building austere overlay nocs for fpgas - fpl 2015 · 2015-09-20 · have a small lut+ff footprint...
TRANSCRIPT

Hoplite Building Austere Overlay NoCs for FPGAs
Nachiket Kapre + Jan Gray [email protected], [email protected]
fpga.org/hoplite

Problem
2

Problem
1. State-of-the-art FPGA-overlay NoCs (academic) are slow/sluggish, large/bloated —> 1-2K LUTs/router, 100-200 MHz
2

Problem
1. State-of-the-art FPGA-overlay NoCs (academic) are slow/sluggish, large/bloated —> 1-2K LUTs/router, 100-200 MHz
2. Limits the range of applications, overlay architectures that can be programmed on the FPGA
2

3
Router LUTs FFs ClockPenn 1.7K 541 4.5nsCMU 1.5K 635 9.6ns
Hoplite 60 100 2.9ns
32b payload + Virtex-6 240T

3
Router LUTs FFs ClockPenn 1.7K 541 4.5nsCMU 1.5K 635 9.6ns
Hoplite 60 100 2.9ns
32b payload + Virtex-6 240T
25x

3
Router LUTs FFs ClockPenn 1.7K 541 4.5nsCMU 1.5K 635 9.6ns
Hoplite 60 100 2.9ns
32b payload + Virtex-6 240T
25x 5x

3
Router LUTs FFs ClockPenn 1.7K 541 4.5nsCMU 1.5K 635 9.6ns
Hoplite 60 100 2.9ns
32b payload + Virtex-6 240T
25x 5x 1.5x

Claim
On-chip FPGA-overlay NoCs can be designed to have a small LUT+FF footprint by using —>
1) 2D unidirectional torus topology —> lower switching/FPGA interconnect complexity
2) deflection routing —> no storage required, bufferless flow control
4

Outline
• Context/Motivation — Review of current state-of-the-art in FPGA NoCs
• Design/Engineering Hoplite
• Hoplite RTL — Jan Gray church of RTL design
• Experimental Evaluation — Results and Analysis
5

Context and Motivation6

Cost of Communication
7

Cost of Communication• Big picture — communication is the critical design
concern in modern VLSI systems — wire delay dominating gate delay — most silicon area devoted to wiring — power usage mostly in wires
7

Cost of Communication• Big picture — communication is the critical design
concern in modern VLSI systems — wire delay dominating gate delay — most silicon area devoted to wiring — power usage mostly in wires
• NoCs one way to handle growing engineering burden— “Route packets not wires” — Bill Dally DAC2001
7

Implementing Communication
• ASICs/Full-Custom IC — dedicated physical resources for wiring
• FPGA — spatially configured routing (pattern known at boot time)
• Packet-switched NoCs — fully configurable routing (changes on each cycle)
8

ASIC Router μarch
9
http://www.m5sim.org/wiki/images/thumb/9/90/Garnet_router.jpg

Design Considerations
10

Design Considerations• On ASICs, design process guided by a truth:
10

Design Considerations• On ASICs, design process guided by a truth:
• wiring costs >> switching costs (gate counts)
10

Design Considerations• On ASICs, design process guided by a truth:
• wiring costs >> switching costs (gate counts)
• Hence: virtual channels, flow-control, complex arbitration policies
10

Design Considerations• On ASICs, design process guided by a truth:
• wiring costs >> switching costs (gate counts)
• Hence: virtual channels, flow-control, complex arbitration policies
• On FPGAs, it’s the opposite
10

Design Considerations• On ASICs, design process guided by a truth:
• wiring costs >> switching costs (gate counts)
• Hence: virtual channels, flow-control, complex arbitration policies
• On FPGAs, it’s the opposite
• wire-rich architectures! Provisioned to fit *any* user design
10

Design Considerations• On ASICs, design process guided by a truth:
• wiring costs >> switching costs (gate counts)
• Hence: virtual channels, flow-control, complex arbitration policies
• On FPGAs, it’s the opposite
• wire-rich architectures! Provisioned to fit *any* user design
• wiring costs << switching costs (LUT/FF counts)
10

11

12
Now here we are making copies in steel and concrete of copies in plaster of copies in marble of copies in wood.
Why? — Fountainhead

Design of Hoplite13

14
[CMU Connect FPGA2012] [Penn Split-Merge FPT2012]

14
[CMU Connect FPGA2012] [Penn Split-Merge FPT2012]
Buffering

14
[CMU Connect FPGA2012] [Penn Split-Merge FPT2012]
Buffering
Flow Control

FPGA-friendly NoCs
15

FPGA-friendly NoCs
(1) Topology — what would fit the FPGA interconnect organization best? — 2D unidirectional torus
15

FPGA-friendly NoCs
(1) Topology — what would fit the FPGA interconnect organization best? — 2D unidirectional torus
15

FPGA-friendly NoCs
(1) Topology — what would fit the FPGA interconnect organization best? — 2D unidirectional torus
• folded torus layout allows fixed distance == delay between hops
15

FPGA-friendly NoCs
(1) Topology — what would fit the FPGA interconnect organization best? — 2D unidirectional torus
• folded torus layout allows fixed distance == delay between hops
• fewer switching paths for unidirectional channels
15

FPGA-friendly NoCs
16

FPGA-friendly NoCs(2) Routing — what would fit the FPGA interconnect organization best? — deflection routing
16

FPGA-friendly NoCs(2) Routing — what would fit the FPGA interconnect organization best? — deflection routing
16
Crossbar
Mux
Mux
address+payload
PE
control
RouteArbiter

FPGA-friendly NoCs(2) Routing — what would fit the FPGA interconnect organization best? — deflection routing
• all incoming packets sent out immediately — hot potato routing
16
Crossbar
Mux
Mux
address+payload
PE
control
RouteArbiter

FPGA-friendly NoCs(2) Routing — what would fit the FPGA interconnect organization best? — deflection routing
• all incoming packets sent out immediately — hot potato routing
• no queueing required! — big savings in implementation cost
16
Crossbar
Mux
Mux
address+payload
PE
control
RouteArbiter

FPGA-friendly NoCs(2) Routing — what would fit the FPGA interconnect organization best? — deflection routing
• all incoming packets sent out immediately — hot potato routing
• no queueing required! — big savings in implementation cost
• flow control is just a valid bit!
16
Crossbar
Mux
Mux
address+payload
PE
control
RouteArbiter

17
Conflict-Free Route
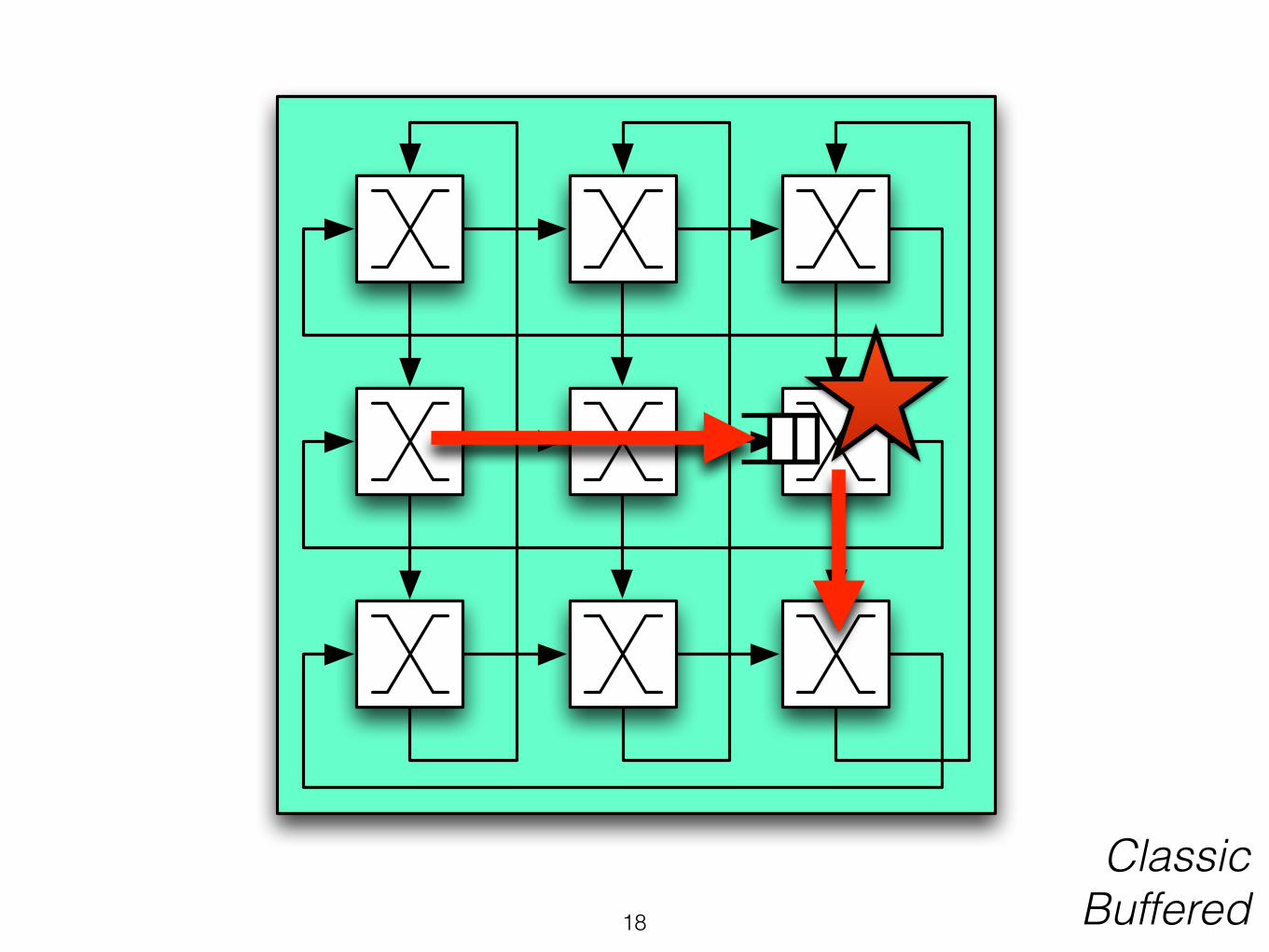
18
Classic Buffered

19
DeflectionRoute

FPGA Implementation
20

FPGA Implementation• Vivado-HLS synthesizable, cycle-accurate
implementations in C/C++ — to retain consistency across implementations — limited engineering effort to build low-level RTL
20

FPGA Implementation• Vivado-HLS synthesizable, cycle-accurate
implementations in C/C++ — to retain consistency across implementations — limited engineering effort to build low-level RTL
• Decomposed into — (1) crossbar, (2) route arbiter, and (3) FIFOs/Queues — independently characterized
20

FPGA Implementation• Vivado-HLS synthesizable, cycle-accurate
implementations in C/C++ — to retain consistency across implementations — limited engineering effort to build low-level RTL
• Decomposed into — (1) crossbar, (2) route arbiter, and (3) FIFOs/Queues — independently characterized
• Constraints to target II=1, high-speed operation
20

21
Mesh Torus HopliteLUTs 2K 1K 0.5KFFs 1.6K 1K 0.5K
Clock 6.8ns 4.8ns 3.1ns

Hoplite RTL
22
Book of Jan Chapter 10x10: Verse 32b
RTL design of Hoplite
23
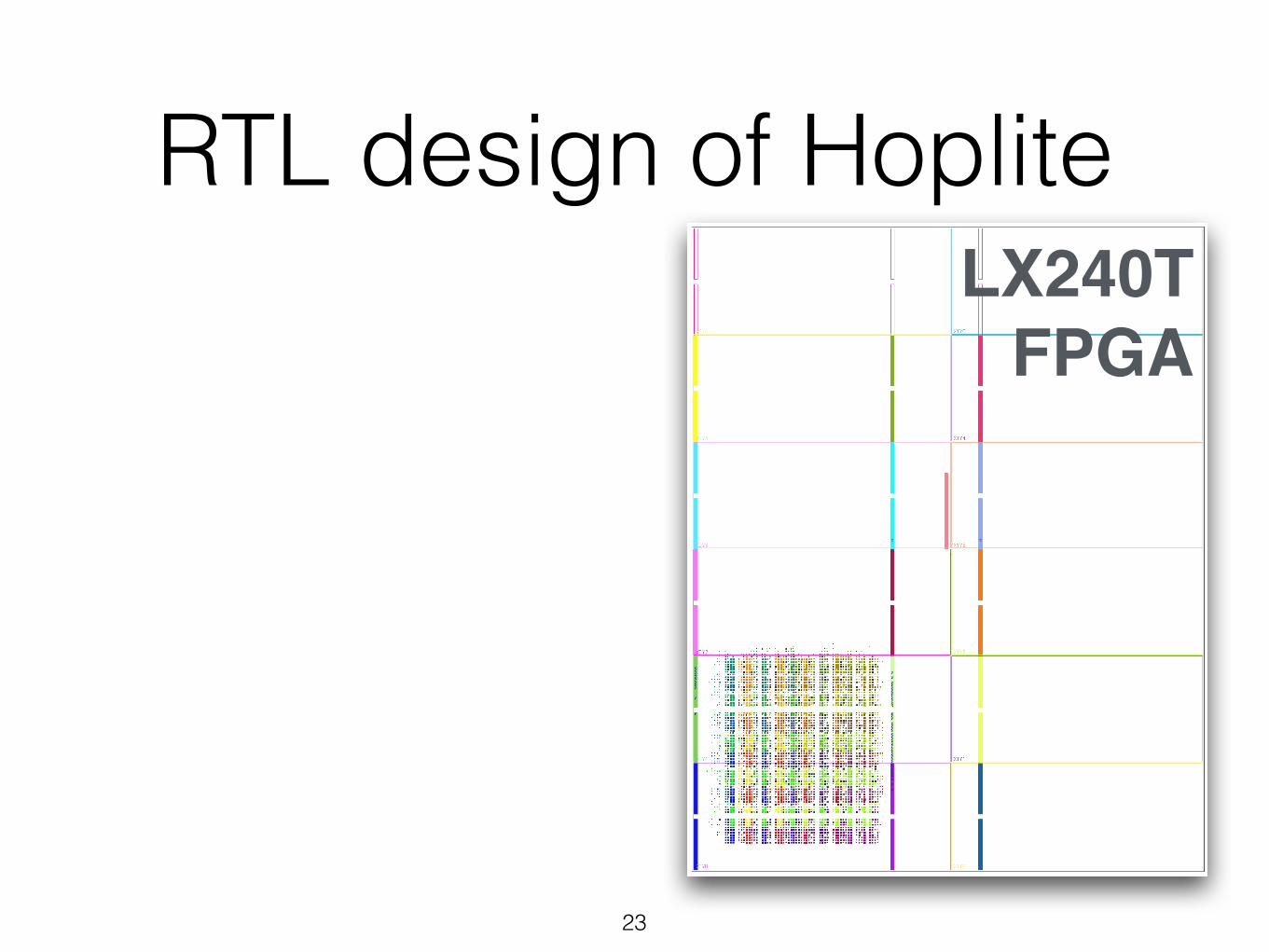
LX240T FPGA

RTL design of Hoplite
• FPGA floorplan — folded layout — 10x10 NoC — 40b data+8b addr. — each color X,Y router
23
LX240T FPGA

RTL design of Hoplite
• FPGA floorplan — folded layout — 10x10 NoC — 40b data+8b addr. — each color X,Y router
• What cost? — 6.1K 6-LUTs, 15K FFs, 2.9ns (4%)
23
LX240T FPGA

Xilinx mapping notes
24

YI
IY
XXI
YIY
XXI
I
Xilinx mapping notes
24

YI
IY
XXI
YIY
XXI
I
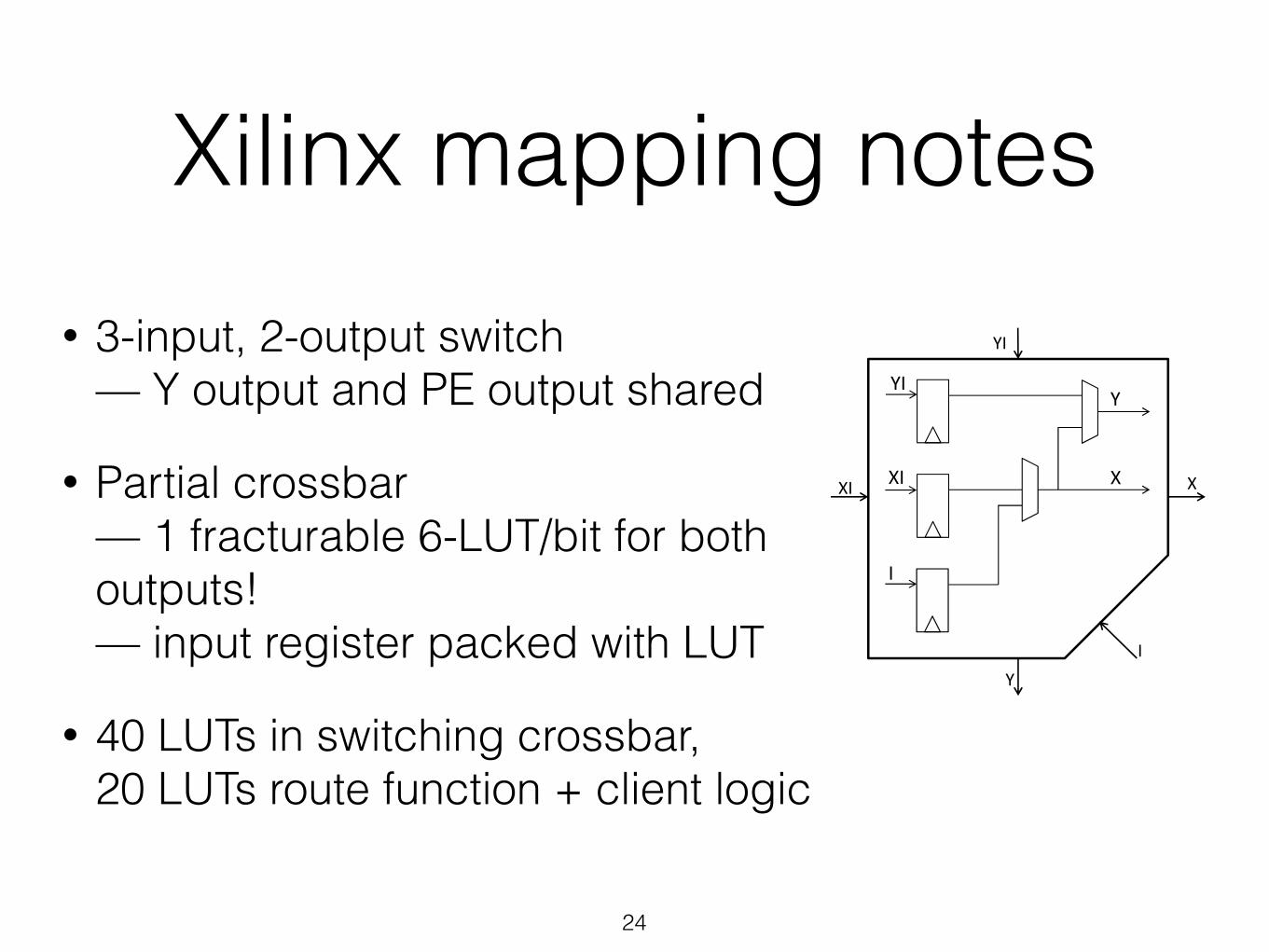
Xilinx mapping notes• 3-input, 2-output switch
— Y output and PE output shared
24

YI
IY
XXI
YIY
XXI
I
Xilinx mapping notes• 3-input, 2-output switch
— Y output and PE output shared
• Partial crossbar— 1 fracturable 6-LUT/bit for both outputs!— input register packed with LUT
24
YI
IY
XXI
YIY
XXI
I
Xilinx mapping notes• 3-input, 2-output switch
— Y output and PE output shared
• Partial crossbar— 1 fracturable 6-LUT/bit for both outputs!— input register packed with LUT
• 40 LUTs in switching crossbar, 20 LUTs route function + client logic
24

Code Sketch
25

Crossbar
Mux
Mux
address+payload
PE
control
RouteArbiter
26
Hopilte-HLS Hoplite-RTLLUTs 576 60FFs 570 100
Clock 3.1ns 2.9ns
YI
IY
XXI
YIY
XXI
I

Experimental Evaluation27
*all calculations use HLS-version for fair comparisons

●
●
●●
●●
●●
●
0
5
10
0 20 40 60 80PEs
Thro
ughp
ut (P
acke
ts/c
ycle
)
● Deflection TorusMeshTorus
Throughput
28

●
●
●●
●●
●●
●
0
5
10
0 20 40 60 80PEs
Thro
ughp
ut (P
acke
ts/c
ycle
)
● Deflection TorusMeshTorus
Throughput• 2D bidirectional mesh
beats Hoplite by 2x — Bidir Mesh has 2x wiring capacity of Hoplite torus
28

●
●
●●
●●
●●
●
0
5
10
0 20 40 60 80PEs
Thro
ughp
ut (P
acke
ts/c
ycle
)
● Deflection TorusMeshTorus
Throughput• 2D bidirectional mesh
beats Hoplite by 2x — Bidir Mesh has 2x wiring capacity of Hoplite torus
• BUT…— x-axis is PE count (ignoring NoC area) — y-axis is Cycles (ignoring clk period)
28

●
●
●
●
●●●●●
2.5x 1.5x
0
1
2
3
0 50000 100000 150000Resource Utilization (LUTs)
Thro
ughp
ut (1
06 Pack
ets/
s)
Cost-aware Throughput
29

●
●
●
●
●●●●●
2.5x 1.5x
0
1
2
3
0 50000 100000 150000Resource Utilization (LUTs)
Thro
ughp
ut (1
06 Pack
ets/
s)
Cost-aware Throughput• Now
— x-axis —> NoC area — y-axis —> Abs. time
29

●
●
●
●
●●●●●
2.5x 1.5x
0
1
2
3
0 50000 100000 150000Resource Utilization (LUTs)
Thro
ughp
ut (1
06 Pack
ets/
s)
Cost-aware Throughput• Now
— x-axis —> NoC area — y-axis —> Abs. time
• Identical FPGA LUT cost, — Hoplite beats 2D Mesh by 2.5x
29

●
●
●
●
●●●●●
2.5x 1.5x
0
1
2
3
0 50000 100000 150000Resource Utilization (LUTs)
Thro
ughp
ut (1
06 Pack
ets/
s)
Cost-aware Throughput• Now
— x-axis —> NoC area — y-axis —> Abs. time
• Identical FPGA LUT cost, — Hoplite beats 2D Mesh by 2.5x
• Identical PE counts, — Hoplite still beats 2D mesh by 1.5x
29

●0 k
50 k100 k150 k200 k250 k
0 M 1 M 2 M 3 M 4 MSystem Throughput
(Packets/s)
Res
ourc
e U
til. (
LUTs
)
● Deflection TorusDeflection Torus (RTL)
MeshTorus
30
10x10 systeminjection rate 0.5
0.0
0.5
1.0
1.5
10 1 k 100 kLatency of a packet (cycles)
Den
sity
Deflection Torus Mesh Torus
31
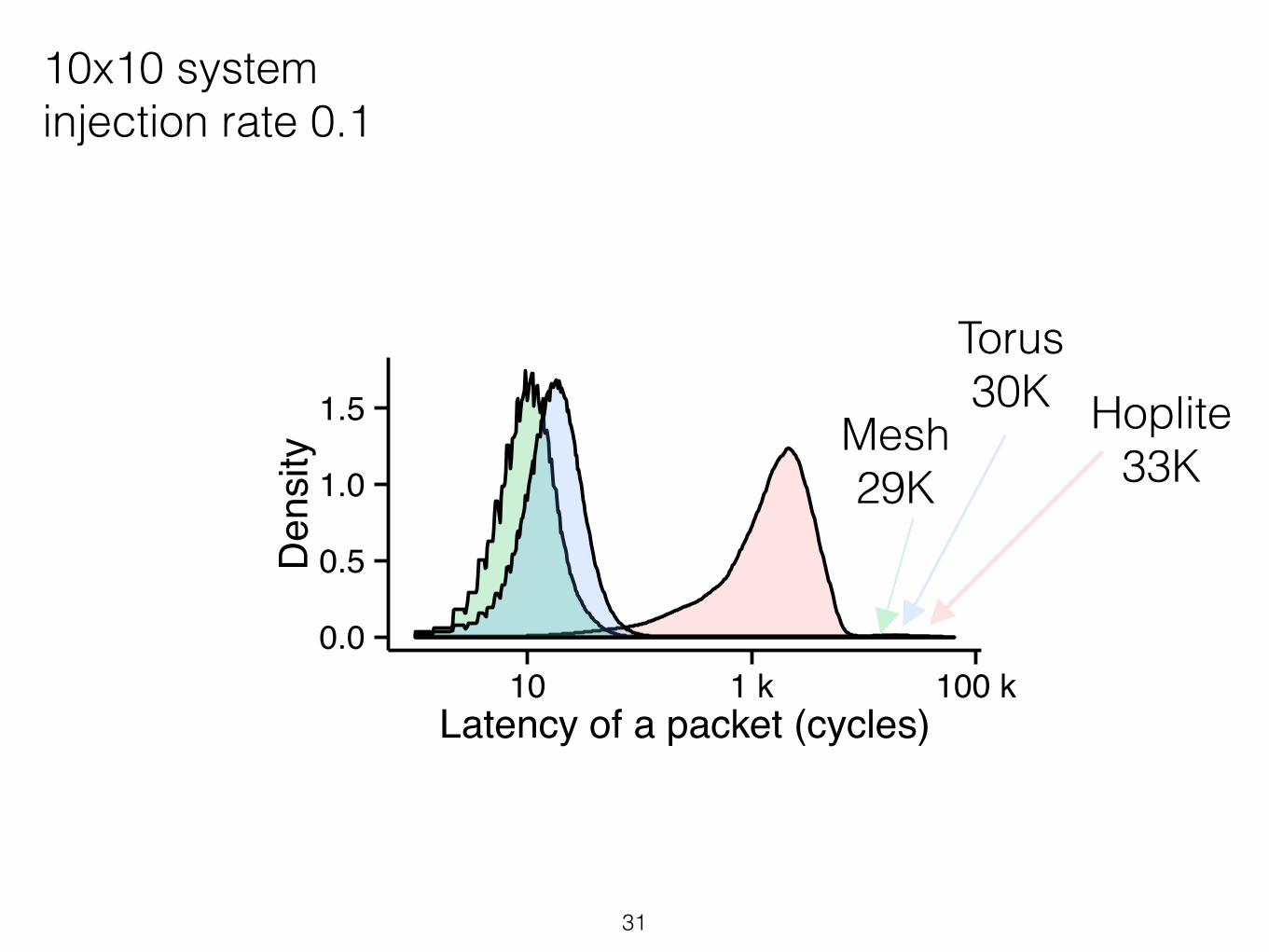
10x10 systeminjection rate 0.1
Mesh 29K
Torus 30K Hoplite
33K

Uses for Hoplite32

Current Uses• Multi-processing NoC (CGRAs, Soft Processors)
• Part of FPGA Driver infrastructure — Interface Ethernet, PCIe, DRAM, Flash interfaces
• LEAP + NoC, CoRAM + NoC, GTX—>Fabric
33
DRAMEthernet
[FPT2012] FPGA driver PCIe

Conclusions34

Conclusions• Design lightweight, fast FPGA overlay NoCs —
Hoplite [60 LUTs + 100 [email protected]] — ~3.5x smaller and ~2x faster — For uniform random@10x10 NoC, 2.5x win
• Open Issues:— Deflections affect worst-case latency — Potential livelock (“mostly harmless”) —> RTL fix possible
35
fpga.org/hoplite

Special Thanks —> Monterey Airbus
36

isoP
E
isoA
rea
0
1
2
3
0 2500 5000 7500 10000LUTs/PE
Thro
ughp
ut (1
06 Pack
ets/
s)
Deflection Torus 9x9Mesh 7x7Mesh 9x9
Impact of PE cost
37

isoP
E
isoA
rea
0
1
2
3
0 2500 5000 7500 10000LUTs/PE
Thro
ughp
ut (1
06 Pack
ets/
s)
Deflection Torus 9x9Mesh 7x7Mesh 9x9
Impact of PE cost• Now
— x-axis —> PE cost — y-axis —> Abs. time
37

isoP
E
isoA
rea
0
1
2
3
0 2500 5000 7500 10000LUTs/PE
Thro
ughp
ut (1
06 Pack
ets/
s)
Deflection Torus 9x9Mesh 7x7Mesh 9x9
Impact of PE cost• Now
— x-axis —> PE cost — y-axis —> Abs. time
• Consider Fmax degradation
37

isoP
E
isoA
rea
0
1
2
3
0 2500 5000 7500 10000LUTs/PE
Thro
ughp
ut (1
06 Pack
ets/
s)
Deflection Torus 9x9Mesh 7x7Mesh 9x9
Impact of PE cost• Now
— x-axis —> PE cost — y-axis —> Abs. time
• Consider Fmax degradation
• Hoplite competitive if, — PE area < 10K LUTs
37

isoP
E
isoA
rea
0
1
2
3
0 2500 5000 7500 10000LUTs/PE
Thro
ughp
ut (1
06 Pack
ets/
s)
Deflection Torus 9x9Mesh 7x7Mesh 9x9
Impact of PE cost• Now
— x-axis —> PE cost — y-axis —> Abs. time
• Consider Fmax degradation
• Hoplite competitive if, — PE area < 10K LUTs
• Large PE sizes — NoC area smaller
37

38
https://www.altera.com/en_US/pdfs/literature/hb/stratix-v/stx5_core.pdf
Altera: Can implement 2x 5-LUTs with only 2 shared inputs!

Open Issues
39

Open Issues• Bounding Worst-Case latency
— Real-time systems demand bounds— Hoplite varies dramaticallywith injection rate— Fix: split traffic across channels
39

Open Issues• Bounding Worst-Case latency
— Real-time systems demand bounds— Hoplite varies dramaticallywith injection rate— Fix: split traffic across channels
39

Open Issues• Bounding Worst-Case latency
— Real-time systems demand bounds— Hoplite varies dramaticallywith injection rate— Fix: split traffic across channels
• Livelock situation under specific conditions— Injection rate=1.0, TORNADO traffic pattern — Fix: periodic injection ban
39

Open Issues• Bounding Worst-Case latency
— Real-time systems demand bounds— Hoplite varies dramaticallywith injection rate— Fix: split traffic across channels
• Livelock situation under specific conditions— Injection rate=1.0, TORNADO traffic pattern — Fix: periodic injection ban
39

Open Issues• Bounding Worst-Case latency
— Real-time systems demand bounds— Hoplite varies dramaticallywith injection rate— Fix: split traffic across channels
• Livelock situation under specific conditions— Injection rate=1.0, TORNADO traffic pattern — Fix: periodic injection ban
• Exact wire cost, switch cost balance
39

40
Crossbar
Mux
Mux
address+payload
PE
control
RouteArbiter
XiYi
PEi
Mux
Xo
XiYi
PEi
Mux
Yo
XiYi
PEi
Mux
PEo

41
Crossbar
Mux
Mux
address+payload
PE
control
RouteArbiter
XiYi
PEiM
uxXo
XiYi
PEi
Mux
Yo/PEo

42
http://www.xilinx.com/support/documentation/user_guides/ug364.pdf
Xilinx: Forced to share 4 inputs to get 2x 5-LUTs with 6 inputs!

43
XiYi
PEi
Mux
Xo
XiYi
PEi
Mux
Yo/PEo
Yi
Mux
Yo/PEo
Xi
PEiM
ux
Xo