big data introduction - arrow ecs€¦ · title: hadoop deep dive author: dan mcclary created date:...
TRANSCRIPT

1 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Big Data Introduction
Ralf Lange
Global ISV & OEM Sales
2 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
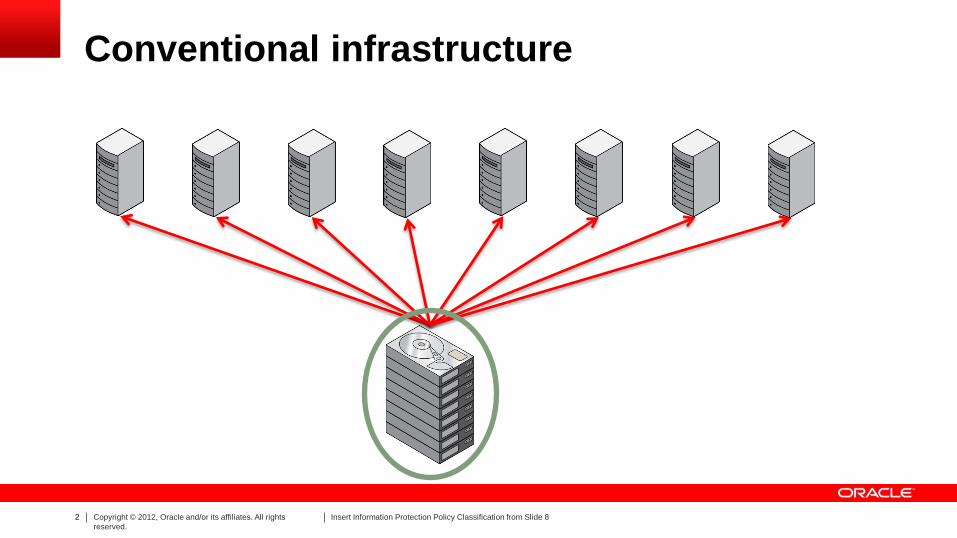
Conventional infrastructure
3 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
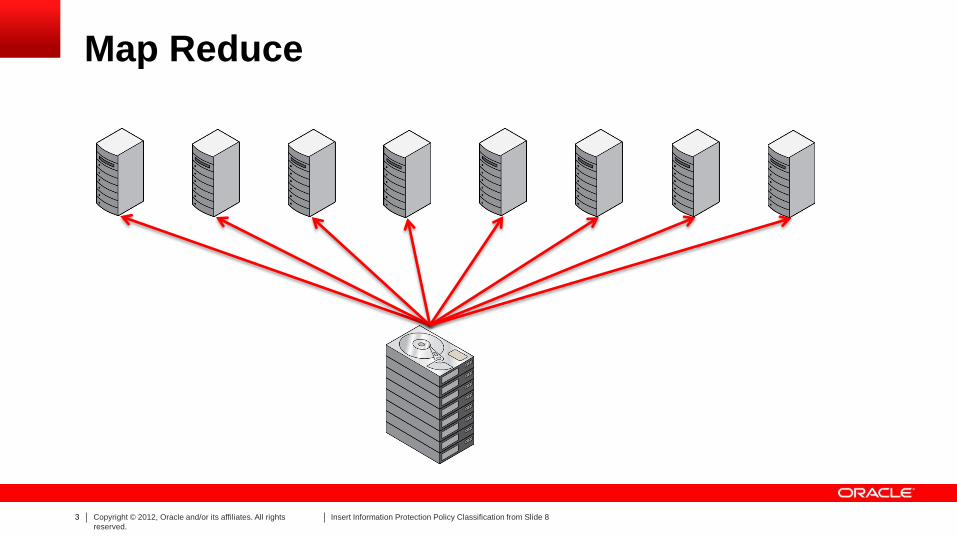
Map Reduce

4 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
In Actuality

5 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
What is Map Reduce
[ , , , , , ]
, , , , , [ ]
6 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
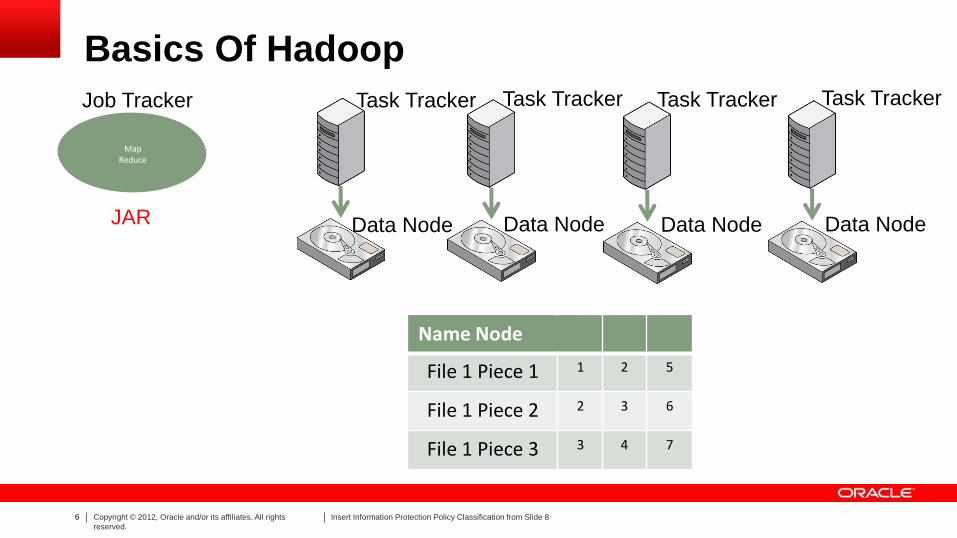
Basics Of Hadoop
In Memory
File 1 Piece 1 1
File 1 Piece 2 2
File 1 Piece 3 3
2 5
3 6
4 7
Name Node
Data Node Data Node Data Node Data Node JAR
Map Reduce
Map Reduce
Map Reduce
Map Reduce
Job Tracker Task Tracker Task Tracker Task Tracker Task Tracker
7 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
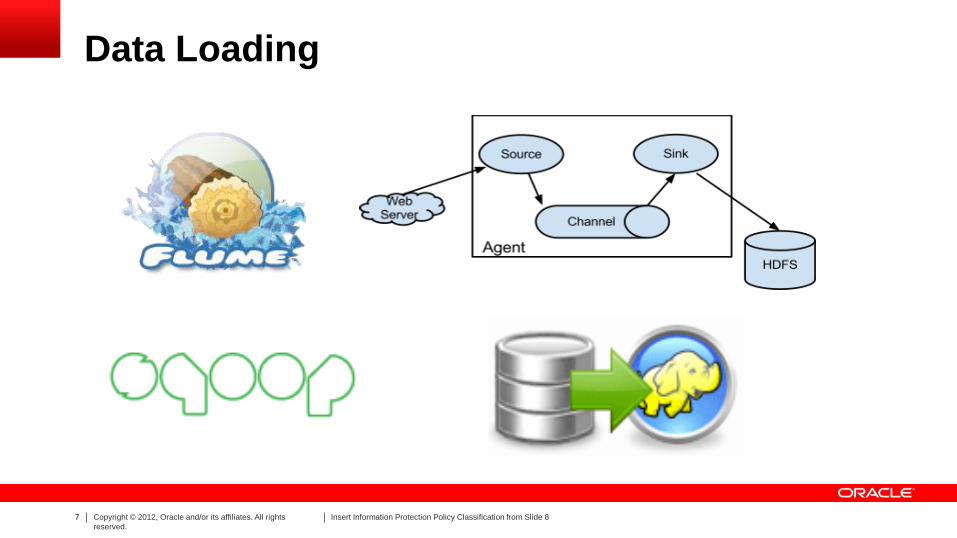
Data Loading
8 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
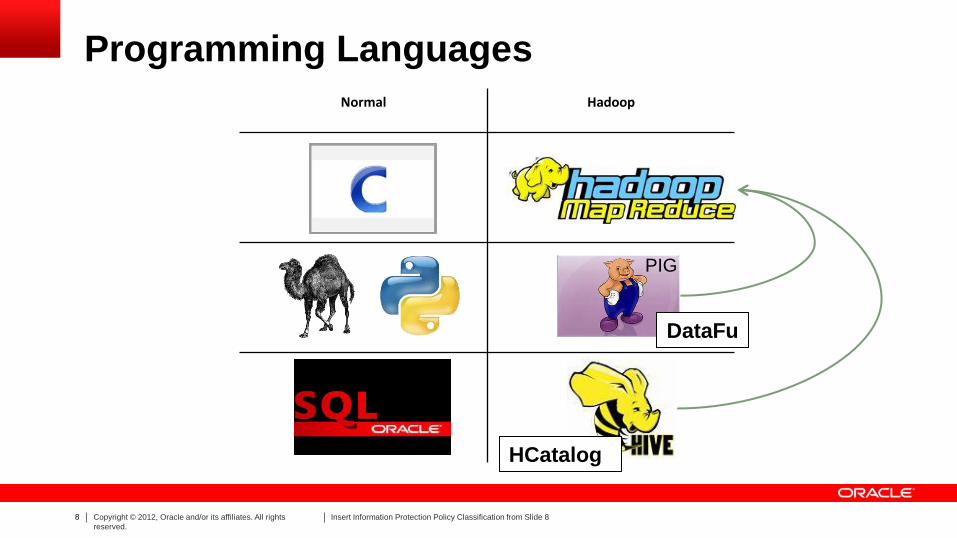
Programming Languages
Normal Hadoop
HCatalog
PIG
DataFu

9 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Management
Thread 2
Thread 1
Process 2
Process 1
ZooKeeper

10 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
GUIs

11 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Similar to Oracle

12 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Big Data @ Oracle

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 13
Oracle Big Data Solution
Oracle BI Foundation Suite
Oracle Real-Time Decisions
Endeca Information Discovery
Decide
Oracle
Advanced
Analytics
Oracle
Database
Oracle
Spatial
& Graph
Acquire – Organize – Analyze
Oracle Big Data Connectors
Oracle Data Integrator
Stream
Oracle Event Processing
Apache Flume
Oracle GoldenGate
Oracle
NoSQL
Database
Cloudera
Hadoop
Oracle R
Distribution
Scalable key-value store
Scalable, low-cost data storage
and processing engine
Statistical analysis framework

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 14
Massive detail data
Big batch jobs
Unifying data sources Many data marts merged in
Hadoop to provide
unified views of data
Long running batch jobs can run
in Hadoop to make the most of
the DB
Store more raw detail data for
less cost, while keeping
aggregates in the DB
Big Data ≠ Unstructured Data

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 15
Big Data ≈ Hadoop
Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 16
Hadoop Can Be Confusing

17 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
What is Hadoop?

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 18
Hadoop
The Apache Hadoop software library is a framework that allows for the
distributed processing of large data sets across clusters of computers
using simple programming models. Hadoop is designed to scale up from
single servers to thousands of machines, each offering local
computation and storage. Rather than rely on hardware to deliver high-
availability, the library itself is designed to detect and handle failures at
the application layer, so delivering a highly-available service on top of a
cluster of computers, each of which may be prone to failures.
Framework for distributed processing
Large Data Sets
Clusters of Computers
Simple Computing Models
Highly Available Service

19 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
What to Pay Attention To
Distributed Storage
– HDFS
Parallel Processing Framework
– MapReduce
Higher-Level Languages
– Hive
– Pig
– Etc.

20 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
HDFS The Distributed Filesystem
What is it?
Benefits
Limitations
The petabyte-scale distributed file system at
the core of Hadoop.
Linearly-scalable on commodity hardware
An order of magnitude cheaper per TB
Designed around schema-on-read
Low security
Write-once, read-many model

21 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Interacting with HDFS
NameNodes and DataNodes
– NameNodes contain edits and organization
– DataNodes store data
Command-line access resembles UNIX filesystems
– ls (list)
– cat, tail (concatenate or tail file)
– cp, mv (copy or move within HDFS)
– get, put (copy between local file system and HDFS)

22 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
HDFS Mechanics
DataNode
DataNode DataNode
DataNode DataNode
DataNode
Suppose we have a large file
And a set of DataNodes

23 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
HDFS Mechanics
DataNode
DataNode DataNode
DataNode DataNode
DataNode
• The file will be broken up into blocks
• Blocks are stored in multiple locations
• Allows for parallelism and fault-tolerance
• Nodes operate on their local data
24 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
MapReduce The Parallel Processing Framework
What is it?
Benefits
Limitations
The parallel processing framework that
dominates the Big Data landscape.
Provides data-local computation
Fault-tolerant
Scales just like HDFS
You are the optimizer
Quasi-functional model is counterintuitive
Batch-oriented
25 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
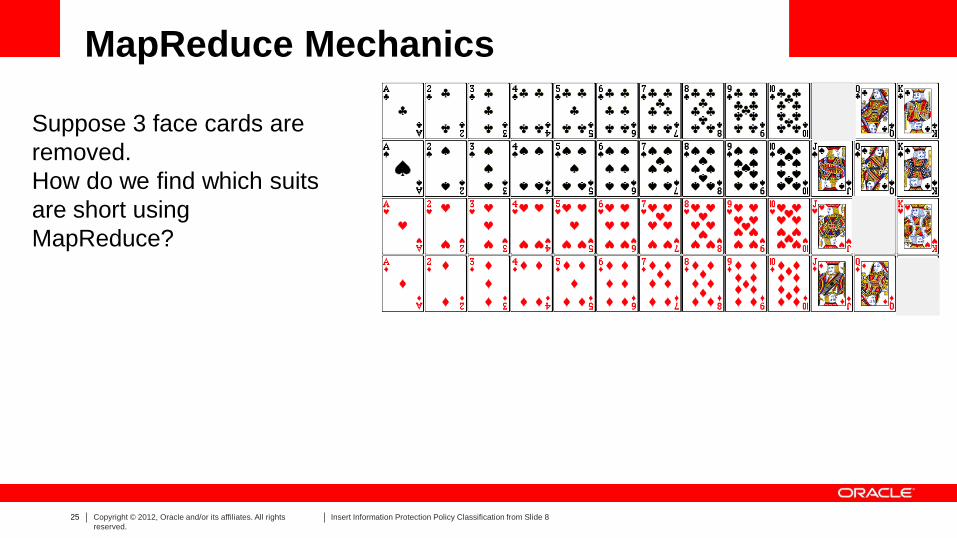
MapReduce Mechanics
Suppose 3 face cards are
removed.
How do we find which suits
are short using
MapReduce?

26 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
MapReduce Mechanics
Map Phase:
Each TaskTracker has some data local to it.
Map tasks operate on this local data.
If face_card: emit(suit, card)
TaskTracker/DataNode
TaskTracker/DataNode
TaskTracker/DataNode
TaskTracker/DataNode

27 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
MapReduce Mechanics
Shuffle/Sort:
Intermediate data is shuffled and sorted for delivery to the reduce tasks
Sort
To Reducers
28 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
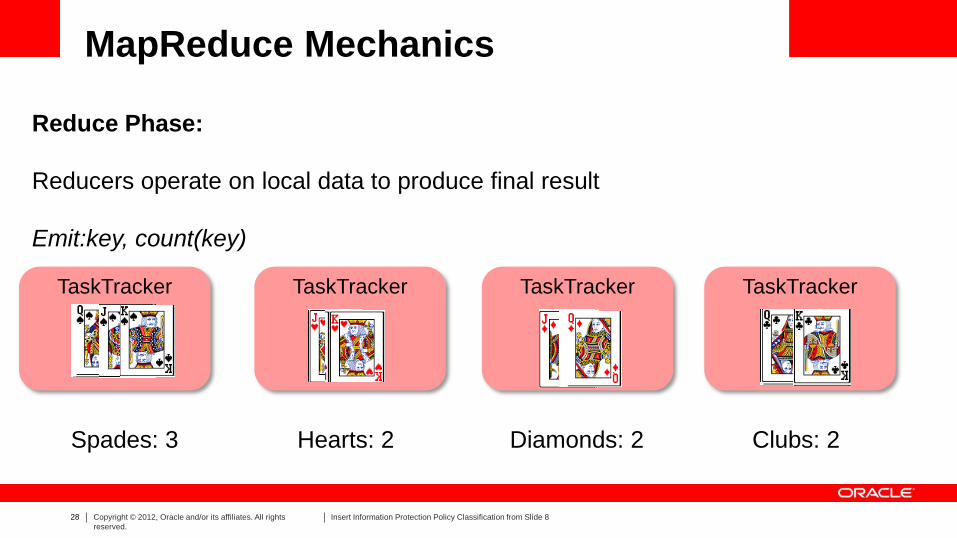
MapReduce Mechanics
Reduce Phase:
Reducers operate on local data to produce final result
Emit:key, count(key)
TaskTracker TaskTracker TaskTracker TaskTracker
Spades: 3 Hearts: 2 Diamonds: 2 Clubs: 2

29 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Hive A move toward declarative language
What is it?
Benefits
Limitations
A SQL-like language for Hadoop.
Abstracts MapReduce code
Schema-on-read via InputFormat and SerDe
Provides and preserves metatdata
Not ideal for ad hoc work (slow)
Subset of SQL-92
Immature optimizer

30 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Storing a Clickstream
Storing large amounts of
clickstream data is a
common use for HDFS
Individual clicks aren’t
valuable by them selves
We’d like to write queries
over all clicks

31 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Defining Tables Over HDFS
Hive allows us to define
tables over HDFS
directories
The syntax is simple SQL
SerDes allow Hive to
deserialize data

32 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
How Does It Work Anatomy of a Hive Query
SELECT suit, COUNT(*)
FROM cards
WHERE face_value > 10
GROUP BY suit;
How does Hive execute
this query?

33 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Anatomy of a Hive Query
SELECT suit, COUNT(*)
FROM cards
WHERE face_value > 10
GROUP BY suit;
1. Hive optimizer builds a MapReduce Job
2. Projections and predicates
become Map code
3. Aggregations become Reduce code
4. Job is submitted to
MapReduce JobTracker
Map task If face_card:
emit(suit, card)
Reduce task emit(suit,
count(suit)) Shu
ffle

34 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Using Hadoop To Optimize
IT

35 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Big Data and Optimized Operations
• Big Data can handle a lot of heavy lifting
– It’s a complement to the database
• Big Data allows access to more detail data for less
• We can use Big Data to make the database do more
Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 36
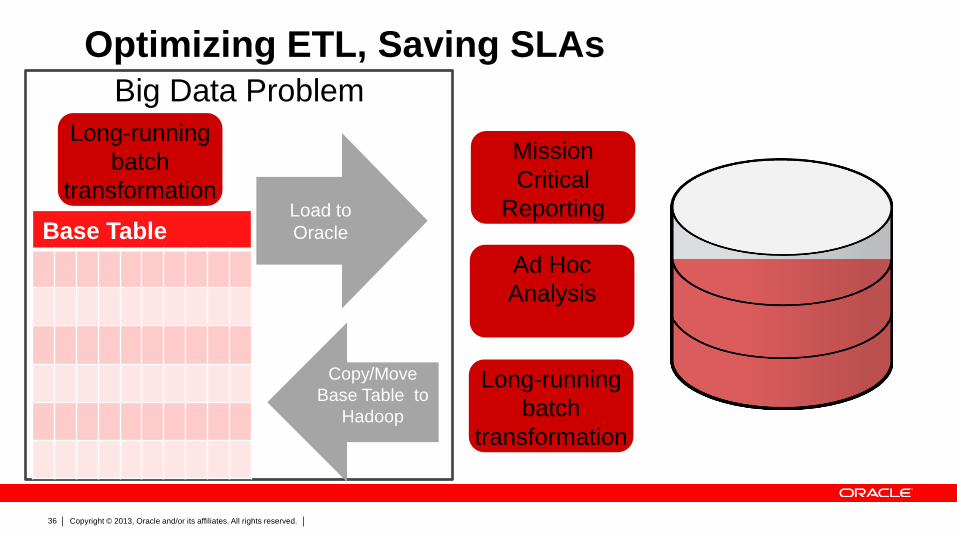
Optimizing ETL, Saving SLAs
Mission
Critical
Reporting
Ad Hoc
Analysis
Long-running
batch
transformation
Big Data Problem
Base Table
Copy/Move
Base Table to
Hadoop
Load to
Oracle
Long-running
batch
transformation

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 37
Big Data Problem
Store More Details For Less
Base Table
Aggregation
Reporting Table
External Table or Aggregate on Hadoop

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 38
Using Hadoop To Build New Datasets

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 39
What Does a Big Data World Look Like? Truck / Motor Manufacturer
Collections Internal sensors
Miles Per Gallon, Driving
techniques
Location information
Uses Better tailored servicing plans
Better targeted marketing
Offer better finance deals or related
options
More data for R&D
Sell on to partners

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 40
Big Data and Analytics
Big Data does not make analytics easier
– There is no magic bullet
Some things work better in a database
Big Data allows the collection of new datasets
Big Data allows modeling on a more granular level

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 41
No Magic Bullets
Food monitoring by RFID tags Fridge monitors food
usage and sell-by dates
Monitor the complete car Better targeted marketing
There is a gap between
– The available dataset
– The value proposition
Big Data helps bridge the gap

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 42
Some Things Work Better in RDBMS
•Time Series
Analysis
•Spatial Analysis
•Linear and
Nonlinear Modeling
•Interaction with
SAS and R
•Clustering on
massive data
•Fine-grained
classification
•Dataset
construction
•Deploying models
on many subgroups

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 43
Collecting New Datasets The Complete Car
Minute-by-
minute
MPH
GPS
Readings
On-board
Vehicle
Diagnostics
How does the
customer
drive?
Where does
the customer
drive?
How do we
maximize their
value?
Trip
(Location and
Speed)
Vehicle Usage
Report
Big Data Problem

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 44
More Granular Modeling Testing Trip Dynamics
Analyst
New Model for
Maintenance
Alerts
Test and
Summarize
On All Engine
Readings
Aggregated
Test
Results
Big Data Problem

Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 45
Fitting Fat Tails Modeling “outlying” customers
Analyst
Significant
value may exist
in the tails
Parallelized
Locally-
weighted
Linear
Regression
Model for all
data
Big Data Problem

46 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8
Q&A

47 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8

48 Copyright © 2012, Oracle and/or its affiliates. All rights
reserved.
Insert Information Protection Policy Classification from Slide 8