compiler support for superscalar processors. loop unrolling assumption: standard five stage pipeline...
TRANSCRIPT

Compiler Support forSuperscalar Processors

Loop Unrolling
• Assumption:• Standard five stage pipeline• Empty cycles between instructions before the result can be
used:– FP-ALU – FP-ALU 3– FP-ALU – Store 2– Load – FP-ALU 1– Load – Store 0
• Jumps have one empty cylce
• Independent operations are important for efficient usage of the pipeline
• Loop unrolling is a very important technique.
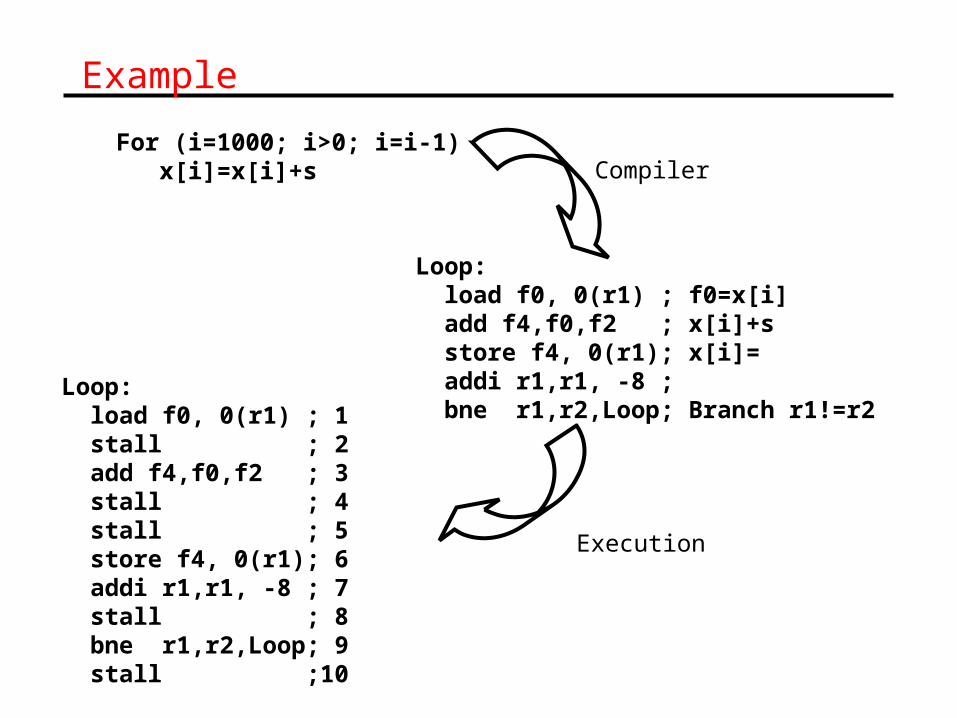
Example
For (i=1000; i>0; i=i-1) x[i]=x[i]+s
Loop: load f0, 0(r1) ; f0=x[i] add f4,f0,f2 ; x[i]+s store f4, 0(r1); x[i]= addi r1,r1, -8 ; bne r1,r2,Loop; Branch r1!=r2
Compiler
Loop: load f0, 0(r1) ; 1 stall ; 2 add f4,f0,f2 ; 3 stall ; 4 stall ; 5 store f4, 0(r1); 6 addi r1,r1, -8 ; 7 stall ; 8 bne r1,r2,Loop; 9 stall ;10
Execution

Instruction Scheduling
• Good instruction scheduling can reduce the execution time from 10 cycles to 6 cycles.
Loop: load f0, 0(r1) ; 1 addi r1,r1, -8 ; 2 add f4,f0,f2 ; 3 stall ; 4 bne r1,r2,Loop; 5 store f4, 8(r1); 6
• Requires• Dependence analysis• Symbolic optimization

Loop Unrolling
• The real computation requires only three instructions• load, add, store
• Additional instruction for loop control (Overhead)• Loop unrolling by a factor of k means
• The loop body is replicated k times.• Accesses to the loop variable have to be adapted. • The loop control needs to be adapted.
• Generation of a post loop if the number of iterations is not divisible by k.

Example
• Advantages of loop unrolling• The ratio between useful instructions and overhead is
improved. • There are more operations available for instruction
scheduling.
For (i=1000; i>0; i=i-4){ x[i]=x[i]+s x[i-1]=x[i-1]+s x[i-2]=x[i-2]+s x[i-3]=x[i-3]+s}

Reduction of overhead
Loop: load f0, 0(r1) ; x[i] add f4,f0,f2 ; store f4, 0(r1) ; load f6, -8(r1) ; x[i-1] add f8,f6,f2 ; store f8,-8(r1) ; load f10,-16(r1) ; x[i-2] add f12,f10,f2 ; store f12,-16(r1); load f14,-24(r1) ; x[i-3] add f16,f14,f2 ; store f16,-24(r1); addi r1,r1, -32 ; bne r1,r2,Loop ;
1367912131518192124252728
• 28 cycles for 4 iterations• Before 40 cycles for 4 iterations

Optimized scheduling of instructions
• Results in 3,5 cycles per iteration (6 before)
Loop: load f0, 0(r1) ; x[i] load f6, -8(r1) ; x[i-1] load f10,-16(r1) ; x[i-2] load f14,-24(r1) ; x[i-3] add f4,f0,f2 ; add f8,f6,f2 ; add f12,f10,f2 ; add f16,f14,f2 ; store f4, 0(r1) ; store f8,-8(r1) ; addi r1,r1, -32 ; store f12,16(r1); bne r1,r2,Loop ; store f16,8(r1) ;
1234567891011121314

Register Allocation
• Using different registers allows reordering
Loop: load f0, 0(r1) ; x[i] add f4,f0,f2 ; store f4, 0(r1) ; load f0, -8(r1) ; x[i-1] add f4,f0,f2 ; store f4,-8(r1) ; …
Loop: load f0, 0(r1) ; x[i] stall add f4,f0,f2 ; load f0, -8(r1) ; x[i-1] stall store f4, 0(r1) ; add f4,f0,f2 ; stall stall store f4,-8(r1) ; …

Register Allocation
• Compiler starts with an unlimited number of virtual registers.
• These registers are then mapped with graph coloring to the registers in the ISA.
• Life range of a register: Instructions where a virtual register is life, i.e., from the definition of the register to the last access.
• Creation of a graph– Nodes are virtual registers– Edges are inserted if the life ranges overlap
• Goal: Coloring of nodes with a minimal number of colors, so that neighboring nodes do not have the same color. The number of colors has to be smaller or equal to the number of ISA registers.
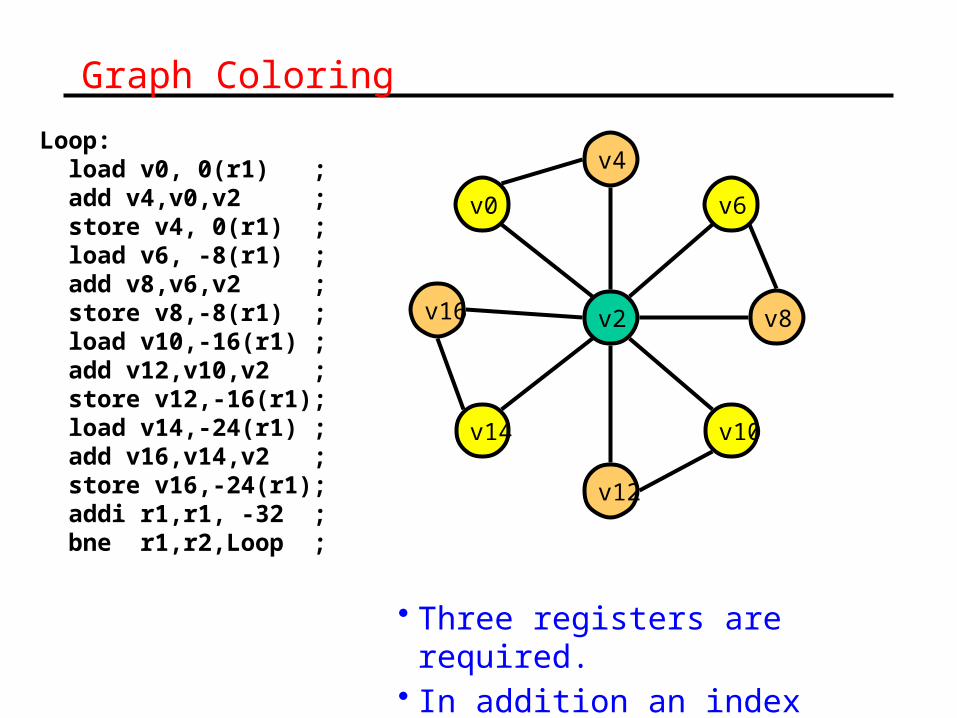
Graph Coloring
• Three registers are required.• In addition an index register.
Loop: load v0, 0(r1) ; add v4,v0,v2 ; store v4, 0(r1) ; load v6, -8(r1) ; add v8,v6,v2 ; store v8,-8(r1) ; load v10,-16(r1) ; add v12,v10,v2 ; store v12,-16(r1); load v14,-24(r1) ; add v16,v14,v2 ; store v16,-24(r1); addi r1,r1, -32 ; bne r1,r2,Loop ;
v0
v2
v4
v6
v8
v10
v12
v14
v16
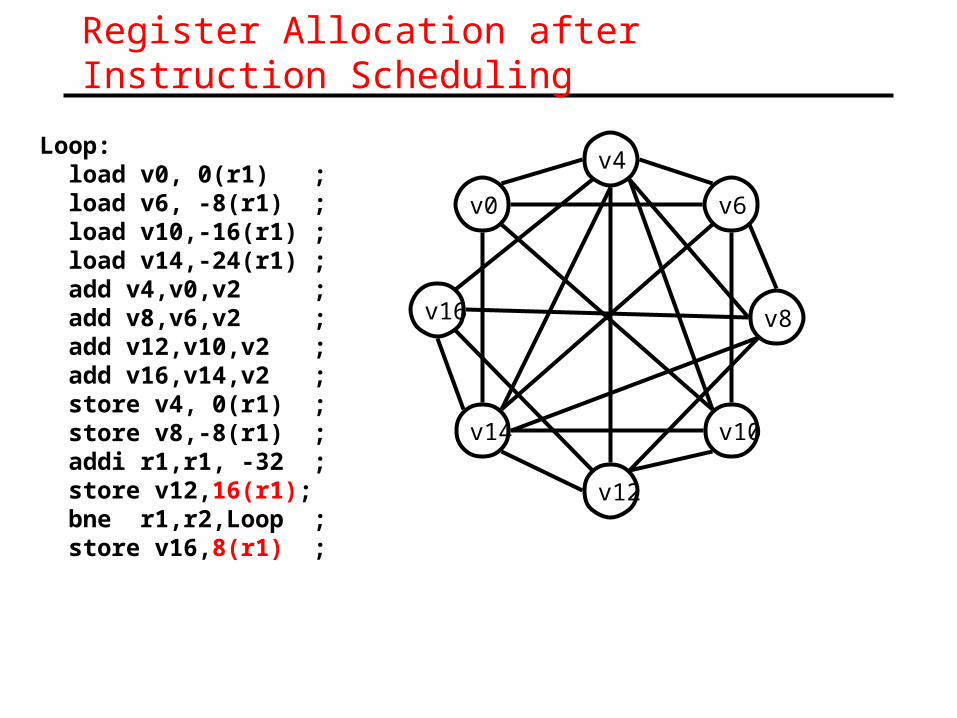
Register Allocation after Instruction Scheduling
Loop: load v0, 0(r1) ; load v6, -8(r1) ; load v10,-16(r1) ; load v14,-24(r1) ; add v4,v0,v2 ; add v8,v6,v2 ; add v12,v10,v2 ; add v16,v14,v2 ; store v4, 0(r1) ; store v8,-8(r1) ; addi r1,r1, -32 ; store v12,16(r1); bne r1,r2,Loop ; store v16,8(r1) ;
v0
v4
v6
v8
v10
v12
v14
v16
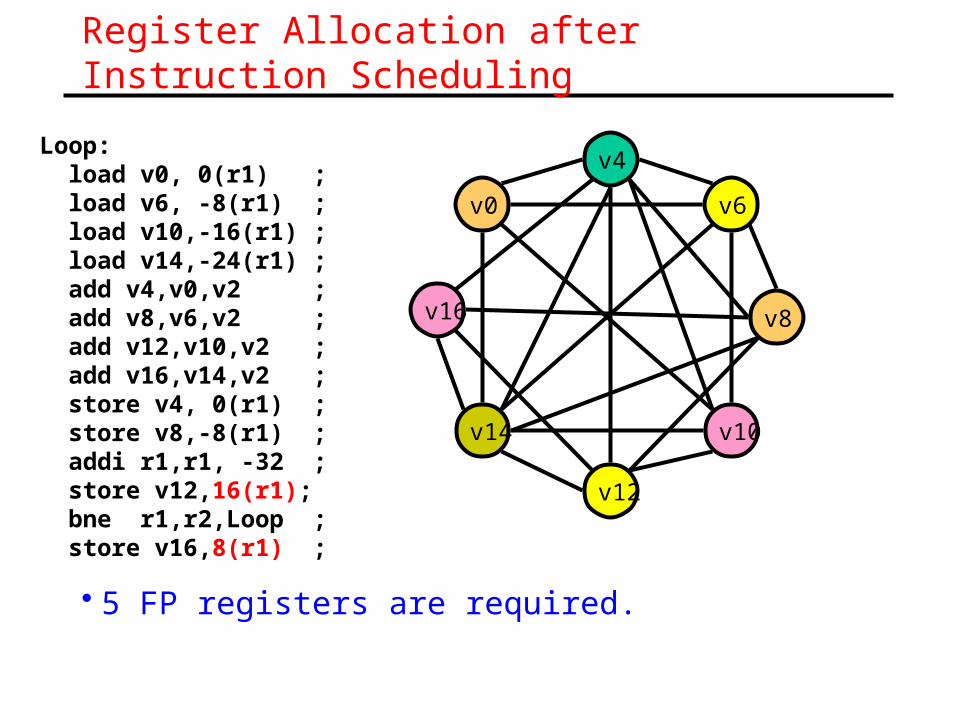
Register Allocation after Instruction Scheduling
• 5 FP registers are required.
Loop: load v0, 0(r1) ; load v6, -8(r1) ; load v10,-16(r1) ; load v14,-24(r1) ; add v4,v0,v2 ; add v8,v6,v2 ; add v12,v10,v2 ; add v16,v14,v2 ; store v4, 0(r1) ; store v8,-8(r1) ; addi r1,r1, -32 ; store v12,16(r1); bne r1,r2,Loop ; store v16,8(r1) ;
v0
v4
v6
v8
v10
v12
v14
v16
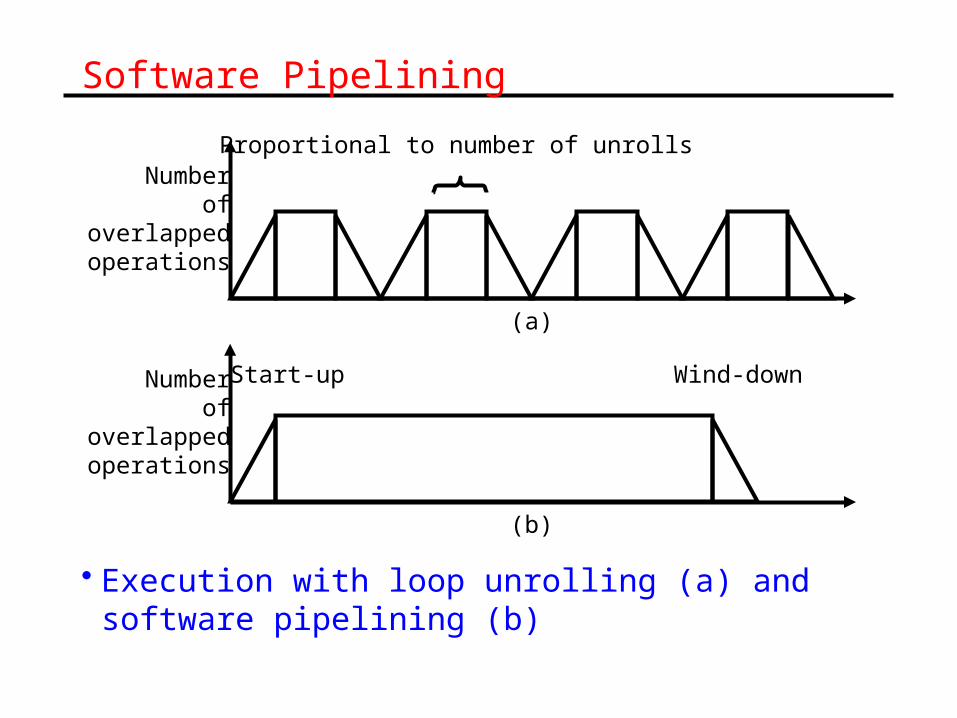
Software Pipelining
• Execution with loop unrolling (a) and software pipelining (b)
Numberof
overlappedoperations
Proportional to number of unrolls
(a)
Numberof
overlappedoperations
(b)
Start-up Wind-down
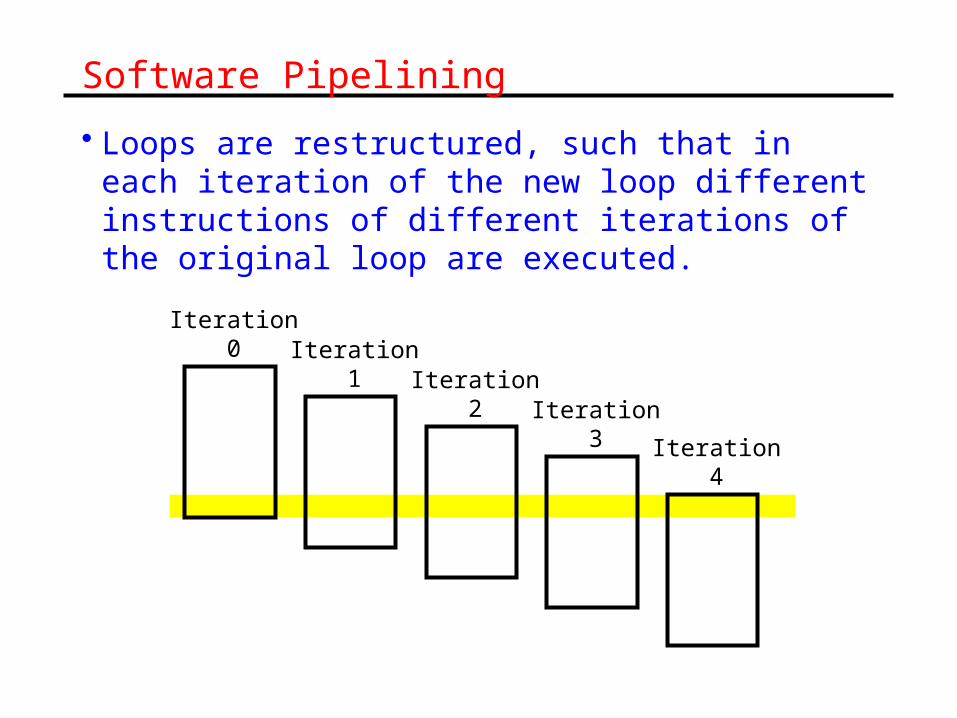
Software Pipelining
• Loops are restructured, such that in each iteration of the new loop different instructions of different iterations of the original loop are executed.
Iteration0 Iteration
1 Iteration2 Iteration
3 Iteration4

Example Software Pipelining
Pipelined loop
load f0, 0(r1)add f4,f0,f2store f4, 0(r1)addi r1,r1, -8bne r1,r2,Loop
load f0, 0(r1)add f4,f0,f2store f4, 0(r1)load f0, 0(r1)add f4,f0,f2store f4, 0(r1)load f0, 0(r1)add f4,f0,f2store f4, 0(r1)
Iteration i:
Iteration i-1:
Iteration i-2:
Loop: store f4,16(r1); stores into M[i] add f4,f0,f2 ; adds to M[i-1] load f0,0(r1) ; loads M[i-2] addi r1,r1, -8 bne r1,r2,Loop
Original loop
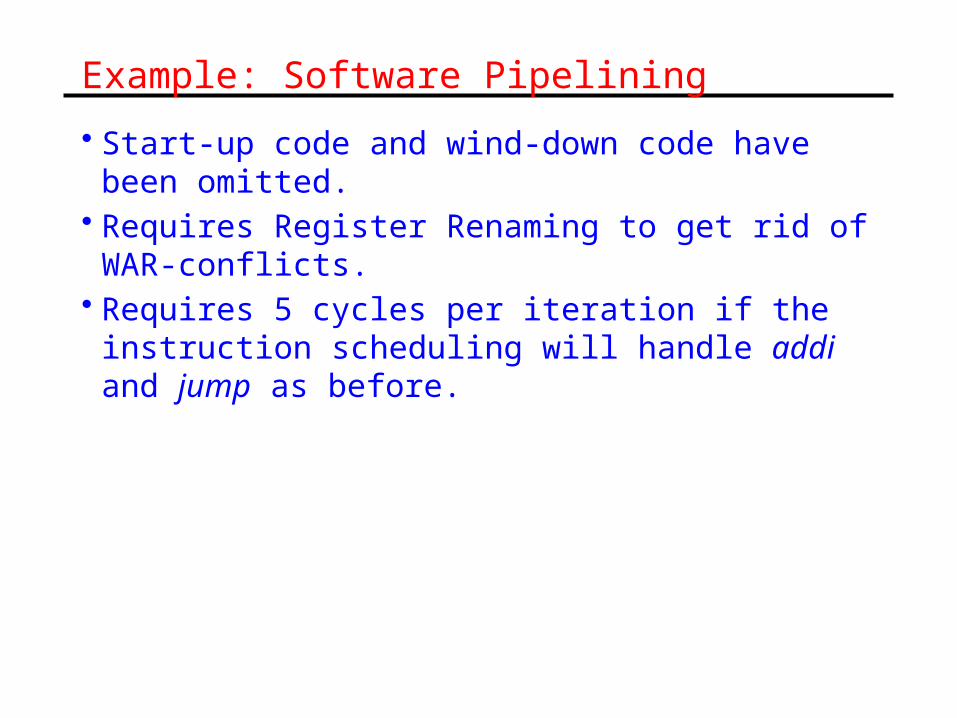
Example: Software Pipelining
• Start-up code and wind-down code have been omitted.• Requires Register Renaming to get rid of WAR-
conflicts.• Requires 5 cycles per iteration if the instruction
scheduling will handle addi and jump as before.

Software Pipelining vs Loop Unrolling
• Software Pipelining is symbolic Loop Unrolling• Algorithms are based on Loop Unrolling• Advantage of Software Pipelining
• Results in shorter code, especially for long latencies.• Reduces area of low overlap to start-up and wind-down loop.
• Advantage of Loop Unrolling• Reduces loop overhead
• Advantage of both techniques• Use independent operations from different loop iterations.
• Best results by combining both techniques.

Loop fusion
• Loop fusion combines subsequent loops with same loop control.
• Instructions might be executed more efficiently. • Loop fusion is not always possible.
do i=1,n a(i)= b(i)+2enddo
do i=1,n c(i)= d(i+1) * a(i)enddo
do i=1,n a(i)= b(i)+2 c(i)= d(i+1) * a(i)enddo
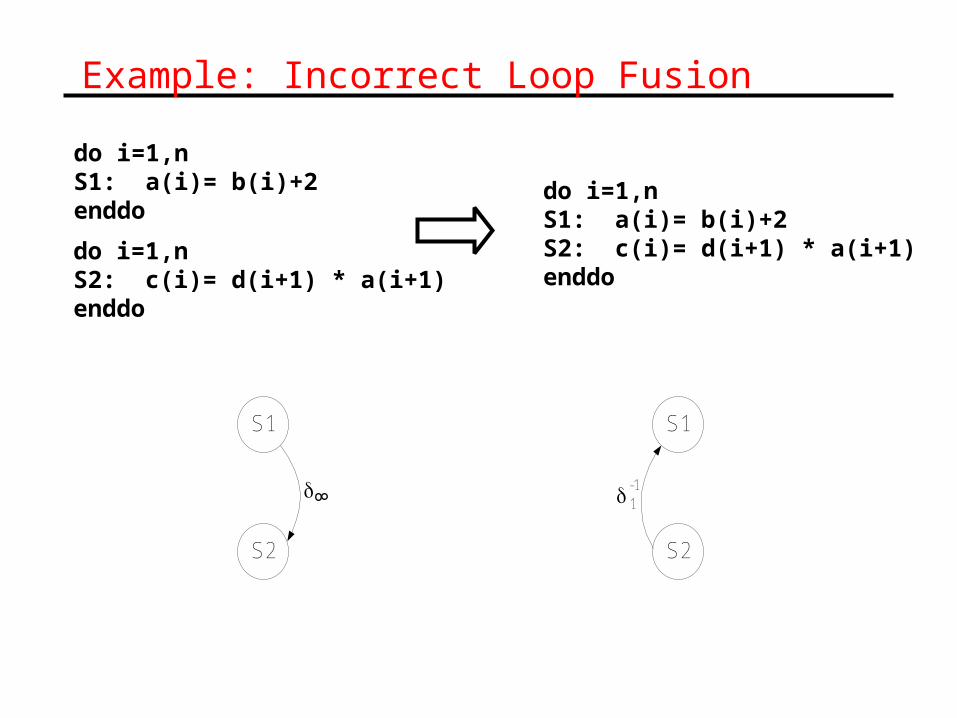
Example: Incorrect Loop Fusion
S1
S2
do i=1,nS1: a(i)= b(i)+2enddo
do i=1,nS2: c(i)= d(i+1) * a(i+1)enddo
do i=1,nS1: a(i)= b(i)+2S2: c(i)= d(i+1) * a(i+1)enddo
S1
S2
-11
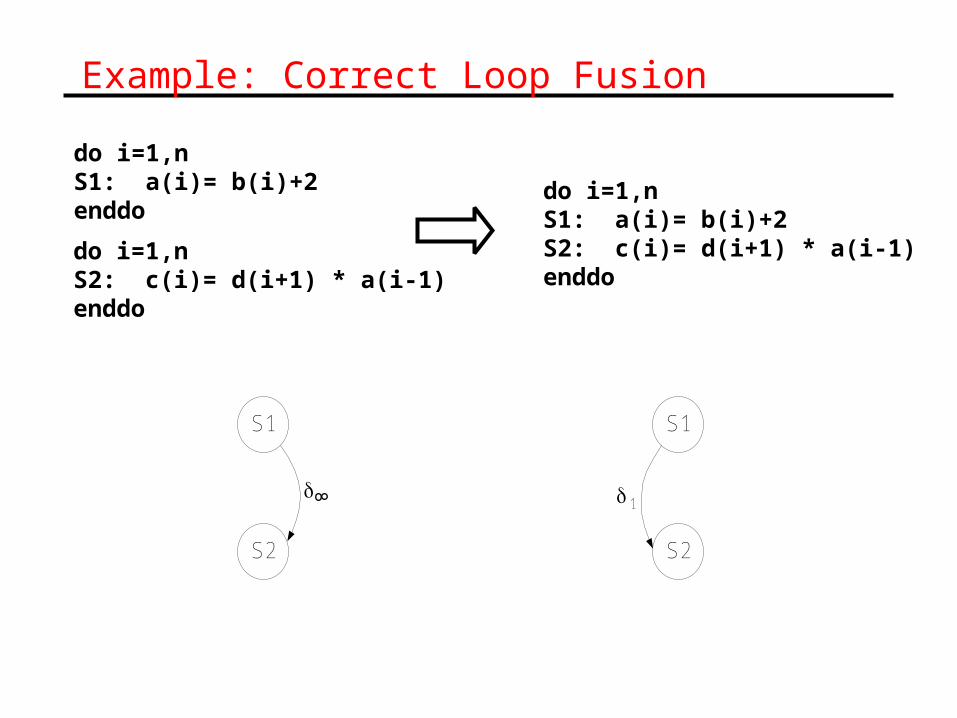
Example: Correct Loop Fusion
S1
S2
do i=1,nS1: a(i)= b(i)+2enddo
do i=1,nS2: c(i)= d(i+1) * a(i-1)enddo
do i=1,nS1: a(i)= b(i)+2S2: c(i)= d(i+1) * a(i-1)enddo
S1
S2
1

Advantages of Transformations
• Increase the number of independent instructions. • These can be scheduled and executed more
efficiently.

Disadvantages of the Transformations
• Transformations increase reigster pressure.• They increase the size of the code which might lead to
a more inefficient usage of the memory hierarchy. • Transformations can also lead to less data locality.

Summary of Transformations
• Compiler has a global overview. • Goal: More operations for instruction scheduling.• Compiler supports efficient execution in other areas.