computational science & engineering department cse quantum chemistry group, 2006 msc in high...
TRANSCRIPT

Computational Science & Engineering Department
CSE
Quantum Chemistry Group, 2006
MSc in High Performance ComputingComputational Chemistry Module
Lecture 9 Parallel Approaches to Quantum Chemistry
(ii) Distributed Data Parallelism
Martyn F Guest, Edo Apra, Huub van Dam and Paul Sherwood
CCLRC Daresbury Laboratory

Computational Science & Engineering Department
CSE
CSE
2Computational Science & Engineering Department
Outline of the Lecture
• Introduction to NWChem– highly efficient and portable Massively Parallel computational
chemistry package from PNNL
• Distributed Data SCF using one-sided communications• Post-Hartree Fock methods
– example Parallel MP2 energy– scalability
• Hybrid Replicated / Distributed implementations– example GAMESS-UK MPI-based SCF scheme– Performance vs. the GA-based code– exploiting shared memory
• Enabling larger calculations on SMP nodes– large scale calculations on enzymes
• Performance and scalability

Computational Science & Engineering Department
CSE
CSE
3Computational Science & Engineering Department
NWChem
• NWChem (North West Chem) from Pacific Northwest National Lab, Washington, USA
• Developed as part of the construction of the Environmental Molecular Sciences Laboratory (EMSL)
• Designed and developed to be a highly efficient and portable Massively Parallel computational chemistry package
• Provides computational chemistry solutions that are scalable with respect to chemical system size as well as MPP hardware size

Computational Science & Engineering Department
CSE
CSE
4Computational Science & Engineering Department
NWChem Overview
Provides major modeling and simulation capability for molecular science
Broad range of molecules, including biomolecules, nanoparticles and heavy elements
Electronic structure of molecules (non-relativistic, relativistic, ECPs, first and second derivatives)
Increasingly extensive solid state capability (DFT plane-wave, CPMD)
Molecular dynamics, molecular mechanics
Emphasis on modularity and portability. Freely distributed (downloaded by 502 research groups in
the last 12 months)
Performance characteristics – designed for MPP Portable – runs on a wide range of computers

Computational Science & Engineering Department
CSE
CSE
5Computational Science & Engineering Department
NWChem Goals
• NWChem would be based on algorithms that: – scale to hundreds, if not thousands, of processors, and,
– use the minimum number of flops consistent with the above.
• NWChem would be affordable to develop, maintain, and extend. • NWChem would be independent of computer architecture to the
maximum extent possible: – a hardware abstraction layer would be used to isolate the most of the
program from the details of the hardware, but
– it would be possible to tune the code to some extent to optimize performance on the specific computer being used.
• Achieving these goals required a combination of – research to determine the best solutions to the above problems,
– modern software engineering practices to implement these solutions,
– a world-wide set of collaborators to provide expertise and experience missing in the core software development team.
• 15 external collaborators were involved in the development of NWChem; 7 from the US, 7 from Europe, and 1 from Australia

Computational Science & Engineering Department
CSE
CSE
6Computational Science & Engineering Department
NWChem – Issues & Problems
• A number of basic computing issues had to be addressed to optimize the performance and scalability of NWChem. These included: processor architecture, node memory latency and bandwidth, interprocessor communications latency and bandwidth, and load balancing.
• Solving the associated problems often required rewriting and restructuring the software, explorations that were carried out by the postdoctoral fellows associated with the NWChem project.
• Another issue that was always in the foreground was the portability of the software. Computational chemists typically have access to a wide range of computer hardware, from various brands of desktop workstations, to various brands of departmental computers, to some of the world’s largest supercomputers. To most effectively support their work, it was important that NWChem run on all of these machine, if possible.

Computational Science & Engineering Department
CSE
CSE
7Computational Science & Engineering Department
Software Engineering Processes
The process for designing, developing and implementing NWChem used modern software engineering practices. The process can be summarized in the following six steps:
1. Requirements gathering. The process began by gathering requirements from the researchers associated with the EMSL Project. This defined functionality that had to be provided by the QC software.
2. Preliminary design and prototyping. After the requirements were gathered, work on NWChem began. This included design of the overall system architecture, identification of the major subsystems, definition of the objects and modules, definition of the internal and external interfaces, characterization of the major algorithms, etc.
3. Resolution of unresolved issues. The preliminary design work led to the identification of a number of major, unresolved issues. Research projects were targeted at each of these issues.
4. Detailed design. In the meantime, the preliminary design was extended to a set of “code to” specifications. As the major issues were resolved, they were included in the “code to” specifications.
5. Implementation. NWChem was then created in well defined versions and revision control was used to track the changes.
6. Testing and Acceptance. Finally, a bevy of test routines were used to verify the code and ensure that the requirements were met.

Computational Science & Engineering Department
CSE
CSE
8Computational Science & Engineering Department
Lessons Learned – Highly Distributed Project
• Although a combination of on-site core team plus off-site collaborators provided the necessary technical capabilities, there are lessons to be learned about managing such a highly distributed project. e.g,
– Time and effort required for integration of existing sequential or parallel codes into the new code framework was always larger than estimated.
– Documentation, for both users and programmers, should have been initiated earlier in the project. The programmer’s manual is especially important because this provides the guidelines needed to ensure that the software produced by the distributed team will work together.
– Software components that are on the critical path should be developed in-house, since the time schedules & priorities of collaborators inevitably differ from those of the core team.
– Vital to implement code reviews both for software developed in-house by the “core” team as well as that developed by the external collaborators.
• Experience suggests that a distributed software development team can be successful if the core team is large enough to develop all of the software components on the critical path and if sufficient guidance is provided to the collaborators on the format and content for their contributions and their progress is carefully monitored.

Computational Science & Engineering Department
CSE
CSE
9Computational Science & Engineering Department
What is NWChem now?
• O(106) lines of code (mostly FORTRAN)• A new version is released on a yearly basis• Freely available after signing a user agreement • World-wide distribution • More than 350 peer-reviewed publications citing NWChem
usage• Most used software on the EMSL Molecular Science
Computing Facility hardware.

Computational Science & Engineering Department
CSE
CSE
10Computational Science & Engineering Department
Framework for Chemical Computation
• The key to achieving the above is a carefully designed architecture that emphasizes layering and modularity.
• At each layer of NWChem, subroutine interfaces or styles were specified in order to control critical characteristics of the code, such as ease of restart, the interaction between different tasks in the same job, and reliable parallel execution.
• Object-oriented design concepts were used extensively within NWChem. Basis sets, molecular geometries, chunks of dynamically allocated local memory, and shared parallel arrays are all examples of “objects” within NWChem.
• NWChem is implemented in a mixture of C and Fortran-77, since neither C++ nor Fortran-90/95 were suitable at the start of the project. Since a true object-oriented language was not used, and in particular did not support inheritance, NWChem does not have “objects” in the strict sense of the word.
• Careful design with consideration of both data and actions performed on the data, plus the use of data hiding and abstraction, permits us to realize many of the benefits of an object-oriented design.
Computational Science & Engineering Department
CSE
CSE
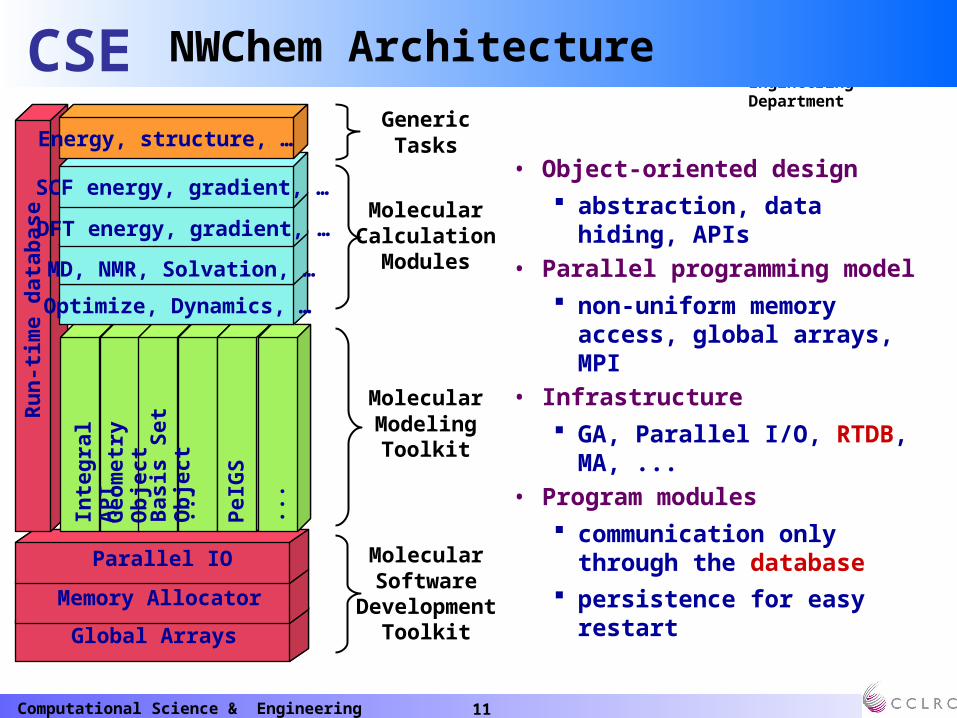
11Computational Science & Engineering Department
NWChem ArchitectureR
un
-tim
e d
atab
ase DFT energy, gradient, …
MD, NMR, Solvation, …
Optimize, Dynamics, …
SCF energy, gradient, …
Inte
gral
AP
I
Geo
met
ry O
bje
ct
Bas
is S
et O
bje
ct
...PeI
GS
...
Global Arrays
Memory Allocator
Parallel IO
MolecularModelingToolkit
MolecularCalculation
Modules
MolecularSoftware
DevelopmentToolkit
GenericTasksEnergy, structure, …
• Object-oriented design abstraction, data hiding, APIs
• Parallel programming model non-uniform memory access,
global arrays, MPI• Infrastructure
GA, Parallel I/O, RTDB, MA, ...• Program modules
communication only through the database
persistence for easy restart

Computational Science & Engineering Department
CSE
CSE
12Computational Science & Engineering Department
1. Software Development Toolkit
• In the very bottom layer of NWChem is the Software Development Toolkit (SDT).
• It includes the Memory Allocator (MA), Global Arrays (GA), and Parallel IO (ParIO). The SDT was (and still is) the responsibility of the computer scientists involved in NWChem.
• It essentially defines a “hardware abstraction” layer that provides a machine-independent interface to the upper layers of NWChem.
• When porting from one computer system to another, nearly all changes occur in this layer, with most of the changes elsewhere being for tuning or to accommodate machine specific problems such as compiler flaws.
• The SDT contains only a small fraction of the code in NWChem, less than 2%, and only a small fraction of the code in the Toolkit is machine dependent (notably the address-translation and transport mechanisms for the one-sided memory operations).

Computational Science & Engineering Department
CSE
CSE
13Computational Science & Engineering Department
2. Molecular Modelling Toolkit
• The next layer, the “Molecular Modelling Toolkit,” provides the functionality commonly required by computational chemistry algorithms.
• This functionality is provided through “objects” and application programmer interfaces (APIs) e.g. objects include basis sets and geometries.
• Examples of the APIs include those for the integrals, quadratures, and a number of basic mathematical routines (e.g., linear algebra and Fock-matrix construction).
• Nearly everything that might be used by more than one type of computational method is exposed through a subroutine interface. Common blocks are not used for passing data across APIs, but are used to support data hiding behind APIs.
• The runtime database (RTDB) is a key component of NWChem, tying together all of the layers. Arrays of typed data are stored in the database using simple ASCI strings for keys (or names) and the database may be accessed either sequentially or in parallel.

Computational Science & Engineering Department
CSE
CSE
14Computational Science & Engineering Department
3. Molecular Calculation Modules
• The next layer within NWChem, the Molecular Calculation Modules, is comprised of independent modules that communicate with other modules only via the RTDB or other persistent forms of information.
• This design ensures that, when a module completes, all persistent information is in a consistent state. Some of the inputs and outputs of modules (via the database) are also prescribed.
• Thus, all modules that compute an energy store it in a consistently named database entry—in this case :energy, substituting the name of the module for. Examples of modules include computation of the energy for SCF, DFT, and MCSCF wave functions.
• The code to read the user input is also a module. This makes the behaviour of the code more predictable, e.g., when restarting a job with multiple tasks or steps, by forcing the state of persistent information to be consistent with the input already processed. Modules often invoke other modules.

Computational Science & Engineering Department
CSE
CSE
15Computational Science & Engineering Department
4. Generic Task Layer
• The highest layer within NWChem is the “task” layer, sometimes called the “generic-task” layer.
• Functions at this level are also modules—all of their inputs and outputs are communicated via the RTDB, and they have prescribed inputs and outputs. However, these capabilities are no longer tied to specific types of wave functions or other computational details.
• Thus, regardless of the type of wave function requested by the user, the energy may always be computed by invoking task_energy() and retrieving the energy from the database entry named task:energy.
• This greatly simplifies the use of generic capabilities such as optimization, numeric differentiation of energies or gradients, and molecular dynamics. It is the responsibility of the “task”-layer routines to determine the appropriate module to invoke.

Computational Science & Engineering Department
CSE
CSE
16Computational Science & Engineering Department
NUMA Model of Computation
Non-uniform memory access (NUMA) model of computation. Each process independently moves data from a shared data structure to local memory for computation. Results can be written or accumulated into another shared structure. A simple performance model can be used to ensure that the cost of moving data is offset by the amount of computation performed.

Computational Science & Engineering Department
CSE
CSE
17Computational Science & Engineering Department
Distributed Data Fock Build
• In contrast to GAMESS-UK, NWChem was designed with parallel machines in mind
• All major data structures can be distributed• Distribution achieved using the Global Array tools
– supporting routines include matrix multiplication, diagonalisation, ...
• SCF solution – makes heavy use of one-sided primitives provided by Global Arrays
• e.g. Fock matrix build
F=H0+P[()-1/2()]
Square Matrices Integrals (computed on the Fly)

Computational Science & Engineering Department
CSE
CSE
18Computational Science & Engineering Department
Parallel SCF & DFT: Replicated vs Distributed Data Strategies
Replicated Data e.g. GAMESS-UK F, H, P held on all nodes Simple and easy to load balance Largest problem is governed by
the memory available to one CPU, (not that of the whole machine)
Harder to parallelise matrix algebra (results of parallel operation must be re-replicated so that each CPU has a current version)
Distributed Data e.g. NWChem F, H, P distributed Limit on system size is now that given
by all memory on the computer, global communications largely avoided
as re-replication is not required, For any integral, part of F or P is likely
to be remote require many 1-sided communications
(e.g. GA tools) or complex systolic strategy
problems with load balancing!
F=H0+P[()-1/2()]
Square Matrices Integrals (computed on the Fly)
Computational Science & Engineering Department
CSE
CSE
19Computational Science & Engineering Department
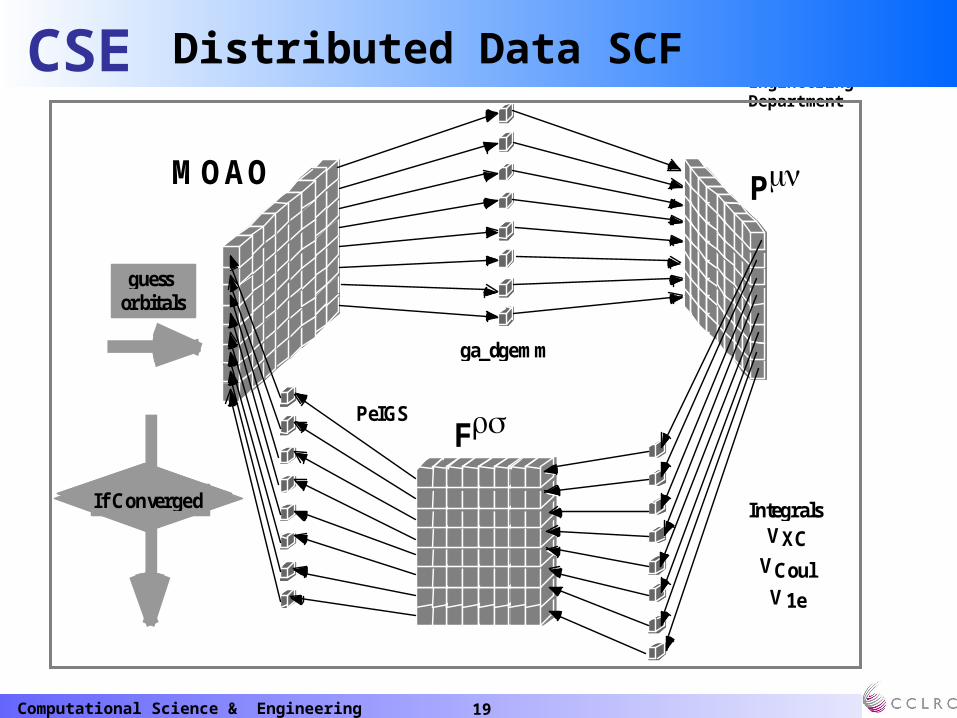
Distributed Data SCF
MOAO P
ga_dgemm
IntegralsVXC
VCoulV1e
PeIGSF
guessorbitals
If Converged

Computational Science & Engineering Department
CSE
CSE
20Computational Science & Engineering Department
Distributed Data Fock Matrix Construction
Computational Science & Engineering Department
CSE
CSE
21Computational Science & Engineering Department
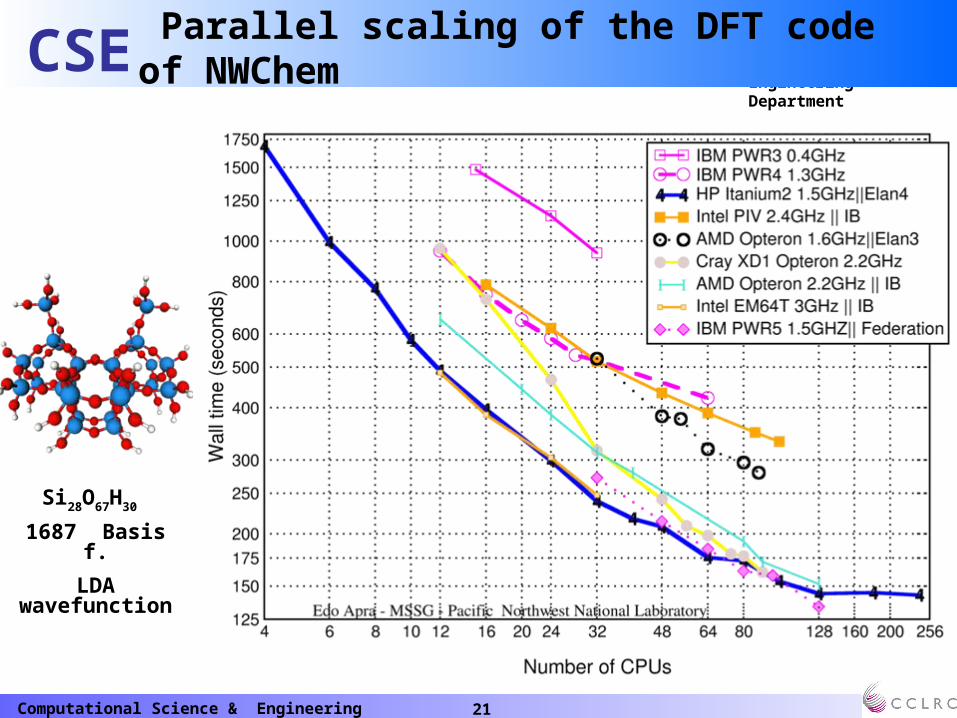
Si28O67H30
1687 Basis f.
LDA wavefunction
Parallel scaling of the DFT code of NWChem

Computational Science & Engineering Department
CSE
CSE
22Computational Science & Engineering Department
Parallelising Post-HF Methods
Key steps are typically– Transformation of integrals from atomic orbital (AO) to molecular
orbital (MO) basis
• Usually all 4 indices ( ) are transformed by multiplication by Molecular Orbital (Ci) matrix to MO basis (a,b,i,j)
• Overall process scales as n5
• Serial algorithms often heavily I/O based
– Aggregate memory of a large parallel machine can eliminate I/O
• Global Arrays and one-sided communications can ensure all integrals are available to all nodes
• Knowledge of GA data distribution can be used to minimise communications
• Dynamic load balancing (DLB) can be used
– Compute integrals, apply partial (1 or 2 index) transformation and store in a Global Array, then repeat….

Computational Science & Engineering Department
CSE
CSE
23Computational Science & Engineering Department
Parallelising Post-HF Methods
Example– Energy at the MP2 (2nd order Moeller-Plesset perturbation
theory) level
– here <ab|ij> are integrals transformed into the MO basis
• i,j are occupied molecular orbitals
• a,b are virtual (unoccupied) molecular orbitals
– This can be computed using a scheme which stores partially transformed integrals (i|j) illustrating the use of Global Arrays
, are atomic orbitals
• two MO indices, two AO indices
baji bajiI I
II abij
EE
VVE
,,,
2
41
)0(0
)0(
)0()1()1()0(
)2(ˆˆ
Computational Science & Engineering Department
CSE
CSE
24Computational Science & Engineering Department
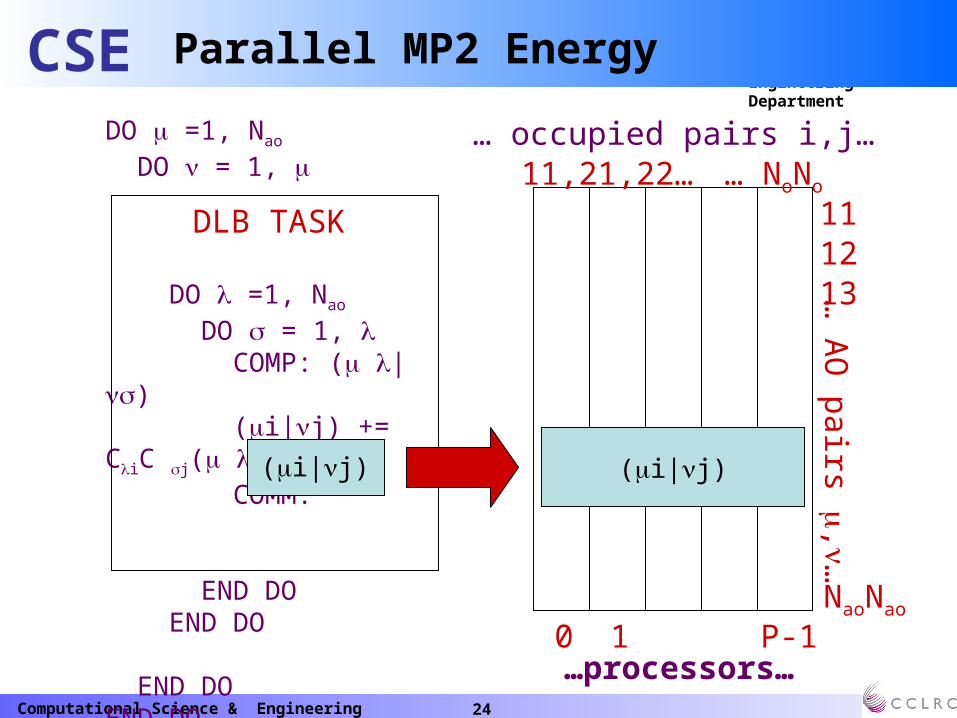
DO =1, Nao
DO = 1,
DO =1, Nao
DO = 1, COMP: ( |) (i|j) += CiC j( |) COMM:
END DO END DO
END DOEND DO
0 1 P-1…processors…
… A
O pairs
,…… occupied pairs i,j…11,21,22… … NoNo
1112
NaoNao
13
DLB TASK
(i|j)(i|j)
Parallel MP2 Energy

Computational Science & Engineering Department
CSE
CSE
25Computational Science & Engineering Department
0 1 P-1…processors…
… A
O pairs
,…… occupied pairs i,j…11,21,22… … NoNo
1112
NaoNao
13..virtual pairs a,b…
1112
NvNv
13
E(MP2) = 0DO i =1, No
DO j = 1, i
IF (i,j is local) THEN
GET (i|j)
(ai|bj) += CaCb (i|j)
PUT (ai|bj)
E(MP2) = E(MP2) +
(ai|bj)[2(ai|bj)-(bi|aj)]
/[e(i)+e(j)-e(a)-e(b)]
END IF
END DOEND DOGSUM (E(MP2))
Parallel MP2 Energy
Computational Science & Engineering Department
CSE
CSE
26Computational Science & Engineering Department
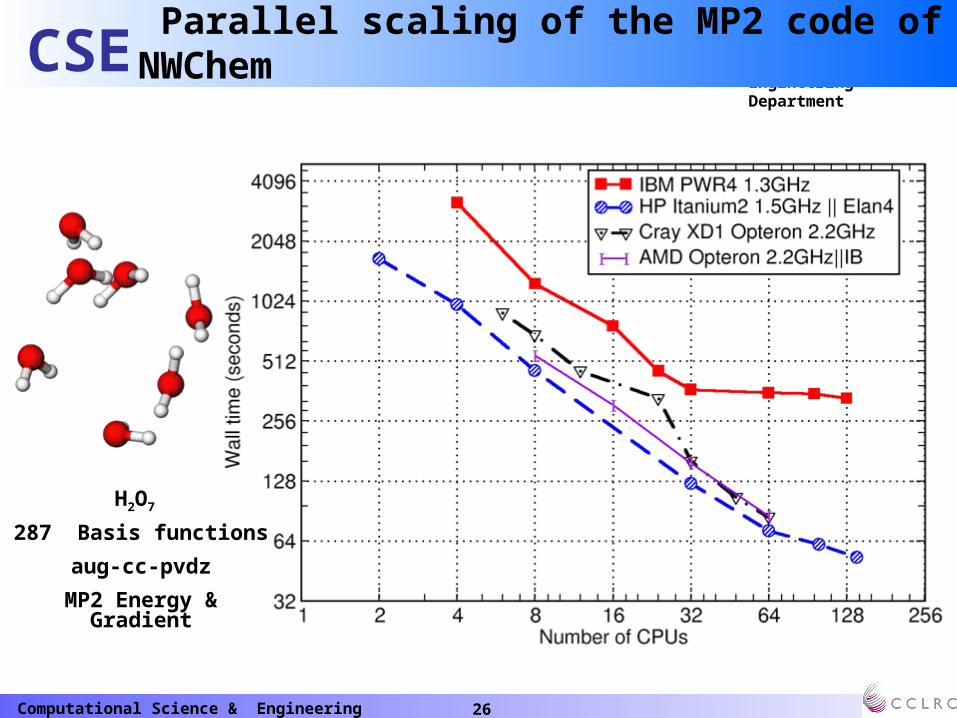
H2O7
287 Basis functions
aug-cc-pvdz
MP2 Energy & Gradient
Parallel scaling of the MP2 code of NWChem

Computational Science & Engineering Department
CSE
CSE
27Computational Science & Engineering Department
Large-Scale Parallel Ab-Initio Calculations
• GAMESS-UK now has two parallelisation schemes:
– The traditional version based on the Global Array tools• retains a lot of replicated data• limited to about 4000 atomic basis functions
– More recent developments by Ian Bush (High Performance Applications Group, Daresbury) have extended the system sizes available for treatment by both GAMESS-UK (molecular systems) and CRYSTAL (periodic systems)
• Partial introduction of “Distributed Data” architecture…• MPI/ScaLAPACK based

Computational Science & Engineering Department
CSE
CSE
28Computational Science & Engineering Department
The MPI/ScaLAPACK Implementation of the GAMESS-UK SCF/DFT module
• Adopt pragmatic, hybrid approach in which– MPI-based tools (such as ScaLAPACK) used
• On HPCx these are more efficient than GA and LAPI– All data structures are fully distributed except those
required for the Fock matrix build (F, P)
• Obvious drawback - some large replicated data structures are required. – These are kept to a minimum. For a closed shell HF or
DFT calculation only two replicated matrices are required, one Fock and one density (doubled for UHF).
– Further the symmetry of these matrices is used to cut down on the required memory.

Computational Science & Engineering Department
CSE
CSE
29Computational Science & Engineering Department
0
100
200
300
400
64 128 256 512 1024
GA-based Implementation
GA-based Implementation (SP9)
MPI/ScaLAPACK
0
2000
4000
6000
8000
64 128 256 512 1024
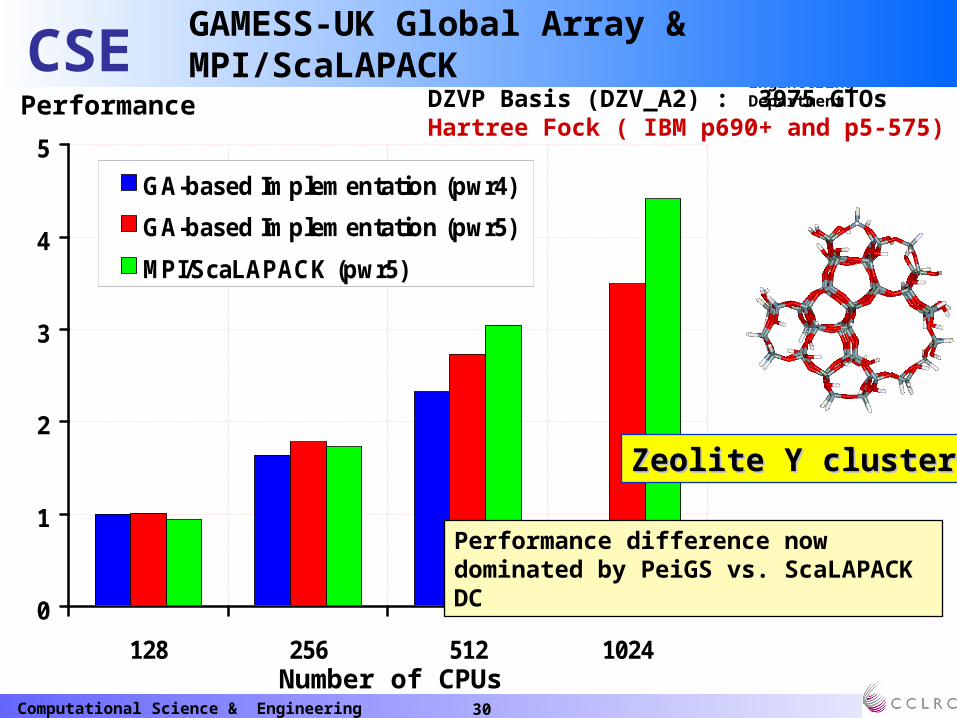
GA-based ImplementationGA-based Implementation (SP9)MPI/ScaLAPACK
DZVP Basis (DZV_A2) : 3975 GTOsHartree Fock ( IBM p690+)
Zeolite Y cluster
Elapsed Time (seconds)
Number of CPUs Number of CPUs
Speed-up
Distributed Data Implementation of GAMESS-UK
Computational Science & Engineering Department
CSE
CSE
30Computational Science & Engineering Department
0
1
2
3
4
5
128 256 512 1024
GA-based Implementation (pwr4)
GA-based Implementation (pwr5)
MPI/ScaLAPACK (pwr5)
DZVP Basis (DZV_A2) : 3975 GTOsHartree Fock ( IBM p690+ and p5-575)
Zeolite Y clusterZeolite Y cluster
GAMESS-UK Global Array & MPI/ScaLAPACK
Performance
Number of CPUs
Performance difference now dominated by PeiGS vs. ScaLAPACK DC

Computational Science & Engineering Department
CSE
CSE
31Computational Science & Engineering Department
Benchmark Systems and Target Application
0
64
128
192
256
64 128 256
Triose Phosphate Isomerase
Superoxide Dismutase
Superoxide Dismutase (SOD) model, 3870 basis functions at 6-31G*Triose Phosphate Isomerase (TIM) model, 3755 basis functions at 6-31G*
Speed-up (HF)
Isocitrate Lyase (mixed basis set, 22,400 basis functions) is the largest calculation performed to date.

Computational Science & Engineering Department
CSE
CSE
32Computational Science & Engineering Department
Isocitrate Lyase: Electrostatic Potentials
• Series of calculations forms part of a drug design study (van Lenthe, Utrecht, de Jonge & Vinkers, MolMo Services BVBA Belgium)
• Using ab-initio results to calibrate excluded volume and electrostatic terms in a docking scheme
• Electrostatic potential from the Hartree-Fock calculations (left) and that calculated from Force-Field charges (right), suggest that commonly used charge models may not be adequate.

Computational Science & Engineering Department
CSE
CSE
33Computational Science & Engineering Department
Exploiting Shared Memory
• Replicated memory Fock build is adopted to avoid large numbers of one-sided communications over the network
• Shared memory nodes offer a way to reduce memory requirement – Allocate one copy of the matrix per shared memory node– Exploit fast one-sided (shared memory) comms within each
node– No additional one-sided communications between nodes
• This concept is available – Within Global Array-based programs using mirrored arrays– Within MPI programs by using standard UNIX System V
Shared memory interface (library written by Ian Bush)
Computational Science & Engineering Department
CSE
CSE
34Computational Science & Engineering Department
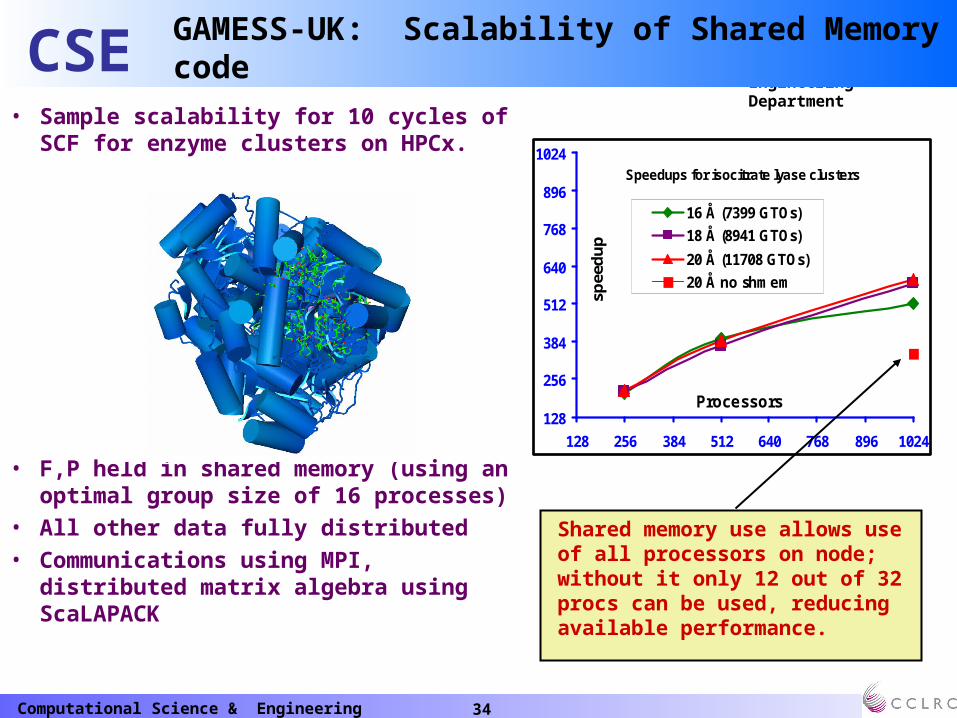
GAMESS-UK: Scalability of Shared Memory code
• Sample scalability for 10 cycles of SCF for enzyme clusters on HPCx.
• F,P held in shared memory (using an optimal group size of 16 processes)
• All other data fully distributed• Communications using MPI, distributed
matrix algebra using ScaLAPACK
Shared memory use allows use of all processors on node; without it only 12 out of 32 procs can be used, reducing available performance.
Speedups for isocitrate lyase clusters
128
256
384
512
640
768
896
1024
128 256 384 512 640 768 896 1024
Processors
spee
du
p
16 Å (7399 GTOs)
18 Å (8941 GTOs)
20 Å (11708 GTOs)
20 Å no shmem

Computational Science & Engineering Department
CSE
CSE
35Computational Science & Engineering Department
The Future - Targeting larger enzymes ...

Computational Science & Engineering Department
CSE
CSE
36Computational Science & Engineering Department
WWW Pages for NWChem & GAMESS-UK
• Capabilities• Platforms• Download• User’s Manual• Programmer's Manual• Release Notes• FAQ’s• Known Bugs• Support• Tutorial• Contributors• Benchmarks• Applications
http://www.emsl.pnl.gov/docs/nwchem/nwchem.html
• Capabilities:www.cfs.dl.ac.uk/gamess-uk/
• User’s Manual:www.cfs.dl.ac.uk/docs
• Tutorial (this material): www.cfs.dl.ac.uk/tutorials
• Benchmarks:www.cfs.dl.ac.uk/benchmarks
• Applications:www.cfs.dl.ac.uk/applications
• FAQ’s:www.cfs.dl.ac.uk/FAQ
• Hardware Platforms:www.cfs.dl.ac.uk/hardware
• Bug Reporting:www.cfs.dl.ac.uk/cgi-bin/bugzilla/index.cgi
NWChem GAMESS-UK

Computational Science & Engineering Department
CSE
CSE
37Computational Science & Engineering Department
Summary
We have considered the role of one-sided communications strategy in quantum chemistry applications– supports a distributed data strategy for SCF
• reduce memory requirements, study larger systems• many small, asynchronous messages impacts on
efficiency
– very valuable for implementation of post-HF methods• algorithms involve transformation of integrals• exploit global memory to hold integrals, reducing I/O
– GAMESS-UK parallel strategy involves a mix of distributed data and replicated data strategies