computers playing games arif zaman cs 101. acknowledgements portions of this are taken from mit’s...
Post on 20-Dec-2015
219 views
TRANSCRIPT

Computers Playing Computers Playing GamesGames
Computers Playing Computers Playing GamesGames
Arif ZamanArif Zaman
CS 101CS 101

Acknowledgements• Portions of this are taken from MIT’s
open-courseware http://ocw.mit.edu/• Some items are adapted from Chapter
5 on Games by some professor who adapted it from notes by Charles R. Dyer, University of Wisconsin-Madison

Why Computers Play?• Humans play for enjoyment, but computers…?• Games of strategy and skill require
“intelligence”. We may learn about thinking by learning how to teach computers.
• Hard but well defined problems, unlike other AI problems like speech, ethics etc.
• Competition, knowledge-representation, …• To provide entertainment, competition and
training to humans (that play or program).

Game Theory• Von Neumann and
Morgenstern analyzed two person zero-sum games, where each person takes a decision simultaneously, and then gets paid according to a payoff matrix.
• Economic games, can be multi-person, multi-stage.
Enemy Strategy
A B
My Strategy
X 10 -10
Y -2 40

Board Games• Two Person• Alternating moves• Zero Sum• Deterministic (not
Backgammon or Ludo)
• Perfect Information (not Bridge, Hearts)
• Examples– Tic-Tac-Toe– Checkers– Chess– Go– Reversi (Othello)

History• 1949 Claude Shannon
paper on Chess• 1951 Alan Turing
simulation on Checkers• 1955 Chess Program
using α-β.• 1966 MacHack• 1990 Belle (harware
assist)• 2000 Deep Blue (serious
hardware)
Belle
Deep Blue
Mac Hack
0
500
1000
1500
2000
2500
3000
3500
3 6 9 12
Depth (ply)
US
CF
Ra
tin
g

Top-down Program• Repeat Until Done
– DrawBoard– GetPlayerMove– CheckLegalMove ‘also check if game over– MakePlayerMove– DrawBoard– FindLegalMoves ‘also check if game over– EvaluateLegalMoves– MakeBestMove

Static Position Evaluator
• Given a position, come up with a “value”.• Values are 0…1 or 0…infinity or –infinity…
infinity.• 0..1 can represent “probability” of my lose/win• In chess can count
– my pieces – enemy pieces.– my total piece value – enemy total piece value.– Add points for Mobility– Add points for Center Control– Negative points for exposed king, etc.
• This is where humans experts excel.

Game Tree Mini-Max

Crude Evaluator• You can start off
with a crude static evaluator, and a high ply minimax.
• Russians believed that better would be an excellent but slow static evaluator with lower plies.
• The extreme strategies are of course a perfect evaluator with 1-ply
• Or the complete game-tree search with trivial evaluator.

Deep Blue• 32 node supercomputer, each with
eight special chess processors.• 50 – 100 billion moves in 3 mins
with a 13-30 ply search
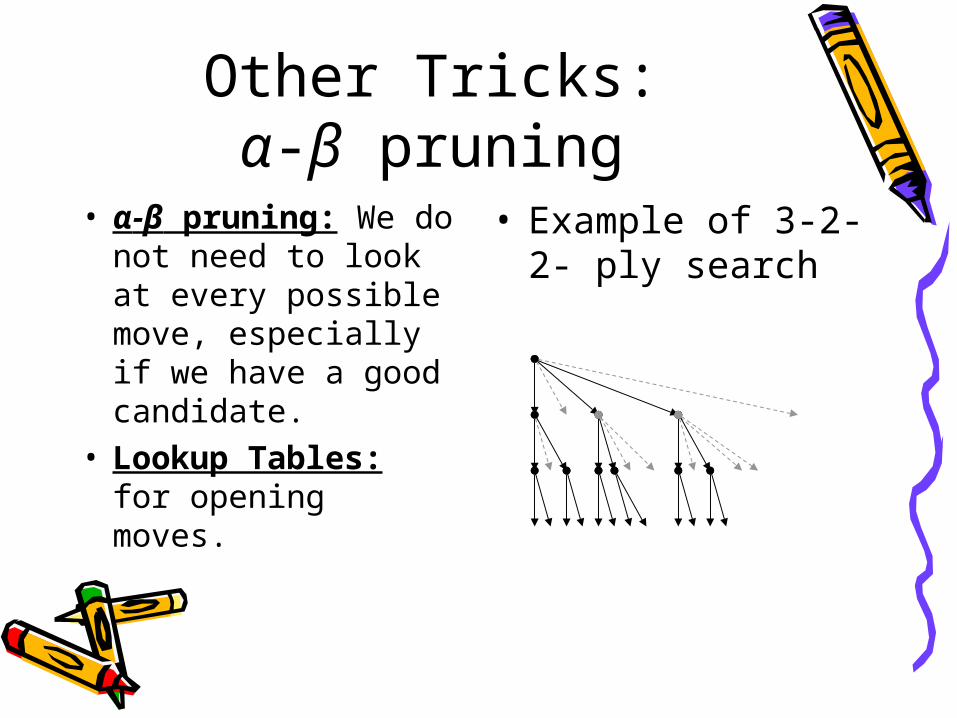
Other Tricks:α-β pruning
• α-β pruning: We do not need to look at every possible move, especially if we have a good candidate.
• Lookup Tables: for opening moves.
• Example of 3-2-2- ply search

Other Tricks:Quiessence Search
• Quiessence: Static evaluate at peaceful situations. Go deeper into fights.
• Tree Folding: Memo-ization
• Special program: for endgames.
• Variable depth trees result from quiessence searches.

Other Games• Go is much harder. The best computer
is far worse than the best human, even though the rules are very simple
• Checkers computers are far better than the best humans
• Tic-Tac-Toe is still a great mystery .• Othello has a very interesting story.

Rules of the game• Start with four
squares filled.• Move next to
opposite colored square.
• Change color of all opposite colored squared surrounded by moved piece and another piece of the same color.
• Must capture.
Reversi (Othello)• D E Moriarty and R
Miikkulainen, “Discovering Complex Othello StrategiesThrough EvolutionaryNeural Networks”
• Created a strong player without any initial knowledge, by “breeding”!
• Start with a “population” of 100 “random” programs.
• Kill the 90 losers in a competition. Breed the 10 winners by “re-combining” their “genes” with a bit of “mutation.”
• Repeat for 1000’s of generations.

Positional StrategyPositional Strategy• Programs quickly
learned the basic positional strategy:
• Take corners.• Avoid neighbors of
corners• Take neighbors of
neighbors of corners.
Mobility Strategy• Keep low piece
count• Restrict opponents
moves• Discovered only
once in Japan, and then everyone learnt it from them.

Mobility vs Positional• The mobility
strategy (learned by ENN = Evolutionary Neural Network) looks like it is loosing, but converts it to a win in the last 3-4 moves!

But…• Specially designed programs to
play Othello still do even better eg. Bill or Logistello.

More Complexities• Randomness
– Dice games• Ludo• Monopoly
Learn Probability Theory, and maximize chance of winning, or expected points.
• Multi-player Games– Collusion strategies
• Scrabble, Monopoly
– Card games
Use AI to recognize typical player types and weaknesses. Try to predict human response.

Write your own game!• By the end of this course, you
should have most of the tools to write your own game player.
• If you are interested, it will help to take “Data Structures”, so that you can represent trees on a computer.