comp 630l paper presentation javy hoi ying lau. selected paper “a large scale evaluation and...
Post on 21-Dec-2015
214 views
TRANSCRIPT

COMP 630L Paper Presentation
Javy Hoi Ying Lau

Selected Paper
“A Large Scale Evaluation and Analysis of Personalized Search Strategies”
By
Zhicheng Dou, Ruihua Song, Ji-Rong Wen
Published In
International World Wide Web Conference, Proceedings of the 16th international conference on World Wide Web
Motivation
Criticisms on Performance of Personalized Search Strategies Query dependent
“mouse” vs “ Google” Neglecting the search context
sports fan submits the query “Office” Short-term vs Long-term Profile
Search for Docs to satisfy short-term needs
Current web search ranking is sufficient for definite queries[1]
Recent and remote histories are equally important[Recent history, Fresh queries] vs [Remote history, Recurring queries][2]
Does personalized search give promising performance under varied setups (e.g. queries, users, search context)
[1] J. Teevan, S.T. Dumais and E Horvitz. Beyond the commons: Investigating the value of personalizing web search. In Proceedings of PIA ’05,2005
[2] B. Tan, X. Shen, and C. Zhai. Mining long-term search history to improve search accuracy. In Proceedings of KDD ’06, pages 718–723, 2006.

Contributions
Proposed Methodology for Evaluation on a Large Scale Main idea: utilize clicking decisions as relevance judgments to
evaluate search accuracy Using click-through data recorded from 12 days MSN query logs Strategies studied: 2 click-based and 3 profile-based strategies
Preliminary Conclusion on Performance of Varied Strategies PS ~ Common Web Search
Performance is query dependent (e.g. click entropy of queries) Straight forward click-based > profile based Long-term and short-term contexts are important to profile-based
strategies

Evaluation Methodology
Typical vs Proposed Evaluation Framework Evaluation Metric

Typical Evaluation Method
Methodology A group of participants in PS system over several days Profile Specification
Specified by users manually Automatically learnt from search histories
Evaluation Participants determine the relevancy of the re-ranked result of some test
queries
Advantages Relevancy is explicitly defined by participants
Drawbacks Only limited no. of participants Test queries may bias the reliability and accuracy of evaluation

Proposed Evaluation Framework
Data stored in MSN search engine “Cookie GUID”: user identifier “Browser GUID”: session identifier Logs the query terms, clicked web pages and their ranks
Methodology Download the top 50 search results and ranking list l1 from MSN
search engine for test query Computer the personalized score of each webpage and generate a
new list l2 sorted by P score
Combine l1 and l2 by Borda’s ranking fusion method to get the relevance scores from MSN search engine
Use the measurement metric to evaluate performance

Proposed Evaluation Framework
Problems of this framework Unfair to evaluate a reordering of the original search results using the
original click data Fail to evaluation the ranking alternation of documents that are
relevant but not clicked by users

Evaluation Metric A – Rank Scoring Metric
Evaluate the effectiveness of the collaborative filtering systems Equations:
1. Expected utility of a ranked list of web pages for query s
2. Utility of all test queries
( 1) /( 1)
( , )
2S jj
s jR
100 SSMaxSS
RR
R
j: rank of a page in the list
s: test query
Alpha: parameter sets to 5
= 1if page j is clicked
= 0 if j is not clicked
Max possible utility: when the list returns all clicked webpage at the
top of the ranked list
Weighted by Ranking

Evaluation Metric B – Average Rank Metric
Equations:
1) Average Rank of query s
2) Final Average Rank on test query set S
1( )
| |s
sp Ps
AvgRank R pP
1
| | ss S
AvgRank AvgRankS
s: test query
Ps: set of clicked web pages on query s
R(p): Rank of page p

Personalization Strategies
Introduction of Personalization Strategies

Personalized Search Strategies Under Studies
Profile-based (User Interests) L-Profile S-Profile LS-Profile
Click-based (Historical Clicks) P-click G-click
Personal Level Re-Ranking
Group Level Re-Ranking

Background – Specifying User Profile
1) General interests specified by users explicitly
2) Learn users’ preference automatically Profiles built using users’ search history
Hierarchical category tree based on ODP (Open Directory Projects) Vectors of distinct terms which has accumulated past preference
User profiles used by this paper Weighted topic categories
Learned from users’ past clicked web pages
1..
[ (1).... ( )] ( ) 1i m
T T T m T i

L-Profile
c(·): Weighting vector of 67 pre-defined topic categories provided by KDD Cup [1]
1. Similarity between category vectors of user’s interest and webpage
2. User’s profile learnt from his past clicked webpages
User u’s interest profile
[1] The KDD-Cup 2005 Knowledge Discovery and Data Mining competition will be held in conjunction with the Eleventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
[2] D. Shen, R. Pan, J.-T. Sun, J. J. Pan, K. Wu, J. Yin, and Q. Yang. Q2c@ust: our winning solution to query classification in kddcup 2005. SIGKDD Explor. Newsl., 7(2):100–110, 2005.
Category vector of webpage p: with confidences of top 6 categories which p belongs to[2]
Prob that user u clicked webpage p before
Set of webpages visited by user u in the past Impact weight: inversely prop to popularity

S-Profile and LS-Profile
S-Profile
1) User’s short term profile
2) Score of webpage p:
LS-Profile
Set of webpages visited by user u in current session

P-Click
Personalized score on page p
Disadvantage: Only works for reoccurred queries
Click number on web page p by user u on query q in the past

G-Click
1) Similarity between two users calculated from their long-term profiles
2) Set of K-Nearest neighbors
3) Score of webpage

Statistics of Experiments
Dataset Queries Test Users Query Repetition Query Session Click Entropies

Statistics of Experiments
Dataset MSN query logs for 12 days in 08/06 Randomly sample 10000 distinct users in US on 19/08/06

Statistics of Experiments
Queries Statistics similar to other papers
80%
47%
use
r

Statistics of Experiments
Test Users

Statistics of Experiments
Query Repetition ~46% of the test queries are repeated ones in training days (72% of repeated ones and 33% of test queries) are repeated by the
same user
Query Sessions

Statistics of Experiments
Query Click Entropies Measure the degree of variation of query among each user
Reasons for large entropies Informational queries Ambiguous queries
collection of webpages clicked on query q
% of the clicks on webpage p among all the clicks on q

Statistics of Experiments
Query Click Entropies Majorities of the popular queries have low entropies

Experimental Results
Overall Performance of Varied Strategies Performance on Different Click Entropies Performance on Repeated Queries Performance on Variant Search Histories Analysis on Profile-based Strategies

Results: Overall Performance
1) Click-based > Web
2) G-Click ~ P-Click Varying the size of K shows no significant enhancement on
performance Reasons: high user query sparsity (similar users have few search
histories on the queries submitted by test user)
3) Profile-based < Click-based

Results: Overall Performance
1) Click-based > Web
2) G-Click ~ P-Click Varying the size of K shows no significant enhancement on
performance Reasons: high user query sparsity (similar users have few search
histories on the queries submitted by test user)
3) Profile-based < Click-based

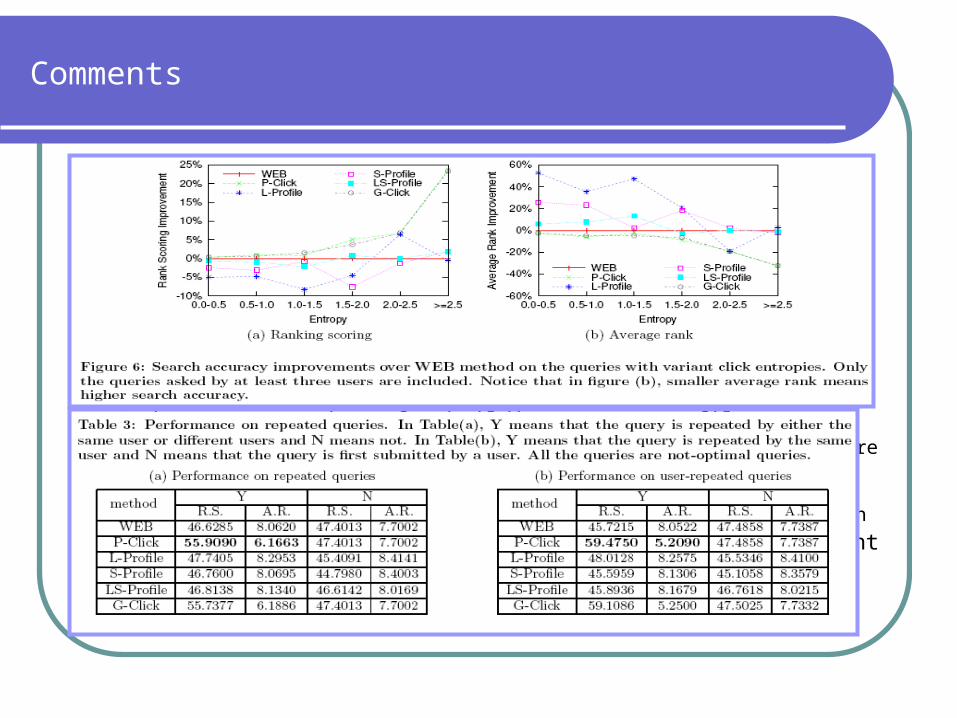
Results: Performance on Different Click Entropies
For low entropies, original web search has done a good job Click-based strategies have great improvement as entropies
increase Profile-based under perform in general Conclusion:
Queries with small click entropy, personalization is unnecessary

Results: Performance on Repeated Queries
46% of test queries are repeated 33% of queries are repeated by the same users Conclusion:
Refinding behavior is common\ High repetition ratio in real world makes click-based strategies work
well Suggestions:
We should provide convenient ways for users to review their search histories

Results: Performance on Variant Search Histories
1. For click-based approach, users with high search activities do not benefit more than other who do less search (higher variability on queries)
2. Long term profile improves performance as histories accumulate, but it also becomes more unstable (more noise)
Suggestions:We should consider user’s real information need and select only appropriate search histories to build up user profiles.

Analysis on Profile based Strategies
Reasons for under-performance of profile-based strategies Rough implementation Rich history contains noisy information which is irrelevant to current
search
LS-Profile is more stable than each of the separate profiles
Comments
√ Statistics of the dataset Justifying the experimental results (biased set?) Providing more information on strategies analysis (dataset vs strategies)
√ Big coverage of conventional personalization strategies√ Capture user’s web searching behavior since no predefined test queries
set× Most of the distinct queries are optimal ones
• Performance of Clicked-based ~ Profile-based for “N”× 12 days are too short for building user’s profiles
• Most of the users only give sparse queries among which most are optimal and definite queries) => User’s true interest profile is not learnt
• The setup of the experiments is biased to click-based approach× For some experimental results, the performance of different strategies
are close and irregular, it is not very convincing to draw a conclusion over their performance based on these results

Questions?