cmu scs i2.2 large scale information network processing inarc 1 overview goal: scalable algorithms...
TRANSCRIPT

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 1
Overview
Goal: scalable algorithms to find patterns and anomalies on graphs
1. Mining Large Graphs: Algorithms, Inference, and Discoveries
2. Spectral Analysis of Billion-Scale Graphs: Discoveries and Implementation
3. Patterns on the Connected Components of Terabyte-Scale Graphs
PI: Christos Faloutsos (CMU) Students: Leman Akoglu, Polo Chau, U Kang

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 2
Mining Large Graphs:Algorithms, Inference, and
Discoveries
U Kang
Duen HorngChau
ChristosFaloutsos
School of Computer ScienceCarnegie Mellon University

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 3
Outline
Problem Definition Proposed Method Experiment Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 4
Motivation
Inference on graph: “guilt by association” Adult sites tend to be connected to adult sites, while
edu. sites are connected to educational ones Given labels(adult or edu) on a subset of the nodes,
infer the labels of other unlabeled nodes on graph Tool: Belief Propagation(BP)
red nodes connected
to red nodes
blue nodes connected
to blue nodes

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Prior prob
Messages from neighbors
Node belief
Propagation matrix
~Messages from neighbors
Messsage from node i to node j
Message computation
Belief computation
Prior prob
Belief Propagation
5

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
A Challenge in BP
Scalability!
Existing works assume that all the nodes (and/or edges) of the input graph fit in memory Problem: what if the graph is too large to fit in
memory? Challenge: Scaling up the inference algorithm
for very large graphs whose nodes do not fit in memory
6

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Problem Definition
How can we scale up the BP algorithm to very large graphs?
Goal Scalability: to billions of nodes and edges Efficiency: fast algorithm
7

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 8
Outline
Problem Definition Proposed Method Experiment Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Main Idea
Our approach Use Hadoop to scale-up BP
Challenge How can we formulate BP using a simple, efficient
operation supported by Hadoop?
9

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Main Idea
Key observation BP message update equation = local message
exchange
10
0 1 2
3
4
m13m31
m01
m10
m12
m21
m24
m42
A message is updated from its neighboring messages.
For example, m12 is updatedfrom m01 and m31

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
BP message update can be expressed by a generalized matrix-vector multiplication on a line graph L(G) induced from the original graph G Nodes in L(G) are edges in G Two nodes in L(G) are connected if they are adjacent in G
Main Idea
11

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
BP message update can be expressed by a generalized matrix-vector multiplication on a line graph L(G) induced from the original graph G
Proposed: HA-LFP algorithm
12
mGLm G )('New message vector
Old message vector
Line graph of G
Generalized m-v multiplication
Multiply repeatedly until convergence

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Complexity
OneIteration of
HA-LFP on L(G)
OneMatrix Vector
Multiplication on G=
Time : O((V+E) / M)Space: O(V + E)
V : # of nodesE : # of nodesM : # of machines
13

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 14
Outline
Problem Definition Proposed Method Experiment Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC15
Questions
Q1: How fast is HA-LFP?
Q2: How does HA-LFP scale-up?
Q3: How can we find `good’ and `bad’ sites in a web graph?

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Running TimeQ1: How fast is HA-LFP?
[10 iteration]
16

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Scale UpQ2: How does HA-LFP scale-up?
Linear on the number of machines, edges
17

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Advantage of HA-LFP
Scalability The only solution when the node information
cannot fit in memory. Near-linear scale up
Running Time Faster than the single-machine, for large graphs
Fault Tolerance
18

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Analysis of Web Graph
Q3: How can we find `good’ and `bad’ sites in a web graph?
Pages whose goodness scores < 0.9are likely to be adult pages
19

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 20
Outline
Problem Definition Proposed Method Experiment Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 21
Conclusion
HA-LFP Belief Propgation for billion-scale graphs on Hadoop Near-linear scalability on # of machines, edges
Many applications Finding `good’ and `bad’ web sites Fraud detection …

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 22
Spectral Analysis of Billion-Scale Graphs:
Discoveries and Implementation
U Kang
BrendanMeeder
ChristosFaloutsos
School of Computer ScienceCarnegie Mellon University

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 23
Outline
Problem Definition Proposed Method Experiment Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 24
Problem Definition
Eigensolver Computes top-k eigenvalues and eigenvectors Application:
SVD, triangle counting, spectral clustering, …
Existing eigensolver Can handle up to millions of nodes
How can we scale up eigensolvers to billion-scale graphs?

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 25
Outline
Problem Definition Proposed Method Experiment Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Main Idea
HEigen algorithm (Hadoop Eigen-solver) Selective parallelize ‘Lanczos’ algorithm
Expensive operation: on Hadoop for scalability Inexpensive operation: on a single-machine for accuracy
Block encoding Block encoding, and then do matrix-vector multiplication
Exploiting skewness in matrix-matrix mult. In matrix-matrix multiplication when a matrix is very large
and the other is very small
26

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Application of HEigen
Triangle Counting Real social networks have a lot of triangles
Friends of friends are friends
But: triangles are expensive to compute (3-way join; several approx. algos)
Q: Can we do that quickly? A: Yes!
#triangles = 1/6 Sum ( λi3 )
(and, because of skewness in eigenvalues, we only need the top few eigenvalues!) [Tsourakakis
ICDM 2008]

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 28
Outline
Problem Definition Proposed Method Experiment Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC29
Questions
Q1: How does HEigen scale-up?
Q2: Which Matrix-Matrix multiplication algorithm runs the fastest?
Q3: How can we find anomalous sites in a web graph?

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Running TimeQ1: How does HEigen scale-up?
Heigen-BLOCK is faster than PLAIN ver.Linear on the number of machines, edges

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Scale Up
Cache-based MM runs the fastest!
Q2: Which Matrix-Matrix multiplication algorithm runs the fastest?

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 32
Results
Triangle counting on Twitter social network
[Twitter 2009; ~ 3 billion edges]
• U.S. politicians: moderate number of triangles vs. degree• Adult sites: very large number of triangles vs. degree
Q3: How can we find anomalous sites in a web graph?

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 33
Outline
Problem Definition Proposed Method Experiment Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 34
Conclusion
HEigen Eigensolver for billion-scale graphs on Hadoop Near-linear scalability on # of machines, edges Cache-based Matrix-Matrix multiplication: fastest! Anomalies in triangle counts
Many applications Triangle counting SVD …

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 35
Patterns on the Connected Components of
Terabyte-Scale Graphs
U Kang*
MaryMcGlohon*†
LemanAkoglu*
ChristosFaloutsos*
(*) SCS, Carnegie Mellon University(†) Google

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 36
Outline
Problem Definition Static Patterns Evolution Patterns Model Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
A large graph is composed of many connected components
37
Problem Definition
Q2: evolution patterns?
Q3: model?
Size
Q1: static patterns?
Count
YahooWeb graph|V| = 1.4 billion|E| = 6.7 billion
120 GBytes

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 38
Outline
Problem Definition Static Patterns Evolution Patterns Model Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 39
Q1: Static Patterns
What are the regularities in the connected components of a static graph? How do they look like? Do the GCC and the other connected
components look similar?
Chain?Clique?
Idea: use ‘density’ and ‘radius’ to find patterns

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Density of Connected Component
What is a good metric for the density of a connected component? A candidate: |E| / |V| (“average degree”) Problem: it increases over time
40
Number of Nodes
Number of Edges

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Density of Connected Component
We want a metric that can measure the ‘intrinsic’ density of a component
Proposed: Graph Fractal Dimension(GFD) log |E| / log |V|
41
[Leskovec+ KDD05]Number of NodesNumber of Nodes
Number of Edges
Number of Edges

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Density of Connected Component
Graph Fractal Dimension(GFD) log |E| / log |V|
42
Chain: GFD ~1
Star: GFD ~1
Bipartite Core: 1 < GFD < 2
Clique: GFD ~2

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Density of Connected Component
43
What are the GFDs of connected components in a large, real graph?

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Density of Connected Component
GFDs of CCs in YahooWeb graph
GFDs of CCs are slightly denser than the tree44
Slope=1.08
GFDs of CCs are constant on average
Number of Nodes Number of Nodes
Number of Edges
Number of Edges

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Radius of Connected Component
45
Q1.1: What does the GCC look like?Q1.2: What do the rest CC’s look like? ( What are the GFDs?)

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Radius of Connected Component
What are the patterns of radii in connected components?
A1.2: Chain-like disconnected components46
Slope=1.38
Core
Chain
Average Radius
A1.1: GCC looks like a ‘kite’
Max.Radius
Avg.
Max.

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 47
Outline
Problem Definition Static Patterns Evolution Patterns Model Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 48
Q2: Evolution Patterns
How do the connected components evolve? Do largest connected components grow with
the same rate? How often does a newcomer join the
disconnected components?newcomer
??
CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
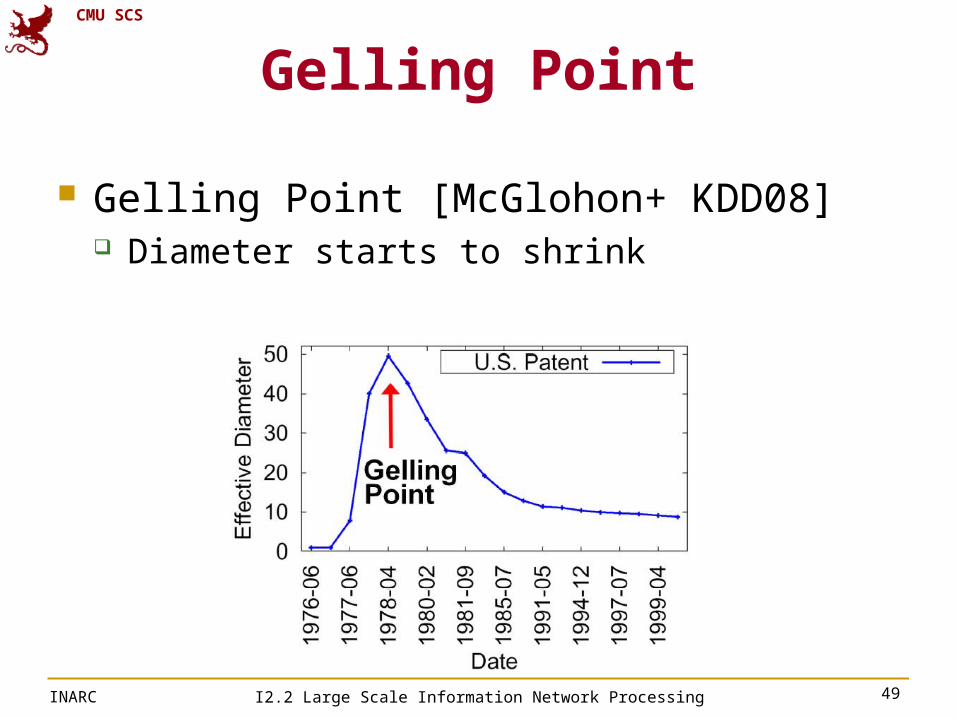
Gelling Point
Gelling Point [McGlohon+ KDD08] Diameter starts to shrink
49

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Growth of Connected Component
GFDs of Top 3 CC’s over time
50
Before “gelling point”: GFDs of Top 3 CC’s stay constant, “tree” like.
After “deviation point”: GFD of GCC takes off, becomes denser.

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
‘Rebel’ Probability
What are the chances that a newcomer doesn’t belong to GCC? (“rebel” prob.)
51
newcomer
?
GCC DCs

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
‘Rebel’ Probability
What are the chances that a newcomer doesn’t belong to GCC? (“rebel” prob.)
52
rebelP
rebelP
newcomer
d: degree of a newcomer
s: size (|V|) of DC
But, how exactly?

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
‘Rebel’ Prob. power of |V| in dc
‘Rebel’ Probability
53
‘Rebel’ Prob. exponential to the degree
drebel sP d: degree of a newcomer
s: size (|V|) of DC

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 54
Outline
Problem Definition Static Patterns Evolution Patterns Model Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 55
Q3: Model
How can we explain the static and the evolution patterns by a generative model?
Modeling Goals (G1) Constant GFDs (G2) ERP (Exponential Rebel Probability) (G3) Disconnected Components

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
CommunityConnection Model
CommunityConnection model Defines a behavior of a new node joining the
network 1. Chooses a host to link to. 2. Visits the neighbors
Repeat the two processes!
56

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
CommunityConnection Model
How does the CommunityConnection model match reality?
57

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
CommunityConnection Model
Results
(G1) Constant GFDs58
Number of Nodes
Number of Edges
Number of Nodes
Number of Edges
<Real Graph> <Our Model>

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
CommunityConnection Model
Results
(G2) ERP (Exponential Rebel Probability)
(G3) Disconnected Components59
Degree log(|V| in DC)
log(RebelProb.)
log(RebelProb.)
<Our Model>
<Real Graph>

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 60
Outline
Problem Definition Static Patterns Evolution Patterns Model Conclusion

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 61
Conclusion
Patterns in the Connected Components Goal 1 : Static Patterns
Chain-like disconnected components ‘Kite’-like GCC
Goal 2 : Evolution Patterns Constant, low GFD(“density”) until the gelling point ERP (Exponential Rebel Probability)
Goal 3 : Model CommunityConnection Model (matches reality)

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC
Hadoop/PEGASUS
Degree Distr.
Pagerank
Diameter
Conn. Comp
Eigensolver
Belief Propagation
Clustering, …
Future Plan
62

CMU SCS
I2.2 Large Scale Information Network ProcessingINARC 63
Thank you!http://www.cs.cmu.edu/~pegasus