chakrabarti alpha go analysis
TRANSCRIPT

AlphaGo Analysis from Deep Learning Perspec6ve
Chayan Chakrabar6 July 11, 2016 Pleasanton, CA

Mastering the game of GO
• DeepMind problem domain • Deep learning and reinforcement learning concepts
• Design of AlphaGo • Execu6on

GO: perfect informa6on game
All possible GO boards = 250150 > Number of atoms in the universe

Reduce search space
• Reduce breadth – Not all moves are equally likely – Some moves are bePer – Leverage moves made by expert players
• Reduce depth – Evaluate strength of board (likelihood of winning) – Collapse symmetrical or similar boards – Simulate the games

Monte Carlo tree search
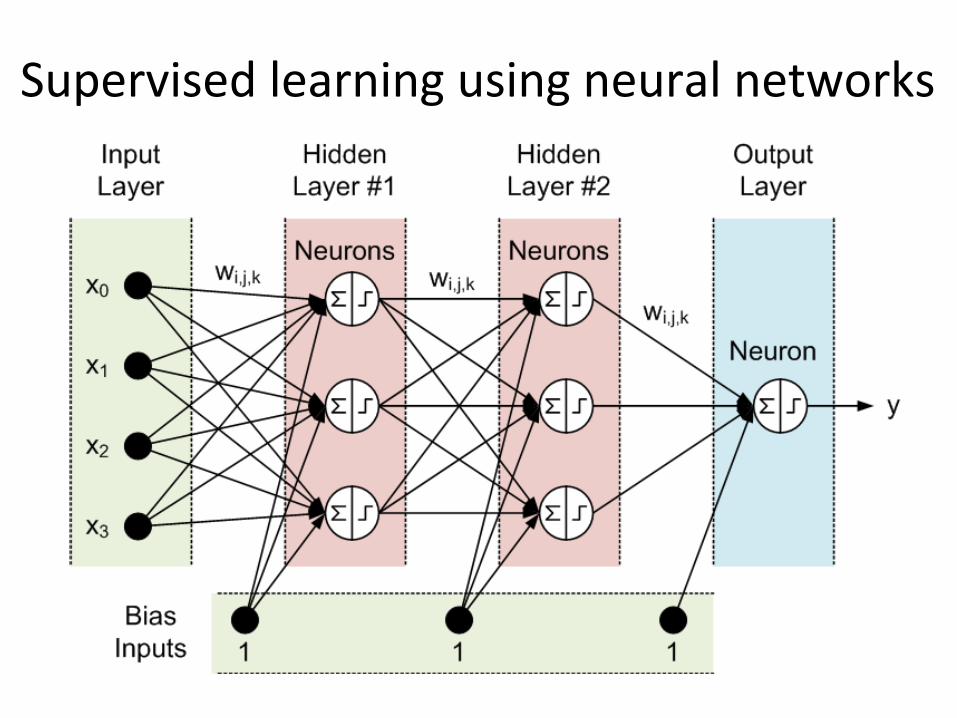
Supervised learning using neural networks
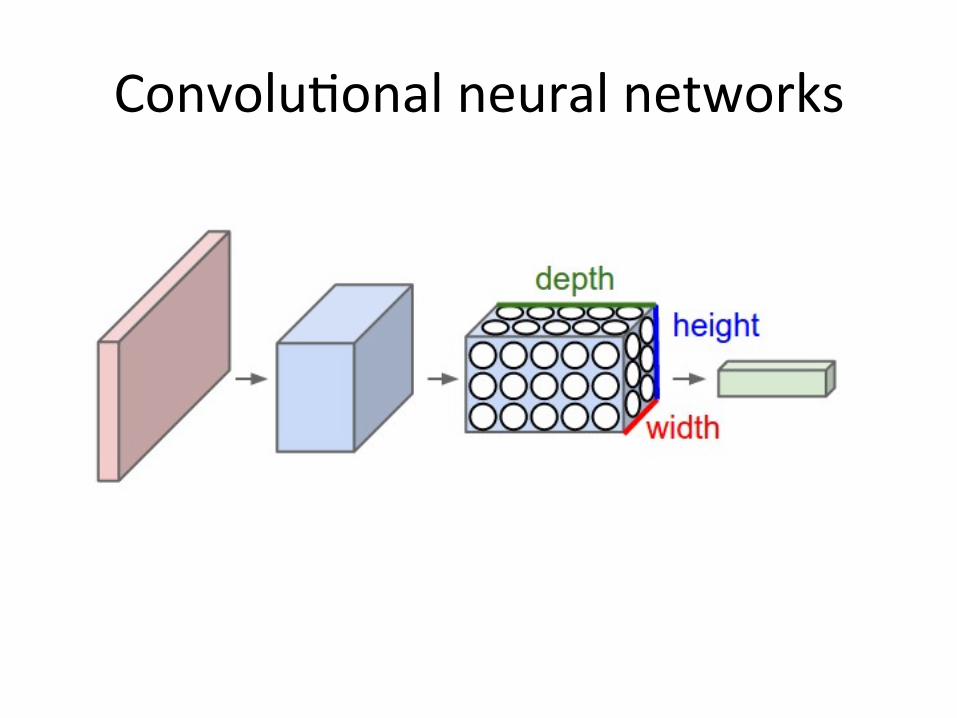
Convolu6onal neural networks

Encode local or spa6al features

Reinforcement learning Reinforcement"Learning""
State:" St
Reward"(Feedback):"Rt
AcIon:"At
• Feedback"is"delayed."• No"supervisor,"only"a"reward"signal."• Rules"of"the"game"are"unknown."• Agent’s"acIons"affect"the"subsequent"state"
Agent"Environment"
40"

Determinis6c policy

Stochas6c policy

Value: expected long term reward

Monte Carlo tree search combined with deep neural networks AlphaGo
neural networks
normal MCTS
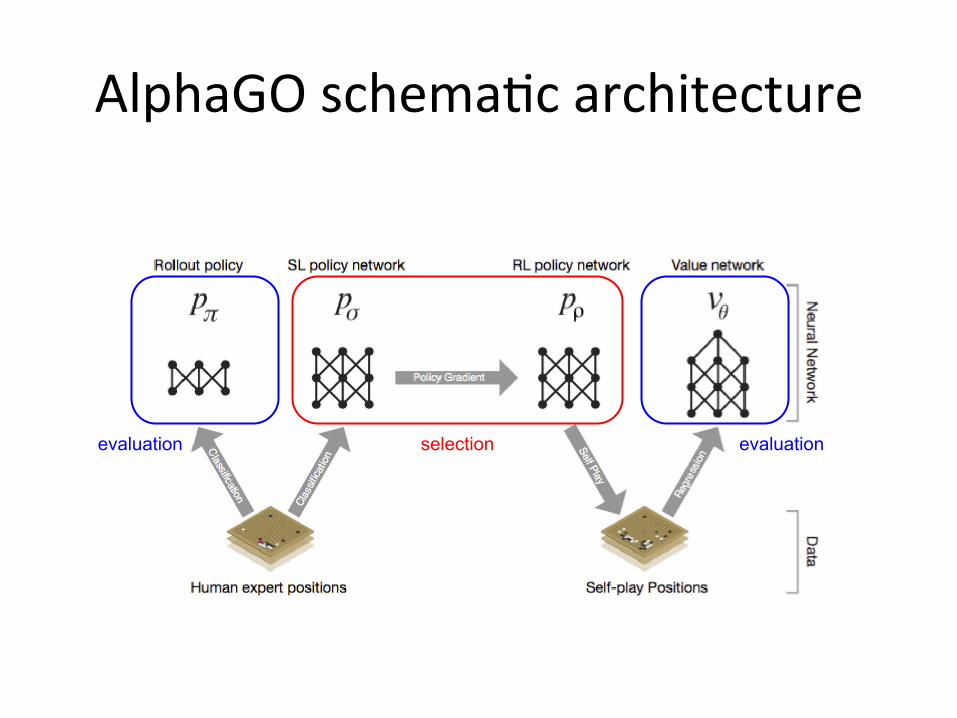
AlphaGO schema6c architecture
AlphaGo neural networks
selectionevaluation evaluation

Reducing breadth of moves

Predic6ng the move 1.*Reducing*“action*candidates”
(1) Imitating+expert+moves+(supervised+learning)
Expert$Moves$Imitator$Model(w/$CNN)
Current$Board Next$Action
Training:
1.*Reducing*“action*candidates”
(1) Imitating+expert+moves+(supervised+learning)
Expert$Moves$Imitator$Model(w/$CNN)
Current$Board Next$Action
Training:
1.*Reducing*“action*candidates”
(1) Imitating+expert+moves+(supervised+learning)
Prediction$Model
0 0+ 0 0 0+ 0 0 0 00 0+ 0 0 0 1 0 0 00 H1 0 0 1 H1 1 0 00 1 0 0 1 H1 0 0 00 0+ 0 0 H1 0 0 0 00 0+ 0 0 0+ 0 0 0 00 H1 0 0 0+ 0 0 0 00 0+ 0 0 0+ 0 0 0 0
0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 00 0 0 0 0 1 0 0 00 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0
s g:$s! p(a|s) p(a|s) aargmax
Current$Board Next$Action
1.*Reducing*“action*candidates”
(1) Imitating+expert+moves+(supervised+learning)
Expert$Moves$Imitator$Model(w/$CNN)
Current$Board Next$Action
Training:

Two kinds of policies
● used a large database of online expert games
● learned two versions of the neural network
○ a fast network Pᶢ for use in evaluation
○ an accurate network Pᶥ for use in selection
Step 1: learn to predict human movesCS63 topic
neural networksweek 7, 14?

Further reduce search space Symmetries"
62"
Input"RotaIon""90"degrees"
RotaIon""180"degrees"
RotaIon""270"degrees"
VerIcal"reflecIon"
VerIcal"reflecIon"
VerIcal"reflecIon"
VerIcal"reflecIon"
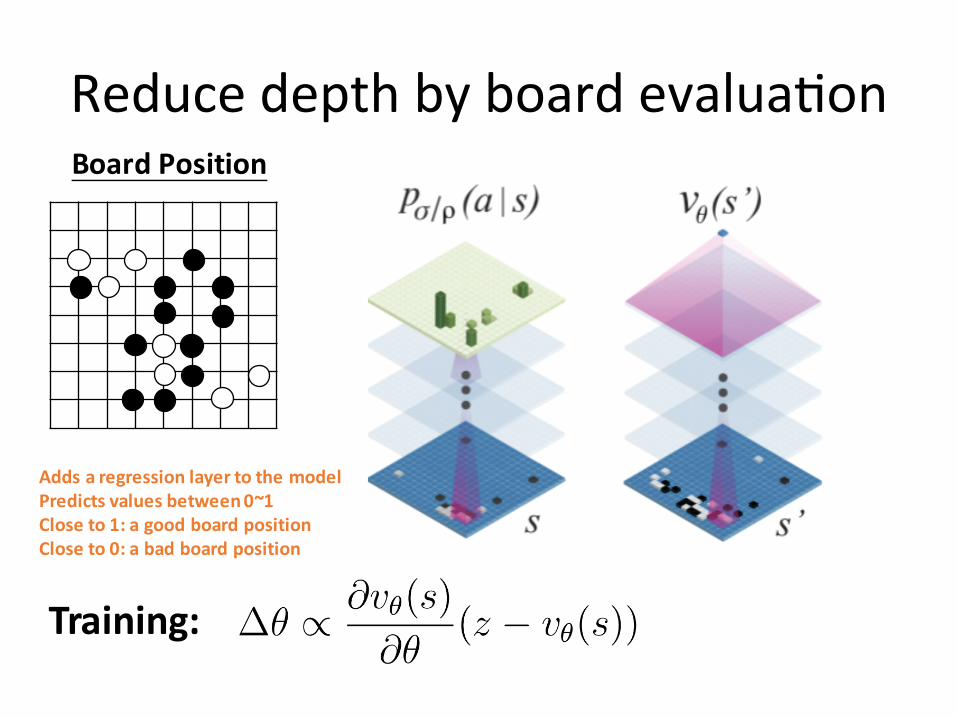
Reduce depth by board evalua6on
2.*Board*Evaluation
Updated$Modelver 1,000,000
Board$Position
Training:
Win$/$Loss
Win(0~1)
Value$Prediction$Model
(Regression)
Adds$a regression$layer$to$the$modelPredicts$values$between$0~1Close$to$1:$a$good$board$positionClose$to$0:$a$bad$board$position
2.*Board*Evaluation
Updated$Modelver 1,000,000
Board$Position
Training:
Win$/$Loss
Win(0~1)
Value$Prediction$Model
(Regression)
Adds$a regression$layer$to$the$modelPredicts$values$between$0~1Close$to$1:$a$good$board$positionClose$to$0:$a$bad$board$position2.*Board*Evaluation
Updated$Modelver 1,000,000
Board$Position
Training:
Win$/$Loss
Win(0~1)
Value$Prediction$Model
(Regression)
Adds$a regression$layer$to$the$modelPredicts$values$between$0~1Close$to$1:$a$good$board$positionClose$to$0:$a$bad$board$position
2.*Board*Evaluation
Updated$Modelver 1,000,000
Board$Position
Training:
Win$/$Loss
Win(0~1)
Value$Prediction$Model
(Regression)
Adds$a regression$layer$to$the$modelPredicts$values$between$0~1Close$to$1:$a$good$board$positionClose$to$0:$a$bad$board$position

Value follows from policy Step 3: learn a board evaluation network, Vᶚ
● use random samples from the self-play database
● prediction target: probability that black wins from a given board

PuWng it all together Looking*ahead*(w/*Monte*Carlo*Search*Tree)
Action$Candidates$Reduction(Policy$Network)
Board$Evaluation(Value$Network)
(Rollout):$Faster$version$of$estimating$p(a|s)! uses shallow$networks$(3$ms! 2µs)

Selec6on

Expansion Expansion"
s
a
s0
Insert"the"node"for"the"successor"state""""".""s0
1"
2"
Nv(s0, a0) = Nr(s
0, a0) = 0
Wr(s0, a0) = Wv(s
0, a0) = 0
P (s0, a0) = p�(a0|s0)
p�(a0|s0)
If"visit"count"exceed"a"threshold":""""""","Nr(s, a) > nthr
a0 a0
For"every"possible"""""","iniIalize"the"staIsIcs:""""
a0
75"

Evalua6on EvaluaIon"
p⇡
1"
2" Simulate"the"acIon"by""rollout"policy"network""""""""."p⇡
Evaluate""""""""""""""by"value"network""""""."v✓(s0) v✓
r(sT )
v✓(s0) When"reaching"terminal""""""",""
calculate"the"reward""""""""""""".""sT
r(sT )
76"
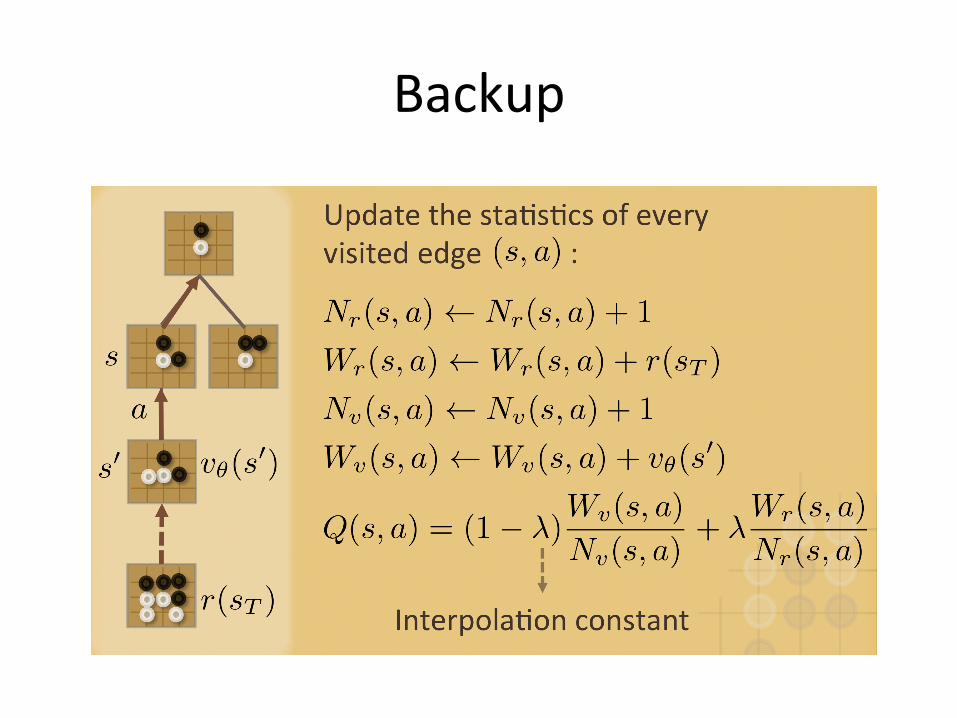
Backup

Distribute search through GPUs Distributed"Search""
p⇡
r(sT )
v✓(s0)
p�(a0|s0)
Main"search"tree"Master"CPU"
Policy"&"value"networks"176"GPUs"
Rollout"policy"networks"1,202"CPUs""
78"

Apply trained networks to tasks with different loss func6on Takeaways
Use+the+networks+trained+for+a+certain+task+(with+different+loss+objectives)+for+several+other+tasks

Single most important takeaway
• Feature abstrac6on is the key component of any machine learning algorithm
• Convolu6onal neural networks are great at automated feature abstrac6on

Reference
Silver et. al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature. 529, 484–489. January 2016.

About the speaker
Chayan Chakrabar6 hPps://www.linkedin.com/in/chayanchakrabar6