best practices for building open source data layers
TRANSCRIPT

© 2016 IBM Corporation
Christopher BienkoWorldwide Technical Sales – Cloud Data [email protected]
August 15, 2016
Best Practices for Building Open Source Data Layers

Compose is for … Builders
IBM Compose Platform

The Compose Open Source Stack
§ A managed platform for open source databases-as-a-service
-Provision services individually via Multi-tenant: deploy in minutes, scale enormously, develop effortlessly
-Reserved infrastructure for production via Enterprise: guaranteed SLA, à la carte licensing to the entire Compose catalogue
IBM Compose Platform

q Open Source Enables Open Architectures–Avoid vendor lock-in–Community-driven projects leading the industry–Cut licensing fees & operationalize hardware costs
q The Database Dilemma: Scoping is Hardq The Infrastructure Quandary: Scaling is Harderq Repeatable Deployments for Standardized Workflow
Data Layer Requirements

The Compose Open Source Stack
IBM Compose Platform
Key-Value Database for
Distributed DBs
etcd
NoSQL (BSON)Document DB
MongoDB
Data Caching Key-Value DB
Redis
Scalable JSON Database for
Real-Time Apps
RethinkDB
Asynchronous Messaging Layer
RabbitMQ
Extensible and Secure Object Relational DB
PostgreSQL
Full-Text Search Indexing Engine
Elasticsearch

The Compose Open Source Stack
IBM SoftLayer Amazon AWS
Compose services are deployable to
both SoftLayerand AWS
Available on SoftLayer as:§ IBM-Managed service§ Public Multi-Tenant
Available on AWS as:§ IBM-Managed service§ Self-Hosted service§ Public Multi-Tenant
IBM Compose Platform
MongoDB Redis Elasticsearch PostgreSQL RethinkDB RabbitMQ etcd
* Self-Hosted services coming soon

The Database Dilemma – What to Choose?
§ Developers that discover the Compose platform are often already using 2–4 of these databases & services in their stack-On-premises or private/public cloud
§ “Have I deployed and configured my services the right way?”
IBM Compose Platform
MongoDB Redis Elasticsearch PostgreSQL RethinkDB RabbitMQ etcd
If you are using one of these, very likely you are building or experimenting with others.
New technologies add to larger architectures, but few will start a project with these alone.

q Open Source Enables Open Architectures
q The Database Dilemma: Scoping is Hard–Selecting the appropriate database on the first attempt is rare–Use cases evolve over time…as do database requirements–Platform services need to be as flexible as your workloads
q The Infrastructure Quandary: Scaling is Harderq Repeatable Deployments for Standardized Workflow
Data Layer Requirements
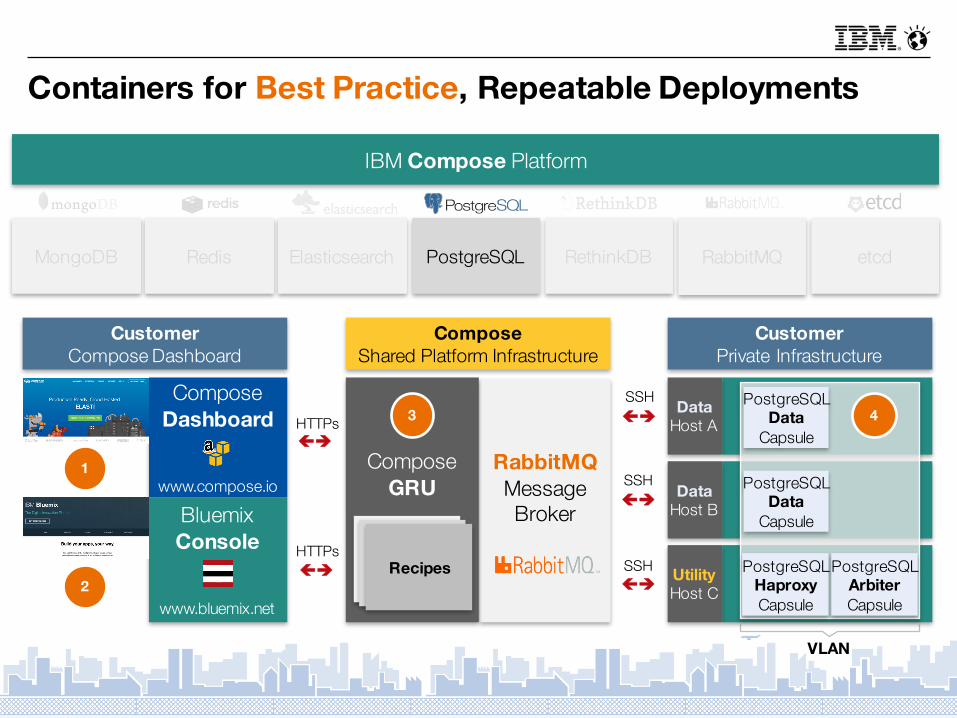
Containers for Best Practice, Repeatable Deployments
IBM Compose Platform
MongoDB Redis Elasticsearch RethinkDB RabbitMQ etcd
Customer Private Infrastructure
ComposeShared Platform Infrastructure
CustomerCompose Dashboard
çèSSH Data
Host A
Data Host B
Utility Host C
PostgreSQLData
Capsule
PostgreSQLData
Capsule
PostgreSQLHaproxyCapsule
PostgreSQLArbiterCapsule
VLAN
çè
çè
SSH
SSH
RabbitMQMessage Broker
ComposeGRU
Recipes
ComposeDashboard
www.compose.io
BluemixConsole
www.bluemix.net2
1
çèHTTPs
çèHTTPs
3 4
PostgreSQL

Compose Platform – 3 Consumption Models
§ Compose Enterprise-For those needing à la carte access to the complete Compose catalogue-Dynamically mix & match, scale & deploy new combinations of Compose-Self-Hosted for those already managing their own virtual private cloud-IBM-Managed takes care of both infrastructure and Compose licensing
IBM Compose Platform
Self-HostedCompose Enterprise
Multi-TenantCompose Public
IBM-ManagedCompose Enterprise
Reserved, SLA-governed Enterprise infrastructure for unlimited licensing of the full Compose catalogue.
Individual services for PAY-GO consumption.

q Open Source Enables Open Architecturesq The Database Dilemma: Scoping is Hard
q The Infrastructure Quandary: Scaling is Harder–Compose services scale elastically and without downtime–Onboard new databases as your platform architecture matures–Reserve enterprise-grade infrastructure that’s managed for you
q Repeatable Deployments for Standardized Workflow
Data Layer Requirements

Simplify Infrastructure Across 3 Configurations & 1 Bill
IBM Compose Platform
Self-HostedCompose Enterprise
Multi-TenantCompose Public
IBM-ManagedCompose Enterprise
Starter16 GB RAM
Transactional64 GB RAM
Large Transactional256 GB RAM
IBM-Managed Compose Enterprise supports three (3) infrastructure configurations.
AWS Only
SL & AWS
SL & AWS

Evolve Composition of Enterprise Services on the Fly
IBM Compose Platform
Self-HostedCompose Enterprise
Multi-TenantCompose Public
IBM-ManagedCompose Enterprise
Starter16 GB RAM
Transactional64 GB RAM
Large Transactional256 GB RAM
AWS Only
SL & AWS
SL & AWS
MongoDB640GB SSD, 64GB RAM Elasticsearch
320GB SSD, 32GB RAMRedis
16GB RAM
Elasticsearch160GB SSD, 16GB RAM
MongoDB320GB SSD, 32GB RAM
MongoDB320GB SSD, 32GB RAM
OR OR
IBM-Managed Compose Enterprise supports three (3) infrastructure configurations.

q Open Source Enables Open Architecturesq The Database Dilemma: Scoping is Hardq The Infrastructure Quandary: Scaling is Harder
q Repeatable Deployments for Standardized Workflow–Services consistently deployed to best-practice configuration–SLA, 3-node HA, automated backups, at-rest encryption–Fully-managed infrastructure & elastically scalable databases
Data Layer Requirements

Building a VR Data Layerwith Compose and IBM

Building a VR Data Layer
§ Selecting the appropriate databases and services in support of a Virtual Reality (VR) headset data layer is complex
§ Multiple requirements with no one-size-fits-all solution:1. Games played with the headset need a responsive, flexible database2. In-store and in-game purchases rely upon dependable record keeping3. Insight into customers and players requires reporting and analytics4. VR headsets generate a wealth of sensor data, demanding streaming
capabilities to ingest the data and big data tools to transform it
Games Micro-transactions Analytics Sensors

Building a VR Data Layer
MongoDB PostgreSQL MySQL(Beta)
Cloudant
Redis
Streams
Elasticsearch
dashDB for Transactions
dashDB for Analytics
Analytics, reporting, and
data visualization
In memory cachingand near/real-time streaming analytics
Transactional data, strongly consistent, systems of record
Operational data, eventually consistent,mobile applications
Apache Spark
DB2 on Cloud
ScyllaDB(Beta)
ComposeServices
IBM CDSServices
Games Micro-transactions Analytics Sensors
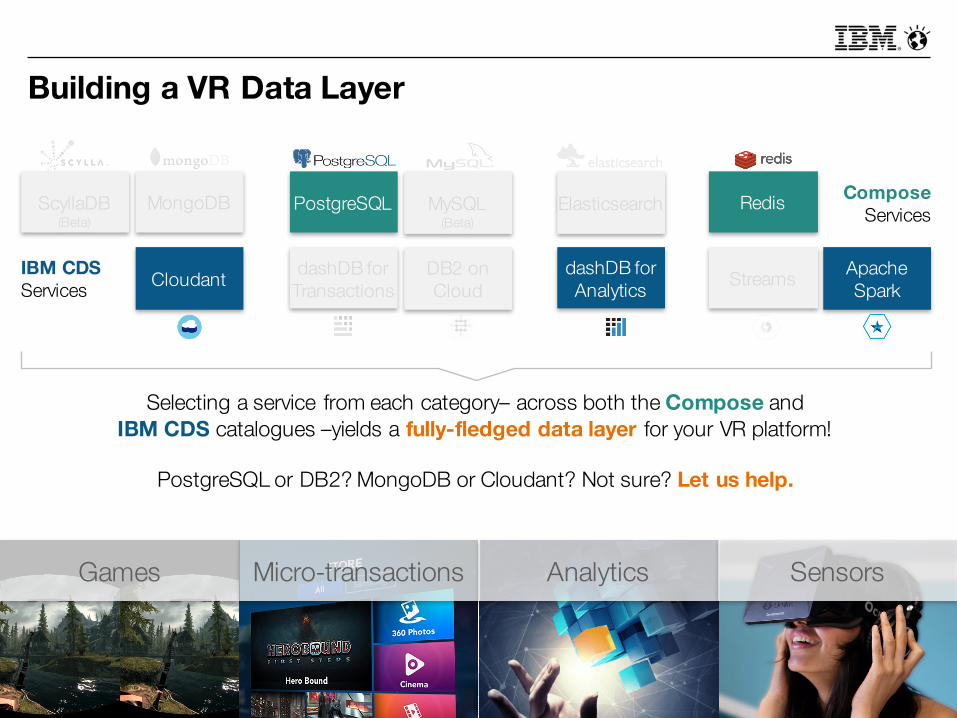
Building a VR Data Layer
MongoDB PostgreSQL MySQL(Beta)
Cloudant
Redis
Streams
Elasticsearch
dashDB for Transactions
dashDB for Analytics
Apache Spark
DB2 on Cloud
ScyllaDB(Beta)
ComposeServices
IBM CDSServices
Games Micro-transactions Analytics Sensors
Selecting a service from each category– across both the Compose and IBM CDS catalogues –yields a fully-fledged data layer for your VR platform!
PostgreSQL or DB2? MongoDB or Cloudant? Not sure? Let us help.
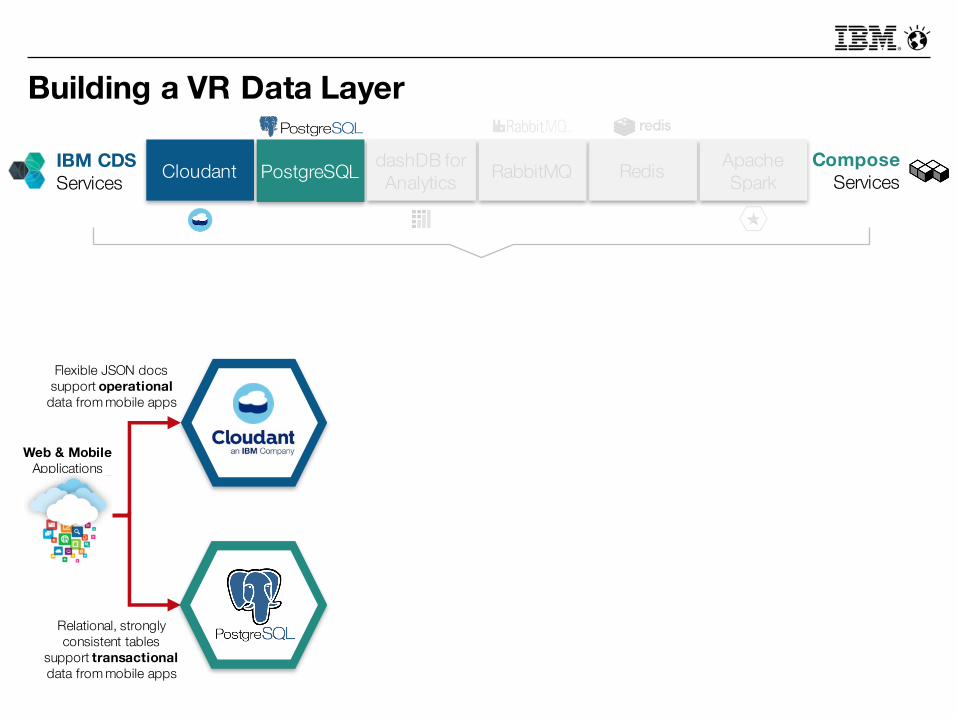
Building a VR Data Layer
PostgreSQLCloudant dashDB for Analytics
ComposeServices
IBM CDSServices
Web & MobileApplications
Flexible JSON docs support operational
data from mobile apps
Relational, strongly consistent tables
support transactionaldata from mobile apps
Apache SparkRabbitMQ Redis

Building a VR Data Layer
PostgreSQLCloudant dashDB for Analytics
ComposeServices
IBM CDSServices
dashDB
Schema Discovery
Schema Discovery applies structure to
unstructured JSON data for reporting & analytics
Web & MobileApplications
Flexible JSON docs support operational
data from mobile apps
Relational, strongly consistent tables
support transactionaldata from mobile apps
Apache SparkRabbitMQ Redis

RabbitMQ
Building a VR Data Layer
PostgreSQLCloudant dashDB for Analytics
ComposeServices
IBM CDSServices
dashDB
Schema Discovery
Schema Discovery applies structure to
unstructured JSON data for reporting & analytics
Web & MobileApplications
SlackDevOps & Support
RabbitMQ notifies DevOps team’s Slack #channel when a mobile app’s micro-transactions hit a new milestone
AMQP
Flexible JSON docs support operational
data from mobile apps
Relational, strongly consistent tables
support transactionaldata from mobile apps
RedisRabbitMQ Apache Spark
RabbitMQ
Redis
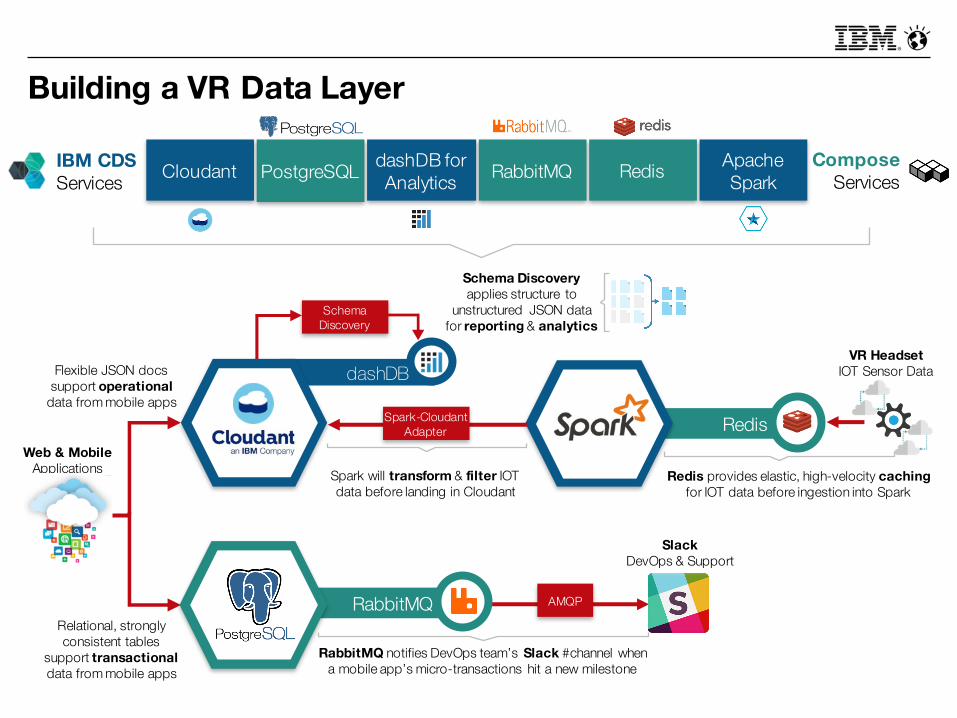
Building a VR Data Layer
PostgreSQLCloudant dashDB for Analytics
ComposeServices
IBM CDSServices
dashDB
Schema Discovery
Schema Discovery applies structure to
unstructured JSON data for reporting & analytics
Web & MobileApplications
VR HeadsetIOT Sensor Data
Spark will transform & filter IOT data before landing in Cloudant
Spark-Cloudant Adapter
SlackDevOps & Support
RabbitMQ notifies DevOps team’s Slack #channel when a mobile app’s micro-transactions hit a new milestone
AMQP
Redis provides elastic, high-velocity cachingfor IOT data before ingestion into Spark
Flexible JSON docs support operational
data from mobile apps
Relational, strongly consistent tables
support transactionaldata from mobile apps
RabbitMQ Apache SparkRedis

© 2016 IBM Corporation
Christopher BienkoWorldwide Technical Sales – Cloud Data [email protected]
August 15, 2016
Want to find out more?Watch the webinar:
http://ibm.biz/BdrNVR