c3: cutting tail latency in cloud data stores via … association 12th usenix symposium on networked...
TRANSCRIPT

This paper is included in the Proceedings of the 12th USENIX Symposium on Networked Systems
Design and Implementation (NSDI ’15).May 4–6, 2015 • Oakland, CA, USA
ISBN 978-1-931971-218
Open Access to the Proceedings of the 12th USENIX Symposium on
Networked Systems Design and Implementation (NSDI ’15)
is sponsored by USENIX
C3: Cutting Tail Latency in Cloud Data Stores via Adaptive Replica Selection
Lalith Suresh, Technische Universität Berlin; Marco Canini, Université catholique de Louvain; Stefan Schmid, Technische Universität Berlin and Telekom Innovation Labs;
Anja Feldmann, Technische Universität Berlin
https://www.usenix.org/conference/nsdi15/technical-sessions/presentation/suresh

USENIX Association 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) 513
C3: Cutting Tail Latency in Cloud Data Stores via Adaptive Replica Selection
Lalith Suresh† Marco Canini� Stefan Schmid†‡ Anja Feldmann†
†TU Berlin �Universite catholique de Louvain ‡Telekom Innovation Labs
AbstractAchieving predictable performance is critical for
many distributed applications, yet difficult to achieve dueto many factors that skew the tail of the latency distribu-tion even in well-provisioned systems. In this paper, wepresent the fundamental challenges involved in design-ing a replica selection scheme that is robust in the faceof performance fluctuations across servers. We illustratethese challenges through performance evaluations of theCassandra distributed database on Amazon EC2. Wethen present the design and implementation of an adap-tive replica selection mechanism, C3, that is robust toperformance variability in the environment. We demon-strate C3’s effectiveness in reducing the latency tail andimproving throughput through extensive evaluations onAmazon EC2 and through simulations. Our results showthat C3 significantly improves the latencies along themean, median, and tail (up to 3 times improvement at the99.9th percentile) and provides higher system through-put.
1 IntroductionThe interactive nature of modern web applications ne-cessitates low and predictable latencies because peoplenaturally prefer fluid response times [20], whereas de-graded user experience directly impacts revenue [11,43].However, it is challenging to deliver consistent low la-tency — in particular, to keep the tail of the latency dis-tribution low [16, 23, 48]. Since interactive web applica-tions are typically structured as multi-tiered, large-scaledistributed systems, even serving a single end-user re-quest (e.g., to return a web page) may involve contactingtens or hundreds of servers [17,23]. Significant delays atany of these servers inflate the latency observed by endusers. Furthermore, even temporary latency spikes fromindividual nodes may ultimately dominate end-to-end la-tencies [2]. Finally, the increasing adoption of commer-
cial clouds to deliver applications further exacerbates theresponse time unpredictability since, in these environ-ments, applications almost unavoidably experience per-formance interference due to contention for shared re-sources (like CPU, memory, and I/O) [26, 50, 52].
Several studies [16, 23, 50] indicate that latency distri-butions in Internet-scale systems exhibit long-tail behav-iors. That is, the 99.9th percentile latency can be morethan an order of magnitude higher than the median la-tency. Recent efforts [2, 16, 19, 23, 36, 44, 53] have thusproposed approaches to reduce tail latencies and lowerthe impact of skewed performance. These approachesrely on standard techniques including giving preferentialresource allocations or guarantees, reissuing requests,trading off completeness for latency, and creating per-formance models to predict stragglers in the system.
A recurring pattern to reducing tail latency is to ex-ploit the redundancy built into each tier of the applica-tion architecture. In this paper, we show that the prob-lem of replica selection — wherein a client node has tomake a choice about selecting one out of multiple replicaservers to serve a request — is a first-order concern inthis context. Interestingly, we find that the impact of thereplica selection algorithm has often been overlooked.We argue that layering approaches like request duplica-tion and reissues atop a poorly performing replica selec-tion algorithm should be cause for concern. For example,reissuing requests but selecting poorly-performing nodesto process them increases system utilization [48] in ex-change for limited benefits.
As we show in Section 2, the replica selection strat-egy has a direct effect on the tail of the latency distribu-tion. This is particularly so in the context of data storesthat rely on replication and partitioning for scalability,such as key-value stores. The performance of these sys-tems is influenced by many sources of variability [16,28]

514 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) USENIX Association
and running such systems in cloud environments, whereutilization should be high and environmental uncertaintyis a fact of life, further aggravates performance fluctua-tions [26].
Replica selection can compensate for these condi-tions by preferring faster replica servers whenever pos-sible. However, this is made challenging by the factthat servers exhibit performance fluctuations over time.Hence, replica selection needs to quickly adapt to chang-ing system dynamics. On the other hand, any reactivescheme in this context must avoid entering pathologi-cal behaviors that lead to load imbalance among nodesand oscillating instabilities. In addition, replica selectionshould not be computationally costly, nor require signif-icant coordination overheads.
In this paper, we present C3, an adaptive replica se-lection mechanism that is robust in the face of fluctua-tions in system performance. At the core of C3’s design,two key concepts allow it to reduce tail latencies andhence improve performance predictability. First, usingsimple and inexpensive feedback from servers, clientsmake use of a replica ranking function to prefer fasterservers and compensate for slower service times, allwhile ensuring that the system does not enter herd be-haviors or load-oscillations. Second, in C3, clients im-plement a distributed rate control mechanism to ensurethat, even at high fan-ins, clients do not overwhelm in-dividual servers. The combination of these mechanismsenable C3 to reduce queuing delays at servers while thesystem remains reactive to variations in service times.
Our study applies to any low-latency data storewherein replica diversity is available, such as a key-valuestore. We hence base our study on the widely-used [15]Cassandra distributed database [5], which is designed tostore and serve larger-than-memory datasets. Cassandrapowers a variety of applications at large web sites such asNetflix and eBay [6]. Compared to other related systems(Table 1), Cassandra implements a more sophisticatedload-based replica selection mechanism as well, and isthus a better reference point for our study. However, C3is applicable to other systems and environments that needto exploit replica diversity in the face of performancevariability, such as a typical multi-tiered application orother data stores such as MongoDB or Riak.
In summary, we make the following contributions:1. Through performance evaluations on Amazon EC2,
we expose the fundamental challenges involved inmanaging tail latencies in the face of service-timevariability (§2).
2. We develop an adaptive replica selection mecha-nism, C3, that reduces the latency tail in the pres-
Cassandra Dynamic Snitching: considers history ofread latencies and I/O load
OpenStack Swift Read from a single node andretry in case of failures
MongoDB Optionally select nearest node by networklatency (does not include CPU or I/O load)
Riak Recommendation is to use an externalload balancer such as Nginx [38]
Table 1: Replica selection mechanisms in popular NoSQLsolutions. Only Cassandra employs a form of adaptivereplica selection (§2.3).
ence of service-time fluctuations in the system. C3does not make use of request reissues, and only re-lies on minimal and approximate information ex-change between clients and servers (§3).
3. We implement C3 (§4) in the Cassandra distributeddatabase and evaluate it through experiments con-ducted on Amazon EC2 (for accuracy) (§5) and sim-ulations (for scale) (§6). We demonstrate that oursolution improves Cassandra’s latency profile alongthe mean, median, and the tail (by up to a factorof 3 at the 99.9th percentile) whilst improving readthroughput by up to 50%.
2 The Challenge of Replica SelectionIn this section, we first discuss the problem of time-varying performance variability in the context of cloudenvironments. We then underline the need for load-basedreplica selection schemes and the challenges associatedwith designing them.
2.1 Performance fluctuations are the normServers in cloud environments routinely experience per-formance fluctuations due to a multitude of reasons. Cit-ing experiences at Google, Dean and Barroso [16] listmany sources of latency variability that occur in prac-tice. Their list includes, but is not limited to, contentionfor shared resources within different parts of and be-tween applications (further discussed in [26]), periodicgarbage collection, maintenance activities (such as logcompaction), and background daemons performing peri-odic tasks [40]. Recently, an experimental study of re-sponse times on Amazon EC2 [50] illustrated that longtails in latency distribution can also be exacerbated byvirtualization. A study [23] of interactive services at Mi-crosoft Bing found that over 30% of analyzed serviceshave 95th percentile of latency 3 times their median la-tency. Their analysis showed that a major cause for thehigh service performance variability is that latency variesgreatly across machines and time. Lastly, a commonworkflow involves accessing large volumes of data froma data store to serve as inputs for batch jobs on large-
2

USENIX Association 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) 515
Server A
Server B
Client
Client
Client
Request Queue
1/μ = 4ms
1/μ = 10ms
LOR strategy(Max Latency = 60ms)
Server A
Server B
Client
Client
Client
Request Queue
1/μ = 4ms
1/μ = 10ms
Ideal allocation(Max Latency = 32ms)
Figure 1: Left: how the least-outstanding requests (LOR)strategy allocates a burst of requests across two serverswhen executed individually by each client. Right: An idealallocation that compensates for higher services time withlower queue lengths.
scale computing platforms such as Hadoop, and inject-ing results back into the data store [45]. These workloadscan introduce latency spikes at the data store and furtherimpact on end-user delays.
As part of our study, we spoke with engineers at Spo-tify and SoundCloud, two companies that use and oper-ate large Cassandra clusters in production. Our discus-sions further confirmed that all of the above mentionedcauses of performance variability are true pain points.Even in well provisioned clusters, unpredictable eventssuch as garbage collection on individual hosts can leadto latency spikes. Furthermore, Cassandra nodes period-ically perform compaction, wherein a node merges mul-tiple SSTables [5, 13] (the on-disk representation of thestored data) to minimize the number of SSTable files tobe consulted per-read, as well as to reclaim space. Thisleads to significantly increased I/O activity.
Given the presence of time-varying performance fluc-tuations, many of which can potentially occur even atsub-second timescales [16], it is important that systemsgracefully adapt to changing conditions. By exploit-ing server redundancy in the system, we investigate howreplica selection effectively reduces the tail latency.
2.2 Load-based replica selection is hardAccommodating time-varying performance fluctuationsacross nodes in the system necessitates a replica selec-tion strategy that takes into account the load across dif-ferent servers in the system. A strategy commonly em-ployed by many systems is the least-outstanding requestsstrategy (LOR). For each request, the client selects theserver to which it has the least number of outstanding re-quests. This technique is simple to implement and doesnot require global system information, which may notbe available or is difficult to obtain in a scalable fash-ion. In fact, this is commonly used in load-balancing ap-plications such as Nginx [34] (recommended as a load-balancer for Riak [38]) or Amazon ELB [3].
However, we observe that this technique is not ideal
for reducing the latency tail, especially since many realis-tic workloads are skewed in practice and access patternschange over time [9]. Consider the system in Figure 1,with two replica servers that at a particular point in timehave service times of 4 ms and 10 ms respectively. As-sume all three clients receive a burst of 4 requests each.Each request needs to be forwarded to a single server.Based on purely local information, if every client selectsa server using the LOR strategy, it will result in eachserver receiving an equal share of requests. This leadsto a maximum latency of 60 ms, whereas an ideal allo-cation in this case obtains a maximum latency of 32 ms.We note that LOR over time will prefer faster servers, butby virtue of purely relying on local information, it doesnot account for the existence of other clients with poten-tially bursty workloads and skewed access patterns, anddoes not explicitly adapt to fast-changing service times.
Designing distributed, adaptive and stable load-sensitive replica selection techniques is challenging. Ifnot carefully designed, these techniques can suffer from“herd behavior” [32,39]. Herd behavior leads to load os-cillations, wherein multiple clients are coaxed to directrequests towards the least-loaded server, degrading theserver’s performance, which subsequently causes clientsto repeat the same procedure with a different server.
Indeed, looking at the landscape of popular data stores(Table 1), we find that most systems only implementvery simple schemes that have little or no ability to re-act quickly to service-time variations nor distribute re-quests in a load-sensitive fashion. Among the systemswe studied, Cassandra implements a more sophisticatedstrategy called Dynamic Snitching that attempts to makereplica selection decisions informed by histories of readlatencies and I/O loads. However, through performanceanalysis of Cassandra, we find that this technique suffersfrom several weaknesses, which we discuss next.
2.3 Dynamic Snitching’s weaknessesCassandra servers organize themselves into a one-hopdistributed hash table. A client can contact any serverfor a read request. This server then acts as a coordinator,and internally fetches the record from the node hostingthe data. Coordinators select the best replica for a givenrequest using Dynamic Snitching. With Dynamic Snitch-ing, every Cassandra server ranks and prefers faster repli-cas by factoring in read latencies to each of its peers, aswell as I/O load information that each server shares withthe cluster through a gossip protocol.
Given that Dynamic Snitching is load-based, we eval-uate it to characterize how it manages tail-latencies andif it is subject to entering load-oscillations. Indeed, ourexperiments on Amazon EC2 with a 15-node Cassandra
3

516 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) USENIX Association
���
�
�
�
�
��
�
�
���
�
�
�
���
����
�
������
�
��
���
���
�
�����
�
�
�
��
�
��
�
�
�
�
�
�
�
�
��
�����
�
�
���
�
�
��
�
�
�
�
�
�
�
��
�
�
��
�
����
�
�
�
�
�
�
�
�
�
�
��
�
����
�
�
�
�
�
�
��
�
�
�
���
�
�
�
�
��
�
��
���
��
�
�
�
�
����
�
��
�����
�
�
�
�
��
�
�
��
�
�
�
��
�
�
�
�
���
�
���
�
�
�
��
�
�
�
�
�
�
���
�
�
�
�
���
�
�
�
�
���
���
�
�
��
�
�
�
�����
�
�
��
�
����
�
�
��
�
�
��
�
�
��
�
�
�
�
�
�
�
����
�
��
�
�
�
�
��
���
����
�
�
�
��
�
�
�
�
�
�
��
�
���
�
�
����
�
�
��
�
��
�
����
�
��
�
�
�
�
�
�
��
�
���
�
�
�
�
�
��
�
�
��
�
�
����
�
�
��
�
�
�
���
��
�
�
�
����
�
�
�
�
��
��
��
�
��
��
�
��
�
�
�
�
��
�
��
�
���
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
��
�
�
���
���
��
��
�
�
�
�
�
��
�
�
�
�
�
����
�
�
�
�
�
����
�
�
�
���
�
�
�
�
�
�
�
��
�
�
��
��
�
�
��
�
��
��
��
�
�
�
�
����
�
�
��
��
����
�
��
�
�
�
�
�
��
�
�
�
�
��
��
�
����
�
�
�
�
�
�
��
�
��
�
�
�
����
�
�
�
�������
�
�
�
�
��
�
�
��
��
�
�
��
�
�
��
�
�
�
��
�
��
�
��
�
���
���
���
���
��
������
�
��
�
�
��
��
�
�
�
�
���
�
���
��
��
�
�
����
�
�
����
��
�
�
��
�
��
�
�
�
���
�
�
�
���
�
�
�������
�������
�
��
��
���
��
�
�
��
�
���
�
�
�
�
�
����
�
�
�
�
��
�����
�
�
�
�
�
�
��
��
��
�
��
�
��
����
�
�
�
�
�
�
�
��
�
�
�
�
�
�
��
��
�
���
�
�
�
�
�
�����
�
��
�
�
�
��
��
�
�
�
�
�
�
�
�
�
�
�
���
�����
�
��
�
��
��
���
����
�
�
����
�
�
�
��
��
��
�
�
�
�
��
����
�����
�
�
�
���
��
�
�
���
�
����
�
�
��������
�
���
�
�
�
�
�
�
�
�
�
�
��
���
��
�
�
�
��
�
��
�
�
����
���
��
�
�
����
��
�
�
��
�
�
�
�
�
�
�
������
�
�
��
�
�
��
��
��
�
��
����
�
�
�
�
���
�
�
�
��
�
�
���
��
�
�
��
�
�
�
�
�
�
�����
�
�
����
���
�
�
�
�
�
���
���
���
�
�
���
���������
�
�
�
����
��
�����������
��
��
��
��������
����
�
���
�
����
�
�
�
��
�����
�
��
��
���
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�����
�
���
��
��
��
����
�
��
�
�
�
�
����
�
���
��
�
�
�
�
�
�
��
�
�
�
���
�
�
�
�
�
�
�
�
�
��
��
�
��
�
����
�
�
��
��
�
�
�
�
��
�
�
��
�
��
�
�
����
���
�
���
�
��
��
���
���
��
�
�
�
��
�
��
��
���
�
��
��
�
�
�
�
�
�
�
�
�
���
�
�
��������
��
���
��
�
����
�����
��
�
�
�
�
���
�
�
�
������������
��
�
�
�
�
�
�
�
��
�
�
�
�
��
�
�
������
�
�
�
��
�
�
��
�
�
���
��
���
���
�
��
�
�
�
�
�
�
�
������
�
�
���
���
�
�
�
�
�
�
��
�
�
��
��
���
����
�
�
�
�
�
�
���
�
�
����
����
����
�
���
�
�
�
�
���
�
�
�
�
��
�
�����
�
�
��
�
�
�
�
��
��
�
�
�
�
�
����
�
�����
��
�
�
�
���
�
��
�
�
��
�
��
�
�
�
�
�
�
�
�
�
��
��
�
�
�
��
�
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
��
�
�
�
�
�
��
�
�
�
�
�
�
��
��
�
�
��
�
�
�
�
�
�
�
��
�
�
�
��
���
��
����
�
�
�
�
�
���
�
�
�
�
�
���
�
�
�����
��
�
�
�
��
�
�
�
�
�
�
��
����
����
����
�
����
���
�
�
�
�
��
�
�
�
���
�
�
�
�
��
��
��
�����
��
���
������
�
��
�
��
�
��
�
�
�
��
�
��
�
�
�
�
��
��
�
��
����
��
���
�
��
��
�
���
�
��
��
�
�
��
��
��
����
�
�
�
��
�
�
�
�
�
�
���
��
�
���
��
����
�
��
�
�
��
��
�
��
��
��
���
�
�
�
��
��
�
�
�
�
�
�
�
���
�
�
�
�
�
�
��
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
����
���
�
�
��
�
��
��
�
�
���
��
��
�
�
��
�
�
�
�
����
�
�
��
�
�
�
�
�
�
�
�
�
�
��
�
�
��
���
�
�
�
�
�
�����
�
���
����
�
��
�
�
�����
�
��
��
�
�
��
�
��
�
�
���
�
�
�
�
���
�
�
�
���
�
����
�
��
����
��
�
����
��
�
�
��
�
��
�
������
�
�
�
���
�
�
�
�
�
�
��
��
�
�����
����
�
��
�
��
�
����
��
�
�������
�
�
�
�
���
������
�
�
�
�
�
�
��
�
�
���
��
�
��
����
��
�
�
�
�
�
�
�
��
���
��
�
�
�
�
��
�
����
������
�
�
�
�
�
�
����
�
�
���
�
�
�
�
�
�
���
�
�
�������
�������
��
��
������
�
�
���
��
�
�
��
�
�
���
��
�
�
���
�
�
��
��
��
��
�
��
�
�
�
�
��
��
��
�
�
�
���
�
��
�
�
��
�
����
��
��
�
�����
��
�
�
��������
�
�
�
��
�
���
�
�
���
�
��
���
�
�
�
�
�
�
��
�
���
��
�
����
���
�
�
�
�
�
����
�
�
��
�
���
�
�
�
�
�
��
�
�
�
�
��
��
�
������
������
�
�
���
������
�
�
�
�
�
�
�
���
���
�
��
�
��
�
�
�
�
�
���
�
�
�����
�
���
��
�
�
�
����
�
�
�
�
�
��
�
���
��
��
���
�
�
��
�
�
��
�
�
�
��
����
�
���
��
���
�
�
�
�
�
�
����
����
��
�
�
�
��
��
�
�
���
�
�
�
�
��
��
��
�
���
�
��
�
���
�
�
����������
�
�
�
�
��
�
����
��
�
�
�
����
�
�
��
�
���
����
���
�
�
��
�
�
��
�
�
������
�
��
�
��
�
��
��
����
�
�����
���
�
�
�
�
�
����
�
�
�
�����
�
�
�
��
�
���
��
��������
�
��
�
�
�
����
���
�
��
�
��
�
�
����
������
�
�
�
����
�
�
��
�
�
�
�
����
�
�
�
��
�
�
�����
��
�
�
�
�
�
��
�
���
�
��
�
�
���
�
�
�����
�
��
����
�
�
��
�����
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
��
��
�
���
�
�
��
�
��
��
�
����
�
���
���
�
�
����
�
�
��
�
���
��
�
��
�
�
��
�
�
��
�
�
�
���
���
�
��
���
�
�����
���
��
��
�
�
��
��
�
��
�
�
�
����
��
���
�
��
���
�
�
�
�
��
�
�
�
�
�
������
����
��
�
��
��
��
�
��
����
�
����
�
�
�
���
�
�
�
�
�
�
����
�
���
�
�
����
��
�
�
�
�
�
�
���
�
��
�
�
�
�
�
�
�
�
��
���
��
�
������
�
��
�
�
���
���
�
��
�
�
����
�
����
�
��
�
�
�
�
�
��
�
�����
��
�
��
�
��
��
���
���
��
����
���
�
�
���
�
�
�
��
�
�
�
�
�
�
�
��
�
�
�
��
�
���
�
�
��
����
��
����
�
�
�
�
�����
�
�
��
����
�
�
����
�
�
�
�
�
��
�
�
�
�
��
�����
���
�
���
�
�
�
�
��
�
��
�
�
��
�
�
�
�
�
�
�
���
�
�
��
�
�
��
�
����
�
�����
�
��
�
���
�
��
�
�
���
�
�
��
��
�
�
���
����
�
��
�
�
���
����
�
�
�
��
��
�����
�
�
��
��
��
�
��
���
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
���
�
�
�
�
�
�
�
�
�
�
�
����
�
�
�
��
�
�
�
�
�
�
��
�
�
�
�
�
�
�
���
�
��
�
�
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
��
�
�
�
��
�
���
�
�
�����
��
��
�
�
�
��
�
�
�
�
�
�
�
��
��
�
�
�
�
�
�
���
��
��
�
�
�
��
�
�
�
�
�
�
�
��
�
��
�
�
�
�
�
�
���
�����
���
����
���
�
�
�
��
�
�
���
�
�
�
�
�
�����
�
�
���
�
��
��
�
���
�
�
�
�
�
���
�
�
�
��
�
�
�
�
�
��
�
��
��
�
�
�
��
�
�
�
�
�
�
�
�
�
��
��
�
�
�
���
�
�����
��
�
�
�
�
�
�
�
�
�
�
���
��
�����
�
�
�
�
��
�
��
�
�
�
�
�
�
�
��
�
��
��
����
�
��
�
��
�
�
�
�
�
�
�
��
�
�
���
�
�
�
�
��
�
�
�
��
�
��
�
��
�
�
��
�
��
�
�
�
���
�
�
�
�
�
�
�
�
�
�
�
�
�
�
������
�
�
��
�
�
�
�
����
�
�
��
�
�
���
�
�
���
�
��
�
�
�
��
��
�
�
�
��
��
�
�
�
�
�
�
�
����
�
��
�
�
�����
�
����
�
��
�
�
�
�
��
����
��
�
��
�
�����
�
��
���
������
��
�
��
����
��
�
�
�
��
��
�
�
�
�
��
�
�
�����
��
�
���
����
�
��
������
�����
����
�
�
�
���
���
�
�
��
��
�
�
�����
��
��
�
�
��
�
�
��
�
�
�
��
������
�
���
�
�
�
�
��
����
����
�
������
�
�
�
��
��
�
��
��
�
���
�
�
�����
�
��
��
�
�
��
���
��
�
��
���
�
��
�
�
��
��
�
�
�
���
�
�������
�
���
�
�
���
�
����
����
��
��
�
�
�����
�
�
�
�
�
�
��
�
�
�
�
�
����
�
����
�
���
��
��
�
�
��
�
�
�
��������
��
�
�
��
���
�
�����
�
�
�
���
���
�
������
�
�
��
���
�
��
�
�
�
��
�
�
��
�
�
�
�
�
�
�
�
��
�
��
���
�
�
�
��
������
��
��
�
�
��
�
�
�
�
��
��
�
�
�
�
�
�
�
��
��
�
��
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
�
��
��
�
��
���
�
�
�
����
�
�
�
�
��
��
�
�
��
�
�
��
�
�
����
�
�
�
�
��
�
���
���
�
��
��
�
�
�
��
�
�
�
��
�
�
��
�
�
�
�
�
�
�
��
���
�
�
�
���
�
�
��
�
��
�
��
��
��
�
�
�
�
��
��
��
�
�
���
����
�
���
�
�
�
�
���
�
�
�
���
�
�
��
�
�
�
��
�
�
��
�
�
�����
�
�
�
�
��
����
�
�
�
�
�
���
��
�
�
�
��
�
��
�
��
���
��
���
�
�
��
���
��
�
�
�
��
���
����
�
�
�
��
�
�
�
�
�
�
�
�����
�
��
�
��
�
�
���
�
�
�
�
�
�
�
�
�
�
�
�
�
��
��
�
�
�
�
�
����
�
�
�
�
�
�
��
��
��
��
�
���
�
����
��
��
�
�
�
�
��
���
�
�
�
�
�
�
���
�
���
���
���
�
�
�
�
�
�
�
��
�
�
�
��
��
��
�
����
�
�
�
�����
�
�
�
�
�
�
�
�
����
�
��
�
�
�
�
�
��
�
�
��
�
�
�
�
��
�
�
��
��
�
�
�
���
��
��
��
��
�
�
��
�
�
���
�
�
��
�
�
�
�
��
�
��
��
���
�
��
�
�
�
�
�
����
���
�
�
�
��
�
�
�
�
��
�
�
�
��
�
��
�
�������
��
�
�
����
�
�����
�
���
�
��
�
��
���
�
��������
���
�
�
�
���
�
�
�
��������
�
�
�
���
�
�
�
���
�
�
�
�
�������
���
�
�
�
��
���
����
�
���
�
�����
������
�
�
��
��
�
�
�
�
�
����
���
�
�
��
�
�
���
�
��
�
�
���
��
�
��
�
��
�
�
���
�
�
�
�
�
�
�
�
�
�
�����
���
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
��
�
��
��
�
�
��
�
�
�
�
�
��
��
�
��
�
������
�
���
�
�
�
���
�
�
���
����������
�
�
��
�
�
�
��
�
�
��
�
�
���
�
�
�
�
�
�
�
�
�
�
��
�
�
�
��
���
��
�
��
�
��
��
��
���
�
�
�
�
�
��
����
�
���
��
��
�
�����
��
�
�
��
���
�
�
��
����
��
�
�
�
�
�
�
�
�
�
�
�
�
�
��
�
��
�
���
�
����
�
�
�
�
�
�
�
�
�
��
�
�
�
��
��
��
�
�
�
�
���
��
�
�
�������
��
�
��
�
�
�
��
�
�
��
��
�
�
�
�
�
���
�����
���
�
��
�
�
�
�
�
�
�
��
�
��
�
��
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
��
�
�
�
������
�����
���
��
�
�
�
�
�
�
�
�
�
�����
��
��
�
��
���
�
��
��
�
�
�
��
�
���
�
��
���
�
�
�
����
�
��
�
���
����
��
�
����
�
����
�
�
����
�
��
�
��
�
�
�
�
��
�
�
�
���
��
�
�
�
��
�
��
�
����
�
��
���
�
�
�
�
�
����
�����
�
�
�
�
��
�
�
��
�
�
�
�
�
��
�
�
����
�
��������
��
�
�
�������
�
�
�
�
�
�
�
��
��
���
��
����
�
�
�
�
�
�
�
�������
�
�
�
��
�
�
�
�
�
���
�
�
�
�
��
��
�
�
��
�
��
����
��
�
�
�
�
�
�����
�
�
�
�
�
�
�
��
�
�
���
�
�
�
�����
�
��
�
�����
����
��������
�
�����
�
�
�
�
�
�
�
�
�
�
��
���
�
���
�����
��
���������
�
�
�
����
�
��
�
�
�
�
�
���
��
���
�
�
�
�
������
�
��������
�
�
�
������
���
��
�
�
��
�
�
�
�
�
�
��
��
���
��
�
�
��
�
��
�
�
�
�
�
�
���
�
�
���
�
�
���
�
�
�
�
�
�
�
�
��
�
��
��
��
�
��
��
��
�
�����
�������
�
�
��������
���
��
�
����
��
��
�
��
��
�
�
�
�
���
�
��
�
�
��
���
�����
��
�
�
�
�
�
���
��
�
�
��
�
�
�
�
�
��
��
���
���
�
��
�
���
�
��
��
�
���
�
�
�
�
�
�
�
�
��
����
�
��
�
���
�
��
��
�
�
���
��
�
��
�
��
����
��
�
��
�
��
�
���
��
�
��
��
�
�
�
��
�
��
�
�
�
�
�
�
��
���
�
�
�
�
���
�
�
�
�
�
�
��
��
�
��
�
���
�
�
�
�
�
��
�
�
�
�
��
�
��
�
�
�
��
�
�
�
�
�
��
�
�
��
�
�
�
�
�
���
�
��
�
�
���
���
��
�
�
�
�
�
���
�
��
��
��
�
�
��
�
��
���
��
�
�
��
��
�
��
�
��
�
����
�
�
�
��
�
�
�
�
�
�
�
���
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
��
�
�
��
�
������
�
�
��
���
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
����
��
�
�
�
����
����
��
��
��
�
�
�
�
�
�
�
����
�
�
�
�
��
�
�
�
�
��
�
�
���
�
�
�
�
�
�
�
�
��
�
�
�
��
�
�
���
�
�
�
���
����
�
�
�
�
�
���
�
�
��
�
�
��
�
�
��
��
��
�
��
�
���
�
��
�
�
��
�
����
�
����
�
���
�
�
�����
�
�������
�
�
�
���
��
��
�
��
�
�
�
��
�
�
�
�
�
�
��
��
��
�
�����
��
��
����
�
�
�
�
���
�
�
��
�
�
�
�
�
��
���
��
�
���
�
��
�
�
��
�
�
��
�
��
��
�
�
�
�
�
�
��
���
�
�
�
�
�
�
����
�
�
��
�
�����
���
�
�
���
���
��
�
�
�
�
�
�
�
�
��
�
��
������
�
�
�
�
���
�
�
�������
�
�
�
�
��
�
����
�
�
�
�
��
��
�
�
�
���
�
�
����
��
������������
������
�
�
���
�
�
��
������
�
��
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
��
�
�
�
�
�
����
�
��
��
�
��
��
�
��
�
�
�
����
��
�
�
���
�
����
��
�
�
��
�
�
���
��
��
�
��
���
��
�
�
�
��
�
�
�
��
�
�
��
��
��
��
�
���
�
��
��
��
�
�
�
�
�
���
�
�
�
�
��
�
�
��
�
�
���
�
�
��
�
��
�
��
�
�
�
�
�
�
��
�
�
�
�
���
�
��
�
�
�
���
�
�
���
�
��
����
�
�
��
�
�
�
��
�
����
���
���
�
�
����
��
�
�
�
�
�
��
�
�
�
�
�
����
�
�
�
�
��
��
�
���
���
�
�
��
��
�
��
���
�
�
�
�����
�
�
��
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
���
�
�����
�
��
��
�
�
��
�
�
�
�
�
�
����
��
�
�
�
�
�
��
�
�
�
�
�
�
��
�
�
�
�
�
��
�
��
�
�
��
�
��
��
�
��
�
��
�
�
�
�
�
���
�����
�
�
�
���
���
�
�����
�
�
��
�
�
�
���
����
�
��
�
�
��
�
�
�
���
��
��
���
�
�
��
�
�
��
�
���
�
�
��
��
�
��
�
�
��
�
�
��
��
�
��
����
�
��
�
��
���
���
�
�
��
��
�
�
�
�
�
�
�
�
�
�
��
�
�
�������
������
�
�
��
�
�
�
�
��
�
���
�
�
�
�
�
���
��
�
�
�
���
�
�
��
�
�
�
�
�
��
�
�
�
�
�
�
�
�����
����
�
�
�
��
�
�
�
�
�
�
����
�
�
�����
����
�
���
�
�
�
������
�
���
�
��
�
��������
��
�
��
�
��
�
�
��
��
��
�
�
�
�
���
�
�
�
�
���
�
�
��
��
�
���
��
�
�
�
�����
�
�
�
�
�
�
��
���
�
�
��
���
����
�
�
�
�
�
�
���������������
�
��
�
�
��
�
�
�
�
���
�
�
���
�
�
�
���
��
�
����
��
��
��
�
�
�
�
�
�
�
�
�
��
��
�
����
�
�
����
�
�
�
�
�
�
��
�
��
���
�
�
��
��
�
��
�
�
��
��
��
��
�
�
�
�
�
�
�
�
�
�
�
��
�����
��
���
�
���
��
�
�
��
��
�
�
�
�
��
�
�
�
�
��
����
�
�
��
�
��
�
�
�
�
��
�
�
�
�
�
���
���
�
�
�
�
�
�
�
��
�
���
�
���
������
�
�
�
����
�
����
�
�
�
���
�
�
�
��
��
��
�
�
�
�
������
�
���
����
�
��
��
�
�
��
���
���
�
�
��
�
�������
��������
������
�
�
��������
�
�����
���
�
��
�
�
�
�
�
�
������
�
�
���
�
���
�
���
�
�
�
�
��
����
�
���
�
�
�
�
���
�
�
�
�
�
�
��
���
��
�
�
��
�
��
��
��
������
�
�
����
��
���
��
��
�
�
�
�
�
�
�
�
�
��
�
����
��
���
�
��
�
��
�
��
�
�
��
��
��
�
�
�
�
�
�
��
��
��
�
��
���
�
�
�
�
��
�
�
��
�
�
���
�
��
�
�
��
�
�
�
�
��
�
�
��
�
�
��
��
�
�
�����
��
�
��
�
�
�
��
�
��
�
�
�
�
�
��
�
���
��
�
�
����
��
�
�
��
��
��
�
�
�
�
�
���
�
�
�
�
�
����
�
�
�
�
����
�
�
����
���
�
�
���
�
�
��
��
����
�
��
����
�
�
��
�
�
�
��
�
�
�
��
�
�
�
�
�
����
�
��
��
�
�
�
����
�
�
�
�
�
��
�
�
�
��
�
�
���
�
���
�
�
��
�
�
�
��
��
�����
��
�
�
��
�
��
�
����
�
�
�
�
��
�
�
�
�
��
��
�
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
���
�
��
�
����
�
�
�
�
�
�
�
�
�
��
�
�
��
���
�
���
�
�
�
���
����
�
�
�
�����
��
��
��
��
�
��
��
�
��
�
�
�
�
�
�
�
��
�
�
�
���
��
�
�
�
��
�
�
��
��
�
�
�
�
�
�
�
�
�����
���
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
����
����
�
�
�
��
�
�
��
��
��
�
�
�
�
�
�
�
�
�
���
�
�
�
�
��
�
��
�
�
����
�
�������
�
�
��
�
�
�
��
�
�
�
�
�
�
���
��
�
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
��
�
�
��
�
�
�
��
�
�
�
�
��
��
����
�
�����
��
�
�
�
��
�
�
��
��
��
�
����
�
�
�
�
�
�
�
�
�
�
�
�����
�
���
�
�
�
�
�
��
��
�
�
�
�
�
�
�
�
�
���
�
�
��
��
�
�
��
�
�
���
�
�
�
���
��
�
��
����
�
��
�
��
�
�
�
�
�
���
�
�
�
��
��
�
�
�
��
�
�
���
�
�
�
�
�
�
���
�
�
�
��
��
����
��
�
�
�
�
�
�
�
�
�
��
�
�
�
�
���
�
�
����
�
�
��
�����
���
���
��
�
�
���
���
�
�
��
�
�
�
�
����
��
�
��
�
��
�
��
��
��
�
�
�
��
�
�
��
�
�
��
�
��
�
���
�
��
�
��
�
�
�
�
��
�
�
�
�
����
�
��
���
����
�
�
�����
��
�
���
�
�
��
������
�
�
�
�
�
��
��
�
��
���
�
�
���
�
����
����
��
�����
����
�
���
�
�
��
�
�
�
�
��
�
�
�
������
�
��
�����
���
��
��������
�
�
�
�
����
�
�
��
�
��
�
�
��
�
��
�����
�
��
���
�
�
�
��
��������
�
�
��
��
���
���
�
��
�
��
�
��
���
�
�
�
�
�
��
�
�
��
�
�
�
��
�
�
��
��
�
��
�
�
�
�
�
�
�
�
�
�
��
�
�
����
�
�
�
�
�
�
�
�
��
�����������
���
�����
��
�
��
��
���
�
���
�
�
�
�
�
�
��
�
�
��
��
��
��
���
�
�
�
�
�
�
��
��
�
�
�
�
�
�
�
��
�
�
�
�
�
��
��
���
��
�
�
��
�����
�
�
�
��
�
�
�
�
�
�
�
�
�
��
�
�
��
�
�
���
�
��
�
���
�
��
���
�
�
�
���
�
��
�
�
�
�����
���
�
���
�
���
�
�
����
���
�
�
�
�
�
����
�
��
�
�
��
�
��
���
�
�
�
��
�
��
�
����
�
��
��
�
�
��
��
�
�����
��
�
�
�
�
��
�
�
�
�
�
�
�
��
���
��������
�
�
�
�
�
�
��
�
������
���
�
�
��
�
�
�
�
�
�
�
�
�
����
�
�
�
�
�
�
�����
�
�
���
��
�
��
�
�
�
�
�
�
�
��
�
�
��
�
����
�
�
�
�
��
�
�
�
�
���
�
���
����
�
���
��
������
�����
�
�
����
�
�
�
��
�
�
�
�
���
�
��
�
��
�
�
���
��
�
�
��
�
�
��
����
�
��
�
�
�
���
���
�
���
�
��
�
�
�����
�
�
�
�
�
�
�
��������
���
��
�
�
�
�
��
�
�
���
�
�
�
���
�
�
�
�
�
�
��
�
�
��
�
��
��
�
�
��
����
�
�
���
��
��
�����
�
�
�
�
��
�
�
��
�
�
�
�
�
�
��
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
���
�
�
�
�
�
�
��
�
�
��
�
�
�
��
�
�
���
����
�
�
���
�
��
�
�
�
�
�
����
���
�
�
�
�
�
��
��
�
�
�
���
��
�
���
���
���
��
���
�
�
�
�
�
�
�
�
��
�
�
��
�
�
�
�
��
�
�
�����
�
�
�
�
�
�
�
�
�
���
�
����
��
��
�
��
�
�
�
���
�
�
�
�
��
�
�
�
�
�
��
�
��
�
��
�
�
�
�
�
�
�
�
�
��
�
�
�
��
���
�
�
�
�
�
�
�
��
��
��
�
��
���
��
�
�
��
�
�
�
��
���
�
��
�
�
���
�
�
�
�
��
�
�
�
�
�
�
�
�
�
�
����
��
�����
����
�
�
�
��
�
�
�
�
�
���
�
�
�
�
�
�
�
��
�
��
�
�
�
��
�
�
�
�
�
�
��
�
��
�
�
���
�
��
�
�
��
�
�
�
��
�
��
��
�
�
�
��
�
�
�
�
�
��
�
�
�
�
�
�
�
�
��
����
�
��
�
�
��
���
�
�
��
�
��
�
�
�
�
�
����
��
�
���
��
��
�
�
�
�
�
����
��
�
�
��
�
�
�
�����
�
����
��
���
�
��
��
�
���
�
�
�
�
�
��
�
���
�
�������
�
�
��
�
�
����
�
�
�
���
�
������
�
�
�
�
��
�
�
�
�
����
�
��
���
�
�
�
�
�
�
�
�
��
��
�
���
�
���
�
��
�
�
�����
������
�
�
�
�
�
�
�
�
�
��
�����
�
�
�
�
�
�
��
�
�
��
��
��
�
��
�
�
�
�
�
�
��
�
�
�
�
�
�
��
�
�
��
�
�
�
�
�
��
���
�
�
�
�
��
�
�
�
�
�
���
�
�
���
�
�
��
��
��
�
���
�
�
��
��
�
�
�
�
��
��
�����
�
���
�
��
���
�
�
�
�
�
��
�
�
�
�
�
��
��
��
�
����
�
�
��
�
�
�
�
�
�
�
���
�
�
��
���
�
�
�����
�
�
�
�
�
����
�
��
�
��
�
�
�
�
�
�����
�
�
�
�����
��
�
�
�
��
��
��
�
�
�
�
��
�
��
�
�
��
�
���
�
�
�
�
�
�
�
��
��
�
��
��
��
��
�
�
�
�
�
�
�
�
�
�
�
�
�
��
�
�
��
����
�
�
�
��
��
�
�
���
���
�
�
�
���
�
�
�
��
�
�
�
��
�����
�
�
�
���
��
���
�
��
�
�����
�
�
�
�
�
��
�������
�
�
�
�
�
�
���
�
�
�
��
���
�
�
�
�
�
�
�
��
�
��
�
�
�
�
��
�
�
�
��
�
�
�
�
���
�
�
�
��
�
�
��
�
�
�
�
�
�
���
�
�
��
�
�
��
���
�
��
�
�
�
�
�
�
�
�
��
�
��
�
�
�
�����
�
�
�
��
�
��
��
�
�
�
�
���������
�
�
�
��
��
�
��
�
���
��
�
��
�
�
�
�
�
�
�
��
�
����
�
�
��
�
�
��
��
�
�
�
�
���
���
��
�
�
�
��
�
������
�
��
�
�
����
�
�
���
�
��
�
�
�
�
�
���
�
��
��
����
�
��
�
����
�
�
�
�
�
���
��
��
�
�
�
�
�
��
����
�
����
�
�
�
�����
�
��
�
�
�
�����
����
��
��
�
�
�
�
�
��
�
�
�
��
�
���
�
��
�
�
�����
����
�
�
�
�
���
�
�
�����
��
�
�
��
�
��
�
�
�
�
�
�
�
�
��
�
�
�
��
�
�
�
��
����
���
�
�
���
�
�
���
�
�
��
��
�
��
�
�
��
�
��
�
�
�
�
�
�
��
���
�
�
�
�
���
�
�
����
�
�
�
���
�
�
�
��
�
�
���
�
�
�
�
�
�
�
����
�
�
�
�
��
��
��
�
�
��
����
�
��
�
�
�
�
��
�
���
�
���
��
�
��
�
�
�
�
�
�
���
�
��
��
�
��
��
�
�
��
�
��
�
��
��
�
����
�
�������
�
�
���
�
����
�
�
�
��
����
�
�
�
����
�
���
�
�
��
���
�
��
��������
��
�
�
����
�
�
�
�
�
���
����
��
��
�
��
�
��
�
�
��
��
�����
�
�
�
�
�
�����
�
��
�
���
�
�
��
�
�
���
���
�
��
�
�
��
�
�
���
�
�
��
�
�
�
��������
�
��
�
��
�
�
�
��
����
�
��
���
��
���
��
�
�
�
����
���
�
������
�
��
�
���
�
��
�
�
�
��
�������
��
�
�
�
�
�
�
��
�
�
�����
�
��
�
�
�
�
����
���
���
�
�
�
�
�
�
�
�
�
���
�
�
���
�
�
�
��
��
�
��
��
�
���
�
�
����
�
��
��
�
�
�
����
�
��
������
�
���
�
�
�
��
�
�
�
�
�
�
��
�
��
�
��
��
���
��
�
���
���
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
��
�
�
�
���
�
�
�
�
��
�
�
��
���
�
�
���������
�
�
�
����
�
�
�
�
�
��
�
��
�
�
����
�
�
�
�
�
����
�
�
�
��
�
�������
�
�
�
����
�
�
��
�
�
�
�
�
��
�
�
�
�����
��
�
�
��
�
�������
�
��
�
��
���
�
��
�
�
�
��
��
�
��
�
����
�
���
��
��
�
�
�
�
�
�
�
�
��
�
�
�
�
����
��
���
��
��
�
�
�
�
�
���
�
�
�
�
�
�
�����
�
�
�
�
�
�
�
��
������
��
�
��
�
��
��
��
�
��
���
�
�
�
�
�
�
��
�
�
�
��
�
�
�
�
����
����
�
�
�
��
��
��
�����
��
���
�
�
���
�
�
�
�
�
�
�
�
�
��
�
��
�
�
�
��
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�
���
�
�
�
�
�
��
�
���
��
�
�
�
�
�
���
�
�����
���
�
���
�
�
��
���
��
��
��
��
�
�������
�
��
�
��
�
��
�
�
�
�
�
�
���
��
�
�
����
�
���
���
�
�
�
�
�
�
�
�
�
�
����
��
��
�
�
�
�
�
������
�
�
�
�
���
�
��
��
�
�
�
�
�
��
�
��
��
�
�
�
�
�
��
�
�
�
�
��
�
�
�
��
�
�
��
�
�
��
��
�
�
�
��
��
�
�
���
�
�
��
�
���
�
��
��
�
�
�����
�
�
�
�
��
�
�
�
�
���
�
�
�
�
�
���������
�
�
�
�
��
��������
�
��
����
��
�
����
��
�
����
�
�
���
�
�
��
��
�
�
��
�
���
�
��
�
���
��
�
��
�
����
���
�
�
�
�
��
���
��
���
�
�
�
����
�
�
�
�
��
������
�
�
���
�
���
�
�
���
�
�
�
�
��
�
�
�
��
�
�
�
�
���
��
��
�
�����
��
�
�
��
���
�
�
�
�
������
�
�
�
��
�����
����
��
������
��
�
�
�
�
�
��
�
���
�
�
�
��
�
��
��
���
��
�
�
�
�
��
�
���
������
�
��
�����
��
�
�
��
�
��
�
�
��
�
�������
��
���
�
�
�
��
��
��
���
�
��
�
�
��
��
��
��
�
�
��
�
�
�
��
�
�
�
�
�
�
��
�
���
�
���
�
�
��
�
���
�
�
�
�
�
���
�
�
��
��
����
�
��
��
�
�
�
��
�
�
���
�
�����
�
�
�
��
�
�
�
��
��
�
�
�
���
�
��
��
��
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
��
��
���
�
�
��
��
�
�
��
���
�
�
���
�
�
�
���
�������
�
�
�
��
�
�
���
�
��
�
�
���
�
�
�
��
�
�
��
�
�
�
���
�
��
�
���
�
�
�
��
�
�
�
�
�
�
�����
�
�
���
���
�
�
��
�
�
��
�
�
���
�
�
�
�
���
�
�
���
�
�
�
��
�
�
�
�
�
�
�
��
�
���
���
���
�
��
�
���
��
�
�
�
�
�
�
��
��
�
�
�
�����
��
�
�
�
�
�
�
���
��
���
��
�
����
�
�
��
�
�
�
���
��
�
�
���
�
�
�
�
�
�
��
�
�
�
�
�
�
��
���
�
��
�
��
��
����
��
�
�
�
�
�
��
�
���
�
�
�
�
��
�
�
�
�
�
�
�
��
��
�
�
��
�
��
�
�
�
��
�
��
���
�
��
���
����
����
�
�
�
�
��
��
�
�
������
����
���
�
��
���
�
�
��
�
�������
�
����
�
�
�
�
����
�
��
�
�����
�����
�
�����
��
��
�
�
�
��
��
����
�
�
�
�
�
���
���
���
�
��
�
�
�
���
�������
��
�
���
�
�
���
�
�
�
����
�
�
�
�
�
�
���
�
�
�
���
��
�
���
�
�
����
�
�
��
��
�
���
��
���
���
�����
��
��
�
��
�
��
�
��
�
�
����
�
���
��������
�
�
������
�
�
�
�
����
���
�
�
�
�������
�
�����
��
�
��
�
�
�
�
�
����
���
�
���
������
�
����
����
���
�
�
�
�
�
��������
��
�
�
�
��
��
��
�
��
�
�
�
�
�
�
�
�
����
�����
��
�
�
�
��������
���
�
��
�
�
�
�
���
�
���
�
��
�
��
�����
���
����
�
�
�
�
���
���
�
�
��
�
���
����
�
�
�����
�
����
�
�
�
�����
�
�
��
�
�
�
������
�
�
�
�
����
�
�
�
�
�
�
����
�
�
����
��
���
���
�
���
�
��
�
�
�
�
�
�
���
�
�
�
���������
��
����������
�
�
�
���
�
�
�
��
�
�
�
�
�
�
��
�����
�
�
��
���
�
��
���
���
���
��
�
����
�
�������
�
�
�
�
�
�
��
����
�
�
�
��
���
�
��
�
�
�
��
���
������
�
�
�
�
�����
��
�
�
�
�
�
�
�
��
�������
�
��
�
�
����������������
����
�
�
����
�
�
�
�
�
�
�
�����������
�
�
�
��
�����
��
��
�
��
���
�
�
���
�
��
��
��
�
���
���
��
�
�
�
�
�
��
�
�
�
��
�
�
�
�
���
������
�
�
�
�
��
�
�
������
��
�
�
��
�
�
�
�����
�����
��
�
�����
�
�����
��
�����������
�
�
�
�
�
�
�
����
�
�
�
�
�
�
�
�
���
������
�
�
�
�
�
�
����
����
�
���������
�
�
�
��
�
��
�
��
�
�
�
��
�
�
�
������
��
�
��
���������
��
��
�
�
��
�
��
���
�
���
����
�
��
�
�
����
�
����
�
�
�
�
�
���
��
�
�
�
�
�
��
�
�
�
��
��
�
�
���
�
�
�������
����
��������
�
�
�
�
�
�
������
����
��
�
�
��
�
�
�
�
��
�
�����
�
����
���
����
�
����
�����
�
�
��
�
�
��
�
��������
���
�
���
��
�
�
�
�
�
�
�
�
�
�
�
�����
��
�
�
���
����
�
�
�
�
����
��
������
�
��
�
�
�
�
�
�
�
�
������
�����
�
����
��
�
��������
�
�
��
���
�
���������
�
���
�����
���
�
�
�
�
��
�
��
�
�
�
�
�
�
��
��
���
�
�
�
�
�
����
�
��
�
�
��
���
����
�
�
��
�
�
�
�
�
��
�
��
��
�
�
��
�
������
�
�
�����
�
�
�����
�
��������
�
�
�
�
�
�
�
�
���
��
�
�
�
��
��
���
�
��
�
�
���
������
���
�
��
�
����
�
�
�
�
�
�
�
�
�
�
����
�
����
�
�
���
�
�
������
����
�
���
��
�
�
�
�
������
��
�
�
�����
�����
��
��
�
��
�
�
�
���
���
��
�
��
�
��
�
��
�
���
�
�
�
���������
������
�
�����
�����
�
��
�
�
����
��
�
�
�
����
�����
�
�
��
�
�
��
���
�
�
�
�
��
�
����
��
��
�
����
�
�
�
���
��
�
�
���
�
�������
�����
�
�
��
�
���
�
�
������
�
�����
����
�
�
��
��
�
�
��
����
�
�
�
��
�
�
�
�
�
�
���
�
�
�
���
�
�
�
��
�
���
�
�
��
�
���
��
�
�
����
�
����
�
��
��
�������������������
�
����
�������
�
������
�
��
�
��
�
�
��
�
��
��������
�
�
��
����
�
�
���
�����
�
���
�
�
��
�
�
��
�
�
�
������
�
��
�����
��
��
�
����
���
����
��
�
��
�
��
���
�
��
�
�
�
�
�
�
�
�
�
�
�
�������
�
�
���
�
�
�
�
�
�
�
������������
����
�
���
�
�
��
�����
�����
��
�
�
����
�
�
�
��
�
�
�
�
���
�
���
�
�
�
����
�
�
�
�
�
�
�
�
�
��
�����������
��
�
�
�
�
�
�
������
�
�
�����
�
����
��
�
��
�
�
�
���
�
��
��
�
�
�
�
��
�
�����
�
�
�
�
�
���
�
�
��
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�������
�
�
�
�
���
�
���������
�
�
�
�
�
���
�
���
�����
���
��
�
���
����
�
�
�
��
������
�
�
�
�
�
�
�
�
������
�
�
�
�
��
�
���
�
��
����
��
�
�
�
�
�
�
�
�
���
��
�
�
�
��
���
�
�
�
��
�
�
���
��
�
�
�
����
��
�
�
�
�����
��
��
�
���
��
�
�
����
�
�
�
��
��
��
�
�
�
�
�
�
��
����
�
��
�
�
�
�
���
�
�
��
�
�
�
��
�
�
�
�
�
����
�
�
����
����
�
�
�
�
���
�
�
�
�
���
�
�
�
�
�
��
��
�
�
�
��
�
�
�
�
�
�
��
�
�
�
��
�
�
����
�
�
�
��
���
�
�
�
��
�
�
��
��
��
��
��
�
�
�
��
�
�
�
��
�
�
�
�
�
�
�
�
��
���
�
��������
�
��
��
�
�
��
�
�
�
�
�
�
�
��
�
�
�
�
��
�
�
�
�
�
�
���
��
�
�
�
�
�
�
�
��
�
�
�
��
�
�
���
�
����
�
�
�
�
��
�
�
�
��
�
�
�
�
�
��
����
�
�
�
�
�
���
�
�
�
��������
��
�
�
�
�
�
�
�
����
�
��
��
�
�
���
�
�
�
�
�
�
�
���
�
����������
�
���
�
�
��
�
�
�
�
�
���
��
��
���
�
���
�
����
���������
��
�
�
�
�
���
�
������
��
���
�
�
�
�
�
�
�
�
���
�
��
�
�
�
��
�
�
�
�
�
�
��
��
��
�
�
�����
�
�
����
�
�
�����
�
�
�
�
�
�
��
��
�
�
��
�
���
����
����
��
�
�
�
�
�
���
�
��
�
���
�
�
�
�
�
�
�
��
�
�
�
�
�
��
�
�
���
��
���
�
����
��
���
�
��
�
�
��
�
������
�
���
�
�
�
�
���
��
��
�
���
�
�
��
�
��
�
�
���
�
��
�
��
�
���
�
��������
�
�
��
�
�
�
�
��
�
��
�
��
�
��
�
��
��
��
�
�
��
�
�
�
���
�
��
���
��
��
�
�
�
��
�
�
�
�
�
�
�����
�
������
���
�
��
�
�����
�
���
�
��
�
�
�
�
�
�
��
�����
�
�
�
��
�
�
��
�
��
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
����
�
�
�
�
�
�
�
�
�
�
�
�
����
�
��
��
�
�
�
�
���
�
�
�
�
�
�
��
�
�
�
���
�
��
��
��
�
�
�
�
�
��
��
�
�
�
�
��
�
��
�
��
�
��
�
�
��
�
��
�
�
�
����
��
���
�
�
�
�
��
���
�
�
�
�
�
�
�
���
��
�
�
���
���
�
��
�
�
��
�
�
�
�
�
���
�
�
�
��
�
��
�
����
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
�
�
���
�
�
���
�
��
�
�
���
��
����
�
�
�
�
�
�
�
�
�
����
��
�
�
�
�
�
�
����
�
�
�
�
��
�
�
��
�
�
�
����
�
�����
�
�
�
�
�
�����
�
��
�
��
�
�
�
���
�
��
�
�
�
�
��
�
�
��
�
�����
���
�
�
�
�
�
�
�
�
�
�
�
��
�
��
�
��
�
�
�
���
����
���
�
����
�
�
�
��
���
�
�
�
�
�
�
�
�
�
�
�
��
���
�
�
�
�
�
�
�
�
�
�
�
�
�
��
��
�
�����������
�
���
�
�
���
�
�
��
�
�
�
�
��
�
��
�
�
�
��
�
�
�
�
�
��
��
�
�
��
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�
����
�
�
�
��
�
�
�
����
�
�
�
�
�
���
�
�
�
�
���
�
�
�
�
�
�
�
����
�
�
��
�
��
��
�
�
�
���
�
�
�
�
�
����
�
�
�
�
�
�����
�
���
��
�
�
�
�����
��
�
�
��
��
�
�
�����
���
��
��
�
�
��
�
�����
�
�
�
���
�
�
�
��
�
�
�
�
�
��
�
���
�
�
�
�
��
��
�
�
���
�
�
������
�
�
�
���
�
���
�
��
�
��
�
��
�
�
�
�����
�
���
�
����
��
��
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
��
��
�
��
��
�
�
��
�
�
������
�
�
����
��
�
�
�
�
�
�
�
�
�
���
�
�
��
��
�
��
�
�
�
�
�
�
��
�
��
�����
���
�
��
��
�
�
����
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
��
�
�
��
��
�����
�
���
�
���
��
���
��
�
�
��
��
�
�
��
��
��
����
�
���
�
�
�
���
�
�
�
�
��
��
�
���
��
�
�
�
�
�
�
�
��
�
��
��
�
�
���
�
�
���
�
�
�
��
��
�
�
�
�
�
�
��
�
�
��
�
�
��
�
��
��
�
�
�
��
�
����
�
�
�
�
�
�
�
�
�
��
��
��
�
�
���
�
�
�
��
��
�
����
�
��
�
�
��
��
��
�
��
�
�
����
�
�
�
��
�����
�
�
��
�
�
�
�
�
�
��
��
�
�
�
�
�
���
����
���
�
�
�
���
�
��
�
�
�
��
�
�
�
�
�
���
�
���
�
�
�
�
��
�
���
�
��
�
�
�
�
�
��
���
��
�
�
��
�
�
��
�
�
�
�
�
��
���
�
�
�
�
�
��
�����
�
�
��
��
���
�
��
�
����
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�
�
����
��
�
�
�
��
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�
��
��
�
��
��
�
�
�
�
�������
�
��
�
��
��
�
�
�
��
�
��
�
�
���
����
�
�
����
���
�
�
�
�
�
�
��
�
���
�
��
�
�
����
�
���
�
�
�
��
��
�
�
�
�
�
���
�
�
�
��
�
�
�
�
���
�
�
�
�
�
�
�
�
�
�
��
��
�
�
������
��
��
�
�
�
�
��
�
�
���
�
�
�
�
�
�
�
�
���
�����
�
�
�
�
�
�
����
���
�
�
�
�
�
�
�
�
�
��
�
�
������
�
�
�
�
�
��
�
�
���
�
�
��
���
�
�
�
�
�
����
�
��������
�
���
�
��
�
���
�
�
�
��
��
�
�
�
��
�
�����������
�
�
��
�
�����
�
��
��
�
�
�
�
�
�
�
�
�
���
���
�
�
�
����
�
���������
�
�
�
�
��
�
���
��
�����
��
�
�
���
�
�
�
�
��
�
�
��
�������
��
��
�
�
�
��
�
�
�
��
�
�
�
�
�����
���
�
�
�
��
��
���
�
�
�
�
��
�
�
��
�
���
�
�
�
�
��
�
�
�
�
�
��
�
�
��
�
�
�
�
������
�
�
��
�
��
�
�
�
��
�
�
�
��
�
�
�
��������
�
�
�
�
����
���
��
��
�
��
�
�
�
�
�
�
�
�
�
���
�
�
�
�
�
�
��
���
�
��
�
���
�
�
�
��
�
��
��
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
�
���
�
��
�
��
�
�
�
����
�����
�
�
�
�
�
�
�
�
��
��
�
�
�
�
�
�
�
�
�
�
��
�
�
�
��
�
�
�
�
�
�
�
�����������
��
�
�
�
��
�
�
�
��
�
�
�
���
��
����
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
��
�
���
�
�
�
���
���
�
��
�
�
��
�
�
��
�
�
�
�
�
���
�
��
��
�
���
�
�
�
��
�
��
�
�
�
�
�
��
�
�����
�
����
�
�������
�
���
�
�
�
�
�
�
�
�
�
����
�
��
�
�
��
�
��
�
�
�
�
���
�
�
�
�
�
�
�
�
�
��
�
������
���
���
��
�
�
�
����
�
�
�
��
�
��
���
�
��
��
����
�
�
�
�
�
�
�
�
�
�
���
��
�
�
�
�
�
�
�
���
�
�
�
�
��
��
���
����
�
�
��
�
�
���
�
�
�
�
�
�
����������
�
�
�
�
�
��
�
��
�
�
�
�
�
�
�
�
�
�
�
�
��
��
�
��
���
��
�
��
�
�
���
�
�
���
�
�
��
�
��
��
�
�
����
�
�
�
�
�
�
��
�
���
�
��
�
�
���
���
�
�
��
�
�
�
�
�
�
�
�
�
��
�
�
�
�����
�
�
��
����
�
�
�
�
��������
�
�����
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
��
�
�
�
�
�
�
�
�
�
�
��
�
��
�
�
�
�
�
�
�
��
��
�
�����
���
�
������
�
�
�
�
���
����
�
�
��
�
�
�
����
�
��
�
�
�
�
��
�
�
��
�
�
���
��
�
�
���
���
�
��
�
�
�
�
�
�
�
��
�
�
��
��
�
�
��
��
��
�
�����
�
�
�
�
�
�
�
�
��
�
�
��
�������
�
����
�
�
�
�
�
�
�
�
�
����
�
�
�
�
��
�
����
�
�
�
���
�
�
�
�
�
�
�
�
��
��
��
�
���
�
�
����
�
��
�
���
�
���
�
�
���
�
�
�
�
����
�
�
�
�
��
�
�
��
��
���
��
�
�
���
���
����
���
����
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
����
�
�
�
�
�
�
�
���
��
�
�
�
�
�
�
�
�
��
�
�
�
�
��
�
�
�
���
��
��
�
�
�
�
�
�
�
�
��
��
�
�
�
�
�
�
�
�
�����
�
�
�
�
�
�
�
��
�����
�
�
��
�
��
�
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�����
�
�
�
�
�
�
�
��
����
�
�
�
�����
���
��
�
�
��
�
�
����
�
�
�
����
�
�
���
�
�
�
�
�
��
�
�
�
�
�
�
�����
�
��
�
���������
�
�
�
�
�
�
���
�
����
�
�
������
��
��
�
���
�
�
��
��
�
�
�
�
�
�
��
��
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�������
�
�
�
�
�
�
�
�
�
�
��
�
��
�
��
�
�
����
����
�
�
�
�
��
��
�
��
�
�
�
�������
�
�
����
�
�����
�
����
��
�
�
��
�
�������
��
��
�
�
�
��
�
�
��
�
�
�
����
�
����
�
�
�
�
�
��
�
����
�
������
���
��
���
�
��
�
�
��
�
�
�
�
�
�
�
��
��
�
�
�
��
�
���
�
�
�
�
�
�
�
�
�
�
�
����
���
���
�
�
�
�
���
���
�
�
�
�
���
�
���
��
��
�
��
�
��
�
��
���
�
�
�
��
�
��
�
�
�
�
�
����
�
���
�
��
��
����
��
�
�
�
�
�
�
�
��
�
�
���
�
����
�
���
�
�
�
�
��
�
��
�
�
�
���
��
�
�
�
�
�
����
�
�
�
�
��
�
��
�
�
�
���
�
����
�
�
�
�
�
�
�
�
�
�
��
�
��
��
�
�
���
��
��
�
��
�
�
��
�
��
�
�
��
�
��
���
�
�
��
�
���
�
�
�
��
��
�
����
�
�
�
�
�
�������
������
�
�
��
���
�
�
�
��
�
�
�
�����
�
�
�
�
����
�
�
���
��
���
�
���
������
�
�
����
�
��
�
�
�
����
�
�
����
���
�
�
���
�
�
�
������
��
�
�����
�
�
��
�
�
���
�
�
�
��
�
�
��
���
��������
����
���
��
�
�
�
�
�
�����
�
�
��
�
�
�
�
��
�
�
�
���
�
�
�
�
��
�
�
�
��
�
��
�
�
�
���
�
�
��
�
�
�
�
�
��
�
��
�
�
�
�
�
�
�
�
�
�
��
�
�
�
��
����
�
�
��
�
��
�
��
����
�
�
����
���
�
�
��
�
�
�������
�
�
���
�
�
�
�
�
��
��
�
�
�
�
���
�
�
�
�
�
�
�
��
��
�
�
��
�
�
����
�
�
��
�
�
�
�
�����
�
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
�
��
�
�
��
�
�
��
��
�
�
�
��������
�
�
�
��
�
�
�
�
��
�
�
�
���
�
�
��
��
�
�
��
�
�
�
�
�
�
��
��
��
�
��
��
�
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
������
�
�
�
�
�
�
�
�
�
����
�
�
��
�
��
�
����
������
��
�
��
���
�
��
�
��
�
�
�
�
�
�
���
�
�
�
��
�
�
���
�
��
�
�
��
���
�
��
�
�
�
�����
��
�
��
�
�
�
�
�
����
�
�
�
�
�
��
�
�
��
��
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
��
�
��
�
���
��
�
�
�
����
�
���
�
�
�
��
�
�
��
�
�
����
�
�
�
�
�
���
��
�
��
�
�
���
�
����
�
�
�
�
�
��
�
�
����
�
�
�
�
�
�
�
�
�
�
�
�
�
�
����
�
���
�
����
�
��
�
�
�
��
�
��
����
��
�
�
�
�
��
�
��
�
���
�
��
��
�
��
�
�����
�����
�
��
��������
�
��
�
�
�
�
��
�
��������
�
�
�
�
�
�
��
�
�
�
����
�
�
�
��
��
�
��
����
��
�
���
�
�
����
�
�����
�����
�
��
�
�
�
��
�
�
�
�
�
�
�
���
�
���
��
�
�
�
�
���
�
�
��
�
�
�
�
�
����
����
�
��
���
�
�
�
�
�
�
��
��
����
�
�
�
�
���
��
���
�
�
��
��
�
�����
�
���
�
�
�
������
�
�
��
�
�����
�
����
�
�
�
��
����
�
�
�
��
�����
�
��
�
��
��
�
��
����
�
�
�
�
��
�
�
���
��
�
��
���
���
��
�
�
��
��
����
�
�
�
�
�
�����
�
�
����
�
�
�
�
��
�
��
���
�
�
�
�
�
�
�
��
�
�
�
���
�
�
��
�
���
�
�
�
���
���
�
�
�
�
����
�
��
�
�
�
�
�������
��
�
�
�
�
���
�
��
����
�
�
�
�
�
��
�
������
�
���
����
�
�
��
��
�
���
�
��
�
�
��
�
�
�
�
�
�
�
�
�
�������
�
�
��
�
�
�
�
�
��
��
�
�
��
���
��
��
���
��
�
�
���
��
�
��
�
�
�
�
��
�
�
��
�
���������
��
�
�
������
�
�
���
�
�
�
�
�
��
�
����
�
��
�
���
�
�
������
��
�
��
���
��
�
�
�
���
�
�
��
�
�
�
��
���
�
��
�
�
�
�
����
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
�
�����
���
��
��
�
�
���
�
�����
�
�
�
�
�
�
��
�
��
�
�
�
���
�
�
���
�
��
�
�
�
�
�
�����
�
�
��
��
�
�
��
�
��
�
���
�
�
�
�
��
�
��
�
�
�
�
��
��
��
�
�
�
�
��
�
��
�
�
�
�
��
�
�
��
��
�
���
�
�
�
�
�
��
�
�
�
�����
��
���
��
�
�����
��
�
�
�
�
�
�
�
�
�
������
�
�
�
���
�
�
�
��
���
��
���
��
������
�
�
�
��
�
��
��
�
��
�
�������
�
�
�
�
��
�
���
�
�
���
��
�
�
�
�
�
����
����
�
��
�
�
�
��������
�
�
���
�
�
��
�
�
�����
�
��
�
�
���
�
�
�
������
�
�
�
�
�
���
�
�
������
�
�
�
�
�
���
�
��
�
��
�
�
�
��
�
��
�
�
�
��
�
�
�
�����
��
�
���
�
��
�
�
����
�
�
�
�����
��
���
�
�
�
�
�
����
�
�
�����
�
�
�
�
��
�
�
�
�
�
�
��
�
�
��
�
�
���
��
�
�
���
�
�
�
�
����
��
�
�
��
��
��
��
�
�
�
�
��
�����
����
���
�
�
�
�
�
�
�
�
�
�
�
���
��
�����
�
��
�
�
��
��
�
�
�
�
�
�
�
�����
�
�����
�
�
��
�
�
����
�
�����
����
�
�
��
���
�
�����
�
�
�
�
�
��
�
�
�
�
�
�
�����
�
���
�
�
�
��
�
��
������
�
�
�
�
��
�
�
�
���
��
��
�
��
��
�
�
�
�
��
�
�
��
�
�
�
�
�
�
�
�
�
��
�
��
��
�
��
�
�
�
�
�
�
�
�
���
���
�
�����
�
�
�
��
�
�
�
�
�
�
�
�
�
���
�
�
���������
�
��
���
��
�
�
�
�
�
���
��
�����
�
�
�
��
��
�
�
��
�
�
�
����
��
��
�
�
�
��
�
����
����
�
�
���
���
�
���
����
�
������
��
�
�
�
�
�
�
�
�
��
�����
�
���
���
�
�����
�
�
�
����
��
�
��
�����
�
������
�
�
��
�
��
�
�
�
�
���
�
�
��
�����
���
�
�
�
�
�
���
����
�
�
�
�
�
�
�
�
�
�����������
�
�
�
�
�
�
��
�
�
�
��
��
�
�
�
��
�
�
�
�
�
�
�
��
�����
��
�
�
�
�
�
�
�
��
������
�
��
�
�����
�
��
�
�
��
�
��
�
�
��
�
��
�
��
�������
�
��
��
�
���������
�
�
�
�
�
�
�
�
����
�
��
�
����������
�
�
�
�
��
��������
�
��
�
�
�
�
�
�
��
�
�
�
�
�
���
����
�
�
�
���
��
��
���
�
�
�
�
�
�
�
�
��
�
����
�
�
���
�
�
�
�
�
�
��
�
��
��
��
�
���
��������
��
�
��
���
�
��
��
�
�
�
��
�
�
�
�
���
�����
���
�
�
�
��
�
�
���������
�
�
�
�
���
�
���
�
�
�
�
��
�
�
����
������
�
�
�
��
�
�
�
�
�
���
�������
�����
�
�
�
�
����
�
�
��
��
�
��
�
�
�
��
�
�
�
�
�
��
�
�
�
�
��
��
�
����
�
�
��
���
�����
�
�
�
�
��
��
�
�
�
�
�
�
�
����
�
�
�
�
��
��
�
�
�����
�
���
�
�
��
�
��
�
�
��
�
��
��
�
��
�
�
����
�
�
�����
�
���
�
�
����
�
��
�
�
�
�
�
�
��
�
�
�
�
�
�
��
�
��
�
�
�
���
����
����
�
�
�
�
�
�
�
���
��
�
��
��
���
�
�
�
�
�
�
�
��
��������
��
��
�
��
�
�
�
��
�
�
�
��
�
��
�
�
������
��
��
�
��
�
��
�
�
�
�
�
�
������
�
�
�
�
�
�
�
�
�
�
�
�
�
����
�
��
�
�
�
�
��
��
����
��
��
�
��
��
�
�
��
�
�
�
��
�
�
�
��
�����
�
�
�
���
���
�
�
�
��
�
��
�
��
�
�
�
�
�
�
�����
�
�
�
�
��
�
�
�
�
�
�
�
�
��
���
���
�����
�
�
�
�
�
���
�
�
�
���
����
�
��
��
�
�
�
�����
�
�
�
��
�
�
�
���
���
����
���
�
�
��
�
�
�
�
��
�
�
�
�����
�
���
�
�
�
��
�
�
�
��
�
��
�
�
�������
�
�
�
��
�
�
�
�
�
�
�
�
�
�
�
�
�
����
�
���
���
����
�
���
����
�
�
�
�
�
�
�
�
��
����
�
��
����
�
�
�
�
�
�
�
�
�
�
�����
��
�
�
�
���
�
��
����
���������
�
�
�
�
��
�
��
�
�
�
�����
�
�
�
�
��
�
�
�
�
�
�
�
�����������
�
�
�
�
�
�
�
���
�
���
�
�
��������
�
�
�
�
�
�
�
�
�
�
��
�
�����
���
��
��
�
�
��
�
���
�
������
�
�
�
�
�
���
�
�����
��
����
�
�����
�
��
�
�
��
��
�
�
�
��
�
����
����
�
�
������
���
���������
����
�
�
���
�
��
�
�
�
��
��
�
�
�
�
�
���
�
�
�
�
�
�
���
�
�
�������
�
��
�
�
�
�
�
��
�
�
��
�
������������
��
��
��
�
�����
����
��
�
�
�
����
�
�
�
��
�
�
��
�
����
�
���
�
�
�
�
�
�
�
������
��
�
�
�
�
��
�
��
�
�
���
�
�
�
�
�����
�����
�
�
�
��
�
��
���
�
�
�
�
�
�
�
�
�
�
�
�
�
�
����
�
��
�
��
�
����
���
�
��
�
�
�
�
�
���
�
��
�
�
�
�
�
���
�
��
�
���
�
�
�������
��
���
���
��
�
��
�
���
�
�
���
�
�
�
�
�
��
��
�
�
�
�
�
�
�����
��
�
�
�
�
�
�
�
�
���
�
�
��
����
�
��
�
�
��
�
�
�
�
�
�
���
�
��
��
�����
�����
�
�
�����
�
�
�
��
�
�
�
��
�
���
�
���
�
�
��
�
��
�
��
�
��
�
��
��
�
��
���
�
��
�
���
�
����
�
�
���
�
��
�
����
�
��
�
�
�
�
�
���
�
�
�
�
�
�
�
������
�
��
�
�
�
�
�
��
����
����
�
�
���
���������
�
��
�
�
�
��
�
�
�
�
��
�
�
�
��
�
�
�����
����
�
�
�
�
�
�
�
����
����
�
��
�
�
��������
�
�
�
��
�
�
�
��
�
�
�
���
��
�
������
�
���
���
�
���
��
���
�
����
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�
�
�
�
����
��
��
�
�
��
�
�
��
��
�
�
�
�
��
����
�
����
�
���
��
�
�
����
�
�
�
�
�
�
����
��
�
�
�
�
��
�
��
��
�
�
���
�������
��
�
�
�
��
�����
�
�
�
�
�
�
�
�
�
�
�
��
������������
���
�
�
�
�
�
��
�
�
�
�
��
�
�
��
���
�
�
�
�
��
�
�
�
�
��
�
�
�
���
�
��
��
�
��
���
���
�
���
�
�
���
�������
�
�
���
��
�
�
�
�
�
�
���
�
�
�
���
��
��
�
�
��
���
�
�
�
�
�
�
�
����������
�
�
���
����
�
���
�������
�
�
�
����
�
�����
�
�
��
�
���
�
������
����
�
��
�
�
���
�
�
�
�
��
�
���
��
�
��
��
�
�
�
�
�
�
�
���
�
��
���
�
�
�
�
���������
��
�
�
�
��
�
�
�
�
����
���
�
�
�����
����
���
�
�
��
�
�
������
��������
�
�
��
��
��
�
�
�
�
�
�
����
����
�
������������
�
��
�
�
�
��
�
�
�
��
�������������
�
����
�
��
����
�
�
�
�
�����
�
��
��
�
�
��������
�
�
�
�
�
�
�
���
�
����
�
�
��
�
�
�
�
��
���
���
�
���
�
�
�
���
���
�
��
��������
�
��
�
�
���
�
�
��
������
��
�
��
�
���
�
�����
���
�
�
�������
�
���
��
����
�
�
�
���
�
��
�
����
�
��
�
�
�
��������
�
�
���
�����
�
�
��
��
�
����������
�
��
�
�
�
��
�
��
������
�
�
��
�
�
�
�
���
�
�
�
�
���
�
�
�
�
����
�
�
�
��
��
��
�
�
��������
�
�
����
�
�
�
�
�
��
�
��
�
�
�
�
�
�
��
�������
�
��
���
�
�
��
�
�
�
���
�
�
��
�
�
�
�
�
��
�
�
�
�
�
�
��
�
����
�����
��
�
���
��
�
�
�
��
���������
�
����
�
��
�
�����
���
���
��
���
�
�
�
���
�
�
��
�
��
���
��
�
�
�
�
�
�
�
�
��
�
�
���
�
�
�
�
�
�
�
�
��
�
�
�
�
�
��
��
�
�
��
�
��
�
��
�
���
�
�
�
�
�
�
�
�
�
�
�
�
�
�
��
��
�
�
�
�
�
����
��
�
�
��
�
�
��
�
�
�
�
��
�
�
�
�
��
�
��
�
�
�
��
�
��
�
�
�
�
��
���
�
��
�
�
��
�
�
�
�
�
�
�
��
�
��
��
��
���
�
�
��
�
�
�
�
����
�
����
�
�
�
�
�
�������������
�
�
�
�
�
���������
����
��
��
�
��
����
�
���
���
��
��
���
�
�
�
�
��
�
�
�
�
�
��
�
�
�
�
�
�
���
�
�
�
����
���
�
�
�����
����
�
�
��
���
�
�������
���
�
�
�
�
�
�
�
�
��
�
�
��
�
����
����
�
���
�
�
����
�
�
�
�����
�
���
������
��
�
��
�
����
�
����
�
�
���
�
��
�
�
�
�
���
�
��
�
�����
�
�
��
�
���
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
���
�
���
��
�
�
��
��
�
�
�
�
���
�
�
�
�
���������
�
�
���
�
���
�
�
�
��
����
�
�
�
��
���
�
�
��
�
�
�
�
���
�
�
���
�
��
�
�
�
�
��
��
�
����
�
�
�
���
�
��
�
�
����
�
���
�����
�
�
�
����
���
�
��
�
�
�
�
������
�
�
��
�
�
�
��
�����
�����
�
�
��
��
�
�
�
�
��
�
��
����
�
���
���
��
�
�
���
�
�
�
���
�
�
��
�
�������
��
���
�
�
��
�
���
���
�
��
�
�
�
�
����
�
�
�
��
�
�
�
�
��
�
�
���
�
�
�
�
��
���
���������
�
�
��
�
��
�
�
��
�
�
�
�
��
�
��
����
�
�
�
���
�
����
�
�
��
��
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
������
�
�
�
�
�
�
�
��
�
�
��
��
�
�
�
�
�
��
�
��
�
�
���
�
�
��
�
�
��
�
�
��
�
���
��
�
�
��
�
�
�
�
�
��
��
�
������
��
���
��
����
�
��
�
��
�
�
�
��
�
������
�
������
�
�
�
���
��
���
����������
�
�
�
�
��
�
�
����
�
�
�
�
�����
��
������
�
�
�
���
�
�
�
��
�
����
�
��
�
�
�
�
��
�
������
�
�
�
�
����
�
�
�
�
��������
�
��
���
�������
���
��
�
�
�
��
�
����
�
��
�
�
�
�
�
��
�
��
�
�������
�
�
�
�
�
�
����
��
�
�
�
�
��
�
�
�
�
�
�
�
���
�
�
������
�
��
�
�
��
�
����
�
�
���
��
���
���
�
��
���
��
�
��
������
�
��
�
�
��
�
�
�
�
�
�
�
���
��
�
��
�
������
��
�
������
�
�
����
�
�
�
��
�
�����
�
����
�
�
���
�
����
��
���
�
�
�
��
��
�
���
�
���
�
�
�
�
��
�
��
�
��
�
�
�
��
�
���
�
�
�
��
�
��
��
�
�
�
�����
�
�
���
�
�
��
����
��
�
��
�
�
��
����
�
�
�
�
�
�
�
�
��
�
���
�
��
��
�
�
�
�
������
�
�
�
��
��
����
�
�
��
�
�
��
�
���
�
��
�����
�
�
��
�
�
�
�
��
�
��
�
�
��
�
�
�
�������
��
���
�
�
�
�
�
�
�
�
�
�
����
��
�
�
��
�
�
�
�
�
�
���
��
�
�
�
�
�
����
��
�
�
�
�����
��
��
��
�
�
�
��
�
�
�
���
�
�
�
����
�
�
�
�
�
�
��
�
�
�
�
�������
�
��
�
���������������
������
�
��
�
��
�
�
�
�
�
�
�
�
���
�
�
���
�����������
�
�
����
�
�
�
�
�
�
����
�
���
���
�����
�
�
�
�
��
�
��
�
�
��
�
�
�
�
�
�
�
��
�
�
�
�
�
�
�
�
���
�
�
�
�
�
�
�
�
�
�
�
�
��
�
�
�
�
��
���
�
�
�
�
���
�
�
�
�
�
�
�
�
�
�
�
���
�
�
�
��
�
��
�
��
��
�
�
�
�
�
�
�
�
�
�
���
���
��
�
�
�
��
�����
�
���
�
��
�
��
��
�
��
�
��
��
�
��
�
�
�
�
�
�
�
�
�
�
�
�
�
����
�
�
�
�
���
�
�
�
�
��
����
�
�
���
�
�
�
�
�
�
���
�
�
�
�
�
�
���
�
�
�
�
���
�
�
���
�
������
�
�
���
���
�������������
�
�
�
�
����
�
�
�
�
��
�
�
��
�
�
���
��
�
�
�
����
���
�
�
��
�
����
�
�
����
�
���
�
���
�
�
�
�
�
�
��
�
�
�
�
�
���
�
���
�
�
�
����
���
�
�
�
��
���
�
�
�
����
�
����
�
�
�
�
�
��
�
�
�
��
�����
���
��
�
�
�
�
�
���
���
�����
��
�
�
�
��
��
���
�
�
�
�
�����
�
�
�
�
�
�
�
�
��
�
�
����
�
�
�
�
�
��
�
���
�
�
�
�
�
�
�
�
��
����
�
��
�
����
�
�
�
�
�
��
�
�
�
�
��
���
�
����
�
������
���
���
�
�
�
��
�
���
��
�
��
��
�
��
�
�
���
��
��
�
��
�
�
��
�����
�
�
��
�
����
����
�
��
������
�
�
�
�
�
��
�
����
�����
�
�����������
�
��
�
������
�
�
�
��
����
�
�
�
�
�
�
�
�
�
�
����
�
����
��
�
��
�
������
�
�
�
��
��
�
�
������
�
�
�
�
�
�����
��
��
�
��
��
�
�
�
�
�
�
�����
�
�
�
�
��
�
�
��
�����
�
�
��
�
�
�
��
��������
��
���
�
�
�
�
�
�
�
���
��
�
�������
�
�
�
����
�
�
���
�
���
�
�
��
�
���
�����
�
��
����
�
��
��
��
��
�
�
����
����
�
�
�����
�����
�
�
�
��
�
�
���������
�
��
�
�
��
�
��
�
�
�
����������
����
��
�
�����
�
��
�
�
�
�
�
��
��
�
��
�
��
�
��
�
�
��
����
������
�
�
�
��
�
�
�
��������
�
�
�
��
��
���
�
������
�
�������
������
�
�
�
���
�
�
�
�
�
��
�
�
�
�
���
�
�
�
�
����
��
��
���
�
�
�
���
�
�
�
���
�
�
�
�
�
��
�
�
�
�
���
�
�
�
�
����
�
�
�
�
���
������
����
�
���
�
�
�
����
�
����
�
����
�
������
�
���
�
�
�
�
�
�
���
�
�
�
�
��
�
�
�����
�
�
�
�
�
��
�
�
�
����
�
�
�
���
���
�
�
�
�
�
��
�
��
�
�
��
�
�
�
��
���
�
��
���
�
�
�
�
�
�
��
��
��
���
�
���
��
�
���
��
��
�
�����
�
�
�
�
�
����
�����
��
�
��
���
�
�
��
�
��
��
�
���
�
��
�
�
��
��
��
����
��
�
�
�
�
�
�
�
�
�
��
�
�
���
�����
����
��
�
������
�
�
�
����
�
��
�
����������
�
�
�
�����
��
�
�
�
�
����
�
�
�
�
��
�
��
�
�
��
��
��
�
���
�
�
�
��
�
�
�
�
�
��
��
��
�
�
�
�
����������
��
������
�
��
���
��
�
�
���
���
�����������
�
��
��
�
�
��
��
�
��
���
�
�
�
�
�
���������
��
�
�
���
���
����
�
�
������
�
�
�
�
�
�
�
�
�
��
�
�
���
�
�
�
�
��
�
�
��������
����
�
��
�
�
�
���
�����
�
�������
�
��
�
�
����
�
�
���
�
�
�
�
�
�
��
����
��
�
����
��
���
��
�
�
���
�
������
�
�
�
�
����
�
�
��
�
���
�
�
��
�
�
�
������������
�
�
��
�
��
��
������
�����
�
��
�
�
�
�����
�
��
��
���
�
�
�
�
�
��
���
��
�
�
�
��
�
��
�
��
��
���
���
�
�
�
�
��
���
�
��
��
�
���
�
�
�
�
�
�
�
�
�
�
�
�
��
�
���
�
�
�
�
��
�
�
�
��
�
�
�
�
�
�
��
��
��
��
�
���
��
�
�
�
���������
�
�
���
�
�
������
��
�
�
�
��
�
��
�
����
�
��
�
��
����
�
�
�
�
��
�
�����
���
�
���
���
�
��������
�
�������
��
�
�
�
��
�
�
���
�
���
�
��
�
���
�
�
���
�
�
�����
���
�
�
�
�
�����������
���
���
�
�������
�
�
�
�
�
�
������������
�
����
�
�
��
��
��
��
�
�
������
�
�
��
�
��
�
���
�
�
�
�
�
��
�
�
�����
�
��
�
��
�
���
�
�
��
�
�
��
�
����
�
����
��
�
�
��
��
�
�
�
�
�
�
��
�
�
���
��
�
����
��
���
����
�
��������
�
�
��
�
�
�
����
�
��
�
�
�
�
���
�
�
�
�
���������
�
����
�
����
�����
�
�
�
�
�
����
���������
����
���
�
��
�
�
��
�
��
�
��
����
�
����
��
�
������
��
�
�
�����
�
��
�
�
���
�
���
�
�
�
�
���
�
�
�
���
��
�
�
�
�
�
�
�
�
���
����
�
����
�
�
�
���
�
�
��
��
�
���
��
�
�
�
�
��
�
�
��
�
�
�
�
�
��
�
�
��
�
�
�
�
���
������
�
�
�
�
�
��
�
��
�
�
�
�
�
�
�
���������
�
�
���������
�
�
�
��������
�����
�
��
�
����
�
����
���
���
�
�
�
�����
��
�
�
��
�
���
�
�
�
�
���
����
������
���
�
�
�
�
����
�
�
��
�
�
��
�
���
�
�
�
�
��
�
��
�
�
�
�
��
��
�
�
���
�
�
�
�
�����
�
�
�
�
�
�
�
�
�������
�
�
�
����
�
����
���
��
�
����
����
�
�
�
�
����
�
�
�
���
�
�
�
��
�
�
���
�
�
�
�
�
�
�
�
����
�
�
��
��
����
�
�
��
��
�
��
�
�
�
��
��
�
�
�
�
�
��
�
�
�
�
�
������
�
�
�
��
��
�
�
�
�����
�
���
�
�
��
��
��
���
�
��
���
��
�
��
�
���
��
���
�
��
�
�
�
�
�
�
��
�
�
��
����
�����
�
�
��
����
�
�
�
��
�
��
�
�
�
�
��
��������
��
�
�
�
����
�
�
��������
�
�����
��
�
�
�
�
���
�
��������������
�
�
�
����
�
�
��
��
�
�
�
���
�
�
�
�
�
������
�
�
��
�
�
�������
�
��
�
�
�
����
���
��
��
�
�
����
��
�
�
�������
�
��������
�
�
����
��
�
�
��
���
�
���
��
�
�
�
�����
�
��
�
��
��
�
�
��
��
�
����
��
�
�����
�
�
��
�
�
�
�
��
�
�
�
�
����������
��
�
�
�
�
�
��
�
�
��
��
��
����
��
��
�
��
�
�
��
��
�
���
�
�
�
�
��
������
�
������
�
���
�
���
�
��
���
����
�
�
�
��
���
�
�
�
���
����
���
���
�
�������
�
�
�
�
���
�
��
��
�
�
�
�
�
�
�
�
�
�
����
�
��
�
������
�
��
��
�
����
�
�
����
��
�
�
���
�
�
�
�
��
�
��
�
�
�
�
��
�
��
�
�
�
���
�
��
�
��
���
�����
���
�
�
�
�
�
�
�
�
�
�
��
�
�
��������
�
�����
�
�
�
��
�
�
�
�
��
�
�
�
����
�
������
�
�
�����
��
�
�����
�
��
�
��
�
�����
�
�
�
�������
�
���
������������
��
�
�
�
���
��
��
�
��
�
���������
�
�
�
��
�
��
�
�
��
�
��
�
�
��
�
���
��
��
�
�����
���
��
�
���
�
�
�
���
��
�
�
�
�
������
�
�
����
��
��
�
��
�
���
�
��
�
��
������
�
�
�
�
��
�
�
��
�
�
���
�
�
�
�
������
�����
������
�
��
�
��
����
�
�����
�
�
�
�
��������
��
�
�
������
���
���
�
��
�
�
�
���
�
�
�
�
�
���
����
��
�����
�
�
������
��
�
�
�
�
�
�
��
�����
�
�
�
�
�
��
��
�
�
�
��
�
��
�
�
�
�
�
�
�
�
�
�
�
�
��
�
�
��
�
�
�
�
�
�
�
�
��
�
�
��
�
�
��
�
��
�
�
�
�
��
��
���
�
�
�
�
�
�
�
�
��
�
�
���
�
�
�
���
�
�
�
�
��
�
�
�����
�
�
�
�
�
�
��
�
��
��
�
�
�
�
�
�
��
��
�
�
��
�
�
���
����
���
�
�
��
��
�
�
�
��
�����
�
�
�
�
�
�
�
�
����
���
�
�
�
�
����
�
���
�
�
���
������
��
�
���
�
��
�
���
�
��
��
�
��
�
�
�
�
�
����
��
����
���
�
�
�
�
���
�
�����
�
�
�
�
����
�
�
�
�
�
�
�
�
�
�
��
���
�
�
�
���
�
��
�
�
�
�
�
�
�
�
�
�
����
�
����
�
�
�
��
�
�
��
�
�
�
�
��
�
��
��
�
��
�
�
�
�
�
��
�
���
�
��
��
��
�
��
�
�
��
�
�
�
�
���
�
����
�
�
�
���
�
�
��
�
�
�
���
�
��
���
�
�
�
�������
���
�
���
�
�
�
��
��
���
�
��
��
��
�����
��
�
�
�
�����
���
�
�
��
�
�
�
�
�
����
�
���
�
���
�
�
���
�
��
�
��
�
�
�
�����
�
�
�
�
�
�
�
�
��
��������
����
��
�����
�
��
���
��
�
������
�
�
�
��
���
�
��
0100200300400500
0100200300400500
0 500 1000 1500Time (seconds)
Req
uest
s re
ceive
d pe
r 100
ms Load pathologies due to Dynamic Snitching
Figure 2: Example load oscillations seen by a given node inCassandra due to Dynamic Snitching, in measurements ob-tained on Amazon EC2. The y-axis represents the numberof requests processed in a 100 ms window by a Cassandranode. Even under stable conditions (bottom), the numberof requests processed in a 100 ms window by a node rangesfrom 0 up to 500, which is symptomatic of herd behavior.
cluster confirm this (the details of the experimental setupare described in § 5). In particular, we recorded heavy-tailed latency characteristics wherein the difference be-tween the 99.9th percentile latencies are up to 10 timesthat of the median. Furthermore, we recorded the num-ber of read requests individual Cassandra nodes servicedin 100 ms intervals. For every run, we observed the nodethat contributed most to the overall throughput. Thesenodes consistently exhibited synchronized load oscilla-tions, example sequences of which are shown in Figure 2.Additionally, we confirmed our results with the Spotifyengineers, who have also encountered load instabilitiesthat arise due to garbage-collection induced performancefluctuations in the system [29].
A key reason for Dynamic Snitching’s vulnerabilityto oscillations is that each Cassandra node re-computesscores for its peers at fixed, discrete intervals. This inter-val based scheme poses two problems. First, the sys-tem cannot react to time-varying performance fluctua-tions among peers that occur at time-scales less than thefixed-interval used for the score recomputation. Second,by virtue of fixing a choice over a discrete time inter-val (100 ms by default), the system risks synchroniza-tion as seen in Figure 2. While one may argue that thiscan be overcome by shortening the interval itself, thecalculation performed to compute the scores is expen-sive, as it is also stated explicitly in the source code; amedian over a history of exponentially weighted latencysamples (that is reset only every 10 minutes) has to becomputed for each node as part of the scoring process.Additionally, Dynamic Snitching relies on gossiping onesecond averages of iowait information between nodesto aid with the ranking procedure (the intuition being thatnodes can avoid peers who are performing compaction).These iowait measurements influence the scores used
Server A
Server B
RSRL
Response
Request
C3 Clients
RL
Feedback
Application
Figure 3: Overview of C3. RS: Replica Selection scheduler,RL: Rate Limiter of server s ∈ [A,B].
for ranking peers heavily (up to two orders of magni-tude more influence than latency measurements). Thus,an external or internal perturbation in I/O activity caninfluence a Cassandra node’s replica selection loop forextended intervals. Together with the synchronization-prone behavior of having a periodically updated ranking,this can lead to poor replica selection decisions that de-grade system performance.
3 C3 DesignC3 is an adaptive replica selection mechanism designedwith the objective of reducing tail latency. Based on theconsiderations in Section 2, we design C3 while keepingin mind these two goals:
i) Adaptive: Replica selection must cope and quicklyreact to heterogeneous and time-varying servicetimes across servers.
ii) Well-behaved: Clients performing replica selectionmust avoid herd behaviors where a large number ofclients concentrate requests towards a fast server.
At the core of C3’s design are the two following com-ponents that allow it to satisfy the above properties:
1. Replica Ranking: Using minimal and approximatefeedback from individual servers, clients rank andprefer servers according to a scoring function. Thescoring function factors in the existence of multi-ple clients and the subsequent risk of herd behavior,whilst allowing clients to prefer faster servers.
2. Distributed Rate Control and Backpressure: Ev-ery client rate limits requests destined to eachserver, adapting these rates in a fully-distributedmanner using a congestion-control inspired tech-nique [22]. When rate limits of all candidate serversfor a request are exceeded, clients retain requests ina backlog queue until at least one server is within itsrate limit again.
3.1 Replica rankingWith replica ranking, clients individually rank servers ac-cording to a scoring function, with the scores serving asa proxy for the latency to expect from the correspond-ing server. Clients then use these scores to prefer fasterservers (lower scores) for each request. To reduce tail la-tency, we aim to minimize the product of queue-size (qs)
4

USENIX Association 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) 517
and service-time (1/µs, the inverse of the service rate)across every server s (Figure 1).Delayed and approximate feedback. In C3, servers re-lay feedback about their respective qs and 1/µs on eachresponse to a client. The qs is recorded after the requesthas been serviced and the response is about to be dis-patched. Clients maintain Exponentially Weighted Mov-ing Averages (EWMA) of these metrics to smoothen thesignal. We refer to these smoothed values as qs and µs.Accounting for uncertainty and concurrency. The de-layed feedback from the servers lends clients only an ap-proximate view of the load across the servers and is notsufficient by itself. Such a view is oblivious to the exis-tence of other clients in the system, as well as the numberof requests that are potentially in flight, and is thus proneto herd behaviors. It is therefore imperative that clientsaccount for this potential concurrency in their estimationof each server’s queue-size.
For each server s, a client maintains an instantaneouscount of its outstanding requests oss (requests for whicha response is yet to be received). Clients calculate thequeue-size estimate (qs) of each server as qs = 1+ oss ·w+ qs, where w is a weight parameter. We refer to theoss ·w term as the concurrency compensation.
The intuition behind the concurrency compensationterm is that a client will always extrapolate the queue-size of a server by an estimated number of requests inflight. That is, it will always account for the possibil-ity of multiple clients concurrently submitting requeststo the same server. Furthermore, clients with a highervalue of oss will implicitly project a higher queue-size ats and thus rank it lower than a client that has sent fewerrequests to s. Using this queue-size estimate to projectthe qs/µs ratio results in a desirable effect: a client witha higher demand will be more likely to rank s poorlycompared to a client with a lighter demand. This henceprovides a degree of robustness to synchronization. Inour experiments, we set w to the number of clients inthe system. This serves as a good approximation in set-tings where the number of clients is comparable to theexpected queue lengths at the servers.Penalizing long queues. With the above estimation,clients can compute the qs/µs ratio of each server andrank them accordingly. However, given the existence ofmultiple clients and time-varying service times, a func-tion linear in q is not an effective scoring function forreplica ranking. To see why, consider the example inFigure 4. The figure shows how clients would score twoservers using a linear function: here, the service time es-timates are 4 ms and 20 ms, respectively. We observe thatunder a linear scoring regime, for a queue-size estimate
0
500
1000
1500
2000
0e+00
1e+05
2e+05
3e+05
4e+05
5e+05
0 25 50 75 100 0 10 20 30 40 50Queue Size Estimate Queue Size Estimate
Scor
e
Scor
e
1 µ = 20 ms1 µ = 4 ms
1 µ = 20 ms1 µ = 4 ms
(qs) / µ (qs)3 / µ
Figure 4: A comparison between linear (left) and cubic(right) scoring functions. For differing values of 1/µ , thedifference in queue-size estimates required for the scores oftwo replicas to be equal is smaller for the cubic function(thus penalizing longer queues).
of 20 at the slower server, only a corresponding valueof 100 at the faster server would cause a client to preferthe slower server again. If clients distribute requests bychoosing the best replica according to this scoring func-tion, they will build up and maintain long queues at thefaster server in order to balance response times betweenthe two nodes.
However, if the service time of the faster server in-creases due to an unpredictable event such as a garbagecollection pause, all requests in its queue will incurhigher waiting times. To alleviate this, C3’s scoringfunction penalizes longer queue lengths using the sameintuition behind that of delay costs as in [10,46]. That is,we use a non-decreasing convex function of the queue-size estimate in the scoring function to penalize longerqueues. We achieve this by raising the qs term in thescoring function to a higher degree, b: (qs)
b/µs.Returning to the above example, this means the scor-
ing function will treat the above two servers as being ofequal score if the queue-size estimate of the faster server(1/µ = 4 ms) is b
√20/4 times that of the slower server
(1/µ = 20 ms). For higher values of b, clients will beless greedy about preferring a server with a lower µ−1.We use b = 3 to have a cubic scoring function (Figure 4),which presents a good trade-off between clients prefer-ring faster servers and providing enough robustness totime-varying service times.Cubic replica selection. In summary, clients use thefollowing scoring function for each replica:
Ψs = Rs −1/µs +(qs)3/µs
where qs = 1+ oss · n+ qs is the queue-size estimationterm, oss is the number of outstanding requests from theclient to s, n is the number of clients in the system, andRs, qs and µs
−1 are EWMAs of the response time (aswitnessed by the client),1 queue-size and service time
1Note Rs implicitly accounts for network latency but we consider
5

518 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) USENIX Association
feedback received from server s, respectively. The scorereduces to Rs when the queue-size estimate term of theserver is 1 (which can only occur if the client has nooutstanding requests to s and the queue-size feedback iszero). Note that the Rs − µ−1
s term’s contribution to thescore diminishes quickly when the client has a non-zeroqueue-size estimate (see Figure 4).
3.2 Rate control and backpressureReplica selection allows clients to prefer faster servers.However, replica selection alone cannot ensure that thecombined demands of all clients on a single server re-main within that server’s capacity. Exceeding capac-ity increases queuing on the server-side and reduces thesystem’s reactivity to time-varying performance fluctua-tions. Thus, we introduce an element of rate-control tothe system, wherein every client rate-limits requests toindividual servers. If the rates of all candidate serversfor a request are saturated, clients retain the request in abacklog queue until a server is within its rate limit again.Decentralized rate control. To account for servers’performance fluctuations, clients need to adapt their es-timations of a server’s capacity and adjust their sendingrates accordingly. As a design choice and inspired by theCUBIC congestion-control scheme [22], we opt to use adecentralized algorithm for clients to estimate and adaptrates across servers. That is, we avoid the need for clientsto inform each other about their demands for individualservers, or for the servers to calculate allocations for po-tentially numerous clients individually. This further in-creases the robustness of our system; clients’ adaptationto performance fluctuations in the system is not purelytied to explicit feedback from the servers.
Thus, every client maintains a token-bucket basedrate-limiter for each server, which limits the number ofrequests sent to a server within a specified time windowof δ ms. We refer to this limit as the sending-rate (srate).To adapt the rate limiter according to the perceived per-formance of the server, clients track the number of re-sponses being received from a server in a δ ms interval,that is, the receive-rate (rrate). The rate-adaptation algo-rithm aims to adjust srate in order to match the rrate ofthe server.Cubic rate adaptation function. Upon receiving a re-sponse from a server s, the client compares the currentsrate and rrate for s. If the client’s sending rate is lowerthan the receive rate, it increases its rate according to acubic function [22]:
srate ← γ ·
(∆T − 3
√(
β ·R0
γ)
)3
+R0
that network congestion is not the source of performance fluctuations.
R0Saddle Region
Low RateRegion
OptimisticProbingRegion
0 50 100 150 200∆T (ms)
Rat
e (re
ques
ts p
er δ
ms)
Cubic growth curve for rate control
Figure 5: Cubic function for clients to adapt their sendingrates
where ∆T is the elapsed time since the last rate-decreaseevent, and R0 is the “saturation rate” — the rate at thetime of the last rate-decrease event. If the receive-rateis lower than the sending-rate, the client decreases itssending-rate multiplicatively by β . γ represents a scal-ing factor and is chosen to set the desired duration of thesaddle region (see § 4 for the values used).Benefits of the cubic function. While we have notfully explored the vast design space for a rate adaptationtechnique, we were attracted to a cubic growth functionbecause of its property of having a saddle region. Thefunctioning of the cubic rate adaption strategy caters tothe following three operational regions (Figure 5): (1)Low-rates: when the current sending rate is significantlylower than the saturation rate (after say, a multiplicativedecrease),the client increases the rate steeply; (2) Saddleregion: when the sending rate is close to the perceivedsaturation point of the server (R0), the client stabilizesits sending rate, and increases it conservatively, and (3)Optimistic probing: if the client has spent enough timein the stable region, it will again increase its rate aggres-sively, and thus probe for more capacity. At any time, ifthe algorithm perceives itself to be exceeding the server’scapacity, it will update its view of the server’s saturationpoint and multiplicatively reduce its sending rate. Theparameter γ can be adjusted for a desired length of thesaddle region. Lastly, given that multiple clients may po-tentially be adjusting their rates simultaneously, for sta-bility reasons, we cap the step size of a rate increase bya parameter smax.
3.3 Putting everything togetherC3 combines distributed replica selection and rate con-trol as indicated in Algorithms 1 and 2, with the controlflow in the system depicted in Figure 3. When a requestis issued at a client, it is directed to a replica selectionscheduler. The scheduler uses the scoring function toorder the subset of servers that can handle the request,that is, the replica group (R). It then iterates through thelist of replicas and selects the first server s that is within
6

USENIX Association 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) 519
Algorithm 1 On Request Arrival (Request req, Replicas R)
1: repeat2: R ← sort(R) � sort replicas by cubic score function3: for Server s in R do4: if s within srates then5: consume token(srates)6: oss ← oss +1 � update outstanding requests7: send(req,s) � send to server s8: return9: if req not sent then
10: wait until token available � Backpressure11: until req is sent
Algorithm 2 On Request Completion (Request req, Server s)
1: oss ← oss −1 � update outstanding requests2: update EWMA of qs, µ−1
s feedback3: if (srates > rrates && now()−Tinc > hysteresis period) then4: R0 ← srates5: srates ← srates ·β6: Tdec ← now()7: else if (srates < rrates) then8: ∆T ← now()−Tdec9: Tinc ← now()
10: R ← γ ·(
∆T − 3√
( β ·R0γ )
)3+R0
11: srates ← min(srates + smax,R)
the rate as defined by the local rate limiter for s. If allreplicas have exceeded their rate limits, the request is en-queued into a backlog queue. The scheduler then waitsuntil at least one replica is within its rate before repeatingthe procedure. When a response for a request arrives, theclient records the feedback metrics from the server andadjusts its sending rate for that server according to thecubic-rate adaptation mechanism. After a rate increase,a hysteresis period is enforced (Algorithm 2, line 3) be-fore another rate-decrease so as to allow clients’ receive-rate measurements enough time to catch up since the lastincreased sending rate at Tinc.
4 ImplementationWe implemented C3 within Cassandra. For Cassandra’sinternal read-request routing mechanism, this means thatevery Cassandra node is both a C3 client and server(specifically, coordinators in Cassandra’s read path areC3 clients). In vanilla Cassandra, every read requestfollows a synchronous chain of steps leading up to aneventual enqueuing of the request into a per-node TCPconnection buffer. For C3, we modified this chain ofsteps to control the number of requests that would bepushed to the TCP buffers of each node. Recall that C3’sreplica scoring and rate control operate at the granular-ity of replica groups. Given that in Cassandra, there areas many replica groups as nodes themselves, we need asmany backpressure queues and replica selection sched-ulers as there are nodes. Thus, every read-request uponarrival in the system needs to be asynchronously routed
to a scheduler corresponding to the request’s replicagroup. Lastly, when a coordinator node performs a re-mote read, the server that handles the request tracks theservice time of the operation and the number of pendingread requests in the server. This information is piggy-backed to the coordinator and serves as the feedback forthe replica ranking.
There are challenges in making this implementationefficient. For one, since a single remote peer can bepart of multiple replica sets, multiple admission con-trol schedulers may potentially contend to push a re-quest from their respective backpressure queues towardsthe same endpoint. Care needs to be exercised that thisdoes not lead to starvation. To handle this complexity,we relied upon the Akka framework [1] for message-passing concurrency (Actor based programming). WithAkka, every per-replica-group scheduler is representedas a single actor, and we configured the underlyingJava thread dispatcher to fair schedule between the ac-tors. This design of having multiple backpressure queuesalso increases robustness, as one replica group enteringbackpressure will not affect other replica groups. Themessage queue that backs each Akka actor implicitlyserves as the backpressure queue per-replica group. Atroughly 600 bytes of overhead per actor, our extensionsto Cassandra is thus lightweight. Our implementationamounted to 398 lines of code.2
For the rest of our study, we set the cubic rate adapta-tion parameters as follows: the multiplicative decreaseparameter β is set to 0.2, and we configured γ to setthe saddle region to be 100 ms long. We define the ratefor each server as a number of permissible requests per20 ms (δ ), and use a hysteresis duration equal to twicethe rate interval. We cap the cubic-rate step size (smax) to10. We did not conduct an exhaustive sensitivity analysisof all system parameters, which we leave for future work.Lastly, Cassandra uses read-repairs for anti-entropy; afraction of read requests will go to all replicas (10% bydefault). This further allows coordinators to update theirview of their peers.
5 System EvaluationWe evaluated C3 on Amazon EC2. Our Cassandra de-ployment comprised 15 m1.xlarge instances. We tunedthe instances and Cassandra according to the officiallyrecommended production settings from Datastax [12] aswell as in consultation with our contacts from the indus-try who operate production Cassandra clusters.
On each instance, we configured a single RAID0 ar-ray encompassing the four ephemeral disks which served
2Based on a Cassandra 2.0 development version.
7
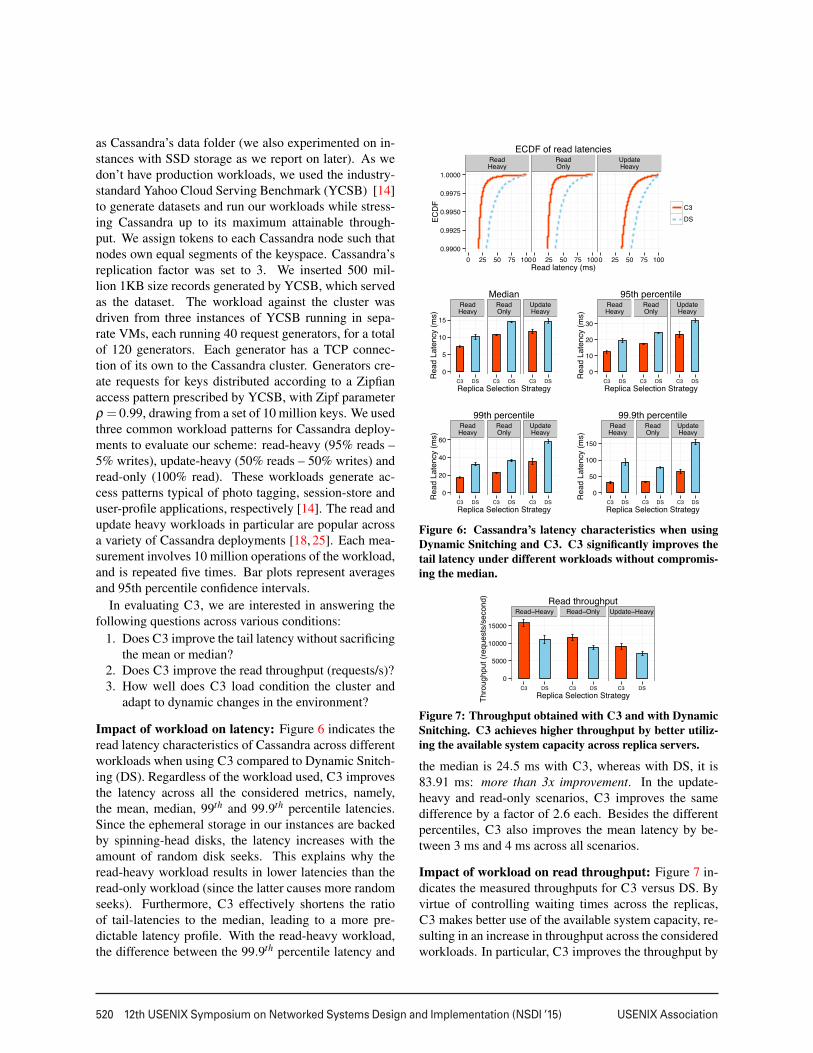
520 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) USENIX Association
as Cassandra’s data folder (we also experimented on in-stances with SSD storage as we report on later). As wedon’t have production workloads, we used the industry-standard Yahoo Cloud Serving Benchmark (YCSB) [14]to generate datasets and run our workloads while stress-ing Cassandra up to its maximum attainable through-put. We assign tokens to each Cassandra node such thatnodes own equal segments of the keyspace. Cassandra’sreplication factor was set to 3. We inserted 500 mil-lion 1KB size records generated by YCSB, which servedas the dataset. The workload against the cluster wasdriven from three instances of YCSB running in sepa-rate VMs, each running 40 request generators, for a totalof 120 generators. Each generator has a TCP connec-tion of its own to the Cassandra cluster. Generators cre-ate requests for keys distributed according to a Zipfianaccess pattern prescribed by YCSB, with Zipf parameterρ = 0.99, drawing from a set of 10 million keys. We usedthree common workload patterns for Cassandra deploy-ments to evaluate our scheme: read-heavy (95% reads –5% writes), update-heavy (50% reads – 50% writes) andread-only (100% read). These workloads generate ac-cess patterns typical of photo tagging, session-store anduser-profile applications, respectively [14]. The read andupdate heavy workloads in particular are popular acrossa variety of Cassandra deployments [18, 25]. Each mea-surement involves 10 million operations of the workload,and is repeated five times. Bar plots represent averagesand 95th percentile confidence intervals.
In evaluating C3, we are interested in answering thefollowing questions across various conditions:
1. Does C3 improve the tail latency without sacrificingthe mean or median?
2. Does C3 improve the read throughput (requests/s)?3. How well does C3 load condition the cluster and
adapt to dynamic changes in the environment?
Impact of workload on latency: Figure 6 indicates theread latency characteristics of Cassandra across differentworkloads when using C3 compared to Dynamic Snitch-ing (DS). Regardless of the workload used, C3 improvesthe latency across all the considered metrics, namely,the mean, median, 99th and 99.9th percentile latencies.Since the ephemeral storage in our instances are backedby spinning-head disks, the latency increases with theamount of random disk seeks. This explains why theread-heavy workload results in lower latencies than theread-only workload (since the latter causes more randomseeks). Furthermore, C3 effectively shortens the ratioof tail-latencies to the median, leading to a more pre-dictable latency profile. With the read-heavy workload,the difference between the 99.9th percentile latency and
ReadHeavy
ReadOnly
UpdateHeavy
0.9900
0.9925
0.9950
0.9975
1.0000
0 25 50 75 1000 25 50 75 1000 25 50 75 100Read latency (ms)
ECD
F C3DS
ECDF of read latencies
ReadHeavy
ReadOnly
UpdateHeavy
0
5
10
15
C3 DS C3 DS C3 DSReplica Selection Strategy
Rea
d La
tenc
y (m
s)
MedianReadHeavy
ReadOnly
UpdateHeavy
0
10
20
30
C3 DS C3 DS C3 DSReplica Selection Strategy
Rea
d La
tenc
y (m
s)
95th percentile
ReadHeavy
ReadOnly
UpdateHeavy
0
20
40
60
C3 DS C3 DS C3 DSReplica Selection Strategy
Rea
d La
tenc
y (m
s)
99th percentileReadHeavy
ReadOnly
UpdateHeavy
0
50
100
150
C3 DS C3 DS C3 DSReplica Selection Strategy
Rea
d La
tenc
y (m
s)
99.9th percentile
Figure 6: Cassandra’s latency characteristics when usingDynamic Snitching and C3. C3 significantly improves thetail latency under different workloads without compromis-ing the median.
Read−Heavy Read−Only Update−Heavy
0
5000
10000
15000
C3 DS C3 DS C3 DSReplica Selection StrategyTh
roug
hput
(req
uest
s/se
cond
) Read throughput
Figure 7: Throughput obtained with C3 and with DynamicSnitching. C3 achieves higher throughput by better utiliz-ing the available system capacity across replica servers.
the median is 24.5 ms with C3, whereas with DS, it is83.91 ms: more than 3x improvement. In the update-heavy and read-only scenarios, C3 improves the samedifference by a factor of 2.6 each. Besides the differentpercentiles, C3 also improves the mean latency by be-tween 3 ms and 4 ms across all scenarios.
Impact of workload on read throughput: Figure 7 in-dicates the measured throughputs for C3 versus DS. Byvirtue of controlling waiting times across the replicas,C3 makes better use of the available system capacity, re-sulting in an increase in throughput across the consideredworkloads. In particular, C3 improves the throughput by
8
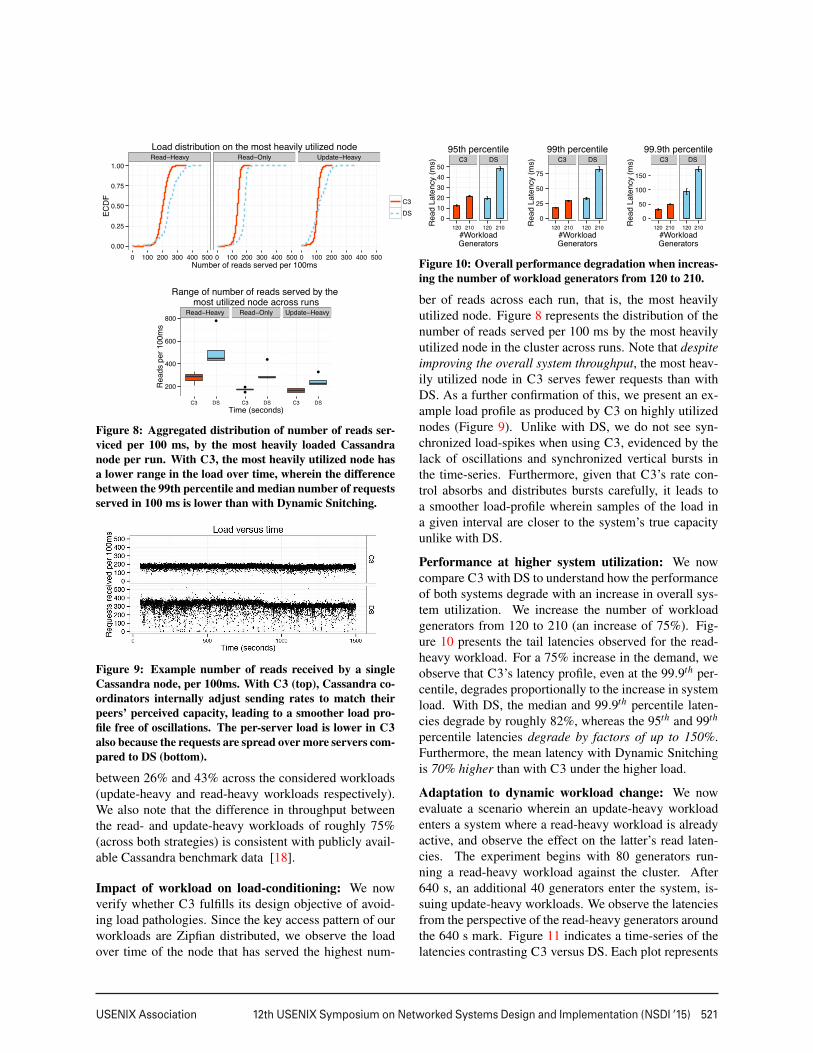
USENIX Association 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) 521
Read−Heavy Read−Only Update−Heavy
0.00
0.25
0.50
0.75
1.00
0 100 200 300 400 500 0 100 200 300 400 500 0 100 200 300 400 500Number of reads served per 100ms
ECD
F C3DS
Load distribution on the most heavily utilized node
Read−Heavy Read−Only Update−Heavy�
�
�
�
�
200
400
600
800
C3 DS C3 DS C3 DSTime (seconds)
Rea
ds p
er 1
00m
s
Range of number of reads served by the most utilized node across runs
Figure 8: Aggregated distribution of number of reads ser-viced per 100 ms, by the most heavily loaded Cassandranode per run. With C3, the most heavily utilized node hasa lower range in the load over time, wherein the differencebetween the 99th percentile and median number of requestsserved in 100 ms is lower than with Dynamic Snitching.
Time (seconds)
Figure 9: Example number of reads received by a singleCassandra node, per 100ms. With C3 (top), Cassandra co-ordinators internally adjust sending rates to match theirpeers’ perceived capacity, leading to a smoother load pro-file free of oscillations. The per-server load is lower in C3also because the requests are spread over more servers com-pared to DS (bottom).
between 26% and 43% across the considered workloads(update-heavy and read-heavy workloads respectively).We also note that the difference in throughput betweenthe read- and update-heavy workloads of roughly 75%(across both strategies) is consistent with publicly avail-able Cassandra benchmark data [18].
Impact of workload on load-conditioning: We nowverify whether C3 fulfills its design objective of avoid-ing load pathologies. Since the key access pattern of ourworkloads are Zipfian distributed, we observe the loadover time of the node that has served the highest num-
C3 DS
01020304050
120 210 120 210#WorkloadGenerators
Rea
d La
tenc
y (m
s)
95th percentileC3 DS
0
25
50
75
120 210 120 210#WorkloadGenerators
Rea
d La
tenc
y (m
s)
99th percentileC3 DS
0
50
100
150
120 210 120 210#WorkloadGenerators
Rea
d La
tenc
y (m
s)
99.9th percentile
Figure 10: Overall performance degradation when increas-ing the number of workload generators from 120 to 210.
ber of reads across each run, that is, the most heavilyutilized node. Figure 8 represents the distribution of thenumber of reads served per 100 ms by the most heavilyutilized node in the cluster across runs. Note that despiteimproving the overall system throughput, the most heav-ily utilized node in C3 serves fewer requests than withDS. As a further confirmation of this, we present an ex-ample load profile as produced by C3 on highly utilizednodes (Figure 9). Unlike with DS, we do not see syn-chronized load-spikes when using C3, evidenced by thelack of oscillations and synchronized vertical bursts inthe time-series. Furthermore, given that C3’s rate con-trol absorbs and distributes bursts carefully, it leads toa smoother load-profile wherein samples of the load ina given interval are closer to the system’s true capacityunlike with DS.
Performance at higher system utilization: We nowcompare C3 with DS to understand how the performanceof both systems degrade with an increase in overall sys-tem utilization. We increase the number of workloadgenerators from 120 to 210 (an increase of 75%). Fig-ure 10 presents the tail latencies observed for the read-heavy workload. For a 75% increase in the demand, weobserve that C3’s latency profile, even at the 99.9th per-centile, degrades proportionally to the increase in systemload. With DS, the median and 99.9th percentile laten-cies degrade by roughly 82%, whereas the 95th and 99th
percentile latencies degrade by factors of up to 150%.Furthermore, the mean latency with Dynamic Snitchingis 70% higher than with C3 under the higher load.
Adaptation to dynamic workload change: We nowevaluate a scenario wherein an update-heavy workloadenters a system where a read-heavy workload is alreadyactive, and observe the effect on the latter’s read laten-cies. The experiment begins with 80 generators run-ning a read-heavy workload against the cluster. After640 s, an additional 40 generators enter the system, is-suing update-heavy workloads. We observe the latenciesfrom the perspective of the read-heavy generators aroundthe 640 s mark. Figure 11 indicates a time-series of thelatencies contrasting C3 versus DS. Each plot represents
9

522 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) USENIX Association
Time (s)
Figure 11: Dynamic workload experiment. The moving me-dian over the latencies observed by the read-heavy gener-ators from a run each involving C3 (left) and DS (right).At time 640 s, 40 new generators join the system and issueupdate-heavy workloads. With C3, the latencies degradegracefully, whereas DS fails to avoid latency spikes.
0
5
10
15
C3 DSReplica Selection
Strategy
Rea
d La
tenc
y (m
s)
95th percentile
0
5
10
15
20
C3 DSReplica Selection
Strategy
Rea
d La
tenc
y (m
s)
99th percentile
0
10
20
30
C3 DSReplica Selection
Strategy
Rea
d La
tenc
y (m
s)
99.9th percentile
Figure 12: Results when using SSDs instead of spinning-head disks.
a 50-sample wide moving median3 over the recorded la-tencies. Both DS and C3 react to the new generatorsentering the system, with a degradation of the read laten-cies observed at the 640 s mark. However, in contrast toDS, C3’s latency profile degrades gracefully, evidencedby the lack of synchronized spikes visible in the time-series as is the case with DS.Skewed record sizes: So far, we considered fixed-lengthrecords. Since C3 relies on per-request feedback of theservice times in the system, we observe whether variablelength records may introduce any anomalies in the con-trol loop. We use YCSB to generate a similar datasetas before, but where field sizes are Zipfian distributed(favoring shorter values). The maximum record length is2KB, with each record comprising the key, and ten fields.Again, C3 improves over DS along all the considered la-tency metrics. In particular, with C3, the 99th percentilelatency is just under 14 ms, whereas that of DS is closeto 30 ms; more than 2x improvement.Performance when using SSDs: As a further demon-stration of C3’s generality, we also perform measure-ments with m3.xlarge instances, which are backed bytwo 40 GB SSD disks. We configured a RAID0 ar-ray encompassing both disks. We reduced the datasetsize to 150 million 1KB records in order to ensurethat the dataset fits the reduced disk capacities of all
3A moving median is better suited to reveal the underlying trend ofa high-variance time-series than a moving average [7]
nodes. Given that with SSDs, the system can sustain ahigher workload, we used 210 read-heavy generators (70threads per YCSB instance). Figure 12 illustrates the la-tency improvements obtained when using C3 versus DSwith SSD backed instances. Even under the higher load,both algorithms have significantly lower latencies thanwhen using spinning head disks. However, C3 againimproves the 99.9th percentile latency by more than 3x.Furthermore, the difference between the 99th and 99.9th
percentile latencies in C3 is under 5 ms, whereas withDS, it is on the order of 20 ms. Lastly, C3 also improvesthe average latency by roughly 3 ms, and increases theread throughput by 50% of that obtained by DS.
Comparison against request reissues: Cassandra hasan implementation of speculative retries [16] as a meansof reducing tail latencies. After sending a read request toa replica, the coordinator waits for the response until aconfigurable duration before reissuing the request to an-other replica. We evaluated the performance of DS withspeculative retries, configured to fire after waiting untilthe 99th percentile latency. However, we observed thatlatencies actually degraded significantly after making useof this feature, up to a factor of 5 at the 99th percentile.We attribute this to the following cause: in the presenceof highly variable response times across the cluster (al-ready due to DS), coordinators potentially speculate toomany requests. This increases the load on disks, furtherincreasing seek latencies. Due to this anomaly, we didnot perform further experiments. We however, leave anote of caution that speculative retries are not a silverbullet when operating a system at high utilization [48].
Sending rate adaptation and backpressure over time:Lastly, we turn to a seven-node Cassandra cluster in ourlocal testbed to depict how nodes adapt their sendingrates over time. Figure 13 presents a trace of the sendingrate adaptation performed by two coordinators against athird node (tracked node). During the run, we artificiallyinflated the latencies of the tracked node thrice (usingthe Linux tc utility), indicated by the drops in through-put in the interval (45, 55) s, as well as the two shorterdrops at times 59 s and 67 s. Observe that both coordina-tors’ estimations of their peer’s capacity agree over time.Furthermore, the figure depicts all three rate regimes ofthe cubic rate control mechanism. The points close to1 on the y-axis are arrived at via the multiplicative de-crease, causing the system to enter the low-rate regime.At that point, C3 aggressively increases its rate to becloser to the tracked saturation rate, entering the saddleregion (along the smoothened median). The stray pointsabove the smoothened median are points where C3 op-timistically probes for more capacity. During this run,
10

USENIX Association 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) 523
Time (s)
Figure 13: Sending rate adaptation performed by two co-ordinators against a third server. The receiving server’slatency is artificially inflated thrice. The blue dots repre-sent the sending-rates as adjusted by the cubic rate controlalgorithm, the black line indicates a moving median of thesending rates, and the red X marks indicate moments whenaffected replica group schedulers enter backpressure mode.
the backpressure mechanism fired 4 times (3 of whichare very close in time) across both depicted coordina-tor nodes. Recall that backpressure is exerted when allreplicas of a replica group have exceeded their rate limits.When the tracked node’s latencies are reset to normal, theYCSB generators throttle up, sending a heavy burst in ashort time interval. This causes a momentary surge oftraffic towards the tracked node, forcing the correspond-ing replica selection schedulers to apply backpressure.
6 Evaluation Using SimulationsWe turn to simulations to further evaluate C3 under dif-ferent scenarios. Our objective is to study the C3 schemeindependently of the intricacies of Cassandra and drawmore general results. Furthermore, we are interested inunderstanding how the scheme performs under differentoperational extremes. In particular, we explore how C3’sperformance varies according to (i) different frequenciesof service time fluctuations, (ii) lower utilization levels,and (iii) under skewed client demands.Experimental setup: We built a discrete-event simula-tor4, wherein workload generators create requests at a setof clients, and the clients then use a replica selection al-gorithm to route requests to a set of servers. A requestgenerated at a client has a uniform probability of beingforwarded to any replica group (that is, we do not modelkeys being distributed across servers according to consis-tent hashing as in Cassandra). The workload generators
4Code at https://github.com/lalithsuresh/absim.
create requests according to a Poisson arrival process, tomimic arrival of user requests at web servers [35]. Eachserver maintains a FIFO request queue. To model con-current processing of requests, each server can service atunable number of requests in parallel (4 in our settings).The service time each request experiences is drawn froman exponential distribution (as in [48]) with a mean ser-vice time μ−1 = 4 ms. We incorporated time-varyingperformance fluctuations into the system as follows: ev-ery T ms (fluctuation interval), each server, indepen-dently and with a uniform probability, sets its service rateeither to μ or to μ ·D, where D is a range parameter (thus,a bimodal distribution for server performance [41]). Weset the D parameter to 3 (qualitatively, our results ap-ply across multiple tested values of D, which we omitfor brevity). The request arrival rate corresponds to 70%(high utilization scenario) and 45% (low utilization sce-nario) of the average service rate of the system, consider-ing the time-varying nature of the servers’ performance(that is, as if the service rate of each server’s proces-sor was (μ + D · μ)/2). As with our experiments us-ing Cassandra, we use a read-repair probability of 10%and a replication factor of 3, which further increases theload on the system. We use 200 workload generators,50 servers, and vary the number of clients from 150 to300. We set the one-way network latency to 250 μs. Werepeat every experiment 5 times using different randomseeds. 600,000 requests are generated in each run.
We compare C3 against three strategies:1. Oracle (ORA): each client chooses based on per-
fect knowledge of the instantaneous q/μ ratio of thereplicas (no required feedback from servers).
2. Least-Outstanding Requests (LOR): each clientselects a replica to which it has sent the least numberof requests so far.
3. Round-Robin (RR): as in C3, each client main-tains a per-replica rate limiter. However, here it usesa round-robin scheme to allocate requests to repli-cas in place of C3’s replica ranking. This allows usto evaluate the contribution of just rate limiting tothe effectiveness of C3.
We also ran simulations of strategies such as uniformrandom, least-response time, and different variations ofweighted random strategies. These strategies did notfare well compared to LOR, and due to space limits,we do not present results for them. We do not modeldisk activity in the simulator, and thus avoid comparingagainst Dynamic Snitching (since it relies on gossipingdisk iowait measurements).Impact of time-varying service times: Given that C3clients rely on feedback from servers, we study the effect
11
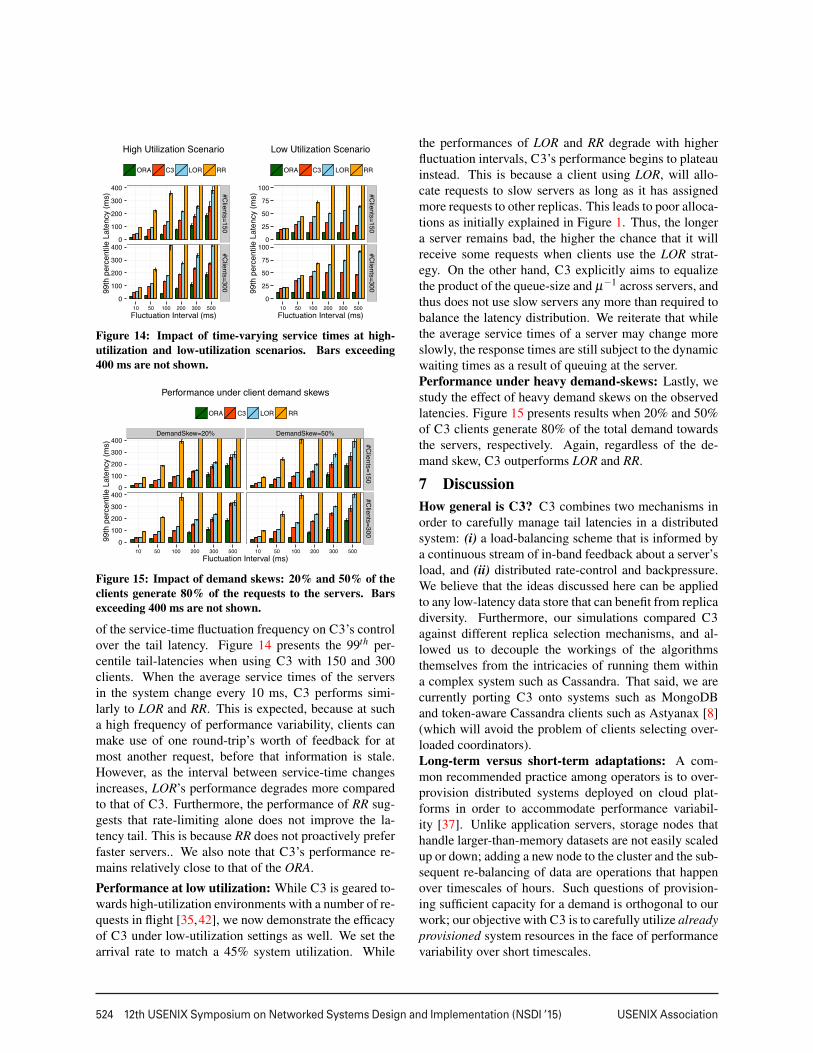
524 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) USENIX Association
0
100
200
300
400
0
100
200
300
400
#Clients=150
#Clients=300
10 50 100 200 300 500Fluctuation Interval (ms)
99th
per
cent
ile L
aten
cy (m
s)
ORA C3 LOR RR
High Utilization Scenario
0
25
50
75
100
0
25
50
75
100
#Clients=150
#Clients=300
10 50 100 200 300 500Fluctuation Interval (ms)
99th
per
cent
ile L
aten
cy (m
s)
ORA C3 LOR RR
Low Utilization Scenario
Figure 14: Impact of time-varying service times at high-utilization and low-utilization scenarios. Bars exceeding400 ms are not shown.
DemandSkew=20% DemandSkew=50%
0100200300400
0100200300400
#Clients=150
#Clients=300
10 50 100 200 300 500 10 50 100 200 300 500Fluctuation Interval (ms)
99th
per
cent
ile L
aten
cy (m
s)
ORA C3 LOR RR
Performance under client demand skews
Figure 15: Impact of demand skews: 20% and 50% of theclients generate 80% of the requests to the servers. Barsexceeding 400 ms are not shown.
of the service-time fluctuation frequency on C3’s controlover the tail latency. Figure 14 presents the 99th per-centile tail-latencies when using C3 with 150 and 300clients. When the average service times of the serversin the system change every 10 ms, C3 performs simi-larly to LOR and RR. This is expected, because at sucha high frequency of performance variability, clients canmake use of one round-trip’s worth of feedback for atmost another request, before that information is stale.However, as the interval between service-time changesincreases, LOR’s performance degrades more comparedto that of C3. Furthermore, the performance of RR sug-gests that rate-limiting alone does not improve the la-tency tail. This is because RR does not proactively preferfaster servers.. We also note that C3’s performance re-mains relatively close to that of the ORA.
Performance at low utilization: While C3 is geared to-wards high-utilization environments with a number of re-quests in flight [35,42], we now demonstrate the efficacyof C3 under low-utilization settings as well. We set thearrival rate to match a 45% system utilization. While
the performances of LOR and RR degrade with higherfluctuation intervals, C3’s performance begins to plateauinstead. This is because a client using LOR, will allo-cate requests to slow servers as long as it has assignedmore requests to other replicas. This leads to poor alloca-tions as initially explained in Figure 1. Thus, the longera server remains bad, the higher the chance that it willreceive some requests when clients use the LOR strat-egy. On the other hand, C3 explicitly aims to equalizethe product of the queue-size and µ−1 across servers, andthus does not use slow servers any more than required tobalance the latency distribution. We reiterate that whilethe average service times of a server may change moreslowly, the response times are still subject to the dynamicwaiting times as a result of queuing at the server.Performance under heavy demand-skews: Lastly, westudy the effect of heavy demand skews on the observedlatencies. Figure 15 presents results when 20% and 50%of C3 clients generate 80% of the total demand towardsthe servers, respectively. Again, regardless of the de-mand skew, C3 outperforms LOR and RR.
7 DiscussionHow general is C3? C3 combines two mechanisms inorder to carefully manage tail latencies in a distributedsystem: (i) a load-balancing scheme that is informed bya continuous stream of in-band feedback about a server’sload, and (ii) distributed rate-control and backpressure.We believe that the ideas discussed here can be appliedto any low-latency data store that can benefit from replicadiversity. Furthermore, our simulations compared C3against different replica selection mechanisms, and al-lowed us to decouple the workings of the algorithmsthemselves from the intricacies of running them withina complex system such as Cassandra. That said, we arecurrently porting C3 onto systems such as MongoDBand token-aware Cassandra clients such as Astyanax [8](which will avoid the problem of clients selecting over-loaded coordinators).Long-term versus short-term adaptations: A com-mon recommended practice among operators is to over-provision distributed systems deployed on cloud plat-forms in order to accommodate performance variabil-ity [37]. Unlike application servers, storage nodes thathandle larger-than-memory datasets are not easily scaledup or down; adding a new node to the cluster and the sub-sequent re-balancing of data are operations that happenover timescales of hours. Such questions of provision-ing sufficient capacity for a demand is orthogonal to ourwork; our objective with C3 is to carefully utilize alreadyprovisioned system resources in the face of performancevariability over short timescales.
12

USENIX Association 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) 525
Strongly consistent reads: Our work has focused onselecting one out of a given set of replicas, which in-herently assumes eventual consistency. This applies tocommon use-cases at large web-services today, includingFacebook’s accesses to its social graph [47], and most ofNetflix’s Cassandra usage [24]. However, it remains tobe seen how our work can be applied to strongly con-sistent reads as well. In particular, the gains in such ascenario depend on the synchronization overhead of therespective read protocol, and the effect of a straggler can-not be easily avoided.
8 Related WorkDean and Barroso [16] described techniques employed atGoogle to tolerate latency variability. They discuss short-term adaptations in the form of request reissues, alongwith additional logic to support preemption of duplicaterequests to reduce unacceptable additional load. In D-SPTF [30], a request is forwarded to a single server. Ifthe server has the data in its cache, it will respond to thequery. Otherwise, the server forwards the request to allreplicas, which then make use of cross-server cancella-tions to reduce load as in [16]. Vulimiri et al. [48] alsomake use of duplicate requests. They formalize the dif-ferent threshold points at which using redundancy aidsin minimizing the tail. In the context of Microsoft Azureand Amazon S3, CosTLO [49] also presents the efficacyof duplicate requests in coping with performance vari-ability. In contrast to these works, our approach doesnot rely on redundant requests and is in essence comple-mentary to the above in that request reissues could beintroduced atop C3.
Kwiken [23] decomposes the problem of minimizingend-to-end latency over a processing DAG into a man-ageable optimization over individual stages, wherein thelatency reduction techniques (e.g., request reissues) arecomplementary to our approach.
Pisces [42] is a multi-tenant key-value store architec-ture that provides fairness guarantees between tenants.It is concerned with fair-sharing the data-store and pre-senting proportional performances to different tenants.PARDA [21] is also focused on the problem of shar-ing storage bandwidth according to proportional-sharefairness. Stout [31] uses congestion control to respondto to storage-layer performance variability by adaptivelybatching requests. PriorityMeister [53] focuses on pro-viding tail latency QoS for bursty workloads in sharednetworked storage by combining priorities and rate lim-iters. As in C3, these works make use of TCP-inspiredcongestion control techniques for allocating storage re-sources across clients. While orthogonal to the problemof replica selection, we are planning to investigate the
ideas embodied in these works within the context of C3.Pisces recognizes the problem of weighted replica selec-tion but employs a round robin algorithm similar to theone used in our simulation results.
Mitzenmacher [33] showed that allowing a client tochoose between two randomly selected servers basedon queue lengths exponentially improves load-balancingperformance over a uniform random scheme. This ap-proach is embodied within systems such as Sparrow [36].However, in our settings, replication factors are typicallysmall compared to cluster size. Given a common replica-tion factor of 3, ranking 3 servers instead of 2 only incursa negligible overhead. Moreover, the basic power of twochoices strategy does not include a rate limiting compo-nent to avoid exceeding server capacities, in contrast toC3. A thorough comparison between the two approachesis left for future work.
Lastly, there is much work in the cluster computingspace on skew-tolerance [4, 19, 27, 44, 51]. In contrastto our work, cluster jobs operate at timescales of at leasta few hundreds of milliseconds [36], if not minutes orhours.
9 Conclusion
In this paper, we highlighted the challenges involvedin making a replica selection scheme explicitly copewith performance fluctuations in the system and envi-ronment. We presented the design and implementationof C3. C3 uses a combination of in-band feedback fromservers to rank and prefer faster replicas along with dis-tributed rate control and backpressure in order to re-duce tail latencies in the presence of service-time fluc-tuations. Through comprehensive performance evalu-ations, we demonstrate that C3 improves Cassandra’smean, median and tail latencies (by up to 3 times at the99.9th percentile), all while increasing read throughputand avoiding load pathologies.
Acknowledgments: We thank our shepherd LidongZhou and the anonymous reviewers for their feed-back. We are grateful to Sean Braithwaite, Conor Hen-nessy, Axel Liljencrantz, Jimmy Mardell, and RadovanZvoncek for their valuable inputs and suggestions. Thispaper benefited greatly from discussions with RaminKhalili, Georgios Smaragdakis and Olivier Bonaventure.This research is (in part) supported by European Union’sSeventh Framework Program FP7/2007-2013 under theBigFoot project (grant agreement 317858) and the Tril-ogy2 project (grant agreement 317756), and by an AWSin Education Grant award.
13

526 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) USENIX Association
References[1] Akka. http://akka.io/, accessed Sept 25, 2014.
[2] M. Alizadeh, A. Greenberg, D. A. Maltz, J. Padhye, P. Patel,B. Prabhakar, S. Sengupta, and M. Sridharan. Data Center TCP(DCTCP). In SIGCOMM, 2010.
[3] Amazon ELB. http://docs.aws.amazon.com/ElasticLoadBalancing/latest/DeveloperGuide/TerminologyandKeyConcepts.html, accessed Sept 24,2014.
[4] G. Ananthanarayanan, S. Kandula, A. Greenberg, I. Stoica, Y. Lu,B. Saha, and E. Harris. Reining in the Outliers in Map-reduceClusters Using Mantri. In OSDI, 2010.
[5] Apache Cassandra. http://cassandra.apache.org/,accessed June 10, 2013.
[6] Apache Cassandra Use Cases. http://planetcassandra.org/apache-cassandra-use-cases/, accessed Sept25, 2014.
[7] G. R. Arce. Nonlinear Signal Processing: A Statistical Approach.Wiley, 2004.
[8] Astyanax. https://github.com/Netflix/astyanax,accessed Jan 5, 2015.
[9] B. Atikoglu, Y. Xu, E. Frachtenberg, S. Jiang, and M. Paleczny.Workload Analysis of a Large-scale Key-value Store. In SIG-METRICS, 2012.
[10] C. F. Bispo. The single-server scheduling problem with convexcosts. Queueing Systems, 73(3), 2013.
[11] J. Brutlag. Speed Matters, accessed Sept 24, 2014.http://googleresearch.blogspot.com/2009/06/speed-matters.html.
[12] Cassandra Documentation. http://www.datastax.com/documentation/cassandra/2.0, accessed Sept 25,2014.
[13] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach,M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. Bigtable:A Distributed Storage System for Structured Data. ACM Trans.Comput. Syst., 26(2), June 2008.
[14] B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, andR. Sears. Benchmarking Cloud Serving Systems with YCSB.In SoCC, 2010.
[15] DB-Engines Ranking of Wide Column Stores. http://db-engines.com/en/ranking/wide+column+store, accessed Sept 25, 2014.
[16] J. Dean and L. A. Barroso. The Tail At Scale. Communicationsof the ACM, 56:74–80, 2013.
[17] G. Decandia, D. Hastorun, M. Jampani, G. Kakulapati, A. Laksh-man, A. Pilchin, S. Sivasubramanian, P. Vosshall, and W. Vogels.Dynamo: Amazon’s Highly Available Key-value Store. In SOSP,2007.
[18] J. Ellis. How not to benchmark Cassandra: a case study,2014. http://www.datastax.com/dev/blog/how-not-to-benchmark-cassandra-a-case-study.
[19] A. D. Ferguson, P. Bodik, S. Kandula, E. Boutin, and R. Fonseca.Jockey: Guaranteed Job Latency in Data Parallel Clusters. InEuroSys, 2012.
[20] W. D. Gray and D. Boehm-Davis. Milliseconds matter: An in-troduction to microstrategies and to their use in describing andpredicting interactive behavior. Journal of Experimental Psychol-ogy: Applied, 6, 2000.
[21] A. Gulati, I. Ahmad, and C. A. Waldspurger. PARDA: Propor-tional Allocation of Resources for Distributed Storage Access. InFAST, 2009.
[22] S. Ha, I. Rhee, and L. Xu. CUBIC: A New TCP-Friendly High-Speed TCP Variant. SIGOPS Oper. Syst. Rev., 42(5), 2008.
[23] V. Jalaparti, P. Bodik, S. Kandula, I. Menache, M. Rybalkin, andC. Yan. Speeding up Distributed Request-Response Workflows.In SIGCOMM, 2013.
[24] C. Kalantzis. Eventual Consistency != Hopeful Consistency, talkat Cassandra Summit, 2013. https://www.youtube.com/watch?v=A6qzx_HE3EU.
[25] C. Kalantzis. Revisiting 1 Million Writes per second,2014. http://techblog.netflix.com/2014/07/revisiting-1-million-writes-per-second.html.
[26] M. Kambadur, T. Moseley, R. Hank, and M. A. Kim. MeasuringInterference Between Live Datacenter Applications. In SC, 2012.
[27] R. Kapoor, G. Porter, M. Tewari, G. M. Voelker, and A. Vahdat.Chronos: Predictable Low Latency for Data Center Applications.In SoCC, 2012.
[28] J. Li, N. K. Sharma, D. R. K. Ports, and S. D. Gribble. Talesof the Tail: Hardware, OS, and Application-level Sources of TailLatency. In SoCC, 2014.
[29] A. Liljencrantz. How Not to Use Cassandra, talk at CassandraSummit, 2013. https://www.youtube.com/watch?v=0u-EKJBPrj8.
[30] C. R. Lumb and R. Golding. D-SPTF: Decentralized RequestDistribution in Brick-based Storage Systems. SIGOPS Oper. Syst.Rev., 38(5):37–47, Oct. 2004.
[31] J. C. McCullough, J. Dunagan, A. Wolman, and A. C. Snoeren.Stout: An Adaptive Interface to Scalable Cloud Storage. InUSENIX ATC, 2010.
[32] M. Mitzenmacher. How Useful Is Old Information? IEEE Trans.Parallel Distrib. Syst., 11(1), Jan. 2000.
[33] M. Mitzenmacher. The power of two choices in randomized loadbalancing. IEEE Trans. Parallel Distrib. Syst., 12(10), Oct. 2001.
[34] Nginx. http://nginx.org/en/docs/http/load_balancing.html, accessed Sept 24, 2014.
[35] R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski, H. Lee, H. C.Li, R. McElroy, M. Paleczny, D. Peek, P. Saab, D. Stafford,T. Tung, and V. Venkataramani. Scaling Memcache at Facebook.In NSDI, 2013.
[36] K. Ousterhout, P. Wendell, M. Zaharia, and I. Stoica. Sparrow:Distributed, Low Latency Scheduling. In SOSP, 2013.
[37] Riak. AWS Performance Tuning, accessed Sept 24,2014. http://docs.basho.com/riak/latest/ops/tuning/aws/.
[38] Riak. Load Balancing and Proxy Configu-ration, accessed Sept 24, 2014. http://docs.basho.com/riak/1.4.0/cookbooks/Load-Balancing-and-Proxy-Configuration/.
[39] M. Roussopoulos and M. Baker. Practical Load Balancing forContent Requests in Peer-to-Peer Networks. Distributed Com-puting, 18(6), 2006.
[40] S. Sanfilippo. Redis latency spikes and the 99th percentile, 2014.http://antirez.com/news/83.
14

USENIX Association 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’15) 527
[41] J. Schad, J. Dittrich, and J.-A. Quiane-Ruiz. Runtime Measure-ments in the Cloud: Observing, Analyzing, and Reducing Vari-ance. VLDB Endowment, 3(1-2), Sept. 2010.
[42] D. Shue, M. J. Freedman, and A. Shaikh. Performance Isolationand Fairness for Multi-tenant Cloud Storage. In OSDI, 2012.
[43] S. Souders. Velocity and the Bottom Line, 2009.http://radar.oreilly.com/2009/07/velocity-making-your-site-fast.html.
[44] C. Stewart, A. Chakrabarti, and R. Griffith. Zoolander: Effi-ciently Meeting Very Strict, Low-Latency SLOs. In USENIXICAC, 2013.
[45] R. Sumbaly, J. Kreps, L. Gao, A. Feinberg, C. Soman, andS. Shah. Serving Large-scale Batch Computed Data with ProjectVoldemort. In FAST, 2012.
[46] J. A. van Mieghem. Dynamic Scheduling with Convex DelayCosts: The Generalized $c|mu$ Rule. The Annals of AppliedProbability, 5, 1995.
[47] V. Venkataramani, Z. Amsden, N. Bronson, G. Cabrera III,P. Chakka, P. Dimov, H. Ding, J. Ferris, A. Giardullo, J. Hoon,S. Kulkarni, N. Lawrence, M. Marchukov, D. Petrov, andL. Puzar. TAO: How Facebook Serves the Social Graph. In SIG-MOD, 2012.
[48] A. Vulimiri, P. B. Godfrey, R. Mittal, J. Sherry, S. Ratnasamy, andS. Shenker. Low Latency via Redundancy. In CoNEXT, 2013.
[49] Z. Wu, C. Yu, and H. V. Madhyastha. CosTLO: Cost-EffectiveRedundancy for Lower Latency Variance on Cloud Storage Ser-vices. In NSDI, 2015.
[50] Y. Xu, Z. Musgrave, B. Noble, and M. Bailey. Bobtail: AvoidingLong Tails in the Cloud. In NSDI, 2013.
[51] M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz, and I. Stoica.Improving MapReduce Performance in Heterogeneous Environ-ments. In OSDI, 2008.
[52] X. Zhang, E. Tune, R. Hagmann, R. Jnagal, V. Gokhale, andJ. Wilkes. CPI2: CPU performance isolation for shared computeclusters. In EuroSys, 2013.
[53] T. Zhu, A. Tumanov, M. A. Kozuch, M. Harchol-Balter, and G. R.Ganger. PriorityMeister: Tail Latency QoS for Shared NetworkedStorage. In SoCC, 2014.
15