compiler construction chapter 2: cfgs &...
TRANSCRIPT

Compiler Construction
Chapter 2: CFGs & Parsing
Slides modified from Louden Book and Dr. Scherger

Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
2
The parser takes the compact representation (tokens) from the scanner and checks the structure
It determines if it is syntactically valid
That is, is the structure correct
Also called syntax analysis
Syntax given by a set of grammar rules of a context-free-grammar
Context-free grammars are much more powerful than REs, they are recursive.
Since not linear as the scanner, we need a parse stack or a tree to represent
Parse tree or syntax tree

What Are We Going To Do?
February, 2010 Chapter 3: Context Free Grammars and
Parsers
3
Actually parsing is only discussed in the abstract in this
chapter
Chapters 4 and 5 are the (real) parsing chapters.
This chapter title could renamed “Context-free Grammars and
Syntax”
Here we introduce a number of basic compiling ideas and
illustrate their usage with the development of a simple
example compiler.

Syntax Definition
February, 2010 Chapter 3: Context Free Grammars and
Parsers
4
A context-free grammar is a common notation for specifying the syntax of a language:
Backus-Naur Form or BNF are synonyms for a context-free grammar. The grammar naturally describes the hierarchical structure of many programming languages. For example, an if-else statement in C has the form:
if ( expression ) statement else statement
In other words, an if-else statement in C is the concatenation of: the keyword if; an opening parenthesis; an expression; a closing parenthesis; a statement; the keyword else; and another statement.

Syntax Definition
February, 2010 Chapter 3: Context Free Grammars and
Parsers
5
If one uses the variable expr to denote an expression and the variable stmt to denote a statement then one can specify the syntax of an if-else statement with the following production in the context-free grammar for C:
stmt --> if ( expr ) stmt else stmt
The arrow is read as "can have the form". This particular production says that "a statement can have the form of the keyword if followed by an opening parenthesis followed by an expression followed by a closing parenthesis followed by a statement followed by the keyword else followed by another statement."

Context Free Grammars
February, 2010 Chapter 3: Context Free Grammars and
Parsers
6
A context-free grammar has four components:
A finite terminal vocabulary Vt
The tokens from the scanner, also called the terminal symbols;
A finite nonterminal vocabulary Vn
Intermediate symbols, also called nonterminals ;
A start symbol S Vn.
All Derivations start here
A finite set of productions (rewriting rules) of the form:
A X1...Xm
where A Vn, Xi Vn Vt,
The vocabulary V is Vn Vt

Context-Free Grammars
February, 2010 Chapter 3: Context Free Grammars and
Parsers
7
Starting with S, nonterminals are rewritten using
productions (P) until only terminals remain
The set of strings derivable from S comprises the
context-free-language of grammar G

CFG Productions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
8
The left hand side (LHS) is a single nonterminal symbol
(from Vn)
The right hand side (RHS) is a string of zero or more
symbols (from V)
A symbol can be the RHS for > 1 rule
Notation
My Symbol Book Symbol What
a,b,c a,b,c symbols in Vt
A,B,C a,b,c symbols in Vn
a,b,g strings in V*
l e special symbol for an empty production

CFG Productions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
9
A X1 ... Xm
A a
A a|b|....|z
Abbreviation for
A a
A b
....
A z

CFG Example
February, 2010 Chapter 3: Context Free Grammars and
Parsers
10
S aSb // rule1
S l// rule2
An example Parse
Start with S, then use rule1, rule1, rule1, then rule 2.
The result is:
S aSb aaSbb aaaSbbb aaabbb
The context free language is anbn

CFG Example
February, 2010 Chapter 3: Context Free Grammars and
Parsers
11
S AB
S ASB
A a
B b
What is the language of this CFG?

CFG Example
February, 2010 Chapter 3: Context Free Grammars and
Parsers
12
S A | S+A | S-A
A B | A*B | A/B
B C | (S)
C D | CD
D 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
What is the language of this CFG?

CFG Productions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
13
S A | B
A a
B B b
C c
C useless, can't be reached via derivation
B useless, derives no terminal string
Grammars with useless nonterminals are “nonreduced”
A “reduced” grammar has no useless NT
If we reduce a grammar do we change its language?

CFG Productions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
14
S A
A a
This grammar has the same language as the
previous grammar
It is reduced

Ambiguous CFG
February, 2010 Chapter 3: Context Free Grammars and
Parsers
15
<expr> <expr> - <expr>
<expr> Id
This grammar is ambiguous since it allows more
than one derivation tree, and therefore a non-unique structure
Ambiguous grammars should be avoided
It is impossible to guarantee detection of ambiguity in any given CFG.

Ambiguous CFG
February, 2010 Chapter 3: Context Free Grammars and
Parsers
16
<expr> <expr>
<expr> - <expr> <expr> - <expr>
<expr> - <expr> Id Id <expr> - <expr>
id id Id Id
Possible derivation trees for Id – Id – Id

Grammars Can’t
February, 2010 Chapter 3: Context Free Grammars and
Parsers
17
Check if a variable is declared before use
Check operands are of the correct type
Check correct number of parameters
Do semantic checking
Underlined words
lettersn backspacen underscoresn
But can do (letters backspaces underscore)n

Context Free Grammars: Simple Integer
Arithmetic Expressions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
18
In what way does such a CFG differ from a regular
expression?
digit = 0|1|…|9
number = digit digit*
Recursion!
exp exp op exp | ( exp ) | number
op + | - | *
2 non-terminals
6 terminals
6 productions (3 on each line)
Recursive rules “Base” rule

Context Free Grammars
February, 2010 Chapter 3: Context Free Grammars and
Parsers
19
Multiple productions with the same nonterminal on the
left usually have their right sides grouped together
separated by vertical bars.
For example, the three productions:
list --> list + digit
list --> list - digit
list --> digit
may be grouped together as:
list --> list + digit | list - digit | digit

Context Free Grammars
February, 2010 Chapter 3: Context Free Grammars and
Parsers
20
Productions with the start symbol on the left side are
always listed first in the set of productions.
Here is an example: list --> list + digit | list - digit | digit
digit --> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
From this set of productions it is easy to see that the
grammar has two nonterminals: list and digit (with list
being the start symbol) and 12 terminals: + - 0 1 2 3 4 5 6 7 8 9

CFGs Are Designed To Represent Recursive
(i.e. Nested) Structures
February, 2010 Chapter 3: Context Free Grammars and
Parsers
21
…But consequences are huge:
The structure of a matched string is no longer given by just a
sequence of symbols (lexeme), but by a tree (parse tree)
Recognizers are no longer finite, but may have arbitrary data
size, and must have some notion of stack.

Recognition Process Is Much More Complex:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
22
Algorithms can use stacks in many different ways.
Nondeterminism is much harder to eliminate.
Even the number of states can vary with the algorithm
(only 2 states necessary if stack is used for
“state”structure.

Major Consequence: Many Parsing
Algorithms, Not Just One
February, 2010 Chapter 3: Context Free Grammars and
Parsers
23
Top down
Recursive descent (hand choice)
“Predictive” table-driven, “LL” (outdated)
Bottom up
“LR” and its cousin “LALR” (machine-generated choice
[Yacc/Bison])
Operator-precedence (outdated)

Productions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
24
A production is for a nonterminal if that nonterminal appears on the left-side of the production.
A grammar derives a string of tokens by starting with the start symbol and repeatedly replacing nonterminals with right-sides of productions for those nonterminals.
A parse tree is a convenient method of showing that a given token string can be derived from the start symbol of a grammar: the root of the tree must be the starting symbol, the leaves must be
the tokens in the token string, and the children of each parent node must be the right-side of some production for that parent node. For example, draw the parse tree for the token string
9 - 5 + 2

Productions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
25
The language defined by a grammar is the set of all token
strings that can be derived from its start symbol.
The language defined by the example grammar contains
all lists of digits separated by plus and minus signs.

Productions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
26
Epsilon, e , on the right-side of a production denotes the
empty string.
Consider the grammar for Pascal begin-end blocks
a block does not need to contain any statements
block --> begin opt_stmts end
opt_stmts --> stmt_list | e
stmt_list --> stmt_list ; stmt | stmt

Ambiguity
February, 2010 Chapter 3: Context Free Grammars and
Parsers
27
A grammar is ambiguous if two or more different parse
trees can derive the same token string.
Grammars for compilers should be unambiguous since
different parse trees will give a token string different
meanings.

Ambiguity (cont.)
February, 2010 Chapter 3: Context Free Grammars and
Parsers
28
Here is another example of a grammar for strings of digits separated by plus and minus signs:
string --> string + string |
string - string |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
However this grammar is ambiguous. Why?
Draw two different parse trees for the token string 9 - 5 + 2 that correspond to two different ways of parenthesizing the expression:
( 9 - 5 ) + 2 or 9 - ( 5 + 2 )
The first parenthesization evaluates to 6 while the second parenthesization evaluates to 2.

Sources Of Ambiguity:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
29
Associativity and precedence of operators
Sequencing
Extent of a substructure (dangling else)
“Obscure” recursion (unusual)
exp exp exp

Dealing With Ambiguity
February, 2010 Chapter 3: Context Free Grammars and
Parsers
30
Disambiguating rules
Change the grammar (but not the language!)
Can all ambiguity be removed?
Backtracking can handle it, but the expense is great

Associativity of Operators
February, 2010 Chapter 3: Context Free Grammars and
Parsers
31
By convention, when an operand like 5 in the expression 9 - 5 + 2 has operators on both sides, it should be associated with the operator on the left:
In most programming languages arithmetic operators like addition, subtraction, multiplication, and division are left-associative .
In the C language the assignment operator, =, is right-associative:
The string a = b = c should be treated as though it were parenthesized a = ( b = c ).
A grammar for a right-associative operator like = looks like: right --> letter = right | letter
letter --> a | b | ... | z

Precedence of Operators
February, 2010 Chapter 3: Context Free Grammars and
Parsers
32
Should the expression 9 + 5 * 2 be interpreted like (9 +
5) * 2 or 9 + (5 * 2)?
The convention is to give multiplication and division
higher precedence than addition and subtraction.
When evaluating an arithmetic expression we perform
operations of higher precedence before operations of
lower precedence:
Only when we have operations of equal precedence (like
addition and subtraction) do we apply the rules of associativity.

Syntax of Expressions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
33
An arithmetic expression is a string of terms separated by left-associative addition and subtraction operators.
A term is a string of factors separated by left-associative multiplication and division operators.
A factor is a single operand (like an id or num token) or an expression wrapped inside of parentheses.
Therefore, a grammar of arithmetic expressions looks like: expr --> expr + term | expr - term | term
term --> term * factor | term / factor | factor
factor --> id | num | ( expr )

Syntax Directed Translation
February, 2010 Chapter 3: Context Free Grammars and
Parsers
34
As mentioned in earlier, modern compilers use syntax-
directed translation to interleave the actions of the
compiler phases.
The syntax analyzer directs the whole process:
calling the lexical analyzer whenever it wants another token
and performing the actions of the semantic analyzer and the
intermediate code generator as it parses the source code.

Syntax Directed Translation (cont.)
February, 2010 Chapter 3: Context Free Grammars and
Parsers
35
The actions of the semantic analyzer and the
intermediate code generator usually require the
passage of information up and/or down the parse
tree.
We think of this information as attributes attached to
the nodes of the parse tree and the parser moving
this information between parent nodes and children
nodes as it performs the productions of the grammar.

Postfix Notation
February, 2010 Chapter 3: Context Free Grammars and
Parsers
36
As an example of syntax-directed translation a simple
infix-to-postfix translator is developed here.
Postfix notation (also called Reverse Polish Notation or
RPN) places each binary arithmetic operator after its two
source operands instead of between them:
The infix expression (9 - 5) + 2 becomes 9 5 - 2 + in postfix
notation
The infix expression 9 - (5 + 2) becomes 9 5 2 + - in postfix
(postfix expressions do not need parentheses.)

Principle of Syntax-directed Semantics
February, 2010 Chapter 3: Context Free Grammars and
Parsers
37
The parse tree will be used as the basic model;
semantic content will be attached to the tree;
thus the tree should reflect the structure of the eventual
semantics (semantics-based syntax would be a better term)

Syntax Directed Defintions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
38
A syntax-directed definition uses a context-free grammar to
specify the syntactic structure of the input, associates a
set of attributes with each grammar symbol, and
associates a set of semantic rules with each production of
the grammar.
As an example, suppose the grammar contains the
production: X --> Y Z so node X in a parse tree has
nodes Y and Z as children and further suppose that nodes
X , Y , and Z have associated attributes X.a , Y.a , and Z.a ,
respectively.

Syntax Directed Definitions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
39
As an example, suppose the grammar contains the production:
X --> Y Z so node X in a parse tree has nodes Y and Z as children and further suppose that nodes X , Y , and Z have associated attributes X.a , Y.a , and Z.a , respectively.
An annotated parse tree looks like this
If the semantic rule
{X.a := Y.a + Z.a } is associated with the X --> Y Z production then the parser should add the a attributes of nodes Y and Z together and set the a attribute of node X to their sum.
X
(X.a)
Z
(Z.a)
Y
(Y.a)

Synthesized Attributes
February, 2010 Chapter 3: Context Free Grammars and
Parsers
40
An attribute is synthesized if its value at a parent node can
be determined from attributes at its children.
Attribute a in the previous example is a synthesized
attribute.
Synthesized attributes can be evaluated by a single
bottom-up traversal of the parse tree.
Example: Infix to Postfix Translation
February, 2010 Chapter 3: Context Free Grammars and
Parsers
41
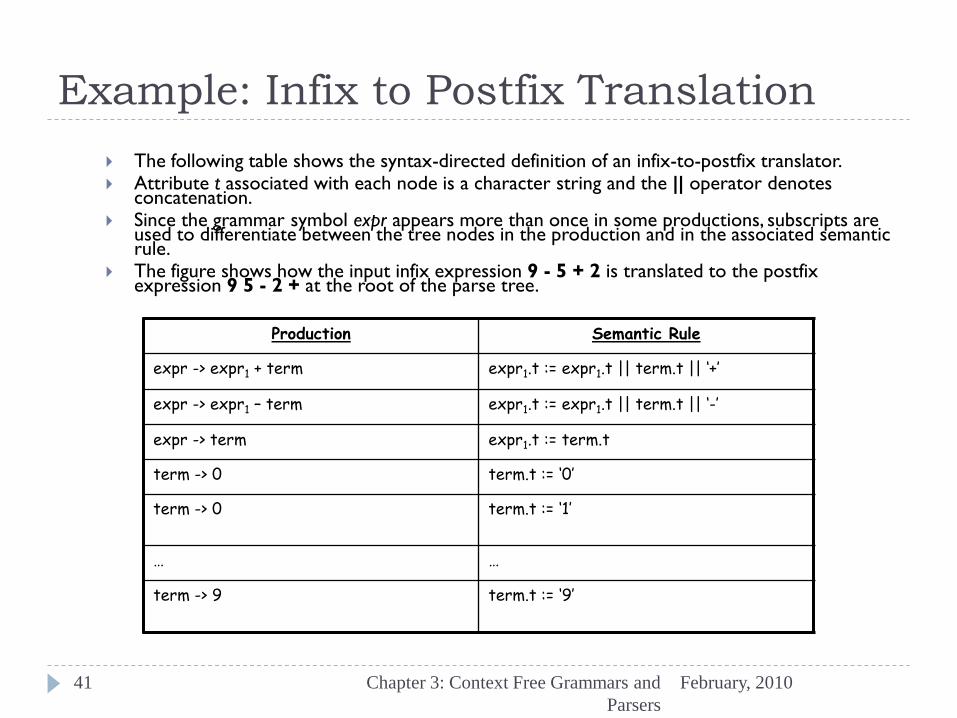
The following table shows the syntax-directed definition of an infix-to-postfix translator. Attribute t associated with each node is a character string and the || operator denotes
concatenation. Since the grammar symbol expr appears more than once in some productions, subscripts are
used to differentiate between the tree nodes in the production and in the associated semantic rule.
The figure shows how the input infix expression 9 - 5 + 2 is translated to the postfix expression 9 5 - 2 + at the root of the parse tree.
Production Semantic Rule
expr -> expr1 + term expr1.t := expr1.t || term.t || ‘+’
expr -> expr1 – term expr1.t := expr1.t || term.t || ‘-’
expr -> term expr1.t := term.t
term -> 0 term.t := ‘0’
term -> 0
term.t := ‘1’
… …
term -> 9
term.t := ‘9’

Example: Infix to Postfix Translation
February, 2010 Chapter 3: Context Free Grammars and
Parsers
42
The following table shows the syntax-directed definition of an infix-to-postfix translator. Attribute t associated with each node is a character string and the || operator denotes
concatenation. Since the grammar symbol expr appears more than once in some productions, subscripts are
used to differentiate between the tree nodes in the production and in the associated semantic rule.
The figure shows how the input infix expression 9 - 5 + 2 is translated to the postfix expression 9 5 - 2 + at the root of the parse tree.
expr.t = 95-2+
expr.t = 95-
expr.t = 9 term.t = 5
term.t = 9
- 5 + 2 9
term.t = 2

Example: Robot Navigation
February, 2010 Chapter 3: Context Free Grammars and
Parsers
43
Suppose a robot can be instructed to move one step east, north, west, or south from its current position.
A sequence of such instructions is generated by the following grammar.
seq -> seq instr | begin
instr -> east | north |
west | south
Changes in the position of the robot on input
begin west south east east
east north north
begin
(0,0)
west
(-1,0)
south
(-1,-1) east east
east
(2,-1)
north
(2,1)
north
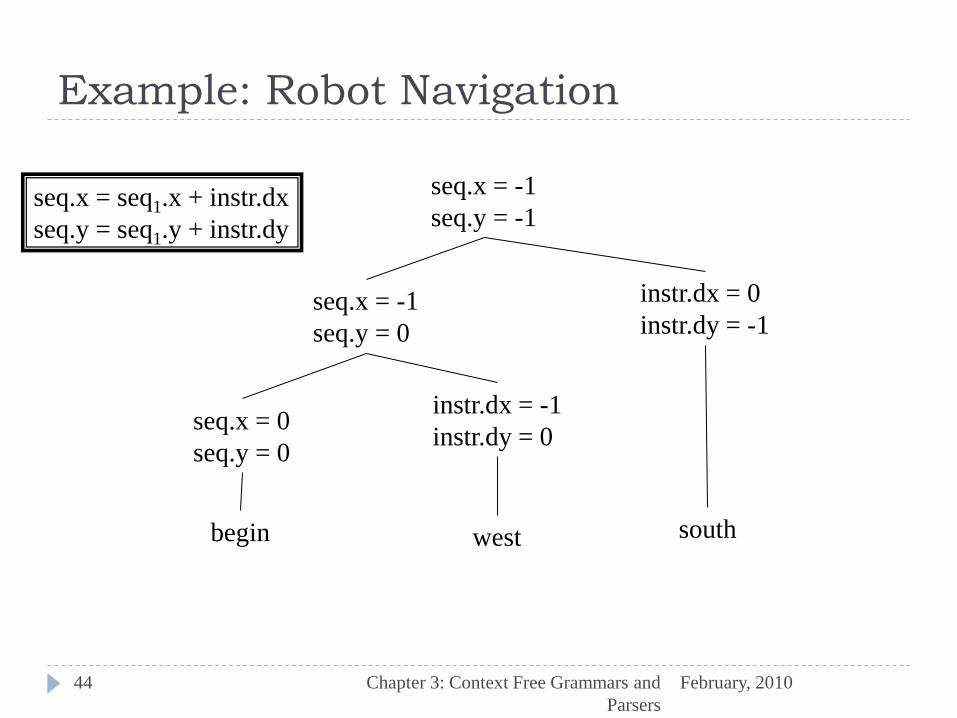
Example: Robot Navigation
February, 2010 Chapter 3: Context Free Grammars and
Parsers
44
seq.x = -1
seq.y = -1
seq.x = -1
seq.y = 0
instr.dx = 0
instr.dy = -1
seq.x = 0
seq.y = 0
instr.dx = -1
instr.dy = 0
begin west south
seq.x = seq1.x + instr.dx
seq.y = seq1.y + instr.dy

Example: Robot Navigation
February, 2010 Chapter 3: Context Free Grammars and
Parsers
45
Production Semantic Rules
seq -> begin seq.x := 0
seq.y := 0
seq -> seq1 instr seq.x := seq1.x + instr.dx
seq.y := seq1.y + instr.dy
instr -> east instr.dx = 1
instr.dy = 0
instr -> north instr.dx = 0
instr.dy = 1
instr ->west instr.dx = -1
instr.dy = 0
instr -> south instr.dx = 0
instr.dy = -1

Depth First Traversals
February, 2010 Chapter 3: Context Free Grammars and
Parsers
46
A depth-first traversal of the parse tree is a
convenient way of evaluating attributes.
The traversal starts at the root, visits every
child, returns to a parent after visiting each
of its children, and eventually returns to
the root
Synthesized attributes can be evaluated
whenever the traversal goes from a node
to its parent.
Other attributes (like inherited attributes)
can be evaluated whenever the traversal
goes from a parent to its children. .
procedure visit(n: node)
begin
for each child m of n, from left to right do
visit( m );
evaluate semantic rules at node n
end

Translation Schemes
February, 2010 Chapter 3: Context Free Grammars and
Parsers
47
A translation scheme is another way of specifying a syntax-
directed translation:
semantic actions (enclosed in braces) are embedded within the
right-sides of the productions of a context-free grammar.
For example,
rest --> + term { print ('+') } rest1
This indicates that a plus sign should be printed between the
depth-first traversal of the term node and the depth-first
traversal of the rest1 node of the parse tree.

Translation Schemes
February, 2010 Chapter 3: Context Free Grammars and
Parsers
48
This figure shows the translation scheme for an infix-to-
postfix translator:
expr -> expr + term { print(‘+’) }
expr -> expr - term { print(‘-’) }
expr -> term
term -> 0 { print(‘0’) }
term -> 1 { print(‘1’) }
…
term -> 9 { print(‘9’) }

Translation Schemes
February, 2010 Chapter 3: Context Free Grammars and
Parsers
49
The postfix expression is printed out as the parse tree is traversed as shown in this figure
Note that it is not necessary to actually construct the parse tree.
expr.t = 95-2+
expr.t = 95- term.t = 2
expr.t = 9 term.t = 5
term.t = 9
-
5 + 2 9 {print(‘9’)} {print(‘5’)}
{print(‘-’)}
{print(‘+’)}
{print(‘2’)}

Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
50
For a given input string of tokens we can ask, “Is this input syntactically valid?”
That is, can it be generated by our grammar
An algorithm that answers this question is a recognizer
If we also get the structure (derivation tree) we have a parser
For any language that can be described by a context-free grammar a parser that parses a string of n tokens in O (n3) time can be constructed.
However, most every programming language is so simple that a parser requires just O (n ) time with a single left-to-right scan over the input.

Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
51
Most parsers are either top-down or bottom-up. A top-down parser “discovers” a parse tree by starting at the root
(start symbol) and expanding (predict) downward depth-first. Predict the derivation before the matching is done
A bottom-up parser builds a parse tree by starting at the leaves (terminals) and determining the rule to generate them, and continues working up toward the root.
Top-down parsers are usually easier to code by hand but compiler-generating software tools usually generate bottom-up parsers because they can handle a wider class of context-free grammars.
This course covers both top-down and bottom-up parsers and the coding projects may give you the experience of coding both kinds:

Parsing Example
Consider the following Grammar
<program> begin <stmts> end $
<stmts> SimpleStmt ; <stmts>
<stmts> begin <stmts> end ; <stmts>
<stmts> l
Input: begin SimpleStmt; SimpleStmt; end $

Top-down Parsing Example
Input: begin SimpleStmt; SimpleStmt; end $
<program>
<program> begin <stmts> end $ <stmts> SimpleStmt ; <stmts> <stmts> begin <stmts> end ; <stmts>
<stmts> l

Top-down Parsing Example
Input: begin SimpleStmt; SimpleStmt; end $
<program>
begin <stmts> end $
<program> begin <stmts> end $ <stmts> SimpleStmt ; <stmts> <stmts> begin <stmts> end ; <stmts>
<stmts> l

Top-down Parsing Example
Input: begin SimpleStmt; SimpleStmt; end $
<program>
begin <stmts> end $
SimpleStmt ; <stmts>
<program> begin <stmts> end $ <stmts> SimpleStmt ; <stmts> <stmts> begin <stmts> end ; <stmts>
<stmts> l

Top-down Parsing Example
Input: begin SimpleStmt; SimpleStmt; end $
<program>
begin <stmts> end $
SimpleStmt ; <stmts>
SimpleStmts ; <stmts>
<program> begin <stmts> end $ <stmts> SimpleStmt ; <stmts> <stmts> begin <stmts> end ; <stmts>
<stmts> l

Top-down Parsing Example
Input: begin SimpleStmt; SimpleStmt; end $
<program>
begin <stmts> end $
SimpleStmt ; <stmts>
SimpleStmts ; <stmts>
l<program> begin <stmts> end $ <stmts> SimpleStmt ; <stmts> <stmts> begin <stmts> end ; <stmts>
<stmts> l

Bottom-up Parsing Example
Scan the input looking for any substrings that appear
on the RHS of a rule!
We can do this left-to-right or right-to-left
Let's use left-to-right
Replace that RHS with the LHS
Repeat until left with Start symbol or error

Bottom-up Parsing Example
Input: begin SimpleStmt; SimpleStmt; end $
<stmts>
l
<program> begin <stmts> end $ <stmts> SimpleStmt ; <stmts> <stmts> begin <stmts> end ; <stmts>
<stmts> l

Bottom-up Parsing Example
Input: begin SimpleStmt; SimpleStmt; end $
<stmts>
SimpleStmts ; <stmts>
l<program> begin <stmts> end $ <stmts> SimpleStmt ; <stmts> <stmts> begin <stmts> end ; <stmts>
<stmts> l

Bottom-up Parsing Example
Input: begin SimpleStmt; SimpleStmt; end $
<stmts>
SimpleStmt ; <stmts>
SimpleStmts ; <stmts>
l
<program> begin <stmts> end $ <stmts> SimpleStmt ; <stmts> <stmts> begin <stmts> end ; <stmts>
<stmts> l

Bottom-up Parsing Example
Input: begin SimpleStmt; SimpleStmt; end $
<program>
begin <stmts> end $
SimpleStmt ; <stmts>
SimpleStmts ; <stmts>
l
<program> begin <stmts> end $ <stmts> SimpleStmt ; <stmts> <stmts> begin <stmts> end ; <stmts>
<stmts> l

Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
63
To introduce top-down parsing we consider the following
context-free grammar:
expr --> term rest
rest --> + term rest | - term rest | e
term --> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
and show the construction of the parse tree for the input
string: 9 - 5 + 2.

Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
64
Initialization: The root of the parse tree must be the
starting symbol of the grammar, expr .
expr
expr --> term rest
rest --> + term rest
| - term rest | e
term --> 0 | 1 | 2 | 3 | 4
| 5 | 6 | 7 | 8 | 9

Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
65
Step 1: The only production for expr is expr --> term rest so the root node must have a term node and a rest node as children.
expr
term rest
expr --> term rest
rest --> + term rest
| - term rest | e
term --> 0 | 1 | 2 | 3 | 4
| 5 | 6 | 7 | 8 | 9
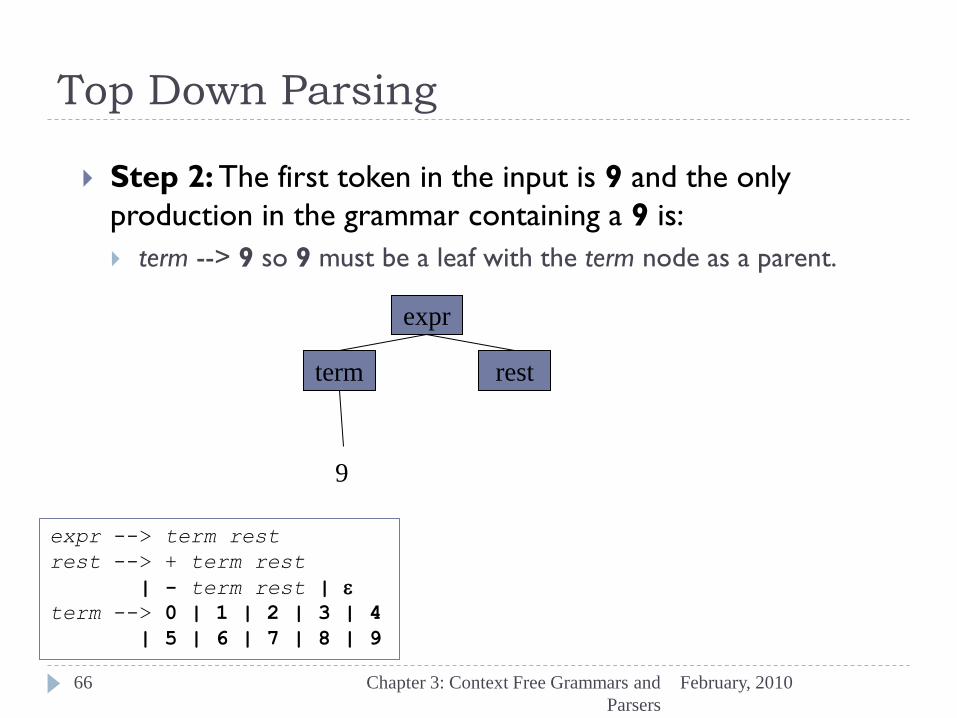
Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
66
Step 2: The first token in the input is 9 and the only
production in the grammar containing a 9 is:
term --> 9 so 9 must be a leaf with the term node as a parent.
expr
term rest
9
expr --> term rest
rest --> + term rest
| - term rest | e
term --> 0 | 1 | 2 | 3 | 4
| 5 | 6 | 7 | 8 | 9
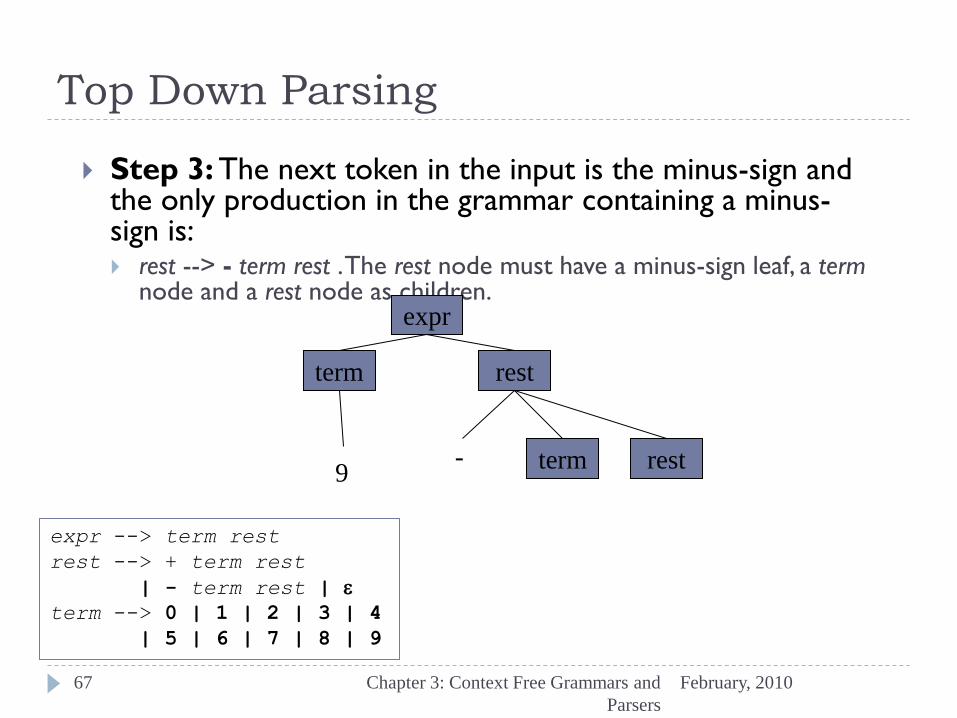
Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
67
Step 3: The next token in the input is the minus-sign and the only production in the grammar containing a minus-sign is: rest --> - term rest . The rest node must have a minus-sign leaf, a term
node and a rest node as children. expr
term rest
term rest - 9
expr --> term rest
rest --> + term rest
| - term rest | e
term --> 0 | 1 | 2 | 3 | 4
| 5 | 6 | 7 | 8 | 9
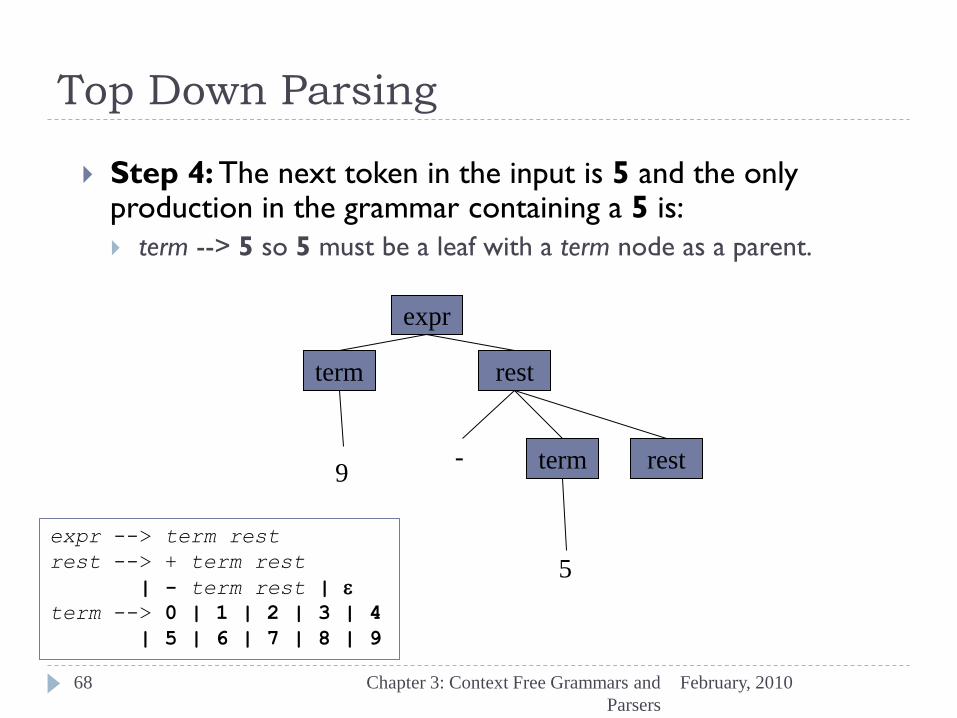
Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
68
Step 4: The next token in the input is 5 and the only production in the grammar containing a 5 is:
term --> 5 so 5 must be a leaf with a term node as a parent.
expr
term rest
term rest
5
- 9
expr --> term rest
rest --> + term rest
| - term rest | e
term --> 0 | 1 | 2 | 3 | 4
| 5 | 6 | 7 | 8 | 9

Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
69
Step 5: The next token in the input is the plus-sign and the only production in the grammar containing a plus-sign is:
rest --> + term rest .
A rest node must have a plus-sign leaf, a term node and a rest node as children. expr
term rest
term rest
term rest + 5
- 9
expr --> term rest
rest --> + term rest
| - term rest | e
term --> 0 | 1 | 2 | 3 | 4
| 5 | 6 | 7 | 8 | 9
Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
70
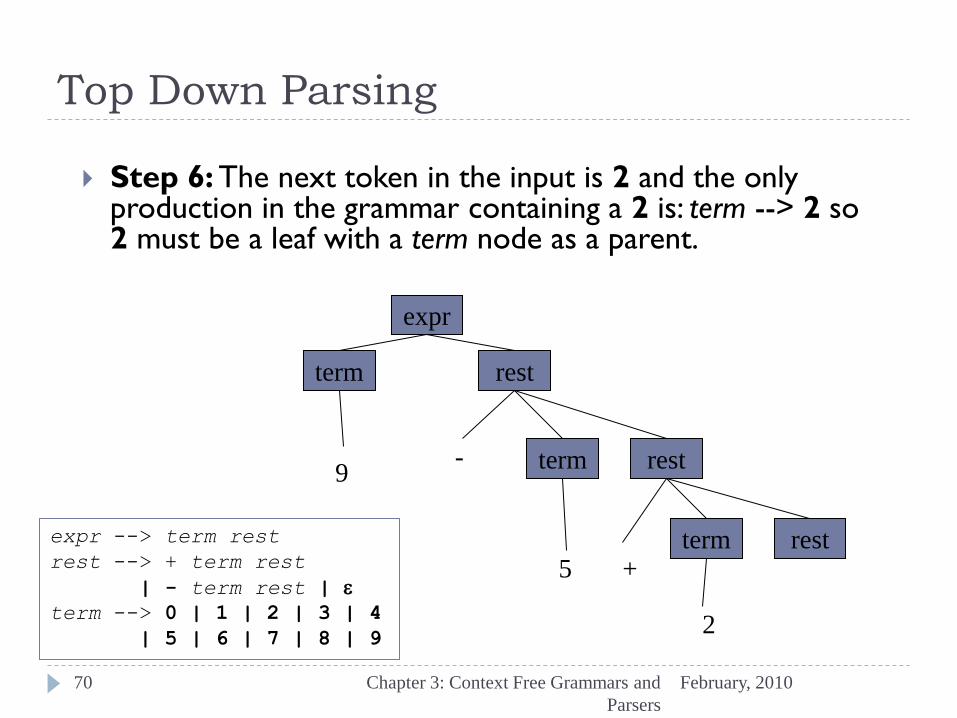
Step 6: The next token in the input is 2 and the only production in the grammar containing a 2 is: term --> 2 so 2 must be a leaf with a term node as a parent.
expr
term rest
term rest
term rest
2
+ 5
- 9
expr --> term rest
rest --> + term rest
| - term rest | e
term --> 0 | 1 | 2 | 3 | 4
| 5 | 6 | 7 | 8 | 9
Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
71
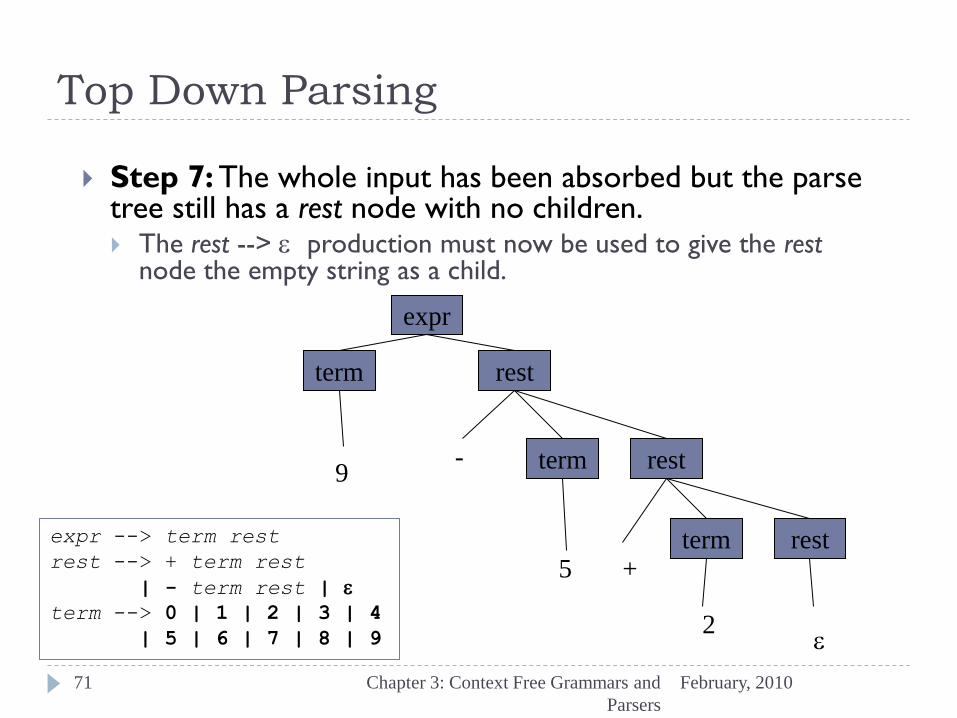
Step 7: The whole input has been absorbed but the parse tree still has a rest node with no children. The rest --> e production must now be used to give the rest
node the empty string as a child.
expr
term rest
term rest
term rest
e2
+ 5
- 9
expr --> term rest
rest --> + term rest
| - term rest | e
term --> 0 | 1 | 2 | 3 | 4
| 5 | 6 | 7 | 8 | 9

Parsing
Only one possible derivation tree if grammar
unambiguous
Top-down use leftmost derivations
Leftmost nonterminal expanded first
Bottom-up use right most derivations
Rightmost nonterminal expanded first
Two most common types of parsers are LL and
LR parsers
1st letter for left-to-right token parsing
2nd for derivation (leftmost, rightmost)
LL(n) – n is # of lookahead symbols

LL(1) Parsing
How do we predict which NT to expand?
We can use the lookahead
However, if more than 1 rule expands given
that lookahead the grammar cannot be parsed
by our LL(1) parser
This means the “prediction” for top-down is
easy, just use the lookahead

Building an LL(1) Parser
We need to determine some sets
First(n) – Terminals that can start valid strings
that are generated by n: n V*
Follow(A) – Set of terminals that can follow A in
some legal derivation. A is nonterminal Predict(prod) – Any token that can be the 1st
symbol produced by the RHS of prod
Predict(AX1 ...Xm) = (First(X1 ...Xm)-l)UFollow(A) if l First(X1 ...Xm)
First(X1 ...Xm) otherwise
These sets used to create a parse table

Parse Table
A row for each nonterminal
A column for each terminal
Entries contain rule (production) #s
For a lookahead T, the production to predict
given that terminal as the lookahead and that
non terminal to be matched.

Example Micro
On handout
Predict(AX1 ...Xm) =
if l First(X1 ...Xm)
(First(X1 ...Xm)-l) U Follow(A)
else
First(X1 ...Xm)
The parse table is filled in using:
T(A,a) = AX1 ...Xm if a Predict(AX1 ...Xm)
T(A,a) = Error otherwise

Making LL(1) Grammars
This is not always an easy task
Must have a unique prediction for each
(nonterminal, lookahead)
Conflicts are usually either
Left-recursion
Common prefixes
Often we can remove these conflicts
Not all conflicts can be removed
Dangling else (Pascal) is one of them

LL(1) Grammars
February, 2010 Chapter 3: Context Free Grammars and
Parsers
78
A grammar is LL(1) iff whenever A a|b are two distinct productions the following conditions hold
The is no terminal a, such that both α and β derive strings beginning with a.
At most one of aandb can derive the empty string
If β derives the empty string, then α does not derive any string beginning with a terminal in FOLLOW(A). Likewise, if α derives the empty string, then β does not derive any string beginning with a terminal in FOLLOW(A).
LL(1) means we scan the input from left to right (first L) and a leftmost derivation is produced (leftmost non terminal expanded) by using 1 lookahead symbol to decide the rule to expand.

Making LL(1) Grammars
Left-recursion
Consider A Ab Assume some lookahead symbol t causes the
prediction of the above rule
This prediction causes A to be put on the parse
stack
We have the same lookahead and the same
symbol on the stack, so this rule will be
predicted again, and again.......

Eliminating Left Recursion
February, 2010 Chapter 3: Context Free Grammars and
Parsers
80
Replace
expr → expr + term
| term
by
expr → term expr'
expr' → + term expr'
| ε

Making LL(1) Grammars
Factoring
Consider <stmt> if <expr> then <stmts> end if;
<stmt> if <expr> then <stmts> else <stmts> end if;
The productions share a common prefix
The First sets of each RHS are not disjoint
We can factor out the common prefix <stmt> if <expr> then <stmts> <ifsfx>
<ifsfx> end if;
<ifsfx> else <stmts> end if;

Properties of LL(1) Parsers
A correct leftmost parse is guaranteed
All LL(1) grammars are unambiguous
O(n) in time and space

Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
83
In the previous example, the grammar made it easy for the parser to pick the correct production in each step of the parse.
This is not true in general: consider the following grammar:
statement --> if expression then statement else statement
statement --> if expression then statement
When the input token is an if token should a top-down parser use the first or second production?
The parser would have to guess which one to use, continue parsing, and later on, if the guess is wrong, go back to the if token and try the other production.

Top Down Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
84
Usually one can modify the grammar so a predictive top-
down parser can be used:
The parser always picks the correct production in each step of
the parse so it never has to back-track.
To allow the use of a predictive parser, one replaces the two
productions above with:
statement --> if expression then statement optional_else
optional_else --> else statement | e

Predictive Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
85
A recursive-descent parser is a top-down parser that executes a set of recursive procedures to process the input: there is a procedure for each nonterminal in the grammar.
A predictive parser is a top-down parser where the current input token unambiguously determines the production to be applied at each step.
Here, we show the code of a predictive parser for the following grammar:
expr --> term rest
rest --> + term rest | - term rest | e
term --> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9

Predictive Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
86
We assume a global variable, lookahead
, holding the current input token and a
procedure match( ExpectedToken )
that loads the next token into
lookahead if the current token is what
is expected, otherwise match reports
an error and halts.
Procedure match( t:token )
Begin
If lookahead = t then
Lookahead := nexttoken
Else
error
end

Predictive Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
87
This is a recursive-descent parser so a procedure is written for each nonterminal of the grammar.
Since there is only one production for expr , procedure expr is very simple:
Since there are three productions for rest , procedure rest uses lookahead to select the correct production.
If lookahead is neither + nor - then rest selects the -production and simply returns without any actions:
expr()
{ term(); rest(); return; }
rest()
{
if (lookahead == '+')
{
match('+'); term();
rest(); return;
}
else if (lookahead == '-')
{
match('-'); term();
rest(); return;
}
else
{
return;
}
}
expr --> term rest
rest --> + term rest | - term rest | e
term --> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7
| 8 | 9

Predictive Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
88
The procedure for term , called term,
checks to make sure that lookahead is
a digit:
term()
{ if (isdigit(lookahead)) {
match(lookahead);
return;
}
else
{ ReportErrorAndHalt();
}
}
expr --> term rest
rest --> + term rest | - term rest | e
term --> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7
| 8 | 9

Predictive Parsing
February, 2010 Chapter 3: Context Free Grammars and
Parsers
89
After loading lookahead with the first input token this parser is started by calling expr (since expr is the starting symbol.)
If there are no syntax errors in the input, the parser conducts a depth-traversal of the parse tree and returns to the caller through expr, otherwise it reports an error and halts.
If there is an e-production for a nonterminal then the procedure for that nonterminal selects it whenever none of the other productions are suitable.
If there is no e-production for a nonterminal and none of its productions are suitable then the procedure should report a syntax error.

Left Recursion
February, 2010 Chapter 3: Context Free Grammars and
Parsers
90
A production like:
expr --> expr + term
Where the first symbol on the right-side is the same as
the symbol on the left-side is said to be left-recursive .
If one were to code this production in a recursive-
descent parser, the parser would go in an infinite loop
calling the expr procedure repeatedly.

Left Recursion
February, 2010 Chapter 3: Context Free Grammars and
Parsers
91
Fortunately a left-recursive grammar can be easily modified to eliminate the left-recursion.
For example,
expr --> expr + term | expr - term | term
defines an expr to be either a single term or a sequence of terms separated by plus and minus signs.
Another way of defining an expr (without left-recursion) is:
expr --> term rest
rest --> + term rest | - term rest | e

A Translator for Simple Expressions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
92
A translation-scheme for converting simple infix expressions to postfix is:
expr --> term rest
rest --> + term { print('+') ; } rest
rest --> - term { print('-') ; } rest
rest --> e
term --> 0 { print('0') ; }
term --> 1 { print('1') ; }
... ...
term --> 9 { print('9') ; }

A Translator for Simple Expressions
February, 2010 Chapter 3: Context Free Grammars and
Parsers
93
expr()
{ term(); rest(); return; }
rest()
{
if (lookahead == '+')
{match('+'); term(); print('+'); rest(); return; }
else if (lookahead == '-')
{match('-'); term(); print('-'); rest(); return; }
else { return; }
}
term()
{
if (isdigit(lookahead))
{ print(lookahead); match(lookahead); return ; }
else { ReportErrorAndHalt(); }
}

Parse Trees
Phrase – sequence of tokens descended from
a nonterminal
Simple phrase – phrase that contains no
smaller phrase at the leaves
Handle – the leftmost simple phrase
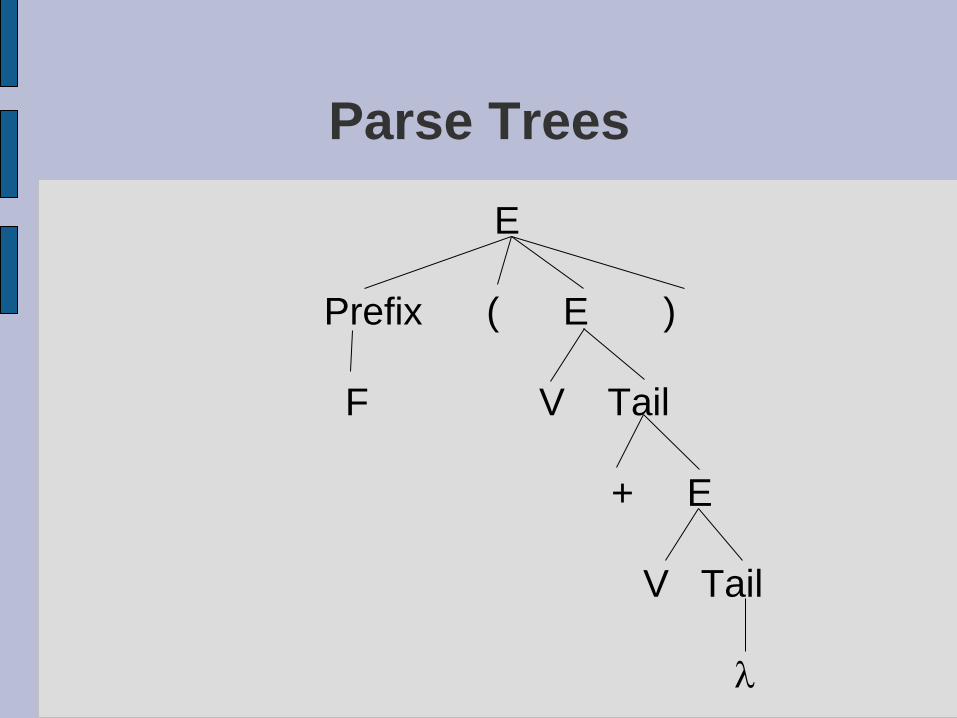
Parse Trees
E
Prefix ( E )
F V Tail
+ E
V Tail
l

LR Parsing
Shift Reduce
Use a parse stack
Initially empty, it contains symbols already
parsed (T & NT)
Tokens are shifted onto stack until the top of
the stack contains the handle
The handle is then reduced by replacing it on
the stack with the non terminal that is its parent
in the derivation tree
Success when no input left and goal symbol on
the stack

Shift Reduce Parser
Useful Data Structures
Action table – determines whether to shift,
reduce, terminate with success, or an error has
occurred
Parse stack – contains parse states
They encode the shifted symbol and the
handles that are being matched
GoTo Table – defines successor states after a
token or LHS is matched and shifted.

Shift Reduce Parser
S – top parse stack state
T – Current input token
push(S0) // start state
Loop forever
case Action(S,T)
error => ReportSyntaxError()
accept => CleanUpAndFinish()
shift => Push(GoTo(S,T))
Scanner(T) // yylex()
reduce => Assume X -> Y1...Ym
Pop(m) // S' is new stack top
Push(GoTo(S',X))

Shift Reduce Parser
Example Consider the following grammar G0:
<program> begin <stmts> end $
<stmts> SimpleStmt ; <stmts>
<stmts> begin <stmts> end ; <stmts>
<stmts> l
using the Action and GoTo tables for G0 what would the
parse look like for the following input:?
Begin SimpleStmt; SimpleStmt; end $

Shift Reduce Parser
Example Parse Stack Remaining Input Action
0 Begin SimpleStmt; SimpleStmt; end $ shift
0,1 SimpleStmt; SimpleStmt; end $ shift

LR(1) Parsers
Very powerful and most languages can be
recognized by them
But, the LR(1) machine contains so many
states the GoTo and Action tables are
prohibitively large

LR(1) Parser Alternatives
LR(0) parsers
Very compact tables
With no lookahead not very powerful
SLR(1) – Simple LR(1) parsers
Add lookahead to LR(0) tables
Almost as powerful as LR(1) but much
smaller
LALR(1) – look-ahead LR(1) parsers
Start with LR(1) states and merge states
differing only in the look-ahead
Smaller and slightly weaker than LR(1)

Properties of LR(1) Parsers
A correct rightmost parse is guaranteed
Since LR-style parsers accept only viable
prefixes, syntax errors are detected as soon as
the parser attempts to shift a token that isn't
part of a viable prefix
Prompt error reporting
They are linear in operation
All LR(1) grammars are unambiguous
Will yacc generate a parser for an
ambiguous grammar?

LL(1) vs LALR(1)
LL(1) and LALR(1) are dominant types
Although variants are used (recursive
descent and SLR(1))
LL(1) is simpler
LALR(1) is more general
Most languages can be represented by an
LL(1) or LALR(1) grammar, but it is easier to
write the LALR(1) grammar
LL(1) can be easier to specify actions
Error repair is easier to do in LL(1)
LL(1) tables will be ~½ size of LALR(1)

Summary
Fundamental concern of a top-down parser is
deciding which production to use to expand a
non terminal
Fundamental concern of a bottom-up parser is
to decide when a LHS replaces a RHS
LL(1) and LALR(1) are dominant types
LL(1) beats LALR(1) in all features except
generality, but very close comparison

Author’s Notes
February, 2010 Chapter 3: Context Free Grammars and
Parsers
106

Structural Issues First!
February, 2010 Chapter 3: Context Free Grammars and
Parsers
107
Express matching of a string
[“(34-3)*42”] by a derivation:
(1) exp exp op exp [exp exp op exp]
(2) exp op number [exp number]
(3) exp * number [op * ]
(4) ( exp ) * number [exp ( exp )]
(5) ( exp op exp ) * number [exp exp op exp]
(6) (exp op number) * number [exp number ]
(7) (exp - number) * number [op - ]
(8) (number - number)*number [exp number ]
exp exp op exp
exp ( exp )
exp number
op + | - | *
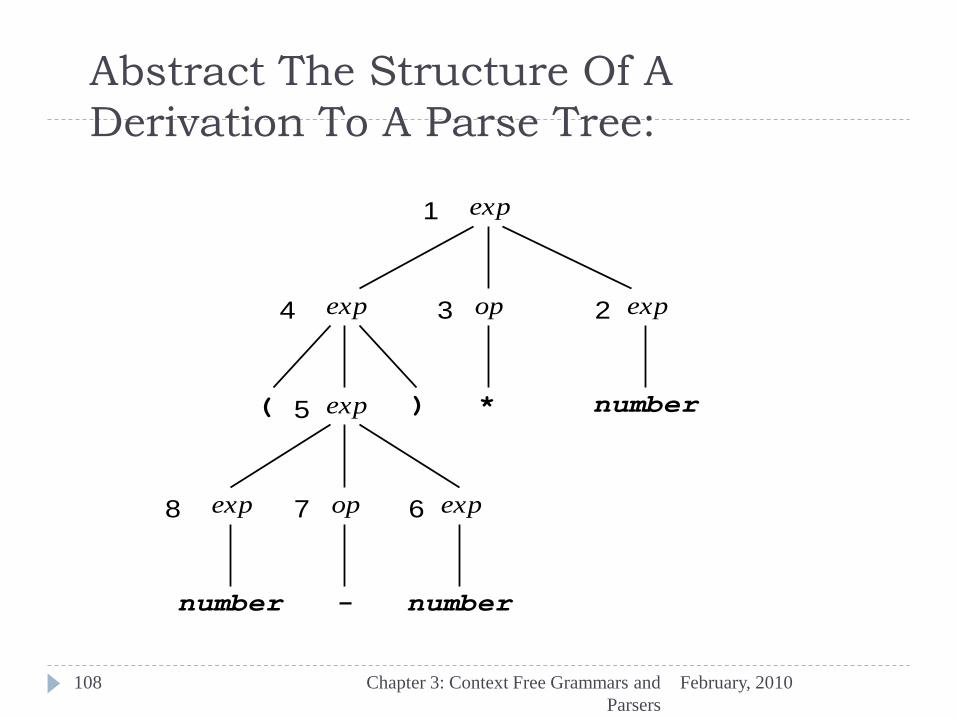
Abstract The Structure Of A
Derivation To A Parse Tree:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
108
exp
op
*
1
exp 4 3 exp
number
2
exp
exp op exp
number - number
5
8 7 6
( )

Derivations Can Vary, Even When The Parse
Tree Doesn’t:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
109
A leftmost derivation (previous was a rightmost):
(1) exp exp op exp [exp exp op exp]
(2) (exp) op exp [exp ( exp )]
(3) (exp op exp) op exp [exp exp op exp]
(4) (number op exp) op exp [exp number]
(5) (number - exp) op exp [op -]
(6) (number - number) op exp [exp number]
(7) (number - number) * exp [op *]
(8) (number - number) * number [exp number]

February, 2010 Chapter 3: Context Free Grammars and
Parsers
110
A leftmost derivation corresponds to a (top-down) preorder traversal
of the parse tree.
A rightmost derivation corresponds to a (bottom-up) postorder
traversal, but in reverse.
Top-down parsers construct leftmost derivations.
(LL = Left-to-right traversal of input, constructing a Leftmost
derivation)
Bottom-up parsers construct rightmost derivations in reverse order.
(LR = Left-to-right traversal of input, constructing a Rightmost
derivation)
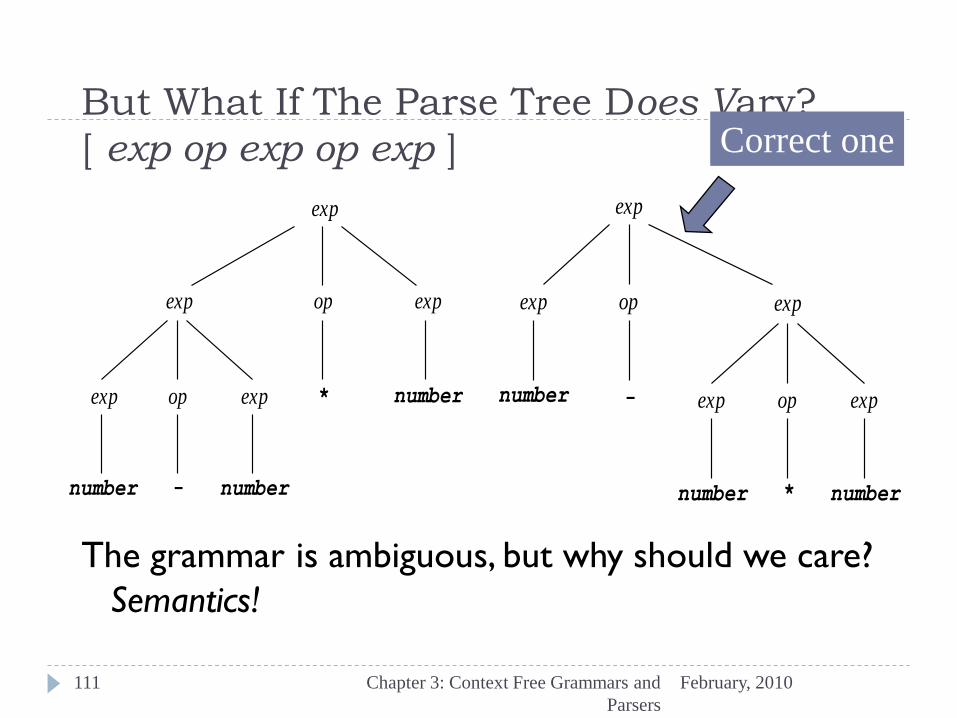
But What If The Parse Tree Does Vary?
[ exp op exp op exp ]
February, 2010 Chapter 3: Context Free Grammars and
Parsers
111
The grammar is ambiguous, but why should we care?
Semantics!
exp
op
*
exp
number
exp
exp op exp
number - number
exp
op
*
exp
number
exp
exp op exp
number
-
number
Correct one

Example: Integer Arithmetic
February, 2010 Chapter 3: Context Free Grammars and
Parsers
112
exp exp addop term | term
addop + | -
term term mulop factor | factor
mulop *
factor ( exp ) | number
Precedence “cascade”
Which operator(s) will appear closer
to the root?
Does closer to the root mean higher
or lower precedence?

Repetition and Recursion
February, 2010 Chapter 3: Context Free Grammars and
Parsers
113
Left recursion: A A x | y
yxx: A
A x
y
x A
Right recursion: A x A | y
– xxy: A
A x
y
x A

Repetition & Recursion, cont.
February, 2010 Chapter 3: Context Free Grammars and
Parsers
114
Sometimes we care which way recursion goes: operator
associativity
Sometimes we don’t: statement and expression sequences
Parsing always has to pick a way!
The tree may remove this information (see next slide)

Abstract Syntax Trees
February, 2010 Chapter 3: Context Free Grammars and
Parsers
115
Express the essential structure of the parse tree only
Leave out parens, cascades, and “don’t-care” repetitive
associativity
Corresponds to actual internal tree structure produced
by parser
Use sibling lists for “don’t care” repetition: s1 --- s2 --- s3

Previous Example [ (34-3)*42 ]
February, 2010 Chapter 3: Context Free Grammars and
Parsers
116
*
42
34 3
-

Data Structure
February, 2010 Chapter 3: Context Free Grammars and
Parsers
117
typedef enum {Plus,Minus,Times} OpKind;
typedef enum {OpK,ConstK} ExpKind;
typedef struct streenode
{ ExpKind kind;
OpKind op;
struct streenode *lchild,*rchild;
int val;
} STreeNode;
typedef STreeNode *SyntaxTree;

Or (Using A union):
February, 2010 Chapter 3: Context Free Grammars and
Parsers
118
typedef enum {Plus,Minus,Times} OpKind;
typedef enum {OpK,ConstK} ExpKind;
typedef struct streenode
{ ExpKind kind;
struct streenode *lchild,*rchild;
union {
OpKind op;
int val; } attribute;
} STreeNode;
typedef STreeNode *SyntaxTree;

Or (C++ but not ISO 99 C):
February, 2010 Chapter 3: Context Free Grammars and
Parsers
119
typedef enum {Plus,Minus,Times} OpKind;
typedef enum {OpK,ConstK} ExpKind;
typedef struct streenode
{ ExpKind kind;
struct streenode *lchild,*rchild;
union {
OpKind op;
int val; }; // anonymous union
} STreeNode;
typedef STreeNode *SyntaxTree;

Sequence Examples
February, 2010 Chapter 3: Context Free Grammars and
Parsers
120
stmt-seq stmt ; stmt-seq | stmt
one or more stmts separated by a ;
stmt-seq stmt ; stmt-seq | e
zero or more stmts terminated by a ;
stmt-seq stmt-seq ; stmt | stmt
one or more stmts separated by a ;
stmt-seq stmt-seq ; stmt | e
zero or more stmts preceded by a ;

Sequence Exercises:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
121
Write grammar rules for one or more statements
terminated by a semicolon.
Write grammar rules for zero or more statements
separated by a semicolon.

“Obscure” Ambiguity Example
February, 2010 Chapter 3: Context Free Grammars and
Parsers
122
Incorrect attempt to add unary minus:
exp exp addop term | term | - exp
addop + | -
term term mulop factor | factor
mulop *
factor ( exp ) | number

Ambiguity Example (cont.)
February, 2010 Chapter 3: Context Free Grammars and
Parsers
123
Better: (only one at beg. of an exp)
exp exp addop term | term | - term
Or maybe: (many at beg. of term) term - term | term1
term1 term1 mulop factor | factor
Or maybe: (many anywhere) factor ( exp ) | number | - factor

Dangling Else Ambiguity
February, 2010 Chapter 3: Context Free Grammars and
Parsers
124
statement if-stmt | other
if-stmt if ( exp ) statement
| if ( exp )statement else statement
exp 0 | 1
The following string has two parse trees:
if(0) if(1) other else other
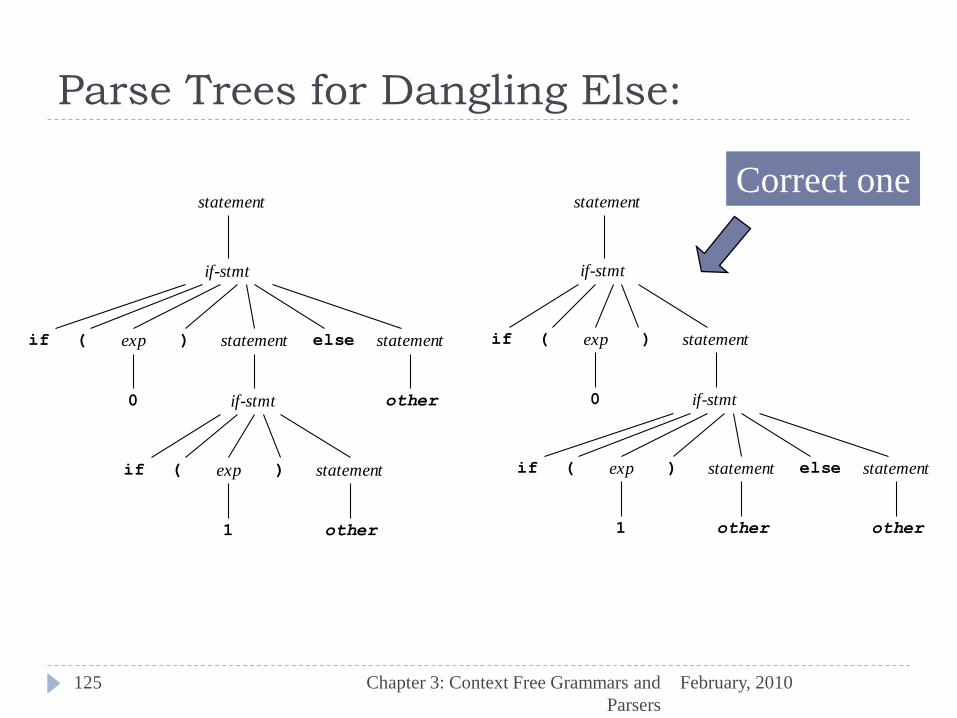
Parse Trees for Dangling Else:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
125
statement
if-stmt
if ( ) else exp statement statement
0 other if-stmt
if ( ) exp statement
1 other
statement
if-stmt
if ( ) exp statement
0 if-stmt
if ( ) else exp statement statement
1 other other
Correct one

Disambiguating Rule:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
126
An else part should always be associated with the nearest if-statement that does not yet have an associated else-part.
(Most-closely nested rule: easy to state, but hard to put into the grammar itself.)
Note that a “bracketing keyword” can remove the ambiguity:
if-stmt if ( exp ) stmt end
| if ( exp )stmt else stmt end
Bracketing keyword

TINY Grammar:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
127
program stmt-sequence
stmt-sequence stmt-sequence ; statement | statement
statement if-stmt | repeat-stmt | assign-stmt | read-stmt | write-stmt
if-stmt if exp then stmt-sequence end
| if exp then stmt-sequence else stmt-sequence end
repeat-stmt repeat stmt-sequence until exp
assign-stmt identifier := exp
read-stmt read identifier
write-stmt write exp
exp simple-exp comparison-op simple-exp | simple-exp
comparison-op < | =
simple-exp simple-exp addop term | term
addop + | -
term term mulop factor | factor
mulop * | /
factor ( exp ) | number | identifier

TINY Syntax Tree (Part 1)
February, 2010 Chapter 3: Context Free Grammars and
Parsers
128
typedef enum {StmtK,ExpK} NodeKind;
typedef enum
{IfK,RepeatK,AssignK,ReadK,WriteK}
StmtKind;
typedef enum {OpK,ConstK,IdK} ExpKind;
/* ExpType is used for type checking */
typedef enum {Void,Integer,Boolean}
ExpType;
#define MAXCHILDREN 3

TINY Syntax Tree (Part 2)
February, 2010 Chapter 3: Context Free Grammars and
Parsers
129
typedef struct treeNode
{ struct treeNode * child[MAXCHILDREN];
struct treeNode * sibling;
int lineno;
NodeKind nodekind;
union { StmtKind stmt; ExpKind exp;} kind;
union { TokenType op;
int val;
char * name; } attr;
ExpType type; /* for type checking */
} TreeNode;

Syntax Tree of sample.tny
February, 2010 Chapter 3: Context Free Grammars and
Parsers
130
read
(x) if
assign
(fact) op (<)
const (0)
id (x)
const (1)
repeat write
assign
(fact)
assign
(x) op (=)
op (*)
op (-)
id (fact)
id (x)
id (x)
const (1)
const (0)
id (x)
id (fact)

A Grammar for 1988 ANSI C
February, 2010 Chapter 3: Context Free Grammars and
Parsers
131
http://www.lysator.liu.se/c/ANSI-C-grammar-y.html

Ambiguities in C
February, 2010 Chapter 3: Context Free Grammars and
Parsers
132
•Dangling else
•One more: cast_expression unary_expression | ( type_name ) cast_expression
unary_expression postfix_expression | ...
postfix_expression primary_expression | ... primary_expression IDENTIFIER | CONSTANT
| STRING_LITERAL| ( expression )
type_name … | TYPE_NAME
Example:
typedef double x;
printf("%d\n",
(int)(x)-2);
int x = 1;
printf("%d\n",
(int)(x)-2);

Removing The Cast Amiguity Of C
February, 2010 Chapter 3: Context Free Grammars and
Parsers
133
TYPE_IDs must be distinguished from other IDs in the
scanner.
Parser must build the symbol table (at least partially) to
indicate whether an ID is a typedef or not.
Scanner must consult the symbol table; if an ID is found
as a typedef, return TYPE_ID, if not return ID.

Extra Notation:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
134
So far: Backus-Naur Form (BNF)
Metasymbols are | e
Extended BNF (EBNF):
New metasymbols […] and {…}
e largely eliminated by these
Parens? Maybe yes, maybe no: exp exp (+ | -) term | term
exp exp + term | exp - term | term

EBNF Metasymbols:
February, 2010 Chapter 3: Context Free Grammars and
Parsers
135
Brackets […] mean “optional” (like ? in regular
expressions):
exp term ‘|’ exp | term becomes:
exp term [ ‘|’ exp ]
if-stmt if ( exp ) stmt
| if ( exp )stmt else stmt
becomes:
if-stmt if ( exp ) stmt [ else stmt ]
Braces {…} mean “repetition” (like * in regexps - see
next slide)

Braces in EBNF
February, 2010 Chapter 3: Context Free Grammars and
Parsers
136
Replace only left-recursive repetition:
exp exp + term | term becomes:
exp term { + term }
Left associativity still implied
Watch out for choices:
exp exp + term | exp - term | term
is not the same as
exp term { + term } | term { - term }

Simple Expressions in EBNF
February, 2010 Chapter 3: Context Free Grammars and
Parsers
137
exp term { addop term }
addop + | -
term factor { mulop factor }
mulop *
factor ( exp ) | number
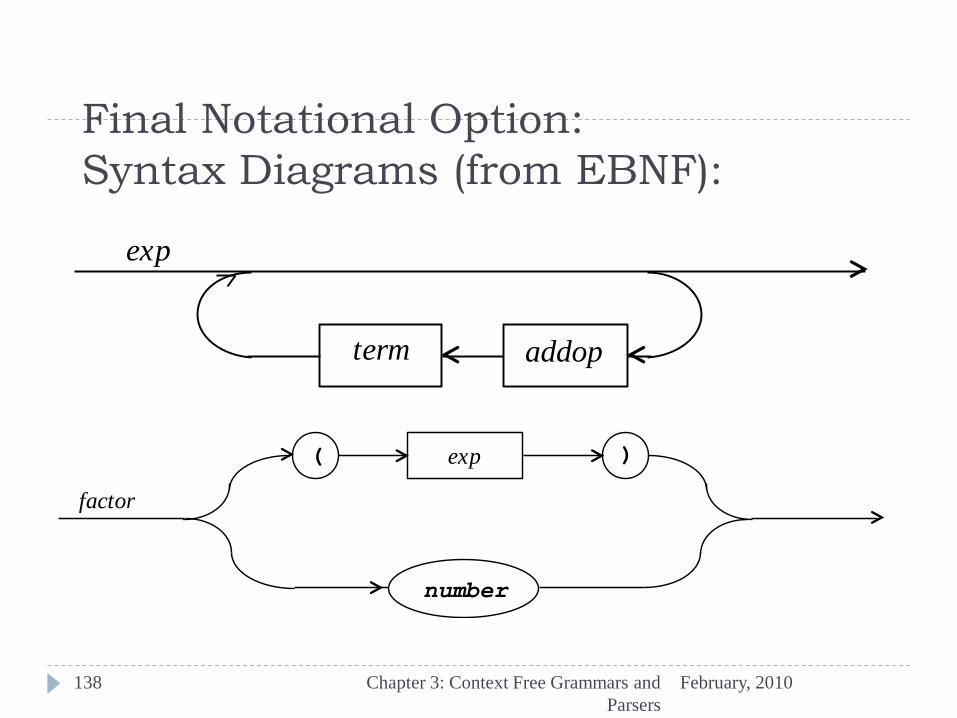
Final Notational Option:
Syntax Diagrams (from EBNF):
February, 2010 Chapter 3: Context Free Grammars and
Parsers
138
number
( ) exp >
>
> >
> factor
term
exp
<
>
addop <