authors' and publications' citations knowledge base
TRANSCRIPT

CEIT-2016
16-18 December 2016 – Hammamet, Tunisia
SCDC Sciences & Culture Development Center
An up to date Dataset
of most Cited Authors and
Publications
Leila Zemmouchi-Ghomari, Dihya Ferhat,
Nour el houda Chellali
USTHB, Université des Sciences et Technologies Houari
Boumediene, Algiers, Algeria
1

Abstract Problem: Literature review is an essential phase in
any research work. However, it is tricky and time
consuming.
Methods & Materials: an approach that combines
data accessible via the available academic search
engine APIs and the rich and constantly up to date
knowledge bases that is part of the linked data
cloud.
Results: A web application that provides most cited
authors and publications related to a research
field.
Conclusion: an up-to-date citations’ knowledge
base and a web interface that aggregates data from
several sources (linked data cloud)
2

3
Web of documents
(data silos)
Introduction …Web of data
The Semantic Web - A Web of Data:
Semantics are made explicit by formal and
standardized knowledge representations.
Thus it will be possible,
○ to process the meaning of information
automatically
○ to relate and integrate heterogeneous
data
○ to deduce implicit information from
existing information in an automated way
The Semantic Web is kind
of a global database that
contains a universal
network of semantic
propositions.

Introduction
4
The benefits of using lined data
• information can be dynamically aggregated from external,
publicly available data
• no specialized API necessary
• all data available as linked open data: encoded as RDF
• available via simple HTTP request
• data is always up-to-date without manual interaction

Aim of the work
Propose a generic approach to design and
implement a web application that exploits
the potential of linked data resources
5
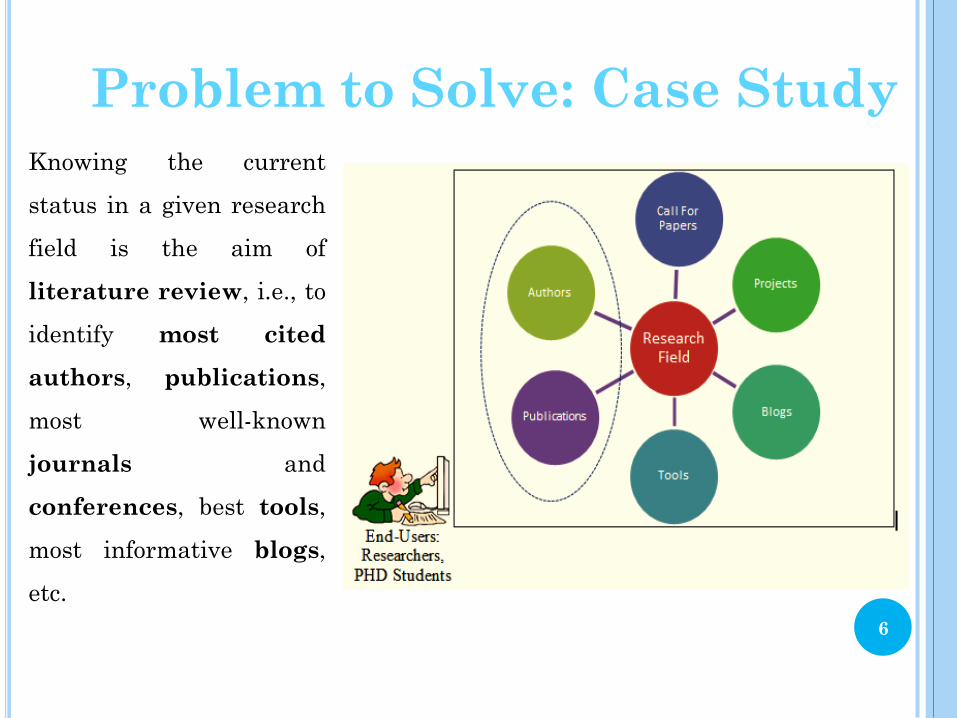
Problem to Solve: Case Study
Knowing the current
status in a given research
field is the aim of
literature review, i.e., to
identify most cited
authors, publications,
most well-known
journals and
conferences, best tools,
most informative blogs,
etc.
6

Materials and Methods
7
A linked data-driven web application (Hausenblas, M. 2009)
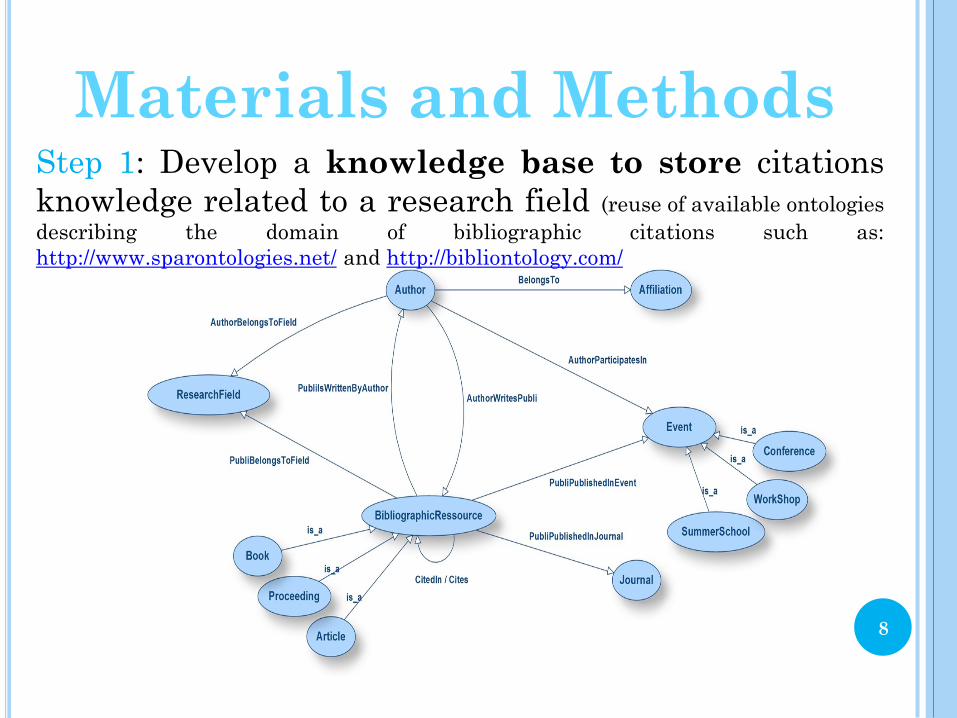
Materials and Methods Step 1: Develop a knowledge base to store citations
knowledge related to a research field (reuse of available ontologies
describing the domain of bibliographic citations such as:
http://www.sparontologies.net/ and http://bibliontology.com/
8

Materials and Methods Step 2: Identify rich and up-to-date knowledge
bases to provide useful information about the authors
and their publications
"ResearcherId" "homepage" and "depiction“
And "affiliation“ and "field“.
Step 3: Identify web applications with available APIs
that deliver data about the most cited academic
authors and publications
9

Materials and Methods
10
Step 4: Query the selected APIs with HTTP requests
and query linked data knowledge bases with SPARQL
queries to populate our knowledge base with
complementary data

Materials and Methods
11
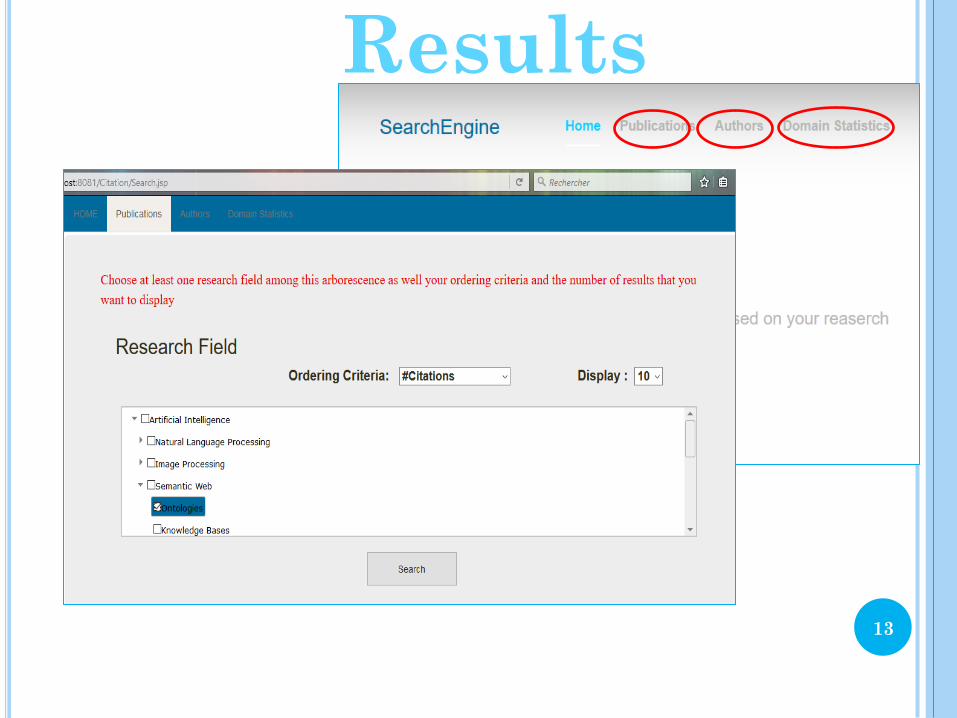
Step 5: Develop a
web page that displays
on one hand a
classification of
research areas based
on well-established
classifications and on
the other hand
criteria of results
presentation (author
or publication).
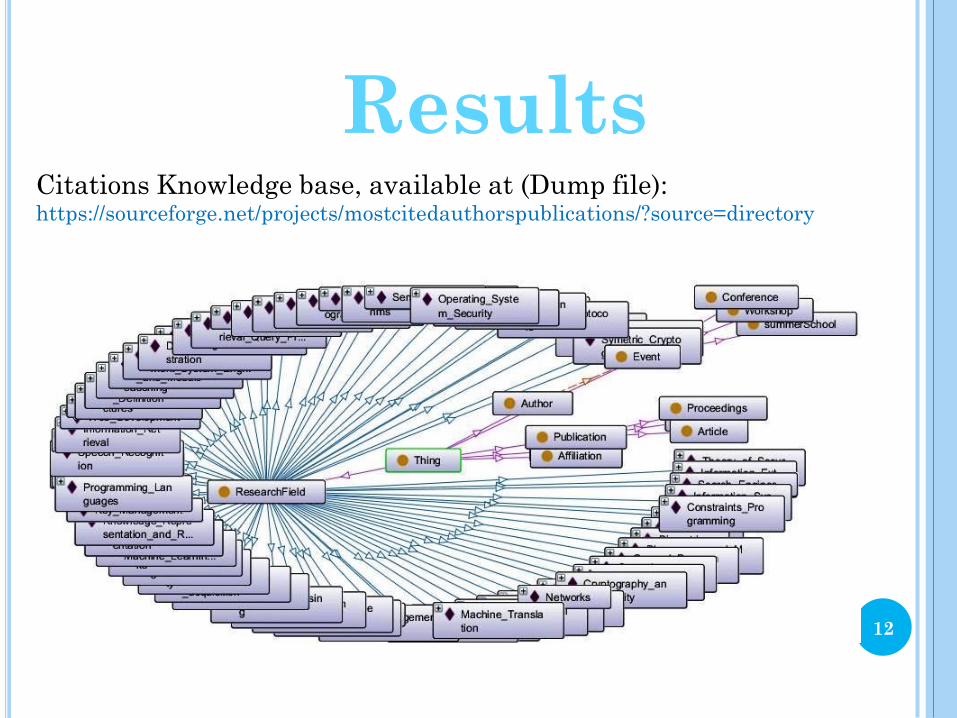
Results Citations Knowledge base, available at (Dump file): https://sourceforge.net/projects/mostcitedauthorspublications/?source=directory
12
Results
13

Results
14

Results
15
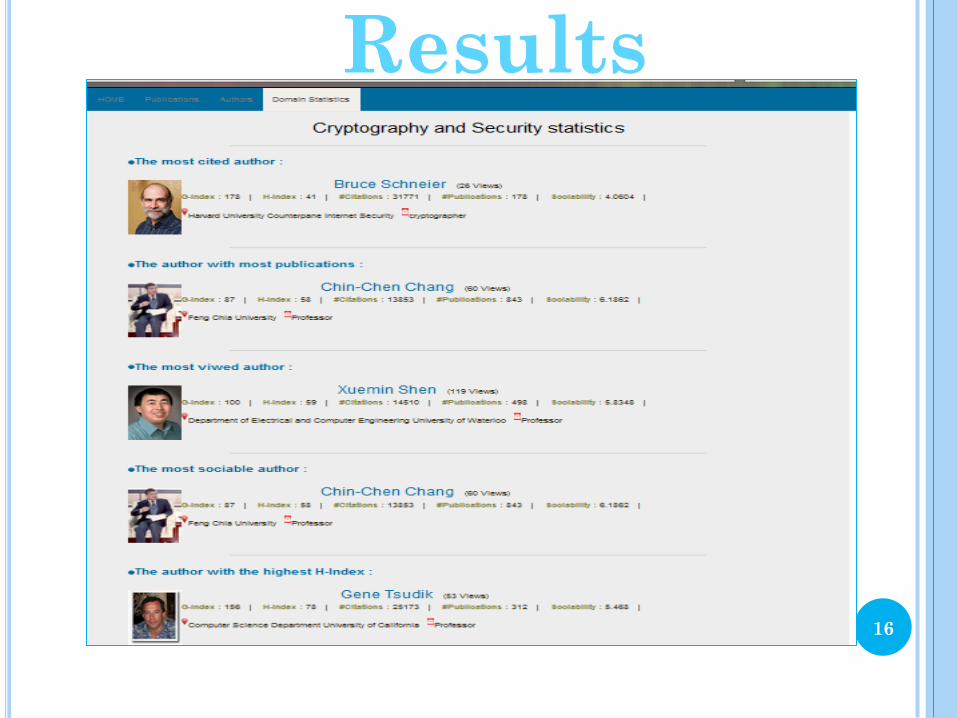
Results
16

17
Results

18
Results Citations Knowledge base has been assessed (task based
assessment) via competency questions technique.
Our web application has not yet been assessed by end-users,
however…
We made the source code available as an open source code at
https://sourceforge.net/projects/authpubli-citations-app/
to enable developers to adapt it to their needs:
• In terms of sources
• In terms of research domain
• In terms of displayed information
Relevance of results depend heavily on the knowledge base
sources.

Conclusion & Discussion
Search engine APIs provide almost all required data from web
applications
Most web APIs have heterogeneous data models and different
access interfaces.
Linked data knowledge bases are based on standard technologies. This
standardization enables to exploit data in an unbounded and global graph
and discover new data sources by following RDF links.
Linked data knowledge bases are not yet rich enough to provide all
required data for web applications
Automatic mechanisms are needed to populate linked datasets from
search engines that crawls regularly millions of web pages (rich and up-to-
date)
19

References
• C. Bizer and T. Heath, T. Berners Lee, “Linked data – the story
so far”, International Journal on Semantic Web and Information
Systems, vol. 5, no. 3, pp. 1–22, 2009.
• T. Berners Lee (2009) Linked data design issues [Online].
Available: http://www.w3.org/DesignIssues/LinkedData.htmls
• C. Bizer and T. Heath, Evolving the Web into a Global Data
Space, Morgan and Claypool Publishers, 2011.
• Hausenblas, M. (2009). Linked data applications. First
Community Draft, DERI.
• L. Richarson and S. Ruby, RESTful web service, O'Reilly Media,
Inc, 2008.
20

21