countrystat team-i 10-13 november 2014, eco secretariat,teheran
TRANSCRIPT

MISSING DATA IMPUTATION
CountrySTAT Team-I10-13 November 2014, ECO Secretariat,Teheran

SUMMARY
Introduction Origin of missing data Nature of missing data Implemented methodologies Proposed methodologies Results Conclusion

INTRODUCTION
The objective of this presentation is to introduce basics tools to handle missing data in CountrySTAT and FAOSTAT domains. They are based on simple and friendly approach, easy to use.
The CountrySTAT agricultural production domain was used as a basis to develop and test imputation and validation methodologies that could assist in standardisation across the different statistical domains presents at FAO level.

ORIGIN OF MISSING DATA
Data are missing for different reasons 1) The value has not been measured (forget...); 2) The value is measured but lost; 3) The value is measured, but considered unusable (outliers, etc.); 4) The value is measured but unavailable.

DATA ARE ESSENTIAL TO RESEARCH, BUT ANY EXPERIENCED RESEARCHER KNOWS THAT IT'S NEARLY IMPOSSIBLE TO COLLECT DATA WITHOUT HOLES, BIASES, OR FLAWS

NATURE OF MISSING DATA
In a dataset, data can be 1) Missing completely at random (MCAR): when the events that lead to any particular data-item being missing are independent both of observable variables and of unobservable parameters of interest, and occur entirely at random.
P(r |Yobserved;Ymissing) = P(r ) 2) Missing at random (MAR): when the missingness is related to a particular variable, but it is not related to the value of the variable that has missing data.
P(r |Yobserved;Ymissing) = P(r |Yobserved) 3) Not missing at random (NMAR): when data are not MCAR or MAR
P(r |Yobserved;Ymissing) = P(r |Yobserved;Ymissing) 4) Censored and Truncated Data.Data use to be MCAR or MAR

OVERVIEW OF DIFFERENT METHODOLOGIES
A) Deductive or logical imputation; B) Mean imputation; C) Ratio imputation; D) Regression imputation; E) Donor imputation (hot-deck, cold-deck, nearest
neighbor); F) Multiple imputation : Because it is not
deterministic, it is not applicable to officials statistics.

IMPLEMENTED METHODOLOGIES: IMPUTATION METHODS IN FAOSTAT
expert judgment last observations carried forward linear interpolation growth-rate benchmarking
• yield estimation• multivariate approach
These imputations are based on deductive or logical imputation, ratio imputation and donor imputation.The selected method is based on Regression imputation method.WHY?
already applied
under development
• trend smoothingtested but not applied

IMPLEMENTED METHODOLOGIES: MOVING AVERAGE
yt* is the value to be imputed. We consider the time serie (yt): y1,
y2,…,yn.
If m=0, yt* is the estimation for the current year.
If m=0 and l=1, the last observation is carried forward.
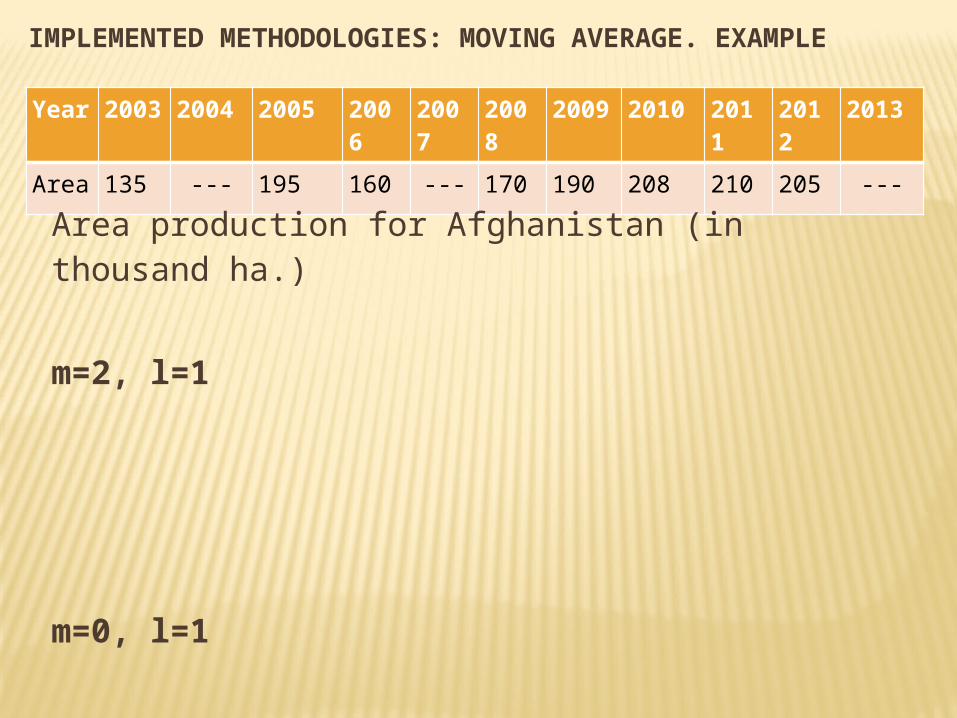
Year 2003
2004 2005 2006
2007
2008
2009
2010 2011
2012
2013
Area 135 --- 195 160 --- 170 190 208 210 205 ---
IMPLEMENTED METHODOLOGIES: MOVING AVERAGE. EXAMPLE
Area production for Afghanistan (in thousand ha.)
m=2, l=1
m=0, l=1

IMPLEMENTED METHODOLOGIES: LINEAR INTERPOLATION
A linear trend is assumed to exist between the start- and endpoints of gaps in the time series.
Let y0, y1, ..., yt-l denote the data points with values obtained from official sources before the gap and yt+r, yt+r+1, ..., ym denote the data points with official values after the gap. The imputed values are calculated as:
rl
yylyy ltrt
ltt
ˆ .

Year 2003
2004 2005 2006
2007
2008
2009
2010 2011
2012
2013
Area 135 195 195 160 --- --- --- 208 210 205 205
IMPLEMENTED METHODOLOGIES: LINEAR INTERPOLATION. EXAMPLE
Area production for Afghanistan (in thousand ha.)

IMPLEMENTED METHODOLOGIES: ESTIMATION BASED ON AVERAGE YIELD (1)
An estimate of the yield in data point 0 is calculated by taking the average of the ratio between agricultural output (y) and agricultural input (x) observed at the three data points with valid observations in both y and x which are nearest to the imputable value in terms of years.
)

IMPLEMENTED METHODOLOGIES: ESTIMATION BASED ON AVERAGE YIELD (2)
If a valid value for agricultural input exists in the current year, x, then the corresponding value of agricultural output is estimated as:
=x x If a valid value for agricultural output exists in the current year, y0, then the corresponding value of agricultural input is estimated as:
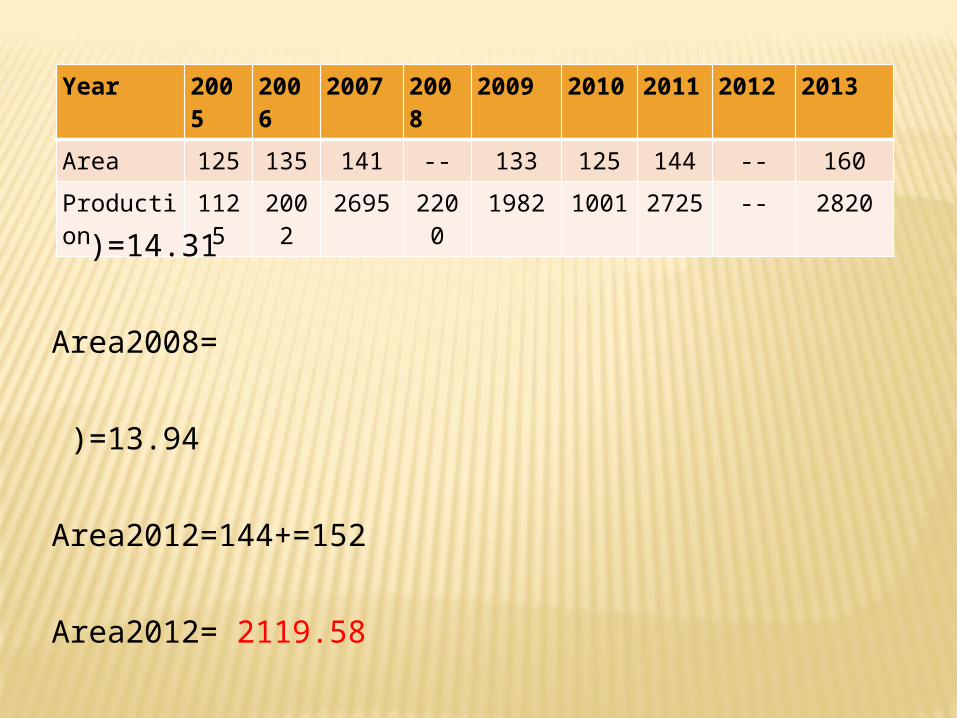
Year 2005
2006
2007 2008
2009 2010
2011
2012 2013
Area 125 135 141 -- 133 125 144 -- 160
Production
1125
2002
2695 2200
1982 1001 2725 -- 2820
)=14.31
Area2008=
)=13.94
Area2012=144+=152
Area2012= 2119.58

IMPLEMENTED METHODOLOGIES: TREND REGRESSION
A polynomial regression is run based on the model:
yt = α+β1 X t + β2 X + β3 X + β4 X + ρ X ut-1
where yt is a valid value observed for year t and ut is the residual in that year.

PROPOSED METHODOLOGIES: REGRESSION IMPUTATION
Used methods are based on regression imputation and used EM-algorithm :
1)Yield estimation: estimate yield using an arima model; 2)Linear regression: Use a linear regression between Pt and At including Trend;
3)Arima model: Estimate Pt and At
using ARIMA model; 4) Spline regression: Estimate Pt and At
using spline;

PROPOSED METHODOLOGIES: LINEAR REGRESSION

EXPECTATION-MAXIMIZATION ALGORITHM (EM)
How it is work ?

4.PROPOSED METHODOLOGIES: YIELD ESTIMATION (EM:EXPECTATION-MAXIMISATION)
Compute a yield time series Yt containing missing data:
Yt=Pt/At, where Pt is the production and At is the area harvested at time t;
Use linear interpolation method to obtain starting values;
ARIMA(0,1,1): Yt =Yt-1 + α+ εt - θ1* εt-1;
EM algorithm. Use Yield estimate to impute Production and Area Harvested. Where Pt and At are missing, we use last observation carried
forward method to impute area harvested.

4.PROPOSED METHODOLOGIES: LINEAR REGRESSION (EM:EXPECTATION-MAXIMISATION)
The model assumes linear relationship between Production and Area Harvested;
Pt= Yt *At
Pt= Production in the year t; At= Area Harvested in the year t; Yt= Yield in the year t.
Algorithm: 1) Linear interpolation for Area for starting values; 2) Repeat and update until the convergence of prediction values:
Pt= α+ β1 *Trend + β2 *At + εt (EM-Algorithm to impute Pt) At= α+ β1 *Trend + β2 *Pt + εt (EM-Algorithm to impute At)

PROPOSED METHODOLOGIES: ARIMA MODEL
The ARIMA models must be identified
ARIMA(0,1,1): Yt =Yt-1 + α+ εt - θ1* εt-1;
Use relation between Production and Area
Use these variable as time series and Impute using EM-algorithm.
Package mtsdi of R.
Impute using ARIMA model for Pt and At imputation

PROPOSED METHODOLOGIES: SPLINE MODEL
Form of interpolation where the interpolant is a special type of piecewise polynomial called a spline.
For each interval, we try estimate a polynomial function which fit well data.
Spline interpolation is preferred over polynomial interpolation because the interpolation error can be made small even when using low degree polynomials for the spline.
Package mtsdi of R.
Impute using Spline regression for Pt and At imputation

RESULTS
We use reals data to test proposed methodologies: Yield estimation, Linear Regression, ARIMA, Spline
We add also linear interpolation
Data are from CountrySTAT-Mali website.
Missing data are generated randomly.
Data are from 1984 to 2012.
Use real data to test.

RESULTS: TEST CASE
Test case: Maize.
Missing data at 10 %.







RESULTS: TESTS CASES
We perform again these methods on the same dataset at different percentages of missing data.
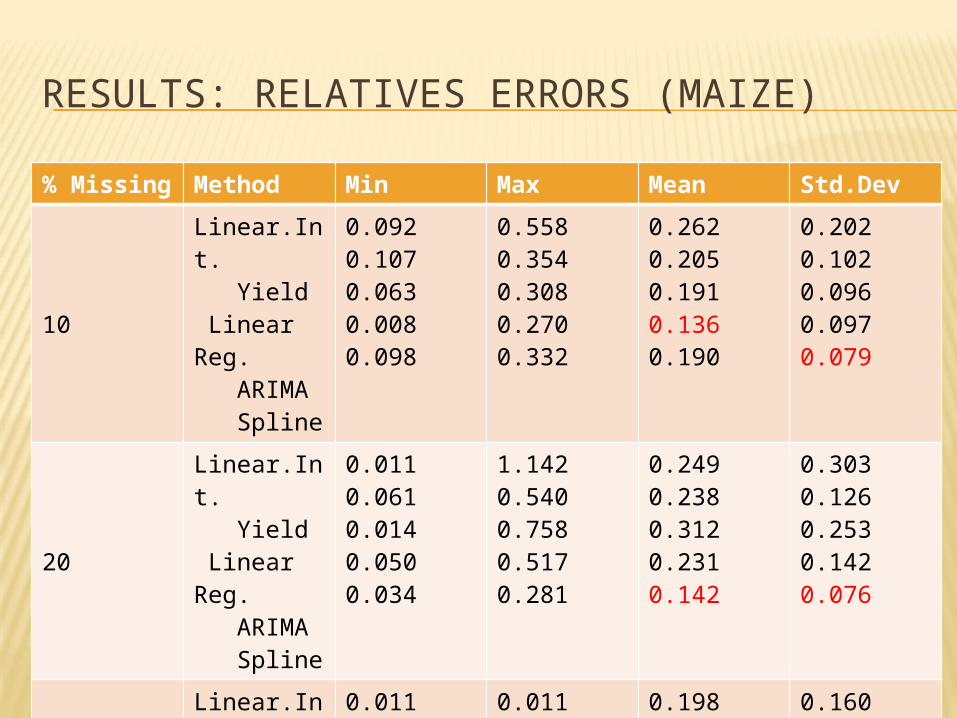
RESULTS: RELATIVES ERRORS (MAIZE)
% Missing
Method Min Max Mean Std.Dev
10
Linear.Int. Yield Linear Reg. ARIMA Spline
0.0920.1070.0630.0080.098
0.5580.3540.3080.2700.332
0.2620.2050.1910.1360.190
0.2020.1020.0960.0970.079
20
Linear.Int. Yield Linear Reg. ARIMA Spline
0.0110.0610.0140.0500.034
1.1420.5400.7580.5170.281
0.2490.2380.3120.2310.142
0.3030.1260.2530.1420.076
40
Linear.Int. Yield Linear Reg. ARIMA Spline
0.0110.0030.1840.0260.013
0.0110.0030.1840.0260.013
0.1980.1740.2350.1820.154
0.1600.0980.1810.1060.096

CONCLUSION
For the 3 tests cases, relatives errors are less for method of Spline in the most of case, when the percentage of missing data is more than 10%.
The method ARIMA is more adapted when we have less than 10% of missing data in the dataset.
The above tests use only two variables for the same crop (area and production). If the number of missing data exceeds 40%, it will be appropriated to use a third correlated control variable.

THANK YOU