clustering - visusalvis.usal.es/rodrigo/documentos/bioinfo/muii/sesiones/6-clustering.pdf ·...
TRANSCRIPT

BioinformáticaClustering
RodrigoSantamaría

DándolealvinoDándolealvino
Saccharomyces cerevisiaeLaexpesióngenéticaElcambiodiáuxico
• Dándolealvino• Clustering• Clústering jerárquico• Anotaciones
2

Dándolealvino
• Hayevidenciasdelaelaboracióndevinoporhumanosdesdehace6000años*
*En2011sedescubrieron enunacuevadeArmeniaunaprensadevino, vasijasdefermentaciónycopas**ProducidoporunaflorquefermentanaturalmentegraciasalalevaduraSaccharomyces cerevisiae***Cualquiermamíferoquetomaralasdosis dealcoholquetoma,proporcionalmente, estamusaraña,moriría
musarañaarborícoladecolaemplumada
• Peroojo,unamusaraña ledaalvinodesdehacemillones deaños– Enparticular,al“vinodepalma”**– Handesarrolladounmetabolismodelalcoholqueevitaqueseemborrachen***

Saccharomyces cerevisiae• Estalevadura*fermentaelvino:– Seencuentraenlosviñedosdeformanatural– Sealimentadelaglucosa delafruta– Produceetanol
• Cambiodiaúxico:sisequedasinglucosa,puede,enpresenciadeoxígeno,alimentarsedeletanol– Convirtiendoelvinoenvinagre– Poresolasbarricasdevinohandesellarse
*Laslevadurasformanpartedelreinoanimaldeloshongos, sonorganismoseucariotas unicelulares.Sonmuyinteresantescomoorganismosmodelo alserfáciles decultivarytenerunaestructuracelularsimilaralanuestra
glucosa etanol ácidoacético
cambio
diaúxico
metabolismo
Scerevisiae
O2

Expresióngénica
DNA
mRNA
transcripción
Proteínas
traducción
expresión
Vídeos sobre losprocesos detranscripción ytraducción delaNDSUhttp://vis.usal.es/rodrigo/documentos/bioinfo/videos/Transcription_eng.mp4http://vis.usal.es/rodrigo/documentos/bioinfo/videos/Translation_eng.mp4
Ladescripción deesteflujo deinformaciónbiológica(simplificadoaquí)seconocecomoeldogmacentraldelabiologíamolecular(Crick,1958)

Elcambiodiaúxico
• Estecambioafectaalaexpresión demuchosgenes
• Esunaventajaevolutivamuygrande– Lalevadurapuedematarasuscompetidoresgenerandoetanol(tóxicoparamuchasbacterias)
– Puedeutilizareseetanolcomofuentedeenergía– EnausenciadeO2 lalevadurahiberna
6

Matricesdeexpresión
• UnamatrizEdedimensiónnxm– ngenes (típicamentetodoslosdelgenoma)– m condiciones experimentales• Distintospuntostemporales• Distintascondicionesambientales,tejidos,etc.
– Eij expresióndelgeni bajolacondiciónj• Permitenrealizarmuchosanálisis– Detectargenesquecambiansuexpresión– Detectargenesquevaríandemanerasimilar,etc.
7

Expresión delcambiodiaúxico
• JosephDeRisi (1997)*hizoelprimerexperimentodeexpresión genómicadecambiodiáuxico– Matriz6400x7• TodoslosgenesdelgenomadeScerevisiae• 7puntostemporales:-6,-4,-2,0,2,4,6
– 0eselpuntodondeseproduceelcambiodiaúxico
8*Elpaper completoaquí:http://vis.usal.es/rodrigo/documentos/bioinfo/papers/DeRisi1997.pdf
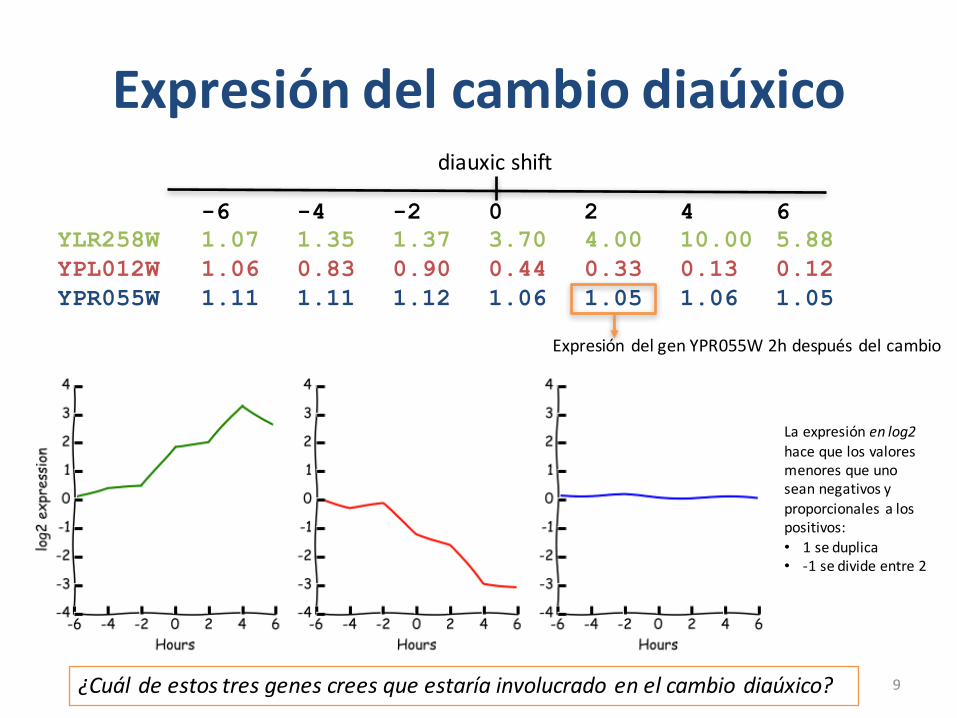
Expresión delcambiodiaúxico
9
-6 -4 -2 0 2 4 6YLR258W 1.07 1.35 1.37 3.70 4.00 10.00 5.88YPL012W 1.06 0.83 0.90 0.44 0.33 0.13 0.12YPR055W 1.11 1.11 1.12 1.06 1.05 1.06 1.05
diauxic shift
Expresión delgenYPR055W2hdespués delcambio
¿Cuál deestostresgenescreesqueestaríainvolucradoenelcambiodiaúxico?
Laexpresión enlog2hacequelosvaloresmenoresqueunoseannegativosyproporcionalesalospositivos:• 1seduplica• -1sedivideentre2

Fold change
10
-6 -4 -2 0 2 4 6YLR258W 1.07 1.35 1.37 3.70 4.00 10.00 5.88YPL012W 1.06 0.83 0.90 0.44 0.33 0.13 0.12YPR055W 1.11 1.11 1.12 1.06 1.05 1.06 1.05
diauxic shift
Estosvaloresestánexpresadosenfold changefold change ~variaciónrespectoalareferencia(doble,triple,mitad,etc.)
fc(-6) = expr(-6)/expr(ref)
Amenudosetransformanalog2 fold changehacesimétricalavariaciónevitaquesedisparenlosvaloresmuyaltos

Ejercicio• 1)DescargaelexperimentodeDeRisi aquí:
– http://vis.usal.es/rodrigo/documentos/bioinfo/expresion/2010diauxic-edited.txt
– Elexperimentoyaseencuentraenlog2fc– ¿Podrías encontrarestamatrizenlared?¿Dónde?
• 2)Cargalamatrizm anteriorconpython– numpy.genfromtxt* ocsv.reader– ¿Quédimensionestiene?**
• 3)Selecciona losgenesconexpresión (log2)envalorabsoluto>2.3paraalgunodelostiempos– Utilizaparaellonumpy.any ynumpy.where– Losllamaremosdgenes yasumatrizdeexpresióndm.¿Cuántosgenesson?
11
*Necesitarás hacerusodelosargumentosdelimiter, names, dtype, skip_header y/ousecolsIMPORTANTE:Tambiénnecesitarásusarfilling_values=0 paralosvaloresperdidos
**Pista:shape

ClusteringCluster yclustering
ErrorcuadráticomedioAlgoritmodeLloyd
• Dándolealvino• Clustering• Clustering jerárquico• Anotaciones
12

Cluster
• Conjunto deelementosconunpatrónsimilar– Ydistinto aldelrestodeelementos– Ennuestrocaso,conjuntosdegenesconnivelesdeactivaciónsimilaresalolargodeltiempo
– Lamayoríadegenestendránseguramenteunpatrónplano,alnoestarinvolucradosenelcambiodiaúxico• Sieliminamostodoslosgenesquetienentodoslosvalores(log2)desuperfilentre-2.3y2.3,nosquedamosconsólounos230de6400genes
13¿porqué2.3comoumbral?
sdev de0.55Sdev*4~2.2

Clustering
• Algoritmoparaencontrarclusters– Caracterizarlosmediantecentroides• puntosenel“medio”decadacluster
– Optimizarladistancia deloscentroides alospuntosqueagrupa• Típicamente,seusaladistanciaeuclídea*
– Seandospuntosm-dimensionalesa=(a1,...,am)yb=(b1,...,bm):
– Definimosladistanciaaunconjuntodecentroides como:
14
𝑑 𝑎,𝑏 = & (𝑎( − 𝑏()+
(,-
�
𝑑 𝑝𝑢𝑛𝑡𝑜, 𝐶𝑒𝑛𝑡𝑟𝑜𝑖𝑑𝑒𝑠 = min∀>?-@?-ABC(D?E
𝑑(𝑝𝑢𝑛𝑡𝑜𝑠, 𝑥)
*Enpython podemos calcularlaconnumpy.linalg.norm(a-b)

Máslejanoprimero
• Estrategiadeoptimización:1. Tomarunpuntocualquieracomocentroide2. Añadirnuevoscentroides eligiendodeentrelos
puntosrestantesaquélmáslejanoatodosloscentroides actualeshastaque|centroides|=k
15
MasLejanoPrimero(Puntos, k)Centroides <- un punto aleatorio de Puntos
mientras |Centroides| < k
punto <- punto en Puntos que maximice d(punto,Centroides)
añadir punto a Centroides
retornar Centroides

Ejercicio1• ImplementarlafunciónfarthestFirst:
– entrada:• E matrizdepuntos nxm• k númerodeclusters• init puntoinicial (envezdealeatoriamente, selosuministramos)
– salida:centroides segúnestealgoritmo• Ejemplo:
– E:np.array([[3,20],[4,22],[5,23],[3,18],[4,21],[5,24], [21,10],[22,12],[23,13],[21,8],[20,11],[24,13], [11,2],[12,1],[13,3],[15,4],[11,3],[14,2]])
– k:3– init: [3,20]– salida:[[3,20], [24,13], [14,2]]
• Prueba:– E=dm (lamatrizdeexpresióndedgenes)– k=3– init=[-0.23, -0.09, -0.27, 0.2 , 0.56, 1.52, 2.64]
16

farthestFirstk=1 k=2
k=4k=3

farthestFirst
• Estealgoritmoesmuyrápido ypuededarbuenosresultados.• Perotieneproblemasparatratarconoutliers (casosatípicos),muy
comunesenbioinformática
18

Errorcuadráticomedio(MSE*)
• Mediadetodaslasdistanciasmínimasacentroides– Másmoderadoquetomarsólolamáxima
19
𝑀𝑆𝐸 =1𝑛 & 𝑑(𝑝𝑢𝑛𝑡𝑜,𝐶𝑒𝑛𝑡𝑟𝑜𝑖𝑑𝑒𝑠)K
�
∀LM-AC?-NM-ACE
*MeanSquared Error

Ejercicio2• Implementarlafunciónmse:
– entrada:• points array depuntosn-dimensionales• centers array decentroides n-dimensionales
– salida:errorcuadráticomedio• Ejemplo:
– points :array([[ 1, 24], [ 4, 2], [23, 20], [24, 22], [25, 23], [23, 18], [24, 21], [25, 24], [31, 10], [32, 12], [33, 13], [31, 8], [30, 11], [34, 13], [21, 2], [22, 1], [23, 3], [25, 4], [21, 3], [24, 2]])
– centers:array([[1,24], [31,8], [4,2]])– salida:104.95
• Prueba:– points= array([[3,20],[4,22],[5,23],[3,18],[4,21],[5,24],
[21,10],[22,12],[23,13],[21,8],[20,11],[24,13], [11,2],[12,1],[13,3],[15,4],[11,3],[14,2]])
– centers=[[3,20], [24,13], [14,2]]
20

AlgoritmodeLloyd
• Centroide:puntocuyascoordenadassonlamediadelascoordenadasdeunconjuntodepuntos
21*Entendidacomoqueloscentroides nocambienocambienmenosqueundeterminadovalorrespectoalaiteración anterior
Lloyd(Puntos, k)Centroides <- k puntos aleatorios en Puntos
Clusters = []
hacerClusters <- asignar cada punto en Puntos al centroide más cercano
Centroides <- recalcular los centroides de cada cluster en Clusters
hasta convergencia*retornar Clusters

it 1it 0
it 0
AlgoritmodeLloydit -
elección aleatoria formar clusters
recalcular centroides formar clusters
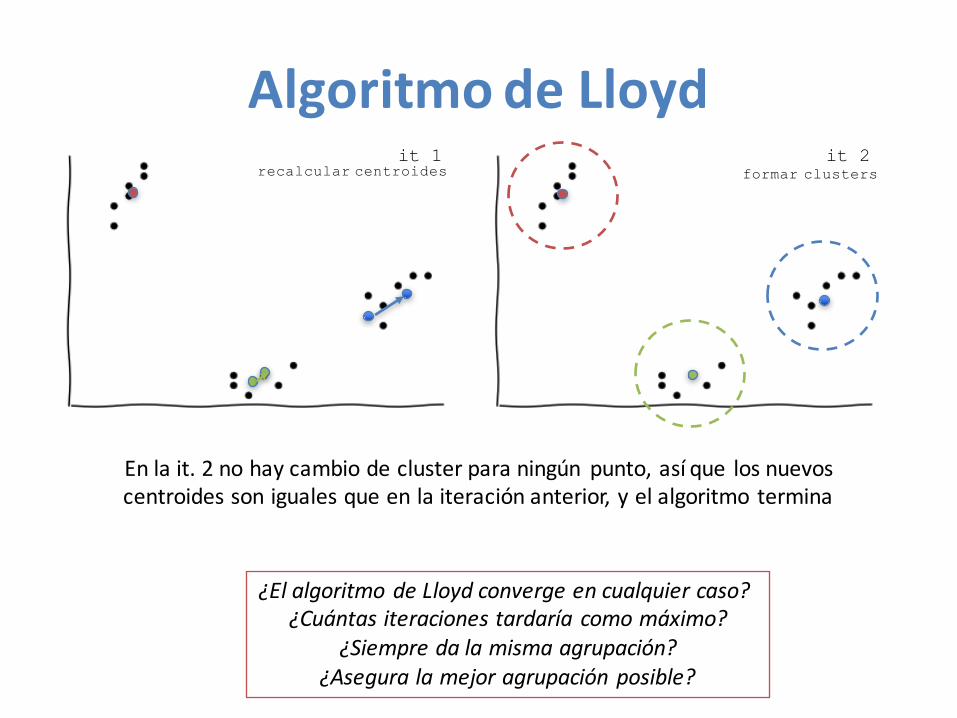
it 2
AlgoritmodeLloydit 1
recalcular centroides formar clusters
Enlait.2nohaycambiodecluster paraningún punto,asíque losnuevoscentroides sonigualesqueenlaiteraciónanterior,yelalgoritmotermina
¿ElalgoritmodeLloydconvergeencualquiercaso?¿Cuántas iteracionestardaríacomomáximo?
¿Siempredalamismaagrupación?¿Aseguralamejoragrupaciónposible?
SíKNoNo

AlgoritmodeLloyd
• Lainicialización aleatoriapuededarlugaraproblemasalahoradedetectarclusters
24
inicializacionKmedias(Puntos, k)Centroides <- un punto aleatorio en Puntos
mientras |Centroides|<k
puntoNuevo <- elegir aleatoriamente un punto de Puntos pero con probabilidades asignadas proporcionales a d(punto, Centroides)2
añadir puntoNuevo a Centroides
retornar Centroides

Ejercicio3• Implementarlafunciónlloyd (conlainicializacióndek-medias)*:
– entrada:• points array depuntosn-dimensionales• k númerodeclusters• convergence distanciamediamáximaentreloscentroides dedositeraciones consideradapara
terminarelalgoritmo• iterations númeromáximodeiteracionesencasodequenosellegueaconvergencia
– salida:array conelnúmerodecluster alquepertenececadapunto• Ejemplo:
– Points:array([[3,20],[4,22],[5,23],[3,18],[4,21],[5,24],[21,10],[22,12],[23,13],[21,8],[20,11],[24,13], [11,2],[12,1],[13,3],[15,4],[11,3],[14,2]])
– k:3– convergence:0.1– iterations:100– Salida…hayunaúnicasolución?
• Prueba:– Añadir un tercer parámetro opcionalinitCenters queindiqueunarray depuntosiniciales
ausarenvezdetomarlosaleatoriamente depoints– Utilizar losmismosparámetrosdelejemplomás:– points= centers=array([[3,20], [24,13], [14,2]])
25

Clusters enelcambiodiaúxico
• AplicandoelalgoritmodeLloydconk=6 adm,obtenemos 6clusters depatronesdistintosrespectoalcambiodiaúxico
• Estospatronesgenerannuevaspreguntasbiológicas:¿Porquéaumentansuexpresiónlosgenesenelcluster 1,3y4?¿porquédisminuyenenlosclusters 2,5o6?¿Enquémedidaesoscambioscontribuyenalcambiodiaúxico?
26

Clustering dek-medias:problemas
• ElalgoritmodeLloydesmuysimilaraotrasaproximacionescomoelclustering dek-medias,ypresentaproblemassimilares:– Problemasdeclasificación– Imposición dekapriori– Noindicalassimilitudesentreclusters– Nodeterminista(aleatorizaciónenelinicio)
27

Clustering jerárquicoMatrizdedistanciasClustering jerárquico
Interpretaciónderesultados
• Dándolealvino• Clustering• Clustering jerárquico• Anotaciones
28

Matrizdedistancias
• SeaunamatrizdeexpresiónE nxm– LamatrizdedistanciasDesunamatriznx ndondeDij=d(gi,gj)• Siendod ladistanciaEuclídea (normalmente)• Siendogi ygj losperfilesdeexpresióndelosgenescorrespondientesalasfilasi yj deE
• Enpython lapodemoscalcularcon:distm=scipy.spatial.distance.pdist(e)
distm=scipy.spatial.distance.squareform(distm)*
29*pdist calculalamatrizdedistanciasenformacondensada (yaqueesunamatriztriangulardediagonalcero).squareform permiterecuperarlamatrizredundantecuadradacorrespondiente

Matrizdedistancias
30
1 hr 2 hr 3 hrg1 10.0 8.0 10g2 10.0 0.0 9.0g3 4.0 8.5 3.0g4 9.5 0.5 8.5g5 4.5 8.5 2.5g6 10.5 9.0 12.0g7 5.0 8.5 11.0g8 3.7 8.7 2.0g9 9.7 2.0 9.0g10 10.2 1.0 9.2
g2 g3 g4 g5 g6 g7 g8 g9 g10g1 8.1 9.2 7.7 9.3 2.3 5.1 10.2 6.1 7.0g2 12.0 0.9 12.0 9.5 10.1 12.8 2.0 1.0g3 11.2 0.7 11.1 8.1 1.1 10.5 11.5g4 11.2 9.2 9.5 12.0 1.6 1.1g5 11.2 8.5 1.0 10.6 11.6g6 5.6 12.1 7.7 8.5g7 9.1 8.3 9.3g8 11.4 12.4g9 1.1
MatrizE (izquierda) ymatrizD (abajo)D seharealizadocondistanciaseuclídeas,yesunamatriztriangularydediagonalcero.

Clustering jerárquico
• Estemétodoagrupaloselementosmáscercanositerativamente
• Unaformacomúnesagruparporparessegúnunadistanciamediaentregrupos– UPGMA(Unweighted Paired GroupMethod withArithmetic mean)
31

32
g2 g3 g4 g5 g6 g7 g8 g9 g10g1 8.1 9.2 7.7 9.3 2.3 5.1 10.2 6.1 7.0g2 12.0 0.9 12.0 9.5 10.1 12.8 2.0 1.0g3 11.2 0.7 11.1 8.1 1.1 10.5 11.5g4 11.2 9.2 9.5 12.0 1.6 1.1g5 11.2 8.5 1.0 10.6 11.6g6 5.6 12.1 7.7 8.5g7 9.1 8.3 9.3g8 11.4 12.4g9 1.1
g3 g5 g8 g7 g1 g6 g10 g2 g4 g9
g2 g3,5 g4 g6 g7 g8 g9 g10g1 8.1 9.2 7.7 2.3 5.1 10.2 6.1 7.0g2 12.0 0.9 9.5 10.1 12.8 2.0 1.0g3,5 11.2 11.1 8.1 1.0 10.5 11.5g4 9.2 9.5 12.0 1.6 1.1g6 5.6 12.1 7.7 8.5g7 9.1 8.3 9.3g8 11.4 12.4g9 1.1
g3 g5 g8 g7 g1 g6 g10 g2 g4 g9
g2,4 g3,5 g6 g7 g8 g9 g10g1 7.7 9.2 2.3 5.1 10.2 6.1 7.0g2,4 11.2 9.2 9.5 12.0 1.6 1.0g3,5 11.1 8.1 1.0 10.5 11.5g6 5.6 12.1 7.7 8.5g7 9.1 8.3 9.3g8 11.4 12.4g9 1.1
g3 g5 g8 g7 g1 g6 g10 g2 g4 g9

Clustering jerárquico
33
clusteringJerarquico(D, k)Clusters <- n clusters de un elemento etiquetados de 1 a nconstruir un grafo T con n nodos aislados etiquetados de 1 a ncont <- nmientras |Clusters|>k
Ccont <- fusión de los Clusters más cercanos Ci y Cjañadir un nodo Ccont a Tconectar Ccont a los nodos Ci y Cjeliminar de D las filas y columnas correspondientes a Ci y Cjañadir una fila/columna a D con D(Ccont,C) para todo C en Clusterseliminar Ci y Cj de Clustersañadir Ccont a Clusterscont <- cont +1
raiz <- nodo en T correspondiente al cluster finalretornar |Clusters|
Unposiblemétodo paralaestructuradeárbolesusarundiccionariodonde lasclavesseannodos ylosvaloresseanlistasdedoselementos conlos nodos hijos

Clustering jerárquico
• LadistanciaD(C1,C2) entreclusters sepuededefinirdedistintosmodos.
• EnUPGMAseusaladistanciamediaentreloselementosdelosdosclusters:
34
𝐷PQR(𝐶1, 𝐶2) =∑ 𝑑(,U�∀LM-AC(?-@VWU?-@K
𝐶1 · |𝐶2|

Ejercicio4
35
• ImplementarlafunciónhierarchicalClustering– entrada:
• E matrizoarray depuntosn-dimensionales– salida:diccionarioconlosclusters formados.Lasclavesindicaránel
nododelárbolqueseusaparaelcluster ylosvaloreslalistadenodoshoja(filasdeE)quecontieneelcluster.
• Ejemplo:– E:array([[ 10.,8.,10.], [10.,0.,9. ], [4. ,8.5,3. ],
[9.5,0.5,8.5], [4.5,8.5,2.5], [10.5, 9.,12. ], [5.,8.5,11.], [3.7,8.7,2. ], [9.7,2. , 9. ], [10.2,1.,9.2]])• Secorresponde con lamatriz 10x3deladiap.30
– Resultado intermedio (árbol):{0:[], 1:[], 2:[], 3:[], 4:[], 5:[], 6:[], 7:[], 8:[], 9:[], 10:[2, 4], 11:[1, 3], 12:[7, 10], 13:[9, 11], 14:[8, 13], 15:[0, 5], 16:[6, 15], 17:[14, 16], 18:[12, 17]}
– Salida:{12: [7, 2, 4], 14: [8, 9, 1, 3], 16: [6, 0, 5]}• Prueba:
– E: dm– k:6

Ejercicio4(estructuradedatos)
36
g2 g3 g4 g5 g6 g7 g8 g9 g10g1 8.1 9.2 7.7 9.3 2.3 5.1 10.2 6.1 7.0g2 12.0 0.9 12.0 9.5 10.1 12.8 2.0 1.0g3 11.2 0.7 11.1 8.1 1.1 10.5 11.5g4 11.2 9.2 9.5 12.0 1.6 1.1g5 11.2 8.5 1.0 10.6 11.6g6 5.6 12.1 7.7 8.5g7 9.1 8.3 9.3g8 11.4 12.4g9 1.1
g3 g5 g8 g7 g1 g6 g10 g2 g4 g9
{0:[], 1:[], 2:[], 3:[], 4:[], 5:[], 6:[], 7:[], 8:[], 9:[], 10: [2, 4]
g1 ag10 (nodoshoja) g3,5
Almacenaremoselárbolcomoundiccionario.Cadaclaveindica1)unabifurcacióndelárbolyelvaloresunarray condosnodos, obien2)unnodohoja(esdecirunafiladelamatrizinicial)ysusuvaloresunarray vacíoLosnodoshojadeben identificarseconvaloresi=0aN-1,donde icorresponde alafiladeEenlaqueseencuentraelpunto.Losnodos intermedios debenidentificarseconvaloresi=N,N+1,...porordendedistancia,siendoNelqueindicalabifurcacióndelosdospuntosdeEconmenordistancia.

Clusters enelcambiodiaúxico
• Cortandopor6clusters,obtenemos clusters detamaños1,6,102,34,10y76,respectivamente
• Losresultadossondistintosalosobtenidos conelclustering dek-medias,yaquehayvariasdiferenciasprocedimentales (cálculodedistancias,mododeagrupamiento,etc.)
37

Clustering einterpretación biológica
• Elclustering essólo unprimerpaso enelanálisisdeunexperimento
• Lesiguenmásexperimentosparaconfirmarquelosclusters tienensentidobiológico
• Haytambiénpruebasbioinformáticasparaidentificarsi– Haymotivosenlassecuenciasencontradas
• P.ej.,elmotivoreguladorCSREseencuentraenvariosgenesconactivacióndiaúxica [Schöler ySchüller,1994]
• Comovimosenlasesión3(muestreodeGibbs,p.ej.)– Hayfuncionesbiológicasconocidasrelacionadasconlosgrupos
38

AnotacionesAnotacionesgenéticasAnotacionesfuncionalesEnriquecimientofuncional
• Dándolealvino• Clustering• Clustering jerárquico• Anotaciones
39

Anotacionesdeungen
• Característicasgenerales(GFF)– Nombreysinónimos– Estructura– Posición
• Locus– Posición(comienzoyfin)enelcromosoma– Cromosomaenelqueseencuentra
• Sentidooantisentido• Secuencia(FASTA)• Funcionesconocidas(OBO,otros)
40

Estructuradeungen
41
https://en.wikipedia.org/wiki/File:Gene_structure_eukaryote_2_annotated.svg

Estructuradeungen
• OpenReadingFrame (ORF):región abiertaparatranscripción porpartedelaDNApolimerasa
• Start/Stop:codonesosecuenciasdeinicio/paradadelatranscripción
• UntranstlatedRegions (UTR):regionesenlosextremos5’o3’queayudanalinicio/findelatranscripciónyqueseincluyen enelmRNA
• Secuenciaregulatoria:secuenciaprevia/posterioraunORFquemodula sutranscripción– Promotor:acumulalasproteínasnecesariasparalatranscripción– Catalizador/Silenciador:mejora/obstaculizalatranscripción
• Exon:sección delORFenelmRNA queterminaráformandolaproteína
• Intron:seccióndelORFenelmRNA queno formalaproteína• SecuenciadeDNAcodificante(CDS):DNAqueformapartedela
proteína.EquivalealosexonessinlosUTR42

GeneralFeature Format (GFF)
Tipodeestructura
Posición
Identificador
Sentido
Otrainformación
https://en.wikipedia.org/wiki/General_feature_format

GeneralFeature Format
44
##gff-version 3#date Thu Jun 30 19:50:03 2016...chrV SGDgene 285241 286914 . - .
ID=YER065C;Name=YER065C;gene=ICL1;Alias=ICL1,isocitrate lyase1;Ontology_term=GO:0004451,GO:0005737,GO:0006097;Note=Isocitrate lyase B catalyzes the formation of succinate and glyoxylate from isocitrate-C a key reaction of the glyoxylatecycle B expression of ICL1 is induced by growth on ethanol and repressed by growth on glucose;display=Isocitratelyase;dbxref=SGD:S000000867;orf_classification=VerifiedchrV SGDCDS285241 286914 . - 0
Parent=YER065C_mRNA;Name=YER065C_CDS;orf_classification=VerifiedchrV SGDmRNA 285241 286914 . - .
ID=YER065C_mRNA;Name=YER065C_mRNA;Parent=YER065C...
Cadaentradaestádelimitadaportabuladores
Loscomentarioscomienzanpor# Escomún queloscamposnoseutilicen correctamente,aquíelcampo1(ID)seusaparaindicarelcromosomaElcampo2nosindicalafuentedelainformación, enestecasoSGD(Saccharomyces Genome Database)Loscamposvacíosseidentificancon.aunquenosiempre!
Elcampo9sesuelesobrecargardeinformaciónnoestandarizada
http://vis.usal.es/rodrigo/documentos/bioinfo/anotaciones/saccharomyces_cerevisiae_R64-2-1_20150113.gff

Ejercicio5• Implementarlafunciónannotations
– Entrada:• ids:array connombresdegenesensegún elexperimentodeDeRisi
– Salida:diccionarioconlosnombresdelosgenescomoclavesycomovaloresundiccionarioconloscamposstart,end,name eid• EsteúltimoseráelnúmeroentreSGD: y;
– UtilizadlaversióndeSGDR64-2-1(30deenerode2016)*• ¿Podríasobtenerunaversiónmásactualizada?
• Ejemplo– [YER065C]– {'YER065C': {'end': '286914', 'id': 'S000000867', 'name':
'ICL1', 'start': '285241'}}
• Prueba:['YPR184W', 'YLR312C', 'YML054C', 'YBR116C', 'YKL187C', 'YLR267W', 'YEL012W', 'YOL084W', 'YJL045W', 'YJR095W']
45*http://vis.usal.es/rodrigo/documentos/bioinfo/anotaciones/scerevisiae/saccharomyces_cerevisiae_R64-2-1_20150113.gff

Anotacionesfuncionales:ontologías
• Ontología:vocabulariocontrolado– Jerarquizadoenformadegrafodirigidoacíclico (DAG)– Sepuedevercomoun‘árbolcomplejo’
• GeneOntology (GO):ontologíasbiológicas*– ComponentesCelulares(CC)– Funcionesmoleculares(MF)– ProcesosBiológicos(BP)– Eslaontologíamásextendida,peronolaúnica
• KEGG(rutasbiológicas),Reactome (reaccionesquímicas),etc.
46*http://www.geneontology.org/

OpenBiomedical Ontologies (OBO)
• Estándar pararepresentarontologías*• Cadatérminodelvocabularioserepresentaconunpárrafo:
47
[Term]id: GO:0000001name: mitochondrion inheritancenamespace: biological_processdef: "The distribution of mitochondria, including themitochondrial genome, into daughter cells after mitosis ormeiosis, mediated by interactions between mitochondria and the cytoskeleton." [GOC:mcc, PMID:10873824, PMID:11389764]synonym: "mitochondrial inheritance" EXACT []is_a: GO:0048308 ! organelle inheritanceis_a: GO:0048311 ! mitochondrion distribution
*Porejemplo, paraGO:http://www.geneontology.org/page/download-ontology

GeneOntology Annotations (GOA)• Enunorganismo,
cadagenestáanotadocontérminosdelaontología
• GeneAssociationFile(GAF)– Formatocomúnpara
representarlasanotaciones
– Formatotabuladode17campos
– Loscomentariosempiezanpor“!”
48

GeneAnnotation File(GAF)
49
SGD S000000349 ADH5 GO:0043458 SGD_REF:S000076493|PMID:15082781 IMP PAlcohol dehydrogenase isoenzyme V YBR145W|alcohol dehydrogenase ADH5 gene taxon:559292 20061114 SGD
1- Basededatosfuentedelaanotación2- Identificadorúnico delgenoentidadbiológica
3- Símbolo comúndelgen4,8,16,17- Algunos campospuedenestarvacíos
5- Identificadordelelementodelaontologíaconelqueseasociaalgen6- Evidenciasenlasquese apoyalaasociación(sihayvariasseseparanpor|),generalmentesonpublicacionesconPMID 7- Tipodeevidencia*
*Muyimportanteparaelbiólogo,pueshayevidenciasmáscontundentesqueotras.Engeneral,sueleserrecomendabletratarconprecauciónaquellasinferidaselectrónicamente(IEA).Paraconsultartodosloscódigos: http://www.geneontology.org/page/guide-go-evidence-codes
9- Tipodeontología:P(BP),F(MF),oC(CC)
10- Nombrecompletodelgen 11- Sinónimos delgen12- Tipodeentidad(enGOsuelen sergenes)13- Id.Taxonómicodelaentidad
14- Fechadelaanotación15- Responsable delaanotación

Ejercicio6• Implementarlafunciónfunctions
– Entrada:• ids:array connombresdegenessegún elexperimentodeDeRisi
– Salida:diccionarioconlosids degenescomoclavesycomovaloresunconjunto(set)conlosnombres delosprocesosbiológicos (P)conlosqueestáanotadoquenoesténinferidoselectrónicamente(IEA)
– Utilizad lasversiones:• GO:laversióndelSGDR64-2-1,de11defebrerode2016*• GAF:versión34023de25dejuniode2016**
– ¿Podrías obtenerunaversiónmásactualizada?¿Dónde?
• Ejemplo– [YER065C]– {'S000000867': set(['glyoxylate cycle'])}
• Prueba:['YPR184W', 'YLR312C', 'YML054C', 'YBR116C', 'YKL187C', 'YLR267W', 'YEL012W', 'YOL084W', 'YJL045W', 'YJR095W']
50* http://vis.usal.es/rodrigo/documentos/bioinfo/anotaciones/scerevisiae/go.obo** http://vis.usal.es/rodrigo/documentos/bioinfo/anotaciones/scerevisiae/gene_association.sgd

Anotaciones:problemas
• Apesardelosesfuerzosdeestandarización– Existenmuchosnombreseidentificadoresdistintosparacadagen
– Losformatoscambianligeramenteentreorganismos
– Hayerroresenelusodelosformatos• Elparseo deestetipodearchivossueleconsumirmuchotiempodeprogramación
51

Enriquecimientoestadístico
• SeandosconjuntosG yF deelementosgi yfitomadosdeununiversodeelementosU– F estáenriquecido porG sicontieneunnúmerodeloselementosdeGquenopuededebersealazar,teniendoencuentalostamañosdeG,F yU
52
FG
U
FG
U
FG
U
F G
U
FG
U
¿Cuál deestosconjuntosG creesqueenriquecemásaF ?
1 2 3 4
5

TestdeFisher• SeandosgruposX eY conelementosquecumplenonounadeterminadacondiciónF
• Seasumatrizdecontingencia:
• Fisherdemostróquelaprobabilidadp deestamatrizes
53
X Y Total
Cumplen F a b a+bNocumplen F c d c+d
Total a+c b+d a+b+d+c=n
𝑝 =𝑎 + 𝑏 ! 𝑐 + 𝑑 ! 𝑎 + 𝑐 ! 𝑏 + 𝑑 !
𝑎!𝑏! 𝑐!𝑑! 𝑛!

TestdeFisher:ejemplo• ConsideremosungrupoGdegenes,yotrogrupoconel
restodegenesdenuestrouniverso(U-G).• RespectoaunaanotaciónF,lamatrizdecontingenciaes:
54
G U-G Total
EnF 10 30 40=|F|
NoenF 20 140 160
Total 30=|G| 170 200=|U|
1. Tenemos40deuntotalde200genesanotadosconlafunción F2. ElgrupoGtiene10desus30genesanotadosconlafunción F3. Asumimos lahipótesisnulaH0 dequetantolosgenesenG comoelresto(U-G)
tienenlamismaprobabilidaddeestarenF4. ¿Sihubiéramoscogido|G|genesalazar,cualeslaprobabilidad detenerestatabla
decontingencia?:𝑝 =
40! 160! 30! 170!10! 30! 20! 140! 200! = 0.01789

Ejercicio7• Implementarlafunciónenrichment
– Entrada:• ids:conjuntocongenesdeinterés• goids:conjuntocongenesanotadosconunafunción• n:númerototaldegeneseneluniverso
– Salida:p-valordeltestdeFisherparaestacomparación*– Utilizad lasversionesdeGOyGAFqueseindicanenelejercicio5
• Ejemplo– ids=set(range(30))– goids=set(range(20,60))– n=200– salida: 0.01789
• Prueba:– ids=dgenes,losgenesrelacionadosconelcambiodiaúxico**– goids=geneseneltérmino alcohol metabolic process (GO:0006066):
• {'S000000056', 'S000000080', 'S000000702', 'S000000826', 'S000004937'}
– n=6034(núm.degenesenlamatrizdeexpresióndeDeRisi)
55
*PISTA:siusaspython, puedes usarlafunción pvalue delalibreríafisher, encuyocasoelvalorautilizareselderight_tail. Investigatambiénelusodeset ysus operaciones paraintersección, unión, diferencia,etc.**http://vis.usal.es/rodrigo/documentos/bioinfo/expresion/diau/dgenes.txt

5656
FG
U
FG
U
FG
U
F G
U
FG
U
¿Cuál deestosconjuntosG creesqueenriquecemásaF ?1
2
3
4
5
|G|=30|F|=50|G∩F|=5|U|=300
|G|=30|F|=50|G∩F|=20|U|=300
|G|=180|F|=50|G∩F|=40|U|=300
|G|=30|F|=160|G∩F|=20|U|=300
|G|=30|F|=50|G∩F|=5|U|=700

5757
FG
U
FG
U
FG
U
F G
U
FG
U
1
2
3
4
5
0.49
0.92·10-12
1.07·10-10
0.28
0.05
|G|=30|F|=50|G∩F|=5|U|=300
|G|=30|F|=50|G∩F|=20|U|=300
|G|=180|F|=50|G∩F|=40|U|=300
|G|=30|F|=160|G∩F|=20|U|=300
|G|=30|F|=50|G∩F|=5|U|=700

TestdeFisher:interpretación
• Sielp-valoressuficientementebajo,podemosdecirquenosedebealazarelhechodequehayamoscogidovarioselementosdeF enG– Esdecir,F seencuentraenriquecido enG
• ¿Quéessuficientementebajo?– Sesueleestimarunumbralα=0.05,0.01o0.001• Probabilidad<=5%,1%o0.1%dequesedebaalazar
58

TestdeFisher:interpretación• UntestdeenriquecimientopermiterechazaronoH0(unadeterminadacircunstancianopareceosíparecedebidaalazar,respectivamente)
• Limitacionesdelostests deenriquecimiento[Khatri2005,Glass2014]:– NosirvenparaconfirmarquelosdatossedebenalazarencasodequenoserechaceH0• Nosepuedeconfirmartotalmenteelazar
– NopermitenconfirmarlahipótesisalternativaH1• Nosepuedeconfirmartotalmentelafaltadeazar
– Losumbralessonarbitrarios– Algunosgenesestánmásanotadosqueotros,conloquenuestraH0 noestotalmentecorrecta
59

Contrastesmúltiples dehipótesis
• Esnormalrealizareltestdeenriquecimientocontodos lostérminos GOalavez– Objetivo:detectaraquellosmásenriquecidos
• Cuantosmástests realicemos,másposibilidadeshaydequealgunodeelloscaigaporazarpordebajodelumbralfijado
60

Correcciones
• CorreccióndeBonferroni– Sedivideelumbralαentreelnúmerodetests• α=0.05,106 testsà α(corregido)=0.05/106 = 5·10-8
• FalseDiscoveryRate (FDR)*1. Secalculanlosp-valoresdenuestrosN tests2. Seordenan:P1≤P2≤P3…≤PN3. Paraunvalorα,se buscaelvalormásgrandePk tal
que:4. SetomacomoFDR(umbralcorregido)Z=Pk
61
Pk <αkN
*También conocidocomoCorreccióndeBenjamini-Hochberg

Ejercicio8• ImplementarlafunciónenrichmentAll
– Entrada:• uids:array contodoslosnombresdegenes ennuestroexperimento• gids:array cont todoslosgenesdeinterés(p.ej.losdeuncluster)• a:umbralparadeterminarsihayenriquecimiento• min:mínimonúmerodeanotacionesquedebeteneruntérminoparaser
considerado• max:máximo númerodeanotacionesquedebeteneruntérminoparaser
considerado• type:carácter‘P’,‘C’ o‘F’ indicandoeltipodetérminosGOquese
consideran– Salida:listadediccionariosconlossiguientescampos:
• name:nombredeltérmino GOenriquecido• pval:p-valor• ngis:número degenesenids anotadosconeltérmino• ngo:número degenesentotalanotadosconeltérmino
– Utilizad lasmismasversionesdeGAFyGOqueenelejercicio5
62

Ejercicio8• Ejemplo– gids=c3genes.txt*– uids=ugenes.txt**– a=10e-20, min=5, max=500, type=‘P’– Salida:[{'name': 'cytoplasmic translation', 'ngis':
45, 'ngo': 170, 'pval': 8.481635678756666e-44}]• Compara este resultado conlosresultados deDeRisi (enparticular su fig.5F)
• Prueba:– ids=randomGenes.txt***– n=númerototaldegenesenDeRisi– a=0.01, min=5, max=500
63
*Sonlos102genesdelgrupo3obtenidoconelclustering jerárquico (diap.35)eval(urllib.urlopen(http://vis.usal.es/rodrigo/documentos/bioinfo/expresion/diau/c3genes.txt))
** TodosaquellosdelosquetenemosanotacionesenelGFF:http://vis.usal.es/rodrigo/documentos/bioinfo/expresion/diau/ugenes.txt***Ungrupode102geneselegidosaleatoriamentehttp://vis.usal.es/rodrigo/documentos/bioinfo/expresion/diau/randomGenes.txt

Elpeligrodelosumbrales• Enlapruebadelej.8existentérminos enriquecidospararandomGenes, inclusoconFDR=0.01!– Esunumbralsuficientementebajo?
• Hay145términosGOBPconentre5y500anotacionesquecontenganalgunodelosgenesenrandomGenes– 145*0.01=1.45à hayposibilidadesdequesenoscuelealguno
• Recomendaciones– Mejorpecardefalsosnegativosquedefalsospositivos
• Usaumbrales<<0.01.Demaneragenérica,10-6 puedeestarbienteniendoencuentaquetenemosunos105 términosGO
• Opuedesafinarmásusandocálculoscomoelanterior– Descartatérminosconmuypocasomuchasanotaciones– Vigilasiemprengis yngo ademásdepval
64

Latrampadelinformático
• Correlaciónnoimplicacausalidad– Nosepuedesaltardeunaafirmaciónestadísticaaunaexplicaciónbiológica
– Necesidaddenuevosexperimentosbiológicosalaluzdelosindicadoresestadísticos
65
“The numbers arewhere the scientific discussion should start,not end.”StevenGoodman (ver[Nuzzo2014])

Latrampadelbiólogo
• Laestadísticanosedebecocinar– Losumbralesestadísticosdebenserrigurosos– Nosepuedenmodificarlosumbralesomodeloshastaqueconfirmenunateoríabiológica
• Muyimportante: estasdos“trampas”hanpobladolasbasesdedatosdefalsospositivosyresultadosnoreplicables
66
“P-hackingis trying multiple things until you get the desired result”UriSimonsohn [verNuzzo2014]

Bibliografía• P.Compeau andP.Pevzner (2015).Bioinformatics
Algorithms:An ActiveLearning Approach,2nded.Vol II.Ch8.
• Respetoalcambiodiaúxico– DeRisi,J.L.,Iyer,V.R.,&Brown,P.O.(1997).Exploring the
metabolic andgenetic controlofgeneexpression on agenomicscale.Science,278(5338),680-686.
– http://vis.usal.es/rodrigo/documentos/bioinfo/papers/DeRisi1997.pdf
• Respectoalaslimitacionesdelp-valor– Nuzzo,R.(2014).Statisticalerrors.Nature,506(7487),150-152.– http://www.nature.com/news/scientific-method-statistical-
errors-1.14700
67

Voronto,unaherramientaparavisualizarelenriquecimiento estadístico http://vis.usal.es/voronto68
Respiratory electron transport chain UPFig 5.DCOXlink torespiration (COX5A, COX6,etc.)Glycogen biosynthetic process UP(GSY1,2,GLG1,2,GLC3)->Fig.3