clusternor: a numa-optimized clustering framework
TRANSCRIPT

1
clusterNOR: A NUMA-Optimized ClusteringFramework
Disa Mhembere1, Da Zheng2, Carey E. Priebe3, Joshua T. Vogelstein4, and Randal Burns1
1Department of Computer Science, Johns Hopkins University2Amazon Inc.
3Department of Applied Mathematics and Statistics, Johns Hopkins University4Institute for Computational Medicine, Department of Biomedical Engineering, Johns Hopkins University
F
Abstract—Clustering algorithms are iterative and have complexdata access patterns that result in many small random memoryaccesses. Also, the performance of parallel implementations sufferfrom synchronous barriers for each iteration and skewed workloads.We rethink the parallelization of clustering for modern non-uniformmemory architectures (NUMA) to maximize independent, asynchronouscomputation. We eliminate many barriers, reduce remote memoryaccesses, and increase cache reuse. Clustering NUMA OptimizedRoutines (clusterNOR) is an open-source framework that generalizesthe knor library for k-means clustering, providing a uniform programminginterface and expanding the scope to hierarchical and linear algebraicalgorithms. The algorithms share the Majorize-Minimization orMinorize-Maximization (MM) pattern of computation.
We demonstrate nine modern clustering algorithms that have simpleimplementations that run in-memory, with semi-external memory, ordistributed. For algorithms that rely on Euclidean distance, we developa relaxation of Elkan’s triangle inequality algorithm that uses asymptot-ically less memory and halves runtime. Our optimizations produce anorder of magnitude performance improvement over other systems, suchas Spark’s MLlib and Apple’s Turi.
Index Terms—NUMA, clustering, parallel k-means, SSD
1 INTRODUCTION
Clustering is a fundamental task in exploratory data anal-ysis and machine learning and, as datasets grow in size,scalable and parallel algorithms for clustering emerge asa critical capability in science and industry. Clustering isan unsupervised machine learning task for datasets thatcontain no pre-existing training labels. For example, userrecommendation systems at Netflix rely on clustering [4].Partitioning multi-billion data points is a fundamental taskfor targeted advertising in organizations such as Google [8]and Facebook [42]. Clustering is widely used in the sciences.Genetics uses clustering to infer relationships between simi-lar species [17], [34]. In neuroscience, connectomics [6], [25],[26] groups anatomical regions by structural, physiological,and functional similarity.
Although algorithms pursue diverse objectives, mostclustering algorithms follow the Majorize-Minimization orMinorize-Maximization (MM) [19] pattern of computation.MM algorithms optimize a surrogate function in order
to minorize or majorize the true objective function. MMalgorithms have two steps that are separated by a syn-chronization barrier. In the MM pattern, the raw data arenot modified. Data are processed continuously in iterationsthat modify algorithmic metadata only. Different algorithmscluster based on centroids, density, distribution, or connec-tivity and generate very different clusterings. Yet, becausethey all follow the MM pattern, we implement a commonframework for parallelization, distribution and memoryoptimization that applies to algorithms of all types. Weoptimize the core computation kernel for MM algorithmsdescribed in Section 4. We derive this computation kernelby generalizing the computation pattern we develop for k-means [31] and apply this kernel to MM algorithms.
We leverage the data access and computing patternscommon to MM algorithms to overcome the fundamentalperformance problems faced by tool builders. These are: (i)reducing the cost of the synchronization barrier betweenthe MM steps, (ii) mitigating the latency of data movementthrough the memory hierarchy, and (iii) scaling to arbitrarilylarge datasets. Fully asynchronous computation of both MMsteps is infeasible because each MM step updates globalstate. The resulting global barriers pose a major challenge tothe performance and scalability of parallel and distributedimplementations.
Popular frameworks [24], [30], [33] emphasize scaling-out computation to the distributed setting, neglecting tofully utilize the resources within each machine. Data arepartitioned among cluster nodes and global updates aretransmitted at the speed of the interconnect.
Our system, Clustering NUMA Optimized Routines orclusterNOR, maximizes resources for scale-up computa-tion on shared-memory multicore machines. This enablesclusterNOR to reduce network traffic and perform fine-grained synchronization. clusterNOR generalizes and ex-pands the core capabilities of the knor [31] library for k-means clustering. clusterNOR supports distributed comput-ing, but prefers to maximize resource utilization on a singlenode before distribution. Recent findings [22], [29], [46],show that the largest graph analytics tasks can be done ona small fraction of the hardware, at less cost, and as fast on
©2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, includingreprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any
copyrighted component of this work in other works.
arX
iv:1
902.
0952
7v6
[cs
.DC
] 1
7 Ja
n 20
21

2
a single shared-memory node as they can on a distributedsystem. Our findings reveal that clustering has the samestructure. Applications (Section 4) are benchmarked on asingle or few machines to minimize network bottlenecks.Single node performance (with SSDs) outperforms competi-tor’s distributed performance in most instances.
ContributionsclusterNOR improves the runtime performance of unsuper-vised machine learning MM algorithms. clusterNOR’s majorcontributions are:• An extensible open-source generalized framework, C++
API, and R package for utilization and the developmentof new pre-optimized MM algorithms.
• A NUMA-aware clustering library capable of operating(i) in-memory, (ii) in semi-external memory, and (iii)in distributed memory. clusterNOR scales to billions ofdata points and improves performance by up to 100xcompared to popular frameworks.
• The minimal triangle inequality (MTI) distance compu-tation pruning algorithm. MTI relaxes Elkan’s triangleinequality (TI) algorithm. MTI reduces the memoryincrement required to only O(n) compared with TI atO(nk). MTI reduces runtime by 50% or more on realworld large-scale datasets despite performing 2X moredistance computations than TI.
Manuscript OrganizationSection 2 introduces frameworks tackling clustering, andthose addressing optimizing computation on NUMA archi-tectures. Section 3 describes computational and algorithmicadvancements clusterNOR introduces to perform clusteringon modern multicore NUMA machines. Next, we reviewcore algorithms implemented within clusterNOR in Section4. Sections 5 - 7 focus on design points developed to opti-mize in-memory, semi-external memory, distributed cluster-ing for both hierarchical and non-hierarchical algorithms.In Section 8, we first conduct an in-depth evaluation ofthe performance and scalability of clusterNOR’s k-means incomparison to other frameworks. Section 8.11 evaluates the9 clustering algorithms implemented within clusterNOR.We conclude with a discussion (Section 9) and API descrip-tion (Appendix A).
2 RELATED WORK
Mahout [33] is a machine learning library that combinescanopy (pre-)clustering [28] alongside MM algorithms tocluster large-scale datasets. Mahout relies on Hadoop! anopen source implementation of MapReduce [9] for paral-lelism and scalability. Map/reduce allows for effortless scal-ability and parallelism, but offers little flexibility in how toachieve either. As such, Mahout is subject to load imbalanceor skew in the second MM phase. The skew occurs becausedata are shuffled to a smaller number of processors than aredesignated for computation.
MLlib is a machine learning library for Spark [44]. Sparkimposes a functional paradigm to parallelism. MLlib’s per-formance is highly coupled with Spark’s ability to efficientlyparallelize computation using the generic data abstraction of
the resilient distributed datasets (RDD) [43]. The in-memorydata organization of RDDs does not currently account forNUMA architectures, but many of the NUMA optimizationsthat we develop could be applied to RDDs.
Popular machine learning libraries, such as Scikit-learn[35], ClusterR [32], and mlpack [7], support a variety of clus-tering algorithms. These frameworks perform computationon a single machine, often serially, without the capacity todistribute computation to the cloud or perform computationon data larger than a machine’s main-memory. clusterNORpresents a lower-level API that allows users to distributeand scale many algorithms.
Several distance computation pruning algorithms for k-means exist [15]. Algorithms tradeoff pruning efficacy formemory usage and runtime. Elkan developed a popular andeffective pruning algorithm, triangle inequality (TI) withbounds [11]. TI reduces the number of distance computa-tions in k-means to fewer than O(kn) per iteration. Themethod relies on a sparse lower bound matrix of sizeO(kn).We present the minimal triangle inequality (MTI) algorithmthat is nearly as effective as TI, but only uses O(n) memory,which makes it practical for use with large-scale data.
The semi-external memory (SEM) optimizations we im-plement are inspired by FlashGraph [46] and implementedusing the same techniques for asynchronous I/O and over-lapped computation. FlashGraph is a SEM graph computa-tion framework that places edge data on SSDs and allowsuser-defined vertex state to be held in memory. FlashGraphruns on top of a userspace filesystem called SAFS [45]that merges independent I/O requests into larger transfersand manages a page cache to reduce I/O. SEM computationallows clusterNOR to capitalize on cheap commodity SSDsto inexpensively scale machine learning applications, oftenoutperforming larger, more expensive clusters of machines.
Modern multi-socket NUMA machines deliver highthroughput and low latency to CPUs local to a NUMAnode while penalizing remote memory accesses to non-localnodes. Column store databases [37] capitalize on NUMAtopologies to design efficient main-memory allocation andscheduling policies at runtime. They demonstrate thatfor column-stores with one or more tables in a multi-tenant environment, static partitioning and task stealing isinsufficient. A scheduler that monitors resource usage andresolves imbalance [38] through work stealing is neededwhen skew exists. clusterNOR uses similar principles.
Asymsched [21] and AutoNUMA [1] automaticallyreconstruct NUMA-sensitive memory policies formultithreaded applications. AutoNUMA collocates threadsthat utilize a shared region of main-memory. AutoNUMAconfigures several properties that affect its efficacy. Tuningthese configuration parameters may need to be done foreach individual application and performance may evendegrade if configured incorrectly. Asymsched specificallyaddresses the asymmetric bandwidth and latency propertiesof NUMA interconnects. Asymsched groups threads thataccess the same regions of memory together then migratesmemory using custom accelerated in-kernel system calls.Kernel level instructions pose a barrier to widespreadadoption of a system. clusterNOR implicitly implementshigh-level ideas within Asymsched and is highly adoptablebecause it executes fulling in user space.

3
3 IMPROVING MM ALGORITHM COMPUTATION
Many MM algorithms for clustering share the same com-putation pattern. We isolate this pattern and optimize thecore computation kernel underlying these algorithms. Tooptimize the computation kernel we:• Adopt a strategy to defer the synchronization barrier
between the two M-steps (see Section 3.2)• Reduce the computation cost of the first M-step by
algorithmically pruning computation (see Section 3.3).We utilize the k-means algorithm described in Section
4.1 to develop these optimizations. The core computationalkernel we optimize for k-means is then generalized for usein other MM algorithms within clusterNOR.
3.1 Notation
Throughout the manuscript, we use the terms defined inTable 1. In a given iteration, t, we can cluster any point, ~vinto a cluster ~c t. d denotes a generic dissimilarity metric.Additionally, we interchangeably use d for Euclidean dis-tance.
TABLE 1: Notation used throughout this manuscript
Term Definitionn The number of points in the datasetP The number of physical CPUs on a machineT The number of threads of concurrent execution~V Collection of data points with cardinality, |~V | = nd The dimensionality (# features) of a data point~v A d-dimensional vector in ~Vj The number of iterations an algorithm performst The current iteration of an algorithm, t ∈ {0...j}~c t A d-dimension centroid vector at iteration t
k The number of clusters 3 | ~Ct| = kL The number of hierarchical partitioning stepsB The batch size of an iteration for an algorithmr The number of runs performed for an algorithm
d(~v,~c t) A dissimilarity metric between any ~v and ~c t
d Euclidean distance,√∑n
i=1(~v1 − ~c t1)
2
f(~c t|t > 0) Dissimilarity between, ~c t & ~c t−1, i.e., d(~c t, ~c t−1)
3.2 Barrier Minimization
clusterNOR minimizes synchronization barriers for algo-rithms in which parts of the MM-steps can be performedsimultaneously. We generalize this pattern directly from theknor library [31] in which Lloyd’s k-means algorithm [23] ismodified, to ||Lloyd’s by merging the two MM-steps. clus-terNOR employs read-only global data and per-thread lock-free structures that are aggregated in user defined parallelreduction procedures at the end of MM-steps. Barrier mini-mization improves parallelism, at the cost of slightly highermemory consumption. This strategy naturally leads to lock-free routines that require fewer synchronization barriers.
3.3 Minimal Triangle Inequality (MTI) Pruning
We relax the constraints of Elkan’s algorithm for triangleinequality pruning (TI) [11] and eliminate the lower bound
matrix of size O(nk). We tradeoff reduced pruning effi-cacy for limited memory consumption and faster compu-tation times. Section 8.6.1 empirically demonstrates on real-world data that MTI drastically reduces computation timein comparison to other pruning methods while producingcomparable pruning efficacy to TI. While MTI consistentlyoutperforms TI on large-scale real-world datasets by a factorof 2X to 5X. MTI does so by minimizing time spent main-taining data structures that TI requires for pruning distancecomputations.
With O(n) memory, MTI modifies and implements threeof the five [11] pruning clauses performed by TI. Let ut =
d(~v, ~c nearestt) + f( ~c nearest
t), be the upper bound of
the distance of a sample, ~v, in iteration t from its assignedcluster ~c nearest
t. Finally, we define U to be an update
function such that U(ut) fully tightens the upper bound ofut by computing d(~v, ~c nearest
t+1).
Clause 1: if ut ≤ mind( ~c nearestt,~c t ∀~c t ∈ ~Ct), then ~v
remains in the same cluster for the current iteration. Forsemi-external memory, this is significant because no I/Orequests are made for data.
Clause 2: if ut ≤ d( ~c nearestt,~c t ∀~c t ∈ ~Ct), then the
distance computation between data point ~v and centroid~c t is pruned.
Clause 3: if U(ut) ≤ d( ~c nearestt,~c t ∀~c t ∈ ~Ct), then the
distance computation between data point ~v and centroid~c t is pruned.
4 APPLICATIONS (ALGORITHM IMPLEMENTATION)We implement 9 algorithms that demonstrate the utility,extensibility and performance of clusterNOR. We show theflexibility of the framework and generalized computationmodel that is exposed via the C++ API (Appendix A). We in-clude a code example in the Appendix A.5 for the G-meansalgorithm described in Section 4.9. Table 2 summarizes thecomputational and memory complexities of all applicationswithin the clusterNOR library. Complexities are of serialimplementations and do not account for additional state orcomputation needed to optimize parallel performance.
TABLE 2: Per-iteration memory and computation complex-ities for algorithms. Brief explanations are provided wherealgorithms are described.
Algorithm Memory Complexity Computation Complexityk-means O(nd+ kd) O(knd)sk-means O(nd+ kd) O(knd+ n)
k-means++ O(nd+ kd) O(kndr)mbk-means O(nd+ kd) O( knd
B)
fc-means O(2nd+ 2kd)) O(2nkd+ nk + n+ k)k-medoids O(nd+ kd+ n) O(k3 + nk)H-means O(nd+ 2Ld) O(2ndL)X-means O(nd+ 2Ld) O(2ndL+ kn)G-means O(nd+ 2Ld) O(2ndL+ 4kn)
4.1 k-meansK-means is an iterative partitioning algorithm in which data,~V , are assigned to one of k clusters based on the Euclideandistance, d, from each of the cluster means ~c t ∈ ~Ct. A serial

4
implementation requires memory of O(nd + kd); O(nd)for the dataset with n data points of d dimensions, andO(kd) for the k centroids of d dimensions. The computa-tion complexity of k-means both serially and parallelizedwithin clusterNOR remains O(knd); O(n) d-dimensionaldata points compute distances to O(k) d-dimensional cen-troids. The asymptotic memory consumption of k-meanswithin clusterNOR isO(nd+Tkd+n+k2). The term T arisesfrom the per-thread centroids we maintain. Likewise, theO(n+ k2) terms allow us to maintain a centroid-to-centroiddistance matrix and a point-to-centroid upper bound dis-tance vector of size O(n) that we use for computation prun-ing as described in Section 3.3. For SEM, the computationcomplexity remains unchanged, but the asymptotic memoryconsumption drops to O(n+ Tkd+ k2); dropping the O(d)term to disk. K-means minimizes the following objectivefunction for each data point, ~v:
min∑~v∈~V
||d(~v,~c t)|| (1)
4.2 Spherical k-means (sk-means)Spherical k-means (sk-means) [10] projects all data points,~V , to the unit sphere prior to performing the k-means al-gorithm. Unlike k-means, spherical k-means uses the cosinedistance function, dcos =
~V ·~Ct
||~V ||||~Ct||, to determine data point
to centroid proximity.
4.3 k-means++k-means++ [3] is stochastic clustering algorithm that per-forms multiple runs, r of the k-means algorithm then selectsthe best run. The best run corresponds to the run thatproduces the minimum squared euclidean distance betweena centroid and constituent cluster members. The k-means++algorithm shares memory complexity with k-means, butruns r times and thus has increased computational complex-ity, compared to k-means, at O(kndr). k-means++ chooseseach new centroid ~c t from the dataset through a weightedrandom selection such that:
~C ← D(~v)2∑
~v∈~V D(~v)2 , (2)
in which D(~v) is the minimum distance of a datapoint tothe clusters already chosen.
4.4 Mini-batch k-means (mbk-means)Lloyd’s algorithm is often referred to as batched k-meansbecause all data points are evaluated in every iteration.Mini-batch k-means (mbk-means) [41] incorporates randomsampling into each iteration of k-means thus reducing thecomputation cost of each iteration by a factor of B, the batchsize, to O(nkdB ) per iteration. Furthermore, a parameterη = 1
~Ctis computed per centroid to determine the learning
rate and convergence. Batching does not affect the memoryrequirements of k-means when run in-memory. In the SEMsetting, the memory requirement is O(kndB ), a reduction bya factor of B. Finally, the update function is as follows:
~Ct ← (1− η)Ct−1 + η~V (3)
4.5 Fuzzy C-means (fc-means)Fuzzy C-means [5] is an iterative ‘soft’ clustering algorithmin which data points can belong to multiple clusters bycomputing a degree of association with each centroid. Afuzziness index, z, is a hyper-parameter used to controlthe degree of fuzziness. fc-means shares a memory com-plexity with k-means. Computationally, fc-means performs2nkd + nk + n + k operations per iteration [5]. As such,fc-means is significantly more computationally intensivethan k-means despite retaining an identical asymptoticallycomplexity of O(nkd).
Fuzzy C-means computes J an association matrix rep-resenting the strength of connectivity of a data point to acluster. J ∈ Rnxk :
J =
|N |∑i=1
|C|∑k=1
uzik||~vi − ~cj ||2, 1 ≤ z < inf, (4)
in which uik is the degree of membership of ~vi in cluster k.
4.6 k-medoidsK-medoids is a clustering algorithm that uses data pointfeature-vectors as cluster representatives (medoids), insteadof centroids like k-means. In each iteration, each clusterdetermines whether to choose another cluster member asthe medoid. This is commonly referred to as the swap stepwith complexity O(n2d). This is followed by an MM step todetermine cluster assignment for each data point given theupdated medoids, resulting in a complexity of O(n − k)2.We reduce the computation cost by implementing a sampledvariant called (CLARA) [18] that is more practical, but stillhas a high asymptotic complexity ofO(k3+nk). This boundis explicitly derived in the work of Kaufman et al. [18].
4.7 Hierarchical k-means (H-means)The hierarchically divisive k-means algorithm recursivelypartitions the dataset in each iteration until a user-definedconvergence criteria is achieved. The computation complex-ity for L hierarchical levels of partitioning is O(2ndL), inwhich the factor 2 is derived from performing k-means withk = 2 centroids for each partition/cluster.
4.8 X-meansX-means [36] is a form of divisive hierarchical clusteringin which the number of clusters is not provided a pri-ori. Instead, X-means determines whether or not a clustershould be split using Bayesian Information Criterion (BIC)[40]. Computationally, it differs from H-means (Section 4.7)by an additional O(kn) term in which a decision is takenon whether or not to split after cluster membership isaccumulated.
4.9 Gaussian Means (G-means)G-means is a hierarchical divisive algorithm similar toX-means in its computation complexity and in that it doesnot require the number of clusters k as an argument.G-means mostly varies from X-means in that it uses theAnderson-Darling statistic [2] as the test to decide splits.The Anderson-Darling statistic performs roughly four timesmore computations than BIC, despite having the sameasymptotic complexity.

5
NUMANode0
CPU 0CPU 1
Core 𝛄-1
Thread 0Thread (𝝰)+1
data[0] … data[𝝰]data[𝜷𝝰] … data[(𝜷+1)𝝰]
Thread (N-1)*T/N data[(𝜷-1)𝛄𝝰] … data[𝛄𝜷𝝰]
: : :
::
::
::
::
NUMANode1
Core P-𝛄Core P-(𝛄+1)
Core P-1
Thread 𝜷-1Thread 2𝜷-1
data[(𝜷-1)𝝰] … data[𝜷𝝰]data[(2𝜷-1)𝝰] … data[2𝜷𝝰]
Thread T-1 data[(T-1)𝝰] … data[T𝝰]
: : :
Fig. 1: The memory allocation and thread assignmentscheme we employ. α = n/T is the amount of data perthread, β = T/N is the number of threads per NUMA node,and γ = P/N is the number of physical processors perNUMA node. Distributing memory across NUMA nodesmaximizes memory throughput whereas binding threads toNUMA nodes reduces remote memory accesses.
5 IN-MEMORY DESIGN
We prioritize practical performance when we implement in-memory optimizations. We make design tradeoffs to balancethe opposing forces of minimizing memory usage and max-imizing CPU cycles spent on parallel computing.
Prioritize data locality for NUMA: To minimize remotememory accesses, we bind every thread to a single NUMAnode, equally partition the dataset across NUMA nodes,and sequentially allocate data structures to the local NUMAnode’s memory. Every thread works independently. Threadsonly communicate or share data to aggregate per-threadstate as required by the algorithm. Figure 1 shows the dataallocation and access scheme we employ. We bind threadsto NUMA nodes rather than specific CPU cores because thelatter is too restrictive to the OS scheduler. CPU thread-binding may cause performance degradation if the numberof worker threads exceeds the number of physical cores.
Customized scheduling and work stealing: clusterNORcustomizes scheduling for algorithm-specific computationpatterns. For example, Fuzzy C-means (Section 4.5) assignsequal work to each thread at all times, meaning it wouldnot benefit from dynamic scheduling and load balancingvia work stealing. As such, Fuzzy C-means invokes staticscheduling. Conversely, k-means when utilizing MTI prun-ing would result in skew without dynamic scheduling andthread-level work stealing.
For dynamic scheduling, we develop a NUMA-awarepartitioned priority task queue (Figure 2) to feed workerthreads, prioritizing tasks that maximize local memory ac-cess and, consequently, limit remote memory accesses. Thetask queue enables idle threads to steal work from threadsbound to the same NUMA node first, minimizing remotememory accesses. The queue is partitioned into T parts,each with a lock required for access. We allow a thread tocycle through the task queue once looking for high prioritytasks before settling on another, possibly lower prioritytask. This tradeoff avoids starvation and ensures threads are
NUMA Node 0 NUMA Node N....
T(N-1)*T/NTTTTT0 TT-1TTTTT𝜷-1Thread
High priority task queue partitionLow priority task queue partition
....0…n/T n/T…2n/T n-2n/T…n-n/T n-n/T…n
Part0 Part1Part T-1 Part T
Data/Task indexrange
....
Fig. 2: The NUMA-aware partitioned task scheduler min-imizes task queue lock contention and remote memoryaccesses by prioritizing tasks with data in the local NUMAmemory bank.
::
Data access patternCache block of dataCache block position
NU
MA
Nod
e 0
…
…
::
Feature Space
NU
MA
Nod
e 1
Sample Space
::
Shared Data
Fig. 3: Data access patterns support NUMA locality, utilizeprefetched data well and optimize cache reuse through acache blocking scheme.
idle for negligible periods of time. The result is good loadbalancing in addition to optimized memory access patterns.
Avoid interference and defer barriers: Whenever possi-ble, per-thread data structures maintain mutable state. Thisavoids write-conflicts and elimiates locking. Per-thread dataare merged using an external-memory parallel reduction op-erator, much like funnel-sort [14], when algorithms reach theend of an iteration or the whole computation. For instance,in k-means, per-thread local centroids contain running totalsof their membership until an iteration ends when they arefinalized through a reduction.
Effective data layout for CPU cache exploitation andcache blocking: Both per-thread and global data structuresare placed in contiguously allocated chunks of memory.Contiguous data organization and sequential access pat-terns improve processor prefetching and cache line utiliza-tion. Furthermore, we optimize access to both input andoutput data structures to improve performance. In the caseof a dot product operation (Figure 3), we access input datasequentially from the local NUMA memory and write theoutput structure using a cache blocked scheme for higherthroughput reads and writes. The size of the block is deter-mined based on L1 and L2 cache specifications reported bythe processor on a machine. We utilize this optimization inFuzzy C-means.

6
5.1 Iterative Hierarchical Design
clusterNOR exposes an iterative interface for recursive hier-archical algorithms. Doing so enables clusterNOR to capital-ize on the hardware by:• eliminating stack duplication during recursive calls• localizing and sequentializing data access• improving the utility of prefetched dataNaıve implementations assign a thread to each cluster
and shuffle data between levels of the hierarchy (Figure 4a).This incurs a great deal of remote memory access and non-contiguous I/O for each thread. clusterNOR avoids thesepitfalls by not shuffling data. Instead, threads are assignedto contiguous regions of memory. Figure 4b shows thecomputation hierarchy in a simple two thread computation.
clusterNOR’s design places computation barriers (i)when the user defined function, fx, completes and (ii) whenclusters spawn at a hierarchical partitioning step. New clustersspawn in a parallel block that only modifies membershipmetadata. Computation is deferred until all clusterscapable of spawning have done so. Cluster assignmentidentifiers are encoded into the leading bits of the data pointidentifier with a bitmap maintained to determine whetherclusters have algorithmically converged. Load balancing isperformed via the NUMA-aware scheduler (Figure 2).
clusterNOR’s design introduces a barrier at the hierar-chical partitioning step. We trade-off the introduction of thisbarrier for the ability to increase memory throughput byissuing iterative contiguous tasks (blocks of data points). Asystem recursively designed will incur stack creation over-head upon spawning. Additionally, each spawned clusterwill naturally operate on increasingly smaller partitions ofthe data with no guarantee of contiguous access for workerthreads. Early results demonstrate at least 1.5x improve-ment in the performance of hierarchical clustering methodsby developing an iterative interface as compared to a recur-sive one.
6 SEMI-EXTERNAL MEMORY DESIGN
The semi-external memory (SEM) model allows a dataset,~V ∈ Rnxd to utilize O(n) main-memory with the remainingO(nd) data in external storage devices. External data areasynchronously streamed into main memory while out oforder execution is performed. The model reduces IO latencyin comparison to a pure streaming model and reducesmemory requirements when compared to purely in-memorycomputation. SEM is well suited for dataset larger thanmain-memory in which distributed solutions are tradition-ally employed.
FlashGraph [46] is a SEM graph engine that supportsasynchronous I/O and out of order execution. FlashGraphtargets scale-up computing on a multi-core NUMAmachine. We modify the FlashGraph kernel to supportmatrix-like computations for use within clusterNOR. Wefind for some datasets single-node systems are faster thandistributed systems that use an order of magnitude morehardware.
We modify FlashGraph to integrate into clusterNORby altering FlashGraph’s primitive data type, thepage_vertex. The page_vertex is interpreted as a
T0
T1
T0
T1
Data ID Reference
T0
T1
T0
T1
(a) Naıve recursive parallel hierarchical clustering exhibits poordata locality, and non-contiguous data access patterns.
f0
T0
T1
f1
T0
T1
c0,v0
c0,v1
c0,v2
c0,v3
c0,v4
c0,v5
c0,v6
c0,v7
c0,v8
Partition-Data ID Bits
c1,v0
c2,v1
c2,v2
c1,v3
c1,v4
c2,v5
c1,v6
c2,v7
c1,v8
f2
T0
T1
c3,v0
c5,v1
c6,v2
c4,v3
c4,v4
c6,v5
c4,v6
c5,v7
c3,v8
Contiguous memory access
Non-contiguous memory access
cx Hierarchical clusterTx Processing threadfx User defined function
vx Vertex identifier Hierarchical partitioning step
(b) clusterNOR transparently provides NUMA-local, sequential,and contiguous data access patterns.
Fig. 4: A naıve hierarchical implementation with unfavor-able data access patterns compared to clusterNOR. cluster-NOR enforces sequential data access and maximizes cachereuse.
vertex with an index to the edge list of the page_vertexon SSDs. We define a row of data to be equivalent to a d-dimension data point, ~vi. Each row is composed of a uniqueidentifier, row-ID, and d-dimension data vector, row-data.The row-data naturally replaces the adjacency list originallystored for FlashGraph vertices. We add a page_row datatype to FlashGraph and modify the asynchronous I/O layerto support floating point row-data reads rather than thenumeric identifiers for graph adjacency lists. The page_rowtype computes its row-ID and row-data location on diskmeaning only user-defined state is stored in-memory. Thepage_row reduces the in-memory state necessary to useFlashGraph by O(n) because it does not store an indexto data on SSDs unlike a page_vertex. This allows SEMapplications to scale to larger datasets than possible beforeon a single machine.
6.1 I/O minimization
I/O bounds the performance of most well-optimized SEMapplications. Accordingly, we reduce the number of data-rows that need to be brought into main-memory each itera-tion. In the case of k-means, only Clause 1 of MTI (Section3.3) facilitates the skipping of all distance computations for adata point. Likewise for mini-batch k-means and k-medoidsthat subsample the data, we perform selective IO in eachiteration. We observe the same phenomenon when data

7
points have converged in a cluster for H-means, G-meansand X-means. In these cases, we issue significantly fewerI/O requests but still retrieve significantly more data thannecessary from SSDs because pruning occurs near-randomlyand sampling pseudo-randomly. Reducing the filesystempage size, i.e. minimum read size from SSDs alleviates thisto an extent, but a small page size can lead to a highernumber of I/O requests, offsetting any gains achieved fromreduced fragmentation. We utilize a minimum read size of4KB. Even with this small value, we receive much more datafrom disk than we request. To address this, we develop alazily-updated partitioned row cache that drastically reducesthe amount of data brought into main-memory.
6.1.1 Partitioned Row Cache (RC)
We add a layer to the memory hierarchy for SEM appli-cations by designing a lazily-updated row cache (Figure5). The row cache improves performance by reducing I/Oand minimizing I/O request merging and page cachingoverhead in FlashGraph. A row is active when it performsan I/O request in the current iteration for its row-data.The row cache places active rows to main-memory at thegranularity of a row, rather than a page, improving itseffectiveness in reducing I/O compared to a page cache. Therow cache is managed at the granularity of an entry (row)at a time rather than a collection (page) of such entries. Thisis the fundamental difference between the row cache andthe page cache or similarly, buffer pools in relation databasemanagement systems.
We partition the row cache into as many partitionsas FlashGraph creates for the underlying matrix, typicallyequal to the number of threads of execution. Each partitionis updated locally in a lock-free caching structure. Thisvastly reduces the cache maintenance overhead, keeping theRC lightweight. The size of the cache is user-defined, but1GB is sufficient to significantly improve the performanceof billion-point datasets.
The row cache operates in one of two modes based uponthe data access properties of the algorithm:
Lazy update mode: the row cache lazily updates onspecified iterations based on a user defined cache updateinterval (Icache). The cache updates at iteration Icache thenthe update frequency increases quadratically such that thenext row cache update is performed after 2Icache, then4Icache iterations and so forth. This means that row-datain the row cache remains static for several iterations beforethe row cache is flushed then repopulated. This tracks therow activation patterns of algorithms like k-means, mb-kmeans, sk-means, and divisive hierarchical clustering. Inearly iterations, the cache provides little benefit, becauserow activations are random. As the algorithm progresses,the same data points tend to stay active for many consecu-tive iterations. As such, much of the cache remains static forlonger periods of time.
Active update mode: the row cache can also function asa traditional Least Recently Used (LRU) cache. This modesimply stores the more recently requested rows and evictsthose that are less popular. This mode has higher mainte-nance overhead, but is more general for cases in which dataaccess patterns are less predictable.
Sock
et0
T0
T2
T4
T6
N0
N1
T1
T3
T5
T7: :
: :
L2
L2
Vertex Cache PartitionsNUMA Node
Thread Affinity
Partition Ownership
Sock
et1
Fig. 5: The structure of the row cache for SEM applicationsin a typical two socket, two NUMA node machine utilizing8 threads on 8 physical CPUs. Partitioning the row cacheeliminates the need for locking during cache population.The aggregate size of all row cache partitions resides withinthe NUMA-node shared L2 cache.
7 DISTRIBUTED DESIGN
We scale to the distributed setting through the MessagePassing Interface (MPI). We employ modular design prin-ciples and build our distributed functionality as a layerabove our parallel in-memory framework. Each machinemaintains a decentralized driver that launches worker threadsthat retain the NUMA performance optimizations across itsmultiple processors.
We do not address load balancing between machinesin the cluster. We recognize that in some cases it may bebeneficial to dynamically dispatch tasks, but this negativelyaffects the performance enhancing NUMA polices we em-ploy. The gains in performance of data partitioning (Figure1) outweigh the effects of skew. We validate this assertionempirically in Section 8.9.
clusterNOR assumes architecture homogeneity for ma-chines identified as cluster members via a configuration file.Data are first logically partitioned into as many partitionsas there are NUMA nodes in the cluster. Next, partitionsare randomly assigned to worker machines to reduce thepotential for data hotspots. Finally, each machine processeslocal data and can merge global state based on a userdefined function that operates across the cluster virtuallytransparent to the programmer. The distributed design issimple and heavily leverages the in-memory optimizationsin Section 5 in order to achieve state-of-the-art runtimeperformance.
8 EXPERIMENTAL EVALUATION
We begin the evaluation of clusterNOR by benchmarkingthe performance and efficacy of our optimizations for thek-means application. k-means is a core algorithm for theframework and a building block upon which other appli-cations like mini-batch k-means, H-means, X-means and G-

8
TABLE 3: k-means routine naming convention.
Routine name Definitionknori knor, i.e., k-means, in-memory modeknori- knori, with MTI pruning disabledknors knor, in SEM modeknors- knors, with MTI pruning disabledknors-- knors, with MTI pruning and RC disabledknord knor in distributed mode in a clusterknord- knord with MTI pruning disabled
MLlib-EC2 MLlib’s k-means, on Amazon EC2 [16]MPI MPI [12] ||Lloyds k-means, with MTI enabledMPI- MPI without MTI pruning
means are built. We refer to the k-means NUMA OptimizedRoutine as knor. Section 8.11 completes our evaluation bybenchmarking all applications described in Section 4.
We evaluate knor optimizations and benchmark againstheavily-used scalable frameworks. In Section 8.3 we eval-uate the performance of the knor baseline single threadedimplementation and show its computation time to be fasterthan competitors. We use this performance baseline to an-chor the strong speedup and scaleup results we demon-strate.
Sections 8.4 and 8.5 evaluate the effect of specific op-timizations on our in-memory and semi-external memorytools respectively. Section 8.7 evaluates the performance ofk-means both in-memory and in the SEM setting relativeto other popular scalable frameworks from the perspectiveof time and resource consumption. Section 8.9 specificallyperforms comparison between knor and MLlib when run ina distributed cluster.
We evaluate knor optimizations on the Friendster top-8 and top-32 eigenvector datasets. The Friendster datasetrepresents real-world machine learning data derived froma graph that follows a power law distribution of edges.As such, the resulting eigenvectors contain natural clusterswith well defined centroids, which makes MTI pruningeffective, because many data points fall into strongly rootedclusters and do not change membership. These trends holdtrue for other large-scale datasets, albeit to a lesser extenton uniformly random generated data (Section 8.7). Thedatasets we use for performance and scalability evaluationare shown in Table 5. A summary of knor routine memorybounds is shown in Table 4. Table 3 defines the naming con-vention we assume for various k-means implementationswithin figures and throughout the evaluation.
All measurements we report are an average of 10 runson dedicated machines. Variance in timings are statisticallyinsignificant. As such, we exclude error bars as they do notadd to the interpretation of the data. We drop all cachesbetween runs.
For completeness we note versions of all frameworksand libraries we use for comparison in this study; Sparkv2.0.1 for MLlib, H2O v3.7, Turi v2.1, R v3.3.1, MATLABR2016b, BLAS v3.7.0, Scikit-learn v0.18, MLpack v2.1.0.
8.1 Single Node Evaluation Hardware
We perform single node experiments on a NUMA serverwith four Intel Xeon E7-4860 processors clocked at 2.6 GHzand 1TB of DDR3-1600 memory. Each processor has 12
TABLE 4: Asymptotic memory complexity of knor routines.The computational complexity of all routines is identical atO(ndk).
Module / Routine Memory complexityNaıve Lloyd’s O(nd+ kd)knors-, knors-- O(n+ Tkd)
knors O(2n+ Tkd+ k2)knori-, knord- O(nd+ Tkd)knori, knord O(nd+ Tkd+ n+ k2)
TABLE 5: The datasets under evaluation in this study.
Data Matrix n d SizeFriendster-8 [13] eigenvectors 66M 8 4GBFriendster-32 [13] eigenvectors 66M 32 16GBRand-Multivariate (RM856M ) 856M 16 103GB
Rand-Multivariate (RM1B) 1.1B 32 251GBRand-Univariate (RU2B) 2.1B 64 1.1TB
cores. The machine has three LSI SAS 9300-8e host busadapters (HBA) connected to a SuperMicro storage chassis,in which 24 OCZ Intrepid 3000 SSDs are installed. Themachine runs Linux kernel v4.4.0-124. Simultaneous multi-processing (Intel Hyperthreading) is enabled. Quick PathInterconnect (QPI) average idle local node latency is mea-sured at 115.3ns with average remote node latency at 174ns.For reads, QPI average local NUMA node bandwidth ismeasured at 55GB/s and average remote node bandwidth at11.5GB/s. The C++ code is compiled using mpicxx.mpich2version 5.5.0− 12 with the -O3 flag.
8.2 Cluster Evaluation HardwareWe perform distributed memory experiments on AmazonEC2 compute optimized instances of type c4.8xlarge with60GB of DDR3-1600 memory, running Linux kernel v3.13.0-91. Each machine has 36 vCPUS, corresponding to 18-coreIntel Xeon E5-2666 v3 processors, clocking 2.9 GHz, sittingon 2 independent sockets. We allow no more that 18 inde-pendent MPI processes or equivalently 18 Spark workersto exist on any single machine. We constrain the clusterto a single availability zone, subnet and placement group,maximizing cluster-wide data locality and minimizing net-work latency on the 10 Gigabit interconnect. We measureall experiments from the point when all data is in RAM onall machines. For MLlib we ensure that the Spark engine isconfigured to use the maximum available memory and doesnot perform any checkpointing or I/O during computation.
8.3 Baseline Single-Thread Performanceknori, even with MTI pruning disabled, performs on parwith state-of-the-art implementations of Lloyd’s algorithm.This is true for implementations that utilize generalizedmatrix multiplication (GEMM) techniques and vectorizedoperations, such as MATLAB [27] and BLAS [20]. We findthe same to be true of popular statistics packages andframeworks such as MLpack [7], Scikit-learn [35] and R [39]all of which use highly optimized C/C++ code, althoughsome use scripting language wrappers. Table 6 shows per-formance at 1 thread. Our baseline single threaded perfor-mance tops other state-of-the-art serial routines.
9
TABLE 6: Serial performance of k-means routines, usingLloyd’s algorithm, on the Friendster-8 dataset. All imple-mentations perform all distance computations. The Lan-guage column refers to the underlying language of imple-mentation and not any user-facing higher level wrapper.
Implementation Type Language Time/iter (sec)knori- Iterative C++ 7.49
MATLAB GEMM C++ 20.68BLAS GEMM C++ 20.7
R Iterative C 8.63Scikit-learn Iterative Cython 12.84
MLpack Iterative C++ 13.09
8.4 In-Memory Optimization
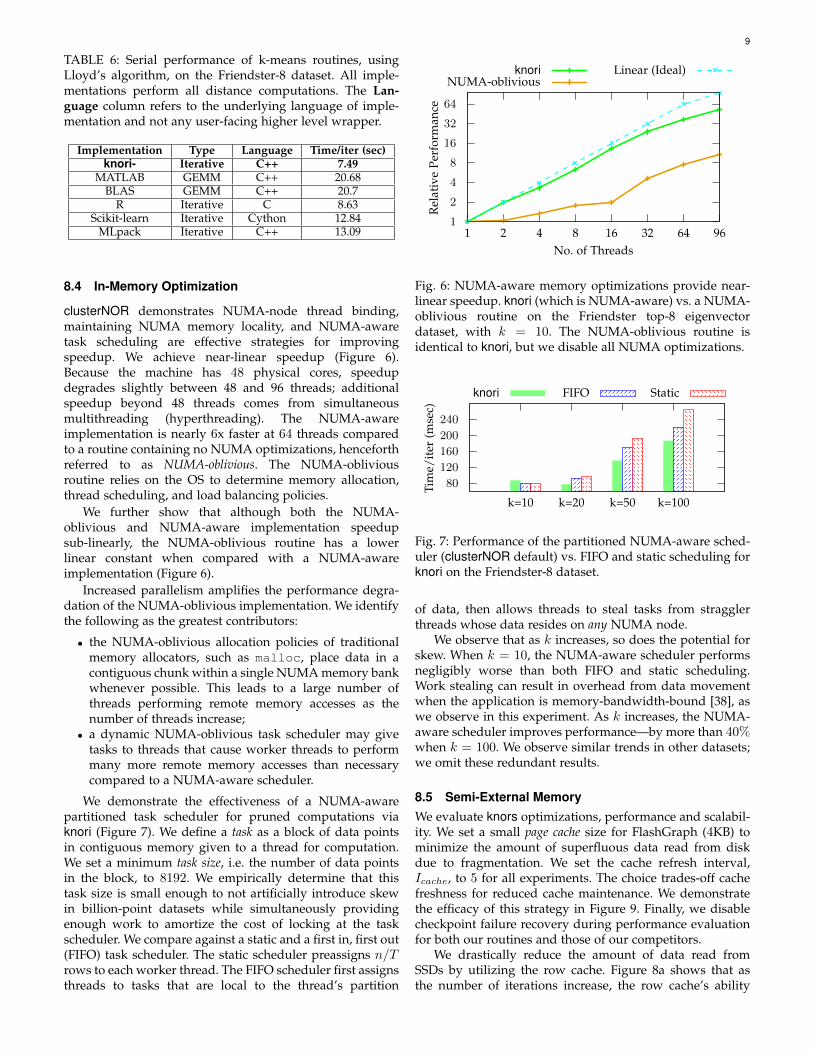
clusterNOR demonstrates NUMA-node thread binding,maintaining NUMA memory locality, and NUMA-awaretask scheduling are effective strategies for improvingspeedup. We achieve near-linear speedup (Figure 6).Because the machine has 48 physical cores, speedupdegrades slightly between 48 and 96 threads; additionalspeedup beyond 48 threads comes from simultaneousmultithreading (hyperthreading). The NUMA-awareimplementation is nearly 6x faster at 64 threads comparedto a routine containing no NUMA optimizations, henceforthreferred to as NUMA-oblivious. The NUMA-obliviousroutine relies on the OS to determine memory allocation,thread scheduling, and load balancing policies.
We further show that although both the NUMA-oblivious and NUMA-aware implementation speedupsub-linearly, the NUMA-oblivious routine has a lowerlinear constant when compared with a NUMA-awareimplementation (Figure 6).
Increased parallelism amplifies the performance degra-dation of the NUMA-oblivious implementation. We identifythe following as the greatest contributors:
• the NUMA-oblivious allocation policies of traditionalmemory allocators, such as malloc, place data in acontiguous chunk within a single NUMA memory bankwhenever possible. This leads to a large number ofthreads performing remote memory accesses as thenumber of threads increase;
• a dynamic NUMA-oblivious task scheduler may givetasks to threads that cause worker threads to performmany more remote memory accesses than necessarycompared to a NUMA-aware scheduler.
We demonstrate the effectiveness of a NUMA-awarepartitioned task scheduler for pruned computations viaknori (Figure 7). We define a task as a block of data pointsin contiguous memory given to a thread for computation.We set a minimum task size, i.e. the number of data pointsin the block, to 8192. We empirically determine that thistask size is small enough to not artificially introduce skewin billion-point datasets while simultaneously providingenough work to amortize the cost of locking at the taskscheduler. We compare against a static and a first in, first out(FIFO) task scheduler. The static scheduler preassigns n/Trows to each worker thread. The FIFO scheduler first assignsthreads to tasks that are local to the thread’s partition
1
2
4
8
16
32
64
1 2 4 8 16 32 64 96
Rel
ativ
ePe
rfor
man
ce
No. of Threads
knoriNUMA-oblivious
Linear (Ideal)
Fig. 6: NUMA-aware memory optimizations provide near-linear speedup. knori (which is NUMA-aware) vs. a NUMA-oblivious routine on the Friendster top-8 eigenvectordataset, with k = 10. The NUMA-oblivious routine isidentical to knori, but we disable all NUMA optimizations.
80
120
160
200
240
k=10 k=20 k=50 k=100
Tim
e/it
er(m
sec)
knori FIFO Static
Fig. 7: Performance of the partitioned NUMA-aware sched-uler (clusterNOR default) vs. FIFO and static scheduling forknori on the Friendster-8 dataset.
of data, then allows threads to steal tasks from stragglerthreads whose data resides on any NUMA node.
We observe that as k increases, so does the potential forskew. When k = 10, the NUMA-aware scheduler performsnegligibly worse than both FIFO and static scheduling.Work stealing can result in overhead from data movementwhen the application is memory-bandwidth-bound [38], aswe observe in this experiment. As k increases, the NUMA-aware scheduler improves performance—by more than 40%when k = 100. We observe similar trends in other datasets;we omit these redundant results.
8.5 Semi-External MemoryWe evaluate knors optimizations, performance and scalabil-ity. We set a small page cache size for FlashGraph (4KB) tominimize the amount of superfluous data read from diskdue to fragmentation. We set the cache refresh interval,Icache, to 5 for all experiments. The choice trades-off cachefreshness for reduced cache maintenance. We demonstratethe efficacy of this strategy in Figure 9. Finally, we disablecheckpoint failure recovery during performance evaluationfor both our routines and those of our competitors.
We drastically reduce the amount of data read fromSSDs by utilizing the row cache. Figure 8a shows that asthe number of iterations increase, the row cache’s ability

10
0.016
0.062
0.25
1
4
16
0 20 40 60 80 100
Dat
a(G
B)
Iteration No.
No RC reqNo RC read
knors reqknors read
(a) knors data requested (req) vs. data read (read) from SSDseach iteration when the row cache (RC) is enabled or disabled.MTI pruning requests fewer data points from SSDs, but the filesystem must still read an entire block in which some data maynot be useful. As a result, there is a discrepancy between thequantity of data requested and the quantity read.
10
100
1000
Req I/O Read from SSDLog
Scal
eD
ata
(GB)
knorsknors-
knors--
(b) Total data requested (req) vs. data read from SSDs when(i) both MTI and RC are disabled (knors--), (ii) Only MTI isenabled (knors-), (iii) both MTI and RC are enabled (knors). Withoutpruning, all data are requested and read.
Fig. 8: The effect of the row cache and MTI on I/O for theFriendster top-32 eigenvectors dataset. Row cache size =512MB, page cache size = 1GB, k = 100.
to reduce I/O and improve speed also increases becausemost rows that are active are cached in memory. Figure 8bcontrasts the total amount of data that an implementationrequests from SSDs with the amount of data SAFS actuallyreads and transports into memory.
When knors disables both MTI pruning and the row cachei.e., knors--, every request issued for row-data is eitherserved by FlashGraph’s page cache or read from SSDs.When knors enables MTI pruning, but disables the row cache,we read an order of magnitude more data from SSDs thanwhen we enable the row cache. Figure 8 demonstrates that apage cache is not sufficient for k-means and that caching atthe granularity of row-data is necessary to achieve signifi-cant reductions in I/O and improvements in performancefor real-world datasets. Additionally, this observation isapplicable to all computation pruning and sub-samplingapplications where selective I/O is possible.
clusterNOR’s lazy row update mode reduces I/O sig-nificantly for this application. Figure 9 justifies our designdecision for a lazily updated row cache. As the algorithmprogresses, we obtain nearly a 100% cache hit rate, mean-ing that knors operates at in-memory speeds for the vastmajority of iterations.
0
2
4
6
8
0 20 40 60 80 100
No.
ofpo
ints
x106
Iteration No.
Cache hits Active points
Fig. 9: Row cache hits per iteration compared with themaximum achievable number of hits on the Friendster top-32 eigenvectors dataset.
8.6 MTI Evaluation
We begin by evaluating the pruning efficacy, runtime perfor-mance and memory consumption of MTI when comparedwith other popular, effective pruning algorithms, includingTI (Section 8.6.1). We then show how MTI improves theperformance of k-means compared to optimized implemen-tations without pruning in Section 8.7.
8.6.1 MTI vs. Other State-Of-The-Art AlgorithmsWe empirically determine the runtime performance, prun-ing efficacy and memory utilization of the Minimal TriangleInequality algorithm. Figure 10 presents findings on the real-world Friendster-8 dataset.
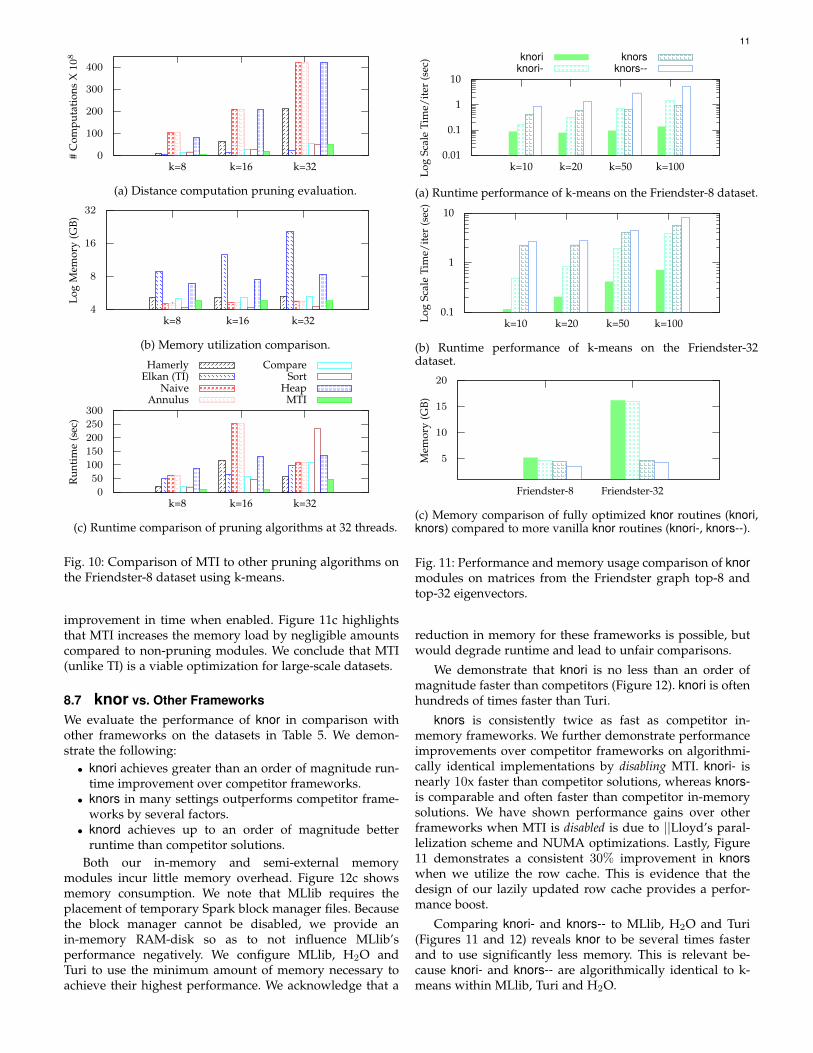
Figure 10a demonstrates that MTI is comparable to state-of-the-art for computation pruning efficacy. MTI performsat most 2X more distance computations than the minimalalgorithm, most often Elkan’s TI. Despite this, MTI consis-tently is at least 2X faster than competitor algorithms anduses up to 5X less memory (Figure 10b).
MTI maintains constant memory consumption with re-spect to the number of clusters. TI in comparison has mem-ory growth that is proportional to the number of clusters,k. We conclude MTI is better suited to large-scale datasetswith many clusters. We recognize that Sort consistentlyutilizes the least amount of memory, but this is achieved atthe cost of runtime performance (Figure 10c), which limitsscalability.
Figure 10c demonstrates the runtime performance ben-efits of MTI over competitor solutions at scale. MTI isconsistently at least 2X faster than other state-of-the-artalgorithms. This is true despite often performing more dis-tance computations. MTI achieves this, by spending lessruntime maintaining data structures to reduce distance com-putations. TI, for example, must spend a large amount oftime updating theO(nk) lower bound matrix which is oftenmore expensive than computations it circumvents withinthe k-means algorithm.
8.6.2 MTI Performance CharacteristicsFigures 11a and 11b highlight the performance improve-ment of knor modules with MTI enabled over MTI disabledcounterparts. We show that MTI provides a few factors of
11
0
100
200
300
400
k=8 k=16 k=32
#C
ompu
tati
ons
X108
(a) Distance computation pruning evaluation.
4
8
16
32
k=8 k=16 k=32
Log
Mem
ory
(GB)
(b) Memory utilization comparison.
0
50
100
150
200
250
300
k=8 k=16 k=32
Run
tim
e(s
ec)
HamerlyElkan (TI)
NaiveAnnulus
CompareSort
HeapMTI
(c) Runtime comparison of pruning algorithms at 32 threads.
Fig. 10: Comparison of MTI to other pruning algorithms onthe Friendster-8 dataset using k-means.
improvement in time when enabled. Figure 11c highlightsthat MTI increases the memory load by negligible amountscompared to non-pruning modules. We conclude that MTI(unlike TI) is a viable optimization for large-scale datasets.
8.7 knor vs. Other FrameworksWe evaluate the performance of knor in comparison withother frameworks on the datasets in Table 5. We demon-strate the following:• knori achieves greater than an order of magnitude run-
time improvement over competitor frameworks.• knors in many settings outperforms competitor frame-
works by several factors.• knord achieves up to an order of magnitude better
runtime than competitor solutions.Both our in-memory and semi-external memory
modules incur little memory overhead. Figure 12c showsmemory consumption. We note that MLlib requires theplacement of temporary Spark block manager files. Becausethe block manager cannot be disabled, we provide anin-memory RAM-disk so as to not influence MLlib’sperformance negatively. We configure MLlib, H2O andTuri to use the minimum amount of memory necessary toachieve their highest performance. We acknowledge that a
0.01
0.1
1
10
k=10 k=20 k=50 k=100
Log
Scal
eTi
me/
iter
(sec
) knoriknori-
knorsknors--
(a) Runtime performance of k-means on the Friendster-8 dataset.
0.1
1
10
k=10 k=20 k=50 k=100Log
Scal
eTi
me/
iter
(sec
)
(b) Runtime performance of k-means on the Friendster-32dataset.
5
10
15
20
Friendster-8 Friendster-32
Mem
ory
(GB)
(c) Memory comparison of fully optimized knor routines (knori,knors) compared to more vanilla knor routines (knori-, knors--).
Fig. 11: Performance and memory usage comparison of knormodules on matrices from the Friendster graph top-8 andtop-32 eigenvectors.
reduction in memory for these frameworks is possible, butwould degrade runtime and lead to unfair comparisons.
We demonstrate that knori is no less than an order ofmagnitude faster than competitors (Figure 12). knori is oftenhundreds of times faster than Turi.
knors is consistently twice as fast as competitor in-memory frameworks. We further demonstrate performanceimprovements over competitor frameworks on algorithmi-cally identical implementations by disabling MTI. knori- isnearly 10x faster than competitor solutions, whereas knors-is comparable and often faster than competitor in-memorysolutions. We have shown performance gains over otherframeworks when MTI is disabled is due to ||Lloyd’s paral-lelization scheme and NUMA optimizations. Lastly, Figure11 demonstrates a consistent 30% improvement in knorswhen we utilize the row cache. This is evidence that thedesign of our lazily updated row cache provides a perfor-mance boost.
Comparing knori- and knors-- to MLlib, H2O and Turi(Figures 11 and 12) reveals knor to be several times fasterand to use significantly less memory. This is relevant be-cause knori- and knors-- are algorithmically identical to k-means within MLlib, Turi and H2O.

12
0.01
0.1
1
10
100
k=10 k=20 k=50 k=100Log
Scal
eTi
me/
iter
(sec
)knoriknors
H2OMLlib
Turi
(a) Runtime performance of k-means on the Friendster-8 dataset.
0.1
1
10
100
k=10 k=20 k=50 k=100Log
Scal
eTi
me/
iter
(sec
)
(b) Runtime performance of k-means on the Friendster-32dataset.
1
10
100
Friendster-8 Friendster-32
Log
Scal
eM
emor
y(G
B)
(c) Peak memory consumption on the Friendster datasets, withk = 10. Row cache size = 512MB, page cache size = 1GB.
Fig. 12: knor routines outperform competitor solutions inruntime performance and memory consumption.
8.8 Single-node Scalability
To demonstrate scalability, we compare the performance ofk-means on synthetic datasets drawn from random distri-butions that contain hundreds of millions to billions of datapoints. Uniformly random data are typically the worst casescenario for the convergence of k-means, because many datapoints tend to be near several centroids.
Both in-memory and SEM modules outperform popularframeworks on 100GB+ datasets. Figure 13a shows thatwe achieve 7-20x improvement when in-memory and 3-6ximprovement in SEM when compared to MLlib, H2O andTuri. As data increases in size, the performance differencebetween knori and knors narrows because there is nowenough data to mask I/O latency which turns knors fromI/O bound to computation bound. We observe knors is only3-4x slower than its in-memory counterpart in such cases.
Memory capacity limits the scalability of k-means andsemi-external memory allows algorithms to scale well be-yond the limits of physical memory. The 1B point matrix
020406080
100120140160
IM SEMH2O
MLlibTuri
Tim
e/it
er(s
ec)
RM856M RM1B RU2B
(a) Per iteration runtime of each routine.
0
50
100
150
200
250
300
350
RM856M RM1B RU2B
Mem
ory
(GB)
(b) Memory consumption of each routine.
Fig. 13: Performance comparison on RM856M and RM1B
datasets. Turi is unable to run on RM1B on our machine andonly SEM routines are able to run on RU2B on our machine.Page cache size = 4GB, Row cache size = 2GB, and k = 100.
(RM1B) is the largest that fits in 1TB of memory on ourmachine. Figure 13 shows that at 2B points (RU2B), semi-external memory algorithms continue to execute propor-tionally and all other algorithms fail.
8.9 Distributed Execution
We demonstrate the performance and scalability of knordand knord-. We analyze their performance on Amazon’sEC2 cloud. We compare against (i) MLlib (MLlib-EC2), (ii)a pure MPI implementation of our ||Lloyd’s algorithm withMTI pruning (MPI), and (iii) a pure MPI implementationof ||Lloyd’s algorithm with pruning disabled (MPI-). H2Ohas no distributed memory implementation and Turi dis-continued their distributed memory interface prior to ourexperiments.
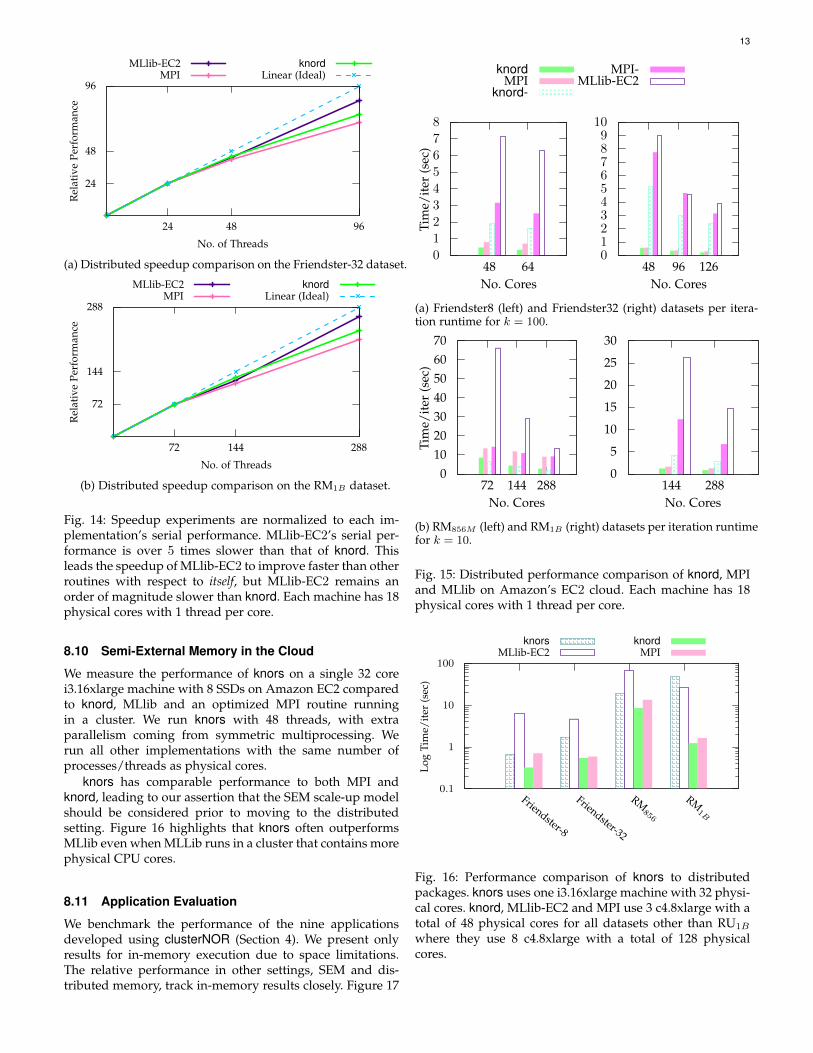
Figures 14 and 15 reveal several fundamental and im-portant results. Figure 14 shows that knord scales wellto very large numbers of machines, performing within aconstant factor of linear performance. This is a necessitytoday as many organizations push big-data computationto the cloud. Figure 15 shows that in a cluster, knord,even with TI disabled, outperforms MLlib by a factor of5 or more. This means we can often use fractions of thehardware required by MLlib to perform equivalent tasks.Figure 15 demonstrates that knord also benefits from ourin-memory NUMA optimizations because we outperform aNUMA-oblivious MPI routine by 20-50%. Finally, Figure 15shows that MTI remains a low-overhead, effective methodto reduce computation even in the distributed setting.
13
24
48
96
24 48 96
Rel
ativ
ePe
rfor
man
ce
No. of Threads
MLlib-EC2MPI
knordLinear (Ideal)
(a) Distributed speedup comparison on the Friendster-32 dataset.
72
144
288
72 144 288
Rel
ativ
ePe
rfor
man
ce
No. of Threads
MLlib-EC2MPI
knordLinear (Ideal)
(b) Distributed speedup comparison on the RM1B dataset.
Fig. 14: Speedup experiments are normalized to each im-plementation’s serial performance. MLlib-EC2’s serial per-formance is over 5 times slower than that of knord. Thisleads the speedup of MLlib-EC2 to improve faster than otherroutines with respect to itself, but MLlib-EC2 remains anorder of magnitude slower than knord. Each machine has 18physical cores with 1 thread per core.
8.10 Semi-External Memory in the Cloud
We measure the performance of knors on a single 32 corei3.16xlarge machine with 8 SSDs on Amazon EC2 comparedto knord, MLlib and an optimized MPI routine runningin a cluster. We run knors with 48 threads, with extraparallelism coming from symmetric multiprocessing. Werun all other implementations with the same number ofprocesses/threads as physical cores.
knors has comparable performance to both MPI andknord, leading to our assertion that the SEM scale-up modelshould be considered prior to moving to the distributedsetting. Figure 16 highlights that knors often outperformsMLlib even when MLLib runs in a cluster that contains morephysical CPU cores.
8.11 Application Evaluation
We benchmark the performance of the nine applicationsdeveloped using clusterNOR (Section 4). We present onlyresults for in-memory execution due to space limitations.The relative performance in other settings, SEM and dis-tributed memory, track in-memory results closely. Figure 17
knordMPI
knord-
MPI-MLlib-EC2
0
1
2
3
4
5
6
7
8
48 64
Tim
e/it
er(s
ec)
No. Cores
012345678910
48 96 126No. Cores
(a) Friendster8 (left) and Friendster32 (right) datasets per itera-tion runtime for k = 100.
010203040506070
72 144 288
Tim
e/it
er(s
ec)
No. Cores
0
5
10
15
20
25
30
144 288No. Cores
(b) RM856M (left) and RM1B (right) datasets per iteration runtimefor k = 10.
Fig. 15: Distributed performance comparison of knord, MPIand MLlib on Amazon’s EC2 cloud. Each machine has 18physical cores with 1 thread per core.
0.1
1
10
100
Friendster-8
Friendster-32
RM856
RM1B
Log
Tim
e/it
er(s
ec)
knorsMLlib-EC2
knordMPI
Fig. 16: Performance comparison of knors to distributedpackages. knors uses one i3.16xlarge machine with 32 physi-cal cores. knord, MLlib-EC2 and MPI use 3 c4.8xlarge with atotal of 48 physical cores for all datasets other than RU1B
where they use 8 c4.8xlarge with a total of 128 physicalcores.
14
1
10
100
1000
k=10 k=20 k=50 k=100
Log
Tim
e(s
ec)
knorsk-means
k-means++fc-means
mb-kmeansh-meansx-meansg-means
Fig. 17: In-memory performance of clusterNOR benchmarkapplications on the Friendster-32 dataset. We fix the numberof iterations to 20 for all applications and use a mini-batchsize of 20% of the data size for mb-kmeans.
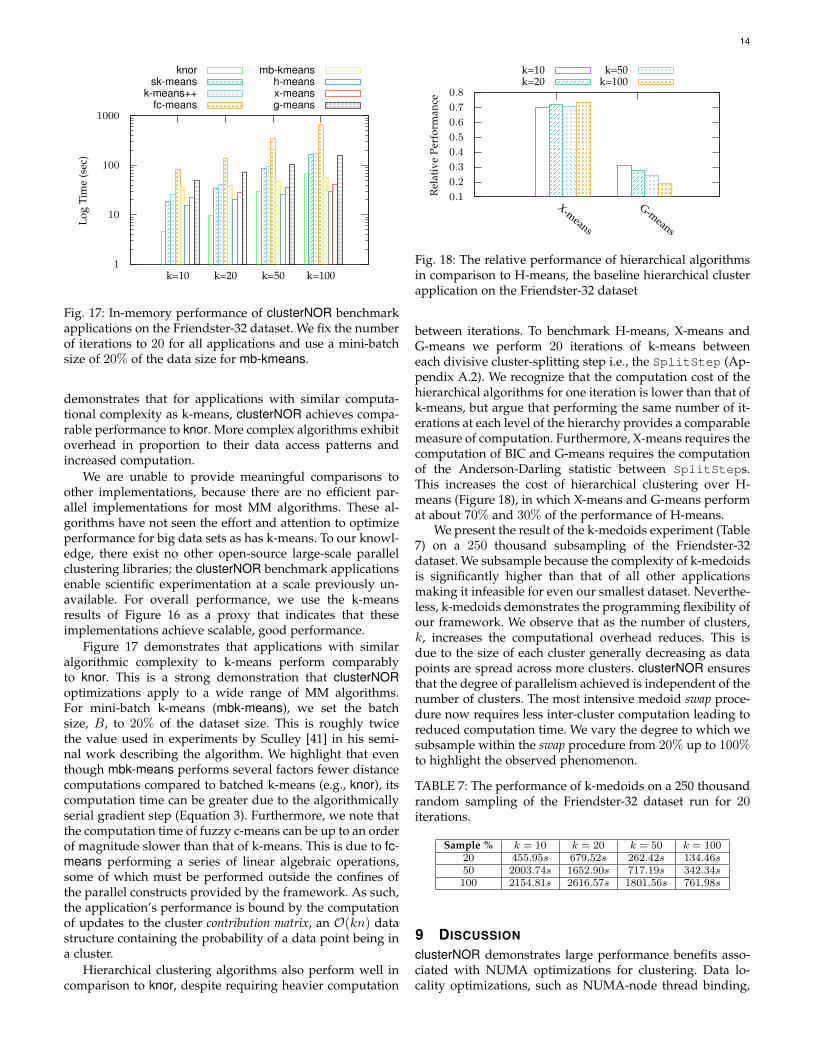
demonstrates that for applications with similar computa-tional complexity as k-means, clusterNOR achieves compa-rable performance to knor. More complex algorithms exhibitoverhead in proportion to their data access patterns andincreased computation.
We are unable to provide meaningful comparisons toother implementations, because there are no efficient par-allel implementations for most MM algorithms. These al-gorithms have not seen the effort and attention to optimizeperformance for big data sets as has k-means. To our knowl-edge, there exist no other open-source large-scale parallelclustering libraries; the clusterNOR benchmark applicationsenable scientific experimentation at a scale previously un-available. For overall performance, we use the k-meansresults of Figure 16 as a proxy that indicates that theseimplementations achieve scalable, good performance.
Figure 17 demonstrates that applications with similaralgorithmic complexity to k-means perform comparablyto knor. This is a strong demonstration that clusterNORoptimizations apply to a wide range of MM algorithms.For mini-batch k-means (mbk-means), we set the batchsize, B, to 20% of the dataset size. This is roughly twicethe value used in experiments by Sculley [41] in his semi-nal work describing the algorithm. We highlight that eventhough mbk-means performs several factors fewer distancecomputations compared to batched k-means (e.g., knor), itscomputation time can be greater due to the algorithmicallyserial gradient step (Equation 3). Furthermore, we note thatthe computation time of fuzzy c-means can be up to an orderof magnitude slower than that of k-means. This is due to fc-means performing a series of linear algebraic operations,some of which must be performed outside the confines ofthe parallel constructs provided by the framework. As such,the application’s performance is bound by the computationof updates to the cluster contribution matrix, an O(kn) datastructure containing the probability of a data point being ina cluster.
Hierarchical clustering algorithms also perform well incomparison to knor, despite requiring heavier computation
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
X-means
G-means
Rel
ativ
ePe
rfor
man
ce
k=10k=20
k=50k=100
Fig. 18: The relative performance of hierarchical algorithmsin comparison to H-means, the baseline hierarchical clusterapplication on the Friendster-32 dataset
between iterations. To benchmark H-means, X-means andG-means we perform 20 iterations of k-means betweeneach divisive cluster-splitting step i.e., the SplitStep (Ap-pendix A.2). We recognize that the computation cost of thehierarchical algorithms for one iteration is lower than that ofk-means, but argue that performing the same number of it-erations at each level of the hierarchy provides a comparablemeasure of computation. Furthermore, X-means requires thecomputation of BIC and G-means requires the computationof the Anderson-Darling statistic between SplitSteps.This increases the cost of hierarchical clustering over H-means (Figure 18), in which X-means and G-means performat about 70% and 30% of the performance of H-means.
We present the result of the k-medoids experiment (Table7) on a 250 thousand subsampling of the Friendster-32dataset. We subsample because the complexity of k-medoidsis significantly higher than that of all other applicationsmaking it infeasible for even our smallest dataset. Neverthe-less, k-medoids demonstrates the programming flexibility ofour framework. We observe that as the number of clusters,k, increases the computational overhead reduces. This isdue to the size of each cluster generally decreasing as datapoints are spread across more clusters. clusterNOR ensuresthat the degree of parallelism achieved is independent of thenumber of clusters. The most intensive medoid swap proce-dure now requires less inter-cluster computation leading toreduced computation time. We vary the degree to which wesubsample within the swap procedure from 20% up to 100%to highlight the observed phenomenon.
TABLE 7: The performance of k-medoids on a 250 thousandrandom sampling of the Friendster-32 dataset run for 20iterations.
Sample % k = 10 k = 20 k = 50 k = 10020 455.95s 679.52s 262.42s 134.46s50 2003.74s 1652.90s 717.19s 342.34s100 2154.81s 2616.57s 1801.56s 761.98s
9 DISCUSSION
clusterNOR demonstrates large performance benefits asso-ciated with NUMA optimizations for clustering. Data lo-cality optimizations, such as NUMA-node thread binding,

15
NUMA-aware task scheduling, and NUMA-aware memoryallocation schemes, provide several times speedup for MMalgorithms. Many of the optimizations within clusterNORare applicable to data processing frameworks built for non-specialized commodity hardware.
For technical accomplishments, we accelerate k-meansand its derived algorithms by over an order of magnitudeby rethinking Lloyd’s algorithm for modern multiprocessorNUMA architectures through the minimization of criticalregions. Additionally, we formulate a minimal triangle in-equality (MTI) pruning algorithm that further boosts theperformance of k-means on real-world billion point datasetsby over 100x when compared to some popular frameworks.MTI does so without significantly increasing memory con-sumption.
Finally, clusterNOR provides an extensible unifiedframework for in-memory, semi-external memory anddistributed MM algorithm development. The clusterNORbenchmark applications provide a scalable, state-of-the-artclustering library. Bindings to the open source library areaccessible within ‘CRAN’, the R Programming Language[39] package manager, under the name clusternor. We are anopen source project available athttps://github.com/flashxio/knor. Our flagship knorapplication, on which this work is based, receives hundredsof downloads monthly on both CRAN and pip, the Pythonpackage manager.
ACKNOWLEDGMENTS
This work is partially supported by DARPA GRAPHSN66001-14-1-4028 and DARPA SIMPLEX program throughSPAWAR contract N66001-15-C-4041. We thank Nikita Ivkinfor discussions that assisted immensely in realizing thiswork.
REFERENCES
[1] Automatic non-uniform memory access (numa) balancing. https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.numactl.html#sec.tuning.numactl.impact.Accessed: 2019-07-01.
[2] T. W. Anderson. An introduction to multivariate statistical analysis,volume 2. Wiley New York, 1958.
[3] D. Arthur and S. Vassilvitskii. k-means++: The advantages ofcareful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, pages 1027–1035. Societyfor Industrial and Applied Mathematics, 2007.
[4] J. Bennett and S. Lanning. The netflix prize. In Proceedings of KDDcup and workshop, volume 2007, page 35, 2007.
[5] J. C. Bezdek, R. Ehrlich, and W. Full. Fcm: The fuzzy c-meansclustering algorithm. Computers & Geosciences, 10(2-3):191–203,1984.
[6] N. Binkiewicz, J. T. Vogelstein, and K. Rohe. Covariate assistedspectral clustering. arXiv preprint arXiv:1411.2158, 2014.
[7] R. R. Curtin, J. R. Cline, N. P. Slagle, W. B. March, P. Ram, N. A.Mehta, and A. G. Gray. Mlpack: A scalable c++ machine learninglibrary. Journal of Machine Learning Research, 14(Mar):801–805, 2013.
[8] A. S. Das, M. Datar, A. Garg, and S. Rajaram. Google news per-sonalization: scalable online collaborative filtering. In Proceedingsof the International Conference on the World Wide Web, pages 271–280.ACM, 2007.
[9] J. Dean and S. Ghemawat. MapReduce: Simplified data processingon large clusters. In Proceedings of the 6th Conference on Symposiumon Opearting Systems Design & Implementation - Volume 6, 2004.
[10] I. S. Dhillon and D. S. Modha. Concept decompositions for largesparse text data using clustering. Machine learning, 42(1-2):143–175,2001.
[11] C. Elkan. Using the triangle inequality to accelerate k-means. InICML, volume 3, pages 147–153, 2003.
[12] M. P. Forum. MPI: A message-passing interface standard. Techni-cal report, Knoxville, TN, USA, 1994.
[13] Frienster graph. https://archive.org/download/friendster-dataset-201107, Accessed 4/18/2014.
[14] M. Frigo, C. E. Leiserson, H. Prokop, and S. Ramachandran.Cache-oblivious algorithms. In Foundations of Computer Science,1999. 40th Annual Symposium on, pages 285–297. IEEE, 1999.
[15] G. Hamerly and J. Drake. Accelerating Lloyd’s algorithm for k-means clustering. In Partitional clustering algorithms, pages 41–78.Springer, 2015.
[16] A. Inc. Amazon web services.[17] L. B. Jorde and S. P. Wooding. Genetic variation, classification and
’race’. Nature genetics, 36:S28–S33, 2004.[18] L. Kaufman and P. J. Rousseeuw. Clustering large applications
(Program CLARA). Finding groups in data: an introduction to clusteranalysis, pages 126–146, 2008.
[19] K. Lange. MM optimization algorithms, volume 147. SIAM, 2016.[20] C. L. Lawson, R. J. Hanson, D. R. Kincaid, and F. T. Krogh. Basic
linear algebra subprograms for fortran usage. ACM Transactionson Mathematical Software (TOMS), 5(3):308–323, 1979.
[21] B. Lepers, V. Quema, and A. Fedorova. Thread and memoryplacement on NUMA systems: Asymmetry matters. In USENIXAnnual Technical Conference (USENIX ATC), pages 277–289, 2015.
[22] H. Liu and H. H. Huang. Graphene: Fine-grained IO managementfor graph computing. In USENIX Conference on File and StorageTechnologies (FAST), pages 285–300, 2017.
[23] S. P. Lloyd. Least squares quantization in pcm. Information Theory,IEEE Transactions on, 28(2):129–137, 1982.
[24] Y. Low, J. E. Gonzalez, A. Kyrola, D. Bickson, C. E. Guestrin, andJ. Hellerstein. Graphlab: A new framework for parallel machinelearning. arXiv preprint arXiv:1408.2041, 2014.
[25] V. Lyzinski, D. L. Sussman, D. E. Fishkind, H. Pao, L. Chen, J. T.Vogelstein, Y. Park, and C. E. Priebe. Spectral clustering for divide-and-conquer graph matching. Parallel Computing, 2015.
[26] V. Lyzinski, M. Tang, A. Athreya, Y. Park, and C. E. Priebe.Community detection and classification in hierarchical stochasticblockmodels. arXiv preprint arXiv:1503.02115, 2015.
[27] MATLAB. version 7.10.0 (R2010a). The MathWorks Inc., Natick,Massachusetts, 2010.
[28] A. McCallum, K. Nigam, and L. H. Ungar. Efficient clustering ofhigh-dimensional data sets with application to reference matching.In Proceedings of the sixth ACM SIGKDD International Conference onKnowledge Discovery and Data Mining, pages 169–178. ACM, 2000.
[29] F. McSherry, M. Isard, and D. G. Murray. Scalability! but at whatcost? In 15th Workshop on Hot Topics in Operating Systems (HotOSXV), 2015.
[30] X. Meng, J. Bradley, B. Yavuz, E. Sparks, S. Venkataraman, D. Liu,J. Freeman, D. Tsai, M. Amde, S. Owen, et al. MLlib: Machinelearning in Apache Spark. arXiv preprint arXiv:1505.06807, 2015.
[31] D. Mhembere, D. Zheng, C. E. Priebe, J. T. Vogelstein, andR. Burns. knor: A numa-optimized in-memory, distributed andsemi-external-memory k-means library. In Proceedings of the 26thInternational Symposium on High-Performance Parallel and DistributedComputing, pages 67–78. ACM, 2017.
[32] L. Mouselimis. ClusterR: Gaussian Mixture Models, K-Means, Mini-Batch-Kmeans, K-Medoids and Affinity Propagation Clustering, 2018.R package version 1.1.7.
[33] S. Owen, R. Anil, T. Dunning, and E. Friedman. Mahout in action.Manning Shelter Island, 2011.
[34] N. Patterson, A. L. Price, and D. Reich. Population structure andeigenanalysis. 2006.
[35] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion,O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Van-derplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, andE. Duchesnay. Scikit-learn: Machine learning in Python. Journal ofMachine Learning Research, 12:2825–2830, 2011.
[36] D. Pelleg, A. W. Moore, et al. X-means: Extending k-means withefficient estimation of the number of clusters. In Icml, volume 1,pages 727–734, 2000.
[37] I. Psaroudakis, T. Scheuer, N. May, A. Sellami, and A. Ailamaki.Scaling up concurrent main-memory column-store scans: towardsadaptive numa-aware data and task placement. Proceedings of theVLDB Endowment, 8(12):1442–1453, 2015.
[38] I. Psaroudakis, T. Scheuer, N. May, A. Sellami, and A. Ailamaki.Adaptive NUMA-aware data placement and task scheduling for

16
analytical workloads in main-memory column-stores. Proceedingsof the VLDB Endowment, 10(2):37–48, 2016.
[39] R Core Team. R: A Language and Environment for Statistical Comput-ing. R Foundation for Statistical Computing, Vienna, Austria.
[40] G. Schwarz et al. Estimating the dimension of a model. The annalsof statistics, 6(2):461–464, 1978.
[41] D. Sculley. Web-scale k-means clustering. In Proceedings of the 19thInternational Conference on the World Wide Web, pages 1177–1178.ACM, 2010.
[42] J. Ugander, B. Karrer, L. Backstrom, and C. Marlow. The anatomyof the facebook social graph. arXiv preprint arXiv:1111.4503, 2011.
[43] M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauley,M. J. Franklin, S. Shenker, and I. Stoica. Resilient distributeddatasets: A fault-tolerant abstraction for in-memory cluster com-puting. In Proceedings of the USENIX conference on NetworkedSystems Design and Implementation. USENIX Association, 2012.
[44] M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Sto-ica. Spark: Cluster computing with working sets. HotCloud, 10:10–10, 2010.
[45] D. Zheng, R. Burns, and A. S. Szalay. Toward millions of file sys-tem IOPS on low-cost, commodity hardware. In Proceedings of theInternational Conference on High Performance Computing, Networking,Storage and Analysis, 2013.
[46] D. Zheng, D. Mhembere, R. Burns, J. Vogelstein, C. E. Priebe, andA. S. Szalay. FlashGraph: Processing billion-node graphs on anarray of commodity SSDs. In 13th USENIX Conference on File andStorage Technologies (FAST 15), 2015.
APPENDIX AAPPLICATION PROGRAMMINGINTERFACE (API)clusterNOR provides a C++ API on which users may definetheir own algorithms. There are two core components:• the base iterative interface, base.• the hierarchical iterative interface, hclust.
, in addition to two API extensions:• the semi-external memory interface, sem.• the distributed interface, dist.
A.1 baseThe base interface provides developers with abstract meth-ods that can be overridden to implement a variety of al-gorithms, such as k-means, mini-batch k-means, fuzzy C-means, and k-mediods (Sections 4.1, 4.4, 4.5, and 4.6).• run(): Defines algorithm specific steps for a particular
application. This generally follows the serial algorithm.• MMStep(): Used when both MM steps can be per-
formed simultaneously and reduces the effect of thebarrier between the two steps.
• M1Step(): Used when the Majorize or Minorize stepmust be performed independently from the Minimiza-tion or Maximization step.
• M2Step(): Used in conjunction with M1Step as theMinimization or Maximization step of the algorithm.
A.2 hclustThe hclust interface extends base and is used to developalgorithms in which clustering is performed in a hierarchicalfashion, such as H-means, X-means, and G-means (Sections4.7, 4.8, and 4.9). For performance reasons, this interfaceis iterative rather than recursive. We discuss this designdecision and its merits in Section 5.1. hclust provides thefollowing additional abstract methods for user definition:
• SplitStep(): Used to determine when a clustershould split.
• HclustUpdate(): Used to update the hierarchicalglobal state from one iteration to the next.
A.3 semThe SEM interface builds upon base and hclust andincorporates a modified FlashGraph [46] API that we extendto support matrices and iterative clustering algorithms. Theinterface provides an abstraction over an asynchronous I/Omodel in which data are requested from disk and computa-tion is overlapped with I/O transparently to users:• request(ids[]): Issues I/O requests to the under-
lying storage media for the feature-vectors associatedwith the entries in ids[].
A.4 distThe distributed interface builds upon base and hclustcreating infrastructure to support distributed processing. Asis common with distributed memory, there also exist optionalprimitives for data synchronization, scattering and gather-ing, if necessary. Mandatory methods pertain to organizingstate before and after computation and are abstractionsabove MPI calls:• OnComputeStart(): Pass state or configuration de-
tails to processes when an algorithm begins.• OnComputeEnd(): Extract state or organize algorith-
mic metadata upon completion of an algorithm.
A.5 Code ExampleWe provide a high-level implementation of the G-meansalgorithm written within clusterNOR to run in parallel on astandalone server. The simple C++ interface provides an ab-straction that encapsulates parallelism, NUMA-awarenessand cache friendliness. This code can be extended to SEMand distributed memory by simply inheriting from andimplementing the required methods from sem and dist.The example illustrates how an application that extendsthe hclust interface also inherits the properties of base.Critically, users must explicitly define the MMstep andSplitStep methods that contain algorithm specific com-putation instructions.
using namespace clusterNOR;
class gmeans : public hclust {void MMstep() {
for (auto& sample : samples()) { // Data ←↩iterator
auto best = min(Euclidean(sample, clusters()←↩));
JoinCluster(sample, best);}
}
void SplitStep() override {for (auto& sample : samples())if (ClusterIsActive(sample))
AndersonDarlingStatistic(sample);}
void run() override {while (nclust() < kmax()) {
17
initialize(); // Starting conditionsMMstep();SplitStep();Sync(); // Split clustersif (SteadyState())break; // Splits impossible
}}