cs 262 discussion section 1. purpose of discussion sections to clarify difficulties/ambiguities in...
Post on 20-Dec-2015
218 views
TRANSCRIPT

CS 262 Discussion Section 1

Purpose of discussion sections
To clarify difficulties/ambiguities in the problem set questions and lecture material.
To supplement class material by going somewhat into the biological concepts and motivations underlying this field.
To discuss more algorithms from a topic, wherever needed.

Antiparallel vs Parallel strands

The DNA strand has a chemical polarity

The members of each base pair can fit together within the double helix only if the two strands of the helix are antiparallel

Prokaryotes do not have a nucleus, eukaryotes do

Eukaryotic DNA is packaged into chromosomes
A chromosome is a single, enormously long, linear DNA molecule associated with proteins that fold and pack the fine thread of DNA into a more compact structure.
Human Genome: 3.2 x 109 base pairs distributed over 46 chromosomes.



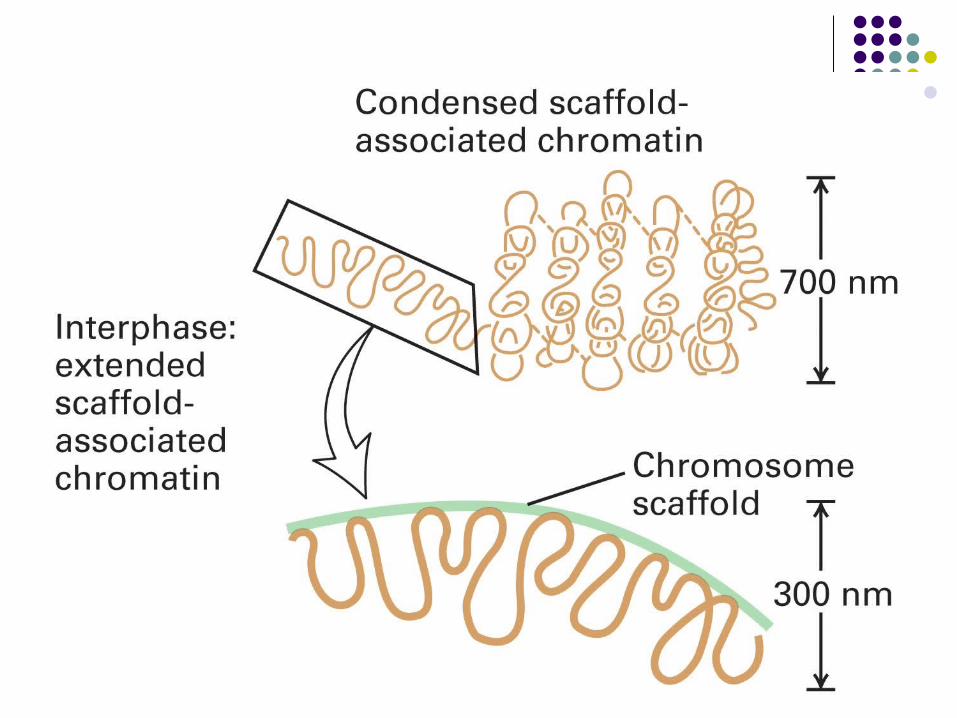



A display of the full set of 46 chromosomes

Sequence similarity

Biological motivation
Sequence similarity is useful in hypothesizing the function of a new sequence…
… assuming that sequence similarity implies structural and functional similarity.
SequenceDatabase
Query
New Sequence
List of similar matches
Response

Case Study: Multiple Sclerosis
Multiple sclerosis is an autoimmune dysfunction in which the T-cells of the immune system start attacking the body’s own nerve cells.
The T-cells recognize the myelin sheath protein of neurons as foreign.
Show movie

A hypothesis: Possibly, the myelin sheath proteins identified by
the T-cells were similar to bacterial/viral sheath proteins from an earlier infection.
How to test this hypothesis?Use sequence alignment.
Why does this happen?
SequenceDatabase
Query
Myelin sheath proteins
List of similar bacterial/viral sequences.
Response
Identification of cause of immune dysfunction
Lab tests

Dynamic Programming
It is a way of solving problems (involving recurrence relations) by storing partial results.
Consider the Fibonacci Series:F(n) = F(n-1) + F(n-2) F(0) = 0, F(1) = 1
A recursive algorithm will take exponential time to find F(n)
A Dynamic Prog. based solution takes only n steps (linear time)

Needleman-Wunsch algorithm
F(i,j) = Maximum of F(i-1, j-1) + s(x[i], y[j]) F(i-1, j) – d F(i, j-1) - d F(i-1,j-1) F(i, j-1)
F(i-1, j)
F(i,j)
-d
-d
+s(X[i],Y[j])Assume that
match = 1, mismatch = 0, indel = 0

Needleman-Wunsch example
0 0 0 0 0 0 0 0 0 0 0 0
0
0
0
0
0
0
0
G T C A G T T ATAA
G
G
A
T
C
G
A

0 0 0 0 0 0 0 0 0 0 0 0
0 1
0
0
0
0
0
0
G T C A G T T ATAA
G
G
A
T
C
G
A
Needleman-Wunsch example

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0
0
0
0
0
0
G T C A G T T ATAA
G
G
A
T
C
G
A
Needleman-Wunsch example

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Needleman-Wunsch example

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
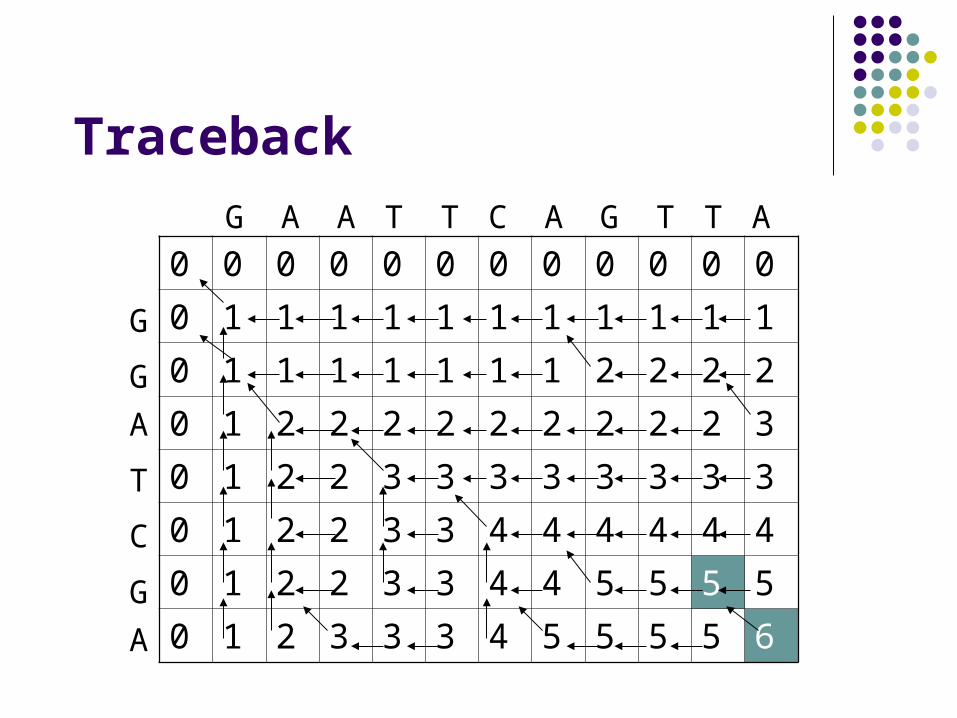
Traceback
0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

0 0 0 0 0 0 0 0 0 0 0 0
0 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 2 2 2 2
0 1 2 2 2 2 2 2 2 2 2 3
0 1 2 2 3 3 3 3 3 3 3 3
0 1 2 2 3 3 4 4 4 4 4 4
0 1 2 2 3 3 4 4 5 5 5 5
0 1 2 3 3 3 4 5 5 5 5 6
G T C A G T T ATAA
G
G
A
T
C
G
A
Traceback

The solution
Optimal alignment has a score of 6.
G _ A A T T C A G T T A
G G A _ T _ C _ G _ _ A

Linear Space Alignment
Serafim talked about the Myers-Miller algorithm in class.
There is another variant of the Hirschberg algorithm, given in Durbin (Pg 35).

Suppose we know that characters X[i] and Y[j] are aligned to each other in the optimal alignment of X[1..n] and Y[1..m].
How can we compute the alignment using this information?
We can partition the alignment into two parts, align X[1..i-1] with Y[1..j-1] and X[i+1..n] with Y[j+1..m] separately.

Middle column

Middle column

F(i,j)
Middle column

F(i,j)
Middle column

F(i,j)
Middle column

F(i,j)
Middle column

F(i,j)
Middle column
This is the cell in the middle column from where the
traceback leaves the column.
Maintain the coordinates of that cell with the value
of F(i,j)
Call it c(i,j)

For every cell in the right half of the matrix, Maintain the F(i,j) value. Maintain the coordinates of the cell in the middle
column from where its traceback path leaves the middle column. Call it c(i, j).
Maintain the direction of that jump as given by the pointer (either or ). Call it P(i,j).

If (i’,j’) is the cell preceding to (i,j), from which F(i,j) is derived, then c(i,j) = c(i’,j’) and P(i,j) = P(i’,j’)
We need only linear space to compute the F,c and P values as we proceed across the matrix.

F(i’,j’)
c(i’,j’)
F(i,j)
c(i,j)
Middle column We know the
traceback from (i’,j’) leaves the
middle column at this cell
Hence, the traceback from this cell will also have
the same c(i,j) value
We are interested in the value of c(n.m)

We use the c(n,m) and P(n,m) values to split the dynamic programming matrix into two parts.
How? Because we know one aligned pair of letters
in the optimal alignment now.