aws re:invent 2016: 20k in 20 days - agile genomic analysis (ent320)
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Chris Johnson, Solutions Architect
Ronen Artzi, R&D Architect and Cloud Evangelist
Michael S. Heimlich, Ph.D., Solution Delivery Manager
December 1, 2016
20k in 20 days – Agile Genomic Analysis
Decoupled Architectures
ENT320

What to Expect from the Session
• Learn about AWS Well-Architected
• Review decoupled architectures in AWS
• Consider how event-based architectures improve this
model
• Learn how AstraZeneca used Agile methods to analyze
20,000 Exomes in 20 days

What is the Well-Architected Program?
ReliabilityEnsuring that a given system is
architected to meet operational
thresholds during a specific
period of time.
PerformanceEnsuring a system delivers maximal
performance for a set of resources
(instances, storage, database and
space/time).
Cost OptimizationCost Optimization helps achieve the lowest
price for a workload or set of workloads
while taking into account fluctuating needs.
SecurityComplimenting the AWS Security
Best Practices whitepaper, our
Security pillar reviews definitions
and compliance best practices.
5 Architectural Pillars
Operational ExcellenceFocusing around operational practices and
procedures used to manage production
workloads.
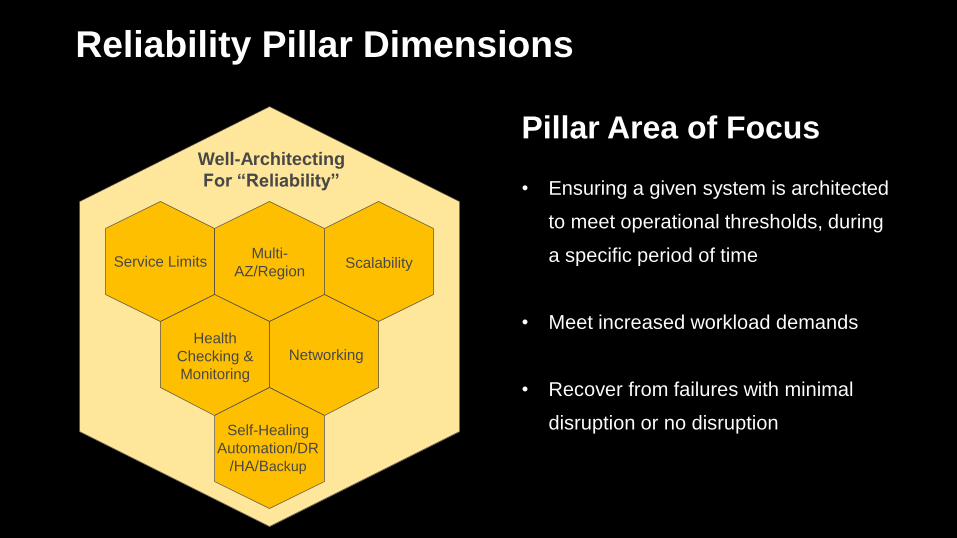
Reliability Pillar Dimensions
Pillar Area of Focus
• Ensuring a given system is architected
to meet operational thresholds, during
a specific period of time
• Meet increased workload demands
• Recover from failures with minimal
disruption or no disruption
Well-Architecting
For “Reliability”
Service LimitsMulti-
AZ/RegionScalability
Health
Checking &
Monitoring
Networking
Self-Healing
Automation/DR
/HA/Backup
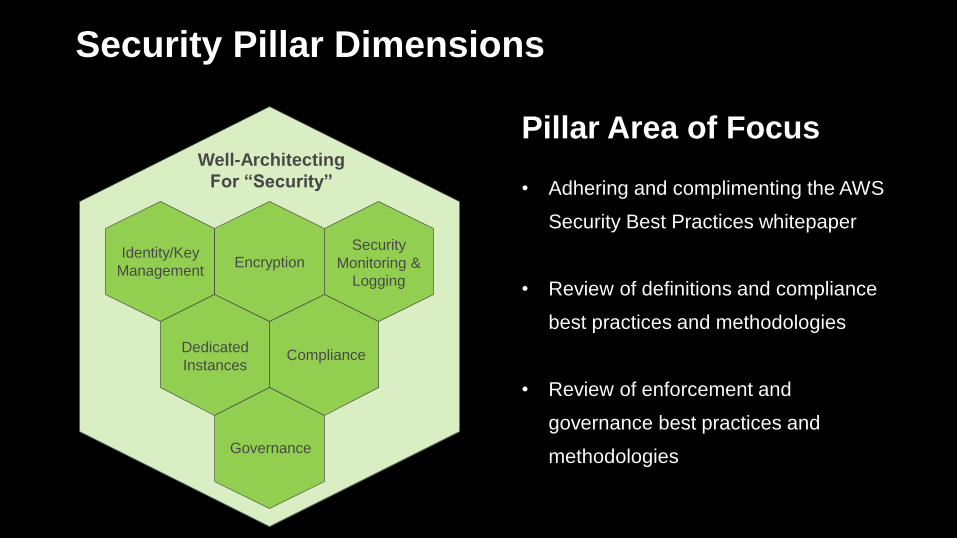
Security Pillar Dimensions
Pillar Area of Focus
• Adhering and complimenting the AWS
Security Best Practices whitepaper
• Review of definitions and compliance
best practices and methodologies
• Review of enforcement and
governance best practices and
methodologies
Well-Architecting
For “Security”
Identity/Key
ManagementEncryption
Security
Monitoring &
Logging
Dedicated
InstancesCompliance
Governance

Operational Excellence Pillar Dimensions
Pillar Area of Focus
• Achieve highly automated and
resilient deployment pipelines for code
changes
• Orchestrate operational requirements
once the workloads are deployed into
production
Well-Architecting
For “Operational Excellence”
Amazon
CloudWatchChange
AuditingCI/CD
Pipeline
Configuration
Management
Service
Catalog
AWS SDKs
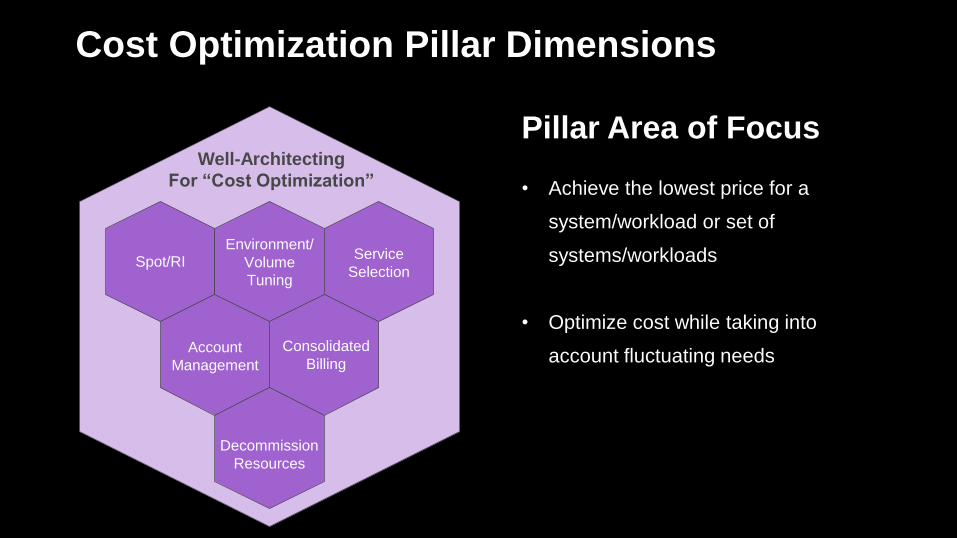
Cost Optimization Pillar Dimensions
Pillar Area of Focus
• Achieve the lowest price for a
system/workload or set of
systems/workloads
• Optimize cost while taking into
account fluctuating needs
Well-Architecting
For “Cost Optimization”
Spot/RIEnvironment/
Volume
Tuning
Service
Selection
Account
Management
Consolidated
Billing
Decommission
Resources
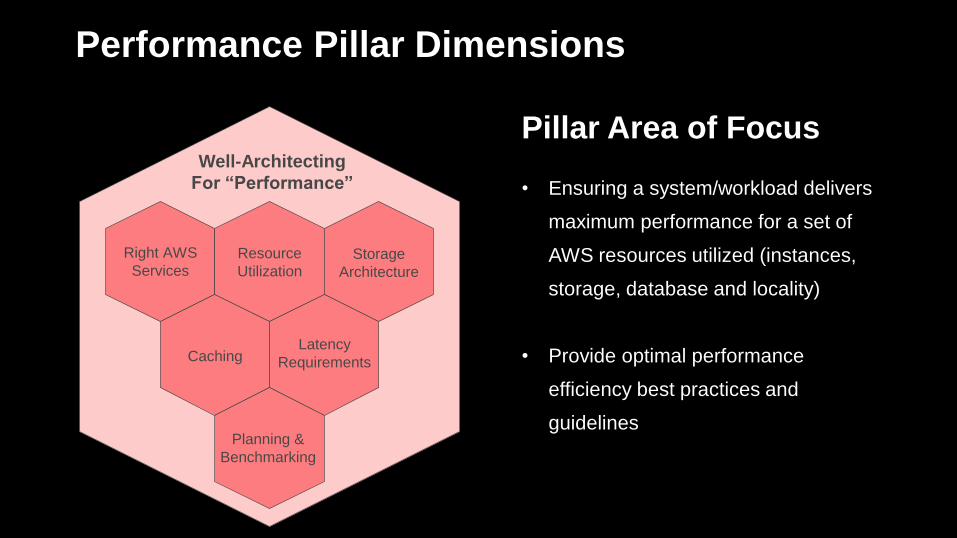
Performance Pillar Dimensions
Pillar Area of Focus
• Ensuring a system/workload delivers
maximum performance for a set of
AWS resources utilized (instances,
storage, database and locality)
• Provide optimal performance
efficiency best practices and
guidelines
Well-Architecting
For “Performance”
Right AWS
Services Resource
UtilizationStorage
Architecture
CachingLatency
Requirements
Planning &
Benchmarking

Let’s consider Performance Optimization. . .
In the beginning there was Amazon SQS:
• First service offered by AWS
• Cornerstone for service-oriented architectures
• Enables decoupling of application components
• Allows for asynchronous processing
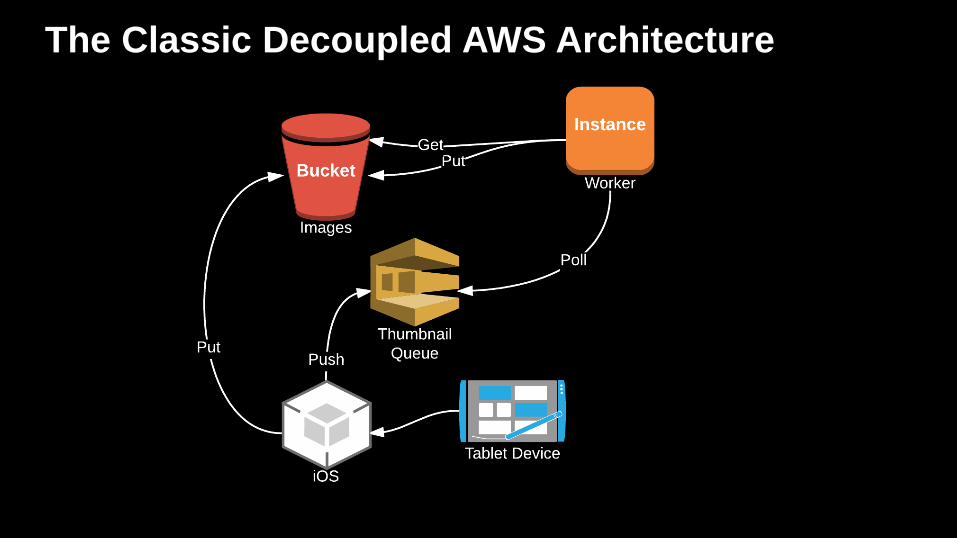
The Classic Decoupled AWS Architecture

Classic Decoupled Architecture
“Pull”
• Uses a queue (like SQS) for passing information between
systems
• Messages are pulled off a queue
• Requires a process that periodically polls the queue for
messages
• Widely used pattern in service-oriented architecture

The Classic Decoupled AWS Architecture
Advantages
• Decoupled
• Clients don’t know about workers and vice versa
• Scalable
• Easy to add workers and queues
• Asynchronous
• Long running jobs are processed in the background
• Highly Available
• Workers and queues run across Availability Zones in an AWS Region

Classic Decoupled AWS Architecture
Aspects to think about …
• AMI Baking
• Use AMIs so that you’re using a preconfigured image for your worker
tier
• Auto Scale Groups
• Use Auto Scaling Groups minimize idle Amazon EC2 instances, and
consider the right metric for triggers
• Undifferentiated Heavy Lifting
• Message Validity and Timeout configurations to manage your queues
and workers effectively

Event-Driven Architecture
What is it?
• A way of responding to certain actions that occur in an AWS
service
• Provides hooks for an application to execute code in response to
an event
• Eliminates the “undifferentiated heavy lifting” of managing and
scaling compute resources and queues to execute event
handling code
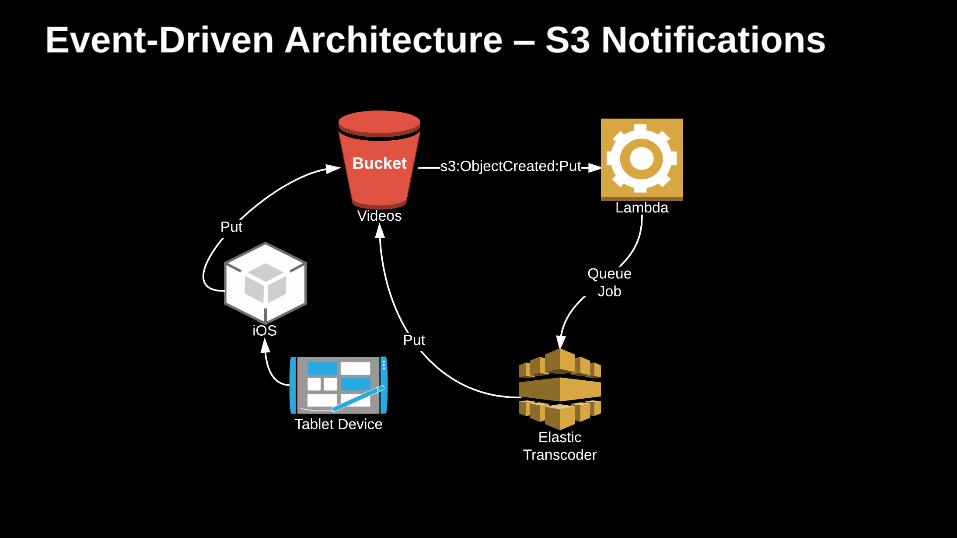
Event-Driven Architecture – S3 Notifications

Event-Driven Architecture - S3 Notifications
S3 will send notifications when certain events happen in a bucket.
Notifications can be published to different targets:
• Amazon SNS
• Useful when the occurrence of an event must be broadcast to a large
number of clients
• Amazon SQS
• Useful when a worker process needs to respond to the S3 event
asynchronously
• AWS Lambda
• Automatically executes code when an S3 event occurs

Event-Driven Architecture – S3 Notifications
SNS Topic
SQS
HTTP/S
SMS
Mobile Push

Event-Driven Architecture & Lambda
“Push”
• S3 Notification pushes an event to Lambda
• Lambda service executes code in response to an event

Event-Driven Architecture
Advantages
• Reduces operational complexity
• No need to manage fleets of EC2 instances that process messages off
a queue
• Cost-Effective
• Pay only for the number of executions of event handling code
• No need to fine-tune auto scaling rules to limit idle CPU cycles

Event-Driven Architecture with Lambda
Aspects to think about …
• Virtual wiring!• Wire up Lambda using SNS, keep Inputs/Outputs simple and within 5
minute durations
• Scratch space• Each Lambda function receives 500 MB of nonpersistent disk space in
its own /tmp directory. If you need more, consider other persistent stores
• Remove Kernel/OS dependencies• Embrace the simplification of no longer worrying about the underlying
OS
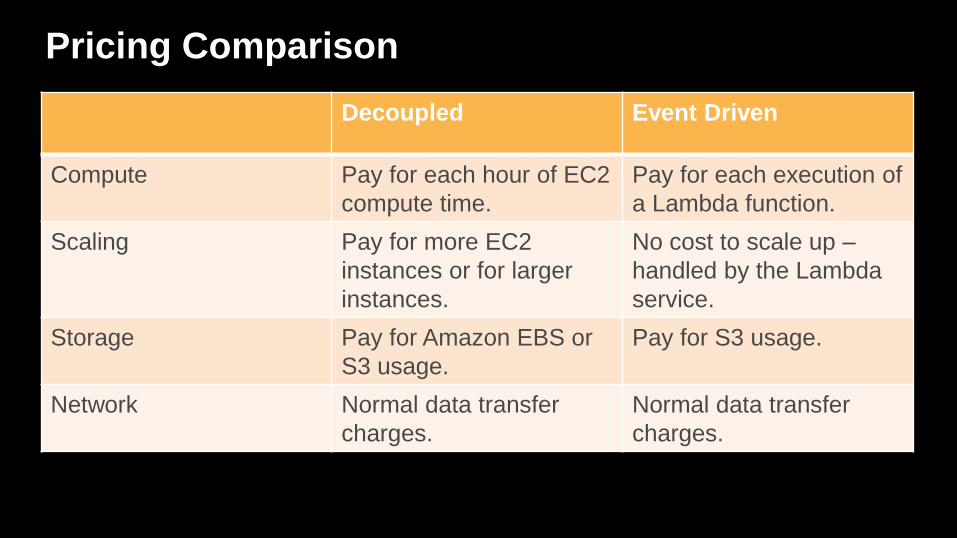
Pricing Comparison
Decoupled Event Driven
Compute Pay for each hour of EC2
compute time.
Pay for each execution of
a Lambda function.
Scaling Pay for more EC2
instances or for larger
instances.
No cost to scale up –
handled by the Lambda
service.
Storage Pay for Amazon EBS or
S3 usage.
Pay for S3 usage.
Network Normal data transfer
charges.
Normal data transfer
charges.

20k in 20 Days - Agile Genomic Analysis

We are a global, science-led
biopharmaceutical business
pushing the boundaries of science
to deliver life-changing medicines.
$24.7bn2015 Revenue*
100+ Countries
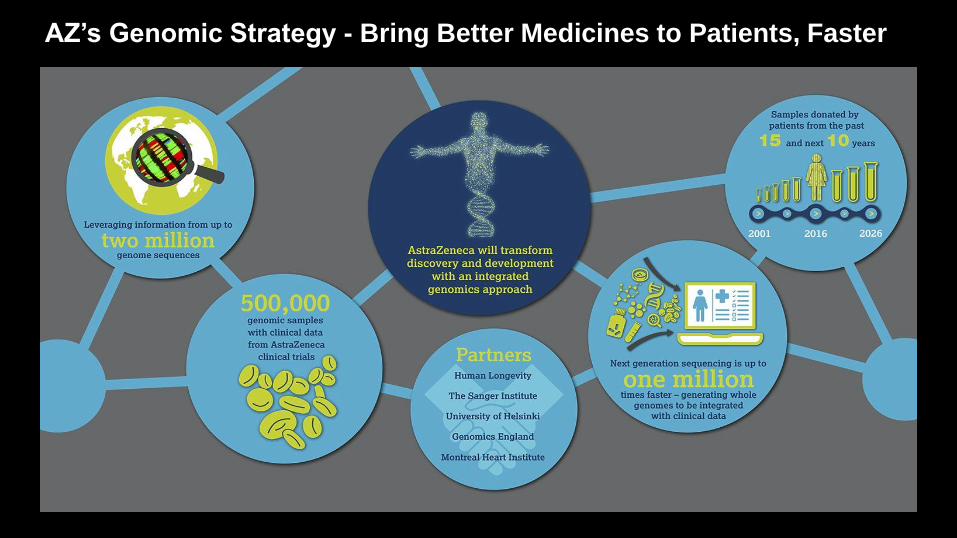
AZ’s Genomic Strategy - Bring Better Medicines to Patients, Faster

Genomic Sequencing – Digitizing the Human
Process and align
to a reference
Fragment the DNA
to create a libraryAmplify and read the
fragments with a sequencer

Whole Exome vs. Whole Genome
Whole Exome Advantages Whole Genome Advantages
Protein coding regions, 2% of genome Contains everything
~ 85% of disease causing mutations More reliable sequence coverage
Lower sequencing cost at a high depth Better coverage uniformity
Reduces storage and analysis costs Minimal amplification needed
Increased number of samples Universal for all species
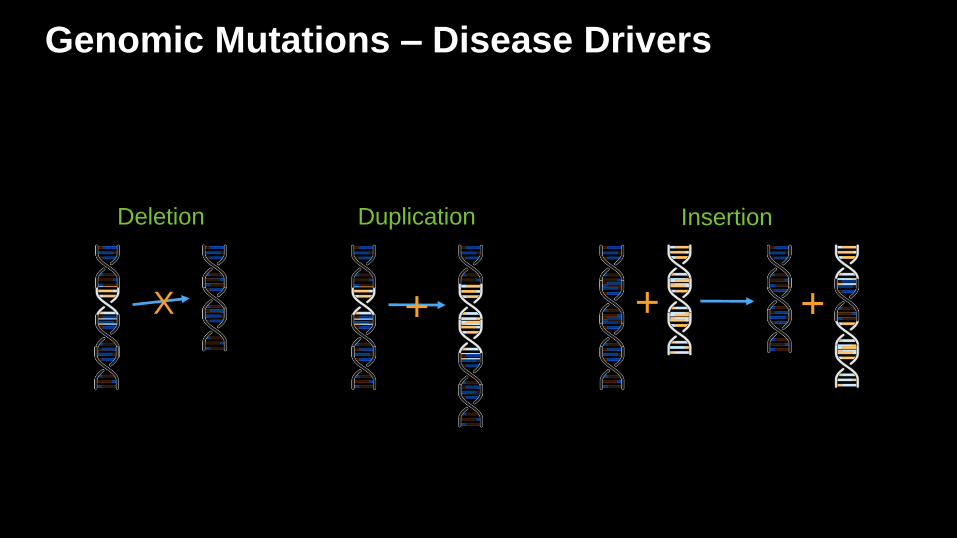
Genomic Mutations – Disease Drivers
X
Deletion Duplication Insertion
+ + +

20 days …
“Give me six hours to chop down a tree and I will spend the first four sharpening the axe.” ― Abraham Lincoln
“Champions do not become champions when they win the event, but in the hours, weeks, months and years they spend preparing for it. The victorious performance itself is merely the demonstration of their championship character.” ― Alan Armstrong
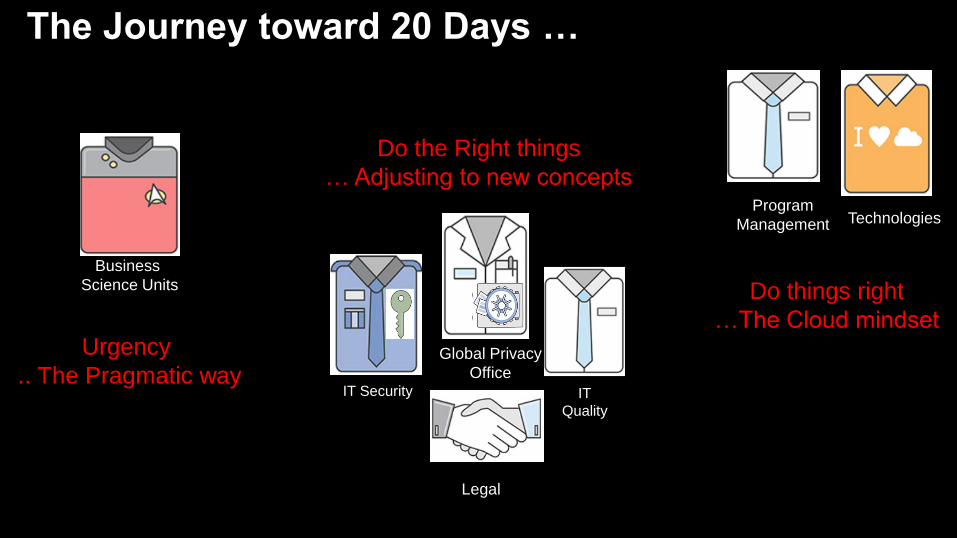
The Journey toward 20 Days …
Program
Management
Global Privacy
Office
Technologies
IT
Quality
IT Security
Business
Science Units
Legal
Urgency
.. The Pragmatic way
Do the Right things
… Adjusting to new concepts
Do things right
…The Cloud mindset

Stacked Security and Compliance ModelS
tacked R
esponsib
ility
APIs
Service Endpoint
Storage
Compute
Networking Management
Services
Regions
Availability Zones
Edge Locations
Amazon
Web
Services
Client Side Encryption Server Side Encryption Network Communication Protection
Operating System Network and Instance Firewall Platform Logging/Monitoring
Identify and Access Management
AZ R&D
Cloud
Project Researcher Collaborator Application End User / App
Data Owner

Genomics has challenged our existing
approaches to data privacy:
Genomes are Sensitive Personal Data
31
De-identification and patient consent
Standards & processes
• Your Genome, your fingerprint
• But … not only yours …

Applied Stacked Security and Compliance Model
dbGap / Genomic Data
Provider
Protecting against risk
associated with
releasing individual’s
genomes.
AstraZeneca
(QA/Privacy/Security)
Protecting AZ patient
Information security
and privacy for risk of
exposure
HIPPA
Protecting against risks
in releasing Personal
Information(PHI)
APIs
Service Endpoint
Storage
Compute
NetworkingManagement
Services
Regions
Availability Zones
Edge Locations
Client/Client Side Encryption Network Communication Protection
Operating System Network and Instance Firewall Platform Logging/Monitoring
Identify and Access Management
Genomic Project
Sta
cked R
esponsib
ility
Project
Team
AZ
Science
Cloud
Platform
AWS

Redefining the Landscape for Genetic Drivers in CancerMotivation for Re-Analysis of TCGA Exome Data
33
Improvements in tools, references, and resources allow us to better define the causes of cancer
• hg38 Reference Genome
• Updated from hg19 – more accurate mutation detection
• VarDict Variant Caller
• 20% better sensitivity finding mutations compared to the best current algorithms
• Developed by AstraZeneca, now open source
• Better Computational Resources
• Quickly re-analyze the data at scale
• Bring computational resources to the data, enabling us to succeed

A Project is Born
34
Project: Re-analyze 20k TCGA Exomes in 20 days
• Use the new hg38 reference genome
• Utilize VarDict to improve the variant calls
• Complete in ~20 days (Between Thanksgiving and Christmas)
Challenges:
20K Exomes = 270TB of Raw Genomic files
• Current Storage
• 500 TB, mostly filled
• Not enough space!
• HPC utilization
• Used for ongoing projects
• Stop everything else for ~ 1 year!
• Internet Connection
• 1Gbps Fastline
• ~25 days just to download!
• Experience to Date
• On-premises: < 3,000 exomes (3 years)
• Process ~ 7x as many in < 1 month!
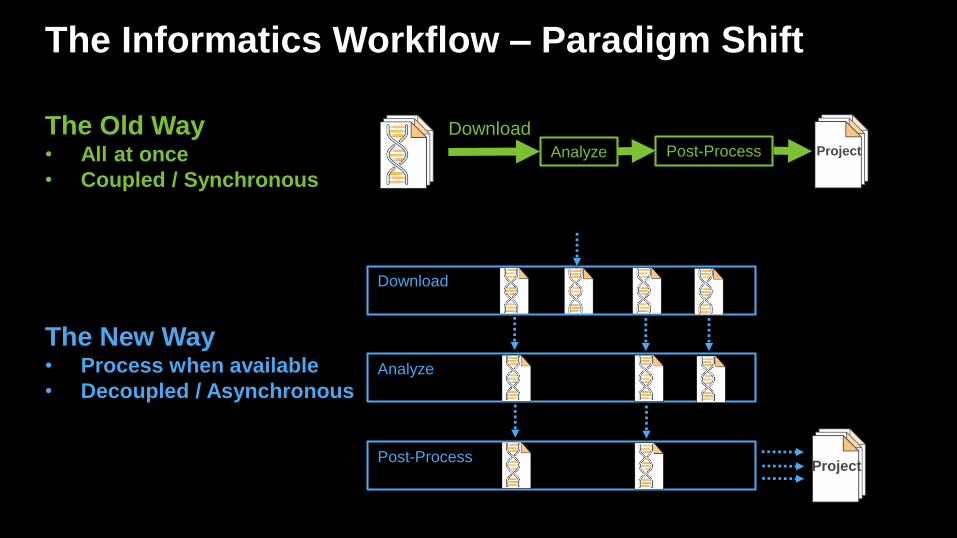
The Informatics Workflow – Paradigm Shift
The Old Way• All at once
• Coupled / Synchronous
Analyze Post-Process
The New Way• Process when available
• Decoupled / Asynchronous
Download
Project
Project
Download
Analyze
Post-Process

PARALLEL INGESTION
AT SCALE
ASYNCHRONOUS
PARALLEL ANALYSIS
AT SCALE
Alignment
Slice Index and Stats
Variant Call
UPLOAD TO
LOCAL HPC FOR
DOWNSTREAM
ANALYSIS
Simplify: Turn It to a Loosely Coupled At Scale Solution
36
PARALLEL INGESTION ASYNCHRONOUS PARALLEL ANALYSIS UPLOAD RESULTS

Simplify: Turn It to a Loosely Coupled At Scale Solution
37
Science
Requested
Target
Samples
CGHub Local Science HPCDevOps Bucket
INGESTION S3 Bucket
Ingestion
Request
Worker
RESULTS S3
Bucket
Automation
Worker VLAD Automation Step
Workers VLAD Loader Worker
INGESTION
Request QueueANALYSIS
Request Queue
PIPELINE AUTOMATION
Results QueuePIPELINE
Results Queue
Queue
Process
Storage
PIPELINE S3 Bucket
BAM, BAI
VCF
Analysis
Request Worker
PARALLEL INGESTION
AT SCALE
ASYNCHRONOUS
PARALLEL ANALYSIS
AT SCALE
Alignment
Slice Index and Stats
Variant Call
UPLOAD TO
LOCAL HPC FOR
DOWNSTREAM
ANALYSIS
PARALLEL INGESTION ASYNCHRONOUS PARALLEL ANALYSIS UPLOAD RESULTS
ASYNCHRONOUS
PARALLEL ANALYSIS
AT SCALE
Alignment
Slice Index and Stats
Variant Call
UPLOAD TO
LOCAL HPC FOR
DOWNSTREAM
ANALYSIS
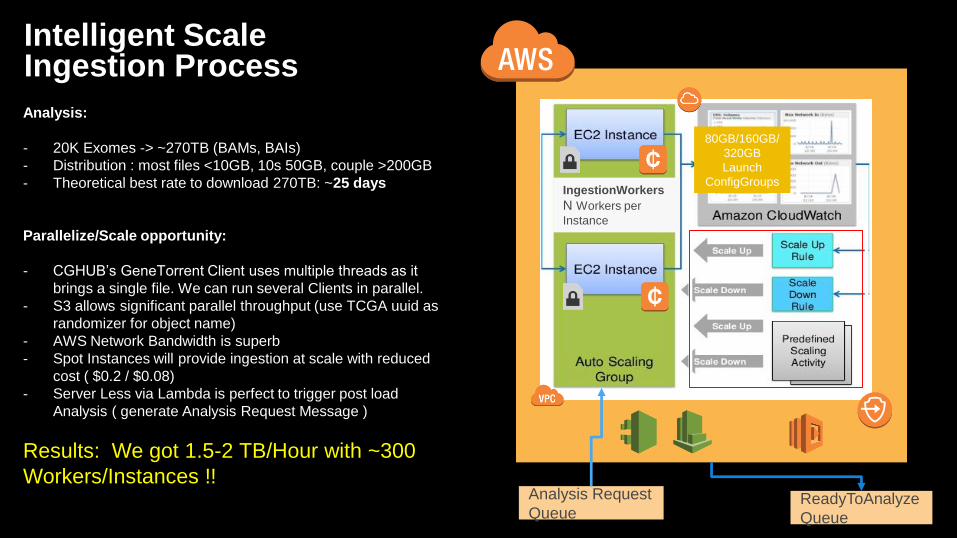
Intelligent Scale Ingestion Process
Analysis:
- 20K Exomes -> ~270TB (BAMs, BAIs)
- Distribution : most files <10GB, 10s 50GB, couple >200GB
- Theoretical best rate to download 270TB: ~25 days
Parallelize/Scale opportunity:
- CGHUB’s GeneTorrent Client uses multiple threads as it
brings a single file. We can run several Clients in parallel.
- S3 allows significant parallel throughput (use TCGA uuid as
randomizer for object name)
- AWS Network Bandwidth is superb
- Spot Instances will provide ingestion at scale with reduced
cost ( $0.2 / $0.08)
- Server Less via Lambda is perfect to trigger post load
Analysis ( generate Analysis Request Message )
Results: We got 1.5-2 TB/Hour with ~300
Workers/Instances !!
IngestionWorkers
N Workers per
Instance
Analysis Request
QueueReadyToAnalyze
Queue
80GB/160GB/
320GB
Launch
ConfigGroups
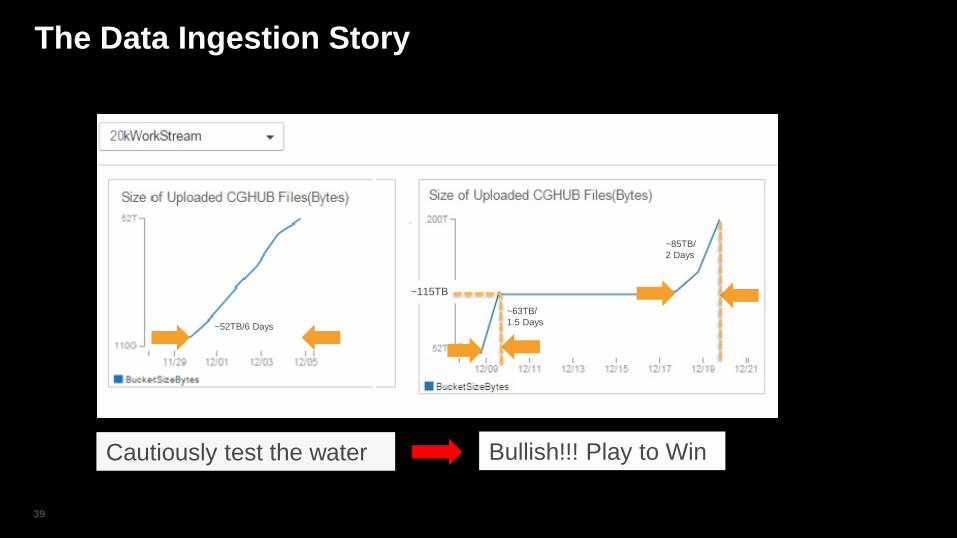
The Data Ingestion Story
39
~52TB/6 Days
~85TB/
2 Days
~115TB
~63TB/
1.5 Days
Cautiously test the water Bullish!!! Play to Win
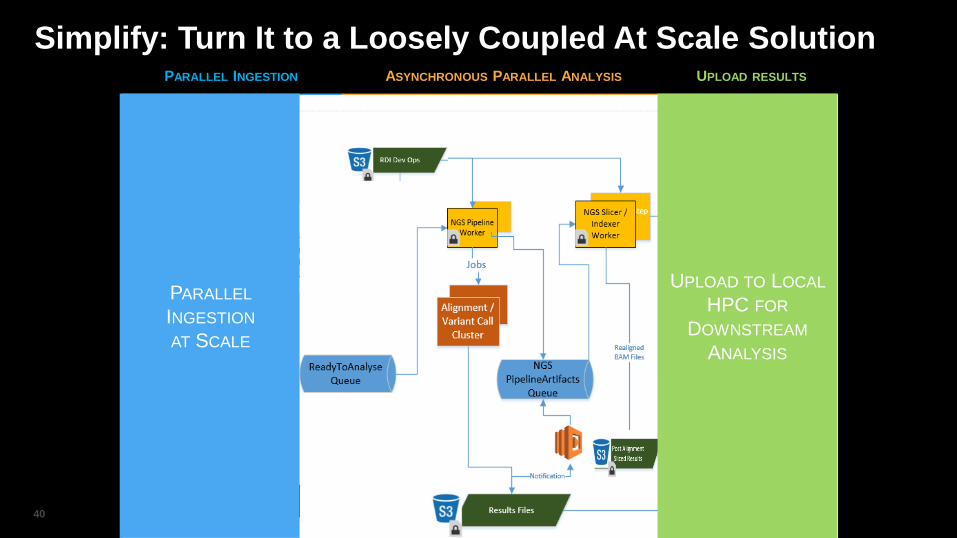
Simplify: Turn It to a Loosely Coupled At Scale Solution
40
Science
Requested
Target
Samples
CGHub Local Science HPCDevOps Bucket
INGESTION S3 Bucket
Ingestion
Request
Worker
RESULTS S3
Bucket
Automation
Worker VLAD Automation Step
Workers VLAD Loader Worker
INGESTION
Request QueueANALYSIS
Request Queue
PIPELINE AUTOMATION
Results QueuePIPELINE
Results Queue
Queue
Process
Storage
PIPELINE S3 Bucket
BAM, BAI
VCF
Analysis
Request Worker
PARALLEL INGESTION
AT SCALE
ASYNCHRONOUS
PARALLEL ANALYSIS
AT SCALE
Alignment
Slice Index and Stats
Variant Call
UPLOAD TO
LOCAL HPC FOR
DOWNSTREAM
ANALYSIS
PARALLEL INGESTION ASYNCHRONOUS PARALLEL ANALYSIS UPLOAD RESULTS
PARALLEL
INGESTION
AT SCALE
UPLOAD TO LOCAL
HPC FOR
DOWNSTREAM
ANALYSIS
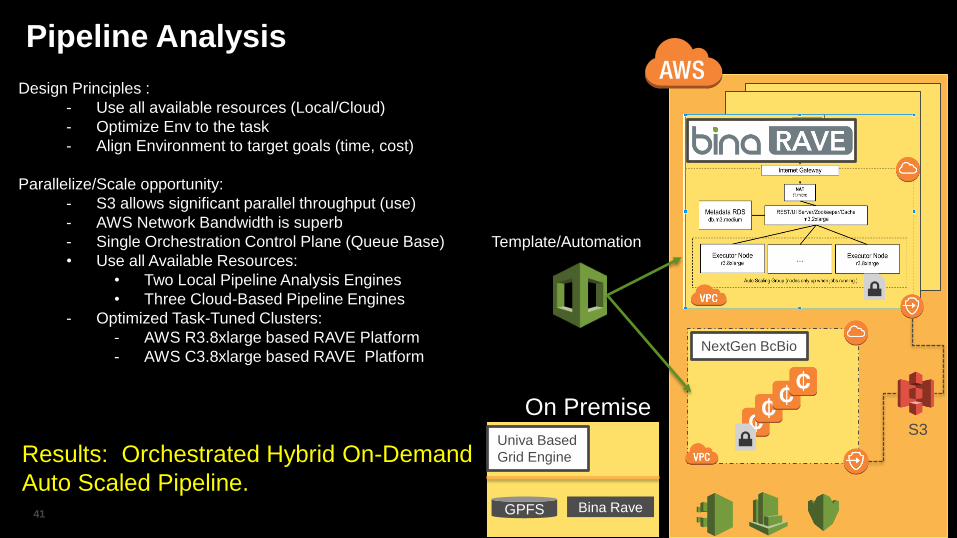
Pipeline Analysis
41
Design Principles :
- Use all available resources (Local/Cloud)
- Optimize Env to the task
- Align Environment to target goals (time, cost)
Parallelize/Scale opportunity:
- S3 allows significant parallel throughput (use)
- AWS Network Bandwidth is superb
- Single Orchestration Control Plane (Queue Base)
• Use all Available Resources:
• Two Local Pipeline Analysis Engines
• Three Cloud-Based Pipeline Engines
- Optimized Task-Tuned Clusters:
- AWS R3.8xlarge based RAVE Platform
- AWS C3.8xlarge based RAVE Platform
Results: Orchestrated Hybrid On-Demand
Auto Scaled Pipeline.
Univa Based
Grid Engine
On Premise
GPFS
NextGen BcBio
S3
Bina Rave
Template/Automation

Post Alignment Slicing
Post Realignment :
- Slice BAM and extract Gene Of Interest List
- Generate Stats
- Index BAM File
Parallelize/Scale opportunity:
- Operation can be done on every realigned BAM file
while it’s being used for further pipeline activities.
- Slice, Stats, Index can be uploaded to local HPC
regardless to Variant call results as long are
distributed to the right canonical named located
(based on tcga uuid)
- S3 bucket can hold “infinite” number of objects
without “folders” structure
- Spot Instances are perfect for cost reduction
Results:
- When Running at 700 Workers (100 nodes) we did
~6000 Slice ,Stats , Index in less than 3 hours
Post Align
N Workers per
Instances
Pipeline Analysis
QueueReadyToUpload
Queue
80GB/160GB/
320GB
Launch
ConfigGroup
S3

Simplify: Turn It to a Loosely Coupled At Scale Solution
43
Science
Requested
Target
Samples
CGHub Local Science HPCDevOps Bucket
INGESTION S3 Bucket
Ingestion
Request
Worker
RESULTS S3
Bucket
Automation
Worker VLAD Automation Step
Workers VLAD Loader Worker
INGESTION
Request QueueANALYSIS
Request Queue
PIPELINE AUTOMATION
Results QueuePIPELINE
Results Queue
Queue
Process
Storage
PIPELINE S3 Bucket
BAM, BAI
VCF
Analysis
Request Worker
PARALLEL INGESTION
AT SCALE
ASYNCHRONOUS
PARALLEL ANALYSIS
AT SCALE
Alignment
Slice Index and Stats
Variant Call
UPLOAD TO
LOCAL HPC FOR
DOWNSTREAM
ANALYSIS
PARALLEL INGESTION ASYNCHRONOUS PARALLEL ANALYSIS UPLOAD RESULTS
INGESTION
AT SCALE
ASYNCHRONOUS
PARALLEL ANALYSIS
AT SCALE
Alignment
Slice Index and Stats
Variant Call
Cleanup and Bring in What Matters
Loader
Developed
+270TB of raw data ~9TB Meaningful Analysis
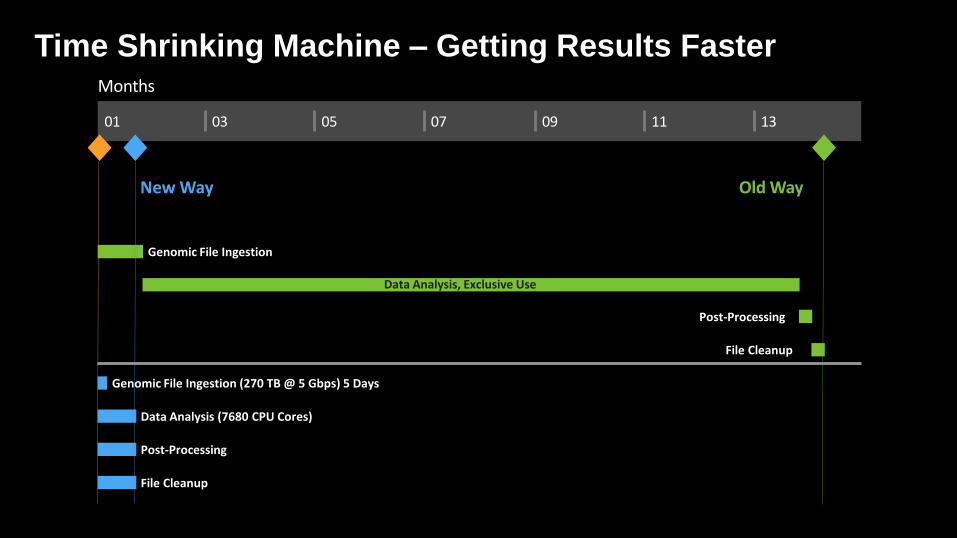
Time Shrinking Machine – Getting Results FasterMonths
01 03 05 07 09 11 13
Start
New Way1/21/2016
Old Way2/8/2017
Genomic File Ingestion1/1/2016 - 1/25/2016
Data Analysis, Exclusive Use1/26/2016 - 1/25/2017
Post-Processing1/26/2017 - 2/1/2017
File Cleanup2/2/2017 - 2/8/2017
Genomic File Ingestion (270 TB @ 5 Gbps) 5 Days1/1/2016 - 1/5/2016
Data Analysis (7680 CPU Cores)1/1/2016 - 1/21/2016
Post-Processing1/1/2016 - 1/21/2016
File Cleanup1/1/2016 - 1/21/2016
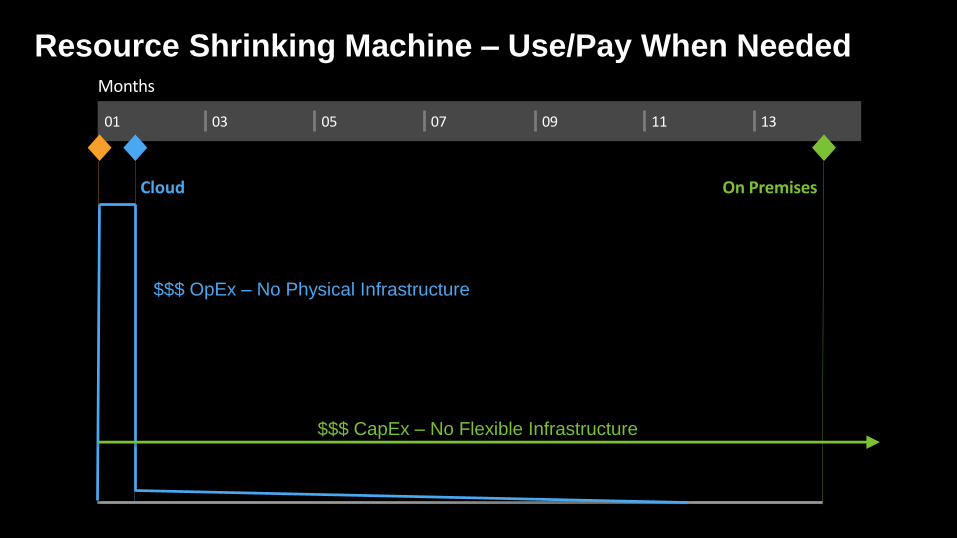
Resource Shrinking Machine – Use/Pay When NeededMonths
01 03 05 07 09 11 13
Start
1/21/2016 2/8/2017
1/1/2016 - 1/25/2016
1/26/2016 - 1/25/2017
1/26/2017 - 2/1/2017
2/2/2017 - 2/8/2017
1/1/2016 - 1/21/2016
Cloud On Premises
$$$ OpEx – No Physical Infrastructure
$$$ CapEx – No Flexible Infrastructure

270 TB
Data Reduction
9 TB
So…How Did We Do?
46
19,690TCGA EXOMES
RE-ALIGNED TO
HG38
>270 TBRAW DATA
UPLOADED AT
1.5-2 TB/HR WITH
300 LOADERS
7680 CPUFOR ALIGNMENT
AND VARIANT
CALLING
>2000/HRFOR SLICE
STATS AND INDEX
W/ 700 WORKERS
$4PER EXOME INCL.
COMPUTE,
STORAGE,
NETWORK

Lessons Learned from the 20k in 20 Days Project
• Plan ahead as much as you can
• Work first on the foundation and enabling factors
• Security and Privacy foundation
• DevOps and Automation
• Understand the details of:
• Process
• Computation and Data Scale
• Leverage the AWS XaaS
• Measure Everything and associate it to Business Outcome

Acknowledgements
AstraZeneca• Vlad Saveliev
• Ronen Artzi
• Michael Heimlich
• Tristan Lubinski
• Jonathan Dry @DrySci
• Danielle Greenawalt @BostonBioinfX
• Justin Johnson @BioInfo
• Zhongwu Lai @ZhongwuL
• Stefanie Rintoul
• Vitaly Rozenman
• Carl Barrett
• Brian Dougherty
• Bryan Takasaki
AstraZeneca Security/Privacy• Richard Paul
• Gayle Pearce
• Lee Ann Heckathorn
• Stephen Weil
• Sheri Arnell
• Tommy Farrell
• Victoria Southern
Bina/Roche• Andi Broka
• Engineering Team
• Product Management Team
• Science Team

Thank you!

Remember to complete
your evaluations!