basi di dati - nuovescuole.com · basi di dati classe v 1 ... dati e possono essere memorizzati su...
TRANSCRIPT

ISTITUTO TECNICO COMMERCIALE INDIRIZZO PROGRAMMATORI
APPUNTI DI
BASI DI DATI
Classe V
1

“E' meglio accendere una piccola candela che
maledire l'oscurità”
(Confucio)
2

INDICE
PREFAZIONE.....................................................................................................................................….....................5
1. Gli archivi....................................................................................................................…........................................6
1.1. Definizione di archivio............................................................................................................... .................................6
1.2. Definizione di record.....................................................……………….......................................................................8
1.3. Sistema informativo o sistema informatico?.................................................................................................................9
1.4. Operazioni sugli archivi................................................................................................................................................9
1.5. La memorizzazione degli archivi..................................................................................................................................9
1.6. Supporti di memorizzazione degli archivi..................................................................................................................11
1.7. Gli archivi e il file system...........................................................................................................................................15
1.8. Organizzazione degli archivi......................................................................................................................................17
1.8.1. Apertura e chiusura di un file...................................................................................................................................17
1.8.2. Organizzazione ad accesso sequenziale...................................................................................................................18
1.8.3. Organizzazione ad accesso diretto...........................................................................................................................19
1.8.4. Organizzazione sequenziale ad indici......................................................................................................................21
2. Il progetto informatico...........................................................................................…........................................25
2.1. Le fasi della progettazione.......................................................................................................... ...............................25
2.1.1 Analisi del problema ..................................................……………….....................................................................26
2.1.2. Progettazione...........................................................................................................................................................26
2.1.3. Realizzazione...........................................................................................................................................................27
2.1.4. Documentazione, Prove e Formazione ...................................................................................................................27
2.1.5. Produzione...............................................................................................................................................................27
3. I database (basi di dati)............................................................................................…......................................28
3.1. I limiti degli archivi tradizionali…............................................................................................... .............................28
3.2. Il DBMS........................................................................……………….....................................................................30
4. Il modello concettuale............................................................................................….........................................31
4.1. La progettazione concettuale e il modello Entità-Relazione (E/R).......................................................................... ..31
4.2. Attributi........................................................................……………….......................................................................32
4.3. Ancora sulla chiave primaria.................................………………..............................................................................33
4.4. Associazioni..........................................................………………..............................................................................33
4.4. I vincoli di integrità..............................................………………..............................................................................37
3

5. Il modello logico: il modello relazionale........................................................….........................................38
5.1. Introduzione............................................................................................................................................................ ..38
5.2. Regole di derivazione del modello logico:le entità......……………….......................................................................39
5.3. Regole di derivazione del modello logico:le associazioni.......……….......................................................................41
5.4. Rappresentazione degli attributi composti..............………………............................................................................47
5.5. Rappresentazione degli attributi multivalore................…………..............................................................................48
5.6. Rappresentazione dei vincoli di integrità..............................……..............................................................................49
5.7. Da cosa deriva il termine “modello relazionale”?..................……............................................................................52
5.8. Operatori relazionali..................…….........................................................................................................................54
5.8.1. Operazione di selezione..........…….........................................................................................................................54
5.8.2. Operazione di proiezione........…….........................................................................................................................55
5.8.3. Selezione e proiezione.............................................................................................................................................56
5.8.4. Operazione di unione, intersezione e differenza......................................................................................................57
5.8.5. Operazione di join (giunzione)...............…….........................................................................................................59
5.9. La normalizzazione...............……..............................................................................................................................63
5.9.1. La prima forma normale (1FN)...............…….........................................................................................................??
5.9.2. La seconda forma normale (2FN)..........……..........................................................................................................??
5.9.3. La terza forma normale (3FN)...............……..........................................................................................................??
4

PREFAZIONEQuesti appunti ricalcano parte delle lezioni svolte a scuola. Essi non costituiscono
documentazione sostitutiva del libro di testo né delle lezioni tenute in classe ma sono
da intendersi semplicemente come documento integrante del libro. Nella lettura del
libro di testo, lo studente può trovare difficoltà nell'interpretare i contenuti e questo
può accadere per svariati motivi, come l'uso di un linguaggio troppo aulico o di
esempi poco significativi. Ho quindi pensato di scrivere questi appunti in modo che
lo studente possa trovare in essi un supporto integrativo a quanto esposto nel libro di
testo. Buon studio a tutti, con l'augurio che esso non sia solo un puro apprendimento
ma anche l'occasione di crescita professionale e di potenziamento di competenze
relazionali.
R. Apisa
5

1. Gli archivi
1.1. Definizione di archivio
Il concetto di archivio non nasce con l'informatica ma è abbastanza radicato nel
tempo. Esso è connesso alla necessità di memorizzare in qualche modo
l'informazione. Pensiamo ai papiri egiziani o alle tavolette di cera che usavano gli
antichi romani. Immaginiamo ora di voler trascrivere nella nostra agenda i nomi dei
nostri amici. Avremo una struttura del tipo:
Cognome Nome Indirizzo TelefonoRossi Mario Via Nazionale 45,
Roma062323233
Verdi Renato Via Leopardi 67, Napoli
081343443
Gialli Daniela Via Tuscolana 345, Roma
063434343
Bruno Anna Piazza Re 34, Milano 023354545Fig. 1.1
Come si può notare, ogni riga rappresenta una informazione relativa ad un amico.
Quindi si può affermare che un archivio è una raccolta di informazioni. Ma dire
questo non basta perché queste informazioni devono soddisfare determinati requisiti.
Vediamo quali. Immaginiamo di apportare alcune modifiche alle informazioni di Fig.
1.1
Cognome Nome Numero notizie PilRossi Mario 6 2
Verdi Renato 0 4
Gialli Daniela 4 3
Bruno Anna 3 5Fig 1.2
6

Prendiamo in esame la prima riga: quale informazione ci fornisce? Abbiamo un nome
e cognome che ci identifica una persona ma il numero di notizie della terza colonna o
il valore del pil non sono associabili direttamente alla persona. Quindi abbiamo delle
informazioni che non sono tra loro omogenee, nel senso che esse non hanno un nesso
logico tra di loro. In definitiva, non si riesce con esse a individuare una entità ben
precisa. Col termine entità vogliamo designare un oggetto come una persona, un
animale, una fattura, un conto corrente, uno studente, un cliente, un immobile, un
detenuto...e così via.
Dunque una prima proprietà che un archivio deve soddisfare è che le informazioni
che esso contiene abbiano un nesso logico, riconducano cioè a precisi oggetti
(entità). Inoltre l'informazione deve essere reperibile, altrimenti non serve a nulla
memorizzarla. Per essere reperibile, l'informazione deve essere memorizzata su un
supporto duraturo, come quello cartaceo o quello magnetico dei computers. Non
sembrano altrettanto valide le epigrafi incise su pietra calcarea duemila anni fa e
conservate fino ad oggi? Una volta reperita, l'informazione deve essere facilmente
consultabile. Immaginiamo di organizzare l'informazione di fig. 1.1 in questo modo:
la lista dei nomi a pagina 2 dell'agenda, quella dei cognomi a pagina 10, quella degli
indirizzi a pagina 20 e quella dei telefoni a pagina 45. In tal caso, anche se reperibile,
l'informazione diventa di difficile consultazione. In definitiva, un archivio è tale se le
informazioni soddisfano i seguenti requisiti:
• Esiste un nesso logico tra esse, ovvero riconducano a precisi oggetti (entità)
• Le informazioni sono reperibili nel tempo
• Le informazioni sono di facile consultazione
7

1.2. Definizione di record
Abbiamo detto che l'informazione deve essere di facile consultazione. Un modo per
ottenere questo è strutturarla in record. Consideriamo l'archivio di figura 1.3
Cognome Nome Indirizzo TelefonoRossi Mario Via Nazionale 45,
Roma062323233
Verdi Renato Via Leopardi 67, Napoli
081343443
Gialli Daniela Via Tuscolana 345, Roma
063434343
Bruno Anna Piazza Re 34, Milano 023354545Fig. 1.3
Ciascuna delle righe della tabella rappresenta un record. Notiamo che ogni record è
formato da unità elementari di informazione (le celle della tabella) dette campi
(fields).
Quindi più campi concorrono a formare un record, per cui si può dire che il record è
una informazione strutturata che descrive un certo oggetto. Nel nostro caso, per
descrivere l'agenda degli amici, abbiamo usato il record formato dai campi
“cognome”, “nome”, “indirizzo” e “telefono”.
Se volessimo descrivere un'automobile potremmo usare un record formato dai campi:
“numero_telaio”,“marca”, “tipo”, “alimentazione”,”anno_immatricolazione”.
L'elenco dei campi viene anche detto tracciato record.
In figura 1.4 è riportata la rappresentazione grafica di un generico record:
Campo 1 Campo 2 Campo 3 ------------------ Campo n-1 Campo nFig. 1.4
8

1.3. Sistema informativo o sistema informatico?
Spesso, parlando di archivi, si parla di sistema informativo e di sistema informatico
trattandoli come dei sinonimi. In realtà, tra essi c'è una sottile differenza. Per sistema
informativo si intende un archivio non elettronico: la classica agenda cartacea, la
vecchia anagrafe con le informazioni presenti nei registri sono esempi di sistemi
informativi. I sistemi informatici (o automatici) sono invece gli archivi memorizzati
in modo che essi siano trattabili in modo elettronico. Quindi l'agenda elettronica e gli
archivi informatizzati del comune sono sistemi informatici.
1.4. Operazioni sugli archivi
Riprendiamo l'esempio fatto sopra sull'archivio degli amici. Quali operazioni
possiamo fare su di esso? Anzitutto, per poter popolare l'archivio, dobbiamo inserire
in esso i record relativi (operazione di inserimento). Poi, se con un amico abbiamo
perso i contatti, possiamo pensare di cancellarlo rimuovendo il record relativo
(operazione di cancellazione). Se un amico ha cambiato indirizzo o il numero di
telefono o entrambi, possiamo pensare di aggiornare il record relativo (operazione di
aggiornamento o modifica). Le operazioni di inserimento, modifica e cancellazione
si chiamano operazioni di manipolazione perché esse producono un cambiamento
dell'archivio. Esiste infine un'ultima operazione che, in fondo, è la ragione per cui ci
sforziamo di realizzare gli archivi. Si tratta dell'operazione di interrogazione. Se mi
serve conoscere le informazioni su uno o più amici, vado ad estrapolare le
informazioni dall'archivio.
1.5. La memorizzazione degli archivi
Gli archivi elettronici sono memorizzati nel computer in svariati supporti di
memorizzazione. Tali archivi vengono memorizzati sotto forma di file (in inglese la
9

parola file vuol dire archivio), anche se il termine “file” designa qualsiasi
informazione che può essere registrata su supporto magnetico (es: immagini, testo) e
quindi non necessariamente. Un archivio è sempre implementato mediante uno o più
file, ma un file non sempre è un archivio. Spesso nel gergo informatico, viene usato
il termine “archivio” come sinonimo di “file”, ma tra i due termini c’è una differenza
sostanziale.
Ad esempio, i dati anagrafici degli studenti, una rubrica telefonica sono archivi di
dati e possono essere memorizzati su un disco come file di dati. Un programma
scritto in linguaggio di programmazione, un documento scritto con Word, un foglio
di Excel, pur essendo memorizzati come file, non costituiscono un archivio, in
quanto i dati contenuti non sono memorizzati secondo una precisa organizzazione,
come avviene invece negli esempi che abbiamo fatto in precedenza.
Nella maggior parte dei casi, gli archivi sono formati da un insieme di record
omogenei, nel senso che tutti i record di un archivio hanno lo stesso tracciato.
Abbiamo visto prima come su un archivio si possano effettuare operazioni di
manipolazione e di interrogazione. Questo vuol dire che l'informazione viene sia
letta dall'archivio che scritta nell'archivio. Quando l'informazione viene letta, essa
transita dal supporto di memorizzazione verso la memoria centrale (operazione di
input), quando invece viene manipolata essa transita dalla memoria centrale verso il
supporto di memorizzazione (operazione di output).
Fig 1.5
10
Memoria centraleRAM
Output
InputArchivio
Blocco
Blocco

Finora abbiamo parlato di record come l'insieme delle informazioni relative all'entità
logica, definito a seconda delle esigenze dell'applicazione. Questa definizione
coincide con quella di record logico, ossia la descrizione di come il progettista
dell'archivio vuole suddividere il gruppo di informazioni che caratterizzano l'oggetto
osservato. Il record logico ha una lunghezza in byte pari alla somma della
dimensione dei suoi campi.
Durante le operazioni di input/output, gli spostamenti riguardano uno o più record
logici. Questa “massa” di informazione che si sposta viene detta blocco (o record
fisico)
Il record fisico (o blocco) rappresenta quindi l'insieme dei byte che possono essere
letti o scritti in memoria di massa con una singola operazione di lettura o scrittura.
Un blocco può contenere più record logici.
Quindi le operazioni di lettura/scrittura su un file riguardano blocchi, ossia gruppi di
record logici: in questo modo diminuisce il numero di accessi alla periferica (perché
ogni volta che si accede alla periferica vengono letti o scritti più record alla volta),
che sono operazioni più lente rispetto agli accessi ai dati contenuti nella memoria
centrale.
1.6. Supporti di memorizzazione degli archivi
I supporti di memorizzazione degli archivi si chiamano memorie di massa o anche
memorie ausiliarie, per indicare il fatto che esse sono memorie permanenti, ovvero
garantiscono la permanenza delle registrazioni nel tempo, mentre la memoria
centrale (RAM) è volatile. Di seguito sono indicati i principali supporti:
• Hard disk (dischi magnetici). I dischi rigidi sono i dispositivi di memoria più
usati; la loro capacità va dai pochi megabytes a diversi gigabyte. La tecnologia
11

degli hard-disk va ogni giorno perfezionandosi e la qualità degli stessi
aumenta sempre più di pari passo con la velocità e la dimensione. Un disco
rigido (o Hard Disk) è formato da un determinato numero di piatti che ruotano
attorno ad un perno centrale. Ogni piatto è composto da due superfici, la
superiore e l’inferiore. In un hard disk a 10 piatti avremo 18 superfici
disponibili in quanto quelle alle due estremità non vengono utilizzate. Ogni
piatto viene diviso a sua volta in n tracce che rappresentano dei cerchi
concentrici sulla superficie del piatto e in settori rappresentati dagli spicchi
del piatto (vedi figura 1.6 e figura 1.7 e 1.8). Lo spostamento della testina di
lettura e scrittura si chiama operazione di seek, mentre il tempo impiegato per
effettuare l’operazione è denominato tempo di seek. Gli Hard Disk attuali
hanno una testina autonoma per ogni superficie. Questo sistema riduce al
minimo il tempo di seek.
Fig 1.6 – Hard Disk
12

Fig 1.7 – Raffigurazione di tracce e settori
Fig 1.8 – Organizzazione dei dischi
13

• Nastri magnetici. Sono supporti simili alle vecchie cassette audio. Pertanto,
sono costituiti da una lunga striscia di materiale plastico, ricoperta da
materiale ferromagnetico (Fig 1.9). I nastri magnetici sono un supporto
ampiamente utilizzato per eseguire le copie di backup dei dati presenti nei
dischi fissi dei computers. Per esempio, l'istituto nazionale di statistica
memorizza su simili supporti le elaborazioni statistiche non attuali per poi
eventualmente recuperarle in seguito. L'operazione di salvataggio dell'archivio
da un supporto all'altro è detta operazione di backup, mentre quella inversa di
recupero dei dati da una copia precedente si chiama restore.
Fig. 1.9
• Floppy Disk. Sono concettualmente simili agli hard disk ma con una capacità
di memorizzazione nettamente inferiore (1,4 Mb). Oggi sono ormai in disuso e
sostituiti dalle più capienti pen drive.
• Dischi ottici. Si tratta di dispositivi di memorizzazione basati sulla tecnologia
di lettura e scrittura ottica, ovvero con l'uso del raggio laser.
• CD- ROM (Compact disc – Read Only Memory), dischi ottici di sola
lettura
• CD- R (Compact disc – Recordable), dischi ottici registrabili che
14

superano la limitazione dei CD-ROM caratterizzati dal fatto di essere di
sola lettura.
• CD-RW (Rewritable), consentono di effettuare registrazioni e anche
modifiche e cancellazioni successive
• DVD (Digital Versatile Disc), progettati per trattare le informazioni
multimediali (suono e video) in alta qualità di riproduzione.
1.7. Gli archivi e il file system
Il sistema operativo (Windows, Linux, etc) è il software di base che gestisce il
funzionamento della macchina. La parte del sistema operativo che gestisce la
memorizzazione dei dati sui dischi e sui vari supporti di memoria di massa prende il
nome di file system.
Esistono diversi tipi di file system (a seconda dei vari sistemi operativi), ma
comunque tutti organizzano il contenuto dei dischi in Files e Cartelle (o Directory o
Folder), seguendo una metafora ripresa dall’archivistica.
Abbiamo già detto che un file può essere un archivio di dati, un programma
eseguibile, un insieme di dati numerici, un documento di testo, un’immagine, un
documento sonoro, un filmato, una pagina web, un’animazione, o qualunque altra
cosa.
Sui dischi di un PC possono trovarsi fino a molte decine di migliaia di file e se non ci
fosse nessun criterio di ordinamento sarebbe molto complicato riuscire a rintracciare
ogni volta il file che ci interessa, per questo motivo il file system permette di creare
dei "contenitori", detti cartelle, che permettono di raccogliere i file in gruppi
logicamente omogenei. A loro volta le cartelle possono contenere altre sottocartelle e
così via, in un gioco di scatole cinesi.
15

Nelle interfacce (GUI) messe a disposizione dal sistema
operativo, i file e le cartelle vengono rappresentati con
dei simboli grafici detti icone. Le cartelle sono quasi
sempre rappresentate con l'immagine di una cartellina
d'archivio , mentre i file hanno le icone più varie, a
seconda del tipo.
Ogni file e ogni cartella deve possedere un nome che lo
distingua dagli altri. Molti sistemi operativi (fra cui
Windows) includono nel nome una sigla aggiuntiva detta
estensione che caratterizza il tipo di file. L'estensione
viene separata con un punto dal resto del nome, così ad
esempio in Windows i file che terminano con .exe sono programmi eseguibili, .txt
sono file di testo semplice, .doc .xls .mdb .ppt sono documenti rispettivamente di
Word, Excel, Access, PowerPoint, .htm e .html sono pagine Web, .wav .mp3 sono file
audio, .jpg .gif .bmp .png sono immagini, .mov .avi .mpg sono filmati, e così via. Di
solito non si usano estensioni con i nomi delle cartelle (ma sarebbe comunque
possibile).
Due oggetti con lo stesso nome (estensione compresa) non possono trovarsi
all'interno di una stessa cartella, ma possono invece esistere in due cartelle diverse
(anche se contenute una nell'altra).
Per quanto riguarda l'hard disk (su cui si trova il sistema operativo), la maggior parte
dei file e delle cartelle che vi si trovano viene creata e gestita direttamente dalle
applicazioni senza l’intervento diretto dell’utente (si tratta di file di sistema, di
configurazione o di dati). Questi documenti, che servono per il corretto
funzionamento dei programmi e del sistema operativo, non devono essere mai
alterati dall’utente se non vuole correre il rischio di bloccare la macchina. Un utente
inesperto deve agire solo sulle cartelle e sui file che lui stesso ha espressamente
inserito nell'hard disk, perché l'alterazione dei file di sistema è un'operazione che
16

rischia di compromettere seriamente il funzionamento della macchina.
È comunque opportuno che l'utente organizzi correttamente il proprio lavoro,
evitando di salvare i documenti dove capita ma creando invece una struttura ordinata
di cartelle e sottocartelle, in modo da rintracciare velocemente i propri file ed evitare
cancellazioni accidentali o sprechi di spazio su disco.
Ogni disco contiene la tabella dei descrittori dei file che è l’indice di tutti i files,
generato e aggiornato automaticamente dal sistema operativo. L’indice
memorizza per ogni file il nome, la posizione fisica nel disco, le dimensioni in byte,
la data di creazione o modifica, la cartella in cui è contenuto e altre informazioni (a
seconda del file system). Il sistema operativo fornisce poi all’utente tutti i programmi
per visualizzare l’indice dei dischi e per organizzarne il contenuto, spostando,
copiando o cancellando i file, cambiandone il nome, creando nuove cartelle, ecc.
Alcuni sistemi operativi pongono infine restrizioni e protezioni sui file, impedendo
(o perlomeno ostacolando) modifiche di files “delicati” (come i file di sistema) o
anche impedendo la visualizzazione di file che contengono informazioni riservate o
personali.
1.8. Organizzazioni degli archivi
Sappiamo che un archivio deve essere organizzato in modo tale che l'informazione
sia facilmente accessibile. Vediamo in questo paragrafo quali sono le principali
organizzazioni degli archivi nell'uso più comune dell'informatica tradizionale. Però è
prima necessario capire il concetto di apertura e chiusura degli archivi (dei file).
1.8.1. Apertura e chiusura di un file
Per poter svolgere le funzioni di interrogazione e di manipolazione su un archivio, è
necessario essere in grado di accedere al file che lo rappresenta. Per apertura di un
17

archivio si intende quell'operazione che stabilisce un collegamento tra la memoria
centrale e il file residente sulla memoria di massa. L'apertura di un file è necessaria
prima di effettuare qualsiasi operazione di lettura e scrittura su un file. La chiusura
del file interrompe il collegamento tra la memoria centrale e il file e dopo tale
chiusura viene aggiornata la tabella dei descrittori del file.
1.8.2. Organizzazione ad accesso sequenziale
In un archivio sequenziale tutti i record sono organizzati e reperiti sequenzialmente,
uno di seguito all'altro. In memorizzazione i record vengono aggiunti alla fine
dell'archivio, dopo l'ultimo record. In lettura si parte sempre dal primo record e, dopo
ogni lettura, si passa automaticamente al successivo. Questo significa che se si vuol
leggere l'n-esimo record occorre sempre leggere tutti i record che lo precedono.
L'archivio termina con EOF (End Of File) che è uno speciale marcatore di fine file
(Fig.1.10). Questo significa che la lettura dei record termina quando viene raggiunto
l' EOF, che deve essere controllato prima di leggere il record allo scopo di verificare
se si è già arrivati alla fine dell'archivio.
L'archivio può essere aperto in
input/read, ovvero per lettura, partendo
dall'inizio. In output/write, ovvero per
scrittura, partendo dall'inizio: se
l'archivio non esiste lo crea mentre, se
esiste, cancella i record che c'erano in
precedenza e inizia a scrivere i nuovi
dall'inizio. In append i record vengono
aggiunti a partire dalla fine dell'archivio.
Fig. 1.10
Nell'organizzazione sequenziale, se si è raggiunto il record i-esimo, non è possibile
ritornare al record precedente ((i-1)-esimo) ma bisogna chiudere il file (close),
18

riaprirlo (open) e rileggerlo fino al record (i-1)-esimo. Infine osserviamo anche che,
se un archivio è memorizzato su nastro, l'unica organizzazione possibile è quella
sequenziale. Invece su disco, oltre all'organizzazione sequenziale, possiamo averne
di altri tipi.
Quando conviene avere l'organizzazione sequenziale? Anzitutto dobbiamo avere un
archivio non troppo grande, con pochi record, visto che siamo costretti a scorrerli
in modo sequenziale. Poi conviene anche nel caso in cui i record devono essere letti
tutti quanti. Pensiamo al caso di file di configurazione, calcolo della media dei
valori di un campo, etc.
1.8.3. Organizzazione ad accesso diretto
In un archivio ad accesso diretto è possibile accedere ai record, sia per scriverli che
per leggerli, direttamente, semplicemente specificando qual'è la loro posizione
rispetto all'inizio dell'archivio stesso. L'apertura dell'archivio è unica: non occorre
specificare se in input, in output o in append (Fig. 1.11)
Fig 1.11
In questo tipo di organizzazione tutti i record devono avere la stessa lunghezza
mentre nell'organizzazione sequenziale possono avere anche lunghezza variabile. Per
variare uno o più campi del record basta leggere il record, modificare i valori e
riscriverlo. La cancellazione è di tipo logico, nel senso che basta memorizzare sopra
19

il record da cancellare un record vuoto. Con questa organizzazione non si ha l' EOF,
come nel sequenziale, e si possono avere record vuoti.
Un'altra considerazione che possiamo fare è che il tracciato record deve contenere
un campo che funge da identificatore univoco del record (chiave primaria) e che
tale identificatore coincide con la posizione del record. Immaginiamo di
memorizzare nell'archivio le informazioni che riguardano i giocatori di una squadra.
Il tracciato record può essere del tipo.
Numero maglia Nominativo Età Ruolo Stipendio annuale
Il campo “Numero maglia” è un numero progressivo che identifica la posizione del
record. Il giocatore con la maglia numero 1 si trova al primo record, quello con la
maglia numero 2 al secondo record e così via. (Fig. 1.12)
Numero maglia Nominativo Età Ruolo Stipendio annuale
1 Mario Rossi 23 Portiere 1000
2 Renato Verdi 26 Terzino 1200
3 Gino Gialli 27 Attaccante 1300
4 Sandro Viola 30 Ala destra 1200
Fig. 1.12
Per accedere al giocatore con maglia 3 bisogna accedere al terzo record. Se
supponiamo che ogni record abbia lunghezza 100, allora bisogna portarsi alla
posizione immediatamente successiva a quella dei primi due record, cioè alla
posizione (100 x 2) +1. In generale, se indichiamo con LR la lunghezza di ogni
record, il record N-esimo si trova alla posizione (LR x (N-1)) +1. Un altro esempio
di archivi con accesso diretto è l'archivio anagrafico degli studenti di una scuola.
Infatti il campo matricola è un numero assegnato al momento dell'iscrizione alla
20

scuola e ottenuto aggiungendo uno all'ultimo numero di matricola assegnato.
Un archivio ad accesso diretto è detto anche archivio random (o casuale) volendo
mettere in evidenza la contrapposizione all'organizzazione sequenziale, cioè il fatto
che l'utente può accedere al record che interessa senza esaminare per forza tutti quelli
che lo precedono. E' ovvio che un archivio ad accesso diretto permette anche un
accesso sequenziale. Basta scandire con un ciclo ad uno ad uno i vari record.
1.8.4. Organizzazione sequenziale ad indici
Abbiamo visto che nell'organizzazione ad accesso diretto il “trucco” sta nel fatto che
la chiave primaria coincide con la posizione del record nell'archivio. Spesso non è
possibile fare tale associazione in quanto la chiave primaria è una variabile
alfanumerica. Per esempio, la matricola del dipendente di un'azienda, il codice di un
articolo, il codice del cliente sono tutte chiavi alfanumeriche. In tal caso è necessario
un meccanismo che consenta di recuperare la posizione del record nell'archivio a
partire dalla chiave alfanumerica. Il principio adottato è quello dell'indice analitico
dei libri. Se prestiamo attenzione, notiamo che l'indice analitico è composto da una
sequenza ordinata di parole chiave ove, a fianco di ciascuna di esse, sono indicate le
pagine del libro che fanno riferimento a tale parola. Negli archivi sequenziali con
indici abbiamo un meccanismo analogo in quanto, a fianco dell'archivio vero e
proprio, abbiamo un indice (o dizionario) ove sono memorizzate le varie chiavi. A
fianco di ogni chiave è indicata la posizione del record che fa riferimento ad essa
(Fig. 1.13) . Dalla figura si nota che nel dizionario le chiavi sono ordinate e a
ciascuna è associata la relativa posizione del record nell'archivio. Poiché le chiavi
sono ordinate, esse possono essere reperite facilmente con una ricerca binaria (o
dicotomica) anziché sequenziale. Il dizionario viene mantenuto logicamente ordinato
quando si inserisce un nuovo record, quando si cancella un record nonché quando si
modifica il valore di una chiave.
21

Fig. 1.13
A questo punto tocca chiarire cosa è la ricerca binaria o dicotomica che si voglia
dire. Consideriamo allora un insieme di numeri ordinato, come mostrato in figura
1.14.
3 7 13 16 20 59 68 73 93 102 114 121 209 240 270Fig. 1.14
Supponiamo di voler cercare il numero 102. L'idea è quella di confrontare
l'elemento cercato con l'elemento centrale della lista, ossia con 73. Il numero 102 non
sta nella posizione centrale però, siccome la lista è ordinata in ordine crescente, si
può dire che l'elemento cercato, se esiste, si trova alla destra dell'elemento centrale.
Dunque si scartano tutti gli elementi che stanno a sinistra di 73 e si ripete la ricerca
su quelli che stanno alla sua destra. Il nuovo elemento centrale è 121. Siccome 102 è
più piccolo di 121, allora si scartano tutti gli elementi a destra di 121 e si fa la ricerca
sugli elementi dal numero 93 al numero 114. Il nuovo elemento centrale è 102 che
coincide proprio con l'elemento che stavamo cercando.
22

La figura a fianco mostra una ricerca dicotomica sulla
chiave F di un dizionario in cui le chiavi sono ordinate in
ordine alfabetico crescente. Con soli 3 step di ricerca la
chiave viene rintracciata e così pure la posizione 6 del
record corrispondente.
Fig. 1.15Se si vuole generalizzare l'algoritmo di ricerca binaria, possiamo identificare i
seguenti passi:
• Si accede alla metà dell'archivio e si confronta la chiave cercata con quella
trovata.
• Se la chiave trovata è quella cercata, la ricerca è finita.
• Se la chiave trovata è maggiore di quella cercata, allora si elimina
logicamente la parte a destra della chiave trovata e si applica la ricerca alla
sua parte sinistra.
• Se la chiave trovata è minore di quella cercata, allora si elimina logicamente
la parte a sinistra della chiave trovata e si applica la ricerca alla sua parte
destra.
• La ricerca termina quando si trova ciò che si cerca oppure quando l'archivio è
ridotto a zero record (nel qual caso si può affermare che ciò che si cerca non
viene trovato)
Quando la ricerca viene effettuata su un numero piccolissimo di elementi, il
vantaggio rispetto alla ricerca sequenziale non è evidente. Lo diventa man mano che
aumenta il numero di elementi, come si può evincere dalla figura 1.16. L'unico scotto
23

da pagare è dato dal fatto che l'archivio deve essere mantenuto ordinato sulla chiave
di ricerca.
Fig. 1.16
24

2. Il progetto informatico
2.1. Le fasi della progettazione
Un progetto, non importa se informatico o meno, può essere visto come l'insieme
delle operazioni che si svolgono per realizzare un prodotto, come una casa, un
software, un impianto elettrico. Un progetto informatico, come qualsiasi progetto,
nasce da un'esigenza. Per esempio, uno studio commerciale può richiedere un
software per gestire la contabilità, un negozio di abbigliamento può richiedere di
sviluppare un sito web dove mostrare l'elenco delle offerte in corso. In un progetto
informatico, si possono identificare le fasi indicate in Fig. 2.1.
Fig. 2.1
25
Analisi del problema
Analisi dei dati Analisi delle funzioni
Progettazione
Progettazione dati Progettazione funzioni
Realizzazione
Documentazione Prove Formazione
Produzione (Rilascio)

2.1.1. Analisi del problema
L'analisi del problema serve a studiare quali esigenze si sta cercando di soddisfare.
Di solito si tratta delle esigenze del cliente che commissiona il prodotto. Durante
questa fase non sono richieste tanto competenze tecniche quanto di capacità
relazionali e interpretative. Infatti non sempre l'utente ha ben chiaro ciò di cui ha
bisogno: spesso si limita ad esporre una generica richiesta ed è compito dell'analista
quello di sviscerarla nel migliore dei modi. Inoltre bisogna tener presente lo stato
dell'arte, ovvero la presenza di determinate situazioni da cui partire. Per esempio,
nel caso di un impianto elettrico, si potrebbe essere in presenza di un edificio storico
ove ci potrebbero essere problemi nell'effettuare opere murarie. Nel caso di un
progetto informatico, potremmo avere già dei programmi e archivi preesistenti con
cui il nuovo prodotto dovrebbe colloquiare. La fase di analisi è quella in cui si deve
stabilire quali sono i dati con cui operare e in che modo essi vanno manipolati,
ovvero come interagire con essi. I dati e le funzioni (che servono a manipolare i dati)
vengono descritti in modo formale (o astratto), ossia in modo totalmente svincolato
da come saranno poi effettivamente implementati. Più precisamente, per i dati non si
specifica come essi saranno archiviati mentre per i programmi non si parla di
linguaggi di programmazione né tanto meno di specifiche tecnologie.
2.1.2. Progettazione
In questa fase vengono descritti come archiviare i dati e le specifiche del software
per interagire con essi. Quindi si decide la modalità di archiviazione dei dati e si
disegna anche il diagramma di flusso del programma che interagirà con la base di
dati.
26

2.1.3. Realizzazione
In questa fase vengono realizzati gli archivi e i moduli software a corredo. Quindi si
realizza il database e si sviluppa il software che si interfaccia ad esso.
2.1.4. Documentazione, Prove e Formazione
Dopo la fase di realizzazione, è opportuno produrre la documentazione a corredo
del progetto. Ci sono tre tipi di documentazione:
• Manuale utente, diretto a chi usa il prodotto realizzato.
• Manuale online, una versione del manuale utente accessibile direttamente dal
contesto applicativo.
• Manuale operativo, ossia la documentazione tecnica degli archivi e dei
programmi. Tale documentazione è rivolta ai progettisti e agli sviluppatori.
Le prove consistono nel verificare eventuali errori, specialmente nel sorgente dei
programmi che costituiscono i moduli software. La formazione consiste
nell'erogazione di corsi di formazione agli utenti finali volti ad erudire gli stessi
sull'utilizzo del prodotto.
2.1.5. Produzione
La produzione, o rilascio, del progetto consiste nel mettere in esercizio il prodotto
presso l'utente. Ovviamente, questa fase prevede un periodo di controllo del buon
funzionamento del sistema.
27

3. I database (basi di dati)
3.1. I limiti degli archivi tradizionali
Immaginiamo che una banca abbia due filiali e che nella banca centrale ci sia
l'archivio dei conti correnti, mentre nelle filiali ci siano gli archivi dei movimenti
fatti su tali conti correnti. La situazione è descritta nella figura 3.1:
Fig. 3.1
Ora rappresentiamo sotto forma tabellare l'archivio usato dalla banca centrale e che
contiene i record relativi ai conti correnti (Fig 3.2)
NUMCONTO INTESTATARIO INDIRIZZO CODFIL DESCRFIL1 Mario Rossi Via Roma 1 FIL1 Filiale uno
2 Gianni Verdi Via Napoli 34 FIL1 Filiale uno
3 Sonia Marrone Via Latina 39 FIL1 Filiale uno
4 Maria Neri Via Viterbo 7 FIL2 Filiale due
5 Renato Grigi Via Rieti 9 FIL2 Filiale due
Fig 3.2
28
Banca centrale
Filiale 1 Filiale 2
ArchivioConti correnti
ArchivioMovimenti
Conti correnti

Ora invece consideriamo la rappresentazione tabellare dell'archivio della Filiale 1,
contenenti i movimenti dei conti correnti della filiale 1 (Fig 3.3)
NUMCONTO NOMINATIVO INDIRIZZO DATA IMPORTO CAUSALE1 Mario Rossi Via Roma 1 25/10/10 700 Euro Bonifico
1 Mario Rossi Via Roma 1 26/10/10 300 Euro Prelievo
2 Gianni Verdi Via Napoli 34 25/10/10 340 PrelievoFig 3.3
Vogliamo calcolare il saldo del conto identificato con 1. Osservando i due archivi,
possiamo constatare i seguenti problemi:
• Ci sono delle ridondanze in quanto nel primo archivio la descrizione della
filiale viene ripetuta più volte, mentre nel secondo vengono ripetuti il nome e
l'indirizzo del correntista. IL fatto che gli stessi dati appaiano in due archivi
diversi è una situazione pericolosa: cosa succede se si cambia l'indirizzo di
Mario Rossi nell'archivio della banca centrale e non in quello della filiale 1? In
tal caso, l'indirizzo di Mario Rossi nell'archivio della filiale risulta errato.
Pertanto, esso risulta corretto in un archivio e errato in un altro e questa è una
situazione di incongruenza dei dati. L'incongruenza comporta anche
l'inconsistenza dei dati, ossia il fatto che essi risultano inaffidabili, perché non
si sa in modo certo quale dei diversi valori sia quello corretto.
• Se due programmi accedono contemporaneamente ad un record e lo
modificano, solo l'ultima operazione di modifica sarà registrata, col risultato
che un'operazione di scrittura andrà persa. Questo è un problema di
concorrenza.
Per far fronte a tutti questi problemi sono stati creati i database, detti anche basi di
dati. Dunque i database sono archivi di dati organizzati in modo integrato e gestiti
sulle memorie di massa dei computer attraverso appositi software. I prodotti software
che servono alla gestione dei database vengono detti Database Management
System (DBMS). Grazie ai DBMS siamo in grado di costruire archivi e interagire
29

con essi ad un livello elevato di astrazione, ossia senza avere bisogno di usare
linguaggi di programmazione per accedere direttamente ai file dell'archivio.
3.2. Il DBMS
Abbiamo visto che il DBMS è l'insieme dei programmi che servono a gestire gli
archivi di dati, detti database o basi di dati. Esso deve svolgere determinate funzioni,
tra cui:
• Permettere le operazioni di manipolazione e di interrogazione della base di
dati in modo efficiente.
• Garantire la consistenza dei dati, ovvero il fatto che non devono esistere due
possibili valori per lo stesso campo.
• Garantire la sicurezza dei dati, ovvero il fatto che solo certi utenti possono
svolgere determinati tipi di operazione. Per esempio, fare in modo che certi
utenti possono solo interrogare i dati mentre altri possono anche manipolarli.
• Dare il supporto alle transazioni. Per transazione si intende un insieme di
operazioni effettuate su una base di dati che possono terminare con successo
oppure no. Nel caso di successo, le modifiche sulla base di dati devono
risultare permanenti, altrimenti non deve rimanere traccia della transazione e
la base di dati deve ritornare nello stato precedente alla transazione stessa. Un
esempio di transazione è dato dall'operazione di prelievo del danaro allo
sportello bancomat.
30

4. Il modello concettuale
4.1. La progettazione concettuale e il modello Entità-Relazione (E/R)
La progettazione concettuale rappresenta il primo passo che bisogna fare per
progettare un database, ossia un archivio strutturato di dati. Essa fornisce una
rappresentazione del tutto teorica della realtà che vogliamo memorizzare a
prescindere da come poi andiamo a rappresentare i dati. Il modello concettuale
fornisce quindi una descrizione della realtà che vogliamo archiviare ma non mi dice
nulla su come i dati vengono poi effettivamente rappresentati. Si potrebbe dire che è
una vera e propria progettazione con “carta e penna”. Il modello concettuale che noi
prendiamo in considerazione è il modello Entità-Relazione (in breve E/R). La realtà
di interesse viene studiata e vengono ricavate le cosiddette entità, che sono gli
elementi rilevanti che descrivono la realtà che vogliamo rappresentare. Una entità
rappresenta sempre un insieme di oggetti, aventi tutti le stesse caratteristiche. Per
esempio, una entità può essere l'oggetto Persona ed è descritta, per esempio, da
cognome, nome, indirizzo e telefono. L'entità Persona la posso pensare come
l'insieme di tutte le persone ognuna delle quali è descritta da cognome, nome,
indirizzo e telefono. Una entità si rappresenta graficamente col simbolo del
rettangolo, mentre le proprietà che la descrivono sono rappresentate da pallini
collegati al rettangolo tramite linee, come mostrato in figura 4.1
Fig. 4.1
Le proprietà di una entità vengono chiamate attributi. Uno degli attributi deve avere
la funzione di chiave primaria ed è riconoscibile in quanto sottolineato. In figura
4.1, il CodiceFiscale rappresenta la chiave primaria per l'entità Persona.
Abbiamo detto che una entità rappresenta un insieme di elementi. Ogni singolo
31

elemento si chiama istanza dell'entità. Nel caso dell'entità Persona un'istanza
potrebbe essere il seguente elemento:
{MRS2382388343, Mario, Rossi, Rovigo, 12/07/1986, Operaio} oppure
{ANNVRD34343K, Anna, Verdi, Lucca, 08/02/1967, Insegnante}
4.2. Attributi
Le proprietà dell'entità sono dette attributi. Un attributo possiede le seguenti
caratteristiche:
• Ha un nome
• Ha un tipo di valori che può assumere (numerico, stringa, data, booleano)
• Ha una dimensione, che indica la quantità massima di caratteri o di cifre
inseribili
• Ha un valore. L'insieme dei possibili valori che un attributo può assumere si
chiama dominio dell'attributo.
Un attributo può essere opzionale oppure obbligatorio. Si dice opzionale quando
esso può accettare valori nulli (esempio il telefono di una persona) mentre si dice
obbligatorio quando non sono consentiti valori nulli (esempio il cognome di una
persona). Un attributo può essere semplice o aggregato. E' semplice quando è
composto da una sola proprietà (esempio il cognome). E' aggregato (o composto)
quando può essere scomposto in più attributi. Per esempio, l'attributo indirizzo può
essere considerato un attributo aggregato in quanto scomponibile nei seguenti
attributi: NomeVia, NumeroCivico, Cap, Città.
32

4.3. Ancora sulla chiave primaria
Per discriminare le varie istanze di una entità c'è bisogno di un attributo che funga da
chiave primaria, ossia esso è tale che il suo valore è diverso per ogni istanza. Ossia
non ci possono essere due istanze con lo stesso valore dell'attributo che funge da
chiave primaria. Nell'esempio della figura 4.1, possiamo dire che tutte le istanze di
Persona hanno un valore diverso per l'attributo CodiceFiscale. Cerchiamo ora di dare
una definiziaone più precisa di chiave primaria. In realtà, si definisce chiave
candidata o superchiave, l'insieme di attributi che consentono di distinguere
un'istanza da un'altra. La chiave primaria(Primary Key) non è altro che la chiave
candidata col minor numero di attributi. Per esempio, una chiave candidata per
l'entità Persona potrebbe essere l'insieme dei seguenti attributi: Cognome, Nome e
DataNascita. Ma si sceglie CodiceFiscale perché è la chiave candidata col minor
numero di attributi.
4.4. Associazioni
Considerate due o più entità, un'associazione è un legame logico che si può stabilire
tra esse. Mentre un'istanza rappresenta una classe di oggetti, un'associazione
rappresenta una classe di fatti. Per esempio, tra l'entità Persona e Automobile esiste
l'associazione “possiede” la quale rappresenta appunto il fatto che “una persona
possiede una o più automobile e, viceversa, un'automobile è posseduta da una
persona”. Graficamente, per rappresentare un'associazione tra due entità si usa un
rombo posto a metà tra le due entità, come in Fig. 4.2. Notiamo che l'associazione
“possiede” ha due attributi che sono la DataAcquisto e il Notaio. Essi non sono
attributi né dell'entità Persona né dell'entità Automobile ma caratterizzano
l'associazione “possiede”. Quindi un'associazione può possedere degli attributi,
così come li posseggono le entità.
33

Fig. 4.2
Un'associazione tra due entità X e Y, detta anche associazione diretta, possiede
sempre la sua inversa, ossia l'associazione tra Y e X. Nel caso della Fig. 4.2
l'associazione “possiede” è l'associazione diretta tra Persona e Automobile.
L'associazione inversa tra Automobile e Persona è “èPossedutaDa”, in quanto ogni
automobile è posseduta da una persona.
Date due entità, tra di esse può non esistere alcuna associazione, può esistere una
sola associazione oppure possono esistere diverse associazioni. Per esempio, tra
l'entità Persona e l'entità Comune possiamo individuare tre possibili associazioni,
come descritto in Fig. 4.3
Fig. 4.3
Le tre associazioni rappresentano rispettivamente i seguenti fatti:
• il comune dove le persone lavorano
• il comune dove le persone sono nate
• il comune dove le persone risiedono
34

Un'associazione tra due entità X e Y può essere di due tipi: totale e parziale. Si dice
totale quando il legame tra le entità deve essere sempre presente, ossia ad ogni
elemento di X deve corrispondere almeno un elemento di Y.
Si dice parziale quando il legame tra le entità potrebbe non essere sempre presente,
ossia esiste almeno un elemento di X a cui non corrisponde nessun elemento di Y.
Dal punto di vista grafico, l'associazione parziale si rappresenta con la linea
tratteggiata mentre quella totale con la linea continua. Facciamo degli esempi.
L'associazione “possiede” tra le entità Persona e ContoCorrente è parziale in quanto
può benissimo esistere una persona che non ha alcun conto corrente. Invece,
l'associazione inversa “èPossedutoDa” tra ContoCorrente e Persona è totale in
quanto ogni conto corrente ha una persona che l'ha stipulato. Non esiste un conto
corrente a cui non sia associata alcuna persona. Dal punto di vista grafico, la
situazione è rappresentata come in figura 4.4
Fig. 4.4
Data un'associazione tra le entità X e Y, la molteplicità di tale associazione indica
quante istanze dell'entità Y possono trovarsi in relazione con un'istanza di X. Per
esempio, l'associazione descritta in Fig. 4.2 ha molteplicità N in quanto ogni persona
può possedere più automobili. L'associazione inversa “èPossedutaDa” tra
Automobile e Persona ha invece molteplicità 1 in quanto ogni automobile è
posseduta da una sola persona.
La cardinalità di un'associazione tra le entità X e Y descrive parallelamente la
molteplicità dell'associazione diretta e quella della sua inversa.
Per questo motivo, le associazioni tra due entità X e Y possono essere di tre tipi:
35

Associazione 1:1 (uno a uno), quando ad ogni istanza di X corrisponde una sola
istanza di Y e viceversa. Un esempio è l'associazione dirige tra le entità
DirigenteScolastico e Scuola (Fig. 4.5).
Fig 4.5
Associazione 1:N (uno a molti), quando ad ogni istanza di X possono corrispondere
più istanze di Y e, ad ogni istanza di Y, deve corrispondere una sola istanza di X. Un
esempio è l'associazione haInOrganico tra le entità Scuola e PersonaleSegreteria
(Fig. 4.6).
Fig 4.6
Associazione N:N (molti a molti), quando ad ogni istanza di X possono
corrispondere più istanze di Y e, ad ogni istanza di Y, possono corrispondere più
istanze di X. Un esempio è l'associazione insegna tra le entità Professore e Classe
(Fig. 4.7).
Fig 4.7
36

4.5. I vincoli di integrità
Sono delle restrizioni imposte sulle entità e sulle associazioni tra di esse. Si
distinguono in vincoli espliciti e vincoli impliciti. I vincoli impliciti, come indica
l'aggettivo stesso, sono quelli che dipendono direttamente dalla natura dell'entità e
dell'associazione. Rispetto all'entità abbiamo il vincolo di chiave primaria, dato dal
fatto che non possono esiste due istanze dell'entità con lo stesso valore della chiave
primaria. Rispetto all'associazione abbiamo il vincolo di integrità referenziale. Vuol
dire che se esiste un'associazione totale tra tra due entità X e Y, non deve esistere un
elemento di X che non sia associato ad alcun elemento di Y e viceversa. Dal punto di
vista grafico, sappiamo che un vincolo di chiave primaria si rappresenta col carattere
di sottolineato, mentre un vincolo di integrità referenziale si rappresenta con la linea
continua delle associazioni per mettere in evidenza la totalità dell'associazione.
I vincoli espliciti sono vincoli di solito posti sugli attributi dell'entità. Per esempio,
l'attributo Eta dell'entità Persona potrebbe avere il vincolo che esso abbia un valore
maggiore di zero e minore di 120. Usando una simbologia matematica, potremmo
scrivere:
V1: (0 < Persona.Eta < 120)
37

5. Il modello logico: il modello relazionale
5.1. Introduzione
Abbiamo visto che il modello concettuale è una rappresentazione astratta della realtà,
ossia esso descrive i dati e le associazioni tra di essi ma non si fa alcun riferimento a
come i dati vengano poi rappresentati. Il modello logico è il successivo passo che
bisogna compiere nella nostra modellazione della realtà. Con il modello logico si
indica come i dati vengono tra loro organizzati dal punto di vista logico, dal punto di
vista organizzativo. Vedremo che esso viene derivato dal modello concettuale
applicando alcuni semplici regole.
Va precisato che il modello concettuale rappresenta un patrimonio importante per le
aziende, in quanto descrive i dati esistenti in azienda: il suo valore informativo può
essere utilizzato sia in ambito informatico che gestionale e diventa un supporto per i
diversi ruoli aziendali. A questo punto è chiaro che il modello logico ha lo scopo di
dotare i dati di una struttura che deve facilitare:
• le operazioni di manipolazione, ossia inserimento, modifica e cancellazione.
• le operazioni di interrogazione
Il modello logico, che fornisce una versione strutturata dei dati, viene rappresentato
fisicamente in un database. Si parla allora di modello fisico. Quindi il modello fisico
rappresenta l'implementazione del modello logico sulle effettive memorie di massa.
La figura 5.1 rappresenta le diverse fasi di rappresentazione di una realtà di interesse.
Il modello logico che prenderemo in considerazione è quello relazionale, ideato da
Edward Codd nel 1970 e detto così perché basato sulla rappresentazione dei dati
mediante tabelle (ma per noi non è una novità!). Infatti le tabelle prendono anche il
nome di relazioni ed in seguito ne spiegheremo anche il motivo. Nel passato (anni
60-70) erano in voga altri altri due tipi di modelli logici: il modello gerarchico e
quello reticolare. Oggi essi sono caduti in disuso a favore del modello relazionale
38

che è molto più vicino al modo in cui noi pensiamo alla realtà. I modelli gerarchico e
reticolare presentavano problemi di ridondanza dei dati e problemi di stretta
dipendenza tra i programmi e i dati, ossia non era possibile modificare la base dati
senza modificare i programmi che le utilizzano.
Fig. 5.1
5.2. Regole di derivazione del modello logico: le entità
Abbiamo già detto che il modello logico relazionale viene ricavato dal modello
concettuale attraverso delle semplici regole. In questo paragrafo le analizzeremo in
dettaglio. Partiamo dall'entità Persona descritta dalla figura 5.2.
39
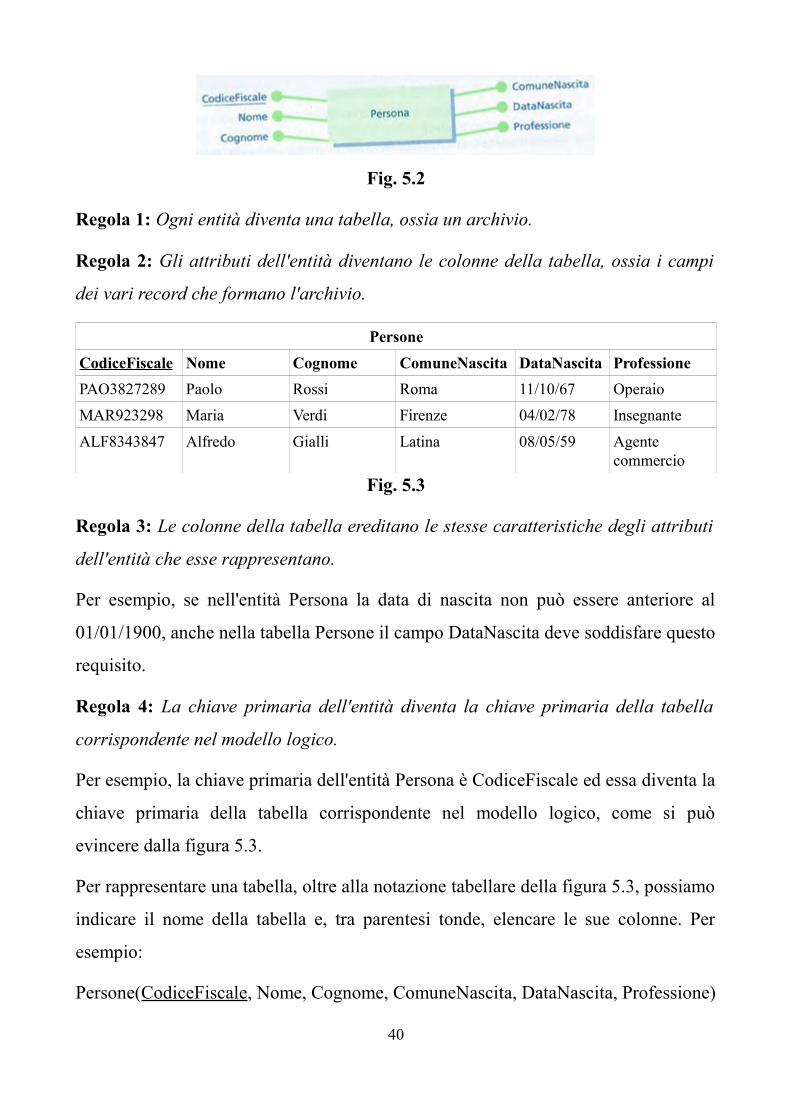
Fig. 5.2
Regola 1: Ogni entità diventa una tabella, ossia un archivio.
Regola 2: Gli attributi dell'entità diventano le colonne della tabella, ossia i campi
dei vari record che formano l'archivio.
PersoneCodiceFiscale Nome Cognome ComuneNascita DataNascita ProfessionePAO3827289 Paolo Rossi Roma 11/10/67 Operaio
MAR923298 Maria Verdi Firenze 04/02/78 Insegnante
ALF8343847 Alfredo Gialli Latina 08/05/59 Agente commercio
Fig. 5.3
Regola 3: Le colonne della tabella ereditano le stesse caratteristiche degli attributi
dell'entità che esse rappresentano.
Per esempio, se nell'entità Persona la data di nascita non può essere anteriore al
01/01/1900, anche nella tabella Persone il campo DataNascita deve soddisfare questo
requisito.
Regola 4: La chiave primaria dell'entità diventa la chiave primaria della tabella
corrispondente nel modello logico.
Per esempio, la chiave primaria dell'entità Persona è CodiceFiscale ed essa diventa la
chiave primaria della tabella corrispondente nel modello logico, come si può
evincere dalla figura 5.3.
Per rappresentare una tabella, oltre alla notazione tabellare della figura 5.3, possiamo
indicare il nome della tabella e, tra parentesi tonde, elencare le sue colonne. Per
esempio:
Persone(CodiceFiscale, Nome, Cognome, ComuneNascita, DataNascita, Professione)
40

Da notare che la chiave primaria è stata rappresentata col carattere della
sottolineatura, allo stesso modo in cui si faceva nel modello concettuale! Inoltre, il
nome delle tabelle è di solito posto al plurale, mentre il nome delle entità del modello
concettuale è posto al singolare.
Possiamo anche usare una notazione simile alla precedente in cui però, oltre a
specificare i nomi delle colonne, specifichiamo anche il tipo di dato della colonna:
Persone(CodiceFiscale:String(16), Cognome:Stringa(30), Nome:Stringa(30), Eta:Intero, Sposato:Booleano)
La figura 5.4 mostra un altro esempio di come trasformare una entità del modello
concettuale in una tabella del modello logico.
Fig. 5.4
Le colonne della tabella sono dette anche attributi o campi della tabella. Le righe
della tabella sono dette invece anche tuple o records. Il numero di colonne si dice
grado della tabella, mentre il numero di righe viene detto cardinalità della tabella.
5.3. Regole di derivazione del modello logico: le associazioni
Ora ci rimane da vedere come trasformare le associazioni del modello concettuale
nel modello logico. Iniziamo col considerare l'associazione uno a molti (1:N) tra due
entità, per esempio l'associazione “frequenta” tra Scuola e Studente mostrata nella
figura 5.5.
41

Fig. 5.5
Notiamo che sono state derivate le due tabelle Studente e Scuole e che nella tabella
Studente è stato aggiunto l'attributo CodScuola che rappresenta la chiave primaria
dell'altra tabella, ossia la chiave primaria della tabella Scuola. Allora, possiamo
dedurre la seguente regola:
Regola 5: Data un'associazione uno a molti tra due entità, si derivano le tabelle
corrispondenti e nella tabella “a molti” viene aggiunta una colonna che è la chiave
primaria della tabella “a uno”.
ScuoleCodScuola NomeScuola IndirizzoAA1 Istituto Aniene Via Giuseppe Galati, Roma
AA2 Istituto Armellini Largo Placido Riccardi, Roma
AA3 Liceo Astarita Viale Parioli, Roma
StudentiMatricola Cognome Nome CodScuola1 Rossi Mario AA1
2 Verdi Anna AA2
3 Marrone Gennaro AA3
4 Viola Simona AA1
5 Azzurro Stefano AA3
6 Gialli Domiziana AA2
42

Fig 5.6
Leggendo la tabella Studenti, ci accorgiamo che gli allievi Rossi e Viola frequentano
l'Istituto “Aniene”, gli allievi Verdi e Gialli frequentano l'Istituto “Armellini”, mentre
gli allievi Marrone e Azzurro frequentano il Liceo “Astarita”.
Il nuovo campo che viene aggiunto alla tabella “a molti” prende il nome di chiave
esterna. Infatti è la chiave primaria della tabella “a uno” che è in associazione con
essa. Notiamo che la chiave esterna non necessita del carattere di sottolineatura.
Ora prendiamo in esame un'associazione uno a uno, per esempio l'associazione
“dirige” tra dirigente scolastico e scuola descritta in figura 5.7
Fig. 5.7
L'associazione uno a uno è un caso particolare di associazione molti a molti. Per tale
motivo, il mapping può essere eseguito usando le stesse regole. In tal caso, in una
delle due tabelle si può aggiungere come chiave esterna la chiave primaria dell'altra
tabella. Si può avere una situazione di questo tipo:
DirigentiScolastici(MatricolaDirigente, Cognome, Nome, Indirizzo)
Scuole(CodiceScuola, Denominazione, Indirizzo, MatricolaDirigente)
in cui MatricolaDirigente è chiave esterna
oppure:
DirigentiScolastici(MatricolaDirigente, Cognome, Nome, Indirizzo,
CodiceScuola)
43

Scuole(CodiceScuola, Denominazione, Indirizzo)
in cui CodiceScuola è chiave esterna.
ScuoleCodScuola NomeScuola IndirizzoAA1 Istituto Aniene Via Giuseppe Galati, Roma
AA2 Istituto Armellini Largo Placido Riccardi, Roma
AA3 Liceo Astarita Viale Parioli, Roma
DirigentiScolasticiMatricola Cognome Nome CodScuola1 Rossi Mario AA1
2 Verdi Anna AA2
3 Marrone Gennaro AA3Fig 5.8
Esaminando la tabella DIRIGENTISCOLATICI, ci si accorge che Rossi dirige l'istituto “Aniene”, Verdi l'Istituto “Armellini” e Marrone il Liceo “Astarita”.
Regola 6: Data un'associazione uno a uno tra due entità, si derivano le tabelle
corrispondenti e in una delle due tabelle viene aggiunta una colonna che è la chiave
primaria dell'altra tabella.
Consideriamo ora l'associazione molti a molti “insegna” tra docente e classe (Fig
5.9)
Fig. 5.9
44
Docente ClasseInsegnaN N
Codice Nome
Qualifica Materia
Sigla
NumeroAlunni Aula
NumeroOre

Tale associazione esprime il fatto che un docente può insegnare in più di una classe e
in una classe possono insegnare più docenti. Per rappresentare questa associazione
nel modello relazionale si usano tre tabelle. Le prime due sono rappresentate dalle
entità coinvolte e quindi sono:
Docenti(Codice, Nome, Qualifica, Materia)
Classi(Sigla, NumeroAlunni, Aula)
Infine viene introdotta una terza tabella, che chiameremo Insegna, la quale contiene
come chiavi primarie le chiavi primarie delle due tabelle coinvolte. Inoltre tale
tabella può contenere anche gli eventuali attributi dell'associazione. Avremo quindi:
Insegna(CodiceDocente, SiglaClasse, NumeroOre)
Possiamo quindi enunciare la seguente regola:
Regola 7: Data un'associazione molti a molti tra due entità, si derivano le tabelle
corrispondenti e si aggiunge una terza tabella che contiene le chiavi delle tabelle
coinvolte nell'associazione. In tale terza tabella possono confluire anche gli
eventuali attributi dell'associazione.
Ma a cosa serve questa terza tabella? Serve semplicemente a trasformare
un'associazione molti a molti in due associazioni uno a molti. Vediamo perché.
Introducendo la tabella Insegna, è come se noi avessimo considerato le seguenti
associazioni:
Ossia l'associazione molti a molti tra Docente e Classe è stata sdoppiata in due
associazioni uno a molti: l'associazione tra Docente e Insegna e l'associazione tra
Classe e Insegna. Diamo un'occhiata alla rappresentazione tabellare di tale relazione
molti a molti (Fig. 5.10)
45
Docente Classe1:N N:1
Insegna
CodiceDocenteSiglaClasseNumero Ore

DocentiCodice Nome Qualifica Materia1 Paolo Rossi Insegnante Informatica
2 Michele Verdi ITP Informatica
3 Anna Marrone Supplente Italiano
4 Giovanna Viola Insegnante Matematica
5 Daniela Neri Insegnante Filosofia
ClassiSigla NumeroAlunni AulaIA 20 23
IB 17 10
VB 25 3
InsegnaCodiceDocente SiglaClasse NumeroOre1 IA 4
1 VB 2
2 IB 1
3 VB 4
4 IA 3
4 IB 2
5 IA 5
5 IB 4
5 VB 3Fig. 5.10
Un record di Insegna rappresenta un'associazione tra Docente e Classe. Infatti, dalla
tabella INSEGNA si evince, ad esempio, che Paolo Rossi insegna nelle classi IA e
VB, che Michele Verdi insegna solo in IB, mentre Daniela Neri insegna nelle classi
IA, IB e VB. Sempre da tale tabella si evince anche che in IA insegnano i docenti
Paolo Rossi, Giovanna Viola e Daniela Neri. In VB insegnano Paolo Rossi, Anna
Marrone e Daniela Neri.
46

Facciamo ora un altro esempio, prendendo in considerazione l'associazione molti a
molti tra film e persone, descritta nella figura 5.11. Tale associazione esprime il fatto
che una persona può partecipare a più di un film e un film può annoverare più
persone nel suo cast.
Notiamo che abbiamo scomposto l'associazione in tre tabelle. Due di queste tabelle
sono derivate direttamente dalle entità coinvolte: si tratta delle tabelle Film e
Persona, con le loro rispettive chiavi primarie. E fin qui nulla di nuovo rispetto a
quello che già sappiamo. La novità è che è stata introdotta una terza tabella (Cast) in
cui sono state messe come chiavi esterne le chiavi primarie delle due entità coinvolte
nell'associazione (Film e Persona) la cui combinazione formerà la chiave primaria di
Cast. La nuova tabella introdotta eredita dall'�associazione anche i suoi eventuali
attributi, nel nostro caso l'attributo Ruolo.
Fig. 5.11
47

5.4. Rappresentazione degli attributi composti
Si rappresenta un unico attributo, ignorando la struttura, ossia si perde visione delle
componenti:
Studente(Matr, Cogn, Nome, Indirizzo)
oppure si rappresentano tanti attributi quante sono le componenti: si perde la visione dell’attributo come insieme di componenti:Studente(Matr, Cogn, Nome, Città,Via, Nro, CAP)
5.5. Rappresentazione degli attributi multivalore
Una entità può possedere un attributo multivalore, ossia che può assumere più di un
valore. Per esempio l'entità Film potrebbe avere l'attributo Attore di tipo multivalore
in quanto in un film recitano più attori. Come facciamo allora a rappresentare un
siffatto attributo nel modello relazionale? Si rappresenta tramite un'associazione uno
a molti (1:N) nel modo seguente: si toglie l'attributo dall'entità a cui appartiene
(Film) e si crea una nuova tabella con due attributi: una chiave esterna che garantisce
la corrispondenza con la chiave primaria di Film e un attributo che corrisponde
all'attributo multiplo che si sta per trasformare (Fig 5.12 e Fig. 5.13)
Fig. 5.12
Notiamo che la chiave primaria della nuova relazione Attori è composta da tutti i
suoi attributi.
48

Fig. 5.13
Un altro esempio che si può fare è considerare l'entità Persona con un attributo
Hobby che è anch'esso multivalore. Allora possiamo creare un'altra relazione che
chiameremo Hobby, in questo modo:
Persona(CodiceFiscale, Cognome, Nome, Citta)
Hobby(CodiceFiscale, Hobby)
5.6. Rappresentazione dei vincoli di integrità
Al paragrafo 4.5 abbiamo parlato dei vincoli di integrità come delle restrizioni
imposte sulle entità e sulle associazioni tra di esse. Abbiamo parlato dei vincoli
espliciti e vincoli impliciti. Ora vediamo di mettere in evidenza gli stessi concetti
traslati nel modello relazionale.
Iniziamo dai vincoli impliciti. Per quanto riguarda il vincolo di chiave primaria,
possiamo dire che in una tabella non ci possono essere due righe (due record) che
hanno lo stesso valore della chiave primaria.
49

StudentiMatricola Nominativo Eta2345 Mario Rossi 15
7628 Pietro Verdi 16
7628 Rosaria Gialli 14Fig. 5.14
Nella figura 5.14 si può osservare che non è soddisfatto il vincolo di chiave primaria
in quanto ci sono due studenti con chiave primaria 7628. Per quanto riguarda il
vincolo di integrità referenziale, consideriamo l'associazione “Rileva” tra Vigili e
Infrazioni. Essa è tradotta nel modello logico dalle tabelle della figura 5.15.
Fig. 5.15
Il vincolo di integrità referenziale vuol dire che per ogni valore non nullo della
chiave esterna, esiste un valore corrispondente della chiave primaria nella tabella
associata. Dalla figura 5.15 si vede che tale vincolo è soddisfatto. Quindi, comunque
si sceglie un'infrazione, si riesce a risalire al vigile che l'ha rilevata. Si può anche
vedere che il vigile Gino Mori (con matricola 7543) non ha rilevato nessuna
infrazione.
50

La figura 5.16 è invece un esempio in cui il vincolo di integrità referenziale non è
soddisfatto. Infatti, al valore 2468 della chiave esterna nella tabella Infrazioni non
corrisponde alcun valore della chiave primaria nella tabella Vigili. Il che vuol dire
che, data un'infrazione, non si riesce a risalire al vigile che l'ha rilevata!
Fig. 5.16
Passiamo ora ai vincoli espliciti. Sappiamo che, nel modello concettuale, essi sono
vincoli di solito posti sugli attributi dell'entità. Nel modello logico relazionale
diventano i vincoli posti sugli attributi della tabella che rappresenta l'entità. Nulla di
più semplice. Il vincolo può coinvolgere un solo attributo o più attributi. Vediamo un
esempio per fare maggiore chiarezza. Consideriamo la tabella Dipendenti descritta
dalla figura 5.17
DipendentiMatricola StipendioLordo Trattenute DataAssunzione DataNascita1 1500 300 01/10/1999 07/02/1979
2 1700 400 10/05/2010 18/09/1981Fig. 5.17
Un vincolo su un solo attributo può essere StipendioLordo > 0 oppure Trattenute > 0
51

mentre un vincolo che coinvolge due attributi è DataAssunzione > DataNascita.
Possiamo esprimere i precedenti vincoli con la seguente notazione:
V1(DIPENDENTI): StipendioLordo > 0
V2(DIPENDENTI): Trattenute > 0
V3(DIPENDENTI): DataAssunzione > DataNascita
5.7. Da cosa deriva il termine “modello relazionale”?
Abbiamo già detto che il modello relazionale si basa sulla rappresentazione dei dati
tramite tabelle e che ogni tabella è detta anche relazione. Già, ma perché una tabella
è detta relazione? Per capirlo, consideriamo la tabella di figura 5.18:
PersoneNominativo EtaMario Rossi 18
Giuseppe Galli 45Fig. 5.18
Osserviamo che tutti i valori di una colonna possono essere rappresentati da un
insieme di valori. La colonna Nominativo è individuata da un insieme di stringhe che
rappresentano nominativi, mentre la colonna Eta è individuata da un insieme di
numeri che rappresentano delle età. Usando la notazione degli insiemi possiamo
scrivere:
Nominativi = {“Mario Rossi”, “Giuseppe Galli”}
Eta = {18, 15}
Adesso proviamo a costruire delle coppie di elementi, in modo tale che il primo
elemento appartenga al primo insieme, mentre il secondo appartenga al secondo
insieme. Allora otterremo l'insieme seguente:
{(“Mario Rossi”, 18), (“Mario Rossi”, 45), (“Giuseppe Galli”, 18), (“Giuseppe
52

Galli”, 45)}. Questo insieme lo chiamiamo prodotto cartesiano tra gli insiemi
Nominativi e Eta. In matematica, tale prodotto cartesiano si indica col simbolo x.
Quindi:
A x B = {(“Mario Rossi”, 18), (“Mario Rossi”, 45), (“Giuseppe Galli”, 18),
(“Giuseppe Galli”, 45)}
Dalla teoria degli insiemi noi sappiamo che, dato un insieme, un suo sottoinsieme si
costruisce considerando alcuni elementi di quell'insieme. In particolare, se considero
tutti gli elementi, il sottoinsieme coincide con l'insieme stesso.
Allora, noi possiamo considerare anche un sottoinsieme del prodotto cartesiano. In
matematica, un sottoinsieme del prodotto cartesiano viene detto relazione.
Indichiamo , per esempio, con R questo sottoinsieme. Usando il simbolismo
matematico, diremo che
R A x B
Come sottoinsieme, possiamo scegliere, ad esempio:
R = {(“Mario Rossi”, 18), (“Giuseppe Galli”, 45)}
Proviamo a dare uno sguardo all'insieme R (la relazione) e alla tabella 5.18. Non
sembra che siano la stessa cosa? Quindi si può affermare che una tabella è una
relazione, ossia è un sottoinsieme del prodotto cartesiano tra gli insiemi individuati
dalle colonne della tabella. Questo è il motivo per cui il modello logico basato su
tabelle si chiama modello relazionale!
Immaginiamo che ci venga posta la seguente domanda: Come mai il modello logico
basato su tabelle è detto relazionale? La risposta l'abbiamo data sopra. Molti,
erroneamente, pensano che il termine “modello relazionale” dipenda dalle relazioni
tra le entità del modello concettuale. Niente di più falso: il termine “relazione” nel
modello concettuale significa una cosa, nel modello logico un'altra. Infatti, le
relazioni tra le entità esprimono un legame logico, un'associazione tra le entità. Nel
53

modello logico relazionale, il termine relazione sta ad indicare un concetto
matematico ben preciso, ossia un sottoinsieme del prodotto cartesiano tra insiemi.
Quindi attenzione a non fare confusione!
5.8. Gli operatori relazionali
Abbiamo detto che una tabella è una relazione. Allora, a partire da una tabella, noi
possiamo fare su di essa delle operazioni in modo tale da produrre una nuova tabella.
Che è come dire che, a partire da una relazione, tramite delle operazioni, possiamo
ottenere una nuova relazione. Gli operatori che applichiamo ad una tabella (o a più
tabelle) per ottenere una tabella risultante si chiamano operatori relazionali.
5.8.1. Operazione di selezione
Supponiamo di avere la relazione Impiegati seguente (fig. 5.19):
ImpiegatiMatricola Cognome Filiale Stipendio7309 Rossi Roma 55
5998 Neri Milano 64
9553 Milano Milano 44
5698 Neri Napoli 64Fig. 5.19
L'operazione di selezione consiste nel selezionare soltanto alcune righe della tabella
che soddisfano una determinata condizione. Per esempio, potremmo aver bisogno di
estrarre solo i dipendenti che guadagnano più di 50. In tal caso otteniamo:
ImpiegatiMatricola Cognome Filiale Stipendio7309 Rossi Roma 55
5998 Neri Milano 64
5698 Neri Napoli 64
54

Si scrive SELStipendio > 50 (Impiegati)
Notiamo che la tabella ottenuta ha lo sesso grado della tabella di partenza, mentre la
cardinalità è più piccola. In una selezione possiamo avere come risultato una tabella
con la stessa cardinalità di quella di partenza ma, solitamente, essa è minore.
Facciamo altri esempi:
• Impiegati che guadagnano più di 50 e lavorano a Milano
ImpiegatiMatricola Cognome Filiale Stipendio5998 Neri Milano 64
SELStipendio >50 AND Filiale=”Milano” (Impiegati)
• Impiegati che hanno lo stesso cognome della filiale presso cui lavorano
ImpiegatiMatricola Cognome Filiale Stipendio9553 Milano Milano 44
SELCognome = Filiale (Impiegati)
5.8.2. Operazione di proiezione
Consiste nel produrre una tabella che è ridotta nel numero di colonne rispetto alla
tabella di partenza. Vuol dire che si selezionano soltanto alcuni attributi della tabella.
Di conseguenza, si ottiene come risultato una tabella che ha un grado inferiore
rispetto a quella di partenza ma ha la stessa cardinalità. Vediamo degli esempi.
Supponiamo di voler recuperare la matricola e il cognome di tutti gli impiegati.
Otteniamo la tabella seguente:
55

ImpiegatiMatricola Cognome7309 Rossi
5998 Neri
9553 Milano
5698 Neri
Per indicare la proiezione scriveremo:
PROJ Matricola, Cognome (Impiegati)
Consideriamo ora la seguente tabella:
ImpiegatiCognome FilialeRossi Roma
Neri Milano
Milano Milano
Neri Napoli
E' evidente che essa rappresenta la proiezione della tabella Impiegati sulle colonne
Cognome e Filiale. In simboli:
PROJ Cognome, Filiale (Impiegati)
La tabella ottenuta da un'operazione di proiezione potrebbe contenere due o più
righe uguali. In tal caso, bisogna richiedere che ne venga conservata una sola perché
non è possibile avere righe uguali tra loro.
5.8.3. Selezione e proiezione
E' possibile combinare tra loro gli operatori di selezione e di proiezione e questo ci
consente di estrapolare delle informazioni interessanti da una relazione. Per esempio,
vogliamo conoscere la matricola e il cognome degli impiegati che guadagnano più di
50.
56

In simboli : PROJ Matricola, Cognome (SEL Stipendio > 50 (Impiegati))
Abbiamo dapprima selezionato tutte le righe per cui lo Stipendio > 50 e poi abbiamo
fatto la proiezione sulle colonne matricole e cognome. Otteniamo la seguente tabella:
ImpiegatiMatricola Cognome7309 Rossi
5998 Neri
5698 Neri
5.8.4. Operazione di unione, intersezione e differenza
Sono operazioni tipiche degli insiemi e si possono applicare a due tabelle che hanno
una struttura omogenea, ossia lo stesso numero di colonne, dello stesso tipo e nello
stesso ordine. Consideriamo le tabelle Laureati e Quadri della figura 5.20:
Fig. 5.20
57

Notiamo anzitutto la struttura omogenea. La terza tabella rappresenta l'unione tra le
tabelle Laureati e Quadri. Essa è ottenuta unendo le righe di entrambe le tabelle con
la condizione che le righe che si ripetono hanno un'unica occorrenza. Per esempio, il
laureato con matricola 9824 viene rappresentato una sola volta nella tabella
risultante. In conclusione, l'unione tra due tabelle omogenee è una tabella che ha le
righe della prima e della seconda tabella con la condizione di rappresentare una sola
volta le righe che si ripetono.
La figura 5.21 rappresenta l'operazione di intersezione tra Laureati e Quadri:
Fig. 5.21
L'intersezione consiste nel considerare tutte quelle righe che appartengono ad
entrambe le tabelle. Quindi, l'intersezione tra due tabelle è una tabella le cui righe
sono quelle comuni alle due tabelle.
La figura 5.22 mostra l'operazione di differenza tra le tabelle Laureati e Quadri. La
differenza tra due tabelle consiste in una tabelle fatta da tutte quelle righe della prima
tabella che non sono contenute nella seconda tabella. Nel nostro esempio,
rappresenta tutti quei laureati che non svolgono la funzione di quadro.
58

Fig. 5.22
5.8.5. Operazione di join (giunzione)
Ci siamo resi conto che le operazioni di selezione e di proiezione consentono di
estrapolare informazioni relative ad una sola tabella. Se vogliamo estrarre
informazioni tra più tabelle tra loro correlate, abbiamo bisogno di un nuovo
operatore che è detto operatore di join. Consideriamo allora le tabelle a una
associazione uno a molti. Possiamo scrivere:
Persone(CodiceFiscale, Cognome, Nome)
Automobili(Targa, Marca, Modello, CodFisc)
Immaginiamo di avere la situazione mostrata in figura 5.23.
59

PersoneCodiceFiscale Cognome Nome1 Rossi Mario
2 Verdi Giacomo
3 Marrone Anna
AutomobiliTarga Marca Modello CodFiscRM1234 Fiat Panda 1300 1
RM1876 Fiat Punto 1900 1
VT1234 Opel Astra 1700 CDTI 2
RI5454 Opel Zafira 1700 TDI 2
BA4348 Citroen C3 3Fig. 5.23
Immaginiamo di voler estrapolare le informazioni sulle automobili e sui proprietari.
In tal caso, mediante l'operatore di natural join, siamo in grado di mettere assieme le
righe della prima tabella con le righe della seconda con la condizione che queste
righe abbiano lo stesso valore per l'attributo comune, ossia il codice fiscale.
Otteniamo:
CodiceFiscale Cognome Nome Targa Marca Modello1 Rossi Mario RM1234 Fiat Panda 1300
1 Rossi Mario RM1876 Fiat Punto 1900
2 Verdi Giacomo VT1234 Opel Astra 1700 CDTI
2 Verdi Giacomo RI5454 Opel Zafira 1700 TDI
3 Marrone Anna BA4348 Citroen C3
Quindi, a partire da due tabelle, il risultato del natural join è quello di produrre una
nuova tabella così formata:
60

• Le colonne sono date dalle colonne della proma tabella e da quelle della
seconda, senza duplicazioni.
• Le righe della prima sono concatenate a quelle della seconda, secondo i valori
uguali dell'attributo comune.
Il natural join viene detto anche inner join o equi-join.
Ora consideriamo la seguente tabella Automobili di figura 5.24 :
AutomobiliTarga Marca Modello CodFiscRM1234 Fiat Panda 1300 1
RM1876 Fiat Punto 1900 1
VT1234 Opel Astra 1700 CDTI 2
RI5454 Opel Zafira 1700 TDI 2
BA4348 Citroen C3Fig. 5.24
Possiamo notare che in essa l'ultimo record non fa riferimento ad alcun proprietario perché il valore del codice fiscale è assente.
Se proviamo a fare il natural join otteniamo:
CodiceFiscale Cognome Nome Targa Marca Modello1 Rossi Mario RM1234 Fiat Panda 1300
1 Rossi Mario RM1876 Fiat Punto 1900
2 Verdi Giacomo VT1234 Opel Astra 1700 CDTI
2 Verdi Giacomo RI5454 Opel Zafira 1700 TDI
La riga relativa alla Citroen C3 con targa BA4348 è stata ignorata in quanto essa non
fa riferimento ad alcuna persona. Così come non compaiono le informazioni di Anna
Marrone.
Siccome il natural join esclude tutti quei record per cui non c'è corrispondenza con
l'attributo comune, sono stati creati gli operatori di outer join che sopperiscono a tale
61
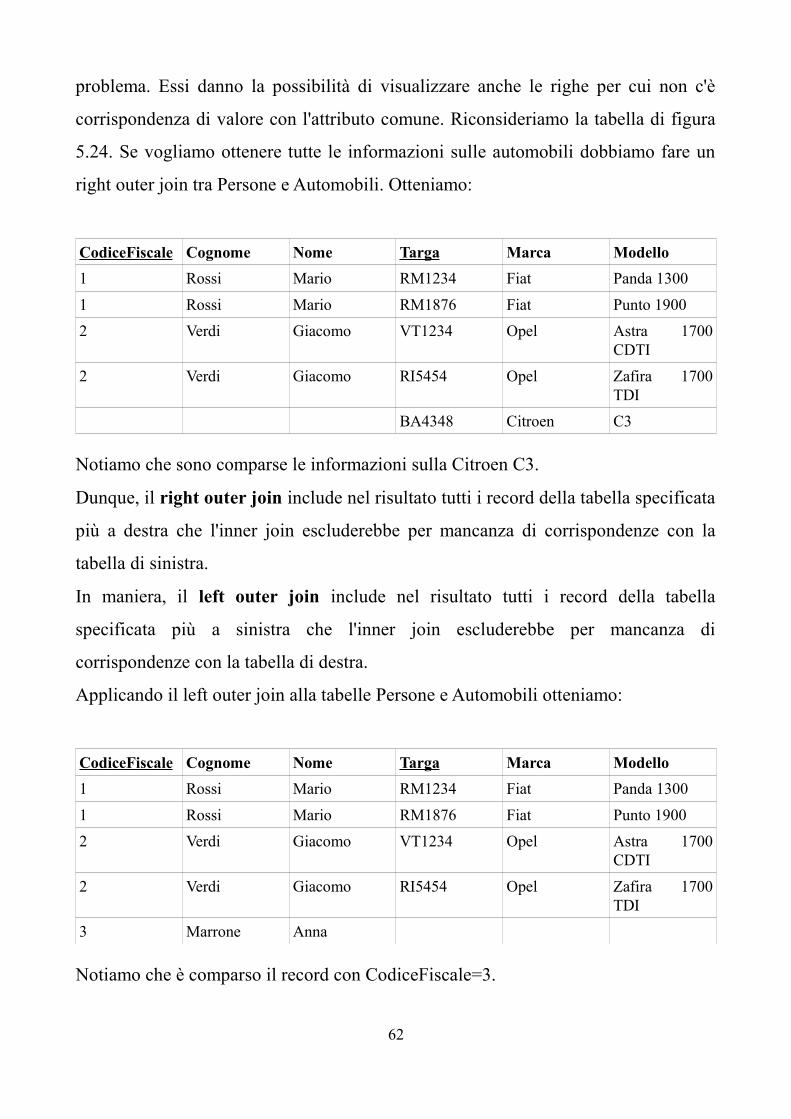
problema. Essi danno la possibilità di visualizzare anche le righe per cui non c'è
corrispondenza di valore con l'attributo comune. Riconsideriamo la tabella di figura
5.24. Se vogliamo ottenere tutte le informazioni sulle automobili dobbiamo fare un
right outer join tra Persone e Automobili. Otteniamo:
CodiceFiscale Cognome Nome Targa Marca Modello1 Rossi Mario RM1234 Fiat Panda 1300
1 Rossi Mario RM1876 Fiat Punto 1900
2 Verdi Giacomo VT1234 Opel Astra 1700 CDTI
2 Verdi Giacomo RI5454 Opel Zafira 1700 TDI
BA4348 Citroen C3
Notiamo che sono comparse le informazioni sulla Citroen C3.
Dunque, il right outer join include nel risultato tutti i record della tabella specificata
più a destra che l'inner join escluderebbe per mancanza di corrispondenze con la
tabella di sinistra.
In maniera, il left outer join include nel risultato tutti i record della tabella
specificata più a sinistra che l'inner join escluderebbe per mancanza di
corrispondenze con la tabella di destra.
Applicando il left outer join alla tabelle Persone e Automobili otteniamo:
CodiceFiscale Cognome Nome Targa Marca Modello1 Rossi Mario RM1234 Fiat Panda 1300
1 Rossi Mario RM1876 Fiat Punto 1900
2 Verdi Giacomo VT1234 Opel Astra 1700 CDTI
2 Verdi Giacomo RI5454 Opel Zafira 1700 TDI
3 Marrone Anna
Notiamo che è comparso il record con CodiceFiscale=3.
62
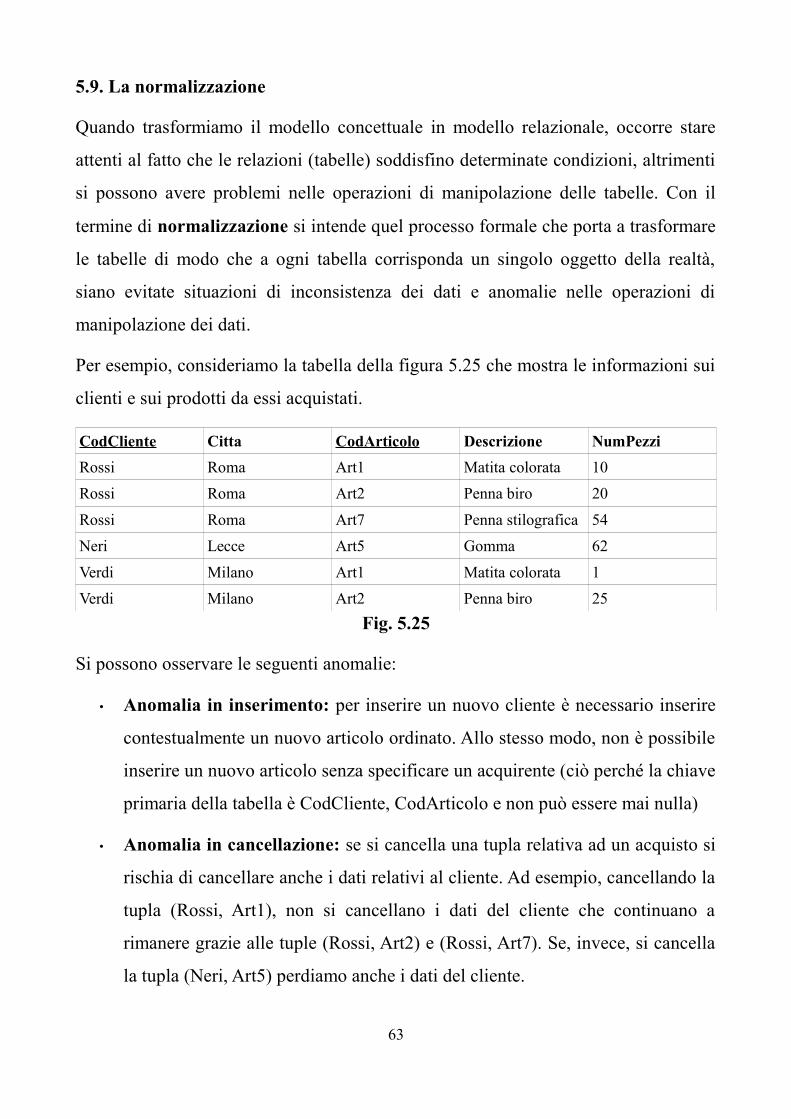
5.9. La normalizzazione
Quando trasformiamo il modello concettuale in modello relazionale, occorre stare
attenti al fatto che le relazioni (tabelle) soddisfino determinate condizioni, altrimenti
si possono avere problemi nelle operazioni di manipolazione delle tabelle. Con il
termine di normalizzazione si intende quel processo formale che porta a trasformare
le tabelle di modo che a ogni tabella corrisponda un singolo oggetto della realtà,
siano evitate situazioni di inconsistenza dei dati e anomalie nelle operazioni di
manipolazione dei dati.
Per esempio, consideriamo la tabella della figura 5.25 che mostra le informazioni sui
clienti e sui prodotti da essi acquistati.
CodCliente Citta CodArticolo Descrizione NumPezziRossi Roma Art1 Matita colorata 10
Rossi Roma Art2 Penna biro 20
Rossi Roma Art7 Penna stilografica 54
Neri Lecce Art5 Gomma 62
Verdi Milano Art1 Matita colorata 1
Verdi Milano Art2 Penna biro 25Fig. 5.25
Si possono osservare le seguenti anomalie:
• Anomalia in inserimento: per inserire un nuovo cliente è necessario inserire
contestualmente un nuovo articolo ordinato. Allo stesso modo, non è possibile
inserire un nuovo articolo senza specificare un acquirente (ciò perché la chiave
primaria della tabella è CodCliente, CodArticolo e non può essere mai nulla)
• Anomalia in cancellazione: se si cancella una tupla relativa ad un acquisto si
rischia di cancellare anche i dati relativi al cliente. Ad esempio, cancellando la
tupla (Rossi, Art1), non si cancellano i dati del cliente che continuano a
rimanere grazie alle tuple (Rossi, Art2) e (Rossi, Art7). Se, invece, si cancella
la tupla (Neri, Art5) perdiamo anche i dati del cliente.
63

• Anomalia in aggiornamento: se occorre variare l'indirizzo di un cliente,
occorrerà farlo in tutte le tuple in cui esso compare.
Il processo di normalizzazione è detto così perché lo stato delle tabelle si trova in un
certa forma, detta forma normale. Esistono diversi tipi di forme normali: prima forma
normale (1FN), seconda forma normale (2FN), terza forma normale (3FN), forma
normale di Boyce_Codd (BCNF), quarta forma normale (4FN) e quinta forma
normale (5FN). Prenderemo in considerazione le prime tre forme normali, lasciando
la trattazione delle altre forme ad eventuali studi universitari.
5.9.1. La prima forma normale (1FN)
Una tabella è in prima forma normale (1FN) quando possiede la chiave primaria e
ogni campo ha un valore semplice, ossia non deve essere composto né multiplo. Per
tale ragione, la prima forma normale è detta anche forma atomica. Vediamo alcuni
esempi. In figura 5.26 abbiamo una relazione Persone in cui il campo Indirizzo è di
tipo composto. Quindi per normalizzare la relazione, se ne costruisce una nuova (fig.
5.27) in cui il campo Indirizzo viene scomposto in campi più semplici: Indirizzo,
Numero, Città.
CodPersona Cognome Nome Indirizzo1 Neri Antonio Via Unità d'Italia 34,
Lecce
2 Verde Marco Via Piave 6/B, Ancona
3 Bianco Piero Piazza Dante 9, MilanoFig. 5.26
CodPersona Cognome Nome Indirizzo Numero Città1 Neri Antonio Via Unità
d'Italia34 Lecce
2 Verde Marco Via Piave, 6/B Ancona
3 Bianco Piero Piazza Dante 9 MilanoFig. 5.27
64

Un altro caso di attributo non semplice è dato dall'attributo multiplo, ossia
quell'attributo che può assumere un insieme di valori. Per esempio, per una persona
l'attributo NumeriDiTelefono può essere multiplo perché una persona può avere più
recapiti telefonici. (fig 5.28). Per realizzare una relazione in 1FN, si costruiscono due
relazioni, una simile a quella d'origine, ma senza l'attributo multiplo, e un'altra
contenente la chiave primaria della prima relazione e un attributo semplice che
contiene ogni singolo valore per i numeri di telefono.(fig 5.29)
CodPersona Cognome Nome NumeroDiTelefono1 Neri Antonio 02/324328525 02/89346874 348/4324324
2 Bianco Marco 06/90596590 335/94054946
3 Testo Piero 06/90596889 380/39676654Fig. 5.28
CodPersona Cognome Nome1 Neri Antonio
2 Bianco Marco
3 Testo Piero
CodPersona NumeroDiTelefono1 02/324328525
1 02/89346874
1 348/4324324
2 06/90596590
2 335/94054946
3 06/90596889
3 380/39676654
Fig 5.29
5.9.2. La seconda forma normale (2FN)
La seconda forma normale riguarda il caso di relazioni con chiavi composte, ossia
formate da più attributi. Una relazione è in seconda forma normale (2FN) quando è
in prima forma normale e tutti i suoi attributi non chiave dipendono dall'intera
chiave, ossia non esistono attributi che dipendono soltanto da una parte della chiave.
65

Quindi, si può affermare che la 2FN serve a eliminare la dipendenza parziale degli
attributi dalla chiave primaria. Consideriamo, ad esempio il problema dell'inventario
delle merci che si trovano in alcuni magazzini dislocati in località diverse. Le
informazioni essenziali possono essere rappresentate con la seguente relazione:
Merci (Codice, Magazzino, Quantità, LocalitàMagazzino)
La chiave primaria è composta, formata dagli attributi Codice e Magazzino in quanto
il solo codice non identifica la merce che si può trovare in diversi magazzini.
Osserviamo che l'attributo LocalitàMagazzino dipende solo da una parte della
chiave, ossia dalla parte Magazzino, mentre Quantità dipende dall'intera chiave
primaria. In termini simbolici, possiamo scrivere:
Codice, Magazzino → Quantità (si dice che Quantità dipende funzionalmente da
Codice e da Magazzino)
Magazzino → LocalitàMagazzino (si dice che LocalitàMagazzino dipende
funzionalmente da Magazzino)
Quindi la relazione non è in seconda forma normale. La soluzione consiste nel
costruire una nuova relazione, togliendo dalla relazione di partenza l'attributo che
dipende solo parzialmente dalla chiave primaria. Si ottiene quindi:
Merci (Codice, Magazzino, Quantità)
Depositi (Magazzino, LocalitàMagazzino)
Facciamo un altro esempio: supponiamo di avere una tabella Ordini fatta in questo
modo:
Ordini (CodOrdine, CodProdotto, CodCliente, DataOrdine, Quantità, PrezzoUnit,
Descrizione)
In forma tabellare:
66

CodOrdine CodProdotto CodCliente DataOrdine Quantità PrezzoUnit Descrizione1 A023 C1 15/12/2004 25 50,25 Cintura
1 A789 C1 15/12/2004 120 25,8 PortachiaviA
1 A976 C1 15/12/2004 100 22,14 PortachiaviB
2 G324 C24 15/12/2004 45 30,25 Portapatente
3 A023 C56 29/12/2004 120 50,25 Cintura
Ora andiamo a studiare le dipendenze funzionali.
Osserviamo che CodCliente e DataOrdine dipendono funzionalmente solo da
CodOrdine, quindi:
CodOrdine → CodCliente, DataOrdine
Poi PrezzoUnit e Descrizione dipendono solo dal prodotto (CodProdotto) e non
dall'ordine, quindi:
CodProdotto → PrezzoUnit, Descrizione
Poi Quantità è l'unico attributo che dipende sia dall'ordine che dal prodotto, quindi:
CodOrdine, CodProdotto → Quantità
Ciascuna di queste dipendenze funzionali deve essere tradotta in una corrispondente
tabella:
Ordini (CodOrdine, DataOrdine, CodCliente)
Prodotti (CodProdotto, PrezzoUnit, Descrizione)
ProdottiOrdinati (CodOrdine, CodProdotto, Quantita)
5.9.3. La terza forma normale (3FN)
Una relazione è in terza forma normale (3FN) quando è in seconda forma normale e
tutti gli attributi non-chiave dipendono direttamente dalla chiave, ossia non esistono
attributi non chiave che dipendono da altri attributi non-chiave. Per esempio,
67
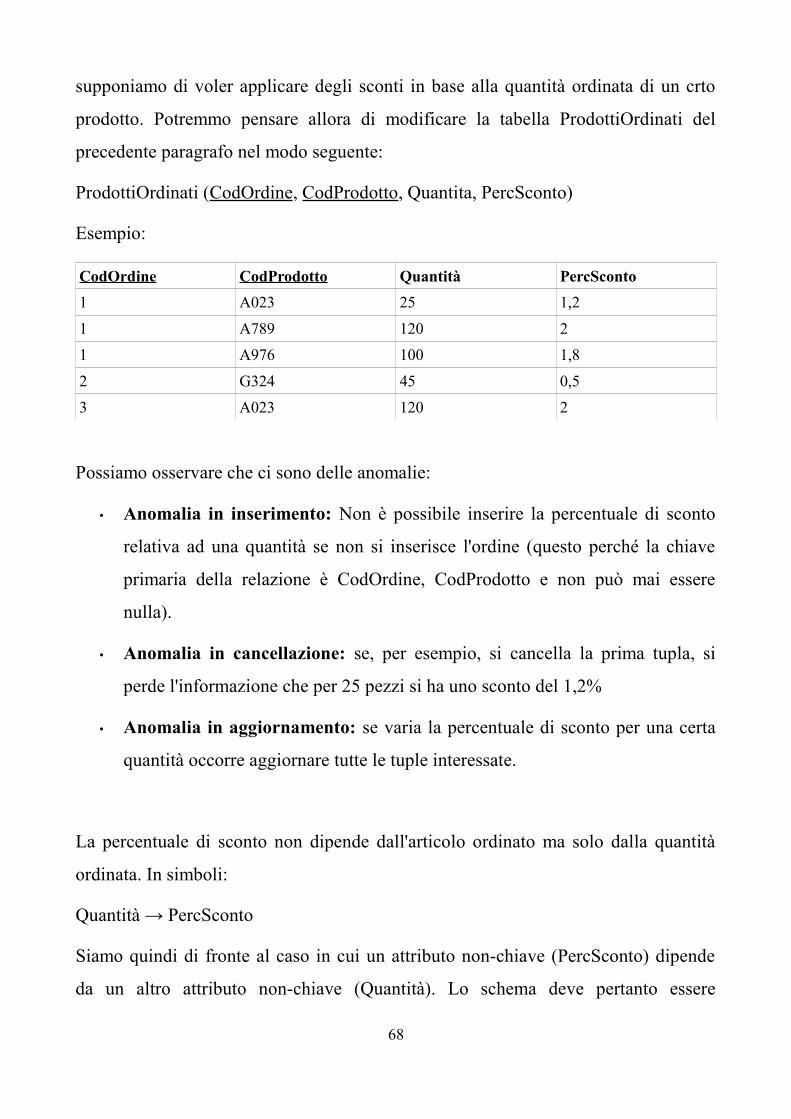
supponiamo di voler applicare degli sconti in base alla quantità ordinata di un crto
prodotto. Potremmo pensare allora di modificare la tabella ProdottiOrdinati del
precedente paragrafo nel modo seguente:
ProdottiOrdinati (CodOrdine, CodProdotto, Quantita, PercSconto)
Esempio:
CodOrdine CodProdotto Quantità PercSconto1 A023 25 1,2
1 A789 120 2
1 A976 100 1,8
2 G324 45 0,5
3 A023 120 2
Possiamo osservare che ci sono delle anomalie:
• Anomalia in inserimento: Non è possibile inserire la percentuale di sconto
relativa ad una quantità se non si inserisce l'ordine (questo perché la chiave
primaria della relazione è CodOrdine, CodProdotto e non può mai essere
nulla).
• Anomalia in cancellazione: se, per esempio, si cancella la prima tupla, si
perde l'informazione che per 25 pezzi si ha uno sconto del 1,2%
• Anomalia in aggiornamento: se varia la percentuale di sconto per una certa
quantità occorre aggiornare tutte le tuple interessate.
La percentuale di sconto non dipende dall'articolo ordinato ma solo dalla quantità
ordinata. In simboli:
Quantità → PercSconto
Siamo quindi di fronte al caso in cui un attributo non-chiave (PercSconto) dipende
da un altro attributo non-chiave (Quantità). Lo schema deve pertanto essere
68

trasformato nel modo seguente:
ProdottiOrdinati (CodOrdine, CodProdotto, Quantita)
Sconti (Quantità, PercSconto)
In conclusione, per normalizzare si procede nel seguente modo:
• Nello schema originario rimane la chiave primaria e tutti gli attributi non
chiave che dipendono direttamente da essa.
• Si crea un nuovo schema di relazione per ogni attributo da cui dipendono altri
attributi non chiave
69