automatic extraction of knowledge from biomedical literature
TRANSCRIPT

Cochrane UK & Ireland Symposium 2016,
Birmingham, UK, 2016-03-16
Automated Extraction of Knowledge from Biomedical
Literature
Peter Murray-Rust1,2
[1]University of Cambridge[2]TheContentMine pm286 AT cam DOT ac DOT uk
Simple, Universal, Knowledge creation and re-use
Our tools and minds are Open.How can we help Cochrane?

Overview
Content Mining:• Why we need it• What it is• How WE can do it• The next steps
• PM-R has worked in Glaxo Group Research on drug discovery, with WHO on adverse events and ICD-10, FDA on NDAs, EPO on patents, etc.

The Right to Read is the Right to Mine* *PeterMurray-Rust, 2011
http://contentmine.org
Not-for-private Profit

My European Heroes
Young People(ContentMine)
NEELIE KROES

Output of scholarly publishing
[2] https://en.wikipedia.org/wiki/Mont_Blanc#/media/File:Mont_Blanc_depuis_Valmorel.jpg
586,364 Crossref DOIs 201507 [1] per month1.5 million (papers + supplemental data) /year [citation needed]*
each 3 mm thick 4500 m high per year [2] * Most is not Publicly readable[1] http://www.crossref.org/01company/crossref_indicators.html

Scientific and Medical publication (STM)[+]
• World Citizens pay $450,000,000,000… • … for research in 1,500,000 articles …• … cost $300,000 each to create …• … $7000 each to “publish” [*]… • … $10,000,000,000 from academic libraries …• … to “publishers” who forbid access to 99.9% of citizens of the
world …• 85% of medical research is wasted (not published, badly conceived,
duplicated, …) [Lancet 2009]
[+] Figures probably +- 50 %[*] arXiV preprint server costs $7 USD per paper

http://www.nytimes.com/2015/04/08/opinion/yes-we-were-warned-about-ebola.html
We were stunned recently when we stumbled across an article by European researchers in Annals of Virology [1982]: “The results seem to indicate that Liberia has to be included in the Ebola virus endemic zone.” In the future, the authors asserted, “medical personnel in Liberian health centers should be aware of the possibility that they may come across active cases and thus be
prepared to avoid nosocomial epidemics,” referring to hospital-acquired infection.
Adage in public health: “The road to inaction is paved with research papers.”
Bernice Dahn (chief medical officer of Liberia’s Ministry of Health)Vera Mussah (director of county health services)
Cameron Nutt (Ebola response adviser to Partners in Health)
A System Failure of Scholarly Publishing


CLOSED ACCESS MEANS PEOPLE DIE

WE pay for scholarly publications that WE
can’t read
[1] The Military-Industrial-Academic complex (1961)(Dwight D Eisenhower, US President)
Publishers AcademiaGlory+?
$$, MSreview
Taxpayer
Student
Researcher
$$ $$
in-kind
The Publisher-Academic complex[1]
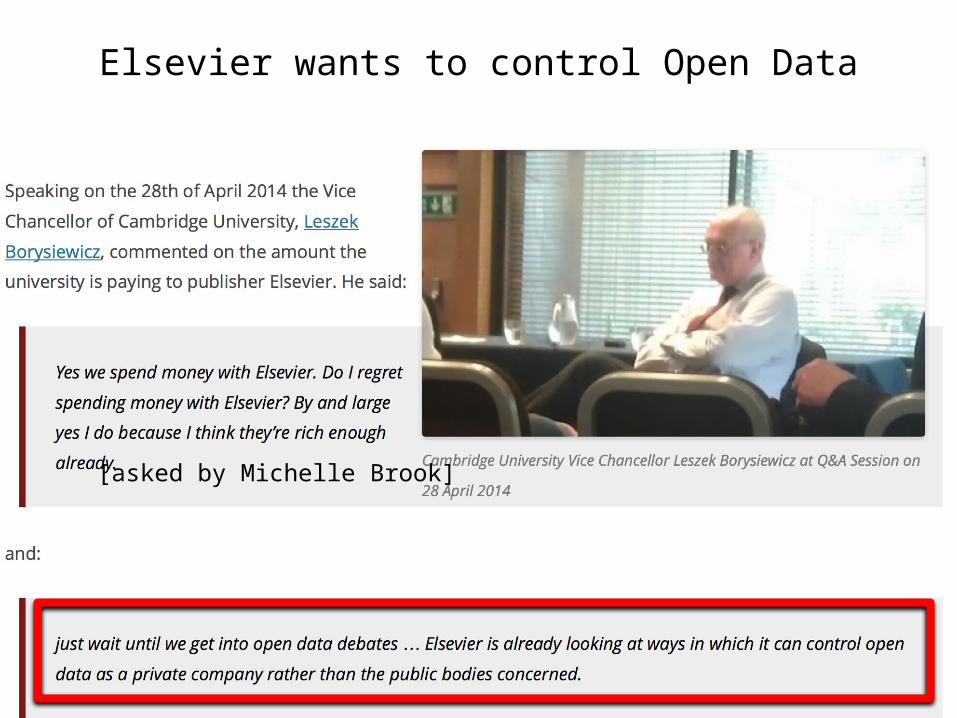
Elsevier wants to control Open Data
[asked by Michelle Brook]

Prof. Ian Hargreaves (2011): "David Cameron's exam question”: "Could it be true that laws designed more than three centuries ago with the express purpose of creating economic incentives for innovation by protecting creators' rights are today obstructing innovation and economic growth?” “yes. We have found that the UK's intellectual property framework, especially with regard to copyright, is falling behind what is needed.” "Digital
Opportunity" by Prof Ian Hargreaves - http://www.ipo.gov.uk/ipreview.htm. Licensed under CC BY 3.0 via Wikipedia - https://en.wikipedia.org/wiki/File:Digital_Opportunity.jpg#/media/File:Digital_Opportunity.jpg

Resources• Europe PubMedCentral http://europepmc.org/ • ContentMine toolkit https://github.com/ContentMine/ • Wikidata: https://www.wikidata.org/wiki/Wikidata:Main_Page • Hypothes.is https://hypothes.is/ [1]
• Etherpad: http://pads.cottagelabs.com/p/cochrane2016
• Note: early adopters can obtain our (Open) software and run it at home…
• [1] Not used in CochraneBham workshop

Europe PubMedCentral

catalogue
getpapers
query
DailyCrawl
EPMC, arXivCORE , HAL,(UNIV repos)
ToCservices
PDF HTMLDOC ePUB TeX XML
PNGEPS CSV
XLSURLsDOIs
crawl
quickscrape
normaNormalizerStructurerSemanticTagger
Text
DataFigures
ami
UNIVRepos
search
LookupCONTENTMINING
Chem
Phylo
Trials
CrystalPlants
COMMUNITY
plugins
Visualizationand Analysis
PloSONE, BMC, peerJ… Nature, IEEE, Elsevier…
Publisher Sites
scrapersqueries
taggers
abstract
methods
references
CaptionedFigures
Fig. 1
HTML tables
30, 000 pages/day Semantic ScholarlyHTML
Facts
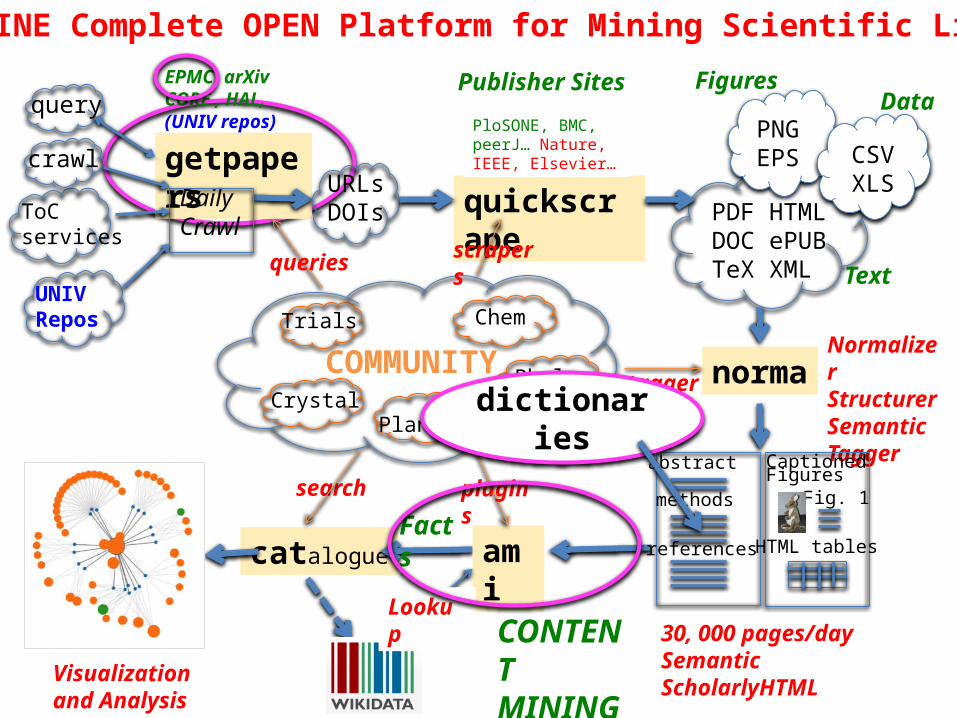
CONTENTMINE Complete OPEN Platform for Mining Scientific Literature
dictionaries

Dictionaries!

abstract
methods
references
CaptionedFigures
Fig. 1
HTML tables
abstract
methods
references
CaptionedFigures
Fig. 1
HTML tables
Dict A
Dict B
ImageCaption
TableCaption
MININGwith sectionsand dictionaries
[W3C Annotation / https://hypothes.is/ ]

How does Rat find knowledge

Demo
PMR runs getpapers and ami
Chris runs Python visualization of drug co-occurrence

I want to see a DEMO
Let’s tryChemicalTagger!

http://chemicaltagger.ch.cam.ac.uk/
• Typical
Typical chemical synthesis

Open Content Mining of FACTs
Machines can interpret chemical reactions
We have done 500,000 patents. There are > 3,000,000 reactions/year. Added value > 1B Eur.

Dictionaries
• Simplest approach to knowledge extraction and management.
We’d love to help integrate your dictionaries and Open authorities

Disease Dictionary (ICD-10)
<dictionary title="disease"> <entry term="1p36 deletion syndrome"/> <entry term="1q21.1 deletion syndrome"/> <entry term="1q21.1 duplication syndrome"/> <entry term="3-methylglutaconic aciduria"/> <entry term="3mc syndrome” <entry term="corpus luteum cyst”/> <entry term="cortical blindness" />
SELECT DISTINCT ?thingLabel WHERE { ?thing wdt:P494 ?wd . ?thing wdt:P279 wd:Q12136 . SERVICE wikibase:label { bd:serviceParam wikibase:language "en" }}
wdt:P494 = ICD-10 (P494) identifierwd:Q12136 = disease (Q12136) abnormal condition that affects the body of an organism
Wikidata ontology for disease

• ChEBI (chemicals at EBI) ftp://ftp.ebi.ac.uk/pub/databases/chebi/Flat_file_tab_delimited/names_3star.tsv.gz)
• combined with WIKIDATA: World Health Organisation International Nonproprietary Name (P2275)
* => 4947 items in the dictionary (inn.xml)
DRUGS<dictionary title="inn"><entry term="(r)-fenfluramine"/><entry term="abacavir"/><entry term="abafungin"/><entry term="abafungina"/><entry term="abafungine"/><entry term="abafunginum"/><entry term="abamectin"/><entry term="abarelix"/><entry term="abatacept"/>

<dictionary title="funders"><!— from http://help.crossref.org/funder-registry with thanks --><entry id="http://dx.doi.org/10.13039/100001436" term="1675 Foundation"/><entry id="http://dx.doi.org/10.13039/100004343" term="3M"/><entry id=“http://dx.doi.org/10.13039/501100005957” term="8020 Promotion Foundation"/><entry id="http://dx.doi.org/10.13039/501100007139" term="A Richer Life Foundation"/><entry id="http://dx.doi.org/10.13039/100006543" term="A World Celiac Community Foundation"/><entry id="http://dx.doi.org/10.13039/100001962" term="A-T Children's Project"/><entry id="http://dx.doi.org/10.13039/100008456" term="A. Alfred Taubman Medical Research Institute"/>
11566 entries
Funders Dictionary

Dengue Mosquito

<dictionary name="genus"> <entry term="Aa"/> <entry term="Aaaba"/> <entry term="Aacanthocnema"/> <entry term="Aaosphaeria"/> <entry term="Aaptos"/> <entry term="Aaptosyax"/> <entry term="Aaroniella"/> <entry term="Aaronsohnia"/> <entry term="Abablemma"/>
Genera from NCBI TaxDump

<dictionary title="hgnc"> <entry term="A1BG" name="alpha-1-B glycoprotein"/> <entry term="A1BG-AS1" name="A1BG antisense RNA 1"/> <entry term="A1CF" name="APOBEC1 complementation factor"/> <entry term="A2M" name="alpha-2-macroglobulin"/> <entry term="A2M-AS1" name="A2M antisense RNA 1 (head to head)"/> <entry term="A2ML1" name="alpha-2-macroglobulin-like 1"/> <entry term="A2ML1-AS1" name="A2ML1 antisense RNA 1"/>
Human Genes (HGNC)

<entry term="Aaas" name="achalasia, adrenocortical insufficiency, alacrimia"/><entry term="Aacs" name="acetoacetyl-CoA synthetase"/><entry term="Aadac" name="arylacetamide deacetylase (esterase)"/><entry term="Aadacl2" name="arylacetamide deacetylase-like 2"/><entry term="Aadacl3" name="arylacetamide deacetylase-like 3"/><entry term="Aadat" name="aminoadipate aminotransferase"/><entry term="Aaed1" name="AhpC/TSA antioxidant enzyme domain containing 1"/><entry term="Aagab" name="alpha- and gamma-adaptin binding protein"/><entry term="Aak1" name="AP2 associated kinase 1"/><entry term="Aamdc" name="adipogenesis associated Mth938 domain containing"/><entry term="Aamp" name="angio-associated migratory protein"/>
Mouse genes (JAXson)

Ebola!

<dictionary title="tropicalVirus"> <entry term="ZIKV" name="Zika virus"/> <entry term="Zika" name="Zika virus"/> <entry term="DENV" name="Dengue virus"/> <entry term="Dengue" name="Dengue virus"/> <entry term="CHIKV" name="Chikungunya virus"/> <entry term="Chikungunya" name="Chikungunya virus"/> <entry term="WNV" name="West Nile virus"/> <entry term="West Nile" name="West Nile virus"/> <entry term="YFV" name="Yellow fever virus"/> <entry term="Yellow fever" name="Yellow fever virus"/> <entry term="HPV" name="Human papilloma virus"/> <entry term="Human papilloma virus" name="Human papilloma virus"/></dictionary>
Terms co-ocurring with “Zika”

<dictionary title="cochrane"> <entry term="Cochrane Library"/> <entry term="Cochrane Reviews"/> <entry term="Cochrane Central Register of Controlled Trials"/> <entry term="Cochrane"/> <entry term="randomize"/> <entry term="meta-analysis"/> <entry term="Embase"/> <entry term="MEDLINE"/> <entry term="eligibility"/> <entry term="exclusion"/> <entry term="outcome"/> <entry term="Review Manager"/> <entry term="STATA"/> <entry term="RCT"/></dictionary>
Terms lexically related to “meta-analysis”

Mining strategy• Discover. negotiate permissions . => bibliography• Crawl / Scrape (download), documents AND
supplemental • Normalize. PDF => XML• Index: facets => Facts and snippets (“entities”)• Interpret/analyze entities => relationships,
aggregations (“Transformative”) • Publish

catalogue
getpapers
query
DailyCrawl
EuPMC, arXivCORE , HAL,(UNIV repos)
ToCservices
PDF HTMLDOC ePUB TeX XML
PNGEPS CSV
XLSURLsDOIs
crawl
quickscrape
normaNormalizerStructurerSemanticTagger
Text
DataFigures
ami
UNIVRepos
search
LookupCONTENTMINING
Chem
Phylo
Trials
CrystalPlants
COMMUNITY
plugins
Visualizationand Analysis
PloSONE, BMC, peerJ… Nature, IEEE, Elsevier…
Publisher Sites
scrapersqueries
taggers
abstract
methods
references
CaptionedFigures
Fig. 1
HTML tables
30, 000 pages/day Semantic ScholarlyHTML
Facts
CONTENTMINE Complete OPEN Platform for Mining Scientific Literature

Precision / Recall

Systematic Reviews
Can we:• eliminate true negatives automatically?• extract data from formulaic language?• mine diagrams?• Annotate existing sources?• forward-reference clinical trials?

Polly has 20 seconds to read this paper…
…and 10,000 more

ContentMine software can do this in a few minutes
Polly: “there were 10,000 abstracts and due to time pressures, we split this between 6 researchers. It took about 2-3 days of work (working only on this) to get through ~1,600 papers each. So, at a minimum this equates to 12 days of full-time work (and would normally be done over several weeks under normal time pressures).”

400,000 Clinical TrialsIn 10 government registries
Mapping trials => papers
http://www.trialsjournal.com/content/16/1/80
2009 => 2015. What’s happened in last 6 years??
Search the whole scientific literatureFor “2009-0100068-41”

What is “Content”?
http://www.plosone.org/article/fetchObject.action?uri=info:doi/10.1371/journal.pone.0111303&representation=PDF CC-BY
SECTIONS
MAPS
TABLES
CHEMISTRYTEXT
MATH
contentmine.org tackles these

Diagram Mining

Examples of plots
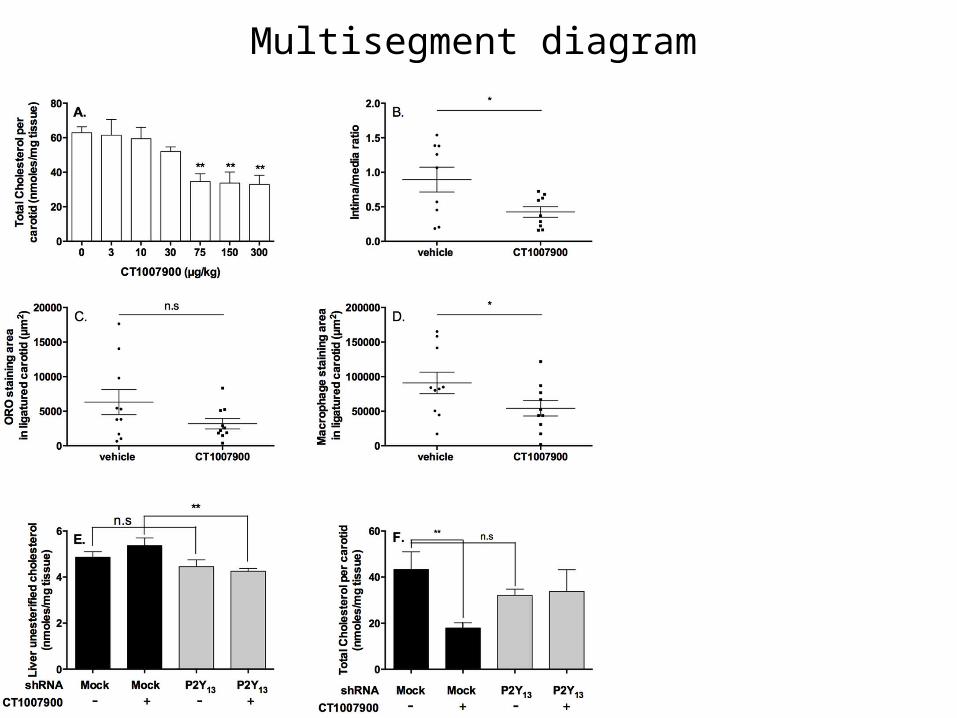
Multisegment diagram

But we can now turn PDFs into
Science
We can’t turn a hamburger into a cow
Pixel => Path => Shape => Char => Word => Para => Document => SCIENCE

UNITS
TICKS
QUANTITYSCALE
TITLES
DATA!!2000+ points
VECTOR PDF

Dumb PDF
CSV
SemanticSpectrum
2nd Derivative
Smoothing Gaussian Filter
Automaticextraction
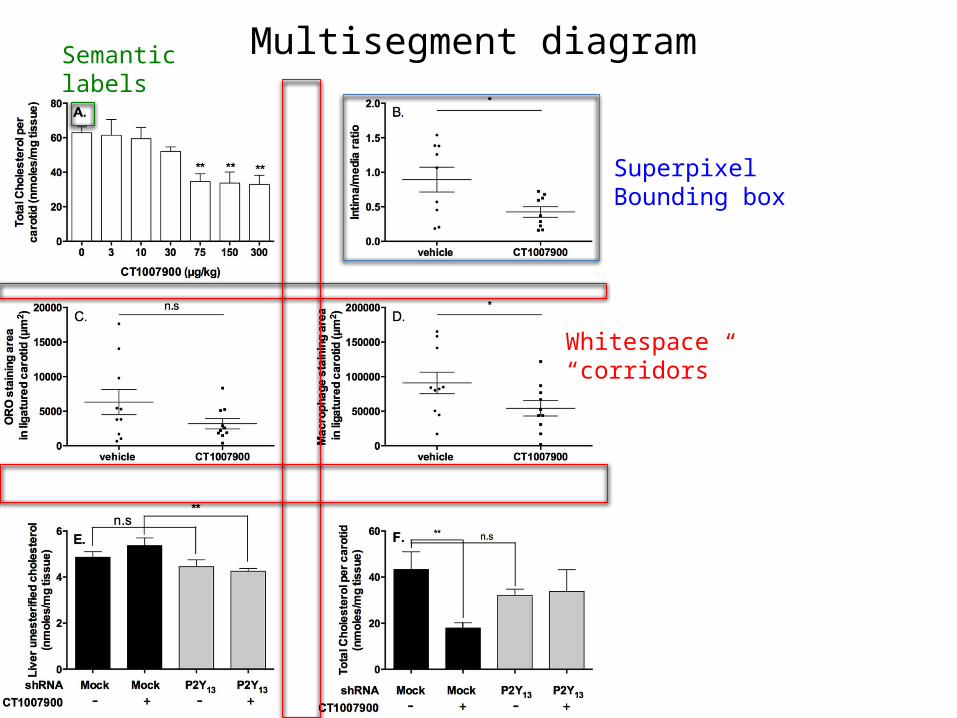
Multisegment diagram
Whitespace “corridors”
SuperpixelBounding box
Semanticlabels

Ln Bacterial load per fly
11.5
11.0
10.5
10.0
9.5
9.0
6.5
6.0
Days post—infection
0 1 2 3 4 5
Bitmap Image and Tesseract OCR



“Root”
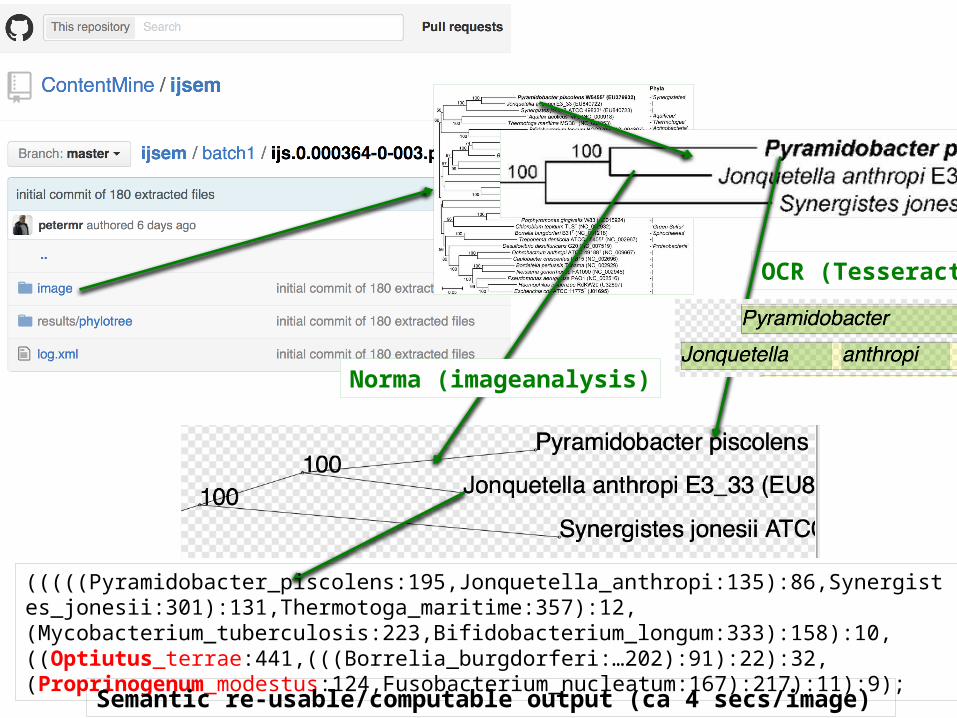
OCR (Tesseract)
Norma (imageanalysis)
(((((Pyramidobacter_piscolens:195,Jonquetella_anthropi:135):86,Synergistes_jonesii:301):131,Thermotoga_maritime:357):12,(Mycobacterium_tuberculosis:223,Bifidobacterium_longum:333):158):10,((Optiutus_terrae:441,(((Borrelia_burgdorferi:…202):91):22):32,(Proprinogenum_modestus:124,Fusobacterium_nucleatum:167):217):11):9);
Semantic re-usable/computable output (ca 4 secs/image)

Politics

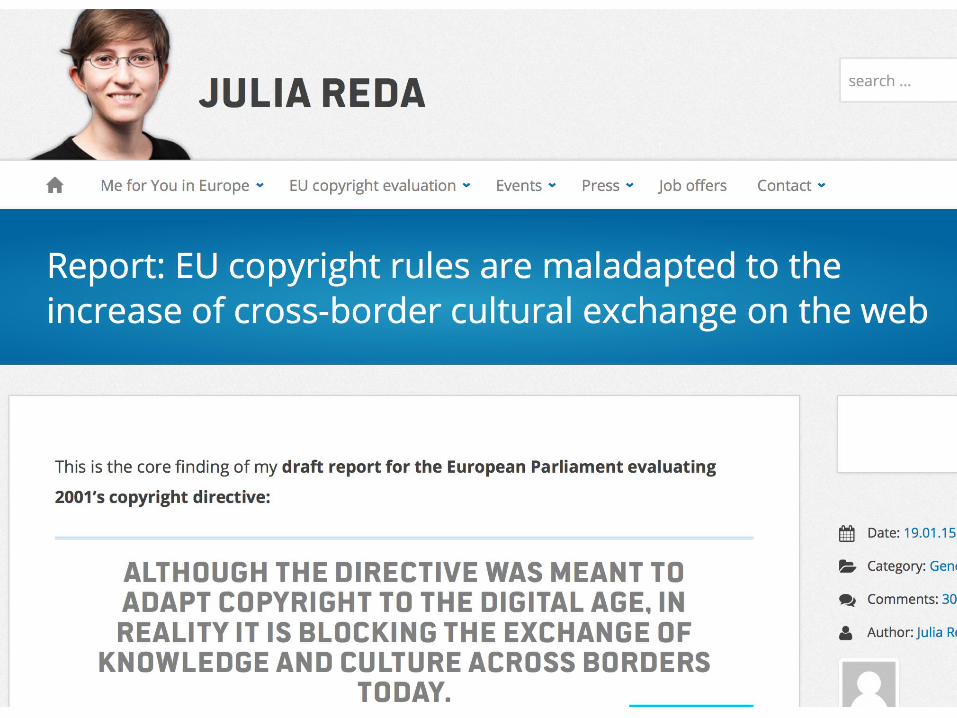
@Senficon (Julia Reda) :Text & Data mining in times of #copyright maximalism:
"Elsevier stopped me doing my research" http://onsnetwork.org/chartgerink/2015/11/16/elsevier-stopped-me-doing-my-research/ …
#opencon #TDM
Elsevier stopped me doing my researchChris Hartgerink

I am a statistician interested in detecting potentially problematic research such as data fabrication, which results in unreliable findings and can harm policy-making, confound funding decisions, and hampers research progress.To this end, I am content mining results reported in the psychology literature. Content mining the literature is a valuable avenue of investigating research questions with innovative methods. For example, our research group has written an automated program to mine research papers for errors in the reported results and found that 1/8 papers (of 30,000) contains at least one result that could directly influence the substantive conclusion [1].In new research, I am trying to extract test results, figures, tables, and other information reported in papers throughout the majority of the psychology literature. As such, I need the research papers published in psychology that I can mine for these data. To this end, I started ‘bulk’ downloading research papers from, for instance, Sciencedirect. I was doing this for scholarly purposes and took into account potential server load by limiting the amount of papers I downloaded per minute to 9. I had no intention to redistribute the downloaded materials, had legal access to them because my university pays a subscription, and I only wanted to extract facts from these papers.Full disclosure, I downloaded approximately 30GB of data from Sciencedirect in approximately 10 days. This boils down to a server load of 0.0021GB/[min], 0.125GB/h, 3GB/day.Approximately two weeks after I started downloading psychology research papers, Elsevier notified my university that this was a violation of the access contract, that this could be considered stealing of content, and that they wanted it to stop. My librarian explicitly instructed me to stop downloading (which I did immediately), otherwise Elsevier would cut all access to Sciencedirect for my university.I am now not able to mine a substantial part of the literature, and because of this Elsevier is directly hampering me in my research.[1] Nuijten, M. B., Hartgerink, C. H. J., van Assen, M. A. L. M., Epskamp, S., & Wicherts, J. M. (2015). The prevalence of statistical reporting errors in psychology (1985–2013). Behavior Research Methods, 1–22. doi: 10.3758/s13428-015-0664-2
Chris Hartgerink’s blog post

WILEY … “new security feature… to prevent systematic download of content
“[limit of] 100 papers per day”
“essential security feature … to protect both parties (sic)”
CAPTCHAUser has to type words

http://onsnetwork.org/chartgerink/2016/02/23/wiley-also-stopped-my-doing-my-research/
Wiley also stopped me (Chris Hartgerink) doing my researchIn November, I wrote about how Elsevier wanted me to stop downloading scientific articles for my research. Today, Wiley also ordered me to stop downloading.
As a quick recapitulation: I am a statistician doing research into detecting potentially problematic research such as data fabrication and estimating how often it occurs. For this, I need to download many scientific articles, because my research applies content mining methods that extract facts from them (e.g., test statistics). These facts serve as my data to answer my research questions. If I cannot download these research articles, I cannot collect the data I need to do my research.I was downloading psychology research articles from the Wiley library, with a maximum of 5 per minute. I did this using the tool quickscrape, developed by the ContentMine organization. With this, I have downloaded approximately 18,680 research articles from the Wiley library, which I was downloading solely for research purposes.Wiley noticed my downloading and notified my university library that they detected a compromised proxy, which they
had immediately restricted. They called it “illegally downloading copyrighted content licensed by your institution”. However, at no point was there any investigation into whether my user credentials were actually compromised (they were not). Whether I had legitimate reasons to download these articles was never discussed. The original email from Wiley is available here.
As a result of Wiley denying me to download these research articles, I cannot collect data from another one of the big publishers, alongside Elsevier. Wiley is more strict than Elsevier by immediately condemning the downloading as illegal, whereas Elsevier offers an (inadequate) API with additional terms of use (while legitimate access has already been obtained). I am really confused about what the publisher’s stance on content mining is, because Sage and Springer seemingly allow it; I have downloaded 150,210 research articles from Springer and 12,971 from Sage and they never complained about it.


ContentMine can Offer
• Collaboration• Prototyping. YOU design the rules and system• Rapid knowledge creation and analysis tools accessible to
EVERYONE and controlled by ANYONE.• Access to ALL daily scientific/medical FACTs
ContentMine needs
• Joint projects with narratives• Support in kind (code, content) and cash.
• http://contentmine.org

ContentMine can Offer
• Collaboration• Prototyping• Rapid knowledge creation and analysis tools accessible to
EVERYONE and controlled by ANYONE.• Access to ALL daily scientific/medical FACTs
ContentMine needs
• Joint projects with narratives• Support in kind (code, content) and cash.
• http://contentmine.org
KNOWLEDGE SAVES LIVES