course plan game playing state-of-the-art
TRANSCRIPT

1
Course plan
State-based models Search problem
Markov decision processes (MDP)
Adversarial games
Variable-based models Constraint satisfaction problem
Bayesian networks
Logic
[These slides adapted ai@stanford, ai@berkeley]
Game Playing State-of-the-Art Checkers: 1950: First computer player.
1994: First computer champion: Chinook ended 40-year-reign of human champion Marion Tinsley using complete 8-piece endgame. 2007: Checkers solved!
Chess: 1997: Deep Blue defeats human champion Gary Kasparov in a six-game match. Deep Blue examined 200M positions per second, used very sophisticated evaluation and undisclosed methods for extending some lines of search up to 40 ply (20 moves). Current programs are even better, if less historic.
Go: Human champions are now starting to be challenged by machines. In go, b > 300! Classic programs use pattern knowledge bases, but big recent advances use Monte Carlo (randomized) expansion methods.
[These slides adapted from ai.Berkeley.edu, ai@stanford]
Game Playing State-of-the-Art
Checkers: 1950: First computer player. 1994: First computer champion: Chinook ended 40-year-reign of human champion Marion Tinsley using complete 8-piece endgame. 2007: Checkers solved!
Chess: 1997: Deep Blue defeats human champion Gary Kasparov in a six-game match. Deep Blue examined 200M positions per second, used very sophisticated evaluation and undisclosed methods for extending some lines of search up to 40 ply (20 moves). Current programs are even better, if less historic.
Go: 2016: Alpha GO defeats human champion. Uses Monte Carlo Tree Search, learned evaluation function.
Pacman
Many different kinds of games!
Mainly: Deterministic or stochastic?
One, two, or more players?
Zero sum?
Perfect information (can you see the states)? Chess
Want algorithms for calculating a strategy (policy) which recommends a move from each state.
Types of Games
Zero-Sum Games
Zero-Sum Games Agents have opposite utilities (values
on outcomes)
Lets us think of a single value that one maximizes and the other minimizes
Adversarial, pure competition
General Games Agents have independent utilities
(values on outcomes)
Cooperation, indifference, competition, and more are all possible
More later on non-zero-sum games
A simple game
Which bin?
1 2
3 5
6 7

2
Roadmap
Modeling: games
Algorithms: Expectimax
Minimax
Expectiminimax
Evaluation functions
Alpha-Beta pruning
Game: modeling
Two-player zero-sum games
Halving game
States = {player (+1/-1), number}Start = {+1/-1, number = N}End = {number =0}Utility = {player*inf}Actions = {-, /}
8 9
10 11
12 13

3
Policies
Let’s play, with humanPolicy .
Game evaluation example Game evaluation recurrence
Assume agent , opp are given.
Minimax Example
14 15
16 17
18 19
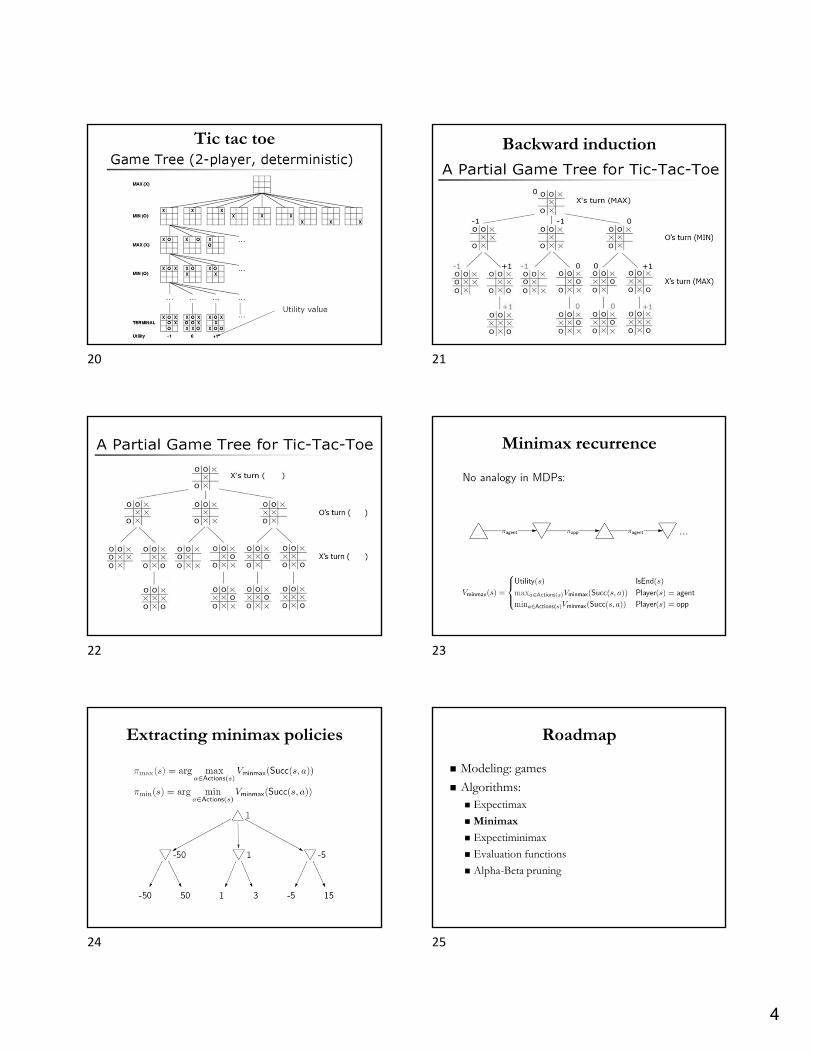
4
Tic tac toe Backward induction
Minimax recurrence
Extracting minimax policies Roadmap
Modeling: games
Algorithms: Expectimax
Minimax
Expectiminimax
Evaluation functions
Alpha-Beta pruning
20 21
22 23
24 25

5
Adversarial Search (Minimax)
Deterministic, zero-sum games:
Tic-tac-toe, chess, checkers
One player maximizes result
The other minimizes result
Minimax search:
A state-space search tree
Players alternate turns
Compute each node’s minimaxvalue: the best achievable utility against a rational (optimal) adversary
8 2 5 6
max
min2 5
5
Terminal values:part of the game
Minimax values:computed recursively
Example
80%20% 100% 0%0% 100%
Expectimax Recurrence
Face off
blue opponent, red agent
Minimax property 1
26 27
28 29
30 31

6
Minimax property 2 Minimax Property 3
Relationship between game values A modified game
example Expectiminimax recurrence
32 33
34 35
36 37

7
Summary so far Computation
Speeding up minimax Depth-limited Search
Evaluation functions Evaluation functions
38 39
40 41
42 43

8
Summary: evaluation functions Roadmap
Modeling: games
Algorithms: Expectimax
Minimax
Expectiminimax
Evaluation functions
Alpha-Beta pruning
Game Tree Pruning
44 45
46 47
48 49

9
Alpha-beta pruning
Alpha-Beta Quiz
Other games
50 51
53 55
56 57

10
58 59
60 61
62 63

11
64 65
66 67
68 69

12
70 71
72 73
74 75

13
76 77
78 79
80 81

14
State-based model's recap
82 83
84 85