binary classifica-on
TRANSCRIPT

BinaryClassifica-on
WeiXu(many slides from Greg Durrett and Vivek Srikumar)

Administrivia
‣ Readingsoncoursewebsite:h>ps://cocoxu.github.io/CS7650_fall2021/
‣ Problemset1isreleasedonGradeScope,dueonAugust30.
‣ TAOfficehours:
‣ Tuesday3-4pm(Nathan),Thursday4-5pm(Mounica),Friday10-11am(Sarah)

CourseworkPlan‣ 3ProgrammingProjects(40%;fairlysubstan-alimplementa-oneffort)
‣ Textclassifica-on
‣ Nameden-tyrecogni-on(BiLSTM-CNN-CRF)
‣ Neuralchatbot(Seq2Seqwitha>en-on)
‣ 2wri>enassignments(20%)+midtermexam(15%)
‣ MostlymathproblemsrelatedtoML/NLP
‣ Finalproject(20%;detailsoncoursewebsite,willdiscusslater)
There will be a lot of math and programming!

Assignments
‣ 3ProgrammingAssignments(40%grade)
‣ Implementa-on-oriented
‣ ~2weeksperassignment,3“slipdays”forautoma-cextensions
Theseprojectsrequireunderstandingoftheconcepts,abilitytowriteperformantcode,andabilitytothinkabouthowtodebugcomplexsystems.Theyarechallenging,sostartearly!

FinalProject
‣ Finalproject(20%grade)‣ Groupsof3-4preferred,1ispossible.‣ Goodideatotalktorunyourprojectideabymeinofficehoursoremail.
‣ 4pagereport+finalprojectpresenta-on.

OutlineoftheCourse
{Applica-ons:MT,IE,summariza-on,dialogue,etc.
MLandstructuredpredic-onforNLP {NeuralNetworks seman-cs {
tenta-veplan(subjecttochange)

ThisandnextLecture
‣ Linearclassifica-onfundamentals
‣ Threediscrimina-vemodels:logis-cregression,perceptron,SVM
‣ NaiveBayes,maximumlikelihoodingenera-vemodels
‣ Differentmo-va-onsbutverysimilarupdaterules/inference!

Classifica-on

Classifica-on
‣ Embeddatapointinafeaturespace
+++ +
++
++
- - -----
--
‣ Lineardecisionrule:
=[0.5,1.6,0.3]
[0.5,1.6,0.3,1]
x y 2 {0, 1}
f(x) 2 Rn
‣ Datapointwithlabel
butinthislectureandareinterchangeablexf(x)
w>f(x) + b > 0
f(x)‣ Candeletebiasifweaugmentfeaturespace:
w>f(x) > 0

�10

f(x)=[x1,x2,x12,x22,x1x2]f(x)=[x1,x2]
Linearfunc-onsarepowerful!
+++ + + +++
- - - -----
-+++ + + +++
- - - -----
-??
x1
x2
+++ + + +++
- - - -----
-
+++ + + +++
- - - -----
-
x1x2
x1
‣ “Kerneltrick”doesthisfor“free,”butistooexpensivetouseinNLPapplica-ons,trainingisinsteadofO(n2) O(n · (num feats))
h>ps://www.quora.com/Why-is-kernelized-SVM-much-slower-than-linear-SVMh>p://ciml.info/dl/v0_99/ciml-v0_99-ch11.pdf

Classifica-on:Sen-mentAnalysis
thismoviewasgreat!wouldwatchagain
Nega-ve
Posi-ve
thatfilmwasawful,I’llneverwatchagain
‣ Surfacecuescanbasicallytellyouwhat’sgoingonhere:presenceorabsenceofcertainwords(great,awful)
‣ Stepstoclassifica-on:‣ Turnexampleslikethisintofeaturevectors
‣ Pickamodel/learningalgorithm
‣ Trainweightsondatatogetourclassifier

FeatureRepresenta-on
thismoviewasgreat!wouldwatchagain Posi-ve
‣ Convertthisexampletoavectorusingbag-of-wordsfeatures
‣ Requiresindexingthefeatures(mappingthemtoaxes)
[containsthe][containsa][containswas][containsmovie][containsfilm]
0 0 1 1 0
posi-on0 posi-on1 posi-on2 posi-on3 posi-on4
‣ Verylargevectorspace(sizeofvocabulary),sparsefeatures…f(x)=[
…

Whatarefeatures?
‣ Don’thavetobejustbag-of-words
‣Moresophis-catedfeaturemappingspossible(t-idf),aswellaslotsofotherfeatures:charactern-grams,partsofspeech,lemmas,…
f(x)

NaiveBayes

NaiveBayes‣ Datapoint,label
P (y|x) = P (y)P (x|y)P (x)
Bayes’Rule
x = (x1, ..., xn) y 2 {0, 1}‣ Formulateaprobabilis-cmodelthatplacesadistribu-on
P (y|x)‣ Compute,predicttoclassify
P (x, y)
argmaxyP (y|x)

�17

NaiveBayes‣ Datapoint,label
P (y|x) = P (y)P (x|y)P (x)
/ P (y)P (x|y)constant:irrelevantforfindingthemax
= P (y)nY
i=1
P (xi|y)
Bayes’Rule
“Naive”assump-on:condi-onalindependence
x = (x1, ..., xn) y 2 {0, 1}‣ Formulateaprobabilis-cmodelthatplacesadistribu-on
P (y|x)
y
nxi
‣ Compute,predicttoclassify
P (x, y)
argmaxyP (y|x)
argmaxyP (y|x) = argmaxy logP (y|x) = argmaxy
"logP (y) +
nX
i=1
logP (xi|y)#

Whythelog?
�19
‣ Mul-plyingtogetherlotsofprobabili-es
P (y|x) = P (y)P (x|y)P (x)
= P (y)nY
i=1
P (xi|y)
‣ Probabili-esarenumbersbetween0and1
Q: What could go wrong here?

Whythelog?
�20
x log(x)
0.0000001 -16.118095651
0.000001 -13.815511
0.00001 -11.512925
0.0001 -9.210340
0.001 -6.907755
0.01 -4.605170
0.1 -2.302585
‣ Problem—floa-ngpointunderflow
‣ Solu-on:workingwithprobabili-esinlogspace

MaximumLikelihoodEs-ma-on‣ Datapointsprovided(jindexesoverexamples)
‣ Findvaluesofthatmaximizedatalikelihood(genera-ve):P (y), P (xi|y)
(xj , yj)
datapoints(j) features(i)
mY
j=1
P (yj , xj) =mY
j=1
P (yj)
"nY
i=1
P (xji|yj)#
ithfeatureofjthexample

MaximumLikelihoodEs-ma-on‣ Imagineacoinflipwhichisheadswithprobabilityp
mX
j=1
logP (yj) = 3 log p+ log(1� p)
loglikelihood
p0 1
P(H)=0.75
‣ Observe(H,H,H,T)andmaximizelikelihood:mY
j=1
P (yj) = p3(1� p)
‣ Easier:maximizeloglikelihood
h>p://fooplot.com/

�23

�24

MaximumLikelihoodEs-ma-on‣ Imagineacoinflipwhichisheadswithprobabilityp
mX
j=1
logP (yj) = 3 log p+ log(1� p)
loglikelihood
p0 1
P(H)=0.75
‣Maximumlikelihoodparametersforbinomial/mul-nomial=readcountsoffofthedata+normalize
‣ Observe(H,H,H,T)andmaximizelikelihood:mY
j=1
P (yj) = p3(1� p)
‣ Easier:maximizeloglikelihood
h>p://fooplot.com/

MaximumLikelihoodEs-ma-on‣ Datapointsprovided(jindexesoverexamples)
‣ Findvaluesofthatmaximizedatalikelihood(genera-ve):P (y), P (xi|y)
(xj , yj)
datapoints(j) features(i)
mY
j=1
P (yj , xj) =mY
j=1
P (yj)
"nY
i=1
P (xji|yj)#
‣ Equivalenttomaximizinglogarithmofdatalikelihood:mX
j=1
logP (yj , xj) =mX
j=1
"logP (yj) +
nX
i=1
logP (xji|yj)#
ithfeatureofjthexample

MaximumLikelihoodforNaiveBayes
P (great|+) =1
2
P (great|�) =1
4
P (+) =1
2
—
+thismoviewasgreat!wouldwatchagain
thatfilmwasawful,I’llneverwatchagain
—Ididn’treallylikethatmovie
dryandabitdistasteful,itmissesthemark—greatpotenCalbutendedupbeingaflop —
+IlikeditwellenoughforanacConflick
IexpectedagreatfilmandleEhappy ++brilliantdirecCngandstunningvisuals
P (�) =1
2
P (y|x) / P (+)P (great|+)
P (�)P (great|�)[ ] = 1/4
1/8[ ]= 2/3
1/3[ ]itwasgreat
P (great|�) =1
4
P (y|x) / P (y)nY
i=1
P (xi|y)
h>p://socialmedia-class.org/slides_AU2017/Shimodaira_note07.pdf
prior
word likelihood

NaiveBayes:Learning
h>p://socialmedia-class.org/slides_AU2017/Shimodaira_note07.pdf
‣ Learning=es-matetheparametersofthemodel
‣ Priorprobability—P(+)andP(-):‣ frac-onof+(or-)documentsamongalldocuments
‣Wordlikelihood—P(wordi|+)andP(wordi|-):‣ numberof+(or-)documentswordiisobserved,dividebythetotalnumberofdocumentsof+(or-)documents
P (y|x) / P (y)nY
i=1
P (xi|y)
ThisisforBernoulli(binaryfeatures)documentmodel!

ZeroProbabilityProblem
�29
‣Whatifwehaveseennotrainingdocumentwiththeword“fantas-c”andclassifiedinthetopicposi-ve?
‣Wordlikelihood—P(wordi|+)andP(wordi|-):‣ frequencyofwordiisobservedplus1,divideby…
‣ Laplace(add-1)Smoothing

NaiveBayes
�30
‣ Bernoullidocumentmodel:‣ Adocumentisrepresentedbybinaryfeatures‣ Featurevaluebe1ifthecorrespondingwordisrepresentinthedocumentand0ifnot
h>p://socialmedia-class.org/slides_AU2017/Shimodaira_note07.pdf
‣Mul-nominaldocumentmodel:‣ Adocumentisrepresentedbyintegerelements‣ Featurevalueisthefrequencyofthatwordinthedocument‣ SeetextbookandlecturenotebyHiroshiShimodairalinkedbelowformoredetails

NaiveBayes
�31 h>p://socialmedia-class.org/slides_AU2017/Shimodaira_note07.pdf
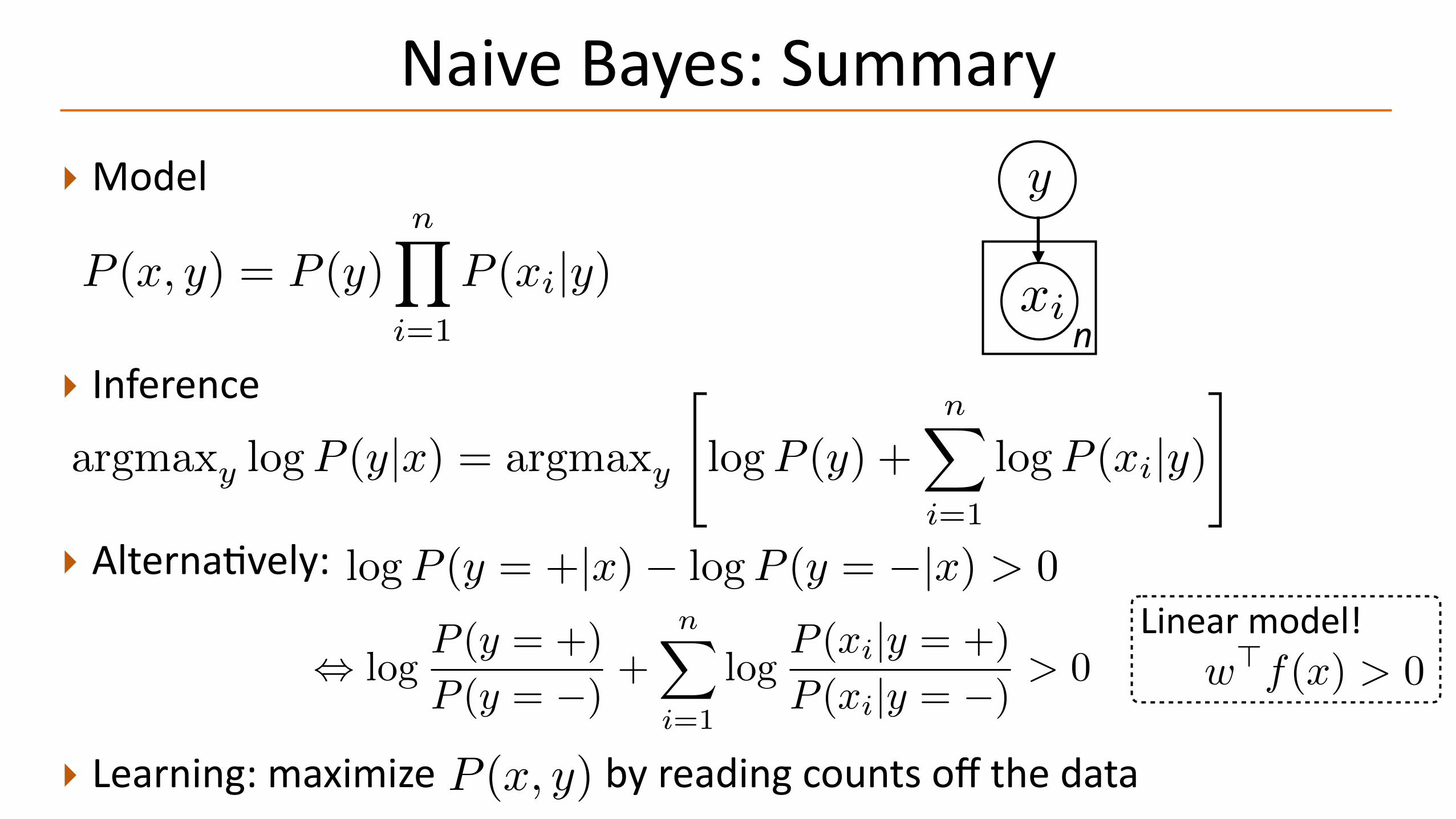
NaiveBayes:Summary
‣Model
P (x, y) = P (y)nY
i=1
P (xi|y)
‣ Learning:maximizebyreadingcountsoffthedata
‣ Inference
P (x, y)
argmaxy logP (y|x) = argmaxy
"logP (y) +
nX
i=1
logP (xi|y)#
‣ Alterna-vely: logP (y = +|x)� logP (y = �|x) > 0
, logP (y = +)
P (y = �)+
nX
i=1
logP (xi|y = +)
P (xi|y = �)> 0
<latexit sha1_base64="FZr/riCBo1+PNx2P5vFNKKQzJnQ=">AAACc3icbZDfTtswFMbdDBhk/CnbJTcWZVIrRJUwJHbDhNgNF1wUiUKlpkSO66QWjh3ZJ2xVlsfbQ+wZuB2XSDhtkSjlSJY/fec78vEvygQ34Hn/as6HpeWVj6tr7qf1jc2t+vbna6NyTVmXKqF0LyKGCS5ZFzgI1ss0I2kk2E1097Pq39wzbbiSVzDO2CAlieQxpwSsFdbD4ILFoHkyAqK1+oUDoRIcxJrQotMcn+y3ysl90CrxPg5MnoYFP/HLWzmf/B3yPy/pqa4mfnhhveG1vUnhReHPRAPNqhPWn4KhonnKJFBBjOn7XgaDgmjgVLDSDXLDMkLvSML6VkqSMjMoJiBK/NU6QxwrbY8EPHFfTxQkNWacRjaZEhiZt73KfK/XzyH+Pii4zHJgkk4finOBQeGKKh5yzSiIsRWEam53xXRELBqw7N25Z4am2m3uI0WWxHbp0nVdy8t/S2dRXB+2/W/tw8ujxunZjNwq2kG7qIl8dIxO0TnqoC6i6C96QP/RY+3R2XF2nb1p1KnNZr6guXIOngEgn75t</latexit>
y
nxi
w>f(x) > 0Linearmodel!

ProblemswithNaiveBayes
‣ NaiveBayesisnaive,butanotherproblemisthatit’sgeneraCve:spendscapacitymodelingP(x,y),whenwhatwecareaboutisP(y|x)
‣ Correlatedfeaturescompound:beauCfulandgorgeousarenotindependent!
thefilmwasbeauCful,stunningcinematographyandgorgeoussets,butboring —P (xbeautiful|+) = 0.1
P (xstunning|+) = 0.1
P (xgorgeous|+) = 0.1
P (xbeautiful|�) = 0.01
P (xstunning|�) = 0.01
P (xgorgeous|�) = 0.01
P (xboring|�) = 0.1P (xboring|+) = 0.01
‣ Discrimina-vemodelsmodelP(y|x)directly(SVMs,mostneuralnetworks,…)

Genera-vevs.Discrimina-veModels
‣ Genera-vemodels:‣ Bayesnets/graphicalmodels‣ Someofthemodelcapacitygoestoexplainingthedistribu-onofx;predic-onusesBayesrulepost-hoc‣ Cansamplenewinstances(x,y)
P (x, y)
P (y|x)‣ Discrimina-vemodels:‣ SVMs,logis-cregression,CRFs,mostneuralnetworks‣Modelistrainedtobegoodatpredic-on,butdoesn’tmodelx
‣We’llcomebacktothisdis-nc-onthroughoutthisclass

Logis-cRegression

Logis-cRegression
‣ Tolearnweights:maximizediscrimina-veloglikelihoodofdataP(y|x)
P (y = +|x) = logistic(w>x)
P (y = +|x) =exp(
Pni=1 wixi)
1 + exp(Pn
i=1 wixi)
L(xj , yj = +) = logP (yj = +|xj)
=nX
i=1
wixji � log
1 + exp
nX
i=1
wixji
!!
sumoverfeatures
P (y = 1|x) � 0.5 , w>x � 0P (y = +|x) = logistic(w>x)‣ Decisionrule:

sumoverfeatures

deriv.ofexp@ex
@x= ex
deriv.oflog@ log x
@x=
1
x
Logis-cRegression
@L(xj , yj)
@wi= xji �
@
@wilog
1 + exp
nX
i=1
wixji
!!
= xji �1
1 + exp (Pn
i=1 wixji)
@
@wi
1 + exp
nX
i=1
wixji
!!
= xji �1
1 + exp (Pn
i=1 wixji)xji exp
nX
i=1
wixji
!
= xji � xjiexp (
Pni=1 wixji)
1 + exp (Pn
i=1 wixji)= xji(1� P (yj = +|xj))
L(xj , yj = +) = logP (yj = +|xj) =nX
i=1
wixji � log
1 + exp
nX
i=1
wixji
!!
@f
@x=
@f
@g
@g
@x=
@f(g)
@g
@g(x)
@x
chainrule:

Logis-cRegression
IfP(+)iscloseto1,makeveryli>leupdateOtherwisemakewilookmorelikexji,whichwillincreaseP(+)
‣ Gradientofwionposi-veexample
‣ Gradientofwionnega-veexample
IfP(+)iscloseto0,makeveryli>leupdateOtherwisemakewilooklesslikexji,whichwilldecreaseP(+)
= xji(�P (yj = +|xj))
= xji(yj � P (yj = +|xj))
‣ Recallthatyj=1forposi-veinstances,yj=0fornega-veinstances.
xj(yj � P (yj = 1|xj))‣ Cancombinethesegradientsas@L(xj , yj)
@wi=

GradientDecent
xj(yj � P (yj = 1|xj))‣ Cancombinethesegradientsas@L(xj , yj)
@wi=
datapoints(j)loglikelihoodofdataP(y|x)
‣ Trainingsetlog-likelihood:
‣ Gradientvector:

GradientDecent
‣ Gradientdecent(orascent)isanitera-veop-miza-onalgorithmforfindingtheminimum(ormaximum)ofafunc-on.
Repeat until convergence {
} learningrate(stepsize)
L
Lmin
L
Lmin
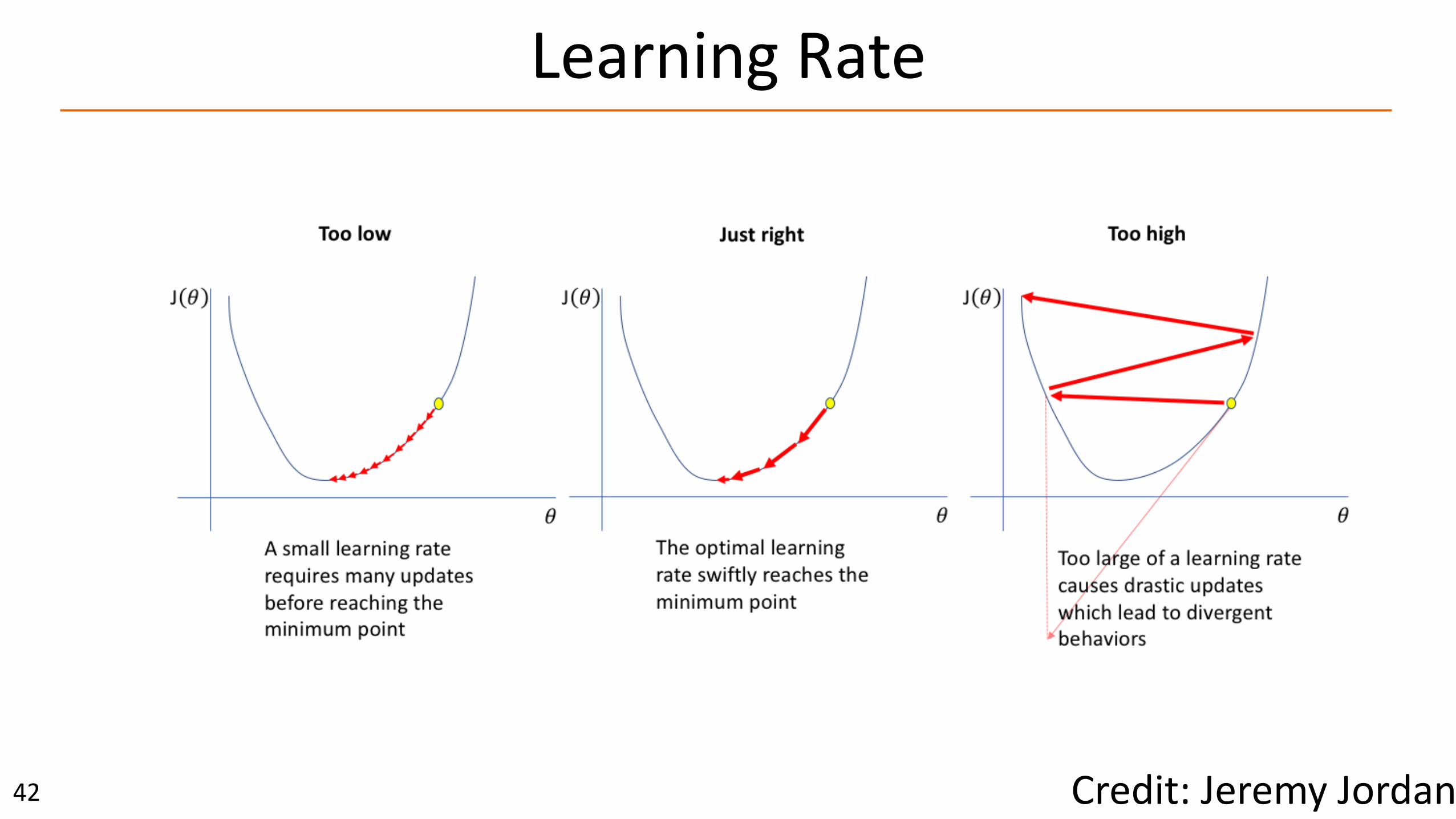
LearningRate
�42 Credit:JeremyJordan

Regulariza-on‣ Regularizinganobjec-vecanmeanmanythings,includinganL2-normpenaltytotheweights: mX
j=1
L(xj , yj)� �kwk22
‣ Keepingweightssmallcanpreventoverfi}ng
‣ FormostoftheNLPmodelswebuild,explicitregulariza-onisn’tnecessary
‣ Earlystopping
‣ Forneuralnetworks:dropoutandgradientclipping‣ Largenumbersofsparsefeaturesarehardtooverfitinareallybadway

Logis-cRegression:Summary
‣Model
‣ Learning:gradientascentonthe(regularized)discrimina-velog-likelihood
‣ Inference
argmaxyP (y|x) fundamentallysameasNaiveBayes
P (y = 1|x) � 0.5 , w>x � 0
P (y = +|x) =exp(
Pni=1 wixi)
1 + exp(Pn
i=1 wixi)

Logis-cRegressionvs.NaiveBayes
‣ Bothare(log)linearmodels
‣ Logis-cregressiondoesn’tassumecondi-onalindependenceoffeatures‣Weightsaretrainedindependently‣ Canhandlehighlycorrelatedoverlappingfeatures
w>f(x) > 0
‣ NaiveBayesassumecondi-onalindependenceoffeatures‣Weightsaretrainedjointly

Perceptron/SVM

Perceptron
‣ Simpleerror-drivenlearningapproachsimilartologis-cregression
‣ Decisionrule:
‣ Guaranteedtoeventuallyseparatethedataifthedataareseparable
‣ Ifincorrect:ifposi-ve,ifnega-ve,
w w + x
w w � x w w � xP (y = 1|x)w w + x(1� P (y = 1|x))
Logis-cRegressionw>x > 0
h>p://ciml.info/dl/v0_99/ciml-v0_99-ch04.pdf
‣ Algorithmisverysimilartologis-cregression

Perceptron
FrankRosenbla>(1928-1971)
PhD1956fromCornell

SupportVectorMachines
‣Manysepara-nghyperplanes—isthereabestone?
+++ +
++
++
- - -----
--

‣Manysepara-nghyperplanes—isthereabestone?
+++ +
++
++
- - -----
-- margin
SupportVectorMachines

‣Manysepara-nghyperplanes—isthereabestone?
+++ +
++
++
- - -----
-- margin
SupportVectorMachines

‣ Constraintformula-on:findwviafollowingquadra-cprogram:
Minimize
s.t.
Asasingleconstraint:
minimizingnormwithfixedmargin<=>maximizingmargin
kwk228j w>xj � 1 if yj = 1
w>xj �1 if yj = 0
8j (2yj � 1)(w>xj) � 1
‣ Generallynosolu-on(dataisgenerallynon-separable)—needslack!
SupportVectorMachines(extracurricular)
h>p://www.cs.toronto.edu/~mbrubake/teaching/C11/Handouts/SupportVectorMachines.pdf

N-SlackSVMs(extracurricular)
Minimize
s.t. 8j (2yj � 1)(w>xj) � 1� ⇠j 8j ⇠j � 0
‣ Thearea“fudgefactor”tomakeallconstraintssa-sfied⇠j
�kwk22 +mX
j=1
⇠j
‣ Takethegradientoftheobjec-ve:@
@wi⇠j = 0 if ⇠j = 0
@
@wi⇠j = (2yj � 1)xji if ⇠j > 0
= xji if yj = 1, �xji if yj = 0
‣ Looksliketheperceptron!Butupdatesmorefrequentlyh>p://www.cs.toronto.edu/~mbrubake/teaching/C11/Handouts/SupportVectorMachines.pdf

LR,Perceptron,SVM(extracurricular)
Logis-cregression
Perceptron
x(1� P (y = 1|x)) = x(1� logistic(w>x))
x if w>x < 0, else 0
SVM(ignoringregularizer)
Hinge(SVM)
Logis-cPerceptron
0-1
Loss
w>x
*gradientsareformaximizingthings,whichiswhytheyareflipped
x if w>x < 1, else 0
‣ GradientsonPosi-veExamples
h>p://ciml.info/dl/v0_99/ciml-v0_99-ch07.pdf

Sen-mentAnalysis
BoPang,LillianLee,ShivakumarVaithyanathan(2002)
themoviewasgrossandoverwrought,butIlikedit
thismoviewasgreat!wouldwatchagain
‣ Bag-of-wordsdoesn’tseemsufficient(discoursestructure,nega-on)
thismoviewasnotreallyveryenjoyable
‣ Therearesomewaysaroundthis:extractbigramfeaturefor“notX”forallXfollowingthenot
++
—

Sen-mentAnalysis
‣ Simplefeaturesetscandopre>ywell!
BoPang,LillianLee,ShivakumarVaithyanathan(2002)
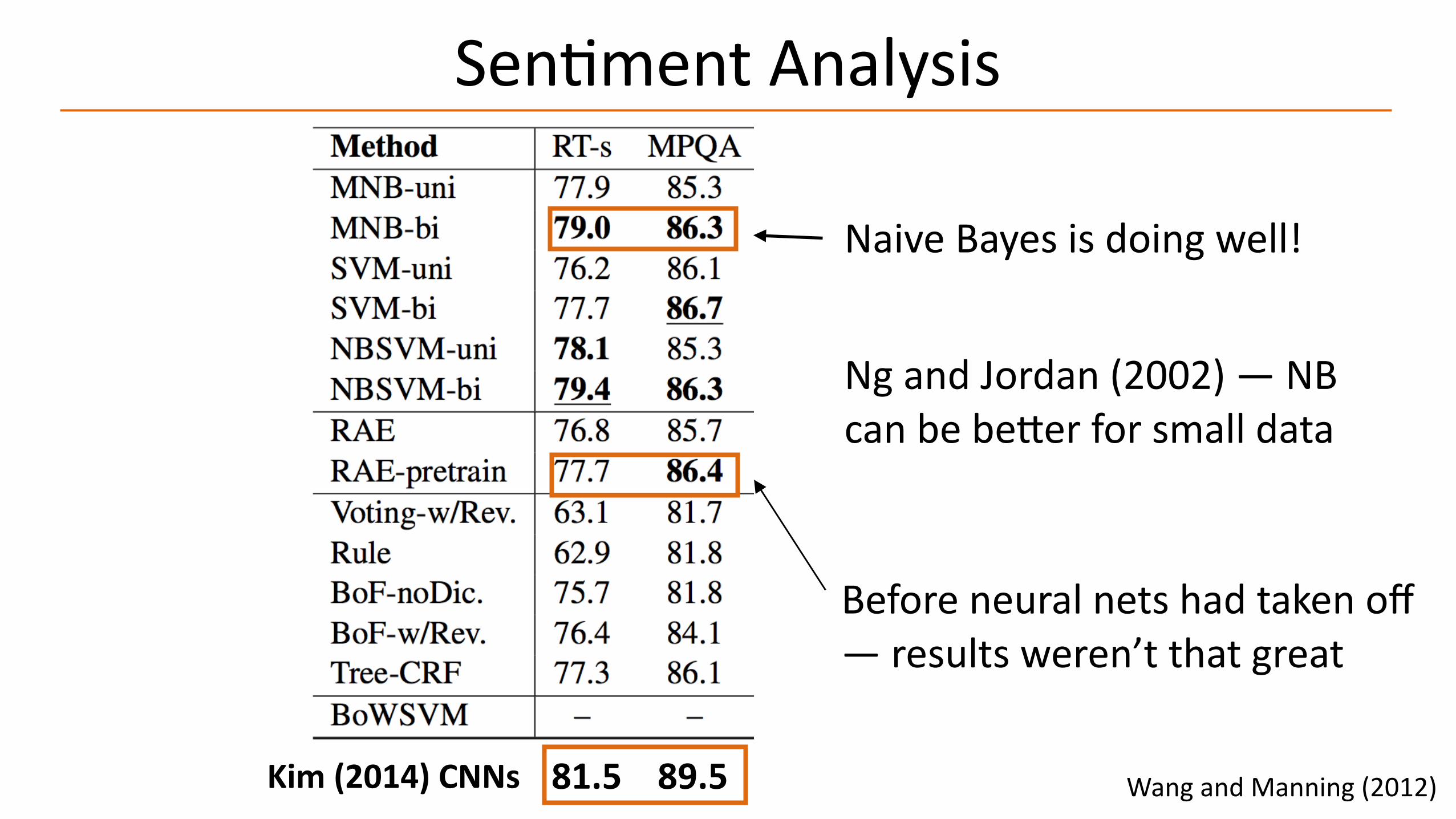
Sen-mentAnalysis
WangandManning(2012)
Beforeneuralnetshadtakenoff—resultsweren’tthatgreat
NaiveBayesisdoingwell!
NgandJordan(2002)—NBcanbebe>erforsmalldata
81.589.5Kim(2014)CNNs

Recap
‣ Logis-cregression: P (y = 1|x) =exp (
Pni=1 wixi)
(1 + exp (Pn
i=1 wixi))
Gradient(unregularized):
‣ Logis-cregression,perceptron,andSVMarecloselyrelated
Decisionrule: P (y = 1|x) � 0.5 , w>x � 0
x(y � P (y = 1|x))
‣ Allgradientupdates:“makeitlookmoreliketherightthingandlesslikethewrongthing”

Op-miza-on—next…
‣ Rangeoftechniquesfromsimplegradientdescent(workspre>ywell)tomorecomplexmethods(canworkbe>er),e.g.,Newton’smethod,Quasi-Newtonmethods(LBFGS),Adagrad,Adadelta,etc.
‣Mostmethodsboildownto:takeagradientandastepsize,applythegradientupdate-messtepsize,incorporatees-matedcurvatureinforma-ontomaketheupdatemoreeffec-ve

QATime
�60