boundary values and automated component testing
TRANSCRIPT

SOFTWARE TESTING, VERIFICATION AND RELIABILITYSoftw. Test. Verif. Reliab.9, 3–26 (1999)
Boundary Values and AutomatedComponent Testing
DANIEL HOFFMAN1*†, PAUL STROOPER2 AND LEE WHITE3
1Department of Computer Science, University of Victoria, P.O. Box 3055 STN CSC, Victoria, B.C., V8W 3P6Canada2Department of Computer Science and Electrical Engineering, The University of Queensland, Brisbane, 4072Australia,3Department of Computer Engineering and Science, Case Western Reserve University, Olin Building, 10900Euclid Avenue, Cleveland, OH 44106–7071, U.S.A.
SUMMARY
Structural coverage approaches to software testing are mature, having been thoroughly studied fordecades. Significant tool support, in the form of instrumentation for statement or branch coverage,is available in commercial compilers. While structural coverage is sensitive to which code structuresare covered, it is insensitive to the values of the variables when those structures are executed. Datacoverage approaches, e.g. boundary value coverage, are far less mature. They are known topractitioners mostly as a few useful heuristics with very little support for automation. Because ofits sensitivity to variable values, data coverage has significant potential, especially when used incombination with structural coverage. This paper generalizes the traditional notion of boundarycoverage, and formalizes it with two new data coverage measures. These measures are used togenerate test cases automatically and from these, sophisticated test suites for functions from theC11 Standard Template Library. Finally, the test suites are evaluated with respect to bothstructural coverage and discovery of seeded faults. Copyright 1999 John Wiley & Sons, Ltd.
KEY WORDS automated testing; boundary values; Standard Template Library; object-oriented
1. INTRODUCTIONWith object-oriented methods, productivity and reliability can be vastly improved, primarilythrough reuse. Libraries of reusable components—classes and stand-alone functions—offersignificant potential for reuse. Such components are now provided in the C11 and Javastandard libraries, and in many proprietary libraries as well. With such widespreadavailability the cost of errors is high, making reliability important. Because assurance ofsoftware reliability depends in part on testing, the effective use of reusable componentsdepends on practical approaches to component testing.
* Correspondence to: Daniel Hoffman, Department of Computer Science, University of Victoria, P.O. Box 3055STN CSC, Victoria, B.C., V8W 3P6 Canada. Email: dhoffmanKcsr.uvic.ca
†Professor Hoffman is currently at Bell Laboratories, Lucent Technologies, 263 Shuman Drive, Naperville, IL60566, U.S.A.
Received 18 May 1998CCC 0960–0833/99/010003–24$17.50 Revised 9 November 1998Copyright 1999 John Wiley & Sons, Ltd. Accepted 24 November 1998

4 D. HOFFMAN, P. STROOPER AND L. WHITE
In the software testing research community, structural coverage has received significantattention. While the definitions of ‘coverage’ and the means for maximizing that coveragehave varied, there has been a crucial unifying concept: the program flowgraph. Statement,branch and dataflow coverage have all been defined in terms of flowgraphs, and thepower of compiler technology has been harnessed to provide tool support. Coverageresearch has matured to the point where the basic concepts and limitations are wellunderstood, and tool support is widely available. It is well known that, while structuralcoverage is sensitive to which flowgraph elements are covered, it is relatively insensitiveto the values that variables attain. As a result, obvious faults can be missed even by100% coverage; in particular, faults caused by omitted code are usually missed.
In contrast, data coverage has received only modest attention from testing researchers.Here there is no universal underlying structure analogous to the flowgraph. Instead thereis a data space that is astronomically large and some heuristics to guide the selection ofvalues from that space. The heuristics are useful and appear to be in regular use bypractitioners. Thorough testing requires exercising the combinations of boundary values;the result is a large number of tests. To test these combinations affordably, automatedsupport is essential, and largely unavailable.
This paper provides a mathematical basis and automated support for a generalizedboundary-value approach to testing. To be successful, any component testing approachmust:
I be simple, intuitive and easily visualizeable—testing is inherently complex, becauseof the complexity of the code under test; the testing approach must not make itmore so;
I be well-suited to automation—automation of both input generation and output check-ing is essential because combinations of values will require many tests;
I generate effective tests—the resulting test cases must achieve good structural coverageand must be effective at revealing faults.
The sections to follow describe a testing approach that satisfies these three criteria.Section 2 surveys the previous work in this area. Section 3 provides definitions ofk-bdyandk-per, and linear congruential sequences, a technique for generating random sequencesof integers. Section 4 briefly describes the Standard Template Library, focusing on thethree functions tested in this paper:partition, splice and sort. Section 5 shows how touse the definitions of Section 3 for test data generation, and presents test drivers forpartition and splice. Section 6 describes experiments that evaluatek-bdy and k-per on amore complex function:sort.
2. RELATED WORKOne of the earliest and most effective strategies for software testing is that of testingboundary values. Standard texts on software testing (Myers, 1979; Beizer, 1990) includeextensive discussion of boundary testing, and many practitioners today argue for itssimplicity and effectiveness. Howden (1980, 1982) and Foster (1980, 1984) providedcareful analyses of the error sensitivity of boundary values for testing arithmetic and logicexpressions. A recent study (Reid, 1997) on retrospective fault data from an industrialproject compared statement coverage, branch coverage, random testing, boundary value
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

5BOUNDARY VALUES TESTING
testing and several other testing approaches to discover these faults. Boundary valuetesting outperformed all the other methods, finding nearly all the faults in nearly all the17 modules; for the 14 modules in which it was effective, over 50 000 random test casesper module would have been required to equal its test effectiveness. Other similarapproaches include domain testing (White and Cohen, 1980), equivalence partitioning(Weyuker and Ostrand, 1980) and domain partitioning (Richardson and Clarke, 1985).
In this paper, the relationship between a generalized approach to boundary values andstatement coverage is explored. Beizer suggests that structural coverage criteria should becomplemented by data coverage (‘Have we tested all reasonable data-usage patterns? Havewe checked all the interesting extreme input combinations?’) (Beizer, 1990, p. 77). Formany industrial organizations, obtaining 100% statement coverage during system testingis extremely difficult (Piwowarskiet al., 1993). Yet, if near 100% unit test coverage isobtained, this can be a major factor in reducing the amount of rework (Holt and Stewart,1997). More general structural coverage measures based on data-flow criteria have beenproposed (Rapps and Weyuker, 1985). There have been a number of attempts to demon-strate experimentally which data-flow criteria yield the most cost-effective and fault-revealing tests (Frankl and Weiss, 1993). Yet it has not been possible to establish thisrelationship definitively or to determine, in practice, which data-flow criterion should beused in a given situation.
Ostrand and Balcer (1988) have developed the category-partition method, including aseven-step methodology, a formal language for specifying software tests, and a generatortool. The tester writes a series of test specifications and then uses the tool to producetest descriptions. Based on these descriptions, actual tests or test drivers are then developedmanually. The category-partition method is quite general and has been used successfullyin industrial practice. The manual steps in the category-partition method are very similarto the manual steps proposed in Section 5.2 of this paper. The key difference is that,while the category-partition method can be applied quite generally, this paper focuses oncomponents with a procedure-call interface. Although our approach has narrower appli-cation, it also offers much better opportunities for automation, because it generates testdrivers, not test scripts from which drivers are written manually.
While most research to date has focused on system testing, specialized techniques havebeen developed for testing the components from which systems are constructed. Earlywork by Panzl (1978) on component testing provided tools and techniques for theregression testing of Fortran subroutines. The DAISTS (Gannonet al., 1981), PGMGEN(Hoffman, 1989; Hoffman and Strooper, 1995) and Protest (Hoffman and Strooper, 1991)systems all automate the testing of modules using test cases based on sequences of calls.In object-oriented testing, Frankl and Doong (1994) have developed a scheme for classtesting using algebraic specifications. Fiedler (1989) describes a small case study ontesting C11 objects. The ACE tool (Murphyet al., 1994) supports the testing of Eiffeland C11 classes and has seen substantial industrial use. Arnold and Fuson (1994) discussclass testing issues and techniques. Binder (1994) describes how classes can be designedto reduce test cost. The ClassBench framework (Hoffman and Strooper, 1997) supports atesting approach based on atestgraph: an abstraction of the state-transition graph of theclass under test.
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

6 D. HOFFMAN, P. STROOPER AND L. WHITE
3. MATHEMATICAL PRELIMINARIESThis section presents definitions ofboundaryand perimeteron ordered domains. With asingle domain, both definitions focus on pairs: the first and last element in the domain,the second and second-to-last element, and so on. With multiple domains, the two conceptsare different. The boundary of a set of domains is the Cartesian product of the boundariesof the individual domains. The perimeter of a set of domains is the boundary plus the‘points in between’. A formalization of these ideas and simple geometric interpretationsare presented next.
Finally, linear congruential sequences, well known in the literature as a mechanism forgenerating random sequences of integers (Knuth, 1969), are defined.
3.1 BoundariesLet D 5 kd0, d1, . . . , dn21l be a non-empty, ordered domain, and letk be a strictly
positive integer.
k-bdy(D) 5def 5{ dk21, dn2k} if n is even` k , n/2
{ d(n/2)21, dn/2} if n is even` k > n/2
{ dk21, dn2k} if n is odd` k , (n 11)/2
{ d(n21)/2} if n is odd` k > (n 1 1)/2
k*-bdy(D) 5def <k
i51i-bdy(D)
When k is smaller thanuDu/2, then the meaning ofk-bdy(D) is simple: the set consistingof the kth and kth-to-last elements ofD. As k grows, this pair of elements gets closertogether. Eventually, the middle pair (or single element ifk is odd) is reached. Whenkis yet larger, a variety of meanings fork-bdy(D) are plausible, including ‘undefined’ and{}. The definition of k-bdy formalizes a third meaning that has proven useful in practice:let k-bdy(D) refer to the middle pair (or single element). Finally,k*-bdy(D) is the unionof the 1, 2, . . .,k boundaries ofD. To illustrate, if D 5 {0, 1, 2, 3} then
1-bdy(D) 5 {0, 3} 1*- bdy(D) 5 {0, 3}
2-bdy(D) 5 {1, 2} 2*- bdy(D) 5 {0, 1, 2, 3}
3-bdy(D) 5 {1, 2} 3*- bdy(D) 5 {0, 1, 2, 3}
Similarly, if D 5 {0, 1, 2, 3, 4} then
1-bdy(D) 5 {0, 4} 1*- bdy(D) 5 {0, 4}
2-bdy(D) 5 {1, 3} 2*- bdy(D) 5 {0, 1, 3, 4}
3-bdy(D) 5 {2} 3*- bdy(D) 5 {0, 1, 2, 3, 4}
4-bdy(D) 5 {2} 4*- bdy(D) 5 {0, 1, 2, 3, 4}
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

7BOUNDARY VALUES TESTING
The extension ofk-bdy and k*-bdy to multiple domains is based on a direct applicationof the Cartesian product. LetD0, D1, . . ., Dm21, where m . 0, be non-empty ordereddomains, and letk be a strictly positive integer.
k-bdy(D0, D1,%, Dm21) 5def k-bdy(D0) 3 k-bdy(D1) 3 % 3 k-bdy(Dm21)
k*-bdy(D0, D1,%, Dm−1) =def <k
i=1i-bdy(D0, D1,%, Dm−1)
Examples with two domains are illustrative. Consider the integer domainsX, of the form{0, 1, . . ., nX 2 1}, and Y, of the form {0, 1, . . .,nY 2 1}. For various choices ofnX
and nY, each diagram in Figure 1 illustratesk-bdy(X, Y) for all k. X 3 Y is representedas a rectangle in the integer plane with the lower left corner at the origin. Each symbolin the rectangle represents anX/Y pair. An integerk indicates that the pair is ink-bdy(X,Y), a bold integerk indicates that the pair is ini-bdy(X, Y) for all i $ k, and a ‘?’indicates that the pair is not ink-bdy(X, Y) for any k. For example, in Figure 1(a):
X 5 Y 5 {0, 1, 2, 3}
1-bdy(X, Y) 5 { k0,0l, k0,3l, k3,3l, k3,0l}
(∀k $ 2)(k-bdy(X, Y) 5 { k1,1l, k1,2l, k2,2l, k2,1l})
The remaining eight points are not ink-bdy (X, Y) for any k. The boldface region, 2-bdy(X, Y) in Figure 1(a), is called the boundarycore.
Figures 1(a) and 1(b) contain squares, and illustrate thek-bdy concepts clearly. Thek-bdys lie on the diagonals and thek-bdy and (k 1 1)-bdy are always disjoint or identical.For squares, the two core shapes shown are the only possible ones. The core shape isdetermined by whether the size ofX and Y is odd or even. In Figures 1(c) to 1(f) arenon-squares where there is more variety. The diagrams show the four possible core shapes.
The rule that determines the core shape is simple. The core width is 1 ifuXu is oddand 2 if uXu is even; similarly, the core height depends on whetheruYu is odd or even.This rule follows directly from thek-bdy definitions. If uXu is odd then, fork $ (uXu 1
Figure 1. k-bdy examples
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

8 D. HOFFMAN, P. STROOPER AND L. WHITE
1)/2, k-bdy(X) is the singleton set consisting of the middle element ofX. If uXu is eventhen, for k $ uXu/2, k-bdy(X) is the pair consisting of the middle two elements ofX.Becausek-bdy(X, Y) 5 k-bdy(X) 3 k-bdy(Y), the core width will be 1 ifuXu is odd and2 if uXu is even. The argument for core height is similar.
3.2. PerimetersPerimeters contain more points than boundaries, but, as demonstrated in Sections 5 and
6, far fewer than the full Cartesian product of the domains. On a single domain, theperimeter and boundary are the same; on multiple domains, there are important differences.For any non-empty ordered domainD and strictly positive integerk
k-per(D) 5def k-bdy(D)
k*-per(D) 5def k*-bdy(D)
For multiple domains, the perimeter contains the boundary points and the points ‘inbetween’. LetD0, D1, . . ., Dm21, where m . 0, be non-empty ordered domains, and letk be a strictly positive integer.
k-per(D0, D1,%, Dm21) 5def { kx0, x1,%, xm21lu
(∃i P [0. .m 2 1])(xi P k-bdy(Di) `
(∀j P [0. .m 2 1])(i Þ j →(xj P Dj ` min(k-bdy(Dj)) # xj # max(k-bdy(Dj)))))}
k*-per(D0 D1,%, Dm21) 5def <k
i51i-per(D0, D1,%, Dm21)
The k-per definition can be paraphrased as follows:k-per(D0, D1, . . ., Dm21) is a set ofm-tuples; for eachm-tuple, some element is on itsk-bdy and all the other elements areon or between theirk-bdys.
Figure 2 illustratesk-per(X, Y) for all k, using the sameX and Y values as in Figure
Figure 2. k-per examples
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

9BOUNDARY VALUES TESTING
1. Figures 2(a) and 2(b) contain squares, and illustrate thek-per concepts clearly. Hereeachk-per forms the perimeter of a square,k-per and (k 1 1)-per are always disjoint oridentical, and only the two core shapes shown are possible. With the non-squares shownin Figures 2(c) to 2(f) the situation is more complex. Eachk-per lies on the perimeter ofa rectangle. However,k-per and (k 1 1)-per are disjoint only until one ofX and Yreaches its core; thenk-per may be a superset of (k 1 1)-per. For example, in Figure2(c), 3-per(X, Y) 5 { k1,2l, k2,2l} and these two points are also in 2-per(X, Y).
The k-bdy and k-per definitions constitute a generalization and formalization of thetraditional notions of boundary testing. Section 5 describes how to usek-bdy and k-per to generate test tuples automatically and from these, sophisticated test suites forSTL algorithms.
3.3. Linear congruential sequences
In automated software testing, it is often necessary to generate sequences of integers.For code that depends on sequence order, a variety of orderings will be needed for thoroughtesting. Checking output correctness can be greatly simplified by using permutations of0, 1, . . .,n21. Linear congruential sequences(LCSs) (Knuth, 1969) provide an easy wayto compute sequences satisfying all of these goals.
Given N $ 0, the sequence length;S P [0. .N 2 1], the starting value; andD P[1. .N 2 1], the increment
lcs(N, D, S) 5 kS, (S1 D)modN, (S1 2D)modN,%, (S1 (N 2 1)D)modNl
If N and D are relatively prime, thenlcs(N,D,S) is guaranteed to be a permutation of 0,1,. . ., N 21.
For example,lcs(5, 2, 0) 5 k0, 2, 4, 1, 3l. Two special cases are worth noting:
lcs(N, 1, 0) 5 k0, 1,%, N 2 1l
lcs(N, N 2 1, 0) 5 kN 2 1, N 2 2,%, 0l
4. THE STANDARD TEMPLATE LIBRARY
This section describes the Standard Template Library, focusing on the three functionstested in this paper.
4.1. Containers, algorithms and iterators
The Standard Template Library (STL) (Musser and Saini, 1996) provides the servicesoutlined in Table I. Seven containers are provided, each implemented as a class templatewith the element type as a template parameter. There are also three container adaptors;each of these is a wrapper around one of the other containers, adapting the container toproduce a new type of container. Eighty-one algorithms are provided, divided into thefour groups shown in Table I. Iterators are used in a clever way to avoid the ‘algorithmexplosion problem’: the need to develop a different version of each algorithm for each
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

10 D. HOFFMAN, P. STROOPER AND L. WHITE
Table 1. STL inventory
Containers Adaptors Algorithms Iterators
set stack non-mutating sequence istreammultiset queue mutating sequence ostream
map priority queue sorting related inputmultimap generalized numeric output
vector forwarddeque bidirectional
list random
container. In the STL, each container provides a standardized iterator interface; thealgorithms access the containersonly through this interface.
An iterator is a generalized pointer, referencing some element in a container andproviding its services through overloaded versions of the C11 pointer operators. Forexample, if i is an iterator, *i returns the element referenced byi and 11i advancesito the next element. Each container provides the functionsbegin(), which returns aniterator pointing to the first element in the container, andend(), which returns an iteratorpointing just after the last element. It is illegal to dereferenceend(). Thus, iteratorsprovide a way to visit all elements in a container sequentially; the sequence order iscontainer-specific.
The concept ofiterator range is central to the STL. The range [first, last) representsthe sequence of elements betweenfirst and last, including *first but excluding *last. For[first, last) to be valid,first and last must reference the same object andfirst must occurat or before last. For example, if x is a container object, then [x.begin(), x.end())represents the sequence consisting of all the elements inx and [x.begin(), x.begin())is empty.
This paper focuses on the testing of three STL functions:partition, sort and splice.Each function comes with several overloaded forms; the next three subsections describejust the forms used in the tests described later in the paper.
4.2. The partition algorithmThe interface topartition is as follows:
iterator partition(iterator, iterator, Predicate)
The call partition(first, last, p) rearranges the elements in [first, last) so that all theelements that satisfyp occur before all those that do not. The algorithm also returns aniterator i such thatp(x) holds for x P [first, i) and does not hold forx P [i, last).
Figure 3 demonstratespartition in action. The classPred defines a function object (aclass that overloadsoperator()) that allows easy definition of predicates for use inpartition. The constructor callPred(n) creates a function object that takes one parameterx and returns true or false according to whetherx , n. The function templateprintRangeprints the contents of an iterator range.
The program in Figure 3 calls each of the three member functions twice and displays
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

11BOUNDARY VALUES TESTING
Figure 3. Demonstration program forpartition, splice and sort
the result after each call. For all of these calls, the arraya which contains the itemsk0,2, 4, 1, 3l, is used to initialize the input variables to the calls. Line 14 shows howiterator ranges apply to conventional C11 arrays. Vectorvec0 is initialized with thecontents of arraya represented by [a,a15). The call in line 15 partitions the contents ofvec0 into two groups—those that are strictly less than 3 on the left and those that arenot on the right—and returns an iterator pointing to the leftmost element not less than 3.Line 16 displays the result
0 2 1 4 3 u 4
Because the STL standard does not specify the ordering of the elements within the twogroups, other results are possible, e.g.
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

12 D. HOFFMAN, P. STROOPER AND L. WHITE
0 2 1 3 4 u 3
Line 19 shows a call topartition in which the left group is empty: no element in therange is less than 0. Line 20 displays the result:
0 2 4 1 3 u 0
4.3. The sort algorithm
The interface tosort is as follows:
void sort(iterator, iterator)
The call sort(first, last) rearranges the elements in [first, last) so that the elements arein non-descending order according tooperator,, which must be defined for the containerelement type.
The program in Figure 3 invokessort twice. In the call on line 23, only the middlethree elements are sorted: [vec3.begin()11,vec3.end()21) contains only (2, 4, 1). Line24 displays the result
0 1 2 4 3
The call on line 27 sorts the entire vector, with line 28 displaying
0 1 2 3 4
4.4. The splice function
Unlike partition and sort, splice is not a generic STL algorithm. Instead, it is amember function of thelist container class. The interface tosplice is as follows:
void splice(iterator, listkTl&, iterator, iterator)
The call splice(pos, list, first, last) destructively copies the sublist [first, last) from listjust before positionpos. The copy is permitted from one list to another or within a singlelist. In the latter case,pos must not be in [first, last), thoughpos and last may be equal.
The program in Figure 3 issues two calls onsplice which sort the contents oflist0 ina roundabout way. The call on line 33 copiesk1, 3l to precede 4, with line 34 displaying
0 2 1 3 4
The call on line 38 finishes the job, shifting 1 one position to the left:
0 1 2 3 4
Lines 31, 32 and 36–38 contain numerous increment operations on thelist iterators,
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

13BOUNDARY VALUES TESTING
making the code somewhat clumsy. Thevector container used to demonstratepartitionand sort provides a random access iterator, which supportsoperator1, as shown on line23. The list container provides a bidirectional iterator, a somewhat weaker form, whichdoes not supportoperator1, because it cannot be implemented efficiently with the linkedlist usually used inlist implementations.
5. TEST AUTOMATIONThis section shows how the definitions ofk-bdy and k-per can be used for test datageneration and presents test drivers forpartition and splice.
5.1. Reusable functionsFour test functions are used extensively in the test suites: one function computes
Cartesian products and the other three are implementations ofk-bdy, k-per, and lcs fromSection 3.
The definitions ofk-bdy and k-per in Section 3 apply to an arbitrary number of finiteand ordered domains of any data type. To automate the generation of boundaries andperimeters, the tester must decide how to parametrize the input domains. The STL vectorclass makes it straightforward to deal with a varying number of domains of differentlengths. The input is defined as a vector of vectors, and each of the vectors in this vectorof vectors can be of different length.
However, to deal with domains of different data types is much more difficult in astrongly-typed language such as C11. The test functions are therefore implemented forinteger domains only. This restriction has not proven to be problematic in practice. It iseasy to generate test cases in integer form and then convert to other types as neededusing simple mapping functions (Hoffman and Strooper, 1997).
Figure 4 shows the declarations for the four functions. The callcp(v) returns theCartesian product of the vectors inv as a vector ofIntVectors, where eachIntVector isof the same length and represents one tuple in the Cartesian product. The callkbdy(k, v)returns thek-bdy of the IntVectors in v. Again, the k-bdy is returned as a vector ofIntVectors, with each IntVector representing one element in thek-bdy of v. The callkper(k, v) returns thek-per of the IntVectors in v. Note that functions fork*-bdy andk*-per are not implemented, because these can easily be obtained usingk-bdy, k-per anda simple loop. Finally, the calllcs(l, d, s) returns lcs(l, d, s).
The implementation of these functions is relatively short (approximately 200 lines ofC11 code), and although it follows the definitions shown in Section 3 quite closely, itcontains some subtle details. As such, this code is a good candidate for reuse. Note that
Figure 4. C11 declaration for cp, kbdy, kper and lcs
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

14 D. HOFFMAN, P. STROOPER AND L. WHITE
the use of a vector ofIntVectors is crucial in this reuse. Otherwise, it would be hard todeal with a varying number of domains of varying lengths, andkbdy, kper and cpwould have to be implemented in every test suite.
5.2. Testing strategyThe same testing strategy is used in all test suites.
Step1. Determine thetest focus. The test focus consists of those aspects of the functionand parameters that are ‘interesting’ for testing purposes. These decisions arebased on an informal notion of functional testing; typical aspects include thenumber of items in a container and the ordering of the elements in the container.
Step 2. Determine thetuple template. A tuple template is a tuplekt0, . . ., tn21l ofelements that is sufficient to specify a test case. Both the syntax and thesemantics of a tuple template must be determined: the syntax determines thenumber of elements in the tuple and their data types (integers in this case),and the semantics determines how a tuple template corresponds to a test case.The tuple template typically follows quite naturally from the test focus, butoften a number of detailed decisions about the semantics of the tuple templatemust be made at this stage.
Step 3. Determine thetuple set. The tuple set consists of all instances of the tupletemplate to be tested. The tuple set is typically generated by selecting a rangeof values for each of the components in the tuple template, and then usingcp, kbdy or kper to generate the tuple set from the resulting sequence ofranges. The range of values is determined by the tester and this is typically astraightforward decision to make.
Step4. Determine thevalid tuple templates. Not all syntactically correct tuples lead tomeaningful test cases, and at this stage the valid tuple templates that do leadto meaningful test cases are determined.
Step 5. Develop the testoracle. The test oracle checks the result for each test casegenerated from a valid tuple in the tuple set. The test oracle is typicallyimplemented as a Boolean C11 function that takes a tuple and the actual testoutput as its input, and returns true or false according to whether the outputis correct.
Step6. Write the testdriver. Figure 5 outlines the steps performed in the test driver.
The first two steps are by far the most creative and important; after that, most of theother steps are straightforward. Although all the important decisions above are made bythe tester, they are implemented in the test driver and thus executed automatically at run-
Figure 5. Pseudo-code for test driver
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

15BOUNDARY VALUES TESTING
time. For example, even though the tester decides on what constitutes a valid tuple, thisdecision is implemented in the test driver and the tuples are checked automatically forvalidity at run-time.
5.3. Testing thepartition algorithm
As described in Section 4, the callpartition(first, last, p) rearranges the elements in[first, last) so that all of the elements that satisfyp occur before all of those that do not.The algorithm also returns an iteratori such thatp(x) holds for x P [first, i) and doesnot hold for x P [i, last). To develop a test driver forpartition, the steps outlined aboveare followed.
Step1. Determine thetest focus. For partition, there are three ‘interesting’ aspects.(a)The number of elements in the range [first, last).(b)The predicate that is used to partition the elements. For simplicity, the
standard order on the integers is used to generate the predicate, which isthe function object from the classPred shown in Figure 3.
(c)The order in which the elements appear in the range [first, last).Step2. Determine thetuple template. Based on the test focus above, the tuple template
kN, P, D, Sl is chosen. The first elementN represents the number of elementsin the range [first, last). Because they are easy to generate and test, the integersare used as elements in the container, and the elements 0, 1, . . .,N 2 1 asthe elements in the range [first, last). To vary the predicate, the second elementin the test tuple is a pivotP, which is the parameter passed toPred and whichis used to partition the elements according to whether they are smaller thanPor greater than or equal toP. To vary the order of elements,D and S areintroduced in the tuple template, andlcs(N, D, S) is used to generate the inputvector for partition.
Step3. Determine thetuple set. In this case, a number of experiments that varied thetuple set were conducted. Each experiment was based on a maximum valueMax of the number of elements in the input vector.N and P were then allowedto range over [0. .Max], D over [1. . Max 2 1], and S over [0. . Max 2 1].The values 0 andMax were not included in the range forD and Max was notincluded in the range forS, because these would not lead to valid tuples. Theexperiments then varied in the value chosen forMax and in the algorithm (cp,kbdy, or kper) used to generate the tuple set from the above ranges.
Step4. Determine thevalid tuples. If N and D are not relatively prime, thenlcs(N, D,S) will not generate all values in the range 0, 1, . . .,N 21. Similarly, valuesof D and S greater thanN, and values ofP greater than or equal toN do notlead to useful test cases.
Step5. Develop the testoracle. For a test case generated from the tuple templatekN,P, D, Sl and a return value ofi from partition, the test oracle checks that:I There areP elements in the range [first, i) and that all these elements belong
to {0, 1, . . ., P 2 1};I There areN 2 P elements in the range [i, last) and that all these elements
belong to {P, P 1 1, . . ., N 2 1}.
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

16 D. HOFFMAN, P. STROOPER AND L. WHITE
Step6. Write the testdriver. Once the above decisions have been made, the test driveris straightforward to implement and follows the outline shown in Figure 5.
As explained in step 3, a number of experiments were conducted, varyingMax and thealgorithm used to generate the tuple set. Table II shows the total number of test tuplesgenerated, and the number of valid test tuples that remained after eliminating the invalidtuples as discussed in step 4.
Note that the total number of tuples forcp andkper increases rapidly asMax increases,whereas the number of tuples forkbdy remains constant and low. Furthermore, relativeto the number of tuples forcp, the number of tuples forkper grows slower asMaxincreases. Fork 5 1 and Max 5 10, kper generates over half the tuples generated bycp. For Max 5 30, this number is reduced to roughly one quarter.
5.4. Testing thesplice functionAs described in Section 4, the callsplice(pos, list, first, last) destructively copies the
sublist [first, last) from list just before positionpos. The copy is permitted from one listto another or within a single list. In the latter case,pos must not be in [first, last), thoughpos and last may be equal.
To test splice, two test suites are used: one to test splice with two different lists, andone where a sub-list of the current list is spliced into itself. Because the second casereveals a fault in the STL, it is described in detail below. In Section 5.5, the first caseis briefly discussed.
The same steps as before are used.
Step1. Test focus. In this case, the test focus consists of (1) the length of the list, (2)the position at which the elements are to be spliced, (3) the position of thefirst element to be spliced, and (4) the number of elements to be spliced.
Step2. Tuple template. The tuple template forsplice contains the four componentskL,P, F, Nl which represent the four aspects of the test focus. To complete thesemantics of the tuple template, the elements to use in the list must bedetermined. That is done in such a way that the oracle for checking the test
Table II. Summary statistics forpartition
Max algorithm k tuples generated valid tuples
10 cp — 12 100 3 63410 kbdy 1 16 1210 kbdy 2 16 410 kper 1 6 916 2 47010 kper 2 3 420 76230 cp — 864 900 205 46230 kbdy 1 16 1230 kbdy 2 16 430 kper 1 205 556 62 02230 kper 2 166 540 44 250
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

17BOUNDARY VALUES TESTING
results becomes straightforward. In particular, the input list is generated in sucha way that the output ofsplice should be the listk0, 1, . . ., L 2 1l.
Step 3. Tuple set. Similar to the testing forpartition, the maximum sizeMax of thelist tested and the algorithms to generate test tuples were varied. In each case,the range of values chosen forL, P, F and N was [0. .Max].
Step4. Valid tuples. In the next step, invalid tuples are eliminated. In this case, thosetuples for whichP, F or N are greater thanL are eliminated. Tuples whereF1 N . L are also eliminated, because for these tuples the sub-list to be splicedwould extend beyond the end of the list, which clearly does not make sense.Finally, tuples whereP P [F, F 1 N) are eliminated, because a preconditionof splice is that the position must not be in the range [first, last) (Musser andSaini, 1996, p. 291).
Step5. Oracle. As explained above, the oracle forsplice is trivial, because the inputis generated in such a way that the output list should bek0, 1,%, L 2 1l.
Step6. Driver. Finally, the test driver is written.
Table III summarizes the results for the testing ofsplice.The first five columns have the same interpretation as in Table II. The last column
indicates the number of failures reported by each of the test runs, caused by a fault inthe STL. For example, out of the 1716 calls tosplice generated when usingcp withMax 5 10, 165 calls reported a failure and exposed the fault insplice.
The relative size of the number of tuples generated by the three algorithms and theincrease in this size is similar topartition. Regarding the number of failures,kbdy doesnot reveal the fault for the cases listed in the table, and in fact it does not reveal thefault for any value ofk. Both cp and kper do reveal the fault through a number of testtuples. The fault occurs when an attempt is made to insert a sub-list in the same positionin which it originally occurs. In terms of the test tuplekL, P, F, Nl the fault is revealedby those test tuples for whichF 1 N 5 P, N . 0 and F 1 N Þ L. The last conditionshows that the fault is not revealed by those tuples for which the sub-list that is to beinserted is the whole list, and this is one of the reasons whykbdy does not reveal the fault.
This fault in the STL is one ofmissing code, where the special case discussed aboveis not dealt with in the code. As such, structural coverage approaches would not have
Table III. Summary statistics for firstsplice test suite
max.N algorithm k tuples generated valid tuples failures
10 cp — 14 641 1 716 16510 kbdy 1 16 6 010 kbdy 2 16 1 010 kper 1 8 080 1 176 8110 kper 2 4 160 435 6430 cp — 194 481 19 481 1 33030 kbdy 1 16 6 030 kbdy 2 16 1 030 kper 1 64 160 8 651 36130 kper 2 46 800 5 390 409
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

18 D. HOFFMAN, P. STROOPER AND L. WHITE
been sufficient to reveal the fault. In fact, the implementation ofsplice is only 7 lineslong, and even a single test case can achieve 100% path coverage. However, the faultdoes show the importance of boundary-value testing.
5.5. Testing splice with two different listsFor the testing ofsplice with two different lists, one component is added to the tuple
template, which represents the length of the second list. This changes the conditions thatdetermine which tuples are valid, but only in a minor way. It also changes the test oracle,because now the two lists must be checked after the call tosplice. Again, the test inputis chosen so that the oracle is trivial. In this case, the input lists are chosen so that thefirst output list should be of the formk0, 1, . . ., L1 2 1l and the second output listshould be of the formk−1, 22, . . ., 2L2l.
Table IV summarizes the results for the testing ofsplice with two different lists. Inthis case, no failures are reported. The number of tuples generated is much larger thanfor the first test suite because a component was added to the tuple template. In fact, inthis casecp does not complete with a maximum value of 20 for the elements in the testtuple, because the machine runs out of memory. Usingkper with k 5 1 in that casegenerates 1 608 002 test tuples, of which 192 501 tuples are valid, and these take lessthan a minute to execute.
6. EXPERIMENTAL EVALUATIONThis section describes experiments that evaluatek-bdy and k-per on the more complexfunction sort.
6.1. Algorithm overviewAs described in Section 4, the callsort(first, last) rearranges the elements in [first,
last) so that the elements are in non-descending order. Thepartition andsplice implemen-tations are short and relatively simple; thesort implementation is considerably morecomplex. A quicksort/insertion sort hybrid is used, with insertion sort applied whenever
Table IV. Summary statistics for secondsplice test suite
max.N algorithm k tuples generated valid tuples failures
10 cp — 161 051 18 876 010 kbdy 1 32 12 010 kbdy 2 32 3 010 kper 1 102 002 13 476 010 kper 2 42 242 4 420 020 cp — ? ? ?20 kbdy 1 32 12 020 kbdy 2 32 3 020 kper 1 1 608 002 192 501 020 kper 2 1 056 242 112 560 0
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

19BOUNDARY VALUES TESTING
a quicksort partition is smaller than 17 elements. Thesort implementation is broken into11 functions; the call graph has a maximum depth of 5.
6.2. Test planThe test suite design uses the six steps presented in the previous section.
Step 1. Test focus. As with partition, the testing focuses on the number of elementsin [first, last) and on the order of those elements.
Step2. Tuple template. The tuple template chosen in this case iskN, D, Sl. To makeinput generation and oracle development simple, permutations of the set {0, 1,%, N 21} are used as the elements of the range [first, last). To vary theelement order,D and S are introduced in the tuple template, andlcs(N, D, S)is used to generate the input vector forsort.
Step 3. Tuple set. A number of experiments were conducted, with wide variation inthe tuple set. The most interesting experiments are described in Section 6.3.
Step4. Valid tuples. In a valid tuple,N and D are relatively prime,D P [1. . N], andS P [0. . N].
Step 5. Oracle. For a valid tuplekN, D, Sl the correct output is the vectork0, 1,%,N 2 1l.
Step6. Driver. Given the decisions described in the previous five steps, the coding ofthe driver is simple. To allow for the experimentation mentioned in step 4, anumber of drivers were written and each of these makes certain values easy tochange, e.g. the tuple valueN is passed as a command-line parameter.
6.3. ExperimentsFour experiments are described below. The first two show what is achievable with
simple tests; experiment one varies onlyN—the sequence length—and experiment twovaries onlyD—the increment determining sequence order. Despite their simplicity, theseexperiments show some interesting coverage trends. The second pair of experimentscompare the effectiveness of thek-bdy and k-per schemes, varyingN, D and S. For theinterested reader, the source code for the test driver used for these last two experimentsis shown in the Appendix. In all four experiments, effectiveness is measured by thestatement coverage achieved and the detection of seeded faults.
Five faults were seeded by a graduate student who understood thesort implementationwell but who was not involved in the test development. As such, the faults should notbe biased towards the test suites that were used to test the faulty implementations. Thestudent was asked to produce faults representative of the types of error commonly madeby programmers. Four of these faults are ‘off by one’ errors and one is an ‘omittedstatement’ error. Four different functions in thesort implementation were modified, atdepths varying from 1 to 4 in the call graph. Five new versions ofsort were developed,each with one seeded fault. Thus, whenever a test produced an incorrect output, it wasassumed that the fault seeded in that implementation had been found. Although thecoverage results presented are all from the original implementation, with no seededfaults, the coverage data for the faulty implementations is nearly identical with nosignificant variations.
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

20 D. HOFFMAN, P. STROOPER AND L. WHITE
To compare the results from the experiments, the authors created two test drivers thatare very short but still achieve 100% statement coverage. The first driver issues onlythree calls tosort: one with an empty list, and the other two with the lists generated bythe callslcs(50, 3, 1) andlcs(50, 17, 1). Clearly these three calls do not provide adequatetesting for sort, and yet they achieve 100% statement coverage. These three calls tosortdetect four of the five seeded faults. The second driver issues five calls tosort, achieves100% coverage, and reveals only three of the five faults. These drivers show the dangerof relying on structural coverage alone.
6.3.1. Vary length
In this experiment,sort was invoked on sequences of the form
k0, 1,%, N 2 1l
for various values ofN. The sort driver was run 51 times, withN ranging from 0 to 50.The upper limit of 50 was chosen somewhat arbitrarily; a value larger than 17 was clearlyneeded and the second consideration for choosing this upper limit was that it should beclear that there is no increase in coverage for larger values ofN. The coverage databelow shows that 50 is sufficient for this purpose.
For a given value ofN, the tuple set was {kn, 1, 0lun P [0. .N]}. For example, withN 5 3, sort was invoked on the following vectors:
kl k0l k0, 1l k0, 1, 2l k0, 1, 2, 3l
The coverage achieved for each value ofN is shown in Figure 6. Coverage increases
Figure 6. Sequence length versus code coverage
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)
21BOUNDARY VALUES TESTING
quickly until N 5 2, where a plateau is reached at 31·7%. AtN 5 17, where thequicksort code is first executed, there is another jump, to 70·7%. The maximum coverageof 73·1% is reached atN 5 18. In all 51 runs, only one of the five seeded bugs wasdetected. The results suggest that simple ascending sequences achieve reasonable statementcoverage but are poor at detecting faults.
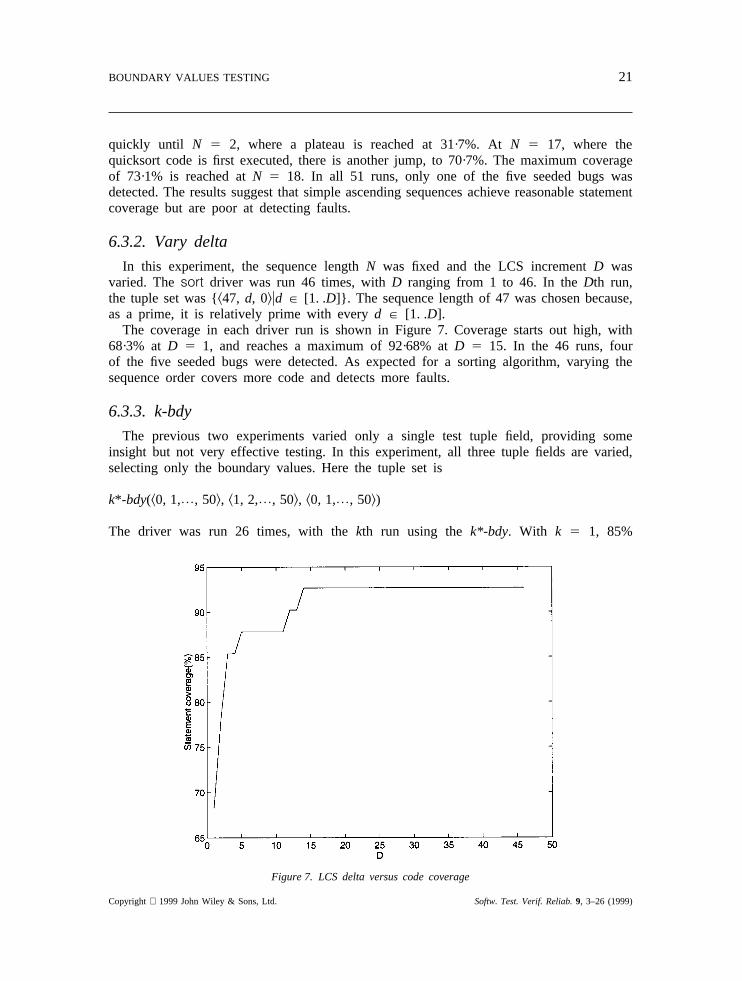
6.3.2. Vary delta
In this experiment, the sequence lengthN was fixed and the LCS incrementD wasvaried. Thesort driver was run 46 times, withD ranging from 1 to 46. In theDth run,the tuple set was {k47, d, 0lud P [1. .D]}. The sequence length of 47 was chosen because,as a prime, it is relatively prime with everyd P [1. .D].
The coverage in each driver run is shown in Figure 7. Coverage starts out high, with68·3% atD 5 1, and reaches a maximum of 92·68% atD 5 15. In the 46 runs, fourof the five seeded bugs were detected. As expected for a sorting algorithm, varying thesequence order covers more code and detects more faults.
6.3.3. k-bdy
The previous two experiments varied only a single test tuple field, providing someinsight but not very effective testing. In this experiment, all three tuple fields are varied,selecting only the boundary values. Here the tuple set is
k*-bdy(k0, 1,%, 50l, k1, 2,%, 50l, k0, 1,%, 50l)
The driver was run 26 times, with thekth run using thek*-bdy. With k 5 1, 85%
Figure 7. LCS delta versus code coverage
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

22 D. HOFFMAN, P. STROOPER AND L. WHITE
coverage was achieved; withk $ 2, the coverage was 100%. For any particular value ofk, k-bdy itself does not achieve 100% coverage. For example, for 1-bdy, 8 test tuples aregenerated, 6 are valid, and these achieve 87% statement coverage. For the other valuesof k other thank 5 26, 8 test tuples are generated and either 2 or 0 of these are valid.The coverage achieved for those values where there are 2 valid tuples ranges between80–90%. Fork 5 26, 4 test tuples are generated, 1 of these is valid, and it achieves73% statement coverage.
In all, the 26 runs detected three of the five seeded faults. One of the bugs was foundonly by 1-bdy, one was found for all values ofk for which there were valid tuples, andone was found by 13 out of the 17 values ofk for which there were valid tuples.
The results show that, forsort, k-bdy is efficient regarding coverage; only 16 calls tosort are needed for 100% coverage. The results also clearly demonstrate that goodcoverage does not imply good fault detection.
6.3.4. k-per
Like the previous experiment, this one varies all three tuple fields. Here the tuple set is
k*-per(k0, 1,%, 50l, k1, 2,%, 50l, k0, 1,%, 50l)
With k 5 1, the coverage was 100% and all five of the seeded faults were detected.For particular values ofk, only k 5 1 achieves 100% statement coverage. As expected,
the coverage goes down for larger values ofk: for 24-per the coverage is still 95%, butfor 25-per it goes down to 90%, and for 26-per it is 73%. Similarly, the fault-detectionefficiency goes down for larger values ofk. For two of the faults, the fault is detectedfor all values ofk. For one fault it is detected by all values exceptk 5 26, for anotherfor all values except 25 and 26, and for the last one by all values ofk , 16.
The results show that, forsort, k-per is effective regarding both coverage and faultdetection. This performance is achieved at some cost: the 1*-per run issued 7042 callsto sort. Because it does not take long to sort a vector of length 50, the execution costis not a problem.
7. CONCLUSIONS
Structural coverage approaches to software testing are mature, having been thoroughlystudied for decades. While structural coverage is sensitive to which code structures arecovered, it is insensitive to the values of the variables when those structures are executed.Data coverage approaches, e.g. boundary value coverage, are far less mature. Because ofits sensitivity to variable values, data coverage has significant potential, especially whenused in combination with structural coverage.
In this paper, the traditional notion of boundary coverage is generalized and formalizedwith two new data coverage measures:k-bdy and k-per. C11 functions were developedbased onk-bdyandk-per, and these functions are used to generate test cases automatically.From these test cases, sophisticated test drivers for functions from the C11 StandardTemplate Library were developed.
Experiments with these drivers provide three main insights. First, achieving 100%statement coverage does not imply correctness. While trivial examples make this point
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

23BOUNDARY VALUES TESTING
clear, many testers believe that on ‘real code’, 100% statement coverage is virtually aguarantee of correctness. The experiments show clearly that, on STL code, 100% statementcoverage is not sufficient. Second, it is feasible to automate fully the execution of thelarge numbers of test cases resulting from boundary values and their combinations, andthe resulting drivers are effective in achieving coverage and detecting faults. While thenumber of test cases is often large, a systematic approach to automation keeps the costslow: drivers are inexpensive to develop and test execution times are short. Third, theinteraction between structural coverage and data coverage is worth exploiting: the twoapproaches in combination are far more effective than either in isolation.
AcknowledgementsThanks to Jason McDonald for seeding the faults insort. Thanks to Jason, Alena Griffiths, and theanonymous referees for thorough and constructive criticism on earlier drafts of the paper.
APPENDIX: TEST DRIVER FOR SORTThe following driver was used for the experiments described in Sections 6.3.3 and 6.3.4.It takes two command line parameters: the first the value ofMax, the number of elementsin the input vector, and the second the stringbdy, per or cp to indicate which testfunction to use to generate the tuple set.
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

24 D. HOFFMAN, P. STROOPER AND L. WHITE
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

25BOUNDARY VALUES TESTING
References
Arnold, T. and Fuson, W. (1994) ‘Testing “in a perfect world” ’,Communications of the ACM, 37(9), 78–86.
Beizer, B. (1990)Software Testing Techniques, 2nd edn, Van Nostrand Reinhold, New York, U.S.A.Binder, R. (1994) ‘Design for testability in object-oriented systems’,Communications of the ACM,
37(9), 87–101.Fiedler, S. (1989) ‘Object-oriented unit testing’,Hewlett-Packard Journal, 40(2), 69–74.Foster, K. A. (1980) ‘Error sensitive test cases analysis’,IEEE Transactions on Software Engineering,
6(3), 258–264.Foster, K. A. (1984) ‘Sensitive test data for logic expressions’,ACM Software Engineering Notes,
9(2), 120–125.Frankl, P. and Doong, R. (1994) ‘The ASTOOT approach to testing object-oriented programs’,ACM
Transactions on Software Engineering Methodology, 3(2), 101–130.Frankl, P. G. and Weiss, S. N. (1993) ‘An experimental comparison of the effectiveness of branch
testing and data flow testing’,IEEE Transactions Software Engineering, 19(8), 774–787.Gannon, J., McMullin, P. and Hamlet, R. (1981) ‘Data-abstraction implementation, specification and
testing’, ACM Transactions on Programming Languages and Systems, 3(3), 211–223.Hoffman, D. (1989) ‘A CASE study in module testing’,Proceedings of the Conference on Software
Maintenance, October 1989, IEEE Computer Society Press, Los Alamitos, California, U.S.A, pp.100–105.
Hoffman, D. and Strooper, P. (1991) ‘Automated module testing in Prolog’,IEEE Transactions onSoftware Engineering, 17(9), 933–942.
Hoffman, D. and Strooper, P. (1995)Software Design, Automated Testing, and Maintenance: APractical Approach, International Thomson Computer Press, Boston, Massachusetts, U.S.A.
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)

26 D. HOFFMAN, P. STROOPER AND L. WHITE
Hoffman, D. M. and Strooper, P. A. (1997) ‘Classbench: A framework for automated class testing’,Software—Practice and Experience, 27(5), 573–597.
Holt, P. and Stewart, R. (1997) ‘Unit test coverage as leading indicator of rework’,Proceedings ofEuroSTAR97: The Fifth European Conference on Software Testing, November 1997.
Howden, W. E. (1980) ‘Functional program testing’,IEEE Transactions on Software Engineering,6(3), 162–169.
Howden, W. E. (1982) ‘Weak mutation testing and completeness of program test sets’,IEEETransactions on Software Engineering, 8(4), 371–379.
Knuth, D. (1969)The Art of Computer Programming, Vol. II, Addison-Wesley, Reading, Massachu-setts, U.S.A.
Murphy, G., Townsend, P. and Wong, P. (1994) ‘Experiences with cluster and class testing’,Communications of the ACM, 37(9), 39–47.
Musser, D. and Saini, A. (1996)STL Tutorial and Reference Guide, Addison-Wesley, Reading,Massachusetts, U.S.A.
Myers, G. J. (1979)The Art of Software Testing, Wiley, New York, U.S.A.Ostrand, T. and Balcer, M. (1988) ‘The category-partition method for specifying and generating
functional tests’,Communications of the ACM, 31(6), 676–686.Panzl, D. (1978) ‘A language for specifying software tests’,Proceedings of the AFIPS National
Computer Conference, AFIPS, pp. 609–619.Piwowarski, P., Ohba, M. and Caruso, J. (1993) ‘Coverage measurement experience during functional
testing’, Proceedings of the 15th International Conference on Software Engineering, Baltimore,Maryland, U.S.A., May 1993, IEEE Computer Society Press, Los Alamitos, California, U.S.A.
Rapps, S. and Weyuker, E. J. (1985) ‘Selecting software test data using data flow information’,IEEE Transactions on Software Engineering, 11(4), 367–375.
Reid, S. C. (1997) ‘Module testing techniques—which are the most effective?’,Proceedings ofEuroSTAR97: The Fifth European Conference on Software Testing, November 1997.
Richardson, D. J. and Clarke, L. A. (1985) ‘Partition analysis: a method combining testing andverification’, IEEE Transactions on Software Engineering, 11(12), 1477–1490.
Weyuker, E. J. and Ostrand, T. J. (1980) ‘Theories of program testing and the application ofrevealing subdomains’,IEEE Transactions on Software Engineering, 6(3), 236–246.
White, L. J. and Cohen, E. I. (1980) ‘A domain strategy for computer program testing’,IEEETransactions on Software Engineering, 6(3), 247–257.
Copyright 1999 John Wiley & Sons, Ltd. Softw. Test. Verif. Reliab.9, 3–26 (1999)