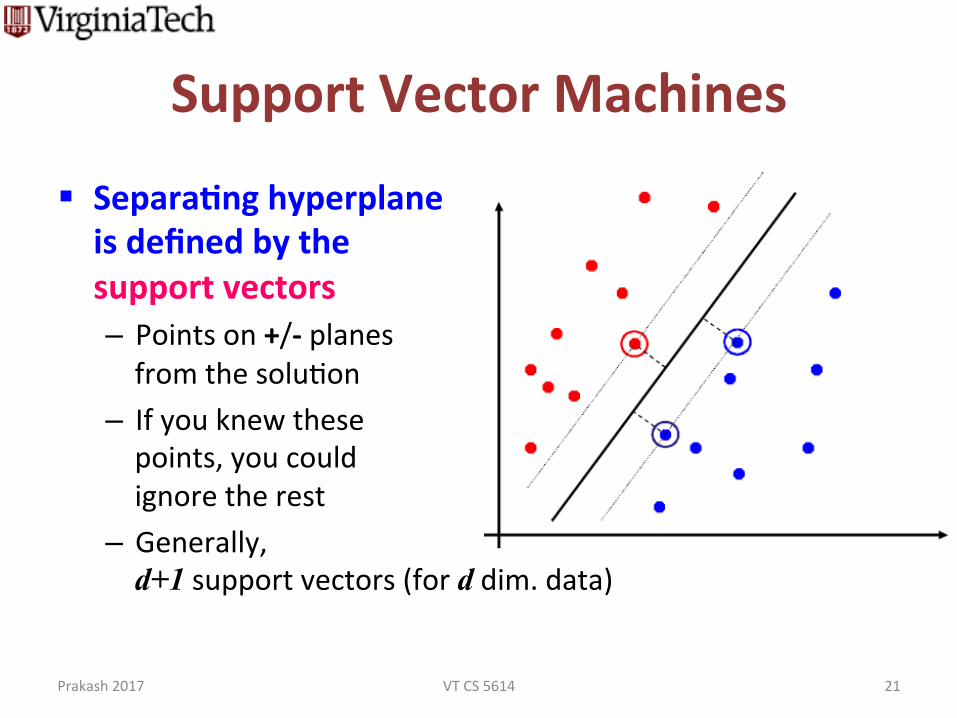
SupportVectorMachines
§ SeparaJnghyperplaneisdefinedbythesupportvectors– Pointson+/-planesfromthesoluEon
– Ifyouknewthesepoints,youcouldignoretherest
– Generally,d+1supportvectors(forddim.data)
VTCS5614 21Prakash2017
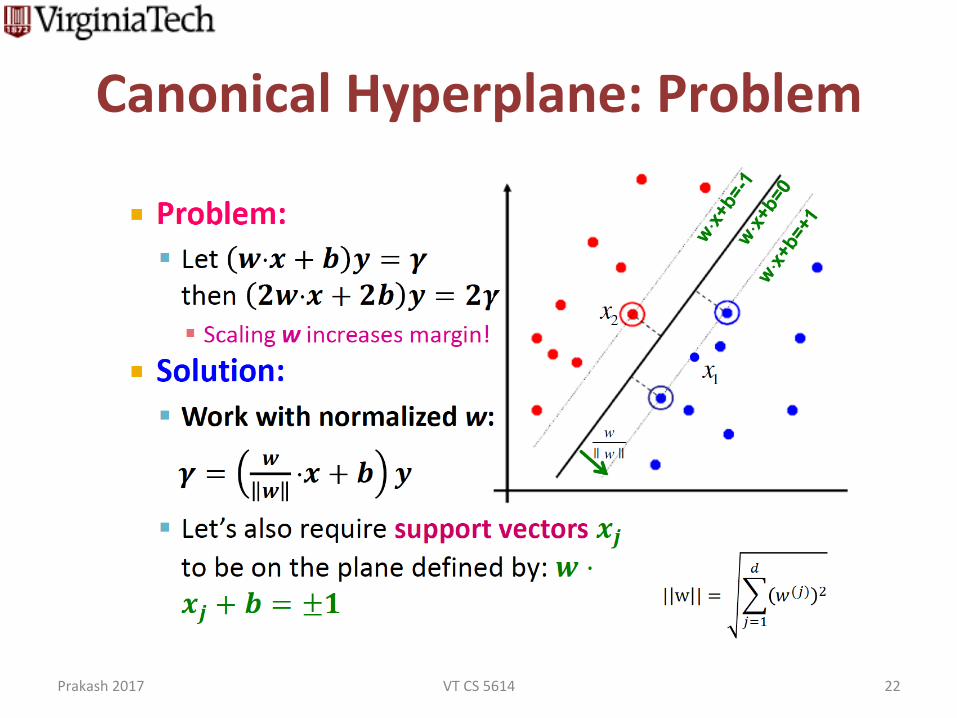
CanonicalHyperplane:Problem
Prakash2017 VTCS5614 22

CanonicalHyperplane:SoluJon
Prakash2017 VTCS5614 23
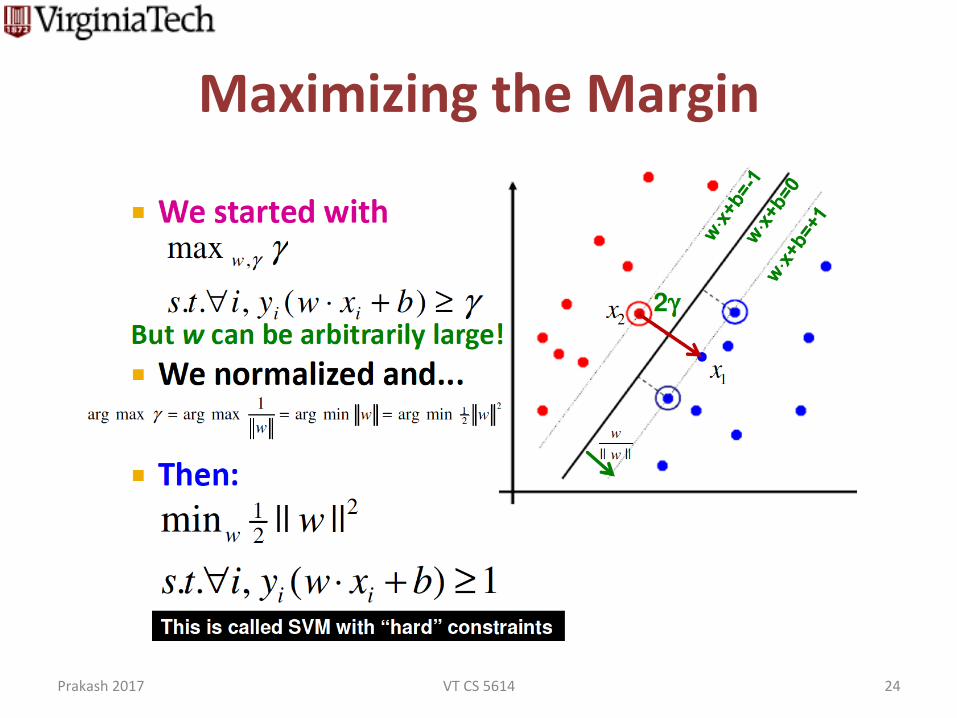
MaximizingtheMargin
Prakash2017 VTCS5614 24

Non-linearlySeparableData
§ Ifdataisnotseparableintroducepenalty:
– Minimizeǁwǁ2plusthenumberoftrainingmistakes
– SetCusingcrossvalidaEon
§ Howtopenalizemistakes?– Allmistakesarenotequallybad!
VTCS5614 25
1)(,..mistakes) ofnumber (# C min 2
21
≥+⋅∀
⋅+
bxwyitsw
ii
w
+ +
++
+
+
+-
--
-
--
-
+-
-
Prakash2017

SupportVectorMachines§ Introduceslackvariablesξi
§ Ifpointxiisonthewrongsideofthemarginthengetpenaltyξi
VTCS5614 26
iii
n
iibw
bxwyits
Cwi
ξ
ξξ
−≥+⋅∀
⋅+ ∑=
≥
1)(,..
min1
221
0,,
+ +
++
+
++ - -
---
For each data point: If margin ≥ 1, don’t care If margin < 1, pay linear penalty
+
ξj
- ξi
Prakash2017

SlackPenalty𝑪
§ WhatistheroleofslackpenaltyC:– C=∞:Onlywanttow,bthatseparatethedata
– C=0:Cansetξitoanything,thenw=0(basicallyignoresthedata)
VTCS5614 27
1)(,..mistakes) ofnumber (# C min 2
21
≥+⋅∀
⋅+
bxwyitsw
ii
w
+ +
++
+
++ - -
---
+ -
big C
“good” C small C
(0,0) Prakash2017

SupportVectorMachines§ SVMinthe“natural”form
§ SVMuses“HingeLoss”:
VTCS5614 28
{ }∑=
+⋅−⋅+⋅n
iii
bwbxwyCww
121
,)(1,0max minarg
Margin Empirical loss L (how well we fit training data)
Regularization parameter
iii
n
iibw
bxwyits
Cw
ξ
ξ
−≥+⋅⋅∀
+ ∑=
1)(,..
min1
221
,
-1012
0/1 loss
pena
lty
)( bwxyz ii +⋅⋅=
Hinge loss: max{0, 1-z}
Prakash2017

SUPPORTVECTORMACHINES:HOWTOCOMPUTETHEMARGIN?
Prakash2017 VTCS5614 29

SVM:HowtoesJmatew?
§ WanttoesJmateand!– Standardway:Useasolver!
• Solver:sopwareforfindingsoluEonsto“common”opEmizaEonproblems
§ UseaquadraJcsolver:– MinimizequadraEcfuncEon– Subjecttolinearconstraints
§ Problem:Solversareinefficientforbigdata!VTCS5614 30
iii
n
iibw
bwxyits
Cww
ξ
ξ
−≥+⋅⋅∀
⋅+⋅ ∑=
1)(,..
min1
21
,
Prakash2017

SVM:HowtoesJmatew?§ WanttoesJmatew,b!§ AlternaJveapproach:
– Wanttominimizef(w,b):
§ Sidenote:– HowtominimizeconvexfuncJons?– Usegradientdescent:minzg(z)– Iterate:zt+1←zt–η∇g(zt)
VTCS5614 31
∑ ∑= = ⎭
⎬⎫
⎩⎨⎧
+−⋅+⋅=n
i
d
j
ji
ji bxwyCwwbwf
1 1
)()(21 )(1,0max),(
iii
n
iibw
bwxyits
Cww
ξ
ξ
−≥+⋅⋅∀
+⋅ ∑=
1)(,..
min1
21
,
g(z)
zPrakash2017

SVM:HowtoesJmatew?§ Wanttominimizef(w,b):
§ Computethegradient∇(j)w.r.t.w(j)
VTCS5614 32
∑= ∂
∂+=
∂
∂=∇
n
ijiij
jj
wyxLCw
wbwff
1)(
)()(
)( ),(),(
else
1)(w if 0),(
)(
)(
jii
iijii
xy
bxywyxL
−=
≥+⋅=∂
∂
( ) ∑ ∑∑= == ⎭
⎬⎫
⎩⎨⎧
+−+=n
i
d
j
ji
ji
d
j
j bxwyCwbwf1 1
)()(
1
2)(21 )(1,0max),(
Empirical loss
Prakash2017
L(xi, yi)

Iterate until convergence: • For j = 1 … d
• Evaluate: • Update:
w(j) ← w(j) - η∇f(j)
SVM:HowtoesJmatew?§ Gradientdescent:
§ Problem:– CompuJng∇f(j)takesO(n)Jme!
• n…sizeofthetrainingdataset
VTCS5614 33
∑= ∂
∂+=
∂
∂=∇
n
ijiij
jj
wyxLCw
wbwff
1)(
)()(
)( ),(),(
η…learning rate parameter C… regularization parameter
Prakash2017

SVM:HowtoesJmatew?§ StochasJcGradientDescent
– InsteadofevaluaEnggradientoverallexamplesevaluateitforeachindividualtrainingexample
§ StochasJcgradientdescent:
VTCS5614 34
)()()( ),()( j
iiji
j
wyxLCwxf
∂
∂⋅+=∇
∑= ∂
∂+=∇
n
ijiijj
wyxLCwf
1)(
)()( ),(We just had:
Iterate until convergence: • For i = 1 … n
• For j = 1 … d • Compute: ∇f(j)(xi) • Update: w(j) ← w(j) - η ∇f(j)(xi)
Notice: no summation over i anymore
Prakash2017

SUPPORTVECTORMACHINES:EXAMPLE
Prakash2017 VTCS5614 35

Example:TextcategorizaJon
§ ExamplebyLeonBo`ou:– ReutersRCV1documentcorpus
• Predictacategoryofadocument– Onevs.therestclassificaEon
– n=781,000trainingexamples(documents)– 23,000testexamples– d=50,000features
• Onefeatureperword• Removestop-words• Removelowfrequencywords
VTCS5614 36Prakash2017

Example:TextcategorizaJon§ QuesJons:
– (1)IsSGDsuccessfulatminimizingf(w,b)?– (2)HowquicklydoesSGDfindtheminoff(w,b)?– (3)Whatistheerroronatestset?
VTCS5614 37
Training time Value of f(w,b) Test error Standard SVM “Fast SVM” SGD SVM
(1) SGD-SVM is successful at minimizing the value of f(w,b) (2) SGD-SVM is super fast (3) SGD-SVM test set error is comparable
Prakash2017

OpJmizaJon“Accuracy”
VTCS5614 38
Optimization quality: | f(w,b) – f (wopt,bopt) |
Conventional SVM
SGD SVM
For optimizing f(w,b) within reasonable quality SGD-SVM is super fast
Prakash2017

SGDvs.BatchConjugateGradient
§ SGDonfulldatasetvs.ConjugateGradientonasampleofntrainingexamples
VTCS5614 39
Bottom line: Doing a simple (but fast) SGD update many times is better than doing a complicated (but slow) CG update a few times
Theory says: Gradient descent converges in linear time . Conjugate gradient
converges in .
𝒌… condition number Prakash2017

PracJcalConsideraJons§ Needtochooselearningrateηandt0
§ Leonsuggests:– Chooset0sothattheexpectediniEalupdatesarecomparablewiththe
expectedsizeoftheweights– Chooseη:
• Selectasmallsubsample• Tryvariousratesη(e.g.,10,1,0.1,0.01,…)• Picktheonethatmostreducesthecost• Useηfornext100kiteraEonsonthefulldataset
VTCS5614 40
⎟⎠
⎞⎜⎝
⎛∂
∂+
+−←+ w
yxLCwtt
ww iit
ttt
),(
01
η
Prakash2017

PracJcalConsideraJons
§ SparseLinearSVM:– Featurevectorxiissparse(containsmanyzeros)
• Donotdo:xi = [0,0,0,1,0,0,0,0,5,0,0,0,0,0,0,…] • Butrepresentxiasasparsevector xi=[(4,1), (9,5), …]
– CanwedotheSGDupdatemoreefficiently?
– Approximatedin2steps: cheap:xiissparseandsofew coordinatesjofwwillbeupdated expensive:wisnotsparse,all coordinatesneedtobeupdated
VTCS5614 41
⎟⎠
⎞⎜⎝
⎛∂
∂+−←
wyxLCwww ii ),(η
wyxLCww ii
∂∂
−←),(
η
)1( η−← ww
Prakash2017

PracJcalConsideraJons
VTCS5614 42Prakash2017

PracJcalConsideraJons
§ Stoppingcriteria:HowmanyiteraJonsofSGD?
– EarlystoppingwithcrossvalidaJon• CreateavalidaEonset• MonitorcostfuncEononthevalidaEonset• Stopwhenlossstopsdecreasing
– Earlystopping• ExtracttwodisjointsubsamplesAandBoftrainingdata• TrainonA,stopbyvalidaEngonB• NumberofepochsisanesEmateofk• Trainforkepochsonthefulldataset
VTCS5614 43Prakash2017

WhataboutmulJpleclasses?§ Idea1:OneagainstallLearn3classifiers– +vs.{o,-}– -vs.{o,+}– ovs.{+,-}Obtain:w+b+,w-b-,wobo
§ Howtoclassify?§ Returnclassc
arg maxc wc x + bc VTCS5614 44Prakash2017

Learn1classifier:MulJclassSVM§ Idea2:Learn3setsofweightssimultaneously!
– ForeachclasscesEmatewc,bc– Wantthecorrectclasstohavehighestmargin:
wyi xi + byi ≥ 1 + wc xi + bc ∀c ≠ yi , ∀i
VTCS5614 45
(xi,yi)
Prakash2017

MulJclassSVM
§ OpJmizaJonproblem:
– Toobtainparameterswc,bc(foreachclassc)wecanusesimilartechniquesasfor2classSVM
§ SVMiswidelyperceivedaverypowerfullearningalgorithm
VTCS5614 46
icicyiy
n
iicbw
bxwbxw
Cw
iiξ
ξ
−++⋅≥+⋅
+ ∑∑=
1
min1c
221
,
iiyc
i
i
∀≥
∀≠∀
,0,
ξ
Prakash2017