biological/ clinical experiments instruments data pre- processing interpretation of results new...
Post on 20-Dec-2015
216 views
TRANSCRIPT

Biological/ Clinical
Experiments
InstrumentsData Pre-
ProcessingInterpretation
of Results
New Paper
New Drug
New Treatment
New DB Entries
Life Science Discovery Phases:• Exploratory/Prototype Analysis
• Application Development
• Production System
Bioinformatics Analytical Pipelines
Analytical Algorithms
FilesFilesFilesFiles
Perl Scripts
Perl Scripts AlgorithmsAlgorithms
Files
DB Files Files
AlgorithmsPerl
Scripts
Files
DBFiles
Oracle Life Sciences Platform
C A T G0 0 1 0 1

Interpretation of Results Discoverer
Reports
Portals
Java Servlets
Biopsies Samples
Instruments
Feature Selection
SQL
Oracle Data Mining
Feature Selection
Molecular Pattern
Recognition
Oracle Data Mining
Bayesian Classifier
Affymetrix Micro-Array
Microarray Lab
Prediction:
DLBC Follicular
DLBC Follicular
Dataset from Golub et al Science 286:531-537.
BioOracleDNA Microarray Analysis of LymphomaIntegrated Demo eSeminar Feb. 13th 2003
Filtering and Pre-
Processing
SQL, XML, Java

•
More Examples
DNA microarray analysis for cancer classification
– Gene expressions from Leukemia cells– Target: Leukemia morphologies & treatment outcome
Early disease screening proteomic analysis
– Mass. spec. “peaks” from patient blood samples – Target: cancer or normal status
Drug activity analysis– Molecular characteristics of new drug candidates – Target: binding affinities to targets

Caprion
Discover & develop innovative products for the diagnosis & treatment of diseases
– Scalability for a multi-TB system– Integration of all components with
existing computing environment– Security & protection of data integrity
Key Advantages of Oracle– Easy access & management of
integrated information– Rapid deployment of new ad hoc
query– Scalability necessary to
accommodate growth
Oracle Environment– Oracle database– Oracle9i Application Server– Oracle9i Developer Suite– Oracle9i AS Discoverer– Oracle Warehouse Builder
“The Oracle Data Warehouse is a key component of our IT platform for proteomics analysis. The massive amount of information we produce every day requires a system with proven performance to effectively capture our biological data”. Bernard Gagnon, IT Director

Myriad Proteomics
Mapping human protein interactions at a system scale using two-hybrid & mass spec.
– Online database system to automate laboratory flows
– Databases for intermediate results for quality control and tracking
– Data marts that are specific to customer needs
Key Advantages of Oracle– Ease of maintenance– Partitioning keeps up with end-user
demands for fast query times– Meets scalability needs
Oracle Environment– Oracle9i database with
partitioning– Oracle Enterprise Manager– Plan to use XML DB and
External Tables in 2003
“One of the keys to the technological success of this project is our use of Oracle software. Every aspect of our business touches Oracle technology; it’s a key component of our work”. Marcel Davidson, Head of DB Architecture & Administration

Applied Biosystems Enterprise software for laboratory
automation and integration – Life Science LIMS– SQL*LIMSTM Software
Key Advantages– Sample and container
management to support complex sample fan-outs
– Full audit trail support to help meet regulatory compliance
– Application specific interfaces to meet customers’ needs
– Integration with third party software– Supported by world-wide
professional services group www.appliedbiosystems.com
Oracle Features– Scalable, highly available– Open standards for
messaging and program integration
– Powerful reporting tools– Web publishing supported

Oracle Collaboration Suite
- Integrated communications – Single enterprise search
across all repositories Internal & external
– Flexible accessWeb, desktop Wireless and telephone
5. Collaborate Securely

5. Collaborate Securely Oracle 10gAS Portal
– Build personalized portals Oracle Workflow
– Automate laboratory and business processes Oracle 10gAS Files
– Enable content management and collaborationRevision control, check-in/check-out, access control
Virtual Private Database– Different users have unique access privileges
Auditing– Create audit trail to facilitate FDA compliance
Oracle 10gAS Web Services– Standard way to collaborate through the web

Taratec e ComplianceTM
– Built specifically to supports FDA 21 CFR Part 11 Compliance
– Designed for Life Sciences Data & File Management
Features– Versioning, Advance Searching,
Check-in/Check-Out– Integrated storage of files from any
source– Universal access through Web
browser– Complete Audit Trail of File
Operations
“With Oracle as the foundation, we were able to develop a solution that can secure a vast array of file-based data with vault like security.”
Bill Gargano, President and COO Taratec Development Corporation
Screen shot or diagram
Taratec and Taratec’s logo are registered trademarks of Taratec Development Corporation
© 1999 Taratec Development Corporation
Taratec e-ComplianceTM
An iFS Application

GenSys Software Products
– GenSys/ELN (Electronic Laboratory Notebook)
– GenSys/R&D (Research & Discovery software integration platform)
Key Advantages– Most dependable
and secure enterprise-wide application
– Easy for Researchers to Learn & Use
– Open – Integrates well with Scientist desktop & back-end applications (i.e. registration, LIMS, search & document management
– Also supports legal, regulatory and records management users
– www.gensys.com
Oracle 9i Features:– XML - Automatic creation of XML
views– Adobe PDF Support– Oracle’s Scalability and flexibility
is key to GenSys’ enterprise solution
– iFS and XML DB offer powerful potential in future releases

Web Services - Life Sciences Data Sources & Applications

WSDL DocumentWSDL Document
Web Service SupplierWeb Service Supplier
3. Invoke3. Invoke
SO
AP
UDDIUDDIRepositoryRepository
1. Publish1. Publish
2. Find2. FindWeb ServiceWeb ServiceConsumerConsumer
ServiceServletServlet
Oracle Web ServicesSOAP, WSDL, UDDI Together
Communicate Oracle’s support for web services industry standards
– I3C participation

Complete data protection Manage user access Detect data misuse with Auditing Facilitate regulatory compliance (HIPPA, 21 CFR PART 11)
Proven against 15 independent evaluations
Security EvaluationsSecurity Evaluations OracleOracle MicrosoftMicrosoft IBMIBMSecurity EvaluationsSecurity Evaluations OracleOracle MicrosoftMicrosoft IBMIBM
US TCSEC, Level B1US TCSEC, Level B1
US TCSEC, Level C2US TCSEC, Level C2
UK ITSEC, Levels E3/F-C2UK ITSEC, Levels E3/F-C2
UK ITSEC, Levels E3/F-B1UK ITSEC, Levels E3/F-B1
ISO Common Criteria, EAL-4ISO Common Criteria, EAL-4
Russian Criteria, Levels III, IVRussian Criteria, Levels III, IV
US FIPS 140-1, Level 2US FIPS 140-1, Level 2
TOTALTOTAL
US TCSEC, Level B1US TCSEC, Level B1
US TCSEC, Level C2US TCSEC, Level C2
UK ITSEC, Levels E3/F-C2UK ITSEC, Levels E3/F-C2
UK ITSEC, Levels E3/F-B1UK ITSEC, Levels E3/F-B1
ISO Common Criteria, EAL-4ISO Common Criteria, EAL-4
Russian Criteria, Levels III, IVRussian Criteria, Levels III, IV
US FIPS 140-1, Level 2US FIPS 140-1, Level 2
TOTALTOTAL
11
11
33
33
44
22
11
1515
11
11
33
33
44
22
11
1515
--
11
--
--
--
--
FailedFailed
11
--
11
--
--
--
--
FailedFailed
11
--
--
--
--
--
--
--
00
--
--
--
--
--
--
--
00
Oracle10g Unbreakable Security

University of California San Diego School of Medicine The Patient Centered Access to Secure
Systems Online (PCASSO)– 178,000 Medical Records– Provides trusted access to a patient’s health
information from healthcare providers over the Internet
– Oracle Label Security & Virtual Private Database The security is locked to the data and therefore
can’t be subverted. No application coding needed to implement
security.

San Diego Supercomputing Center
“In the beginning, we considered using MySQL, Oracle, and another database. But when we
evaluated our project needs over the next ten years and realized that our database could grow to terabytes, we decided we needed a scalable
database and one that was reliable. We didn’t want to be forced to change databases in the middle of the project. …. “We do not need a lot of DBAs to
maintain the database.” Joshua Li, Senior Computational Scientist, University of California, San
Diego, Supercomputing Center
Systemwide, SDSC relies on only three DBAs to run over 40 Oracle databases.

AMR Research“Regulatory compliance has become a business risk. Big
fines can be levied and the FDA can shut down manufacturing lines. The FDA wants to make sure
companies have electronic signatures and a full, auditable track record. All the IT systems deployed have to guarantee full accountability and change management. Oracle offers full traceability of the database. In other products, you have to make sure the application that’s using the data gives you
the change management. Oracle provides security and authentication built into the database technology.”
Roddy Martin, Service Director of Consumer Package Goods and Life Sciences, AMR Research

European Bioinformatics Institute
“Our mission is to build molecular biology databases of importance and place them in the
public domain so they can be used by the research community as easily as possible.”
Peter Stoehr, Head of Database Operations, EBI
“Researchers tap directly into the data repository we host here. We’re an international
data repository.”
Weimin Zhu, Head of Database Application Group, EBI

Find me any compound that looks like my current structure, and that has been tested on any assay in my company where the IC50>200nM, where I know that I have a unique patent position, and hasn't been published in any journal?
Find me any compound that looks like my current structure, and that has been tested on any assay in my company where the IC50>200nM, where I know that I have a unique patent position, and hasn't been published in any journal?
select c.id, p.structure, from compound c, protein p, assay awhere a.compound_id = c.idand a.protein_id = p.idand a.company = “BIO_SYS” and a.IC50 > 200nM and similar_to(p.id, “protein kinase”)and not_published(p.id, “Medline”)and extract_value(value(p.id), ‘Dgene/Protein/Id’) = p.id
select c.id, p.structure, from compound c, protein p, assay awhere a.compound_id = c.idand a.protein_id = p.idand a.company = “BIO_SYS” and a.IC50 > 200nM and similar_to(p.id, “protein kinase”)and not_published(p.id, “Medline”)and extract_value(value(p.id), ‘Dgene/Protein/Id’) = p.id
Oracle9Oracle9iiOracle9Oracle9ii
RelationalRelational
MessageMessage
XMLXML
TextText
ImageImage
Oracle’s Contribution to Life Sciences

IDC Analysts
“Even IBM's own partners say that DB2 and DiscoveryLink have failed to gain
much ground in the life sciences despite IBM's giveaways. According to Hall,
Oracle, the "de facto standard," still holds a commanding 75 percent to 80 percent
market share in this vertical.” Mark Hall, Director of Life Sciences, IDC, in InfoWeek 12/12/2002

Life Sciences Highlights Life Sciences featured in Oracle Magazine
– Features San Diego Supercomputer Center, European Bioinformatics Institute, and Celera Genomics Group
InfoWorld article– Even IBM's own partners say that DB2 and DiscoveryLink have failed to
gain much ground in the life sciences despite IBM's giveaways. According to Hall, Oracle, the "de facto standard," still holds a commanding 75 percent to 80 percent market share in this vertical.
Mark Hall, Director of Life Sciences, IDC, in InfoWeek 12/12/2002
BioInform article, Feb 2003– Oracle currently claims to hold 85 percent of the life science research
database market, but the company isn't resting on its laurels. On the contrary, the database giant is expanding the capabilities of its software in a bid to retain its edge in the increasingly competitive market.

Additional Life Sciences Information Server Technology Development,
Life Sciences Product Management Team– [email protected]– [email protected]– [email protected]
OTN – http://otn.oracle.com/industries/life_sciences/content.html
Oracle Life Sciences Platform Tech eSeminars, white papers, Partner Solutions, Customer Profiles, OTN
Discussion Forum, etc.
Oracle.com– http://www.oracle.com/industries/life_sciences/index.html?content.html
Internal site– http://bioinformatics.us.oracle.com

Customer Advisory Board (CAB) User group meetings being formed in North
America, Europe, and Asia Pacific.– May 2003 in Hinxton Hall Conference Centre, Wellcome Trust
Genome Campus, Hinxton, UK– Sept 10, 2003, OracleWorld, San Francisco
Discussion Forum on OTN “Oracle Life Sciences” SourceForge.net project
administered by SDSC to facilitate code & experience sharing: http://sourceforge.net/projects/oraclelifesci/
Oracle Life Sciences User Community

Oracle10g “The Bioinformatics Release”

Life Sciences 10g Features
Data Access– Heterogeneous transportable tablespaces – Merge enhancements
Variety of Data Types– XML DB enhancements – Enhanced text processing and searches (to cluster and classify)– Network Data Model feature for managing “graph” databases
Scalability and High Throughput– Grid– Distributed query optimization– Data pump
Finding Patterns and Insights– Data Mining: DM4J GUI, 2 New Algorithms (SVMs & NMF) , PL/SQL API – BLAST– Text Mining – Regular expression searches– Expanded basic statistics– IEEE floating point
Collaborate Securely

Oracle Data Mining BLAST
Implemented using a table function interface
BLAST search functions can be placed in SQL queries
Different functions for match & alignment
SQL queries can be used to pre-filter database of sequences & post-process the search results
Combination of SQL queries & BLAST is very powerful and flexible
C A T G0 0 1 0 1

Oracle Data Mining BLAST Web Services GUI (available via OTN)
C A T G0 0 1 0 1

C A T G0 0 1 0 1
Sample BLAST Query
For the query sequence “ATCGCGTT”, find the top 3 matches above a similarity threshold from each organism
select seq_id, organism, score, expect from (select t.seq_id, t.score, t.expect, g.organism, RANK() OVER (PARTITION BY organism ORDER BY score DESC) as o_rank from SwissProt_DB g, Table(SYS_BLASTP_MATCH (‘ATCGCGTT’,
cursor (select seq_id, sequence from SwissProt_DB), 5)) t /* expect_value */
where t.seq_id = g.seq_id) where o_rank <= 3
BLAST “Delighters”– Queries performed in the database– Ability to perform combinatorial
queries e.g. sequence similarity AND annotation contains “Lymphoma”
SYS_BLASTP_MATCH
SwissProt_DB
seq_id, score, expect
query_sequence, parameters
seq_id, organism, score, expect
t.seq_id = g.seq_id
o_rank <= 3
RANK
seq_id, organism, score, expect
SwissProt_DB
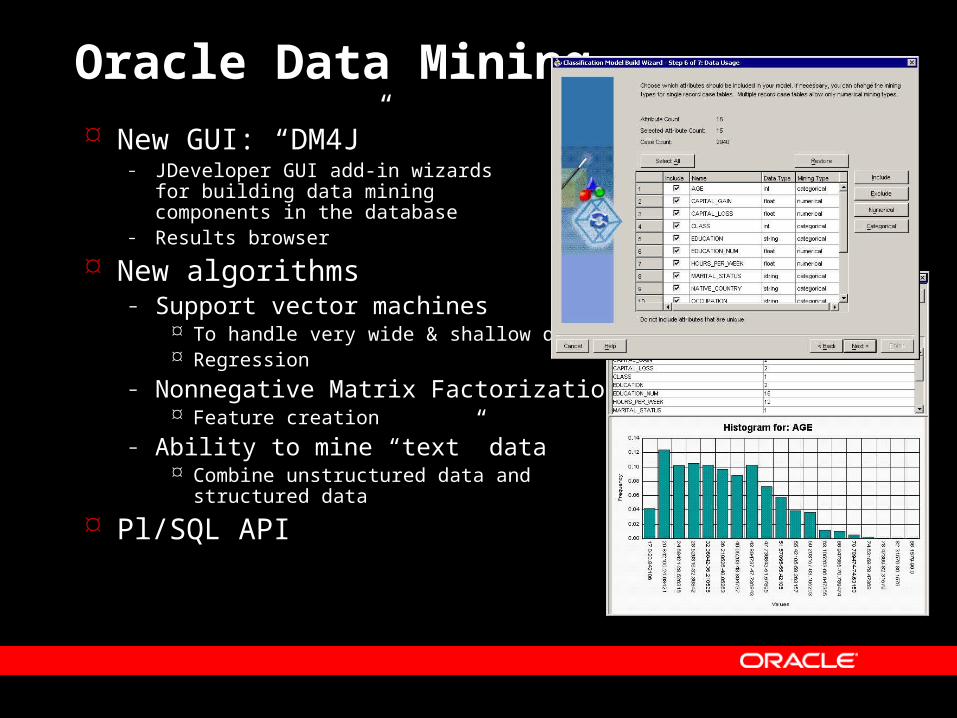
Oracle Data Mining
New GUI: “DM4J”– JDeveloper GUI add-in wizards
for building data mining components in the database
– Results browser
New algorithms– Support vector machines
To handle very wide & shallow data Regression
– Nonnegative Matrix Factorization Feature creation
– Ability to mine “text” data Combine unstructured data and
structured data
Pl/SQL API

Oracle Text Enhanced Advanced Text Searches
Perform enhanced information searches (using Oracle data mining functionality)
Ability to perform fast auto-clustering of documents, URLs etc. into natural groupings for more useful searches
Ability to provide “example documents” search and classify documents “likely” to be similar based on patterns beyond simple key word searches

New Statistics & SQL Analytics
Ranking functions– rank, dense_rank, cume_dist, percent_rank, ntile
Window Aggregate functions (moving and cumulative)
– Avg, sum, min, max, count, variance, stddev, first_value, last_value
LAG/LEAD functions– Direct inter-row reference using offsets
Reporting Aggregate functions– Sum, avg, min, max, variance, stddev, count,
ratio_to_report
Statistical Aggregates– Correlation, linear regression family, covariance
Linear regression– Fitting of an ordinary-least-squares regression line
to a set of number pairs. – Frequently combined with the COVAR_POP,
COVAR_SAMP, and CORR functions.
Descriptive Statistics– average, standard deviation, variance, min, max, median (via
percentile_count), mode, group-by & roll-up– DBMS_STAT_FUNCS: summarizes numerical columns of a
table and returns count, min, max, range, mean, stats_mode, variance, standard deviation, median, quantile values, +/- 3 sigma values, top/bottom 5 values
Correlations– Pearson’s correlation coefficients, Spearman's and Kendall's
(both nonparametric).
Cross Tabs– Enhanced with % statistics: chi squared, phi coefficient,
Cramer's V, contingency coefficient, Cohen's kappa
Hypothesis Testing– t-test , F-test, One-way ANOVA, Chi-square, Mann Whitney,
Kolmogorov-Smirnov, Wilcoxon signed ranks
Distribution Fitting– Normal, uniform, Poisson, exponential, Weibull
Pareto Analysis (documented)– 80:20 rule, cumulative results table

Other Features Important to Life Sciences Grid Computing IEEE Floating Point XML DB Heterogeneous Transportable Tablespaces Distributed Query Optimization Network Data Model Upsert” (Merge), or not Regular Expression Searches

Grid Computing
Automated job scheduling across Grid
Already has been lots of support for Grid concepts provided within Oracle environment
– Distributed queries– External tables– Security – RAC
Participate in Global Grid Forum Incremental Grid support

IEEE Floating Point
Support for industry standard treatment of numbers and precision
Critical for compute intensive operations Faster performance

XML DB
Already have best support for XML today Applications can use standard SQL/XML operators to
generate complex XML documents from SQL queries and to store XML documents
The XML Parser is also extended to support the updated and new W3C XML standards
Support for evolution of XML schemas Major improvements in XML processing performance
– XML Developer Kit (XDK) libraries and interfaces in Java, C, and C++ all transparently support the database XMLType, increasing throughput and scalability without high resource and processing costs. Additionally, the architectures been redesigned using a pipeline process model and SAX to increase performance while reducing resources.

Heterogeneous Transportable Tablespaces
sourcedatabase
targetdatabase
• Mechanism to quickly move a tablespace across Oracle databases
• Most efficient means to move bulk data between databases.
• Enhance to support cross platforms and operating systems

Distributed Query Optimization
Excellent support for distributed queries today
Performance addressed in each release
Cost-based optimizer enhanced to capture complete statistics for remote tables
Considers network bandwidth and latency in deciding what parts of the query plan should be remotely mapped
Flat filesMySQL

Network Data Model Model, store, manage and
analyze generic connectivity relationships in the DB,
– i.e. represent data as nodes and links
– Can model hierarchies, logical or spatial information, directionality
Network analysis at client or application level, e.g. shortest-path, tracing, within-distance analysis, minimum cost spanning tree, nearest neighbor
– Network management, e.g. add, delete, modify, load

“Upsert” (Merge), or not
Provides conditional “insert or update” processing – e.g. perform check sum on annotation or DNA sequence
Used in periodic data loads where new data is merged with existing data and the content of source and/or destination are unknown so INSERT or UPDATE cannot be used exclusively

Merge Statement Example
MATCHED THEN insert clauseWHEN NOT
WHENSKIP ( condition )
MERGE INTO table
USING table/view/subquery
ON ( condition )
WHEN MATCHED THEN update clause

Regular Expression Searches
Enable Regexp support in database through SQL and PL/SQL
Provide SQL and PL/SQL functions for Regexp matching and string manipulations
Follow POSIX style Regexp syntax Support standard Regexp operators including *, +, ?, |,
^, $, ., [ ], {m, n}, etc. Include common extensions such as case-insensitive
matching, sub-expression back-references, etc. Compatible with popular Regexp implementations like
GNU, Perl, Awk

Oracle10g Customer Quotes"Oracle 10g's new BLAST feature will enable us to easily integrate multiple types of genomic and proteomic data for complicated queries used in the mining of our proprietary protein-protein interaction and cDNA sequence datasets."
- Jake Chen, Principal Bioinformatics Scientist, Myriad Proteomics
“Using InforSense discovery workflows built upon the world leading Oracle data mining, text mining and R&D Database functionality, researchers and organizations can now automate large scale and complex knowledge discovery and management activities with performance and reliability.”
- Yike Guo, CEO InforSense
"Oracle 10g's Network Data Model feature is great for building a semantic work infrastructure. Oracle 10g's graphical representation is an excellent tool for planning our Y2H protein interaction data storage needs and for building a signaling network from our Nature-AfCS Molecule Pages Database."
- Joshua Li, Sr. Computational Scientist, San Diego Supercomputer Center / UCSD
"Thanks to Oracle 10g's Regular Expressions (RE) query support, it's no longer necessary to export data from the database, process it with a RE enabled tool and then import the data back into the database. Now, RE processing can be handled with a single query."
- Marcel Davidson, Head of Database Administration, Myriad Proteomics

Oracle10g Customer Quotes
"With Oracle 10g, sequence data that formerly needed to exported, BLASTed, and reimported, can now be analyzed with a single SQL statement."
- Marcel Davidson, Head of Database Administration, Myriad Proteomics
"Oracle 10g's implementation of REs enables the expression of complex Query logic-particularly against text strings-which is extremely useful in bioinformatics applications where queries are often formulated against complex genetic or proteomic code patterns."
- Jake Chen, Principal Bioinformatics Scientist, Myriad Proteomics
"Beyond Genomics, Inc., as a leading systems biology company, believes that Oracle 10g's network data model will significantly advance the integration of metabolomic, proteomic, transcriptomic, and clinical data sets and the applications that derive value from these data."
– Eric Neumann, Vice President Strategic Informatics, Beyond Genomics, Inc.

Life sciences not just a “wet lab” environment– In silico drug discovery now a critical component– Oracle, the “de facto standard”, enjoys an 80% market share - IDC
Enables you to– Access data from multiple sources– Integrate a variety of data types– Manage vast quantities of data– Find patterns and insights– Collaborate securely with other
researches
Oracle 10g is an ideal platform for life sciences
Oracle Life Sciences Platform Summary

AQ&Q U E S T I O N SQ U E S T I O N SA N S W E R SA N S W E R S
