breaking the latency barrier strong scaling lqcd on … · cuda aware mpi: mpi can take gpu pointer...
TRANSCRIPT

Kate Clark, Mathias Wagner, Evan Weinberg
BREAKING THE LATENCY BARRIERSTRONG SCALING LQCD ON GPUS

!2
QUDA• “QCD on CUDA” – http://lattice.github.com/quda (open source, BSD license) • Effort started at Boston University in 2008, now in wide use as the GPU backend for BQCD,
Chroma, CPS, MILC, TIFR, etc. • Provides:
— Various solvers for all major fermionic discretizations, with multi-GPU support — Additional performance-critical routines needed for gauge-field generation
• Maximize performance • Exploit physical symmetries to minimize memory traffic • Mixed-precision methods • Autotuning for high performance on all CUDA-capable architectures • Domain-decomposed (Schwarz) preconditioners for strong scaling • Eigenvector and deflated solvers (Lanczos, EigCG, GMRES-DR) • Multi-source solvers • Multigrid solvers for optimal convergence
• A research tool for how to reach the exascale

!3
QUDA CONTRIBUTORS
§ Ron Babich (NVIDIA) § Simone Bacchio (Cyprus) § Michael Baldhauf (Regensburg) § Kip Barros (LANL) § Rich Brower (Boston University) § Nuno Cardoso (NCSA) § Kate Clark (NVIDIA) § Michael Cheng (Boston University) § Carleton DeTar (Utah University) § Justin Foley (Utah -> NIH) § Joel Giedt (Rensselaer Polytechnic Institute) § Arjun Gambhir (William and Mary) § Steve Gottlieb (Indiana University) § Kyriakos Hadjiyiannakou (Cyprus)
§ Dean Howarth (BU) § Bálint Joó (Jlab) § Hyung-Jin Kim (BNL -> Samsung) § Bartek Kostrzewa (Bonn) § Claudio Rebbi (Boston University) § Hauke Sandmeyer (Bielefeld) § Guochun Shi (NCSA -> Google) § Mario Schröck (INFN) § Alexei Strelchenko (FNAL) § Jiqun Tu (Columbia) § Alejandro Vaquero (Utah University) § Mathias Wagner (NVIDIA) § Evan Weinberg (NVIDIA) § Frank Winter (Jlab)
10+ years - lots of contributors
!4
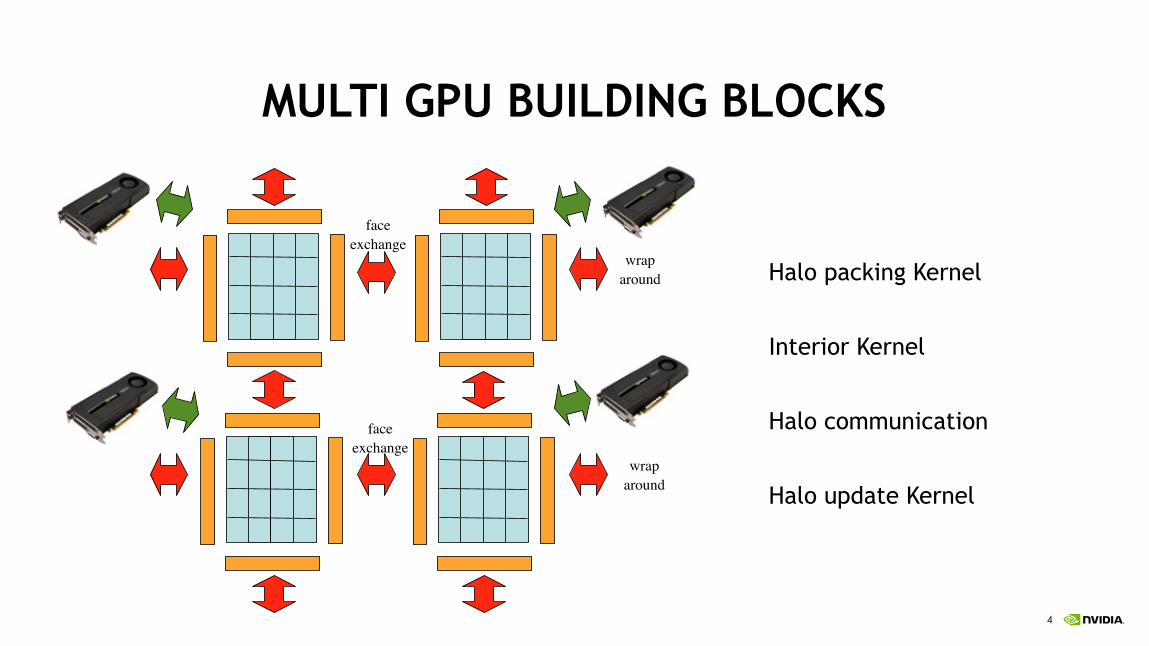
MULTI GPU BUILDING BLOCKS
Halo packing Kernel
Interior Kernel
Halo communication
Halo update Kernel
Multi GPU Parallelization
faceexchange
wraparound
faceexchange
wraparound
Tuesday, July 12, 2011
Halo packing Kernel
Interior Kernel
Halo communication
Halo update Kernel

!5
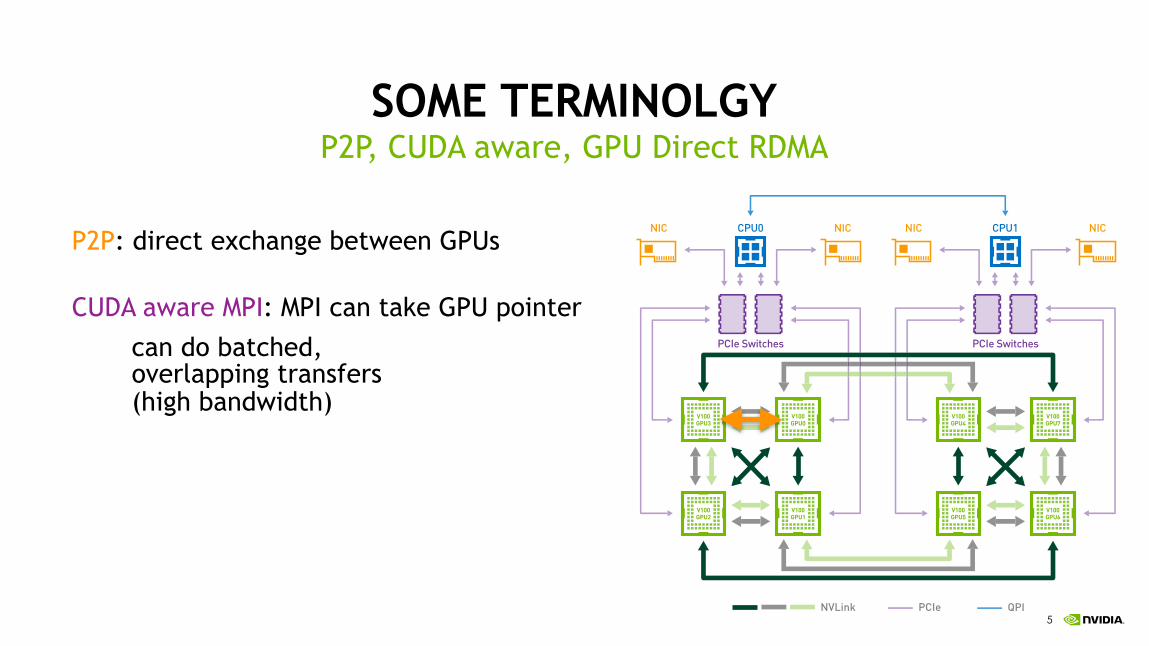
SOME TERMINOLGY
P2P: direct exchange between GPUs
P2P, CUDA aware, GPU Direct RDMA
NVIDIA DGX-1 With Tesla V100 System Architecture WP-08437-002_v01 | 9
V100GPU7
V100GPU4
V100GPU6
V100GPU5
CPU1NIC NIC
PCIe Switches
V100GPU0
V100GPU3
V100GPU1
V100GPU2
CPU0NIC NIC
PCIe Switches
NVLink PCIe QPI
Figure 4 DGX-1 uses an 8-GPU hybrid cube-mesh interconnection network topology. The corners of the mesh-connected faces of the cube are connected to the PCIe tree network, which also connects to the CPUs and NICs.

!5
SOME TERMINOLGY
P2P: direct exchange between GPUs
P2P, CUDA aware, GPU Direct RDMA
NVIDIA DGX-1 With Tesla V100 System Architecture WP-08437-002_v01 | 9
V100GPU7
V100GPU4
V100GPU6
V100GPU5
CPU1NIC NIC
PCIe Switches
V100GPU0
V100GPU3
V100GPU1
V100GPU2
CPU0NIC NIC
PCIe Switches
NVLink PCIe QPI
Figure 4 DGX-1 uses an 8-GPU hybrid cube-mesh interconnection network topology. The corners of the mesh-connected faces of the cube are connected to the PCIe tree network, which also connects to the CPUs and NICs.
!5
SOME TERMINOLGY
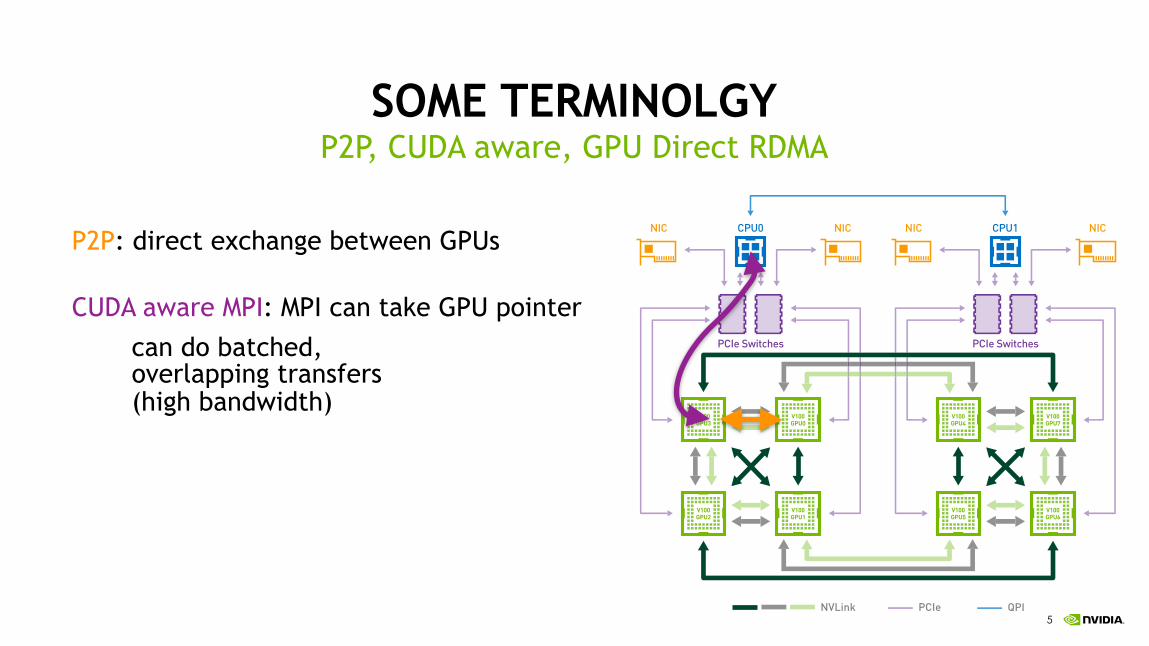
P2P: direct exchange between GPUs
CUDA aware MPI: MPI can take GPU pointer
can do batched, overlapping transfers (high bandwidth)
P2P, CUDA aware, GPU Direct RDMA
NVIDIA DGX-1 With Tesla V100 System Architecture WP-08437-002_v01 | 9
V100GPU7
V100GPU4
V100GPU6
V100GPU5
CPU1NIC NIC
PCIe Switches
V100GPU0
V100GPU3
V100GPU1
V100GPU2
CPU0NIC NIC
PCIe Switches
NVLink PCIe QPI
Figure 4 DGX-1 uses an 8-GPU hybrid cube-mesh interconnection network topology. The corners of the mesh-connected faces of the cube are connected to the PCIe tree network, which also connects to the CPUs and NICs.
!5
SOME TERMINOLGY
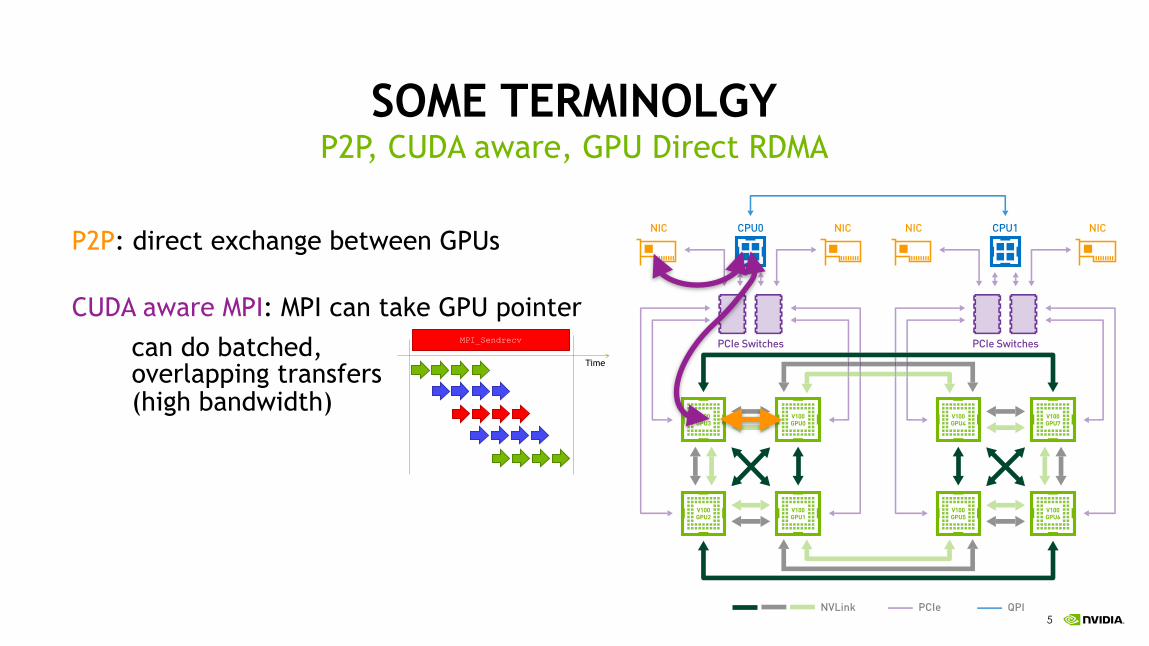
P2P: direct exchange between GPUs
CUDA aware MPI: MPI can take GPU pointer
can do batched, overlapping transfers (high bandwidth)
P2P, CUDA aware, GPU Direct RDMA
NVIDIA DGX-1 With Tesla V100 System Architecture WP-08437-002_v01 | 9
V100GPU7
V100GPU4
V100GPU6
V100GPU5
CPU1NIC NIC
PCIe Switches
V100GPU0
V100GPU3
V100GPU1
V100GPU2
CPU0NIC NIC
PCIe Switches
NVLink PCIe QPI
Figure 4 DGX-1 uses an 8-GPU hybrid cube-mesh interconnection network topology. The corners of the mesh-connected faces of the cube are connected to the PCIe tree network, which also connects to the CPUs and NICs.
!5
SOME TERMINOLGY
P2P: direct exchange between GPUs
CUDA aware MPI: MPI can take GPU pointer
can do batched, overlapping transfers (high bandwidth)
P2P, CUDA aware, GPU Direct RDMA
NVIDIA DGX-1 With Tesla V100 System Architecture WP-08437-002_v01 | 9
V100GPU7
V100GPU4
V100GPU6
V100GPU5
CPU1NIC NIC
PCIe Switches
V100GPU0
V100GPU3
V100GPU1
V100GPU2
CPU0NIC NIC
PCIe Switches
NVLink PCIe QPI
Figure 4 DGX-1 uses an 8-GPU hybrid cube-mesh interconnection network topology. The corners of the mesh-connected faces of the cube are connected to the PCIe tree network, which also connects to the CPUs and NICs.
MPI_Sendrecv
Time

!5
SOME TERMINOLGY
P2P: direct exchange between GPUs
CUDA aware MPI: MPI can take GPU pointer
can do batched, overlapping transfers (high bandwidth)
GPU Direct RDMA: (implies CUDA aware MPI) RDMA transfer from/to GPU memoryhere NIC <-> GPU
P2P, CUDA aware, GPU Direct RDMA
NVIDIA DGX-1 With Tesla V100 System Architecture WP-08437-002_v01 | 9
V100GPU7
V100GPU4
V100GPU6
V100GPU5
CPU1NIC NIC
PCIe Switches
V100GPU0
V100GPU3
V100GPU1
V100GPU2
CPU0NIC NIC
PCIe Switches
NVLink PCIe QPI
Figure 4 DGX-1 uses an 8-GPU hybrid cube-mesh interconnection network topology. The corners of the mesh-connected faces of the cube are connected to the PCIe tree network, which also connects to the CPUs and NICs.
MPI_Sendrecv
Time
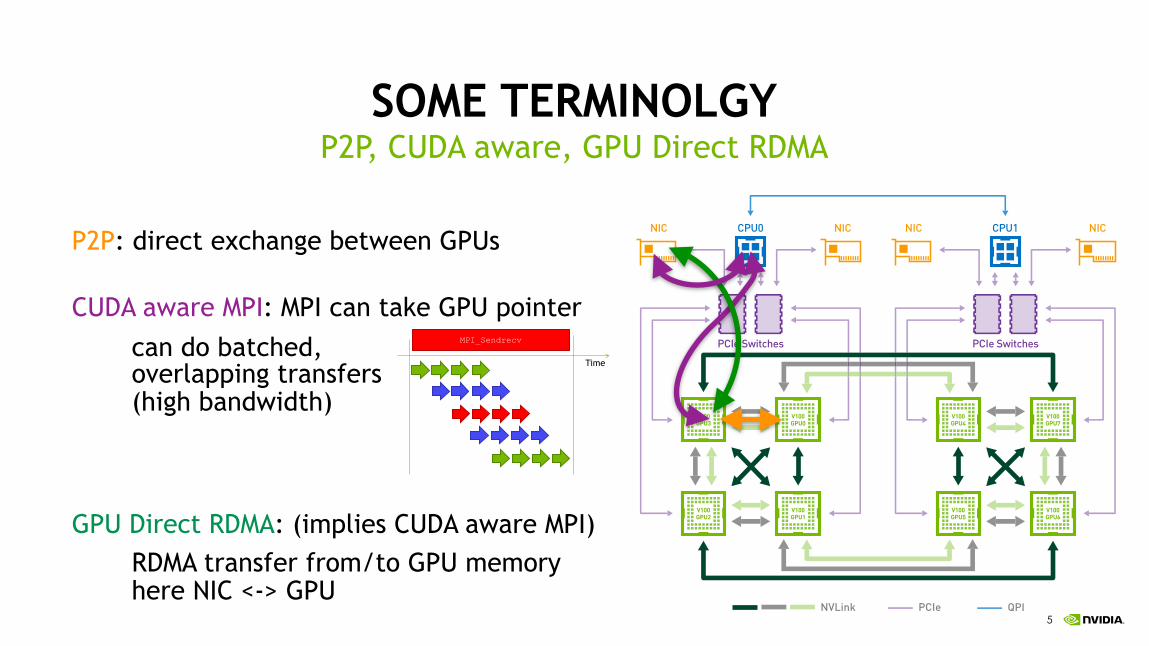
!5
SOME TERMINOLGY
P2P: direct exchange between GPUs
CUDA aware MPI: MPI can take GPU pointer
can do batched, overlapping transfers (high bandwidth)
GPU Direct RDMA: (implies CUDA aware MPI) RDMA transfer from/to GPU memoryhere NIC <-> GPU
P2P, CUDA aware, GPU Direct RDMA
NVIDIA DGX-1 With Tesla V100 System Architecture WP-08437-002_v01 | 9
V100GPU7
V100GPU4
V100GPU6
V100GPU5
CPU1NIC NIC
PCIe Switches
V100GPU0
V100GPU3
V100GPU1
V100GPU2
CPU0NIC NIC
PCIe Switches
NVLink PCIe QPI
Figure 4 DGX-1 uses an 8-GPU hybrid cube-mesh interconnection network topology. The corners of the mesh-connected faces of the cube are connected to the PCIe tree network, which also connects to the CPUs and NICs.
MPI_Sendrecv
Time

6
STRONG SCALING

!7
STRONG SCALING
Multiple meanings Same problem size, more nodes, more GPUs Same problem, next generation GPUs Multigrid - strong scaling within the same run (not discussed here)
To tame strong scaling we have to understand the limiters Bandwidth limiters Latency limiters

!8
SINGLE GPU PERFORMANCEWilson Dslash
Tesla V100 CUDA 10.1 GCC 7.3
0
500
1000
1500
2000
2500
3000
8121620242832
GFLO
PS
Lattice length
half blocksize=32 single blocksize=32 double blocksize-32
half tuned single tuned double tuned
“strong scaling”1180 GB/s
1291 GB/s
1312 GB/s

!8
SINGLE GPU PERFORMANCEWilson Dslash
Tesla V100 CUDA 10.1 GCC 7.3
0
500
1000
1500
2000
2500
3000
8121620242832
GFLO
PS
Lattice length
half blocksize=32 single blocksize=32 double blocksize-32
half tuned single tuned double tuned
“strong scaling”1180 GB/s
1291 GB/s
1312 GB/s Look at scaling of Dslash on one DGX-1:half precision with 164 local volume

!9
WHAT IS LIMITING STRONG SCALING
Staging MPI transfers through host memory
classical host staging
D2H copies H2D copy t H2D copy y H2D copy z
DGX-1,164 local volume, half precision, 1x2x2x2 partitioning
Interior kernel
Packing kernel
Halo t Halo z Halo y
297 µs

!10
API OVERHEADS
Staging MPI transfers through host memory
CPU overheads and synchronization are expensive
Pack Interior
Halo zD2H copies Halo t Halo y
H2D copy H2D copy H2D copy
Sync
DGX-1,164 local volume, half precision, 1x2x2x2 partitioning

!11
USING NVLINK AND FUSING KERNELS
Staging MPI transfers through host memory
fewer copies with higher bandwidth, fewer kernels, less API overhead
DGX-1,164 local volume, half precision, 1x2x2x2 partitioning
P2P copies
Interior kernelPacking kernel Fused Halo
129 µs
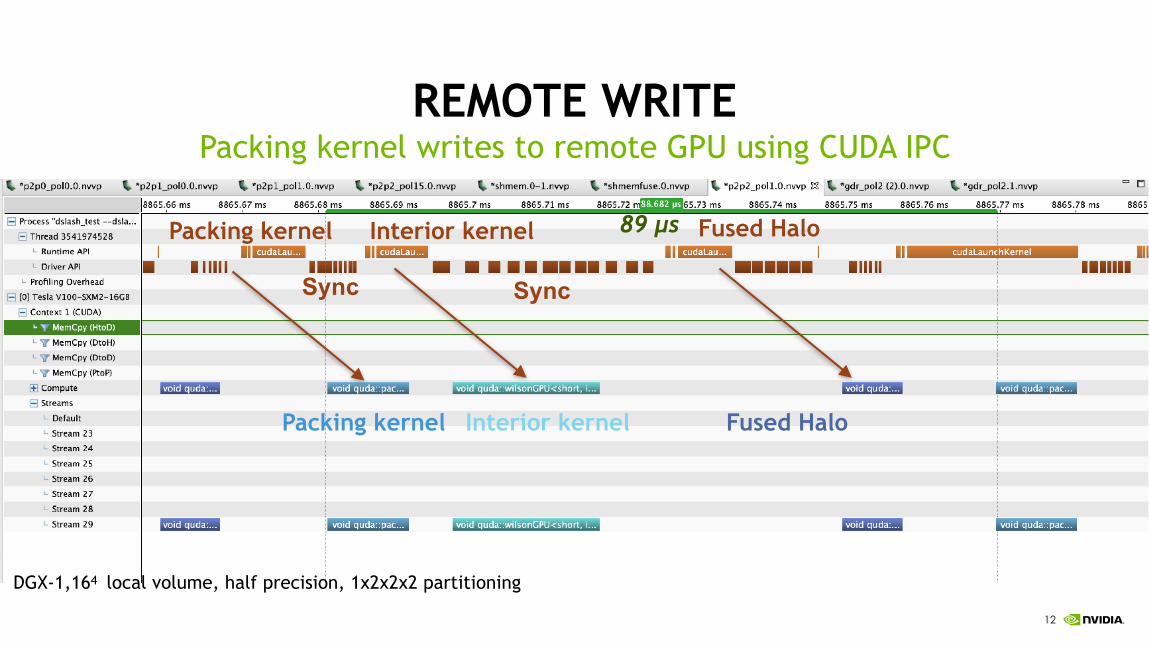
!12
REMOTE WRITE
Staging MPI transfers through host memory
Packing kernel writes to remote GPU using CUDA IPC
DGX-1,164 local volume, half precision, 1x2x2x2 partitioning
Interior kernelPacking kernel Fused Halo
Interior kernelPacking kernel Fused Halo
SyncSync
89 µs

13
NVSHMEM

14
NVSHMEM
Implementation of OpenSHMEM, a Partitioned Global Address Space (PGAS) library
NVSHMEM features Symmetric memory allocations in device memory Communication API calls on CPU (standard and stream-ordered) Allows kernel-side communication (API and LD/ST) between GPUs
NVLink and PCIe support (intranode), InfiniBand support (internode) X86 and Power9 support Interoperability with MPI and OpenSHMEM libraries
Early access (EA2) available – please reach out to [email protected]
GPU centric communication

15
DSLASH NVSHMEM IMPLEMENTATION
Keep general structure of packing, interior and exterior Dslash
Use nvshmem_ptr for intra-node remote writes (fine-grained)
Packing buffer is located on remote device Use nvshmem_putmem_nbi to write to remote GPU over IB (1 RDMA transfer)
Need to make sure writes are visible: nvshmem_barrier_all_on_stream
or barrier kernel that only waits for writes from neighbors
Disclaimer:Results from an first implementation in QUDA with a pre-release version of NVSHMEM
First exploration
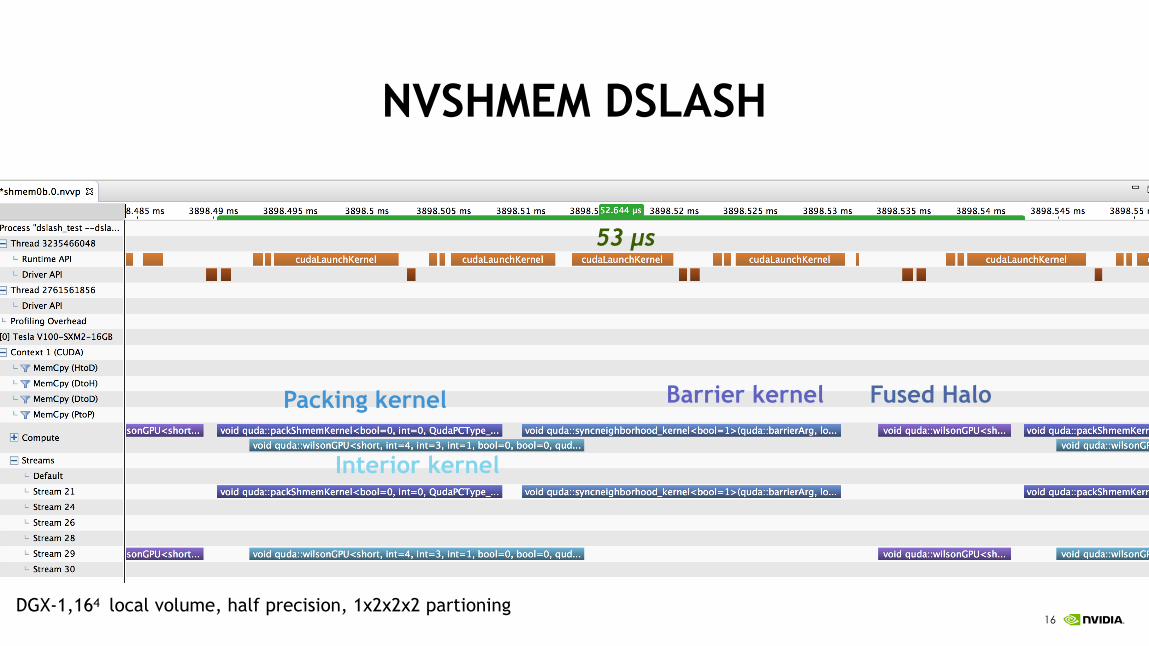
!16
NVSHMEM DSLASH
Staging MPI transfers through host memory
DGX-1,164 local volume, half precision, 1x2x2x2 partioning
Packing kernel Fused Halo
Interior kernel
Barrier kernel
53 µs

!17
NVSHMEM + FUSING KERNELS
Staging MPI transfers through host memory
no extra packing and barrier kernels needed
DGX-1,164 local volume, half precision, 1x2x2x2 partioning
Barrier + Fused HaloInterior + Pack + Flag kernel
36 µs

!18
LATENCY OPTIMIZATIONSDifferent strategies implemented
0
250
500
750
1,000
1,250
IPC co
pies
IPC re
mote w
rite
NVSH
MEM w
/ bar
rier
NVSH
MEM ke
rnel
fusio
n
GFl
op/s
DGX-1,164 local volume, Wilson, half precision, 1x2x2x2 partitioning

!19
DGX-2: FULL NON-BLOCKING BANDWIDTH2.4 TB/s bisection bandwidth
8
FULL NON-BLOCKING BANDWIDTH
GPU8
GPU9
GPU10
GPU11
GPU12
GPU13
GPU14
GPU15
GPU0
GPU1
GPU2
GPU3
GPU4
GPU5
GPU6
GPU7
NVSwitch
NVSwitch
NVSwitch
NVSwitch
NVSwitch
NVSwitch
NVSwitch
NVSwitch
NVSwitch
NVSwitch
NVSwitch
NVSwitch

!20
DGX-2 STRONG SCALINGGlobal Volume 324, Wilson-Dslash
0
4,000
8,000
12,000
16,000
20,000
1 2 4 8 16
MPI double SHMEM doubleMPI single SHMEM singleMPI half SHMEM half
GFl
op/s
#GPUs

!20
DGX-2 STRONG SCALINGGlobal Volume 324, Wilson-Dslash
0
4,000
8,000
12,000
16,000
20,000
1 2 4 8 16
MPI double SHMEM doubleMPI single SHMEM singleMPI half SHMEM half
GFl
op/s
#GPUs

!20
DGX-2 STRONG SCALINGGlobal Volume 324, Wilson-Dslash
0
4,000
8,000
12,000
16,000
20,000
1 2 4 8 16
MPI double SHMEM doubleMPI single SHMEM singleMPI half SHMEM half
GFl
op/s
#GPUs

!21
DGX-2 STRONG SCALINGGlobal Volume 324, HISQ-Dslash
0
2,400
4,800
7,200
9,600
12,000
1 2 4 8 16
MPI double SHMEM doubleMPI single SHMEM singleMPI half SHMEM half
GFl
op/s
#GPUs

!21
DGX-2 STRONG SCALINGGlobal Volume 324, HISQ-Dslash
0
2,400
4,800
7,200
9,600
12,000
1 2 4 8 16
MPI double SHMEM doubleMPI single SHMEM singleMPI half SHMEM half
GFl
op/s
#GPUs

!21
DGX-2 STRONG SCALINGGlobal Volume 324, HISQ-Dslash
0
2,400
4,800
7,200
9,600
12,000
1 2 4 8 16
MPI double SHMEM doubleMPI single SHMEM singleMPI half SHMEM half
GFl
op/s
#GPUs

!22
NVSHMEM OUTLOOKintra-kernel synchronization and communication

!22
NVSHMEM OUTLOOKintra-kernel synchronization and communication
One kernel to rule them all ! Communication is handled in the kernel and latencies are hidden.

23
MULTI-NODE SCALING

!24
SCALING TESTBEDS
NVIDIA DGX-1 8 V100 (16GB) 4 EDR IB 50/100 GB/s NVLink P2P*
Top500 #22
NVIDIA DGX-2H 16 Tesla V100 (32GB) 8 EDR IB 300 GB/s NVLink P2P*
Top500 #1
IBM AC 922 6 Tesla V100 (16GB) 2 EDR IB 100 GB/s NVLink P2P*
PROMETHEUS (NVIDIA) DGX SuperPOD (NVIDIA) SUMMIT (OLCF)
*) bi-directional bandwidth between two GPUs
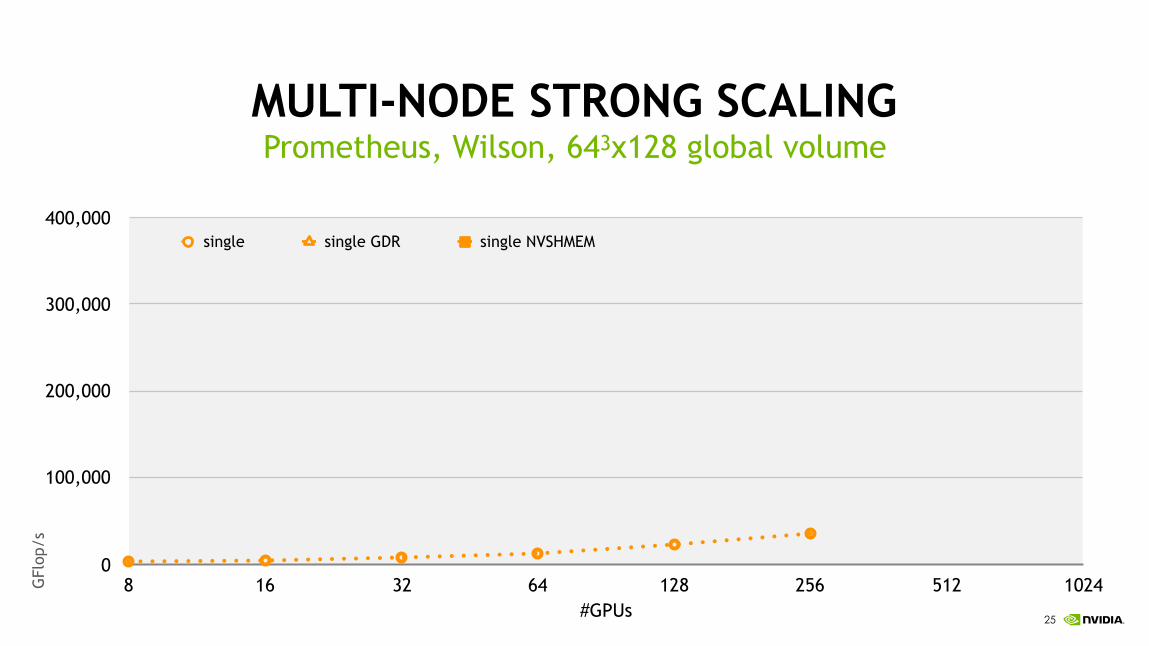
!25
MULTI-NODE STRONG SCALINGPrometheus, Wilson, 643x128 global volume
0
100,000
200,000
300,000
400,000
8 16 32 64 128 256 512 1024
single single GDR single NVSHMEM
GFl
op/s
#GPUs
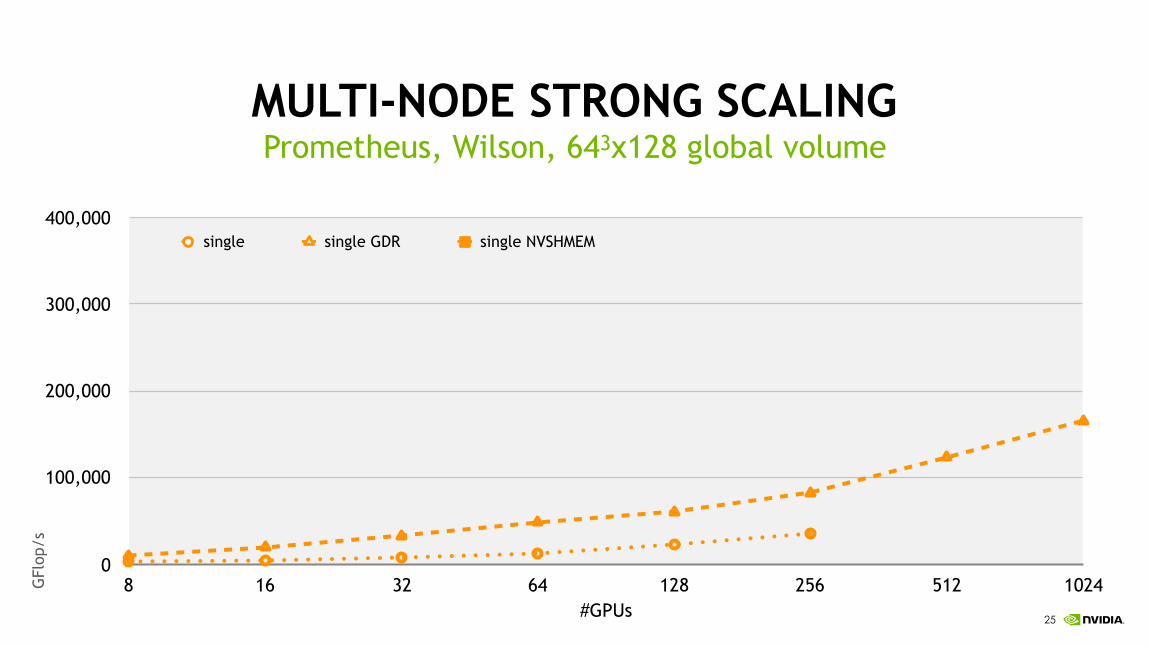
!25
MULTI-NODE STRONG SCALINGPrometheus, Wilson, 643x128 global volume
0
100,000
200,000
300,000
400,000
8 16 32 64 128 256 512 1024
single single GDR single NVSHMEM
GFl
op/s
#GPUs

!25
MULTI-NODE STRONG SCALINGPrometheus, Wilson, 643x128 global volume
0
100,000
200,000
300,000
400,000
8 16 32 64 128 256 512 1024
single single GDR single NVSHMEM
GFl
op/s
#GPUs

!26
MULTI-NODE STRONG SCALINGPrometheus, Wilson, 643x128 global volume
0
100,000
200,000
300,000
400,000
8 16 32 64 128 256 512 1024
single single GDR single NVSHMEMhalf half GDR half NVSHMEMdouble double GDR double NVSHMEM
GFl
op/s
#GPUs

!26
MULTI-NODE STRONG SCALINGPrometheus, Wilson, 643x128 global volume
0
100,000
200,000
300,000
400,000
8 16 32 64 128 256 512 1024
single single GDR single NVSHMEMhalf half GDR half NVSHMEMdouble double GDR double NVSHMEM
GFl
op/s
#GPUs

!27
MULTI-NODE STRONG SCALINGhalf precision, Wilson, 643x128 global volume
0
100,000
200,000
300,000
400,000
8 16 32 64 128 256 512 1024
Prometheus MPI Prometheus NVSHMEMDGX SuperPOD MPI DGX SuperPOD NVSHMEMSUMMIT* MPI SUMMIT* NVSHMEM
GFl
op/s
#GPUs

!27
MULTI-NODE STRONG SCALINGhalf precision, Wilson, 643x128 global volume
0
100,000
200,000
300,000
400,000
8 16 32 64 128 256 512 1024
Prometheus MPI Prometheus NVSHMEMDGX SuperPOD MPI DGX SuperPOD NVSHMEMSUMMIT* MPI SUMMIT* NVSHMEM
GFl
op/s
#GPUs

!27
MULTI-NODE STRONG SCALINGhalf precision, Wilson, 643x128 global volume
0
100,000
200,000
300,000
400,000
8 16 32 64 128 256 512 1024
Prometheus MPI Prometheus NVSHMEMDGX SuperPOD MPI DGX SuperPOD NVSHMEMSUMMIT* MPI SUMMIT* NVSHMEM
GFl
op/s
#GPUs
*) NOTE: SUMMIT results have been obtained using 64^3x96 global volume and scaled by 8/6 (x and y-axis) to make up for 6 GPUs/node. At a given number of GPUs the local volume per GPU is identical for all systems.

!28
STRONG SCALING LATTICE QCD …
Optimize for latency and bandwidth Autotune kernel performance and comms policy
GPU centric communication with NVSHMEM reduce number of kernels through fusion reduce API overheads and synchronizations simplify code (fewer lines)
Significantly improved strong scaling … … but still early results (stay tuned)
generalize for all Dirac operators including Multigrid (coarse operators)
… FURTHER WITH NVSHMEM
0
100,
000
200,
000
300,
000
400,
000
16 32 64 128 256 512 1024
Prometheus MPI Prometheus NVSHMEMDGX SuperPOD MPI DGX SuperPOD NVSHMEM
GFl
op/s
#GPUs
half precision, Wilson, 643x128 global volume

!29
POSTER SESSION
RAFFLE
Tuesday, 17:50
REFERENCEShttps://lattice.github.io/qudahttps://developer.nvidia.com/cuda-zonehttps://devblogs.nvidia.com/parallelforall/inside-volta/Copyright © 2019 NVIDIA Corporation. All rights reserved.
TALKS
LATTICE QCD ON NVIDIA® TESLA® V100
QUDA 1.0
Tuesday, 15:20, Algorithms & Machines: Leadership-Class Multi-Grid Algorithms for HISQ Fermions on GPUs.Tuesday, 15:40, Algorithms & Machines: Breaking the latency barrier: Strong scaling LQCD on GPUs.Thursday, 11:15, Plenary: GPUs for Lattice Field Theory.
QUDA: A LIBRARY FOR QCD AND BEYOND ON GPUs
QUDA is an open source community-developed and NVIDIA-supported library for performing LQCD and strongly coupled BSM calculations on GPUs, leveraging NVIDIA’s CUDA platform. QUDA provides highly optimized mixed-precision linear solvers, eigenvector solvers, multi-grid algorithms, gauge-link fattening and fermion force algorithms Supported fermion types are: Wilson, Wilson-clover, twisted mass singlet and doublet, twisted mass clover, naïve staggered, improved staggered (ASQTAD or HISQ), domain-wall (4-d or 5-d) and möbiusUse of multiple GPUs in parallel is supported throughout the library, with inter-GPU communication achieved using MPI or QMP. Several commonly used LQCD applications integrate support for QUDA as a compile-time option, including Chroma, MILC, CPS, BQCD, TIFR and tmLQCDQUDA is an unparalleled research tool for reaching the exascale. With its new high-level C++11 framework, QUDA enables testing new fermion discretizations and new algorithms performantly and at scale with relative ease
WHY GPUs?LQCD simulations are typically memory-bandwidth bound, and so run very efficiently on GPUsLQCD simulations have high degrees of data parallelism that can be expressed effectively using the single instruction multiple data (SIMD) paradigm. This makes LQCD ideal for GPU deploymentMost LQCD calculations require only local communication on the 4-d lattice. This makes them suitable for deployment on multiple GPUs through partitioning the lattice into disjoint equal sub-lattices and distributing these between GPUs GPUs are prevalent on the fastest computing clusters and supercomputers in the world
QUDA REWRITEOld Dslash kernel code became increasingly limitingRewrite brings a lot of benefits:- Extensibility, composability and maintainability: “one Wilson kernel to rule them all”- Ability to add new discretizations easily: e.g. Twisted clover doublet- Changing representation, Nc, etc: Accessor abstraction- Larger local volumes- Ability to run on CPU: Future framework for all architectures??
Same or better performance
ROAD TO THE FUTUREBlock solvers for all fermion actionsEigenvector compressionContinuous optimization of multi-grid algorithmsImproved scaling: NVSHMEMC++ InterfaceAlternative compilation targets (e.g., C++17 pSTL)
ANNOUNCING QUDA 1.0
Complete re-write of all operators in a new Dslash framework Jitify support: huge reduction in compile time, enabling even more rapid algorithm developmentImproved Multi-GPU performance taking advantage of latest GPU Direct RDMA and NVLink technologiesAdaptive Multigrid for Wilson, Wilson-clover, Twisted-mass, Twisted-clover, Staggered, and Improved Staggered fermionsA polynomial-accelerated Lanczos as well as deflated CG, communication-avoiding (CA) CG, and SVD-deflated (CA-)GCRSignificantly improved build system and automated unit testsVarious other new routines and algorithms, code cleanup and bug fixes
TESLA VOLTA V10021B transistors
815 mm2
16/32 GB HBM2900 GB/s HBM2300 GB/s NVLink
80 SM5120 CUDA Cores640 Tensor Cores
MULTI-GPU WILSON DSLASHGlobal Volume = 324, DGX-2, NVLink + NVSwitch
GPUs
GFLOPS Double MPIDouble NVSHMEM
Single MPISingle NVSHMEM
Half MPIHalf NVSHMEM
1 42 1680
2000400060008000
1000012000140001600018000
Authors: Kate Clark, Mathias Wagner, Evan Weinberg, NVIDIA
Two GPU Boards8 V100 32GB GPUs per board6 NVSwitches per board512GB Total HBM2 Memoryinterconnected byPlane Card
Eight EDR Infiniband/100 GigE1600 Gb/sec Total Bi-directional Bandwidth
PCIe Switch Complex
Two Intel Xeon Platinum CPUs
1.5 TB System MemoryDual 10/25 Gb/secEthernet
30 TB NVME SSDs Internal Storage
Twelve NVSwitches2.4 TB/sec bi-sectionbandwidth
NVIDIA Tesla V100 32GB
9
9
1
3
8
2
4
6
7
5
NVIDIA DGX-2
QUDA NODE PERFORMANCE OVER TIME
Time to solution is measured for solving the Wilson operator against a random source on a 24x24x24x64 lattice, β=5.5, Mл= 416 MeV.One node is defined to be 3 GPUs.
GFLOPS SPEEDUPWilson FP32 GFLOPs Speedup
2008 2010 2012 2014 2016 2018 2019
0
50
100
150
200
250
300
0
500
1000
1500
2000
2500
3000
Multi GPUcapable
AdaptiveMG
Optimized MG
DeflatedMG>
>
>
>
>
>
>
>
>>
>
>
>
>>
>>
>
>>>>>>
NVSHMEMImplementation of OpenSHMEM standard for GPUsGPU-centric communicationCommunication controlled in the kernels Fine-grained load/store over NVLink Bulk transfers over Infiniband using RDMAReduce number of required kernels by enabling kernel fusionRemove API overheads and GPU-CPU synchronizations
>>>
--
>>
DEFLATED ADAPTIVE MG AT THE PHYSICAL POINTIn collaboration with Dean Howarth (BU)
Multigrid shifts the lowest eigenvalues to the coarse gridsSome Dirac operators (staggered and twisted mass) end up with pathological coarse-grid spectrumFor Twisted-clover operator, solution has been to add a fictitious heavy twist to the coarse operator to improve its condition number at the cost of decreased multigrid efficiency [Alexandrou et al]Instead we deflate the coarse grid operator recovering optimal MG convergence and a 3x speedup over ”mu scaling”
>>
>
>
CHROMA HMC-MG ON SUMMITIn collaboration with Bálint Joó – Chroma, Boram Yoon – Force gradient integrator, Frank Winter – QDP-JIT
From Titan running 2016 code to Summit running 2019 code we see >82x speedup in HMC throughputMultiplicative speedup coming from machine and algorithm innovationHighly optimized multigrid for gauge field evolution
Wal
lclo
ck T
ime
(sec
onds
)
Titan (1024x K20X)
Summit (128x V100)
Summit (128x V100, Nov 2019)
Summit (128x V100, Mar 2019)
Titan (512x K20X)
0500
10001500200025003000350040004500
4006
1878
974439 392
>
>>
4.1x faster on 2x fewer GPUs ~8x gain
10.2x faster on 8x fewer GPUs ~82x gain
MULTI-GPU HISQ DSLASHGlobal Volume = 324, DGX-2, NVLink + NVSwitch
GFLOPS
GPUs1 42 168
0
2000
4000
6000
8000
10000
12000
Double MPIDouble NVSHMEM
Single MPISingle NVSHMEM
Half MPIHalf NVSHMEM
We are pleased to announce QUDA 1.0
>>
>
SUMMIT AND SIERRA ARE NOW LIVEIBM POWER9 + NVIDIA Volta V100 + NVLinkSummit: 4608 nodes (6 GPUs/node): 200 PFLOPS peak - The most powerful computer in the world
Sierra: 4320 nodes (4 GPUs/node): 125 PFLOPS peak - 2nd most powerful computer in the world
MULTI-NODE WILSON DSLASHGlobal Volume = 643x128, DGX1 with 8 V100, NVLink, 4 EDR IB
GFLOPS
0
50000
100000
150000
200000
250000
GPUs8 16 32 64 128 256 512
MPI P2P off, GDR off half MPI P2P off, GDR off single MPI P2P off, GDR off double
MPI P2P on, GDR on half MPI P2P on, GDR on single MPI P2P on, GDR on double
NVSHMEM half NVSHMEM single NVSHMEM double
Time to solution is measured running QUDA on 4 DGX-1 (32 V100) for solvingthe Twisted-mass + clover operator against a random source on a 643x128 lattice, β = 1.778, κ = 0.139427, µ = 0.000720, solver tolerance 10-7
CG double CG double-single CG double-half Baseline muscaling MG
CA-GCR
Time
Tim
e (s
)
Speedup
Spee
dup
Deflate 512vectors
Deflate 1024vectors
01020304050607080
100
01020304050607080
1009090
mass
4-level MG, deflate 64 eigenvectorsCG
0
5
10
20
15
Tim
e to
Sol
utio
n (s
)
0.001 0.002 0.004 0.008 0.016 0.032
HISQ MULTIGRID483x96, β = 6.4 (quenched), HISQ fermions
Time to solution is measured time for solving the HISQ operator against a random source. Runs were performed on 3 DGX-1 (24 V100 total).

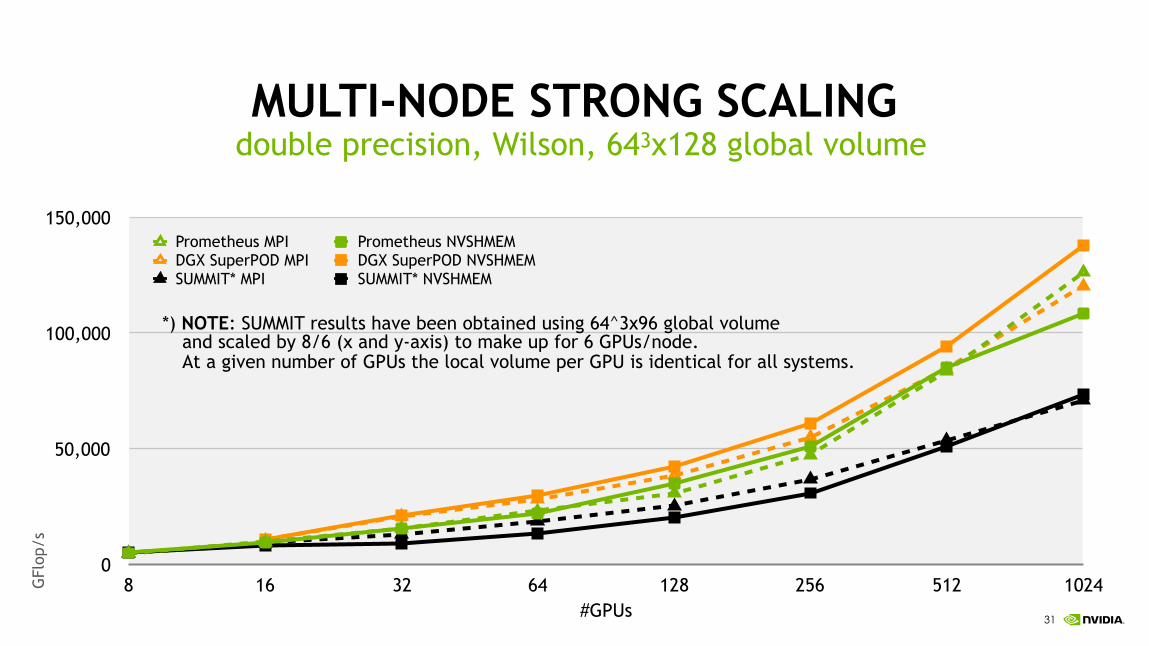
!31
MULTI-NODE STRONG SCALINGdouble precision, Wilson, 643x128 global volume
0
50,000
100,000
150,000
8 16 32 64 128 256 512 1024
Prometheus MPI Prometheus NVSHMEMDGX SuperPOD MPI DGX SuperPOD NVSHMEMSUMMIT* MPI SUMMIT* NVSHMEM
GFl
op/s
#GPUs
*) NOTE: SUMMIT results have been obtained using 64^3x96 global volume and scaled by 8/6 (x and y-axis) to make up for 6 GPUs/node. At a given number of GPUs the local volume per GPU is identical for all systems.
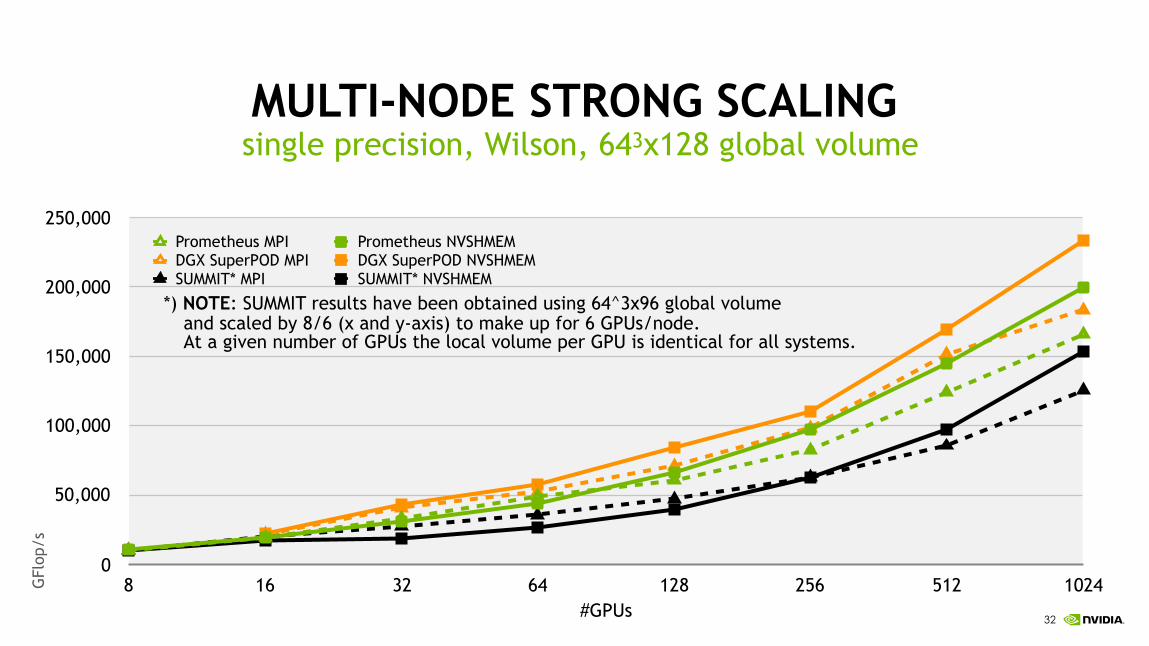
!32
MULTI-NODE STRONG SCALINGsingle precision, Wilson, 643x128 global volume
0
50,000
100,000
150,000
200,000
250,000
8 16 32 64 128 256 512 1024
Prometheus MPI Prometheus NVSHMEMDGX SuperPOD MPI DGX SuperPOD NVSHMEMSUMMIT* MPI SUMMIT* NVSHMEM
GFl
op/s
#GPUs
*) NOTE: SUMMIT results have been obtained using 64^3x96 global volume and scaled by 8/6 (x and y-axis) to make up for 6 GPUs/node. At a given number of GPUs the local volume per GPU is identical for all systems.