cs 2130
DESCRIPTION
Revised Version. CS 2130. Lecture 18 Bottom-Up Parsing or Shift-Reduce Parsing. Warning: The precedence table given for the Wff grammar is in error. Top-down Parsing 1. Root node leaves 2. Abstract concrete 3. Uses grammar left right 4. Works by "guessing". Bottom-up Parsing - PowerPoint PPT PresentationTRANSCRIPT

CS 2130
Lecture 18
Bottom-Up Parsing
or
Shift-Reduce Parsing
Warning: The precedence table givenWarning: The precedence table givenfor the Wff grammar is in error.for the Wff grammar is in error.

Parsing
Top-down Parsing
1. Root node leaves
2. Abstract concrete
3. Uses grammar left right
4. Works by "guessing"
• Parsing -- Syntax/Semantic Analysis
Bottom-up Parsing
1. Leaves root node
2. Concrete abstract
3. Uses grammar right left
4. Works by "pattern matching"

Introduction
• Top down parsing – Scan across the string to be parsed– Attempt to find patterns that match the right hand
side of a rule– Reduce them to the left hand side of the rule– If the eventual result is reduction to the start
symbol then parse is successful

Imagine...
• We are parsing
1 + 2 * 3• or
num + num * num
• We need some way to make sure that we don't turn the num + num into <expr> + <term> and reduce it to <expr>
• Can num + num be reduced to <expr> ?• Why is it a problem?

Problem...
• We cannot reduce
<expr> * num
• What we need is a way of recognizing that we must reduce first
num + num * numnum * num

Recall our expression grammar
<expr> ::= <expr> + <term> | <term><expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor><term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id<factor> ::= '(' <expr> ')' | num | id
• It would suggest that what follows a ++ must be a term.
• It would also suggest that if a num is followed by a **
then we will somehow need to find a factor to perform
<term> ::= <term> * <factor><term> ::= <term> * <factor>

Bottom Up Parsing
• Bottom up parsing tries to group tokens into things it can reduce (based on a rule in the grammar) in the correct sequence
• This group of symbols is known as a handle.• Handles are indicated using special symbols known
as Wirth-WeberWirth-Weber operators• These symbols function likelike parentheses which can
be used to indicate precedence
1 + (2 * 3)1 + (2 * 3)• We will determine where to put these symbols by
examining the grammar and developing additional information to assist us

Wirth-Weber Operators
x <• y y has higher precedence than x
(We expect y will be involved in a reduction before x)
x = y x and y have equal precedence(We expect x and y will be involved in a reduction
together)
x •> y x has higher precedence than y
(We expect y will be involved in a reduction before x)

Bottom Up Parsing
• Two Things must be understood:
– Given the ability to determine precedence between symbols how can we use this to parse a string?
– How do we determine this precedence between symbols/tokens?
• We deliberately choose to explain in this order and we'll use a very simple grammar to explain

Recall Well Formed Formulae
<wff> ::= p | q | r | s<wff> ::= N <wff><wff> ::= ( C | A | K | E ) <wff> <wff>
Suppose we wish to parse
CANpqp

Bottom Up Parsing
C A N p q p

Bottom Up Parsing
<• C A N p q p
• We can assume that the string has a leading less than precedence operator

Bottom Up Parsing
<• C <• A N p q p
• We move from left to right (and in fact in reality we would normally proceed by asking a lexical scanner for the next token
• As we get to each token or symbol we get its precedence from a precedence table that we'll present later

Bottom Up Parsing
<• C <• A <• N p q p
• We continue in this fashion as long as we place the < and = operators

Bottom Up Parsing
<• C <• A <• N <• p q p
• We continue in this fashion as long as we place the < and = operators

Bottom Up Parsing
<• C <• A <• N <• p q p
• We continue in this fashion as long as we place <• and = operators
• We are postponing the discussion on the precedence table because this part of the algorithm must be clear to be able to understand where the precedence table comes from!

Bottom Up Parsing
<• C <• A <• N <• p •> q p
• When we place a > operator we have found a handle or something that we should be able to reduce
• We examine the rules of the grammer to see if there is a rule to match this handle

Bottom Up Parsing
<• C <• A <• N <• p •> q p
• We find
<wff> ::= p
• Note: If no rule is found we have a parse errorIf no rule is found we have a parse error

Bottom Up Parsing
<• C <• A <• N <wff> q p
• Note that we have removed the entire handle and replaced it with the appropriate symbol from the grammar. We "backup" to examine the relationship between N and <wff>

Bottom Up Parsing
<• C <• A <• N = <wff> q p
• We continue

Bottom Up Parsing
<• C <• A <• N = <wff> •> q p
• We continue, again, until we find a handle

Bottom Up Parsing
<• C <• A <wff> q p
• We can reduce this using the rule
<wff> ::= N <wff>

Bottom Up Parsing
<• C <• A = <wff> q p
• We continue

Bottom Up Parsing
<• C <• A = <wff> <• q p
• We continue

Bottom Up Parsing
<• C <• A = <wff> <• q •> p
• We can reduce this one also

Bottom Up Parsing
<• C <• A = <wff> <wff> p
• Once again backtracking

Bottom Up Parsing
<• C <• A = <wff> = <wff> p
• Once again backtracking

Bottom Up Parsing
<• C <• A = <wff> = <wff> •> p
• Continuing

Bottom Up Parsing
<• C <wff> p
• Continuing

Bottom Up Parsing
<• C = <wff> p
• Continuing

Bottom Up Parsing
<• C = <wff> <• p
• Continuing

Bottom Up Parsing
<• C = <wff> <• p •>
• A greater than precedence symbol is assumed after the last symbol in the input.

Bottom Up Parsing
<• C = <wff> <wff>
• Continuing

Bottom Up Parsing
<• C = <wff> = <wff>
• Continuing

Bottom Up Parsing
<• C = <wff> = <wff> >
• Again a trailing greater than can be added

Bottom Up Parsing
<wff>
• Since <wff> is our start symbol • (and we have nothing left over)
• Successful Parse!

Bottom Up Parsing
• What kind of algorithm?– Stack based– Known as semantic stack or shift/reduce algorithm
• We won't code this algorithm but understanding this parsing technique will make some concepts found in yacc clearer

ExampleOur stream of tokens
C A N p q p

ExampleOur stream of tokens
C A N p q p
StackStack

ExampleOur stream of tokens
C A N p q p
StackStack
Color Commentary
• Welcome to Monday Night Parsing

ExampleOur stream of tokens
A N p q p
<• C
StackStack
We will place the Wirth-Weber operator and following token on the stack.
Encountering the end of a handle •> will initiate additional processing

ExampleOur stream of tokens
N p q p
<• A<• C
StackStack
Working

ExampleOur stream of tokens
p q p
<• N<• A<• C
StackStack
Working

ExampleOur stream of tokens
q p
<• p<• N<• A<• C
StackStack
Working

ExampleOur stream of tokens
q p
<• p<• N<• A<• C
StackStack
Now, between the next token in the stream (q) and the symbol on top of the stack, we find a greater than precedence >• indicating we have the end of a handle. We must now go down the stack and search for the beginning

ExampleOur stream of tokens
q p
<• N<• A<• C
StackStack
We can remove the p and looking at the grammar determine it can be reduced to be a <wff>. We then examine the <wff> in relation to the top of the stack

ExampleOur stream of tokens
q p
= <wff><• N<• A<• C
StackStack
We can remove the p and looking at the grammar determine it can be reduced to be a <wff>. We then examine the <wff> in relation to the top of the stack

ExampleOur stream of tokens
q p
= <wff><• N<• A<• C
StackStack
Looking at the <wff> followed bt the q we again find a greater than precedence relationship. We find that we can reduce the N <wff> to a <wff>.

ExampleOur stream of tokens
q p
<• A<• C
StackStack
Now have <wff> from previous reduction.
Compare it with A

ExampleOur stream of tokens
q p
= <wff><• A<• C
StackStack
Now have <wff> from previous reduction.
Compare it with A

ExampleOur stream of tokens
p
<• q= <wff><• A<• C
StackStack
Working

ExampleOur stream of tokens
p
= <wff>= <wff><• A<• C
StackStack
q followed by p yields greater than allowing us to reduce the q to a <wff>

ExampleOur stream of tokens
p
= <wff>= <wff><• A<• C
StackStack
<wff> followed by p yields greater than •>
so we reduce the A<wff><wff> to a <wff>

ExampleOur stream of tokens
p
= <wff><• C
StackStack
C followed by a <wff> yields equal precedence

ExampleOur stream of tokens
<• p= <wff><• C
StackStack
Working

ExampleOur stream of tokens
EOS<• p= <wff><• C
StackStack
End of input stream (EOS) allows us to place greater than precedence operator

ExampleOur stream of tokens
EOS= <wff>= <wff><• C
StackStack
End of input stream allows us to reduce C<wff><wff>

ExampleOur stream of tokens
StackStack
End of input stream allows us to place greater than precedence operator allowing reduction to final <wff>
Since <wff> is our start symbol:
Successful Parse

Questions?

Constructing the Precedence Table
Being a table which when given two successive symbols will return to us the correct interstitial Wirth-Weber Operator
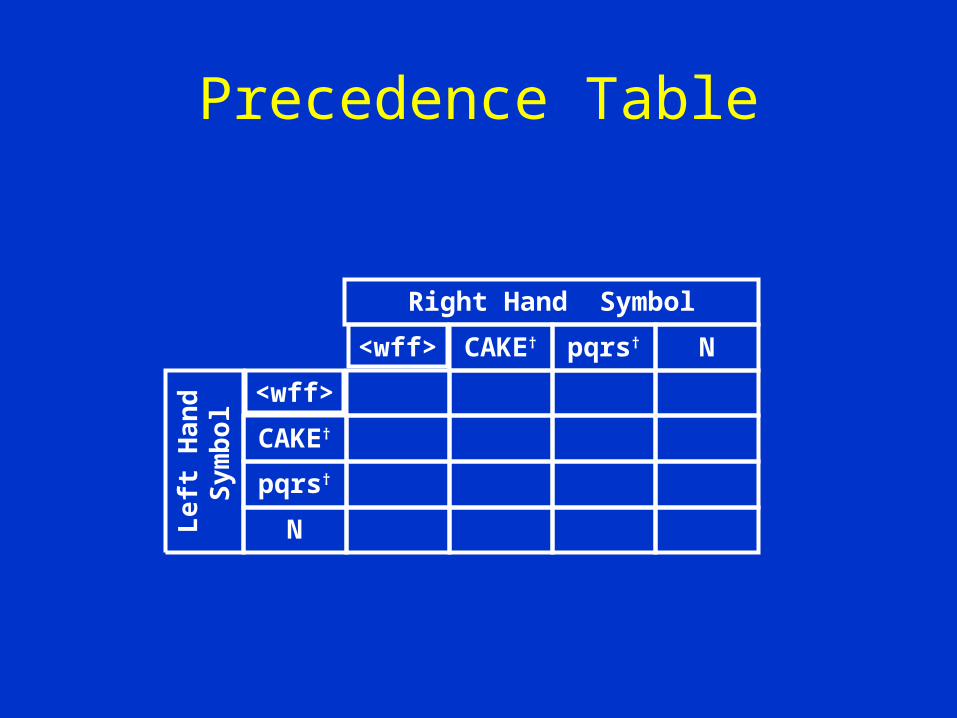
Precedence Table
<wff>
CAKE†
pqrs†
N
<wff> CAKE† pqrs† N
Left Hand
Symbol
Right Hand Symbol

The Grammar
<wff> ::= p | q | r | s
<wff> ::= N <wff>
<wff> ::= C <wff> <wff>
<wff> ::= A <wff> <wff>
<wff> ::= K <wff> <wff>
<wff> ::= E <wff> <wff>
• Consider the previous slides
• As we move through a string we want to capture as a handle an occurrences of the rules above

The Grammar
<wff> ::= p | q | r | s
<wff> ::= N = <wff>
<wff> ::= C = <wff> = <wff>
<wff> ::= A = <wff> = <wff>
<wff> ::= K = <wff> = <wff>
<wff> ::= E = <wff> = <wff>
• Does this seem logical???

Precedence Table
<wff>
CAKE†
pqrs†
N
<wff> CAKE† pqrs† N
=
=
=Left Hand
Symbol
Right Hand Symbol

Now consider
• Whenever we come across a p, q, r or s• We will want to follow this sequence
A p
A <• p
A <• p •>
A <wff>
• So we might reason that any of the terminals C, A, K, E or N followed by a p, q, r,s will be <•
• And a p, q, r or s will always be followed by a >•

Precedence Table
<wff>
CAKE†
pqrs†
N
<wff> CAKE† pqrs† N
=
=
•>
=
•>
<•
<•
•>
<•
•>
Left Hand
Symbol
Right Hand Symbol

We
• continue to use this reasoning• Note that anything followed by a C, A, K, E or N
should have <• precedence to allow a proper WFF to be formed first i.e.
<anything> C ???
• Note also that the exception which we have already taken care of is p, q, r or s followed by C, A, K, E or N

Precedence Table
<wff>
CAKE†
pqrs†
N
<wff> CAKE† pqrs† N
=
=
•>
=
<•
<•
•>
<•
<•
<•
•>
<•
<•
<•
•>
<•Left Hand
Symbol
Right Hand Symbol
Note: The exception which we have already taken care of is p, q, r or s followed by C, A, K, E or N

So
• It appears that this technique is quite simple• We
– Construct a grammar– Examine it to produce a precedence table– Write a program to execute our stack based algorithm
• Not so fast!• There are two issues to deal with
– Simple precedence– Size

Simple Precedence
• The technique we have been using is known as Bottom-Up Parsing or Shift-Reduce Parsing
• The action we take during operation is based on the precedence relationship found
x <• y
x = y
x >• y• What happens if there is no relationship in the table?
• What happens if there is more than one relationship in the table???
Shift
Reduce

More than one relationship!
• Gadzooks!
• Actually we could deal with <• = using lookahead(we'll see that in a moment)
• However rules that allowed •>= or •><• would be known as a shift reduce error
• Speaking of errors finding two rules that match is known as a reduce-reduce error
• Not finding a rule that matches is a syntax error

But how can we have multiple precedence relationships?

Recall our expression grammar
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id

Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)

Some things are impossible
<expr> <expr>
+ +
()
)(

Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)

We know
• From our WFF example we note that certain items must be reduced immediately (e.g. p, q, r and s)
• In a similar fashion we have
<factor> ::= num | id
• So, anything followed by a num or an id will have <• and a num or an id followed by anything will have •>
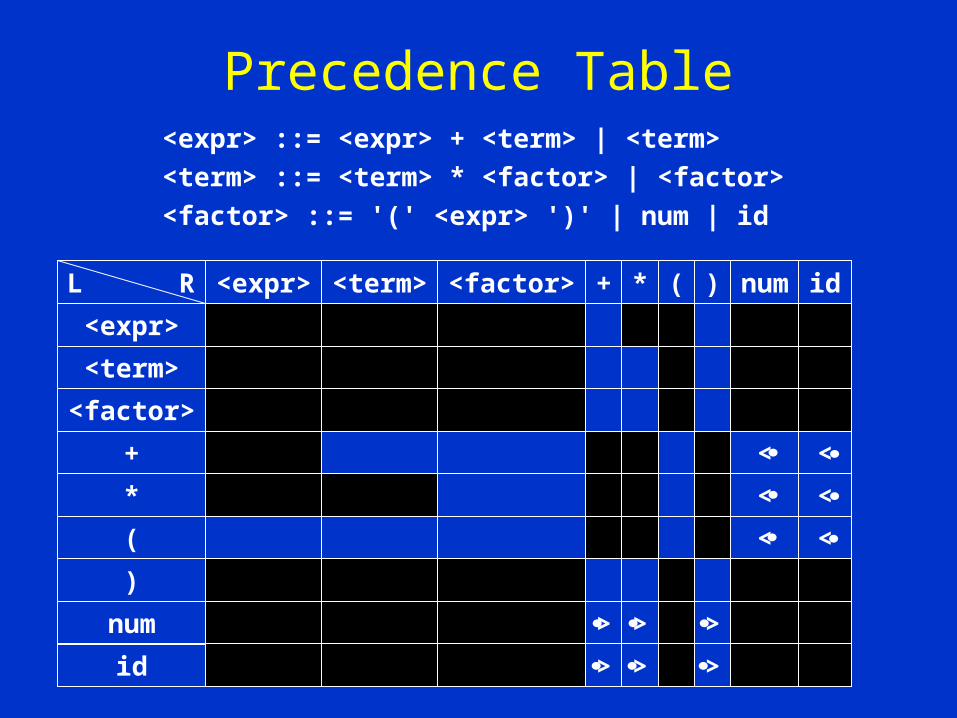
< <
< <
< <
> > >
> > >
Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)

Precedence
Between symbols there must be ?
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id

Precedence
Between symbols there must be =
<expr> ::= <expr> = + = <term> | <term>
<term> ::= <term> = * = <factor> | <factor>
<factor> ::= '(' = <expr> = ')' | num | id

= =
=
= < <
= < <
< <
> > >
> > >
Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)
=

Precedence
• To determine "end points" we must look at multiple rules to see how they interact...
<wff><wff>
NN <wff><wff>==
Do not be alarmedDo not be alarmedWe are returning to We are returning to the wff example justthe wff example just
for a momentfor a moment

Precedence
• To determine "end points" we must look at multiple rules to see how they interact...
<wff><wff>
NN <wff><wff>==
To determine what goes here...To determine what goes here... Do not be alarmedDo not be alarmedWe are returning to We are returning to the wff example justthe wff example just
for a momentfor a moment

Precedence
• To determine "end points" we must look at multiple rules to see how they interact...
<wff><wff>
NN <wff><wff>==
We look here.We look here. Do not be alarmedDo not be alarmedWe are returning to We are returning to the wff example justthe wff example just
for a momentfor a moment

Precedence
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
* * ?? ( (
What is the relationshipWhat is the relationshipbetween * and (between * and (
??

Precedence
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
* * ?? ( ( = <expr> = )= <expr> = )
What is the relationshipWhat is the relationshipbetween * and (between * and (
If we have parentheses itIf we have parentheses itmust be this formmust be this form

Precedence
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
* = <factor>* = <factor>
* <• (* <• ( = <expr> = )= <expr> = )
We go up the parse tree.We go up the parse tree.Since ( <expr> ) will beSince ( <expr> ) will bea factor and a factor willa factor and a factor willneed to be reduced as partneed to be reduced as partof <term> * <factor> weof <term> * <factor> weconclude that we will needconclude that we will needto reduce the ( <expr> ) firstto reduce the ( <expr> ) first

Precedence
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
+ ? (+ ? (
What is the relationshipWhat is the relationshipbetween + and (between + and (

Precedence
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
+ ? (+ ? ( = <expr> = )= <expr> = )
Again the grammar revealsAgain the grammar revealsthat ( must come from that ( must come from ( <expr> )( <expr> )

Precedence
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
+ <• <factor>+ <• <factor>
+ <• (+ <• ( = <expr> = )= <expr> = )
+ = <term>+ = <term>
We examine the parse treeWe examine the parse treenoting that a + can only benoting that a + can only befollowed by a <term>followed by a <term>
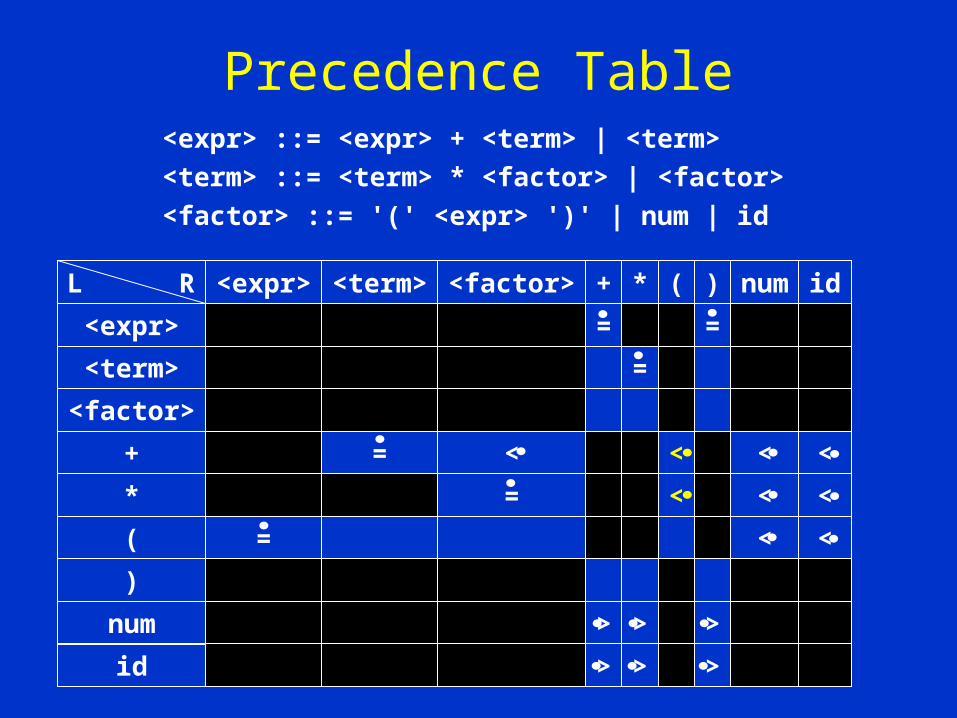
= =
=
= < <
= < <
< <
> > >
> > >
Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)
=
< <
<

Continuing to analyze in this way...

<
= =
> = >
> > >
< < <
= < < <
< < <
> > >
> > >
> > >
Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)
=
=

<
= =
> = >
> > >
< < <
= < < <
< < <
> > >
> > >
> > >
Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)
'(' <expr>...
'(' < '(' <expr>...

Now for the complex part
• Consider ( followed by <expr>
( <expr>
• Is it
( <expr> ) =• or
( <expr> + <•
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id

Or
• Consider + followed by <term>
+ <term>
• Is it
+ <term> + =
+ <term> ) =
+ <term> * <•
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id

<
= =
> = >
> > >
= < < < <
= < < <
< < <
> > >
> > >
> > >
Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)
= <

<
= =
> = >
> > >
= < < < <
= < < <
< < <
> > >
> > >
> > >
Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)
= <

<
= =
> = >
> > >
= < < < <
= < < <
< < <
> > >
> > >
> > >
Precedence Table<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
L R
<expr>
<term>
<factor>
+
*
(
)
num
id
<expr> <term> <factor> + ( num* id)
= <
'(' = <expr> ')'
'(' < <expr> +

Resolving Ambiguity
+ = <term>
+ < <term> * <factor>
• Solve by lookahead:
+ = <term> + or )
+ < <term> *
• Ambiguity can be resolved by increasing k in LR(k) but that's not the only way:
• We could rewrite grammar

Original Grammar
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id

Sources of Ambiguity
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id

Add 2 New Rules
<expr> ::= <expr> + <term> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <expr> ')' | num | id
<e> ::= <expr>
<t> ::= <term>

Modify
<expr> ::= <expr> + <t> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <e> ')' | num | id
<e> ::= <expr>
<t> ::= <term>

Original Grammar
<expr> ::= <expr> + <t> | <term>
<term> ::= <term> * <factor> | <factor>
<factor> ::= '(' <e> ')' | num | id
<e> ::= <expr>
<t> ::= <term>
Rewritten Grammar
<expr> ::= <expr> + <term> | <term><term> ::= <term> * <factor> | <factor><factor> ::= '(' <expr> ')' | num | id

Bottom-Up Parsing
• No issues regarding left-recursive versus right-recursive such as those found with Top-down parsing
• Note: There are grammars that will break a bottom-up parser.

So
• It appears that this technique is quite simple• We
– Construct a grammar– Examine it to produce a precedence table– Write a program to execute our stack based algorithm
• Not so fast!• There are two issues to deal with
– Simple precedence– Size

Performance
• Size of table is O(n2)• For a "real" language this can be a problem• One possibility: Use operator precedence
– Only uses terminals – Thus the table size is not affected by adding non-
terminals
• We will not go into details of Operator Precedence Tables
• You should be aware that they exist

Question
• Where do precedence relationships come from?
– Make a table by hand– Write a program to make table
• How such a program works or how to write it are topics beyond the scope of this course.

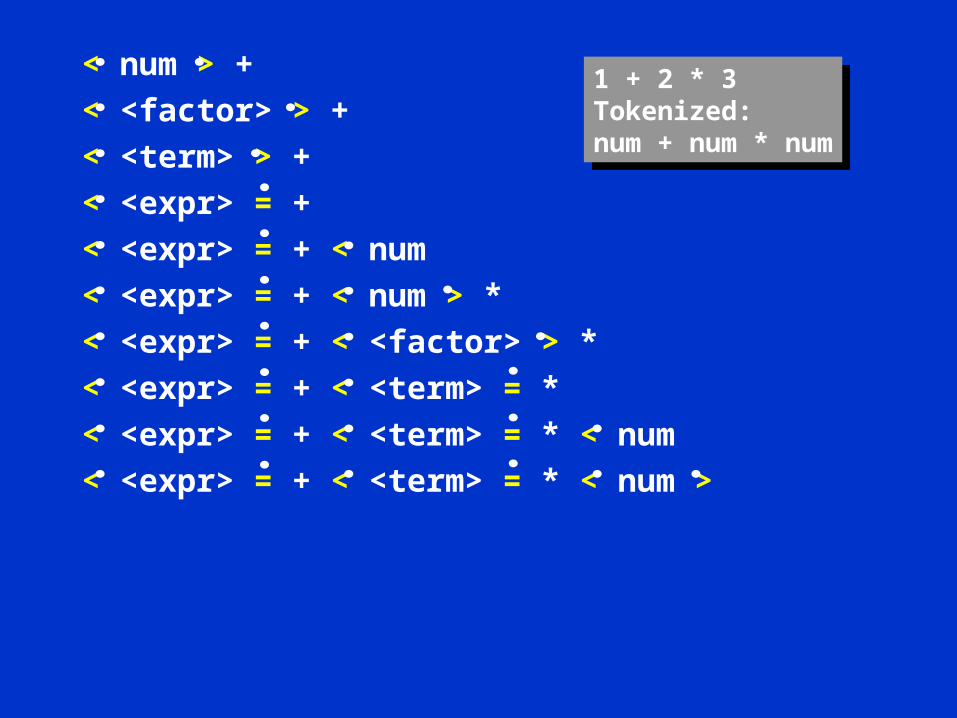
Example

< num > + 1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

< num > +
< <factor> > +1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

< num > +
< <factor> > +
< <term> > +
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

< num > +
< <factor> > +
< <term> > +
< <expr> = +
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

< num > +
< <factor> > +
< <term> > +
< <expr> = +
< <expr> = + < num
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num
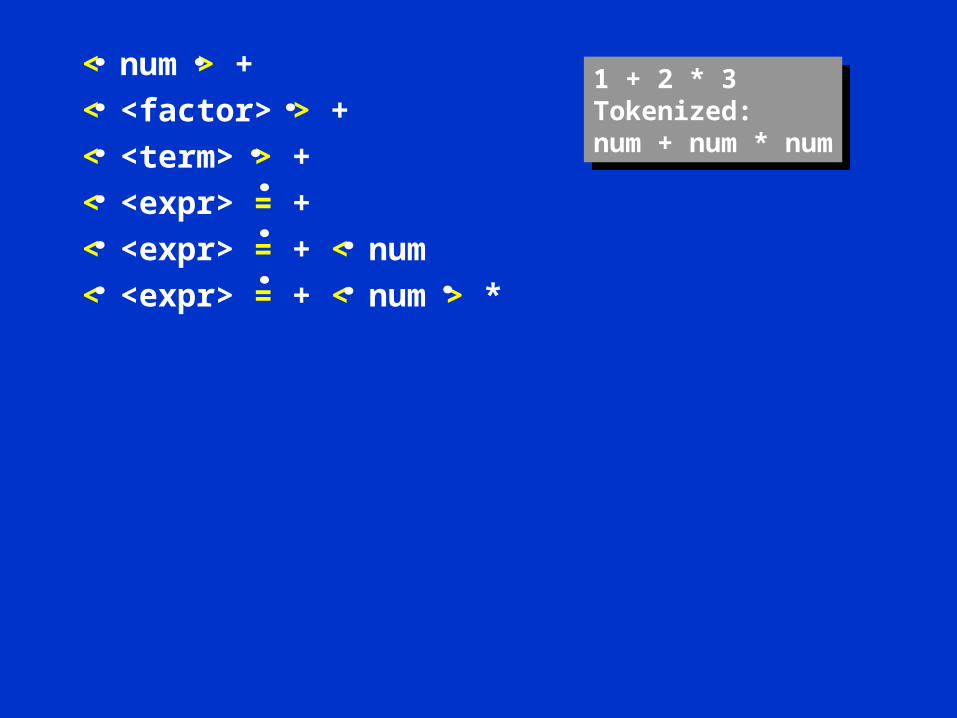
< num > +
< <factor> > +
< <term> > +
< <expr> = +
< <expr> = + < num
< <expr> = + < num > *
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

< num > +
< <factor> > +
< <term> > +
< <expr> = +
< <expr> = + < num
< <expr> = + < num > *
< <expr> = + < <factor> > *
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

< num > +
< <factor> > +
< <term> > +
< <expr> = +
< <expr> = + < num
< <expr> = + < num > *
< <expr> = + < <factor> > *
< <expr> = + < <term> = *
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

< num > +
< <factor> > +
< <term> > +
< <expr> = +
< <expr> = + < num
< <expr> = + < num > *
< <expr> = + < <factor> > *
< <expr> = + < <term> = *
< <expr> = + < <term> = * < num
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num
< num > +
< <factor> > +
< <term> > +
< <expr> = +
< <expr> = + < num
< <expr> = + < num > *
< <expr> = + < <factor> > *
< <expr> = + < <term> = *
< <expr> = + < <term> = * < num
< <expr> = + < <term> = * < num >
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num
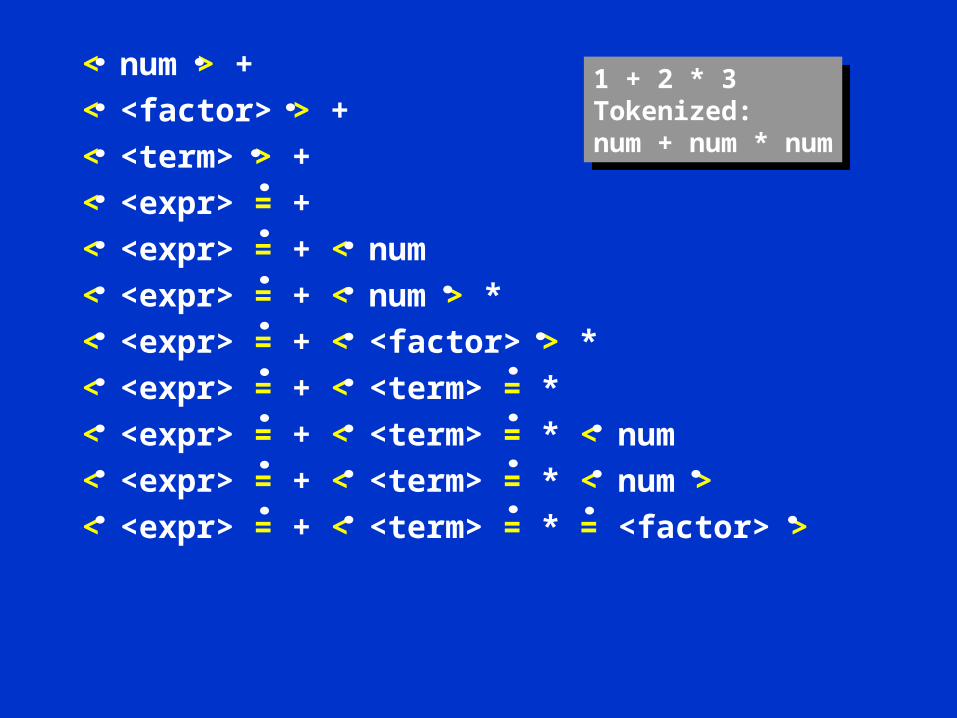
< num > +
< <factor> > +
< <term> > +
< <expr> = +
< <expr> = + < num
< <expr> = + < num > *
< <expr> = + < <factor> > *
< <expr> = + < <term> = *
< <expr> = + < <term> = * < num
< <expr> = + < <term> = * < num >
< <expr> = + < <term> = * = <factor> >
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

< num > +
< <factor> > +
< <term> > +
< <expr> = +
< <expr> = + < num
< <expr> = + < num > *
< <expr> = + < <factor> > *
< <expr> = + < <term> = *
< <expr> = + < <term> = * < num
< <expr> = + < <term> = * < num >
< <expr> = + < <term> = * = <factor> >
< <expr> = + = <term> >
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

< num > +
< <factor> > +
< <term> > +
< <expr> = +
< <expr> = + < num
< <expr> = + < num > *
< <expr> = + < <factor> > *
< <expr> = + < <term> = *
< <expr> = + < <term> = * < num
< <expr> = + < <term> = * < num >
< <expr> = + < <term> = * = <factor> >
< <expr> = + = <term> >
< <expr> >
1 + 2 * 3Tokenized:num + num * num
1 + 2 * 3Tokenized:num + num * num

Questions?
