comparison of monte carlo methods for model probability distribution determination … ·...
TRANSCRIPT

December 11, 2009 1
Comparison of Monte Carlo Methods for Model Probability Distribution Determination in SAR
Interferometry
Andy Hooper1 and Tim Wright2,
1Delft University of Technology2University of Leeds

12/11/2009 2
Interferogram

Model
12/11/2009 3
?

Non-linear Modelling
12/11/2009 4
(model) (data)

Non-linear Modelling
12/11/2009 5

Non-linear Modelling
12/11/2009 6

Non-linear Modelling
12/11/2009 7

Non-linear Modelling
• Optimal M, from e.g. simulated annealing, at minimum/maximum value of f(D).
12/11/2009 8

Non-linear Modelling
• Optimal M, from e.g. simulated annealing, at minimum/maximum value of f(D).
• Acknowledging we have measurement errors, aim is to find a probability distribution of model parameters.
12/11/2009 9

Simulated Noise Method
12/11/2009 10

Simulated Noise Method
12/11/2009 11
• Adding simulated noise changes f(D).
+noise

Simulated Noise Method
12/11/2009 12
• Adding simulated noise changes f(D).• Find optimal M again and repeat.
Wright et al, 1999

Simulated Noise Method
12/11/2009 13
• Adding simulated noise changes f(D).• Find optimal M again and repeat.
Wright et al, 1999
+noise

Simulated Noise Method
12/11/2009 14
• Adding simulated noise changes f(D).• Find optimal M again and repeat.
Model Parameters
Wright et al, 1999
P(M|D)

Markov-Chain Method
12/11/2009 15
• Set f(D) as probability density of data.
Includesnoise covariance

Markov-Chain Method
12/11/2009 16
• Set f(D) as probability density of data.• Bayes Theorem: P(M|D)=K.P(M).P(D|M)

Markov-Chain Method
12/11/2009 17
• Set f(D) as probability density of data. • Bayes Theorem: P(M|D)=K.P(M).P(D|M)• Build P(M|D) directly by repeated sampling from
M, mapping M to D, and keeping or rejecting sample based on p(D) e.g. Metropolis algorithm.
Mosegaard and Tarantola, 1995; Hooper et al, 2007

Markov-Chain Method
12/11/2009 18
• Set f(D) as probability density of data. • Bayes Theorem: P(M|D)=K.P(M).P(D|M)• Build P(M|D) directly by repeated sampling from
M, mapping M to D, and keeping or rejecting sample based on p(D) e.g. Metropolis algorithm.
Mosegaard and Tarantola, 1995; Hooper et al, 2007

Markov-Chain Method
12/11/2009 19
• Set f(D) as probability density of data. • Bayes Theorem: P(M|D)=K.P(M).P(D|M)• Build P(M|D) directly by repeated sampling from
M, mapping M to D, and keeping or rejecting sample based on p(D) e.g. Metropolis algorithm.
Mosegaard and Tarantola, 1995; Hooper et al, 2007

Markov-Chain Method
12/11/2009 20
Model Parameters
• Set f(D) as probability density of data. • Bayes Theorem: P(M|D)=K.P(M).P(D|M)• Build P(M|D) directly by repeated sampling from
M, mapping M to D, and keeping or rejecting sample based on p(D) e.g. Metropolis algorithm.
Mosegaard and Tarantola, 1995; Hooper et al, 2007

Comparison of Methods
12/11/2009 21
Markov-chain
Simulated noise

Comparison of Methods
12/11/2009 22
Markov-chain
Simulated noise
(Bayesian, so can also include prior model distribution)

Questions
• Do the results of the 2 methods agree
• What is the performance of each method?
12/11/2009 23

12/11/2009 24
Synthetic Data
Deformation Atmosphere+Decorrelation Total phase

12/11/2009 25
Optimal Models
Simulated noise
True Model Residual
Markov-chain

12/11/2009 26
Simulated Noise Method

12/11/2009 27
Markov-Chain Method

95% Bounds comparison
12/11/2009 28
Normalised by true values
Generally, good agreement
Markov-chain method
Sim
ulat
ed n
oise
met
hod

Convergence Simulated Noise
12/11/2009 29
Number of iterations

Convergence Simulated Noise
~900 iterations needed
12/11/2009 30
Number of iterations

Convergence Simulated Noise
~900 iterations needed
BUT, 37 000 forward models per iteration ~3 x 107 runs.12/11/2009 31
Number of iterations

Convergence Markov-Chain
12/11/2009 32
Number of iterations

Convergence Markov-Chain
12/11/2009 33
~400,000 iterations needed
BUT, 1 forward model per iteration
Number of iterations
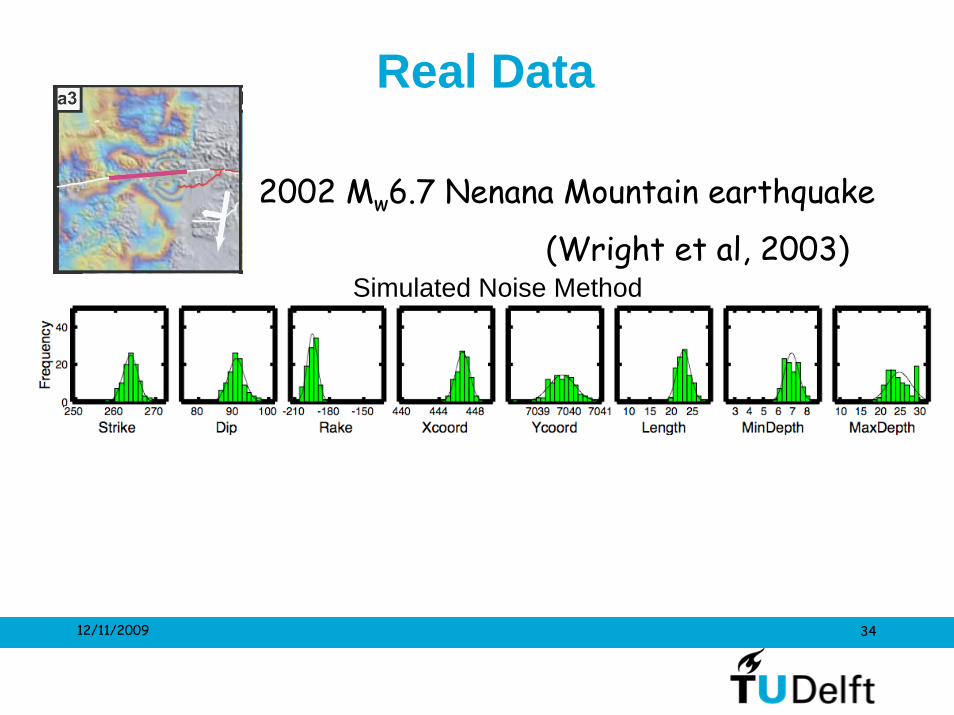
Real Data
12/11/2009 34
2002 Mw6.7 Nenana Mountain earthquake
(Wright et al, 2003) Simulated Noise Method

Real Data
12/11/2009 35
2002 Mw6.7 Nenana Mountain earthquake
(Wright et al, 2003) Simulated Noise Method
Markov-Chain Method

Agreement
12/11/2009 36
Agreement not as good, as simulated data, but reasonable
(only 100 runs using simulated noise)
Markov-chain method
Sim
ulat
ed n
oise
met
hod

Conclusions• Probability distributions from both methods agree.
• Optimal models differ (simulated noise gives non-weighted least-squares, Markov-chain gives maximum likelihood).
• Markov-chain method more efficient (2 orders of magnitude).
• Markov-chain method can include prior constraints.
12/11/2009 37