contextual search and name disambiguation in email using graphs
DESCRIPTION
Contextual Search and Name Disambiguation in Email Using Graphs. Einat Minkov, William W. Cohen, Andrew Y. Ng Carnegie Mellon University and Stanford University SIGIR 2006. INTRODUCTION. 計算文件的 similarity 除了 textual feature 外 , 其實還有一些其它的資訊可以用 - PowerPoint PPT PresentationTRANSCRIPT

Contextual Search and Name Disambiguation in Email Using Graphs
Einat Minkov, William W. Cohen, Andrew Y. NgCarnegie Mellon University and Stanford University
SIGIR 2006

INTRODUCTION
計算文件的 similarity 除了 textual feature 外 ,其實還有一些其它的資訊可以用 Ex. Hyperlinks in webs, meta-data, and header i
nformation in e-mail
In this paper we consider extended similarity metrics for documents and other objects embedded in graphs, facilitated via a lazy graph walk

INTRODUCTION
In a lazy graph walk, there is a fixed probability of halting the walk at each step
Two problem disambiguating personal names in email E-mail Threading

EMAIL AS A GRAPH

EMAIL AS A GRAPH “Einat Minkov <[email protected]>”
person node “Einat Minkov” email-address node “[email protected]”
其它規則

Edge weights To walk away from a node x, one first picks a
n edge label l We assume that the probability of picking th
e label l depends only on the type T (x)

Edge weights once l is picked, y is chosen uniformly from t
he set of all y

Graph walks a lazy graph walk, there is some probabilit
y °staying at x
if V0 is some initial probability distribution over nodes, then the distribution after a k-step walk is proportional to

Graph walks In our framework, a query is an initial distr
ibution Vq over nodes, plus a desired output type Tout Ex. “economic impact of recycling tires” wo
uld be an appropriate distribution Vq over query terms, with Tout = file

Relation to TF-IDF Suppose we restrict ourselves to only two ty
pes, terms and files, and allow only in-file edges common term “the” will spread its probability
mass into small fractions over many file nodes unusual term “aardvark” will spread its weigh
t over only a few files the effect will be similar to use of an IDF weighti
ng scheme

LEARNING Previous researchers have described sche
mes for adjusting the parameters using gradient descent-like methods
In this paper, we suggest an alternative approach of learning to re-order an initial ranking

LEARNING The reranking algorithm is provided with a
training set containing n examples Example i includes a ranked list of li nodes Let wij be the j th node for example i A candidate node wij is represented through m
features, which are computed by m feature functions f1, . . . , fm

LEARNING ranking function for node x is defined as:
where L(x) = log(p(x)) and ᾱY is a vector of real-value parameters
minimizes the following loss function on the training data

Corpora Cspace corpus
contains email messages collected from a management course conducted at Carnegie Mellon University in 1997
The Enron corpus a collection of mail from the Enron corpus that h
as been made available for the research community

Person Name Disambiguation
“Andrew” = “Andrew Y. Ng” or “Andrew McCallum” ???
The Cspace corpus, We collected 106 cases in which single-token names were mentioned in the the body of a message but did not match any name from the header

Person Name Disambiguation
For Enron, two datasets were generated automatically. we eliminate the collected person name from the email header
the namesin this corpus include people that are in the email header,but cannot be matched because

Results for person name disambiguation
Baseline method The similarity score between the name term an
d a person name is calculated as the maximal Jaro similarity score between the term and any single token of the personal name (ranging between 0 to 1)
In addition, we incorporate a nickname dictionary, such that if the name term is a known nickname of the person name, the similarity score of that pair is set to 1

Results for person name disambiguation
Graph walk methods 嘗試兩種 Vq
query distribution on the name term equal weight to the name term node and the fi
le in which it appears Tout=person type we will use a uniform weighting of labels

Reranking the output of a walk
Edge unigram features for each edge label L , whether L was used in r
eaching x from Vq Edge bigram features
whether L1 and L2 were used (in that order) in reaching x from Vq
Top edge bigram features paths leading to a node originate from on
e or two nodes inVq

Person name disambiguation results: Recall at rank k
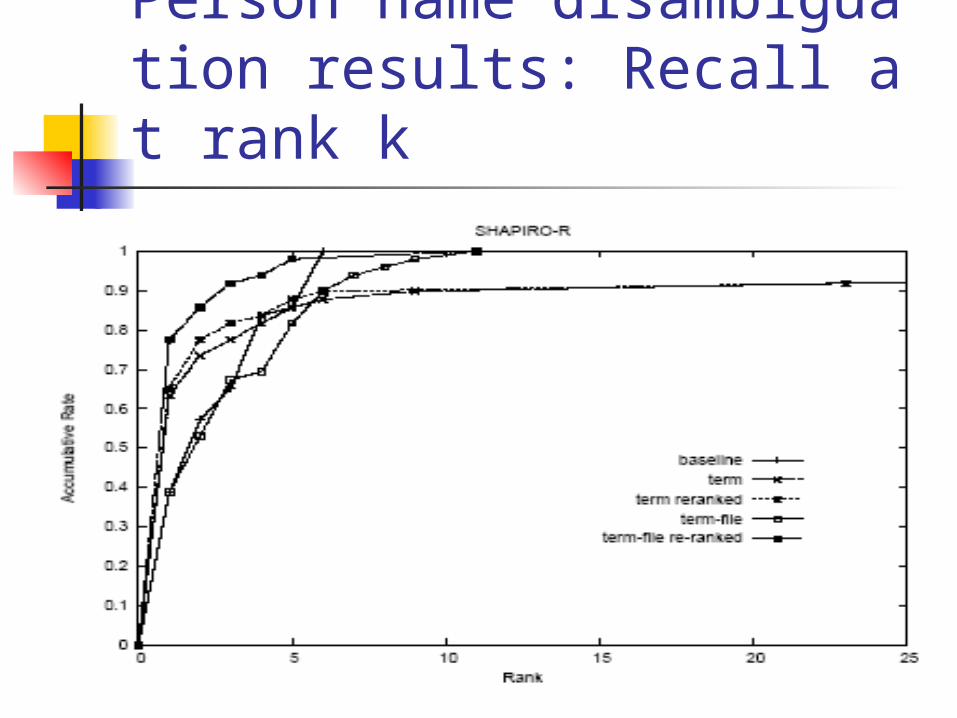
Person name disambiguation results: Recall at rank k
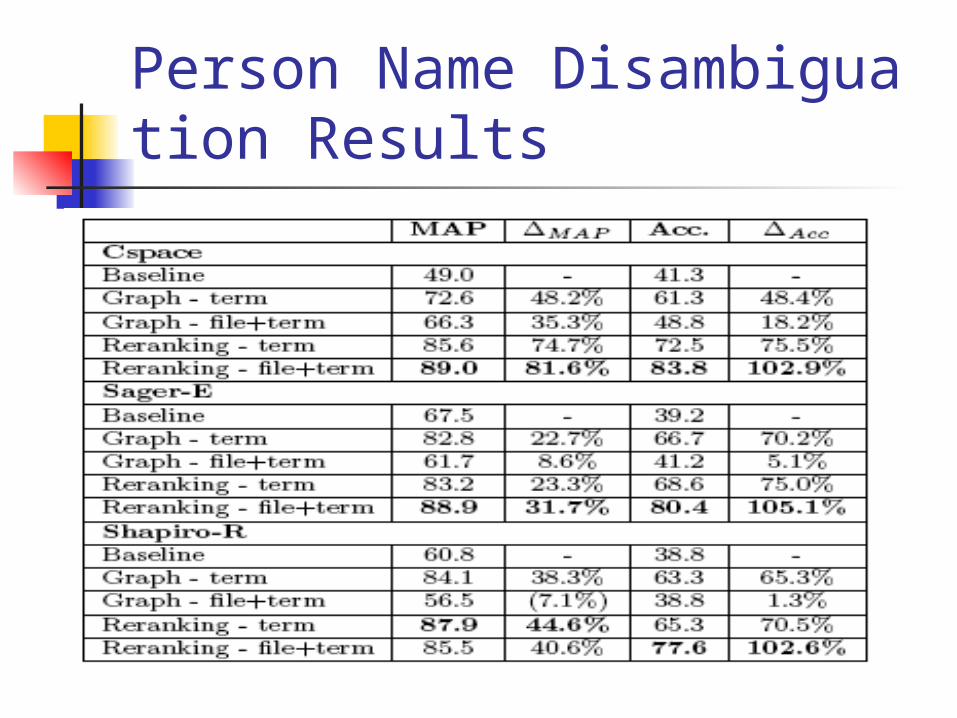
Person Name Disambiguation Results

Threading A thread is a conversation among 2 or more
people carried out by exchange of messages Threading problem
Retrieving other messages in an email thread given a single message from the thread
Given an email file as a query, produce a ranked list of related email files, where the immediate parent and child of the given file are considered to be “correct” answers.

Threading several information types are available
Header - sender, recipients and date Body - the textual content of an emai reply lines - quoted lines from previous messa
ges Subject - the content of the subject line

Threading
Baseline method TF-IDF term weighting+cosine similarity
Graph walk methods Vq assign probability 1 to the file node corresp
onding to the original message, Tout = file

Graph walk methods weight-tuning method
we evaluate 10 randomly-chosen sets of weights and pick the one that performs best (in terms of MAP) on the CSpace training data
Reranking the output of walks The features applied are edge unigram, edge big
ram and top edge bigram
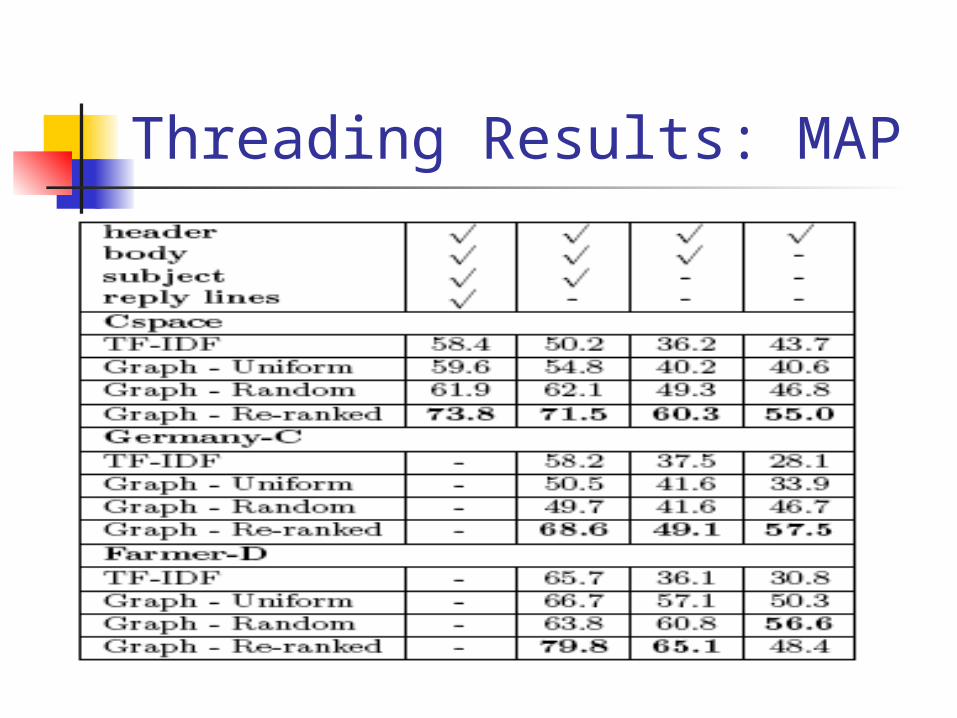
Threading Results: MAP
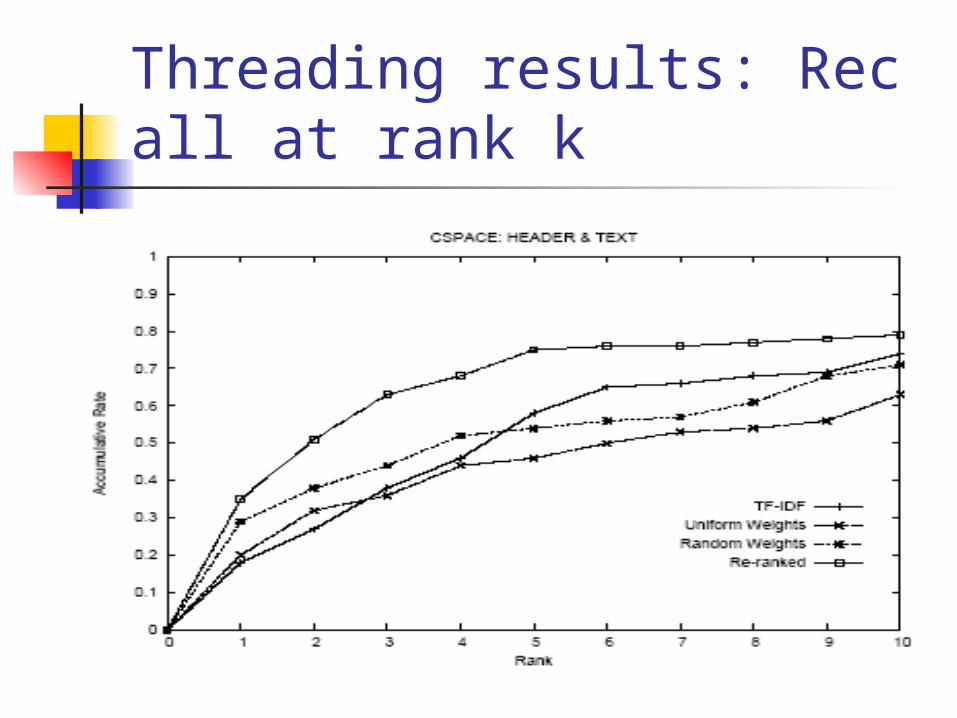
Threading results: Recall at rank k

CONCLUSION We have presented a scheme for representi
ng a corpus of email messages with a graph of typed entities
This scheme provides good performance on two representative email-related tasks: disambiguating person names, and email threading.