body language animation synthesis from prosody an honors thesis · pdf file ·...
TRANSCRIPT

BODY LANGUAGE ANIMATION
SYNTHESIS FROM PROSODY
AN HONORS THESIS
SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE
OF STANFORD UNIVERSITY
Sergey Levine
Principal Adviser: Vladlen Koltun
Secondary Adviser: Christian Theobalt
May 2009

Abstract
Human communication involves not only speech, but also a wide variety of gestures and
body motions. Interactions in virtual environments often lack this multi-modal aspect of
communication. This thesis presents a method for automatically synthesizing body lan-
guage animations directly from the participants’ speech signals, without the need for addi-
tional input. The proposed system generates appropriate body language animations in real
time from live speech by selecting segments from motion capture data of real people in
conversation. The selection is driven by a hidden Markov model and uses prosody-based
features extracted from speech. The training phase is fullyautomatic and does not require
hand-labeling of input data, and the synthesis phase is efficient enough to run in real time
on live microphone input. The results of a user study confirm that the proposed method is
able to produce realistic and compelling body language.
ii

Acknowledgements
First and foremost, I would like to thank Vladlen Koltun and Christian Theobalt for their
help and advice over the course of this project. Their help and support was invaluable at
the most critical moments, and this project would not have been possible without them. I
would also like to thank Jerry Talton for being there to lend aword of advice, and never
hesitating to point out the occasional glaring flaws that others were willing to pass over.
I would like to thank Stefano Corazza and Emiliano Gambarettoof Animotion Inc.,
Alison Sheets of the Stanford BioMotion Laboratory, and all of the staff at PhaseSpace
Motion Capture for the time and energy they spent helping me with motion capture pro-
cessing and acquisition at various stages in the project. I would also like to thank Sebastian
Calderon Bentin for his part as the main motion capture actor, and Chris Platz, for help with
setting up scenes for the figures and videos. I would also liketo thank the many individuals
who reviewed my work and provided constructive feedback, including Sebastian Thrun,
Matthew Stone, Justine Cassell, and Michael Neff.
Finally, I would like to thank all of the participants in my evaluation surveys, as well as
all other individuals who were asked to evaluate the resultsof my work in some capacity.
The quality of body language can only be determined reliablyby a human being, and the
human beings around me were often my first option for second opinions over the entire
course of this project. Therefore, I would like to especially thank all of my friends, who
remained supportive of me throughout this work despite being subjected to an unending
barrage of trial videos and sample questions.
iii

Contents
Abstract ii
Acknowledgements iii
1 Introduction 1
1.1 Background and Motivation . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Gesture and Speech . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 System Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Motion Capture Processing 9
2.1 Motion Capture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 Motion Segmentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3 Segment Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Audio Segmentation and Prosody 14
3.1 Gesture Synchrony and Prosody . . . . . . . . . . . . . . . . . . . . . .. 14
3.2 Audio Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.3 Syllable Segmentation . . . . . . . . . . . . . . . . . . . . . . . . . . . .15
3.4 Feature Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .15
4 Probabilistic Gesture Model 17
4.1 Probabilistic Models for Body Language . . . . . . . . . . . . . . .. . . . 17
4.2 Gesture Model State Space . . . . . . . . . . . . . . . . . . . . . . . . . .18
iv

4.3 Parameterizing the Gesture Model . . . . . . . . . . . . . . . . . . .. . . 19
4.4 Estimating Model Parameters . . . . . . . . . . . . . . . . . . . . . . .. . 20
5 Synthesis 22
5.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.2 Forward Probabilities . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 23
5.3 Most Probable and Coherent State . . . . . . . . . . . . . . . . . . . . .. 25
5.4 Early and Late Termination . . . . . . . . . . . . . . . . . . . . . . . . .. 27
5.5 Constructing the Animation Stream . . . . . . . . . . . . . . . . . . .. . 27
6 Evaluation 29
6.1 Evaluation Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . .29
6.2 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
6.3 Video Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
7 Discussion and Future Work 33
7.1 Applicability of Prosody and the Synchrony Rule . . . . . . . .. . . . . . 33
7.2 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
7.3 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
7.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Bibliography 37
v

List of Tables
2.1 This table shows the number of segments and clusters identified for each
body section in each training set. Training set I consisted of 30 minutes
divided into four scenes. Training set II consisted of15 minutes in eight
scenes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.1 This table presents a summary of the audio features used by the system.
For each continuous variableX, µX represents its mean value andσX rep-
resents its standard deviation. . . . . . . . . . . . . . . . . . . . . . . .. 16
vi

List of Figures
1.1 Training of the body language model from motion capture data with simul-
taneous audio. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1 The body parts which constitute each section are shown in(a) and the mo-
tion summary is illustrated in (b). . . . . . . . . . . . . . . . . . . . . .. . 11
4.1 The hidden state space of the model consists of the index of the active
motion,At = si or ci, and the fraction of that motion which has elapsed up
to this point,τt. ObservationsVt are paired with the active motion at the
end of the next syllable. . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.1 Diagram of the synthesis algorithm for one observation.At is thetth ani-
mation state,Vt is thetth observation,~αt is the forward probability vector,
τt is the vector of expectedτ values, and~γt is the direct probability vector. 23
5.2 The image shows the states selected over40 observations withmaxi γt(i)
(red) andmaxi αt(i) × γt(i) (green), with dark cells corresponding to high
forward probability. The graph plots the exact probabilityof the selections,
as well asmaxi αt(i). . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
6.1 An excerpt from a synthesized animation used in the evaluation study. . . . 30
6.2 Mean scores on a 5-point Likert scale for the four evaluation surveys. Error
bars indicate standard error. . . . . . . . . . . . . . . . . . . . . . . . . .. 31
7.1 An excerpt from a synthesized animation. . . . . . . . . . . . . .. . . . . 34
7.2 Synthesized body language helps create an engaging virtual interaction. . . 36
vii

Chapter 1
Introduction
1.1 Background and Motivation
Today, virtual worlds are a rapidly growing venue for entertainment, with socialization
and communication comprising some of their most important uses [54]. Communication
in virtual environments may be accomplished by means of textchat or voice. However,
human beings do not communicate exclusively with words, andvirtual environments often
fail to recreate the full, multi-modal nature of human communication. Gestures and speech
coexist in time and are tightly intertwined [30], but current input devices are far too cum-
bersome to allow body language to be conveyed as intuitivelyand seamlessly as it would be
in person. Current virtual worlds frequently employ keyboard or mouse commands to allow
participants to utilize a small library of pre-recorded gestures, but this mode of communi-
cation is unnatural for extemporaneous body language. Given these limitations on direct
input, body language for human characters must be synthesized automatically in order to
produce consistent and believable results. Though significant progress has been made to-
wards automatic animation of conversational behavior, as discussed in the next section, to
the best knowledge of the author no current method exists which can animate characters in
real time without requiring specialized input in addition to speech.
In this thesis, I present a data-driven method that automatically generates body lan-
guage animations from the participant’s speech signal. Thesystem is trained on motion
capture data of real people in conversation, with simultaneously recorded audio. The main
1

CHAPTER 1. INTRODUCTION 2
contribution is a method of modeling the gesture formation process that is appropriate for
real-time synthesis, as well as an efficient algorithm that uses this model to produce an
animation from a live speech signal, such as a microphone.
Prosody is known to correspond well to emotional state [1, 46] and emphasis [49].
Gesture has also been observed to reflect emotional state [50, 32] and highlight empha-
sized phrases [30]. Therefore, the system generates the animation by selecting appropriate
gesture subunits from the motion capture training data based on prosody cues in the speech
signal. The selection is performed by a specialized hidden Markov model (HMM), which
ensures that the gesture subunits transition smoothly and are appropriate for the tone of the
current utterance. In order to synthesize gestures in real time, the HMM predicts the next
gesture and corrects mispredictions. The use of coherent gesture subunits, with appropriate
transitions enforced by the HMM, ensures a smooth and realistic animation. The use of
prosody for driving the selection of motions also ensures that the synthesized animation
matches the timing and tone of the speech.
Four user studies were conducted to evaluate the effectiveness of the proposed method.
The user studies evaluated two different training sets and the ability of the system to gen-
eralize to novel speakers and utterances. Participants were shown synthesized animations
for novel utterances together with the original motion capture sequences corresponding to
each utterance and an additional sequence of gestures selected at random from the training
set. The results of the study, presented in Chapter 6, confirm that the method produces
compelling body language and generalizes to different speakers.
By animating human characters from live speech in real time with no additional input,
the proposed system can seamlessly produce plausible body language for human-controlled
characters, thus improving the immersiveness of interactive virtual environments and the
fluidity of virtual conversations.
1.2 Related Work
Although no system has been proposed which both synthesizesfull-body gestures and oper-
ates in real time on live voice input, a number of methods havebeen devised that synthesize
either full-body or facial animations from a variety of inputs. Such methods often aim to

CHAPTER 1. INTRODUCTION 3
animate Embodied Conversational Agents (ECAs), which operate on a pre-defined script
or behavior tree [10], and therefore allow for concurrent planning of synthesized speech
and gesture to ensure co-occurrence. Often these methods rely on the content author to
specify gestures as part of the input, using a concise annotation scheme [17, 23]. New,
more complete annotation schemes for gestures are still being proposed [21], and there
is no clear consensus on how gestures should be specified. Some higher-level methods
also combine behavioral planning with gesture and speech synthesis [11, 39], with ges-
tures specified as part of a scripted behavior. However, all of these methods rely on an
annotation scheme that concisely and completely specifies the desired gestures. Stone et
al. [48] avoid the need for annotation of the input text with adata-driven method, which
re-arranges pre-recorded motion capture data to form the desired utterance. However, this
method is limited to synthesizing utterances made up of pre-recorded phrases, and does
require the hand-annotation of all training data. The proposed system also employs a data-
driven method to avoid a complex annotation scheme, but is able to decouple speech from
motion data and retarget appropriate pre-recorded motion to a completely novel utterance.
Since the proposed system must generate animations for arbitrary input, it also cannot
require any form of annotation or specification from the user. Several methods have been
proposed that animate characters from arbitrary text usingnatural language processing.
Cassell et al. [12] propose an automatic rule-based gesture generation system for ECAs,
while Neff et al. [36] use a probabilistic synthesis method trained on hand-annotated video.
However, both of these methods rely on concurrent generation of speech and gesture from
text. Text does not capture the emotional dimension that is so important to body language,
and neither text communication, nor speech synthesized from text can produce as strong an
impact as real conversation [18].
Animation directly from voice has been explored for synthesizing facial expressions
and lip movements, generally as a data-driven approach using some form of probabilistic
model. Bregler et al. [9] propose a video-based method that reorders frames in a video
sequence to correspond to a stream of phonemes extracted from speech. This method is
further extended by Brand [8] by retargeting the animation onto a new model and adopting
a sophisticated hidden Markov model for synthesis. Hidden Markov models are now com-
monly used to model the relationship between speech and facial expression [25, 53]. Other

CHAPTER 1. INTRODUCTION 4
automatic methods have proposed synthesis of facial expressions using more sophisticated
morphing of video sequences [15], physical simulation of muscles [47], or by using hybrid
rule-based and data-driven methods [5].
Although speech-based synthesis of facial expressions is quite common, it does not
generally utilize vocal prosody. Since facial expressionsare dominated by mouth move-
ment, many speech-based systems use techniques similar to phoneme extraction to select
appropriate mouth shapes. However, a number of methods havebeen proposed that use
speech prosody to model expressive human motion beyond lip movements. Albrecht et al.
[2] use prosody features to drive a rule-based facial expression animation system, while
more recent systems apply a data-driven approach to generate head motion from pitch [13]
and facial expressions from vocal intensity [19]. Incorporating a more sophisticated model,
Sargin et al. [42] use prosody features to directly drive head orientation with a HMM. Al-
though these methods only animate head orientation from prosody, Morency et al. [33]
suggest that prosody may also be useful for predicting gestural displays.
The proposed system selects appropriate motions using a prosody-driven HMM remi-
niscent of the above techniques, but each output segment corresponding to an entire ges-
ture subunit, such as a “stroke” or “hold.” This effectivelyreassembles the training motion
segments into a new animation. Current techniques for assembling motion capture into
new animations generally utilize some form of graph traversal to select the most appro-
priate transitions [3, 24]. The proposed system captures this notion of a motion graph in
the structure of the HMM, with high-probability hidden-state transitions corresponding to
transitions which occur frequently in the training data. While facial animation synthesis
HMMs have previously used remapping of observations [8], orconditioned the output an-
imations on the input audio [25], the proposed method maps animation states directly to
the hidden states of the model. This allows a simpler system to be designed that is able
to deal with coherent gesture subunits without requiring them to directly coincide in time
with audio segments.
While the methods described above are able to synthesize plausible body language or
facial expression for ECAs, none of them can generate full-body animations from live
speech. Animating human-controlled characters requires real-time speeds and a predictive
model that does not rely on looking ahead in the audio stream.Such a model constitutes

CHAPTER 1. INTRODUCTION 5
the main contribution of this work.
1.3 Gesture and Speech
The most widely-used taxonomy for gestures was proposed by McNeill [30], though he
later suggested that a more continuous classification wouldbe more appropriate [31]. Mc-
Neill’s original taxonomy consists of four gesture types: iconics, metaphorics, deictics, and
beats. Iconics present images of concrete objects or actions, metaphorics represent abstract
ideas, deictics serve to locate entities in space, and beatsare simple, repetitive motions
meant to emphasize key phrases [30].
In addition to the above taxonomy, McNeill made several other relevant observations.
In regard to beat gestures, he observed that “beats tend to have the same form regardless of
content” – that is, an up/down or sideways flick of the hand. Healso observed that beats are
generally used to highlight important concepts or emphasize certain words, and constitute
almost half of all gestures in both narrative and non-narrative speech. While narrative
speech contains many iconic gestures, beats were observed by McNeill to constitute about
two thirds of the gestures accompanying non-narrative speech, suggesting that synthesizing
only beats would adequately animate non-narrative conversations [30].
McNeill also observed that metaphoric gestures vary acrosscultures, but within the
same culture tend to be drawn from a small pool of possible options. While narrative
speech tends to be dominated by iconic gestures, over 80% of the gestures accompanying
non-narrative speech were observed by McNeill to be either beats or metaphorics, suggest-
ing that synthesizing only beats and metaphorics would adequately animate non-narrative,
conversational speech [30].
As observed in [14], the overall amplitude and frequency of gestures varies across cul-
ture, so it is necessary for us to restrict the proposed method to a single cultural context.
Since metaphoric gestures are drawn from a small pool of options within a single such con-
text, they are also good candidates for synthesis. Even if metaphoric gestures depend on the
semantic meaning of the utterance, the probability of selecting an appropriate metaphoric
is quite high due to the small number of options. The abstractnature of the gesture further
increases the likelihood that it will be seen as plausible even if it does not correspond to the

CHAPTER 1. INTRODUCTION 6
semantic meaning, provided it occurs at the right time. Since such gestures often accom-
pany a central or emphasized idea, we can hypothesize that their occurrence may also be
signaled by prosody cues.
Since prosody correlates well to emphasis [49], it should correspond to the empha-
sized words that gestures highlight, making it useful for selecting gestures, such as beats
and metaphorics, with the appropriate timing and rhythm. Inaddition, there is evidence
that prosody carries much of the emotive content of speech [1, 44], and that emotional
state is often reflected in body language [50, 32]. Therefore, we can hypothesize that a
prosody-driven system would produce accurately timed and appropriate beats, as well as
more complex abstract or emotion-related gestures with theappropriate emotive content.
The system captures prosody using the three features that itis most commonly associ-
ated with: pitch, intensity, and duration. Pitch and intensity have previously been used to
drive expressive faces [13, 19], duration has a natural correspondence to the rate of speech,
and all of these aspects of prosody are informative for determining emotional state [43].
While semantic meaning also corresponds strongly to gesture, the system does not attempt
to interpret the utterance. This approach has some limitations, as discussed in Section 7.2,
but is more appropriate for online, real-time synthesis. Extracting semantic meaning from
speech to synthesize gesture without knowledge of the full utterance is difficult because it
requires apredictivespeech interpreter, while prosody can be obtained efficiently without
looking ahead in the utterance.
1.4 System Overview
During the training phase, the system processes a corpus of motion capture and audio data
to build a probabilistic model that correlates gesture and prosody. The motion capture data
is processed by extracting gesture subunits, such as “strokes” and “holds.” These subunits
are then clustered to identify recurrences of the same motion, as described in Chapter 2.
The training speech signal is processed by extracting syllables and computing a set of
prosody-based features on each syllable, as described in Chapter 3.
Finally, the parameters of a hidden Markov model are estimated directly from the two
resulting state-streams, with clustered animation segments as hidden states and the audio

CHAPTER 1. INTRODUCTION 7
Motion Capture Speech
Segmentation Segmentation
Clustering Feature Extraction
Combined Motion/Speech State Stream
HMM Parameter Estimation
Figure 1.1: Training of the body language model from motion capture datawith simulta-neous audio.
segments as observations. Mapping hidden states directly to clustered motions allows us to
build a model which can handle non-synchronized motion and audio segments efficiently.
The head, upper body, and lower body are processed separately into three distinct HMMs,
since the gestures of these body parts do not always coincide. The hidden state space of the
HMM consists of “start” and “continuation” states for each motion, along with the fraction
of the motion which has elapsed up to the current time step. This allows motions to last
for multiple time steps to handle the common case of multiplesyllable-observations within
one long motion. The model is described in more detail in Chapter 4. The entire training
process is summarized in Figure 1.1.
The HMM produced in the training phase is used in the synthesis phase to drive the
animation in real time based on a novel audio signal. Each time a new syllable is identified
in the audio stream, the system computes the most probable hidden state based on the
previous state, as well as the most probable state based on the current vector of forward
probabilities. These vectors are then combined to find the state that is bothprobableand
coherent. The synthesis process is described in Chapter 5.

CHAPTER 1. INTRODUCTION 8
The correlation between speech and body language is inherently a many-to-many map-
ping: there is no unique animation that is most appropriate for a given utterance [8]. This
ambiguity makes validation of synthesis techniques difficult. Since the only way to judge
the quality of a synthesized body language animation is by subjective evaluation, surveys
were conducted to validate the proposed method. The resultsof these surveys are presented
in Chapter 6.

Chapter 2
Motion Capture Processing
2.1 Motion Capture
The final training set for the system consists of30 minutes of motion capture data with
accompanying speech, divided into four scenes. An additional 15 minute training set from
a different speaker was also used in the user study. Each scene was excerpted from an
extemporaneous conversation, ensuring that the body language was representative of real
human interaction. Although the topic of each conversationwas not selected in advance,
conversations were intentionally selected to provide a variety of common behaviors, in-
cluding turn-taking, extended periods of fluent speech, theasking of questions, and the
expression of a few simple emotions (such as anger and excitement). Training data from
different speakers was not mixed together to avoid creatingan inconsistent gesturing style.
Additional motion capture data from other speakers was usedto test the ability of the sys-
tem to generalize to other gestural styles and for comparison evaluation of the synthesized
sequence, as described in Chapter 6.
For capture, I employed the markerless technique proposed by Mundermann et al. [35],
as well as the motion capture facilities at PhaseSpace Motion Capture. The markerless
system computes a visual hull using silhouettes taken from eight cameras and fits a high-
resolution scan of the speaker’s body to the visual hull withappropriate joint orientations.
The PhaseSpace motion capture system operates using conventional active markers. The
resulting marker location data was processed with AutodeskMotionBuilder to compute
9

CHAPTER 2. MOTION CAPTURE PROCESSING 10
joint orientations. Both the markerless data and the active marker data obtained from the
PhaseSpace system is processed to obtain an animated14-joint skeleton. The data is then
segmented into gesture unit phases, henceforth referred toas gesture subunits. These seg-
ments are then clustered to identify recurrences of similarmotions.
2.2 Motion Segmentation
Current motion segmentation methods identify broad categories of motion within a corpus
of motion capture data, such as walking and sitting [4, 34]. Perceptually distinct gesture
subunits are not as dissimilar as these broad categories, and much of the existing work on
data-driven gesture animation segments training data manually [48, 36]. However, manual
annotation does not scale gracefully to large amounts of training data. Therefore, a more
sensitive automatic segmentation algorithm is needed.
Gesture units consist of the “pre-stroke hold,” “stroke,” and “post-stroke hold” phases
[30, 20], which provide natural boundaries for segmentation of gesture motions. Such
phases have previously been used to segment hand gestures [29]. From this we deduce that
a gesture unit consists of alternating periods of fast and slow motion. To segment the motion
capture data into gesture unit phases (or “subunits”), boundaries are placed between strokes
and holds using an algorithm inspired by [16]. Since individual high-velocity strokes are
separated by low-velocity pauses, we may detect these boundaries by looking for dips in
the average angular velocities of the joints. For each frameof the motion capture data, let
ωj be the angular velocity of jointj, and letuj be a weight corresponding to the perceptual
importance of the joint. This weight is chosen to weigh high-influence joints, such as
the pelvis or abdomen, higher than smaller joints such as thehands or feet. We can then
compute a weighted average of the angular velocities as following:
z =14
∑
j=1
uj||ωj||2.
A stroke is expected to have a highz value, while a hold will have a low value. Similarly,
a pause between a stroke and a retraction will be marked by a dip in z as the arm stops

CHAPTER 2. MOTION CAPTURE PROCESSING 11
(a) The body parts whichconstitute each of thethree body sections arehighlighted in differentcolors.
(b) Displacement of the keyparts, shown here, is usedalong with velocity to sum-marize the dynamics of a seg-ment for clustering.
Figure 2.1: The body parts which constitute each section are shown in (a) and the motionsummary is illustrated in (b).
and reverses direction. Therefore, segment boundaries areinserted when this sum crosses
an empirically determined threshold. To avoid creating small segments due to noise, the
system only creates segments which exceed either a minimum length or a minimum limit
on the integral ofz over the segment. To avoid unnaturally long still segments during long
pauses, the algorithm places an upper bound on segment length. The motions of the head,
arms, and lower body do not always coincide, so these three body sections are segmented
separately and henceforth treated as separate animation streams. The joints which consti-
tute each of the sections are illustrated in Figure 2.1(a). The number of segments extracted
from the training sets is summarized in Table 2.1.
2.3 Segment Clustering
Once the motion data has been segmented, the segments are clustered to identify recurring
gesture subunits. The clustering algorithm is based on Wardhierarchical clustering [52],

CHAPTER 2. MOTION CAPTURE PROCESSING 12
though a variety of methods may be appropriate. Ward hierarchical clustering merges two
clusters at every iteration so as to minimize the error sum-of-squares criterion (ESS) for
the new cluster. If we defineCi to be the center of theith cluster, andS(j)i to be thej th
segment in that cluster, we may defineESSi as
ESSi =
Ni∑
j
D(Ci, S(j)i ),
whereD is the distance metric. The algorithm is modified to always select one of the exist-
ing sample points as a cluster center (specifically, the point which minimizes the resulting
ESS value), thus removing the requirement that a Euclidian metric be used. This allows
the distance function to be arbitrary complex.
Segments are compared according to a three-part distance function that takes into ac-
count length, starting pose, and a fixed-size “summary” of the dynamics of the segment.
The “summary” holds some measure of velocity and maximum andaverage displacement
along each of the axes for a few key body parts in each section,as in Figure 2.1. The head
section uses the rotation of the neck about each of the axes. The arm section uses the po-
sitions of the hands, which often determine the perceptual similarity of two gestures. The
lower body uses the positions of the feet relative to the pelvis, which capture motions such
as the shifting of weight. For the arms and lower body, velocity and maximum and average
displacement each constitute a six-dimensional vector (three axes per joint), while for the
head this vector has three dimensions. Each vector is rescaled to a logarithmic scale, since
larger gestures can tolerate greater variation while remaining perceptually similar. Using
six-dimensional vectors serves to de-emphasize the unusedhand in one-handed gestures: if
instead a three-dimensional vector for each hand was rescaled, small motions in the unused
hand would be weighted too heavily on the logarithmic scale relative to the more important
large motion of the active hand. To compare two summaries, the algorithm uses the sum of
the distances between the three vectors.
Although the “summary” is the most significant part of the distance function, it is im-
portant that all gestures in a cluster have roughly the same length and pose, as this allows
us to synthesize a smooth animation stream. In particular, still segments or “holds” (seg-
ments without much motion – e.g., az value that is consistently below the threshold) tend

CHAPTER 2. MOTION CAPTURE PROCESSING 13
Final Training Data Motion StatisticsTraining Set Body Section Total Segments Total Clusters Avg Segments/Cluster
Set IHead 2542 20 127.1Arms 2388 45 53.1Lower Body 1799 6 299.8
Set IIHead 1349 17 79.4Arms 1272 32 39.8Lower Body 919 3 306.3
Table 2.1: This table shows the number of segments and clusters identified for each bodysection in each training set. Training set I consisted of30 minutes divided into four scenes.Training set II consisted of15 minutes in eight scenes.
to have very similar summaries, so the weight of the pose is increased on such segments
to avoid clustering all still segments together. The starting pose is far more important for
still segments, which remain in their starting pose for their duration, while active segments
quickly leave the starting pose.
Table 2.1 provides a summary of the number of clusters identified in each training
set. It should be noted that the lower body section generallycontained very few unique
segments. In fact, in training set II, only two holds and one motion were identified. The
motion corresponded to a shifting of weight from one foot to the other. The larger training
set contained a few different weight shifting motions. The arms and head were more varied
by comparison, reflecting their greater prominence in body language.

Chapter 3
Audio Segmentation and Prosody
3.1 Gesture Synchrony and Prosody
Gesture strokes have been observed to consistently end at orbefore, but never after, the
prosodic stress peak of the accompanying syllable. This is referred to as one of the gesture
“synchrony rules” by McNeill [30]. Due to the importance of syllables for maintaining
the rhythm of gestures, syllables serve as the basic segmentation unit for audio data in the
proposed system. During both training and synthesis, the audio data is parsed to identify
syllable boundaries, and a concise prosody descriptor is computed for each syllable. Dur-
ing real-time synthesis, the syllable segmentation algorithm identifies syllables precisely
when the peak of thenextsyllable is encountered, making it easier to produce gestures in
accordance with the synchrony rule. This algorithm is further discussed in Section 3.3.
As noted earlier, prosody carries much of the emotive content of speech, and therefore
is expected to correlate well to body language. Prosody alsoallows the system to operate
independently of language. Therefore, the features extracted for each syllable reflect some
aspect of prosody, which is defined as pitch, intensity, and duration, as described in Section
3.4.
14

CHAPTER 3. AUDIO SEGMENTATION AND PROSODY 15
3.2 Audio Processing
For both syllable segmentation and feature extraction, thesystem continuously extracts
pitch and intensity curves from the audio stream. The intensity curve is used to drive
segmentation, and both curves are used after segmentation to compute a concise prosody
descriptor for each audio segment. Pitch is extracted usingthe autocorrelation method, as
described in [6], and intensity is extracted by squaring waveform values and filtering them
with a Gaussian analysis window. For both tasks, componentsof the Praat speech analysis
tool [7] were used. Components of the tool were modified and optimized to run in real
time, allowing for continuous extraction of pitch and intensity.
3.3 Syllable Segmentation
For efficient segmentation, the system employs a simple algorithm inspired by Maeran
et al. [28], which identifies peaks separated by valleys in the intensity curve, under the
assumption that distinct syllables will have distinct intensity peaks. In order to segment the
signal progressively in real time, the algorithm identifiesthe highest peak within a fixed
radius, and continues scanning the intensity curve until the next local maximum is found.
If this maximum is at least a fixed distance away from the previous one, the previous peak
is identified as the peak of the syllable terminating at the lowest point between the two
peaks. Finally, segment boundaries are inserted at voiced/unvoiced transitions, and when
the intensity falls below a fixed silence threshold. As stated previously, one effect of using
this algorithm is that a syllable is only detected once the intensity peak of the next syllable
is found, so syllable observations are issued precisely at syllable peaks, which allows the
system to more easily follow the previously mentioned synchrony rule.
3.4 Feature Extraction
In order to train the system on a small corpus of training data, the size of the observation
state space is limited by using a small set of discrete features, rather than the more standard
mixture of Gaussians approach. The selected features concisely describe each of the three

CHAPTER 3. AUDIO SEGMENTATION AND PROSODY 16
Audio FeaturesFeature Variable Value 0 Value 1 Value 2
Inflection up Pitch changedF0 dF0 − µdF0< σdF0
dF0 − µdF0≥ σdF0
Inflection down Pitch changedF0 dF0 − µdF0> −σdF0
dF0 − µdF0≤ −σdF0
Intensity IntensityI I < Csilence I − µI < σI I − µI ≥ σI
Length Syllable lengthL L − µL ≤ −σL
2−σL
2< L − µL < σL L − µL ≥ σL
Table 3.1: This table presents a summary of the audio features used by the system. Foreach continuous variableX, µX represents its mean value andσX represents its standarddeviation.
aspects of prosody: pitch, intensity, and duration. The features are summarized in Table
3.1. Pitch is described using two binary features indicating the presence or absence of sig-
nificant upward or downward inflection, corresponding to onestandard deviation above the
mean. Intensity is described using a trinary feature indicating silence, standard intensity,
or high intensity, corresponding to half a standard deviation above the mean. Length is
also described using a trinary feature, with “long” segments one deviation above the mean
and “short” segments half a deviation below. This asymmetryis necessitated by the fact
that syllable lengths are not normally distributed. The means and deviations of the training
sequence are established prior to feature extraction. During synthesis, the means and devi-
ations are estimated incrementally from the available audio data as additional syllables are
observed.
This set of discrete prosody-based features creates an observation state-space of36
states, which enumerates all possible combinations of inflection, intensity, and duration. In
practice, the state space is somewhat smaller, since silentsegments do not contain inflec-
tion, and are restricted to short or medium length. Long silent segments are truncated, since
they do not provide additional information over a sequence of medium segments, though
short segments are retained, as these usually correspond tobrief pauses between words.
This effectively limits the state space to about26 distinct observation states.

Chapter 4
Probabilistic Gesture Model
4.1 Probabilistic Models for Body Language
Previously proposed HMM-driven animation methods generally use temporally aligned
animation and speech segments. The input audio is remapped directly to animation output
[8], or is coupled to the output in a more complex manner, suchas conditioning output
and transition probabilities on the input state [25]. The HMM itself is trained with some
variation on the EM algorithm [25, 53].
Since the input and output states in the proposed system are not temporally aligned,
and since each of the animation segments corresponds to a meaningful unit, such as a
“stroke” or a “hold,” the model takes a different approach and maps animation segments
directly to the hidden states of the model, rather than inferring hidden structure with the EM
algorithm. This allows greater control in designing a specialized system for dealing with
the lack of temporal alignment even when using a small amountof training data, though
at the expense of being unable to infer additional hidden structure beyond that provided by
the clustering of gesture subunits. The hidden state space of the HMM consists of “start”
and “continuation” states for each motion, along with the fraction of the motion which
has elapsed up to the current observation. This allows the same motion to span multiple
observations and handle the common case of multiple syllables within a single stroke or
hold.
17

CHAPTER 4. PROBABILISTIC GESTURE MODEL 18
In Section 4.2, I formulate the hidden state space for the gesture model. A parametriza-
tion of the model which allows efficient inference and training is described in Section 4.3,
and the estimation of model parameters from training data isdetailed in Section 4.4.
4.2 Gesture Model State Space
The process of gesture subunit formation consists of the selection of appropriate motions
that correspond well to speech and line up in time to form a continuous animation stream.
As discussed in Section 3.1, gesture strokes terminate at orbefore syllable peaks, and syl-
lable observations arrive when the peak of the next syllableis encountered. In the training
data, less than0.4% of motion segments did not contain a syllable observation, so we may
assume that at least one syllable will be observed in every motion, though we will often ob-
serve more. Therefore, syllable observations provide a natural discretization for continuous
gesture subunit formation, allowing us to model this process with a discrete-time HMM.
Under this discretization, we assume that gesture formation is a Markov process in
whichHt, the animation state at syllable observationVt, depends only onVt and the previ-
ous animation stateHt−1. As discussed in Section 3.4,Vt contains a small set of discrete
prosody features, and may be expressed as the index of a discrete observation state, which
is denoted byvj. We define the animation stateHt = {At, τt(i)}, whereAt = mi is the
index of the motion cluster corresponding to the desired motion, andτt(i) is the fraction
of that motion which has elapsed up to the observationVt. This allows motions to span
multiple syllables.
To prevent adjacent motions from overlapping, one could usea temporal scaling factor
to ensure that the current motion terminates precisely whenthe next motion begins. How-
ever, during real-time synthesis, there is no knowledge of the length of future syllables, and
it is therefore not possible to accurately predict the scaling factor. Instead, we may inter-
rupt a motion and begin a new one when it becomes unlikely thatanother syllable will be
observed within that motion, thus ensuring that motions terminate at syllable observations
and do not overlap.

CHAPTER 4. PROBABILISTIC GESTURE MODEL 19
m0 m1 m2
V1 V2 V3 V4 V5
V1 V2 V3 V4
A1 : s1
τ1 : −.1
A2 : c1
τ2 : .3
A3 : c1
τ3 : .5
A4 : s2
τ3 : −.2
Figure 4.1: The hidden state space of the model consists of the index of the active motion,At = si or ci, and the fraction of that motion which has elapsed up to this point, τt.ObservationsVt are paired with the active motion at the end of the next syllable.
4.3 Parameterizing the Gesture Model
In order to compactly express the parameters of the gesture model, first note thatτ evolves
in a very structured manner. If observationVt corresponds to the continuation of the current
motionmi, then the following equations describe the evolution ofA andτ :
At = At−1 = mi
τt(i) = τt−1(i) + 4τt(i),
where4τt(i) is the fraction of the motionmi which has elapsed since the previous ob-
servation. If instead the current motion terminates at observationVt and is succeeded by
At = mj, then we simply haveτt(j) = 0.
Let τ ′
t(i) = τt−1(i)+4τt(i), thenτt is completely determined byτ ′
t andAt, except in the
case when motionmi follows itself, andAt = At−1 = mi but τt(i) = 0. To disambiguate
this case, we introduce a start statesi and a continuation stateci for each motion clustermi,
so thatAt may take on eithersi or ci (we will denote an arbitrary animation state asaj).
This approach is similar to the “BIO notation” (beginning, inside, outside) used in semantic
role labeling [41]. Under this new formulation,τt(i) = τ ′
t(i) whenAt = ci andAt−1 = ci

CHAPTER 4. PROBABILISTIC GESTURE MODEL 20
or si. Otherwise,τt(i) = 0. Therefore,τt is completely determined byτ ′
t andAt.
The transition probabilities forAt are a function ofAt−1 = mi andτ ′
t(i). While this dis-
tribution may be learned from the training data, we can simplify it considerably. Although
the precise length of a motion may vary slightly for syllablealignment, the transitions out
of that motion do not depend strongly on this length, and we can assume that they are in-
dependent. Therefore, we can defineTcias the vector of transition probabilities out of a
motionmi:
Tci,sj= P (At = sj|At−1 = ci, At 6= ci).
We can also assume that the continuation ofci depends only onτ ′
t(i), since ifAt = ci,
At−1 = ci or si, providing little additional information. Intuitively, this seems reason-
able, since encountering another observation within a motion becomes less probable as the
motion progresses. Therefore, we can construct the probabilities of transitions fromci as
a linear combination ofTciandeci
, the guaranteed transition intoci, according to some
functionfi of τ ′
t(i):
P (At|At−1 = ci) =
fi(τ′
t(i)) At = ci
(1 − fi(τ′
t(i)))Tci,Atotherwise
(4.1)
We now define the vectorTsias the distribution of transitions out ofsi, and construct the
full transition matrixT = [Ts1, Tc1 , ..., Tsn
, Tcn], wheren is the total number of motion
clusters. The parameters of the HMM are then completely specified by the matrixT , a ma-
trix of observation probabilitiesO given byOi,j = P (vi|aj), and the interpolation functions
f1, f2, ..., fn.
4.4 Estimating Model Parameters
The transition and observation matrices are estimated directly from the training data by
counting the frequency of transitions and observations. When pairing observations with
animation states, we must consider the animation state thatis active at the end of thenext
observation, as shown in Figure 4.1. When a motionmi terminates on the syllableVt, we
must predict the next animation segment. However, if we associateVt with the current

CHAPTER 4. PROBABILISTIC GESTURE MODEL 21
segment, the observed evidence would indicate thatci is the most probable state, which is
not the case. Instead, we would like to predict thenextstate, which is precisely the state
that is active at the end of the next syllableVt+1.
The value of an interpolation function,fi(τt(i)), gives the probability that another syl-
lable will terminate within motionmi after the current one, which terminated at pointτt(i).
Since motions are more likely to terminate asτt(i) increases, we may assume thatfi is
monotonically decreasing. From empirical observation of the distribution ofτ values for
final syllables within training motions, I concluded that a logistic curve would be well
suited for approximatingfi. Therefore, the interpolation functions are estimated by fitting
a logistic curve to theτ values for final syllables within each training motion cluster by
means of gradient descent.

Chapter 5
Synthesis
5.1 Overview
The model assembled in the training phase allows the system to animate a character in real
time from a novel speech signal. Since the model is trained onanimation segments which
follow audio segments, it is able to predict the most appropriate animation as soon as a new
syllable is detected. As noted earlier, gesture strokes terminate at or before the intensity
peak of the accompanying syllable [30]. The syllable segmentation algorithm detects a
syllable in continuous speech when it encounters the syllable peak of thenextsyllable, so
new gestures begin at syllable peaks. Consequently, the previous gesture ends at or before
a syllable peak.
To synthesize the most probable and coherent animation, thesystem computes a vector
of forward probabilities along with direct probabilities based on the previously selected
hidden state. The forward probabilities carry context fromprevious observations, while the
direct probabilities indicate likely transitions given only the last displayed animation and
current observation. Together, these two vectors may be combined to obtain a prediction
that is bothprobablegiven the speech context andcoherentgiven the previously displayed
state, resulting in animation that is both smooth and plausible. The synthesis process is
illustrated in Figure 5.1.
Once the most probable and coherent motion cluster has been selected, the system
selects a single segment from this cluster which blends wellwith the current pose of the
22

CHAPTER 5. SYNTHESIS 23
Previous Update
Next Update
Syllable ObservationVt
At−1 ~αt−1, τt−1ForwardDirect
ProbabilitiesProbabilities
Update: Equations 5.1,5.3Update: Equation 5.4
~γt ~αt, τt~αt × ~γt
At Stochastic Sampling
Figure 5.1: Diagram of the synthesis algorithm for one observation.At is thetth animationstate,Vt is the tth observation,~αt is the forward probability vector,τt is the vector ofexpectedτ values, and~γt is the direct probability vector.
character. This segment is then blended into the animation stream, as described in Section
5.5.
5.2 Forward Probabilities
Given the parameters of a hidden Markov model and a sequence of syllable-observations
{V1, V2, ..., Vt}, the most probable hidden state at timet may be efficiently determined from
forward probabilities [40]. Since transition probabilities depend on the valueτt(i) at the
current observation, we must take it into account when updating forward probabilities. To
this end, the system maintains both a vector of forward probabilities ~αt, and a vectorτt of
the expected valuesE(τt(i)|At = ci) at thetth observation.
Using the expected value ofτt(i) rather than a more complex probability distribution
over possible values implies the assumption that the distribution ofτt(i) is convex - that is,

CHAPTER 5. SYNTHESIS 24
that using the expected value gives a good approximation of the distribution. This assump-
tion may not hold in the case of two or more probable timelineswhich transition intomi
at different points in the past, resulting in two or more peaks in the distribution ofτt(i).
However, we assume that this case is not common.
As before, we define a vectorτ ′
t(i) = τt−1(i)+4τt(i). Using this vector, computing the
transition probabilities between any two states at observation Vt is analogous to Equation
4.1:
P (At|At−1) =
fi(τ′
t(i)) At = At−1 = ci
(1 − fj(τ′
t(j)))Tcj ,AtAt−1 = cj
TAt−1,Atotherwise
With this formula for the transition between any two hidden states, we can use the usual
update rule for~αt:
αt(i) = η
2n∑
k=1
αt−1(k)P (At = ai|At−1 = ak)P (Vt|ai), (5.1)
whereη is the normalization value. Once the forward probabilitiesare computed,τt must
also be updated. This is done according to the following update rule:
τt(i) = E(τt(i)|At = ci) =
2n∑
k=1
P (At = ci, At−1 = ak)E(τt(i)|At = ci, At−1 = ak)
P (At = ci). (5.2)
Since onlysi andci can transition intoci, P (At = ci, At−1) = 0 if At−1 6= ci and
At−1 6= si. If At−1 = si, this is the first event during this motion, so the previous
value τt−1(i) must have been zero. Therefore,E(τt(i)|At = ci, At−1 = si) = 4τt(i).
If At−1 = ci, the previous expected valueτt−1(i) is simply τt−1(i), so the new value is
E(τt(i)|At = ci, At−1 = ci) = τt−1(i) + 4τt(i) = τ ′
t(i). Therefore, we may reduce Equa-
tion 5.2 to:

CHAPTER 5. SYNTHESIS 25
τt(i) =P (At = ci, At−1 = ci)E(τt(i)|At = ci, At−1 = ci)
P (At = ci)
+P (At = ci, At−1 = si)E(τt(i)|At = ci, At−1 = si)
P (At = ci)
=αt−1(ci)fi(τ
′
t(i))τ′
t(i) + αt−1(si)Tsi,ci4τt(i)
αt(ci). (5.3)
Once the forward probabilities andτt are computed, the most probable state could sim-
ply be selected fromαt(i). However, choosing the next state based solely on forward
probabilities would produce an erratic animation stream, since the most probable state may
alternate between several probable paths as new observations are provided.
5.3 Most Probable and Coherent State
Since the system has already displayed the previous animation stateAt−1, it can estimate
the current state from only the previous state and current observation to ensure a high-
probability transition, and thus a coherent animation stream. Givenτ ′
t(i) = τt−1(i)+4τt(i)
for currently active motioni, the system computes transition probabilities just as in Section
4.3. If the previous state is the start statesi, transition probabilities are given directly as
P (At|At−1 = si) = Tsi,At. If the previous state is the continuation stateci, the transition
probabilityP (At|At−1 = ci) is given by Equation 4.1. With these transition probabilities,
the vector of direct probabilities~γt can be computed in the natural way as:
γt(i) = ηP (At = ai|At−1)P (Vt|ai). (5.4)
Using~γt directly, however, would quickly drive the synthesized animation down an im-
probable path, since context is not carried forward. Instead,~γt and~αt can be used together
to select a state which is both probable given the sequence ofobservations and coherent
given the previously displayed animation state. The final distribution for the current state
is therefore computed as the normalized pointwise product of the two distributions~αt ×~γt.
As shown in Figure 5.2, this method also generally selects states that have a higher forward

CHAPTER 5. SYNTHESIS 26
stat
ein
dex
0 10 20 30 40
maxi αt(i)
maxi αt × γt(i)
maxi γt(i)
0.3
0.2
0.1
0 10 20 30 40
Figure 5.2: The image shows the states selected over40 observations withmaxi γt(i) (red)andmaxi αt(i) × γt(i) (green), with dark cells corresponding to high forward probability.The graph plots the exact probability of the selections, as well as maxi αt(i).
probability than simply using~γt directly. The green lines, representing states selected us-
ing the combined method, tend to coincide with darker areas,representing higher forward
probabilities, though they deviate as necessary to preserve coherence.
To obtain the actual estimate, the most probable and coherent state could be selected as
arg maxi(~αt × ~γt)(i). However, always displaying the “optimal” animation is notneces-
sary, since various gestures are often appropriate for the same speech segment. Instead, the
current state is selected by stochastically sampling the state space according to this prod-
uct distribution. This has several desirable properties: it introduces greater variety into the
animation, prevents grating repetitive motions, and makesthe algorithm less sensitive to
issues arising from the specific choice of clusters.
To illustrate this last point, consider a case where two fastgestures receive probabilities
of 0.3 each, and one slow gesture receives a probability of0.4. Clearly, a fast gesture is
more probable, but a highest-probability selection will play the slow gesture every time.
Randomly sampling according to the distribution, however, will properly display a fast
gesture six times out of ten.

CHAPTER 5. SYNTHESIS 27
5.4 Early and Late Termination
As discussed in Section 4.2, the system accounts for variation in motion length by termi-
nating a motion if another syllable is unlikely to occur within that motion. In the case that
this event is mispredicted and the motion is not terminated,it may end between syllable
observations. To handle this case, the system re-examines the last observation by restoring
~αt−1 andτt−1 and performing the update again, with the new evidence that,if At−1 = ci or
si, At 6= ci. This corrects the previous “misprediction,” though the newly selected motion
is not always as far along as it should be, since it must start from the beginning.
5.5 Constructing the Animation Stream
Once the animation state and its corresponding cluster of animation segments is chosen, we
must blend an appropriate animation segment from this cluster into the animation stream.
Although segments within a motion cluster generally share asimilar pose, there is some
variation. Because of this, some segments in a cluster may be closer to the last frame in the
animation stream than others. The system performs the actual segment selection by consid-
ering only the segments which begin in a pose similar to that of the last frame. In practice,
the system selects a subset of a cluster, the pose differenceof every element of which is
within some tolerance of the minimum pose difference for that cluster. One of the seg-
ments that fall within this tolerance is randomly selected.Random selection avoids jarring
repetitive motion when the same animation state occurs multiple times consecutively.
Once the appropriate segment is selected, it must be blendedwith the previous frame to
create a smooth transition. Although linear blending is generally sufficient for a perceptu-
ally smooth transition [51], it requires each motion to haveenough extra frames at the end
to accommodate a gradual blend, and simply taking these frames from the original motion
capture data may introduce extra, unwanted gestures. For many of the motions, the blend
interval would also exceed the length of the gesture, requiring many gestures to be linearly
blended simultaneously.
Instead, the proposed method uses a velocity-based blending algorithm, which keeps
the magnitude of the angular velocity on each joint equal to that of the desired animation,

CHAPTER 5. SYNTHESIS 28
and adjusts joint orientations to be as close as possible to the desired pose within this
constraint. For a new rotation quaternionrt, previous rotationrt−1, desired rotationdt, and
the derivative in the source animation of the desired frame4dt = dtdt−1, the orientation
of a joint at framet is given by
rt = slerp
(
rt−1, dt;angle(4dt)
angle(dtrt−1)
)
,
where “slerp” is the quaternion spherical interpolation function [45], and “angle” gives
the angle of the axis-angle representation of a quaternion.The rotation of each joint can
be represented either in parent-space or world-space. Using a parent-space representation
drastically reduces the chance of “unnatural” interpolations (such as violation of anatomic
constraints), while using a world-space representation preserves the “feel” of the desired
animation, even when the starting pose is different, by keeping to roughly the same align-
ment of the joints. For example, a horizontal gesture performed at hip level would remain
horizontal even when performed at chest level, so long as world-space representation of the
joint rotations is used. In practice, the artifacts introduced by world-space blending are ex-
tremely rare, so all joints are blended in world-space with the exception of the hands, which
are blended in parent-space. Being farther down on the skeleton, the hands are particularly
susceptible to unnatural poses as a result of world-space blending.
The velocity-based method roughly preserves the “feel” of the desired animation even
when the starting pose is different, by maintaining the samevelocity magnitude. One effect
of this is that the actual pose of still segments, or “holds,”is relatively unimportant, since
when4dt ≈ 0, the last frame is held indefinitely. Due to noise and low-level motion, these
segments will still eventually “drift” toward the originalsegment pose, but will do so very
gradually.

Chapter 6
Evaluation
6.1 Evaluation Methodology
There is no single correct body language sequence for a givenutterance, which makes
validation of the system inherently difficult. The only known way to determine the quality
of synthesized body language is by human observation. To this end, I conducted four
surveys to evaluate the method. Participants unfamiliar with the details of the system were
recruited from a broad group of university students. Participants were asked to evaluate
three animations corresponding to the same utterance, presented in random order on a web
page. The utterances ranged from40 to 60 seconds in length.
In addition to the synthesized sequence, two controls were used. One of the controls
contained motion capture of the original utterance being spoken. The other control was
generated by randomly selecting new animation segments whenever the current segment
terminated, producing an animation that did not correspondto the speech but still appeared
generally coherent. The original motion capture provides anatural standard for quality,
while random selection represents a simple alternative method for synthesizing body lan-
guage in real time. Random selection has previously been usedto animate facial expres-
sions [38] and to add detail to coarsely defined motion [26]. As observed in [22], the lack of
facial animation tends to distract viewers from evaluatingsynthesized gestures. Therefore,
the videos featured a simplified model without a face, as shown in Figure 6.1.
Two sets of training data were used in the evaluation, from two different speakers.
29

CHAPTER 6. EVALUATION 30
“We just, uh, you know ... we just hung around, uh ... went to the beach.”
Figure 6.1: An excerpt from a synthesized animation used in the evaluation study.
Training set I consisted of30 minutes of motion capture data in four scenes, recorded from
a trained actor. Training set II consisted of15 minutes in eight scenes, recorded from a
good speaker with no special training. For each training set, two surveys were conducted.
Surveys AI and AII sought to determine the quality of the synthesized animation compared
to motion capture of the same speaker, in order to ensure a reliable comparison without
interference from confounding variables, such as gesturing style. These surveys used ut-
terances from the training speakers that were not present inthe training data. Surveys BI
and BII sought to determine how well the system performed on anutterance from a novel
speaker.
6.2 Results
After viewing each animation, participants rated each animation on a five-point Likert scale
for timing and appropriateness. To determine timing, participants were asked their agree-
ment on the statement “the movements of characterX were generally timed appropriately.”
To determine the appropriateness of the motions for the current speech, they were asked
their agreement on the statement “the motions of characterX were generally consistent
with what he was saying.” The questions and average scores for the surveys are presented
in Figure 6.2.
In all surveys, the synthesized sequence outperformed the random sequence, withp <
0.05. In fact, with the exception of survey AI, the score given to the synthesized sequences
remained quite stable. The relatively low scores of both thesynthesized and randomly
constructed sequences in survey AI may be accounted for by the greater skill of the trained
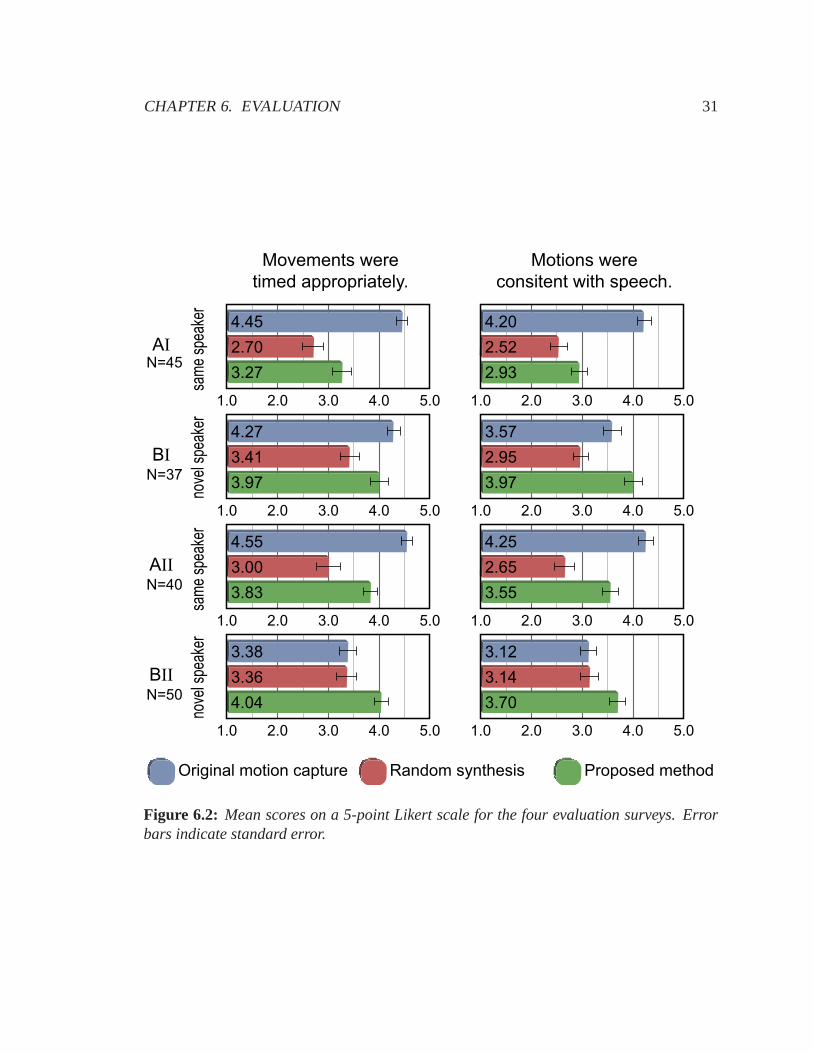
CHAPTER 6. EVALUATION 31
Movements were
timed appropriately.
Motions were
consitent with speech.
1.0 2.0 3.0 4.0 5.0
Original motion capture Random synthesis Proposed method
4.45
2.70
3.27
AI
BI
sam
e sp
eake
rno
vel s
peak
er
1.0 2.0 3.0 4.0 5.0
1.0 2.0 3.0 4.0 5.0
1.0 2.0 3.0 4.0 5.0
1.0 2.0 3.0 4.0 5.0
4.55
3.00
3.83
3.38
3.36
4.04
4.25
2.65
3.55
3.12
3.14
3.70
AII
BII
sam
e sp
eake
rno
vel s
peak
er
N=45
N=37
N=40
N=50
1.0 2.0 3.0 4.0 5.0
4.27
3.41
3.97
1.0 2.0 3.0 4.0 5.0
3.57
2.95
3.97
1.0 2.0 3.0 4.0 5.0
4.20
2.52
2.93
Figure 6.2: Mean scores on a 5-point Likert scale for the four evaluationsurveys. Errorbars indicate standard error.

CHAPTER 6. EVALUATION 32
actor in set I, which is the reason that training set I is used in all other examples in this
thesis and the accompanying videos discussed in Section 6.3.
In the generalization surveys BI and BII, the original motion capture does not always
outperform the synthesized sequence, and in survey BII, its performance is comparable
to that of the random sequence. This indicates that the two speakers used in the general-
ization tests had body language that was not as compelling asthe training data. This is
not unexpected, since skilled speakers were intentionallychosen to create the best possi-
ble training data, and different individuals may appear more or less comfortable with their
body language in conversation. It may be difficult for viewers to separate their notions of
“believable” and “effective” speakers (e.g., an awkward speaker will appear less “realistic,”
even though he is just as human as a more skilled speaker). Even the random sequence used
the gesture subunits from the training data, and the transitions in the random sequence were
smooth, due to the fact that motion segments were segmented at low-velocity boundaries
and the blending was velocity-based. Therefore, it is reasonable to conclude that even a
random sequence from a skilled speaker might appear more “believable” than the original
motion capture of a less confident speaker.
It is notable, however, that our system was able to synthesize gestures that were as
appropriate as those in the same-speaker tests. The stability of the scores for our system
across the surveys indicates that it was able to successfully transplant the training speakers’
more effective gesturing styles to the novel speakers.
6.3 Video Examples
In addition to the images provided in this thesis, a number ofvideos were created to demon-
strate the quality of animations synthesized with the proposed system. The videos present
examples of animations for numerous speakers, utterances with pronounced emphasis, and
utterances with a clear emotional atmosphere. One of the sets of videos from the surveys
is also included, along with separate evaluations of the selection and synchronization com-
ponents, as discussed in Section 7.1. The videos may be viewed on a website, located at
http://www.stanford.edu/ ˜ svlevine/vids/svlugthesis.htm .

Chapter 7
Discussion and Future Work
7.1 Applicability of Prosody and the Synchrony Rule
I presented a system for generating expressive body language animations for human charac-
ters from live speech input. The system is efficient enough torun on a 2 GHz Intel Centrino
processor, making it suitable for modern consumer PCs. While drawing on previous work
on animated ECAs, the proposed method addresses the somewhatneglected problem of
animating human characters in networked virtual environments, which requires a real-time
technique to handle unpredictable and varied extemporaneous speech. The system works
off of two assumptions: the co-occurrence of gestures and syllable peaks and the useful-
ness of prosody for identifying body language. The former assumption is justified by the
“synchrony rule” described in [30], and the latter by the relationship between prosody and
emotion [1], and by extension body language. The effectiveness of the proposed method
was validated by a comparative study that confirmed that these assumptions produce plau-
sible body language that often compares well to the actual body language accompanying a
sample utterance.
In addition to the survey discussed in Chapter 6, a pilot studywas conducted in which
participants were also shown a random animation with gestures synchronized to syllable
peaks, and an animation generated with the proposed system but without the synchrony
rule (e.g., all gestures ran to completion). Although theseanimations were not included
33

CHAPTER 7. DISCUSSION AND FUTURE WORK 34
“Motorcycles become a fully immersive experience, where the sound of it, the vibration, the seating, it all matters.”Figure 7.1: An excerpt from a synthesized animation.
in the final survey to avoid fatiguing the responders, comments from the pilot study indi-
cated that both synchrony and proper selection were needed to synthesize plausible body
language. Responders noted that the randomly animated character “felt a little forced” and
“didn’t move with the rhythm of the speech,” while the character which did not synchronize
with syllable peaks appeared “off sync” and “consistently low energy.” Example anima-
tions that use random selection with synchronization and HMM-driven selection without
synchronization may be viewed online, as discussed in Section 6.3. These findings suggest
that both the “synchrony rule” and prosody-based gesture selection are useful for gesture
synthesis.
7.2 Limitations
Despite the effectiveness of this method for synthesizing plausible animations, it has several
inherent limitations. Most importantly, relying on prosody alone precludes the system from
generating meaningful iconic gestures when they are not accompanied by emotional cues.
Metaphoric gestures are easier to select because they originate from a smaller repertoire and
are more abstract [30], and therefore more tolerant of mistakes, but iconic gestures cannot
be “guessed” without interpreting the words in an utterance. This fundamental limitation
may be addressed in the future with a method that combines rudimentary word recognition
with prosody-based gesture selection. Word recognition may be performed either directly
or from phonemes, which can already be extracted in real time[37].
A second limitation of this method is that it must synthesizegestures from information
that is already available to the listener, thus limiting itsability to provide supplementary

CHAPTER 7. DISCUSSION AND FUTURE WORK 35
details. While there is no consensus in the linguistics community on just how much infor-
mation is conveyed by gestures [27], a predictive speech-based real-time method is unlikely
to impart on the listener any more information than could be obtained from simply listen-
ing to the speaker attentively, while real gestures often convey information not present in
speech [30]. Therefore, while there are clear benefits to immersiveness and realism from
compelling and automatic animation of human-controlled characters, such methods cannot
provide additional details without some form of additionalinput. This additional input,
however, need not necessarily be as obtrusive as keyboard ormouse controls. For example,
facial expressions carry more information about emotionalstate than prosody [1], which
suggests that more informative gestures may be synthesizedby analyzing the speaker’s
facial expressions, for example though a consumer webcam.
7.3 Future Work
Besides addressing the limitations of the proposed system, future work may also expand
its capabilities. Training data from multiple individuals, for example, may allow the syn-
thesis of “personalized” gesture styles, as advocated by [36]. A more advanced method
of extracting gestures from training data may allow for the principal joints of a gesture to
be identified automatically, which would both eliminate theneed for the current separation
of leg, arm, and head gestures and allow for more intelligentblending of gestures with
other animations. This would allow a gesturing character toengage in other activities with
realistic interruptions for performing important gestures.
In addition to animating characters, I hope that the proposed method will eventually
reveal new insight into how people form and perceive gestures. The pilot survey already
suggests that the method may be useful for confirming the validity of the synchrony rule
and the relationship between prosody and gesture. Further work could explore the relative
importance of various gesture types, as well as the impact oftiming and appropriateness on
perceived gesture quality.

CHAPTER 7. DISCUSSION AND FUTURE WORK 36
“Which is also one of those very funny episodes that are in thismovie.”
Figure 7.2: Synthesized body language helps create an engaging virtualinteraction.
7.4 Conclusion
In this thesis, I present a new method for generating plausible body language for a variety of
utterances and speakers, such as the virtual interaction portrayed in Figure 7.2, or the story
being told by the character in Figure 7.1. The use of vocal prosody allows the system to
detect emphasis, produce gestures that reflect the emotional state of the speaker, and select
a rhythm that is appropriate for the utterance. Since the system generates compelling body
language in real time without specialized input, it is particularly appropriate for animating
human characters in networked virtual worlds.

Bibliography
[1] Ralph Adolphs. Neural systems for recognizing emotion.Current Opinion in Neuro-
biology, 12(2):169–177, 2002.
[2] Irene Albrecht, Jorg Haber, and Hans peter Seidel. Automatic generation of non-
verbal facial expressions from speech. InComputer Graphics International, pages
283–293, 2002.
[3] Okan Arikan and David Forsyth. Interactive motion generation from examples.ACM
Transactions on Graphics, 21(3):483–490, 2002.
[4] Jernej Barbic, Alla Safonova, Jia-Yu Pan, Christos Faloutsos, Jessica K.Hodgins,
and Nancy S. Pollard. Segmenting motion capture data into distinct behaviors. In
Proceedings of Graphics Interface 2004, pages 185–194, 2004.
[5] Jonas Beskow.Talking Heads - Models and Applications for Multimodal Speech
Synthesis. PhD thesis, KTH Stockholm, 2003.
[6] Paul Boersma. Accurate short-term analysis of the fundamental frequency and the
harmonics-to-noise ratio of a sampled sound. InProceedings of the Institute of Pho-
netic Sciences, volume 17, pages 97–110, 1993.
[7] Paul Boersma. Praat, a system for doing phonetics by computer. Glot International,
5(9-10):314–345, 2001.
[8] Matthew Brand. Voice puppetry. InSIGGRAPH ’99: ACM SIGGRAPH 1999 Papers,
pages 21–28, New York, NY, USA, 1999. ACM.
37

BIBLIOGRAPHY 38
[9] Christoph Bregler, Michele Covell, and Malcolm Slaney. Video rewrite: driving vi-
sual speech with audio. InSIGGRAPH ’97: ACM SIGGRAPH 1997 Papers, pages
353–360, New York, NY, USA, 1997. ACM.
[10] Justine Cassell. Embodied conversational interface agents. Communications of the
ACM, 43(4):70–78, 2000.
[11] Justine Cassell, Catherine Pelachaud, Norman Badler, Mark Steedman, Brett Achorn,
Tripp Becket, Brett Douville, Scott Prevost, and Matthew Stone. Animated conver-
sation: rule-based generation of facial expression, gesture & spoken intonation for
multiple conversational agents. InSIGGRAPH ’94: ACM SIGGRAPH 1994 Papers,
pages 413–420, New York, NY, USA, 1994. ACM.
[12] Justine Cassell, Hannes Hogni Vilhjalmsson, and Timothy Bickmore. Beat: the be-
havior expression animation toolkit. InSIGGRAPH ’01: ACM SIGGRAPH 2001
Papers, pages 477–486, New York, NY, USA, 2001. ACM.
[13] Erika Chuang and Christoph Bregler. Mood swings: expressive speech animation.
ACM Transactions on Graphics, 24(2):331–347, 2005.
[14] David Efron.Gesture, Race and Culture. The Hague: Mouton, 1972.
[15] Tony Ezzat, Gadi Geiger, and Tomaso Poggio. Trainable videorealistic speech anima-
tion. In SIGGRAPH ’02: ACM SIGGRAPH 2002 Papers, pages 388–398, New York,
NY, USA, 2002. ACM.
[16] Ajo Fod, Maja J. Mataric, and Odest Chadwicke Jenkins. Automated derivation of
primitives for movement classification.Autonomous Robots, 12:39–54, 2002.
[17] Bjorn Hartmann, Maurizio Mancini, and Catherine Pelachaud. Formational parame-
ters and adaptive prototype instantiation for mpeg-4 compliant gesture synthesis. In
Proceedings on Computer Animation, page 111, Washington, DC, USA, 2002. IEEE
Computer Society.

BIBLIOGRAPHY 39
[18] Carlos Jensen, Shelly D. Farnham, Steven M. Drucker, andPeter Kollock. The effect
of communication modality on cooperation in online environments. InProceedings
of CHI ’00, pages 470–477, New York, NY, USA, 2000. ACM.
[19] Eunjung Ju and Jehee Lee. Expressive facial gestures from motion capture data.
Computer Graphics Forum, 27(2):381–388, 2008.
[20] Adam Kendon.Gesture. Cambridge University Press, New York, NY, USA, 2004.
[21] Michael Kipp, Michael Neff, and Irene Albrecht. An annotation scheme for conversa-
tional gestures: how to economically capture timing and form. Language Resources
and Evaluation, 41(3-4):325–339, December 2007.
[22] Michael Kipp, Michael Neff, Kerstin H. Kipp, and Irene Albrecht. Towards natural
gesture synthesis: Evaluating gesture units in a data-driven approach to gesture syn-
thesis. In7th international conference on Intelligent Virtual Agents, pages 15–28,
Berlin, Heidelberg, 2007. Springer-Verlag.
[23] Stefan Kopp and Ipke Wachsmuth. Synthesizing multimodal utterances for conversa-
tional agents: Research articles.Computer Animation and Virtual Worlds, 15(1):39–
52, 2004.
[24] Lucas Kovar, Michael Gleicher, and Frederic Pighin. Motion graphs.ACM Transac-
tions on Graphics, 21(3):473–482, 2002.
[25] Yan Li and Heung-Yeung Shum. Learning dynamic audio-visual mapping with input-
output hidden markov models.IEEE Transactions on Multimedia, 8(3):542–549, June
2006.
[26] Yan Li, Tianshu Wang, and Heung-Yeung Shum. Motion texture: a two-level statisti-
cal model for character motion synthesis. InSIGGRAPH ’02: ACM SIGGRAPH 2002
Papers, pages 465–472, New York, NY, USA, 2002. ACM.
[27] Daniel Loehr.Gesture and Intonation. PhD thesis, Georgetown University, 2004.

BIBLIOGRAPHY 40
[28] O. Maeran, V. Piuri, and G. Storti Gajani. Speech recognition through phoneme
segmentation and neural classification.Instrumentation and Measurement Technology
Conference, 1997. IMTC/97. Proceedings. ’Sensing, Processing, Networking.’, IEEE,
2:1215–1220, May 1997.
[29] Anna Majkowska, Victor B. Zordan, and Petros Faloutsos.Automatic splic-
ing for hand and body animations. InProceedings of the 2006 ACM SIG-
GRAPH/Eurographics symposium on Computer animation, pages 309–316, 2006.
[30] David McNeill. Hand and Mind: What Gestures Reveal About Thought. University
Of Chicago Press, 1992.
[31] David McNeill. Gesture and Thought. University Of Chicago Press, November 2005.
[32] Joann Montepare, Elissa Koff, Deborah Zaitchik, and Marilyn Albert. The use of body
movements and gestures as cues to emotions in younger and older adults.Journal of
Nonverbal Behavior, 23(2):133–152, 1999.
[33] Louis-Philippe Morency, Candace Sidner, Christopher Lee, and Trevor Darrell. Head
gestures for perceptual interfaces: The role of context in improving recognition.Ar-
tificial Intelligence, 171(8-9):568–585, 2007.
[34] Meinard Muller, Tido Roder, and Michael Clausen. Efficient content-based retrieval
of motion capture data. InSIGGRAPH ’05: ACM SIGGRAPH 2005 Papers, vol-
ume 24, pages 677–685, New York, NY, USA, 2005. ACM.
[35] Lars Mundermann, Stefano Corazza, and Thomas P. Andriacchi. Accurately measur-
ing human movement using articulated ICP with soft-joint constraints and a repository
of articulated models. InComputer Vision and Pattern Recognition, pages 1–6, June
2007.
[36] Michael Neff, Michael Kipp, Irene Albrecht, and Hans-Peter Seidel. Gesture model-
ing and animation based on a probabilistic re-creation of speaker style.ACM Trans-
actions on Graphics, 27(1):1–24, 2008.

BIBLIOGRAPHY 41
[37] Junho Park and Hanseok Ko. Real-time continuous phonemerecognition system us-
ing class-dependent tied-mixture HMM with HBT structure forspeech-driven lip-
sync. IEEE Transactions on Multimedia, 10(7):1299–1306, Nov. 2008.
[38] Ken Perlin. Layered compositing of facial expression.In SIGGRAPH ’97: ACM SIG-
GRAPH 97 Visual Proceedings, pages 226–227, New York, NY, USA, 1997. ACM.
[39] Ken Perlin and Athomas Goldberg. Improv: a system for scripting interactive actors
in virtual worlds. InSIGGRAPH ’96: ACM SIGGRAPH 1996 Papers, pages 205–216.
ACM, 1996.
[40] Lawrance R. Rabiner. A tutorial on hidden markov models and selected applications
in speech recognition.Proceedings of the IEEE, 77(2):257–286, Feb 1989.
[41] Lance A. Ramshaw and Mitchell P. Marcus. Text chunking using transformation-
based learning. InProceedings of the Third Workshop on Very Large Corpora, pages
82–94, 1995.
[42] M. E. Sargin, E. Erzin, Y. Yemez, A. M. Tekalp, A.T. Erdem, C. Erdem, and
M. Ozkan. Prosody-driven head-gesture animation. InICASSP ’07: IEEE Inter-
national Conference on Acoustics, Speech, and Signal Processing, April 2007.
[43] Klaus R. Scherer, Rainer Banse, Harald G. Wallbott, and Thomas Goldbeck. Vocal
cues in emotion encoding and decoding.Motivation and Emotion, 15(2):123–148,
1991.
[44] Marc Schroder.Speech and Emotion Research: An overview of research frameworks
and a dimensional approach to emotional speech synthesis. PhD thesis, Phonus 7,
Research Report of the Institute of Phonetics, Saarland University, 2004.
[45] Ken Shoemake. Animating rotation with quaternion curves. InSIGGRAPH ’85: ACM
SIGGRAPH 1985 Papers, pages 245–254, New York, NY, USA, 1985. ACM.
[46] Marc Shroder. Speech and Emotion Research: An overview of research frameworks
and a dimensional approach to emotional speech synthesis. PhD thesis, Phonus 7,
Research Report of the Institute of Phonetics, Saarland University, 2004.

BIBLIOGRAPHY 42
[47] Eftychios Sifakis, Andrew Selle, Avram Robinson-Mosher, and Ronald Fedkiw. Sim-
ulating speech with a physics-based facial muscle model. InProceedings of the 2006
ACM SIGGRAPH/Eurographics symposium on Computer animation, pages 261–270,
Aire-la-Ville, Switzerland, Switzerland, 2006. Eurographics Association.
[48] Matthew Stone, Doug DeCarlo, Insuk Oh, Christian Rodriguez, Adrian Stere, Alyssa
Lees, and Chris Bregler. Speaking with hands: creating animated conversational char-
acters from recordings of human performance. InSIGGRAPH ’04: ACM SIGGRAPH
2004 Papers, pages 506–513, New York, NY, USA, 2004. ACM.
[49] Jacques Terken. Fundamental frequency and perceived prominence of accented syl-
lables.The Journal of the Acoustical Society of America, 89(4):1768–1777, 1991.
[50] Harald G. Wallbot. Bodily expression of emotion.European Journal of Social Psy-
chology, 28(6):879–896, 1998.
[51] Jing Wang and Bobby Bodenheimer. Synthesis and evaluation of linear motion tran-
sitions.ACM Transactions on Graphics, 27(1):1:1–1:15, Mar 2008.
[52] Joe H. Ward. Hierarchical grouping to optimize an objective function.Journal of the
American Statistical Association, 58(301):236–244, 1963.
[53] Jianxia Xue, J. Borgstrom, Jintao Jiang, Lynne E. Bernstein, and Abeer Alwan.
Acoustically-driven talking face synthesis using dynamicbayesian networks.IEEE
International Conference on Multimedia and Expo, pages 1165–1168, July 2006.
[54] Nick Yee. Motivations for play in online games.Cyberpsychology and Behavior,
9:772–775, 2006.