boosted decision trees - desy autermann seminar 6.7.2007 3 play tennis? the manager of a tennis...
TRANSCRIPT

Christian Autermann Seminar 6.7.2007
1
Boosted Decision TreesA modern method of data analysisChristian Autermann University of Hamburg• Decision Trees• “Boosting”• νe – ID at MinibooNE• Evidence for single-top Production at DØ

Christian Autermann Seminar 6.7.2007
2Boosted Decision Trees References
• Talk from B. Roe, U. Michigan (MiniBooNE)• Studies of Boosted Decision Trees for MiniBooNE Particle Identification,
H.-J. Yang, B. Roe, J. Zhu, arXiv:physics/0508045• Wine&Cheese Talk, D. O’Neil, Evidence for Single Top at DØ
R.E. Schapire ``The strength of weak learnability.’’ Machine Learning 5 (2), 197-227 (1990). First suggested the boosting approach for 3 trees taking a majority vote
Y. Freund, ``Boosting a weak learning algorithm by majority’’, Information and Computation 121(2), 256-285 (1995) Introduced using many trees
Y. Freund and R.E. Schapire, ``Experiments with an new boosting algorithm, Machine Learning: Proceedings of the Thirteenth International Conference, Morgan Kauffman, SanFrancisco, pp.148-156 (1996). Introduced AdaBoost
J. Friedman, T. Hastie, and R. Tibshirani, ``Additive logistic regression: a statistical view of boosting’’,Annals of Statistics 28 (2), 337-407 (2000). Showed that AdaBoost could be looked at as successive approximations to a maximum likelihood solution.
T. Hastie, R. Tibshirani, and J. Friedman, ``The Elements of Statistical Learning’’ Springer (2001). Good reference for decision trees and boosting.
→→→→ used for this talk

Christian Autermann Seminar 6.7.2007
3Play Tennis?
The manager of a tennis court wants to optimize the personnel costs:
Number of players ↔ weather conditions; but how ?

Christian Autermann Seminar 6.7.2007
4Decision Tree: “Play Tennis ?”
• Many possibilities tobuild a tree
• No real „rules“• Criteria like Outlook,Wind, etc. can be usedmore than once in a single tree
“node”“leaf”
signal like leafbackground like leaf

Christian Autermann Seminar 6.7.2007
5Some Physics Example
•• Go through all Go through all variables and variables and find best find best variable and valuevariable and value to to split events.split events.
•• For each of the two For each of the two subsets repeat the subsets repeat the processprocess
•• Proceeding in this way Proceeding in this way a tree is built.a tree is built.
•• Ending nodes are Ending nodes are called leaves.called leaves.
Background/Signal
( ~ νe – ID at MiniBooNE)

Christian Autermann Seminar 6.7.2007
6Optimizing the Decision Tree (1)
Equivalent to optimizing “cuts”
• Assume an equal weight of signal and background training events.
• If more than ½ of the weight of a leaf corresponds to signal, it is a signal leaf; otherwise it is a background leaf.
• Signal events on a background leaf or background events on a signal leaf are misclassified.
Very important to optimize the DT Very important to optimize the DT consistently and automaticallyconsistently and automatically

Christian Autermann Seminar 6.7.2007
7Optimizing the Decision Tree (2)
Criterion for “Best” Split
• Signal Purity,P, is the fraction of the weight of a leaf due to signal events.
• Gini: Note that Gini is 0 for all signal or all background. Wi is the weight of event “i”.
• The criterion is to minimize gini_left + gini_right of the two children from a parent node
( )PPWGn
iiini −
= ∑=
11

Christian Autermann Seminar 6.7.2007
8Optimizing the Decision Tree (3)
Criterion for Best Split
• Pick the branch to maximize the change in gini.
• Criterion C = Giniparent– Giniright-child –Ginileft-child
• Optimize each node (e.g. pT>30 GeV) by maximizing “C”.
cut pT>30 GeV →→→→ C = 4.0
(112 / 44)
(40 / 33) (72 / 11)
parent
left right
P = 0.28, Gini = 31.6
P = 0.45, Gini = 18.1
P = 0.13, Gini = 9.5
Example:

Christian Autermann Seminar 6.7.2007
9
[GeV]T
p1
µ0 20 40 60 80 100 120
Eve
nts
/ 8.
0 G
eV
0
1000
2000
3000
4000
5000
6000
0 20 40 60 80 100 1200
1000
2000
3000
4000
5000
6000-1, 0.38 fbOD
100, #58× µ1
0χ∼→µ∼
100, #58× µ2
0χ∼→µ∼
100, #58× µ1
±χ∼→µν∼
µµ → *γZ/
other SM
[GeV]T
p1
µ0 20 40 60 80 100 120
Eve
nts
/ 8.
0 G
eV
0
1000
2000
3000
4000
5000
6000
Optimizing the Decision Tree (4)
Example: (Resonant Sleptons)
Variable: pT(1. muon)
[GeV]T
p1
µ0 20 40 60 80 100 120 140 160 180 200
crit
erio
n c
0.5
0.55
0.6
0.65
0.7
0.75
0.8
[GeV]T
p1
µ0 20 40 60 80 100 120 140 160 180 200
crit
erio
n c
0.5
0.55
0.6
0.65
0.7
0.75
0.8

Christian Autermann Seminar 6.7.2007
10Decision Trees: Advantages
• Already known for quite some time• Easy to understand • We understand (at each node) how a decision
is derived, in contrast to Neural Nets
• As simple as a conventional cut approach• No event is removed completely,
no information is lost

Christian Autermann Seminar 6.7.2007
11Decision Trees: Disadvantages
• Decision trees are not stable,a small change/fluctuation in the data can make a large difference! This is also known from Neural Nets.
• Solution: Boosting!→ Boosted Decision Trees

Christian Autermann Seminar 6.7.2007
12Overview
● Decision Trees
● “Boosting”
● νe – ID at MinibooNE
● Evidence for single-top
Production at DØ

Christian Autermann Seminar 6.7.2007
13Boosting
• Idea: Built many trees O(1000), so that the weighted average over all trees is insensitive to fluctuations
• Impossible to build & weight 1000 trees by hand. How to do it automatically?
→ Reweight misclassified events (i.e. signal events on a background leaf and background events on a signal leaf)
→ Build & optimize new tree with reweighted events→ Score each tree→ Average over all trees, using the tree-scores as
weights

Christian Autermann Seminar 6.7.2007
14Boosting
Several Boosting Algorithms for changing weights of misclassified events:
1. AdaBoost (Adaptive Boosting)
2. Epsilon boost (“shrinkage”)
3. Epsilon-Logit Boost
4. Epsilon-Hinge Boost
5. Logit Boost
6. Gentle AdaBoost
7. Real AdaBoost
8. ...
covered here

Christian Autermann Seminar 6.7.2007
15Definitions
Wi = weight of event i
Yi = +1 if event i is signal,
–1 if background
Tm(xi) = +1 if event i lands on a signal leaf of tree m
–1 if the event lands on a background leaf.
Goal: Y i = Tm(xi)
misclassified event: Y i ≠ Tm(xi)

Christian Autermann Seminar 6.7.2007
16AdaBoost
Define errm = weight wrong/total weightfor tree m
αm is the score(weight) of tree m
Increase weight for misidentified events:
m
mm err
err−⋅= 1lnβα
meWW iiα⋅→
(ß: constant)
∑≠
=)( imi xTY
im Werr
Renormalize all events:1
/N
i i ii
w w w=
→ ∑

Christian Autermann Seminar 6.7.2007
17Scoring events with AdaBoost
m treeshave been optimized and scored (αm) with Monte
Carlo training events. (Knowledge of Yi was necessary.)
Now, score test-sample and databy summing over trees
T(xi) final BDT output variable
equivalent to NN output
∑=
=treeN
mimmi xTxT
1
)()( ααm score/weight for each tree m
Tm(xi) = +1 event lands on a signal leaf– 1event lands on a backgd leaf

Christian Autermann Seminar 6.7.2007
18MiniBooNE Training / Test Samples
High Purity
Scoresincrease with Ntree since
1
( ) ( )treeN
m mm
T x T xα=
= ∑

Christian Autermann Seminar 6.7.2007
19Epsilon Boost (shrinkage)
•• After tree After tree mm, change weight of , change weight of misclassified events, typical ~ O(0.01):misclassified events, typical ~ O(0.01):
•• Renormalize weightsRenormalize weights
•• Score by summing over treesScore by summing over trees
•• Here: all trees have same score/weightHere: all trees have same score/weight
1
/N
i i ii
w w w=
→ ∑
1
( ) ( )treeN
mm
T x T xε=
= ∑
εexp(2 )i iw w ε→
Training Sample
Test Sample & Data

Christian Autermann Seminar 6.7.2007
20Example
• AdaBoost: Suppose the weighted error rate is 40%, i.e., errw= 0.4 and ß = 0.5
• Then α = (1/2)ln((1-.4)/.4)= .203
• Weight of a misclassified event is multiplied by exp(0.203) = 1.225
• Epsilon boost: The weight of wrong events is increased by exp(2*.01) = 1.02
• always the same factor

Christian Autermann Seminar 6.7.2007
21Boosting Summary
•• Give the training Give the training events misclassified events misclassified under this under this procedure a higher procedure a higher weight.weight.
•• Continuing build Continuing build perhaps 1000 trees perhaps 1000 trees and do a weighted and do a weighted average of the average of the results (1 if signal results (1 if signal leaf, leaf, --1 if 1 if background leaf).background leaf).

Christian Autermann Seminar 6.7.2007
22Coding* 1/2
class TNode {TNode * left_childTNode * right_childint cutdouble valuebool * passed()
}Build tree:
TNode * tree
TNode * node2TNode * node1
TNode * node3........
class TEvent {vector<double> variable_value
double weightint type
}Fill all events (signal, background, data) in:
vector<TEvent *> AllEvents
Split Samples:vector<TEvent *> Training
vector<TEvent *> Test
* Not necessarily the best way to do it

Christian Autermann Seminar 6.7.2007
23Coding 2/2
The following functions are needed:
Now it’s easy to put a BDT program together:
TNode* OptimizeNode (TNode*, vector<TEvent*>)double ScoreTree (TNode*, vector<TEvent*>)void ReweightMisclassified (TNode*, vector<TEvent*>&, “AdaBoost”)double ScoreEvent (vector<TNode*>, TEvent*)
// Trainingloop over 1000 Decision trees: {
NewTree = OptimizeNode( OldTree, TrainingSample) //Optimization off all cuts in one treeTreeScores->push_back( ScoreTree( NewTree, TrainingSample) ) //Calculate ααααmTrees->push_back( NewTree ) //vector<TNode*> containing all 1000 optimized Decision TreesReweightMisclassified( NewTree, TrainingSample, “AdaBoost” ) //BoostingOldTree = NewTree
}// TestSample and Data:for (vector<TEvent*>::iterator it = TestSample->begin(); it!=TestSample->end(); it++)
hist_bdt_output->Fill( ScoreEvent(Trees, it) )

Christian Autermann Seminar 6.7.2007
24Overview
● Decision Trees
● “Boosting”
● νe – ID at MinibooNE
● Evidence for single-top
Production at DØ
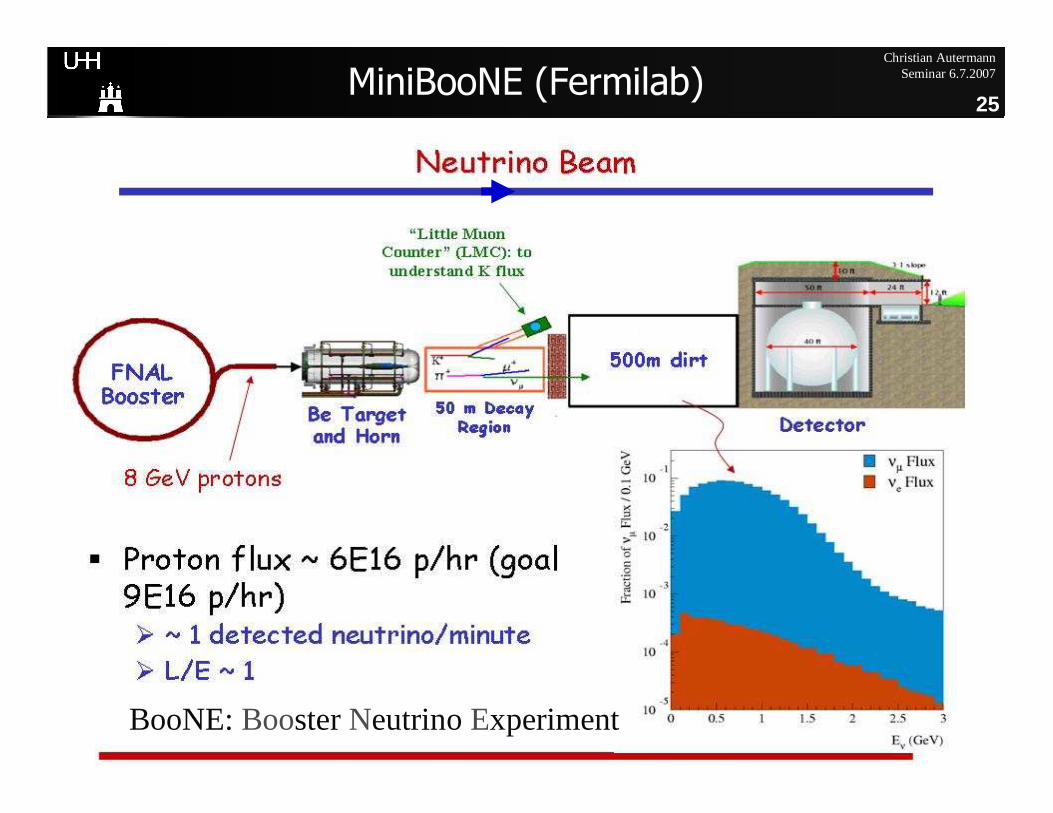
Christian Autermann Seminar 6.7.2007
25MiniBooNE (Fermilab)
BooNE: Booster Neutrino Experiment

Christian Autermann Seminar 6.7.2007
26MiniBooNE

Christian Autermann Seminar 6.7.2007
27MiniBooNE

Christian Autermann Seminar 6.7.2007
28MiniBooNE
eeµµ

Christian Autermann Seminar 6.7.2007
29Examples of data events

Christian Autermann Seminar 6.7.2007
30Numerical Results
• There are 2 reconstruction-particle id packages used in MiniBooNE
• The best results for ANN (artificial neural nets) and Boosting used different numbers of variables, 21 or 22 being best for ANN and 50-52 for boosting
• Only relative results are shown• Results quoted are ratios of backgroundkept by
ANN to backgroundkept for boosting, for a given fraction of signal events kept
ε<1: ANN better than BDTε>1: BDT better

Christian Autermann Seminar 6.7.2007
31Comparison of Boosting and ANN
Relative ratioRelative ratio is is ANN ANN bkrdbkrd kept / kept / Boosting Boosting bkrdbkrd keptkept
�� a. a. BkrdBkrd are cocktail are cocktail events. events. RedRed is 21 and is 21 and blackblack is 52 training is 52 training var.var.
�� b. b. BkrdBkrd are pi0 are pi0 events. events. Red Red is 22 and is 22 and black black is 52 training is 52 training var.var. νe selection eff.

Christian Autermann Seminar 6.7.2007
32MiniBooNE
Reference point

Christian Autermann Seminar 6.7.2007
33AdaBoost vs. Epsilon Boost
�� 8 leaves/ 45 leaves. 8 leaves/ 45 leaves. Red Red is is AdaBoostAdaBoost, , BlackBlack is Epsilon Boostis Epsilon Boost
�� AdaBoostAdaBoost/ Epsilon / Epsilon Boost (Boost (NleavesNleaves = 45).= 45).

Christian Autermann Seminar 6.7.2007
34For Neural Nets (ANN)
• For ANN one needs to set temperature, hidden layer size, learning rate… There are lots of parameters to tune.
• For ANN if onea. Multiplies a variable by a constant,
var(17)� 2.var(17)b. Switches two variables
var(17)��var(18)c. Puts a variable in twice
• The result is very likely to change.

Christian Autermann Seminar 6.7.2007
35For Boosting
• Boosting can handle more variables than ANN; it will use what it needs.
• Duplication or switching of variables will not affect boosting results.
• Suppose we make a change of variables y=f(x), such that if x_2>x_1, then y_2>y_1. The boosting results are unchanged. They depend only on the ordering of the events
• There is considerably less tuning for boosting than for ANN.

Christian Autermann Seminar 6.7.2007
36Robustness
• For either boosting or ANN, it is important to know how robust the method is, i.e. will small changes in the model produce large changes in output.
• In mini-BooNE this is handled by generating many sets of events with parameters varied by about 1 sigma and checking on the differences. This is not complete, but, so far, the selections look quite robust.

Christian Autermann Seminar 6.7.2007
37Summary MiniBooNE
• For MiniBooNE boosting is better than ANN by a factor of 1.2—1.8
• AdaBoost and Epsilon Boost give comparable results within the region of interest (40%--60% nue kept)
• Use of a larger number of leaves (45) gives 10--20% better performance than use of a small number (8).
• Preprint Physics/0408124; N.I.M., in press
• C++ and FORTRAN versions of the boost program (including a manual) are available on homepage:
• http://www.gallatin.physics.lsa.umich.edu/~roe/

Christian Autermann Seminar 6.7.2007
38Overview
● Decision Trees
● “Boosting”
● νe – ID at MinibooNE
● Evidence for single-top
Production at DØ

Christian Autermann Seminar 6.7.2007
39Single Top Production
~|Vtb|

Christian Autermann Seminar 6.7.2007
40Motivation

Christian Autermann Seminar 6.7.2007
41Decision Tree Application to Single Top

Christian Autermann Seminar 6.7.2007
42The 49 input variables

Christian Autermann Seminar 6.7.2007
43Decision Tree Output: 2 jet, 1 tag

Christian Autermann Seminar 6.7.2007
44Invariant W – b mass: M(W, b)
DT: Decision Tree output

Christian Autermann Seminar 6.7.2007
45DT Single Top Results

Christian Autermann Seminar 6.7.2007
46Single Top – All methods

Christian Autermann Seminar 6.7.2007
47Conclusion
• The Boosted Decision Tree is a modern (5-10 years old) concept in data analyses
• Very successfully established at MiniBooNEand at DØ
• Might become a standard method in future

Christian Autermann Seminar 6.7.2007
48Boosting with 22 and with 52 variables
Vertical axisVertical axis is the is the ratio of ratio of bkrdbkrd kept kept for 21(22) var./that for 21(22) var./that kept for 52 var., kept for 52 var., both for boostingboth for boosting
�� RedRed is if training sample is cocktail is if training sample is cocktail and and blackblack is if training sample is pi0is if training sample is pi0
�� Error bars are MC statistical errors Error bars are MC statistical errors onlyonly
Ratio