chapter 4 _lectures 5 _ 6-1
TRANSCRIPT

Chapter 4: DNA, RNA, and the Flow of
Genetic Information

DNA History
1869 Miescher: Discovered a weak acid in the nuclei 1928 Griffith: Genetic information can be transferred
(transformation) 1944 Avery et al.: Identify Griffith’s transforming agent as DNA 1953 Watson and Crick: Molecular structure of DNA 1958 Meselson-Stahl: DNA is semiconservatively replicated 1961 Nirenberg et al.: Genetic code 1970 Smith: Restriction enzymes 1977 Sanger, Gilbert, Maxam: DNA sequencing 1983 Mullis: PCR 2001 Human genome

Transformation (Griffith’s Experiment)

A. DNA and RNA
DNA: deoxyribonucleic acid. • A polymer of deoxyribonucleotides. • Found in the nucleus of all animal and plants cells.
RNA: ribonucleic acid. • A polymer of ribonucleotides. • Found in the nucleus and cytoplasm of all animal and plant cells.

Backbones of DNA and RNA
Phosphodiester linkage
nucleotide
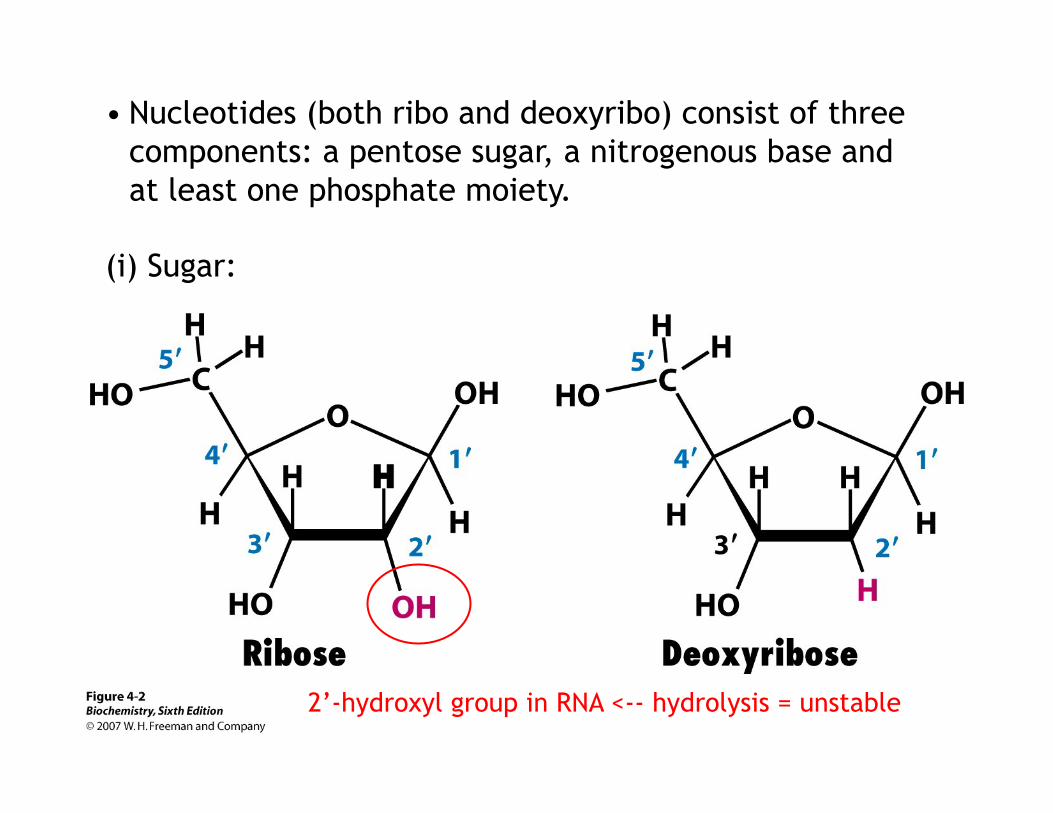
• Nucleotides (both ribo and deoxyribo) consist of three components: a pentose sugar, a nitrogenous base and at least one phosphate moiety.
(i) Sugar:
2’-hydroxyl group in RNA <-- hydrolysis = unstable

(ii) Nucleoside – A Pentose Sugar and a Nitrogenous Base (either purine or pyrimidine)
e.g.: Adenosine
H: deoxyadenosine
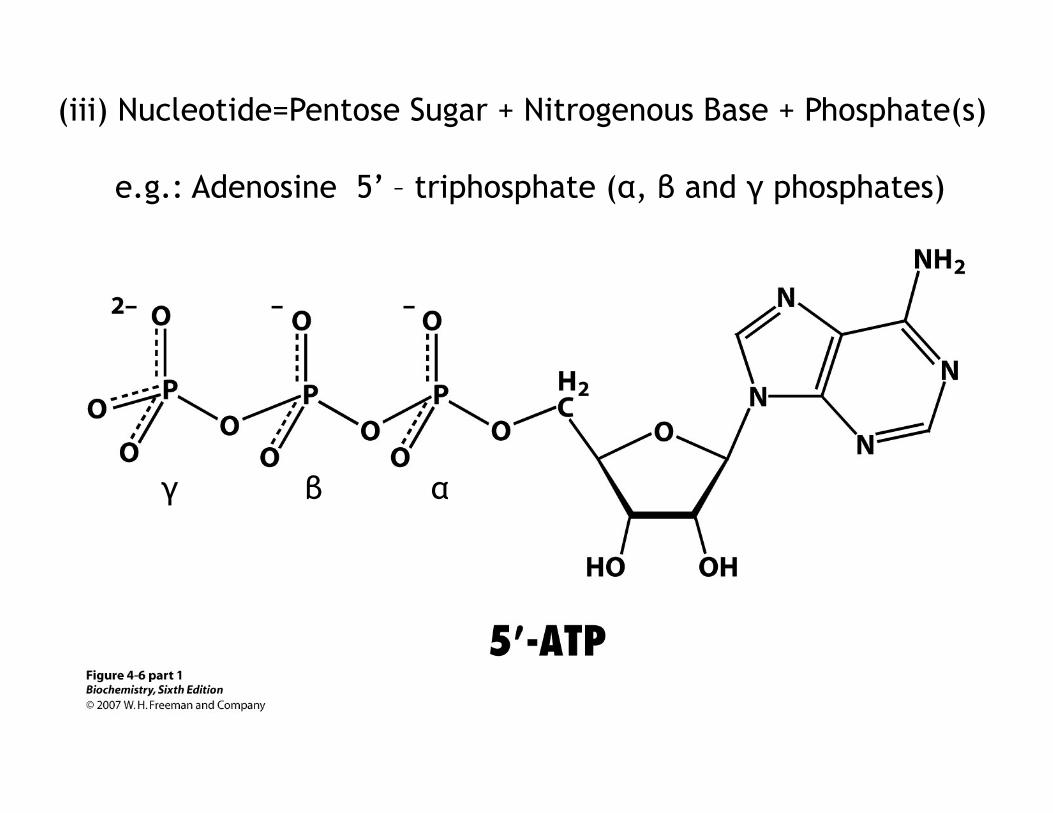
(iii) Nucleotide=Pentose Sugar + Nitrogenous Base + Phosphate(s)
e.g.: Adenosine 5’ – triphosphate (α, β and γ phosphates)
α β γ
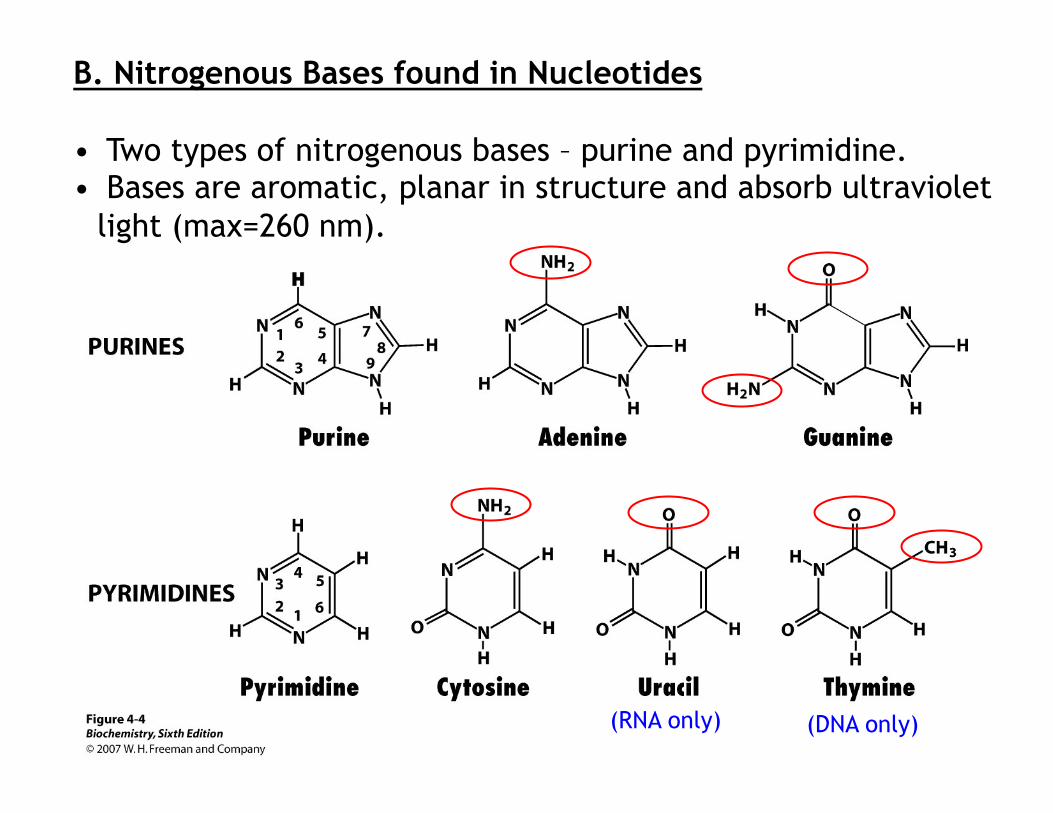
B. Nitrogenous Bases found in Nucleotides
• Two types of nitrogenous bases – purine and pyrimidine. • Bases are aromatic, planar in structure and absorb ultraviolet
light (max=260 nm).
(RNA only) (DNA only)

C. DNA Structure
1. Chargaff’s rule – Ratio of A to T and G to C is very close to one in DNA from all species
A+G (purine) = T+C (pyrimidine)

2. X-ray diffraction photograph of a hydrated DNA fiber
by Rosalind Franklin

3. Watson-Crick Model of DNA: Proposed in 1953
Main Features:
a) Two helical polynucleotide chains which are in an anti-parallel orientation.
b) Bases are in the interior of the helix and the plane of the bases is perpendicular to the helix axis.
c) Diameter of helix is 20 Å and helical structure repeats every 34 Å or 10 bases.
d) The two chains of the double helix are held together by hydrogen bonding of the bases. Adenine is hydrogen bonded to Thymine and Guanine is paired with Cytosine.
e) The sequence (order) of bases is not restricted other than complementary; it is the precise order of bases in the DNA that carries the genetic information.
5’
5’ 3’ 3’
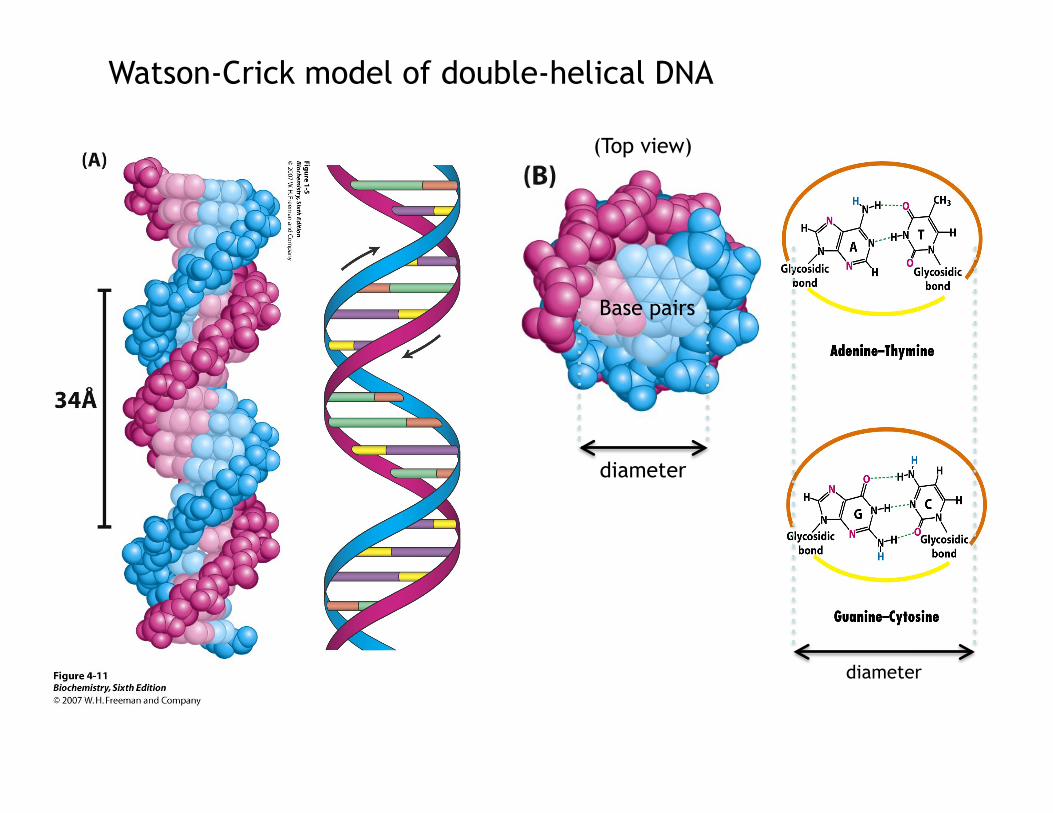
diameter
(Top view)
Base pairs
Watson-Crick model of double-helical DNA
diameter

Structures of the base pairs proposed by Watson and Crick
: tighter

Major and minor grooves

• The double helix is stabilized by hydrogen bonds and hydrophobic interactions.
• Stacking of base pairs inside the helix contributes to the stability of the double helix in 2 ways:
(i) the hydrophobic bases cluster in the interior of the helix and hydrophobic effect stacks the bases one on top of another.
(ii) the stacked base pairs attract one another through Van der Waals forces.

5’ ACG 3’ 3’ TGC 5’
→ → ACG
4. Writing DNA sequence
Sense (coding) strand
Antisense strand
5’ 3’

5. Mechanism of DNA replication:
The double helix facilitate the accurate transmission of information – semi conservative. (Each strand of DNA molecule serves as a template for the synthesis of a new molecule)
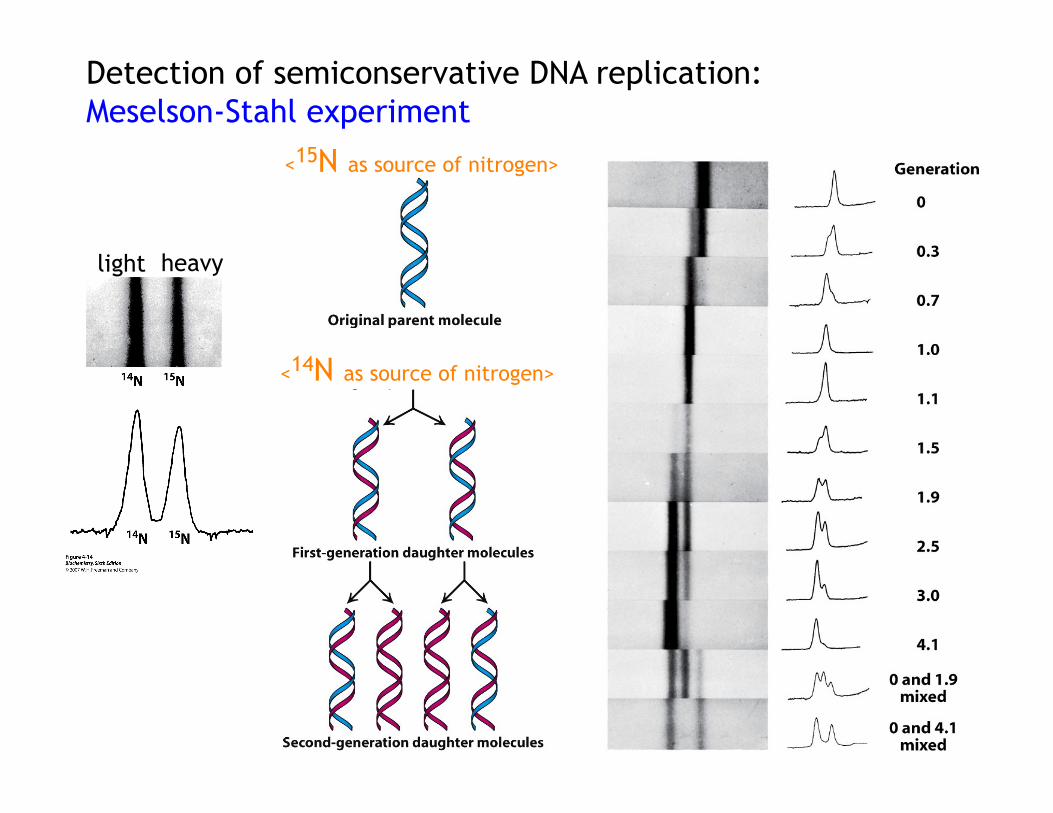
light heavy
<15N as source of nitrogen>
<14N as source of nitrogen>
Detection of semiconservative DNA replication: Meselson-Stahl experiment

<15N as source of nitrogen>
<14N as source of nitrogen>
Detection of semiconservative DNA replication: Meselson-Stahl experiment
0
1
2
3
Semi-conservative Conservative
Replication

6. The DNA double helix can be “melted”
• The two strands of the DNA double helix can be separated by heating/alkali (breaks hydrogen bonds). • Strand separation can be monitored by the hyperchromic effect.

Tm (half the helical structure is lost)
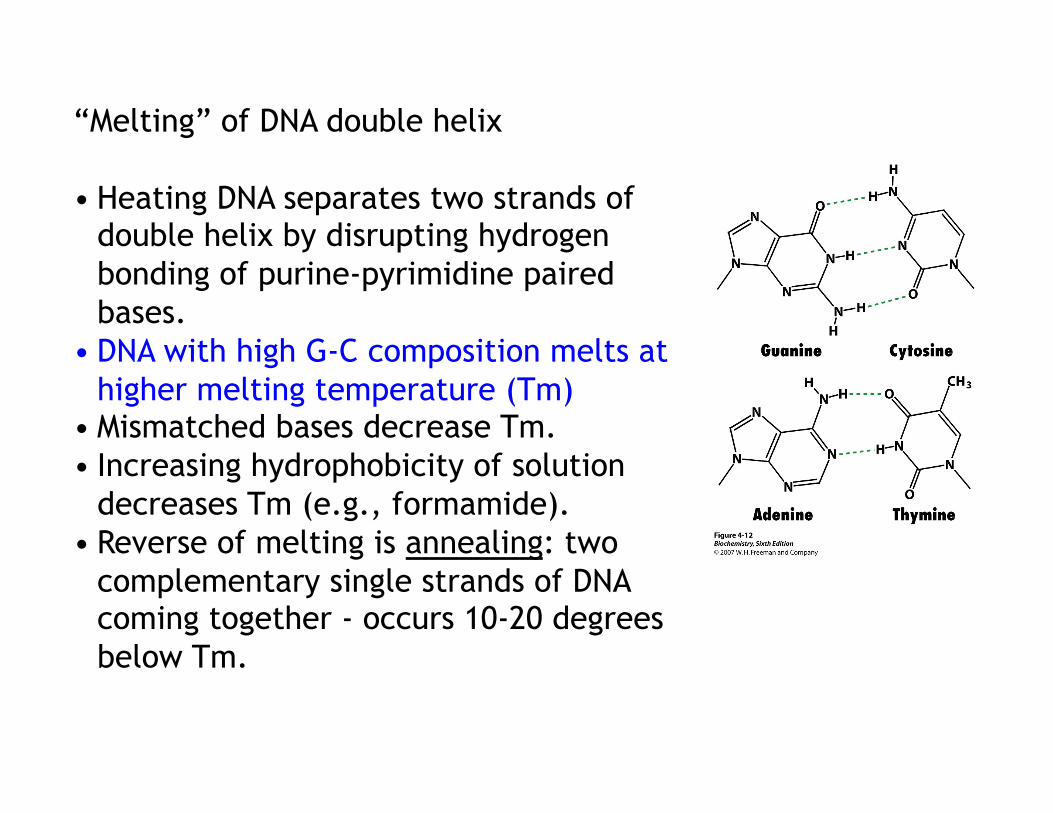
“Melting” of DNA double helix
• Heating DNA separates two strands of double helix by disrupting hydrogen bonding of purine-pyrimidine paired bases.
• DNA with high G-C composition melts at higher melting temperature (Tm)
• Mismatched bases decrease Tm. • Increasing hydrophobicity of solution
decreases Tm (e.g., formamide). • Reverse of melting is annealing: two
complementary single strands of DNA coming together - occurs 10-20 degrees below Tm.
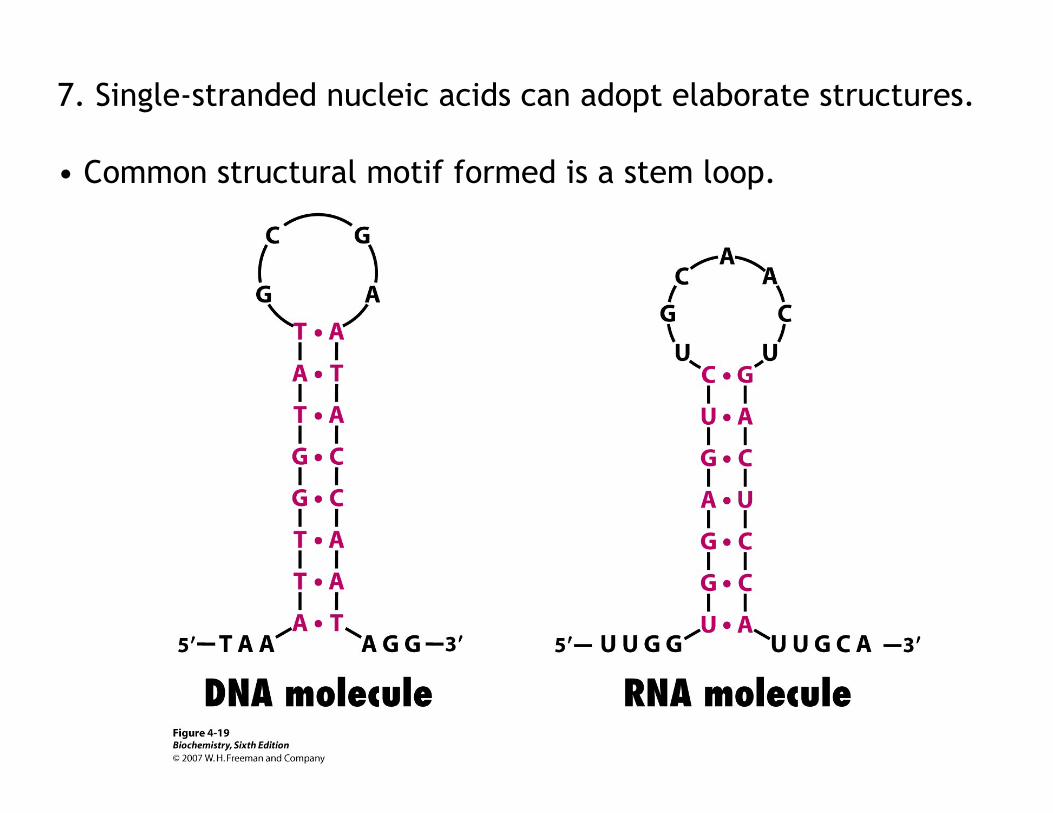
7. Single-stranded nucleic acids can adopt elaborate structures.
• Common structural motif formed is a stem loop.

D. Replication of DNA
Replication of DNA is catalyzed by enzymes called DNA polymerases. • Example: DNA Polymerase I (E.coli; A. Kornberg, 1956)
DNA polymerases catalyze the addition of deoxyribonucleotides to 3’ end of an elongating DNA chain (one at a time)
(DNA)n residues+dNTP ↔ (DNA)n+1 residues+PPi

Requirements for polymerization 1. all four deoxyribonucleotides and Mg++
2. template DNA strand-to be used for synthesis of new complementary strand 3. primer DNA strand – with free 3’ OH group for addition of dNTP’s
Enzyme mechanism involves nucleophilic attack of 3’OH group of the primer on alpha phosphate of the incoming nucleotide (triphosphate). Therefore, polymerization of DNA proceeds in 5’ to 3’ direction.
Reaction direction
Fast!
complementary
5’
3’

Genetic information is mostly carried by DNA.
Exceptions: (1) RNA virus (eg. Influenza): RNA to RNA (replicase) to Protein (2) Retrovirus (eg. HIV):
Integrated into host cell’s chromosomal DNA

E. Gene expression/Transcription (transformation of DNA information into functional molecules=RNA)
RNA carries information for protein synthesis. RNA is synthesized in a sequence specific manner from DNA.
- Three different major forms of RNA exist in all cells
Other RNAs: • micro RNA - inhibit protein synthesis • small interfering RNA - degrade mRNA • small nuclear RNA - splicing
Protein synthesis
Genetic information

RNA polymerase – enzyme that catalyzes the formation of an RNA strand complementary to a DNA template.
(RNA)n residues+ribonucleoside triphosphate (RNA)n+1 residues+PPi
(no repair function)
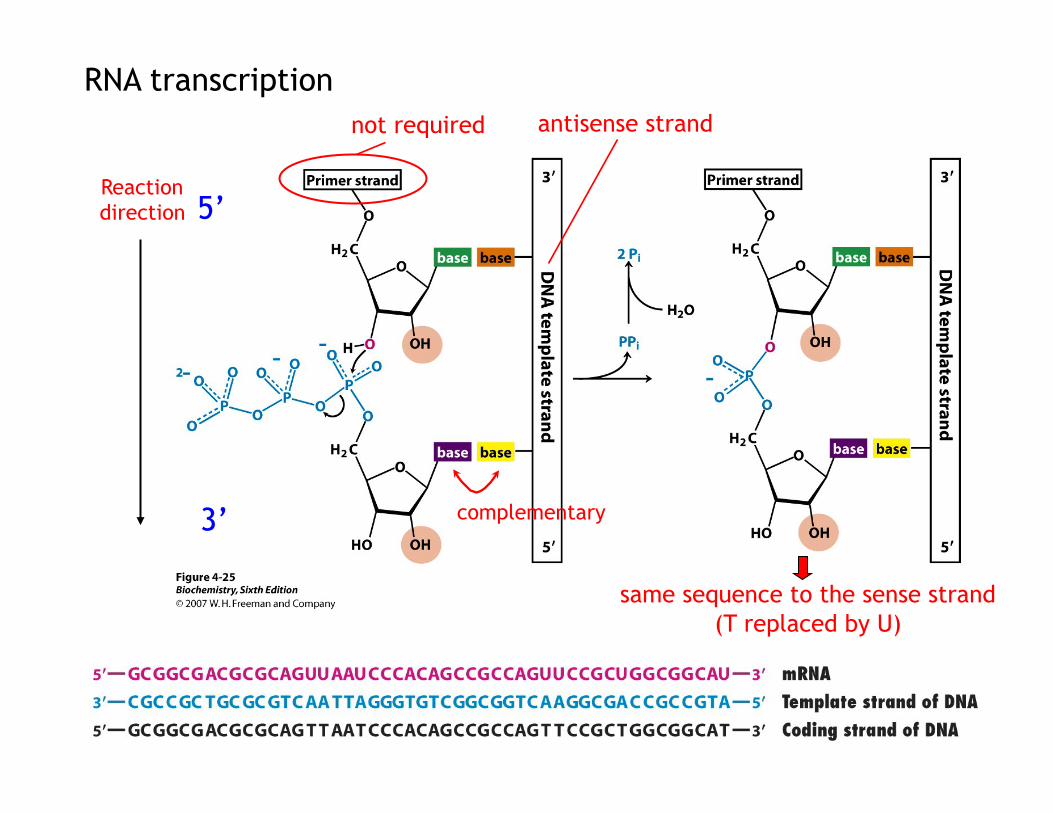
RNA transcription
Reaction direction
complementary
not required antisense strand
same sequence to the sense strand (T replaced by U)
5’
3’

• Promoter sequences specific for the start of transcription
~2000 promoters in E.coli genome Sigma(σ) subunit specific initiation
i. decreases affinity of the enzyme for DNA in non-promoter sites ii. reads DNA sequence – find specific promoter sequences
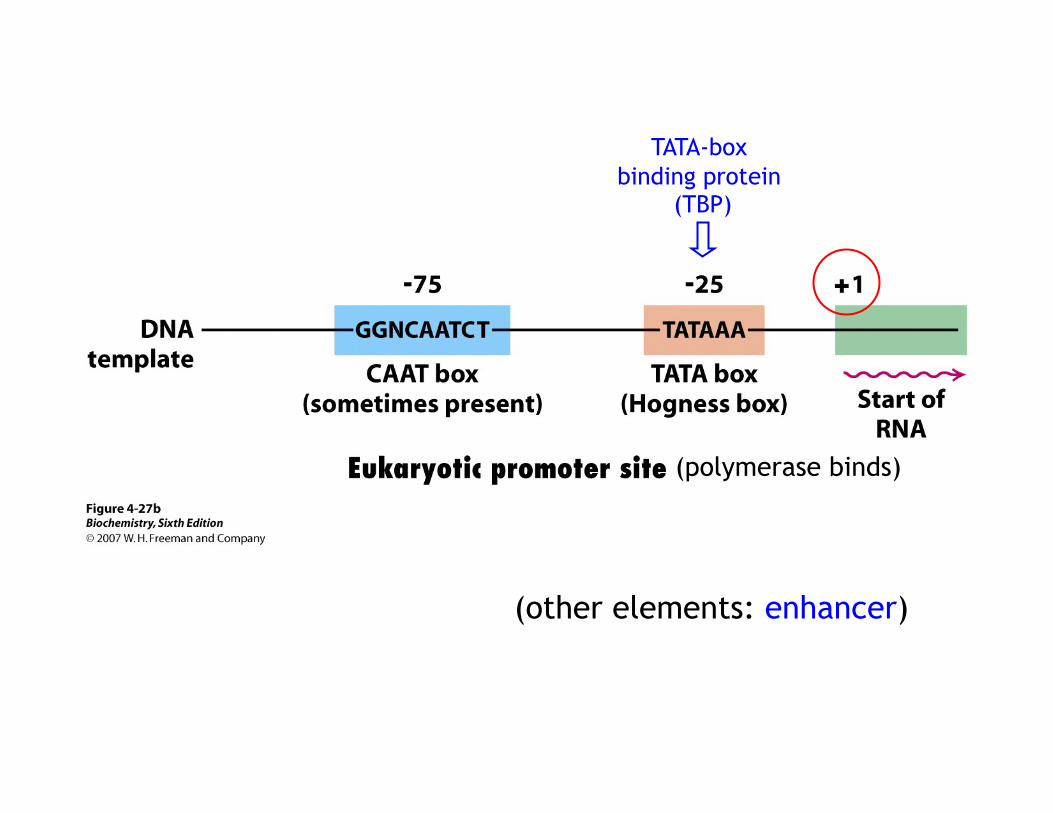
(other elements: enhancer)
(polymerase binds)
TATA-box binding protein
(TBP)

In eukaryotes, the mRNA is modified right after transcription.
• A cap structure (methylguanylate) is attached at the 5’ end (important for protein synthesis).
• A sequence of adenylates (poly A tail) is added to the 3’-end.

• Most eukaryotic mRNAs are spliced to remove introns.
Most eukaryotic genes are mosaics of introns and exons. The coding sequences (exons) are interrupted by non-coding sequences (introns).

G. Protein translation involves all three types of RNA
(i) tRNA (ii) rRNA: ribosome
(iii) mRNA: genetic information

Translation start sites
(formyl-methionine)

AGCTAG
• Protein translation is the process of decoding the nucleotide sequence of mRNA into amino acid sequence of proteins.
1. Breaking the genetic code:
How many nucleotides is a codon? - must code for all twenty amino acids with the combination of 4 nucleotides. 41=4, 42=16, 43=64
2. Features of the genetic code
Three nucleotides encode an amino acid The code is non-overlapping The code has no punctuations The code is degenerate – most amino acids are encoded by more
than one codon (first two nucleotides are usually same) The genetic code is nearly universal
